
The next workshop panel considered the key challenges of data interoperability and platform usability in the context of three case examples. Ernest Hawk, vice president and head of the Division of Cancer Prevention and Population Sciences at MD Anderson, discussed issues of data interoperability and platform usability in the context of cancer prevention trials. Tianjing Li, associate professor at the University of Colorado Denver, described an example of an unsuccessful attempt to conduct an individual patient data network meta-analysis (IPD-NMA). Bill Louv, president of Project Data Sphere, discussed Project Data Sphere as an example of an open-access, data-sharing model and described some of the challenges faced. The session was moderated by Timothy Coetzee, chief advocacy, services, and research officer at the National Multiple Sclerosis Society, and Dina Paltoo, assistant director of Policy Development at the National Library of Medicine at the National Institutes of Health.
WORKING WITH POPULATION DATA
Ernest Hawk, Vice President and Head, Division of Cancer Prevention and Population Sciences, MD Anderson
Hawk discussed issues of data interoperability and platform usability in the context of cancer prevention trials. He shared three case examples illustrating (1) the value of collecting “the right data” in a standardized form that enables both primary and secondary analyses, (2) the importance of external validity of the trial sample, and (3) the significance of governance and data sharing prior to trial conclusion to enable safety assessment.
Data Standardization and Collection
Data standardization and collection in cancer prevention trials are often insufficient, Hawk said. Standardized questionnaires are not used for data collection, and there is no systematic collection of data on either exposure across the life span or concomitant medication use. Data on concomitant medications are valuable, he explained, because there is a lack of directed investment in drug development for cancer prevention, and insights about preventive medications have been largely serendipitous. Behavioral data are often not collected, and there is also the challenge of incorporating data from mHealth (mobile phone apps and wearables) observations.
Hawk discussed tobacco use as a case example. For more than 50 years, tobacco use has been associated with a range of adverse health consequences, including cancer and cancer-related outcomes. In addition, he said, tobacco use reduces cancer treatment efficacy, and tobacco users experience more significant adverse effects of treatments (e.g., second
primary tumors, treatment-related toxicities and morbidities) than former tobacco users or those who never used tobacco. Despite the known negative consequences of tobacco use on cancer outcomes, information about tobacco use has not been systematically collected from participants during oncology clinical trials (Gritz et al., 2005).
A study published in 2012 found that about one-third of trials in the National Cancer Institute’s (NCI’s) Clinical Trials Cooperative Group Program1 had assessed tobacco use upon enrollment of participants, less than 5 percent assessed tobacco use during the course of the trial, and none of the trials asked if tobacco users were interested in quitting, Hawk reported. Less than 3 percent of the trials assessed secondhand smoke at enrollment. Any tobacco use data that were collected, he said, were not captured in a standardized form (Peters et al., 2012).
To help address these issues, a task force convened by NCI and the American Association for Cancer Research developed the Cancer Patient Tobacco Use Questionnaire (Land et al., 2016). Hawk said this standardized questionnaire has four core questions to collect a minimal set of data as well as an extended survey, and allows for harmonization of data across studies.
External Validity of Trial Samples
External validity is the extent to which the trial population represents the broader population the trial intends to serve. Hawk pointed out that the underrepresentation of women and minorities in cancer clinical trials persists, despite years of efforts intended to address this issue. Trials also lack diversity in other characteristics that impact cancer outcomes, including genetics and socioeconomic and demographic factors.
Hawk elaborated on recruitment of minority populations to clinical trials, showing recent data on cancer prevalence and cancer trial participation in the United States relative to 2018 U.S. Census data. As shown in Figure 5-1, there is a lack of minority representation in cancer trials. He highlighted several of the barriers to recruitment of underrepresented and minority populations, including lack of awareness of or access to trials, less trust in the health care system, language barriers, and importantly, socioeconomic factors, including lack of insurance coverage (Duma et al., 2018). Great time, effort, and expense go into conducting clinical trials that often do not represent uninsured and under-insured populations in whom cancer diagnoses and poor outcomes are concentrated, Hawk said.
___________________
1 The NCI Clinical Trials Cooperative Group Program is now known as the NCI National Clinical Trials Network. See https://www.cancer.gov/research/areas/clinical-trials/nctn#groups (accessed March 2, 2020).
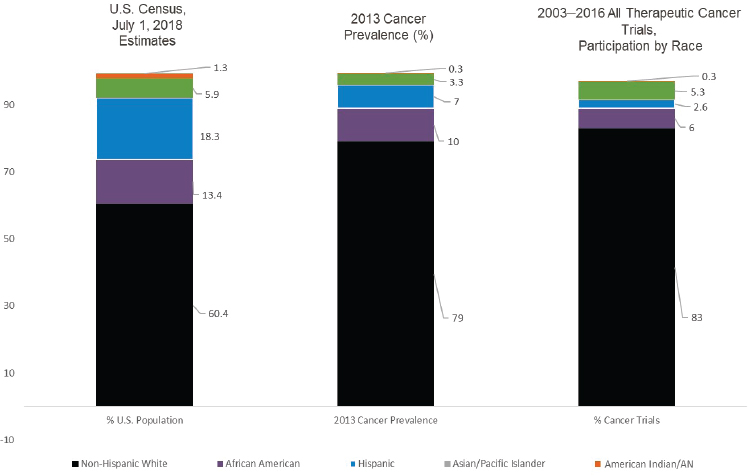
NOTE: AN = Alaska Native.
SOURCES: As presented by Ernest Hawk, November 18, 2019; based on 2018 U.S. Census data and Duma et al., 2018.
To try to improve minority representation in cancer clinical trials, Regnante and colleagues (2019) looked to U.S. cancer centers of excellence to identify practices that facilitate recruitment and enrollment of racial and ethnic minorities. Examples of strategies identified, Hawk said, included an organizational commitment to diversity, an institutional presence in the community that fosters trust (e.g., community advisory boards, sharing research findings with the community), provider recommendation to a trial, and availability of culturally appropriate materials.
Governance and Data Sharing
Hawk’s final example demonstrated the importance of data sharing prior to trial completion to amplify potential safety signals. He described the Adenoma Prevention with Celecoxib (APC) trial of the selective COX-2 inhibitor, celecoxib, for the prevention of colorectal adenomas (Solomon et al., 2005).2 Although the trial demonstrated efficacy of the intervention, the
___________________
2 See https://clinicaltrials.gov/ct2/show/NCT00005094 (accessed March 2, 2020).
trial was stopped early due to concerns over the potential cardiovascular toxicity of the treatment, Hawk said. To better assess the cardiovascular risk, data were pooled across the APC trial and five other publicly funded, ongoing trials testing celecoxib for different therapeutic or preventive indications (Solomon et al., 2008). Individually, each trial had too few adverse events to assess the cardiovascular risk associated with celecoxib. However, when data were combined, the number of adverse events from the six trials allowed for the elucidation of the dose-related cardiovascular safety concern. Nevertheless, Hawk noted that different baseline data collected in each trial presented a challenge for the analysis.
CHALLENGES FOR META-ANALYSIS
Tianjing Li, Associate Professor, University of Colorado Denver
Li shared a case example of a failed attempt to conduct an individual participant data network meta-analysis. The uniqueness of this approach, she explained, is that the data for the meta-analysis were obtained from data-sharing platforms. As background, she said that greater than 95 percent of published meta-analyses are based on aggregate data, not IPD. Researchers who have done IPD meta-analyses have generally obtained data directly from the trial investigators.
This project was part of the doctoral thesis of Lin Wang, a Ph.D. candidate at Johns Hopkins University, where Li is an adjunct associate professor. Li explained that the student proposed to conduct a systematic review and IPD-NMA on competing treatments for advanced prostate cancer, and to explore whether treatment effect differs by patient characteristics for two tumor types. Wang identified relevant clinical trials that claimed to share IPD on four data-sharing platforms: Vivli, the Yale University Open Data Access (YODA) Project, ClinicalStudyDataRequest.com, and Project Data Sphere.3 Li said the project faced three key challenges, including IPD availability, cross-platform compatibility, and timeframe and practicality.
Challenges
Lack of IPD Availability
Li explained that, in reviewing the eligible trials for the two tumor types of interest, the student found that IPD were available for only two
___________________
3 For information on Project Data Sphere, see https://projectdatasphere.org/projectdatasphere/html/home (accessed March 2, 2020).
of the six trials for one tumor type, and for one of the seven trials for the other tumor type. According to Li, the trial sponsors gave the student the following reasons for the inability to share IPD:
- The trial was still ongoing or recently had been completed (within 18 or 24 months).
- Regulatory review and approval in the United States and/or European Union were still pending for the product or indication studied.
- “The trial sponsor is not a data contributor, or is a data contributor but the trial of interest is not yet listed, or declined the request because of similar research questions.”
The student found that it was relatively easy to find the trial registration numbers, search the data-sharing platforms, identify which trials would share IPD, and submit her data request applications. After that point, however, the process was “out of her control,” Li relayed. Although she sent each platform a similar proposal, her experience varied (e.g., some granted permission based on the application as submitted while others required multiple iterations providing additional detail about the research plan).
Cross-Platform Incompatibility
Li said the student also experienced challenges conducting her meta-analysis with IPD obtained from different platforms because of the following:
- Most of the available IPD are not in a downloadable format.
- The data cannot be merged across platforms (cross-platform transmission is prohibited).
- Quality of IPD is inconsistent, metadata are incomplete, and there is a lack of standardization.
- Data of interest might not be in the database.
Timeframe and Practicality
Another challenge the student faced, Li said, was the lag time from the request for IPD to approval by the platform, which ranged from 1 to 8 months. Li pointed out that, after approval, it can take significant time to prepare the dataset for analysis. “Navigating through the different data-sharing models, multiple user accounts, access policies, and procedures … can be challenging for a student or even for a researcher,” Li said.
Approaches to Facilitate IPD Meta-Analysis
Li offered her perspective on what is needed to enable meta-analysts to more readily curate data from data-sharing platforms for systematic review. More IPD should be made available on data-sharing platforms, she said. There is also a need for a “single, searchable database that catalogs all IPD available across different platforms,” and Li offered the World Health Organization (WHO) International Clinical Trials Registry Platform (ICTRP) as a model.4 Data-sharing platforms need to have simplified, harmonized, and tiered data request procedures, and she suggested that the institutional review board approval process offers one example of such procedures. A mechanism to allow data merging across different data-sharing platforms is also needed, she said. Data analysts seeking to conduct an IPD meta-analysis “need proper funding, resources, and skills,” she continued. In the interim, Li concluded, analysts will need to “consider meta-analysis with both IPD data and aggregate data.”
PLATFORM PERSPECTIVE
Bill Louv, President, Project Data Sphere
Louv discussed the unique aspects of the Project Data Sphere open-access, data-sharing platform and described some of the challenges faced.
The Project Data Sphere Model
Project Data Sphere, launched in 2014, is an open-access “digital library-laboratory” created to “broadly share, integrate, and analyze cancer clinical trial data,” Louv said. Submission of a research protocol is not required, and access to the full database is provided in about 48–72 hours. Users have free access to SAS analytics software, although Louv noted that most investigators choose to download data and use their own analytical tools. Louv echoed Li’s comments and said that “downloading is the only pragmatic way to do meta-analysis across platforms.” Thus far, more than 2,500 investigators have collectively made nearly 20,000 data downloads.
The database houses more than 150 datasets from industry and NCI Phase 2 and Phase 3 clinical trials, which include data from more than 125,000 patients. Louv added that about 40 percent of the data are from the experimental arm of the trials and 60 percent are from the comparator arm.
___________________
4 ICTRP is a searchable database of national and regional clinical trial registries. See https://www.who.int/ictrp/search/en (accessed February 10, 2020).
One aspect that sets Project Data Sphere apart is the open-access, data-sharing model (Bertagnolli et al., 2017). Louv observed that YODA and Project Data Sphere are very different models of data sharing, but they have resulted in a similar number of publications, and importantly, there is no evidence of misuse of data or spurious observations made from the data shared on either platform.
Another unique element of Project Data Sphere is its funded research programs (see Figure 5-2). One example, Louv said, uses IPD from comparator arms of small cell lung cancer randomized controlled trials to develop an external control arm. Another program is focused on training machine-learning algorithms to augment radiologist interpretation of cancer progression in images from oncology clinical trials. All the research projects funded by Project Data Sphere are “leveraging the consolidation of data to do something that is not available otherwise,” Louv said.
Challenges
Platform Usability
Platforms, such as Project Data Sphere, rely on data providers for quality assurance of the data to be shared. Providers, in turn, rely on the platform to ensure the terms of the data use agreement (DUA) are met, Louv said. With regard to the former, Louv said Project Data Sphere
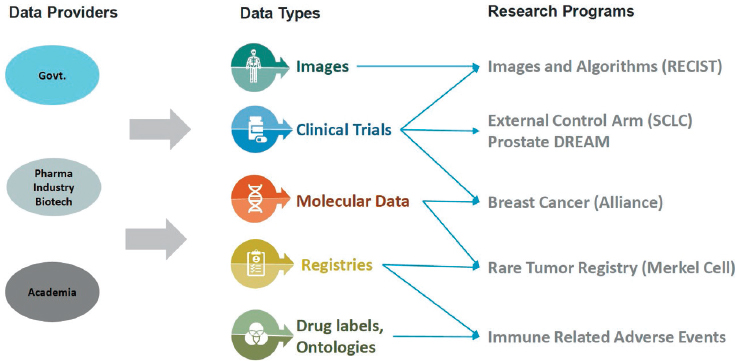
NOTE: DREAM = Dialogue for Reverse Engineering Assessments and Methods; RECIST = Response Evaluation Criteria in Solid Tumors; SCLC = small cell lung cancer.
SOURCE: As presented by Bill Louv, November 18, 2019.
assumes that providers will adhere to its recommended standard for sharing data (Clinical Data Interchange Standards Consortium [CDISC]), will properly deidentify data, and that the metadata provided match the data files. A challenge, he said, is that data files “decay” over time as files in the database go unused and those most familiar with the data move on. To address this, Louv said that Project Data Sphere implements a “light-touch dataset acceptance protocol” before including data in the platform. Project Data Sphere also focuses on the usability of metadata, optimizing it for searchability. Louv noted that they have learned from Vivli’s work on curation of metadata.
With regard to controlling access to the data, Louv reiterated that Project Data Sphere has an open-sharing model and allows users to download datasets. A challenge for open-access models is that the nature of their openness can be a barrier—causing some data generators to choose not to share on Project Data Sphere. He said, however, that the other data-sharing platforms are also “self-selected groups” and that self-selection of where to share by data providers limits the ability to compare the metrics across platforms.
Data Interoperability
As discussed throughout the workshop, data interoperability across platforms is a key challenge. Currently, Louv said, data users must find ways to work across platforms on their own. To address this, Louv highlighted the need to establish “a federation of data-sharing platforms” that would “establish and maintain standard metadata” at both the platform and the study levels.
Interoperability across data domains is also an ongoing challenge. There are particular challenges for sharing imaging and genomic data, for example. Louv said that data standards and deidentification protocols are “less mature” than those for other types of shared data.
Another challenge is that imaging and genomic data are inherently different from other clinical trial data (e.g., outcomes data) and generally exist in different formats and ontologies. Raw imaging and genomic data are often collected in central specialty laboratories that have different data structures, data stewards (who might have different priorities for data sharing), and data deidentification schemes. Louv explained that it can be difficult to associate the deidentified genomic data with deidentified clinical data, often requiring reidentification, linking, and then deidentification again. As a potential solution, Louv proposed to “limit copying of genomic and imaging data into clinical platforms (and vice versa),” and “enable interoperability with standards for core data, and global patient identifiers.”
DISCUSSION
A Searchable Catalog of IPD Available Across Platforms
Participants discussed further Tianjing Li’s recommendation for a searchable catalog of IPD that is available across different platforms. Deborah Zarin suggested that ClinicalTrials.gov could potentially serve this function, and she encouraged further discussion on this issue with the registry. Brittany Maguire from the Infectious Diseases Data Observatory (IDDO) pointed out that not all trials of interest with available IPD are registered in ClinicalTrials.gov. There are clinical trials in other registries that can be identified via other databases, such as the WHO ICTRP (mentioned by Tianjing Li above). David Sampson of the American Society of Clinical Oncology shared his perspective as a publisher. He suggested that “data platforms … are analogs of journals” and that the data-sharing community should look to journal publishing for lessons learned about ethics, abstracting and indexing, standards, infrastructure, workflows, and tagging content, for example. He suggested that there is a need to form organizations to support data sharing and to help overcome this lack of coordination. Louv observed that there is still much work to be done on the infrastructure for data sharing, which requires funding, and he expressed hesitancy to form organizations in the absence of a sustainable structure. In response to a question from Hawk, Louv elaborated that Project Data Sphere is a not-for-profit organization that is sustained by its membership structure as well as grants and contracts. Money from funders goes both to the research programs as well as to platform improvements.
A Culture of Data Sharing for Oncology Trials
Coetzee asked whether the fact that Project Data Sphere is focused on a single disease state and indication provides an advantage in creating a sustainable data-sharing platform by essentially creating a supportive community. Louv agreed that the exclusive focus on cancer likely did offer an advantage, although he questioned the ability to scale that advantage in a bigger structure. He described the oncology field as a “tight-knit community” and added that the field is somewhat unique in that “it is reasonable to take more risk to find innovation,” and that extends to data sharing. Coetzee suggested that the community aspect creates a culture of accountability with regard to data sharing. Louv agreed, but added that when a company is not willing to share information similar to what other companies have already shared, it is important to have conversations to understand why they are hesitant while others are eager. Ultimately, Louv
emphasized, there must be respect for each potential data sharer’s situation within his or her organization.
Timely Sharing of Data
Matthew Sydes asked whether the analysis described by Hawk (of the pooled data from six celecoxib trials to amplify safety signals) could have been done sooner, or if the analysis was done at the earliest opportunity. Hawk responded that it was done at the earliest opportunity. Specifically, it was the first time his division at NCI attempted to pool safety data from ongoing, publicly funded trials. He described it as “extremely challenging” because they were not aware of existing models for evaluating safety data from ongoing trials, and they were developing the process as expeditiously as possible as they went along. Although dosing was suspended across all six federally sponsored trials of celecoxib after the initial safety finding, he said it took time to convince the sponsors, trial leaders, and DSMBs for each study of the need to compile the data, to then secure DUAs, and to establish the adjudication process to evaluate an event that was not a primary endpoint.
Avoiding Duplication of Effort
Sydes also raised the issue of avoiding unnecessary duplication of effort in secondary analyses. He noted that he was aware of several other efforts to conduct essentially the same meta-analysis that Tianjing Li’s student was attempting. Li acknowledged the difficulty of avoiding duplication of effort and said that groups working on the same or similar topics might collaborate.
Data Quality
Paltoo asked panelists to elaborate on data quality challenges relative to interoperability and usability. Louv reiterated that a key challenge is the “perishability” of clinical trial data. In the time since a study has been archived, the technology and analysis software used have often evolved. For example, when the information in the metadata file does not match the actual trial records, it can be difficult to resolve as study staff with knowledge of the trial have moved on or there are not resources to dedicate to preparing the data for sharing. Louv added that, although more recent studies in newer databases are better suited to sharing with respect to data quality, there are often issues that delay or inhibit sharing, such as intellectual property concerns, a publication plan, or pending regulatory activity.
Another challenge, Tianjing Li said, is the difference in quality, consistency, and harmonization between the data that are currently accessible through data-sharing platforms, and the data one might request from trial investigators at academic institutions, which she described could be “much messier” than the data available for use through the data-sharing platforms. Harmonization is a particular challenge. Data collected using the same instrument or scale might be coded completely differently. As an example, she said that in the data gathered for an IPD meta-analysis, “one trial coded race and ethnicity as two variables and another trial coded it as one variable,” which she said eliminated the possibility of conducting subgroup analysis by race/ethnicity. She also raised workforce issues as a challenge, and the importance of having people with the necessary skillsets to use shared data “in a meaningful way.”
Hawk emphasized the need to standardize the assessment of behavioral variables and other contextual factors in the conduct of Phase 3 trials, and to consistently assess those variables for trials that might offer the most benefit for data sharing. For example, cancer treatment trials have long focused on the treatment being tested, with limited attention to the broader context in which those treatments are being applied (e.g., concomitant use of tobacco or alcohol). Li added that the development and implementation of core sets of outcomes and common data elements would improve the quality of shared data.
Sonali Kochhar suggested that funding infrastructure development could include the development of basic criteria to facilitate harmonization and data comparability (e.g., core outcomes, core data points to collect for each outcome, basic metadata requirements), and funders could encourage academic and industry trial sponsors to follow these basic criteria.
Tianjing Li said that criteria to consider for outcomes include the name of the outcome (i.e., domain), the preferred measurement instrument, metrics (e.g., relative risk, mean difference from baseline and time point), and time points, for example. Variation in these elements can lead to heterogeneity in treatment effect, and makes meta-analysis very difficult, she said. When a trial cannot be summarized in a meta-analysis, it is difficult to include it in the “totality of the evidence” about the intervention. Li referred participants to the Core Outcome Measures in Effectiveness Trials initiative in the United Kingdom as a model.5
Trials for Rare, Neglected, and Emerging Diseases
Maguire said IDDO aggregates data on neglected and poverty-related diseases and emerging infections, and that the clinical datasets they obtain
___________________
5 See http://www.comet-initiative.org (accessed March 2, 2020).
are most often from trials conducted by academia and other institutions, not by industry, and are smaller scale. She raised concern about prioritizing data sharing from large-scale, pivotal Phase 3 clinical trials as trials for neglected diseases would be overlooked. “The totality of evidence should be considered when recognizing the value of IPD,” she said. IDDO is also using its disease-focused data platforms to develop a research agenda, which, in turn, facilitates the data-sharing process and the reuse of those data. Maguire said that clinical datasets from neglected disease clinical trials are very heterogeneous, and IDDO is currently curating data to CDISC standards. This is challenging for non-industry trials, but it is feasible, she said. In addition, following the CDISC standard helps to inform prospective data collection by researchers.
Louv said there are similar issues for trials of rare diseases. Few randomized controlled trials exist for rare tumors, for example, and Project Data Sphere is developing rare tumor registries to collect high-quality data.
Data Sharing Impacts the Design and Conduct of Future Trials
Tianjing Li added to the comment by Maguire that the IDDO data-sharing platforms inform their research agendas and that their standardization efforts inform prospective data collection. Li observed that although much of the discussion has been focused on the public health impact of data sharing, data sharing influences the design and conduct of clinical trials (e.g., trials intended for sharing are being designed around a set of core outcomes and common data elements and are appropriately powered statistically). This is a positive outcome of clinical trial data sharing that is difficult to quantify, but that should be acknowledged, Li said.
This page intentionally left blank.














