
Humans and Computers Working Together to Measure Machine Learning Interpretability
JORDAN BOYD-GRABER
University of Maryland
Machine learning is ubiquitous: it is involved in detecting spam emails, flagging fraudulent purchases, and providing the next movie in a Netflix binge. But few users at the mercy of machine learning outputs know what is happening behind the curtain. My research goal is to demystify the black box for nonexperts by creating algorithms that can inform, collaborate, and compete in real-world settings.
This is at odds with mainstream machine learning. Topic models, for example, are sold as a tool for understanding large data collections: lawyers scouring Enron emails for a smoking gun, journalists making sense of Wikileaks, or humanists characterizing the oeuvre of Lope de Vega. But topic models’ proponents never asked what those lawyers, journalists, or humanists needed. Instead, they optimized held-out likelihood.
THE NEED FOR IMPROVED INTERPRETABILITY
When my colleagues and I developed an interpretability measure to assess whether topic model users understood the models’ outputs, we found that interpretability and held-out likelihood were negatively correlated (Chang et al. 2009)! The machine learning community (including me) had fetishized complexity at the expense of usability.
Understanding what users want and need offers technical improvements to machine learning methods, and it improves the social process of machine learning adoption. A program manager who used topic models to characterize National Institutes of Health (NIH) research investments uncovered interesting synergies and trends, but the results were unpresentable because of a fatal flaw: one of the
700 clusters lumped urology together with the nervous system, anathema to NIH insiders (Talley et al. 2011). Algorithms that prevent nonexperts from fixing such obvious problems (obvious to a human, that is) will never overcome the social barriers that often hamper adoption.
These problems are also evident in supervised machine learning. Ribeiro and colleagues (2016) cite an example of a classifier to distinguish wolves from dogs that detects only whether the background is snow. More specifically for deep learning, Karpathy and colleagues (2015) look at the computational units responsible for detecting the end of phrases in natural language or computer code.
These first steps at interpretability fall short because they ignore utility. At the risk of caricature, engineers can optimize only what they can measure. How can researchers actually measure what machine learning algorithms are supposed to be doing?
QUESTION ANSWERING
A brief detour through question answering (QA) can shed light on the answer to that question. QA is difficult because it has all the nuance and ambiguity associated with natural language processing (NLP) tasks and it requires deep, expert-level world knowledge.
Completely open-domain QA is considered AI-complete (Yampolskiy 2013). Short-answer QA can be made more interactive and more discriminative by giving up the assumptions of batch QA to allow questions to be interrupted so that answers provided earlier reward deeper knowledge.
Quiz Bowl
Fortunately, there is a ready-made source of questions written with these properties from a competition known as Quiz Bowl. Thousands of questions are written every year for competitions that engage participants from middle schoolers to grizzled veterans on the “open circuit.” These questions represent decades of iterative refinement of how to best discriminate which humans are most knowledgeable (in contrast, Jeopardy’s format has not changed since its debut half a century ago; its television-oriented format is thus not considered as “pure” a competition among trivia enthusiasts).
Interpretability cannot be divorced from the task a machine learning algorithm is attempting to solve. Here, the existence of Quiz Bowl as a popular recreational activity is again a benefit: thousands of trivia enthusiasts form teams to compete in Quiz Bowl tournaments. Thus far, our algorithm has played only by itself. Can it be a good team player? And can it learn from its teammates? The answers to these questions can also reveal how useful it is at conveying its intentions.
Box 1 shows an example of a question written to reward deeper knowledge and the places in the text where our system (**) and Ken Jennings1 (*) answered the question.
A moderator reads the question word by word and the first player who knows the answer uses a signaling device to “buzz in.” If the player has the correct answer, he earns points; if not, the moderator reads the rest of the question to the opponent. Because the question begins with obscure clues and moves to more well-known information, the player who can buzz first presumably has more knowledge.
We have good evidence that Quiz Bowl serves as a good setting for conveying how computers think. Our trivia-playing robot (Boyd-Graber et al. 2012; Iyyer et al. 2014, 2015) faced off against four former Jeopardy champions in front of 600 high school students.2 The computer claimed an early lead, but we foolishly projected the computer’s thought process for all to see (Figure 1). The humans learned to read the algorithm’s ranked dot products and schemed to answer just before the computer. In five years of teaching machine learning, I have never had students catch on so quickly to how linear classifiers work. The probing questions from high school students in the audience showed that they caught on too.
___________________
1 Ken Jennings holds the record for longest winning streak—74 consecutive games in 2004—on the quiz show Jeopardy.
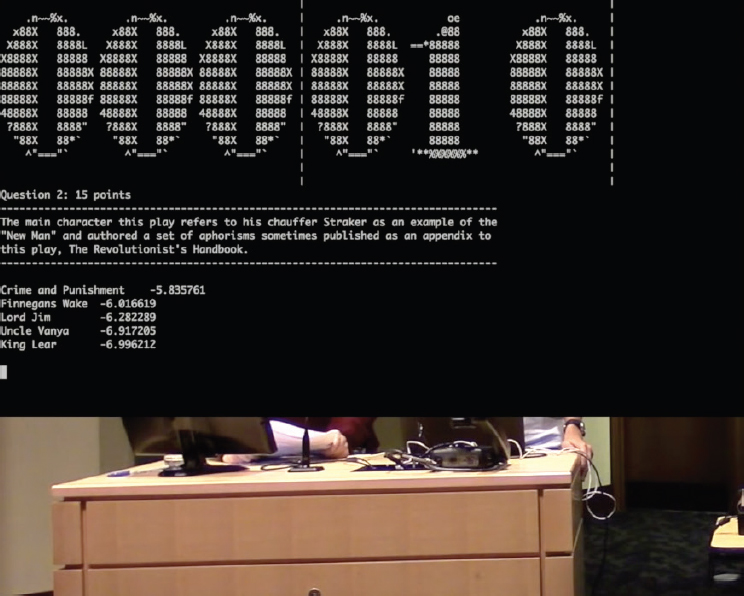
(Later, when we played against Ken Jennings,3 he was not able to see the system’s thought process and our system did much better.)
“Centaur Chess”
A growing trend in competitive chess is “centaur chess” (Thompson 2013). The best chess players are neither a human nor a computer but a computer and a human playing together. The language of chess is relatively simple; given a single board configuration, only a handful of moves are worthwhile. Unlike chess, Quiz Bowl is grounded in language, which makes the task of explaining hypotheses, features, and probabilities more complicated.
I propose a “Centaur Quiz Bowl” as a method of evaluating the interpretability of predictions from a machine learning system. The system could be part of a team with humans if it could communicate its hypotheses to its teammates.
___________________
EFFORTS TO EXPLAIN MACHINE LEARNING ANSWERS
At our exhibitions, we have shown ordered lists of predictions while the system is considering answers. This is effective for communicating what the system is “thinking,” but not why it provides an answer. Thus, a prerequisite for cooperative QA is the creation of interpretable explanations for the answers that machine learning systems provide.
Linear Approximations
Deep learning algorithms have earned a reputation for being uninterpretable and susceptible to tampering to produce the wrong answer (Szegedy et al. 2013). But, instead of making predictions based on explicit features, one of their strengths is that they embed features in a continuous space. These representations are central to deep learning, but how they translate into final results is often difficult—if not impossible—to determine. Ribeiro and colleagues (2016) propose local interpretable model-agnostic explanations (LIME): linear approximations of a complicated deep learning model around an example.
LIME can, for example, create a story of why a particular word caused an algorithm to provide a specific answer to a question. A logistic regression (a linear approximation of a more complicated predictor) can explain that seeing the words “poet” and “Leander” in a question would be a good explanation of why “John Keats” would be a reasonable answer. But individual words are often poor clues for why the algorithm suggests a particular answer. It would be even better to highlight the phrase “this poet of ‘On a Picture of Leander’” as its explanation.
Human-Computer Teamwork
I propose to extend LIME’s formula to capture a larger set of features as possible explanations for a model’s predictions. For example, “And no birds sing” is a well-known line from Keats’ poem “La Belle Dame sans Merci,” but explaining the prediction by providing a high weight for just the word “sing” would be a poor predictor. The algorithm should make itself clear by explaining that the whole phrase “no birds sing” is why it cites “La Belle Dame sans Merci” as the answer. While recurrent neural networks can discover these multiword patterns, they lack a clear mechanism to communicate this clue to a user.
Fortunately, Quiz Bowl provides the framework needed to measure the collaboration between computers and humans. The goal of a Quiz Bowl team is to take a combination of players and produce a consensus answer. It is thus the ideal proxy for seeing how well computers can help humans answer questions—if it is possible to separately assess how well the computer aids its “teammates.”
Statistical Analyses and Visualizations
Just as baseball computes a “runs created” statistic (James 1985) for players to gauge how much they contribute to a team, Quiz Bowlers create statistical analyses to determine how effective a player is.4 A simple version of this analysis is a regression that predicts the number of points a team will win by (a negative number if it is a loss) with a given set of players.
There are two independent variables we want to understand: the effect of the algorithm and the effect of visualizations. We analyze the effect of a QA system and a visualization as two distinct “team members.” The better a visualization is doing, the better its individual statistics will be. This allows us to measure the contribution of a visualization to overall team performance and thus optimize how well a visualization is communicating what a machine learning algorithm is thinking.
CONCLUSION
Combined with the renaissance of reinforcement learning (Thrun and Littman 2000) in machine learning, having a clear metric based on interpretability allows algorithms to adapt their presentations to best aid human collaboration. In other words, the rise of machine learning in everyday life becomes a virtuous cycle: with a clear objective that captures human interpretability, machine learning algorithms become less opaque and more understandable every time they are used.
Despite the hyperbole about an impending robot apocalypse associated with artificial intelligence killing all humans, I think a bigger threat is automation disrupting human livelihood. In juxtaposition to the robot apocalypse is a utopia of human-computer cooperation, where machines and people work together using their complementary skills to be better than either could be on their own. This is the future that I would like to live in, and if we are to get there as engineers we need to be able to measure our progress toward that goal.
REFERENCES
Boyd-Graber J, Satinoff B, He H, Daumé H III. 2012. Besting the quiz master: Crowdsourcing incremental classification games. Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, July 12–14, Jeju Island, Korea.
Chang J, Boyd-Graber J, Wang C, Gerrish S, Blei DM. 2009. Reading tea leaves: How humans interpret topic models. Proceedings of Advances in Neural Information Processing Systems, December 7–10, Vancouver.
Iyyer M, Boyd-Graber J, Claudino L, Socher R, Daumé H III. 2014. A neural network for factoid question answering over paragraphs. Proceedings of Empirical Methods in Natural Language Processing, October 25–29, Doha.
___________________
4 The Quiz Bowl Statistics Program (SQBS), http://ai.stanford.edu/~csewell/sqbs/.
Iyyer M, Manjunatha V, Boyd-Graber J, Daumé H III. 2015. Deep unordered composition rivals syntactic methods for text classification. In: Association for Computational Linguistics, August 15–20, Beijing.
James B. 1985. The Bill James Historical Baseball Abstract. New York: Villard.
Karpathy A, Johnson J, Li F-F. 2015. Visualizing and understanding recurrent networks. arXiv, abs/1506.02078. http://arxiv.org/abs/1506.02078.
Ribeiro MT, Singh S, Guestrin C. 2016. “Why should I trust you?”: Explaining the predictions of any classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 13–17, San Francisco.
Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow IJ, Fergus R. 2013. Intriguing properties of neural networks. arXiv, abs/1312.6199. http://arxiv.org/abs/1312.6199.
Talley EM, Newman D, Mimno D, Herr BW II, Wallach HM, Burns GAPC, Leenders AGM, McCallum A. 2011. Database of NIH grants using machine-learned categories and graphical clustering. Nature Methods 8(6):443–444.
Thompson C. 2013. Smarter Than You Think: How Technology Is Changing Our Minds for the Better. London: Penguin Group.
Thrun S, Littman ML. 2000. EW of reinforcement learning. AI Magazine 21(1):103–105.
Yampolskiy RV. 2013. Turing test as a defining feature of AI-completeness. In: Artificial Intelligence, Evolutionary Computing and Metaheuristics: In the Footsteps of Alan Turing, ed. Yan X-S. Berlin: Springer-Verlag. pp. 3–17.
This page intentionally left blank.







