
3
The State of Open Science
SUMMARY POINTS
- Despite the barriers discussed in Chapter 2, open science has made steady progress over the past several decades. More and more research products are available on an open basis. Still, this progress has been uneven, and the research enterprise remains some distance from achieving complete open science.
- Several significant trends have expanded the possibilities for publishing articles on an open basis. These trends include the emergence of open publishing venues, author self-archiving through institutional repositories and preprint servers, and open publication mandates adopted by funders and institutions. However, a large percentage of the world’s scientific literature is still only available via subscription. Achieving universal or near-universal open publication in a way that serves the research enterprise and its stakeholders remains a challenging, pressing task.
- In the area of data, code, and other research products, there has also been significant progress toward developing practices and infrastructure that would support openness under FAIR principles. There are wide disparities by discipline, with some coming close to the expectations of open data and others quite far away. Different disciplines face different challenges in fostering open data related to cost and infrastructure. For example, some disciplines lack well-developed metadata standards, researchers may not have the incentives or resources to prepare data according to FAIR principles, and repositories that support FAIR data might not be available.
GENERAL STATE OF OPEN SCIENCE
In the 15 years since the Budapest Open Access Initiative (BOAI) issued its declaration, there have been numerous efforts to promote and realize open science. A growing number of public and private research sponsors around the world are mandating open publication, open data, or both, on the part of grantees, with some variety in the specifics of their policies, including the National Institutes of Health, the National Science Foundation, the Bill & Melinda Gates Foundation,
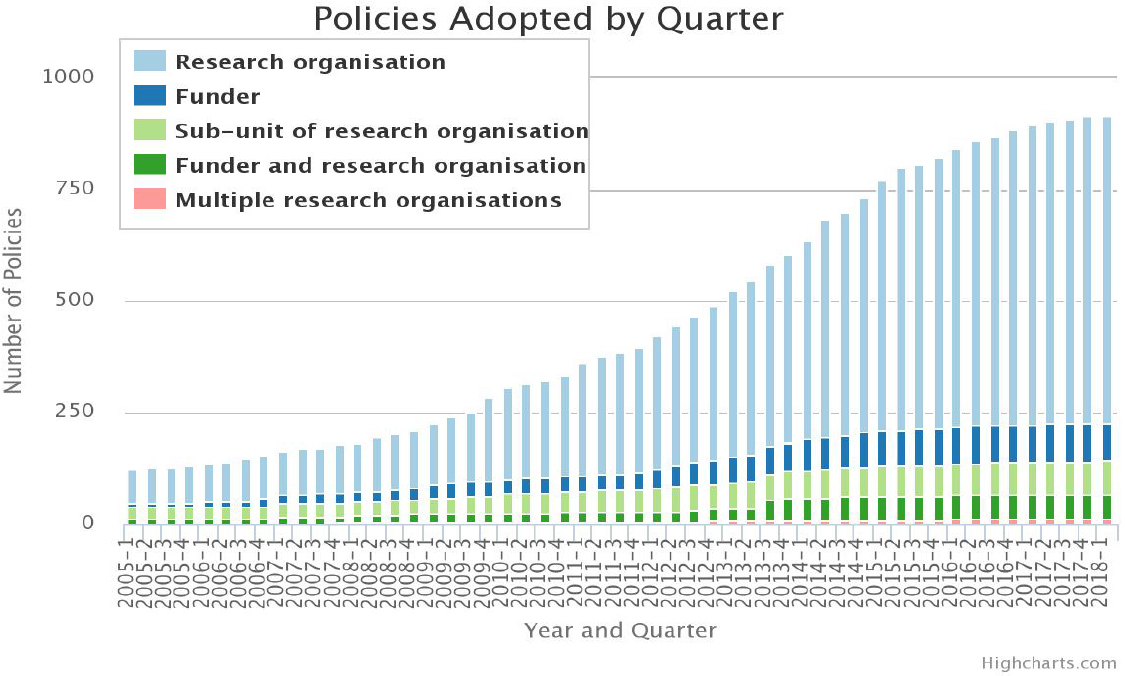
the European Commission (EC), and the Wellcome Trust. The University of Southampton maintains a repository of open science policies adopted by funders and research organizations (Figure 3-1; ROARMap, 2018). Supportive tools and infrastructure have been developed, including discovery platforms (e.g., Science-Open and 1Science) and browser-based extensions (e.g., Open Access Button, Canary Haz, and Unpaywall) (Piwowar et al., 2018). Academic social networks, such as ResearchGate and Academia.edu, provide an increasingly popular but controversial solution to author self-archiving (Van Noorden, 2014). At the same time, some articles are shared in copyright-violating pirate sites, such as Sci-Hub and LibGen, provoking debate over the efficiency and ethics of traditional models of scientific publishing (Björk, 2017b; Piwowar et al., 2018). The open science movement has catalyzed new investment, prompted controversy, and had a significant impact on the global research enterprise and its stakeholders. While underscoring the impact of existing policies and progress made, Figure 3-1 also reveals the speed of change and puts in perspective the need for additional efforts.
Several entities have monitored and analyzed the progress and status of open science. Most of these efforts focus on open publication. For example, Science-Metrix, a Canadian science data analytics company, found that as of 2013 over half the articles published during the period 2007–2012 were available for free download (Science-Metrix, 2014). Using oaDOI technology, an open online service that determines open publication status for 67 million articles, it is estimated that at least 28 percent of the literature is open (green or gold, 19 million articles in total) and that this proportion is growing, driven particularly by growth in gold and hybrid open access adoption (Piwowar et al., 2018). Piwowar et al. (2018) also suggested that the most common mechanism for open publication is not gold, green, or hybrid open access, but rather an under-discussed category of articles made free-to-read on the publisher website, without an explicit open license (Piwowar et al., 2018). In December 2017, Web of Science, a large bibliographic database, began to release more detailed data on the availability of publications than were available previously, categorizing open articles as “gold,” “green accepted,” or “green published” (Bosman and Kramer, 2018; Library Research News, 2018). Most recently, Science-Metrix (2018), analyzed three bibliographic databases (1Science database, Scopus, and Web of Science) to measure the availability of open publications, finding that at least two-thirds of the articles published between 2011 and 2014 and having at least one U.S. author could be downloaded for free as of August 2016 (Science-Metrix, 2018).
Using newly available open publication status data from oaDOI in Web of Science, Bosman and Kramer (2018) explored year-on-year open access levels across research fields, countries, institutions, languages, funders, and topics by relating the resulting patterns to disciplinary, national, and institutional contexts. They find that openness varies significantly by discipline, with the highest levels (over 50 percent) in some life sciences/biomedicine and physical sciences/technology fields and lower levels (under 20 percent) in social sciences and arts/humanities (Bosman and Kramer, 2018). Within the broad category of social
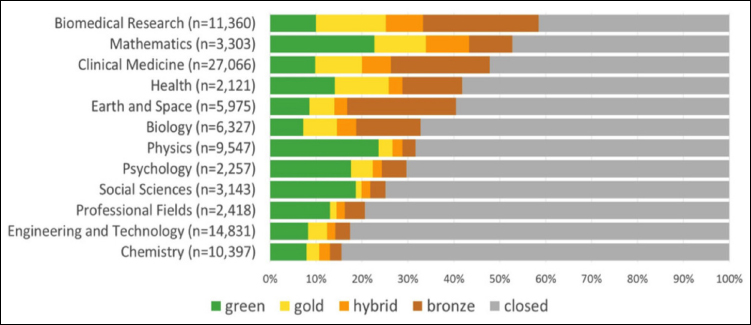
sciences, psychology registers the highest levels of open publication, possibly because its publication culture is more similar to life sciences/biomedicine than to the other social and behavioral sciences. Similarly, Piwowar et al. (2018) found that over half of the papers are freely available in biomedical research and mathematics, while less than one-fifth of the publications in the disciplines of chemistry and engineering and technology are freely open (see Figure 3-2). The figure demonstrates that green open access is popular in physics and mathematics, while hybrid articles are common in mathematics and biomedical research. Authors in biomedical research, mathematics, health, and clinical medicine often publish in gold journals. Regarding specialties within disciplines, over 80 percent of publications in astronomy and astrophysics, fertility, and tropical medicine were open. On the other hand, more than 90 percent of publications are hidden behind a paywall in pharmacy, inorganic and nuclear chemistry, and chemical engineering (Piwowar et al., 2018). Different fields of science have different cultures, and common issues are availability of infrastructures, policies and standards, and culture. Astronomy has had a culture of sharing, for example, in part because of limited access to the equipment to conduct observations and experiments (NASEM, 2018c). There is a need for raising awareness within different disciplines about the value of open science. Examples of disciplinary approaches are described in the boxes throughout this chapter, including biological sciences such as genomic research and precision medicine; astronomy and astrophysics; earth sciences; and economics. Regarding funders, the proportion of open publications that are based on research supported by NIH and the Wellcome Trust is high and increasing, which is understandable given their mandates requiring deposit in PubMed Central or Europe PubMed Central (PMC) within 12 and 6 months after publication respectively for all research funded (Bosman and Kramer, 2018; Open Access Oxford, 2018).
The United Kingdom and Austria, through the Universities UK and the Austrian Science Fund respectively, have conducted quantitative studies to monitor the transition to open publication. Universities UK, the representative organization for the United Kingdom’s universities (2017), recently found that the proportion of journals published globally with immediate open access increased from under 50 percent in 2012 to over 60 percent in 2016, while the proportion of subscription-only journals has fallen (Universities UK, 2017). The global proportion of articles accessible immediately on publication rose from 18 percent in 2014 to 25 percent in 2016; and the global proportion of articles accessible after 12 months increased from 25 percent to 32 percent (Universities UK, 2017). The Austrian Science Fund—Austria’s main public funder of basic research—actively monitors compliance with its open publication mandate (ASF, 2018). The 2017 assessment found that 92 percent of all peer-reviewed publications listed in final reports of ASF-funded projects were openly available (Kunzman and Reckling, 2017).
Status and trends related to open data and open code are more difficult to track than those related to open publication. In October 2017, Figshare, an open access repository that is part of the Holtzbrinck Publishing Group, released its second State of Open Data report (Figshare, 2017). The report includes perspectives from leaders in the open data field and results of a survey of researchers. The survey discovered that 82 percent of nearly 2,300 respondents are aware of open datasets and that 74 percent of their respondents are curating their data for sharing (Figshare, 2017). A global online survey of 1,200 researchers, conducted by the Leiden University and Elsevier in 2017, found that less than 15 percent of researchers share data in a data repository and most (>80 percent) researchers only share data with direct collaborators (Berghmans et al., 2017). In 2017, the International Development Research Centre launched the State of Open Data project, which includes a plan to “critically review the current state of the open data movement” and produce a core reference publication during 2018 (State of Open Data, 2018).
CURRENT APPROACHES TO OPEN SCIENCE
This section explores various approaches to open science, focusing on open publication and open data. Part of the committee’s task was to provide illustrations from several scientific disciplines within the biological sciences, social sciences, physical sciences, and earth sciences. The section includes examples drawn from biomedical sciences, economics, astronomy and astrophysics, and earth sciences, along with other examples from outside of those disciplines. A comprehensive assessment of open science within individual disciplines or across disciplines is
beyond the scope of the study. Nonetheless, this overview and the illustrative examples provide insight on how policies, practices, and resources that support open science can be developed and implemented.
Open Publications
Open Access Journals
Open access journals are freely available to readers online “without financial, legal, or technical barriers other than those inseparable from gaining access to the internet itself” (Suber, 2015). In contrast to traditional subscription models of scientific publishing, open access publishers typically charge an article processing charge (APC), which is paid by the author or the author’s home institution. Open access facilitates free and unrestricted access to articles for everyone immediately after publication (gold open access). As described in Chapter 2, less open approaches to publication include green open access, in which authors are able to self-archive a version of the article in an open access repository when access to the final published version requires a subscription to the journal. Open publication may also be provided following an embargo period. A list of open access journals in all fields and languages is available in the Directory of Open Access Journals (DOAJ), a community-based online directory launched in 2003 in Sweden with 300 open access journals (DOAJ, 2018). As of March 2018, this number has increased to over 11,100 open access journals, with nearly 2,982,000 articles in 124 countries (DOAJ, 2018).1
Although the majority of open access journals do not require APCs, these journals account for a minority of the open access articles published worldwide, and only 18 percent of the open access articles published in the United States (Crawford, 2018). A wide range of APCs is charged by open access journals. For example, F1000 Research charges $150 to $1,000 depending on word count (F1000 Research, 2018). F1000 Research gives discounts or waivers to its referees, advisory board members, and authors from institutions in some developing countries (F1000 Research, 2018).
A successful case of open access publishing is the Public Library of Science (PLOS), a nonprofit scientific organization founded in 2001. PLOS launched its first journal, PLOS Biology, in 2003 (see Box 3-1). PLOS publishes several peer-reviewed journals, providing free and unrestricted access to research and an open approach to scientific assessment (PLOS, 2017a). PLOS One, a multidisciplinary peer-reviewed journal launched in 2006, had been the largest journal in the world in terms of articles published until 2017, when it was passed by Scientific Reports (Davis, 2017).
___________________
1 DOAJ does not include “hybrid” journals that contain open access and subscription access articles.
Several entities provide guidelines for assessing the quality of open access journals. DOAJ, in collaboration with the Committee on Publication Ethics (COPE), Open Access Scholarly Publishers Association (OASPA), and World Association of Medical Editors (WAME), identifies principles of transparency and best practice for scholarly publications according to several criteria, such as peer review process, governing body, copyright, ownership and management,
conflicts of interest, revenue sources, etc. (DOAJ, 2018). Publishers or journals that do not meet these criteria will not be included in their publisher’s list. Additionally, the Open Access Directory (OAD) provides guidelines, best practices, and recommendations for open access journals (OAD, 2017), while COPE offers resources in the current debates related to promoting integrity in research and scholarly publication (COPE, 2017). OASPA has strict criteria for becoming a member of its organization. The Think, Check, and Submit website provides a checklist for selecting trusted journals (Think, Check, and Submit, 2017).
Some journals exhibit questionable marketing schemes via spam e-mails, perform only cursory peer-review procedures, lack transparency in publishing operations, and imitate legitimate journals (Beall, 2016; Pisanski, 2017). Researchers who are eager to publish or scientists who lack sufficient time to investigate a publisher may submit their papers without verifying a journal’s reputability. Beall recommends that scholars read the available reviews and descriptions, and then decide whether they want to submit articles, serve as editors, or serve on editorial boards.
Open Access Repositories
An open access repository is “a set of services that provides open access to research or educational content created at an institution or by a specific research community. Repositories may be comprehensive or may focus on publications or data. They may be institutionally-based or subject-based collections” (COAR, 2015a, p. 3). Lynch (2003) defined the institutional repository as “a set of services that a university offers to the members of its community for the management and dissemination of digital materials created by the institution and its community members” (Lynch, 2003, p. 2).
While institutional repositories were developed as a new strategy for universities to accelerate changes in scholarly communication, disciplinary repositories have been established since the early 2000s, often focused on preprints and rapid dissemination of research results. To improve the visibility and impact of research, the majority of open access policies and laws require or request authors to deposit their articles into an open access repository, which has become a key infrastructure component to support these policies. Networked open access repositories enable funders and institutions to track funded research output across repositories, deliver data usage, host collections of academic journals, and link related content across the network (COAR, 2015a). The Confederation of Open Access Repositories (COAR) has developed a roadmap to identify key trends to identify priorities for further investments in interoperability (COAR, 2015b). PubMed Central, managed by the National Library of Medicine, is one of the largest and best-known public access repositories of publications in the biomedical sciences (See Box 3-2).
University Open Access Policies
Open access policies have become increasingly adopted in academia. Since 2008, faculties of over 70 universities, schools, and departments have established open access policies to make their publications and research more accessible to policy makers, educators, scholars, and the public (Columbia University, 2017). In 2008, the Harvard Faculty of Arts and Sciences voted unanimously to grant the university a nonexclusive, irrevocable right to disseminate their scholarly articles for non-commercial purpose (Harvard Library, 2017). By June 2014, the remaining eight Harvard schools, including the law school and medical school, adopted similar open-access policies. Scholarly articles provided by Harvard faculty and researchers are stored, preserved, and made available in the Digital Access to Scholarship at Harvard (DASH), a free open access repository available to anyone with internet access. Similarly, Massachusetts Institute of Technology (MIT) faculty voted unanimously in 2009 to make their scholarly articles available free online through DSpace, the open source software created by Hewlett-Packard and the MIT Libraries. Faculty authors may opt out on a paper-by-paper basis (MIT Libraries, 2009). The faculty of the University of California (UC) adopted an open-access policy in 2013. The policy was amended in 2015 to include all researchers employed by the UC. The UC open access policies require that UC faculty and other employees provide a copy of their scholarly articles for inclusion in the eScholarship.org repository, or provide a link to an open version of their articles elsewhere.
A number of guidelines are available to facilitate open access to faculty research and improve scholarly communication. For example, A SPARC Guide for Campus Action includes suggestions related to understanding rights as an author and making informed choices about publication venues (SPARC, 2012). Recommendation 4.2 of the 10-year anniversary statement of the Budapest Open Access Initiative (2012) states, supporters of open access “should develop guidelines to universities and funding agencies considering OA [open access] policies, including recommended policy terms, best practices, and answers to frequently asked questions” (BOAI, 2012). As part of the BOAI recommendation, the Harvard Open Access Project (HOAP) released a comprehensive guide, Good Practices for University Open Access Policies in 2012 and 2015, based on policies adopted at Harvard University, Stanford University, MIT, and the University of Kansas (Shieber and Suber, eds., 2015). The guide has been endorsed by 15 organizations and projects in the U.S., Europe, and Australia. Similarly, open tools and resources for data management have been promoted in the research library world in the “23 Things: Libraries for Research Data” overview (23 Things, 2018) by the Libraries for Research Data Interest Group of the Research Data Alliance. The overview has been widely disseminated and translated from English into 10 languages.
According to the guide, there are at least six types of university open access policies. Among those types, Shieber and Suber recommend a policy that “provides for automatic default rights retention in scholarly articles and a commitment
to provide copies of articles for open distribution” (Shieber and Suber, eds., 2015., p. 6). To be consistent with copyright law, the guide recommends a policy that “grants the institution certain nonexclusive rights to future research articles published by faculty. This sort of policy typically offers a waiver option or opt-out for authors. It also requires deposit in the repository” (Shieber and Suber, eds., 2015, p.7). However, compliance involving deposits in a repository requires time, which necessitates education, assistance, and incentives. The guide suggests “when the institution reviews faculty publications for promotion, tenure, awards, funding, or raises, it should limit its review of research articles to those on deposit in the institutional repository” (Shieber and Suber, eds., 2015, p. 22). Indiana University-Purdue University Indianapolis (IUPUI) has become one of the first institutions to include open access as a value in its promotion and tenure guidelines, through librarian-facilitated efforts (Odell et al., 2016).
While an effective open access policy can build support for open access, institutions considering adopting their own open access policies are able to refer to the current Harvard model policy (see Box 3-3), which incorporates the latest recommended practices described in their 2015 guide (Shieber and Suber, eds., 2015). To date, over 60 organizations worldwide have adopted a version of the Harvard policy for the development and promotion of open access (Harvard Library, 2017). Internationally, the Registry of Open Access Repository Mandates and Policies (ROARMAP) lists over 200 open access mandates and policies adopted by universities, research institutes, and research funders across the globe (ROADMAP, 2017). In addition to the policy guidelines published by the United Nations Education, Scientific and Cultural Organization (UNESCO) (Swan, 2012) and Mediterranean Open Access Network (MedOANet, 2013), the European University Association (EUA) provides a practical guide for universities in the context of current European open access policies (EUA, 2015).
Preprints
A preprint is defined as “a complete written description of a body of scientific work that has yet to be published in a journal” (Bourne et al., 2017). Preprints can be the complete and original manuscripts of scientific documents, including a research article, review, editorial, commentary, and a large dataset. that are not yet certified by peer review. Preprint servers can also host other objects such as posters presented at scientific meetings. The purpose of preprint distribution is “to share the results of recent research freely and openly before they are certified by peer review, in a manner that permits immediate discovery and discussion of the results and feedback to authors from the research community at large” (Inglis, 2017).
Providing preprint services is not without costs. For large services such as arXiv and bioRxiv, extensive hardware and software infrastructure is required. Although articles are not peer reviewed, they are screened and categorized, which requires staffing. Costs are typically covered by the host institutions and by foundation grants.
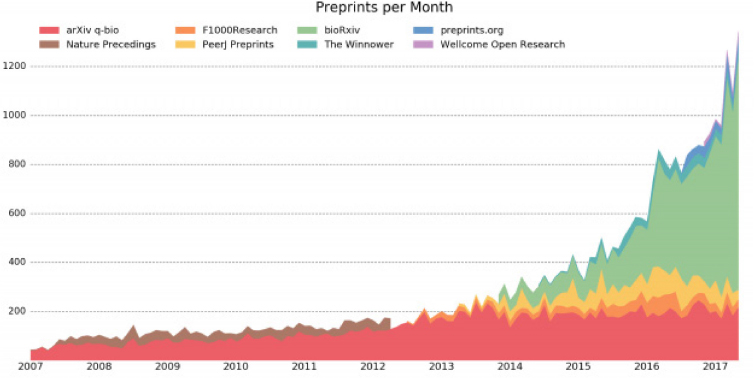
Preprints are gaining momentum among the scientific community. Since 1991, researchers in disciplines such as physics (and later mathematics, computer science, and quantitative biology) have been able to access preprints through arXiv, a repository of electronic preprints of scientific papers. arXiv is operated by the Cornell University Library and currently contains over 1.3 million preprints (Cornell University Library, 2017). In 2013, bioRxiv was launched as a repository of life science preprints covering all of the life sciences, clinical trials, epidemiology, as well as science communication and education (see Figure 3-3). Operated by the Cold Spring Harbor Laboratory, bioRxiv is modeled conceptually on arXiv but uses different technology, and offers somewhat different features and functions (Inglis, 2017). Economics has a long history of utilizing preprints, which are called working papers in that discipline (See Box 3-4).
Preprint services are being launched in a growing number of disciplines, as indicated in Table 3-1. For example, the American Chemical Society (ACS) and its global partners launched ChemRxiv, a preprint server for chemistry-related information. The Center for Open Science (COS) has launched PsyArXiv (psychology), AgriXiv (agriculture), SocArXiv (social sciences), engrXiv (engineering), and LawArXiv (law), with the most recent additions including NutriXiv (nutritional sciences) and SportRxiv (sport) (COS, 2017; Luther, 2017). In 2017, the American Geophysical Union and Atypon announced the development of Earth and Space Science Open Archive (ESSOAr). This preprint server will join the existing EarthArXiv as preprint servers for the earth and space science community (Voosen, 2017).
There are other services that provide preprint functions. For example, the Social Science Research Network (SSRN) was created in 1994 as a tool for rapid dissemination of scholarly research in the social sciences and humanities. The SSRN, bought by Elsevier in 2016, facilitates the free posting and sharing of research material, including preprints, conference papers, and non-peer-reviewed papers in social science research (Gordon, 2016). F1000Research is “an open research publishing platform for life scientists that offers immediate publication and transparent peer review” (F1000 Research, 2018). An article submitted to F1000 Research also requires data and code deposition, either in an F1000 approved repository or in an institutional repository.
Bourne et al. (2017) described a number of advantages of preprint submission from the standpoint of both individual researchers and the broad community. Preprints are free to post and to read, which provides accelerated transmission of scientific results. Researchers can evaluate new findings and their reliability without the delay introduced by journal peer review. Some funders are now providing incentives to those who submit preprints (Inglis, 2017). However, there are challenges associated with managing preprints, including anxieties about “scooping” (other researchers using the preprint to publish work in advance of those submitting a preprint) and reluctance to use open licenses (Inglis, 2017; INLEXIO, 2017). There is a need for more education and discussion regarding the choice of licenses and ways to prevent unattributed use of the results. NIH is working with
an international group of research funders to examine the feasibility of establishing a central service of preprints to encourage sharing of preprints in the life sciences (NIH, 2017b).
TABLE 3-1 Preprint Servers
| Name | Fields | Start Year | Owned/Operated by | Submissions in 2016 |
|---|---|---|---|---|
| Selected preprint services | ||||
| arXiv | Physics, mathematics, computing, quantitative biology, quantitative finance, statistics | 1991 | Cornell University Library | 113,308 |
| bioRxiv | Life sciences | 2013 | Cold Spring Harbor Laboratory | 4,712 |
| PeerJ Preprints | General | 2013 | PeerJ | ~1,000 |
| Preprints (MDPI) | General | 2016 | Multidisciplinary Digital Publishing Institute (MDPI) | ~1,000 |
| SocArXiv | Social sciences | 2016 | Open Science Framework (OSF) | 633 |
| PsyArXiv | Psychology | 2016 | OSF | 191 |
| engrXiv | Engineering | 2016 | OSF | 35 |
| ChemRxiv | Chemistry | 2017 | ACS | N/A |
| AgriXiv | Agriculture | 2017 | OSF | N/A |
| EarthArXiv | Earth Sciences | 2017 | OSF | N/A |
| LawArXiv | Law | 2017 | OSF | N/A |
| NutriXiv | Nutritional Sciences | 2017 | OSF | N/A |
| Sport RXiv | Sport science | 2017 | OSF | N/A |
| Services with preprint functions | ||||
| Social Science Research Network (SSRN) | Social sciences | 1994 | Elsevier | 66,310 |
| Figshare | General | 2012 | Figshare | Unknown |
| Zenodo | General | 2013 | OpenAire/CERN | 318 |
| F1000Research | General | 2013 | F1000Research | 215 |
| Authorea | General | 2013 | Authorea | Unknown |
SOURCE: https://www.inlexio.com/rising-tide-preprint-servers; https://researchpreprints.com/2017/03/09/a-list-of-preprint-servers.
European Commission Open Research Publishing Platform
The European Commission (EC) has proposed to fund the EC Open Research Publishing Platform for Horizon 2020 beneficiaries to comply with the Horizon 2020 open access mandate and to increase open access peer reviewed publications in Horizon 2020 (EC, 2017c). The platform will provide an easy, fast, and reliable open access publishing venue free to Horizon 2020 grantees on a voluntary basis, including preprints support, open access, open peer review, and innovative research indicators most appropriate for individual disciplines and/or national context. Building on the best practices of other funders, such as the Bill & Melinda Gates Foundation and the Wellcome Trust, the commission hopes that the platform will contribute to a more diversified and competitive open access publishing market. One contractor or a consortium led by one contractor will be selected to run the platform with a 4-year initial contract. The contractor will be required to commit to a minimum number of preprints and articles to be published during the initial 4-year period and to develop a plan for sustainability of the service beyond the 4 years. While some experts such as Jacobs (2018) interpret this movement as “a sign of increasing frustration on the part of research funders and institutions at the pace and cost of the change to open access,” the success of the platform will depend on the quality of the scientific publication service provided (EC, 2017c). Current international approaches to open science are described further in the final section of this chapter.
Pay It Forward Initiative
The University of California (UC), Davis and the California Digital Library (CDL) conducted a study in 2015 and 2016 to examine the economic implications of large North American research institutions converting to an entirely article processing charge (APC) business model. With support from the Andrew W. Mellon Foundation, the study was conducted in partnership with Harvard University, Ohio State University, the University of British Columbia, and University of California Libraries, along with the Association of Learned and Professional Society Publishers (ALPSP) and the private sector, including Thomson Reuters (Web of Science) and Elsevier (Scopus). These large North American research institutions would assume the large part of the financial burden in an APC-driven open access model, the predominant open access business model of gold open access publishers (Anderson, 2017). The study involved a number of qualitative analyses based on academic author surveys and publisher surveys, as well as quantitative analyses based on data for a 5-year period (2009-2013), including library subscription expenditures, university publishing output, and potential APCs (UC Libraries, 2016; Anderson, 2017).
The final report, Pay It Forward: Investigating a Sustainable Model of Open Access Article Processing Charges for Large North American Research Institutions (2016), has the following three major findings:
- The total cost to publish in a fully APC-funded journal will exceed current library journal budgets for the most research-intensive North American research institutions;
- This cost difference could be covered by grant funds, already a major source of funding for publishing fees; but
- Ultimately, author-controlled discretionary funds, such as research grants and personal research accounts that incentivize authors to act as informed consumers of publishing services, are necessary to introduce both real competition and pricing pressures into the journal publishing system (UC Libraries, 2016).
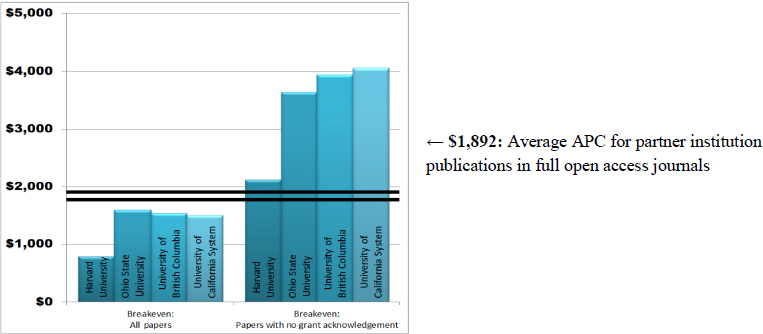
To establish these findings, the study examined the level of APCs each institution could afford, based on its current subscription spending. The study discovered that the average APC for partner institution publications in full open access journals is $1,892 (Figure 3-4). While research-intensive institutions would be unable to convert to the APC model if they had to rely solely on their existing subscription budgets, the study found that those institutions could afford a transition to APC, if grant funds were applied to the cost (Anderson, 2017). This is not an entirely novel idea, as many authors are already using grant funds for APCs. A key strategy could be a multi-payer model involving library subsidies, together with grants, startup packages, and discretionary research funds (Anderson, 2017). For example, the Wellcome Trust notes that its APC payments, which cover both full open access and high-cost hybrid journals, consume less than 1 percent of its overall research budget (UC Libraries, 2016; Anderson, 2017). According to the report, incorporating grant and discretionary funds into the financial flow for a full APC business model may be a viable direction for both research-intensive institutions and their funders.
The report emphasizes that it is essential to introduce competition for authors to ensure that APCs remain affordable in the future. This can be accomplished by giving authors some financial responsibility in deciding where to publish, using funds that they control directly. Additionally, the report acknowledges that the information available on current APCs is almost entirely derived from STEM fields, which historically have higher subscription costs than social science and humanities disciplines (Crotty, 2016; UC Libraries, 2016). Because the report provides APC estimations based on available data, it likely overestimates costs for non-STEM fields, and additional analysis may be needed for other disciplines. There is also a need to monitor global developments on an ongoing basis to assess opportunities for collaboration with European countries toward more immediate, large-scale transition to an open science enterprise.
A recent report from the Max Planck Digital Library (MPDL) has claimed that a large-scale open access transformation is possible without financial risk (MPDL, 2015). Yet this is a contentious issue. Some argue against efforts to promote publishing models based on gold open access enabled by APCs, and instead advocate for a combination of green open access mandates and community efforts to create and sustain new institutions for publishing and expert review (Shulenberger, 2016).
As a recent development, the UC Libraries released a new report, Pathways to Open Access, in February 2018 that identifies the current state of open access approaches, a set of strategies to achieve those approaches, and possible next steps to assist UC campus libraries and the California Digital Library to pursue a large-scale transition to open access (UC Libraries, 2018). An accompanied published chart summarizes those approaches and strategies identified in the report, including green open access, gold open access-APC based, gold open access-non APC based, and universal strategies.
Private Foundation Initiatives
Open access publishing has increasingly become part of the business process among the philanthropic community. For example, the Bill & Melinda Gates Foundation has one of the most stringent open-access policies. After a 2-year transition period for policy compliance, the foundation’s Open Access Policy has been fully operational as of January 1, 2017, with no exceptions to the policy (Bill & Melinda Gates Foundation, 2017; Hansen, 2017; Adams, 2018). Under its policy, the foundation requires grantees to make their research papers and data available immediately upon publication without any embargo period and allow for their unrestricted use under the Creative Commons Attribution Generic License
(CC BY 4.0) or an equivalent license (Bill & Melinda Gates Foundation, 2017; Hansen, 2017; Adams, 2018). The foundation will pay reasonable fees in order to publish on its open access terms. Launched in July 2016, the web-based service Chronos tracks the impact of research while simplifying research publishing. As a new initiative, Gates Open Research was launched in late 2017, with a model used by the Wellcome Trust in the United Kingdom (Wellcome Open Research), to provide their grantees with an open research platform for open peer review and rapid author-led publication (Butler, 2017; Open Research Central, 2017; Van Noorden, 2017; Bill & Melinda Gates Foundation, 2018). As one of the most influential global health philanthropic organizations, the foundation emphasizes that “the free, immediate, and unrestricted access to research will accelerate innovation, helping to reduce global inequity and empower the world’s poorest people to transform their own lives” (Bill & Melinda Gates Foundation, 2017). Because of a rapidly changing landscape in scholarly communications, the Wellcome Trust will conduct its first review of its open access policy and a result will be announced by the end of 2018 (Wellcome Trust, 2018).
While a growing number of funding organizations are committing to open sharing of research, the funder community is building effective partnerships in an effort to meet current and future open science challenges. One major effort is the creation of the Open Research Funders Group (ORFG)2 in December 2016, following a forum of open access stakeholders convened by The Robert Wood Johnson Foundation and the Scholarly Publishing and Academic Resources Coalition (SPARC) in late 2015. The ORFG develops actionable principles and policies that encourage innovation, increase access to research articles and data, and promote reproducibility (ORFG, 2018). While many organizations have expressed an interest in developing their own open policies, a significant challenge is the lack of clarity about an effective policy. In an attempt to describe the variation in interpretation of openness by funding organizations, ORFG has published a guide, HowOpenIsIt? Guide to Research Funder Policies (2017), building on the success of HowOpenIsIt? Guide for Evaluating the Openness of Journals described in Chapter 2 (see Table 2-2). During recent infectious diseases outbreaks in 2016, the publishing community largely agreed, at the prompting of WHO and funders such as the Bill & Melinda Gates Foundation and the Wellcome Trust, to adopt open science practices, including early publication of data and preprints and open access publication (PLOS, 2016). Such agreements applied in times of international public health emergencies underscore the benefits of an open science approach.
___________________
2 As of January 2018, ORFG members include the Alfred P. Sloan Foundation, American Heart Association, A Charitable Fund of Peter Baldwin and Lisbet Rausing (ARCADIA), the Bill & Melinda Gates Foundation, Eric & Wendy Schmidt Fund for Strategic Innovation, James S. McDonnell Foundation, John Templeton Foundation, Laura and John Arnold Foundation, Leona M. and Harry B. Helmsley Charitable Trust, Open Society Foundation, Robert Wood Johnson Foundation, and Wellcome Trust. Additional information can be found at http://www.orfg.org/members.
Publisher and Society Initiatives
Publishers and professional societies are exploring options for expanding open access to accelerate scientific discovery. The American Geophysical Union (AGU), which consists of 60,000 members from 137 countries, is the largest society publisher in the discipline of Earth and space science with 20 peer-reviewed scholarly journals and over 6,000 published papers in 2016 (Stall, 2017). The AGU produces four open access journals, including Journal of Advances in Modeling Earth Systems, Earth’s Future, Earth and Space Science, and Geo-Health, with content currently representing nearly 100,000 articles (AGU, 2017a). Articles published in those journals become freely available immediately online upon publication, and authors can select one of several Creative Commons (CC) licenses. AGU allows a draft or the author’s version of the accepted manuscript to be posted to any nonprofit preprint server to encourage community engagement. Through its publishing partner Wiley, AGU offers discounts or waivers on fees from researchers in developing countries to increase access to research. Additionally, AGU is part of the innovative Research4Life program, which provides over 5,000 institutions in low- and middle-income countries free or low-cost access (AGU, 2017a; Research4Life, 2018). In addition to these gold open access options, AGU also makes all publications open after a 2-year embargo period. (See Chapter 2 and above for more explanation on gold and green access.)
Open Data
Most research data in repositories today is not available under FAIR principles. Realizing this availability will entail significant costs and complexities. The wide variety of types and sizes of research datasets means that developing effective tools and practices will require significant and sustained community input. Long-term curation of data and research software will require standards for the types of data that should be stored and how long they should be stored. This section considers several examples and potential lessons.
Big Science Data
Open data is largely the norm in fields such as high-energy physics and astronomy, as funding for these projects is significant, and as such data distribution is well thought out and closely monitored by the respective federal agencies. Good examples include the Large Hadron Collider, and some of the large scale astrophysical archives (Hubble Legacy Archive, Sloan Digital Sky Survey, etc.). They typically started in areas where the data were far removed from any financial impacts. More recently data from other areas, like genomics (Human Genome Project, 1000 genomes, etc.) and material science (Material Genome Initiative) are also heading towards data sharing in large open archives. Such a transition for a given field typically requires a decade of focused effort by the community, and
a substantial federal investment. Boxes 3-5 and 3-6 illustrate examples of open practices in the fields of astronomy and astrophysics as well as genomics research, respectively. With the size and complexity of datasets continually increasing, yesterday’s “big data” appears less big today, today’s “big data” will appear small in five or ten years, and so forth.
A major consideration is what happens to data from a major research facility, which often takes hundreds of millions of dollars and decades of effort, once the facility is shut down (e.g., BaBaR at SLAC3). The legacy value of the investments made remain in the data, which need to be preserved and curated for at least several additional decades. This preservation phase of the data lifecycle requires skills different from those needed for capturing and analyzing data from an active instrument. Several major facilities are getting closer and closer to this point.
___________________
3 BaBaR is a large-scale particle physics experiment conducted at the SLAC National Accelerator Laboratory and designed to study fundamental questions about the universe, including the nature of antimatter, the properties and interactions of the particles known as quarks and leptons, and searches for new physics. For more information, see http://wwwpublic.slac.stanford.edu/babar.
Maintaining and reinventing the data curation for each project in isolation will be very inefficient, and the task requires economies of scale. The expertise for curation will require active involvement by librarians and archivists, augmenting the legacy and corporate knowledge of the individual projects.
The Long Tail of Science
The long tail of science is increasingly gaining attention in the open science community. While big data tend to comprise homogeneous, standardized, and regulated data, long-tail data can be relatively small and heterogeneous individually but very large in the number of datasets (Heidorn, 2008; Borgman, 2015; e-IRG, 2016; see Table 3-2). Data heterogeneity includes differences in the size, structure, format, and complexity of research data.
Long tail data exist across all disciplines, mostly only in individual computers or personal websites with minimal or no attached metadata or documentation, resulting in issues such as irreproducibility of research, duplicate research, and, potentially, innovation loss (e-IRG, 2016). For example, environmental science research involves enormous complexity of its datasets, including physical, chemical, and biological data that reside in small files (e.g., spreadsheets and tables) collected in laboratories (Szalay, 2014). Other challenges associated with long-tail data include data quality due to varying technology across disciplines, difficulty of discoverability in diverse repositories, and lack of incentives for researchers to deposit their data. Mostly, the demands for metadata are simply too cumbersome for normal scientists, who feel that the relatively small amounts of data to be published do not justify the effort that needs to be spent to add the required extra information for the publishing process. Part of the reason for the balkanization of long-tail data is its isolation/geographic segregation. Most of such data sit on tens of thousands of personal computers, or personal websites. If all data could be stored on the same “science cloud,” where it would take a mouse click to upload and link new information, a complex network of interrelated datasets could rapidly be built. It is quite likely that the relationships between datasets would resemble the network graphs of co-authorship. The technology to do automatic discovery of a wider context from data tables on the web is already here (Cafarella et al., 2008). A substantial amount of data currently resides in “Supplementary Information” accompanying journal articles—in front or behind paywalls, but mostly in formats that do not lend themselves to text- or data-mining. Several publishers are currently moving towards ensuring at least one copy of article-related datasets is available in open repositories (e.g., Dryad, Figshare), as well as in the journal record (COPDESS, 2015; Byrne, 2017).
TABLE 3-2 Big Data vs. Long-Tail Data
| Big Data | Long-Tail Data | |
| 1 | Homogeneous | Heterogeneous |
| 2 | Large | Small |
| 3 | Common standards | Unique standards or no standards |
| 4 | Regulated | Not regulated |
| 5 | Central curation | Individual curation |
| 6 | Disciplinary repositories | Institutional, general or no repository |
SOURCE: e-IRG, 2016.
Discovering, transforming and reusing data collected by others has become a major part of science today, yet the process is still painful. The Research Data Alliance (RDA) and the National Data Service (NDS) are leading the way in the path towards establishing a universal, easy-to-use data publishing and management framework, but this is an area that will require consistent long-term attention before it can be said that the problem has been solved (See Box 3-7). Clearly, scientists can learn from best practices in industry, but those techniques need to be carefully tailored to the specific needs of science (assessing data quality, refereeing process, relation to publications, easy attribution, tracking provenance).
A number of initiatives address challenges involved in managing long-tail data. For example, the RDA’s Long Tail of Research Data Internet Group, launched in 2013 with over 90 members from around the world, has developed a set of good practices for managing research data archived in the university context (RDA, 2017a). The European Library Federation (LIBER) released 10 recommendations for libraries to get started with research data management (LIBER, 2012); the Confederation of Open Access Repositories (COAR) issued the repository Interoperability roadmap (COAR, 2014); and the Open Access Infrastructure for Research in Europe (OpenAIRE) links literature to data. Additional work is needed to establish a relevant, operational ecosystem for the long tail of science during the implementation of international, national, and local e-infrastructures, possibly using automated techniques to extract the metadata needed for discovery and indexing (Cafarella, 2008). While reuse of data remains highly dependent on discipline- and data-specific metadata, which have long been recognized as critical for reuse (Brazma et al., 2001), support for researchers willing to invest time and efforts in establishing such standards is also critical.
Scientific Collections and Sample Preservation
While much of this report focuses on digital research products, a significant percentage of research effort continues to involve collection, analysis, and use of physical specimens and materials. Metadata about specimen collections may or may not be available in digital form online.
Historically, scientists (especially natural scientists) have kept their collections either in museums or in central locations in their university departments, but also as personal collections in their own laboratories for their use and that of their research groups. These samples had collection data with varying levels of specificity associated with them; however, neither these data nor the physical samples were easily accessible by others. The preservation of scientific collections and data acquired with public and/or private funding, and their wide accessibility now and in the future as a public good, is supported and encouraged by professional scientific societies (e.g., AGU, 2016; GSA, 2018). McNutt et al. (2016) stated that “access to data, samples, methods, and reagents used to conduct research and analysis, as well as to the code used to analyze and process data and samples, is a fundamental requirement for transparency and reproducibility” (McNutt et al., 2016, p. 1024).
The Role of the U.S. Government
The U.S. government has supported the creation of scientific collections and their long-term management and use as far back as the early 19th century (Sztein, 2016). Federal spending comprises a high percentage of the total amount of money spent on research.
In the last two decades, there has been a drive to make scientific samples that were obtained or generated with support provided by taxpayer dollars more readily available to different actors in the scientific community. Two important reports on this topic have been published by the National Research Council (2002) and the Interagency Working Group on Scientific Collections (IWGSC) (2009, known as the “Green Report”). Reasons for preserving physical collections include: (1) preserved collections allow the replication of the original experiments; (2) samples are sometimes used as standards; (3) samples may be irreplaceable or too expensive to recollect; (4) samples can be sources of ideas and can be used for education and training; (5) samples can be used for future analysis or experimental use; (6) scientific collections can be used for purposes unforeseen when the collection was created; and (7) reprocessing of old samples with new technology allows for the generation of new knowledge.
The IWGSC was created in 2006 by the White House National Science and Technology Council to focus attention and planning for federal/federally funded collections management (IWGSC, 2016). It is managed by the White House Office of Science and Technology Policy (OSTP) and co-chaired by the U.S. Department of Agriculture and the Smithsonian Institution. Fifteen federal agencies have scientific collections and/or granting programs. The variety of physical collections is considerable. Some collections include rocks, minerals, meteorites, cellular and tissue samples, fossils, soils, and water, rock, soil, and ice cores. Others include type specimens of plants, microbes, and animals. Scientific collections can also include living organisms, such as type culture microorganism collections, seed banks and plant germplasm repositories, and other biological resource centers (IWGSC, 2009). An IWGSC survey to identify the scope and range of federally held scientific collections conducted a decade ago (IWGSC, 2009) revealed that, of the 291 responses received, cellular/tissue scientific collections represented 22 percent (held in 10 of the 14 responding agencies), geological collections comprised 21 percent of the collections (held in eight agencies); paleontological collections represented 14 percent (held in four agencies), and vertebrate and botanical collections each represented 12 percent and 11 percent, respectively (each held by seven agencies).
The Green Report contained several recommendations, including the need for the development of budgeting information for collections and assessing and projecting costs; the identification and dissemination of policies and best practices on organization, management, physical and online access, and long-term preservation; and issues related to data and metadata accessibility, especially the need to document physical objects and make collection information available online, and develop an online clearinghouse for information on contents and access to federal scientific collections.
The OSTP issued a Scientific Collections memo in March 2014 (OSTP, 2014; see Appendix D), where object-based scientific collections are defined as “sets of physical objects, living or inanimate, and their supporting records and documentation, which are used in science and resource management and serve as long-term research assets that are preserved, catalogued, and managed by or supported by Federal agencies for research, resource management, education, and other uses” (OSTP, 2014, pp. 2-3). The memo asks each agency to develop plans to manage their physical scientific collections “to improve management of and access to scientific collections,” and to function as “an essential base for developing scientific evidence and … resource for scientific research, education, and resource management.”
The end goal of this effort is the “systematic improvement of the development, management, accessibility, and preservation of scientific collections owned and/or funded by Federal agencies.” This initiative is only for long-term institutional, archival collections, not for short-term project collections. The agencies were to include, among other requirements, consideration of legislative and regulatory requirements, clarification on who has the responsibility to carry out policies, projection of the costs of developing, preserving, and managing scientific
collections, agency requirements and standards for long-term preservation, maintenance, accessibility for public use, strategies to provide online information about physical collection contents and access to objects and digital files, unless limited by law or to protect national interests, definition of the process to de-access, transfer, dispose of collections, assignation of resources within each agency to implement policy, consistency with the 2013 Open, Machine-Readable Data OSTP memo (White House, 2013), and a request to agencies to work together and coordinate through the IWGSC (GSA, 2018).
The registry of U.S. Federal Scientific Collections is a curated source of information about object-based science collections owned or managed by U.S. federal departments and agencies (USFSC, 2018). The registry is a collaboration among the IWGSC, Scientific Collections International (SciColl), and the Smithsonian Institution, which manages the registry. At the time of this writing, 485 institutions are involved in this initiative, which includes 148 institutional and project collections. The main goals of this registry are to improve access to information about U.S. Federal scientific collections and the institutions that maintain them; and to improve interoperability among databases by providing an authority file of unique codes and machine-readable identifiers for institutions and their collections (OSTP, 2014).
The IWGSC compiled a list of the status of scientific collection policies by federal agencies (IWGSC, 2018). Of the 15 federal agencies, eight have scientific collections policies: the National Aeronautics and Space Administration, the Smithsonian Institution, the U.S. Department of Agriculture, the U.S. Department of Defense, the U.S. Department of Health and Human Services, the U.S. Food and Drug Administration, the National Institutes of Health, and the U.S. Environmental Protection Agency. The U.S. Department of Interior has Interior-wide Museum collection policies, and agencies within the department, such as the U.S. Geological Survey (USGS), are developing their own scientific collection policies.
For example, USGS is developing its policies based on comprehensive documents such as the USGS Geologic Collections Management System (USGS, 2018), a process to help determine the best fate for a given collection. The management of these collections and data is done through the National Geological and Geophysical Data Preservation Program (USGS, 2018). USGS provides some funds for intramural collection management and grants to State Geological Surveys and other Department of Interior agencies. The National Science Foundation’s data sharing policy states “Investigators are expected to share with other researchers, at no more than incremental cost and within a reasonable time, the primary data, samples, physical collections and other supporting materials created or gathered in the course of work under NSF grants. Grantees are expected to encourage and facilitate such sharing” (NSF, 2018a).
A good physical scientific collection is properly documented, well preserved, and curated. The metadata attached should include field number, geographic location, collector, date collected, sample type, reason for collection, project name, other important data, and include analyses and derivative samples. Research specimens can be added to permanent scientific collections following
different pathways: from intramural federal sources, from one federal agency to another, from non-federal researchers, from private collectors, and from international collaborations and exchange (IWGSC, 2009).
In addition, in order to organize the samples in any given collection, sample identification needs to be standardized. One such approach is to assign a Universally Unique Identifier (UUID) to each sample and its associated metadata. In the geosciences, the System for Earth Sample Registration (SESAR) (SESAR, 2018), hosted at the Lamont-Doherty Earth Observatory of Columbia University, and supported by NSF as part of the Interdisciplinary Earth Data Alliance, operates a registry that distributes the International Geological Sample Number (IGSN). The IGSN consists of an alphanumeric code assigned to specimens and related sampling features to ensure both unique identification and unambiguous referencing of data generated by the study of the samples with UUIDs (USFSC, 2018). SESAR catalogs and preserves sample metadata profiles, and provides access to the sample catalog via the Global Sample Search. Individual researchers can obtain their own accounts, which allows them to register their samples. Using UUIDs such as the IGSN is a concrete step towards making samples FAIR (AGU, 2017b). Multidisciplinary meetings (EOS, 2017) are bringing together researchers from disciplines with different approaches to sampling and informatics specialists to discuss relationships between data and samples, issues of data representation, and the challenges of creating and maintaining links between the physical samples and the data derived from them at different collection scales. The Integrated Digitized Biocollections website is an initiative aimed at making “data and images for millions of biological specimens” available online (iDigBio, 2018). Box 3-8 describes examples of open data in the discipline of the earth sciences.
The Role of Universities
In addition to government and museum repositories, universities have played an important role in the curation and archiving of scientific collections. They maintain scientific collections that are funded from both governmental and nongovernmental sources. While many are members of the Natural Science Collections Alliance (http://nscalliance.org), several large repositories are not. A few examples of such university repositories are the International Ocean Discovery Program, the Oregon State University Marine and Geology repository, the Scripps Institution of Oceanography Collections, and the University of California, Berkeley Museum of Paleontology.
Many university repositories have maintained funding through difficult times, but an alarming number are facing budget cuts that have led to closure and loss of valuable scientific collections. The fate of collections held by individual scientists working in university settings can be particularly complex. As the current generation of senior scientists retires, their collections become the responsibility of institutions that must decide what to keep and what to discard and also to find and manage space for such collections. It is not uncommon that the scientist’s university department disposes of the collections once he/she retires, with the loss
of potentially valuable samples and the information associated with them. This can be the case despite the fact these samples may be unique and irreplaceable (AGU, 2017b). Even in the cases where the scientist is proactive and tries to place these collections in museums or other institutions before retirement, success is not guaranteed. One of the main reasons given for the rejection of these collections by the institutions is the high cost associated with their proper curation and storage. Universities or other institutions holding collections sometimes decide, usually because of lack of space, funds, curatorial staff, or because of a change in scientific direction, to divest themselves from those collections. (For a recent case regarding a collection of Antarctic marine sediment cores, see Witze, 2016.) While the Antarctic collection has found a new home (Oregon State University, 2017), many other high-value research collections remain at risk.
While specimen images and other analytical information can be placed online and used by researchers around the world, this does not mean that the actual specimens can be discarded (Nature, 2017). Technologies not yet developed might yield important discoveries when applied to scientific specimens in the future, and analyses performed with those new techniques can supplement original analyses to test novel questions (McNutt, 2016). One such case is the reconstruction of the 1918 influenza virus through RNA sequencing of highly degraded virus fragments recovered from tissue samples from victims of that pandemic, only possible after the development of PCR techniques in the 1980s. The reconstruction of the 1918 influenza virus allowed the development of novel insights into its biology and pathogenesis, and provided important information about prevention and control of future pandemics (Taubenberger et al., 2012). Box 3-9 describes recent examples of scientific collections in the field of biological sciences.
All researchers in any type of setting need to consider their physical collection and data management plans at the earliest stages of their research. The preservation of physical samples has similar challenges to those presented by digital datasets: accessibility, decisions on what to save and what to discard, how to manage what is being saved, and issues of discoverability and of reuse (Sztein, 2016). Funding considerations frequently determine the preservation of collections, their associated metadata, and the databases that permit the discoverability and reuse of those collections. Funding stability would greatly assist in the preservation of those valuable resources for future generations.
Open Repositories
A number of organizations provide repositories for archiving datasets. For example, the Registry of Research Data Repositories (Re3Data), formerly Data-Bib, provides the largest and most comprehensive registry of over 1,500 data repositories, with a wide range of disciplines from around the world. A publication, Metadata Schema for the Description of Research Data Repositories (Version 3.0), released in 2015, describes the re3data.org properties (Rücknagel et al., 2015). PLOS has identified a set of trusted repositories that are recognized within their communities (see Table 3-3). For example, the Inter-university Consortium for Political and Social Research (ICPSR) is a large archive of digital social science data (MIT Libraries, 2018). For biomedical and environmental science repositories and field standards, PLOS suggests that researchers utilize FAIRsharing (FAIRsharing, 2017) and Re3Data that provide criteria to identify appropriate
data repositories, including licensing, certificates and standards, policy, and other criteria. Additionally, Scientific Data (http://www.nature.com/sdata/policies/repositories) provides a list of repositories that have been evaluated to ensure that they meet their requirements for data access, preservation, and stability. Box 3-10 illustrates open data practices for economics research.
A growing number of universities are starting to build research data repositories to help researchers manage data, preserve data for the long term, and allow permanent access to datasets in a reliable environment. MIT offers DSpace, a repository established to capture, distribute, and preserve the digital products of MIT faculty and researchers. The Harvard Dataverse Network (DVN), supported by the Harvard-MIT Data Center and Institute for Quantitative Social Science (IQSS), is a repository infrastructure that includes a large collection of research data in the social sciences (Harvard Dataverse, 2018; MIT Library, 2018). The University of Minnesota Libraries also list popular data repositories categorized by subject, including agricultural sciences; archaeology; astronomy; biological and life sciences; chemistry; computer science and source code; earth, environmental, and geosciences; GIS and geography; health and medical sciences; physics; and social sciences (University of Minnesota Libraries, 2018). Data availability facilitates reproducibility of research; allows validation, replication, reanalysis, new analysis, reinterpretation or inclusion into meta-analyses; and makes citation of data and research articles easier by ensuring recognition for authors (PLOS One, 2018).
TABLE 3-3 Open Data Repositories
| Disciplines | Repositories | Links |
|---|---|---|
| Cross-disciplinary | Dryad Digital Repository Figshare Harvard Dataverse Network Open Science Framework Zenodo |
http://datadryad.org http://figshare.com http://thedata.harvard.edu/dvn http://osf.io http://zenodo.org |
| Biochemistry | caNanoLab Kinetic Models of Biological Systems (KiMoSys) Mass spectrometry Interactive Virtual Environment (MassIVE) PubChem Standards for Reporting Enzymology Data (STRENDA DB) |
http://cananolab.nci.nih.gov/caNanoLab http://www.kimosys.org http://massive.ucsd.edu http://pubchem.ncbi.nlm.nih.gov https://www.beilstein-strenda-db.org/strenda/index.xhtml |
| Biomedical Sciences | The Cancer Imaging Archive (TCIA) Influenza Research Database National Addiction & HIV Data Archive Program (NAHDAP) National Database for Autism Research (NDAR) PhysioNet SICAS Medical Image Repository |
http://www.cancerimagingarchive.net http://www.fludb.org http://www.icpsr.umich.edu/icpsrweb/NAHDAP/index.jsp http://ndar.nih.gov http://physionet.org https://www.smir.ch |
| Marine Sciences | SEA scieNtific Open data Edition (SEANOE) | http://www.seanoe.org |
| Model Organisms | The Arabidopsis Information Resource (TAIR) Eukaryotic Pathogen Database Resources (EuPathDB) FlyBase Mouse Genome Informatics (MGI) Rat Genome Database (RGD) SmedGD VectorBase WormBase Xenbase Zebrafish Model Organism Database (ZFIN) |
http://www.arabidopsis.org http://eupathdb.org/eupathdb http://flybase.org http://www.informatics.jax.org http://rgd.mcw.edu http://smedgd.neuro.utah.edu http://www.vectorbase.org/index.php http://www.wormbase.org/#01-23-6 http://www.xenbase.org/common http://zfin.org |
| Disciplines | Repositories | Links |
|---|---|---|
| Neuroscience |
Functional Connectomes Project International Neuroimaging Data-Sharing Initiative (FCP/INDI) NeuroMorpho.orgOpenfMRI |
http://fcon_1000.projects.nitrc.org http://neuromorpho.org/neuroMorpho/index.jsp http://neuromorpho.org http://openfmri.org |
| Omics | ArrayExpress Biological General Repository for Interaction Datasets (BioGRID) Database of Interacting Proteins (DIP) dbGAP The European Genome-phenome Archive (EGA) Gene Expression Omnibus (GEO) GenomeRNAi GPM DB IntAct Molecular Interaction Database MetaboLights NURSA PeptideAtlas ProteomeXchange Proteomics Identifications (PRIDE) |
http://www.ebi.ac.uk/arrayexpress http://thebiogrid.org http://dip.doe-mbi.ucla.edu/dip/Main.cgi http://www.ncbi.nlm.nih.gov/gap http://www.ebi.ac.uk/ega http://www.ncbi.nlm.nih.gov/geo http://www.genomernai.org http://gpmdb.thegpm.org/index.html http://www.ebi.ac.uk/intact http://www.ebi.ac.uk/metabolights https://www.nursa.org/nursa/index.jsf http://www.peptideatlas.org http://www.proteomexchange.org http://www.ebi.ac.uk/pride/archive |
| Physical Sciences |
Australian Antarctic Data Centre (AADC) Cold and Arid Regions Science Data Center (CARD) Environmental Data Initiative Repository National Climatic Data Center (NCDC) National Environmental Research Council Data Centres (NERC) Oak Ridge National Laboratory Distributed Active Archive Center (ORNL DAAC) PANGAEA Reaction Database Standard Search InterfaceSIMBAD Astronomical Database UK Solar System Data Centre World Data Center for Climate at DKRZ (WDCC) |
http://www1.data.antarctica.gov.au http://card.westgis.ac.cn https://portal.edirepository.org/nis/home.jsp http://www.ncdc.noaa.gov http://www.nerc.ac.uk/research/sites/data http://daac.ornl.gov http://www.pangaea.de http://durpdg.dur.ac.uk/HEPDATA/REAC http://simbad.u-strasbg.fr/simbad |
| http://www.ukssdc.ac.uk http://www.wdc-climate.de |
||
| Sequencing | Database of Genomic Variants Archive (DGVa) dbSNP dbVar DNA DataBank of Japan (DDBJ) EBI Metagenomics EMBL Nucleotide Sequence Database (ENA) European Variation Archive (EVA) GenBank miRBase NCBI Sequence Read Archive (SRA) NCBI Trace Archive Uniprot |
http://www.ebi.ac.uk/dgva http://www.ncbi.nlm.nih.gov/snp http://www.ncbi.nlm.nih.gov/dbvar http://www.ddbj.nig.ac.jp http://www.ebi.ac.uk/metagenomics http://www.ebi.ac.uk/ena http://www.ebi.ac.uk/eva/?Home http://www.ncbi.nlm.nih.gov/genbank http://www.mirbase.org http://www.ncbi.nlm.nih.gov/sra http://www.ncbi.nlm.nih.gov/Traces/home http://www.ebi.ac.uk/uniprot |
| Social Sciences | Data Archiving and Networking Services (DANS) Inter-university Consortium for Political and Social Research (ICPSR) Qualitative Data Repository |
https://easy.dans.knaw.nl/ui/home https://www.icpsr.umich.edu/icpsrweb/landing.jsp https://qdr.syr.edu |
| Structural Databases | Biological Magnetic Resonance Data Bank (BMRB) Cambridge Crystallographic Data Centre (CCDC) Coherent X-ray Imaging Data Bank (CXIDB) Crystallography Open Database (COD) Electron Microscopy Data Bank (EMDB) FlowRepository Protein Circular Dichroism Data Bank (PCDDB) Worldwide Protein Data Bank (wwPDB) |
http://www.bmrb.wisc.edu https://www.ccdc.cam.ac.uk http://www.cxidb.org http://www.crystallography.net http://www.emdatabank.org https://flowrepository.org http://pcddb.cryst.bbk.ac.uk http://wwpdb.org |
| Disciplines | Repositories | Links |
|---|---|---|
| Taxonomic & Species Diversity | Global Biodiversity Information Facility (GBIF) Integrated Taxonomic Information System (ITIS) Knowledge Network for Biocomplexity (KNB) NCBI Taxonomy |
http://www.gbif.org http://www.itis.gov https://knb.ecoinformatics.org http://www.ncbi.nlm.nih.gov/taxonomy |
| Unstructured and/or Large Data | BioStudies CSIRO Data Access Portal GigaDB SimTK Swedish National Data Service |
https://www.ebi.ac.uk/biostudies https://data.csiro.au http://gigadb.org https://simtk.org https://snd.gu.se/en |
SOURCE: http://journals.plos.org/plosone/s/data-availability#loc-recommended-repositories.
Sharing and Preserving Research Software
Sharing and preserving research software code has become an increasingly important issue in recent years Journals have been introducing policies and new capabilities, including new editorial staff and technical tools, to ensure that the analytical code associated with an article meets certain quality standards and is made available (Baker, 2016). Concerns about reproducibility have provided a major impetus for this trend. Reanalyzing or verifying data requires use of the original code.
Regarding long-term preservation of code, the relevant practices, barriers, and considerations are largely the same as those related to data. The challenges of ensuring that data are properly cited are covered in Chapter 4—citation practices for software are even less developed. Some institutional repositories have developed guidelines and best practices in software preservation that they are using in their communities (Rios, 2016).
Reproducing a study or using older data requires the code and/software utilized during the experiment or the research undertaken. Oftentimes, researchers do not believe that they have the right to preserve software due to licensing terms and conditions. Aufderheide et al. (2018) addressed the issue of software preservation and found that “individuals and institutions need clear guidance on the legality of archiving legacy software to ensure continued access to digital files of all kinds and to illuminate the history of technology” (Association of Research Libraries, 2018). Additional information relating to code and reproducibility is further described in Chapter 4.
Considering the importance of code in the vision of open science, there is a need to address non-computational methodologies. These methods include preregistration of studies, most common in clinical research and psychology, which could be expanded in other areas of science. Kimmelman et al. (2014) stressed the importance of separating exploratory from confirmatory research, and in this context, registration of confirmatory experiments in preclinical research has been suggested (Kimmelman et al., 2014; Mogil and Macleod, 2017). Additionally, publication of laboratory protocols via electronic research notebooks or open access repository for science methods such as protocols.io, which allows forking and amendments to existing protocols, is a helpful feature to accelerate methodological development toward an open science enterprise (PLOS, 2017b; Goodman, 2018).
International Approaches
Open science approaches are being broadly assessed and adopted throughout the world. The British Royal Society has prepared an extensive report on issues related to open science (The Royal Society, 2012). In 2015, the European Council and the Group of Seven (G7) adopted open science and the reusability of research data as a priority. The FAIR principles were adopted by Science Europe and endorsed by the G20 in the 2016 Hangzhou summit (Mons et al., 2017). At its September 2017 meeting in Turin, Italy, the G7 committed to giving incentives
for open science activities and to providing global research infrastructures on the basis of FAIR data (G7, 2017). While the FAIR principles are increasingly recognized by governments, the private sector, and the scientific community globally, infrastructure needs have been addressed most intensively in Europe, Australia, and Africa. This section describes key community-driven initiatives toward an open science enterprise at a global level.
Research Data Alliance
The Research Data Alliance (RDA) is a global community-driven organization, launched in 2013 with support from the EC, U.S. National Science Foundation (NSF), U.S. National Institute of Standards and Technology (NIST), and Australia’s Department of Industry, Innovation and Science, to accelerate data sharing and data-driven innovation. As of October 2017, the RDA comprises more than 6,000 individuals from over 130 countries, including researchers, policy makers, and open science enablers and promoters (RDA, 2017b). Through its Working and Interest Groups, RDA creates infrastructure (tools, models, preliminary standards, code, curriculum, policy, etc.) that is developed and deployed to support specific challenges in data sharing and data-driven research. For example, the RDA Data Publishing Services Working Group developed a model for “an open, universal literature-data cross-linking service that improves visibility, discoverability, reuse, and reproducibility by bringing existing article/data links together, normalizes them using a common schema, and exposes the full set as an open service” (RDA, 2017b). Other RDA outputs include models for machine readable data type registries, approaches to data citation for data collections that change over time, curriculum for data science instruction, a common metadata vocabulary for agricultural data, and other infrastructure needed to enable data-driven research.
The RDA meets twice a year at Plenaries around the world to accommodate its global community. Its meetings are working meetings where many of its Interest and Working groups get together to advance the conceptualization, development, deployment, and adoption of its infrastructure outputs, and meet with a broad spectrum of stakeholders and communities. Both the U.S. and European regions of the RDA support the engagement of early career professionals with RDA Working and Interest Groups. RDA plenaries, programs, and operations are supported through its regions by funders from around the world including the National Science Foundation, the National Institute of Standards and Technology, the EC, the Australian Government Department of Education and Training, the United Kingdom’s nonprofit company JISC (formerly the Joint Information Systems Committee), the Japan Science and Technology Agency, Research Data Canada, University of Montreal, the Alfred P. Sloan Foundation, the John D. and Catherine T. MacArthur Foundation, and others.
International Council for Science
The Committee on Data for Science and Technology (CODATA) was created by the International Council for Science (ICSU) in 1966 with the mission “to improve the quality, reliability, management, accessibility and use of data of importance to all fields of science and technology” (CODATA, 2016). As the ICSU Committee on Data, CODATA promotes international collaboration to improve the availability, usability, and interoperability of research data. CODATA’s 2015 Strategic Plan and 2016 Prospectus of Strategy and Achievement identify its three priority areas (CODATA, 2017):
- Promoting principles, policies and practices for open data and open science;
- Advancing the frontiers of data science; and
- Building capacity for open science by improving data skills and the functions of national science systems needed to support open data.
CODATA achieves these objectives through its standing committees, strategic initiatives, and Task Groups and Working Groups. CODATA supports the Data Science Journal and collaborates on major data conferences, such as SciDataCon and IDW. A landmark publication of Science International (composed of ICSU, the InterAcademy Partnership, The World Academy of Sciences, and the International Social Science Council) entitled Open Data in a Big Data World highlights critical issues related to open data and open science while laying out a framework for how the vision of Open Data in a Big Data World can be achieved (Science International, 2015). Additionally, CODATA supports educational opportunities for early career researchers, including the International Training Workshop in Open Data for Better Science, through a grant from the Chinese Academy of Sciences.
Another ICSU interdisciplinary body, the World Data System (ICSU-WDS), was created in 2008, building on the over 50-year legacy of the World Data Centers and Federation of Astronomical and Geophysical data analysis Services. ICSU-WDS promotes universal and equitable access to scientific data and data services, products, and information across a range of disciplines including the natural and social sciences and humanities (ICSU-WDS, 2017).
European Activities
Open Science is one of three priority areas for research, science, and innovation policy in Europe (EC, 2017d). To support the transition to more effective open science, the EC launched the European Open Science Cloud (EOSC) in 2016, with a vision for “a federated, globally accessible environment where researchers, innovators, companies and citizens can publish, find and reuse each other’s data and tools for research, innovation and educational purposes” (EC,
2016). The EOSC High Level Expert Group, including 10 members from European countries, Japan, and Australia, released its first report, Realising the European Open Science Cloud, which provides specific recommendations to the Commission regarding actions needed to implement the EOSC (EC, 2016). In June 2017, the EOSC summit was held in Brussels to further discuss how to make EOSC a reality by 2020.
The EC also established the Open Science Policy Platform (OSPP) in 2016, a high-level expert advisory group that will support the development and implementation of open science policy in Europe. The group is tasked with addressing various dimensions of open science, including the establishment of a reward system, the measurement of quality and impact, the change of business models for publishing, FAIR open data, EOSC activities, research integrity, and open education (EC, 2017e). At the request of the Commission, RAND Europe and other entities, such as Deloitte, Digital Science, Altmetric, and Figshare, developed a monitor that tracks open science trends in Europe while identifying the main drivers, incentives, and constraints on its evolution.
Additionally, a group of European Union (EU) member states is preparing the Global Open (GO) FAIR initiative that focuses on involving all networked initiatives, research disciplines, and interested EU member states to make research data FAIR. The Netherlands has initiated and co-leads the early development of the GO FAIR initiative. Three pillars of GO FAIR include: (1) GO CHANGE, which aims to promote cultural change to make the FAIR principles a working standard; (2) GO TRAIN, which deals with locating, creating, maintaining, and sustaining the required data expertise in Europe through training and education; and (3) GO BUILD, regarding the need for interoperable and federated data infrastructures (Dutch Techcentre for Life Sciences, 2016). GO FAIR encourages close cooperation with activities in other regions, such as the NIH Commons (Bonazzi and Bourne, 2017) to build an Internet of FAIR data and services.
The European Southern Observatory (ESO) has recently endorsed the EOSC Declaration and expressed its support for the EOSC initiative on open access to scientific data. The ESO emphasizes that astronomy has been leading well-managed, curated open access to data in scientific research (ESO, 2017).
Other Global Initiatives
Significant efforts are also underway in Australia and Africa to promote the transition towards an open science system. The Australian National Data Service (ANDS), established in 2008, is a joint collaboration between Monash University and the Australian National University and the Commonwealth Scientific and Industrial Research Organisation (CSIRO) that addresses the challenges of managing research data in the country. Another effort is Australia’s Academic and Research Network (AARNet), a high speed low latency network infrastructure for research and education across a diverse range of disciplines in the sciences and humanities (AARNet, 2017). In Africa, the East African Community has recently adopted the Dakar Declaration on Open Science in Africa, following the Sci-GaIA
workshops (Barbera et al., 2015) related to the promotion of open science across Africa (CODESRIA, 2017). In South Africa, the African Data Intensive Research Cloud “aims to establish resources to support data intensive radio astronomy research among collaborating partners in South Africa and African Square Kilometer Array telescope partner countries” (Simmonds et al., 2016, p. 1). Additionally, CODATA is supporting the African Open Science Platform to improve the impact of open data across the research community.
This page intentionally left blank.
















































