














Below is the uncorrected machine-read text of this chapter, intended to provide our own search engines and external engines with highly rich, chapter-representative searchable text of each book. Because it is UNCORRECTED material, please consider the following text as a useful but insufficient proxy for the authoritative book pages.
9 The focus of this synthesis was on the governance and tools used to manage transit service data, also referred to in the literature as âITS dataâ (Strathman et al. 2008). Transit service data are described as the data used to generate transit service performance such as schedule, facilities (stops), and archived operations data. There are many studies, assessments, and lessons learned about multiple industry data management current practices, fewer for transportation organiza- tions, and fewer yet that explicitly describe current practices and initiatives for transit organiza- tions. The most relevant literature for transit agencies is presented at conferences like the American Public Transportation Association (APTA) APTAtech (also known as the Fare Collection and TransiTech conferences). Although the U.S. DOT initiated a series of workshops and best practices for data governance, they targeted state and regional planning organizations, not transit. The U.S. DOT data governance effort predated their traffic, service, maintenance, and operations (TSMO) efforts, which by its mission necessitates breaking data silos and transforming an organization to be data driven. The literature review investigated the current transit practice in managing service data. Service data and tools used to create, collect, and curate the data are described in the Transit Data and Data Management section. Collection tools drive the need to clean, integrate, store/archive, and provide access to data to analyze performance (e.g., compare planned to actual), generate perfor- mance indicators, and visualize the results. To understand how transit is positioned relative to current practices deployed in other indus- tries, the Data Management: Industry Practices section describes industry practices from the literature. In this section, the needs for data management, functional elements of data manage- ment architectures, and trends are presented. Finally, industry practices around data governance are described in the Data Governance Prac- tices section. This section presents a concise description of the elements of a data governance program and how state and regional planning organizations are implementing data governance. Transit Service Data Transit Service Data Sources and Uses Many studies described analytical methods for developing transit service performance measures that are derived from transit service data. Studies such as Furth et al. (2006), Cevallos and Wang (2008), Strathman et al. (2008), Hemily (2015), and Iliopoulou and Kepaptsoglou (2019) identi- fied tools to create, collect, and qualify (clean and validate) transit service data. Many additional studies illustrate the opportunities to develop performance and visual information once archived (Berkow et al. 2009, Schweiger 2015). C H A P T E R 2 Literature Review
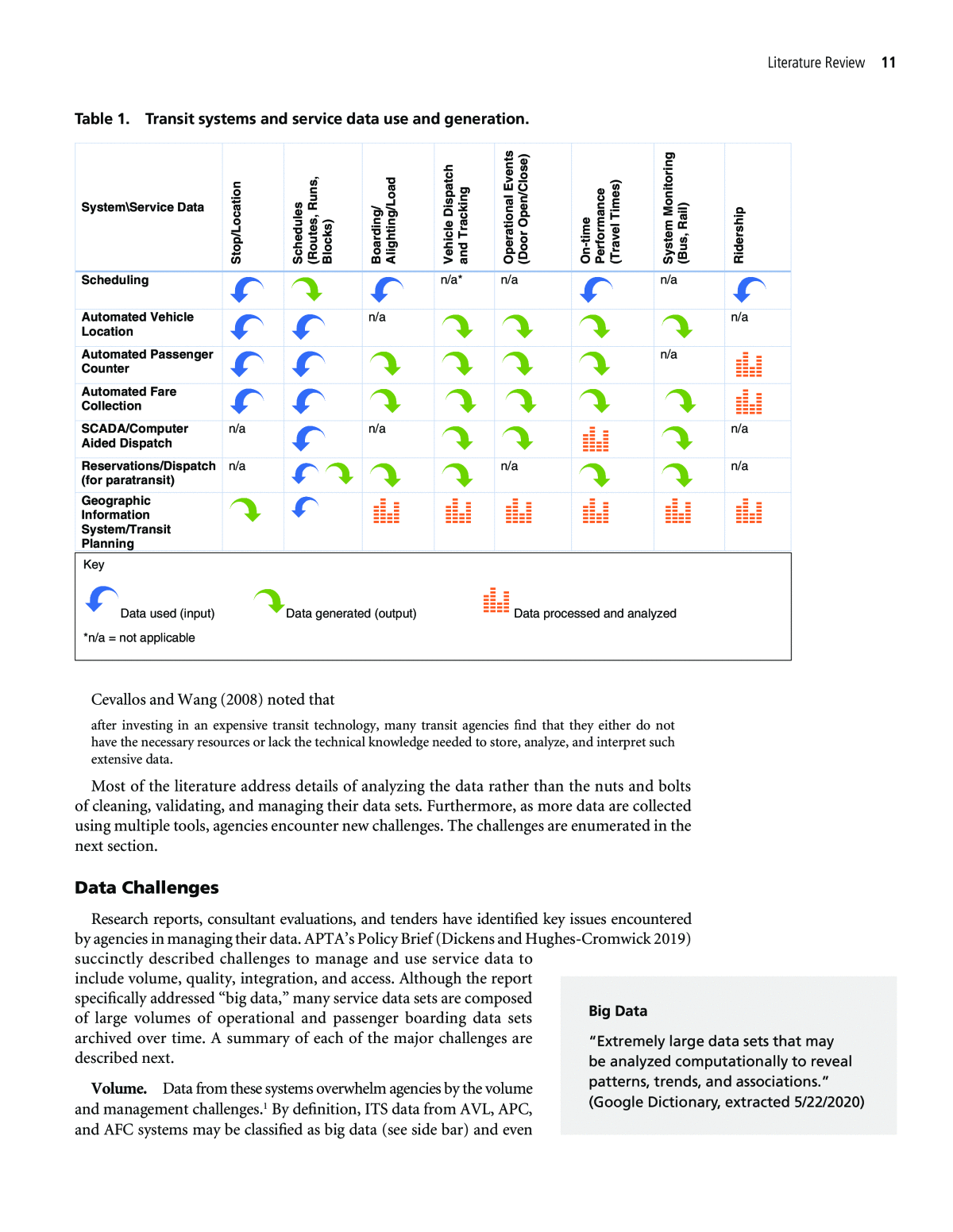
10 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data For most transit modes, the data creation and collection tools used for transit planning and operational performance include SchedulingâUsing stop (and right-of-way) locations, generating the planned trips, and vehicle and operator work. Bus, rail, ferry, and paratransit systems use different tools (see reservations and dispatch system for paratransit). The scheduling system provides planned work by which operations is measured. Automated Vehicle Location (AVL)âSystem that tracks a vehicle location and monitors it for schedule and route adherence. In addition, operational events tagged by time and loca- tion such as door open/close, layover times, travel time, dwell times, are also collected by the AVL. Automated Passenger Counter (APC)âSystem that detects passengers boarding and alighting a transit vehicle (or turnstiles). The system must also track location by stop to collect accurate boardings, so APC collected data overlaps with AVL data. Sensors may be positioned at all doors, in all vehicles, or a subset of vehicles and doors. Statistical methods are required to calculate ridership when only a fraction of vehicles have APCs installed. Automated Fare Collection (AFC)âSeveral types of AFC systems are currently deployed that collect financial and transaction data. The AFC cash box is primarily used for collecting finan- cial data at a trip or block level. AFC card- and account-based (including mobile fare app) systems (Okunieff 2017) are increasingly being used to collect data that are used to generate performance information because the systems tag each transaction by time and location/stop, links card, or account numbers that provide information on the rider such as rider class (e.g., regular, discount), previous travel history, and more. In TCRP Synthesis 77: Mobile Data Terminals, Boyle reported that fewer raw data were usable (average 74% in 2008) âcompa- rable to findings from 10 years ago, with a median value of 80%.â This is contrasted with the threshold for acceptance cited by respondents who indicated that â90 to 95% was needed to meet the level of accuracyâ (Boyle 2008). SCADA/CAD SystemsâSupervisory control and data acquisition (SCADA) systems are typi- cally deployed to monitor, control, and collect data for rail systems, while Computer Aided Dispatch (CAD) is used to monitor and collect data for bus and ferry systems. These systems collect and aggregate information on fleets and monitor information of individual vehicles relative to other vehicles. Reservations and Dispatch (for Paratransit)âThe demand-responsive tools differ in that many of them combine scheduling vehicle and driver assignments, passenger manifests, dispatch, and tracking into a single system. There is typically an on-board tracking tool that collects events by location and time, and a centralized system that collects, manages, and stores the data. Additional tools, such as GIS, may be used to support data collection of stop and event infor- mation, although many of the other systems (e.g., APC or AVL) include modules to collect and use their own geocoded stop and event information. Finally, the differences and inconsistencies are minimized when the on-board systems (AVL, APC, AFC) share geotemporal and event data, as in when the AVL provides location and time values to the AFC, or when the AVL and APC use the same event information (e.g., speedometer or door sensors). Even though the data are âintegratedâ on-board prior to archiving, errors still exist, and quality and integration processes are still required during the curation processes. The systems that use (input) specific service data sets to generate (output) useful information are shown in Table 1. The table shows the dependency of deriving good information for âdownstreamâ systems that use the information. The literature details that transit staff continue to describe the volume and lack of resources that are available to curate, manage, and use the data to generate performance metrics and implement the visualizations.
Literature Review 11 Cevallos and Wang (2008) noted that after investing in an expensive transit technology, many transit agencies find that they either do not have the necessary resources or lack the technical knowledge needed to store, analyze, and interpret such extensive data. Most of the literature address details of analyzing the data rather than the nuts and bolts of cleaning, validating, and managing their data sets. Furthermore, as more data are collected using multiple tools, agencies encounter new challenges. The challenges are enumerated in the next section. Data Challenges Research reports, consultant evaluations, and tenders have identified key issues encountered by agencies in managing their data. APTAâs Policy Brief (Dickens and Hughes-Cromwick 2019) succinctly described challenges to manage and use service data to include volume, quality, integration, and access. Although the report specifically addressed âbig data,â many service data sets are composed of large volumes of operational and passenger boarding data sets archived over time. A summary of each of the major challenges are described next. Volume. Data from these systems overwhelm agencies by the volume and management challenges.1 By definition, ITS data from AVL, APC, and AFC systems may be classified as big data (see side bar) and even System\Service Data S to p /L o ca ti o n S ch ed u le s (R o u te s, R u n s, B lo ck s) B o ar d in g / A lig h ti n g /L o ad V eh ic le D is p at ch an d T ra ck in g O p er at io n al E ve n ts (D o o r O p en /C lo se ) O n -t im e P er fo rm an ce (T ra ve l T im es ) S ys te m M o n it o ri n g (B u s, R ai l) R id er sh ip Scheduling n/a* n/a n/a Automated Vehicle Location n/a n/a Automated Passenger Counter n/a Automated Fare Collection SCADA/Computer Aided Dispatch n/a n/a n/a Reservations/Dispatch (for paratransit) n/a n/a n/a Geographic Information System/Transit Planning Key Data used (input) Data generated (output) Data processed and analyzed *n/a = not applicable Table 1. Transit systems and service data use and generation. Big Data âExtremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations.â (Google Dictionary, extracted 5/22/2020)
12 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data more so as Location-Based Service (LBS) data, that is, a large volume of geocoded, time series data sets. Resources and tools are needed to manage large data sets; data anomalies such as missing time ranges or inconsistencies require procedures and rules to identify the issues. Quality. Data cleanup and validation is a normal process of managing data. Operational systems will not collect data without anomalies and errors such as missing data due to commu- nication disruptions and vehicles offloading their data to the central computer days late. Rules and procedures are typically applied to data prior to usage. In developing their data management system, Community Transit recognized that cleanup was necessary by identifying the old-adage âGarbage In, Garbage Outâstart at the sourceâ (Heim 2019). Cevallos, in developing a data mining tool, stated: âEstablish data integrity before creating a data mining model [when data are inte- grated] is paramountâ (Cevallos 2008). Although there are vendor tools that correct and clean data errors, agencies apply specialized tools to detect, clean, and validate data. TCRP Synthesis 125: Multiagency Electronic Fare Payment Systems (Okunieff 2017) includes an example of Washington Metropolitan Area Transit Authority (WMATA)âs quality process to clean ridership information prior to loading it into the data warehouse. As noted by WMATA, WMATA differentiates cleaning [quality] from integration processes. A cleaning process validates that every mandatory field is filled and the data in those fields are formatted correctly, and the data are meaningful and logically consistent. The OD pair example [when fare card tap in matches tap out] is a logical consistency rule. Many data integration errors can be mitigated if quality control rules or detection are applied prior to storage.2 Examples of quality control rules or detection include ⢠Inconsistent data, inconsistent spelling, abbreviations, naming, unique references ⢠Persistent (recurring) errors versus missing data (from data collection tools) Integration. Data integration is critical to enrich and measure transit service. Integration takes the form of applying software procedures and logic to data. These may be as simple as changing data to a different format, or more complex like combining operational data from mul- tiple operational systems (e.g., AVL and AFC using time and stop location), comparing planned to actual service, and assessing service performance over time. Integration challenges come from inconsistencies in using different identifiers, location or location referencing systems, time-tags, or applying different procedures calculating the same parameters with different results (e.g., calculating active buses using different methods3). As further described in TCRP Synthesis 125, an integration process may assign a different format to data (change date format), aggregate data (group bus stops to zip codes), or apply an algorithm to data (assume OD pair for bus travel based on tracking the fare card through its daily usage). Integration implies that an inference or analysis is made about the data. Although referring to transit spatial data, the 2005 Best Practices Guide for Using Geographic Data in Transit ascribed integration challenges to ⢠Inconsistent naming [and referencing] conventions, ⢠Different transit data models [and business rules that describe data and their relationship], ⢠Different data representations, ⢠Differences in data source quality, ⢠[Procedures for] transformations and translations, ⢠Poor documentation (metadata) [that tracks back to data source, quality, quality procedures, and integration procedures], and ⢠Use of different location referencing systems. Agency data management staff 4 and other literature on transit data quality (Hemily 2015) describe challenges managing multiple reference identifiers for fundamental service data sets
Literature Review 13 including references to bus stops, routes, runs, and buses that were stored in separate planning and operational systems. They may generate duplicate location information for their opera- tional systems (AVL, APC, or AFC) using specialized system tools, or because departments have different needs for how they measure stops.5 Metadata are mentioned in the list of integration challenges and often overlooked as an integration obstacle; poor documentation may render archived data obsolete after information about the data are forgotten. Altered processing logic or collection technology, system changes (route adjustments, stop changes), or even short-term events such as road closures, snowstorms, and longer-term impacts like âstay-at-homeâ orders will corrupt downstream performance metrics. Access. Data access occurs after curation (data cleaning, validation, integration, and storage). During this stage, data in storage requires information on how the data are organized (schema), its meaning, and formats (data dictionary). Additionally, it requires information on how to link and acquire the data set (methods). In the context of this report, the term âaccessâ excludes authorization and security procedures, rather it focuses on discovery and distribution of the data. Within that context, access requires a data dictionary, data schema, and information exchange procedures. This last item, information exchange procedures, may be manifest as publishing data in its source or aggregated formats, or data visualization through graphics or animation tools. Access methods may use structured query language procedures (Structured Query Language [SQL] queries), formatted data files, or application programming interfaces (API). GTFS, for example, is a set of comma delimited value (CSV) formatted data files. In addition, data standards used to publish the data are of critical concern. With the multiplicity of operational systems, standards support the exchange and integration of data sets from different sources; however, there are few open standards in the United States used to share opera- tional data between systems, or even with the public. Schweiger (2015) and Hemily (2015) discuss open standard formats in the United States used to publish, extract, and share service data including GTFS. Additional transit data standards were also mentioned such as Transit Communications for Interface Profiles, Siri, GTFS-rides, and TCRP efforts (TCRP Research Report 215: Minutes Matter: A Bus Transit Service Reliability Guidebook [Danaher et al. 2020]) but are not widely accepted (Hemily 2015; Lawson et al. 2019) or are under development. Network Timetable Exchange (NeTEX) and Transmodel (2018) provide detailed specifi- cations that define public transport data concepts, rules, relationships, and data formats for storing and disseminating transit information for both operational and public users. These standards are widely used throughout Europe because transport organizations are mandated by their countries. Yet, even with open data standards, there are other factors that contribute to providing data to the public. First, and foremost, a major challenge to making data discoverable comes down to resourcesâhiring staff who have the skills and time to clean, validate, integrate, process, and store the data (Schweiger 2015, Hemily 2019, APTA 20191). Then the agency is faced with identifying which data to provide to the public. In TCRP Report 213: Data Sharing Guidance for Public Transit AgenciesâNow and in the Future, Viggiano et al. (2019) described how transit agencies decide what and how to publish service information. The study identifies five data processing tasks prior to compiling the data for distribution. They include data cleaning, merging, aggregation, sanitization, and formatting. The data documentation is stored in a data catalog for discovery prior to sharing. Several factors drive the sharing process, including federal and state laws, risks related to privacy, security, misuse, costs, and benefits. With the increasing service data volume and variety, many transit agencies turn to data manage- ment tools to support their integration and data archiving needs. These challenges can be mitigated
14 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data by applying data management methods and practices using tools adopted by other industries. However, industry best practices related to data management have not been promulgated or researched to any major extent. Data Management and Industry Practices Transit Data Management Although data management tools were addressed as early as 1994 in TCRP Synthesis 5 (Boldt 1994), data management practices and best practices were not directly addressed by the indus- try until the TCRP Report 126: Leveraging ITS Data for Transit Market Research: A Practitionerâs Guidebook was published in 2008. Chapter 4 of the guidebook (Strathman et al. 2008) directly addressed best practices for data management of ITS data to support market research. The guide- book focuses on service data, and the âkey elementsâ include ⢠An information system for archiving ITS data; ⢠Enterprise-level applications, the most important of which in the context of this guidebook is GIS; ⢠Processes for screening and validating ITS data to ensure its integrity; ⢠Software tools that support reporting and analysis; and ⢠Human resources with the skills to maintain the infrastructure and, through analysis of ITS data, inform strategic decisions in marketing and other agency functions. The guidebook recommended steps to build the infrastructure. These steps are composed of: 1. Develop an enterprise data management system, which includes an enterprise database design â âA first step in enterprise data management is to develop a database design. The database design is a detailed plan for organizing and structuring data maintained across the organi- zation. This is also called a database schema, with depictions of how the data are diagramed and charted.â â The reason for the design is because âthe database design shows how the whole organiza- tion will use, share, and sustain data over time when incorporated into database software.â 2. Design an architecture to support data integrationââA database architecture, like a data warehouse, can provide for automated data collection, storage, archiving, and retrieval.â 3. Implement data integration methods such as file transfers, Extract Transform Load (ETL) procedures, data replication [and APIs]. 4. Apply ITS data validation procedures to ensure accuracy and integrity of ITS data. âITS data recovered from on-board systems must be validated before being forwarded to the enterprise data system. An essential task in this process involves matching vehiclesâ AVL data records to their schedules and the base map of stops and time points associated with assigned work.â Although there are other sources that focus on transit data management, most describe a data management solution such as APTS Data Archiving and Mining System (ADAMS; Cevallos and Wang 2008) or reference data architecture Transit ITS Data Exchange Specification (TIDES; Levin 2019)6 although none of them identify IT tools, practices, and processes that are adopted in the other industries to support data management. Many of the current studies on data manage- ment address specific topics such as generating better performance metrics (ridership, on-time performance, etc.), not necessarily tools and methods for supporting enterprise systems. TIDES, as reference architecture, provides the closest model to identify the elements needed to curate and govern quality service data. The reference architecture describes a general frame- work of flows and processes necessary for managing ITS data in an enterprise. The processes
Literature Review 15 include managing data for strategic, tactical, operational, and perfor- mance decision-making purposes. As shown in Figure 1, the TIDES model presents the information flow from bus source systems as it progresses through the various curation processes. Specifically, data are extracted from source systems using exchange procedures like APIs, ETL procedures, or file imports. The data are then integrated, quality reviewed, and stored for use. The integrated data, stored in raw, discrete formats, is then aggregated, based on facts and dimensions terms used by data warehouse. The aggregated data are typically organized to answer commonly asked questions and stored in a data warehouse. Standard tools, procedures, and reports that are used to extract, clean, integrate, or present the data are also documented and stored. This last boxâStandard Tools and Reportsâmay be expanded to include all the procedures and rules used to manage data quality, inte- gration, and discovery processes. In general, CMM7 typically describes level 3 as âdefinedâ where these procedures, tools, and rules are well documented and applied systematically. TIDES is missing this physical component in its architecture. The component is not only a policy directive. Among IT management tools, a Master Data Management (MDM) system stores, configures, and controls these rules and procedures, including report scripts, quality checklists, data interface specifications, data dictionary, and more. The MDM and other industry IT systems that support data management are described in Data Management Industry Practices. Data Management Industry Practices Data management industry practices emerge from the need to access complete, quality infor- mation that can be integrated with other data to support decision making. Many best practices recommendations have been written on data management approaches, and the best tools to use by leading vendors of these tools, as well as IT Management firms such as Forrester and Gartner. Associations of professionals have developed best practices guides such as the Data Management Dimension A dimension provides structured labeling information to otherwise unordered numeric measures such as location, time, identifiersâtrip, stop, route. Fact A fact captures measurement or a metric of business processes such as on-time performance, ridership (by dimension). Key to Functionality Pink = dependent on specific vendor systems; yellow = code; green = standardized databases; and blue = standardized APIs. Databases Figure 1. TIDES high level architecture (Source: Levin 20196).
16 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data Body of Knowledge (DMBOK) (edited by Earley et al. 2009), curation,8 data governance,9 or organizations like NASCIO and U.S. DOT FHWA. FHWA has developed several documents on data management, governance, and planning. The practices described by these associations reflect the guidance offered by the Data Management Association International (DAMA) DMBOK. Data management, as described by the DAMA DMBOK, is a general term that describes the processes used to plan, specify, enable, create, acquire, maintain, use, archive, retrieve, control, and purge data. The DMBOK Version 3 identifies 10 data management knowledge areas: ⢠Data Governanceâplanning, supervision, and control over data management and use. ⢠Data Architecture Managementâas an integral part of the enterprise architecture. ⢠Data Developmentâthe data-focused activities within the system development life cycle (SDLC), including data modeling and data requirements analysis, design, implementation, and mainte- nance of databases data-related solution components. ⢠Database Operations Managementâplanning, control, and support for structured data assets across the data life cycle, from creation and acquisition through archival and purge. ⢠Data Security Managementâensuring privacy, confidentiality, and appropriate access. ⢠Reference and Master Data Managementâplanning, implementation, and control activities to ensure consistency of contextual data values with a âgolden versionâ of these data values. ⢠Data Warehousing and Business Intelligence Managementâenabling access to decision support data for reporting and analysis. ⢠Document and Content Managementâstoring, protecting, indexing, and enabling access to data found in unstructured sources (electronic files and physical records). ⢠Metadata Managementâintegrating, controlling, and delivering metadata. ⢠Data Quality Managementâdefining, monitoring, and improving data quality. As shown in Figure 2, data governance is the core function associated with the other nine functions. Several of these functions are discussed in more detail. They are ⢠Data Development ⢠Reference and Master Data Management ⢠Metadata Management A more detailed description of data governance is provided in the next section. Data Development. As defined by the DMBOK, data development includes âdata modeling and data requirements analysis, design, implementation and maintenance of databases data- related solution components.â A data model lays out the definitions, business rules, and rela- tionships between data. In addition, as described in TCRP Report 126, a data model âdefines the organization of the information such that systems can understand what data resides therein, where it resides, how it is stored, and how the data are related.â According to this guidance docu- ment, a data model is the first step in ensuring access to data across the transit enterprise. There are few example data models that can be used as a reference. Transmodel, a European reference data model for public transport, provides a detailed logical data model that describes the transit service data domain. The model is detailed, complex, and serves as a foundation for agency data models as well as European public transport data standards. The data model may generate an enterprise data dictionary with a well-defined glossary of transit concepts and how they are used by the agency. A data dictionary consists of the meaning, syntax, and naming conventions of data collected, stored, and accessed. The physical data model or schema provides a blueprint of how the database is built in a database management system (DBMS). It is the repository of the data, but it does not describe how the data are loaded, validated, or accessed from the database. That is the domain of the MDM system. Reference and Master Data Management. As defined by Gartner,10 MDM processes provide âworkflow and business process management (BPM), loading, synchronization, and business
Literature Review 17 services integration, data modeling, and information quality and semantics.â The MDM enforces the data requirements implemented in the database schema through procedures developed to clean, validate, quality check, and integrate data. The MDM processes generate the SOR or single version of truth. The MDM stores the procedures that clean, validate, check for completeness and errors, match, aggregate, consolidate, as well as ETL procedures: essentially most of the quality control and integration functions used to standardize and ready data for use. These procedures provide insight into how data are changed from its raw to clean format, enabling recovery of raw data if necessary. The procedures may be stored online, embedded in software or database, or it may be a paper process used to describe a series of steps a data manager takes to acquire, download, and process a data set. âAt its core MDM can be viewed as a discipline for specialized quality improvement defined by the policies and procedures put in place by a data governance organization. The ultimate goal being to provide the end user community with a trusted single version of the truth from which to base decisions.â11 In the TIDES model, these procedures are located in several processes including all the APIs and data processes (source data, data integration process, integrated data API, data quality process, and data aggregation process). The procedures are typically stored and version controlled in a master data management tool where their functions, algorithms, and version can be controlled and managed. This function is the place where algorithms that process ridership data may be stored. Metadata Management. Managing metadata applies directly to the data, that is, describing the provenance of the data, or who, what, when, and how the data were created and changed. It is not enough that the information is collected; in order to trace back from the SOR to the raw collection, information on the flow, procedures, and changes need to be tracked. Metadata can Figure 2. Data management framework (Source: Dama.org).
18 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data provide information on lineage, collection, quality, integration, and aggregation processes applied to the data, but only if the information about the data is discovered and accessed. To that end, metadata also requires processes for creating, storing, and accessing data. As defined by Wikipedia, âMetadata management involves managing metadata about other data, whereby this âother dataâ is generally referred to as content data.â12 Some metadata may be stored in a database when fields are uploaded or changed. But most data flow through a disconnected data curation process where the tools, procedures, and people collecting, cleaning, integrating, and aggregating data are diverse and siloed. Managing the actions, methods, and procedures that occur at each stage comes down to governing data curation from its source to its end use. Other Data Management Concerns These are other concerns that are not necessarily central to the data management toolbox but are of significant concern to data security and ownership. Data security infiltrates all aspects of managing data from securing and protecting data from unauthorized access, corruption, and theft to protecting, preserving, and destroying data, particularly personally identifiable information (PII). Data ownership and licensure involves the fiduciary and curation responsibilities associated with data access roles and methods. Often, transit service and operations data managed by industry applications and Software as a Service (SaaS) tools are not owned by the agency (Center for Urban Transportation Research 2019). Data access and sharing may become problematic over the terms of agreement if agency needs change or evolve.13 Data Governance Data have become one of the most important assets collected, stored, and maintained by any organization. Customer expectations, data-driven systems, and data-driven decision making have become the cornerstones of policy and management. These programs and outcomes are based on having consistent, accurate data across an enterprise. Data governance, as described by the data management literature, is not the collection, opera- tional, and maintenance tasks associated with data, but rather, the formal structures applied to ensure that data are consistent, integrity, secured, and accessible. Challenges to acquire and sustain good quality data drive the need for people who are trained and promote good data management, systems that implement those policies, and rules about how data are curated. In a nutshell, data governance is high-level planning and control over data management (Al-Ruithe et al. 2018). Though only in the last few years has this discipline been applied by transit agencies, data governance is used by many industries to help control and manage their data enterprises. Benefits, frameworks, approaches to implemen- tation, and applicability to transportation agencies are described in this chapter. Why Govern Data? The types of challenges faced by agencies to management data are daunting. In a data workshop held by the Atlanta Regional Commission (ARC 2019), constituent transportation organizations were asked about their major challenges with managing transportation data. Responses identified key challenges in collecting, analyzing, and sharing data including the following five issues: ⢠Challenge 1: Find and access data. ⢠Challenge 2: Inconsistent structures, formats, and semantics. ⢠Challenge 3: Unclear data responsibility. ⢠Challenge 4: Data restrictions. ⢠Challenge 5: Limited and costly resources to manage data. Data Governance Defined âRules of engagement for how institutions (people and policies) manage and sustain data across the enterprise, over their life cycle.â (ARC 2019, p. 8)
Literature Review 19 Common to these challenges are establishing clear roles for data management, policies for providing access, and resources needed to manage data. These challenges are also echoed by trans- portation and transit agencies. In a 2020 presentation on data governance, Vandervalk-Ostrander identified similar barriers described by transportation executives, including the institutional challenges: ⢠Limited data sharing plans and policies ⢠Limitations on combining data sources ⢠Silos ⢠No rules for standardization ⢠Access Data governance provides for a formal method for addressing the institutional challenges. According to Gartner research, âdata governance has been indispensable for . . . controlling the ever-growing amount of data in order to improve business outcomes.â14 What Is Data Governance? Industry practice recognizes data governance as the approach to achieve a consistent, repeatable, and sustainable quality of data for an organization. According to DAMA, âdata governance is the exercise of authority and control (planning, monitoring, and enforcement) over the management of data assetsâ (edited by Earley et al. 2009). NASCIO (2008) defined data governance as the operating discipline for managing data and information as a key enterprise asset. This operating disci- pline includes organization, processes and tools for establishing and exercising decision rights regarding valuation and management of data. Key aspects of data governance include decision-making authority, compliance monitoring, policies and standards, data inventories, full lifecycle management, content management, records management, preservation, data quality, data classification, data security, data risk management, and data validation. DAMAâs definition focuses on the operating processes and controls over data assets, while NASCIOâs definition of data governance spotlights the rules of engagement and operating princi- ples for managing data. MDM Institute defines data governance with a focus on people, processes, and technology, while Forrester Research, a leading IT research center, emphasizes âassets,â citing the businessâs fiduciary and organizational planning responsibility for managing data. A common, recurring theme of these definitions is the need to set rules for accountability, describing planning goals, processes, and policy provisions for data over its life cycle. A complete framework for a data governance framework provides descriptions of governance structures and components. Several frameworks are described in the next section. Data Governance Framework A data governance framework emerges from how an organization describes governance. Some organizations focus on data roles and responsibilities, data policies such as privacy, sharing and security, rules for data integrity, consistency and interoperability, or organizational accountability. A complete framework for data governance includes all these components. For example, the Florida DOT (FDOT) Reliable, Organized, Accurate, Data Sharing (ROADS) Project Data Governance framework is one of the most mature state DOT data governance frameworks (Figure 3). They adopted a simplified framework organized around: ⢠Peopleâroles and responsibilities that ensures accountability from the operational, tactical, strategic, and executive levels. ⢠Processesâtraining FDOT staff on the standard rules and procedures that support similar functions as described by the DMBOK (see Figure 3). ⢠Technologyâadopting standardized tools, technologies that are used to make data and infor- mation more accessible.
20 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data The FDOT ROADS framework was established by implementing several basic initiatives: ⢠Applications and Reporting Inventoryâa listing of internal/external applications and other information assets used across the agency. ⢠Data Governance Checklistâa quick-reference guide for data governance considerations in transportation technology projects. ⢠Data Governance Rolesâcommon position description language for the Enterprise Data Steward, Data Steward, and Data Custodian roles and responsibilities. ⢠Data Management Handbookâa data management tool that is based on the data life cycle and provides additional documentation for each phase, such as metadata templates. ⢠Enterprise Business Glossaryâdefines key terms and definitions for agency-wide use. ⢠Enterprise Data Managementâdefines key considerations and provides related resources for each phase of the data life cycle. ⢠Technology Process Proposalâa comprehensive process for evaluating promising tech- nology projects. The initiatives were crafted through personnel assignments and internal projects to build the artifacts. Many of the artifacts in the list of initiativesâinventory, checklist, handbook, and glossaryâimplement the data management practices espoused by DMBOK with structures in place for update and control. For example, the data management handbook and resources are stored in the MDM. The application inventory and business glossary were identified as critical enterprise artifacts by TCRP Report 126. A foundational element is the roles and responsibilities to ensure update, maintenance, and compliance of the artifacts. Hence, defining the data governance roles and responsibilities is a critical step in implementing a framework. FDOT, ARC, and other public agencies define four levels of roles, as depicted in Figure 4. Although different organizations use different names, the four levels may be categorized as executive, strategic, tactical, and operational, similar to categories described by FDOT. Figure 3. Information management framework (Source: FDOT ROADS).
Literature Review 21 Involvement of executives provides oversight, and accountability to the organization is critical to data governance, which was promoted as a lesson learned in a recent case study by Data Gover- nance and Data Management Case Study (Green and Lucivero 2018). Perhaps more critical is the involvement of the business. According to the ARC data governance role model (see Figure 4), IT is typically assigned the role of data custodian, performing the day-to-day activities to ingest, process, and provide data. The business data stewards are the users of the data who experience the inadequacies when data are âdirty,â that is, bad quality, missing, or inaccurate; for example, customer service personnel who deal with customer complaints or the planners who analyze the data. The enterprise data stewards are typically both data and business savvy; they understand the end user needs and understand the technical details of processing the data. Implementing Data Governance Many organizations implement governance charter, roles and responsibilities, meetings, process, and documentation requirements. In their systematic review of data governance, Al-Ruithe et al. (2018) reported that several publications recommend adopting data governance when imple- menting an Enterprise Data Warehouse (EDW). A robust EDW depends on accurate, consistent, and complete data, application of consistent rules, and normalized processes. These processes are typically captured in procedure libraries or master data management tools. Because EDW tend to be large, costly projects, there is buy-in from multiple departments including IT staff, management, and senior-level executives. This approach is reflected in two of the three data governance case examples (KCM and AC Transit). Other authors promote a bottom-up, agile approach to applying data governance. Figure 4. Data governance roles for a distributed enterprise (Source: ARC).
22 The Transit Analyst Toolbox: Analysis and Approaches for Reporting, Communicating, and Examining Transit Data In his book, Non-Invasive Data Governance, Robert Seiner (2014) asserted that many organi- zations fail in implementing data governance because while it formalizes âdiscipline (behavior) around the management of data [it makes], the discipline appear threatening and difficult.â Seinerâs noninvasive approach and other agile methods advocate building governance one data set at a time by small data governance teams who work directly with data users and owners. The UTA case example details the approach used by UTA to begin their data governance framework after several unsuccessful attempts at an enterprise implementation approach. Data Governance in Transportation Agencies Data governance, as a discipline, is new to transit agencies. Some transit agencies who are part of a local transportation organizationâcounty or cityâmay be subject to their jurisdictional data governance charter, organizational structure, and processes. However, few transit agencies provide an insight on what and how they apply their governance framework. Data governance made a cameo appearance in a 2019 APTAtech conference presentation by AC Transit. Governance was identified as a core element of their enterprise data management system (see case example for description of their approach). Agencies undergoing large IT projects, such as data warehouse projects, realize the need for data governance, but these are described anecdotally. Even at the few transit data conferences, data governance has taken a back seat to analytic techniques. In the TransitData 2020 conference, governance and quality were conflated with the focus on managing inconsistencies among APC and AVL data. However, organizational structures, implementation methods, and artifacts to support governance processes were not described in the workshop. Most closely related to building and implementing a data governance framework is the guidance and programs implemented by the NASCIO and the U.S. DOT FHWA initiative. NASCIO initiated data governance activities as early as 2005 with the publication of their âConnecting the Silos: Using Governance Models to Achieve Integrationâ and with the publication of their three-part series on data management, maturity models, and frameworks. U.S. DOT FHWA implemented a program in 2013 for state DOTs and later for municipal plan- ning organizations (MPOs) to comply with the Moving Ahead for Progress in the 21st Century Act (MAP-21). Several guidance documents were developed to reach out and train states and local transportation organizations on data governance planning and architecture strategies. FHWA implemented a peer exchange program and workshops that were implemented across the United States. The workshop described data governance as the application of data ownership and controls ranging from standards to enforcing data management policies and procedures to ongoing monitoring for sustained integrity throughout the life cycle of core data assets (Vandervalk-Ostrander 2020). Spurred on by this initiative, several DOTs and MPOs began building data governance programs. In 2017, the National Cooperative Highway Research Program (NCHRP) published a state-of-the- practice synthesis, NCHRP Synthesis 508: Data Management and Governance Practices (Gharaibeh et al. 2017), which documented current data governance practices for state DOTs and local trans- portation agencies. At the time of the study, the synthesis concluded the following: ⢠A bottom-up approach for data management appears to be taking place. A more top-down data governance approach could help recognize and leverage the value of data generated and/or stored in various agency silos and could spur increased data integration and sharing. In most cases, DOTs have data stewards and data coordinators for managing individual data sets and coordinating data management within a business area (e.g., asset management or safety). What is lacking, in most cases, is a data governance council/board for policy making and coordination at the enterprise level.
Literature Review 23 ⢠Most survey respondents described the following as major factors in limiting progress toward implementing data governance: (1) lack of staffing, (2) other mission-related issues that are more pressing, and (3) lack of resources. Data stewards, coordinators, and custodians hold various positions in their business areas, such as planners, engineers, GIS specialists, and IT specialists. ⢠Data governance is more mature in DOTs than in local agencies. However, this conclusion should be viewed with caution because (1) a small sample of local agencies responded to the survey, and (2) some local agencies commented that their agencies are users, rather than owners, of data. Since its publication, more state DOTs have implemented and progressed their data governance organizations. Under NCHRP Project 20-44(11), âAdvancing Practices for Data Governance, Information Management, and Managing the Impact of Digitalization on DOT Workforces,â a peer exchange workshop to âadvance the state of the practice surrounding data governanceâ was held with state DOTs and American Association of State Highway and Transportation Officials participants (Vandervalk-Ostrander 2020).
