4
Tools and Practices for Risk Management, Data Preservation, and Accessing Decisions
DATA—WHAT’S IT GOING TO COST, AND WHAT’S IN IT FOR ME?
Philip Bourne, University of Virginia
Philip Bourne, University of Virginia, described an ongoing fundamental shift in academia, particularly around the notion of data science. However, he noted that data science has been part of biomedicine for several years, starting with the creation of the Human Genome Project. He expects that other disciplines (e.g., religious studies, politics, and environmental science) will also embrace data science and explained that members of the biomedical community can both teach these disciplines and learn from them moving forward.
He discussed the various stakeholders in data supply chains: Funders contribute to the development of resources, publishers provide resources to both readers and authors, the National Institutes of Health (NIH) impacts researchers, and university deans and presidents guide faculty and students. He emphasized that neither the institution of higher education itself nor these supply chains are sustainable in their current forms. Bourne described the Protein Data Bank (PDB), a research collaboratory for structured bioinformatics, as “an exemplar of biological resources.” PDB is run on a 5-year funding cycle with no guarantee that it will be funded for the next 5-year increment, despite the fact that the PDB has more than 1 million users each year and it would cost $14 billion to recreate its contents. He said that there was a reluctance on the part of
developers of the PDB to seek private funding for fear that doing so would reduce federal funding and destabilize the project. This raises questions about the value of resources that exist under a tenuous model. This level of uncertainty also prompts people to leave academia for careers in industry, where incentives and stability are more prominent. Thus, people and resources that are fundamental to underlying science should be sustained appropriately, he asserted. He added that increased international cooperation is needed at the funding level of the supply chain.
Bourne turned to a discussion of publishers’ involvement in the data supply chain. He noted that data are being maintained by publishers, but only large publishers can sustain a data ecosystem. For example, the Public Library of Science (PLOS) requires authors to deposit their data in a repository in order to publish. However, PLOS does not have the expertise or resources to maintain a repository, so it proposed the use of FigShare and Dryad. It remains to be seen whether these approaches are reliable and sustainable, Bourne explained. He also pointed out that PubMed is now including and supporting data because data sets that are aggregated are more useful than a single data set.
In the NIH and university portions of the data supply chain, Bourne observed that the difference between data science and data management needs to be clarified. He also suggested that the distinction between computational and experimental research be eliminated, as the next generation of researchers will have crosscutting skill sets. Alternative business models and an increased emphasis on data management plans would also be beneficial. For example, researchers should begin to acknowledge their funding source(s) when posting data in a repository (which could then be searched as metadata), thus revealing whether they have complied with their data management plans. He asserted that university administrators might not fully appreciate the value of data and how important data access is to the future success of their institutions. Faculty and students, in turn, often lack appropriate access even to their own data.
Bourne explained that there is a new level of disruption as a result of digitization. He described future drivers of change, including the fact that there are more data available than people know what to do with and the demand continues to grow. Tools have improved dramatically (e.g., Python, R, deep artificial neural networks) and have become more robust and reusable, computing power has increased, and training data are doubling every 2 years. Many of these improvements are happening in the private sector but not in academia, he noted.
Bourne predicted that it is going to become even more difficult to forecast data costs in the coming years. Sharing an anecdote about a trauma surgeon who sought correlations between public vehicle crash data and electronic health records data that would allow him to better
treat future patients, Bourne emphasized data integration of diverse data by new types of researchers can lead to important biomedical outcomes. He noted the need to preserve data collectively to enhance reproducibility; however, in the case of the trauma surgeon, no suitable repository exists to sustain his work.
Unique opportunities are emerging in higher education—for example, the University of Virginia is establishing a new school of data science, and nearly 200 U.S. postsecondary institutions offer some form of data science training. Although postsecondary institutions are training excellent data scientists, they have no way to retain them as employees. He asserted that the institutional culture around data needs to change. Postsecondary institutions need to use their own data effectively to improve productivity. He emphasized the importance of rewarding reproducible science and open science in which data play a prominent role—via the faculty/staff handbook, the hiring process, and the promotion process. He explained that the university library also plays a critical role, working across the institution and moving from data preservationist to data analyst. He noted the need for better data governance in postsecondary institutions to manage metadata and data sharing—it is imperative that postsecondary institutions develop an infrastructure for moving data, moving from siloes to commons-like environments. Postsecondary institutions can thus relieve the burden from federal funders and begin to maintain more useful research output through a combination of (1) internal resources (i.e., if reference data sets and quality data can be used year after year by incoming students, they could be supported by tuition funds), (2) federal funding, (3) philanthropy, and (4) public–private partnerships (e.g., relationships can begin via student capstone experiences, which generate data, larger projects, and a talent pipeline).
Bourne highlighted the “data deluge and opportunities lost” in cost forecasting. Bourne said that data preservation can cost as much as people are willing to spend. He said that because the demand (science) far outweighs the supply (data resources), it is important to support the resources that make the most strategic sense (e.g., foster public–private relationships and give postsecondary institutions and the private sector more responsibility for data). If data are considered part of a broader ecosystem with many stakeholders, costs will decrease, research will improve, and health care will advance, he asserted. He posed the following questions for participants to consider throughout the rest of the workshop: What role do you think postsecondary institutions and the private sector should play in the support of data? Does the emergence of data science present opportunities?
David Chu, Institute for Defense Analyses, asked Bourne how he has dealt with the private sector’s desire to retain ownership of its data.
Bourne said that in some partnerships, students have to sign contracts to transfer the intellectual property. That approach, however, encourages the use of synthetic data. Maryann Martone, University of California, San Diego, observed that data ownership policies in many postsecondary institutions have not been revised in more than 50 years, which creates confusion among researchers about data responsibility, ownership, and stewardship. Bourne agreed with the urgent need to update university data policies and commended those institutions that have hired chief data officers. Resources such as the PDB are assets that attract strong faculty candidates—in the future, the value of a postsecondary institution will be directly related to the data assets it has and makes public, he commented. Sarah Nusser, Iowa State University, said that transformations are needed in academia and for research practice more broadly. She wondered what role a postsecondary institution and, more specifically, the library would play in helping researchers prepare to share data. Bourne said that faculty researchers will think more about the value of data and the need to provide metadata when they are evaluated by how much data they share and their degree of cooperation. When students begin to use those data and credit the use to those researchers, a new wave of data sharing could begin within a postsecondary institution.
Nuno Bandeira, University of California, San Diego, explained that as postsecondary institutions begin to embrace data, metrics will be needed to assess the value of data sets and database interaction. Bourne said that if good data citation practices are in place, standard bibliometric techniques could be used to determine the number of citations given to data sets. People should have the opportunity to evaluate data in the same way that they can evaluate narratives, he added. Monica McCormick, University of Delaware Library, cautioned about making intellectual property agreements with publishers that are becoming data analytics firms. Bourne wholeheartedly agreed, emphasizing how discouraging it would be if researchers had to buy back their own data because they had not managed them properly.
PRECISELY PRACTICING MEDICINE FROM 700 TRILLION POINTS OF DATA
Atul Butte, University of California, San Francisco
(participating remotely)
Atul Butte, University of California, San Francisco, opened his presentation with a description of the National Center for Biotechnology Information (NCBI) Gene Expression Omnibus and the European Bioinformatics
Institute (EBI) ArrayExpress.1 In 2012, these two data archives collectively contained 1 million samples; they now already contain more than 2.25 million samples. He noted that NCBI provides access to this information without even requiring users to use a username or password. He remarked on the successes of several open data repositories. For example, The Cancer Genome Atlas2 references more than 14,000 cases across 39 types of cancers and includes 13 types of data (e.g., molecular, clinical, and sequencing), some of which are accessible at various levels. Genetics researchers also share a vast array of data via the Database of Genotypes and Phenotypes (dbGaP),3 access to which requires the completion of paperwork and an occasional Institutional Review Board application. Chemical biologists use PubChem4 to share their data, which references 227 million substances, 1.3 million assays, and more than 1 billion measurements within a grid of 300 trillion cells. Molecular biologists share their data via ENCODE,5 which has 442 principal investigators across 32 institutes and 15 TB of data.
Butte explained that immunologists and clinical trialists also share their data. For example, with nearly 400 data sets and approximately 1,000 users each month, ImmPort6 is likely the largest repository for flow cytometry data and the one repository that allows raw, deidentified clinical trials data to be downloaded by the public. ImmPort has expanded by collecting data beyond the National Institutes of Health—for example, vaccine data from the Bill and Melinda Gates Foundation and preterm birth data from the March of Dimes. He noted that all requests for applications (RFAs) from the National Institute of Allergy and Infectious Diseases (NIAID) require researchers to deposit data to ImmPort. NIAID also offers funding to download and use data from ImmPort. He proposed that NIH continue to develop RFAs with similar requirements in the future. Google Cloud, which contains many high-level data sets (e.g., population health, Centers for Disease Control data, Centers for Medicaid and Medicare Services data, Google Data Set Search), provides another avenue for data sharing. He wondered why so few researchers take advantage of all of
___________________
1 For more information about ArrayExpress, see https://www.ebi.ac.uk/arrayexpress, accessed September 25, 2019.
2 For more information about The Cancer Genome Atlas, see https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga, accessed October 1, 2019.
3 For more information about the Database of Genotypes and Phenotypes, see https://www.ncbi.nlm.nih.gov/gap, accessed October 1, 2019.
4 For more information about PubChem, see https://pubchem.ncbi.nlm.nih.gov, accessed October 1, 2019.
5 For more information about ENCODE, see https://www.encodeproject.org, accessed October 1, 2019.
6 For more information about ImmPort, see https://www.immport.org/home, accessed October 1, 2019.
these available data for experiments that could identify new drugs for patients.
Butte suggested that postsecondary institutions become more involved in motivating researchers to share data. For example, with assistance from the campus library, the University of California, San Francisco, distributes citable Digital Object Identifiers so that researchers can make their data publicly available. The entire University of California system utilizes a digital library system, which provides open access guidelines for publication. He asserted that researchers will not be convinced to change their behavior and share data with the motivation of citation or promotion alone.
Butte provided 10 reasons to archive and share study data openly:
- Enhance reproducibility,
- Improve transparency,
- Support public policy,
- Return data to the community,
- Make failed trials and studies visible,
- Enable learning,
- Speed results reporting,
- Enable new ventures,
- Increase trust and believability, and
- Develop new science.
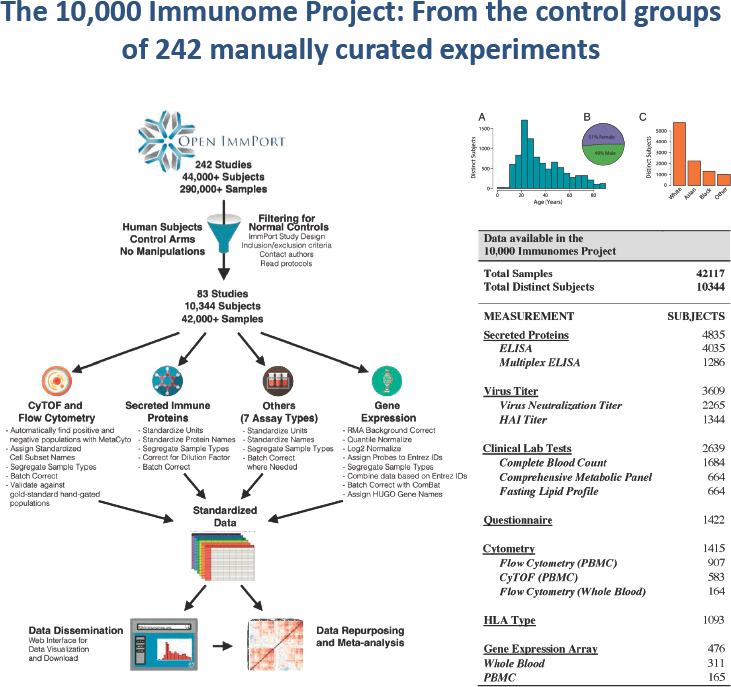
He described the need to develop new science as the key driver for scientific data sharing. For example, ImmPort’s 10,000 Immunome Project, which contains data on 10,000 people in control groups from clinical trials, generates a multiethnic, multirace, multiage, and multigender representation of a normal healthy immune system (see Figure 4.1).
Butte shared three anecdotes about the value of shared data. He noted that because preeclampsia screening was inadequate, his team sought to develop a more precise diagnostic tool for the potentially lethal condition. The team searched NCBI’s Gene Expression Omnibus and EBI’s ArrayExpress, found dozens of experiments with hundreds of samples, looked for commonalities and repeating patterns, and conducted tests. The result of this research was the spin-out and formation of Carmenta Bioscience after $2 million in seed funding was raised. A second study was inspired by the high costs (e.g., between $4 billion and $12 billion) associated with developing new drugs. The PubChem and the NIH Library of Integrated Network-Based Cellular Signatures7 repositories have data that can be
___________________
7 For more information on the Library of Integrated Network-Based Cellular Signatures, see http://www.lincsproject.org, accessed October 1, 2019.
used to develop new drugs, find new uses for old drugs, and reposition drugs. Through computation and testing, his team identified a drug that could potentially be used to treat liver cancer. This work led to the development of another company, NuMedii, which has raised more than $10 million, continuing the research on drugs to treat other diseases. Lastly, with an interest in using genome sequencing to predict disease based on genetic polymorphisms, he co-founded the company Personalis—an endeavor that began with a high school student reading articles and has now successfully completed an Initial Purchase Offering, raising more than $200 million with approximately 150 employees.
Butte shared four important guidelines for building big data ecosystems: (1) sufficient data that can impact health care already exist (i.e., diagnostics and drugs can be developed from public big data), (2) extremely high-quality public and open data are readily available, (3) “sticks” seem to work better than “carrots” to motivate data sharing, and (4) the field needs more inquisitive researchers and trained students to initiate data science.
Chu asked Butte to elaborate on his perspective about strategies to motivate researchers to share data. Butte described a fundamental problem: Because the person who submits data often does not benefit in the same way as the person who uses data, it might be necessary to “force” or otherwise incentivize people to share their data. In addition, NIH program directors cannot be the ones responsible for enforcing data sharing because they have to maintain positive relationships with the best scientists from the best laboratories, he continued. Thus, another entity is needed to enforce data sharing. In that case, NIH can then work in partnership with the researchers to make the process as painless as possible. Patricia Flatley Brennan, National Library of Medicine, asked Butte whether charging people to reuse data would accelerate or decelerate research. Butte replied that researchers already pay for high-value data sets, but it is not a model that they appreciate. Alexa McCray, Harvard Medical School, pointed out that if there is a fee for the use of “high-value” data sets, free data will no longer be available and it will be impossible to aggregate across multiple data sets. Such a cost model could lead to discrimination against those who cannot pay as well as heterogeneity in the type of data that is available. Brennan asserted that grants provide a pathway to payment; direct pay is not a strategy that NIH has discussed. Martone pointed out that when a researcher pays for data, he or she has the right to redistribute them. Margaret Levenstein, University of Michigan, cautioned against creating processes that could make data access even more difficult for junior researchers. Bandeira reiterated that extraordinary value can be derived from data that already exist and asked how much of that value is returned to the community and shared publicly. Butte replied that none of the value is returned if no sharing mechanism (beyond articles) exists.