
CHAPTER 2
FATE AND TRANSPORT
INTRODUCTION
Upon discharge to the environment, dispersants and oil are subject to a host of processes that act to transport and transform that discharge. Because such processes act in concert, the phrase “fate and transport” is commonly used to describe the collective action of these processes. The limited literature available on the fate and transport of dispersant components is briefly summarized at the start of this chapter. The remainder of this chapter examines how the use of dispersants as an oil spill countermeasure changes the characteristics of oil and the relative importance of physical, chemical, and biological processes that impact oil upon discharge to the environment. As an update from the 2005 National Research Council (NRC) report, this chapter includes a combination of foundational information and new knowledge gained since the publication of the previous report. While the primary focus is on the capacity of dispersants to alter oil’s fate and transport, the chapter also considers feedbacks between processes with a leaning toward the subsurface, owing to studies that followed the Deepwater Horizon (DWH) oil spill (also known as the Macondo spill).
FATE AND TRANSPORT OF DISPERSANT COMPONENTS
The mixture of solvents and nonionic and anionic surfactants that comprise typical commercial dispersants (Place et al., 2010) contains compounds with different physicochemical properties and therefore potential fates in the environment. Once introduced to open ocean waters, dispersant mixtures will be quickly diluted (Lee et al., 2013a) and subjected to degradation processes, including biodegradation and photodegredation.
Laboratory-based experiments have shown that components of the dispersant mixture are biodegradable on the order of days. This biodegradability includes the petroleum distillates (Bælum et al., 2012) as well as the surfactant compounds dioctyl sodium sulfosuccinate (DOSS), Tween 80, and Tween 85 (Brakstad et al., 2018b; Campo et al., 2013; Garcia et al., 2009). Direct sunlight and indirect photolysis via reaction with a hydroxyl radical have also been shown to degrade the surfac-
tant components of dispersants on the order of hours. These studies include the photodegradation of DOSS, 2-butoxyethanol, dipropylene glycol butyl ether, and propylene glycol (Glover et al., 2014; Kover et al., 2014). These lab-based studies indicate that dispersant mixtures, when released into the environment, are generally biodegraded and/or photodegraded on the order of hours to days. In the few field studies conducted, the effects of dilution on dispersant fate and transport have also been observed. Measured concentrations of dispersants after surface applications reached a maximum of 5-13 parts per million (ppm) at 1-0.6 m depth (Bocard et al., 1984; Lewis and Aurand, 1997). Prior research suggests that concentrations should decrease to < 1 ppm within minutes to hours (Lewis and Aurand, 1997).
Research examining the long-term fate of dispersant mixtures in the environment indicates that DOSS is not always completely degraded. Studies have shown that DOSS persisted for up to 4 years following the DWH spill in oil-sand patties collected from beaches along the Gulf of Mexico (McDaniel et al., 2015; White et al., 2014) and in marine sediment material (Perkins et al., 2017). DOSS measured in samples collected from beaches is thought to originate from dispersant applications at the surface, while DOSS in the deep sea could originate from both surface applications and subsea dispersant injection (SSDI). In the aforementioned scenarios, however, the concentrations of DOSS observed were extremely low (~1-260 ng/g or parts per billion [ppb]) indicating that dissolution, biodegradation, and photodegradation likely acted on the bulk of dispersant released in response to the DWH spill.
CHARACTERIZATION OF OIL CHEMISTRY
The chemical composition of an oil dictates its physical properties, which in turn dictate the initial physical interactions of oil with applied dispersant. The chemical composition of an oil further dictates the long-term behavior of dispersed oil through processes such as evaporation, dissolution, biodegradation, aggregation, and adhesion. This section introduces oil chemistry, especially as it relates to spill response and dispersant application.
Throughout this report the term “oil” is used as a general term referring to complex crude and refined chemical mixtures of hydrophobic compounds derived from geological sources. The term “petroleum” is used interchangeably with oil for the purpose of this report, and both terms are used with various modifiers for added specificity. The chemical composition of an oil typically includes thousands of different compounds (Frysinger et al., 2003; Hsu et al., 2011) and can vary significantly between geological sources based on the organic source material, geologic setting, thermal history, occurrence of subsurface biodegradation, and physical fractionation processes (Hunt, 1996; Peters et al., 2005). Following extraction, an oil may be further altered by various industrial actions, among them simple phase separations at the site of production; refining process, including various modes of distillation, condensation, desulfurization, and cracking; and blending of crude or refined materials for transport or sale. The combination of source-specific compositional variability with complex and variable industrial processing leads to a complex terminology for oil spill responders that includes functional classification of industrial products, functional descriptions of chemical composition, specific methodologies used to derive chemical composition, and multiuse terminology. Because any of these products can spill to the environment, nuances of the terminology are relevant to the issue of dispersant application.
Crude petroleum is typically described by bulk physical or chemical properties relevant to transport, refining, or potential profitability. Common descriptors include categorization of the American Petroleum Institute (API) Gravity (a measure of density) as light, medium, or heavy, and categorization of the sulfur content as sweet or sour. Other common descriptors define the method by which the petroleum was extracted—conventional versus nonconventional—as well as
select physical properties relevant to its handling, such as viscosity, vapor pressure, and tendency to solidify as wax. Following processing or refining of crude oil the product is referred to explicitly, with an implicit understanding of the associated properties and behavior. Examples include gasoline, jet fuel, avgas, diesel fuel, heavy fuel oil, natural gas, gas condensate, light naphtha, and kerosene. Such products typically contain a subset of compounds found in crude petroleum, and their chemical composition is thus more readily defined. Subsea well blowouts such as occurred in the DWH, the 1969 Santa Barbara, and the Ixtoc I oil spills occur at seafloor temperature and pressure conditions and involve the unprocessed reservoir fluids that may include natural gas, reservoir water, carbon dioxide, and crude oil. More so than for surface spills, the circumstance of such blowouts—particularly the gas composition (see Box 2.1)—necessitates a situational understanding of the basic chemical properties of the discharge at in situ conditions, relevant to the consideration of response options, including SSDI.
In the absence of published studies on the compositional variability of discharge from a well blowout, the committee turned to reservoir geochemistry (Hunt, 1996) to assess potential heterogeneity in discharged fluids. While large reservoirs are relatively homogenous, smaller or complex reservoirs tend to exhibit greater heterogeneity relevant to a blowout scenario. For example, the pressure change in a small reservoir over the course of a blowout could be substantial, and if the reservoir pressure passes near the bubble point of the oil it will result in a change in the gas-to-oil ratio (GOR), which in turn can result in a migration of the lighter oil constituents from the oil to the gas. In other words, not only will the GOR change but both the oil and gas components will become heavier. In complex reservoirs—which may be faulted, be partially biodegraded, or have non-horizontal strata—the oil may have fractionated during its geological life such that as a blowout progresses, different fractions may emerge. This tendency will be enhanced for smaller reservoirs. The relative proportions of gas, water, and oil typically change over the production life of a well, with an expectation that these proportions could vary for a blowout scenario.
Comprehensive and quantitative chemical inventories exist for some refined petroleum products, whereas molecular complexity has challenged such characterization for crude oil. As a result, chemical descriptions of crude oil rely on distinctions between molecular composition at the level of functional moieties, molecular weight distribution, solubility behavior, volatility distribution (e.g., volatile organic compounds [VOCs], semi-volatile organic compounds [SVOCs], and intermediate-volatility organic compounds [IVOCs]), physical transformations (such as wax formation, as occurred extensively during the Montara oil spill), abundance of minor elements, and the relative abundance of readily quantified compounds. Various methods have been developed to quantify oil’s chemical composition, though no single method is able to provide a complete chemical inventory.
According to various dispersant application guidelines, many liquid petroleum products have too high a viscosity or pour point to be effective targets for chemical dispersion. Key compositional determinants of physical behavior include the molecular weight distribution of hydrocarbons, the abundance of other elements (e.g., N, S, and O), and the relative abundance of saturates, aromatics, resins, and asphaltenes. As a general rule, a disproportionate abundance of high molecular weight hydrocarbons (exemplified by the Montara oil spill), high relative concentrations of resins or asphaltenes (exemplified by the 1969 Santa Barbara oil spill), and high abundances of other elements are associated with high viscosity and high pour point. In cases of dispersant application, it is important not only to know the initial properties of the discharged oil but also to know sufficient compositional details in order to predict how the oil might change as it weathers. Such compositional information is useful for predicting fate and transport processes.
Oil fate and transport mechanisms are governed by the laws of physics and chemistry. In practice, the application of these laws is strongly modulated by the chemical composition of the oil, the spill environment, human intervention, biological processes, and time (Daling et al., 1997). This
chapter is arranged to follow the major processes that act on oil in the environment, which provide the context for subsequent chapters.
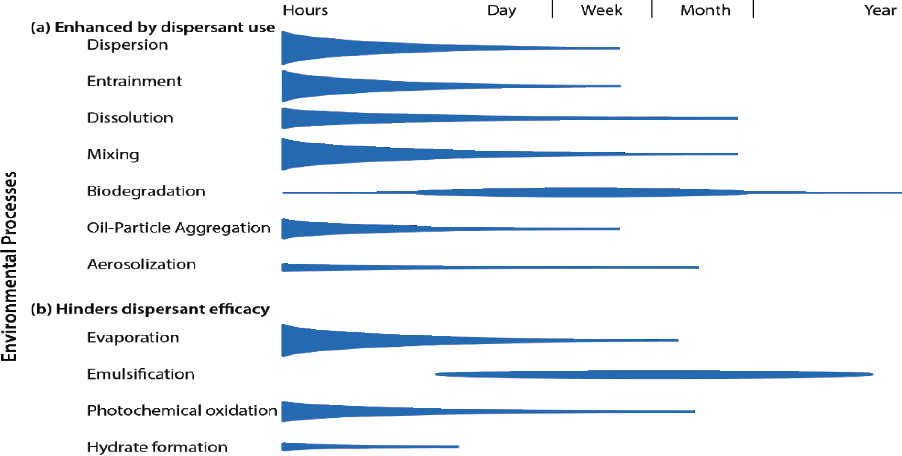
The application of dispersant can alter the relative importance of different fate and transport processes as outlined in Figure 2.1, with the intention of enhancing processes such as dispersion, oil droplet formation, dissolution, vertical and horizontal mixing, and biodegradation (see Figure 2.2a). Aerosolization and aggregate formation may also be enhanced by chemical dispersants (see Figure 2.2a). The efficacy of dispersants can be hindered directly or indirectly by processes such as evaporation, emulsification, and photochemical oxidation (see Figure 2.2b). This chapter focuses on processes that inform or influence the effects of chemical dispersant use, with a brief overview of other processes.
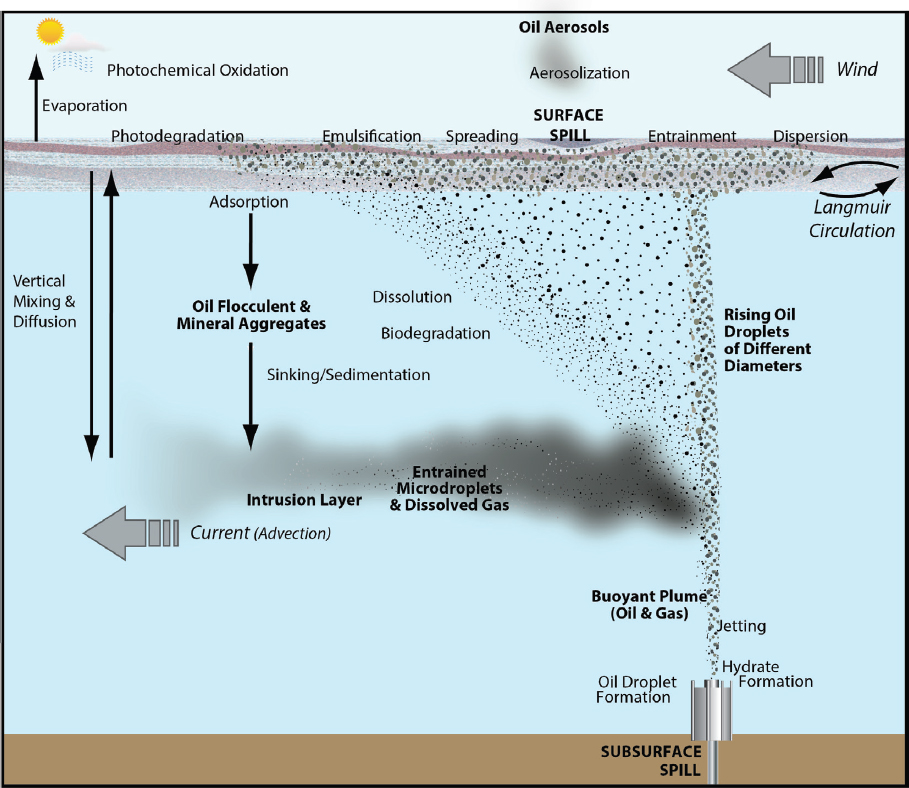
THE EFFECT OF NATURAL GAS IN BLOWOUTS
The occurrence of natural gas is a defining feature of a blowout scenario, and it affects myriad processes, as described in this section and in Box 2.1. Natural gas refers to the low molecular weight hydrocarbons that maintain a gaseous state at atmospheric pressure and temperature, typically comprising methane as the bulk constituent with variable concentrations of ethane, propane, butanes, and pentanes. These hydrocarbons are produced through the same geologic processes that produce higher molecular weight petroleum hydrocarbons, though natural gas occurrence is variable among oil reservoirs because of reservoir source material and thermal history, phase separation, and microbiological activity. Natural gas is typically separated from crude oil following extraction and prior to transport; as a result, it is a nonissue for many oil spills. The major exception is for well blowouts. Natural gas discharged from the seafloor during a blowout can be dissolved in oil (referred to as live oil), or it can occur as a separate phase with consequences on the fate and transport of the oil and, therefore, on the response efforts. Box 2.1 outlines several impacts that the presence of gas had on the response operations during the DWH spill: hydrate formation, estimation of flow rate, dispersant-to-oil ratio (DOR), and mass balance calculations. The occurrence of natural gas can impact oil droplet formation and transport in various ways, relevant to SSDI. The occurrence of the gas phase at the point of discharge played an important role in droplet formation and rise velocity, as identified in various models: for example, SINTEF’s model1; VDROP-J (Zhao et al., 2014a); and RPS ASA’s model.2 These models assume that the gas and oil are co-flowing, in which case the oil is effectively squeezed through a smaller cross-section with commensurate increase to its velocity and Weber number, predictably decreasing droplet size
___________________
1 For the purpose of clarity, in this discussion, the committee uses “SINTEF’s model” here and henceforth to refer to the model initially developed by Johansen et al. (2013) and subsequent modifications of that model.
2 For the purpose of clarity, in this discussion, the committee uses “RPS ASA’s model” here and henceforth to refer to the model initially developed by Li et al. (2017c) and subsequent modifications of that model.
(Brandvik et al., 2019b). However, interactions between the two phases are also known to generate a variety of secondary flows, including churn flow (Boufadel et al., 2018b), which complicates assessment of flow rate and droplet size distribution. Degassing of oil in the rising plume has also been hypothesized to accelerate rise velocity for dual-phase droplets (Pesch et al., 2018).
Natural gas may also impact an SSDI scenario through physical and chemical interaction with dispersants, and through two or more possible mechanisms of action. A first point of uncertainty is the impact of a gas phase on the microscale distribution of surfactants because surfactants will migrate to oil–water, gas–water, and gas–oil interfaces, with impacts for efficacy of oil dispersion. A second point of uncertainty is the formation of gas hydrate rinds at the bubble interface and their potential to impact dispersant efficacy. The DWH discharge and the intrusion layers occurred within the gas hydrate stability field, and while direct evidence of water column hydrate formation presented by Joye et al. (2011) is weak, microscale formation remains a possibility.
Upon discharge to the environment from the Macondo well natural gas would have existed in three key forms: gas, liquid, and aqueous dissolved. The gas phase observed exiting the Macondo well is assumed to be primarily methane, whereas ethane, propane, butanes, and pentanes were presumably condensed to the liquid phase at these conditions and occurred homogenously with the higher molecular weight petroleum hydrocarbons. Because of their high solubility and partial pressure, dissolution to the aqueous phase commenced upon aqueous exposure. Observations from June 2010, during a period of regular SSDI, indicate extensive natural gas dissolution to the intrusion layers (Kessler et al., 2011a; Valentine et al., 2010) and minimal atmospheric release (Ryerson, 2010, 2012; Yvon-Lewis, 2011). Limited observations from May 2010, prior to regular SSDI, also indicate extensive dissolution of natural gas to the deep intrusion layers (Joye et al., 2011a).
The natural gas dissolved in the deep-sea intrusion layers (see Figure 2.3) became bioavailable to microbial populations that use these compounds as sources of energy and cellular carbon (Dubinsky et al., 2013; Redmond and Valentine, 2012; Rivers et al., 2013). Several works address the sequence and rate at which microbial populations responded to the input of natural gas and other soluble compounds. Measurements and incubations from June 2010 indicate that propane and ethane consumption were the dominant microbial processes, with lesser rates of methane
consumption (Valentine et al., 2010). Several lines of evidence suggest that methane consumption followed in July and August 2010 (Du and Kessler, 2012; Dubinsky et al., 2013; Kessler et al., 2011a), though with some contention (Crespo-Medina et al., 2014, 2015; Joye et al., 2011b; Kessler et al., 2011b). Butanes and pentanes may have evoked a similar microbial response as ethane and propane (Rubin-Blum et al., 2017), though this assumption was not tested in the context of DWH. Spatial integration of oxygen anomalies from the depth of the intrusion layers in the months that followed DWH revealed a deficit that was similar in magnitude to the respiratory demand of discharged natural gas (Du and Kessler, 2012; Kessler et al., 2011a) consistent with its complete consumption by the bacterial community.
Because of its aqueous solubility natural gas serves as a potential tracer of deep ocean processes associated with well blowouts or other subsea discharge scenarios. During DWH, methane was proposed as a molecular target to calculate total discharge (Valentine, 2010), and ultimately an integrated subsea oxygen anomaly was used to estimate the total hydrocarbon respiration from the deep intrusion layers (Du and Kessler, 2012; Kessler et al., 2011a). Methane concentrations in the deep-sea intrusion layers were also found to correlate with observed anionic surfactant DOSS concentration, presumably because both are soluble in aqueous solution and dissolve rapidly (Kujawinski et al., 2011).
OIL FATE
Evaporation
Evaporation of lighter surface oil components occurs rapidly after an oil spill, which causes the loss of smaller, more volatile petroleum compounds with boiling points typically lower than that of n-pentadecane (Stout et al., 2017). Evaporation is quantitatively significant, and it is often the dominant process initially altering both the chemical composition and the physical properties of spilled oil. Typical crude oils lose 20%-50% of their mass from evaporation, whereas refined petroleum products can lose 75% and residual fuel oils typically lose ~10% of their mass (NRC, 2003, 2005). The loss of volatile petroleum compounds leaves behind an oil residue with higher density, lower solubility, and higher viscosity than the original oil, which makes it more likely to form water-in-oil emulsions and more difficult to disperse.
Evaporation reduces the water-soluble fraction of oil, and the loss of specific compounds such as benzene, toluene, ethylbenzene, and xylene (BTEX) to the atmosphere reduces the toxicity of the remaining oil to marine organisms. The transfer of BTEX compounds to the atmosphere, however, can pose an inhalation-related health risk to response workers and other exposed individuals and animals breathing air at the water surface (see Chapter 4). Dispersants were applied subsea during the DWH event with one justification being the reduction of VOCs surfacing around active response vessels (USCG, 2011). VOC concentrations were measured from surface vessels responding to well control between May 30 and June 10. Measurements taken from these vessels were summed and compared to SSDI hourly rates and hourly wind speeds to examine whether periods of low or no SSDI were followed by increased atmospheric concentrations of VOCs (Nedwed, 2017). While there were significant variations in measured VOC concentrations, there has not been sufficient analysis of the data collected to determine a relationship between the dispersant volume, VOC concentration, and environmental conditions at the DWH. However, some responders working at the wellhead area were reportedly convinced by their observations that dispersant use effectively reduced VOC levels (personal communications from Ken Lee, Rich Camilli; National Commission, 2011). It is challenging to make statistical correlations and draw robust conclusions from the available data because information regarding vessel location in relation to the well, surface oil slick, and prevailing winds was unavailable, and the tests performed were designed to inform immediate action, not for statistical validation. To further investigate SSDI and atmospheric VOC
concentrations, additional VOC data collected from three surface vessels (Ryerson et al., 2012) was compared to model data generated for a representative day during the DWH event, after the riser was cut, when SSDI was being used (Gros et al., 2017). Although there were limitations in the VOC data available from response vessels (Nedwed, 2017), this study by Gros et al. (2017) supports the conclusion that the use of SSDI prolonged dissolution of water-soluble petroleum compounds (including BTEX) during the transport of oil to surface waters, resulting in fewer of the volatile oil components being present at the water surface for evaporation to take place (Gros et al., 2017). Rates of evaporation are further complicated by wind speed. For example, high wind speeds increase evaporation rates; but, they also promote dissolution of oil in the water column and diffusion of VOCs in the air, muddling the overall effect of wind (Crowley et al., 2018).
In addition to the compound-selective reduction in VOCs, SSDI during DWH is also assumed to have broadened the footprint of surfacing oil (Ryerson et al., 2012), with two important effects. First, the slow rise of small droplets allows for currents to shift the zone of surfacing oil away from the location of the wellhead and the intervention efforts. Second, a broadened surface expression equates to a dilution of atmospheric VOC concentration, other factors being equal. Both of these effects are important to response operations in that they reduce VOC exposure to personnel at the site of intervention, though not necessarily through a reduction in the quantity of surfacing oil.
The evaporation of oil is challenging to model because oils consist of thousands of different compounds, each with different physical and chemical properties. Early models focused on the loss of individual compounds as a function of their volatility (vapor pressure), wind speed, sea state, and temperature (e.g., Brutsaert, 1982; Sutton, 1934). Later models considered that there would be a decrease in the rate of evaporation as evaporation proceeds and so they incorporated a mass transfer coefficient dependent on wind speed (Stiver and Mackay, 1984). Comparisons of the model developed by Stiver and Mackay (1984) to experimental data indicated that the model performed well for the first 8 hours, but over longer periods of time, the model overestimated long-term evaporation (Bobra, 1992). Overestimation of evaporative losses of petroleum compounds arises from the presumption that the oil is a well-mixed phase; while true for thin slicks, however, this is not the case for thicker slicks. The thickness of the slick is important because evaporation from an oil slick is regulated by the diffusion of petroleum compounds within the oil to the oil-atmosphere interface, as opposed to diffusion across the air-boundary layer (Fingas, 2011, 2013, 2015). Further information and more detailed descriptions of these oil evaporation models are provided elsewhere (NRC, 2003, 2005).
Aerosolization
Bubble bursting and aerosolization are non-evaporative processes that transport oil into the atmosphere. Breaking waves entrain air into surface waters creating bubbles, which rise to the surface and burst to form marine aerosols in the atmosphere (Blanchard and Woodcock, 1980; Leifer et al., 2000). When surface waters are contaminated with oil, the aerosols formed contain these petroleum hydrocarbons. These aerosols may be comprised of ultrafine particles containing oil-derived VOCs with a higher toxicity compared to the spilled oil (Nel et al., 2006). Aerosolization also occurs as oil compounds that have evaporated into the atmosphere are oxidized to form secondary organic aerosols (SOAs). SOA formation generates compounds with lower volatilities that nucleate new particles or condense onto existing aerosol particles. Oil compounds of varying volatilities can be precursors for SOAs, including VOCs, SVOCs, and IVOCs (Robinson et al., 2007). The formation of SOAs from IVOCs present in surface oil slicks can be particularly significant owing to the slower evaporation rates of IVOCs and the greater time available for them to be transported and distributed over a wide sea surface area (de Gouw et al., 2011). Understanding the lifetime of individual petroleum compounds in the gas phase, and the formation and particle size of the SOAs they form (Brock et al., 2011), contributes to our overall understanding of their transport in air. Vertical dispersion and long-range atmospheric transport of SOAs is of particular
interest because it has implications for air quality and public health both at the site of and downwind from an oil spill (Middlebrook et al., 2012).
Effective applications of dispersants to oil released into the environment is intended to increase the dispersion of oil compounds in the water column and reduce evaporation and subsequent aerosol formation. However, laboratory studies have shown that the application of dispersants to surface oil slicks can increase the number of aerosol particles produced by breaking waves by one to two orders of magnitude compared to untreated oil slicks (Afshar-Mohajer et al., 2018). The overall increase in aerosolization of oil compounds is attributed to an increase in the dispersion of oil in the water column as well as the flotation capacity of bubbles (Ehrenhauser et al., 2014). The applicability of these lab-based studies to real-world systems is yet to be determined.
Photochemical Oxidation
Photooxidation can significantly alter the composition of oil released into the aquatic environment (Fathalla and Anderson, 2011; Garrett et al., 1998; Payne and Phillips, 1985). Photochemical oxidation of oil occurs in sunlit waters via direct mechanisms, where light is absorbed by oil hydrocarbons, or by indirect mechanisms, where photosensitizers (e.g., dissolved organic matter) absorb light to produce reactive intermediates such as singlet oxygen or radicals that subsequently react with oil hydrocarbons (summarized in NRC, 2003, 2005). The chemical composition of oil is an important determinant for photochemical reactivity. The intensity and duration of light exposure is also important for evaluating the relative importance of photochemical oxidation to the fate of spilled oil. Light exposure is modulated by geographic location, season, local shading by cloud cover, and—in the case of dispersed oil—water depth and slick coverage.
Partial oxidation of oil hydrocarbons is the norm, producing compounds not originally present in the spilled oil (Aeppli et al., 2012). Some products of photooxidation are more water soluble than their hydrocarbon precursor(s) and can then be carried by water flow (Chapelle, 2001). Photo-modification and photosensitization of polycyclic aromatic hydrocarbons (PAHs) have been found to increase the toxicity of residual oil following spills (Barron et al., 2003). Other compounds produced are high molecular weight products that form tar and gum-like residues (NRC, 1985, 2003, 2005), which increase the viscosity of oil and decrease the utility and efficacy of dispersants (Ward et al., 2018a).
Laboratory studies exposing a crude oil from Basilicata, Italy, to 100 hours of direct irradiation resulted in changes in the chemical composition of oil from photochemical reactions, with branched alkanes, linear alkanes, and aromatic hydrocarbons being photooxidized to different extents (D’Auria et al., 2009). Using a simulated freshwater environment, Yang et al. (2015) observed more rapid photooxidation of lower molecular weight alkanes than of the higher molecular weight compounds. In addition, PAHs were more susceptible to photooxidation than were alkanes, consistent with previous reports (D’Auria et al., 2009; Díez et al., 2007; Ebrahimi et al., 2007; Fathalla and Anderson, 2011; Garrett et al., 1998; Maki et al., 2001; Prince et al., 2003; Radović et al., 2014). Prince et al. (2003) also reported that most of the aromatic fractions were converted to resins and asphaltenes, while the saturates were unaffected. They further suggested that the photodegradation rate of PAHs was positively correlated to the number of aromatic rings and the extent of alkylation, which was inverse to biodegradation rates (Ebrahimi et al., 2007; Garrett et al., 1998; Prince et al., 2003; Stout et al., 2016; Wardlaw et al., 2011; Yang et al., 2016b).
Biodegradability and environmental persistence of the residual oil may be affected by changes in the physicochemical properties of aromatic compounds and their related components (King et al., 2014a; Lee, 2003). Photooxidation may increase biodegradation rates due to increased hydrocarbon bioavailability, or it may decrease rates due to toxic by-products, depending on the oil composition and response of the microbial community (Mallakin et al., 1999; Yang et al., 2017).
The DWH spill provided an opportunity to test existing conceptual models of photooxidation by tracking changes to the chemical composition of petroleum hydrocarbons in the environment. Petroleum hydrocarbons in oil residues were found to be converted to oxygen-containing products, including abundant hydroxyl and carbonyl functional groups, which accumulated in the residues within weeks of discharge (Aeppli et al., 2012). Hall et al. (2013) demonstrated that the oxidation process—especially photooxidation—is a major factor in the chemical changes of oil still left in the environment following the spill. Based on measured losses and altered asphaltenes from their experiments, Lewan et al. (2014) indicated that within the first 80 days of oil release from the DWH spill, a mean of 61 vol% of the spilled oil was lost from the surface. Reconnaissance experiments suggest that the composition changes occurred primarily as a consequence of the combined effects of photooxidation and evaporation rather than microbial degradation, dissolution, dispersion, or burning.
A study by King et al. (2014a) on photolytic and photocatalytic degradation of surface oil from the DWH spill indicated that the photodegradation of PAHs was rapid in the first few hours at the rate of 10% per hour. The process slowed to near zero after 6 days. While solar irradiation increased the evaporative loss of n-alkanes < C17, the loss of n-alkanes by photodegradation was not observed with the equivalent of 3 days of solar radiation. Bacosa et al. (2015) incubated surface water from the DWH site in quartz glass bottles under natural sunlight and temperature conditions to determine the contributions of photooxidation and biodegradation to the weathering of Light Louisiana Sweet crude oil. They reported that following the loss of lighter hydrocarbon components by evaporation, photooxidation rates exceeded that of biodegradation in the transformation of PAHs and alkylated PAHs in surface water oil sheens, while biodegradation was the main driver in the disappearance of alkanes. Compared to biodegradation, photooxidation increased transformation of 4-5 ring PAHs by 70% and 3-4 ring alkylated PAHs by 36%.
Photooxidation can produce tar and gum residues from surface oil when higher molecular weight products are produced through the condensation of peroxide and other free-radical intermediates (NRC, 1985, 2003), while some laboratory studies showed insignificant differences in oil density following irradiation (NRC, 2013; Short, 2013). It has also been suggested that the formation of microbial flocs in seawater, and the subsequent sinking of oily marine snow, may be associated with the exposure of light Macondo oil to ultraviolet irradiation (Chanton et al., 2014; Passow, 2016).
A recent study that merged field data from the DWH spill and modeling with laboratory experimentation found that oxygenation of petroleum hydrocarbons by sunlight occurred rapidly—with major compositional changes occurring in a matter of days (Ward et al., 2018b). During these environmental studies the chemical composition of oil residues changed substantially, with greater than half the mass of oil residues ultimately comprising oxygen-containing compounds. The oxygen-containing molecular products produced by photochemical transformation have been referred to as oxygenated hydrocarbons (or oxyhydrocarbons), and the process has been referred to as partial oxidation or oxygenation, as an attempt to distinguish this chemical route from complete mineralization to carbon dioxide (i.e., complete oxidation). The authors note that partial photooxidation at the sea surface could account for as much hydrocarbon as microbial biodegradation (to CO2) in deep water, in contrast to the previous assumption that oxidation by sunlight is a relatively insignificant process for determining the fate and mass balance of oil.
By lowering oil-water interfacial tension (IFT) to enhance the breakup of oil into small droplets, dispersants may accelerate the photooxidation rates of spilled oil. Gong et al. (2015) reported that the presence of 18 and 180 mg/L of dispersant in seawater increased the first-order photodegradation rate of pyrene (at a test concentration of 60 µg/L) by 5.5% and 16.7%, respectively. Mechanistic studies suggested that the dispersant enhanced the formation of superoxide (O2–) radicals that contributed toward the photodegradation of the pyrene. Fu et al. (2017) investigated the photodegradation of pyrene with different dispersants. The results showed that increasing the concentration of either Corexit® 9500A or Corexit® 9527A enhanced
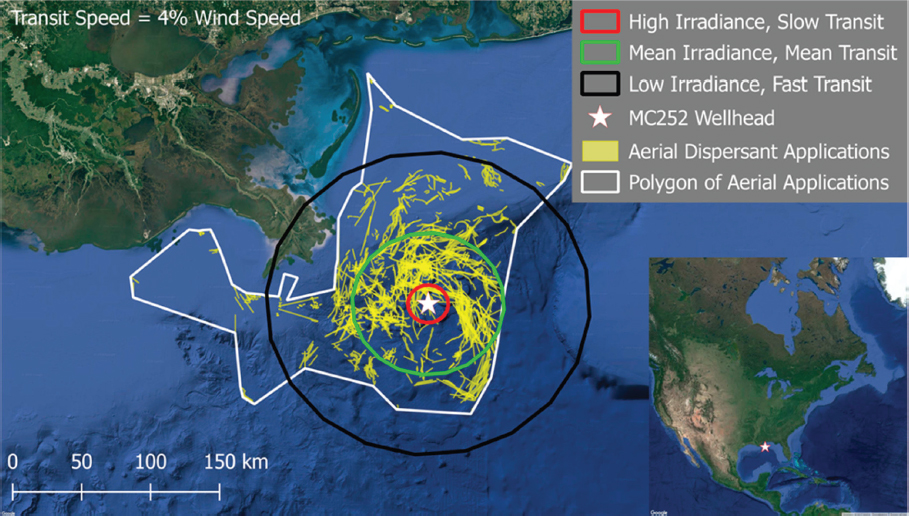
the photodegradation of pyrene in comparison to SPC1000, which modestly inhibited the reaction rate. Under similar test conditions (18 mg/L dispersant; 60 µg/L pyrene, and 6 hours of incubation), the loss of pyrene was 89% for Corexit® 9500A, 85% for Corexit® 9527A, and 49% for SPC1000 compared to 55% without dispersants. Furthermore, they also noted that Corexit® 9500A was prone to photochemical decomposition, with > 95% degradation after 6 hours of solar radiation. They concluded that accelerated rates of photodegradation in the presence of Corexit® 9500A could benefit ecosystems through increased dissolution and decomposition of persistent hydrocarbons and higher biodegradation rates as well as reduced chemical toxicity. Zhao et al. (2016c) evaluated the response of different petroleum species within water accommodated oil prepared with Louisiana Sweet crude oil to photodegradation in the presence and absence of Corexit® 9500 at a DOR of 1:20. They concluded that under simulated sunlight, both n-alkanes and PAHs were susceptible to photodegradation, and the co-presence of oil PAHs and dispersant facilitated photodegradation of n-alkanes. In contrast to these previous studies, Ward et al. (2018a) reported that photochemical transformations over a simulated exposure period of 53 hours reduced the effectiveness of dispersant applications by 29%-34%. While this recent study is specific to the oil and laboratory exposure conditions employed (including the choice of glass type), it flags the possible importance of properly accounting for photochemical transformation in the dispersant application decision process, particularly in identifying temporal and spatial limits for dispersant efficacy at the sea surface, which is an especially difficult endeavor considering the assumptions that must be made with respect to complex on-water surface movements (see Figure 2.4).
Dissolution
Many compounds that comprise oil are slightly soluble in water. The solubility for a given oil hydrocarbon for a given solvent (e.g., seawater) is a function of its molecular properties and can be predicted using Linear Solvation Energy Relationships (Abraham et al., 2004; Goss, 2005). In general, aqueous solubility is quite low for hydrocarbons containing more than 10 carbons and increases among low molecular weight compounds, particularly those that are branched or contain aromatic functional groups. The extent to which any given oil hydrocarbon dissolves into an aqueous solution such as seawater is a function of its aqueous solubility but is modulated by various environmental conditions, including temperature, salinity, pressure, duration of exposure, chemical and physical properties of the oil, microscale characteristics of the interface through which it must travel to enter the aqueous phase, and its aqueous-phase concentration (Gros et al., 2017; Jaggi et al., 2017; Ryerson et al., 2011). Oil solubility and dissolution should not be confused here with the water-accommodated fraction of oil, which is an empirical quantity that includes both the dissolved and the suspended components.
Depending on the environmental context of its discharge, oil may experience prolonged exposure to water, allowing for dissolution of its more soluble compounds with or without the application of dispersants. Scenarios for which dissolution is an important consideration include subsea discharge; trapping of oil under ice; large entrainment of oil droplets in the upper water column, such as through breaking waves; and situations involving rapid sedimentation or flocculation. When oil is exposed to the atmosphere, such as at the sea surface, the extent of dissolution is dramatically reduced because many of the aqueous-soluble compounds are also highly volatile (as discussed above). The application of dispersant to oil, leading to dispersion in the water column, can reduce atmospheric exposure and increase aqueous exposure; thus, dissolution remains relevant for considering the fate of dispersed oil.
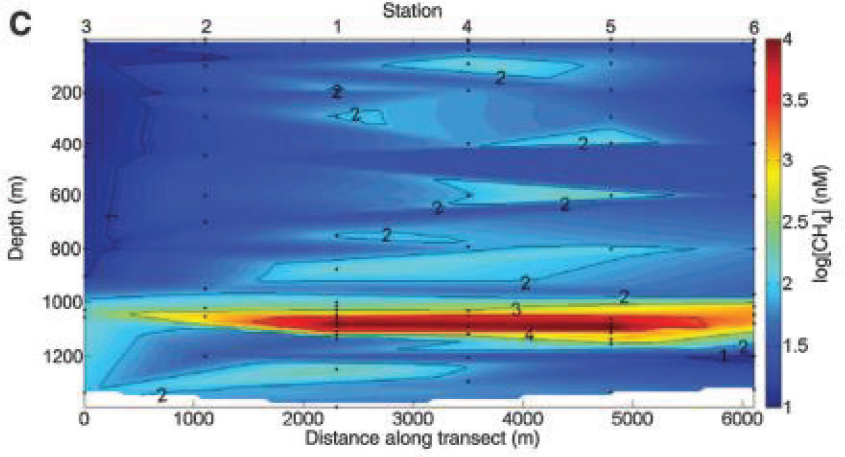
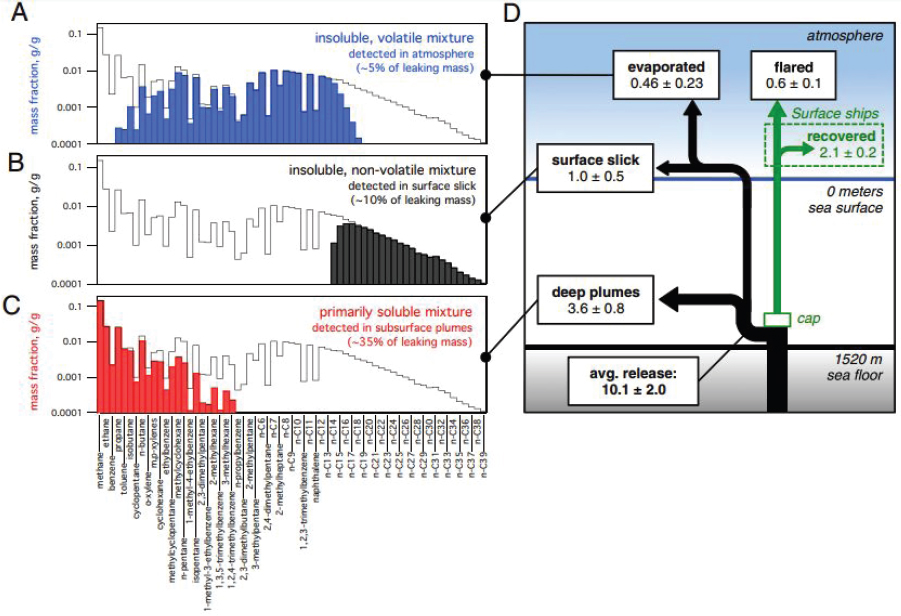
The effect of dissolution was pronounced in the environmental distribution of hydrocarbons resulting from the DWH event (Joye et al., 2011; Reddy et al., 2012; Ryerson et al., 2012; Valentine et al., 2010) because discharged oil traveled through more than 1,500 m of ocean water prior to
reaching the sea surface. The aqueous exposure resulting from this situation caused nearly complete dissolution of natural gas compounds and benzene as well as partial dissolution of several other alkanes, cycloalkanes, and BTEX compounds. The resulting oil hydrocarbon deficits in the atmosphere and enrichments in the ocean’s subsurface (detailed in Figure 2.5) were important factors modulating the fate and effects of the discharge.
While the true aqueous solubility of oil hydrocarbons depends on their physical-chemical properties, hydrocarbons also partition to the water phase as microscopic aggregates, as considered in the “Dispersion” section below. The distinction between these phases is important not only for understanding fate and transport but also for understanding toxicological effects in the water column, as reviewed in Chapter 3. One emergent property of hydrocarbon dissolution in the presence of microdroplets is a buffering of dissolved hydrocarbon concentration caused by the presence of microdroplets suspended within the aqueous phase. For the case where droplets contain a greater mass of a soluble hydrocarbon than can dissolve in the aqueous phase, dilution of the solution will reduce the concentration of liquid-phase droplet hydrocarbons in proportion to the dilution. In a closed system, however, the aqueous-soluble components will reestablish equilibrium following the dilution, leading to no change in the aqueous-phase hydrocarbon concentration.
Subsequent dilutions may achieve dilution to extinction for the most highly soluble compounds, but the extent of dilution will vary based on compound solubility.
Hydrate Formation
Gas hydrates, or clathrates, are solid-phase materials that form spontaneously from water and hydrocarbon gases at high pressure and low temperature. For the context of this report, hydrates are thermodynamically stable at ocean depths greater than ~450 m and are thus most relevant to deep ocean discharge scenarios such as SSDI application. However, hydrate formation and stability also require high dissolved hydrocarbon gas concentrations and nucleation sites, the former of which are diluted by plume entrainment and mixing. This leads to stability near the point of discharge and instability owing to dilution that occurs as water moves away from the gas source. As reference, the highest concentrations of dissolved hydrocarbon gases measured in the DWH spill intrusion layers were ~100-fold below the requirement for gas hydrate stability (Joye et al., 2011; Valentine et al., 2010). Finally, hydrate formation requires a nucleation site. The combination of confinement (leading to high gas concentrations) and solid surfaces for nucleation led to the problem with hydrate
buildup on several devices used in early attempts to cap the DWH blowout. Hydrate formation is thus most relevant to this study through its potential to affect processes near the point of discharge (e.g., see Box 2.1), with recent relevant studies in high-pressure laboratory facilities (Warzinski et al., 2014) and at natural seeps (Wang et al., 2016a). In the latter study, in situ high-speed imagery of seep bubbles near 1,000 m depth confirmed the formation of hydrate skins on gas bubbles from natural seeps, and field measurements indicate that mass transfer rates vary between the higher rates for clean and the lower rates for “dirty” bubbles (i.e., gas bubbles coated by another substance, such as hydrate) (Rehder et al., 2009; Wang et al., 2016a). The observation that mass transfer is not reduced below the dirty bubble rate may be due to cracks on the hydrate skin, as observed by Warzinski et al. (2014), and to the fact that the height to which the bubbles rise before they are completely dissolved depends mainly on the largest gas bubbles released from the seep.
In the DeepSpill field experiments, where oil was released as a plume at a depth of about 840 m, hydrates were not observed, even though it was noted that the methane dissolution rate in the water column was roughly half the value for clean bubbles which suggested that hydrate skinning might have been important (Johansen et al., 2003). On the other hand, it is possible that the bubbles were simply coated with natural surfactants (i.e., they were “dirty bubbles”), because surfactants (natural and in the form of chemical dispersants) reduce mass transfer when they coat bubbles. Evidence for hydrate formation during the DWH spill (oil released as a plume at a depth of about 1,500 m) is weak beyond the solid nucleation surfaces such as the cofferdam (see Box 2.1). Note that while a hydrate skin is sufficient to affect mass transfer, it has negligible thickness and thus little effect on bulk bubble density and rise velocity. The effect of dispersants on hydrocarbon fate and transport, due to any potential effect on hydrate formation, is not expected to be significant.
Emulsification
Emulsification of oil commonly occurs at the sea surface as a result of physical mixing of seawater into oil, creating a substance commonly described as mousse (depicted in Figure 2.6). The type and stability of the water-in-oil emulsion formed depends on the properties of the starting oil, in particular the viscosity as well as the proportion of high molecular weight components such as resins and asphaltenes. Environmental processes such as evaporation, dissolution, and photooxidation alter the chemical composition and viscosity of oil, thereby affecting the formation and stability of emulsions. Emulsified oil is a semisolid material with considerably different physical properties and characteristics than those of the original liquid oil. Information regarding the formation and stability of emulsions is detailed elsewhere (e.g., NRC, 2005).
Low molecular weight oil compounds are lost in the environment by processes such as evaporation and dissolution, leading to an enrichment in the relative concentration of emulsifying agents such as resins and asphaltenes, which enhance the formation of stable emulsions (Fingas et al., 2000). Photooxidative processes produce compounds that can act as emulsifying agents (NRC, 2005). Considering these environmental factors, the size and thickness of oil slicks on the sea surface are important for emulsification, because it relates directly to how much oil is exposed to the atmosphere and water and subsequently how much evaporation, dissolution, and photooxidation can occur. Other environmental factors influencing emulsification include temperature (emulsification occurs more rapidly at lower temperatures) and the energy of mixing in the marine environment (increased energy accelerates emulsification).
Emulsification subsequently reduces oil evaporation and dissolution (Ross and Buist, 1995; Xie et al., 2007). The increase in water content, density, and volume of emulsified oil is also important and has implications for the fate and recovery of oil in the environment. The most substantial change in physical properties to oil when it is emulsified is the increase in its viscosity (Davies et al., 1998; Fingas et al., 1994), which is particularly relevant as it may hinder oil dispersion both with and without the use of dispersants. Dispersants may be used on emulsified oil, but they are

potentially less effective and may require a higher DOR (NRC, 2014). Emulsion viscosity and the type of dispersant applied determine the dispersant effectiveness, with emulsions composed of higher viscosity oils being the most difficult to effectively disperse (Belore et al., 2008).
Solid-Phase Interactions
Upon exposure to the ocean or other aquatic environments, petroleum hydrocarbons may contact various solid or semisolid phases, including mineral and biological materials, and may induce changes within such materials. Such interactions have been studied for select scenarios, which are considered in this section. These may include adhesion to a bulk phase; aggregation with mineral or biological particles (Lee, 2002); conversion to petroleum-derived bacterial flocculent (Bælum et al., 2012; Hazen et al., 2010; Valentine et al., 2014); and flocculation with marine snow or other would-be sediment particles (Passow, 2014). Importantly, such interactions are situational. The formation of oil-particle aggregates (OPAs), for example, requires proximity to a source of relevant particles, which provides a geographic constraint. The chemical properties of the oil also impact deposition and preservation, as exemplified by a fallout plume of heavy oil from natural seeps (Farwell et al., 2009) and the pattern of long-term geologic preservation for oil-stained foraminiferal tests in (anoxic) marine sediments (Hill et al., 2006). This section focuses on key processes by which petroleum hydrocarbons interact with particles and on the potential for dispersant application to affect these processes. Ultimately, these interactions structure transport
of oil to the benthic environment, inclusive of sediment deposition, benthic exposure, and burial. OPAs are considered first, followed by marine oil snow (MOS).
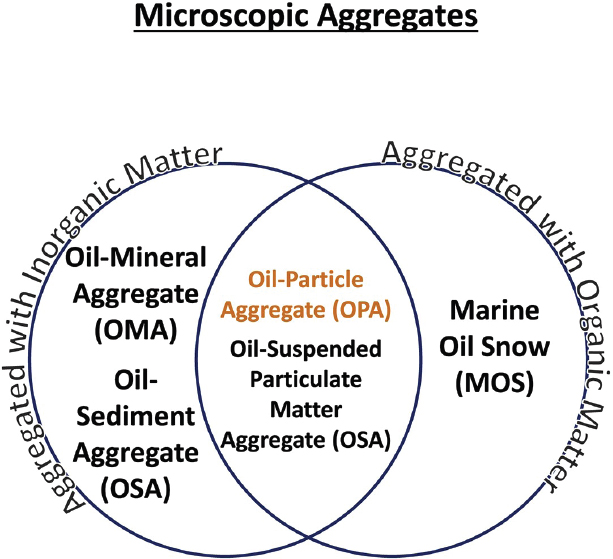
Oil-Particle Aggregates (OPAs)
The term “oil-mineral aggregate” (OMA) was first used by Lee et al. (1998) to describe the observed formation of microaggregates between fine-grained sediment and oil. It was initially described as “clay-oil-flocculation” by scientists as a mechanism that accounted for the loss of stranded oil from intertidal low-energy coastal environments impacted by the Exxon Valdez spill (Bragg and Owens, 1995; Bragg and Yang, 1995). While OMA was used extensively in studies working on oil-mineral interactions (Ajijolaiya et al., 2006; Khelifa et al., 2002; Lee, 2002; Niu et al., 2011; Stoffyn-Egli and Lee, 2002), the terms “oil-sediment aggregate” (Bandara et al., 2011; Cai et al., 2017) and “oil-suspended particulate matter aggregates” (Gong et al., 2014; Loh et al., 2014) have also been used to describe the natural interaction between oil and suspended particulate material that may also include organic matter. As detailed in the next section, aggregates of oil with organic matter (e.g., bacteria, phytoplankton, dead cells, or extracellular polymers) have been described as “marine oil snow” (Daly et al., 2016; Fu et al., 2014; Passow and Ziervogel, 2016; Passow et al., 2012). OPAs has now been used to account for interactions of oil with both inorganic and organic material (Fitzpatrick et al., 2015; Zhao et al., 2016b, 2017c) and was defined by Gustitus and Clement (2017) as a term to describe aggregates on a scale of 1 mm or less for nearshore environments. The relationship across these terms is depicted in Figure 2.7.
Oil-particle interactions alter the buoyancy of oil droplets because the OPAs formed are negatively or near neutrally buoyant, allowing their transportation in the water column and eventual sediment deposition (Bragg and Owens, 1995; Lee et al., 2003). OPAs suspended in the water column or resting on the bottom can be subsequently carried upward by larger currents, enabling
oil to be transported from one environmental compartment to another (Fitzpatrick et al., 2015; Waterman and Garcia, 2015). The interactions of oil droplets and particles following oil spills is now considered to be an important process in the natural attenuation of oil spilled at sea (Bragg and Owens, 1995; Bragg and Yang, 1995; Lee, 2002).
OPA formation depends on the properties of the oil (oil type and concentration, droplet size), particle size, shape, and concentration as well as density and organic matter content and the ambient conditions (temperature, water salinity, mixing energy) (Ajijolaiya et al., 2006; Frelichowska et al., 2010; Gong et al., 2014; Gustitus et al., 2017; Lee, 2002; Payne et al., 1989; Stoffyn-Egli and Lee, 2002).
Because OPA formation prevents oil droplets from recoalescing and may keep the oil-water interfacial area suspended within the aerobic zone of the water column over a longer period of time, hydrocarbon dissolution and oil biodegradation rates are enhanced (Ajijolaiya et al., 2006; Aveyard et al., 2003; Gong et al., 2014; Khelifa et al., 2002; Lee et al., 1997; Weise et al., 1999). Laboratory (e.g., Stoffyn-Egli and Lee, 2002; Wang et al., 2011; Zhang et al., 2010) and shoreline data (e.g., Bragg and Owens, 1995; Lee et al., 2003) have shown that OPAs enhance the dispersion of oil and can be considered the basis for an oil spill countermeasure strategy (e.g., surf washing) for oil stranded in the shore zone (Lee, 2002; Owens and Lee, 2003).
Oil dispersion is positively correlated to the formation of OMAs, as smaller oil droplets require fewer suspended particles to form OMAs (Gong et al., 2014; Gustitus et al., 2017). Zhang et al. (2010) found smaller particle sizes of solids with larger specific area favored the formation of OMAs. It was reported that the formation of OMAs was negligible when the particle size was larger than 10 microns (µm). When the particle size was less than 2 µm, OMAs were readily formed. The lowering of oil-water interfacial tension by the addition of dispersants has been linked to the formation of smaller oil droplet size (Li et al., 2008b; Zhao et al., 2014b) and higher effectiveness values for oil dispersion and formation of OMAs (Khelifa et al., 2008).
The surface properties of the particles also play an important role in determining the size and the type of OMAs as well as the fraction of oil that can be dispersed as OMAs. Wang et al. (2011) examined the interactions between oil and three types of solids: namely, kaolin, modified kaolin, and diatomite. They found that solids with higher hydrophobicity have more oil-mineral attraction. The enhancement of the surface hydrophobicity of these naturally occurring minerals by addition of dispersants or treatment with cetyltrimethyl ammonium bromide improved the effectiveness of the OMA formation (Chen et al., 2013; Lee et al., 2012; Wang et al., 2011; Zhang et al., 2010).
Changes in oil characteristics from natural weathering processes may also affect the formation of OMAs. Studies by Bragg and Yang (1995) and Wood et al. (1998) suggested that weathered oils tend to form OMAs more readily. In contrast, Guistitus et al. (2017) recently reported that formation of OMAs was substantially hindered when oil was weathered. Their findings suggested that the increased viscosity associated with the weathering process outweighed the increased fraction of polar or charged compounds.
Hydrodynamic conditions and the associated energy dissipation rates are important factors governing the dispersion of oil slicks (Li et al., 2008a) and thus the formation of OMAs (Ma et al., 2008; Omotoso et al., 2002; Sun et al., 2010, 2014; Wincele et al., 2004). In general, higher mixing energy favors the formation of smaller OMAs and reduces mixing time for the formation of OMAs (Sun and Zheng, 2009; Sun et al., 2010, 2014). Once OMAs are formed, they tend to be relatively stable against continued turbulence. Zhao et al. (2017c) recently reported, however, on the breakdown of OMAs under turbulence and the formation of larger OMAs composed of multiple small droplets. Temperature affects the formation of OMAs primarily by influencing the viscosity and adhesion properties of oil. The formation of OMA under low temperature conditions (–1-4°C) has been observed in laboratory batch scale tests (Lee et al., 2012; Wang et al., 2013); pilot scale
flume tank (Jézéquel et al., 2018); and field scale in ice-infested waters in the St. Lawrence Estuary under Arctic conditions (Lee et al., 2009, 2011). Elevated temperatures, too, have been found to favor the formation of OMAs (Lee et al., 2012; Stoffyn-Egli and Lee, 2002; Wang et al., 2013).
The addition of dispersants has been primarily demonstrated as a synergic practice for OMA-induced oil dispersion; Mackay and Hossain (1982), however, found that chemical dispersion of oil reduces its tendency to associate with mineral matter. Guyomarch et al. (1999) demonstrated that the dispersant Inipol IP90 favored the formation of OMAs in a wave tank experiment. Li et al. (2007) reported the combination of mineral fines and dispersants (Corexit® 9500) significantly increased the dispersion efficiency and formed smaller OMAs. Khelifa et al. (2008) found with addition of dispersant, the oil sedimentation was three to five times higher than the control without dispersant at sediment concentrations of 25 and 50 mg/L. The enhancement was not significant for sediment concentrations higher than 100 mg/L. Wang et al. (2013) tested the synergic effect of dispersant on the formation of OMAs in a low temperature environment. They also verified the synergic effects especially for viscous oil IFO-40 and found that Corexit® 9500 performed better than Corexit® 9527. They suggested that optimal oil-to-dispersant and oil-to-mineral ratios could be found, and that higher ratio of dispersant led to small, spherical OMAs with greater negative bouyancy. The study further suggested that the combined minerals and dispersants may maximize the overall performance of the response, especially under cold conditions when oil becomes harder to disperse with exclusive use of either agent. The settling rate of OMAs has been reported to be correlated with the viscosity/density of the crude oil (Omotoso et al., 2002). Furthermore, higher concentrations of oil droplets in the mixing system were associated with the observation of higher ratios of solid OMA/droplet OMA (Stoffyn-Egli and Lee, 2002).
The concentration of particles affects the effectiveness of OMA formation (Ajijolaiya et al., 2006; Sun et al., 2010). O’Laughlin et al. (2017b) found that the OMAs were formed with larger size when the concentration of the particles was increased. Zhao et al. (2016b) developed the A-DROP model to predict the formation of OPA based on particles depositing on the oil droplets (i.e., based on Type I OPA). The A-DROP model was based on population balance equation for three entities: the oil droplets, the particles, and the OPA. The disadvantage of the model is that it is computationally demanding. Its advantage is that it accounts for other characteristics on OPA formation, including the effect of the coated area on the droplet surface as well as hydrophobicity and the particle-to-droplet-size ratio.
The surface coverage assumed by these works came under scrutiny in the work of Zhao et al. (2017c), who, using confocal microscopy, showed that the particles with plate morphologies penetrate the droplets and do not rest on their surface. In addition, the study revealed that the OPA is unstable, and that it would fragment within 12 hours to form much smaller OPAs (going from 30 µm in diameter to less than 5 µm). This raises the possibility of using particles to mitigate an oil spill at locations where dispersants cannot be used.
OPA formation has been associated with previous oil spills such as Tsesis, Ixtoc I, and others (Jernelöv and Lindén, 1981; Johansson et al., 1980; Teal and Howarth, 1984; Vonk et al., 2015). The magnitude of the DWH and the corresponding efforts to understand the fate of the spilled oil, however, have provided unique insights into the formation mechanisms and quantity of different OPAs as well as the spatial footprint of the sedimented oil (Bagby et al., 2017; Brooks et al., 2015; Chanton et al., 2014; Daly et al., 2016; Passow, 2016; Romero et al., 2015, 2017; Schwing et al., 2017; Stout et al., 2016; Valentine et al., 2014). Estimates of the quantity of oil reaching the seafloor range from 2% to 11% of the total oil released and not recovered (Chanton et al., 2014; Romero et al., 2017; Valentine et al., 2014).
Marine Oil Snow (MOS)
During and briefly after the DWH oil spill, MOS was observed in the vicinity of the wellhead followed by its disappearance from the surface after a month (Passow et al., 2012). Based on these observations, a significant fraction of the oil components deposited on the seafloor is hypothesized to have arisen from a transport process known as Marine Oil Snow Sedimentation and Flocculent Accumulation, or MOSSFA, whereby oil is captured by marine snow, which in turn traps other particles such as minerals and other organic matter (Kinner et al., 2014; Montagna et al., 2013; Passow et al., 2012; Romero et al., 2015; White et al., 2012), as outlined in Figure 2.8 (Daly et al., 2016; Romero et al., 2017). For a 4- to 5-month period during and after the oil spill, Brooks et al. (2015) interpreted the sediment accumulation rate through MOSSFA to exceed the pre-spill sediment accumulation rates. By using biomarker-hopanes as tracers, Valentine et al. (2014) estimated that 1.8%-14% of the oil was transported to the seafloor through, for example, bacterial-induced flocculation in the deep ocean intrusion layers. Chanton et al. (2014) estimated the percentage of
sunken oil at 0.5%-9% by radiocarbon analysis. Schwing et al. (2017) identified two regions with heavy MOS and estimated the total sedimentary spatial extent of MOSSFA from 12,805 to 35,425 km2. By using sediment trap and hopane-based biomarkers, Stout and German (2018) estimated that more than 76,000 barrels (bbl) of oil sank over an area of approximately 7,600 km2. It is important to note, however, that the use of recalcitrant hydrocarbon compounds to calculate a volume of crude oil remaining in the environment provides a normalized value that excludes the action of weathering processes and is therefore an overestimate. Other processes have also been proposed to account for deposition of oil to the seafloor, including sinking of burn residues (Stout and Payne, 2016a) and adhesion of oil to clay and barite that comprised drilling muds/fluids (Stout and Payne, 2016b) used for well intervention.
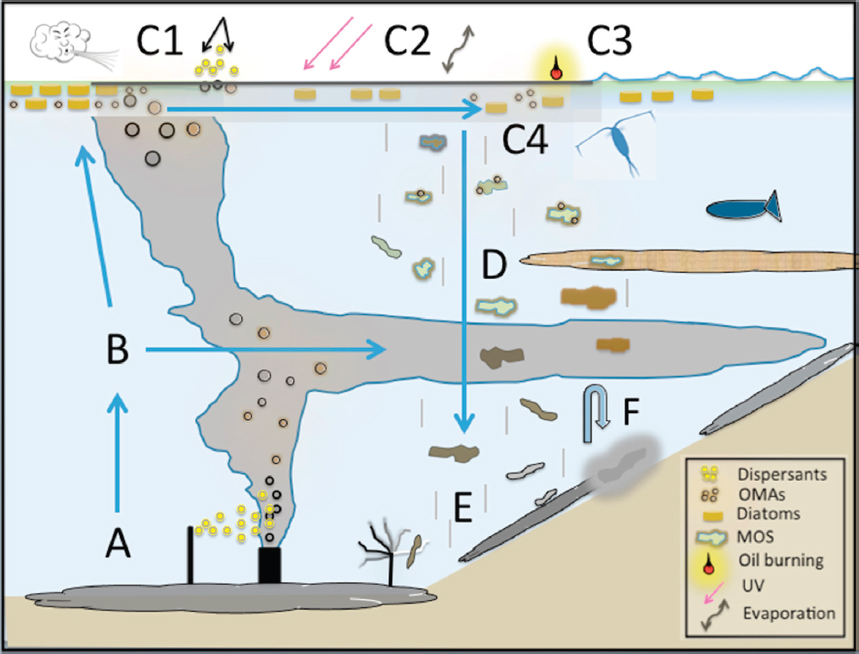
Factors controlling the creation of depositional events, in the presence of oil and dispersants, are varied and their interactions complex (Daly et al., 2016; Gong et al., 2014). Passow et al. (2012) speculated that the MOS was formed through the interaction of three mechanisms: (1) production of mucous webs made of extracellular polymeric substances (EPSs; a mucilaginous material comprised predominately of carbohydrates and protein), especially the sticky transparent exopolymeric particles through the activities of bacterial oil-degraders associated with the surface oil layer; (2) formation of OMAs that integrated with the mucous webs upon collisions; and (3) incorporation of phytoplankton into aggregates. Oil and dispersants are implicated in the formation of the EPSs, which act as a matrix upon which OPAs, dead phyto- and zooplankton, fine clay particles, burned oil and soot residues, and bacteria can accumulate (Bælum et al., 2012; Daly et al., 2016; Fu et al., 2014; Hazen et al., 2010; Passow, 2016; van Eenennaam et al., 2016). The EPSs are thought to be synthesized and excreted as a stress response of surface-dwelling biota (e.g., phytoplankton, zooplankton, and bacteria) possibly to form a physical and chemical boundary limiting direct contact of potentially toxic oil compounds and dispersants to their cell membranes. Passow (2016) investigated the mechanisms and placed the focus on the impact of oil type, photochemical aging of oil, and the presence of phytoplankton and dispersants. Laboratory studies indicate that in the presence of dispersants and oil, phytoplankton and bacteria increased quantity and changed the properties of the EPS(s) and marine snow they produced (Fu et al., 2014; Hatcher et al., 2018; Passow, 2016; van Eenennaam et al., 2016), although some inhibition of OPA formation in the presence of weathered crude oil has also been observed under certain conditions (Passow et al., 2012, 2017). The observed phenomena were not specific to the Gulf of Mexico region; similar results have been observed in field experiments conducted during the winter in the Faroe-Shetland Channel (Suja et al., 2017) and experiments with bacteria from the deep ocean (Bælum et al., 2012). Figure 2.9 illustrates the MOSSFA-like flocculation process that occurred near the wellhead following the DWH spill.
Fu et al. (2014) noted that the addition of dispersant increased the total n-alkane adsorbed on MOS by 1.23-fold, which increased its buoyancy over control samples without dispersant treatment. Kleindienst et al. (2015b) found that the addition of dispersants and nutrients induced a rapid onset of MOS formation (5 days versus 2 weeks in the treatment without dispersant and nutrients). The sizes of the MOS in the former case were much larger (2 cm versus 0.5 cm). Without nutrients, the addition of dispersants changed the morphology of MOS from fractal-looking aggregates to aggregates associated with filaments (Kleindienst et al., 2015b). Furthermore, bacteria belonging to the genus Colwellia were found to be enriched in all dispersant-amended treatments. Suja et al. (2017) echoes the finding that dispersants triggered the formation of MOS, which is magnified by the addition of nutrients. On the other hand, Passow (2016) found that the addition of dispersants inhibited the formation of MOS. In this particular case, however, results could have been influenced by the fact that test oil had been amended previously with dispersants and, therefore, further addition of dispersants may have elicited an overdose response.
Brakstad et al. (2018a) recently completed a comprehensive review of literature related to marine snow studies following the DWH oil spill, with a focus on the use of oil spill dispersants and the formation, fate, and transport (i.e., sedimentation) of oil-related marine snow (ORMS). Contrary to the literature supporting the MOSSFA hypothesis, they concluded that the contribution of dispersant or any treatment to the formation of ORMS during the DWH spill could not be determined from the results of existing laboratory studies as experiments were only performed at high oil concentrations that did not take into account rapid dilution within the open sea. In summary, studies are still required to determine ORMS processes at oil concentrations under environmentally realistic conditions wherein dispersed oil plumes are expected to rapidly dilute to concentrations below 1 ppm (Lee et al., 2013a; Prince et al., 2016).
For the case of DWH, a potential sequence of events is provided in Figure 2.8 as a conceptual model specific to formation and deposition of MOS. According to this hypothesis, nutrient flow to nearshore waters was enhanced by flooding of marshes with fresh water to prevent oil washing ashore (Bianchi et al., 2011; Daly et al., 2016; Passow, 2016). An enhanced nutrient supply from this remedial strategy and inflow from the Mississippi River system may have stimulated phytoplankton blooms (Hu et al., 2011; O’Connor et al., 2016) and provided large quantities of fine-grained, clay-based particles into the nearshore oceanic environment. The addition of large quantities of surface-applied dispersants to weathered crude at the surface apparently induced EPS formation and helped form large OPA particles, up to tens of cm (Daly et al., 2016; Fu et al., 2014; see Figure 2.8). The clay particles entrained within OPAs helped ballast the particles, accelerating sinking rates and increasing mass accumulation rates over background levels (Romero et al., 2015, 2017).
Multiple studies have investigated the ecological impacts of enhanced mass accumulation of sedimented oil on deep-sea benthic organisms. Declines in macro- and meiofauna (Montagna et al., 2013; van Eenennaam et al., 2018) as well as mortality and morbidity of deep coral communities (Fisher et al., 2014; White et al., 2012) have also been documented within the Gulf of Mexico.
Although various mechanisms, including MOSSFA, have been postulated to transport oil to the floor of the deep ocean, the relative importance of these mechanisms has not been quantified for the DWH spill and remains difficult to predict for other discharge scenarios. Given the paucity of sampling that occurred during the active depositional phase of the DWH spill, latent deposition mechanisms could have gone unnoticed; for example, those associated with apparent blooms and mortality of deep ocean filter feeders. Nonetheless, the conceptual model of Daly et al. (2016; see Figure 2.8) comports well with a number of mechanisms related to MOSSFA identified in both field collections and laboratory experiments, and other identified mechanisms remain viable as well (Gros et al., 2017; Stout and Payne, 2016a,b; Valentine et al., 2014). However, critical details leading to significant depositional events have not been quantified. Key uncertainties include the concentrations of oil, dispersants, nutrients, plankton densities, bacterial growth response, and sediment particles/fractions. To close this gap, Daly et al. (2016) have identified a research framework to better elucidate deposition specific to MOSSFA-type scenarios.
Biodegradation
The diverse assortment of chemical compounds comprising petroleum provide a potential source of energy and carbon to microbes that have evolved for their consumption. The environmental relevance and distribution of hydrocarbon biodegradation is underscored by the diversity of microbes capable of consuming hydrocarbons as a source of carbon and energy—including at least 175 genera in 7 phyla of bacteria and archaea, in addition to eukarya such as fungi (McGenity, 2018). The focus here is on biodegradation activities for petroleum discharged to the ocean, with particular emphasis on the potential interplay between chemical dispersant and the responsible microbial community.
While many microbial taxa have evolved to consume petroleum hydrocarbons, numerous variables—chemical, environmental, and situational—serve to control the rate and extent of degradation for any given circumstance. The large number of genera hosting hydrocarbon-degraders is itself a direct reflection of the evolutionary pressure imposed by these variables. Many of the key variables that control biodegradation have been reviewed previously (Leahy and Colwell, 1990; NRC, 2003), and studies have demonstrated a spectrum of effects when dispersant is provided to hydrocarbon-degrading bacteria (Kleindienst et al., 2015b; NRC, 2005; Prince et al., 2016). The focus here is on recent findings that inform the relationship between petroleum hydrocarbon biodegradation and the application of chemical dispersant, particularly for realistic encounter scenarios. Box 2.2 specifically considers the issue of biodegradation and SSDI, drawing on observations from DWH.
Upon discharge or exposure to the environment, petroleum hydrocarbons become available for biodegradation. The first step toward biodegradation is the encounter between the would-be consumers and their substrate, which will depend on the abundance, distribution, and metabolic status of the seed population as well as the physical and chemical properties and spatial distribution of the hydrocarbons. Following an encounter, the microbial population must adapt to consume the available substrate, and growth of the community will occur, anchored by the microbes that adapt most quickly to the ambient conditions. The early stages of microbial community growth and development are expected to have minimal impact on the petroleum hydrocarbons, because seed populations must generally grow by order(s) of magnitude to induce a measurable change, as modeled for the DWH spill by Valentine et al. (2012). The early stages of biodegradation are highly relevant for the purposes of this report, however, because dispersants are typically applied to fresh
oil, and the time frame for development of a microbial community runs concurrent with the window for dispersant application. Microbial community development is itself a dynamic process that incorporates inherent properties of the microbes and oil with environmental variables and ecological feedbacks. Several key processes are considered below for their relevance to dispersant application.
Petroleum hydrocarbons provide carbon and energy substrate for the community of microbial consumers, but petroleum contains insufficient quantities of bioavailable nitrogen, phosphorous, or iron to support nutrient demand for growth. As a result, nutrient availability is key to the development of a petroleum-hydrocarbon-degrading community and, in turn, to the rate of petroleum hydrocarbon degradation. In this regard, the DWH spill provided a stark contrast to previous research on this topic because the surface waters in the vicinity of discharge were nutrient depleted. As would be predicted from this circumstance, biodegradation of floating oils was slow to occur (Edwards et al., 2011), and its cumulative effect on the chemical composition of floating oils was minimal (Ward et al., 2018b). Many previous studies included nutrient amendments (e.g., Hazen et al., 2010; Wardlaw et al., 2011); used nutrient-rich seawater (e.g., Brakstad et al., 2018b; McFarlin et al., 2014; Prince et al., 2013, 2016); or provided no information about nutrients (e.g., Wammer and Peters, 2005)—highlighting the need to rigorously consider nutrient availability specific to any discharge or biodegradation scenario. This line of reasoning further raises an important point with regard to dispersant application in low-nutrient waters: If biodegradation is limited by nutrient availability, then dispersion of oil is predicted to have little or no effect on the rate or extent of biodegradation.
Microbial communities are known to structure along the ocean’s thermal gradients (Sunagawa et al., 2015; Swan et al., 2013), with a range of adaptations to cold water that include tolerance
to cold temperature—psychrotolerance—and an absolute need for low temperature to support growth—psychrophily. Adaptation to cold temperature occurs among hydrocarbon degraders as evidenced from studies both in the polar regions (McFarlin et al., 2014) and in the deep ocean (Cao et al., 2014). Two key points about petroleum hydrocarbon degradation in cold environments are relevant to this report. First, some models (OSCAR3) assume exponential temperature dependence on reaction rates, commonly known as the Q10. This approach is potentially flawed, because the actual environmental rate is also dependent on the population size, which violates the assumptions that underlie the presumed exponential dependence (Bagi et al., 2013). Second, for the case of petroleum hydrocarbons discharged to or entering cold waters, the environmental factors structuring microbial response are expected to differ compared to warmer waters. Notably, growth rates are expected to be slower, though many cold water environments are rich in nutrients, and here nutrient limitation is less likely to occur.
Microbes can biodegrade petroleum hydrocarbons dissolved in the aqueous phase or present at the oil-water interface (CRRC, 2017), and physical access to oil is an important consideration for biodegradation. Several physical processes may influence microbial access to oil. Droplet size is an important consideration for biodegradation, and reduction in droplet size is the primary objective of dispersant application. Assuming no other limitation on microbial growth, increased surface area is expected to enable greater colonization of oil, which has been observed in laboratory studies (Brakstad et al., 2014, 2015; Ribicic et al., 2018) and is consistent with environmental observations (Bagby et al., 2017). Wax formation is also a relevant process that potentially links temperature, biodegradation, and dispersant efficacy (NRC, 2005). Biodegradation can enhance the overall wax content of the oil by depleting low molecular weight compounds, and hydrocarbon phase transformation to wax has recently been shown to suppress the biodegradation rates for a model hydrocarbon-degrading microbe (Lyu et al., 2018). Wax formation is also temperature and composition dependent, which opens the possibility that biodegradation, temperature change, and dispersant application could collectively modulate phase transition. During DWH, for example, wax formation could be inferred from imagery (Joye et al., 2011) and enrichment of high molecular weight alkanes (Bagby et al., 2017; Stout et al., 2016) but was never conclusively demonstrated in the deep ocean. Sediment deposition is also a relevant process that potentially links biodegradation and dispersant insomuch as dispersant application may affect the sedimentation of petroleum hydrocarbons by any of several mechanisms, as discussed in the section above regarding oil particle aggregates. When petroleum hydrocarbons are deposited on the deep seafloor (Stout et al., 2016; Valentine et al., 2014), biodegradation slows substantially (Bagby et al., 2017)—perhaps because of limitations to oxygen supply (Mason et al., 2014) or perhaps because of limited physical access to the oil.
The DWH spill provided impetus to study the interaction of microbial communities with dispersed oil in the context of deep ocean discharge and SSDI. Laboratory-based studies have considered both the rate and the extent of biodegradation as well as the dynamics of the microbial population (Bælum et al., 2012; Hu et al., 2017; Kleindienst et al., 2015b), while field studies have focused primarily on interpreting the observed patterns of chemical compounds and microbial communities in the deep ocean (Crespo-Medina et al., 2014; Dubinsky et al., 2013; Hazen et al., 2010; Kessler et al., 2011a; Lu et al., 2012; Mason et al., 2012; Rivers et al., 2013; Valentine et al., 2010). The environmental relevance of laboratory studies is confounded by the inherent limitations of study design. For example, Kleindienst et al. (2015b) and Hu et al. (2017) attempted to mimic in situ conditions but used a closed system approach for incubations exceeding 1 month duration, which excludes the many effects from mixing (e.g., dilution of hydrocarbon concentration and the introduction of nutrients, particles, microbial competitors, and predators). One key discrepancy between closed system experimentation and in situ conditions derives from the aqueous solubility
___________________
of surfactants used in most chemical dispersant formulations. Compounds such as DOSS are aqueous soluble and are expected to gradually dissolve from suspended droplets and partition to the large volume of the ocean (Kujawinski et al., 2011). But in closed system experiments (Hu et al., 2017; Kleindienst et al., 2015b), dispersant remains with the oil, deviating substantially from in situ conditions and potentially explaining why observed taxon abundance differs from field observations (Delmont and Eren, 2017) and from parallel experimental treatments lacking dispersant (Kleindienst et al., 2015b). For these reasons, the extrapolation of findings from these laboratory studies to in situ behavior is avoided here. A second key discrepancy between closed system experimentation and in situ conditions derives from sample treatment. For example, Hu et al. (2017) pretreated samples with oil weeks before initiating incubations, which nullifies claims about initial population growth rates, succession patterns, and reaction rates.
Field studies conducted following DWH (Crespo-Medina et al., 2014; Dubinsky et al., 2013; Hazen et al., 2010; Kessler et al., 2011a; Kleindienst et al., 2015a; Lu et al., 2012; Mason et al., 2012; Rivers et al., 2013; Valentine et al., 2010) have provided insight as to the identities and mechanistic pathways for hydrocarbon-utilizing bacteria in the deep ocean. However, these studies also face limitations because each provides only snapshots of a complex and changing landscape, and in aggregate they suggest as-yet undiscovered processes or methodological inconsistencies. While deep ocean microbial communities clearly bloom in response to input of petroleum with or without SSDI, the exact sequencing of substrate consumption, the dynamic factors that structure the microbial response, and the in situ impact(s) of SSDI are viable research questions.
TRANSPORT PROCESSES
Subsurface Transport
Importance of Droplet Size
Oil fate and transport in the water column are largely determined by the size distribution of oil droplets. On the surface, oil droplets form when turbulence generated by waves and currents acts on a surface slick and drives oil into the water column. The depth of penetration of oil droplets into the water column and the time it takes for the droplets to rise back to the surface depend on the oil droplet size (as well as the oil density, presence of currents, and turbulence). For droplets smaller than ~70 µm, there is some evidence suggesting that, effectively, they will remain permanently suspended in the water column (Lunel et al., 1995). In the event of a subsurface deepwater release, such as a well blowout, droplets formed at the point of release will rise through the water column as a function of their size. Larger diameter droplets rise more quickly than do smaller diameter droplets, as described by the generalized Stokes’ Law for the drag force on a spherical object (e.g., Zheng and Yapa, 2000). The importance of droplet size on the rise time in a deepwater spill is illustrated in Figure 2.10, where the droplet rise was modeled using the generalized Stokes’ Law. Figure 2.10 indicates substantial delays in oil surfacing time for smaller droplet sizes. Very small droplets and dissolved oil lack buoyancy to reach the surface, and they can become trapped in deep intrusion layers (see Figure 2.10).
As discussed earlier in the chapter, dissolution of soluble components increases with time spent in the water column, such that the longer a droplet is submerged, the more dissolution will occur. In surface waters, atmospheric exposure results in volatilization of the lower molecular weight components of the oil reducing the extent of its dissolution. In a deepwater spill, smaller oil droplets with a larger surface area will lose more of their soluble components and hence release fewer volatiles to the atmosphere when they reach the surface. This is a major consideration for response operations because exposure to VOCs is a key health concern for the response workers
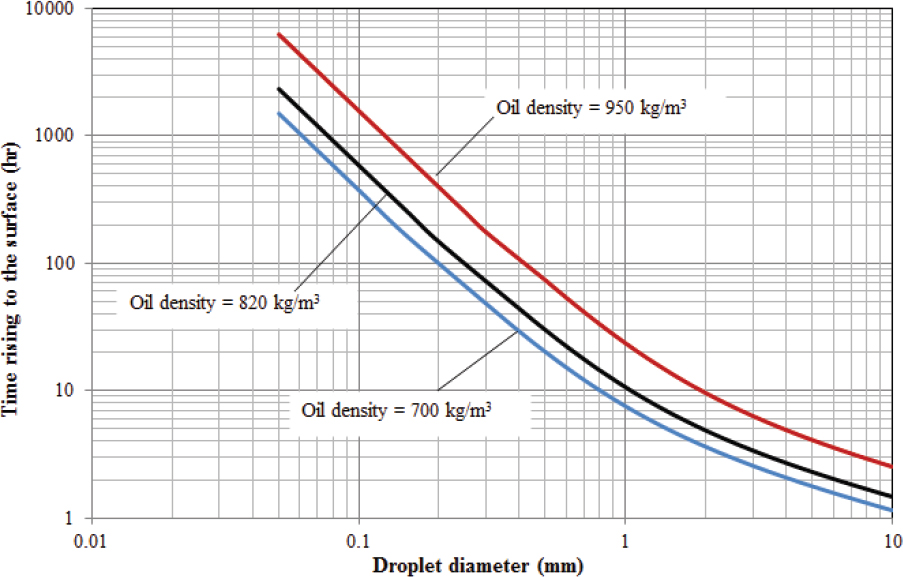
in the area of the spill. The increased surface area and time in the water column associated with smaller droplets may also potentially promote biodegradation depending on the specific conditions and extent of exposure; however, limited empirical studies have directly tested this hypothesis for a response-relevant scenario, preventing generalized conclusions on this point.
From an ecological perspective, enhanced dissolution, enhanced biodegradation, and entrainment of small oil droplets reduces the amount of oil that reaches the surface, potentially reducing the impact on organisms that live at or near the surface, such as air-breathing turtles, marine mammals, and seabirds. Furthermore, a reduction in the amount of oil at the surface may lower the amount of oil reaching sensitive shoreline habitats, such as marshes (Boehm et al., 1987). However, greater concentrations of oil and oil components, including BTEX compounds and PAHs, sequestered in the deep sea may have serious implications for benthic, mesopelagic, and potentially epi-pelagic resources (Romero et al., 2018), including deep-diving marine mammals foraging at depth. Because the primary objective of dispersants is to promote the formation of smaller droplets, understanding the implications of varying droplet size distributions is critical to making decisions and predictions regarding dispersant use. Chapter 6 provides some insights into this complex set of response trade-offs using integrated models.
Droplet Models
Due to disparity of scale in droplet formation processes, potentially high pressure, and other factors, no experimental system or model will perfectly replicate conditions in the field associated
with an actual spill. Instead, experiments and models provide a way for scientists to understand how different components and processes may influence the size, distribution, and behavior of droplets. For example, experimental systems can examine the effect of different oil types, different proportions of methane, the effect of different dispersants, and DORs. Similarly, models can be used to explore different spill scenarios by varying parameters—such as flow rate, depth, or DOR—that are described by the models. Experiments can be designed to test how well models perform at different scales. Because experiments and models are simplifications of actual conditions, however, their predictive power rests on their ability to replicate the most impactful of the processes. For any particular spill, unforeseen conditions may impact droplet size formation and complicate reconstruction of the actual conditions, such as ancillary small-aperture fissures or changes in pressure, fraction of methane, and others.
Understanding the dynamics associated with droplet formation and transport is important to forecasting and preparing for the impacts of an oil spill. In a deepwater spill, droplets will diffuse in three dimensions as they rise through the water column. Models for droplet formation and transport have been developed to help understand the factors that affect these processes and improve capabilities to forecast the fate of spilled oil. The focus of these models has been on processes, including turbulence produced by the discharge as well as physicochemical properties of the oil, water, and dispersant (i.e., IFT and viscosity). Several such models are discussed below, while surface droplet formation models are discussed later in this chapter.
The basic tenet of droplet formation is captured by the Weber number (We; Hinze, 1955), which represents the ratio of destructive forces due to turbulence to resisting forces due to surface tension. Amendments to this approach have been made to account for the resisting role of oil viscosity, which resulted in the introduction of a dimensionless viscosity number (Calabrese et al., 1986; Hinze, 1955; Wang and Calabrese, 1986). Johansen et al. (2013) used this concept, developed for oil dispersion in reactors at steady-state, and applied it to the droplet formation from jets. Their approach became known as an “equilibrium” model, and a similar model was adopted by RPS ASA (Li et al., 2017c). These models predict the median droplet size (d50) and specify a spread coefficient (width parameter) of the droplet size distribution (DSD), either as log-normal (LN) or Rosin-Rammler. The d50 is expressed in terms of nondimensional numbers that include a We and either a viscosity number (Vi; Johansen et al., 2013) or an Ohnesorge number (Oh; Li et al., 2017c) to account for the combined resistance of oil-water interfacial tension and oil viscosity to droplet breakup. All quantities for the prediction of the DSD were evaluated based on the conditions at the source (e.g., velocity and orifice diameter), and while the models are physically based, they involve calibration coefficients. Both models account for oil constriction due the flow of gas from the orifice, but neither accounts for the interaction between oil droplets and gas bubbles. Nor are the models capable of predicting gas bubble size, at least not with the existing calibration coefficients. Both models can predict DSDs where some of the droplet sizes exceed the maximum stable droplet size. To resolve this, they redistribute those droplets using heuristic approaches. It should also be pointed out that the RPS ASA’s model uses oil properties at the surface; thus, it does not account for the change in oil physical properties at depth in the presence of natural gas (e.g., larger interfacial tension, lower viscosity and density).
Paris et al. (2012) also used the equilibrium-model approach and predicted the d50 for the DWH in the absence of dispersant to be less than 100 µm. Adams et al. (2013) argued that the constant of proportionality used by Paris et al. (2012) was 100-fold smaller than that used by Johansen et al. (2013), likely because the Paris et al. (2012) model was based on droplets observed in a stirred reactor as opposed to droplets formed by a jet of oil. Further modeling done by Socolofsky and Gros (see Appendix E), and described in Chapter 6, suggests that the d50 used by Paris et al. (2012) for the DWH simulations were smaller than those generated from most ambient pressure jet-based experiments.
In contrast with the equilibrium models described above, “population” models are numerical models that solve for the hydrodynamics at each distance from the orifice and allow for the evolution of the DSD. Examples are VDROP-J (Zhao et al., 2014b) and Oildroplets (Nissanka and Yapa, 2016). The models incorporate the local physics (mixing energy, droplet density) to track the evolution of each droplet size and gas bubble size and simulate droplet breakup and coalescence as a function of distance along the plume trajectory. Unlike equilibrium models, this type of model can compute spatially varying DSDs. The models assume a continuous discharge at statistical steady-state and move fluids downstream of the orifice while accounting for water entrainment and the change of jet hydrodynamics with distance from the orifice. Both models include a calibration coefficient that depends on the jet hydrodynamics.
These models address how turbulence induces droplet breakup (i.e., dynamic breakup), but they do not consider an additional breakup mechanisms when dispersant is present known as tip streaming (Gopalan and Katz, 2010). Tip streaming results from capillary instability on the droplet surface caused by the migration of surfactants on the droplet surface driven by water vorticity (Tseng and Prosperetti, 2015); the surfactant concentration on the oil droplet reaches maximum values at locations where the water vorticity vanishes. Tip streaming has been observed to cause dispersant-coated oil droplets—with initial diameters of several mm—to form much smaller microdroplets over a time scale of several minutes (Nagamine, 2014). Zhao et al. (2017b) measured DSDs from a horizontal jet of oil in seawater using a laser light scattering instrument (i.e., Sequoia’s Laser In-Situ Scattering and Transmissometry [LISST] instrument). The unimodal DSD was measured at d50 = 114 mm without dispersant, while with dispersant premixed at a DOR of 1:20, the distribution was strongly bimodal, with d50 = 5.9 mm and a plurality of the droplets having diameters less than 2.7 mm. The bimodal distribution with this range in the presence of dispersant has been observed in the literature of oil release from jets (Gopolan and Katz, 2010; Murphy et al., 2016) and from oil spills on the water surface (Li et al., 2009b). Zhao et al. (2017b) inferred that tip streaming occurred in their experiment, and they introduced into VDROP-J a mechanism to account for tip streaming. With a calibrated rate constant, they were able to reproduce numerically the observed bimodal DSD.
The presence of microdroplets in the intrusion layer at DWH was verified by observations made with a holographic camera system—holocam (White et al., 2016)—and other systems (Li et al., 2015), but they show very low concentrations. Microdroplets were formed in both the presence and the absence of dispersants premixed with oil. As the holocam measurement only captures part of one side in the intrusion layer, it is difficult to extrapolate to the full volume. Microdroplets were entrained in the subsurface plume prior to the application of SSDI, indicating that some process other than SSDI was responsible. This may have included escaping small droplets from small fissures in the broken riser pipe or explosive oil releases from the large end of the open riser due to the large pressure drop associated with release of oil and gas into the environment. However, the microdroplets do not appear to have been sufficiently abundant to account for a large fraction of the oil mass (Gros et al., 2017).
There are several physical processes that could potentially influence droplet sizes in certain release scenarios, and which are not considered by either equilibrium models or the population models. Those processes include oil droplet degassing, and pressure drop and churn flow in the blowout preventer (BOP). The first process is the degassing of saturated oil droplets. Using a counterflow apparatus, Pesch et al. (2017) showed that, if the rate of degasification exceeds the rate of gas dissolution, the degassed bubbles could cling to the oil droplets, thus reducing the time they take to reach the surface relative to similar-size purely liquid droplets.
A second process derives from observations from the DWH spill that there was a substantial pressure drop between the reservoir and the end of the BOP-riser where the oil and gas discharged to the ambient ocean (Aliseda et al., 2010; Wereley, 2010). The pressure gradient was no doubt complicated in the BOP-riser by the BOP geometry, the broken BOP rams, and other debris. A
pressure gradient with live oil, if steep enough, could conceivably cause smaller droplets than are calculated in present versions of the equilibrium and population models.
Finally, both the equilibrium models and the population models assume that the live oil exits the orifice uniformly. An argument has been made (Boufadel et al., 2018b) that churn flow could occur, which would also lead to smaller droplet sizes. However, their analysis was also based on the assumption of a relatively unobstructed riser pipe.
The manner in which various mechanisms involved in oil and gas fate and input parameters are incorporated may contribute to the differences observed in model results. The occurrence of these processes in the DWH spill is contentious (Malone et al., 2018; Paris et al., 2012; Pesch et al., 2018), and these processes (degassing, pressure drop, and churn flow) deserve further study.
Observations of Droplets in the Laboratory and Field
Since DWH, measurements of droplet and bubble formation using different fluid mixtures in blowout-like conditions at different depths and flow rates have been conducted by various groups. With respect to dispersant use, these studies suggest that SSDI with a DOR of 1:50-1:100 reduces the IFT of oil by roughly two orders of magnitude for the lighter oils that characterize high-volume blowouts. This corresponds to roughly one order of magnitude reduction in the d50 (Brandvik et al., 2013, 2014a, 2017b, 2018, 2019a,b). In addition, SSDI effectiveness is demonstrated to be fairly insensitive to the injection method at laboratory scales (release orifice of 1.5 mm), and even a wand placed up to 6 diameters away from the discharge orifice worked well in dispersing oil. No evidence was found of partially treated oil as suggested by Spaulding et al. (2015), even when the DOR was dropped to less than 1:250 (Brandvik et al., 2014a, 2018). However, the extent to which these findings may be valid at a full-scale field blowout remains uncertain. Brandvik et al. (2014b) found that dispersant effectiveness decreases as oil temperature rises, but this impact could be largely countered by increasing the DOR from 1:100 to 1:50. They also found that dispersants were not as effective on waxy oils compared to lighter oils. Finally, this study suggests that the solvent component of Corexit® may not contribute to its effectiveness when used in SSDI. This finding, coupled with the temperature sensitivity noted above, suggests that further research could result in a more optimized dispersant for SSDI use.
Direct measurement of droplet/bubble sizes in the lab or field has been a challenge. The LISST instrument cannot measure droplet sizes above 500 mm, cannot distinguish between oil droplets and gas bubbles, and does not work at high concentrations of droplets/bubbles. Recent advances in instrumentation have produced the Silhouette camera (SilCam) (Davies et al., 2017a) and the Shadowgraph camera (developed by the consortium CARTHE), which appears to overcome the first two limitations and push the concentration threshold considerably higher than the LISST’s. Holographic imaging has also been used (Murphy et al., 2016a; White et al., 2016).
In experimental systems, the problem with measuring droplet size at high oil concentrations can also be resolved by using a horizontal discharge or by applying horizontal currents, either of which will dilute the droplet concentration. At the same time, these approaches risk biasing results due to droplet fractionation.
Observations of the physicochemical characteristics of oil that reached the surface following the DWH spill have been used to estimate the rise velocity of oil droplets and droplet size distribution (Ryerson et al., 2011, 2012). This team observed that large volumes of oil surfaced within 3-10 hours of wellhead discharge and surfaced within 2 km of the wellhead. Recent modeling by Gros et al. (2017) validated with field data of oil composition in different compartments, inferred that the DSD with dispersant application in the DWH spill had a d50 of around 1 millimeter, which falls within the range of 0.5 to 5 mm estimated by Ryerson et al. (2012).
Model Validation
The committee members could not reach consensus on the merits of including a model-data comparison. Some committee members had concerns about the lack of peer-reviewed, published analyses of the datasets, with some members also concerned about the representativeness of the experimental data, in particular the issue of droplet fractionation in horizontally directed droplet plumes. Two committee members disagreed, however, arguing that model-data comparisons were vital to understanding model uncertainty, and hence addressing the sixth task of the committee’s Statement of Task. Their opposing view and analysis are contained in Appendix D.
Model Predictions at Field Scale
The values of d50 predicted by SINTEF’s model, RPS ASA’s4 model, VDROP-J, and Paris et al. (2012) models when applied to the DWH spill are shown in Table 2.1. The most relevant row is the 1:250 DOR that corresponds to the average dispersant injected during this time period (Spaulding et al., 2017). VDROP-J and SINTEF calculate a droplet size of 1.3 to 1.8 mm. Gros et al. (2017) show that droplets of this size can reasonably replicate the observations. The droplet sizes produced by the Paris et al. (2012) model are substantially smaller.
For RPS ASA’s model, two columns are shown. The first from Spaulding et al. (2017) shows two d50s corresponding to the two peaks assumed in their DSD. Spaulding et al. (2017) suggest that the oil was only partially treated by dispersant based on video taken at the wellhead, in which bands of whitish and darkish oil imply that some oil was dispersed and some was not. Their dual-peaked DSD model reasonably reproduces the subsurface observations during the periods examined, but they did not look at the surfacing times estimated by Ryerson et al. (2012). Further work done by Socolofsky and Gros (see Appendix E) compares the dual-peaked DSD to the dataset assembled by Gros et al. (2017) and shows that it does not fit observations nearly as well as the single-peaked distribution from the VDROP-J or SINTEF models.
Table 2.1 also includes a column showing the droplet size predicted by RPS ASA’s model assuming 100% mixing of the dispersant (fully mixed). In general, these numbers are within about two times of SINTEF’s model numbers and VDROP-J numbers.
Nearfield Plume Dynamics
Gas bubbles and oil droplets released from a blowout create a buoyant multiphase plume. The plume entrains ambient seawater, elevating it within the water column. As the plume rises, the gas bubbles and smaller molecules of the oil droplets dissolve into the entrained seawater. This decreases plume buoyancy and reduces bubble and droplet diameters, thereby affecting their rise velocity and the concentration of dissolved hydrocarbons in the plume. Eventually, ambient density stratification and currents cause the entrained seawater to detrain from the plume, forming lateral intrusion layers of enhanced hydrocarbon content, as were observed more than 100 km downstream of the DWH blowout (Du and Kessler, 2012; Kessler et al., 2011a). The plume width and intrusion layer thickness span scale up to a few hundred meters (see Figure 2.3), much smaller than the resolution of ocean circulation models; hence, these features are simulated using sub-models specifically designed to capture fine-scale dynamics. Because of the plume effect, droplets rise more rapidly below the intrusion layer than they do above it, where they rise as individual droplets.
Buoyant multiphase plumes in stratification and crossflow have been studied in the laboratory and the DeepSpill field experiment (Johansen et al., 2003). Key parameters include wr = bubble/-
___________________
4 For the purpose of clarity in this discussion, the committee uses “RPS ASA’s model” here and henceforth to refer to the model initially developed by Li et al. (2017c) and subsequent modifications of that model.
TABLE 2.1 The d50 Predicted by Four Models (SINTEF’s model; RPS ASA’s model; VDROP-J; and the Paris et al. [2012] model) for Both Untreated Oil and Oil Treated with 1:250 and 1:100 DOR in a Scenario That Simulates the DWH Spill
| DOR | SINTEF’s Modela (µm) |
RPS ASA’s Modelb Partially Mixed (µm) |
RPS ASA’s Modelc Fully Mixed (µm) |
VDROP-Jd (µm) |
Paris et al., 2012 (µm) |
|---|---|---|---|---|---|
| 0 | 5,800 | 2,600 | 10,200 | 4,200 | 190 |
| 1:250 | 1,800 | 100/2,600 | 3,400 | 1,300 | 70 |
| 1:100 | 530 | 200/2,600 | 740 | 140 | 10 |
aCalculated using ρo = 707kg/m3, µ = 0.74cp, GOR = 0.41 at seabed, σ = 24.5 cp (DOR = 0), σ = 4.54 mN/m (1:250), σ = 0.24 mN/m (1:100). For diameters > the stable droplet size, sets d95 = max stable droplet size.
bThese are approximate peaks taken from Figure 9 of Spaulding et al. (2017). The 1:250 DOR case in the table comes from their “Best Estimate,” while the 1:100 comes from their “high dispersant” case. The dual peaks in the DSD arise because they have assumed only partial mixing of the dispersant. See further discussion in the text.
cThese are estimates assuming that the dispersant is 100% mixed and uses oil characteristics at the surface as per Li et al. (2017c). ρo = 862 kg/m3, µ = 0.74 cp, GOR = 0.4 at seabed, σ = 24.5 mN/m (DOR = 0), σ = 4.54 mN/m (1:250), σ = 0.24 mN/m (1:100).
dFrom Gros et al., 2017.
droplet rise velocity; B = kinematic buoyancy flux of dispersed-phase particles; N = buoyancy frequency of ambient stratification; and ua = ambient current velocity (Socolofsky and Adams, 2002, 2005). (BN)1/4 is a characteristic velocity and B1/4/N3/4 and B/wr3 are characteristic lengths of a multiphase plume (Bombardelli et al., 2007). Combinations of these parameters have been used to predict plume characteristics.
Although self-similarity is not strictly valid for multiphase plumes, integral models based on the entrainment hypothesis have been successfully applied to predict multiphase plume dynamics (Milgram, 1983). Major blowout simulation models are DeepBlow (Johansen, 2003), the Clarkson Deep Oil and Gas (CDOG) model (Zheng and Yapa, 2002), and the Texas A&M modeling system (Texas A&M Oilspill Calculator [TAMOC]; Dissanayake et al., 2018). These models have been carefully validated and can simulate some fate processes. Disadvantages are that they cannot resolve unsteady flow features or the complex processes of detrainment, intrusion formation, and weak plume dynamics above the detrainment point.
Recently, large-eddy simulation models have been developed to treat complex oil and/or gas plumes in stably stratified conditions (Fabregat et al., 2015, 2016; Fraga et al., 2016; Yang et al., 2016a). These models do not rely on self-similarity. Instead, they are fully three-dimensional and are able to directly resolve large- and intermediate-scale turbulent motions, relying on turbulence closure models for the effects of subgrid-scale features. Yang et al. (2016a) used their large-eddy simulation model to assess the flux parameterizations typically used in integral plume models, and they proposed a new continuous peeling model for double-plume integral models with a more self-consistent performance than previous models.
Intrusion Layer Formation
The previous discussion described nearfield plume dynamics, showing how buoyant oil and gas released at the bottom of a stratified ocean can become trapped in layers, centered on the level of neutral buoyancy of the entrained seawater. It is of interest to know whether oil droplets also
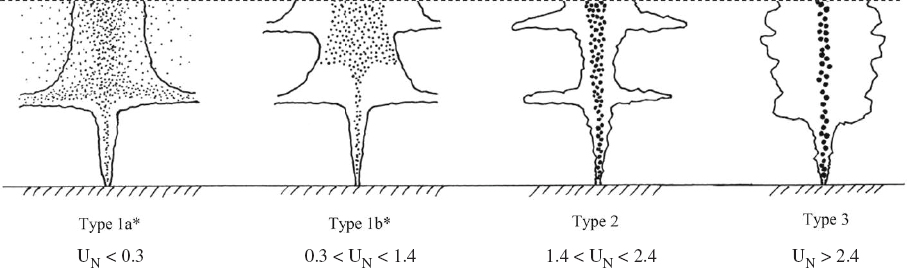
become trapped. Experimental studies suggest the classification shown in Figure 2.11 (Chan et al., 2015), indicating that as the characteristic velocity UN = wr/(BN)1/4 decreases, droplets become more effective in pumping ambient water upward to one or more intrusion layers, and there is greater tendency for droplets to detrain and enter the intrusion themselves. Chan et al. (2015) found a threshold value of UN = 0.2 to 0.4 below which droplets intrude. They also derived theoretically and confirmed experimentally a relationship for the distance sr that a droplet travels within the first intrusion layer before escaping, given by
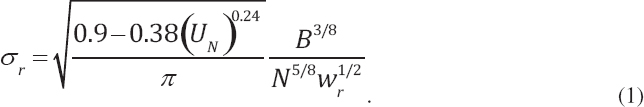
Additional experiments have been conducted to establish similar threshold values of UN and lateral transport distances for oil discharging into a mild current (Wang and Adams, 2016).
Using Equation 1 for an oil with a density of 0.85 g/cm3:
- droplets with a diameter of 2 to 20 mm, typical of those expected for untreated oil at DWH (Testa et al., 2016), would have been transported 50-100 m radially within the intrusion layer;
- droplets with a diameter of 0.2 to 2 mm, typical of those for dispersant treated oil not experiencing any tip-streaming breakup (Zhao et al., 2015), would have traveled 100-500 m laterally; and
- droplets with a diameter of 0.02 to 0.2 mm, typical of those expected at DWH for dispersant treated oil experiencing significant tip streaming or rapid pressure drops following release, could theoretically have been transported 3-20 km before rising out of the intrusion layer.
These transport distances are in general agreement with predictions for similar droplet sizes in farfield transport models (North et al., 2015; Paris et al., 2012).
In an ambient current, the rising plume is pushed downstream and forms an intrusion layer composed of a pair of counter-rotating vortices (Murphy et al., 2016a; Socolofsky and Adams, 2002). Droplets and bubbles rise out of the intrusion in accordance with their size. The intrusion thickness also reflects the droplet size, with larger droplets producing a thicker intrusion due to their faster rise velocity (Murphy et al., 2016a). Plumes have been modeled for both quiescent and flowing environments (e.g., Dissanayake et al., 2018).
Surface Transport
Oil Dispersion
The formation of oil droplets in water is commonly referred to as “dispersion” in the oil literature, and it is distinct from the traditional definition of dispersion in fluid mechanics introduced by Taylor (1953), which means the spreading of solute in a solvent due to the spatial variation of velocity. Oil dispersion forms as a result of “destructive” forces due to water hydrodynamics (e.g., turbulence) and “resisting” forces due to oil-water IFT and the oil viscosity (Grace, 1982; Hinze, 1955).
Models of Droplet Breakup Under Surface Slicks
Oil that is spilled on the surface is also subject to dispersion caused by breaking waves. Though this occurs naturally, it can be enhanced by surface application of dispersants. The dispersion causes the oil to break into small droplets, which can be entrained below the surface by waves, turbulence, and Langmuir circulation. Their depth and the persistence of the dispersion in the water column depend on droplet size, where smaller droplets are less buoyant and tend to entrain deeper into the water column and persist there longer. Droplets smaller than 70 µm have been observed to remain permanently suspended in the water column (Lunel et al., 1995).
Until recently, most models of surface oil dispersion have relied on the study by Delvigne and Sweeney (1988, DS model), which was summarized in the NRC (2005) study. In the DS model, the number of oil droplets for each size is a power law of that size, namely:
![]()
where “a” is a constant around 2.3. The committee notes that Equation 2 describes a DSD based on the number of droplets, rather than mass, as described earlier in connection with subsurface droplet size distributions. The simplicity of Equation 2, and the fact that the model provides a way for entraining droplets into the water column, has contributed to the popularity of the DS model. A group of researchers at the Department of Fisheries and Oceans (DFO; also known as Fisheries and Oceans Canada) reported a series of dispersion experiments in the wave tank at the Bedford Institute of Oceanography (Li et al., 2008a,b, 2009a,b,c, 2010). They found the total oil concentration to be related to the energy dissipation rate through the equations c ~ e0.32 and c ~ e0.43 for oils without and with dispersant, respectively. They observed the droplet size mass distribution to be log-normal in the absence of dispersant and bimodal when dispersants were used. In the latter case, they found one peak to be below 10 µm and another at 100 µm or larger, depending on the oil and mixing energy. Attempts at modeling the DSD of the DFO data were conducted by Boufadel et al. (2008) and Chen et al. (2009). Zhao et al. (2014b) used the VDROP-J model to predict the DSD under hypothetical breaking waves at sea. They accounted indirectly for the entrainment by removing droplets smaller than 100 µm from the slick. However, the approach is very demanding computationally and requires detailed data for calibration, which are not available for different wave configurations.
A limitation of the DS model is that, while it accounts for viscosity, it does not consider IFT. Indeed, the range of IFT used by DS was narrow from 18 to 30 mN/m, which is representative of untreated oil but not chemically dispersed oil. More recently, Zeinstra-Helfrich et al. (2017) revisited the DS equations, introduced the impact of IFT, and proposed a dispersibility factor to determine when dispersants should be used. Their approach assumes that the DSD follows a log-normal mass distribution, which agrees with observations in the absence of dispersant.
Johansen et al. (2015) developed a semiempirical model for oil DSD generated by single breaking wave events based on the theoretical framework of the Weber and viscosity numbers
(Calabrese et al., 1986; Hinze, 1955) adopted in Johansen et al. (2013) for jets. The model has several improvements over that of Delvigne and Sweeney (1988). In particular, the roles of both IFT and viscosity are physically represented, and the results are expressed in dimensionless form. In addition, the underlying lab experiments were shown to support a log-normal relationship for DSD. Like Johansen et al. (2013), the model expresses droplet diameter—in this case, normalized by the slick thickness—as a function of two nondimensional groups: We and the Reynolds number (Re). The velocity in the two numbers is given by U = sqrt(gH), where H is the wave height. An experimental full-scale oil spill, conducted offshore Norway in July 1982, was used to validate the model. However, the range of independent variables that were varied in the laboratory was limited, making it tenuous to extrapolate the predictions to the field.
RPS ASA’s model used a similar approach as did Johansen et al. (2015) to derive a generalized droplet model that would apply to natural dispersion at the surface as well as the previously described dynamic breakup due to a deepwater5 blowout. Their formulation relates normalized droplet size to We and Oh and was calibrated to droplet data collected in a wave tank for a broad range of viscosity and IFT. They used various DORs for the latter. Noting that Li’s Oh can be related to Johansen’s Re and Vi, both models can express normalized droplet size as a function of two dimensionless variables, say We and Re.
As with subsurface droplets treated with dispersants (discussed earlier), surface oil treated with dispersants can break down into micron (and smaller) sized droplets due to tip streaming. In this process, dispersant migrates on the oil droplets to form a cone where the oil and dispersant leave the droplets and form microdroplets (Gopalan and Katz, 2010; Tseng and Prosperetti, 2015). The presence of microdroplets has been inferred by Zhao et al. (2017b). However, turbulence-based models—such as presented by Johansen et al. (2013), Zhao et al. (2014a), and Li et al. (2017c, RPS ASA’s model)—cannot predict microdroplets. This fact was noted by Zhao et al. (2017b), and they proposed for this purpose a formulation for predicting tip streaming based on the surfactant concentration and the droplet Re. Due to their small size, the microdroplets are likely to be volatilized and thus have potential adverse implications on air quality (Sampath et al., 2017).
The spreading of oil on calm seas has been well predicted by the works of Fay (1969) and Hoult (1972), who used dimensional analysis to obtain order-of-magnitude type equations. At first, the oil spread due to gravity because oil rises to the top of the water surface and then it spreads because of the IFT between oil and water. They also argued that in the initial phase, spreading is impeded by inertia of the water, with water viscosity becoming the main resisting force after the initial phase. Their approach forms the basis of most oil spill models. However, the assumption of an infinitesimally thick oil slick floating on a stagnant water column does not apply well at sea due to the presence of wind, currents, and waves. For example, Lehr et al. (1984) conducted experiments and provided a model favoring the elongation of the oil with the direction of the wind. This results in a spill shaped as an ellipse with the long axis aligned with the wind direction.
The traditional approach for modeling an oil spill on the water surface assumes that the slick consists of many Lagrangian elements (sometimes called spillets), with each getting displaced by advection (due to currents), Stokes drift of waves (in the propagation sense of waves), wind (fraction of the wind speed), and turbulence (Boufadel et al., 2014; MacFadyen et al., 2011). The propagation speed of oil due to wind is typically taken as a fraction of the wind speed (obtained at 10 m above the water), and the fraction varies between 1% and 6% (ASCE Task Committee, 1996). Although the Stokes drift depends on wave properties, it is also taken for simplicity as a
___________________
5 The committee recognizes there are varying definitions for the terms “deep water” or “deep-water,” which largely depend on the context of their use; however, for the purposes of this report, the committee generally considers “deep water” to be approximately 500 m or greater.
fraction of the wind speed, typically a few percent. The spread of oil spillets on the water surface is assumed to occur by diffusion, typically using a random walk process with a select turbulent diffusion coefficient. For the DWH, the coefficient was taken to be approximately 10 m2/s in various studies (Barker, 2011; Boufadel et al., 2014).
These approaches are expedient but could fail in some cases. In particular, they do not account for convergence of ocean currents as revealed by D’Asaro et al. (2018), whereby drifters initially separated by 10 km converge within hours to within 10 m from each other. In addition, they do not account for the formation of windrows due to Langmuir cells (Golshan et al., 2017; Langmuir, 1938; Leibovich, 1980).
Entrainment
The vertical transport of oil droplets due to waves was first investigated experimentally and numerically (using an Eulerian approach) by Elliott et al. (1986), who noted also the formation of a comet-shape oil plume. They also reported the relative absence of oil droplets smaller than 70 µm from the surface layer. Various investigators found that “particles” released at the water surface tend to propagate downward. However, the downward migration is usually much slower than the horizontal migration. For example, a field study by French-McCay et al. (2008) found that the vertical diffusion coefficient is around 10 cm2/s, while the horizontal diffusion coefficient is on the order of m2/s. Attempts to understand the downward movement were conducted by Boufadel et al. (2006, 2007), who surmised that it is due to the orbital motion of waves combined with turbulent diffusion. They assumed second-order regular waves and investigated the impact of buoyancy and vertical diffusion on the migration of oil droplets released at the water surface. They noted that after 1 hour, the centroid of plumes of droplets of a given size stabilized at a depth directly related to the buoyancy (the larger the buoyancy, the smaller the depth). The exception was for the neutrally buoyant droplets that continued to propagate downward. A recent work by Geng et al. (2016) extended the work to irregular waves (Kitaigordskii et al., 1983) and found similar general conclusions.
Existing approaches for the displacement of oil droplets tend either to ignore the vertical profile of the vertical eddy diffusivity or to neglect it during simulations. The eddy diffusivity is expected to be small at the water surface, to increase with depth until reaching a maximum, and subsequently to decrease slowly with depth. However, most studies assume a uniform eddy viscosity with depth, which is contrary to the physics (Boufadel et al., 2018a; Marusic et al., 2013; Townsend, 1980). Studies by Visser (e.g., 1997) demonstrated that neglecting the viscosity gradient would erroneously accumulate particles at the water surface, a finding that was confirmed recently by Boufadel et al. (2018a). A recent numerical study using a Reynolds Average Navier Stokes model predicted that oil droplets tend to persist longer in the high-viscosity region (Golshan et al., 2018).
Existing approaches that rely on random walk for displacing oil droplets have come under scrutiny through a series of theoretical works (Eames, 2008; Santamaria et al., 2013) due to the neglect of the droplet inertia. These works did not account for turbulence, but they demonstrated that using the standard particle tracking approach would underestimate the rise rate of oil droplets due to the droplet inertia. In the presence of turbulence, studies found that droplets can rise three times faster than at the speed given by Stokes’ Law (in quiescent water) (Friedman and Katz, 2002), which is through a mechanism known as trajectory biasing. However, this seems to apply to droplets that are larger than 500 µm.
Transport in the Water Column
Effect of Oil Droplet and Gas Bubble (Impact of Shapes)
With regard to blowouts, the above discussion has addressed the formation of oil droplets and gas bubbles and how these buoyant fluids interact in the nearfield with local ocean currents and stratification to form a plume and intrusion layers. In the farfield, mixing of oil droplets and dissolved hydrocarbons is considered passive, and Lagrangian stochastic models can be used to simulate subsequent fate and transport (North et al., 2015; Paris et al., 2012), especially when focus is on the large scale.
The locations, flow rates, and composition of oil droplets leaving the intrusion layers become initial conditions for the farfield transport models. These inputs can be obtained from integral or large-eddy simulation models of the nearfield, as discussed previously, or from correlation equations, as reported in Socolofsky et al. (2011). In the Lagrangian stochastic models, particles sizes are typically selected from the DSD at the end of the nearfield, either by binning the data (North et al., 2015) or by a random number generator matched to the DSD probability function (Paris et al., 2012).
The boundary conditions specifying the three-dimensional flow field come from ocean circulation models. Currently, the coupling between the nearfield plume and ocean circulation models is only in one direction (i.e., the nearfield model depends on the farfield flow field but not the reverse). This one-way coupling is also true between the farfield tracking and ocean circulation models. Because the nearfield plume induces a significant vertical velocity and the intrusion layer can generate a large flow rate (about 1,000 m3/s for the primary intrusion during DWH), two-way coupling may be important between the buoyancy-dominated nearfield and intermediate-field (region of the intrusion formation) and the ocean circulation. For the DWH oil spill, the primary intrusion was at approximately 350 m above the source, but the elevation of the intrusion layer is determined by oceanographic conditions and other factors and may vary. (Socolofsky et al., 2011) Research groups are actively studying this problem, but to date, no two-way coupled hindcast simulations for the nearfield and the farfield of the DWH spill have been reported.
For a Lagrangian stochastic models, oil is typically represented by numerical particles, or Lagrangian elements, that are advected by mean ocean currents and droplet rise velocity, diffused by ambient turbulence, and transformed by a host of physical, chemical, and biological processes, including dissolution, biodegradation, sediment particle interactions, etc. While oil transformations are important for determining oil fate, we focus here on transport and mixing.
Typically, ocean circulation models, such as the SABGOM (South Atlantic Bight—Gulf of Mexico) model and HYCOM (Hybrid Coordinate Ocean Model), are used to provide detailed velocity fields. Transport models, such as LTRANS (Lagrangian Transport; North et al., 2015, used with SABGOM) and CMS (Connectivity Modeling System; Paris et al. [2012] used with HYCOM), then calculate oil transport based on local currents interpolated from the gridded circulation model velocities. Alternatively, circulation and transport can be calculated in an integrated model such as GNOME (General NOAA Operational Modeling Environment; Macfadyen et al. [2011]). Circulation models generate three-dimensional flow fields over complex bathymetry—often using nested domains that provide added resolution in critical areas—and may respond to tides, wind, air/sea fluxes, density variations, and Earth’s rotation (Coriolis force), among others. Many ocean circulation models also rely on data assimilation (i.e., periodic updating of predictions using measurements, such as water levels from satellites) to keep model predictions on track.
The rise velocity of droplets is added to the advection from the ocean currents. Because smaller droplets rise more slowly than larger droplets, horizontal ocean currents stretch the spatial distribu-
tion of droplets in the horizontal dimension as they rise through the water column. The smallest droplets surface farthest from the source. Mitigation measures to reduce droplet size (e.g., subsea dispersant injection) or more energetic breakup regimes can cause the surface expression of the oil to move downstream relative to the unmitigated case (Socolofsky et al., 2015).
The total rise time of droplets and bubbles is the sum of the time spent in the buoyant plume plus the time it takes the individual droplet to rise the remaining distance to the surface. In deep water, the buoyant plume will be a few hundred meters above the source and take only about 30 minutes to transit regardless of droplet and bubble size. In contrast it can take several hours to many days for individual oil droplets to rise the remaining distance, depending on their size and density. Thus, accurately estimating the vertical velocity of individual droplets and bubbles is an important factor in modeling blowout and pipeline leaks in deep water.
A commonly used algorithm for calculating the rise velocity is based on the generalized Stokes’ Law to include situations where the flow around the droplet is turbulent. The first application of this approach in the oil spill literature was done by Zhao et al. (2014a). The rise velocity also depends on the shape of the droplets and bubbles, and the algorithm is more elaborate (Zhao et al., 2016a; Zheng and Yapa, 2000).
There are several factors that can further affect the rise velocity that are still not routinely accounted for by most integrated spill models. The most well-established of these arises from the formation of a hydrate skin on the surface of a gas bubble formed in deep water as documented by Chen et al. (2014) and Rehder et al. (2009). This hydrate skin serves to stiffen the droplet surface and alter the drag calculated by the modified Stokes’ Law. Gros et al. (2017) account for this effect in a farfield transport model. The second factor that may affect rise velocity is the presence of saturated gas in oil droplets released in deep water as described by Pesch et al. (2017). As mentioned earlier in this chapter, “live-oil” contains liquid oil saturated with gas (primarily methane). As live oil droplets rise through the water column, the pressure decreases and the temperature increases. As a result, the gas comes out of solution and may form bubbles that cling to the rising oil droplets. Pesch et al. (2017) label this as “internal de-gassing” and performed laboratory experiments and independent calculations that support their hypothesis. However, in order for this to occur in a DWH-like scenario, the rate of droplet ascent (implied by the rate of depressurization) would have to be quite high such that the gas formed bubbles before they could diffuse; evidence from the DWH suggests that most of the gas entered the intrusion as dissolved phase rather than ascending to the surface as bubbles. While measurements to date suggest little impact above the intrusion layer, the impact below the intrusion layer remains uncertain.
Farfield tracking models generally treat horizontal and vertical turbulent mixing using random walk (or similar) algorithms, as in Macfadyen et al. (2011), North et al. (2015), and Paris et al. (2012). One way to obtain diffusivities used in these models is from the horizontal and vertical turbulent diffusivities computed in the ocean circulation models. However, this presumes that diffusion is a Fickian process and the computed diffusivities may be artificially high in order to keep the circulation model stable. Another approach is to estimate diffusivities directly from field measurements of an introduced tracer. For example, Ledwell et al. (2016) measured concentrations of SF5CF3 introduced near the DWH site. In analyzing data from such experiments, horizontal ocean currents are usually assumed to be spatially uniform, in which case the unresolved spatial variability is manifest as a scale-dependent diffusivity (i.e., one that depends on the size of the tracer). Strongly variable currents can spread the tracer widely, and while the horizontal spreading of the tracer can be represented by a large diffusivity, details of the concentration distribution will be lost. A different approach was used by Wang et al. (2016c), who studied vertical mixing near the DWH site using a microstructure profiler to determine small-scale turbulent properties. Vertical mixing, in particular,
has been found to be spatially variable (e.g., diffusivities in the thermocline are several orders of magnitude smaller than those near the surface or in the deeper abyssal waters).
In addition to contributing to droplet diffusion, turbulence can also alter droplet rise velocity dependent on the mass of the oil droplets (Maxey and Riley, 1983): very small droplets usually move with the flow and large droplets tend to withstand turbulent fluctuations impacting them. A range of droplet sizes could be impacted by turbulence through two mechanisms, which both depend on the density and the size of droplets with respect to turbulence intensity. The first mechanism is trajectory biasing, in which droplets tend to avoid intense vortices and thus could migrate through them causing the droplets to rise faster than their rise rate under quiescent conditions. This was observed by Friedman and Katz (2002). The second is vortex trapping, where a droplet in an eddy will tend to be displaced to its center due to inertia, because the droplet is lighter than the water in the eddy. This is the converse of a centrifuge, which pushes particles heavier than water to the outer edge. Comparing field measurements of turbulent velocities with droplet rise velocities, Wang et al. (2016c) concluded that droplets larger than 0.4 mm (rise velocity 6 mm/s) were unlikely to be significantly affected by turbulence, while those smaller than 0.04 mm (rise velocity 0.1 mm/s) were expected to become so entangled with turbulence that they might be permanently trapped below the surface.
FINDINGS AND RECOMMENDATIONS
Finding: Models and experiments using oil jets discharged to seawater consistently demonstrate that when dispersant is applied to oil releases deep beneath the water surface it can dramatically reduce (5-10 times) the droplet size. The interplays of subsea dispersant injection (SSDI) and other processes—such as the role of natural gas, and the flow field and pressure drop upstream of the release point—may be important, but are not completely understood or represented in existing models.
Finding: Droplet size is a major factor determining the fate and transport of oil spilled at depth. Both natural processes and the application of subsurface dispersants affect droplet size distributions (DSDs), in varying degrees. Small droplets take longer to rise to the surface and microdroplets may remain suspended in the water column. When oil droplets take longer to rise to the surface, processes such as dissolution and biodegradation have more time to alter the chemical composition of the oil that surfaces, reducing the transfer of volatile organic compounds (VOCs) to the atmosphere.
Finding: Existing droplet models have been compared to varying degrees with laboratory studies and the DeepSpill field experiment. The models have also been used to predict droplet sizes at Deepwater Horizon scales where they generally show a variation of about two times. Further modeling uncertainty derives from our lack of understanding of such processes as tip streaming, pressure gradients, and out-gassing.
Recommendation: Additional observations of droplet formation are needed as close to field scale as possible. An extensive, dedicated field study would be highly desirable; but, should cost and permitting prove prohibitive, a spill of opportunity should be considered. Field experiments will be inherently restricted in the phenomena that can be studied because of logistical challenges and open boundaries. They will also face legal and regulatory challenges. Thus, it would be highly desirable to develop a large-scale laboratory facility with the ability to include high ambient pressure and observation of droplets as they evolve over time.
Recommendation: Droplet models should be extended to further include large pressure gradients, the role of gas, and tip streaming.
Recommendation: In the event of another subsea release, droplet size near the source should be measured, as the technology is available.
Finding: Photochemical oxidation of oil may occur quickly (hours to days), potentially reducing the time window during which surface dispersant use is most effective.
Recommendation: Photochemical oxidation of oil will vary at different locations and at different times of the year. Therefore, the importance of this process needs to be examined for individual oil spill scenarios, oil types, and slick characteristics so that it may be considered for incorporation into oil spill response strategies.
Finding: The use of surface dispersants may enhance the formation of oil-containing marine snow leading to enhanced transport of oil to the deep sea.
Recommendation: End-to-end oil spill trajectory and fate models should simulate the sedimentation of oil spill residues with the inclusion of validated oil-containing marine snow formation mechanisms.
Finding: Oil transport on the water surface is different from that of neutrally buoyant material, as oil can gather in convergence zones and/or move relative to the water surface.
Recommendation: Oil spill models should account for sharp vertical and horizontal variations in oil transport.
Finding: The use of SSDI in a blowout hinges in part on whether it would reduce VOCs and enhance the safety of local response personnel. Depending on the exact scenario, SSDI can be effective at reducing VOC concentrations above the wellhead, although the specific details of atmospheric VOC dynamics remain uncertain.
Recommendation: A model hindcast of the VOCs generated around the Macondo well should be performed in order to better validate available models and to better understand the various processes affecting VOC concentrations.
Finding: Biodegradation is a key factor potentially impacted by dispersant application, both directly and indirectly.
Recommendation: Studies are needed to quantify the early stages of bacterial community response and development that precede rapid biodegradation as well as to further test the hypothesis that small droplets facilitate biodegradation through increasing the surface-area-to-volume ratio. The interactions of bacteria, photooxidation, emulsions, and dispersant efficacy should also be explored to understand the overall influence of dispersant use on biodegradation of oil.
Finding: The occurrence of natural gas in an oil well blowout can strongly impact discharge velocity and DSD and, therefore, environmental partitioning of discharge and associated weathering processes.
Recommendation: Additional modeling and experimental studies are needed at large scales and at high pressures to better define natural gas’s impacts on subsea discharge and fate and transport processes.
Finding: The dissolution of surfactants from oil droplets occurs during buoyant rise associated with SSDI. However, different components of the dispersant formulation may dissolve at different rates, leading to molecular fractionation.
Recommendation: Industry or regulatory agencies should sponsor a study to determine how dissolution and molecular fractionation of dispersant may affect the behavior of oil at the surface following SSDI, particularly with respect to any impacts to the effectiveness of other response options.












































