
Perceptions of Low-Cost Autonomous Driving
TAE EUN CHOE, XIAOSHU LIU, GUANG CHEN, WEIDE ZHANG, YULIANG GUO, AND KA WAI TSOI
Baidu
The paper introduces perception algorithms for low-cost autonomous driving in a platform with a full stack of hardware and software developed by the autonomous driving community. We review pros and cons of each sensor and discuss what functionality and level of autonomy can be achieved with them. We also discuss perception modules for dynamic and stationary object detection, sensor fusion (using Dempster–Shafer theory), and virtual lane line and camera calibration.
INTRODUCTION
The development of longer-range and higher-resolution lidar enabled Level 4 autonomous driving with more accurate perception and localization. However, lidar is a less reliable sensor under extreme weather conditions such as heavy rain or snow. Furthermore, its high cost prevents its use in consumer-targeted autonomous cars. In contrast, a camera is more cost-effective and more robust to weather and is a key sensor for traffic light recognition and lane line detection. We present algorithms to achieve autonomous driving using economical sensors such as a camera and a radar.
There are four main pillars in camera- and radar-based perception: preprocessing, deep network, postprocessing, and fusion (figure 1).
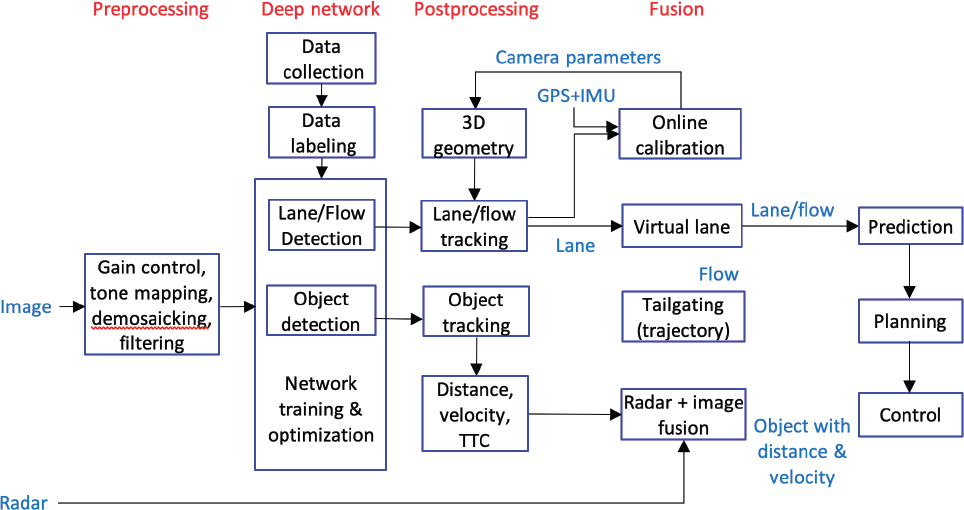
DEEP NETWORK
Data Collection and Labeling
Balanced Data Collection
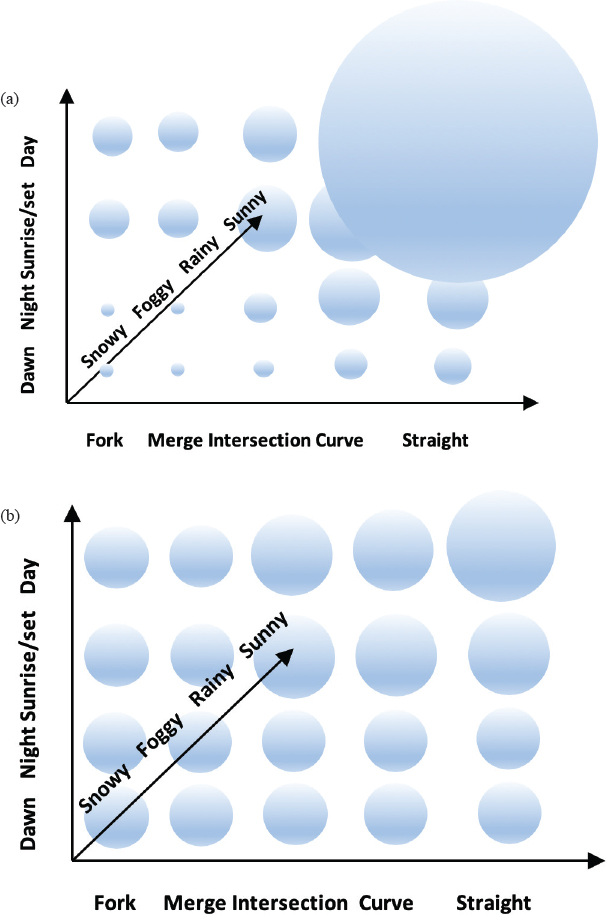
For deep learning, data collection and labeling are important tasks. Labeled data should be well balanced over time, weather, and road conditions, and should cover night, dawn, sunrise, strong shadow, and sunset on one axis. Another axis is for weather (sunny, rainy, snowy, foggy). The third axis is for road conditions such as straight, curved, fork, merge, or intersection. All the data should be evenly distributed on each axis. Figure 2(a) illustrates the actual data distribution for different environments and 2(b) shows the distribution of data after balanced data collection.
Data Labeling
Before driving, the routine to log vehicle information (yaw rate, speed), GPS, wipers (rain, snow), low/high beam, timestamp, location, and all sensor data should be implemented. The more such data are saved, the easier the labeling process. The car should be driven in the center of a lane as much as possible to imitate autonomous driving. In addition, there should be a simple button to save the past 30 seconds of data when the car experiences specific or rare events. After driving, any duplicated or similar scenes should be removed, especially when the car stops. Pedestrian faces and license plates of other vehicles should also be removed to protect privacy. After such processes are completed, data can be labeled.
Autolabeling
Because manual labeling is costly and subject to human error, automatically labeled data should be included in the training dataset. A good candidate for autolabeling is a stationary object such as a lane, traffic light, traffic sign, or any road landmark. First, near-view objects are detected by an existing detector while driving. After driving some distance (e.g., 200 meters), the previous scenes are reviewed. Assuming near-view object detection and motion estimation are accurate, the accumulated set of detected near-view objects can be labeled far away.
For smart recording, we designed multiple events such as deceleration, curves, cut-in of a neighboring vehicle, cut-out of a closest in-path vehicle, and bumps in the road. When such an event occurs, the data before and after it are saved automatically.
For autolabeling, speed and yaw rate from the vehicle’s Controller Area Network (CAN) bus or inertial measurement unit (IMU) data should be recorded for accurate motion estimation. IMU is a useful sensor to measure a vehicle pose.
With IMU data accumulated over time, motion from time t to time t−n can be easily estimated.
When the ego-vehicle’s pose at time t is Mt®t−1, where M is a 4 × 4 matrix with rotation and translation elements, the motion from time t to t−n will be
Mt®t−n = Mt®t−1Mt−2®t−3Mt−3®t−4…Mt−n+1®t−n
The simple motion matrix Mt®t−n directly converts the current vehicle pose to n-th previous pose. For autolabeling, multiple nearview detections are accumulated over time with the estimated motion. The accumulated detections are later projected to the image 200 meters ago for autolabeling. Unlike manual labeling, autolabeling captures objects in threedimensonal form (3D); this includes the road surface, which is reconstructed in 3D to label hill crests, bumps, and even clover leaves. An example of automated labeling is illustrated in figure 3. Autolabeling can capture invisible lane lines (figure 3a) and 3D lane lines (figure 3b).
Network Training and Optimization
Preprocessed images are transferred to a deep neural network for object detection and tracking, lane line and landmark detection, and other computer vision problems. For real-time processing of high-framerate and high-resolution imagery data, network compression is required. In the literature, there are two main network compression approaches:
- Lower-bit approximation: Rather than using the conventional 32-bit float as a weight representation, float32 is quantized into INT8 to achieve real-time implementation (Dettmers 2016).
- Network layer reorganization: When there are multiple tasks, the network structure can be reorganized by sharing common layers and removing unnecessary layers.
Object Detection
In a traffic scene, there are two kinds of objects, stationary and dynamic. The former includes the lane, traffic lights, streetlamps, barriers, bridges over the road, and the skyline; dynamic objects are pedestrians, cars, trucks, bicycles, motorcycles, and animals, among others. For object detection, YOLOv3 (darknet) is used as a base network (Redmon and Farhadi 2018); it accounts for additional object attributes such as 3D size, 3D position, orientation, and type. Detected multiple objects are tracked across multiple frames using a cascadebased multiple hypothesis object tracker.

Lane Detection
Among stationary objects, a lane is a key stationary object for both longitudinal and lateral control. An “egolane”1 monitor guides lateral control, and any dynamic object in the lane determines longitudinal control. We use the same YOLO (darknet) as a base network and add extra lane tasks to detect the relative positions (left, right, next left, next right, curb lines) and types (white/yellow, solid/broken, fork/split) of lanes.
___________________
1 The “egolane” is that of the autonomous vehicle.
POSTPROCESSING AND FUSION
Sensor Fusion
Installation of multiple sensors around a vehicle facilitates full coverage of the environment and redundancy for safety. Each sensor has different capacities: the range of lidar is short but its 3D measurement is accurate; radar provides longitudinally accurate but laterally inaccurate distance and velocity measurements; a camera is accurate for lateral measurement but less so for longitudinal measurement. We learn a prior and belief function of each sensor and fuse all sensor output using Dempster–Shafer theory (Wu et al. 2002).
CIPV Detection and Tailgating
The trajectories of all vehicles are captured with respect to the autonomous vehicle. Among them, the closest inpath vehicle (CIPV) is chosen for longitudinal control and for tailgating a CIPV when, for example, there is no lane, such as at an intersection.
Camera Calibration
Camera calibration is challenging but the most important procedure. There are three categories of camera calibration:
- Factory (initial) calibration: At the factory, we estimate intrinsic and extrinsic camera parameters using fixed targets. However, the camera position changes over time and therefore the parameters need to be updated frequently.
- Online calibration: The long-term position of the camera must be estimated with respect to the car body. An online camera calibration module calibrates the camera position in every frame. A change in pitch angle of even 0.3 degrees can result in seriously incorrect vehicle control. For calibration, any object on the road can be used, such as parallel lane lines, vertical landmarks, or any known size of cars or optical flow.
- Instant pose estimation: The pose of a car changes in every frame. When the vehicle passes over a bump, the pose changes a lot. The pose can be estimated by IMU but these data are too noisy to use directly. It can instead be estimated by visual features: by tracking stationary objects, it is possible to estimate motion and provide a much more accurate 3D perception of the scene.
Virtual Lane
When there is no lane line, all lane detection results and tailgating flow are combined spatially and temporally to determine a virtual lane. The virtual lane output is fed to planning and control modules for actuation of the self-driving vehicle.
CONCLUSION
We have shown perception algorithms for low-cost autonomous driving using a camera and radar. As deep neural networks are the key tool for solving perception issues, data collection and labeling became more important tasks. For sustainable data labeling, autolabeling is introduced. For autonomous driving, dynamic object detection/tracking and stationary object detection algorithms are discussed. A Dempster–Shaferbased sensor fusion algorithm is used to handle multiple sensor fusion. Additionally CIPV, tailgating, and camera calibration algorithms are introduced.
REFERENCES
Dettmers T. 2016. 8bit approximations for parallelism in deep learning. International Conference on Learning Representations, May 2–4, San Juan, Puerto Rico. Available at arXiv:1511.04561.
Redmon J, Farhadi A. 2018. YOLOv3: An incremental improvement. https://arxiv.org/abs/1804.02767.
Wu H, Siegel M, Stiefelhagen R, Yang J. 2002. Sensor fusion using Dempster–Shafer theory. Proceedings, IEEE Instrumentation Technology Conference, May 20–22, Vail.








