
5
Enablers of Machine Learning Algorithms and Systems
IMPACT OF NEUROSCIENCE ON DATA SCIENCE FOR PERCEPTION
John Tsotsos, York University, Canada
John Tsotsos, York University, described that much has been written on how neuroscience and other brain sciences have inspired artificial intelligence (AI). In the context of human and non-human primate vision systems, he discussed the following: (1) how knowledge of the brain is being used to enable progress, (2) the notion that the predictive value of AI models has not been well exploited, and (3) whether modern AI has the right paradigm.
First, Tsotsos explained that human vision and brain sciences have inspired computer vision since its inception; a deep understanding of human vision helps better target and constrain solutions. He added that it is challenging to determine what level of abstraction to use to address a problem. Tsotsos provided a brief and selective history starting with Roberts (1963), who was inspired by Gibson (1950), whose work focused on the notion that if an object changes orientation or pose in a scene, a computer vision system must be able to recognize the object equally well. Rosenfeld and Thurston (1971) developed algorithms to employ grouping principles, which served as the foundation for perceptional organization. Julesz (1971) found stereovision to be a cooperative process, which led to the development of Marr and Poggio’s (1979) classic stereo algorithm. Uhr (1972) proposed layered recognition cones for image processing, and Fukushima (1975) added the self-organizing component. Tsotsos (1987) demonstrated that the self-organizing architecture satisfies basic resource constraints in the brain as well as provides a resolution of the combinatorial problems of visual information processing. These layered hierarchies are now part of most of today’s successful systems, Tsotsos explained. He said that behavioral studies also played an important role, beginning in the 1960s; Potter (1975) and Thorpe et al. (1996) later revealed that categorization could occur in very short presentation times. Marr’s approach to visual processing, that discrimination had to be made in less than 160 milliseconds, was consistent with Potter and Thorpe’s findings, although his work had been interpreted incorrectly by others as applying to everything instead of to the first segment.
Tsotsos shared a brief and selective timeline to AlexNet (see Figure 5.1). He noted, however, that the timeline does not end here; graphics processing units (GPUs) and increased memory enable the ability to
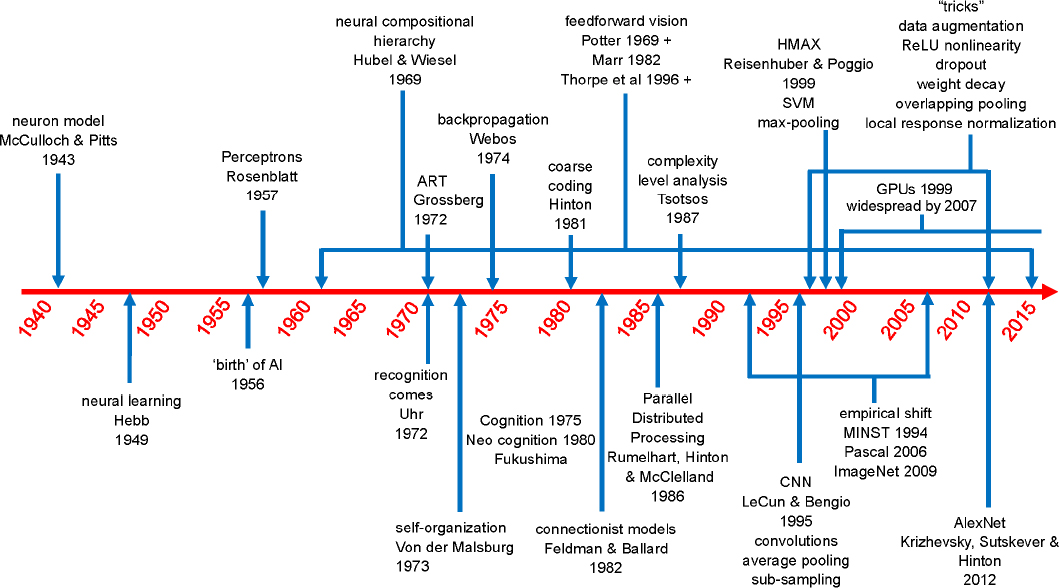
train on data sets. This indicates an empirical shift in how problems are solved. Previously, since answers were constrained by often limited resources, strategies followed a classic scientific method and, since large test sets were unavailable, solutions were generally independent of data. Modern AI, however, has adopted two premises in the meaning of solving a problem: (1) the solution should be “probably close to correct” (Valiant, 1984) and (2) the inductive learning hypothesis is used, which means that “any hypothesis found to approximate the target function well over a sufficiently large set of training examples will also approximate the target function well over other unobserved examples” (Mitchell, 1997). Tsotsos clarified that these can be formalized, but the solution strategies focus on data-driven learning, rejecting the classic scientific method, and measuring success using statistical uncertainty measures. Also, large test data sets are widely available and solutions are developed by incorporating statistical regularities from those data. Krizhevsky et al. (2017) said that “results can be improved simply by waiting for faster GPUs and bigger data sets to become available,” but Tsotsos suggested that we are up against the Pareto Principle (i.e., 20 percent of the occurrences do not fit the abstraction) and that to succeed, the entire strategy has to change because the initial model was incorrect.
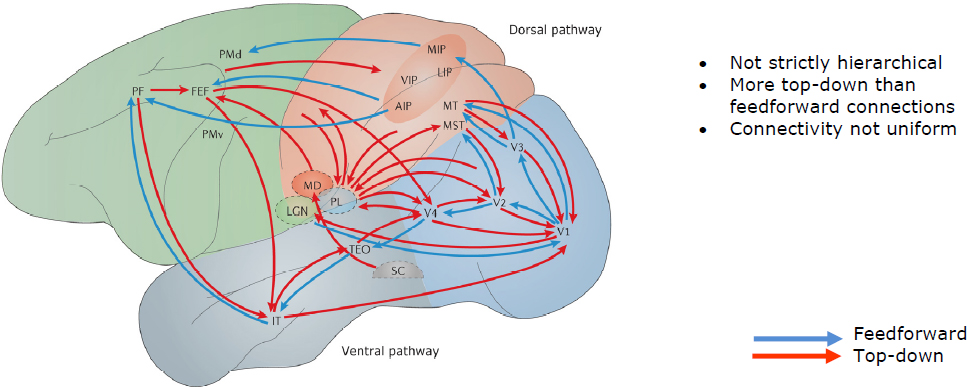
Tsotsos next discussed other aspects of the brain and human vision that have influenced the development of AI. He described the human retina, which is highly variable and does not generate homogenous and uniform representations, such as images. As he discussed the receptive field size in the visual cortex and spatial layout of brain neurons, he noted that this is a characteristic of machine vision system hierarchies that has not yet succeeded. Convolutional neural networks, he continued, do not mimic the architecture of the brain. The pathways in the brain are more top-down than feedforward, they are not strictly hierarchical, and the strength of connectivity is not uniform (see Figure 5.2).
The data structure more representative of the brain’s pathways in Figure 5.2 is a lattice. Tsotsos called this a lattice of pyramids (P-Lattice) because each of the brain areas in Figure 5.2 is actually many sheets of neurons, where each has a particular retinotopic relationship to the others. This structure more closely models the network of the brain. He explained that due to the architecture and the connectivity, three problems arise: the crosstalk problem, the context problem, and the boundary problem.
In terms of the crosstalk problem, he explained that the anatomical structure of connectivity leads to signal interference in overlap areas. To demonstrate an example of feedforward crosstalk, or entanglement, Tsotsos and his team manipulated images that were part of a training set to see how the best object detectors would perform. They used a state-of-the-art object detection method applied to an image of a living room from the Microsoft Common Objects in Context object detection benchmark. The image of an elephant placed in the room interfered with the network that represents the whole room and was thus not recognized unless it was to be moved slightly.
He explained that “predictive value” of AI models does not mean that a model predicts known observations—he defined that process as “explaining” instead. “Predictive value” means that a model makes a claim that needs to be tested. He said that a theory in the empirical sciences can never be proven, but it can be falsified. He explained that when one positively tests predictions, model believability increases.
Negatively tested predictions provide the impetus for model refinement, and better models enable an understanding of why failures occur. He stressed that this example of the elephant in the room showed that the underlying architecture of deep learning systems has inherent failures, and the only way to improve is to change the systems themselves. This is a more effective long-term solution than simply finding a defense for an attack on a system, he continued, as this example has often been criticized.
The second problem in network properties is the context problem. Tsotsos hopes in the future to see trained neural networks (with dynamic tuning) functioning correctly. He provided some history of developments in human learning relevant to this area. The understanding of how neurons change their behavior dynamically became more clear upon discovery of papers by von der Malsberg (1981) and Moran and Desimone (1985). Moran and Desimone (1985) performed an experiment with monkeys to identify neurons that responded strongly to stimuli; the monkeys were trained to attend to a response. This study led to Tsotsos’ creation of a model of selective tuning in 1990 that showed a pattern of suppression around items attended all through the visual hierarchy. This led to an overall model of vision that uses visual hierarchy over time in both feedforward and feedback directions (Tsotsos et al., 2008). Another experiment (Cutzu and Tsotsos, 2003) asked subjects to fixate on a black dot and attend to a grey disk and then tested their ability to detect items near and far from that grey disk. This confirmed that Tsotsos’ initial prediction about suppressive surround was true. Hopf et al. (2006) studied how attentional suppressive surround is used in neurophysiology, showing the same pattern around a central point of surround suppression. Boehler et al. (2009) confirmed that attentional suppressive surround was due to recurrent activations. Bartsch et al. (2017) revealed that attentional suppressive surround exists not only in the spatial dimension but also in the feature dimension.
Tsotsos explained that the third problem in such hierarchical networks, the boundary problem, is well known in computer vision. This is an important problem to consider because the human visual system overcomes it with eye movements—not image padding, as most current methods use. This will lead to a different eye fixation scheme than has been considered. Classically, one first makes a saliency map of an image, does a selection on the map, and then finally moves. That approach is insufficient because it lacks a good representation of the periphery. Tsotsos et al. (2016) developed a different fixation model: A number of different representations contribute to a priority map from which a selection is made. The first is a representation of the peripheral attentional map, and the second is a representation of the central attentional map. These are combined with what has been seen and what should have been seen, modulated by task information, which is then combined into a priority map for selection. The model does an excellent job of fixation in comparison to humans: accuracy is almost within human error. Selective tuning models can make predictions of new knowledge, and AI can help neuroscience in this way (instead of only providing analysis tools). Tsotsos summarized that it is unclear whether there have been any falsifiable predictions made by deep learning models. He added that attentional mechanisms are often ignored yet critical for generalization and that selective tuning offers an example of what is possible without machine learning.
In considering the question about whether AI has the right paradigm (i.e., a data-driven machine learning approach to AI), Tsotsos said that it may be too early to reject other approaches. Human learning is not based only on data: statistical information in a data set may not provide any insight into human learning processes. He explained that computer vision is task-directed, and single images under a variety of instructions are labeled differently; thus, it would not make sense to train a system with all possible instructions. He described visual processing as intractable; a single solution that is optimizable in all instances is impossible, so it is necessary to reframe the original problem. The space of all problem instances can be partitioned into subspaces where each may be solvable by a different method. Given that the brain is a fixed processing resource, the need to employ a variety of different solution strategies in a situation-dependent manner implies that those resources must be dynamically tunable to the current situation and that there exists an executive controller that orchestrates the process.
Tsotsos showed results that demonstrated how human visual capabilities are not fully present at birth, including those driven by the predictions of his Selective Tuning model. The suppression he showed was discovered to need 17-18 years to mature fully. He indicated that although it takes time for each human visual mechanism to mature, it is possible for humans to learn while these mechanisms are still maturing. This is important to consider when building learning algorithms, although he added that we do not fully understand the interplay between how we learn content while developing mechanisms. And, human learning is far more complex than current machine learning might capture.
In conclusion, Tsotsos said that neural and behavioral scientists need to be convinced that AI can contribute in the path to emulate human intelligence. He said that practical applications should not emulate human failings, but it is important to understand why those failings exist. AI cannot be superficial about the brain, and AI seems not to be moving in the direction of understanding or creating human-like intelligence: chasms have developed between current AI systems and what is known about human intelligence. Tsotsos emphasized that neural inspiration seems to have stalled decades ago, and the community is unsure of what it is trying to build. In response to a question from a workshop participant, Tsotsos said that there has not been work in his community about a system that has the ability to reason that something is not there. To solve that problem, he continued, active, inductive inference is needed to predict when something is there, to go and look for it, and to confirm whether it is there. In response to a question from Rama Chellappa, University of Maryland, College Park, Tsotsos said that difficulties arise in applications in which humans and machines work together because humans expect robots to work in ways they understand to be correct and rational (i.e., like a human). Both human and machine should know the goal of a joint task and develop an intention contract so that each would know what steps the other would take toward that goal in order to make things work out as each expected, he explained. A workshop participant wondered if the suppression observed in the experiment by Cutzu and Tsotsos (2003) was the same as the non-maximum suppression in neural networks, and Tsotsos responded that the suppression is not the same.



