
5
Exploring Approaches to Evaluating the Evidence
OVERVIEW
The focus of session 2, moderated by Ann Prentice, was on approaches to evaluating evidence in the scientific literature. This chapter summarizes the session 2 presentations and discussion, with major points highlighted here and in Box 5-1.
“Not all evidence is created equal,” George Wells said, as he began his overview of tools for assessing the quality of evidence from individual studies and systematic reviews. Based on an evaluation of many of the hundreds of available quality assessment instruments (QAIs), Wells and colleagues selected one known as SIGN 50 to use for assessing both randomized controlled trials (RCTs) and observational studies, but they believed that a nutrition-specific QAI would be even more sensitive to identifying bias in nutrition studies in particular. He explained how, using SIGN 50 as a starting point, they developed their own nutrition-specific QAI guidance for use by Health Canada. Among the many available instruments for quality assessment of nutrition studies at the systematic level review, Wells remarked that probably the most widely used for RCTs is AMSTAR, published in 2007. He noted that an updated AMSTAR2 for use with nonrandomized studies in addition to RCTs, and thus of relevance to the types of reviews being discussed at this workshop, will be the latest QAI tool to the marketplace.
“We have arrived at a stage in which the use and usefulness of systematic reviews to inform nutrition decisions are no longer debated,” Joseph Lau claimed. This was not true 10–15 years ago. Lau explained the value
of using a predefined analytic framework to help clarify systematic review questions, using his work with vitamin D as an example. Additionally, he described several available resources to facilitate global harmonization of systematic review methods, including standards for conducting systematic reviews (e.g., Cochrane Handbook for Systematic Review of Interventions) and Web-based collaborative systematic review tools such as the open-access Systematic Review Data Repository (SRDR). In closing, Lau emphasized the likelihood that different countries may need to convene their own expert panels to develop nutrient intake recommendations but with the different panels using the same systematic reviews. As he put it, “Evidence is global, decision is local.”
In the final presentation of this session, Hans Verhagen used past work with folic acid to illustrate how risk–benefit assessment can be used to estimate the public health burden associated with risk of inadequacy (at low intake levels) and/or risk of an adverse effect (at high intake levels). He and colleagues modeled the public health burden of folic acid fortification of flour at different doses and found that fortification would have both benefits and risks, including a decreased incidence of neural tube defects and an increased incidence of masked vitamin B12 deficiency. The potential public health burden associated with risk of colorectal cancer was less clear,
according to Verhagen. Overall, their results suggested that a moderate level of fortification would decrease the public health burden associated with folic acid intake. Verhagen emphasized, however, that the work of scientists is to describe risk–benefit relationships, in contrast to the work of policy makers which is to do something with that information. In fact, he noted, the government decided not to fortify with folic acid, but to supplement instead.
TOOLS FOR EVALUATING STRENGTH AND QUALITY OF EVIDENCE1
George Wells began by commenting on the presentations he had heard thus far and the studies discussed. “All of them go back to the evidence itself,” he said. “Not all evidence is created equal.”
Evaluating Evidence at the Individual Study Level
At the individual study level, in order to obtain information about an intervention or exposure, there needs to be a comparison, Wells explained. This comparison can be made using any of a number of different study designs: experimental, including RCTs; quasi-experimental; or observational, including cohort, case-control, and cross-sectional studies (Reeves et al., 2017). He agreed with Amanda MacFarlane that observational studies will likely be the mainstay of future harmonization work around chronic disease endpoints (a summary of MacFarlane’s presentation is included in Chapter 3).
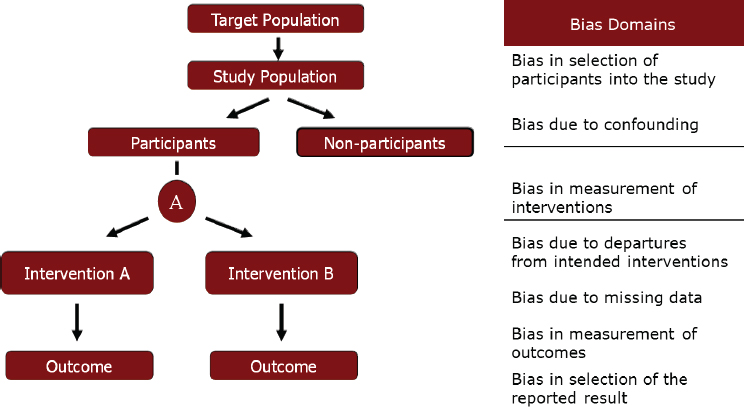
All of these different types of studies can be arranged into a levels-of-evidence hierarchy, with RCTs generally providing the strongest evidence and therefore occupying the top tier (see Figure 3-1 from MacFarlane’s presentation). Quasi-experimental studies occupy the next lowest tier, followed by cohort studies, then case-control studies, and cross-sectional studies at the bottom. The interesting feature of this evidence pyramid, Wells opined, is that, even within each tier there are different levels of quality of evidence depending on specific design features and conduct. “Different things can go wrong,” he said, with “thousands and hundreds” of biases that can affect a study.
Biases can affect a study at any point along the course of events that occur during a study, as illustrated in Figure 5-1. Wells categorized these biases into seven “buckets,” or domains, two of which can occur before an intervention, one at the time of intervention, and the other four after an
___________________
1 This section summarizes information presented by George Wells, Ph.D., director, Cardiovascular Research Methods Centre, University of Ottawa, Ontario, Canada.
SOURCE: Presented by George Wells, HMD Workshop, Rome, Italy, September 21, 2017 (reprinted with permission).
intervention or exposure. Each of these buckets contains a number of different biases, he clarified. The selection bias bucket, for example, is not just selection bias, but also includes allocation bias, case mix bias, channeling bias, and so forth. Of interest, he noted, is that the four biases that occur after an intervention has been assigned can operate in both randomized and nonrandomized study designs. The other three biases are not an issue for well-designed RCTs, only for observational studies.
The Use of QAIs to Evaluate Bias
One way to evaluate the quality of evidence of individual studies, Wells continued, is through the use of QAIs. There are hundreds of such instruments. In a 2012 review, he and colleagues (Bai et al., 2012) identified 94 QAIs for RCTs, of which 32 reached a second-level evaluation. Of those 32, Bai et al. (2012) identified SIGN 50 as the most appropriate QAI. Similarly, they identified 99 QAIs for observational studies, of which 23 reached the second-level evaluation. Of those 23, they selected, again, SIGN 50.
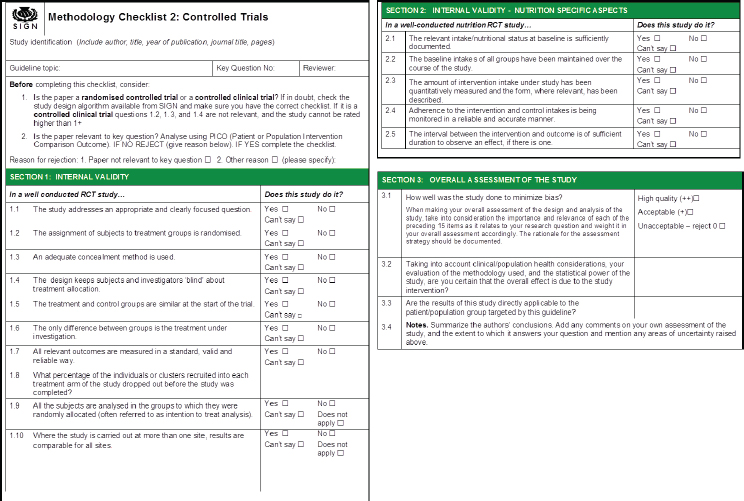
Wells explained that the SIGN 50 methodological checklist for RCTs contains 10 items for what SIGN 50 calls “internal validity.” These 10 items address, for example, how participants were randomized, how they
were concealed, and whether the assessment was done in a blinded fashion. After looking at these items, rather than assigning a number or some sort of grade, an overall assessment is made based on which of the criteria were met. If the majority of criteria were met and the results unlikely to be changed by future research, then internal validity receives a “high-quality” rating. If most criteria were met, but there were some flaws in the study with an associated risk of bias such that the conclusions of the study may change in light of further studies, then the study receives an “acceptable” rating. However, if either most criteria were not met or there were significant flaws relating to critical aspects of the study design, such that the conclusions are likely to change in light of future research, then the study receives a “low-quality” rating. In addition to the actual assessment questions, the SIGN 50 instrument also provides guidance for answering each question, Wells noted. Similarly, for case-control and cohort studies, an overall assessment is made after assessing each criterion separately. “It is a well-used approach,” Wells said.
Although he did not delve into the details of how Bai et al. (2012) conducted their review, Wells did note that very few of the 32 RCT QAIs that reached the second-level evaluation fully satisfied the seven criteria used to evaluate them (i.e., study population, randomization, blinding, interventions, outcomes, statistical analysis, funding). Similarly for the observational studies, very few of the 23 that reached the second-level evaluation fully satisfied the five criteria used to evaluate them (i.e., comparability of subjects, exposure/intervention, outcome measure, statistical analysis, funding).
In addition to QAIs, Bai et al. (2012) also evaluated evidence grading systems and selected, among the 60 identified and 23 that made it to the second-level evaluation, the Grading of Recommendations Assessment, Development and Evaluation (GRADE) approach.
Health Canada’s Nutrition-Specific QAI Project
MacFarlane and her colleagues at Health Canada, along with Wells and his colleagues at the University of Ottawa, were currently (at the time of this workshop) working on developing a nutrition-specific QAI. The genesis of this work was the “Options Report” (Yetley et al., 2016). It became quite apparent during that process, Wells recalled, that the existing QAIs were not sensitive enough to evaluate nutrition evidence relating to chronic disease endpoints for Dietary Reference Intakes (DRIs), nor were they sensitive enough to determine which studies had high bias versus low bias. He and others felt that a nutrition-specific QAI would be useful, as it would be made more sensitive by taking into account the specific covariates, confounders, and sources of error unique to nutrition.
Wells described in detail the seven critical steps he and his Health Canada and University of Ottawa colleagues have taken to develop a nutrition-specific QAI. First, they established some general development principles. They wanted to conduct the process in a simple way that allowed them to incorporate components of nutrition studies that would make the tool more sensitive. They decided they would do this through what Wells called “bolt on.” That is, they would “bolt on” to an existing QAI-specific question related to nutrition. They would also build guidance for the nutrition-specific questions, similar to the guidance that existed for the SIGN 50 internal validity questions. They planned to borrow all of the same psychometric properties of the original QAI.
Second, they needed to identify which QAI to use. According to Wells, upon examining the newest literature, their opinion about SIGN 50 did not change (i.e., based on their Bai et al. [2012] review of QAIs), and they decided to use it.
Third, they conducted a scoping review to identify which nutrition-specific appraisal items to include in the new tool, building on the seven nutrition-specific items proposed by Chung et al. (2009a) to consider based on the concern that failure to consider these items could lead to a biased synthesis or interpretation of results in a nutrient-related systematic review. There was then some discussion about the items in Washington, DC, and then a panel was convened to refine the list of proposed items.
Fourth, they decided on five nutrition-specific items for RCTs, five for cohort studies, and two for case-control studies. Specifically, for RCTs, they decided, first, that the relevant intake nutritional status at baseline should be documented and taken into account. Second, they decided that the background intakes of all groups should be maintained over the course of the study. Third, they decided that the amount of intervention intake under study should be quantitatively measured and the form, where relevant, described. Fourth, adherence to the intervention and control intakes should be monitored in a reliable and accurate manner. And fifth, the interval between intervention and outcome should be of sufficient duration to observe an effect if there is an effect to observe. The five items for cohort studies were similar, Wells said.
The fifth step in their development of a nutrition-specific QAI was to format the questions. For RCTs, for example, they kept the same general quality appraisal items as the original SIGN 50 QAI and then, Wells said, they “bolted on” the nutrition-specific items. They did the same for cohort and case-control studies.
Sixth, they developed guidance for completing the questionnaire for each newly added item. Adding guidance was an important part of the process, Wells emphasized. Failure to provide good guidance is, he said, “usually the failure of these types of instruments.”
Finally, they conducted a reliability and validity check. They selected 10 published studies of RCTs of nutrient-health outcomes and asked two independent reviewers to apply the newly developed QAI for RCTs to each of these 10 studies. Wells explained that the purpose of this step was to evaluate the reliability of the reviewers’ assessments, determine validity of the QAI, and identify the effect of the additional information provided by the nutrition-specific items. They did the same for the cohort and case-control QAIs.
The end result of this process is illustrated in Figure 5-2, although only the item checklist and overall assessment portions are shown, not the accompanying guidance. The guidance took an enormous amount of time to develop, Wells remarked. It includes both overall information on assessing intake and nutritional status, as well as several other concepts, plus information for each individual question.
According to Wells, the status of this project (at the time of the workshop) was that both the forms and guidance had been developed for RCTs, case-control, and cohort studies. In addition, for the RCT QAI, testing had
SOURCES: Presented by George Wells, HMD Workshop, Rome, Italy, September 21, 2017 (adapted from SIGN, 2015).
been completed, and modifications were being made. The cohort and case-control QAIs were still being tested. Manuscripts were also being prepared for submission.
Risk of Bias
Today, the current trend when examining quality of evidence is to examine risk of bias, Wells continued. The difference between risk-of-bias instruments and QAIs is subtle, he said. Risk of bias usually involves examining one particular outcome and anything that can go wrong that will shift the estimate of that outcome; whereas, QAIs are more like quality appraisals. That is, they examine how explicit and transparent the methods are and apply the rules of evidence to factors such as internal validity, adherence to reporting standards, conclusions, and generalizability. In his opinion, there is a need for both types of tools.
As an example of a risk-of-bias tool being used to evaluate RCTs, Wells mentioned the Cochrane Risk of Bias Tool, included in the Cochrane Handbook for Systematic Reviews of Interventions (“the Cochrane handbook”) (Higgins and Green, 2011). The tool assesses six domains of bias, judging each as low, unclear, or high risk.
An example of a risk-of-bias tool being used to evaluate nonrandomized studies is the ROBINS-1 tool (Sterne et al., 2016). It is a little bit more involved, Wells remarked, and difficult to fill out. It would be particularly difficult to fill out for a systematic review. In his opinion, its best use may be for individual observational studies. It includes the seven bias domains mentioned previously and listed in Figure 5-1, with signaling questions pertaining to each particular bias. Signaling questions, Wells explained, are factual questions that lead the user to respond “yes,” “possibly yes,” “possibly no,” or “no.” There is also free text to help users decide their answers. Then, an assessment of each bias is made by looking across all the signaling questions for that bias. One can also examine the direction of each bias. Finally, by combining all the biases, one can make a judgment about the overall risk of bias as either low, moderate, serious, or critical.
Evaluating Evidence at the Systematic Review Level
At the systematic review level, one could collate and assemble into summary tables or figures all of the QAIs and risk-of-bias assessments for all of the individual studies. Wells showed a couple of what he considered classical examples of these summary tables and figures from the Cochrane hand-
book. Or, one could use a measurement instrument known as AMSTAR to assess the methodological quality of the review. In the Bai et al. (2012) review of QAIs, AMSTAR was selected as the most appropriate QAI for systematic reviews. Although AMSTAR is widely used (Shea et al., 2007), it was not designed to handle nonrandomized studies.
An updated AMSTAR2 that will allow for evaluation of nonrandomized studies, in addition to RCTs, will be the latest QAI tool to the marketplace, according to Wells. Described in Shea et al. (2017), AMSTAR2 was developed by a global group. The tool asks about study selection and data exclusion, risk of bias, sources of funding, inclusion of nonrandomized studies, issues around heterogeneity, and other items.
Next Steps
Wells summarized several recent developments: the Reeves et al. (2017) taxonomy of individual level studies (i.e., experimental, quasi-experimental, and observational); publication of AMSTAR2 (Shea et al., 2017), which, because it will cover nonrandomized studies, will be important for the types of reviews being discussed at this workshop, Wells predicted; and the ROBINS-1 risk-of-bias tool, which was specifically designed for nonrandomized studies and thus, again, is relevant to harmonization, in Wells’s opinion.
Currently in development, but ready soon, is the nutrition-specific QAI that Wells and colleagues have been developing for RCTs, cohort studies, and case-control studies (i.e., the SIGN 50 bolt-on). Also currently in development is a nutrition-specific QAI for cross-sectional studies, which will be analogous to the SIGN 50 QAI, but requires more than a simple “bolt-on;” and a revised risk-of-bias tool for RCTs (i.e., by the Bristol Appraisal and Review of Research group at the University of Bristol, United Kingdom).
Finally, in planning are de novo (i.e., not bolt-on) nutrition-specific QAIs for RCTs, cohort studies, case-control studies, and cross-sectional studies; a nutrition-specific risk-of-bias tool (i.e., a bolt-on tool); and a nutrition-specific tool for evaluating systematic reviews (i.e., an AMSTAR2 bolt-on).
In conclusion, Wells reflected on a lesson learned from his involvement in these recent and current developments, which is the value of developing a nutrition-specific QAI from the start (i.e., not as a bolt-on). Such a tool may take longer to develop, he said, but it could streamline the actual evaluation process. Evaluating a nutritional intervention is not the same as developing a drug or device.
GLOBAL SYSTEMATIC REVIEWS: HOW CAN IT BE DONE?2
Joseph Lau began his talk by listing four assumptions. First, he said, “We have arrived at a stage in which the use and usefulness of systematic review to inform nutrition decisions is no longer debated.” This was not true 10 to 15 years ago. Second, much of what has been learned about the methods and processes of systematic reviews comes from the health care arena, but that knowledge can be applied to the nutrition world. “We should try to minimize reinventing the wheel whenever possible,” he said. Third, evidence is global, but decisions are local. “Because we are all human,” he explained, the same evidence can be used to inform nutrient intake recommendations. Finally, conducting a systematic review is laborious and requires a significant amount of resources, including expertise, time, and money; thus, it is desirable to minimize replication of effort and to collaborate and share resources. Lau then went on to discuss systematic reviews in detail, beginning with the importance of such reviews and the value of a harmonized systematic review protocol.
Applying Systematic Reviews and a Harmonized Protocol to Review Evidence
In a 2005 World Health Organization (WHO)/Food and Agriculture Organization (FAO) report on nutrient risk assessment, Lau and Alice Lichtenstein contributed a discussion paper titled “Evidence-Based Approach to Nutrient Hazard Identification” (WHO/FAO, 2005). At that time, Lau recalled, there was growing international interest in the use of nutrient risk assessment to identify the tolerable upper level of intake (UL) for nutrients and related substance, but also recognition of the need for a common approach. Different authoritative bodies had come up with different ULs, including for vitamin A (i.e., in relation to bone health), which Lau and Lichtenstein were asked to use as an example in their paper. The U.S. Institute of Medicine (IOM) recommended (in 2001) 3,000 micrograms of vitamin A per day (µg/d) for adults; the European Union (EU) Scientific Committee on Food recommended (in 2002) that postmenopausal women restrict their intake to 1,500 µg/d; and the United Kingdom (UK) Expert Group in Vitamins & Minerals suggested (in 2003) that daily total intake should not exceed 1,500 µg/d.
Lau and Lichtenstein compared the evidence that these different groups had examined, the questions they had asked, and the methodologies they applied. For example, Lau described how they categorized the approxi-
___________________
2 This section summarizes information presented by Joseph Lau, M.D., professor, Center for Evidence-based Medicine, School of Public Health, Brown University, Providence, Rhode Island.
mately 30 references used in the three reports to justify or support their recommendations by type of study: in vitro (e.g., cell or bone culture), animal, or human. They found that the EU study cited many of all three types of studies, the UK report cited several animal studies and many human studies, and the U.S. report cited mostly human studies and one animal study. Thus, different work groups used different sets of studies. Moreover, Lau added, none described how they selected their studies, that is, what their inclusion/exclusion criteria were, or how the included studies were used to support their recommendations.
Based on their examination, Lau and Lichtenstein concluded the following:
- Lack of a preanalytical framework affected the selection of specific outcomes to assess evidence.
- Lack of a common set of research questions and review criteria led to the selection of different studies.
- Use of different types of studies (i.e., in vitro, animal, human) and the different emphasis placed on the evidence might have led to different interpretations of the data and characterization of the hazard.
- The composition of the work groups may have been different, with different groups of experts weighing evidence differently (e.g., one group may have had more toxicologists than another).
A Representative Systematic Review Process
To illustrate a representative systematic review process, Lau described the “evidence report” employed by the Agency for Healthcare Research and Quality (AHRQ) for the past 20 years. The process involves five main steps:
- Prepare the topic—refine questions and develop an analytic framework
- Search for and select studies—identify eligibility criteria, search for relevant studies, and select evidence for inclusion
- Abstract data—extract evidence from studies and construct evidence tables
- Analyze and synthesize data—assess quality of studies, assess applicability of studies, apply qualitative methods, apply quantitative methods such as meta-analysis, and rate the strength of a body of evidence
- Present findings
Not included in this list of steps, Lau pointed out, are identifying a systematic review team, forming a technical expert panel, and performing peer review of the draft report. Importantly, he added, the end product, the evidence report itself, does not constitute either clinical or policy recommendations. “It is just information,” he said, that is interpreted and used by the appropriate committee to draft recommendations.
A well-conducted systematic review takes about 1 year, according to Lau. The literature search, which includes both the screening of abstracts and extracting data from primary articles, occupies the largest amount of time (i.e., 6 months of a year-long review). Another large amount of time is spent on peer review and revision of the draft paper. In the United States, if conducted through the Evidence-based Practice Centers (EPCs) Program of the AHRQ, a review may cost anywhere from $300,000 to $500,000.
The Use of an Analytic Framework to Help Identify Systematic Review Questions
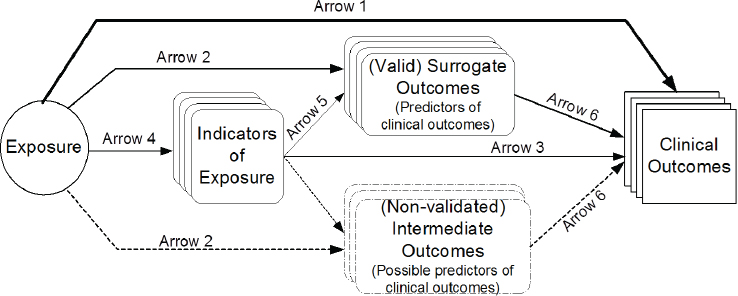
Lau emphasized the value of using an analytic framework (e.g., a causal pathway) to clarify and generate systematic review questions. Constructing such a framework involves formulating and organizing relevant questions into a model that analyzes all the effects and interactions between intervention or exposure and outcomes (see Figure 5-3). The value of such a framework, Lau explained, is that it helps to define the scope of the evidence and to construct an evidence map of the many questions that potentially could be addressed. “It gives you the lay of land of the literature to see whether a systematic review is even possible,” Lau said. If there is not enough evidence, then money should not be invested in a systematic review; on the other hand, if there is too much evidence, one should probably find a way to reduce the scope of the work. It is valuable in other ways as well, Lau continued: It uses experts efficiently; the framework and process can be open to public review, thereby providing transparency and minimizing biases; it can help to highlight what aspects are known and unknown; it can clarify which study designs (e.g., experimental or observational) may be best to address specific questions; and it can be used to facilitate future updates of systematic reviews as new evidence emerges.
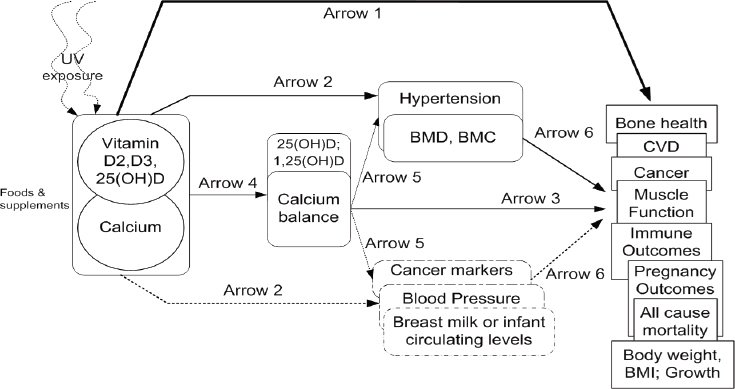
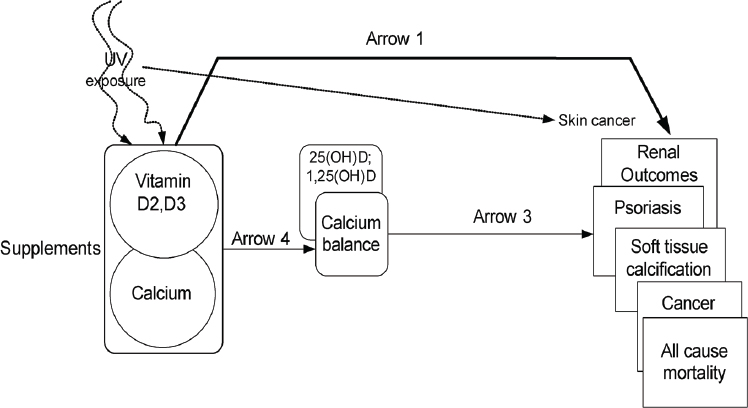
As an example of how an analytic framework has been used to inform DRI development, Lau described the framework he and his team at Tufts University provided to IOM in 2009 for vitamin D and/or calcium and associated health outcomes (see Figure 5-4). Lau noted the framework also captured ultraviolet exposure and that an expert panel was convened to help define which health outcomes to study. A strategic question in the framework (illustrated by arrow 1 in Figure 5-4) was: What is the effect of vitamin D, calcium, or combined vitamin D and calcium intake on clinical
SOURCES: Presented by Joseph Lau, HMD Workshop, Rome, Italy, September 21, 2017 (reprinted with permission, Russell et al., 2009).
NOTE: BMC = bone mineral content; BMD = bone mineral density; BMI = body mass index; CVD = cardiovascular disease; UV = ultraviolet radiation.
SOURCES: Presented by Joseph Lau, HMD Workshop, Rome, Italy, September 21, 2017 (reprinted with permission, Chung et al., 2009b).
SOURCES: Presented by Joseph Lau, HMD Workshop, Rome, Italy, September 21, 2017 (reprinted with permission, Chung et al., 2009b).
outcomes, including growth, cardiovascular diseases, weight outcomes, cancer, immune function, pregnancy or birth outcomes, mortality, fracture, renal outcomes, and soft tissue calcification? A second question (illustrated by arrow 2 in Figure 5-4) was: What is the effect of vitamin D, calcium, or combined vitamin D and calcium on surrogate or intermediate outcomes, such as hypertension, blood pressure, and bone mineral density? Additionally, a separate analytic framework was constructed for safety-related outcomes related to the UL, as illustrated in Figure 5-5.
Using these two analytic frameworks, a technical expert panel specified the PICOS (population, interventions/exposures, comparators, and outcomes of interest) selection criteria for each question. Of this step in general, Lau said that it “could be very involved.” He shared a partial list of the PICOS criteria specified for the vitamin D and/or calcium frameworks. For example, the population criteria included generally healthy people with no known disorders, studies that enrolled fewer than 20 percent of patients with common diseases, and any population for adverse effects of high intake. The outcome criteria included 17 outcomes selected by the technical expert panel.
With this information, the systematic review team was then able to conduct its literature search. They reviewed more than 16,000 primary study citations and ended up selecting 165 of these, plus some additional systematic reviews. Specifically, they identified 16,733 citations in a MEDLINE
and Cochrane Central database search for primary studies published between 1969 and April 2009, and 1,746 citations in a MEDLINE, Cochrane Database of Systematic Reviews, and the Health Technology Assessments database search for systematic review articles published before December 2008. Of these, they retrieved 584 primary study articles for full-text review and 68 systematic review articles for full-text review. Of these, they reviewed 165 primary study articles (60 RCTs, 3 nonrandomized controlled trials, and 102 cohort or case-control studies) and 11 systematic reviews.
Without going into detail regarding the specifics of the 2009 vitamin D/calcium review, Lau explained that, after a literature search and selection is completed, the next step is to report the evidence. Data are extracted from each study and entered into evidence tables and summaries of each study (i.e., outcomes, study design) are entered into summary tables. From these, figures and graphs can be constructed. Additionally, meta-analyses can be conducted, if appropriate. A narrative, highlighting features and limitations of the review in answering the question, is also included. Finally, Lau reiterated that an evidence report in itself does not make recommendations.
Global Harmonization of Systematic Reviews
Several resources are available to facilitate the global harmonization of systematic reviews. First among these are standards that exist for the conduct of a systematic review. Lau mentioned AHRQ’s very detailed Methods Guide for Effectiveness and Comparative Effectiveness Reviews (AHRQ, 2008–2017); Cochrane’s Handbook for Systematic Review of Interventions, also a very detailed manual, he noted (Higgins and Green, 2011); and the IOM’s 2011 Finding What Works in Health Care: Standards for Systematic Reviews (IOM, 2011b). There are also standards for reporting systematic reviews and meta-analyses. Additionally, although not part of a review of evidence, Lau mentioned standards for clinical practice guidelines.
In addition to these standards, there are several Web-based collaborative systematic review tools that could be helpful to facilitating a harmonized approach. One of these is the SRDR (srdr.ahrq.gov), of which Lau disclosed that he had been the director since 2010. He described the depository as an open access systematic review tool that can be used collaboratively. It creates data abstraction forms, collects data, produces reports, and interfaces with other systematic review tools, such as the Data Abstraction Assistant. Users voluntarily contribute and share data used in systematic reviews so the data can be reused for updated reviews and so the transparency of the systematic review process is improved. The SRDR was developed and is currently (at the time of this workshop) maintained
by Brown University’s EPC. Launched in 2012, the depository also involves an international governance board.
The Structure of a Systematic Review
Based on the recently released National Academies report Redesigning the Process for Establishing the Dietary Guidelines for Americans (NASEM, 2017b), Lau offered some suggestions on structure for ensuring high-quality systematic reviews. First among these is that there should be an oversight body to provide strategic direction. This could be the sponsor, he noted. Second, already there are what are known as nutrient intake recommendation committees, which make recommendations informed by systematic reviews. Some of these committee members, Lau suggested, should be part of the technical expert panel. Third, the technical expert panel assists the systematic review team in refining critical questions and helps to develop review criteria. Importantly, Lau emphasized, to minimize bias, members of the technical expert panel should not participate in the actual systematic review. Fourth, the systematic review team should be a group that independently carries out the systematic review once a protocol has been developed. Finally, all reviews should be reviewed by peers.
Regarding membership on a systematic review team, Lau cited Finding What Works in Health Care: Standards for Systematic Reviews (IOM, 2011b), where it was stated that the teams should be multidisciplinary and include methodologists, content experts, librarians or information scientists, statisticians, and additional members as needed, such as editors and research assistants, and that members should be free of conflict of interest.
Closing Thoughts
Lau shared several closing thoughts. First, he said, “Evidence is not static.” Nutrient intake recommendations may need to be updated. Thus, there is a need to monitor new evidence and to have a process for updating systematic reviews and nutrient intake recommendations. Second, repeating one of his opening statements that evidence is global, but decisions are local, he suggested that different countries convene their own expert panels to come up with nutrient intake recommendations, using the same framework and evidence base but incorporating local dietary patterns and other factors. Third, he emphasized that his presentation focused on the synthesis of evidence, not on decision making around recommendations. Finally, he emphasized the importance of separating tasks and using separate expert groups to review the evidence and interpret the results.
RISK–BENEFIT ASSESSMENT OF FOODS IN A EUROPEAN PERSPECTIVE3
Across the globe, it is believed that “food should be safe,” Hans Verhagen began. Yet, humans are inclined to take risks, he said. Some people dare to smoke, some buy lottery tickets or stock shares, while others practice dietary habits that are not fully compatible with dietary recommendations. He elaborated, “We are inclined to take risks if we get something out of it—something better.”
Before presenting his overview of risk–benefit assessment in relation to nutrition and food safety, using his past work at the Netherlands National Institute for Public Health and the Environment (RIVM) with folic acid as an example, Verhagen noted that the European Food Safety Authority (EFSA) has done considerable work in the area of dietary reference values (DRVs), with DRVs for only three nutrients still outstanding (chloride, sodium, sugars). He referred workshop participants to EFSA’s recently published summary report of completed DRV reports (EFSA, 2017a). Additionally, in 2006, EFSA completed an overview of ULs established by either EFSA or its predecessor, the EU Scientific Committee for Food. Those UL values are still valid today, with only a few updates having been proposed since 2006.
Dietary Reference Values: Risk–Benefit Assessment
To illustrate risk–benefit assessment, Verhagen considered a hypothetical micronutrient and a population distribution of daily intake for that nutrient. As shown in Figure 5-6a, where the average intake of this hypothetical micronutrient is 120 (units unspecified), there is a small percentage of people, say 5 percent, whose intake is low. “They may constitute a public health risk,” Verhagen said. Because 5 percent of a population is a lot of people, policy makers might decide to do something to reduce the public health risk. For example, one might decide to increase intake through fortification or supplementation. But then, as shown in Figure 5-6b, while the initial public health risk will have been solved by increasing intake of the problem micronutrient, another problem will have been created: Now there is a small percentage of the population, in this example, 5 percent, whose intake is so high that, again, there is a public health risk. A combination of these two scenarios, Verhagen explained, illustrates risk–benefit (see Figure 5-6c).
___________________
3 This section summarizes information presented by Hans Verhagen, Ph.D., head, Risk Assessment and Scientific Assistance Department, European Food Safety Authority (EFSA), Parma, Italy.
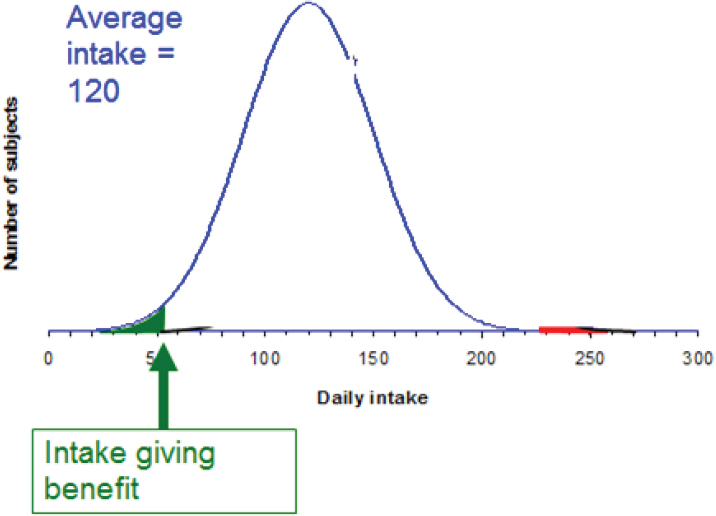
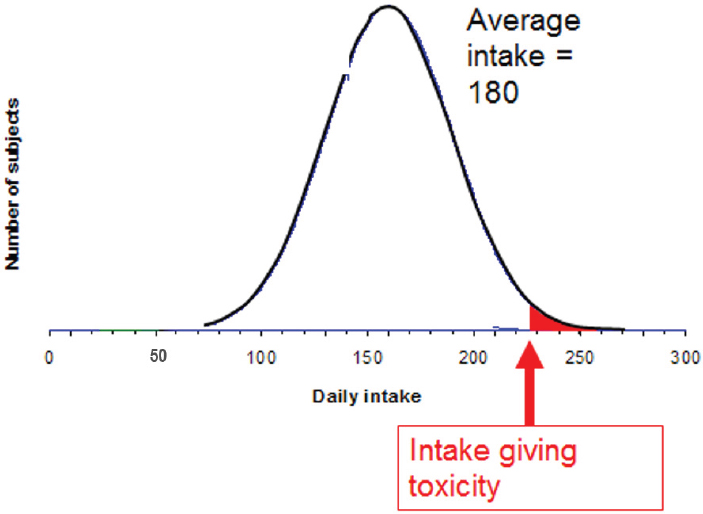
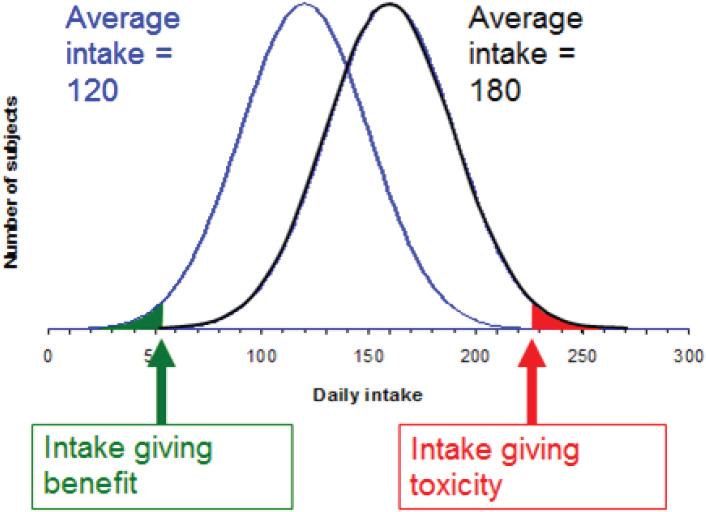
FIGURE 5-6A–C Population distribution (y-axis) versus intake (x-axis; units unspecified) for a hypothetical nutrient. Subjects receiving daily intake below the “intake giving benefit” threshold are at risk because of their low intake (green area of curve); subjects receiving daily intake above the “intake giving toxicity” threshold are at risk because of their high intake (red area of curve).
SOURCE: Presented by Hans Verhagen, HMD Workshop, Rome, Italy, September 21, 2017.
Verhagen emphasized the difference between the role of the scientist in risk–benefit assessment versus the role of the policy maker. “As a scientist, you describe the curves,” he said, referring to the curves in Figure 5-6, and “as a policy maker or politician, you make the decisions on the basis of the scientific information.”
As an example of an actual nutrient risk–benefit assessment, Verhagen described his past work on folic acid, when he and colleagues at RIVM examined the huge database on folic acid in the literature (Hoekstra et al., 2007). They found, among the 30 to 40 potential effects reported, only a handful had sufficient evidence. Namely, they found that it is well established that folic acid can prevent neural tube defects. It is also well established that folic acid can also mask a vitamin B12 deficiency, typically in older age. A masked B12 deficiency, in turn, may lead to neurological
damage that can be irreversible if maintained too long. Additionally, it is well established that folic acid can change the incidence of colorectal cancer, either increasing or decreasing it. Finally, folic acid intake can overcome a folate deficiency.
After identifying these handfuls of effects with well-established evidence, Hoekstra et al. (2007) used data from the Netherlands to calculate the expected public health effects of fortifying flour with different amounts of folic acid, from 70 micrograms (µg) through 420 µg per 100 grams (g). They found that, on a yearly basis, at 70 µg/100 g of flour, there would be 83 fewer incident cases of neural tube defects, amounting to a 37 percent decrease; an additional 53 people with masked vitamin B12 deficiencies, or a 1 percent increase; and 405 fewer cases of colorectal cancer, a 4.1 percent decrease. In terms of disability-adjusted life years (DALYs), neural tube defect DALYs would increase by 5,474, masked B12 deficiency DALYs would decrease by 53, and colorectal cancer DALYs would increase by 2,217, with many uncertainties.
Thus, the public health effects related to neural tube defects and colorectal cancer would represent a gain, but the effects related to masked B12 deficiency would be a loss. Additionally, for DALYs, Table 5-1 shows a clear dose–response relationship for all three effects, with the effects becoming more pronounced at higher fortification levels.
Verhagen emphasized that while there is a great deal of uncertainty especially around the colorectal cancer estimates shown in Table 5-1 a moderate fortification level of 70 µg would decrease the public health burden associated with folic acid intake. Additionally, he repeated that it is the scientists’ job to present the evidence, but it is “at the discretion of the authorities to make a decision.” In fact, the Netherlands government decided not to fortify in this case, but to supplement.
| Level of Folic Acid Fortification (micrograms [µg] per 100 g) | ||||
|---|---|---|---|---|
| 70 | 140 | 280 | 420 | |
| Neural tube defects | 5,474 | 7,710 | 9,812 | 10,855 |
| Masked B12 deficiency | –53 | –76 | –120 | –165 |
| Colorectal cancer | 2,217 | 4,146 | 167 | –21,740 |
| Total | 7,662 | 11,812 | 9,899 | –11,006 |
SOURCES: Presented by Hans Verhagen, HMD Workshop, Rome, Italy, September 21, 2017 (Hoekstra et al., 2007, with permission from Elsevier).
Conducting Risk–Benefit Analysis: Things to Keep in Mind
When toxicologists think about risk–benefit, they think about it differently than nutritionists do, Verhagen continued. Toxicologists typically calculate things intended to not happen, he said. They do this by conducting animal studies and identifying no-observed-adverse-effect-levels (NOAELs) for food additives, pesticides, and other exposures. NOAELs are dose levels at and below which an effect no longer occurs. Then, so these values can be translated to humans, a safety factor is applied and an acceptable daily intake (ADI) determined. The ADI is an intake at which nothing happens. The safety factor is typically 100, and the ADI is typically two orders of magnitude below the NOAEL. According to Verhagen, this is the same thinking that is used to set safe ULs, although not by applying a safety factor of 100.
In contrast, he continued, “a nutritionist argues the other way around. In nutrition, we want something to happen.” Rather than calculating the absence of an effect, a nutritionist calculates effects that will happen. This difference is illustrated in Figure 5-7, where a risk–benefit assessment of,
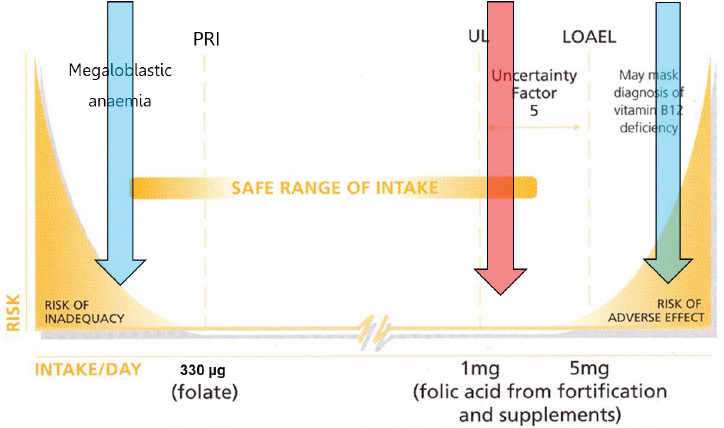
NOTE: LOAEL = lowest-observed-adverse-effect-level; PRI = population reference intake; UL = upper limit.
SOURCES: Presented by Hans Verhagen, HMD Workshop, Rome, Italy, September 21, 2017 (modified with permission, European Responsible Nutrition Alliance).
in this case, folic acid or folate requires comparing “risk of inadequacy” effects at the low end of the intake range (i.e., folate deficiency, neural tube defects) with “risk of adverse effect” effects at the high end (i.e., masking vitamin B12 deficiency). Too often, Verhagen said, people make comparisons with the UL, represented by the red arrow in the figure. But, again, the UL is set at a point at which nothing happens.
Verhagen mentioned several recently completed large risk–benefit assessment projects in Europe (i.e., Quality of Life–Integrated Benefit and Risk Analysis, Benefit–Risk Analysis for Foods, Benefit–Risk Analysis for Food: An Iterative Value-of-Information Approach, and Best Practices for Risk–Benefit Analysis), then posed the question, “What are the main outcomes of these big projects?” First, he said, “When doing risk–benefit, always think of at least two scenarios.” For example, compare fortification with no fortification or sugar-sweetened beverages with artificially sweetened beverages. Second, use a common currency to describe the health effects. It could be DALYs, deaths, incident cases, or euros spent on health care. But it should be the same, he said. And third, conduct the analysis in a tiered approach in order to make it cost-effective.
In the literature, risk–benefit analysis sometimes shows up in disguise, for example, as risk ranking (e.g., WHO, 2015b), which Verhagen said is typically used for microbiological contamination, or as a risk–risk comparison. As an example of the latter, he mentioned a 2004 RIVM report on the public health burden of food safety versus an unhealthy diet (e.g., eating too many calories, eating the wrong types of foods), where it was found that unsafe foods contribute only about 1 percent to the public health burden (van Kreijl et al., 2004). Knowing this, in Verhagen’s opinion, the best approach to increasing public health is to focus on the effect of unhealthy diets, rather than on the effect of unsafe foods. However, again, he repeated that the scientist’s role is to offer the science. It is up to governmental policy makers to decide which risk to take on.
Improving Risk–Benefit Assessment
A couple of very recent developments in EFSA could contribute to improving risk–benefit assessment in the future, Verhagen opined. He mentioned a recently published report on biological relevance and weight of the evidence, specifically on the identification of effects that truly contribute to the toxicologist-defined adverse effects (EFSA, 2017b). Verhagen explained that sometimes a plethora of information is available, with not all studies pointing in the same direction. This does not mean that if there is one study that points in a different direction than another 999 studies, that one study should receive the same weight as the others. According to Verhagen, this same weight of evidence approach as described in EFSA
(2017b) can also be used to identify those effects that truly contribute to nutritionist-defined beneficial effects.
In addition to EFSA (2017b), EFSA was nearing completion of its uncertainty guidance at the time of this workshop.4 Verhagen recalled a couple of recent developments in EFSA where clarity around uncertainty contributed to a better understanding of the message. He opined that consideration of uncertainty would be helpful in the setting of dietary reference values.
Finally, he mentioned what he considered one of the most important EFSA publications in the last 15 years: its scientific report on its PROMETHEUS (Promoting Methods for Evidence Use in Scientific Assessments) approach (EFSA, 2015). When conducting a risk–benefit assessment, the first step is to design a path, or process, he explained. The PROMETHEUS approach is a way to design this path such that after an assessment has been completed, the outcome would be essentially similar if another team of scientists were to run the same assessment at a later point. The approach leads to “good and robust science,” he said.
In closing, Verhagen encouraged use of risk–benefit assessment in the future setting of dietary reference values.
DISCUSSION
Following Verhagen’s presentation, he, Wells, and Lau participated in a discussion with the audience. This section summarizes that discussion.
Risk–Benefit of an Unhealthy Diet Versus Food Contamination
Peter Clifton asked about the balance between an unhealthy diet, which potentially has a very large effect, and food contamination, which potentially has a small effect. However, while the effect of food contamination is potentially small, it is also immediate and observable. “The person cannot escape it,” he said, creating “quite a bit of burden” that can be “actually very serious.” In contrast, even though recommendations may suggest that people change their unhealthy diets, the actual translation into action and the benefit resulting from this translation is much smaller in reality than it could be potentially.
Verhagen agreed that, in fact, the public health burden of food safety issues, particularly those related to microbiology, can be acute. However, based on calculations that served as the basis for the van Kreijl et al. (2004) report that he had mentioned, most of these infections last 1 or 2 days,
___________________
4 The final version of this guidance was published while this proceedings was being prepared; it can be viewed at https://www.efsa.europa.eu/en/efsajournal/pub/5123 (accessed April 25, 2018).
possibly a week, then they are over, so the overall public health burden is relatively low. But there are other calculations, he acknowledged, where food contaminants contribute to lifelong effects, namely cancer. Rather than focusing on individual acute effects, he encouraged taking a population-based approach when balancing the different types of outcomes.
Dietary Reference Values: Considering Additional Health Benefits, Not Just Acute Effects of Deficiencies
James Ntambi commented on the additional beneficial health effects of increasing nutrient intake and wondered if there is any particular nutrient recommendation that has actually yielded a beneficial effect on a global scale. Verhagen responded by, first, clarifying that his interpretation of Ntambi’s comment was that there may be additional health benefits to take into consideration when setting nutrient reference values, that is, benefits beyond simply the overcoming of deficiencies. Verhagen recalled that when he first became active in this field, dietary reference values were focused mostly on acute effects, such as scurvy for vitamin C. But gradually, over time, the focus shifted more toward subclinical chemical effects. Most recently, several dietary reference value studies have also begun to consider additional public health effects. He cited potassium as an example.
The Use of RCTs in Nutrition Studies
Regarding the hierarchies of evidence presented by Wells, with RCTs at the top (also, see the summary of MacFarlane’s presentation in Chapter 3), Caryl Nowson commented on the fact that RCTs were designed for drug trials. When RCTs are used for nutrition trials, the doses tend to be higher because supplements are being used. For example, she has run calcium trials where participants were administered not 300 milligrams, but 1,000 milligrams. Plus, according to Nowson, none of the very few long-term trials of dietary patterns that have been run have been blinded. She asked Wells to comment on the use of RCTs for nutrition studies.
Wells agreed that RCTs are geared toward drugs, as well as devices and sometimes programs. In his opinion, one of the Achilles’ heels of RCTs is the precise, pristine way they move forward, particularly efficacy trials, such as the use of a high dose of calcium in a particular population. An effectiveness trial, in contrast, would be “more real world,” he said, and would apply more broadly across the population. However, even then, because a study population is never exactly the same as the target population, generalizability will always be a problem.
Lau disagreed with the notion that RCTs are not appropriate for nutrition studies. If they are well conducted, they are just as appropriate and
could be very useful, in his opinion. “However,” he said, “the interpretation of the results is more problematic because a lot of information is not collected.”
Evidence for Risk
Patrick Stover questioned the standard of evidence for a requirement, or benefit, versus an upper level or risk. He mentioned the very well-established evidence for the role of folic acid in neural tube defect prevention. In contrast, many authoritative bodies have concluded that there is no definitive risk of colorectal cancer, although the data indicate concern and that there should be a research agenda to establish whether or not there is a risk. “How should that bar be different for risk?” he asked.
Lau replied that, when evidence is summarized, there is always uncertainty around the estimates. This uncertainty provides guidance for how strong a recommendation should be, he said. It is not just the magnitude of effect, but also the confidence interval, representing uncertainty, that should be part of decision making. The outcomes of interest and how outcomes are weighted also matter, he added.
Verhagen remarked that, in Europe, they have taken a grading approach to assessing health claims on food products. He described it as a simple, three-option approach: either a claim is substantiated by the evidence, a claim is not substantiated by the evidence, or there is insufficient evidence. Members of the European Commission have decided to accept only those health claims fully substantiated by the evidence. He mentioned the weight-of-evidence approach that he had described during his presentation, as well as the PROMETHEUS approach, as additional useful approaches to evaluating evidence.
Systematic Review Depository
Mary L’Abbé remarked that there are two approaches to applying inclusion/exclusion criteria in a systematic review. One could accept all studies initially and then conduct the quality assessment later in the process, or one could enter into review only those studies with certain qualities. She asked the speakers to comment on these different approaches.
Lau responded that, in an ideal world with unlimited resources, “you would do everything.” He suggested starting with the most comprehensive, broadest review. But he also acknowledged that, because scientists live, he said, “in the real world,” there are time and resource constraints. Evidence mapping can provide a sense of the scope of work that a review will require before actually extracting data. If the work appears too great, then one can constrain the review or modify the protocols. He emphasized that
systematic reviews are not static and that the act of systematic review is an iterative process.
Wells agreed with Lau, adding that even if one were to do a number of different analyses, one would still have what economists call a “base case.” One can start with that base case and examine different aspects of it. Additionally, he mentioned something called a “living systematic review,” which he noted was a relatively new concept. Although when the Cochrane reviews began, they were intended to be updated every so often, unfortunately, Wells said, they have not been. But with the living systematic review, there is a process in place for updating the information and any recommendations that may come out of it. He mentioned a series of papers on the living systematic review that were recently published by Journal of Clinical Epidemiology.
Lau added that use of the SRDR will also allow for continuous updating, as well as global collaboration. He emphasized the labor intensive nature of systematic review. “If the world wants to collaborate in this effort, it becomes much easier and faster,” he said.
Ruth Charrondiere agreed that the SRDR is a good step in a very good direction in terms of saving time and funds, as well as making systematic reviews more harmonized. However, she opined that one’s use, or interpretation, of a systematic review depends on one’s predefined view. For example, people who expected a decrease often question the results of a study that indicate an increase (or vice versa). They will wonder if the study contains a bias of some sort (e.g., if there are questions about the quality of a biomarker used to assess food consumption) or is an outlier and therefore cannot be true.
There are multiple ways to interpret results across many studies, Lau replied. For example, a sensitivity analysis could be conducted and that information made available in the results of the review. “It does not need to be a single view,” he said, referring to the interpretation of results. Wells recalled some of the approximately 700-page systematic reviews that he has been involved with that have included sensitivity analyses as well as various subgroup analyses. Agreeing with Lau, he said, “Very rarely do we actually analyze it in one direction.”


























