
4
Detection and Mitigation of Adversarial Attacks and
Anomalies
USING AI FOR SECURITY AND SECURING AI
Joysula Rao, IBM Corporation
Joysula Rao, IBM Corporation, opened his presentation by explaining that security attacks have been prevalent throughout the past 2 years.1 New attacks use disruptive technology to create devastating results, and attackers are the first to exploit new technologies and platform shifts (e.g., to the cloud) to launch sophisticated attacks at scale. Those in the position of defense are always trying to catch up in order to protect the technologies. With artificial intelligence (AI), Rao continued, attacks are getting smarter. For example, Deeplocker is a type of AI-powered malware that avoids detection by most security controls in place today. With the cloud, attack surfaces are increasing in size and becoming more sophisticated. These systems were not originally designed to prevent micro-architectural attacks. And with the Internet of Things, attack targets have become physical—for example, vehicles, medical devices, and navigation systems. Automation enables attack campaigns to increase in speed and has contributed to the rise of both devastating malware and “fake news.” Rao hypothesized that attackers will use AI to launch much more sophisticated attacks, at scale and on more targets, which will be more evasive. He said that it is difficult to anticipate what kind of AI tools attackers will use, so preparation for the future must begin now.
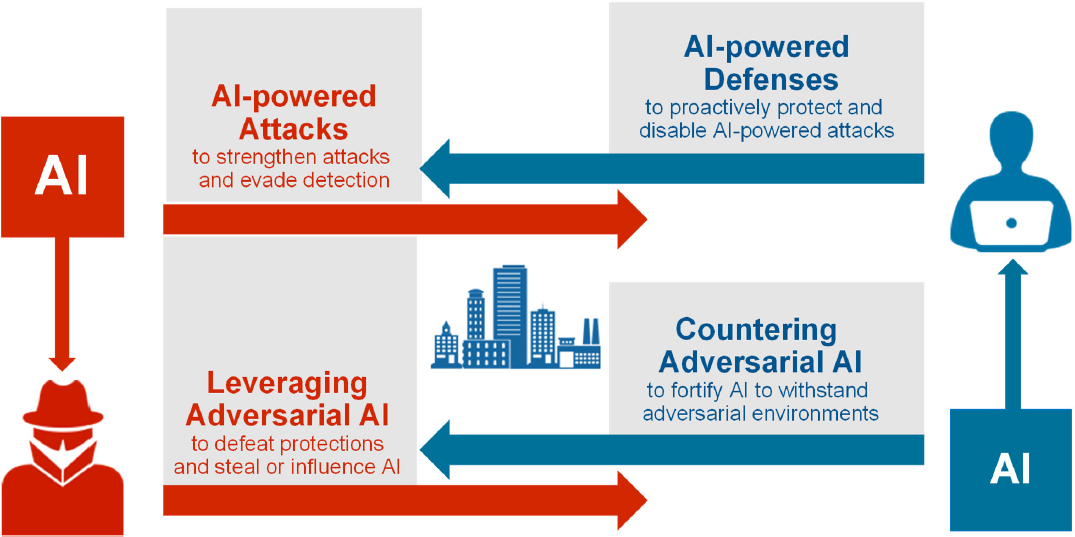
Rao explained that cybersecurity and AI is a dual problem, when considering the roles of both attackers and defenders (see Figure 4.1). Thinking about this dual problem enables one to better secure AI and to develop better security. AI can be used to bolster defenses and proactively disable AI-powered attacks. It is also necessary to counter adversarial AI and protect against adversarial environments, theft of data and models, corruption, and evasion.
___________________
1 For more information on the sampling of security incidents, see IBM Corporation, “X-Force Threat Intelligence Index,” https://xforceintelligenceindex.mybluemix.net/documents/IBM-X-ForceThreat-Intelligence-Index-2019.pdf, accessed August 7, 2019.
Rao noted that it is common for attackers to use AI and reinforcement learning techniques to craft emails that avoid enterprises’ spam filters—similar to the work that has been done to mutate malware. In the Defense Advanced Research Projects Agency’s Cyber Grand Challenge,2 machines are used to find vulnerabilities of other machines and exploit them. Rao expects the future will be similar: AI versus AI. He next described Deeplocker, an example of an AI-embedded attack, which embeds a neural net within a piece of malware. A secret key within the neural net identifies certain attributes of a target and then embeds a concealed encrypted payload into software. Rao pointed out that no known antivirus software or other types of controls will currently pick up on such a targeted attack. This malware is equipped with the capability to show up only on the target’s machine. This kind of targeted attack is extremely difficult to predict and protect against and will likely become more prevalent in the near future. Rao commented that the following series of techniques could be used to defend against AI-powered malware:
- Feature extraction and pattern recognition to improve decision making and detect unknown threats;
- Natural language processing to collect text on past and current breaches, consolidate threat intelligence, and increase security knowledge;
- Use of reasoning to locate evidence of breaches, remediate planning and outcomes, and anticipate new threats and next steps; and
- Automation of tasks to reduce the burden on the human analyst and decrease reaction time.
AI can also be used to address the following types of security needs:
- Improving modeling of behaviors to better identify emerging and past threats and risks. Relevant applications include the network, user, endpoint, app and data, and cloud. The examples are
___________________
2 To learn more about the Cyber Grand Challenge, see Defense Advanced Research Projects Agency (DARPA), “Cyber Grand Challenge (CGC) (Archived),” https://www.darpa.mil/program/cyber-grand-challenge, accessed July 19, 2019.
-
beaconing detection, network anomaly detection, domain-name system analytics, and user behavior analytics.
- Consolidating intelligence sources, including structured and unstructured data sources. An example of this approach is Watson for Cyber Security.
- Integrating feedback from trusted advisors who can provide context and assess analyses. The applications are cognitive security operations center analyst, orchestration, automation, and digital guardian. An example is the Cognitive Threat Insights Platform.
Rao alluded to the success of image recognition; around 2015, human classification errors exceeded ImageNet’s.3 However, it is important to strive to improve further. He provided an example of a picture of an ostrich, which was labeled variously by different image recognition systems as a shoe shop, a vacuum, a safe, and an ostrich, to demonstrate that models are brittle and easily breakable. In cases of adversarial AI, Rao explained that problems arise not only with images but also with text and audio recordings. He explained that if predictions are inaccurate or systems are not understood completely, tragedies could occur, such as the self-driving Uber vehicle responsible for the death of a cyclist. In response to a question from an audience participant, Rao noted that these are all examples of human–machine issues.
He explained that people have been using different norms (e.g., L1 and L2) to represent the distance of pixel changes and therefore identify changes in images and adversarial attacks. L2 norms do not reflect human perception; the machine can get easily confused and misclassify an image. Similar issues arise with malware. He said that it remains unclear what the right approach is to protect against adversarial attacks.
Privacy is another key issue in security. Rao noted that model inversion and membership inference could be useful and adversaries can learn a representative sample from a class as well as other sensitive information. Differential privacy, which protects individual privacy, does not address privacy protection in the aggregate.
Trained models can be poisoned, and their accuracy or performance decreased, through the insertion of a malicious payload or trigger. Adversaries can generate “backdoors” into neural networks by poisoning the training data. This type of manipulation is difficult to detect because the models perform well on standard training and validation samples but behave badly on backdoor keys. State-of-the-art detection methods require trusted training data. Backdoor detection using activation clustering is one way to protect against poisoning attacks.
He shared a historical overview of various defenses to adversarial techniques and how they were subsequently not robust. He began with models and defensive distillation; moved to other methods to add adversarial noise such as feature squeezing, principal component analysis, and adversarial training; and on to MagNet (see Meng and Chen, 2017, for example), and BReLU (see Liew et al., 2016, for example) and Gaussian. Moving forward, Rao said that some level of accuracy has to be reduced in order to achieve robustness, and some promising techniques are emerging. Rao reiterated that a duality exists between the attacker and the defender. With the application of a watermark in a model’s training data that alters the final class, it is possible to leverage the ability to poison models, with negligible impact to the accuracy of the model. In this case, the adversary will not have access to the training data, and the watermark can be much more subtle, specific images.
Rao described IBM’s open-source Adversarial Robustness Toolbox, which is continually updated with attacks and countermeasures; this can be a resource to developers of AI services. A workshop participant asked if a balance exists between research work in adversarial attacks and adversarial defenses and whether there is a reward system for doing one over the other. He noted that at least in academia, more publication opportunity and credit seems to be given to papers on attacks. Rao said that research in adversarial AI has gained momentum in the past 2 years, and that is reflected in the rate of publications. Rao agreed that although the attack papers are gaining more attention, the hard work is building systems that are secure against such attacks; some of the best minds are working on defense. A workshop participant disagreed and
___________________
3 For more information on ImageNet, see http://www.image-net.org/, accessed February 19, 2019.
said that there is a huge bias toward publishing defense papers; many have been published despite their weak solutions and disingenuous messages. He emphasized that the need is for more effective attack papers.
Ruzena Bajcsy, University of California, Berkeley, asked Rao to explain his definition of AI, because it seemed to her that he was describing search and pattern recognition instead. Rao said that when industry talks about AI, it really refers to augmented intelligence (i.e., pattern recognition, machine learning, data mining, natural language processing, human–computer interfaces, and reasoning). He added that the goal is to offload the cognitive overhead that subject-matter experts would have and automate that with a machine, which is not general purpose AI. A workshop participant suggested that AI is practiced on an extremely narrow set of tools today, such as deep learning, which has many opportunities to fail. Rao agreed that many AI problems remain open and, even in narrow domains, deep learning may not be the right approach. Rama Chellappa, University of Maryland, College Park, said that no one is saying AI is working and added that deep learning should not be called AI because it has no statistical backing. However, Rao concluded that the attackers are not going to wait for the community to resolve these issues.
CIRCUMVENTING DEFENSES TO ADVERSARIAL EXAMPLES
Anish Athalye, Massachusetts Institute of Technology
Anish Athalye, Massachusetts Institute of Technology, opened his presentation by acknowledging that machine learning has enabled great progress in solving difficult problems in recent years (e.g., super-human classification, object detection, machine translation, game-playing bots, self-driving cars testing on public roads). Much of this has been enabled by deep learning. He elaborated that although machine learning systems achieve great “average-case” performance on these difficult problems, machine learning is fragile and has terrible performance in “worst-case” situations, such as adversarial or security-sensitive settings. An audience participant said that machine learning is performing well in test cases and wondered how Athalye defined average. Athalye responded that average performance indicates a level of comfort with deployment.
Athalye explained that imperceptible perturbations in the input to a machine learning system could change the neural network’s prediction and dramatically affect the model and its output. A small adversarial perturbation can lead a state-of-the-art machine learning model to mislabel otherwise identifiable images. These attacks can be executed with just a small number of steps of gradient descent. An audience participant wondered whether when looking at the difference between the original image and the adversarial example and magnifying noise if it is possible to see anything interpretable. Athalye responded that while noise may be more interpretable with more robust machine learning models, in these cases only noise is perceptible.
Athalye described machine learning as not being robust for image classification and for many other problems such as semantic segmentation, reading comprehension, speech-to-text conversion, and malware detection. Attackers can tweak metadata to produce functionally equivalent malware that can evade a detector. An audience participant wondered if training models using adversarial examples could help build in a resistance to attacks. Athalye noted that this process has been shown to increase robustness to some degree, but current applications of adversarial training have not fully solved the problem, and scaling is a challenge.
Athalye noted that contradictory evidence exists as to whether real systems are at risk from adversarial examples. He described a study in which natural image transformations were applied to adversarial examples, thus breaking the adversarial example and classifying the image correctly in its true class. However, adversarial examples can be robust, and this approach does not always work.
He presented a basic image-processing pipeline in which an attacker gains control of an image, the image is fed into a machine learning model, and the resulting predictions are affected. However, the physical-world processing pipeline looks a bit different: a transformation with randomized parameters occurs between the image and the model. In this case, the attacker no longer has direct control over the model input (see Figure 4.2).
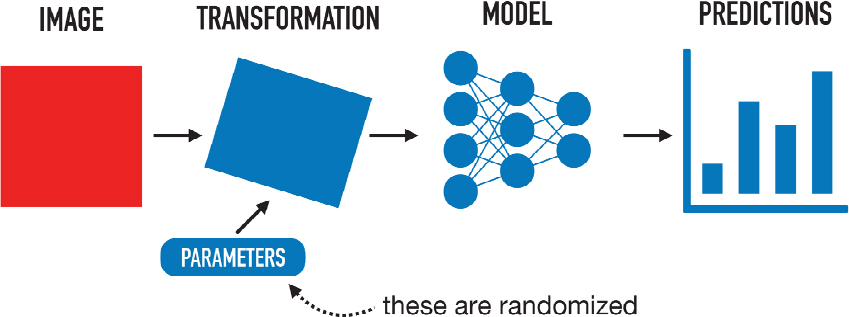
An attack is still possible in this real-world setting because, even though one does not know what the exact transformation will be, the distribution of transformations is known. The transformation needs to be differentiable, he continued, and instead of optimizing the input to the model, one can optimize over all possible transformations to find a single point that no matter how it is transformed will confuse the model in all settings. This approach (i.e., expectation over transformation), which still uses gradient descent, can produce real-world robust adversarial examples.
Athalye then considered a three-dimensional (3D) processing pipeline, which is similar to the real-world pipeline. He explained that for any pose, 3D rendering is differentiable with respect to texture. He demonstrated a 3D adversarial object where no matter how the object is rotated, the machine learning model still classifies it incorrectly. In response to an audience participant, Athalye confirmed that, in this example, only the texture of the object was changed. He said that other researchers have also tested manipulating geometry rather than texture to construct adversarial objects. Athalye reiterated that machine learning is not robust in controlled and real-world settings, noting that even in a world filled with noise, the models can still be fooled.
Black-box models, too, are susceptible to adversarial attacks, Athalye explained. In a black-box threat model, the attacker has no visibility into the details of the model—the attacker can only construct an image, feed it in, and watch what emerges. Gradient descent is still used, but now so too is an estimate using queries to the classifier. Even more restricted settings, such as the Google Cloud Vision Application Programming Interface, are vulnerable to adversarial attacks, Athalye continued. He noted that in the hundreds of papers published on defenses for adversarial attacks, many of the proposed defenses lack mathematical guarantees. He added that many defenses submitted to the 2018 International Conference on Machine Learning (ICML)4 were not robust, confirming that defending against adversarial attacks is a difficult problem. In closing, Athalye emphasized that robustness is a real-world concern because attacks are outpacing defenses. He said that it is crucial to understand the risks of adversarial attacks to current systems through rigorous evaluations and a principled approach that will lead to the construction of secure machine learning systems.
Chellappa suggested that Athalye revisit his conclusion that machine learning defenses are not robust, given that the MNIST database5 (Modified National Institute of Standards and Technology database) of handwritten digits was labeled with 55 percent accuracy. He emphasized the value of describing both when
___________________
4 For more information about the 2018 International Conference on Machine Learning, see https://icml.cc/Conferences/2018, accessed February 19, 2019.
5 For more information on the MNIST database (Modified National Institute of Standards and Technology), see Y. LeCun, C. Cortes, and C. Burges, “The MNIST Database of Handwritten Digits,” http://yann.lecun.com/exdb/mnist/, accessed April 8, 2019.
systems are working and when they are not. Chellappa also suggested that if a forensic examiner is working alongside a machine learning algorithm, many of the real-world problems Athalye described could disappear. He added that with knowledge of time series models from the 1970s, the concept of adversarial examples should not come as a surprise to anyone. Another audience participant discussed the black-box inversion that results from making many queries against a model and the characterization that is needed to produce an adversarial example. Athalye noted that although he is not aware of much research in this area, some are working on decreasing the number of queries required.






