
2
Patient-Centered Outcomes Research Data Standards
This chapter summarizes presentations and discussion focused on data standards. As discussed in Chapter 1, the Office of the Assistant Secretary for Planning and Evaluation (ASPE) considers standards to be one of the building blocks of the patient-centered outcomes research (PCOR) infrastructure. Specifically
Standards represent information and meaning to patient-centered data to ensure that health-specific information can be accurately (and securely) exchanged and used. In most cases standards should be nationally accepted, widely approved, or broadly adopted either through market forces, community approval, or regulatory requirements. These include such items as data standards for capturing, storing, representing, and exchanging data in a secure manner such that accurate information is conveyed to the recipient of the data.1
Speakers participating in this session were asked to focus on the questions below. The brief overview of the input received from the presenters is followed by the committee’s conclusions.
- What data standards could make the PCOR data infrastructure more useful for research and other data needs? What data standards are likely to become more relevant looking forward? What needs to be prioritized?
___________________
1https://aspe.hhs.gov/patient-centered-outcomes-research-trust-fund-faqs.
- What role can ASPE play in supporting effective standards to build data capacity that supports PCOR studies? What characteristics of the U.S. Department of Health and Human Services’ (HHS’) public mission, programs, or authorities could be leveraged?
John Halamka, Mayo Clinic, provided some context for the session by describing three ways of thinking of data standards. First, there is a need for standards for presenting content from data sources such as electronic health records or other administrative records. Second, there is a need for vocabulary standards that would provide semantic interoperability for the content (e.g., SNOMED CT, RxNorm, and LOINC). Third, standards are needed for transporting the data from one place to another in a secure way (such as HL7 Version 2, EDIFACT, X12, and XML standards of various kinds). Ultimately, this led to the development of the Fast Healthcare Interoperability Resources (FHIR), which enable provider-to-provider, provider-to-patient, and provider-to-payer workflows to be supported by FHIR/JavaScript object notation and rest parameters. Halamka said that this is a good development, though it is not enough.
Looking ahead at the next 10 years, the Mayo Clinic has an initiative to move to a digital-first approach in its operations, undertake clinical research and clinical trials with less friction, and enable global access to new kinds of ideas. To accomplish this, the Mayo Clinic needs access to more types of data, and expanding the FHIR standard is one way to enable that. Two interesting examples are the Minimal Common Oncology Data Elements (mCODE) and the Mobile Health Augmented Cardiac Rehabilitation (MCard) data sets. Taking the basic FHIR construct and adding domain-specific data elements will be useful for research, but thousands of data elements may be needed to deal with various use cases.
Halamka also discussed an example of data standards applicable to research on COVID-19 treatment. There is a need to define “ventilator days” for research on when medications versus other interventions would make a difference to COVID-19 patients, he noted; at present, ventilator days are not defined in electronic health records in a standard way. Ultimately, a working group of about 100 experts might be involved in deciding on the definitions of data elements that are needed to answer process questions.
The challenges associated with data standards are heightened, Halamka added, when the research goes beyond structured and unstructured clinical data to incorporate other forms of data, such as research data emerging from various “omics” fields (e.g., genomics). Data from wearable devices, or what he called “high-velocity continuous data,” comprise another area where standards are lacking.
Halamka also discussed the topic of data de-identification. He said that the Mayo Clinic has de-identified its data for use in clinical research and
scientific discovery, but de-identification is itself a science that is evolving. For example, when using information from computed tomography (CT) on a patient’s head, the patient’s name and medical number would be removed, but it remains possible to reconstruct the person’s face from the CT with 3D reconstruction software. Halamka said that he and his colleagues found that they have been able to re-identify a person this way 27 percent of the time using publicly available images and photo matching. Because of this, they have been working to develop technologies that would prevent head CT data from being used to reconstruct a face. This area needs attention, because de-identified information that cannot lead to unique identification today could nevertheless potentially become identifiable in the future as technologies evolve. Halamka also highlighted the related consideration of ways of obtaining consent for the future use of data, and specifically the reuse of de-identified, aggregate data.
Shaun Grannis, Regenstrief Institute and Indiana University, focused on standards for data linkage, particularly for participant-provided information. Within this area, he discussed the topics of (1) patient identity strategy, (2) digital identity and federation, (3) privacy-preserving record linkage, and (4) linking of social determinants of health (SDOH) data.
Grannis noted that the patient identity strategy in the United States is evolving based on a recognition that matching patient records from different sources is one of the few remaining large holes in the electronic health data infrastructure. For this reason, Congress charged the Office of the National Coordinator for Health Information Technology with writing a report focused on effective matching methods. While the report had not been released at the time of this workshop, Grannis underscored the importance of monitoring developments in this area to understand how PCOR can benefit from any changes.
Within the digital identity framework, Grannis noted, not everyone is willing to wait for the U.S. government to develop a national strategy. He pointed out that “matching on devices” is an area where a lot of work is taking place. Organizations such as the CARIN Alliance are working to develop a digital identity and a federated trust agreement to increase and federate trust in digital identity credentials. They are also considering digital identity frameworks that work well within FHIR. Grannis noted that there are also new developments in the more technical areas of identity certification or proofing. Examples of this include the work of FIDO and DirectTrust, as well as identity assigners such as ID.me, AllClearID, and Okta. These organizations are beginning to work on identity approaches at scale in health care, so it is important to observe these developments and learn from these experiences.
Concerning privacy issues, Grannis mentioned that he is working on two projects to advance privacy-preserving record linkage. This is a
maturing field, with some maturing technologies that already work well. There is a need to establish best practices, use cases, and evidence-based guidance on how to conduct this work to ensure that this field does not become too fragmented and those participating in it do not find themselves doing everything differently. Specifically, it would be helpful to have widely shared technical descriptions of what types of data, what types of tokens, and what types of information combinations work well.
Grannis also discussed his work on linking nontraditional, nonclinical SDOH data in Indiana. He noted that there are various methods for linking these types of data, including linking by person, place, or time—or some combination of those—but work remains to identify the best approaches. Grannis argued that for the SDOH data, the main considerations are granularity, standardization, and linkage. For example, in some cases using zip code-level data is valuable, but in other cases more granular information is needed. A variety of data are available on SDOH, and Grannis said that coordinating work on PCOR with the work carried out by the Office of the National Coordinator for Health Information Technology in this area would be important.
Concerning the challenge of matching data, Grannis noted that there have been sustained efforts over the years to find new approaches to matching, and many researchers have been advocating for similar things. What is needed is alignment in this area. As an example of building on evidence-based research to develop standards, Grannis mentioned a 2019 paper that showed that standardizing address and last name significantly improves matching accuracy.2 This research led to a bipartisan Senate bill calling to address standardization, and work is now in progress on developing a universal standard.
Evelyn Gallego, EMI Advisors, discussed her work on the Gravity Project, which focuses on developing consensus-driven data standards to support use and exchange of SDOH within the health care sectors and between the health care sector and other sectors, including research. She said that even before the onset of COVID-19, there was growing awareness that SDOH information improves whole-person care and lowers health care costs, and that unmet social needs negatively impact health outcomes.
Gallego discussed several uses of social risk data, identified by the Social Interventions Research and Evaluation Network (SIREN). These areas include medical care, population health management, community health improvement, social risk interventions, risk adjustment, and
___________________
2 S.J. Grannis, H. Xu, J.R. Vest, S. Kasthurirathne, N. Bo, B. Moscovitch, R. Torkzadeh, and J. Rising. (2019). Evaluating the effect of data standardization and validation on patient matching accuracy. Journal of the American Medical Informatics Association, 26(5), 447–456. https://doi.org/10.1093/jamia/ocy191.
research. Despite a clear business case, clinical systems face challenges in capturing and exchanging this type of data. Gallego cited a 2020 paper from the National Association of Social Determinants of Health that identified the key challenges as follows:
- Consent management.
- Standardization of SDOH data collection and storage.
- Data sharing between ecosystem parties.
- Access and comfort with digital solutions.
- Concerns about information collection and sharing.
- Social-care sector capacity and capability.
- Unnecessary medicalization of SDOH.3
Gallego discussed two of these areas in detail: standardization and data sharing.
The Gravity Project was launched in 2019 with the goal of developing data standards for domains that Gallego described as grounded in a 2014 National Academies report.4 The domains include items such as education, elder abuse, environment, financial insecurity, food deserts, food insecurity, homelessness, housing instability, inadequate housing, interpersonal violence, material hardship, neighborhood safety, racism, social isolation, stress, transportation insecurity, unemployment, and veteran status.
The Gravity Project develops data standards to represent patient-level SDOH data documented across four clinical activities: screening, assessment/ diagnosis, goal setting, and treatment/interventions. Described as a “public collaborative,” the project convenes participants from across the health and human services ecosystem, including clinical provider groups, community-based organizations, standards development organizations, federal and state government, payers, technology vendors, and others.
Gallego described the Gravity Project as having two workstreams: work on terminology, focused on SDOH domains; and technical work, focused on specifications for Health Level Seven International (HL7) FHIRs. The terminology workstream focuses on defining data elements for each SDOH domain by asking What concepts need to be documented across the four activities of screening, diagnosis, goal setting, and interventions? What codes reflecting these concepts are currently available? and, What codes are missing? On the technical side, the HL7 SDOH clinical care FHIR implementation guide provides guidance on how to do assessment screening,
___________________
3https://www.nasdoh.org/wp-content/uploads/2020/08/NASDOH-Data-Interoperability_FINAL.pdf.
4https://www.nap.edu/catalog/18709/capturing-social-and-behavioral-domains-in-electronic-health-records-phase.
how to capture health concerns or problems that inform the diagnosis, goal setting, interventions, capturing consent, and aggregation for data exchange and reporting.
When the Gravity Project was launched, according to Gallego, its leaders developed a conceptual framework that accounts for various entry points for the data (e.g., a digital application used by a patient or the health care providers’ electronic health records). They defined SDOH data concepts that can be documented and shared across the four activities discussed above, regardless of the initial input system. This framework emphasizes the value of these data for secondary use by public and private payers, social service providers, public health entities, and researchers.
Rachel Richesson, University of Michigan, discussed the concept of a learning health care system, where research influences practice and practice influences research. Standards could provide the infrastructure for turning real-world data into real-world evidence, and thereby be the foundation for enabling real-world evidence to influence practice.
Richesson shared her perspective on the key data needed for PCOR and the associated standards to consider. Box 2-1 summarizes these data types and relevant standards. She argued that there is a need for robust data that describe patients and patient populations, including patient problems, in a standard way, with up-to-date problem lists. There is also a need to capture treatments and interventions, broadly defined. Richesson said that patient goals and preferences are increasingly important. Standards exist for some clinical domains, but they are not widely used. Richesson argued that the outcomes and endpoints most useful for PCOR are those that are condition-specific.
In terms of standards (the right-hand column in Box 2-1), Richesson said that it is important to have terminology that can represent related concepts at different levels of granularity while at the same time being suitable for being combined analytically. She highlighted the Gravity Project and the Gender Harmony Project as approaches that start with the high-level question of what concepts need to be measured and then look at what data are available and how those data can be pulled together in a useful way. The information is then shared with those who need to implement the standards. She cited SNOMED CT as the recognized standard for nursing data, such as nursing goals, nursing diagnosis, and nursing-related outcomes, and also noted that a set of standards is quickly emerging from the work of BPM+ Health group, an organization that is modeling clinical pathways and clinical workflows.
Richesson summarized her perspective on the key steps for developing standards as the following:
- Leverage processes of existing standards organizations;
- Encourage patient engagement in standards developing organizations;
- Support tools for use of standards in real-world settings;
- Promote semantic interoperability and intrinsic value sets or “groupers”;
- Use concept maps/information models (e.g., recent nursing work5);
- Show value of standards for application development and dissemination;
- Create tools to make it easy for application developers of all types;
- Develop standards roadmaps;
- Make use of feedback loops on standards (e.g., to understand whether they are useful or whether they are granular enough); and
- Repeat the steps above, as needed.
Patrick Ryan, of both Janssen Research and Development and Columbia University, discussed data standards based on his experiences with the Observational Health Data Sciences and Informatics (OHDSI) collaborative. OHDSI is an open, multistakeholder, interdisciplinary collaborative whose mission is to improve health by empowering communities to collaboratively generate the evidence that promotes better health decisions and better care. OHDSI is driving development and adoption of open community data standards, open-source analysis software, and open-science best practices among regulators, academia, industry, payors, and health systems. While OHDSI is not a data standards organization, it is a heavy user of those standards and a steward of them simply because they advance the collaborative’s goal of generating reliable evidence to improve health.
OHDSI has a data network that includes organizations with patient-level data in more than 150 databases. Standardization, Ryan said, is about structure, content, and learning from the differences among data sources, rather than trying to create something that is homogeneous. The data in this network are not centralized, and organizations can decide whether and how to participate in the network. Researchers can conduct “network studies” by identifying a research question and then reaching out to the data network to generate standardized aggregate results.
Ryan argued that data standards are a means to an end, not an end in itself. In this context, the key questions to ask would be (1) What evidence would be useful to improve health policy and health care, which could be reliably generated by the PCOR data infrastructure? (2) How can data standards enable real-world analytics to meet the relevant evidence needs moving forward? and (3) What needs to be prioritized?
___________________
5 B.L. Westra et al. (2020). A refined methodology for validation of information models derived from flowsheet data and applied to a genitourinary case. Journal of American Medical Informatics Association, 27(11), 1732–1740. doi: 10.1093/jamia/ocaa166. PMID: 32940673.
Ryan said that the OHDSI community has given a lot of thought to the topic of reliable evidence. Data standards are necessary, he pointed out, to enable replicability, generalizability, and robustness, because answering questions requires that disparate data be brought together, and there is a need for a mechanism that enables examining the same question in different data sets in some reliable way. It is also clear that data standards without standardized analytics are not sufficient to ensure reliable evidence. Ryan also argued that public health questions require global data to generate global evidence, and standards that are not limited to data in the United States are more useful, even for research specific to the population in the United States.
Thinking about the specific role of standards in generating evidence, and working backward from the question of what evidence would be helpful to improve health policy and health care, Ryan discussed three analytical use cases on which the OHDSI community focuses: (1) characterization, or producing descriptive statistics to understand what is happening in the world; (2) estimation, or causal inference, to understand the effects of medical interventions and the comparative effectiveness of interventions; and (3) prediction of risks. Data standards need to be based on the evidence needed and the type of use case it needs to support.
The ecosystem of complementary standards discussed by Ryan includes data standards to enable data exchange (e.g., the FHIR from HL7), data standards to harmonize data structure and enable analytics (e.g., the Observational Medical Outcomes Partnership Common Data Model or OMOP CDM6), and analytics standards to generate and disseminate evidence (e.g., the Health Analytics Data-to-Evidence Suite or HADES). Underlying all of this, there are vocabulary standards that harmonize data content and also enable analytics (e.g., ATHENA). The OHDSI community works on bringing these standards together. For example, they developed a suite of open-source analytic tools that sit on top of the OMOP CDM as their open community data standard, but they are also collaborating with HL7 on the interoperability of FHIR standards and the OMOP CDM standards for enabling analytics.
Ryan said that the initial focus of the OMOP CDM was on health systems data, clinical data, and health economics data, because those are the analytical use cases and the evidence needs that OHDSI is trying to fill within their community. Underlying the data model are the infrastructure of vocabulary standards and the mappings from source codes onto standards, which enable the adoption of standards. He added that the use of vocabularies is not just an obligation, but an opportunity to expand the
___________________
6 For an overview of the CDM, see https://ohdsi.github.io/TheBookOfOhdsi/CommonDataModel.html#fn20.
value of the data. The OMOP data partners have different data structures and different data contents. Each partner goes through its own journey to standardize its data under a common data model, and OMOP enables those data to be analyzed through standardized analytic routines.
Ryan said that the OHDSI community has done a lot of work to try to help policy makers, regulators, and clinicians with questions related to COVID-19. One of the first efforts was related to examining the safety of hydroxychloroquine. Starting with the need, they reached out to their data network across the world to find out who had standardized data that could meaningfully contribute to this question. They then worked on developing the right analytic approach to apply to the question. While this work ultimately resulted in academic publications,7 the primary goal was to generate evidence that could inform policy decisions and the work of the European Medicines Agency and the U.S. Food and Drug Administration (FDA).
VG Vinod Vydiswaran, University of Michigan, focused on the role of natural language processing (NLP) in the use of PCOR data. He argued that three of the areas deserving attention to make the PCOR data infrastructure more useful are (1) the informatics infrastructure that includes clinical notes, (2) computable phenotypes as knowledge objects, and (3) looking beyond electronic health records for health data.
To illustrate the use of clinical notes, Vydiswaran discussed his work with the Patient-Centered Network of Learning Health Systems (LHSNet), a Clinical Data Research Network funded by the Patient-Centered Outcomes Research Institute. The common data model for LHSNet focuses on structured data typically available in clinical settings, such as demographic information, laboratory values, and ICD-9 and -10 codes. Vydiswaran worked on extending the common data model to include textual components and extract clinically relevant information from free text. This work built on a prior study, the Clinical Language Engineering Workbench (CLEW), developed as part of the National Program of Cancer Registries of the Centers for Disease Control and Prevention.
Figure 2-1 shows the CLEW NLP machine learning process functionalities. Vydiswaran noted that it is important to expand the component that creates a pipeline for extracting features, not only to look at individual attributes but also to look at concepts and relationships between concepts.
Vydiswaran said that the second area of work where advances could make the PCOR data infrastructure more useful is the use of computable phenotypes as knowledge objects, specifically standardized definitions for analysis across multiple sites. By knowledge objects, he meant the
___________________
7https://www.medrxiv.org/content/10.1101/2020.04.08.20054551v2; https://www.thelancet.com/journals/lanrhe/article/PIIS2665-9913(20)30276-9/fulltext; https://academic.oup.com/rheumatology/article/60/7/3222/6048420.
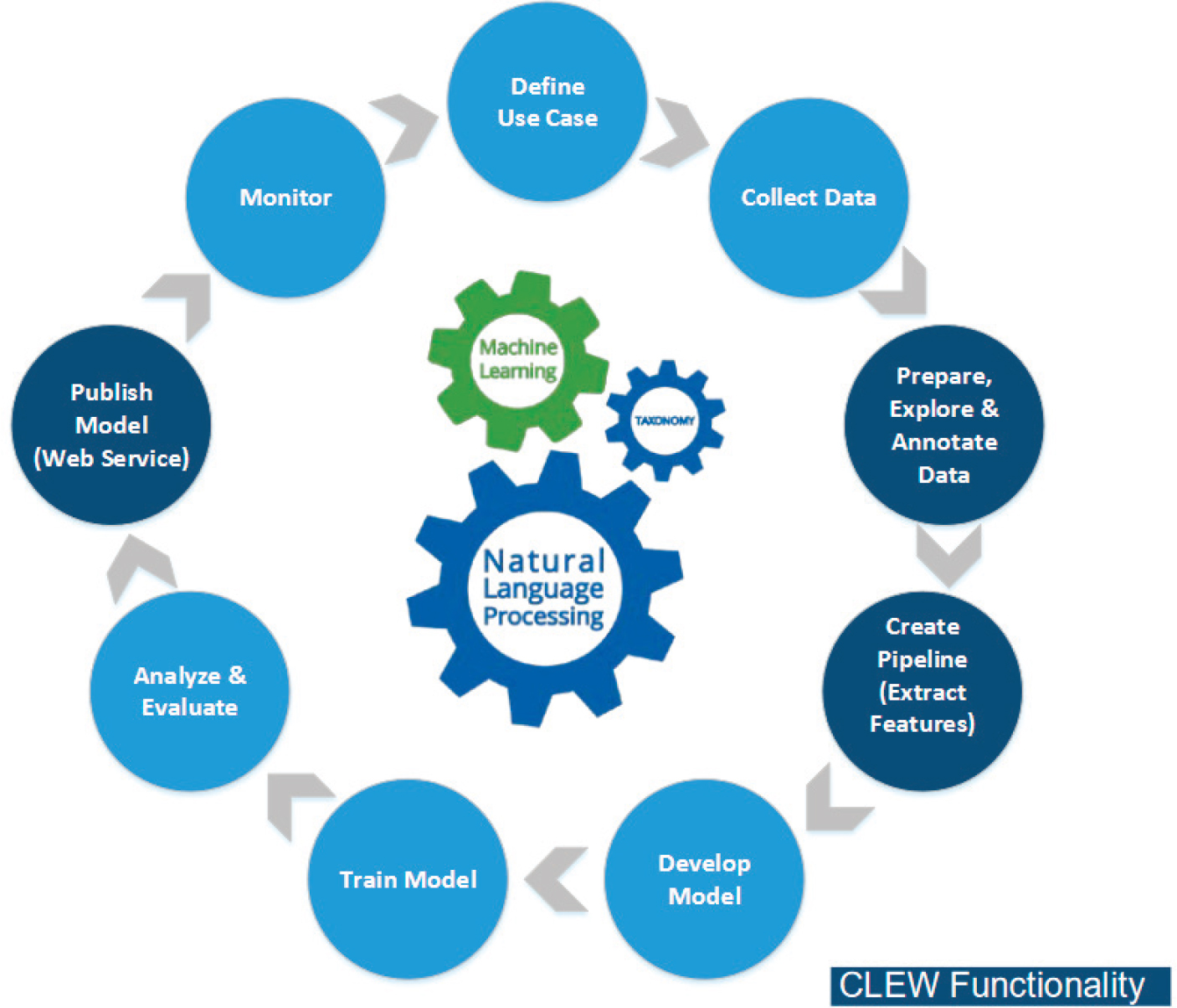
SOURCE: Workshop presentation by VG Vinod Vydiswaran, May 24, 2021; ASPE, 2019.8
computational components of research that can be used and expanded on by others. This includes standardized clinical natural language tools for processing text so that it is interpreted the same way across multiple sites.
The typical data elements in computable phenotypes, Vydiswaran said, are structured components such as ICD-9 and -10 codes, Current Procedural Terminology (CPT) codes, information about medications, and sometimes key terms and phrases, along with the frequency of their mentions. Novel areas for consideration include patient-reported outcomes such as symptoms, medication response, and adverse events in telephone notes, medication refill requests through web portal requests, and care provider information, especially for patients unable to independently manage their
___________________
8https://aspe.hhs.gov/system/files/pdf/259016/NLP-CLEW-UserGuidanceDocument-508.pdf.
health care needs. A lot of information about patient-reported outcomes is available in electronic health records in text form.
Vydiswaran mentioned his prior work on self-reporting behavior concerning the toxicity of oral anticancer agents in clinical notes.9 In that work, he found that 23.5 percent of the clinical oral anticancer agent toxicity notes were based on telephone encounters. In another study, Vydiswaran and his colleagues are working on extracting patient-provided information on Crohn’s disease symptoms, medication response, and adverse events using email and telephone notes stored in electronic medical records.
Vydiswaran also encouraged looking beyond electronic health records for health data. For example, information on the adverse effects of drugs can increasingly be found on social media. However, Vydiswaran noted that processing consumer-generated text is even more challenging than processing clinical text, due to the prevalence of grammatical errors, typos, new acronyms, and abbreviations.
Text found on social media can be useful for a variety of purposes, beyond collecting data on drugs’ adverse effects. For example, geo-located social media can be useful for exploring community health information. Social media can be analyzed through the lens of communities (e.g., affluent versus disadvantaged neighborhoods), demographics (e.g., “BlackTwitter”), or patient cohorts (e.g., smoking cessation patient groups). Spatio-temporal factors that can be linked to patients include air pollution, neighborhood walkability, rurality, and “food deserts.”
Vydiswaran mentioned that his current work includes the use of social media to augment information in the FDA Adverse Event Reporting System and the Vaccine Adverse Event Reporting System. NLP can be helpful for parsing text from both social media and the federal adverse event reporting databases.
As a summary of his key points, Vydiswaran emphasized (1) the need for an enhanced informatics infrastructure for processing textual clinical notes; (2) treating computable phenotypes as knowledge objects, and incorporating patient-reported outcomes derived using NLP; and (3) taking advantage of health-related social media to augment existing data.
After the presentations, participants in this session were asked to comment on what the federal government could do to accelerate work on standards for patient-centered outcomes data and research. Halamka said that one of the strengths of the federal government is that of a convener of meetings. As an example, he mentioned the role of the Office of the
___________________
9 Y. Jiang, V.G.V. Vydiswaran, Y.L. Eun, H. Joo, A. Zheng, and M.R. Harris. (2018). Feasibility of Identifying Oral Anticancer Agent Toxicity Self-Reporting and Management Advice from Clinical Notes. AMIA Annual Symposium, November 3–7, San Francisco, CA.
National Coordinator for Health Information Technology in convening meetings to attempt to harmonize U.S. and international standards on vaccine credentials. He added that he does not believe that attempting to regulate standards would be advisable. If the federal government facilitates the harmonization of standards, those standards will be adopted because they will bring value. Grannis agreed that convening and building consensus is what the government does well. He argued that this would be especially useful for accelerating work in areas that are “hotspots” of nonstandardized data, such as SDOH.
Gallego highlighted creating incentives for testing the standards as a need that could be filled by federal or state governments, through mechanisms such as grants. Richesson argued for a library of computable phenotypes. She noted that there is a need for better organizing information on existing standards. ASPE could facilitate the sharing of tools and metadata standards and incentivize the reporting of results. She said that currently it is almost easier to develop new standards than to find something that has already been done and that would work in a particular situation. Ryan agreed with the idea of a phenotype library, and argued that the scope could be broadened to other types of information about what was learned from a study. He also agreed with Gallego on the need for testing, and with Halamka and Grannis on ASPE’s potential role in community building. Vydiswaran highlighted the need for maintaining analytic tools over the years, by updating documentation to facilitate their use and progress toward eventual standardization.
DISCUSSION
During the workshop, the formal presentations were followed by additional discussion among the workshop participants, including the speakers, committee, and audience members. Among the topics that were explored in further detail were arguments for and against additional standards. One of the themes that emerged is the inherent difficulty associated with the process of agreeing on standards. It could be argued that an adequate variety of standards already exists for most situations, and the challenge is to converge around a single standard. Despite the challenges, past experience in a variety of domains indicates that convergence can be accomplished by bringing together communities and increasing communication around these topics. Participants also acknowledged that the context around standards is continuously evolving because the use cases, workflows, and information flows are always changing. This means that standards will also have to evolve over time.
Another topic that was discussed by workshop participants was the role of the federal government, and particularly HHS, in the context of
standards for PCOR. Convening stakeholders emerged as a role that is especially well suited for HHS to handle. Participants cautioned against the blunt instrument of regulation, arguing that standards are most likely to be adopted when they bring value, because without a clear purpose and value for the standards, clinician frustration with electronic health records could increase. HHS could play a role in facilitating discussions to prioritize areas where standardization could be most useful and convening activities around topics such as SDOH, where there is a notable lack of standards and a common language.
Speakers also highlighted the need for a support infrastructure that would facilitate activities such as testing and enable the adoption of standards. Examples of the support infrastructure focused on building community and collaboration around standards. At the same time, views differed on a potential role for HHS in incentivizing the use of standards, and what those incentives could look like.
Workshop participants noted that there was a need for cataloging existing standards, because currently it is almost easier to develop a new approach than to figure out what already exists and whether and how it applies to a particular situation. This need extends to the cataloging of analytic tools, which are easier to use when documentation from earlier studies is maintained and updated.
Another theme addressed by the speakers and revisited as part of the discussion was that of the relationship between U.S. and international data standards. Participants noted that there are a variety of differences among countries, ranging from population differences to differences in health care systems. The use of standards also differs, but common international standards would facilitate a better understanding of the heterogeneity and could inform policy decisions everywhere, including in the United States.
CONCLUSIONS
The workshop session demonstrated that, within the context of PCOR, standardization is increasingly and ever more widely applied to the processes of collecting, storing, analyzing, and exchanging data. These standards are most useful when they are focused on addressing a specific problem or are driven by a specific use case. The needs and norms evolve over time, and because of this, standards need to evolve too. Lessons might be learned from best practices that emerge for the development of standards.
The workshop made it clear that in some areas there is a fair amount of agreement around what standards are needed and what useful standards look like. In other areas, for example, for data on SDOH, the work is just beginning, so these areas might not be ready for wide agreement on standards. In all cases, extensive testing of the potential standards is necessary.
CONCLUSION 2-1: Standards are most useful when their development is driven by their potential uses and a clear concept of the value they can contribute.
Participants in this session did not see a large role for ASPE in developing standards or deciding what the standards should be. ASPE’s most valuable contributions could be in developing an architecture and an implementation strategy that facilitate common language and interoperability across data sets, as well as accessibility of the data. Other areas where ASPE could play an important role include convening stakeholder meetings to discuss and develop standards, as well as taking the lead in cataloguing existing standards.
CONCLUSION 2-2: The Office of the Assistant Secretary for Planning and Evaluation could add significant value in the area of standards for patient-centered outcomes research by
- continuing to promote the development of a data infrastructure and an implementation strategy that facilitates the use of standards and access to the data;
- convening stakeholder meetings to enhance communication and work toward developing a common language for standards;
- facilitating accessibility to the data and collaborations with existing organizations working in this area; and
- leading efforts to catalogue and exemplify data standards and analytic standards.
The speakers touched on the need for a broad interpretation of standards, to include not only the data but also the methods used to analyze PCOR data.
CONCLUSION 2-3: While data standards are important to conducting patient-centered outcomes research, applying standards to the analytic methods as well is important to facilitate the reliability and reproducibility of study results.
Speakers also highlighted the potential benefits of staying abreast of the standards development that happens not only in the United States but also internationally. Learning from experiences across the globe would further advance PCOR and benefit patients in the United States.
CONCLUSION 2-4: An international perspective is an important consideration for the patient-centered outcomes research data infrastructure, and the infrastructure focused on standards specifically would benefit from building on work that happens internationally.















