
8
Strengthening Data Collection and Research Methodology
Chapters 2 through 7 describe many priorities for social and behavioral research with the potential to reduce the negative impacts of dementia. In nearly every domain discussed, however, there are challenges related to data infrastructure and research methodology that could hamper the realization of these opportunities. New data and methodological developments shape social and behavioral research just as advances in genetic sequencing or DNA manipulation accelerate bench science. The committee has highlighted many specific evidence gaps and methodological challenges in prior chapters. In this chapter, we focus on issues of quantitative methodology because they present particular opportunities and challenges in the context of dementia research. Qualitative methods remain essential tools in social and behavioral research on dementia, especially when integrated with other approaches, but it is primarily in the quantitative domain that we see specific opportunities for notable theoretical and technical advances in the next decade.
Innovations and improvements in research methodology to address the challenges associated with quantitative dementia research could significantly increase the potential for research to reduce the negative impacts of dementia in the coming decade. This chapter reviews those challenges and then explores opportunities and challenges in four areas: data infrastructure, measurement, study design, and integration of evidence from varied sources to yield stronger conclusions (meta-research). The chapter closes with discussion of the importance of investing in human capital and research capacity, and directions for research.
CHALLENGES OF QUANTITATIVE RESEARCH ON DEMENTIA
Dementia research presents unique challenges for quantitative researchers (Weuve et al., 2015). For example, the relevant risk factors and outcomes are difficult to measure. The data sources often underrepresent or exclude the most relevant populations, such as racial/ethnic groups disproportionately affected by dementia or the caregivers and families of people living with dementia. And many of the data sources for which there are high-quality outcome measures are not large or diverse enough to support research on differences across diverse subgroups. Some of these difficulties arise in other fields as well, but in the context of dementia they have hindered progress in identifying effective preventive measures, managing disease, improving quality of life for people with dementia and their families, and even fully quantifying dementia’s social impact.
One issue in dementia research is that the analytic approaches and study designs applied have been predominantly observational, sometimes longitudinal—designs that draw on covariate-controlled regression models. In other words, they seek to estimate causal effects by identifying and fully adjusting for all factors that may influence both the exposure and outcome under consideration (Matthay et al., 2020). This approach is likely to be biased in the study of dementia, a disease that develops and progresses slowly and has symptoms that are subtle, particularly in early stages.
The subtle early cognitive changes seen in dementia may induce changes in the constructs researchers seek to evaluate in their study of risk factors (see Chapter 2), such as social experiences, behaviors, health care utilization, emotions, or even physiology (e.g., body mass index). Establishing temporal order is foundational for establishing causality, but the long, slow development of dementia makes it difficult to pinpoint when someone does or does not have the disease. Thus, it is difficult to disentangle factors that increase the risk of developing dementia from factors that are influenced by incipient dementia. The slowly progressing nature of dementia in many patients necessitates long follow-up periods to detect changes using standard clinical measurements. Because its symptoms include diminishing capacity and because the disease is ultimately fatal, follow-up and longitudinal studies present particular challenges. As the disease progresses, patients are less able to communicate and require more help and input from their caregivers, which exacerbates measurement challenges and biases. The impact of these measurement biases depends on inclusion criteria, the prevalence of other risk factors in the population, and the outcomes that are selected for study, creating extreme difficulties in interpreting observational results.
These problems are even more acute because of the challenges of diagnosing and measuring dementia. As discussed in Chapters 1 and 3,
diagnosis of dementia is not straightforward. The clinical tools and criteria for tracking and assessing cognitive changes have evolved over time (see Jack et al., 2018; Glymour et al., 2018; McCleery et al., 2019), and as researchers develop improved tools, patients will be better served. However, such changes make conducting long-term cohort studies or evaluating temporal trends more difficult. Ambiguity in diagnosis also makes it difficult to anticipate the likely benefits of proposed interventions, since the individuals in any specific group of patients will be at different disease stages. Based on differing social, demographic, and economic considerations, moreover, patients may receive care in heterogeneous settings. Similarly, the lack of data about family members and friends who provide care or are otherwise affected by dementia hampers research on interventions to support them. Because no one dataset encompasses all these kinds of information as well as clinical and patient-reported outcomes, it is impossible to identify the effectiveness of interventions in general or across different populations.
FOUR OPPORTUNITIES FOR IMPROVEMENTS IN METHODOLOGY
There are four broad areas in which significant advances can be made to address these challenges. These areas correspond to four primary domains of emerging, priority opportunities for research methodology development (see Figure 8-1).
Progress in any one of these areas will be relevant for one or more of the others. For example, research is constrained by the data sources available and the exposure and outcome measures that can be extracted from those sources. Novel data sources and linkages can both expand the measures available for dementia research and support the inclusion of populations
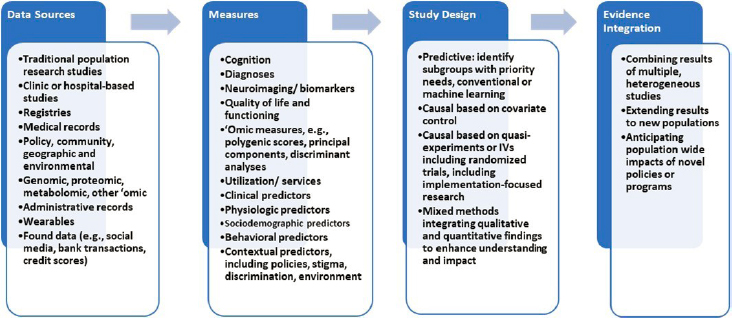
that have been underrepresented in dementia research (including specific racial/ethnic, socioeconomic, and geographically defined groups). Similarly, new data infrastructure can support novel study designs to improve identification, and more rigorous study designs to estimate biases and heterogeneity across populations will support stronger population effect estimates.
Data Sources
The availability of data fundamentally shapes the types of research that are conducted, so decisions about investments in data infrastructure have substantial influence. The strengths and weaknesses must be considered based on the goal of a particular research project. The discussion below considers data sources used in research to examine such topics as
- which treatments or exposures influence risk;
- the effectiveness of interventions to improve survival, functioning, and quality of life of people with dementia and their caregivers; and
- ways to identify individuals with incipient dementia and predict who will develop the disease.
Researchers studying aspects of dementia have relied heavily on a handful of sources. For example, analyses of community-based cohort studies, which often reflect a limited number of communities, are a primary source for prevention research (Fried et al., 1991; White et al., 1996; Bild et al., 2002). Outcomes research is often based on cohorts recruited through specialized memory clinics or Alzheimer’s disease centers. Research based on billing records or more comprehensive electronic health record data has been informative in many cases because studies of such large size offer diversity and easy linkage with information on comorbidities, medications, or laboratory tests. Electronic health record data also have many weaknesses that have limited their usefulness (Beekly et al., 2004; Haneuse and Daniels, 2016; Jutkowitz et al., 2020). These include inconsistencies in how dementia is diagnosed, and selection biases based on when records were created (at what point in the disease trajectory individuals entered the system) and who is covered by the record system.
The available data sources shape who is included in studies, what risk factors or outcomes are measured, and what opportunities exist for estimating causal effects. One significant problem with current sources of data for dementia research is underrepresentation of population groups. Because of limitations in available data sources, non-Hispanic White individuals are particularly overrepresented in existing research; individuals from other racial/ethnic groups or multiracial individuals are underrepresented
(Wilkinson et al., 2018; Dahl et al., 2007; Brewster et al., 2019; Bynum et al., 2020). Recent estimates indicate, for example, that fewer than 200 American Indians are represented in the data on more than 40,000 individuals housed in the National Alzheimer’s Coordinating Center’s Uniform Data Set (NACC, 2021). These gaps are especially troubling because of dementia’s disproportionate impact, with respect to incidence, caregiving needs, and economic consequences, on non-White individuals and families, as discussed in earlier chapters.
Individuals with less education and those from geographically underserved communities (e.g., rural towns far from tertiary care centers) are also underrepresented in datasets. Much research includes volunteers who are not only more likely to identify as White but also have high levels of education and convenient access to study centers. Data from the large UK Biobank cohort indicate that study participants not only are of higher socioeconomic status, more likely to be White, and healthier relative to average Britons, but also are of taller stature (likely indicating advantages during early-life growth periods) (Fry et al., 2017).
We review four paths forward for addressing these limitations: developing new data sources and adding items to existing sources, linking existing data sources in new ways, improving recruitment, and improving measuring exposures and outcomes.
Developing New Data Sources and Adding Items to Existing Sources
New data sources with potential relevance to dementia are rapidly emerging. These include “found” data, such as digital health data, phone records, and social media, as well as increasingly well-documented administrative sources, such as comprehensive electronic health records, claims records for health service billing, and the Minimum Data Set reported by nursing homes (Nicholas et al., 2021). While these data may offer powerful new research tools, however, their strengths and limitations and potential applications are as yet not well understood. Use of these sources to produce sound conclusions will require understanding of, for example, selection processes (who is represented and what data elements are present), the measurement limitations of the tool and individual data elements, and statistical considerations involved in analyzing the data.
Some of these data sources will be useful for dementia research only after transformation or screening with various algorithms (e.g., natural language processing algorithms to identify dementia cases based on language use or algorithms to identify stressful experiences). Innovations in machine learning offer promise for improving case identification but also introduce potential major problems because of algorithmic bias (Obermeyer et al., 2019). Without consistent and careful evaluation, existing biases or
stereotypes can be built into new algorithms, or algorithms can be trained to recognize the experiences of the most well-represented groups. One study, for example, showed that a widely used algorithm intended to identify patients most in need of additional resources was based on health service utilization as a proxy for health (Obermeyer et al., 2019). Because barriers to access reduced utilization among Black patients, the algorithm systematically underestimated the degree of health need among Black patients and inappropriately deprioritized them for the additional resources.
Other challenges call for special consideration in dementia research. Respecting privacy while also fostering the use of new data sources is one. Dementia researchers also must grapple with identifying the most relevant data sources and needed data infrastructure. These determinations will be important for research investigating such emerging questions as how physical isolation affects people (e.g., whether electronic tools can partially or fully replace in-person interactions).
Disease registries, such as the Surveillance, Epidemiology, and End Results (SEER) registries for cancer, have been invaluable resources for the study of some diseases. No national registry is available to document and support the development of strategies for addressing dementia, but there have been some efforts to address this gap. One such effort is the Alzheimer’s Disease Research Centers supported by the National Institute on Aging. These centers, housed in medical institutions that conduct a wide range of research activities, use a common study protocol and store data in a central repository, but are limited by variable sampling and follow-up priorities across the centers and over time, and lack of generalizability; there are particular concerns about race, socioeconomic status, and family history (NACC, 2021; Beekley et al., 2004; Besser et al., 2018; Weintraub et al., 2009, 2018). Registry efforts are also under way in a handful of states, including South Carolina, Georgia, West Virginia, and New York (Krysinska et al., 2017). However, access for research purposes is limited, and issues that have arisen regarding consent and reporting point to challenges for a national registry effort. Nonetheless, a national registry or improved coordination among existing registries with links to other data sources could provide improved resources for researchers.
The use of rich individual-level data presents ethical and legal challenges. Securing the consent of participants for the sharing and use of data about their health can be challenging when language barriers or limited education may hamper understanding of the issues at stake, and such issues are particularly challenging when participants have diminished decision-making capacity. Recommendations from a multidisciplinary team may provide best practices for consent in data-intensive dementia research and can support harmonization of consent practices across institutions and countries while facilitating data sharing (Thorogood et al., 2018).
Another way to create “new” data sources is to improve the dementia-relevant measures in available data sources. For example, the Health and Retirement Study used a comprehensive set of cognitive assessments in a small substudy (Langa et al., 2005), an important investment in validating the brief core assessments currently used (Plassman et al., 2008).1 Substantial effort has gone into creating a crosswalk with clinical diagnoses, such as those in Medicare data (i.e., a mapping between the measures used in the Aging, Demographics, and Memory Study component of the Health and Retirement Study2 and clinical diagnoses).
These findings frequently indicate that sources differ notably in their classifications at the individual level (although their performance may be acceptable at the population level if most people are cognitively normal). These variations indicate that one or all sources are fraught with substantial misclassification. For some purposes, this misclassification will not introduce bias or reflect authentic ambiguity as individuals progress through early stages of disease development. For many research questions, however, the misclassification is quite problematic, especially because it is likely to be differential across racial/ethnic groups, education levels, or other social indicators (Gianattasio et al., 2019, 2020; Power et al., 2020; Berkman, 1986).
Similar efforts to weave simple and more complex cognitive measures into other datasets are under way. In 2017, for example, the Panel Study of Income Dynamics added the AD8 dementia screen into the national household study. The National Longitudinal Study of Youth is adding cognitive measures that match those used in the Health and Retirement Study, and the National Longitudinal Study of Adolescent to Adult Health has incorporated various cognitive measures over the years and is adding more detailed neurocognitive assessments in planned future waves. Since 2006, the National Longitudinal Survey of Youth has administered a cognition module. Investments in these types of data enhancements pay off disproportionately, but research is needed to foster such additions and make it easier to establish links among relatively small studies.
Linking Existing Data Sources in New Ways
Linking different data sources can create powerful research opportunities. For example, establishing connections between self-reported
___________________
1 More recently, the standard core assessments have been expanded to include the Harmonized Cognitive Assessment Protocol, which is integrated into many international sister studies, such as the Longitudinal Aging Study in India, the Health and Aging in Africa: A Longitudinal Study of an INDEPTH Community in South Africa Study, and the English Longitudinal Study of Aging.
quality-of-life outcomes and environmental or policy data from administrative records can allow researchers to examine many of the critical questions identified in Chapters 2 through 7. Linkages may be at the individual level (e.g., linkage of the 1940 detailed census data with data from participants in the Health and Retirement Study) or at a geographic level (e.g., linkage of state or county school policy changes with individual cognitive outcomes). The Health and Retirement Study’s contextual data resource series links respondents to a variety of resources for data on crime, health care, and state policies.3 Probabilistic linkages based on combinations of covariates (e.g., eligibility for social resources) or other units (e.g., schools, hospitals) are also possible.4
Further work on these methods is needed to expand and validate their applications. One challenge is building linkage opportunities into existing datasets. For example, collecting data on place of residence across the life course in cohorts for which detailed outcome data are available would make it possible to analyze age-specific place-level exposures to such variables as policies, pollution, and social context. However, few datasets include such life-course geographic data.
Another priority, alluded to above, is balancing the essential importance of data privacy with the goals of fostering data linkage. While many existing data security policies hamper research, alternative approaches that facilitate research while ensuring privacy have not been clearly established. Privacy is both an ethical concern (e.g., defining an acceptable probability of reidentification) and a technical concern (e.g., how to ensure adequate encryption when using cloud computing). Efforts to reduce cost and administrative barriers other than those strictly necessary to ensure privacy would accelerate research and help the field avoid the problem of researching only the most easily measured, most accessible risk factors. Data merges will not necessarily prevent “looking under the lamppost” (seeing only what happens to be easy to see or what is conveniently measured), but they effectively build more lampposts.
Data merges also need conceptual attention. Theories about the most important determinants of dementia have likely been constrained by limits on what it has been possible to measure. An example of an innovative approach that can open up new research opportunities is linking sources
___________________
3https://hrs.isr.umich.edu/data-products/restricted-data/available-products
4 In the basic sciences, this type of linkage is also creating powerful study designs, such as two-sample Mendelian randomization analyses (in which genetic variants established in one sample as influencing a phenotype of interest are used as instrumental variables to estimate the effect of that phenotype on an outcome in a second sample) or research on gene expression profiles (in which information on genetic variants is scored based on tissue-specific data about how each variant relates to RNA or protein levels).
of data about exposures that may predict or increase dementia risk with data on cognitive or dementia-related outcomes. Recent work linking credit histories to cognitive status highlights the potential value of this type of innovation. Credit histories may reveal cognitive risk years before a dementia diagnosis, with implications for research design, public policy, and clinical care. For example, linking data from the Federal Reserve Bank of New York/Equifax Consumer Credit Panel with Medicare outcomes data made it possible to identify this connection and quantify how early it was detectable. This innovative work also illustrates the challenges involved: the link was based on census block, birth year, and zip code history and thus was not conducted at the individual level (Nicholas et al., 2021). Other valuable opportunities would come from linking health data with data from other sectors, such as data on labor experiences, trauma/violence exposures, income and social safety net protections, and educational resources.
Numerous relatively small or localized studies have used such approaches. To date, however, there has been little effort to synthesize those studies, compare their findings with national patterns, or even consider preferred settings for new proposed studies. A linked data resource tying together data from multiple sources—such as existing or newly reconstructed surveys and population-based, longitudinal population and health services data—could serve as the basis for a reference database. Such a reference database could in turn provide a comparator with more detailed localized databases that could be used, for example, to test the extent of representativeness of small trials or transfer results from small localized studies to new settings, or to guide design and settings for proposed new observational or intervention studies.
Creating such a database would require identifying studies with harmonizable measures; evaluating how each of those studies relates to a larger population (i.e., whether they are representative or approximately so); harmonizing the measures, which may entail creating latent variables if different instruments are used for the same construct; combining the datasets; developing recommended strategies for handling inconsistent measure availability (e.g., when multiple imputation is appropriate); and possibly creating weights to apply to the overall sample based on the intended reference population. Each of these tasks is technically difficult, but the payoff could be great.
Improved understanding of potential biases in selection and data collection is necessary to make new data linkage opportunities possible. No dataset is perfect. More systematic evaluation of selection biases and the differential effects of the data that are missing would strengthen research using both new and old data sources. Bias can be an issue with almost any existing data source, but this is an understudied topic that will become ever more urgent as new “big data” sources become popular.
Improving Recruitment
Although better leveraging of existing datasets will be valuable, improving recruitment is critical. The lack of racial/ethnic, socioeconomic, and geographic diversity in many major studies of dementia is well documented (e.g., Brewster et al., 2019). Lack of diversity in dementia research is now broadly recognized as a critical barrier to scientific progress and the achievement of health equity, and it is exacerbated in studies with intensive measurement protocols, such as neuroimaging. The lack of representation of many groups in dementia research has cascading effects that limit the relevance of scientific findings and in some cases may directly exacerbate health disparities that have adversely affected communities of color, individuals from disadvantaged socioeconomic backgrounds, and people living in certain geographic regions (see Chapters 2 and 5).
Developers of new data sources, such as the All of Us research program, have made impressive commitments to achieving racial/ethnic diversity (as of this writing, the 316,760 All of Us participants include 21% Black-, 17% Hispanic-, and 3% Asian-identified participants [National Institutes of Health, 2021]). An important challenge for All of Us will be ensuring that participants who provide more detailed measures, such as from wearables or linked data, are also diverse. Because All of Us is not based on a probability sample, opportunities for crosswalks between All of Us and representative samples will be important, for example, to reweight to U.S. population distributions. Although such reweighting is often based on only a handful of characteristics (e.g., age, sex, and race), it may fail to represent heterogeneity within these groups and paint very misleading pictures of population patterns (see below).
Nevertheless, although the importance of increased inclusion of underrepresented groups is widely recognized, efforts to this end are often isolated or cursory, or they occur too late in the scientific development process to be effective. In some cases, they may exacerbate bias by creating completely different recruitment paths for different groups (e.g., recruiting most White study participants from memory impairment clinics but most Black participants from church congregations).
The field needs insights from behavioral economics, social networks theory, or communications to create a toolbox of effective recruitment strategies. Researchers currently lack a coherent, comprehensive scientific framework for the inclusion of diverse groups (Dankwa-Mullan et al., 2021). Indeed, the definition of “diversity” is continually evolving, and ways to include people from varied racial/ethnic groups, geographic areas, sexual and gender minorities, cultural identities, and socioeconomic circumstances will need to evolve as well. The issue may require different remedies depending on the study focus: studies of dementia prevention,
brain pathology, and quality of life among individuals living with dementia, for example, may each present different representation challenges. But regardless, a rigorous systematic framework that can be evaluated, challenged, modified, and adapted for varied research contexts is needed (Gilmore-Bykovskyi et al., 2021).
Measurement
Measurement of both exposures and outcomes presents another set of challenges for dementia researchers. The controversies about measurement of dementia will become even more salient as new data sources become available and as currently underrepresented groups are included more effectively in research. Selection and measurement of relevant exposures for dementia prevention and for improvement of quality of life for people living with dementia and caregivers are similarly critical and evolving. Social and behavioral researchers will need to be fully engaged to challenge narrow conceptualizations of relevant risk factors and consider the implications of alternative measurement approaches.
The challenge of measuring biologically meaningful and patient- and family-centered outcomes in dementia research is relevant to nearly every topic addressed in this report, but one example will illustrate the issues involved. The relatively modest correspondence between neuroimaging markers of pathophysiology and clinical or functional manifestations of disease has disappointed researchers who had hoped it would spur progress in research on both prevention and therapeutic responses (see Chapter 3). Some of the discrepancy may be the result of inadequacies in the measures used in neuropsychological assessments, including random noise, insensitivity to subtle early cognitive changes, or insensitivity to cultural context or test-taking artifacts. On the other hand, the discrepancy is at least in part a sign that the biomarkers are only modestly related to functional outcomes, either because meaningful cognitive reserve or resilience can counteract the damage indicated by the biomarkers or because researchers have not accurately measured or identified the relevant biological factors.
Another need is for evidence from cognitive assessments that are better able to capture the symptoms of dementia compared with most current measures.5 Sensory, motor, and mood changes common in old age complicate the assessment of cognition, and assessments may conflate changes in capacity to participate in the assessment (e.g., to hear words read out loud
___________________
5 Such properties include equal interval scaling, lack of ceilings/floors, absence of differential item functioning across sociodemographic groups, and adaptive test design to reduce participant burden. Differential item functioning is a special concern for evaluating the impact of many important social risk factors, which are very plausible sources of measurement bias.
from a verbal memory test) with changes in cognition. Substantial progress has recently been made in implementing advanced psychometric methods, but most commonly used measures still have important limitations in reliability and validity across linguistic background, educational attainment, and cultural identity.
To the extent that these limitations intersect with critical predictors or outcomes, they can also lead to significantly biased results. Cultural differences may relate to comfort level with the examiner (as well as other characteristics, such as pitch and enunciation) and may also intersect with other important predictors (Gershon et al., 2020; Kobayashi et al., 2020; Mukherjee et al., 2020; Gross et al., 2020; Walter et al., 2019). In addition, there are significant differences by mode of assessment (in person, video, phone) that contribute to variable results (particularly during the COVID-19 pandemic). Many of these challenges will require qualitative work to understand how people from different communities interpret and respond to the phrasing of specific assessments and the cultural norms or expectations that shape their responses. Passive cognitive measures (discussed below) may be helpful with respect to equivalence across groups and would support the collection of data from large samples, thus facilitating rigorous study designs.
Advances in two areas—measuring exposures and identifying valid early predictors of cognitive outcomes—show particular promise for improving measurement in the context of dementia research.
Measuring Exposures
Given the constrained set of measures available in datasets used in dementia research, research on risk factors has focused primarily on those that can be identified relatively late in life, which are most easily self-reported or documented in electronic health records. Researchers have been much less likely to evaluate life-course measures; contextual factors; social network variables, such as size, density, position of the respondent in the network, strength of ties, or support delivered by different ties; or other difficult-to-measure variables. This is an important limitation, especially when one is considering opportunities to prevent dementia. Earlier chapters have pointed to many early or midlife exposures that are likely to be profoundly important for dementia. Factors driven by structural racism contributing to disparities, structures and processes related to gender across the life course, and paid and unpaid work experiences, for example, have received short shrift because of the measurement challenges. Research on the progression and impacts of dementia could be especially enhanced by better access to measures of the social networks of individuals living with dementia, yet such measures are difficult to access. New technologies and other measurement innovations may help address this gap.
Concerns about establishing consent for people living with cognitive impairment is another serious issue for researchers. Some researchers avoid engaging people with dementia to circumvent this problem, which also emerges in longitudinal studies when people deteriorate. Evaluations of this issue are inconsistent across institutional review boards, so standardized guidance and best practices for establishing capacity to consent would be invaluable.
Novel insights will emerge from novel measures. Building out older datasets with risk information from earlier in the life course for individuals who are now older adults is another approach to help address the problem of measuring exposure (e.g., by following up old studies to incorporate late-life cognitive assessments). Since many of these datasets are unformatted, investments would be required to convert them to electronic format or machine learning or natural language processing tools so that relevant, analyzable data could be extracted. Funding to support this conversion and documentation for these sources would therefore be an important part of the larger data infrastructure buildout efforts. Linking of data sources (as discussed above) would also support this type of innovation, but would require methodological work on how to collect linking variables and how to complete probabilistic linkages.
Identifying Valid Early Predictors of Cognitive Outcomes
Dementia and the underlying pathological conditions that contribute to the disease develop and progress over decades, far beyond the time scale of typical research studies. Thus, substantial benefits could be realized with the development of methods for identifying outcomes that could serve as proxies for long-term outcomes but be accessible within the relatively short time frame of most research. Innovative research designs to identify the early manifestations of disease—for example, leveraging genetic factors to identify leading indicators of cognitive change—could help pinpoint the most sensitive markers. Such research will, however, require validation of proxies, perhaps through retrospective analyses of existing data, as well as tools for easily capturing such data.
Multiple efforts are under way to improve the sensitivity of cognitive tests for early recognition of cognitive loss while addressing some of the major deficits of existing cognitive assessment tools. Some new, more challenging, measures are designed to be more engaging (some are based on games, for example) as a means of improving participation and limiting educational bias. Some can be administered repeatedly to address significant reliability concerns related to such factors as illness, mood, and other fluctuations not related to underlying cognitive change. Some extract additional data from digital tasks to improve the reliability and granularity of measurement.
Strategies for extracting cognitive information from incidental data sources—such as metadata6 from surveys, phone or other device usage, social network site activities, financial transactions, or writing samples—could provide longer timelines for cognitive assessments, better ways to control for early-life cognition, and a wide range of outcome measures. People reveal cognitive function or cognitive deterioration through such common daily activities as phone usage, bill paying, completion of routine forms, or travel outside the home. However, despite a handful of innovative efforts, no simple ways of routinely incorporating this information into research studies or clinical assessments currently exist (James et al., 2011; Nicholas et al., 2021). Protocols for extracting, calculating, and calibrating such assessments are therefore needed. Innovative work using survey metadata is promising, especially if it could be applied to extract comparable cognitive information across time from waves of survey assessments before the cohort had undergone formal cognitive assessment. In some cases, metadata from existing surveys may also reveal cognitive information.
New data sources are transforming many areas of research, but researchers with both data science skills and substantive knowledge of dementia research will be needed to take advantage of these possibilities (Salganik, 2019). Moreover, most cognitive measures assess proxies for cognitive functioning, such as processing speed, and more work is needed to identify their relationship to the capacities that decline with dementia. Measurement strategies spanning the entire spectrum of dementia, from the very subtle incipient changes through late-stage disease, are needed. To describe the full range of patient experience, it will be necessary to connect the various measures—not just cognitive measures but also measures that reflect individual priorities for a meaningful life, such as social connections, autonomy, dignity, and freedom from pain—to show the individual’s disease trajectory.
Defining outcomes related to quality of life for people living with dementia, their caregivers, and other loved ones is another key goal for dementia researchers. In some cases, imperfect measurement is inevitable, but it is possible to use statistical tools to quantify the measures and correct for bias. Possible approaches include both contemporary quantitative psychometric methods and qualitative research methods.
___________________
6 Metadata are data about the administration and completion of a survey rather than the survey responses specifically. Potentially useful metadata would include the time respondents needed to complete sections of the survey, which participants were interviewed by the same interviewers, the number of contacts before a participant agreed to taking part in the survey, and the date or time of survey completion.
Study Design
Although prediction and early identification have received extensive attention in recent dementia research, the ultimate goal is to identify interventions to prevent dementia, improve the well-being of individuals living with dementia and their loved ones, and ameliorate the potential adverse societal impact of expenses related to these diseases. Identifying such interventions—including both pharmacologic and behavioral approaches, resource programs, systems changes, social and health policies, and other strategies—will require methods for anticipating their causal effects. However, researchers in social and behavioral disciplines are far from having established standard methods for causal research, and indeed this challenge is the source of profound disagreements (Matthay et al., 2020) This state of affairs obscures the fact that researchers across these divides share goals and are developing new data sources and measures that may support the development of consensus on how to leverage the most relevant study design in any given setting. This section highlights a number of opportunities for supporting advances in study design.
Broadening the Repertoire of Tools
The challenge of disentangling causal determinants of dementia or dementia progression from noncausal correlates pervades nearly all dementia literature. Randomized controlled trials (RCTs) of nonpharmacologic interventions are often difficult and slow, and sometimes simply infeasible. Pragmatic trials can be more feasible, and their importance is likely to grow in the future as data options improve. However, the predominant methodologies to date have been based on observational cohort studies, often with diagnostic time-to-event outcomes, in which the causal identification strategy is based on measuring and controlling for all factors that might influence both exposure and outcome (Pearl, 2009). Alternative methodologies applied to observational data, such as difference-in-difference, interrupted time series, regression discontinuity, or instrumental variables methods, are much less commonly used, possibly because these methods must be modified or adapted for dementia outcomes.
These methods have various names but are based on the idea that some of the exposures individuals experience vary as a result of arguably random events or characteristics that would otherwise have no association with their health outcomes. For example, the date when a state adopts legalization of recreational marijuana may have nothing to do with the quality of life of people in the state, but if marijuana use influences quality of life, it would be reasonable to expect a change in quality of life to occur in that state after that date. The timing of the policy adoption introduces
a quasi-random source of variation in the exposure to marijuana use. Put simply, most quantitative methods rely either on experimental (exogenous) variation in the treatment or on controlling for all common causes of treatment and outcome. Machine learning analytic approaches can be applied in either setting and may be useful, for example, in identifying and optimizing statistical control for potential confounders.
Quasi-experimental methods (including instrumental variables methods, regression discontinuity, and others noted above) can be powerful complements to conventional observational analyses because they often depend on entirely different assumptions. In many settings, the key assumptions for conventional analyses (e.g., no confounding of the exposure–outcome association) are clearly implausible. For example, it is not credible that there are no confounders of the association between engagement in cognitively demanding tasks in late life and subsequent dementia risk. In this situation, quasi-experimental and related methods can be invaluable. Policy changes and other sources of exogenous variation in important exposures have long been used for causal research in economics (Matthay et al., 2020).
Work is needed to improve causal methodologies for dementia-related outcomes: accommodating the slow and insidious development of dementia and distinguishing those changes from the physiologic changes related to age. New data sources would improve the feasibility of approaches based on instrumental variables, both because new potential instruments may be embedded in the new data and because these methods need very large samples to be informative. Some approaches that were promising but not quite workable in the past may be viable and informative as large administrative datasets become available. Research to identify, evaluate, and apply instrument-based approaches and compare their findings with those from conventional, covariate-control approaches is needed.
Likewise, methods for dealing with time-varying confounder mediators have been rapidly adopted in some domains of epidemiology but remain rare in dementia (Hernán et al., 2000; Robins et al., 2000), Time-varying confounder mediators are common in dementia research because the exposures of interest change over time, influencing mediators that in turn also influence future values of exposure. Leisure-time cognitive activities are an example: leisure-time cognitive engagement may preserve cognitive function, and preserved cognitive function may in turn lead older individuals to continue to engage in cognitively demanding activities (McDonald et al., 2003). Time-varying confounder mediators affect both prevention research and research on strategies for maintaining quality of life for people living with dementia. Specialized statistical tools are available for evaluating complex longitudinal exposures that may have different effects based on timing or duration of exposure. These tools are also helpful for quantifying and correcting bias attributable to selective mortality and selective attrition
(Hernán et al., 2004), both of which are common in dementia research. These methods remain challenging and underutilized, however.
Many argue that analyses of observational data should be structured to mirror RCTs; that is, they should have a defined moment of “randomization,” no control for postrandomization variables, and clearly defined follow-up rules (Hernán and Robins, 2016; Labrecque and Swanson, 2017). This approach gained traction when it was found that the discrepancy between observational studies of postmenopausal hormone replacement and RCTs of the same medications could be almost fully accounted for by differences in the analytic approach. When the observational data were analyzed as an RCT, results were very similar to those from actual RCTs (Hernán et al., 2008). Emulated trial designs are seeing rapid uptake because of their conceptual clarity and natural alignment with the goal of developing actual RCTs based on observational studies (Caniglia et al., 2020; Rojas-Saunero, 2021).
Creating Opportunities for Quasi-Experimental Discovery, Including Leveraging Instrumental Variables Analyses
In many cases, major programs or interventions are rolled out with limited understanding of their likely impacts. Resource limitations or feasibility issues result in some individuals receiving the intervention while others do not, so in theory, it would be possible to learn about the intervention’s effects. Yet it is rare for such roll-outs to be organized intentionally to create opportunities for rigorous program evaluation. Such methods as stepped wedge designs (in which a new treatment is introduced to a population in a staggered fashion with randomly selected units or clusters chosen for treatment initiation at successive time points across the follow-up) are powerful tools for enhancing what can be learned about interventions (Bärnighausen et al., 2017; Oldenburg et al., 2016; Handley et al., 2018), and many related designs could be introduced to take advantage of settings where there is true uncertainty or disagreement about the best treatments or the merits of a program. Researchers need to understand better why health care system administrators may not randomly allocate the units or settings where clinical innovations are to be implemented so that the results can be rigorously evaluated. Furthermore, study of ethical issues inherent in doing this kind of research is needed, as is methodologic work to optimize design and demonstrate most rapidly what works and what does not.
Enhancing Analyses of Randomized Controlled Trials
Many types of interventions are particularly well suited to RCT evaluations. For example, observational studies of cognitive engagement, social
networks, or screening interventions are particularly problematic because of the powerful selection processes at work in such exposures. Although quasi-experimental approaches may help remediate these biases, RCTs are both feasible and particularly valuable in these settings. RCTs of both pharmacologic and nonpharmacologic interventions provide unique information for dementia research because they are already randomized for other purposes. Mediation models of RCT-based data can help inform theoretical understanding of disease progression and mechanisms. Instrumental variables analyses applied to RCTs are typically uncontroversial but have not been widely adopted in health research (Glymour et al., 2017). Such analyses would yield more relevant estimates of the impact of interventions as received rather than as randomized.
Careful comparisons of RCTs and observational studies can provide bias estimates to support interpretation of nonrandomized results and evaluation of heterogeneity in treatment responses. Precision medicine has popularized the idea that responses to treatment may vary substantially across individuals, but the focus has been on genetic determinants of that heterogeneity, whereas social and contextual factors are likely to be equally relevant. Large heterogeneity in treatment responses undermines the interpretation of RCT results because trial participants generally are not representative of the target population for inference purposes. Formal methods for assessing heterogeneity and the application of the assessment results to RCTs would provide more generalizable interpretations of RCT findings (Mehrotra et al., 2019). This is one form of the evidence integration discussed earlier, and further below.
RCTs are typically expensive and slow in comparison with pragmatic trials and quasi-experimental approaches. However, many existing large RCTs have not been fully leveraged for dementia research. For example, many RCTs of cardiovascular risk factor reduction, chronic disease and substance use treatment interventions, social determinants of health or social support, or pharmacologic interventions were never followed up for impacts on dementia. This is rigorous evidence simply awaiting data collection to determine the impacts of these interventions on dementia risk (see, e.g., Robertson et al., 2021; Dahabreh et al., 2021). When RCTs do show that a behavioral or social intervention does not have the desired outcome, qualitative research may help reveal the mechanistic misunderstanding and guide improvements in future interventions.
Moving from Evidence to Implementation
Rigorous evidence will not improve the lives of people affected by dementia unless there is a pipeline from the scientific results to implementation. Implementation entails a new set of challenges beyond establishing
that a proposed intervention or treatment could, in theory, reduce disease incidence or improve quality of life (Glasgow et al., 2012; Green et al., 2009, 2014). Implementation needs to be considered not at the end of the pipeline but from the beginning of the research generation process: Who could use this evidence and how would they use it? Is this study going to provide actionable evidence? Research across the spectrum from theory-building to directly actionable work is essential. Various categorizations of work across this spectrum have been offered, but a consistent theme is the value of intentionality in translating evidence into clinical, behavioral, or policy interventions and supporting widespread adoption.
Incorporating stakeholder perspectives from the outset is critical to delivering actionable work that will be implemented. The stakeholders include individuals living with dementia, their families and social networks, and the individuals who would use the evidence and implement innovations. For example, translation efforts focused on changes in clinical processes require adoption by clinicians or health system administrators. Translation efforts focused on local, state, or federal policy adoption require input from advocates and policy makers who understand the range of possible policy options and the kinds of evidence needed to influence the debate.
A key consideration is whether an innovation is likely to scale well. For example, complex, high-touch, expensive intervention programs may be difficult to implement at a scale that will have substantial population health impact. Considerations of scalability should lead researchers—even people working on theory-building interventions—to focus efforts on particular types of risk factors and exposures amenable to scaling. Interventions that depend on individual adoption of long-term behavior change (e.g., increased exercise) without changing the context and resources that facilitate or create barriers to those behaviors are often ineffective. One approach, developed by the World Health Organization, involves itemizing seven characteristics of scalable interventions (using the acronym CORRECT): Credible and based on sound evidence; Observably effective; Relevant for addressing the problems experienced by stakeholders; Relatively better than other options; Easy and simple to understand and adopt; Compatible with stakeholders’ established values, norms, and practices; and Testable so stakeholders can see the results (World Health Organization, 2010). Another approach to addressing the problem, seen in the National Institute of Health’s Science of Behavior Change initiative,7 focuses on the small effect sizes common in individual-level interventions.
Formal training programs related to implementation science, which include teaching about developing theory-guided interventions, evidence dissemination, and intentional consideration of how to account for implementation
___________________
settings, have emerged in recent years. This movement has been valuable but will benefit from formal attention to causal inference and adoption of tools from multiple disciplines, including domains outside the typical sphere of clinical or epidemiologic research: communications, economics, policy analysis, legal scholarship, human factors psychology, and organizational psychology.
Because there is currently no effective treatment for dementia and many individuals will survive for many years after diagnosis, interventions to improve quality of life are particularly important (Karlawish, 2021).8 Like other interventions, those designed to improve quality of life require rigorous study designs that integrate qualitative and quantitative methods to improve quality and allow for adaptation of programs to accommodate context-specific constraints and modifications based on what is learned.
Conducting Pragmatic Clinical Trials Embedded in Health Systems
Traditional explanatory RCTs are designed to evaluate whether an intervention can improve health outcomes under ideal, highly controlled conditions. In the case of nonpharmacologic interventions, research staff deliver the intervention under strict protocols that are generally more intensive and focused relative to similar services provided by health care personnel in such normal settings as hospitals, nursing homes, and physicians’ offices. Efficacy trials of nonpharmacologic interventions are expensive and often underpowered, and they commonly generate findings that are not applicable to normal practice (Scales et al., 2018). In contrast, pragmatic clinical trials are embedded in functioning health care systems and are designed to evaluate the effectiveness of interventions implemented under real-world conditions.9
Typically, researchers conducting pragmatic trials randomize and deliver the intervention at the level of the unit of care (e.g., nursing home, physician practice) rather than the individual (Mitchell et al., 2020, p. S2). In addition, the intervention is implemented as part of the delivery of routine clinical care rather than by researchers under artificial circumstances. Instead of enrolling
___________________
8 A 2021 National Academies of Sciences, Engineering, and Medicine report, Meeting the Challenge of Caring for Persons Living with Dementia and Their Care Partners and Caregivers, notes that the results of the systematic review conducted for that report reflect the high uncertainty about benefits of all interventions other than REACH II and collaborative care models. The report does not imply that the other interventions were found to be ineffective; rather, the high uncertainty on which the review’s results were based was due to limitations of the evidence base and the approach used in the review to support conclusions on readiness for implementation and dissemination (National Academies of Sciences, Engineering, and Medicine 2021).
9 The Pragmatic Explanatory Continuum Indicator Summary (PRECIS)-2 framework describes how pragmatic and efficacy trials differ across nine domains, illustrating that most trial design features lie somewhere along the continuum between pragmatic and explanatory; see https://www.precis-2.org.
highly selected participants, such trials minimize restrictive eligibility criteria and attempt to expand recruitment to all individuals receiving care in a particular setting. Researchers using pragmatic trials also aim to leverage existing administrative or electronic health records to identify participants and ascertain outcomes, avoiding the need for a special research infrastructure to collect data. Intervention delivery, participant follow-up, and adherence are typically more flexible and closely aligned with usual care (Mitchell et al., 2020, p. S2). In many cases, people in settings randomly assigned to the control group need not even know they are part of a research study, as their care processes are not affected in any way (Mitchell et al., 2021).
Relative to researcher-implemented trials, pragmatic trials must be undertaken in close collaboration with the health care system. The clinical care problem being addressed must be salient to the system and to the providers on the front line of care. The saliency of the problem of meeting the needs of persons living with dementia and their caregivers will, of course, vary as a function of their prevalence in the care setting. Thus, any individual primary care practice may have relatively few such patients; caring for them may be more time-consuming than caring for other patients but not enough so to require restructuring of the practice’s workflow. On the other hand, emergency departments in urban settings or acute care hospitals may be confronted daily with the inadequacy of current models for caring for persons living with dementia, and so may be motivated to test the effectiveness of various interventions to ameliorate the challenges they face in caring for these individuals.
Interventions in such pragmatic trials need not be restricted to hospitals, nursing homes, or other traditional health care systems. Exercise programs or even caregiver support groups, whether in person or online, can be delivered by community-based organizations and may even be paid for under arrangements in Medicare Advantage plans that now may cover nonmedical services. Many such insurance plans already have discounted membership relationships with health clubs, which could be the perfect vehicle for implementing pragmatic trials designed to deliver exercise and other social support programs to older persons at risk of cognitive impairment. These kinds of efforts are likely to be become more common as the line between medical and nonmedical health services blurs, making it possible to evaluate rigorously the effectiveness of these kinds of services.
The discrepancy between intent-to-treat effect estimates (the effect of randomization) and per-protocol effect estimates (the effect that would have occurred had everyone adhered to the assigned treatment) that is typically observed in any randomized study can be especially large in a pragmatic trial. Since researchers using pragmatic trials hope to apply relatively few exclusion criteria and may need to recruit a large number of providers to be part of the study, many providers may fail to implement the intervention protocol as designed and intended. As a result, statistical power is reduced,
and the likelihood of detecting the hypothesized effect is small. Engaging with the health care system at all levels is thus important to improve intervention fidelity. Augmenting intent-to-treat analyses with analyses based on instrumental variables or identifying adherent subgroups based on prerandomization characteristics can yield additional relevant effect estimates.
Thus, even though sample sizes will be very large, and the population of providers and patients will be much more representative than is the case in researcher-based trials, the challenges of implementing pragmatic trials can be considerable. Implementation science—study of the processes necessary to implement an intervention effectively at scale—is coming into its own, but its application to the field of dementia care is in its infancy. Work in this area will be needed to support the translation of interventions that are efficacious into the real world of health care systems serving the population of persons living with dementia.
Evaluating Complex, Dynamic Interventions
Community-based initiatives are often developed by the communities involved and funded by nonresearch sources. These programs are designed to meet the social service or health needs of a specified population rather than to generate knowledge that can be generalized to other settings. Thus, these programs are highly relevant to the local community, including accommodating diversity and encouraging the widest possible participation. Their evaluation, however, is frequently limited to counts of participants and other descriptive or process measures rather than assessment of impact. The Dementia Friendly America Program mentioned in Chapter 5 is an example of such an initiative (Dementia Friendly America, 2021).
Although some efforts have been made to bridge science and service programs (e.g., community-based participatory research), challenges based on the cultures and regulations of the different approaches and goals remain. For example, most research on effectiveness places additional demands on participants (e.g., responding to surveys) and may require informed consent. Some people interested in participation may be excluded based on entry criteria. Randomization or other assignment methods may be needed to establish appropriate comparison groups, which may further discourage participation.
The location of the program’s base is also an important factor. Academic institutions have infrastructure to support research but frequently do not have the community contacts needed to implement programs or the trust of the community. Conversely, community-based programs are usually highly pragmatic, allowing considerable flexibility in implementation instead of requiring adherence to strict protocols that may be needed to draw conclusion about effectiveness. Methods for promoting the implementation
and evaluation of these programs with respect to participants’ health and well-being while minimizing their burden are needed.
Simulations, Microsimulations, Agent-Based Models, and Complex Systems Models
A host of methods that generally fall under the umbrella of complex systems methods—including agent-based models, dynamic models (also known as mathematical or mechanistic models), and dynamic microsimulation models—may prove valuable for examining the possible consequences of certain interventions. In simple causal structures, these models may be equivalent to conventional regression modeling approaches (see, e.g., Ackley et al., 2017), but dynamic models can sometimes more easily represent known biological constraints on a data-generating structure, allow for feedback processes in which variables influence one another in near-continuous time, and represent emergent processes that would not be manifest when individual units are considered in isolation. Many of these methods have been widely used in infectious disease epidemiology but less frequently in chronic disease research (Murray et al., 2017). One challenge for agent-based models, for example, is that they require inputs for parameter values that are typically drawn from conventional observational studies.
Modeling and simulation techniques have been used to support policy through models of dementia prevalence and costs and how they are affected by innovations and changing population health. Dynamic microsimulation models individual-level actions but can then illustrate how community-level patterns may emerge from individual-level decision rules. Agent-based models may provide additional insight by including interactions among individuals, such as patients and physicians or patients and family caregivers. The full value of these methods for dementia research is as yet unclear, but they certainly hold promise. Researchers will need training in these domains as well as expertise in the substantive problems in dementia research to take advantage of these methods.
Formalizing Study Design Approaches
A formal framework is useful for understanding how study design should guide the selection of acceptable exposure and outcome measures. For example, some exposure–outcome measures (e.g., retirement effects on mild cognitive impairment) may be more vulnerable than others to reverse causation (i.e., if early memory loss leads to early retirement), an issue that could be addressed with different choices of measures (e.g., a statutory retirement age requirement or longitudinal cognitive change). Similarly, measurement invariance (the principle that a measurement instrument is
capturing the same construct across different subgroups) is a challenge for both exposure and outcome measures. Large samples are needed to evaluate the assumption of measurement invariance, and qualitative methods can be valuable for understanding whether violations are likely and if so, how to correct them. Issues of mode effects—the possibility that people perform differently on a measurement instrument if it is administered in person versus over the phone or on a computer—emerged very strongly in the context of the COVID-19 pandemic.
Currently, researchers have a very ad hoc strategy for selecting study designs and are driven as much by the convenience of an approach or access to data as by scientific priority based on the available evidence and limitations of prior studies. Figure 8-2 illustrates these trade-offs. For example, if the most important challenge in studying, say, participant experiences or the information to be gleaned from biomarkers is
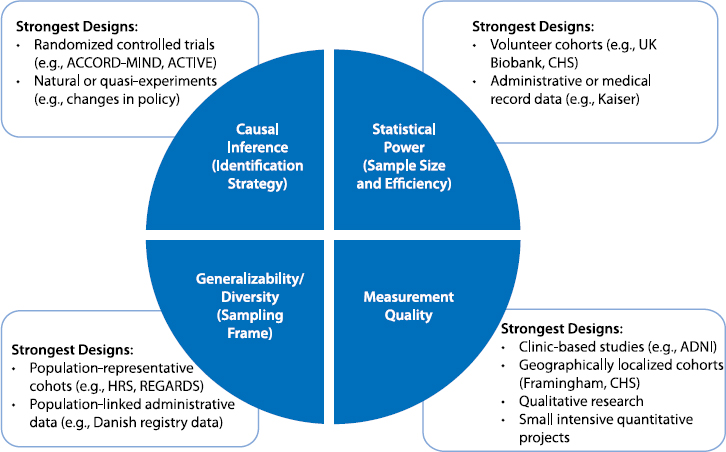
NOTES: The text in the blue wedges refers to the study design issues or priorities (with examples of how these concepts are referred to in different disciplines); the examples in the white boxes refer to the types of data sources that are typically strongest with respect to this dimension of good study design. ACCORD-MIND = Action to Control Cardiovascular Risk in Diabetes Memory in Diabetes study; ACTIVE = Advanced Cognitive Training for Independent and Vital Elderly study; ADNI = Alzheimer’s Disease Neuroimaging Initiative; CHS = Cardiovascular Health Study; HRS = Health and Retirement Study; REGARDS = Reasons for Geographic and Racial Differences in Stroke study.
measurement, large population-representative cohorts are unlikely to provide the best approach. The strongest study designs might include qualitative work to yield richer understanding of participant experiences. In the study of technical biomarkers, clinic-based or geographically restricted studies may be best. But it should be recognized that in making such choices, researchers may be compromising on the generalizability of the sample, diversity of inclusion, statistical power, and often causal identification strategies. Likewise, convenience sampling, such as that used in the UK Biobank or All of Us, may increase sample size and therefore statistical power, but at the cost of representativeness. Special attention in such studies (as in All of Us) may help in addressing these issues by aggressively recruiting from underrepresented communities. It is unclear to what extent this recruitment is as good as representative sampling or leads to new types of selection bias—the answer would depend on the setting.
Evidence Integration
Evidence integration, drawing on research triangulation, refers to the idea of combining findings from multiple studies with complementary strengths and weaknesses to develop a better understanding of a problem (Lawlor et al., 2017). Research triangulation is an intentional process of proposing new study designs that address the weaknesses of prior work, for example, by using negative controls, instrumental variables, or study populations with very likely different patterns of confounding. This process is the essence of scientific thinking but is often conducted informally. Recognition of the importance of systematic, principled approaches to evidence integration is growing in part because the sheer volume of research is expanding. Moreover, traditional perspectives on the hierarchy of evidence (with RCTs recognized as providing the highest-quality evidence) are being challenged because excellent, well-conducted RCTs are often not feasible for important research questions. And even with excellent RCTs, findings may not be conclusive because participant samples are small or unrepresentative, follow-up time is relatively short, or there is uncertainty about how variations in the treatment might influence findings. Thus, it is important to supplement even evidence from RCTs with observational evidence. Perfect studies are rare, moreover, and the more similar two studies are, the more likely it is that they share the same limitations. There is often a direct trade-off between desirable study features, such as sample size and quality of measurement. For most important questions, then, it is necessary to patch together evidence from work that uses varied study designs and populations and varies in other research characteristics as well.
Methods for Assessing Heterogeneity and Generalizing Results
Generalizing from study samples to new populations is essential. Major discrepancies between general-population characteristics and the characteristics of people who participate in research studies have been well documented in comparisons of RCTs and clinic-based observational studies, and are also a concern when more or less data-intensive observational studies are compared (Gianattasio et al., 2021). These differences are not well understood, and there has been little effort to date to compare effect estimates formally across highly selected and less-selected samples. This is an area in which machine learning methods may be useful, in that exploratory evaluations across a wide swath of possible modifiers may be enlightening. Although machine learning methods have focused predominantly on prediction questions, recent applications in the context of causal questions have been important (Athey, 2015; Wager and Athey, 2018).
A growing array of quantitative tools can aid in generalizing findings from a study sample to a target population. These tools depend on understanding the drivers of selection, the potential modifiers, and the availability of relevant measures for both study samples and the target population (Bareinboim and Pearl, 2016). Rapid progress on methods for addressing such problems has not yet been widely seen in dementia research (Bareinboim and Pearl, 2016; Westreich et al., 2017, 2019). These methods would help clarify whether what is learned from the often highly selected participants in RCTs is applicable more broadly. They also would indicate whether meaningful heterogeneity exists across populations with respect to predictors of disease incidence or outcomes, and whether this heterogeneity can be accounted for by incorporating sociodemographic, behavioral, or contextual modifiers. For these methods to be successful, however, it will be essential to model and understand the selection process. Unfortunately, the selection mechanisms for convenience samples are opaque and difficult to model well. Just as new data linkages will support novel exposure assessments, new data linkages can also be valuable for investigating heterogeneity and generalizing results beyond the selected samples in some datasets.
Tools for Systematically Combining Evidence
Only a few methods are currently available for systematically combining evidence from multiple sources, and these tools are woefully limited and underused. Meta-analyses emphasize selection of highly parallel studies with similar exposure and outcome definitions and study designs. Meta-analyses are thus of limited utility in evidence integration, which focuses on combining results from varied study designs. Meta-analyses can be especially challenging in dementia research because the studies
considered may use quite different methods to address the same question based on the disciplinary background of the researcher, the data available, or particular analytic approaches. Meta-regression methods are used to address a narrow slice of questions related to ways in which easily quantified and routinely reported variables modify the analysis findings. Most meta-analyses give limited attention to evaluating the biases implicit in various study designs and the extent to which different studies address those biases. Better tools are therefore needed for triangulating evidence and quantifying how findings from different study designs fit together.
Needed, for example, are tools with which to establish a crosswalk between studies with different but conceptually related exposure and outcome measures (i.e., to create a mapping between measures that correspond with each other in the two studies and ideally illustrate how transformations can make the measures directly comparable). Modern psychometric methods foster specification of latent variables to allow data pooling but are still underused. Because datasets typically specialize in careful measurement of some but not all domains and/or recruitment of specific populations, ways to analyze heterogeneous datasets jointly are another need.
Still another valuable set of tools facilitates quantification and correction of bias from various sources. For example, “borrowing” of bias estimates across studies so that information on confounding or selection bias from a study with good measures could be used to estimate and correct that bias in a study without such measures could be powerful. Bias quantification might be based on simulations or simple, intuitive calculations (Mayeda et al., 2016; VanderWeele and Ding, 2017). Such statistical tools as reweighting are a standard approach to addressing selection bias. Improvements to basic weighting tools can yield better understanding of the selection process. (Methods building on Robins’ g-formula and formalization of counterfactual frameworks can avoid bias or provide simpler ways to quantify bias and extend results from one sample to another; see VanderWeele et al., 2008; Danaei et al., 2016; Dahabreh et al., 2019.) Newer data sources (e.g., social media data; financial transaction data; convenience cohorts, such as those used by UK Biobank or All of Us) have strong selection processes, but the impact of these processes on research results is unclear and likely varies across settings. There is currently no standardized approach to evaluating concerns about selection bias.
Tools for Quantifying Impacts of Policies, Interventions, or Therapies
A disconnect exists between the typical structure of research results (which present, for example, differences in the likelihood of an outcome for different groups, or hazard ratios) and important measures of impact relevant to dementia. In general, outcome measures must be thoughtfully
matched to the question at hand. Hazard ratios may be useful for understanding the magnitude of a causal effect but are less useful for personal or policy decision making. Thus, measures that take into account absolute as well as relative risk at both the individual and population levels and account for a broad array of outcomes may be more useful. For example, cost/benefit analyses may provide insight into the broader impact of policy changes in monetary terms, or decision analytic tools may help individuals understand the consequences of behavioral changes in terms of their own personal values or quality of life.
Important diagnostic and therapeutic innovations on the horizon, such as new imaging modalities, fluid biomarkers, and pharmacologic treatments (see Chapter 3), illustrate the importance of tools for quantifying broad impacts. Such innovations may have important clinical consequences, but some will likely have marginal clinical benefit. Thus, diagnostic innovations need to be scrutinized specifically in relation to the potential therapeutic options and the potential impact of those treatments for patients who are identified as at high risk for dementia long before symptoms are evident. Beyond the clinical impacts, technical innovations may alter the social costs of dementia, change the landscape of research, and influence disparities.
It has been noted that diagnosing Alzheimer’s disease using only a neuroimaging biomarker exposes people to adverse effects and complications, and, particularly when diagnosis is based solely on biomarker evidence, many people receive completely ineffective treatment (Langa and Burke, 2019). By one estimate, one-half of adults with preclinical Alzheimer’s disease are treated with medications priced in the same range as monoclonal antibody drugs to treat cholesterol, which would represent nearly one-third of 2017 total costs for retail prescriptions. Another recent estimate is that if just one-fourth of Medicare beneficiaries currently taking Alzheimer’s treatments covered under Part D were prescribed aducanumab, the drug approved by the U.S. Food and Drug Administration just as this report was going to press (see Chapter 9), the cost of drug alone, apart from associated delivery costs, could be $29 billion annually (current total Medicare spending for Part B drugs is $37 billion) (Cubanski and Neuman, 2021). In addition, Medicare beneficiaries would likely face approximately $11,500 in coinsurance costs, or approximately 40 percent of the median annual income of Medicare beneficiaries.
The criteria for the clinical importance of innovations need always to be based on patient- and family-centered outcomes related to quality and length of life. Therefore, tools that can quantify these impacts more easily are needed. It is important to note here that, because of the high costs of some technical innovations, their widespread adoption could result in the displacement of established and effective lower-cost alternatives, such as supportive services. In addition, defining disease in terms of the presence
of a biomarker could lead to use of the biomarker as a surrogate outcome in trials of new therapies. Such a change would be troubling. For example, evidence from prior RCTs indicates that it is possible to change biomarker indicators of Alzheimer’s without offering clinical benefit (Ackley et al., 2021; Richard et al., 2021). Likewise, the adoption of marginally beneficial diagnostic or therapeutic tools could have a chilling effect on future research to identify effective options or evaluate adverse consequences of medications approved on the basis of minimal evidence (Musiek and Morris, 2021). These problems raise questions of social policy and regulatory design, solidly within the domain of social science research.
It is well established that new technologies in any health domain have the potential to exacerbate inequalities because those individuals who already have resources are best positioned to take advantage of new tools (Phelan and Link, 2005; Phelan et al., 2004, 2010). Anticipating such consequences for equity and proposing policy and systems solutions to ameliorate them are important responsibilities for researchers. Other technical innovations (e.g., low-cost fluid biomarkers) hold promise for improving health equity by promoting access to diagnostic information and improving the inclusivity of biomarker-based research. As discussed in Chapter 3, however, such innovations may bring their own ethical challenges and social consequences. For example, what are the consequences of informing a large fraction of middle-aged adults that they have biomarkers indicating that they could develop Alzheimer’s disease when it is not possible to inform them of how likely that outcome is or offer meaningful treatment to delay or prevent symptoms?
Simulation studies may be important tools for helping to anticipate the effects of complex developments in dementia care and treatment and integrate evidence from disparate types of studies. Dynamic microsimulations for cognitive decline and dementia could support the development of both U.S. and international projections of dementia prevalence and costs associated with new diagnostics and treatments, changes in population health, and changes in policies affecting people living with dementia and their caregivers (Zissimopoulos et al., 2014, 2018). Simulations often depend on valid input assumptions from other study designs. Also essential to note is that these tools will not work without data on the “target” population. Thus, a key priority is ensuring that major data sources include sufficient diversity to support well-powered analyses of racial/ethnic groups and intersectionally defined identities. Attention to intersectionality—the multiple identities individuals have that may each interact in shaping health risk or resilience—is essential. For example, it is important to study not only broad racial/ethnic differences in the incidence of and prognosis for dementia but also how they may be different for men versus women, or for gay versus straight men.
Finally, even when interventions are demonstrated to work in the setting of a trial, they may not scale well to new settings. Research is needed to understand what types of interventions scale, and scalable interventions are a research priority. Evaluation of interventions also needs to incorporate potential population impact.
INVESTMENT IN HUMAN CAPITAL AND RESEARCH CAPACITY
None of the above suggestions are feasible without research leaders who have the needed skills, including proficiency with quantitative and qualitative methodologies, applied understanding of the needs of people living with dementia and their networks, insights into biological mechanisms relevant to disease incidence and progression, and skills related to dissemination and implementation. Applicable methods are evolving rapidly, so even recently trained researchers need ways to constantly update and improve their knowledge. Training often occurs in research silos, without clear communication across disciplines. For example, instrumental variables and quasi-experimental methods are not part of the core quantitative methods covered in typical epidemiology training but are central tools for economics. Clinician-scientists are essential to the research workforce but often receive shockingly limited training in statistical methods. On the opposite end of the spectrum, many quantitative methodologists receive almost no exposure to applied or clinical settings where their evidence would be used, which inevitably reduces the impact of their work. Scientific communication and dissemination training is often minimal and may even be considered a problematic distraction from research. Moreover, the lack of racial/ethnic and socioeconomic diversity in the health research workforce has been widely recognized as a major barrier to progress and is equally problematic in dementia research.
Efforts to build researchers’ capacity to design and run pragmatic trials, such as the IMbedded Pragmatic Alzheimer’s disease and Alzheimer’s disease-related dementias Clinical Trials Collaboratory (IMPACT), are promising. IMPACT focuses on developing and disseminating best-practice research methods, including giving due attention to inclusive and representative methods, supporting pilot studies for pragmatic trials, taking account of issues of training and knowledge generation, and catalyzing collaboration. Smaller initiatives have also proven useful but provide fewer direct training activities. Institutional training grants restrict the training period in ways that make truly challenging interdisciplinary experiences less likely. The typical cost of living for students also discourages extended training activities and restricts the pipeline of researchers because of the need for substantial subsidies. Despite these challenges, networks dedicated to interdisciplinary training and combining substantive
and technical skills, such as the Training in Advanced Data and Analytics for Behavioral and Social Sciences Research Program, can have powerful influences on the field. Investing in training, across the career spectrum, pays off.
RESEARCH DIRECTIONS
This is a moment of opportunity for investments in strengthening research methods for the study of dementia in four areas: data sources that support new, more inclusive, and more rigorous research; measurement of factors that influence both dementia risk and progression, of patient- and family-centered outcomes related to dementia, and of outcomes that are appropriate for diverse populations and settings; study designs that offer greater rigor and relevance to diverse populations; and meta-research methods with which to integrate disparate sources of evidence and guide decision making.
These opportunities are interrelated: better data sources will support the development of more rigorous study designs; innovations in measurement will make previously nonviable data sources potentially useful; and thinking about the weaknesses implicit in any single study will help researchers better integrate the available evidence to provide guidance for the development of systems, policies, and interventions to prevent dementia, improve prognosis and quality of life for people living with dementia, and ameliorate the adverse consequences of the disease for families and society. Advances in these areas will be relevant to and strengthen research in every area discussed in this report. Social and behavioral scientists from numerous specific disciplines are the natural leaders in meeting these methodological challenges.
The committee identified five priority areas for research in the domain of improved methodologies for dementia research. These priorities are summarized in Conclusion 8-1 and detailed in Table 8-1.
CONCLUSION 8-1: Advances in research methodology are needed to support progress in virtually every domain of dementia research. Progress in five areas will support a research agenda to reduce the negative impacts of dementia by strengthening data collection and research methodology:
- Expansion of data infrastructure.
- Improved measurement of exposures and outcomes.
- Support for the adoption of more rigorous study designs, particularly in the realm of implementation science, so that research findings can be successfully integrated into clinical and community practices.
- Development of systematic approaches for integrating evidence from disparate studies.
- Improved inclusion and representation among both research participants and researchers.
TABLE 8-1 Detailed Research Needs
| 1: Expansion of Data Infrastructure |
|
| 2: Improved Measurement |
|
| 3: Support for the Adoption of More Rigorous Study Designs |
|
| 4: Development of Systematic Approaches for Evidence Integration |
|
| 5: Improved Inclusion and Representation Among Research Participants and Researchers |
|
REFERENCES
Ackley, S., Mayeda, E., Worden, L., Enanoria, W., Glymour, M., and Porco, T. (2017). Compartmental model diagrams as causal representations in relation to DAGs. Epidemiologic Methods, 6(1), 20160007. https://doi.org/10.1515/em-2016-0007
Ackley, S.F., Zimmerman, S.C., Brenowitz, W.D., T chetgen, E.J., Gold, A.L., Manly, J.J., Mayeda, E.R., Filshtein, T.J., Power, M.C., Elahi, F.M., and Brickman, A.M. (2021). Effect of reductions in amyloid levels on cognitive change in randomized trials: Instrumental variable meta-analysis. British Medical Journal, 372(156). https://doi.org/10.1136/bmj.n156
Athey, S. (2015). Machine learning and causal inference for policy evaluation. Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 5–6. https://doi.org/10.1145/2783258.2785466
Bareinboim, E., and Pearl, J. (2016). Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences, 113(27), 7345–7352. https://doi.org/10.1073/pnas.1510507113
Bärnighausen, T., Røttingen, J.A., Rockers, P., Shemilt, I., and Tugwell, P. (2017). Quasi-experimental study designs series—Paper 1: Introduction: Two historical lineages. Journal of Clinical Epidemiology, 89, 4–11. https://doi.org/10.1016/j.jclinepi.2017.02.020
Beekly, D.L., Ramos, E.M., van Belle, G., Deitrich, W., Clark, A.D., Jacka, M.E., and Kukull, W.A. (2004). The National Alzheimer’s Coordinating Center (NACC) database: An Alzheimer disease database. Alzheimer Disease & Associated Disorders, 18(4), 270–277.
Berkman, L.F. (1986). The association between educational attainment and mental status examinations: Of etiologic significance for senile dementias or not? Journal of Chronic Diseases, 39(3), 171–174.
Besser, L., Kukull, W., Knopman, D., Chui, H., Galasko, D., Weintraub, S., Jicha, G., Carlsson, C., Burns, J., Quinn, J., Sweet, R., Rascovsky, K., Teylan, M., Beekly, D., Thomas, G., Bollenbeck, M., Monsell, S., Mock, C., Zhou, X., Thomas, N., Robichaud, E., Dean, M., Hubbard, J., Jacka, M., Schwabe-Fry, K., Wu, J., Phelps, C., and Morris, J.C. (2018). The neuropsychology work group, directors, and clinical core leaders of the National Institute on Aging-funded US Alzheimer’s disease centers version 3 of the National Alzheimer’s Coordinating Center’s uniform data set. Alzheimer Disease & Associated Disorders 32(4), 351–358. https://doi.org/10.1097/WAD.0000000000000279
Bild, D.E., Bluemke, D.A., Burke, G.L., Detrano, R., Diez Roux, A.V., Folsom, A.R., Greenland, P., Jacobs Jr., D.R., Kronmal, R., Liu, K., and Nelson, J.C. (2002). Multiethnic study of atherosclerosis: Objectives and design. American Journal of Epidemiology, 156(9), 871–881.
Brewster, P., Barnes, L., Haan, M., Johnson, J.K., Manly, J.J., Nápoles, A.M., Whitmer, R.A., Carvajal-Carmona, L., Early, D., Farias, S., and Mayeda, E.R. (2019). Progress and future challenges in aging and diversity research in the United States. Alzheimer’s & Dementia, 15(7), 995–1003.
Bynum, J.P.W., Dorr, D.A., Lima, J., McCarthy, E.P., McCreedy, E., Platt, R., and Vydiswaran, V.G.V. (2020). Using healthcare data in embedded pragmatic clinical trials among people living with dementia and their caregivers: State of the art. Journal of the American Geriatrics Society, 68(Suppl 2), S49–S54. https://doi.org/10.1111/jgs.16617
Caniglia, E.C., Rojas-Saunero, L.P., Hilal, S., Licher, S., Logan, R., Stricker, B., Ikram, M.A., and Swanson, S.A. (2020). Emulating a target trial of statin use and risk of dementia using cohort data. Neurology, 95(10):e1322–1332.
Cubanski, J., and Neuman, T. (2021). FDA’s approval of Biogen’s new Alzheimer’s drug has huge cost implications for Medicare beneficiaries. Kaiser Family Foundation. https://www.kff.org/medicare/issue-brief/fdas-approval-of-biogens-new-alzheimers-drug-has-huge-cost-implications-for-medicare-and-beneficiaries
Dahabreh, I.J., Robins, J.M., Haneuse, S.J., and Hernán, M.A. (2019). Generalizing causal inferences from randomized trials: Counterfactual and graphical identification. arXiv, 1906.10792.
Dahabreh, I.J., Haneuse, S.J.P.A., Robins, J.M., Robertson, S.E., Buchanan, A.L., Stuart, E.A., and Hernán, M.A. (2021). Study designs for extending causal inferences from a randomized trial to a target population. American Journal of Epidemiology, 190(8), 1632–1642. https://doi.org/10.1093/aje/kwaa270
Dahl, A., Berg, S., and Nilsson, S.E. (2007). Identification of dementia in epidemiological research: A study on the usefulness of various data sources. Aging Clinical and Experimental Research, 19(5), 381–389.
Danaei, G., Robins, J.M., Young, J., Hu, F.B., Manson, J.E., and Hernán, M.A. (2016). Estimated effect of weight loss on risk of coronary heart disease and mortality in middle-aged or older women: Sensitivity analysis for unmeasured confounding by undiagnosed disease. Epidemiology, 27(2), 302.
Dankwa-Mullan, I., Pérez-Stable, E., Gardner, K., Zhang, X., and Rosario, A. (Eds.). (2021). The Science of Health Disparities Research. Hoboken, NJ: John Wiley and Sons.
Dementia Friendly America. (2021). What is DFA? https://www.dfamerica.org/what-is-dfa
Fried, L.P., Borhani, N.O., Enright, P., Furberg, C.D., Gardin, J.M., Kronmal, R.A., Kuller, L.H., Manolio, T.A., Mittelmark, M.B., Newman, A., and O’Leary, D.H. (1991). The cardiovascular health study: Design and rationale. Annals of Epidemiology, 1(3), 263–276.
Fry, A., Littlejohns, T.J., Sudlow, C., Doherty, N., Adamska, L., Sprosen, T., Collins, R., and Allen, N.E. (2017). Comparison of sociodemographic and health-related characteristics of UK Biobank participants with those of the general population. American Journal of Epidemiology, 186(9), 1026–1034.
Gershon, R., Nowinski, C., Peipert, J.D., Bedjeti, K., Ustsinovich, V., Hook, J., Fox, R., and Weintraub, S. (2020). Use of the NIH Toolbox for assessment of mild cognitive impairment and Alzheimer’s disease in general population, African American and Spanish speaking samples of older adults: Neuropsychology: Cognitive and functional assessment in diverse populations. Alzheimer’s & Dementia, 16(S6), e043372. https://doi.org/10.1002/alz.043372
Gianattasio, K.Z., Wu, Q., Glymour, M.M., and Power, M.C. (2019). Comparison of methods for algorithmic classification of dementia status in the Health and Retirement Study. Epidemiology, 30(2), 291.
Gianattasio, K.Z., Ciarleglio, A., and Power, M.C. (2020). Development of algorithmic dementia ascertainment for racial/ethnic disparities research in the US Health and Retirement Study. Epidemiology, 31(1), 126–133.
Gianattasio, K.Z., Bennett, E.E., Wei, J., Mehrotra, M.L., Mosley, T., Gottesman, R.F., Wong, D.F., Stuart, E.A., Griswold, M.E., Couper, D., and Glymour, M.M. (2021). Generalizability of findings from a clinical sample to a community-based sample: A comparison of ADNI and ARIC. Alzheimer’s & Dementia. https://doi.org/10.1002/alz.12293
Gilmore-Bykovskyi, A., Jackson, J.D., and Wilkins, C.H. (2021). The urgency of justice in research: Beyond COVID-19. Trends in Molecular Medicine, 27(2), 97–100. https://doi.org/10.1016/j.molmed.2020.11.004
Glasgow, R.E., Vinson, C., Chambers, D., Khoury, M.J., Kaplan, R.M., and Hunter, C. (2012). National Institutes of Health approaches to dissemination and implementation science: Current and future directions. American Journal of Public Health, 102(7), 1274–1281.
Glymour, M.M., Walter, S., and T chetgen T chetgen, E.J. (2017). Natural experiments and instrumental variables analyses in social epidemiology. In J. Oakes and J. Kaufman (Eds.), Methods in Social Epidemiology (pp. 493–537). Hoboken, NJ: John Wiley & Sons.
Glymour, M.M., Brickman, A.M., Kivimaki, M., Mayeda, E.R., Chêne, G., Dufouil, C., and Manly, J.J. (2018). Will biomarker-based diagnosis of Alzheimer’s disease maximize scientific progress? Evaluating proposed diagnostic criteria. European Journal of Epidemiology, 33(7), 607–612.
Green, L.W., Ottoson, J.M., Garcia, C., and Hiatt, R.A. (2009). Diffusion theory and knowledge dissemination, utilization, and integration in public health. Annual Review of Public Health, 30, 151–174. https://doi.org/10.1146/annurev.publhealth.031308.100049
Green, L.W., Ottoson, J.M., García, C., Hiatt, R.A., and Roditis, M.L. (2014). Diffusion theory and knowledge dissemination, utilization and integration. Frontiers in Public Health Services & Systems Research, 3(1), 3.
Gross, A.L., Khobragade, P.Y., Meijer, E., and Saxton, J.A. (2020). Measurement and structure of cognition in the Longitudinal Aging Study in India–Diagnostic Assessment of Dementia. Journal of the American Geriatrics Society, 68(S3), S11–S19. https://doi.org/10.1111/jgs.16738
Handley, M.A., Lyles, C.R., McCulloch, C., and Cattamanchi, A. (2018). Selecting and improving quasi-experimental designs in effectiveness and implementation research. Annual Review of Public Health, 39, 5–25. https://doi.org/10.1146/annurev-publhealth-040617-014128
Haneuse, S., and Daniels, M. (2016). A general framework for considering selection bias in EHR-Based studies: What data are observed and why? Journal of Electronic Health Data and Methods, 4(1), 1203. https://doi.org/10.13063/2327-9214.1203
Hernán, M., Brumback, B., and Robins, J. (2000). Marginal structural models to estimate the causal effect of zidovudine on the survival of HIV-positive men. Epidemiology, 11(5), 561–570. https://doi.org/10.1097/00001648-200009000-00012
Hernán, M., Hernández-Díaz, S., and Robins, J. (2004). A structural approach to selection bias. Epidemiology, 15(5), 615–625. https://doi.org/10.1097/01.ede.0000135174.63482.43
Hernán, M.A., Alonso, A., Logan, R., Grodstein, F., Michels, K.B., Stampfer, M.J., Willett, W.C., Manson, J.E., and Robins, J.M. (2008). Observational studies analyzed like randomized experiments: An application to postmenopausal hormone therapy and coronary heart disease. Epidemiology, 19(6), 766.
Hernán, M.A., Robins, J.M. (2016). Using big data to emulate a target trial when a randomized trial Is not available, American Journal of Epidemiology,183(8), 758–764, https://doi.org/10.1093/aje/kwv254
Jack Jr., C.R., Bennett, D.A., Blennow, K., Carrillo, M.C., Dunn, B., Haeberlein, S.B., Holtzman, D.M., Jagust, W., Jessen, F., Karlawish, J., and Liu, E. (2018). NIA-AA research framework: Toward a biological definition of Alzheimer’s disease. Alzheimer’s & Dementia, 14(4), 535–562.
James, B.D., Boyle, P.A., Buchman, A.S., Barnes, L.L., and Bennett, D.A. (2011). Life space and risk of Alzheimer disease, mild cognitive impairment, and cognitive decline in old age. American Journal of Geriatric Psychiatry, 19(11), 961–969.
Jutkowitz, E., Bynum, J.P.W., Mitchell, S.L., Cocoros, N.M., Shapira, O., Haynes, K., Nair, V.P., McMahill-Walraven, C.N., Platt, R., and McCarthy, E.P. (2020). Diagnosed prevalence of Alzheimer’s disease and related dementias in Medicare Advantage plans. Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring, 12(1), e12048. https://doi.org/10.1002/dad2.12048
Karlawish, J. (2021). The Problem of Alzheimer’s: How Science, Culture, and Politics Turned a Rare Disease into a Crisis and What We Can Do About It. New York: St. Martin’s Press. https://us.macmillan.com/books/9781250218742
Kobayashi, L.C., Gross, A.L., Gibbons, L.E., Tommet, D., Sanders, R.E., Choi, S.E., Mukherjee, S., Glymour, M., Manly, J.J., Berkman, L.F., and Crane, P.K. (2020). You say tomato, I say radish: Can brief cognitive assessments in the US Health Retirement Study be harmonized with its International Partner Studies? Journals of Gerontology, Series B. https://doi.org/10.1093/geronb/gbaa205
Krysinska, K., Sachdev, P., Breitner, J., Kivipelto, M., Kukull, W., and Brodaty, H. (2017). Dementia registries around the globe and their applications: A systematic review. Alzheimer’s & Dementia, 13(9), 1031–1047. https://doi.org/10.1016/j.jalz.2017.04.005
Labrecque, J.A., and Swanson, S.A. (2017). Target trial emulation: Teaching epidemiology and beyond. European Journal of Epidemiology, 32(6), 473–475. https://doi.org/10.1093/aje/kwv254
Langa, K.M., and Burke, J.F. (2019). Preclinical Alzheimer disease—Early diagnosis or overdiagnosis? JAMA Internal Medicine, 179(9), 1161–1162. https://doi.org/10.1001/jamainternmed.2019.2629
Langa, K.M., Plassman, B.L., Wallace, R.B., Herzog, A.R., Heeringa, S.G., Ofstedal, M.B., Burke, J.R., Fisher, G.G., Fultz, N.H., Hurd, M.D., and Potter, G.G. (2005). The aging, demographics, and memory study: Study design and methods. Neuroepidemiology, 25(4), 181–191
Lawlor, D., Tilling, K., and Davey Smith, G. (2017). Triangulation in aetiological epidemiology. International Journal of Epidemiology, 45(6), 1866–1886. https://doi.org/10.1093/ije/dyw314
Matthay, E.C., Hagan, E., Gottlieb, L.M., Tan, M.L., Vlahov, D., Adler, N.E., and Glymour, M.M. (2020). Alternative causal inference methods in population health research: Evaluating tradeoffs and triangulating evidence. SSM-Population Health, 10, 100526. 10.1016/j. ssmph.2019.100526
Mayeda, E.R., T chetgen T chetgen, E.J., Power, M.C., Weuve, J., Jacqmin-Gadda, H., Marden, J.R., Vittinghoff, E., Keiding, N., and Glymour, M.M. (2016). A simulation platform for quantifying survival bias: An application to research on determinants of cognitive decline. American Journal of Epidemiology, 184(5), 378–387.
McCleery, J., Flicker, L., Richard, E., and Quinn, T. (2019). When is Alzheimer’s not dementia—Cochrane commentary on The National Institute on Ageing and Alzheimer’s Association Research Framework for Alzheimer’s Disease. Age and Ageing, 48(2), 174–177. https://doi.org/10.1093/ageing/afy167
McDonald, S., Hultsch, D., and Dixon, R. (2003). Performance variability is related to change in cognition: Evidence from the Victoria Longitudinal Study. Psychology and Aging, 18(3), 510–523. https://doi.org/10.1037/0882-7974.18.3.510
Mehrotra, M.L., Petersen, M.L., and Geng, E.H. (2019). Understanding HIV program effects: A structural approach to context using the transportability framework. Journal of Acquired Immune Deficiency Syndromes, 82, S199–S205.
Mitchell, S.L., Mor, V., Harrison, J., and McCarthy, E.P. (2020). Embedded pragmatic trials in dementia care: Realizing the vision of the NIA IMPACT Collaboratory. Journal of the American Geriatrics Society, 68(Suppl 2), S1–S7. https://doi.org/10.1111/jgs.16621
Mitchell, S., Volandes, A., Gutman, R., Gozalo, P., Ogarek, J., Loomer, L., McCreedy, E., Zhai, R., and Mor, V. (2021). Advance care planning video intervention among long-stay nursing home residents: A pragmatic cluster randomized clinical trial. JAMA Internal Medicine, 180(8), 1070–1078. https://doi.org/jamainternmed.2020.2366
Mukherjee, S., Mez, J., Trittschuh, E.H., Saykin, A.J., Gibbons, L.E., Fardo, D.W., Wessels, M., Bauman, J., Moore, M., Choi, S.E., and Gross, A.L. (2020). Genetic data and cognitively defined late-onset Alzheimer’s disease subgroups. Molecular Psychiatry, 25(11), 2942–2951.
Murray, E.J., Robins, J.M., Seage, G.R., Freedberg, K.A., and Hernán, M.A. (2017). A comparison of agent-based models and the parametric g-formula for causal inference. American Journal of Epidemiology, 186(2), 131–142.
Musiek, E.S., and Morris, J.C. (2021). Possible Consequences of the approval of a disease-modifying therapy for Alzheimer disease. JAMA Neurology, 78(2), 141–142. https://doi.org/10.1001/jamaneurol.2020.4478
National Academies of Sciences, Engineering, and Medicine (2021). Meeting the Challenge of Caring for Persons Living with Dementia and Their Care Partners and Caregivers: A Way Forward. Washington, DC: The National Academies Press. https://doi.org/10.17226/26026
NACC (National Alzheimer’s Coordinating Center). (2021). UDS Subject Demographics by Cognitive Status. https://naccdata.org/requesting-data/data-summary/uds
National Institutes of Health. (2021). All of Us Research Hub: The Basics Survey. https://databrowser.researchallofus.org/survey/the-basics
Nicholas, L.H., Langa, K.M., Bynum, J.P., and Hsu, J.W. (2021). Financial presentation of Alzheimer disease and related dementias. JAMA Internal Medicine, 181(2), 220–227.
Obermeyer, Z., Powers, B., Vogeli, C., and Mullainathan, S. (2019, October 25). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453. https://doi.org/10.1126/science.aax2342
Oldenburg, C.E., Moscoe, E., and Bärnighausen, T. (2016). Regression discontinuity for causal effect estimation in epidemiology. Current Epidemiology Reports, 3(3), 233–241.
Pearl, J. (2009). Causality: Models, Reasoning, and Inference. Cambridge: Cambridge University Press. http://bayes.cs.ucla.edu/BOOK-2K
Phelan, J.C., and Link, B.G. (2005). Controlling disease and creating disparities: A fundamental cause perspective. Journals of Gerontology, Series B, 60(Special_Issue_2), S27–S33.
Phelan, J.C., Link, B.G., Diez-Roux, A., Kawachi, I., and Levin B. (2004). “Fundamental causes” of social inequalities in mortality: A test of the theory. Journal of Health and Social Behavior, 45(3), 265–285.
Phelan, J.C., Link, B.G., and Tehranifar, P. (2010). Social conditions as fundamental causes of health inequalities: Theory, evidence, and policy implications. Journal of Health and Social Behavior, 51(Suppl 1), S28–S40.
Plassman, B., Langa, K., Fisher, G., Heeringa, S., Weir, D., Ofstedal, M.B., Burke, J., Hurd, M., Potter, G., Rodgers, W., Steffens, D., McArdle, J., Willis, R., and Wallace, R. (2008). Prevalence of cognitive impairment without dementia in the United States. Annals of Internal Medicine. https://doi.org/10.7326/0003-4819-148-6-200803180-00005
Power, M.C., Gianattasio, K.Z., and Ciarleglio, A. (2020). Implications of the use of algorithmic diagnoses or Medicare claims to ascertain dementia. Neuroepidemiology, 54(6), 462–471.
Richard, E., den Brok, M.G., and van Gool, W.A. (2021). Bayes analysis supports null hypothesis of anti amyloid beta therapy in Alzheimer’s disease. Alzheimer’s & Dementia, 17(6), 1051–1055. https://doi.org/10.1002/alz.12379
Robertson, S.E., Leith, A., Schmid, C.H., and Dahabreh, I.J. (2021). Assessing heterogeneity of treatment effects in observational studies. American Journal of Epidemiology, 190(6), 1088–1100. https://doi.org/10.1093/aje/kwaa235
Robins, J.M., Hernán, M., and Brumback, B. (2000). Marginal structural models and causal inference in epidemiology. Epidemiology, 11(5), 550–560. https://doi.org/10.1097/00001648-200009000-00011
Rojas-Saunero, L.P., Hilal, S., Murray, E.J., Logan, R.W., Ikram, M.A., and Swanson, S.A. (2021). Hypothetical blood-pressure-lowering interventions and risk of stroke and dementia. European Journal of Epidemiology, 36(1), 69–79.
Salganik, M. (2019). Bit by Bit: Social Research in the Digital Age. New Jersey: Princeton University Press.
Scales, K., Zimmerman, S., and Miller, S.J. (2018). Evidence-based nonpharmacological practices to address behavioral and psychological symptoms of dementia. Gerontologist, 58(1), S88–S102. https://doi.org/10.1093/geront/gnx167
Thorogood, A., Mäki-Petäjä-Leinonen, A., Brodaty, H., Dalpé, G., Gastmans, C., Gauthier, S., Gove, D., Harding, R., Knoppers, B., Rossor, M., and Bobrow, M. (2018). Consent recommendations for research and international data sharing involving persons with dementia. Alzheimer’s & Dementia, 14(10), 1334–1343. https://doi.org/10.1016/j.jalz.2018.05.011
VanderWeele, T.J., and Ding, P. (2017). Sensitivity analysis in observational research: Introducing the E-value. Annals of Internal Medicine, 167(4), 268–274.
VanderWeele, T.J., Hernán, M.A., and Robins, J.M. (2008). Causal directed acyclic graphs and the direction of unmeasured confounding bias. Epidemiology, 19(5), 720.
Wager, S., and Athey, S. (2018). Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113(523), 1228–1242.
Walter, S., Dufouil, C., Gross, A.L., Jones, R.N., Mungas, D., Filshtein, T.J., Manly, J.J., Arpawong, T.E., and Glymour, M.M. (2019). Neuropsychological test performance and MRI markers of dementia risk. Alzheimer Disease & Associated Disorders, 33(3), 179–185.
Weintraub, S., Salmon, D., Mercaldo, N., Ferris, S., Graff-Radford, N., Chui, H., Cummings, J., DeCarli, C., Foster, N., Galasko, D., Peskind, E., Dietrich, W., Beekly, D., Kukull, W., and Morris, J. (2009). The Alzheimer’s Disease Centers’ Uniform Data Set (UDS). Alzheimer Disease and Associated Disorders, 23(2), 91–101. https://doi.org/10.1097/WAD.0b013e318191c7dd
Weintraub, S., Besser, L., Dodge, H.H., Teylan, M., Ferris, S., Goldstein, F.C., Giordani, B., Kramer, J., Loewenstein, D., Marson, D., Mungas, D., Salmon, D., Welsh-Bohmer, K., Zhou, X.H., Shirk, S.D., Atri, A., Kukull, W.A., Phelps, C., and Morris, J.C. (2018). Version 3 of the Alzheimer Disease Centers’ neuropsychological test battery in the Uniform Data Set (UDS). Alzheimer Disease and Associated Disorders, 32(1), 10–17. https://doi.org/10.1097/WAD.0000000000000223
Westreich, D., Edwards, J.K., Lesko, C.R., Stuart, E., and Cole, S.R. (2017). Transportability of trial results using inverse odds of sampling weights. American Journal of Epidemiology, 186(8), 1010–1014.
Westreich, D., Edwards, J.K., Lesko, C.R., Cole, S.R., and Stuart, E.A. (2019). Target validity and the hierarchy of study designs. American Journal of Epidemiology, 188(2), 438–443.
Weuve, J., Proust-Lima, C., Power, M.C., Gross, A.L., Hofer, S.M., Thiébaut, R., Chêne, G., Glymour, M.M., Dufouil, C., and MELODEM Initiative. (2015). Guidelines for reporting methodological challenges and evaluating potential bias in dementia research. Alzheimer’s & Dementia, 11(9), 1098–1109.
White, A.D., Folsom, A.R., Chambless, L.E., Sharret, A.R., Yang, K., Conwill, D., Higgins, M., Williams, O.D., Tyroler, H.A., and ARIC Investigators. (1996). Community surveillance of coronary heart disease in the Atherosclerosis Risk in Communities (ARIC) Study: Methods and initial two years’ experience. Journal of Clinical Epidemiology, 49(2), 223–233.
Wilkinson, T., Ly, A., Schnier, C., Rannikmäe, K., Bush, K., Brayne, C., Quinn, T.J., Sudlow, C.L., UK Biobank Neurodegenerative Outcomes Group, and Dementias Platform. (2018). Identifying dementia cases with routinely collected health data: A systematic review. Alzheimer’s & Dementia, 14(8), 1038–1051. https://doi.org/10.1016/j.jalz.2018.02/016
World Health Organization (2010). Nine Steps for Developing a Scaling-Up Strategy. https://apps.who.int/iris/bitstream/handle/10665/44432/9789241500319_eng.pdf
Zissimopoulos, J., Crimmins, E., and St. Clair, P. (2014). The value of delaying Alzheimer’s disease onset. Forum for Health Economics and Policy, 18(1), 25–39. https://doi.org/10.1515/fhep-2014-0013
Zissimopoulos, J., Tysinger, B., St. Clair, P., and Crimmins, E. (2018). The impact of changes in population health and mortality on future prevalence of Alzheimer’s disease and other dementias in the United States. Journals of Gerontology, Series B, 73(Suppl_1), S38S47. https://doi.org/10.1093/geronb/gbx147








































