






















Below is the uncorrected machine-read text of this chapter, intended to provide our own search engines and external engines with highly rich, chapter-representative searchable text of each book. Because it is UNCORRECTED material, please consider the following text as a useful but insufficient proxy for the authoritative book pages.
16 By 1996, digital storage became a more cost-effective option for storing data than paper (SB 2016). Companies began switching to digital files to store and archive their data, which allowed for a large amount of digital data to become available and ready for analysis. At the same time, the number of Internet users started to grow, rapidly multiplying the genera- tion of data at a rate that only increases each year, as is evidenced by the counters visible on www.InternetLiveStats.com (accessed in 2017). These two events mark the beginning of what is called Big Data. Moreover, the size of Big Data only continues to grow. In 2013, anything over 500 gigabytes (GB) was considered Big Data; now, Big Data involves terabytes (TB) of data. 3.1 Big Data Definition As a popular term, Big Data often is used simply to mean a volume of data that is so massive it is difficult to process using traditional database and software techniques; however, the volume of data only tells part of the story. To better understand what constitutes Big Data, it is helpful to distinguish among three types of data: ⢠Structured data: The data in traditional relational databases follows a specific structure and format and resides in a fixed field within a record according to a database schema. Traditional relational databases require that the ingested data be processed through a process called ETL (extract-transform-load) to formally organize the data before it can be queried. The queries themselves are commonly written using a structured query language (SQL). Familiar names associated with relational databases include Oracle, MySQL, Microsoft SQL Server, and PostgreSQL. ⢠Semi-structured data: This is a form of structured data that does not conform to the formal structure of the data models associated with relational databases but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data. Extensible mark-up language (XML) and JavaScript Object Notation (JSON) are open standards for structuring semi-structured data. ⢠Unstructured data: This term usually refers to data that is not organized and that does not reside in a traditional relational database. Examples of unstructured data are e-mail messages, word processing documents, videos, photos, audio files, presentations, webpages, and many other kinds of business documents. Significantly, Big Data expands the scope of traditional relational databases to include data that is unstructured. Big Data storage and analytics take place in a distributed computing environment, meaning that these tasks are performed across multiple servers and/or in the cloud. An effective rule of thumb is that if the analysis can be run on a laptop or workstation, it is not Big Data. C H A P T E R 3 State of the Practice of Big Data
State of the Practice of Big Data 17 Big Data datasets often are characterized using five attributes, referred to as the âfive Vsâ: volume, variety, velocity, veracity, and value. 3.1.1 Volume Volume characterizes the main aspect of a Big Data dataset. In 2007, a manufacturer of data storage devices predicted that the size of the digital universe in 2010 would be close to 988 exabytes, and that it would grow by 57 percent every year (Gantz 2007). In 2010, Thomson Reuters estimated in its annual report that the world was âawash with dataâ800 exabytes and risingâ (Thomson and Glocer n.d.). In 2013, IBM estimated that the world produced about 2.5 billion gigabytes (GB)âequivalent to 2.5 EBâeach day and that 80 percent of that data was unstructured (IBM 2013). The Intelligence Community Comprehensive National Cybersecurity Initiative Data Center, which opened in Utah in 2014, is one of the largest data centers in the world, with an estimated storage capacity between 3 EB and 12 EB. The center occupies an area of about 1,500,000 million square feet and cost $1.5 billion to build (Lima 2015). Figure 3-1 shows a representation of the data size scale. Currently, Big Data is generally considered more than 1 TB; however, the size characterization of Big Data is continuously changing. For example, in 2013 the 90 petabytes (PB) of data stored by eBay was considered a large volume; by comparison, in 2017, Walmart was handling 200 billion rows of transactional data every few weeks, pulling in information from 200 streams of internal and external data, including meteorological data, economic data, Nielsen data, telecommunications data, social media data, gas prices, and local events databases, and processing 2.5 petabytes of data every hour (Tay 2013, Marr 2017). Crash data and most TMC data are generated on a much smaller scale. Five years of crash data from Florida represents less than 50 megabytes (MB). A yearâs worth of data in the National BSM = basic safety message(s); CV = connected vehicle; GB = gigabyte(s); PB = petabyte(s); PDM = probe data message(s); TB = terabyte(s); TMC = traffic management center(s); CCTVs = closed circuit televisions Sources: Gettman et al. 2017, Marr 2017, Tay 2013 Figure 3-1. Data size scale with example dataset sizes.
18 Leveraging Big Data to Improve Traffic Incident Management Emergency Medical Services Information System (NEMSIS)âconsisting of 30.2 million records from 15,000 EMS agenciesâmakes up about 40 gigabytes (GB). On the other hand, the data generated by 300 TMC field devices currently is estimated at approximately 635 GB per year and, if stored, the data from 300 closed circuit television (CCTV) cameras would require hundreds of terabytes of storage each year (Gettman et al. 2017). Likewise, emerging connected vehicle data is expected to generate many terabytes of data per year. 3.1.2 Variety Variety is one of the most interesting characteristics of Big Data datasets. As new information is created and older data is digitized, the diversity of data that can be processed and analyzed also is growing. Traditional data analysis, performed using relational databases or statistical software, only allowed for âtable friendlyâ (i.e., structured) data to be processed. Some kinds of information, like that contained in a traditional bank statement (e.g., data, amount, balance, and time) can be expressed using data fields and can fit neatly in a relational database without extensive manipulation (i.e., ETL). Unstructured data (e.g., images or free text) is not table friendly. Without manual processing of the content, unstructured data can only be stored within tables as a series of unsearchable objects, and the ability of relational databases and statistical software to analyze such objects is limited. Big Data technologies do not require data to be neatly organized (structured) to be searched. Unstructured data like Twitter feeds, email content, audio files, MRI images, webpages, or web logs now can be processed directly as part of a Big Data query. No pre-processing is required, which greatly augments the amount of data that can be exploited. Consequently, virtually anything that can be captured and stored digitally can be analyzed and queried, even if the digital content does not include a meta model (i.e., a set of rules that defines a class of information and how to express it) that neatly defines it. Unstructured data is fundamental to Big Data, and one of the main goals in leveraging Big Data technology is to make sense of unstructured data. 3.1.3 Velocity Velocity refers to the speed or frequency of data coming into Big Data datasets. Velocity adds another dimension to the increasing scale of Big Data datasets, particularly in regard to the complexity of processing this flow of data. When thinking about the frequency of text messages (technically, short message service [SMS] messages), social media status updates, or credit card swipes sent over the Internet daily, it is easy to have an appreciation for velocity. Not only do large amounts of unstructured data need to be processed rapidly, but that data is being augmented or modified constantly. Credit card fraud detection is a good example of a For a sense of scale, consider that: 1 exabyte (EB) = 1,000,000,000,000,000,000 bytes 1 petabyte (PB) = 1,000,000,000,000,000 bytes 1 terabyte (TB) = 1,000,000,000,000 bytes 1 gigabyte (GB) = 1,000,000,000 bytes 1 megabyte (MB) = 1,000,000 bytes 1 kilobyte (KB) = 1,000 bytes
State of the Practice of Big Data 19 rapidly changing Big Data dataset that needs to be processed quickly to catch suspicious transac- tions and deny payments. 3.1.4 Veracity Veracity refers to the trustworthiness of the data in Big Data datasets. Traditional data analy- sis requires the raw data to go through an ETL process to be reformatted, cleaned, and purged of illogical, erroneous or outlying data. In contrast, Big Data datasets are all-inclusive; data is stored âas isâ with minimal processing before being queried. Traditional data analysis through ETL could ensure that the data being queried is of high-quality and accuracy and can be trusted. Because Big Data datasets are all-inclusive, the quality, accuracy, and trustworthiness of the data is not guaranteed on query and therefore needs to be assessed by applying domain knowledge to the output to verify/validate the data or by exploring the data with separate queries for data validation. It is interesting to note that the newer the data, the less knowledgeable we are about it; as such, the trustworthiness of the data can only be derived from the patterns or trends observed in the data. 3.1.5 Value Value denotes how Big Data datasets contribute to improving the status quo. Value involves determining a benefit and estimating the significance of that benefit across any conceivable circumstance. Value may be the most important of the five Vs, as investments in Big Data initia- tives require a clear understanding of the benefits and associated costs. Before any attempt to collect or leverage Big Data, business cases need to be developed to assess the benefits and costs associated with data collection and analysis efforts. 3.2 The Move from Traditional Data Analysis to Big Data Analytics 3.2.1 Traditional Data Analysis Data analysis can be separated into two main categories: historical data analysis and real-time data analysis. Historical data analysis is the analysis of a large set of data collected over time to identify patterns or outliers. Traditionally, this type of analysis has been referred to as online analytical processing (OLAP). Typical applications of OLAP include business analytics such as reporting for sales, marketing, management reporting, business process management, budget- ing and forecasting, and financial reporting. Databases configured for OLAP use a multidimen- sional data model, allowing for complex analytical and ad hoc queries with a rapid execution time (Mailvaganam 2007). Real-time data analysis is the analysis of a single datum within a few moments of its cre- ation to assess its quality or react to its content. Traditionally, this type of analysis has been referred to as online transactional processing (OLTP). OLTP applications facilitate and manage transaction-oriented applications. The key goals of OLTP applications are availability, speed, concurrency, and recoverability (Oracle 1999). An example of real-time data analysis is the detection of fraudulent credit card transactions and the blocking of such transactions within seconds of their submission because the data does not appear to be in line with the previous purchases made by the account holder. Figure 3-2 illustrates the value of both types of analysis. For OLTP, the value of a single datum is very high immediately after it has been created; a quick analysis can lead to immediate
20 Leveraging Big Data to Improve Traffic Incident Management corrective or augmentative action(s). As the datum ages, analysis supporting immediate actions is less valuable. Conversely, for OLAP, the value of a single datum is very low immediately after its creation. However, as a collection of data is created over time, the data accumulates into larger and more diverse datasets that can be analyzed effectively to reveal patterns and trends that inform and improve decision-making. Before the advent of Big Data analytics, both OLTP and OLAP generally were performed using relational database management systems (RDBMSs). Although relational databases are a reliable way to store and search data, they tend to be strict. Consequently, the view of the world through the lens of a relational database is restricted. In addition, the schema used within a relational database is not easily changed, sometimes requiring months or years to modify. Relational data- bases were designed at a time when data did not change rapidly; therefore, they are not designed to handle change. Although the use of relational databases has been satisfactory, the advent of larger, more complex, and more frequently changing datasets (i.e., datasets with greater volume, variety, and velocity) has rapidly increased the cost of developing and operating data stores using relational databases. These changes have led database architects and developers to seek less expensive, albeit more complex, alternatives to store and analyze new, large, and intricate datasets. The shift from relational databases to Big Data began in the early 2000s, when online com- panies sought to index the content of the entire Internet to make it efficiently searchable. Even in those days, the Internet (essentially a very large dataset) held content so diverse it could not be organized into a relational database schema. Exponential growth and the very rapid pace of change in content and uses of the Internet contributed additional indexing challenges. Engineers faced four distinct issues in building a tool to complete the desired index, as follows: 1. The tool had to be schema-less (i.e., it could not be based on tables and columns). 2. The tool had to be durable (i.e., once written, data should never be lost). Source: Adapted from VoltDB, Inc. (Stonebreaker and Jarr 2013) Figure 3-2. Value of data.
State of the Practice of Big Data 21 3. The tool had to be capable of handling component failure (e.g., failure of the CPU, or memory, or of the network). 4. The tool had to be capable of automatically re-balancing its resources (e.g., allocating disk space consumption). The solution was the development of Hadoop: an open-source, Java-based programming framework that supports the processing and storage of extremely large datasets in a distributed computing environment. 3.2.2 Hadoop: The Start of Big Data Tools In the pursuit of an efficient way to index and search the Internet, efforts first focused on developing a file system capable of storing the data collected from the entire Internet. The file system had to run across multiple servers and be able to meet complex requirements. This indexing file system became known as the Hadoop Distributed File System (HDFS). Next, efforts focused on developing a rapid processing framework that could handle the data stored on the new file system in a fault-tolerant, distributed, and parallel fashion across all the servers. The processing framework became known as MapReduce. HDFS and MapReduce were then merged into a single product called Hadoop. Hadoop makes it possible to run applications on systems with thousands of inexpensive servers (nodes) and to handle thousands of terabytes of data. Its distributed file system facili- tates rapid data transfer rates among nodes and allows the system to continue operating in case of a node failure. This approach lowers the risk of catastrophic system failure and unexpected data loss, even if a significant number of nodes becomes inoperative. Hadoop quickly emerged as a foundation for Big Data processing tasks such as scientific analytics, business and sales planning, and processing enormous volumes of sensor data like that generated by the Internet of Things (IoT). Since its initial release in 2011, Hadoop has been continuously developed and updated. Organizations have adopted it, modified it, and used it as a basis for new Big Data tools. Contrary to the approach taken with relational databases, the development of Hadoop did not culminate in a single specialized tool; rather, the indexing and processing framework has evolved as a series of specialized tools, each with distinct capabilities ranging from simple aggregation to complex text analysis and image analysis, and able to work on both historical and real-time datasets. Modified versions of Hadoop can now be found among the many cloud provider ser- vices. Turnkey services now available from many commercial providers can analyze extremely large and varied datasets, either historically or in real time, without incurring the large cost associated with building and maintaining separate server clusters. 3.2.3 Current Big Data Tools Big Data analytics is not bound to a single set of tools to perform an analysis; rather, it encompasses a wide variety of proprietary and open-source tools that can be customized and modified by users. This section provides brief descriptions of the types of tools that compose the Big Data ecosystem. 3.2.3.1 Hadoop-Based Programming Frameworks Based on the Hadoop software library created by the Apache Software Foundation, these programming frameworks allow for the distributed processing of large datasets across clusters of computers using a simple Hadoop-based programming frameworks allow for the distributed processing of large datasets across clusters of computers using a simple programming model.
22 Leveraging Big Data to Improve Traffic Incident Management programming model. They can scale up from single servers to thousands of machines, each offering local computation and storage. These frameworks are not databases. They store data, and users can pull data from them, but there are no queries involved. Data is stored on a distributed shared file system and then processed into a new dataset using a distributed processing framework such as MapReduce. The resulting dataset can then be retrieved by users. The data processing runs as a series of jobs, with each job essentially a separate Java application that goes into the data and pulls out information as needed. This approach gives data analysts a lot of power and flexibility in comparison to the tradi- tional SQL queries used with relational databases. Analysts can customize their jobs as needed, adding additional software such as text mining or image analysis software libraries, to process unstructured data like emails or photos. This flexibility also adds a lot of complexity to the data mining process. Customizing jobs to incorporate text mining, image analysis, or other software typically requires software programming knowledge, whereas executing SQL queries generally does not. Hadoop-based programming frameworks are now being greatly modified to optimize their ability to manage their data and run concurrent jobs more efficiently. Many modifications have already been made to take advantage of memory storage instead of disk storage, as memory storage has become less expensive. These improvements have afforded the frameworks the ability to process very large datasets in batch (i.e., conduct historical analysis) and the ability to conduct real-time processing of large amounts of data flowing into the framework storage. Common Hadoop-based programming frameworks include Apache Hadoop, Apache Spark, Apache Storm, and AWS Elastic MapReduce. 3.2.3.2 NoSQL Databases NoSQL databases are databases that began to be built in the early 2000s for large-scale database clustering in cloud and web applica- tions. NoSQL databases are essentially Hadoop-based frameworks with an added interface to allow data to be queried. The query inter- face helps convert the query language for use in distributed jobs. The query layer works in combination with a query language. NoSQL databases cannot offer the same consistency as relational databases and often are limited in their ability to run complex data analyses. Consequently, NoSQL databases are used more often for combining information from several sources into one comprehensive database and subse quently running aggregation and filtering queries on very large datasets. NoSQL databases do not require an established relational schema, but they often are used in combination with relational databases. Large- scale web organizations use NoSQL databases to focus on narrow operational goals and employ relational databases as add-ons when higher data consistency and data quality is necessary. Four types of NoSQL databases are: ⢠Key-value databases: Also called key-value stores, these databases imple- ment a simple data model that pairs a unique key with an associated value. Because of their simplicity, key-value databases can lead to the development of extremely âperformantâ and highly scalable databases for session manage- ment and caching in web applications. (The word performant is a French word essentially meaning âable to perform at or above an expected level.â In software engineering, the term is commonly used to describe efficient and well-optimized software applications.) Implementations differ in the way they are oriented to NoSQL databases are used to combine information from several sources into one comprehensive database and subsequently to run aggregation and filtering queries on the very large dataset. Key Value
State of the Practice of Big Data 23 work with random access memory (RAM), solid-state drives, or disk drives. Exam- ples of key-value databases include Aerospike, Berkeley DB, MemcacheDB, Redis and Riak. ⢠Document-oriented databases: Also called document stores, these databases focus on efficient storage, retrieval, and management of document-oriented information or semi-structured data, as well as on descriptions of that data in document format. They allow developers to create and update programs without the need to reference a master schema. Document-oriented databases often are used in combination with the scripting language JavaScript and its associated data interchange format, JSON, but XML and other data formats also are supported. Document-oriented databases often are used for content management and mobile application data handling. Examples of document-oriented databases include Couchbase Server, CouchDB, DocumentDB, MarkLogic, and MongoDB. ⢠Wide-column stores: These databases orga- nize data tables as columns instead of rows. In wide-column stores, a column family consists of multiple rows. Each row can contain a different number of columns, and the columns (names and data types) do not have to match the columns in the other rows. Within its row, each column contains a name-value pair and a timestamp. Wide-column stores can be found in both SQL and NoSQL databases (Ian 2016). Wide-column stores can query large data volumes faster than conventional relational databases can. Wide- column data stores often are used for recom- mendation engines, catalogs, fraud detection, and other types of data processing. Examples of wide-column stores include Google BigTable, Cassandra, and HBase. ⢠Graph stores: Also called graph data- bases, graph stores organize data as nodes and edges, which represent connections between nodes. For example, a node could be a person, another node could be a specific name, and the edge (the con- nection or relationship between the two nodes) could be âhas this name.â Because the graph system stores the relationship between nodes, it can support richer rep- resentations of data relationships. Also, unlike relational models that rely on strict schemas, the graph data model can evolve and adapt to data changes over time without requiring a complete redesign. Graph stores are applied in systems that must map relationships, such as reservation systems or customer relationship management systems. Examples of graph stores include AllegroGraph, IBM Graph, Neo4j, and Titan. 3.2.3.3 NewSQL Databases NewSQL databases are basically clustered relational databases that are augmented with Hadoop-inspired, distributed, fault-tolerant architectures. The goal of NewSQL databases is Source: https://www.marklogic.com/blog/making-new-connections-ml-semantics/
24 Leveraging Big Data to Improve Traffic Incident Management to deliver high availability and performance to NoSQL databases with- out sacrificing the robust consistency requirements and transaction capabilities found in relational databases. NewSQL databases also support the standard relational database language, SQL, to access and modify their data. NewSQL databases are usually employed in applica- tions within which many short database transactions accessing small amounts of indexed data are executed repetitively. These applications are typical of OLTP processing for activities such as shopping cart management or mobile phone tracking. 3.2.3.4 In-Memory/Graphics Processing UnitâAccelerated Databases In-memory/graphics processing unitâaccelerated databases (GPU- accelerated databases) are like NewSQL databases, but they use GPUs (microchips originally designed for video processing) instead of CPUs (central processing units) to perform query operations. GPU- accelerated databases can perform queries sometimes hundreds of times faster than in-memory NewSQL databases, and they can search through billions of records in less than a second. GPU-accelerated databases are still relatively new, but they are starting to generate inter- est because they often require fewer servers per cluster than NewSQL databases, which offsets the additional cost of server GPUs. Examples of GPU-accelerated data- bases include Kinetica, MapD, and Blazing DB. 3.2.3.5 Summary Many tools have been derived from the original Hadoop software. From leveraging in-memory and GPU-processing to incorporating relational database standards, the number and specifici- ties of Big Data tools keep growing, but one convention seems to be common to all these tools: schema-on-read. The schema-on-read convention imposes a structure on raw data after it has been stored and as it is being read or queried. This approach contrasts with the schema-on-write conventionâthe foundation of relational databasesâwhich imposes a structure before the data has been stored (i.e., ETL). The shema-on-read approach was not possible in earlier systems, as they did not have the capabilities required to handle less-structured data. As both hardware and software capabilities have increased, schema-on-read has now emerged as the main approach to organizing Big Data. Figure 3-3 builds on the data value chart from Figure 3-2 by adding the volume processing capabilities (y-axis on the right) of traditional and new Big Data analytics tools. Looking at Figure 3-3, it is easy to identify how Big Data tools have brought significant improvement in handling the analysis of greater volumes of data, as well as in handling a wider range of data based on data age (from more rapidly changing, newer data to fixed, older data). Traditional RDBMSs running on a single server are limited in that they typically have difficulties ingesting and analyzing large amounts of data in real time, as compared to Big Data databases. Relational databases also have difficulties performing quick analyses on large datasets covering several years without pre-calculating and pre-aggregating the historical data (e.g., in a data cube). These limitations can be attributed to the limits of relational database server hardware (e.g., memory, network, CPU, storage). Additionally, relational databases are based on relational algebra, which creates strict models of how data can be stored and queried. Because they work on a schema-on-write basis, data entered into relational databases must be prepared and tailored to a template or database schema at the time of entry (e.g., using the ETL process) before any queries or analysis can occur. When users query the data in a traditional RDBMS, the data The goal of NewSQL databases is to deliver high availability and performance without sacrificing the robust consistency requirements and transaction capabilities found in relational databases. GPU-accelerated databases can perform queries sometimes hundreds of times faster than in-memory NewSQL databases and can search through billions of records in less than a second.
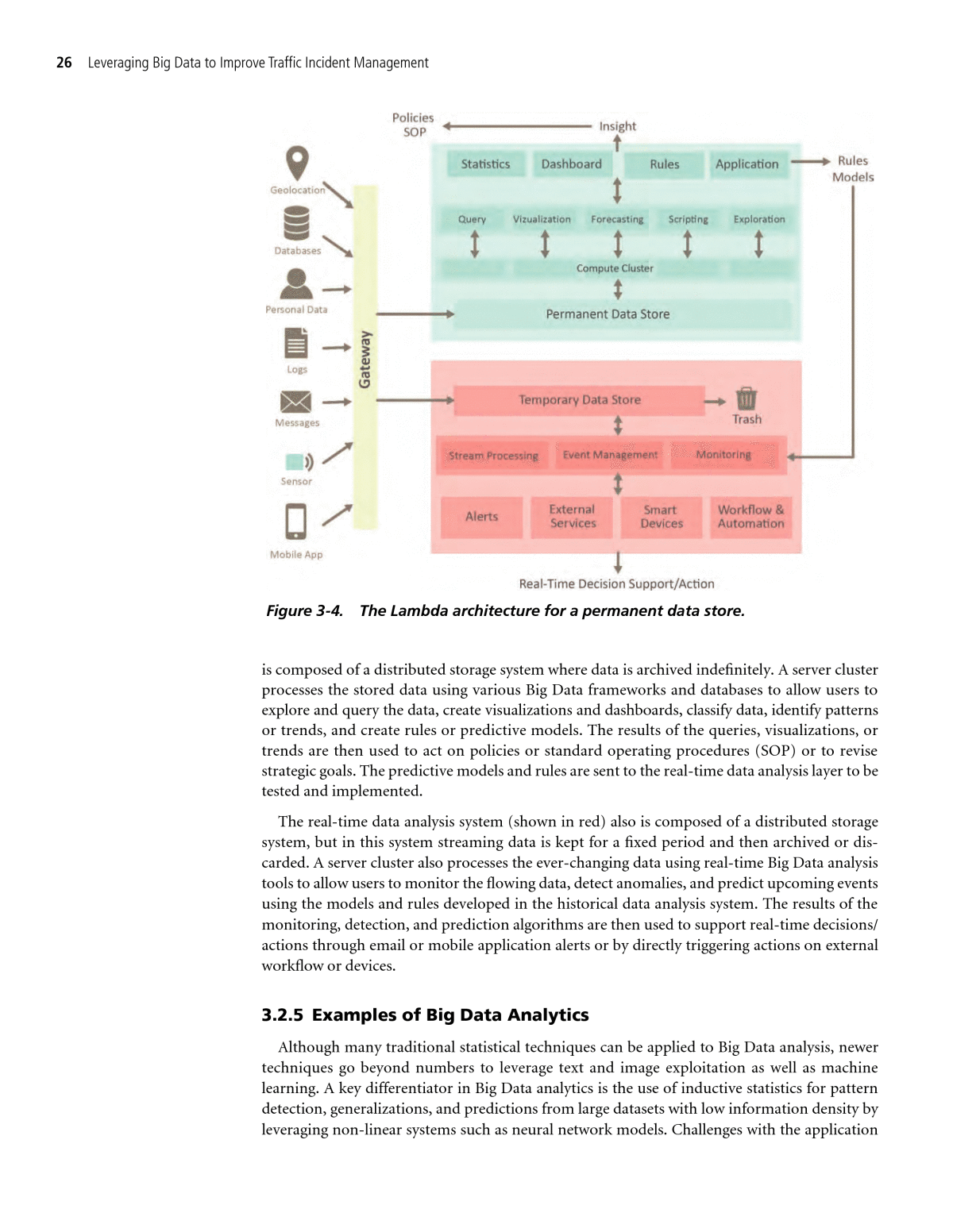
State of the Practice of Big Data 25 has already been organized into an easily manageable format that facilitates sorting, merging, aggregating, and calculating. It should be noted that a traditional data warehouseâwhich is a complex analytical system composed of one or more relational databasesâis not the same as a Big Data store. Traditional data warehouses were designed for historical analysis and deal with larger and more complex datasets by applying a âdivide and conquerâ approach, splitting the tasks of importing and orga- nizing the data across multiple custom ETL processes and multiple domain-specific relational databases. Traditional data warehousing systems are very complex and difficult to maintain in the face of ever increasing and changing data. 3.2.4 Big Data Architecture The architecture used to support the development of Big Data stores is called the Lambda architecture. The Lambda architecture is a data processing architecture designed to handle massive quantities of data by taking advantage of both batch-processing (i.e., historical data) and stream-processing (i.e., real-time data) methods. The Lambda architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The outputs of batch-processed historical data and real-time data streams may be joined before presentation of the data. The rise of the Lambda architecture has correlated with the growth of real-time analytics. Figure 3-4 shows a graphical representation of the Lambda architecture. The left part of the chart shows the many data inputs (including geodata, sensor data, mobile data, logs, and so forth) entering the Big Data store though a common gateway. The data is then streamed to the historical data analysis system (shown in blue, in the top, shaded area) and the real-time data analysis system (shown in red in the bottom, shaded area). The historical data analysis system Traditional Source: Adapted from VoltDB, Inc. (Stonebreaker and Jarr 2013) Figure 3-3. Big Data exploitation of data value.
26 Leveraging Big Data to Improve Traffic Incident Management is composed of a distributed storage system where data is archived indefinitely. A server cluster processes the stored data using various Big Data frameworks and databases to allow users to explore and query the data, create visualizations and dashboards, classify data, identify patterns or trends, and create rules or predictive models. The results of the queries, visualizations, or trends are then used to act on policies or standard operating procedures (SOP) or to revise strategic goals. The predictive models and rules are sent to the real-time data analysis layer to be tested and implemented. The real-time data analysis system (shown in red) also is composed of a distributed storage system, but in this system streaming data is kept for a fixed period and then archived or dis- carded. A server cluster also processes the ever-changing data using real-time Big Data analysis tools to allow users to monitor the flowing data, detect anomalies, and predict upcoming events using the models and rules developed in the historical data analysis system. The results of the monitoring, detection, and prediction algorithms are then used to support real-time decisions/ actions through email or mobile application alerts or by directly triggering actions on external workflow or devices. 3.2.5 Examples of Big Data Analytics Although many traditional statistical techniques can be applied to Big Data analysis, newer techniques go beyond numbers to leverage text and image exploitation as well as machine learning. A key differentiator in Big Data analytics is the use of inductive statistics for pattern detection, generalizations, and predictions from large datasets with low information density by leveraging non-linear systems such as neural network models. Challenges with the application Figure 3-4. The Lambda architecture for a permanent data store.
State of the Practice of Big Data 27 and use of Big Data analytics arise from the absence of theory to drive the analytics and critical judgment in interpreting the analytics. These shortcomings are of particular concern for evolving social systems. This section describes a few examples of Big Data analytics, how they are performed, what kinds of results or insights they can provide, and what tools can be used to perform them. 3.2.5.1 Classification Using Clustering Analysis Clustering analysis is a data mining task that consists of grouping a set of records in such a way that objects in the same group, called a cluster, are more like each other than they are to objects in other groups or clusters. Clustering analysis is a main task of exploratory data mining and a common technique for statistical data analysis, and is used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, bioinformatics, data compression, and computer graphics. The technique allows the categorization or group- ing of records in datasets to uncover their natural organization or the natural affinities between records or groups of records. Figure 3-5 shows a generic example of a set of data points that have been grouped into three clustersâgreen (at top), blue (lower and toward the right) and red (roughly from the middle and extending to the bottom)âusing a two-dimensional clustering analysis (Chire 2011). Note that not all points have been added to a cluster. Many algorithms can perform clustering analysis. One of the most popular clustering algo- rithms, K-means, aims to partition a limited number of data points into a specified number Source: Chire (2011), CC BY-SA 3.0 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Figure 3-5. Example of two-dimensional clustering analysis visualization.
28 Leveraging Big Data to Improve Traffic Incident Management of clusters in which each observation belongs to the cluster with the nearest mean. Examples of software programs capable of performing clustering analysis include Apache Mahout, Apache Spark, and Revolution R Enterprise. Example Application: The following scenario shows one way a clustering analysis could be used in a TIM application. A police department wants to make its presence in the field more efficient and decides to station its patrol cars so that patrol cars are near areas with high incident rates. A clustering analysis can be used to identify the best locations for the patrol cars, so that the right people and resources can be in position to respond to incidents more quickly. 3.2.5.2 Text Analysis Text analysis, also called text mining, refers to techniques that extract information from textual data sources such as social network feeds, emails, blogs, online forums, survey responses, corporate documents, and news articles. Text analysis involves statistical analysis, computa- tional linguistics, and machine learning. A popular Big Data text analysis performed on social media data is called sentiment analysis or opinion mining. Sentiment analysis is widely used in marketing and finance, and also in the political and social sciences. This type of text analysis analyzes social media messages that contain peopleâs opinions about âentitiesâ such as products, organizations, or individuals, and about events such as traffic incidents. Figure 3-6 shows an example of one type of visualization that can be generated by text analysis: a word cloud that represents the most frequently occurring terms encountered in a set of recruiting documents. A word cloud is a visual representation of text data in which the font size or color of each word indicates its frequency or importance. Many distinct text mining libraries exist, such as tm, NLTK, or GATE. Generally, their application to Big Data datasets occurs in three stages: The first stage, called the information retrieval stage, involves the retrieval of plain text from semi-structured documents such as word-processing documents, social media posts, or even emails. This stage may include or be followed by natural language processing, which identi- fies grammatical, usage, or other features in the text to facilitate its use in computations and algorithms. The second stage, called the information extraction phase, is the stage during which text min- ing libraries are used to mark up the text to identify meaning. During this phase, the text corpus (the entire text dataset) is augmented using metadata about the text. The metadata can Figure 3-6. SSP word cloud example.
State of the Practice of Big Data 29 be information about the text (e.g., its author, title, date, edition) and/or information that has been extracted using the text mining libraries (e.g., all names or locations mentioned in the text). The third stage, called the data mining phase, is when Big Data tools are used to perform analysis on the augmented text corpus to extract information and identify relationships between texts. The results of this third-stage analysis always reflect the preconceptions of those who created the metadata. Some examples of the types of analysis that can be performed on an augmented text corpus include: ⢠Text categorization: cataloguing texts into categories; ⢠Text clustering: clustering groups of automatically retrieved text into a list of meaningful categories; ⢠Concept/entity extraction: locating and classifying elements in text into predefined catego- ries, such as persons, organizations, locations, monetary values, and so forth; ⢠Granular taxonomies: enabling organization or classification of information as a set of objects that can be displayed as a taxonomy; ⢠Sentiment analysis: identifying and extracting subjective information in source materials (e.g., emotions or beliefs); ⢠Document summarization: creating a shortened version of a text containing the most important elements; and ⢠Entity relation modeling: automated learning of relationships between data items. Examples of software capable of performing text analysis include Apache Spark Machine Learning Library (MLlib) and Microsoft Azure Cognitive Services text analytics API. Example Application: During the 2012 presidential election campaign, President Barack Obamaâs campaign team applied sentiment analysis to Twitter posts to identify swing voters and to spot the campaign discussion topics most likely to make these voters change their minds. The discussion topics identified were then used to create custom advertising for each of the identified swing voters (Issenberg 2012). 3.2.5.3 Image Analysis Image analysis, also called image analytics, is a Big Data analysis performed on streamed (video) or archived image content. Image analysis involves using a variety of techniques to ana- lyze, extract, and monitor meaningful information detected within images. This type of analysis is already being applied to closed-circuit television (CCTV) camera systems and video-sharing websites, primarily in relation to retail marketing and operations management. The images gen- erated by CCTV cameras in retail outlets are extracted for business intelligence (Rice 2013). Algorithms allow retailers to measure the volume and movement patterns of customers in the store and to collect demographic information about customersâsuch as age, gender, and ethnicityâfrom video content. Valuable insights are then derived by correlating the extracted information with customer demographics to drive decisions about product placement, price, promotion, layout, and staffing. Figure 3-7 shows an image that was analyzed using one of the Big Data image processing services (Amazon 2017). The table shows the list of terms detected by the image processing service, as well as the level of confidence. For a long time, image analysis has been conducted using a process that converts color images to gray scale images; locates geometric shapes by means of edges, shades, or other defining features; and combines them to identify relevant image elements such as the location of a nose or eyes on a face. From the location and distance between these discovered features, an assessment can be made as to what the features together mean (e.g., the gender associated with
30 Leveraging Big Data to Improve Traffic Incident Management a face). Recently, important progress has been made in the field of neural networks to improve analysis performance. Neural networks are computational models that emulate the structure and functions of biological neural networks (brains). Neural networks are not new, but their application to image analysis has been rather unsuccessful in the past, mostly because of cost-prohibitive computing and a problem called overfitting. Overfitting occurs when a model (in this case, a neural network) tailors itself too closely to the data on which it has been trained and is not able to perform well on new data. Combined with the massive number of images generated by social media, advances in the design of neural network structures (often called deep learning) have allowed neural networks to become very effective at image analysis. Neural networks are now the basis of many Big Data image analysis software systems, whether custom or turnkey. Examples of software capable of performing image analysis include AWS Rekognition, Google Cloud Vision, and IBM Watson Visual Recognition. Example Application: The public TV channel C-SPAN, which provides gavel-to-gavel pro- ceedings of the U.S. House of Representatives, U.S. Senate, and other forums where public policy is discussed, debated, and decided, recently started to use a cloud-based Big Data image analysis service to tag its archived videos and associate each video frame with information such as who is speaking, who is on camera, and other details. The goal was to allow C-SPANâs video content to be easily indexed and made searchable. By performing image recognition analysis on more than 7,500 hours of video frame content, C-SPAN has been able to identify more than 97,000 entities, create a new database to store the newly indexed content, and allow its video archive to be searched much more effectively than before (Amazon Web Services n.d.). 3.2.5.4 Graph Analysis Graph analysis techniques are derived from graph theory and are primarily based on the analysis of the structure of data and how data elements relate to each other. Social network analytics, for example, may use graph analysis to structure attributes of a social network and extract intelligence from the relationships among the participating entities. The structure of a social network can be modeled through a set of nodes and edges that represent participants and their relationships. The model can be visualized as a series of graphs composed of the nodes and the edges. The graphs can be mined to identify communities and influencers or to identify the shortest path between two individuals. This type of analysis is commonly found in social media and advertising, enterprises in which the insights gained can be leveraged in viral marketing to Figure 3-7. Traffic incident scene and associated image recognition results.
State of the Practice of Big Data 31 enhance brand awareness and adoption. Figure 3-8 shows an example of the results of a graph analysis called betweenness centrality. This analysis identifies which nodes within a graph are the most connected (blue) and which are the least connected (red) (Rocchini 2007). Many techniques are used to analyze graphs. The most popular technique is certainly the shortest-path calculation, often performed using the Dijkstraâs algorithm, which calculates the shortest distance between two nodes of a graph. A real-life example of this technique is the calculation of driving directions between two locations used by any of several popular mobile applications. But graph analysis is much broader than shortest-path calculations. Four types of graph analysis are widely used: 1. Path analysis: This technique is used to determine the distances between nodes in a graph, and includes but is not limited to the shortest-path calculation. An obvious use case is route optimization that is particularly applicable to logistics, supply, and distribution chains, and to traffic optimization for âsmartâ cities. 2. Connectivity analysis: This technique can be applied to determine weaknesses in networks such as a utility power grid. It also enables comparisons of connectivity across networks. 3. Community analysis: This technique uses distance and density information to identify groups of people interacting with a social network. Community analysis can, for example, identify whether the interactions are transient, and it can predict if the network will grow. 4. Centrality analysis: This technique enables the identification of the nodes or edges that are the most connected to the rest of the graph. Centrality analysis makes it possible to find the most influential people in a social network or to identify the most frequently accessed web pages. Although graph analysis techniques can be performed on small datasets, they often encounter problems at scale due to the nature of the algorithms used, the characteristics of the graph data, and the limitations of having commodity hardware clusters (i.e., the cloud) performing the analyses. These limitations often constrain graph analysis to approximate solutions rather than exact ones. Examples of software capable of performing graph analysis include Apache Spark GraphX, Titan, Neo4j, and Microsoft Azure Cosmos DB. Source: Rocchini (2007) Figure 3-8. Example of graph node centrality (betweenness centrality) analysis.
32 Leveraging Big Data to Improve Traffic Incident Management Example Application: Graph analysis often is used in fraud detection. In 2016, the Inter- national Consortium of Investigative Journalists (ICIJ) exposed highly connected networks of offshore tax structures used by the worldâs richest elites to circumvent their countriesâ offshore limitations. To uncover these networks, an ICIJ journalist used more than 11.5 million leaked documents (40 years of data totaling around 2.6 TB) to build a graph representing the connec- tions between individuals and companies such as banks, law firms, and company incorporators found in the documents. The journalist then performed several analyses on the graph to iden- tify the most central companies and individuals, eventually uncovering an entire network of 16,000 tax havens created by 500 banks hiding the money of 140 politicians in more than 50 countries (ICIJ 2016). 3.3 Big Data Applications in Transportation Within the transportation industry, the concept of Big Data has become increasingly relevant over the past several years, particularly with the advancements in connected vehicle research and the availability of massive datasets. Big Data has been applied to public transportation, trucking/freight, logistics, planning, parking, rail, traffic operations, calibration and validation of traffic simulation models, asset management and maintenance, and even TIM. This section presents a high-level overview of some of the Big Data approaches, findings, recommendations, and lessons learned, as presented in a wide range of publications most relevant to NCHRP Project 17-75. 3.3.1 Transportation Planning Much focus is being placed on the application on Big Data in transportation planning. Of particular interest is the use of mobile phone data from telecommunication companies to identify travel patterns. Every time a mobile network subscriber uses the phone to make or receive a call, send or receive a text via SMS or an image via multimedia messaging service (MMS), or access the Internet, a record of that event is generated. These records are collectively termed âcall detail recordsâ (CDRs). Each record includes information about party identifica- tion, date, time, duration, and cell ID (antenna), which in turn has geolocation and antenna orientation (azimuth) (Lokanathan 2016). Dong et al. (2015) found that using CDR data from mobile communication carriers provides an opportunity to improve the analysis of complex travel patterns and behaviors for travel demand modeling to support transportation planning. Lokanatha et al. used 4 months of passive CDR data of voice calls for several million SIMs from a Sri Lankan mobile operator to explore to what degree the data could be used to create origin-destination (O/D) matrices that represent the flow of travelers between different geo- graphic areas in the city of Colombo, Sri Lanka. The results illustrated that, despite some limita- tions, mobile network Big Data shows promise as a source of timely and relatively inexpensive insights for transportation planning in developing countries (Lokanathan 2016). Colak et al. (2014) developed a method to use passive CDR data as a low-cost option to improve trans- portation planning. The resulting trip matrices for Boston, Massachusetts, and Rio de Janeiro, Brazil, were comparable with existing information from local surveys in Boston and with existing OD matrices in Rio de Janeiro (Colak 2014). CDR data is inexpensive compared to active positioning data (e.g., global positioning systems, or GPS), but the data exists at the level of the active cells and is therefore less precise. In addition, not all mobile operators generate continuous active positioning data for all their subscribers, and even fewer operators store the data (Lokanathan 2016).
State of the Practice of Big Data 33 One benefit Big Data holds for transportation planners is the ability to track movements of vehicles and people on a scale never before imagined. Recent advances in crowd modeling systems have led to more focus on modeling complex locations; however, accurate data collec- tion is one of the biggest limitations that crowd specialists face today (Alvarez 2015). Although researchers are exploring ways to track pedestrians, CDR data is not able to directly inform detailed analysis and understanding of movements at that level. New technology, like the fifth- generation (5G) mobile network, is needed to allow more detailed and more accurate tracking of mobile devices. 3.3.2 Parking The parking industry has access to more data today than ever before, and the amount of data collected is growing both quickly and exponentially. Incredible amounts of data can be generated from a variety of sources, including space availability tools, meter and parking man- agement systems, credit card and other electronic payment transactions, financial systems, and social media. For parking, the real value of Big Data comes when the data is compiled from all garages, meters, and parking spaces in a region (or the industry) and then that data is merged with data from local events (e.g., sporting events, festivals), holidays, weather patterns, and other drivers of customer activity. The analysis of this large amount of data allows insights to be gleaned into what drives demand peaks on a certain day of the week at a certain garage but not on other days or at other garages within the same vicinity. These insights can help garage operators refine their services and pricing to better meet the actual needs of customers who use their facilities at various times during the week, month, or year (Drow, Lange, and Laufer 2015). 3.3.3 Trucking Trucking operations generate billions of pieces of information each day, including admin- istrative data (e.g., human resources systems/driver histories), telematics data (e.g., position, speed, time, heading, fast acceleration, over-speed, hard cornering/braking), vehicle data from sensors (e.g., pressure monitoring systems, stability/control systems, refrigerated container monitoring, cargo status sensors), driver performance data, warehouse information, routing information, point of sale in the stores, driver interactions (e.g., enhanced messaging, naviga- tion, re-routing), and fuel cards (e.g., vehicle identification or driver number, odometer reading, purchase number plus the date, time, location and total purchase). Big Data has been used to help fleets identify potential safety risks within their driver pools; provide detailed information on fuel consumption; determine which vehicles or components will need service based on per- formance metrics rather than a static schedule; provide insights on ways to improve customer service; issue alerts when preset thresholds or key performance indicators are exceeded; and develop scorecards showing multiple key performance indicators to show drivers how they are doing, how divisions are doing, how regions are doing, and so on. During the last 5 years, lead- ing providers have developed a cloud platform that allows them to create and provide tools that simplify and automate activities from real-time operations to long term planning (Beach 2014). Trucking companies use data to save money on fuel by using predictive modeling to select fuel-efficient trucks. One company depended on this data to help them make the right choice in selecting a new fleet of 50 trucks (a $6 million decision). A predictive model was used to determine the actual fuel economy of the trucks being considered. The company combined data variables like driving behavior, fuel tank levels, load weight, road conditions, and much more. The details from the data provided executives with a clear picture of which trucks would provide the most fuel savings over time (Nemschoff 2014).
34 Leveraging Big Data to Improve Traffic Incident Management 3.3.4 Public Transportation Many city administrations recognize the value of using Big Data for public transportation, particularly for improving the management of bus fleets and optimizing maintenance and operations. In Sao Paulo, Brazil, Big Data collected in real time provides a more accurate picture of how many people ride the buses, which routes are on time, how drivers respond to changing conditions, and many other factors. The data helps to optimize operations by providing addi- tional vehicles where demand warrants and by identifying which routes are the most efficient. Big Data analytics reduces the time needed to identify problems and make changes and with more accuracy and certainty (Delgado 2017). Big Data played a big part in re-energizing Londonâs transport network. Transport for London (TfL) collects data through ticketing systems, vehicle sensors, traffic signals, surveys, and social media. The use of prepaid travel cards, swiped to gain access to buses and trains, has enabled a huge amount of precise journey data to be collected. The data is anonymized and used to produce maps showing when and where people travel, giving a far more accurate overall picture and allowing more granular analysis at the level of individual journeys. TfL plans to increase the capacity for real-time analytics and work on integrating an even wider range of data sources to better plan services and inform customers (Marr 2015). The New York City Transit Authority (NYCTA) developed a Big Data tool to assess the effects of planned service changes and unplanned disruptions and to support the monitoring of fast-changing patterns and trends in ridership behavior. The application combines data from the Metropolitan Transit Authority (MTA) bus automated vehicle location (AVL) system, an automated fare collection (AFC) system, the general transit feed specification (GTFS) schedule, and shapefile streams. (Shapefiles store information about the locations and attributes of geo- graphical features.) The application is responsive to daily detours, special events, and weather- driven ridership. It also allows multiple days of route-level program output to be aggregated for schedule-making purposes, providing a significantly more representative understanding of typical passenger loads than was historically estimated using a few labor-intensive, on-board observations collected over a multi-year period (Zeng et al. 2015). 3.3.5 Transportation Operations and ITSs The objective of a 2014 white paper by the U.S. DOTâs ITS Joint Program Office was to expand the understanding of Big Data for transportation operations, the value it could provide, and the implications for the future direction of the U.S. DOT Connected Vehicle Real-Time Data Capture and Management (DCM) Program (Burt, Cuddy, and Razo 2014). The report summarizes recommendations and next steps from several recent U.S. DOT and other studies regarding how Big Data approaches may be applied in transportation operations. The white paperâs recommendations and next steps included the following: ⢠Engage with a broad range of stakeholders (e.g., public and private, transportation and non- transportation, data analytic product and service providers, modelers, algorithm developers, and decision-support system developers) to disseminate the value proposition for applying Big Data in transportation operations; ⢠Develop a framework to identify and evaluate options pertaining to the potential roles and responsibilities for state, local, and federal government and the private sector; ⢠Resolve data ownership issues and the implications for roles; ⢠Investigate the potential use of a third-party data broker (or multiple brokers), which may help address ownership and funding needs (as the cost of capturing and managing data may be cost-prohibitive for government but profitable for the private sector);
State of the Practice of Big Data 35 ⢠Develop data standards, especially if transportation agencies are not collecting and managing the data themselves; ⢠Consider approaches to reduce the volume of connected vehicle and traveler data so that it is more manageable while ensuring that all valuable data is collected; ⢠Utilize specific technologies and techniques like crowdsourcing, cloud computing, and federated database systems that have come to characterize the state-of-the-practice in Big Data and which will facilitate transportation operators or private sector data service providers in extracting value from connected-vehicle and traveler data; ⢠Develop connected vehicle Big Data use cases that incorporate Big Data analytics approaches and the operational strategies that could derive from the knowledge gained through those approaches; and ⢠Further investigate the potential cost and other resource implications of adopting Big Data approaches based on the outcome of the use-case investigation. Shi and Abdel-Aty (2015) explored the viability of a proactive, real-time traffic monitoring strategy to evaluate operation and safety simultaneously. Data was obtained from a microwave vehicle detection system (MVDS) deployed along a 75-mile section of an Orlando expressway using a network of 275 detectors. Data mining using the random forest technique and Bayesian inference techniques were implemented to unveil, in real time, the effects of traffic dynamics on crash occurrence (Shi and Abdel-Aty 2015). The Colorado Department of Transportation (Colorado DOT) is looking toward Big Data to solve growing everyday challenges. One challenge area involves winter weather. During snow events, hits on the public website can overload the internal servers, requiring that the CCTV cameras be temporarily turned off to accommodate the load. The Colorado DOT realizes that it cannot add servers to accommodate the relatively few days each year when this happens, and that a scalable Big Data architecture would allow them to expand or lower the system as needed. A second challenge area involves the amount of time that operators at Colorado DOT traffic operations centers spend manually entering data into the system. By moving toward Big Data, these manual activities can be automated using cloud-based systems, enhancing functionality and efficiency. To support the Big Data approach, the Colorado DOT developed a white paper, âIntegrating Big Data into Transportation Servicesâ (Wiener and Braeckel 2016). The purpose of this paper was to provide an overview of current and future Big Data processing challenges at the state DOT as well as to present a set of candidate technologies that could be used to address such challenges. Based on the identified challenges, a list of Big Data needs for the Colorado DOT was developed, which included: ⢠Improving internal and external data sharing, including effective search and acquisition methods; ⢠Enhancing domain datasets such as AVL data, work zone data, and incident data by improving coverage, timeliness, and resolution; ⢠Integrating connected and autonomous vehicle data into Colorado DOT operations; ⢠Enhancing data analytics through improved capability, ease of application, and timeliness; ⢠Utilizing scalable and reliable computing and storage; and ⢠Handling high data volumes. As a follow-on to the white paper, the Colorado DOT is working to implement the Data Analytics Intelligence System (DAISy), a Big Data platform that integrates a wide range of data sources (e.g., real-time video analytics, CAD, crowdsourced data, ATMS, safety patrol, AVL, vehicle probes, weather, connected vehicles, traffic signals, truck parking, CCTV, tolling, freight,
36 Leveraging Big Data to Improve Traffic Incident Management tunnel operations, chain stations, maintenance, and GIS shape files) in a cloud-based data lake. The project involves three phases: ⢠Phase 0, project documentation, was underway at time of the research for this project. ⢠Phase I, planned to begin by late 2018, involves the development and implementation of three use cases (one of which is advance incident detection) to prove the value of the Big Data approach. Phase I also will involve elicitation of stakeholder requirements and the development of a business case and functional/technical requirements for each of the three use cases. ⢠Phase II, anticipated for 2019, involves a full test of the DAISy system, including the testing of several more use cases. The data integration has already started and will continue throughout the three phases of the project. The U.S. DOT recently published a report to provide agencies responsible for traffic manage- ment with an introduction to Big Data tools and technologies that can be used to aggregate, store, and analyze new forms of traveler-related data (i.e., connected travelers, connected vehicles, and connected infrastructure), and to identify ways these tools and technologies can be integrated into traffic management systems and TMCs (Gettman et al. 2017). Key contributions of the report include the following: ⢠Identification of how sharing data with other TMCs, systems, connected vehicles, travelers, and agency business processes or systems could affect the performance of a traffic management system or TMC; ⢠Identification of challenges and options for compiling, using, and sharing this emerging data; ⢠Presentation of potential use cases for integrating Big Data technology and tools into traffic management systems or TMCs; ⢠Identification of a national system architecture that illustrates the types of tools and interfaces that will be needed; ⢠Examples of the data processing and storage requirements for a typical agency when con- nected vehicle, traveler, and infrastructure data is being transferred to the TMC at significant levels; and ⢠Key questions to be addressed in developing a plan for leveraging the emerging data sources with Big Data tools and technologies. The Big Data Europe (BDE) project seeks to develop an adaptable, easily deployable and usable solution that will allow interested user groups to extend their Big Data capabilities or to introduce Big Data technologies to their business processes. The project involves building a Big Data community and developing a Big Data Aggregator infrastructure that meets the require- ments of users from the key societal sectors, minimizes the disruption to current workflows, and maximizes the opportunities to take advantage of the latest European research and technologi- cal developments, including multilingual data harvesting, data analytics, and data visualization (BDE n.d.). Within the framework of the BDE project, ERTICO-ITS Europe organized a 2015 workshop on âBig Data for Smart, Green and Integrated Transportâ (BDE and ERTICO-ITS Europe 2015). The workshop focused on the elicitation of requirements for Big Data management within the intelligent transportation domain. The workshop consisted of three sessions that were ded- icated to data-centric initiatives in transportation, Big Data use cases in transportation, and technologies and tools used and envisioned. The workshop results indicated a clear need for Big Data solutions in transportation, and that the areas for Big Data application are diverse. Particularly significant and relevant outcomes/recommendations from this workshop included the following:
State of the Practice of Big Data 37 ⢠Big Data in transport will lead to improved multi-source traffic and travel data availability and processing as well as to tools that improve multi-source traffic and travel data fusion. Combining big, open, and linked data will foster innovation and economic benefits. ⢠A future Big Data platform must allow real-time data analysis, which includes visualization tools that allow data mining and the visualization of analysis results, as well as automated coding and delivery of video data over cellular/Wi-Fi to cloud-based storage. The platform should use data structures that allow efficient data extraction and support open repositories with high-quality context information. ⢠If a common standard will be developed, it should be a non-discriminatory standard with open application programming interfaces (APIs). ⢠Policy-makers should provide clarity on the re-use rights of data. ⢠There should be a âfree flow of data initiativeâ in the EU [European Union], and the EU should promote the use of open data. ⢠Current businesses are challenged by Big Data. An issue is to have the right mindset to make data available in the first place. ⢠Making data available also involves a risk factor. Public education/outreach is required to make people aware that data needs to be shared and that specific data is available and accessible. ⢠Transportation stakeholders need to contribute to the creation of large pools of well-documented and accessible road data (i.e., open and with known velocity, volume, and variety). 3.3.6 Emergency and Incident Management The Rio de Janeiro Operations Center (ROC) is the first application of a citywide system to integrate all stages of crisis management from prediction, mitigation and preparation to immediate response. In traditional applications of top-down sensor networks, data from each department operates in isolation. The ROCâs approach to information exchange, on the other hand, is based on the understanding that overall communication channels are essential to getting the right data to the right place, which can make all the difference in an effective response. The ROC gathers data in real time through fixed sensors, video cameras, and GPS devices from 30 government departments and public agencies (including water, electricity, gas, trash collection and sanitation, weather, and traffic monitoring)in real time. Data fusion software collates the data using algorithms to identify patterns and trends, including where incidents are most likely to occur (International Transport Forum 2015). The Waze Connected Citizens Program (CCP) brings cities and citizens together to identify whatâs happening and where. The CCP promotes more efficient traffic monitoring by sharing crowdsourced incident reports from Waze users. Established as a two-way data share, Waze receives partner input such as feeds from road sensors, adds publicly available incident and road closure reports from the Waze traffic platform, and returns succinct, thorough overviews of current road conditions (Connected Citizens Program 2016). Genesis PULSE is an example application that makes use of Waze crowdsourced Big Data to improve incident response. Genesis PULSE is a decision-support and situational awareness software solution that enhances existing CAD systems. As Waze users report traffic events, emergency call centers that are also Genesis PULSE customers can immediately see and pinpoint the incident in real time and use this information to effectively dispatch units. The results are increased situational awareness for dispatch personnel and administrative staff and decreased response times to incidents (GenCore Candeo, Ltd. 2017). Continuous streams of video, traffic volume, speed, backups, weather, and more come into the Iowa State REACTOR lab from across the state every 20 seconds to 1 minute. Using the
38 Leveraging Big Data to Improve Traffic Incident Management data, researchers are developing the TIMELI system (Traffic Incident Management Enabled by Large-data Innovations), which will make use of emerging large-scale data analytics to reduce the number of incidents and improve incident detection. New traffic models, computer algo- rithms, computer display interfaces, and information visualizations will help operators make decisions and take actions (Iowa State University 2017). Researchers at the University of California, Davis (UC Davis) Advanced Highway Main- tenance and Construction Technology Research Center (AHMCT) are developing the third generation of the Responder system, which allows first responders to collect and share at-scene information quickly and efficiently. Unique features of Responder allow users to capture, annotate, and transmit images. Using GPS readings, the system automatically downloads local weather data, retrieves maps and aerial photos, and pinpoints the responderâs location on the maps. Data includes CAL FIRE, InciWeb, CCTV camera images, Caltrans Chain Control, California Highway Patrol (CHP), daily and hourly forecasts, road information, Roadway Information System (RWIS), stream flow, changeable message signs (CMS), zone alerts, and zone forecasts (Clark et al. 2016). Two caveats should be noted for these emergency and incident management examples: 1. Although the TIMELI system is a start to the application of Big Data in TIM, the amount of data generated in Iowa may not be sufficient to train algorithms that can be applied in other locations. Big Data tools are data hungry. As an example, the reason why Facebookâs image recognition process is effective is not just because deep learning has been applied to the data; it is because Facebook was able to train the image recognition algorithms using hundreds of millions of images. 2. On its own, the Responder system in California likely is not a Big Data system, but rather a start that could be augmented to become a Big Data system. Ways exist to expand on these initial approaches to Big Data for TIM, but first the data needs to be prepared, and enough historical data needs to be assembled to be able to find meaningful patterns.
