
5
Trends in Social Science Methods
Andrew Bennett, Georgetown University, presented a broad overview of social science methods relevant to the Intelligence Community (IC). He began by noting two countervailing trends in these methods.
First, Bennett highlighted the replication crisis—the inability to reproduce published scientific findings—as a trend that has affected disciplines across the social, physical, and medical sciences. This bias, he suggested, is likely due to such bad practices as p-hacking, or mining data to uncover statistically significant results not included in the original study hypothesis, and publication bias, or only publishing statistically significant findings. As a countermeasure to publication bias, he noted, journals have started preregistering experimental trials.
Countering publication bias, however, are methodological advances in the social sciences, Bennett asserted. He cited big data, computer-assisted content analysis, machine learning, agent-based modeling (ABM), natural experiments, group-based superforecasting, new methods in case studies, and multimethods research as examples of emerging tools and methods benefiting the social sciences.
Discussing such technological advances as big data, computer-assisted content analysis, and machine learning, Bennett observed that big data has changed research practices in a number of ways. First, he said, researchers now have access to a growing amount of real-time and more fine-grained data from a variety of sources, such as social media activities, event data, and geographic information systems. He gave the example of satellite images, such as those recently taken of burning villages in Myanmar, which
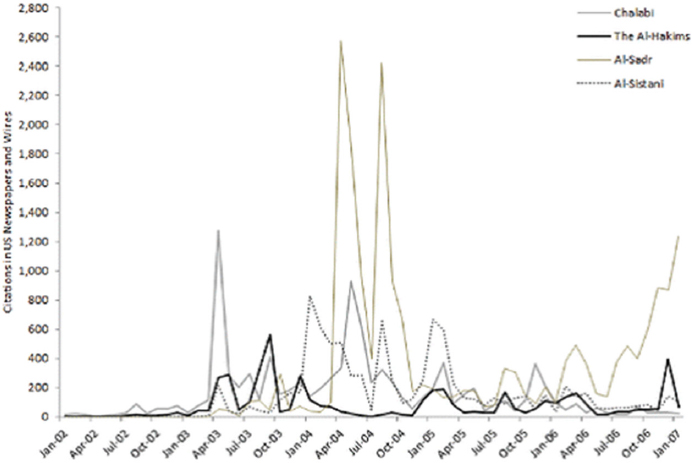
SOURCE: Sargsyan, I., and Bennett, A. (2016). Discursive emotional appeals in sustaining violent social movements in Iraq, 2003–2011. Security Studies, 25(4), 630. Reprinted with permission.
allow researchers, policy makers, and other government officials to monitor events across the globe.
Bennett then turned to computer-assisted content analysis, which, he observed, has increased in both speed and accuracy as a result of improved models of syntax and natural language processing. He noted that researchers have further benefited from advances in audio and visual data processing. However, he cautioned, these advances also give people the ability to create false audio and video clips, similar to the recent Obama lip syncing video,1 helping to make fake news appear more convincing.
Bennett shared the results of a study he conducted with one of his students to show how even something as simple as word counts can provide revealing insights (see Figure 5-1). By tracking media mentions for Iraqi leaders, Bennett and his student could identify when the influence of politi-
___________________
1 Suwajanakorn, S., Seitz, S.M., and Kemelmacher-Shlizerman, I. (2017). Synthesizing Obama: Learning lip sync from audio. ACM Transactions on Graphics, 36(4, Art. 95), 1–13. Available: https://grail.cs.washington.edu/projects/AudioToObama/siggraph17_obama.pdf [January 2018].
cal leaders was rising and falling. As an example, he pointed to Figure 5-1, which shows a sudden jump in mentions for Muqtada Al-Sadr around 2004, suggesting that he went undetected until it became obvious that he was a key figure in the Iraqi leadership.
Bennett continued by highlighting significant advances in machine learning. As Christopher Gelpi had discussed in his presentation on forecasting military conflict and violence (see Chapter 4), the random forest approach is one example of a machine learning technique that has improved the predictive power of logistic regression. However, Bennett suggested, random forest and other machine learning techniques have their limitations. As an example, he cited the need for a significant amount of data for machine learning models to be effective. Furthermore, he observed, while machine learning techniques are helpful tools when a researcher is attempting to predict events, they do not help explain why an event occurred. Another limitation, he added, is that machine learning models have the ability to analyze only historical data.
Bennett identified ABM as another useful computational tool. Using ABM, he explained, researchers can test theories about behavior by simulating how an actor or group of actors might behave in a specific situation or environment. To illustrate, he noted that, by entering population data, geographic checkpoints, and other relevant data, ABM allows researchers to predict outcomes related to specific events, such as where refugees may flee during an outbreak of violence.
Bennett also pointed to a resurgence of interest in experiments, particularly natural experiments. The reason for this resurgence, he suggested, is that experiments, including natural experiments, are more accurate than other methods in identifying causal connections. However, he observed, the IC may want to proceed with caution when planning experiments of their own, and in some cases, it may be more appropriate for them to encourage or sponsor experimental research.
Turning to group-based superforecasting, Bennett described the Good Judgment Project, a 5-year government-funded study of the use of crowd-sourcing to improve the accuracy of forecasting world events. He explained that this project is relevant because it has demonstrated that, with training, group forecasters (superforecasters) are more accurate than individual forecasters at predicting events. Currently, group superforecastering methods achieve 80–85 percent accuracy, whereas an individual forecaster is able to achieve 50–60 percent accuracy. Although it is hoped that the project will improve prediction accuracy by coupling human analysis with computer algorithms, Bennett suggested that research should also be initiated to identify the best methods for training superforecasters. Furthermore, he observed, research incorporating Bayesian analysis might be useful in improving accuracy.
Bennett next reported that he is currently working on two new case study methods: Bayesian process tracing and typological theorizing. He explained that process tracing is much like detective work: it involves identifying “suspects” (alternative explanations) and examining “clues” (evidence) to determine what caused the outcome of the case being studied. Bennett and his colleagues, however, have initiated research to assess the usefulness of explicit Bayesian process tracing. According to Bennett, the 2003 assessment that Iraq possessed weapons of mass destruction would likely have been dismissed if the forecasters had used explicit Bayesian analysis. This is because, he elaborated, even if Iraq’s aluminum tubes were meant to be used in a nuclear weapons program, the nonexistence of evidence on the many other components that would have been necessary for a nuclear program would have been a strong indication that Iraq did not have such a program. However, he suggested that more research is needed to confirm whether explicit Bayesian process tracing improves explanations and predictions.
Bennett then introduced the second new case study method, typological theorizing, which involves “trying to theorize about how different mechanisms and variables interact in different combinations.” He explained that cases are categorized as either theoretical types or combinations of variables to address “high-order interaction effects.” In process tracing, typological theorizing can help with case selection, he noted. He described the method as similar to statistical matching, except that it uses “coarsened exact matching” to identify good analogies for current policy cases and cast doubt on bad historical analogies to current events.
Finally, Bennett elaborated on multimethods research—the combined use of quantitative and qualitative methods—as another major trend in the social sciences. The combination of these methods, he explained, allows researchers to analyze both population-wide and individual patterns. Furthermore, he suggested, multimethods research may be especially helpful in reducing the number of false positives in the forecasting of rare events.
Bennett closed by suggesting that both academia and the IC consider combining methods when possible. In his view, a best practice would be to combine machine learning, group forecasting, and automated real-time data collection. Moreover, he believes that case studies should be used to identify holes in the data collection and explain outlier cases, or cases that do not have the predicted outcomes. Doing so, he argued, can help identify variables that were omitted from the quantitative models that produced the wrong predictions on the outlier cases.




