
3
Understanding Reproducibility and Replicability
THE EVOLVING PRACTICES OF SCIENCE
Scientific research has evolved from an activity mainly undertaken by individuals operating in a few locations to many teams, large communities, and complex organizations involving hundreds to thousands of individuals worldwide. In the 17th century, scientists would communicate through letters and were able to understand and assimilate major developments across all the emerging major disciplines. In 2016—the most recent year for which data are available—more than 2,295,000 scientific and engineering research articles were published worldwide (National Science Foundation, 2018e).
In addition, the number of scientific and engineering fields and subfields of research is large and has greatly expanded in recent years, especially in fields that intersect disciplines (e.g., biophysics); more than 230 distinct fields and subfields can now be identified. The published literature is so voluminous and specialized that some researchers look to information retrieval, machine learning, and artificial intelligence techniques to track and apprehend the important work in their own fields.
Another major revolution in science came with the recent explosion of the availability of large amounts of data in combination with widely available and affordable computing resources. These changes have transformed many disciplines, enabled important scientific discoveries, and led to major shifts in science. In addition, the use of statistical analysis of data has expanded, and many disciplines have come to rely on complex and expensive instrumentation that generates and can automate analysis of large digital datasets.
Large-scale computation has been adopted in fields as diverse as astronomy, genetics, geoscience, particle physics, and social science, and has added scope to fields such as artificial intelligence. The democratization of data and computation has created new ways to conduct research; in particular, large-scale computation allows researchers to do research that was not possible a few decades ago. For example, public health researchers mine large databases and social media, searching for patterns, while earth scientists run massive simulations of complex systems to learn about the past, which can offer insight into possible future events.
Another change in science is an increased pressure to publish new scientific discoveries in prestigious and what some consider high-impact journals, such as Nature and Science.1 This pressure is felt worldwide, across disciplines, and by researchers at all levels but is perhaps most acute for researchers at the beginning of their scientific careers who are trying to establish a strong scientific record to increase their chances of obtaining tenure at an academic institution and grants for future work. Tenure decisions have traditionally been made on the basis of the scientific record (i.e., published articles of important new results in a field) and have given added weight to publications in more prestigious journals. Competition for federal grants, a large source of academic research funding, is intense as the number of applicants grows at a rate higher than the increase in federal research budgets. These multiple factors create incentives for researchers
___________________
1 “High-impact” journals are viewed by some as those which possess high scores according to one of the several journal impact indicators such as Citescore, Scimago Journal Ranking (SJR), Source Normalized Impact per Paper (SNIP)—which are available in Scopus—and Journal Impact Factor (IF), Eigenfactor (EF), and Article Influence Score (AIC)—which can be obtained from the Journal Citation Report (JCR).
to overstate the importance of their results and increase the risk of bias—either conscious or unconscious—in data collection, analysis, and reporting.
In the context of these dynamic changes, the questions and issues related to reproducibility and replicability remain central to the development and evolution of science. How should studies and other research approaches be designed to efficiently generate reliable knowledge? How might hypotheses and results be better communicated to allow others to confirm, refute, or build on them? How can the potential biases of scientists themselves be understood, identified, and exposed in order to improve accuracy in the generation and interpretation of research results? How can intentional misrepresentation and fraud be detected and eliminated?2
Researchers have proposed approaches to answering some of the questions over the past decades. As early as the 1960s, Jacob Cohen surveyed psychology articles from the perspective of statistical power to detect effect sizes, an approach that launched many subsequent power surveys (also known as meta-analyses) in the social sciences in subsequent years (Cohen, 1988).
Researchers in biomedicine have been focused on threats to validity of results since at least the 1970s. In response to the threat, biomedical researchers developed a wide variety of approaches to address the concern, including an emphasis on randomized experiments with masking (also known as blinding), reliance on meta-analytic summaries over individual trial results, proper sizing and power of experiments, and the introduction of trial registration and detailed experimental protocols. Many of the same approaches have been proposed to counter shortcomings in reproducibility and replicability.
Reproducibility and replicability as they relate to data and computation-intensive scientific work received attention as the use of computational tools expanded. In the 1990s, Jon Claerbout launched the “reproducible research movement,” brought on by the growing use of computational workflows for analyzing data across a range of disciplines (Claerbout and Karrenbach, 1992). Minor mistakes in code can lead to serious errors in interpretation and in reported results; Claerbout’s proposed solution was to establish an expectation that data and code will be openly shared so that results could be reproduced. The assumption was that reanalysis of the same data using the same methods would produce the same results.
In the 2000s and 2010s, several high-profile journal and general media publications focused on concerns about reproducibility and replicability (see, e.g., Ioannidis, 2005; Baker, 2016), including the cover story in The
___________________
2 See Chapter 5, Fraud and Misconduct, which further discusses the association between misconduct as a source of non-replicability, its frequency, and reporting by the media.
Economist (“How Science Goes Wrong,” 2013) noted above. These articles introduced new concerns about the availability of data and code and highlighted problems of publication bias, selective reporting, and misaligned incentives that cause positive results to be favored for publication over negative or nonconfirmatory results.3 Some news articles focused on issues in biomedical research and clinical trials, which were discussed in the general media partly as a result of lawsuits and settlements over widely used drugs (Fugh-Berman, 2010).
Many publications about reproducibility and replicability have focused on the lack of data, code, and detailed description of methods in individual studies or a set of studies. Several attempts have been made to assess non-reproducibility or non-replicability within a field, particularly in social sciences (e.g., Camerer et al., 2018; Open Science Collaboration, 2015). In Chapters 4, 5, and 6, we review in more detail the studies, analyses, efforts to improve, and factors that affect the lack of reproducibility and replicability. Before that discussion, we must clearly define these terms.
DEFINING REPRODUCIBILITY AND REPLICABILITY
Different scientific disciplines and institutions use the words reproducibility and replicability in inconsistent or even contradictory ways: What one group means by one word, the other group means by the other word.4 These terms—and others, such as repeatability—have long been used in relation to the general concept of one experiment or study confirming the results of another. Within this general concept, however, no terminologically consistent way of drawing distinctions has emerged; instead, conflicting and inconsistent terms have flourished. The difficulties in assessing reproducibility and replicability are complicated by this absence of standard definitions for these terms.
In some fields, one term has been used to cover all related concepts: for example, “replication” historically covered all concerns in political science (King, 1995). In many settings, the terms reproducible and replicable have distinct meanings, but different communities adopted opposing definitions (Claerbout and Karrenbach, 1992; Peng et al., 2006; Association for Computing Machinery, 2018). Some have added qualifying terms, such as methods reproducibility, results reproducibility, and inferential reproducibility to the lexicon (Goodman et al., 2016). In particular, tension has emerged between the usage recently adopted in computer science and the way that
___________________
3 One such outcome became known as the “file drawer problem”: see Chapter 5; also see Rosenthal (1979).
4 For the negative case, both “non-reproducible” and “irreproducible” are used in scientific work and are synonymous.
researchers in other scientific disciplines have described these ideas for years (Heroux et al., 2018).
In the early 1990s, investigators began using the term “reproducible research” for studies that provided a complete digital compendium of data and code to reproduce their analyses, particularly in the processing of seismic wave recordings (Claerbout and Karrenbach, 1992; Buckheit and Donoho, 1995). The emphasis was on ensuring that a computational analysis was transparent and documented so that it could be verified by other researchers. While this notion of reproducibility is quite different from situations in which a researcher gathers new data in the hopes of independently verifying previous results or a scientific inference, some scientific fields use the term reproducibility to refer to this practice. Peng et al. (2006, p. 783) referred to this scenario as “replicability,” noting: “Scientific evidence is strengthened when important results are replicated by multiple independent investigators using independent data, analytical methods, laboratories, and instruments.” Despite efforts to coalesce around the use of these terms, lack of consensus persists across disciplines. The resulting confusion is an obstacle in moving forward to improve reproducibility and replicability (Barba, 2018).
In a review paper on the use of the terms reproducibility and replicability, Barba (2018) outlined three categories of usage, which she characterized as A, B1, and B2:
B1 and B2 are in opposition of each other with respect to which term involves reusing the original authors’ digital artifacts of research (“research compendium”) and which involves independently created digital artifacts. Barba (2018) collected data on the usage of these terms across a variety of disciplines (see Table 3-1).5
___________________
5 See also Heroux et al. (2018) for a discussion of the competing taxonomies between computational sciences (B1) and new definitions adopted in computer science (B2) and proposals for resolving the differences.
TABLE 3-1 Usage of the Terms Reproducibility and Replicability by Scientific Discipline
| A | B1 | B2 |
|---|---|---|
| Political Science | Signal Processing | Microbiology, Immunology (FASEB) |
| Economics | Scientific Computing | Computer Science (ACM) |
| Econometry | ||
| Epidemiology | ||
| Clinical Studies | ||
| Internal Medicine | ||
| Physiology (neurophysiology) | ||
| Computational Biology | ||
| Biomedical Research | ||
| Statistics | ||
NOTES: See text for discussion. ACM = Association for Computing Machinery, FASEB = Federation of American Societies for Experimental Biology.
SOURCE: Barba (2018, Table 2).
The terminology adopted by the Association for Computing Machinery (ACM) for computer science was published in 2016 as a system for badges attached to articles published by the society. The ACM declared that its definitions were inspired by the metrology vocabulary, and it associated using an original author’s digital artifacts to “replicability,” and developing completely new digital artifacts to “reproducibility.” These terminological distinctions contradict the usage in computational science, where reproducibility is associated with transparency and access to the author’s digital artifacts, and also with social sciences, economics, clinical studies, and other domains, where replication studies collect new data to verify the original findings.
Regardless of the specific terms used, the underlying concepts have long played essential roles in all scientific disciplines. These concepts are closely connected to the following general questions about scientific results:
- Are the data and analysis laid out with sufficient transparency and clarity that the results can be checked?
- If checked, do the data and analysis offered in support of the result in fact support that result?
- If the data and analysis are shown to support the original result, can the result reported be found again in the specific study context investigated?
- Finally, can the result reported or the inference drawn be found again in a broader set of study contexts?
Computational scientists generally use the term reproducibility to answer just the first question—that is, reproducible research is research that is capable of being checked because the data, code, and methods of analysis are available to other researchers. The term reproducibility can also be used in the context of the second question: research is reproducible if another researcher actually uses the available data and code and obtains the same results. The difference between the first and the second questions is one of action by another researcher; the first refers to the availability of the data, code, and methods of analysis, while the second refers to the act of recomputing the results using the available data, code, and methods of analysis.
In order to answer the first and second questions, a second researcher uses data and code from the first; no new data or code are created by the second researcher. Reproducibility depends only on whether the methods of the computational analysis were transparently and accurately reported and whether that data, code, or other materials were used to reproduce the original results. In contrast, to answer question three, a researcher must redo the study, following the original methods as closely as possible and collecting new data. To answer question four, a researcher could take a variety of paths: choose a new condition of analysis, conduct the same study in a new context, or conduct a new study aimed at the same or similar research question.
For the purposes of this report and with the aim of defining these terms in ways that apply across multiple scientific disciplines, the committee has chosen to draw the distinction between reproducibility and replicability between the second and third questions. Thus, reproducibility includes the act of a second researcher recomputing the original results, and it can be satisfied with the availability of data, code, and methods that makes that recomputation possible. This definition of reproducibility refers to the transparency and reproducibility of computations: that is, it is synonymous with “computational reproducibility,” and we use the terms interchangeably in this report.
When a new study is conducted and new data are collected, aimed at the same or a similar scientific question as a previous one, we define it as a replication. A replication attempt might be conducted by the same investigators in the same lab in order to verify the original result, or it might be conducted by new investigators in a new lab or context, using the same or different methods and conditions of analysis. If this second study, aimed at the same scientific question but collecting new data, finds consistent results or can draw consistent conclusions, the research is replicable. If a second study explores a similar scientific question but in other contexts or
populations that differ from the original one and finds consistent results, the research is “generalizable.”6
In summary, after extensive review of the ways these terms are used by different scientific communities, the committee adopted specific definitions for this report.
CONCLUSION 3-1: For this report, reproducibility is obtaining consistent results using the same input data; computational steps, methods, and code; and conditions of analysis. This definition is synonymous with “computational reproducibility,” and the terms are used interchangeably in this report.
Replicability is obtaining consistent results across studies aimed at answering the same scientific question, each of which has obtained its own data.
Two studies may be considered to have replicated if they obtain consistent results given the level of uncertainty inherent in the system under study. In studies that measure a physical entity (i.e., a measurand), the results may be the sets of measurements of the same measurand obtained by different laboratories. In studies aimed at detecting an effect of an intentional intervention or a natural event, the results may be the type and size of effects found in different studies aimed at answering the same question. In general, whenever new data are obtained that constitute the results of a study aimed at answering the same scientific question as another study, the degree of consistency of the results from the two studies constitutes their degree of replication.
Two important constraints on the replicability of scientific results rest in limits to the precision of measurement and the potential for altered results due to sometimes subtle variation in the methods and steps performed in a scientific study. We expressly consider both here, as they can each have a profound influence on the replicability of scientific studies.
PRECISION OF MEASUREMENT
Virtually all scientific observations involve counts, measurements, or both. Scientific measurements may be of many different kinds: spatial dimensions (e.g., size, distance, and location), time, temperature, brightness, colorimetric properties, electromagnetic properties, electric current,
___________________
6 The committee definitions of reproducibility, replicability, and generalizability are consistent with the National Science Foundation’s Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science (Bollen et al., 2015).
material properties, acidity, and concentration, to name a few from the natural sciences. The social sciences are similarly replete with counts and measures. With each measurement comes a characterization of the margin of doubt, or an assessment of uncertainty (Possolo and Iyer, 2017). Indeed, it may be said that measurement, quantification, and uncertainties are core features of scientific studies.
One mark of progress in science and engineering has been the ability to make increasingly exact measurements on a widening array of objects and phenomena. Many of the things taken for granted in the modern world, from mechanical engines to interchangeable parts to smartphones, are possible only because of advances in the precision of measurement over time (Winchester, 2018).
The concept of precision refers to the degree of closeness in measurements. As the unit used to measure distance, for example, shrinks from meter to centimeter to millimeter and so on down to micron, nanometer, and angstrom, the measurement unit becomes more exact and the proximity of one measurand to a second can be determined more precisely.
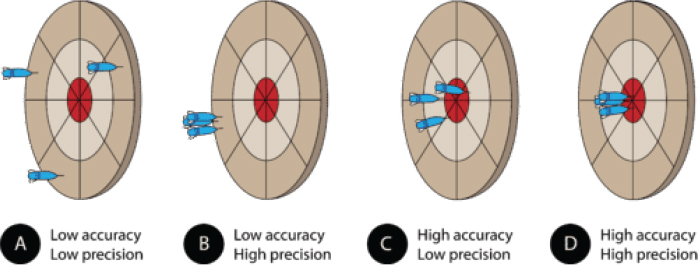
Even when scientists believe a quantity of interest is constant, they recognize that repeated measurement of that quantity may vary because of limits in the precision of measurement technology. It is useful to note that precision is different from the accuracy of a measurement system, as shown in Figure 3-1, demonstrating the differences using an archery target containing three arrows.
In Figure 3-1, A, the three arrows are in the outer ring, not close together and not close to the bull’s eye, illustrating low accuracy and low precision (i.e., the shots have not been accurate and are not highly precise). In B, the arrows are clustered in a tight band in an outer ring, illustrating
NOTE: See text for discussion.
SOURCE: Chemistry LibreTexts. Available: https://chem.libretexts.org/Bookshelves/Introductory_Chemistry/Book%3A_IntroductoryChemistry_(CK-12)/03%3A_Measurements/3.12%3A_Accuracy_and_Precision.
low accuracy and high precision (i.e., the shots have been more precise, but not accurate). The other two figures similarly illustrate high accuracy and low precision (C) and high accuracy and high precision (D).
It is critical to keep in mind that the accuracy of a measurement can be judged only in relation to a known standard of truth. If the exact location of the bull’s eye is unknown, one must not presume that a more precise set of measures is necessarily more accurate; the results may simply be subject to a more consistent bias, moving them in a consistent way in a particular direction and distance from the true target.
It is often useful in science to describe quantitatively the central tendency and degree of dispersion among a set of repeated measurements of the same entity and to compare one set of measurements with a second set. When a set of measurements is repeated by the same operator using the same equipment under constant conditions and close in time, metrologists refer to the proximity of these measurements to one another as
measurement repeatability (see Box 3-1). When one is interested in comparing the degree to which the set of measurements obtained in one study are consistent with the set of measurements obtained in a second study, the committee characterizes this as a test of replicability because it entails the comparison of two studies aimed at the same scientific question where each obtained its own data.
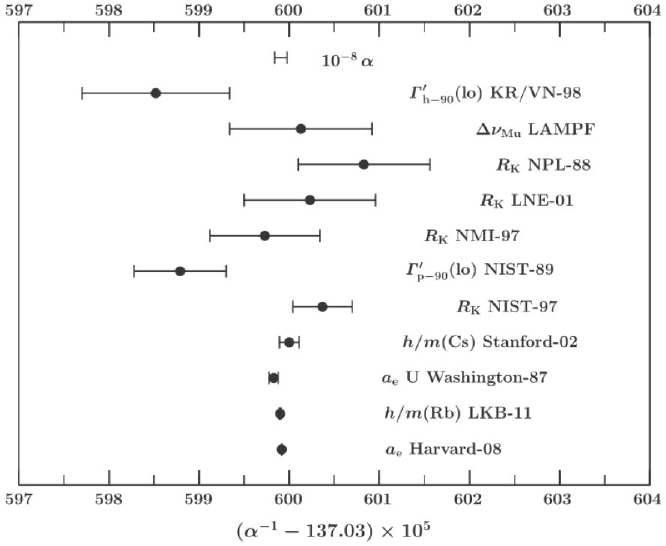
Consider, for example, the set of measurements of the physical constant obtained over time by a number of laboratories (see Figure 3-2). For each laboratory’s results, the figure depicts the mean observation (i.e., the central tendency) and standard error of the mean, indicated by the error bars. The standard error is an indicator of the precision of the obtained measurements, where a smaller standard error represents higher precision. In comparing the measurements obtained by the different laboratories, notice that both the mean values and the degrees of precision (as indicated by the width of the error bars) may differ from one set of measurements to another.
NOTES: Error bars indicate the experimental uncertainty of each measurement. See text for discussion.
SOURCE: Reprinted figure with permission from Peter J. Mohr, David B. Newell, and Barry N. Taylor (2016). Reviews of Modern Physics, 88, 035009. CODATA recommended values of the fundamental physical constants: 2014. Copyright 2016 by the American Physical Society.
We may now ask what is a central question for this study: How well does a second set of measurements (or results) replicate a first set of measurements (or results)? Answering this question, we suggest, may involve three components:
- proximity of the mean value (central tendency) of the second set relative to the mean value of the first set, measured both in physical units and relative to the standard error of the estimate
- similitude in the degree of dispersion in observed values about the mean in the second set relative to the first set
- likelihood that the second set of values and the first set of values could have been drawn from the same underlying distribution
Depending on circumstances, one or another of these components could be more salient for a particular purpose. For example, two sets of measures could have means that are very close to one another in physical units, yet each were sufficiently precisely measured as to be very unlikely to be
different by chance. A second comparison may find means are further apart, yet derived from more widely dispersed sets of observations, so that there is a higher likelihood that the difference in means could have been observed by chance. In terms of physical proximity, the first comparison is more closely replicated. In terms of the likelihood of being derived from the same underlying distribution, the second set is more highly replicated.
A simple visual inspection of the means and standard errors for measurements obtained by different laboratories may be sufficient for a judgment about their replicability. For example, in Figure 3-2, it is evident that the bottom two measurement results have relatively tight precision and means that are nearly identical, so it seems reasonable these can be considered to have replicated one another. It is similarly evident that results from LAMPF (second from the top of reported measurements with a mean value and error bars in Figure 3-2) are better replicated by results from LNE-01 (fourth from top) than by measurements from NIST-89 (sixth from top). More subtle may be judging the degree of replication when, for example, one set of measurements has a relatively wide range of uncertainty compared to another. In Figure 3-2, the uncertainty range from NPL-88 (third from top) is relatively wide and includes the mean of NIST-97 (seventh from top); however, the narrower uncertainty range for NIST-97 does not include the mean from NPL-88. Especially in such cases, it is valuable to have a systematic, quantitative indicator of the extent to which one set of measurements may be said to have replicated a second set of measurements, and a consistent means of quantifying the extent of replication can be useful in all cases.
VARIATIONS IN METHODS EMPLOYED IN A STUDY
When closely scrutinized, a scientific study or experiment may be seen to entail hundreds or thousands of choices, many of which are barely conscious or taken for granted. In the laboratory, exactly what size of Erlenmeyer flask is used to mix a set of reagents? At what exact temperature were the reagents stored? Was a drying agent such as acetone used on the glassware? Which agent and in what amount and exact concentration? Within what tolerance of error are the ingredients measured? When ingredient A was combined with ingredient B, was the flask shaken or stirred? How vigorously and for how long? What manufacturer of porcelain filter was used? If conducting a field survey, how exactly, were the subjects selected? Are the interviews conducted by computer or over the phone or in person? Are the interviews conducted by female or male, young or old, the same or different race as the interviewee? What is the exact wording of a question? If spoken, with what inflection? What is the exact sequence of questions? Without belaboring the point, we can
say that many of the exact methods employed in a scientific study may or may not be described in the methods section of a publication. An investigator may or may not realize when a possible variation could be consequential to the replicability of results.
In a later section, we will deal more generally with sources of non-replicability in science (see Chapter 5 and Box 5-2). Here, we wish to emphasize that countless subtle variations in the methods, techniques, sequences, procedures, and tools employed in a study may contribute in unexpected ways to differences in the obtained results (see Box 3-2).
Finally, note that a single scientific study may entail elements of the several concepts introduced and defined in this chapter, including computational reproducibility, precision in measurement, replicability, and generalizability or any combination of these. For example, a large epidemiological survey of air pollution may entail portable, personal devices to measure various concentrations in the air (subject to precision of measurement), very large datasets to analyze (subject to computational reproducibility), and a large number of choices in research design, methods, and study population (subject to replicability and generalizability).
RIGOR AND TRANSPARENCY
The committee was asked to “make recommendations for improving rigor and transparency in scientific and engineering research” (refer to Box 1-1 in Chapter 1). In response to this part of our charge, we briefly discuss the meanings of rigor and of transparency below and relate them to our topic of reproducibility and replicability.
Rigor is defined as “the strict application of the scientific method to ensure robust and unbiased experimental design” (National Institutes of Health, 2018e). Rigor does not guarantee that a study will be replicated, but conducting a study with rigor—with a well-thought-out plan and strict adherence to methodological best practices—makes it more likely. One of the assumptions of the scientific process is that rigorously conducted studies “and accurate reporting of the results will enable the soundest decisions” and that a series of rigorous studies aimed at the same research question “will offer successively ever-better approximations to the truth” (Wood et al., 2019, p. 311). Practices that indicate a lack of rigor, including poor study design, errors or sloppiness, and poor analysis and reporting, contribute to avoidable sources of non-replicability (see Chapter 5). Rigor affects both reproducibility and replicability.
Transparency has a long tradition in science. Since the advent of scientific reports and technical conferences, scientists have shared details about their research, including study design, materials used, details of the system under study, operationalization of variables, measurement techniques,
uncertainties in measurement in the system under study, and how data were collected and analyzed. A transparent scientific report makes clear whether the study was exploratory or confirmatory, shares information about what measurements were collected and how the data were prepared, which analyses were planned and which were not, and communicates the level of uncertainty in the result (e.g., through an error bar, sensitivity analysis, or p-value). Only by sharing all this information might it be possible for other researchers to confirm and check the correctness of the computations, attempt to replicate the study, and understand the full context of how to interpret the results. Transparency of data, code, and computational methods is directly linked to reproducibility, and it also applies to replicability. The clarity, accuracy, specificity, and completeness in the description of study methods directly affects replicability.
FINDING 3-1: In general, when a researcher transparently reports a study and makes available the underlying digital artifacts, such as data and code, the results should be computationally reproducible. In contrast, even when a study was rigorously conducted according to best practices, correctly analyzed, and transparently reported, it may fail to be replicated.
















