
Appendix A
Statistical Metadata Standards—in Detail
THE UNECE FAMILY OF METADATA STANDARDS
The United Nations Economic Commission for Europe (UNECE), headquartered in Geneva, manages a number of cooperative international projects of interest to national statistical offices within UNECE and sometimes around the world. These efforts include demographic, economic, methodological, and computing-related activities. The activities sponsored by the High Level Group for the Modernization of Official Statistics (HLG-MOS) are of particular interest here. HLG-MOS oversees the development of metadata and interoperability standards developed by and for the use of national statistical offices. In the following, we discuss four of them, in this order: Generic Statistical Business Process Model, Generic Statistical Information Model, Common Statistical Production Architecture, and Common Statistical Data Architecture.
All four of these standards are equitable. The program overseen by HLG-MOS is for national statistical offices, the standards development is open to any of them, the work is conducted by consensus among the participating agencies, the work is open for inspection (transparent) on a publicly accessible wiki, and the groups of developers of the standards represent the stakeholder community in a balanced way.
Generic Statistical Business Process Model (GSBPM)
The Generic Statistical Business Process Model (GSBPM) is an outline of processes, and the names it attaches to the business processes are
those a statistical agency might use to produce its data. It was produced under the auspices of the statistical program of UNECE. Representatives from national and international statistical offices throughout the world were invited to participate in the development of GSPBM under an open, consensus-driven process. As such, the GSBPM is a standard that U.S. federal statistical agencies can have confidence in and with which they can engage in its further development.
Version 4 of GSBPM was released in 2009; the current version was released in 2019 (GSBPM v5.1-UNECE Statswiki). Over this time, many countries have put it to use. It is a companion standard to the three other UNECE statistical standards described later in this Appendix: Generic Statistical Information Model (GSIM), Common Statistical Production Architecture (CSPA), and Common Statistical Data Architecture (CSDA). The relationship between GSBPM and each of these other standards is described with them.
Standards in the statistics community are possible because of the remarkable similarity of the work across national statistical offices. This is not to say that surveys are the same in every agency where they are used. Rather, an outline of the steps needed to plan, design, and conduct a survey are similar wherever they are used. So while particular questionnaires, sample designs, and variables differ across surveys, agencies, and countries, the need to design and produce questionnaires, samples, and data dictionaries persists over these divides. These similarities are the drivers behind the need to produce GSBPM and the reason it is an effective tool.
The U.S. Bureau of Labor Statistics and the U.S. Census Bureau have both adapted GSBPM to their own uses and in their own languages. GSBPM is written in English, but the international character of the group that developed the standard means some of the names for the processes described are not typically those used in the United States.
Structure of GSBPM
One way to think about a process is to compare that concept with activity, process, and capability. For the purposes of this discussion, we will define an activity as something a statistical office does, a process is how the office conducts that activity (the steps taken to accomplish a goal), and a capability is the potential for being able to carry out some activity. So, with these ideas in mind, GSBPM is not really a process model; rather, it is an activity model. And it is not really a model either; instead it is an organized list of activities. GSBPM does not tell one how to conduct the business of a statistical office; rather, it describes what needs to be done.
The GSBPM is intended to be interpreted and used flexibly. The framework is laid out in a particular way, but it is not rigid and the activities may be followed in any order. It specifies the possible steps in a statistical
business life cycle. In fact, even though the activities are presented in an order typical of the work of statistical agencies, they may occur in many different orders in practice, and some steps may even be repeated in iterative applications, such as with some machine learning applications or imputation methods. Viewed as a checklist, GSBPM may be used to ensure that all necessary steps have been considered for conducting some statistical activity.
GSBPM is similar to a lattice, one that has many possible paths through it. This is what makes GSBPM generic and, therefore, widely applicable. It provides a standard view of statistical business process, yet it is neither too restrictive nor too theoretical. The GSBPM comprises three levels:
- Level 0, the statistical business life cycle;
- Level 1, the eight phases of the life cycle; and
- Level 2, the sub-activities within each phase.
GSBPM also recognizes three overarching activities that apply to all eight phases. They are as follows:
- Quality management—includes quality assessment and control mechanisms, recognizing the importance of evaluation and feedback;
- Metadata management—metadata describe each activity and describe the inputs, outputs, quality assessments, and steps used in a process to implement an activity; and
- Data management—includes database schemas, security, stewardship, ownership, quality, and all aspects of archiving (preservation, retention, and disposal).
The eight phases in the GSBPM are as follows: (1) Specify needs; (2) Design; (3) Build; (4) Collect; (5) Process; (6) Analyze; (7) Disseminate; and (8) Evaluate.
In the following, we describe each of these phases, but the details of the sub-activities contained within each are left out.1 Note that, in the official GSBPM document, the term process rather than activity is used throughout. We chose to use the latter term here for clarity.
The Specify needs phase or high-level activity comprises six sub-activities. This phase includes all activities involving interactions with stakeholders to identify their statistical requirements (current or future). This results in proposing high-level solution options and the preparation of a business case to meet the requirements. This phase is initiated when
___________________
1 We direct the interested reader to the GSBPM document on the UNECE Website at https://statswiki.unece.org/display/GSBPM/GSBPM+v5.1.
the need for new statistics is identified or feedback about current statistics is requested.
The Design phase also comprises six sub-activities. This phase includes development and design activities for concepts, methodologies, collection, processes, and output. This could include practical research. Included are the design features needed to define or refine the statistical products or services identified in the business case. All relevant metadata and quality assurance procedures are specified. This phase occurs at the first iteration for statistics produced on a regular basis. When improvements are identified in the Evaluate phase, the Design phase may be revisited. The Design phase may also make use of standards to reduce the length and cost of development and increase the ability to share, compare, and combine outputs and processes.
The Build phase comprises seven sub-activities. In this phase the production system is built, tested, and refined so it is ready for use. The results of the Design phase are configured to create the complete operational environment to run the production system. New services are built in response to gaps in the existing set of services, both from within and outside the organization. These new services are built to be broadly reusable and consistent with the business architecture of the organization. Typically, this phase occurs during the first iteration of a statistical activity.
The Collect phase comprises four sub-activities. In this phase all necessary information (e.g., data, metadata, and paradata) is collected or gathered by employing various collection mechanisms (e.g., acquisition, collection, extraction, transfer). Data are loaded into the appropriate environment, where further processing can occur. Validation of data formats is possible, but this does not include transformations of the data themselves. For statistics produced on a regular basis, this phase occurs in each iteration.
The Process phase comprises eight sub-activities. In this phase input data are processed and prepared for analysis. This includes steps to integrate, classify, check, clean, and transform input data, with the result that they can be analyzed and disseminated as statistical outputs. This phase occurs in each iteration for statistical outputs produced regularly. Data from both statistical and nonstatistical sources are included. The Process and Analyze phases can be iterative and parallel. Analysis can sometimes reveal more about the data, which might mean additional processing is necessary. Activities within the Process and Analyze phases may start before the Collect phase is completed. Provisional results are possible in this scenario.
The Analyze phase comprises five sub-activities. In this phase, statistical outputs are created and examined, statistical content prepared, and outputs determined as fit for purpose. Statistical analysts work to understand the
data and the statistics produced. The outputs in this phase could also be used as inputs to sub-activities in other phases. This phase occurs in every iteration for statistical outputs produced regularly.
The Disseminate phase comprises five sub-activities. In this phase the release of statistical products is managed. All activities undertaken to ensure release of each product, via one or more channels, are included. This phase occurs in each iteration for statistical products produced regularly.
The Evaluate phase comprises three sub-activities. The evaluation of a specific instance of a statistical business process is in this phase. It can take place when a process finishes and can be done on an ongoing basis. Evaluation relies on information obtained during the previous phases. Included is the evaluation of the success of a particular process, with priority on potential improvements. Evaluation should, at least in theory, occur for each iteration for regular statistical production. Determining if additional iterations are warranted is the objective. If that is decided, whether any improvements should be implemented is the next question. See Figure A-1 for a view of GSBPM in outline form.
Using the GSBPM
GSBPM is a standard recognized by the international community of national and international statistical offices. It serves as a reference model. Reference models are frameworks that consist of clearly defined concepts for promoting unambiguous communication, produced by a body of experts within some community. As such, a reference model can then be used to communicate ideas clearly among members of that same community. In the case of GSBPM, the relevant community is the national and international statistical offices throughout the world.
GSBPM is a standard without conformance criteria. It does not contain any requirements. That is reasonable, because as a reference model, GSBPM is meant for communication as guidance. It is informational in character. There are no set paths through the activities defined in GSBPM. Which activities each statistical program uses and the order in which they are used is determined by the needs of the program.
GSBPM can also be used for classification, and this represents one of the important use cases for GSBPM. Every statistical agency develops software and builds systems for processing the data surveys and other statistical programs it produces. The systems and the projects to build them can be classified according to the phases and sub-activities in GSBPM.
GSBPM is also an abstraction of the steps statistical agencies need to address to conduct surveys and other statistical programs with care. Therefore, GSBPM is very flexible. It can be used in a myriad of ways. The most direct kind of usage is to interpret the set of phases and activities literally,
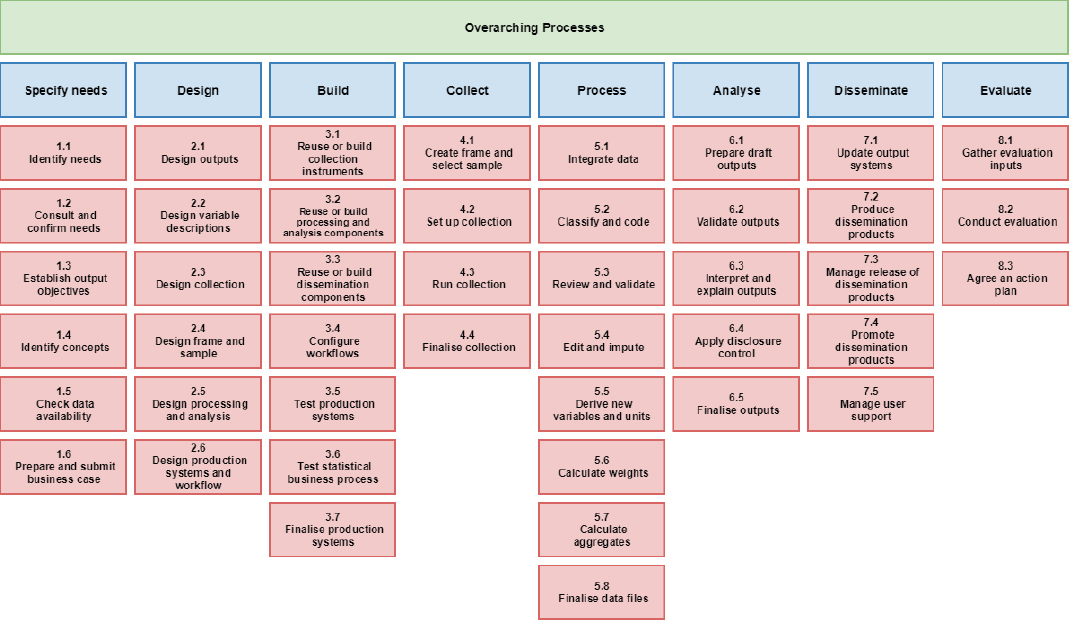
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/GSBPM/Clickable+GSBPM+v5. Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
and use the standard as a guide on how to conduct surveys and other statistical studies. However, doing this may not be useful, as the language used in GSBPM may not correspond to the terms used in each agency.
To make GSBPM useful at the U.S. Bureau of Labor Statistics (BLS), staff there reformulated the standard to meet the specific needs of the agency. The result is an outline (the model) that maps back to GSBPM but uses its own terms, phases, and sub-activities. The results appear in Figure A-2. BLS named the resulting agency standard BLSBPM. BLSBPM is in use at BLS mainly as a means to classify IT development projects and systems supporting the work of the statistical programs: censuses (e.g., QCEW), surveys (e.g., CES), and other statistical programs (e.g., CPI). Other uses for BLSBPM are planned.
The U.S. Census Bureau also developed its own version of GSBPM. This model was embedded in a larger effort called the Activity-Based Management program. This is organized as a series of top-level outlines broken into details with examples for each. The top levels are Survey life cycle (i.e., business process model, similar to GSBPM) and Mission enabling and support.
As with GSBPM, the survey life-cycle top level has eight phases associated with it. These are broken into a total of 33 sub-activities. Each of these is described with up to seven examples. The mission-enabling and support top level also is divided into eight phases, and these address work that is not directly part of the statistical life cycle. The 66 sub-activities are described with up to seven examples.
Generic Statistical Information Model (GSIM)
In the same way GSBPM depends on the similarities among the activities that agencies need to carry out to produce data and estimates, the Generic Statistical Information Model (GSIM) depends on the similarities among the kinds of objects agencies need to manage in describing their work. For example, questionnaires, sample designs, and data dictionaries are designed and produced in every traditional survey. GSIM expresses how to describe them in a uniform way.
GSIM is an internationally endorsed reference framework for statistical information developed under the auspices of UNECE, and it is an equitable standard, just as GSBPM is. This generic conceptual framework is designed, in part, to help modernize, streamline, and align the work of official statistics in and across national and international statistical offices or agencies. It is one of the building blocks for modernizing official statistics. An effect of implementing GSIM in a statistical office is the abandonment of subject-matter silos, due to the organizationwide view that GSIM promotes. This
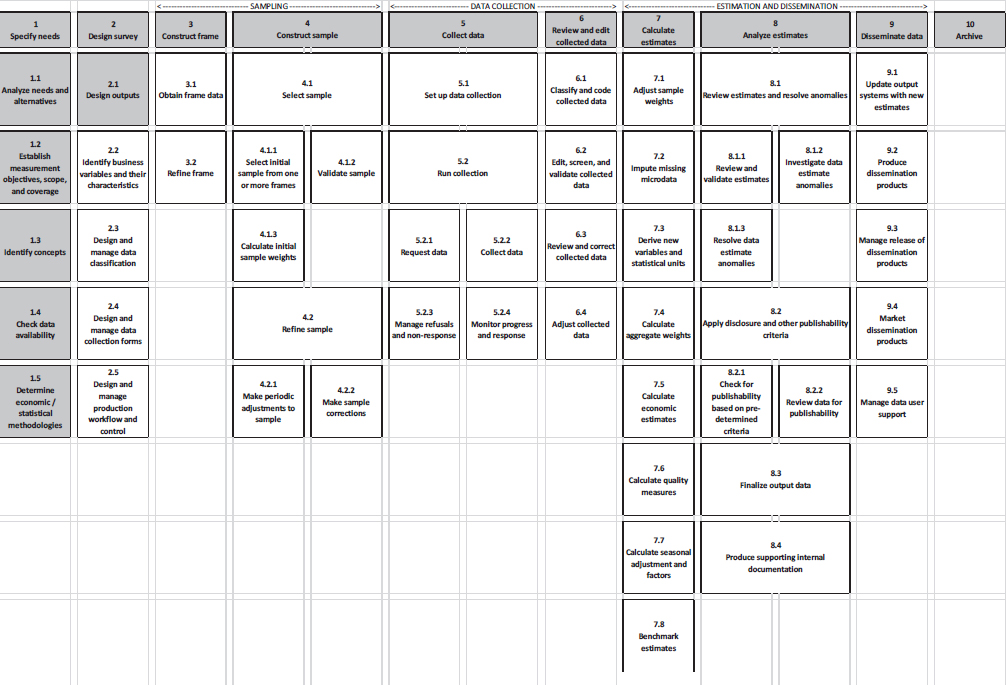
SOURCE: Adapted from Gillman (2018).
is a fundamental precept of the strategic vision under HLG-MOS and is sanctioned by the Conference of European Statisticians.2
GSIM is a conceptual model containing classes and relationships that identify, describe, and relate the objects used by statistical offices to conduct statistical programs. These objects, corresponding to the classes of GSIM, are informational. They describe things statistical agencies need to manage. The data associated with the objects are metadata. This means GSIM is a statistical metadata standard.
The inputs and outputs of the processes implementing the activities of GSBPM are the classes in GSIM. This duality between GSIM and GSBPM is characteristic of the relationship between process and information models.
This section provides an introduction to GSIM. Some technical detail is provided, but for a full detailed technical explanation, please see the specification document and related material, available on the UNECE Website.3
Scope of GSIM
GSIM is written as a conceptual model, which means it makes no assumptions about other standards and technologies needed to build an implementation of the model. A conceptual model is for communicating ideas and is human readable.
The model provides a framework for describing all statistical production processes, and these are described in GSBPM. It provides names, definitions, properties, and relationships (plus related classes) for each class in the model. Each class corresponds to a useful set of objects that statistical offices should manage.
Areas such as finance, human resources, legal, and operational (building, furniture, and equipment) are not within the scope of this framework, although in some cases, when these areas touch on statistical production, those objects are described.
Structure of GSIM
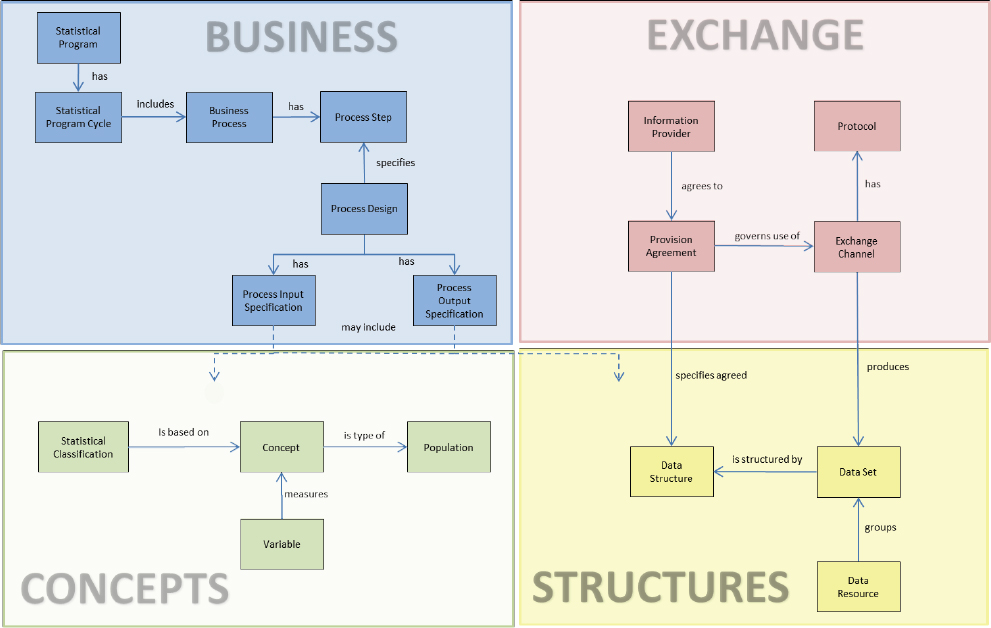
When speaking of GSIM, the model presented in the standard is the main content. So, from this point on in this Appendix section, any reference to GSIM is a reference to a model. GSIM is divided into four sections, as depicted in Figure A-3. These sections are known as the top-level groups:
___________________
2 See https://statswiki.unece.org/display/hlgbas.
3 See http://www1.unece.org/stat/platform/display/metis/Generic+Statistical+Information+Model+(GSIM).
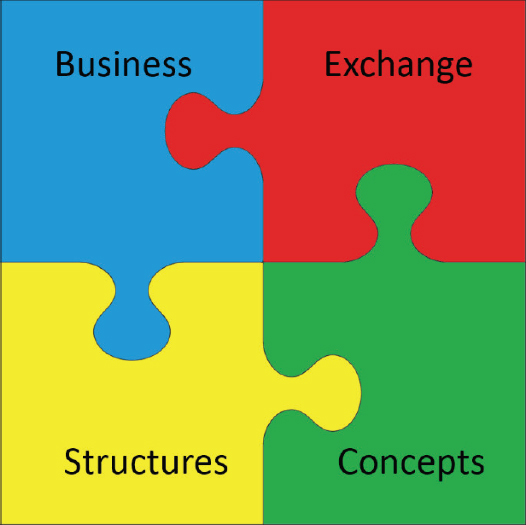
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/gsim/GSIM+v1.2+Communication+Paper (Figure 1).
Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
- The Business group is used to capture the planning, designs, and processes built to implement statistical programs.
- The Exchange group is used to describe the data and information that are acquired and disseminated from a statistical organization via interchange mechanisms called exchange channels. Both the collection and dissemination of data can be described.
- The Concepts group is used to define the basic constructs for data: concepts, variables, classifications, code lists, and their interconnections are described. Together, they convey the meaning of data.
- The Structures group is used to describe how data are structured in datasets, files, and exchange channels.
Figure A-4 shows a simplified view of some of the classes identified in GSIM. It gives users examples of the kinds of objects that are in each of the four top-level groups.
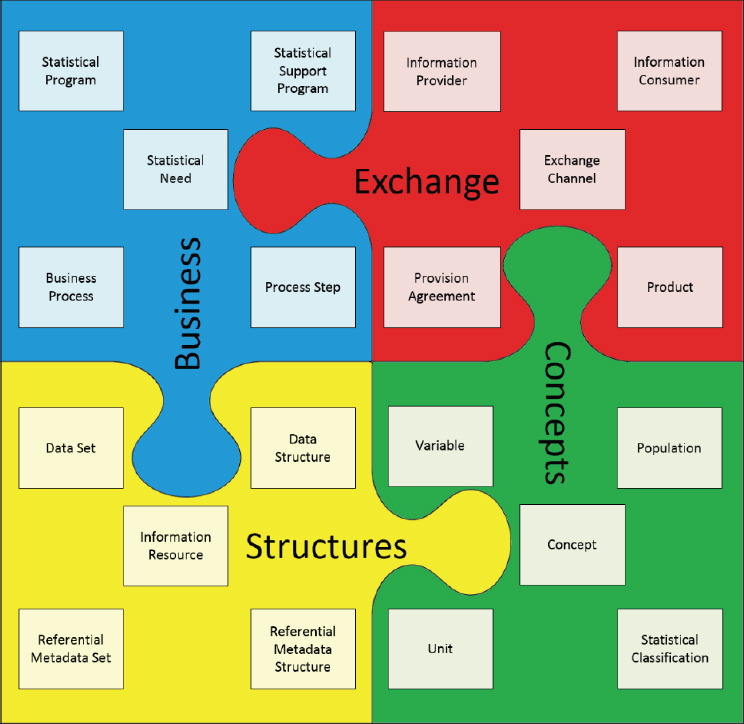
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/gsim/GSIM+v1.2+Communication+Paper (Figure 2). Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
Figure A-5 shows a slightly more technical view of GSIM. Both Figures A-4 and A-5 provide the interested reader with examples of the kinds of objects (classes) GSIM is able to manage. These correspond to the typical objects program managers need to address as part of the statistical life cycle.
Figure A-5 provides the ability to tell a story about objects associated with statistical programs that are important within a national statistical office. The story derives from the connection between objects described in GSIM and the necessary activities chosen from GSBPM. This interconnection is described next.
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/gsim/GSIM+v1.2+Communication+Paper (Figure 3). (Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
Interconnection with GSBPM
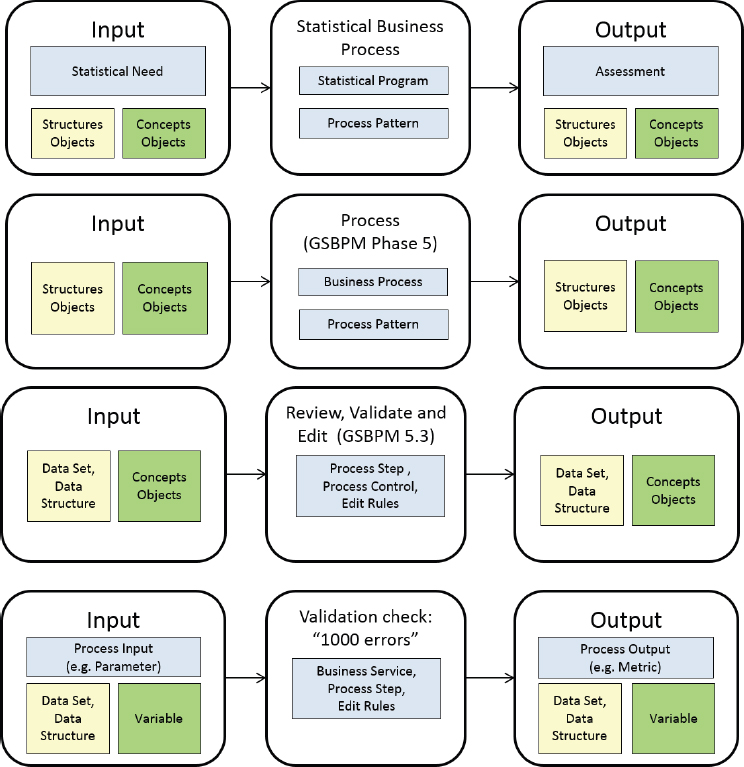
As briefly described above, GSIM and GSBPM are complementary or dual models. They can be used together, with GSBPM defining the activities for which GSIM describes the process implementing the activity. The inputs and outputs are described and linked to the GSIM process. This is illustrated in Figure A-6. GSIM helps describe GSBPM activities by describing the flow of information—the inputs and outputs.
Both GSIM and GSBPM are enhanced if they are used together. Greater value can be obtained, since each standard is designed for and addresses the needs of statistical agencies. Figure A-7 illustrates some specific ways GSBPM and GSIM enhance each other. Here, the levels of GSBPM are used to provide activities at ever lower detail, and these in turn define processes described in GSIM.
Restrictions on Using GSIM
In the same way that GSBPM is a reference model, so is GSIM. GSIM is a conceptual model, meant to convey to people an understanding of the information needs of a statistical office. It is not in an implementable form. Some of the details needed for an implementation were left deliberately vague in GSIM, and some parts of the model are very abstract. No specific physical representation of the model exists. Instead, GSIM provides statistical agencies with a common language and understanding related to the statistical life cycle. With GSIM, an agency has a standard way to talk about data, metadata, and all the objects the agency needs to manage.
Describing statistical information using GSIM as a common point of reference helps users (especially agencies) identify the relationship between two sets of statistical information which are represented differently from a technical perspective. This is important now that agencies are considering

SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/gsim/GSIM+v1.2+Communication+Paper (Figure 4). Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/display/gsim/GSIM+v1.2+Communication+Paper (Figure 5). Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
the needs of integrating data from multiple sources. In this case, finding the relationships between the meanings of data in different datasets is key.
Common Statistical Production Architecture (CSPA)
The Common Statistical Production Architecture (hereafter referred to as CSPA) is a reference architecture for and created by the official statistical
industry. As part of the family of UNECE standards, it has the same maintenance and governance administration as GSBPM and GSIM. Version 1 of CSPA was published and updated to version 1.5 in 2015. Version 2 is currently being drafted.
The main vision of CSPA is to enable the development of “plug and play” statistical services, which will increase the reuse of systems, thereby reducing costs and increasing the speed of implementation. This is in comparison to the traditional development of “stovepipe” or “silo” systems where the same kinds of services are developed many times throughout the statistical community to solve the same problems but in different places. An important outcome of CSPA is that the resulting service is interoperable with other CSPA services (and, to a certain extent, non-CSPA services).
CSPA consists of application and technology architectures and principles for the delivery of statistical services. One way to think of CSPA is as a service-oriented architecture (SOA) that has been specially adapted for statistical activities and processes. CSPA is not prescriptive of specific technologies or platforms.
CSPA can be combined with the GSBPM and GSIM frameworks. For example, if an agency has adopted GSBPM and it has been identified that a service is required for a GSBPM activity, then either
- the agency may develop a CSPA service, describing it in terms of the GSBPM activities it is used for, and other agencies may reuse it for those same activities, or
- the agency may identify and reuse a CSPA service already developed by another agency that matches the same GSBPM activity.
A CSPA Global Artefact Catalogue exists for such services. However, an agency may still benefit from the CSPA principles without fully implementing GSBPM or GSIM, especially to move toward a service-oriented architecture for statistical systems. The sections below illustrate the issues that CSPA is designed to address.
Accidental Architectures
When statistical agencies build systems without a standard architecture, the result is that it is very difficult for those systems to communicate with each other, and this results in “accidental architectures.” It is also difficult to reuse systems across programs. For example, reusing an editing system written for one program may not work in the computing environment for another; therefore, a new system has to be developed and maintained. This new editing program may contain much of the same logic as the older one, necessitating a rewrite of the same algorithms and the implementation of
another maintenance schedule, resulting in a continual waste of money and time.
These types of systems are known as silos or stove-pipe systems. If a statistical agency wishes to benefit from adopting a new technology or business process, or to align with standards, these are particularly cumbersome because there may be many duplicate systems that all have to be adapted.
The Result of Standardization within an Organization
To address the issues outlined above, an organization may adopt an enterprise architecture that can help standardize systems, processes, and interfaces within the agency. This offers the benefit of enabling the reuse of systems and services, for example the same editing software can be reused.
However, even with an enterprise architecture, this still means the statistical agency itself is operating in a silo where it cannot easily integrate a service developed by another agency. Figure A-8 (see the following subsection) shows how the Swedish systems do not fit with the Canadian systems; that is, they cannot be integrated. Indeed, most statistical agencies have very similar statistical life cycles and activities (e.g., imputation, data validation, dissemination, mapping), and very similar services have been built many times over for the same statistical processes, but those services are very hard to share and reuse. Figure A-9 illustrates this problem, in that Sweden requires a service for a particular process for dissemination that they do not have. Canada has already developed a service that proves to have exactly the functionality that Sweden needs, but it cannot be integrated by Sweden. The result is that a stove-pipe service must be created by Sweden.
To avoid this duplication of effort, what is required is a common reference architecture for both agencies. CSPA provides this so that agencies that adopt it should be able to share and integrate their services much more easily.
Using CSPA
To use CSPA as a technology architecture, an agency requires an infrastructure or platform “backbone” that allows services to be combined and run in different ways and allows the monitoring of the service runs.
CSPA has a logical information model (CSPA LIM) which is designed for developers to increase the plug-and-play compatibility of CSPA services, especially in terms of their interfaces. Full details of the CSPA LIM are on the UNECE wiki.
Adoption of CSPA also requires institutional backing, governance, and capacity building to make it a reality. For an agency to be able to efficiently
make a gap analysis and match available CSPA services to statistical activities, a mapping of the agency’s business process model to GSBPM is required.
In order to reuse existing CSPA services, the CSPA Global Artefact Catalogue can be checked to see if an appropriate service exists.
It should be noted that CSPA is not essential for an agency to be able to reuse other agencies’ systems and tools, especially if those systems support standards such as DDI or SDMX or are based on manual input. However, CSPA is designed to make it easy to integrate services that are part of tools and systems, that could be part of an automated statistical pipeline, and to avoid silos.
The CSPA architecture, usage patterns, and principles are fully described in the UNECE wiki along with a more comprehensive description of the purpose, benefits, and use cases.
Common Statistical Data Architecture (CSDA)
The Common Statistical Data Architecture (CSDA) is a reference architecture and set of guidelines for managing statistics data and metadata throughout an agency’s statistical life cycle. Version 1.0 was published in 2017 and the latest version, 2.0, was published in 2018. As part of the family of UNECE standards, it has the same maintenance and governance administration as GSBPM and GSIM.
The purpose and use of the CSDA as a reference architecture is to act as a template for statistical agencies in the development of their own Enterprise Data Architectures. In turn, this will guide Solution Architects and Builders in the development of systems that will support users in doing their jobs (that is, the production of statistical products).
Data are useless without metadata, so CSDA covers data and metadata and calls them together “information.” CSDA treats the physical location of the data as something that does not matter, the same principles that apply using cloud storage. CSDA stresses that statistical information should be treated as an asset. The benefits of using CSDA are
- Independence from technology: Statistical organization processes and systems will, eventually, become more robust to technological evolution;
- Sustainability: A reference architecture that is shared by the worldwide statistical community is necessary as a common vocabulary for exchanging ideas and collaboration on development and maintenance of new solutions, processes, and systems;
- Maintainability: Maintenance of statistical organization architectures and solutions is facilitated by the availability of a reference architecture that is shared by a larger community; and
- Cost saving to global optimization strategies/solutions: By referencing a shared framework, statistical organisations can better collaborate in the development, maintenance, and use of common solutions.
The CSDA standard consists of a set of key principles. Table A-1 describes each principle’s rationale and implications.
The CSDA Information Model
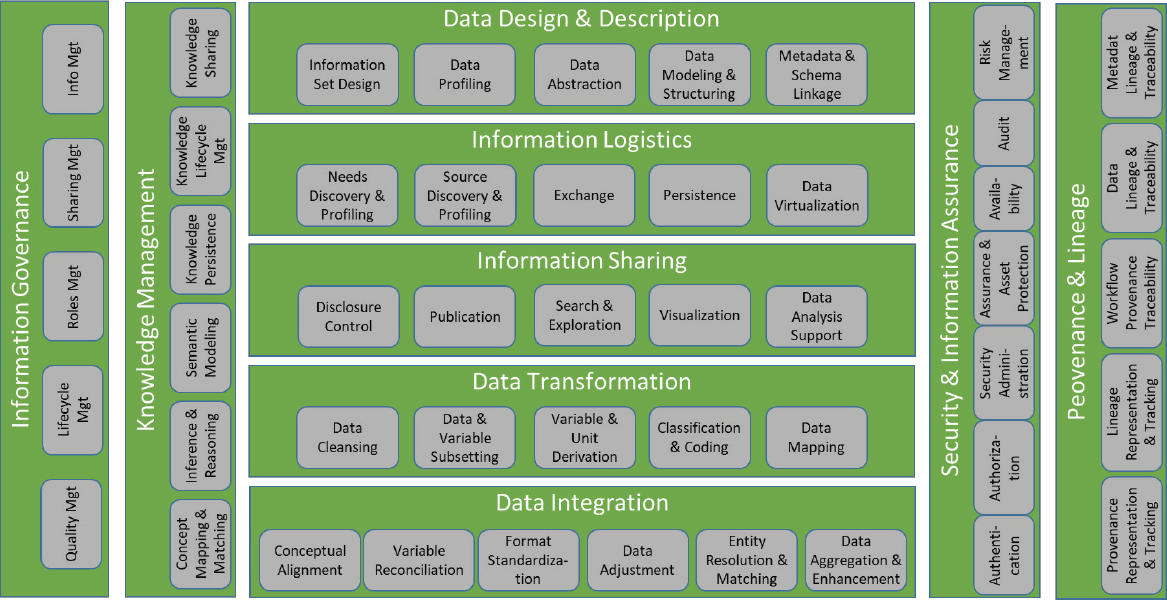
CSDA includes an information model that consists of “Capabilities” based on the TOGAF 9 definition. A Capability is
an ability that an organization, person, or system possesses. Capabilities are typically expressed in general and high-level terms and typically require a combination of organization, people, processes, and technology to achieve. For example, marketing, customer contact, or outbound telemarketing.4
The CSDA information model (see Figure A-8) comprises high-level capabilities: five core (horizontal bands) and four cross-cutting (vertical bands). These bands contain a number of lower-level capabilities (the boxes). The model and each capability are fully described in the CSDA Documentation.
The CSDA architecture is fully described in this UNECE document5 and in the UNECE wiki, along with a more comprehensive description of the purpose and benefits and use cases.
Data Documentation Initiative (DDI)
The Data Documentation Initiative (DDI) is a family of statistical metadata standards and other work products. The work is organized under a consortium called the DDI Alliance, which is managed through a secretariat at the Inter-University Consortium for Political and Social Research (ICPSR). What follows below is a short description of each of the standards, either published or in substantial draft form.
DDI2: Codebook, version 2.5, is used to describe a social, behavioral, or economic (SBE) research study, a one-time survey or experiment, or the data each might produce. There are many applications of Codebook in
___________________
4https://pubs.opengroup.org/architecture/togaf9-doc/arch/chap03.html.
5https://statswiki.unece.org/display/DA/Data+Architecture+Home.
TABLE A-1 CSDA Principles: Statements, Rationales, and Implications
| Principle | Statement | Rationale | Implications |
|---|---|---|---|
|
|
|
|
|
|
|
|
| Principle | Statement | Rationale | Implications |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/download/attachments/314934281/CSDA%20v2.0.pdf?version=1&modificationDate=1623921475467&api=v2 (Table 1, pp 12–16). Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community: https://statswiki.unece.org/download/attachments/314934281/CSDA%20v2.0.pdf?version=1&modificationDate=1623921475467&api=v2 (Figure 3, p. 29). Reproduced under Creative Commons Attribution 3.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
use. The data archive managed by ICPSR and the International Household Survey Network, managed by the World Bank, both use Codebook as their underlying standard. However, Codebook does not support reuse of metadata, so any interconnections have to be maintained outside Codebook itself. This feature makes it easy to implement, and Codebook is often used as a first development step toward more complex metadata management systems in the statistical domain. Codebook is managed in a directly implementable form in XML.6
DDI3: Lifecycle, version 3.3, is used to describe the entire production cycle for statistical activities—be they censuses, surveys, or some others—conducted by national statistical offices. This capability corresponds to the work in U.S. federal statistical agencies, and the statistical life cycle is consistent with the phases of the GSBPM. Multiple surveys, each iteration of an ongoing survey, and their data can be described together, so reuse is necessary in the design of Lifecycle. Increasingly, national statistical offices around the world are turning to DDI3 for their metadata needs, including the Bureau of Labor Statistics, Statistics Canada, and the Australian Bureau of Statistics. Lifecycle is also managed as XML and is directly implementable.
DDI4: Cross-Domain Integration (DDI-CDI) was released as a substantial draft for public review and comments in April 2020. Upon resolution of all the comments, the standard is expected to be approved and released by the DDI-Alliance sometime in the latter half of 2021. The existing draft includes the ability to describe data from any source in several easily expandable logical data formats. In addition to traditional survey data (microdata and multidimensional), sources include administrative, remote sensor, Web scraping, and Internet streaming. A generalized process model is included for describing how data are processed or produced, including the provenance of data. A new datum-centered approach allows any datum to be tracked through processing or across data structures. DDI-CDI supports metadata reuse and the needs of managing data from multiple sources. The specification is managed through a UML (Unified Modeling Language) model, which allows for easy maintenance and the generation of several language representations, e.g., XML (exists), RDF7 (in production), SQL8 (easily generated), and others.9
___________________
6 XML is eXtensible Markup Language, described at https://www.w3.org/XML/; for more details see http://www.ddialliance.org/Specification/DDI-Codebook/2.5/.
7 RDF is Resource Description Framework, described at https://www.w3.org/TR/rdf-primer/.
8 SQL is Structured Query Language, described at https://www.infoworld.com/article/3219795/what-is-sql-the-first-language-of-data-analysis.html.
9 See https://ddi-alliance.atlassian.net/wiki/spaces/DDI4/pages/491703/Moving+Forward+Project+DDI4.
There are several other work products under DDI,10 and these include
- DISCO—DDI-RDF Discovery vocabulary
- XKOS—eXtended Knowledge Organization System
- SDTL—Structured Data Transformation Languages
- Controlled Vocabularies.
Why Use DDI?
The rules governing standards development and participation in DDI activities, as defined for the DDI Alliance, mean that all DDI work products are equitable standards. Organizations are members of the DDI Alliance, and employees of those organizations can be designated as experts, anticipated to contribute to the work of the DDI Alliance, either technical or administrative.
Membership in the DDI Alliance allows any designated employee to participate in the technical development of DDI standards, join committees and working groups to further the Alliance or its work products, as well as vote if the member organization elects to pay its annual fee. The DDI Alliance has grown to include close to 50 members. Any organization with a material interest in the work of the DDI Alliance is encouraged to join. Several national statistical offices around the world have chosen to join the DDI Alliance, including BLS. It is expected that adoption or consideration of adopting a DDI standard is the main incentive behind joining the DDI Alliance.
The design of DDI standards is geared toward supporting several types of users. DDI encourages describing data and the programs that produce them to the fullest extent possible. Doing this supports the discovery, understanding, and usage of data (including sharing) described in this way.
DDI standards are structured, and this supports capture and maintenance of machine-readable and machine-actionable metadata.11 This structure is a result of using the formal language for interoperability in XML, called XML-Schema.12 Documents marked up using XML have a reusable and testable structure if the XML elements are defined using XML-Schema. In this case, there is a formal validation procedure to make sure documents follow all the rules. DDI standards take advantage of this feature.
___________________
10 The interested reader can explore these specifications on the DDI Website at https://ddialliance.org/Specification/RDF for DISCO and XKOS, at https://ddialliance.org/products/developing-products-of-the-alliance for SDTL and again for DISCO, and at https://ddialliance.org/controlled-vocabularies for controlled vocabularies.
11 See https://www.icpsr.umich.edu/web/pages/about/continuous-capture.html for a project led by George Alter to operationalize continuous capture of metadata.
12 XML-Schema is described at https://www.w3schools.com/xml/schema_intro.asp.
This means DDI standards are implementable immediately. Anyone with the tools to use XML-Schema and XML can create, manipulate, validate, maintain, and use documents structured in XML. This differentiates the DDI standards from GSIM. GSIM is a conceptual model expressed in UML. It is not written in an immediately implementable form. In addition, GSIM is missing some details in areas that some of the DDI standards provide, such as the detailed description of multidimensional data in DDI-CDI. However, the combination of DDI-Lifecycle and DDI-CDI incorporates GSIM.
As mentioned above, the DDI standards support several kinds of users: librarians, archivists, researchers, software developers, standards developers, managers, survey methodologists, and subject-matter experts. As the potential application areas for DDI standards increase, more types of users will need to be included, thus increasing the kinds of organizations with a material interest in the work of the DDI Alliance.
DDI Data Life Cycle
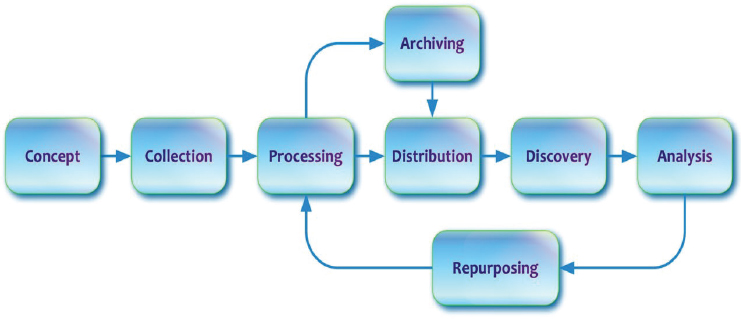
The data life cycle in use in the DDI community (see Figure A-9) appears very similar to the set of phases as laid out in GSBPM. This is purposeful, because DDI-Lifecycle is intended to incorporate the survey life cycle in use in national statistical offices. However, there are a few differences in focus.
SOURCE: United Nations Economic Commission for Europe (UNECE), on behalf of the international statistical community, https://ddi-lifecycle-documentation.readthedocs.io/en/latest/User%20Guide/Introduction.html. Reproduced under Creative Commons Attribution 4.0 International License: https://creativecommons.org/licenses/by/4.0/legalcode.
The main differences are around Archiving and what happens to data after they are disseminated (Distribution in DDI). Since the DDI standards were originally developed to help data archives, this is not a surprise, and this phase is provided to address these needs. A bigger difference is in supporting Discovery and Analysis after achieving Distribution. This is outside the scope of GSBPM, but it is an important part of the data life cycle for librarians, archivists, and researchers.
DDI Standards
DDI-Codebook. The DDI-Codebook (Codebook) was the first work product produced under DDI. It is being used throughout the world. As a result, the standard continues to be maintained with corrections added as they are found. The latest version of the standard is labeled 2.5, the “2” signifying Codebook.
As explained earlier, Codebook does not support reuse. The focus is on a class of objects called Study, described one at a time. Think of a Study as a research project, based on a one-time survey or experiment. What follows, then, is a short discussion of the objects needed by Codebook to describe that Study.
The main kinds of metadata needed to describe a Study are
- Contact—information about subject-matter experts (e.g., the researcher conducting a Study);
- Study information—basic and high-level descriptions of a Study;
- Variables—details describing the variables needed to describe the data produced;
- File information—details describing data files (there can be more than one);
- File format—details showing how the data in a file correspond to the variables, and this includes rectangular formats (e.g., for microdata) and tabular formats (e.g., for multidimensional data);
- Questions—the questions from a questionnaire or form that lead to the variables, if applicable; and
- Methodology—short descriptions of methodological issues, such as sample design, estimation procedures, analytical procedures (e.g., imputation), and processing (e.g., editing and classification).
There are other details as well. The interested reader is encouraged to visit the DDI-Codebook pages on the DDI Alliance Website under “Specifications” (https://ddialliance.org/explore-documentation).
DDI-Lifecycle. DDI-Lifecycle (Lifecycle) resulted from more demanding requirements uncovered through the use of Codebook, especially as the needs of national statistical offices and support for the statistical survey life cycle were recognized. Support for the phases of GSBPM and the reuse requirements for describing ongoing surveys (and not just one-time studies) were major factors.
Lifecycle has many additions that differentiate it from Codebook. The idea of a Study persists, but now Studies fit into larger groupings and contain smaller groupings that provide a very flexible means for linking surveys and other statistical programs to the relevant metadata needed in each case. Some metadata, such as statistical classifications, are not developed with a single survey in mind. They are sharable. Lifecycle supports this idea, and this is a prime example of the idea of reuse.
This means that a complex statistical program, such as the Consumer Expenditure Surveys (CE) series at BLS, is describable. CE is conducted through two ongoing data collections, the quarterly Interview Survey and the weekly Diary. The Interview Survey is conducted monthly on a rotating sample, and the Diary is collected weekly, with each sampled household providing two consecutive weeks of data. Interview households are in the sample for one year, so each household is interviewed four times.
Data are processed through four post-collection editing, imputation, and allocation phases, with several activities included under each. Finalized data are ultimately sent to the Consumer Price Index program every month and combined in quarterly estimates to produce yearly estimates every six months. Yearly microdata files are also produced, one for public use and one with confidential information attached for restricted use.
Changes to the surveys occur in the odd years, though some very small corrections may be made at any time. So, metadata describing CE need to cross surveys, concepts, designs, time, processing, and datasets. Codebook is not up to this task, but Lifecycle was designed to handle this kind of complexity.
Lifecycle versions are designated with a “3”; the current release is 3.3. As with Codebook, Lifecycle was built and is maintained as a series of XML-Schemas. Therefore, it can be implemented directly, just as Codebook can. Commercial, open-source, and shareable software produced in various offices and universities exist to help federal agencies implement Lifecycle. The implementation describing CE at BLS took advantage of this, and the system there implements Lifecycle 3.3.
There are many areas of increased detail, reuse, and management supported by Lifecycle that are not available through Codebook. Some of these are the following:
-
Variable cascade – The ability to describe variables in four sharable levels. These levels are
- Concept—the concept defining a variable, such as marital status, which of course can be shared;
- Conceptual variable—the additional concepts associated with a variable, e.g., allowed categories (single, married, widowed, divorced for marital status) and the universe, e.g., adults;
- Represented variable—the additional codes or representations the categories, numeric ranges, or textual constraints needed, including the data type as intended; and
- Variable—the use of a variable in a dataset or application, such as an SAS® dataset; the codes representing missing data are added here.
- Design considerations—Questionnaire design, sampling plan, and weighting are all included, each providing substantial detail. For instance, it is possible to describe each stage of a multistage sample.
- Questionnaires—The wording of questions, response choices, and question flow are all part of the description. This makes it possible to use Lifecycle as the framework for building a complex questionnaire before it is sent to developers to build an instrument, for example using Blaise® or some other system. This has the potential for substantially shortening the development time of questionnaires and their instruments.
- Groups—Kinds of metadata can be grouped for sharing. For instance, if the same set of variables is used to describe the data in datasets representing each of the major statistical packages, it is very inefficient to link each variable to each, especially if this does not change over time as well. By assigning the relevant variables to a group, one associates the variables just by linking the group.
- The ability to describe the flow of a questionnaire is very similar to describing the steps in the processing of data. So, processing steps are describable using this feature. This means Lifecycle can be used to describe all the phases in GSBPM.
DDI–Cross Domain Integration (DDI-CDI). DDI–Cross Domain Integration (DDI-CDI) is the latest in the family of DDI standards, though at this writing it is still in draft form. The final release of the standard is expected in late 2021. Readers of this report should assume the current draft is substantially correct and complete and that the draft available prior to its release will be quite similar to that version that is released. Versions of DDI-CDI will be designated with “4,” so the first release will be 4.0.
DDI-CDI represents some significant changes to the management and scope of the DDI standards. First, DDI-CDI is built as a UML13 model. This means the standard must be “serialized” into an implementable framework if it is to be used immediately. The current draft release contains such an XML serialization, based again on XML-Schema. There are plans to build serializations in RDF, SQL, and others as time permits. But DDI-CDI is immediately implementable, just as Codebook and Lifecycle are. At this time, there is no external software that supports DDI-CDI such as there is for Codebook and Lifecycle.
The decision to use UML was based on the realization that it is easier to maintain and modify a UML model than a collection of XML-Schemas. UML has many technical advantages for describing metadata, the most important being the ease with which UML represents relationships among classes of objects. These relationships are what make reuse possible. For XML-Schemas, relationships across schemas are not a natural part of that standard. XML-Schemas express rules for hierarchies, so UML is a more natural fit. The reason XML-Schema was chosen for Codebook and Lifecycle is that XML can be used directly to build a system.
The reasons behind the development of DDI-CDI are somewhat varied. At first, the idea was to express Codebook and Lifecycle in UML and add new capabilities that neither currently has into one manageable system. The work ended up as an attempt to redesign Codebook and Lifecycle from scratch. This turned out to be too ambitious.
At the same time, members of the development team for DDI-CDI began consulting with people outside the DDI community to make sure DDI-CDI is compatible with other standards and the needs of other domains. The need for a cross-domain specification became apparent during this work. Serendipitously, efforts in the statistical community showed the need for combining data from multiple sources, thus the idea for a new standard within the DDI family, this time DDI-CDI.
Several World Wide Web Consortium14 (W3C) standards were tested against DDI-CDI for compatibility. The standards DCAT (for a data catalog) and PROV (for dataset provenance) are especially popular and useful. DDI-CDI conforms to DCAT and PROV. PROV was especially important since the provenance of datasets outside the statistical domain is so important for understanding how to use them.
DDI-CDI is intended to address the ever-increasing need for integration of data from multiple sources. Codebook and Lifecycle are designed for describing SBE data. DDI-CDI is more generic, intended to describe data from many domains. Interesting and useful data are produced by
___________________
13 UML is Unified Modeling Language. It is described at https://www.uml.org/.
many organizations and for many purposes. DDI-CDI is able to describe datasets, organized in a variety of ways, with any provenance, independent of subject, and independent of technology.
DDI-CDI borrows heavily from Lifecycle, but it expands the descriptive capability in new and detailed ways. Here is a list of the several innovations in DDI-CDI:
- Expanded and more detailed description of variables. The variable cascade is more carefully modeled. It relies on linking to concepts more than before, and the management of subject-matter categories (substantive) and missing categories (sentinel) clearly separates them;
- Understanding data, universes, populations, categories, and variables as concepts is fundamental. Now, a datum can be followed across datasets and through processing—the datum-centered approach;
- Expanded process model for describing how data are produced and their provenance, from any domain;
- Ability to describe ordered and unordered collections or groupings of objects;
- Expanded ways data can be structured in files, including rectangular (the typical way in statistics), long (for event history data or a data warehouse), and key-value pairings (for Web scraping, sensor data, satellite imagery, etc.);
- New description of multidimensional data, providing an integrated approach to describing time series and n-cubes; and
- Borrowed and expanded idea from GSIM to assign roles to variables (measures, auxiliary attributes, identifiers, dimensions) for analytic purposes. The roles are not fixed, the same variable may be assigned a different role in another context, and variables are used to convey to another user which data are under analysis.
Statistical Data and Metadata eXchange (SDMX)
The main purpose of the Statistical Data and Metadata eXchange (SDMX) standard is to format multidimensional data and metadata into a framework for automated exchange among organizations. The accompanying metadata make the data semantically interoperable, so SDMX supports full interoperability of multidimensional statistical data. See https://sdmx.org/ for more details.
The standard was developed by seven international statistical offices and banks: Bank of International Settlements (BIS), European Central Bank (ECB), Eurostat (the statistical office of the European Union), International Monetary Fund (IMF), Organisation for Economic Co-operation
and Development (OECD), United Nations Statistics Division (UNSD), and World Bank. It undergoes periodic updates, and a new version will be released soon.
SDMX was approved as an international statistical standard in 2008. The United Nations Statistical Commission at its 39th session “recognized and supported SDMX as the preferred standard for the exchange and sharing of data and metadata, requested that the sponsors continue their work on this initiative and encouraged further SDMX implementations by national and international statistical organizations.”15 SDMX was also approved as a technical specification by ISO/TC154 in ISO TS 17369 in 2013. This ISO approval means users can have confidence that SDMX products are reliable and of good quality.
From the technical perspective, SDMX is an integrated solution consisting of three main elements:
- technical standards (including the Information Model),
- statistical-content-oriented guidelines, and
- IT architecture and tools.
These three elements can be implemented in a stepwise approach.
An SDMX exchange package includes a Data Structure Definition (DSD), and its construction is the elemental aspect of using the standard. A DSD consists of a description of the measure, the dimensions associated with it that describe some multidimensional data, and attributes that describe additional information about the data. Dimensions and attributes may be coded (using an associated code list) or not. Each code list representing a dimension has an identifier (or, in the parlance of the Web, a Uniform Resource Identifier, or URI) that allows interoperable exchange.
SDMX incorporated the idea of a registry to handle the DSDs, code lists, and other resources needed to make exchanges work in a seamless (interoperable) way between partners. The scope of a registry can be global or less so (parochial). The global registry holds resources that may be used within exchanges anywhere in the world. More parochial registries, say one for the U.S. federal statistical agencies or one for just the Census Bureau, BEA, BLS, or any other agency, are for the data and metadata each agency exchanges. SDMX includes a standard for registries, so different software may provide the function of a registry but they should all be compatible with other SDMX registries and tools.
Some dimensions are common across all subject domains, and these are called cross-domain code lists. These are maintained among the content-oriented guidelines. Some DSDs (known as global DSDs) are used by many
___________________
15https://sdmx.org/?sdmx_news=un-statistical-commission-sdmx-is-preferred-standard.
organizations, because there are internationally agreed ways to represent some multidimensional data. Both the cross-domain code lists and global DSDs are maintained in the global registry. The global registry identifier for each of its entries is its URI.
Since the initial publication of SDMX in 2004, many tools have been developed to assist implementers in using the standard. Some are devoted to the use of the registries, both global and parochial, and all are being improved and fine-tuned regularly. Most tools are free and open source. The number of global implementations is growing, covering many domains in statistics, and the existence of the tools has helped considerably in the expansion of the systems. The current developments are geared toward making SDMX easier to use and implement, and they broaden the features and data types of SDMX.
In this context, statistical agencies may be confronted with the question of considering SDMX as a solution for harmonizing and automating their multidimensional data and metadata exchanges with international organizations or within their own organization. For instance, the U.S. agencies providing national indicators to the IMF Statistical Data Bulletin Board do so through the U.S. Department of the Treasury via SDMX. Several years ago, BLS, BEA, and the Board of Governors of the Federal Reserve built a pilot system for exchanging some U.S. national indicators with the ECB, although that system was never fully developed. Even agencies that have not yet adopted SDMX may reconsider their decision, taking into account the significant progress made over the years.
Typical Use Cases and Scenarios for SDMX
SDMX can support various use cases and implementation scenarios, as described below. To do so, a set of common tools, processes, terminologies, and methodologies to facilitate the exchange of information between producers and consumers has been produced. We describe two important use cases here.
The most typical use case for SDMX is data and metadata reporting. This is the case where an agency exchanges some data with another statistical agency or organization. The circumstances for why the exchange happens vary, of course, but the fundamentals of an exchange are the same. The infrastructure used by SDMX to achieve this objective contains a network of registries that make DSDs and code lists available for use. Also, a set of reporting formats and IT tools to assist implementers are included. Full implementation of such infrastructure results in direct machine-to-machine exchange.
Data discovery and visualization is another important use case. Here, the objective is to make statistical data and metadata findable and accessible
by external users. Under this scenario, queries based on the SDMX information model drive Website presentation of data and metadata. Based on user selections, the application retrieves the requested information (data and metadata) from SDMX structural repositories, and transforms it into tables, graphs, charts, etc.
Also, SDMX can be used to consistently model data and metadata (e.g., an agency’s internal data) in order to improve harmonization and reduce the metadata maintenance burden. This can help reduce duplicate data storage, improve metadata quality, and enable linkages between datasets.
Benefits of SDMX
Due to the similar nature of the statistical activities across all national and international statistical organizations, many face similar challenges. Solutions to these challenges vary, but implementing standards in statistical offices has advantages, as Chapter 5 addresses. SDMX provides some benefits beyond those of other standards, and we discuss these here. These areas are
- Harmonization of statistical data and metadata,
- Cost reduction to end users who build applications for accessing data,
- Data quality improvement through faster validation, and
- Reduction in the reporting burden for data providers.
These benefits are described through a discussion around some tools and resources that are part of the SDMX system of tools and the content-oriented guidelines.
Harmonization. At its core, harmonization requires that the meaning of data be presented in a way that can be compared. SDMX is designed to do this in a natural and automated way. Dimensions are a fundamental part of multidimensional data, and these are managed as code lists in SDMX. Code lists are made available for inspection and comparison through the network of registries.
Codes and terms play the same terminological role in code lists. They represent the concepts (categories) in the code lists, and they are used to convey those meanings just as words do in natural language. And as with natural language, some terms or codes are spelled the same but have different meanings (homographs), while some terms or codes are spelled differently but have the same meaning (synonyms). Examples are many, but as one example: in gender and marital status code lists, the string ‘m’ can represent male (as a gender) and married (as a marital status). This is an example of
a homograph. Similarly, different systems might use their own representations for a gender code list, for example one might use ‘m’ for male and the other might use ‘1’ instead, even though the meaning is the same; this is an example of synonyms.
Harmonization is the process of cleaning up these ambiguities, and SDMX, through the network of registries, directly supports this activity. This is achieved in part by making differences visible, creating the pressure to remove differences that are gratuitous (having no substantive meaning). As a code list in the network of registries becomes more global, data using that code list as a dimension are more harmonized or standardized.
The SDMX glossary provides a common resource to understand the terms used in SDMX, and this helps provide an unambiguous interpretation of the standard. For any standard, the number of varieties it allows, based on multiple interpretations, is a measure of how hard it is to use. The glossary reduces this inconsistency, and this makes each implementation more like all the others. Importantly, each glossary term is coded so that it may be consistently used in data structures, mappings, and machine-actionable processing.
The advantages of harmonizing and standardizing statistical data and metadata content and structure are numerous:
- Implementers and users speak the same language.
- Reusing existing material saves time and resources.
- Reuse is facilitated by the existence of SDMX registries.
- There is less mapping and data processing.
- Numerous existing SDMX objects are available for defining data and metadata.
- Tools based on a commonly agreed format have a wider audience.
SDMX improves interpretability because it harmonizes structural metadata (the identifiers and descriptors of data, such as table columns and stubs) and their terminology (the SDMX Glossary). SDMX, therefore, contributes to the development of a global statistical language (along the lines of the models developed under the auspices of UNECE: GSBPM, GSIM, CSPA, and CSDA).
SDMX can also be said to improve coherence through the use of cross-domain concepts, shared code lists, harmonized statistical guidelines, and the extensive reuse of SDMX objects across domains and agencies.
But harmonization comes at a cost. On the technical side, unifying disparate systems is usually a major project that needs proper planning and allocation of resources. On the substantive side, developing common classifications and code lists requires an ongoing organizationwide effort that individual departments may see as interfering with their work. These challenges are inherent in any harmonization effort.
Reducing Costs. SDMX can reduce IT development and maintenance costs, mainly through its open-source approach, as many SDMX tools exist. Other open-source tools are available: Statistical Information System-Collaboration Community. Stat Suite, SDMX Reference Infrastructure, and Fusion Registry. It is strongly recommended to consider these tools before developing a new platform. SDMX has always taken seriously the idea that different organizations will implement at their own speed and with their own objectives. The result of this is the “toolkit” approach: SDMX offers many different tools, but they need not all be adopted or used together. Differentiated implementation strategies are thus possible, making the standard accessible to countries or entities of varying capacity levels.
A large community offering to share expertise around the standard exists as well. Furthermore, sharing resources worldwide is better than working nationally, as it promotes cross-fertilization of ideas and practices. This open-source approach thus means no licensing costs, a shared toolbox, and the sharing of development burden among the international community.
SDMX has a strong user base, sponsors yearly user conferences, and has active user groups, and the standard has broad support. All these factors help to reduce the rather steep learning curve that using SDMX entails. Further, as a reminder to the reader, SDMX does not have as broad a scope as some of the other standards discussed in this Appendix. More than just SDMX is required to capture the metadata for the entire statistical life cycle.
Data validation. SDMX natively provides structural validation of data and metadata. This means that a data message can be checked to be sure it matches the structure described by the DSD and dataflow and does not contain invalid dimensions or codes.
To enable data content validation, the SDMX community developed the Validation and Transformation Language (VTL) standard. The purpose of VTL is to allow a formal and standard definition of algorithms to validate statistical data and calculate derived data.
The language is designed for users who may not have information technology (IT) skills (such as statisticians) who should be able to define calculations and validations independently, without the intervention of IT personnel. It is based on a “user” perspective and a “user” information model (IM) and not on possible IT perspectives. As much as possible, the language is able to manipulate statistical data at an abstract/conceptual level, independently of the IT representation used to store or exchange the data.
The language is intuitive and friendly (users should be able to define and understand validations and transformations as easily as possible), so the syntax is
- designed according to mathematics;
- expressed in English to be shareable in all countries;
- as simple, intuitive, and self-explanatory as possible;
- based on common mathematical expressions; and
- designed with minimal redundancies.
The language is oriented to statistics. For example, it contains
- operators for data validations and edit;
- operators for aggregation, even according to hierarchies; and
- operators for dimensional processing (e.g., projection, filter).
At a later stage, it contains
- operators for time series processing (e.g., moving average, seasonal adjustment), and
- operators for statistics (e.g., aggregation, mean, percentiles, variance, indexes).
The language is designed to be applied not only to SDMX but also to other standards. To varying degrees, it can work with GSIM and DDI. In particular, it can operate on all the various data structures that GSIM and DDI describe.
Reducing the reporting burden. SDMX is designed to significantly reduce the effort and resources required by reporting agencies in a typical reporting framework. It does this in the following ways:
- SDMX enables the “pulling” of data and metadata from a single cross-domain exit point, which is the standard SDMX Web interface. A reporting agency that implements SDMX may replace multiple reporting systems with the SDMX Web interface. Data collection becomes more practical for data collectors, as they can query the data as they want rather than downloading a full snapshot of a dataset, and the query format is the same across SDMX-implementing agencies.
- Efficiencies can be gained by avoiding round trips of checking and fixing data between reporter and collector agencies, because SDMX enables the validation of data structure and coding before and after the data transmission (by the reporter and collector). The validation can be easily automated, and existing tools may be used by all agencies.
- Traditional exchange frameworks often rely on multiple, bespoke exchange agreements because of the different formats required by
- each agency and the different times collectors may require the data. SDMX can simplify and reduce the exchange agreements required by harmonizing the data structures and formats. For example, an exchange agreement can reference a global DSD, such as for National Accounts. Reporting calendars and frequencies may be simplified, as the reporter can publish the data as soon as they are ready and the collecting agencies can “pull” the data from the agency’s SDMX Web interface as and when required. >
Comparing VTL with DDI SDTL. The Structured Data Transformation Language (SDTL) under DDI is not the same as VTL. SDTL does not support validation. VTL is designed to be executable, whereas SDTL is for documentation. SDTL is readable through a set of structured JSON (JavaScript Object Notation) tags, but VTL must be parsed based on syntax rules. Finally, SDTL includes a schema and software to translate into a natural language description.
GENERAL METADATA STANDARDS
There are a number of highly adopted metadata standards (many from the library and digital curation communities). These commonly used standards may be invoked with other standards, or they may be worth using as part of an application profile.
Dublin Core Metadata Element Set (DCMES)
The Dublin Core Metadata Element Set (DCMES) is a “vocabulary of fifteen properties for use in resource description.”16 Though it was created initially with the goal of supporting the description of born-digital resources such as digital images, digital documents, e-books, and so on, it also can be used to describe physical objects (e.g., paintings, books, DVDs, etc.). It can also be used to describe datasets, albeit with some limitations (described further below).
Development of Dublin Core began in 1995 at an OCLC/NCSA workshop in Dublin, Ohio.17 The “core” refers to the broad nature of the standard: the terms are intended to be generic enough to be applied to a wide range of resources. The 15 elements are contributor, coverage, creator, date, description, format, identifier, language, publisher, relation, rights, source, subject, title, and type. Descriptions of each element and notes on
___________________
16https://www.dublincore.org/specifications/dublin-core/dces/.
17 See the following page for additional details on this: http://www.dlib.org/dlib/July95/07weibel.html.
how to use them can be found on the Dublin Core Metadata Initiative (DCMI) Website.
When people talk about Dublin Core, they are most often referring to the 15-element Metadata Element Set. However, there are several additional vocabularies created and maintained by the Dublin Core Metadata Initiative that are important to be aware of as well. Two to be aware of are these:
- DCMI Metadata Terms [DCMI-TERMS]: This is the set of all the terms/elements defined by the DCMI, including the Metadata Element Set, as well as “several dozen properties, classes, datatypes, and vocabulary encoding schemes.”
- DCMI Type Vocabulary [DCMI-TYPE]: This is a controlled vocabulary for describing the “nature or genre”18 of a resource, e.g., “Physical Object,” “Dataset,” etc.
Dublin Core is meant to describe resources at the file level. Key to DC’s design is the “1-to-1 principle.” That is, for every resource being described, there should be one Dublin Core metadata record. This is meant to facilitate disambiguation between variations of the same resource, e.g., between a thumbnail image and the main version of a file. A common example considers multiple versions of the Mona Lisa: the original painting, a high-resolution .tiff photograph of the painting; and a smaller .jpg thumbnail. For each of these resources, there should be a corresponding Dublin Core metadata record. While this may seem straightforward, this can potentially lead to situations in which the creator of the tiff of the Mona Lisa is not listed as Leonardo Da Vinci—but rather, the name of the photographer who took the photo. Thus, it is important to clearly articulate a workflow for accurately cataloging different versions of resources and linking records accordingly.
Dublin Core is one of the most commonly adopted metadata standards in academic digital repositories and digital libraries. The generic focus of the element set makes it broadly applicable to most collections, particularly collections of documents, books, musical works, artistic works, and so on. Because it can describe both physical and digital objects, it is popular with libraries, archives, and museums. However, the generic nature of the elements means that Dublin Core is not necessarily useful for repositories seeking to serve a very specific community or use. This standard does not have any official standing with any national or international statistical agencies, but it is worth noting that it has been ratified as an ISO standard.
With regard to describing datasets, Dublin Core can be used to create very general metadata, but it is not designed to provide much variable-level
___________________
18https://www.dublincore.org/specifications/dublin-core/dcmi-terms/#section-7.
documentation, or even to provide much description of methodological considerations. Again, Dublin Core is meant to describe resources at the file level, which means a Dublin Core metadata record for a dataset would be intended to describe the dataset as a whole—not specific variables or observations within the dataset. Consider again the 15 terms in this element set:
contributor, coverage, creator, date, description, format, identifier, language, publisher, relation, rights, source, subject, title, type
Many of these can be adapted to be used to describe statistical datasets, but the fit may be somewhat awkward. For instance, “coverage” can be used to describe the geospatial and temporal range of a dataset. But this is truly meant to encompass a range, such as a geometric polygon on a map, rather than specific geolocalities. The “description” field is broad enough that it could be used to describe all the variables within a dataset, but this would not necessarily be machine readable without specific adaptations. This general, file-level approach means that Dublin Core could potentially be used to describe disparate types of statistical dataset, such as administrative records, quality reports, or various types of text-based data, but only at the aggregate (dataset) level.
Dublin Core is often used as part of a metadata “application profile,” in which multiple standards are combined for a bespoke use, and/or are applied in a unique way. It is likely that Dublin Core could be used in combination with another standard to provide the interoperability that it affords in combination with more domain-specific applications. Dublin Core also has numerous published crosswalks to other standards, notably from the Getty Center, an institution focused on visual art and cultural heritage.19 However, these crosswalks typically focus on other standards intended for libraries, archives, and museums, rather than ones such as the others covered in this Appendix.
Software support for Dublin Core is focused in the areas in which it is heavily used. Several digital library and digital asset management platforms have built-in support for Dublin Core, including Fedora and Omeka. Fedora is “a robust, modular, open-source repository system for the management and dissemination of digital content. It is especially suited for digital libraries and archives, both for access and preservation.”20 Similarly, Omeka is an open-source Web publishing platform for the organization and display of archival, library, and digital scholarship collections.21 However, Dublin Core is not produced, handled, or otherwise supported by any
___________________
19https://www.getty.edu/about/.
statistical software. Its metadata can be serialized into HTML, XHTML, XML, and XML/RDF syntax, with XML being a common choice.
One considerable upside of Dublin Core is ease of use. It is among the easier standards to implement and customize, which is one reason for its popularity. Every Dublin Core record refers to one, and only one, object and consists of a number of attribute-value pairs. Implementing Dublin Core can become somewhat more involved when combining it with other standards in an application profile, as mentioned above, but when used on its own it is fairly straightforward and minimally complex. Because Dublin Core does not require any proprietary software or platform to use, it would also be minimally costly to any institution that wished to begin using it. While Dublin Core can only be effectively applied to statistical data at the dataset level, it has the advantage of applying equally well and with equal ease to any type of dataset.
Overall, Dublin Core is an unusual standard to include in a report about statistical data. It is included here not only because it is an important metadata standard, broadly speaking, but also because it is a simple, general standard that may be worth using in tandem with another standard covered here to record metadata at the dataset level. In this role, Dublin Core could be used in order to capture and document potentially important information at the aggregate level and facilitate the organization and retrieval of statistical datasets. While it is possible to find discussion of Dublin Core and its use in many places on the Web, particularly among library and information science communities, the primary resource and reference for Dublin Core is the DCMI website, specifically the terms list.22
PREMIS (PREservation Metadata: Implementation Strategies)
Developed by the Library of Congress, PREMIS (PREservation Metadata: Implementation Strategies) is “the international standard for metadata to support the preservation of digital objects and ensure their long-term usability.”23 Simply put, PREMIS specializes in expressing preservation metadata about digital objects—“the information a repository uses to support the digital preservation process.”24 The PREMIS data dictionary defines a core set of concepts needed by repositories to perform preservation actions on their digital collections. This includes information about formats, implementations, hardware and media, agents, rights, and provenance. PREMIS is rarely used as a stand-alone standard but, rather,
___________________
22https://www.dublincore.org/specifications/dublin-core/dcmi-terms/.
23 See Reference: https://www.loc.gov/standards/premis/.
24 From “Understanding PREMIS,” https://www.loc.gov/standards/premis/understandingpremis.pdf.
is typically used in combination with other standards that provide more descriptive metadata. It therefore could likely be used in conjunction with the metadata standards described below.
METS (Metadata Encoding and Transmission Standard)
METS (the Metadata Encoding and Transmission Standard) was also developed by the Library of Congress. It is a “standard for encoding descriptive, administrative, and structural metadata regarding objects within a digital library”25 and is often used as a “wrapper” for other metadata from other schemas. One of METS’s particular strengths is its ability to record complex links between different kinds of metadata and multiple digital objects. For instance, a METS wrapper can be used to encode and transmit all the metadata about individual page scans that make up a digital book. METS may be useful to the statistical community as a way to store and transmit metadata about complex data objects. METS is specifically designed to be encoded in XML and takes advantage of XML’s hierarchical document structure.
ISO 19115
The ISO 19115: Geographic information metadata standard supports the documentation of geospatial data and services. This standard was harmonized from the Federal Geographic Data Committee’s geospatial metadata standard and other commonly used geospatial standards in 2003. The resulting standard is widely adopted by geographic information system (GIS) software, and is important in facilitating the use, storage, management, and analysis of complex geographic datasets. These often include maps, charts, and text documents in addition to numeric and other non-geographic data. Many types of statistical data may have a geographic component or may need to be combined with geographic data. Additionally, some statistical metadata standards may be usable in combination with ISO 19115. Statistical agencies with a geographic focus should also review this standard.
PROV
The PROV family of standards was developed by the World Wide Web Consortium (W3C) to express provenance metadata for a wide range of information objects, including news articles, datasets, and more. Provenance metadata are important to scientific reproducibility and transparency, and
___________________
as such, could be important to include with statistical metadata. PROV models provenance as an interaction between three classes of elements: Agents, Entities, and Activities. Entities are the physical, digital, or conceptual things that are being created or altered; Agents are the people or software doing the alteration; and activities are the specific actions taken upon an Entity.26 The W3C has developed specifications for encoding the PROV data model in a range of formats (e.g., XML and RDF), and for using it with a range of existing metadata standards (e.g., Dublin Core).
DCAT (Data Catalog Vocabulary)
A newer W3C standard, DCAT is the Data Catalog Vocabulary, a “vocabulary for publishing data catalogs on the web.”27 Where many of the standards being described in this document are meant to describe individual digital objects, DCAT is meant to describe the catalogs for those objects and therefore facilitate the sharing and aggregation of catalogs between/among multiple institutions or repositories. DCAT could therefore be useful to individual agencies or repositories wishing to eventually aggregate their data together.
Schema.org
Finally, schema.org is both the name and URL of a vocabulary created by Google, Microsoft, Yahoo, and Yandex, meant to semantically annotate resources on the Web. The schema.org terms describe a wide range of entities—everything from events to “friending actions” on social media to airline flight schedules—but most germane to this report is their set of terms for datasets and data catalogs. In short, this vocabulary is meant to be embedded in the HTML of the landing page of a dataset or catalog, where it can then be harvested by generic search engines such as Google. In this way, schema.org terms are quite different from traditional approaches to metadata, which are typically stored in a repository that cannot be Web indexed. A few scientific agencies are exploring the use of schema.org terms on their Web pages, and the use of Web protocols for dataset search (e.g., the EarthCube funded Project 418, https://github.com/earthcubearchitecture-project418). However, few repositories (if any) have yet to adopt these terms beyond pilot projects.
__________________
___________________
26 See https://www.w3.org/TR/2013/NOTE-prov-primer-20130430/.










































