
9
Machine Learning Systems
BUILDING DOMAIN-SPECIFIC KNOWLEDGE WITH HUMAN-IN-THE-LOOP
Yunyao Li, IBM Corporation
Yunyao Li, IBM Corporation, focused on systems that IBM has built that leverage the human in the loop. She noted that IBM is building technologies spanning multiple steps in the artificial intelligence (AI) life cycle: knowledge representation, creation, and refinement. These steps include the following:
- Document ingestion, in which the document is converted into a machine-consumable form;
- Capture of domain-specific knowledge, including vocabulary, constraints, logical expressions, rules, and domain schema;
- Document understanding, during which knowledge is extracted from individual documents;
- Integration of (un/semi-structured) information across data, using entity understanding and resolution;
- Evaluation of knowledge quality to validate the model’s performance over in-domain and out-of-domain areas; and
- Knowledge base consumption when building predictive models and query abstraction for programmatic/human access to knowledge bases.
The objectives for creating industry-specific knowledge applications are to (1) build AI using scalable and explainable tools to cover these life-cycle steps by including human-in-the-loop to capture knowledge from domain experts, knowledge workers, and end users, with systems supporting provenance, debugging, and error analysis and (2) to construct and refine domain knowledge using machine learning and deep learning techniques. These technologies can be applied in a variety of industry domains, including finance, health care, compliance, and national security.
Li described two IBM systems that assist in knowledge representation and creation with a human in the loop: SystemT1 for enterprise text understanding and SystemER2 for entity understanding and resolution. She shared a use case for building financial entity profiles from various companies’ Security and Exchange Commission and Federal Deposit Insurance Corporation filings from over a 20-year span. First, information must be extracted from the individual documents; then one must construct an entity-centric view with information about the individual companies to understand how different financial companies deal with different learning risks. Domain modeling is the first building block that enables the creation of this domain-specific knowledge base. This is important because it is impossible to learn everything from data only—a domain expert is needed to help understand the domain, including the domain schema (i.e., key entities and relationships that will help address the question at hand), hard and soft constraints, and vocabulary (e.g., similar names might have different metrics, while similar metrics might have different names).
Backend analytics is the second building block that enables the creation of a domain-specific knowledge base; this is about building and maintaining the models and algorithms to understand the individual documents and link them to each other. IBM takes a layered approach to accomplish this: the application layer, models and algorithms layer, computing platform layer, and hardware layer, one built upon the next. The main focus is to attain key categories of tasks to solve in the models and algorithms layer (e.g., natural language processing) and define a domain-specific language that captures the primitives to such tasks so that it is easier to program and apply automatic optimization. This also enables platform independence.
One backend analytics system uses domain-specific language for natural language processing. The SystemT architecture has Annotation Query Language to specify extractor semantics declaratively, a compiler and optimizer to choose a different execution plan that implements semantics, and operator run time. The fundamental results and theorems show that the language is expressive and performs well. Given that language understanding is the foundation of many AI applications, an alternative view of this system shows the layered semantic linguistic abstractions. The abstraction operators can be very simple; the basic operators are at a syntactical level. She added that it could also be more complex, when the semantic meaning of every sentence is understood. The cross-lingual semantic analysis capability is embedded as part of the system. More sophisticated operators allow people with domain knowledge to easily build domain-specific extractors. For example, to categorize each sentence in a contract for IBM, a domain expert can use this semantic layer to write highly precise algorithms with abstraction that are more portable than doing a deep learning model. IBM has also done some work on using deep learning to automatically learn transparent domain-specific analysis that enables domain experts to co-create meaningful interpretable models.
Li emphasized that IBM works on important real-world problems by doing long-term, well-funded research, which makes an impact in business, science, and education. SystemT, for example, ships with more than 10 IBM products, has resulted in more than 50 research papers, and is taught in universities and online courses. The ultimate goal is to use machine learning to help more customers to use IBM’s systems faster and for a broader range of use cases.
She then explained SystemER, another backend analytics system that uses a high-level integration language for entity resolution. She explained that entity resolution is used to build curated knowledge from hard data that can be loosely structured, heterogeneous, and sparse. Its goal is to infer explicit links among entities that otherwise would remain hidden in the data. As an example, in one application, Li constructed author profiles from publication records in medical research by identifying and linking all of the occurrences of the same author across different publications. In another example of using an entity resolution system to integrate all of the information about an entity, Li reiterated that matching across
___________________
1 The website for SystemT is https://researcher.watson.ibm.com/researcher/view_group.php?id=1264, accessed February 19, 2019.
2 For more information, see IBM Corporation, “Medium Energy Ion Scattering” https://researcher.watson.ibm.com/researcher/view_group.php?id=2171, accessed May 31, 2019.
sparse heterogeneous data sets is difficult and ambiguous. The goal is to understand the structure of various entry attributes, learn different combinations of attributes whenever available, and leverage new types of matching functions, which may exploit additional knowledge. To express, reuse, and relearn these entity resolution operations, a domain-specific, high-level integration language is needed. It is possible to generate algorithms that can do entity resolution automatically, which are comparable to a manually curated data set but with less effort.
The third building block to enable the creation of this domain-specific knowledge base is the human in the loop. The human can be involved in data labeling, model development, and deployment and feedback. As an example, high-quality, expert-level labeled data can be produced at low cost using auto-generation and crowdsourcing and then used for semantic role labeling, which indicates who did what to whom, when, where, and how. Li said that the goal is to develop a cross-lingual capability for this kind of representation, but obtaining labeled data for semantic role labeling is challenging. There are difficulties with both generalization and models: linguistic expertise as well as language or domain expertise is required, and semantic role labeling models are often black-box models with high complexity, so a traditional active learning framework does not fit. To generate high-quality labeled data for semantic role labeling, researchers have leveraged the preexisting high resources for English and parallel corpora through automatic generation, but this is still insufficient. Expert curation with active learning has also been used, although that process still generates some errors. Because not all of the tasks are equally difficult, crowdsourcing has also been employed to create high-quality training data. By developing classifiers that can automatically determine the level of difficulty of a task, the expert effort is reduced and results can be improved because experts curate difficult tasks and the crowd curates easy tasks.
If humans are in the loop for model development, it is possible to develop self-explaining models in a target language that humans can manipulate as well as reduce the amount of labeled data required with transfer learning and active learning. For instance, having a human in the loop to learn extraction by example is particularly useful in creating rules with higher accuracy more quickly. The user would load a document, highlight text, label positive or negative examples, and then ask the system to suggest some rules. The system has automatically learned rules and makes suggestions. The user can browse each rule and either accept a rule or provide feedback to the system to refine the rule further. With this tool, SystemT creates extractors that are comparable in quality to those of a human expert. Another example she shared used active learning for entity resolution. For a typical machine learning method (i.e., creation of training data, feature engineering, and entity resolution model learning), all steps require a significant amount of human effort; the goal is to reduce the labeling effort as much as possible by automating and learning some of the complex features. Active learning significantly reduces human effort in training data creation, learning matching and normalization functions, and learning high-accuracy entity resolution models. This active learning–based approach enables the completion of use cases in a few days or weeks instead of in a few months. During the deployment/feedback stage, the end user provides feedback on the AI services and influences the entire AI life cycle, from data acquisition to model development. Li explained that utilizing AI accelerates model improvement.
Li provided a brief overview of how extraction and entity resolution are used to build a financial knowledge base using data sources (both structured and unstructured) from the Security and Exchange Commission and the Federal Financial Institutions Examination Council. The first challenge to overcome is that it is difficult to identify and integrate information distributed across a document. Ultimately, it is possible to build a fairly large financial content knowledge base and help answer questions of importance to financial domain experts. This financial knowledge base can help in solving other business problems, such as comparing industry key performance indicators and understanding counterparty relationships and loan exposure. In closing, Li reiterated that having a human in the loop is very important. All of the tools available today (e.g., deep learning, reinforcement learning) can be leveraged, but the concept of human-in-the-loop needs to be explored further. Because the human is the customer, it is important to leverage domain expertise instead of turning everything into a labeling problem. Aram Galstyan, University of Southern California, asked how much effort it would take to generalize this to multilingual settings, and Li responded that the effort could be divided into first building the foundational technology (which would
require years of effort) and then doing the language adaptation (which should only take a few months). She said IBM will test this next year, and the ultimate goal is to do all the difficult work for the consumers.
ROBUST DESIGNS OF MACHINE LEARNING SYSTEMS
Anthony Hoogs, Kitware, Inc.
Anthony Hoogs, Kitware, Inc., opened his presentation by giving the audience a broad perspective on deep learning, open-source software and data, and machine learning systems. He then moved to a discussion of case studies for interactive machine learning, before concluding with his thoughts about relevance to and prognostications for the Intelligence Community (IC). The commercial industry has made substantial investments in AI and has had great successes, but it can be difficult to transfer these technological successes into the IC domain. Project Maven was one effort to energize machine learning and get it quickly fielded into operations in the Department of Defense (DoD), but one of the problems faced over and over again is that commercial data (e.g., from Internet videos) does not look like military data (e.g., from surveillance videos), so methods do not transfer across domains. How these differences are dealt with has been a long-running theme, Hoogs mentioned. Because mission-critical life and death situations are more apparent in defense and intelligence communities, robustness in AI is essential.
Hoogs described open source software and data as “the unsung hero of deep learning.” Everyone focuses on graphical processing units, but open-source software, specifically Caffe,3 from the University of California, Berkeley, is truly responsible for the deep learning revolution. Open-source practice in the deep learning world enables a model to operate within industry or government within a few months. This facilitates transition across domains, has fueled more development, and allows engineering-level applications to be released more quickly.
Kitware is an open-source company with several toolkits including Kitware Imagery and Video Exploitation and Retrieval (KWIVER)4 and Video and Imagery Analytics for the Marine Environment (VIAME),5 which is a specialized version of KWIVER for underwater environments. KWIVER has a number of toolkits loosely coupled together; one feature is interactive machine learning. He reiterated that most of what he shared in this presentation is openly available at the source code level.
He noted that deep learning enables engineering and operations for machine learning problems; these systems need to be assured and robust. The success of adversarial attacks does not mean that machine learning is brittle, he continued. As applied research moves toward operations, there is an increased focus on data provenance, model assurance, guaranteed performance, and explainability, which are especially challenging problems for complex models. He encouraged funding research in those areas, especially considering the need for robust systems.
With the VIAME toolkit, the goal was to develop an open source software platform for the National Marine Fisheries Science Centers’ image and video analysis in close coordination with the National Oceanic and Atmospheric Administration (NOAA). He explained that VIAME is having great impact across NOAA. There are many analogues for the IC, as this is a good use case of interactive machine learning with a straightforward and simple method. NOAA has six National Marine Fisheries Science Centers in the United States, and each was doing some form of underwater data collection with camera rigs at different depths for fisheries stock assessment and then developing algorithms to analyze these data. However, they had a problem trying to classify fish from hours of footage. NOAA’s Strategic Initiative (2013-2018) on Automated Image Analysis had a mission to develop guidelines, set priorities, and fund projects to develop broad-scale, standardized, efficient automated analysis of still and video imagery for
___________________
3 To learn more about Caffe, see University of California, Berkeley, “Caffe” http://caffe.berkeleyvision.org/, accessed February 19, 2019.
4 For more information about KWIVER, see http://www.kwiver.org/, accessed February 19, 2019.
5 For more information about VIAME, see http://www.viametoolkit.org/, accessed February 19, 2019.
use in stock assessment. This work began with a National Academies of Sciences, Engineering, and Medicine-hosted workshop in 2014, which convened computer vision experts and produced a summary report (NRC, 2015). Organizations such as NOAA have important societal problems, which are often more appealing to academic researchers then IC problems, but NOAA’s types of problems are not well funded.
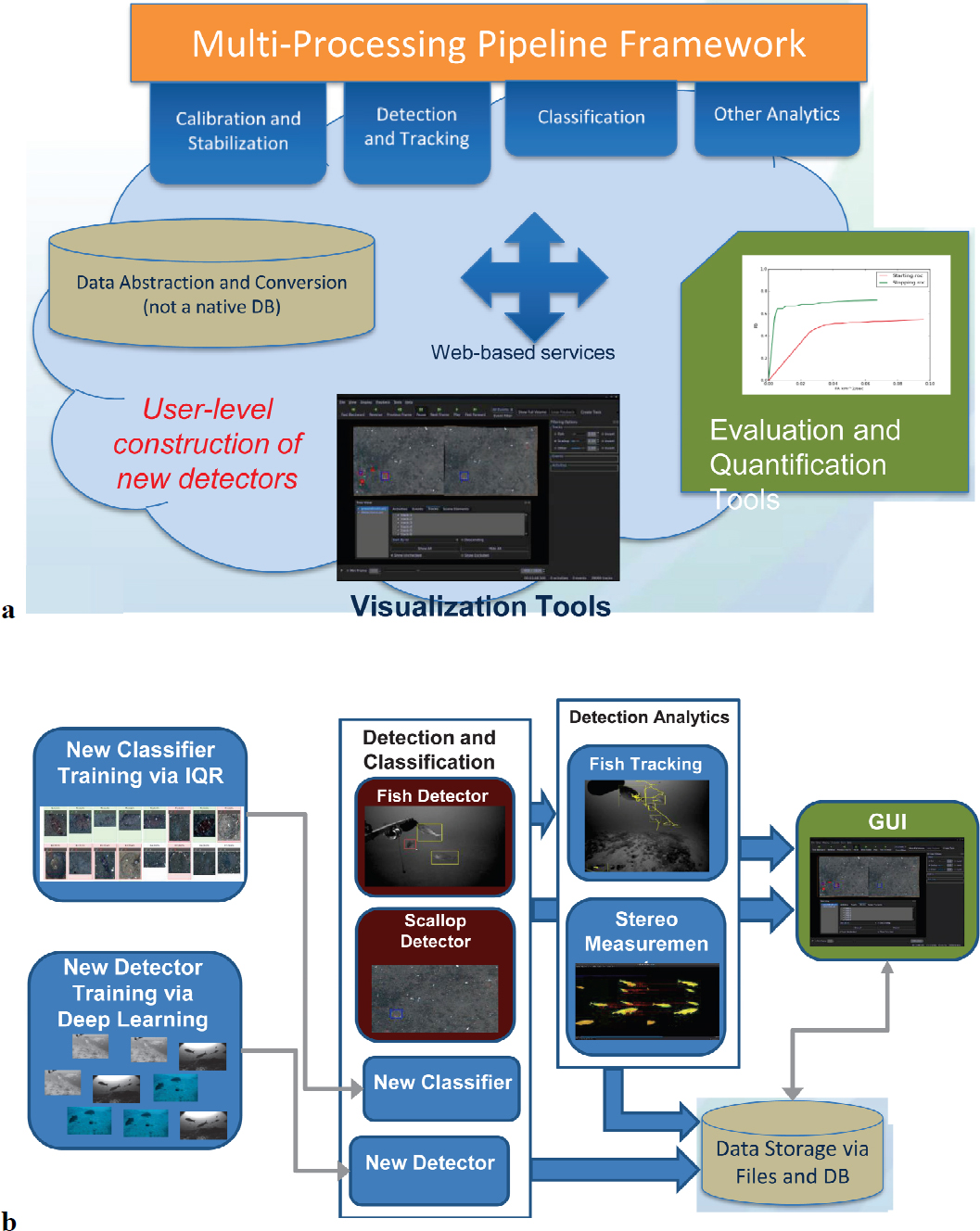
Hoogs gave an overview of NOAA’s example data collectors; data streams exceed the capabilities of human analysts, so automated tools must be developed to increase the speed of analysis, reduce costs, and improve assessments. These data collectors include towed-camera or towed-diver benthic surveys, remotely operated vehicle fish surveys, net camera platforms, stereo-camera platforms, and animal body cameras. As impactful as deep learning is, Hoogs continued, counting and classifying all fish still exceeds the state of the art; algorithms still cannot do what humans can do, even with the stereo-camera platforms. Kitware built, installed, and trained users on VIAME at all six fisheries centers to help with their analyses of all of these data collection videos. VIAME utilizes deep learning and a variety of other methods. It has databases to store data, user interfaces, and tools for quantification (see Figure 9.1a). What is most challenging is that this system has to fit in and around systems that the fisheries centers already use.
Hoogs next described the components of the VIAME system (see Figure 9.1b). He said that there are two deep learning ways to build classifiers: classifiers can apply to an entire frame or to a detection paradigm. Kitware has supplied and built a generic fish detector, training across a variety of fish instances from the cameras mentioned previously. The users have the ability to build new detectors and new classifiers on their own. Once they create those, they can run them on arbitrary amounts of new data. They also have the ability to do specialized things such as stereo measurements. Kitware has also supplied user interfaces to look at outputs.
Hoogs explained that, from the interactive machine learning perspective, there are two options. The first option is to label the data, train a deep learning model, run it, see how it works, add more training data, balance training data, and repeat. With the second option—the interactive classifier construction method—users can solve simpler problems easier and quicker for themselves. They start with an image archive, run a generic object detector generator to detect anything a biologist could be interested in, get many objects, perform classification on each object, and then each goes into an archive. The goal is to have a lot of data, and then it is possible to query and train on these data, as well as do analysis on these data. Once the archive is complete, queries begin (i.e., start with an image example, find similar ones, get results, give feedback on results, build a classifier online based on results, go back to archive to re-rank results, and improve). Hoogs mentioned that knowledge of deep learning is not necessary to use this system.
For image and video search process, the system produces bounding boxes around particular fish and are compared to similar fish imagery in the archive. The query runs interactively; the task is to compute the deep learning feature vector and use it to find the nearest neighbors in the archive. This process takes only a few seconds before top results are generated. The user will then select and label which images are correct and which are not. Offline and unknown to the user, Kitware builds a support vector machine to differentiate between the positive and negative examples to help refine results. The user can repeat this process until he/she is satisfied with the result. People have also used the VIAME system to detect seals through aerial imagery—for full-frame classification and for object detection adjudication and annotation. In this domain, the data provenance is known because the fisheries centers collect the images themselves, which makes the system more robust overall. This also gives the users adequate control over the training set. Users, however, create an interesting bias since they are creating classifiers interactively, and Kitware is working on methods with the fisheries centers to make sure they understand the problem of bias and the importance of validation.
NOAA’s problems have relevance to the IC. They have similar problems with fine-grained classification, instance counting, aerial/overhead imagery with resolution challenges, camouflage, complex backgrounds, busy scenes, and a wide range of image and video types. Environmental monitoring is a compelling surrogate problem for IC and DoD problems, he continued. However, the only way that people will work on these problems is with increased funding.
Hoogs described another system, the Visual Global Intelligence and Analytics Toolkit, which is used for satellite imagery. The software is almost the same as that in VIAME, and the domains and problems are similar. The interactive system enables search for entities that do not have models (e.g., surface-to-air missile site detection). Hoogs also gave an overview of the Defense Advanced Research Projects Agency’s Explainable AI (XAI) program.6 In this program, researchers aimed to explain image querying while using a saliency algorithm designed for image classification and created a new algorithm for image matching. This algorithm is helpful when there are multiple objects in a scene and the user is running a query. The user can select images with correct matching and proper justifications. This technology is still a work in progress and does not work well if scene content is more salient than the desired object. There are a number of robust machine learning systems for the IC. User adaptation, extension, and specialization is a critical capability since IC analysts have highly specialized, unique problems. A question arises as to whether machine learning introduces significant robustness vulnerabilities for the IC, but Hoogs is not convinced it does. He said, however, that there are user biases, unvetted data, and validation challenges to consider.
In summary, Hoogs said that open-source software, models, and data have enabled the deep learning revolution and should continue to be supported. He stressed that IC funding should leverage (rather than compete with) commercial development and transfer expertise, models, and data to IC problems. The machine learning and computer vision research communities are experiencing typical growing pains as engineering and operations expand exponentially. He reiterated the importance of engaging academic researchers who may be interested in IC/DoD problems with compelling challenges and complete data sets. While interactive AI for online specialization is very promising, he noted that deep learning has had less impact, thus far, on high-level reasoning and contextual problems than image recognition. Data provenance and assurance continue to be important. Open research questions include how best to defeat physical adversarial attacks, understand black-box attacks, and infer the relationship among unbalanced training sets, rare objects and events, anomaly detection, and adversarial attacks.
___________________
6 For more information about the XAI program, see M. Turek, “Explainable Artificial Intelligence (XAI),” DARPA, https://www.darpa.mil/program/explainable-artificial-intelligence, accessed February 19, 2019.







