
5
Metadata and Standards
INTRODUCTION
In order to ensure that an archived dataset can used in the future, sufficient information must be provided detailing what the columns and rows (in a typical rectangular dataset) represent. For an input dataset, this necessitates providing the units of analysis as defined by the rows, and the variables defining the columns, including what the questions and transformations underlying each variable are and what the various responses are and what they mean. If the dataset contains output estimates, again what the rows and columns signify needs to be stated. To assess the fitness for use of estimates, especially if they are to be used in combination with other estimates in some way, the variability of the estimates (assuming they are the result of a sample survey) due both to sampling error and to nonresponse also needs to be provided. All of this information needed to analyze a dataset is called metadata.
In providing these metadata, it is extremely helpful if the information is structured using standard schemas so that users understand what information is being provided in each portion of the metadata file. When that is done, the users do not have to figure out how to interpret each element of the metadata. Standardized metadata allow automation of data analysis, transfer, and aggregation.
METADATA: THE BASICS
The term metadata was invented by several researchers independently around 1970 (Bagley, 1969; Sundgren, 1973). In practice, though, the need
for metadata has been around for as long as humans have organized information. Examples include library card catalogs and classification schemes. For many years, the extent of metadata management and usage was due to information professionals engaged in cataloging, classifying, and indexing things; but as the use of the Internet and the Web has grown, the need for digital information has grown along with it. Now, metadata, originally defined as data about data, has come to mean any descriptive information about some objects of interest, because it is simple to attach digital descriptions to a list of objects online.
We now define metadata as data being used to describe some object(s). Library books, data and datasets, museum artifacts, telephone calls, and survey questionnaires are all examples of objects that can be described. Data describing a telephone call (e.g., calling number, receiving number, length of the call) are metadata, unless they are used to create a network of callers and receivers, in which case the data are not being used to describe. This expanded view means use of the term metadata indicates a role played by some data; it is not a fixed property.
Statistical metadata are data (information) used to describe statistical objects. Statistical metadata are best understood as structured information. In the statistical community, efforts to begin the management and use of metadata to describe data, datasets, and the methodology used to create them began in the 1970s. In the 1980s the efforts expanded to include research data libraries, data archives, and national statistical offices; and they expanded even more widely in the 1990s as the online digital revolution exploded. This expansion in use is continuing, but metadata management has not kept pace with the ever-increasing amount of data available.
As noted above, metadata is a role for data, and metadata are often further categorized as being, for example, descriptive, administrative, or structural.1 These too are roles that metadata can play for a user or administrator.2 The roles are as follows:
- Descriptive metadata are needed to describe a resource for discovery and identification; examples include basic elements such as “title,” “keywords,” and other ways of explaining what a digital object is about.
___________________
1 From An Introduction to Metadata: https://www.getty.edu/publications/intrometadata/setting-the-stage/.
2 Also, the categories are neither exclusive, exhaustive, nor definitive. Other roles may be identified as desirable, and each statistical object may perform more than one. These categories can help statistical agencies think about how to organize their metadata usefully. One caveat here: there are indeed niche metadata standards designed to play specific roles. For instance, the PREMIS metadata standard is meant to particularly record provenance and administrative metadata (https://www.loc.gov/standards/premis/).
- Structural metadata indicate how compound objects are put together; for example, how pages are ordered to form chapters, or how different observed events were combined to create a “set” of data observations.
-
Administrative metadata provide information to help manage a resource, such as when and how the resource was created, its file type and other technical information, and who can access it. Administrative metadata can include the following subsets:
- Preservation metadata, which contain information needed to archive and preserve a resource;
- Rights management metadata, which deal with intellectual property rights or restrictions on access or use (note: often embedded in preservation metadata); and
- Provenance metadata, which contain information about where the data came from and how they were created.
Metadata are provided in two major forms: as text in documents or as formal attributes corresponding to characteristics of some classes of objects. For instance, most cans of food can be described by the following: food name, manufacturer, list of ingredients, and nutritional information such as amounts of sugar, fat, and protein. A picture of what the food looks like after preparation is often included on the label as an enticement to consumers. For statistics, a microdataset may be described by name, producer, size in bytes, record length, number of records, file location, link to a data dictionary, and so on. An attribute is the combination of a characteristic and its value associated with some object, and it is descriptive of that object—for instance, a can of food or microdataset. Descriptions may be presented as prose in text format, as a list of the attributes, or as some combination of the two.
Metadata provided as text in documents are called passive, and they are human readable only. Machine-readable metadata are in a form that can be easily processed by a computer. Machine-readable metadata used as input or created as output in systems are called active. For example, metadata stored as prose in PDF documents are human readable and passive. Metadata stored in formal databases as numbers, codes, or entries from controlled vocabularies are designed to be machine readable; they are active when used to control the execution of some system in a particular way.
In this report, statistical metadata (hereafter, metadata) are data used to describe statistical objects (see below). Data used in this role are metadata. This means data are considered metadata when they are used in a certain way, specifically as describing some “things.” As a means for comparison, in traditional statistical surveys data are collected from persons in households or business establishments. Data collected about an individual
could be used to describe that person. In that case, they are metadata. For statistical surveys, however, the data are also used to represent the properties of similar members of a population, so the data then have a statistical role, not a descriptive one.
Usually, metadata are a product of statistical agencies. The agencies produce metadata to describe the statistical objects they produce, for example data, datasets, and questionnaires. However, data users may also construct additional metadata based on their experiences and uses of statistical data. If a user constructs a new dataset based on integrating data produced at several statistical offices, then the new dataset needs its own metadata. For scientific research data, metadata are particularly important in facilitating the machine readability of a dataset (the automatic use of a dataset by software), data sharing and reuse, and transparency and reproducibility. Recent pushes to make scholarly data that are “findable, accessible, interoperable and reusable” (FAIR3) emphasize the critical role that metadata play in achieving all of these goals (Wilkinson et al., 2016).
For computational and statistical research, it is particularly important to record the workflows and methods used in an analysis (Stodden, Seiler, and Ma, 2018). This might be expressed as an executable workflow—a piece of code that could be used to precisely recreate a computational output—or in some other kind of provenance metadata that clearly show how a final data product was created from raw data sources. (Chapter 5 describes tools to preserve and share such code.)
Common Metadata Objects
There are many kinds of objects produced by statistical agencies in the course of their work. They can all be described, of course, but the kinds of objects each agency needs to describe may vary; the selection of the objects depends on specific needs. Generally, the statistical community produces objects of the following kinds:
- Concepts (especially their definitions)
- Questionnaires and forms
- Questions
- Wording
- Response choices
- Flows (for example, skip pattern)
- Instruments (implemented questionnaires)
- Variables
- Value domains
___________________
3 For more information, see the GO-FAIR Website at https://www.go-fair.org/fair-principles/.
- Classification systems
- Code lists
- Datasets
- Data flows
- Sampling plans
- Processing algorithms and systems
- Editing and validation
- Coding
- Allocation
- Estimators
- Imputation methods
- Disclosure control methods, and
- Application programming interfaces (APIs) and other data channels or services.
For instance, metadata about a dataset include descriptions of the dataset itself and the underlying data. For a machine-readable dataset, describing the variables is just as important as describing the set overall. Characteristics typically used when describing variables include these:
- The concept a variable represents (say, marital status)
- Value domain (<s, single>, <m, married>, <sp, separated>, <d, divorced>, <w, widowed>)
- Datatype (in the case of marital status, nominal datatype),4 and
- Universe (say, adults in the United States).
Once a list of characteristics is developed, it may be reused for describing any dataset elsewhere, and this can be generalized to any kind of statistical object. Reuse supports compatibility by showing when items are similar in some way. Both similarity and lack of similarity are supported. In this sense, comparability is an important consequence of reuse.
Reuse of metadata is achieved by identifying similarities among objects. For instance, in our example above, we apply the concept marital status to a variable. There might be many such variables, especially if an agency conducts a single survey that produces a similar dataset on a regular ongoing basis or conducts several surveys that each collect a marital status variable. If the same concept applies to each, one can simply apply its description each time it is needed. This is called the reusability principle: describe once, use many times.
___________________
4 The nominal datatype is one where the values are categorized with no ordering imposed. Marital status is an example. The set of states in the United States is another.
Metadata Encoding
Metadata can be recorded in multiple ways. The simplest way might be a README file—a human-readable document explaining how a dataset was created, by whom, and why.5 However, in order to make metadata machine actionable and indexable in a database, it must be encoded in some sort of structure for a computer. ISO/IEC 11179, from the International Organization for Standardization (ISO), specifies a structure for metadata (a schema) that supports machine readability and inclusion in some sort of registry or catalog, and this standard has been foundational in the development of many metadata standards and registries. In particular, ISO/IEC 11179’s notion of a data element (or variable) will come up again later in this report, for example in our reviews of the Data Documentation Initiative (DDI) and the Generic Statistical Information Model (GSIM). A data element is an atomic unit of data, with precise semantics. Even the most rudimentary metadata standards will take care to define a schema for describing the data elements in datasets. However, ISO/IEC 11179 does not specify the encoding format for the metadata. This is because there is a need to support multiple kinds of encoding, as different approaches have different strengths and weaknesses. The three kinds most relevant to metadata system developers are XML, JSON, and RDF.
Schemas are important because they provide a way to learn of the attributes describing a given kind of object, often through automated means. Which attributes are used to describe a variable? Look at the schema. But the schema also provides information about which attributes are related to which others, which attributes are required, and what rules the allowable values for each attribute need to follow. A schema provides valuable information that a description of some object cannot. In some ways, a schema is metadata describing other metadata.
Schemas are developed by analyzing what kinds of information are needed to describe a particular kind of object. For instance, a description of a dataset might differ depending on information needs, especially for transparency and reproducibility. For example, in a system that is a catalog for files containing satellite images, what is required might be the date and time the image was received, the subject of the image (what body or feature is depicted), and the name of the satellite and imaging camera. In that instance, little about the underlying data is needed. If the system is a catalog of statistical datasets, however, much more has to be known about the variables in the dataset. The needs of the system determine the attributes a schema has to define. It is often the case that relevant schemas
___________________
5 See https://data.research.cornell.edu/content/readme and https://ropensci.github.io/reproducibility-guide/sections/metaData/.
already exist, so the need to develop one independently is greatly reduced. Standards are a good source of such schemas, and schemas already in use by other federal statistical agencies are another.
XML (eXtensible Markup Language)
XML stands for eXtensible Markup Language. XML gained popularity as an encoding format in many libraries, museums, and data repositories in the late 1990s and 2000s, and it persists today. Syntactically similar to the HTML used to encode the display of Web pages, XML was designed to be both machine and human readable. Metadata elements are enclosed within pointy brackets (“<” and “>”), which makes it possible for a computer to easily retrieve all the information recorded within one. Elements can also be embedded within another element, providing a hierarchical structure. Each element has a name associated with it, called a tag.
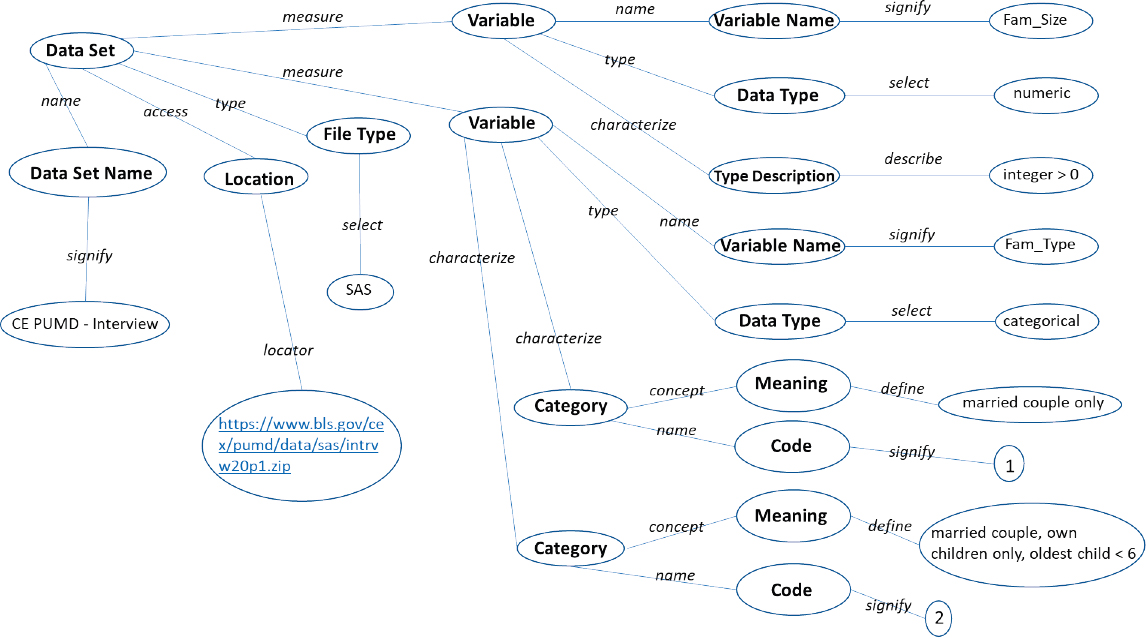
Unlike HTML, XML is user defined. This means the elements and their tags are defined by their needs within the design of some system and are not predefined as they are in HTML. There is no preset list of elements that needs to be used within an XML document; rather, different metadata languages can be written (or referenced) for different purposes. However, element requirements can be encoded in a schema language called XML-Schema, and this feature allows for the same element set to be reused. Figure 5-1 contains an example of a metadata document.

In the example displayed in Figure 5-1, the metadata record is describing a public-use microdata set from the Consumer Expenditure Interview Survey from 2020. Note the hierarchical structure of this document in Figure 5-1; every indented node is read as the “child” of the node above. This hierarchical structure makes XML particularly useful for encoding metadata by describing objects that fit a hierarchical, part-whole or parent-child structure, as well as for encoding documents.
JSON (JavaScript Object Notation)
JSON (JavaScript Object Notation) is a data-interchange format. It is lightweight, meaning the syntax for using the language is uncomplicated, easy for humans to read and write, and easy for machines to process. JSON is based on the JavaScript language. It is a text format that is independent of other language but uses conventions that are familiar to programmers. For these reasons, JSON is ideal for data interchange.
JSON has a simple structure based in name/value pairs and lists. Illustrating this here is beyond the scope of this report, as it requires some technical knowledge. But JSON’s simple structure means it may be used as a substitute for XML. XML is very verbose, and some files marked up in XML take a long time to process. The simplicity of JSON is designed to avoid that problem. Finally, as with XML, JSON has a schema language, which allows designers to construct reusable JSON elements and structures.
RDF/RDFS (Resource Description Framework)
The Resource Description Framework (RDF) was designed as a language for representing metadata about Web resources, or information about physical resources that can be identified on the Web. This framework is not meant to be particularly human readable, but rather is meant to work behind the scenes to facilitate search and retrieval (see Figure 5-2 for an example). Where XML is inherently document-like and hierarchical in its structure, RDF is a methodology for creating individual, simple, and interconnected statements about resources. Each individual statement may be represented as a graph—two nodes and an arc connecting them. So a set of many interconnected statements is representable as a complex graph. These statements are structured as subject-predicate-object triples (named for the trio of elements a triple contains). The subject is the entity being described; the predicate is the relationship between the subject and object; and the object is the value, entity, or other characteristic being ascribed to the subject. The object in one triple can be used as the subject of another triple, thus enabling a rich set of interconnected triples. In the graph representation of a single RDF triple, the nodes represent the subject and object, and the arc represents the predicate.
The semantics (or meaning) of the subject, predicate, and object should all be designated by a Uniform Resource Identifier (URI), which is used to refer to a meaning or value. The ability to create an interconnected graph from individual statements depends on the consistent use and linking of URIs. Data formatted in RDF are often referred to as “Linked Data” because of this.
Just as with XML and JSON, there is a schema language for RDF, which is called RDFS (Resource Description Framework Schema). The schema allows designers to build an RDF structure that can be reused. This is important when using RDF to represent metadata describing similar resources.
RDF is increasingly used by institutions that preserve information (see, for example, the Library of Congress’s Linked Data Service6). However, it is important to keep in mind that RDF is designed to be consumed by machines, not people. A graphic user interface is needed to resolve URIs into human-readable text about resources. Any adoption of RDF needs to be accompanied by suitable software for end users.
METADATA SYSTEMS7
Metadata systems are built to organize recorded metadata. They are designed to make use of metadata in some way, either to provide human-readable metadata for informational purposes or to provide machine-readable metadata for guiding further processing and possibly for humans to read. There are two main components of any metadata system:
- The metadata repository is a database of metadata, the basic storage component for all metadata systems. The organization of the repository is based on a schema (e.g., column headings, relationships, and data types) to help formalize and organize the attributes, or metadata elements, of the system. See Appendix A for more details.
- The user interface is the means, possibly in the form of software, for a user to interact with a metadata system. Users can be humans or other systems, and these correspond roughly to whether the metadata are human readable or machine readable, respectively. The interfaces will be built based on which kind of user they
___________________
6 See https://id.loc.gov/ for details.
7 Much of this section is taken from Scope Metadata Team, “Metadata Systems for the U.S. Statistical Agencies, in Plain Language,” 10 July 2020. The SCOPE Metadata team is an informal, longstanding interagency group of U.S. federal statistical agency representatives. Authors here include Daniel Gillman (BLS), Kathryn McNamara (Census), Peter B. Meyer (BLS), Francisco Moris (NSF/NCSES), William Savino (Census), and Bruce Taylor (IES/NCES).
- address. In each case, an API is the software designed to communicate with the repository, and the API gets its guidance, that is, what commands to send to the repository, from either a human or another system. The API sends a query desired by the user to the repository and returns metadata to the user.
The FAIR guidelines, mentioned earlier, are a generic set of principles for direction on how to make scientific data Findable, Accessible, Interoperable, and Reusable. These four goals are each subdivided into three or four principles (15 in total) that bear on data and metadata management and dissemination. Therefore, they need to be applied to the development of metadata systems, as these systems will be expected to support the FAIR guidelines in time. And, as we shall see, these principles support the efforts to make data and processes transparent and the results of these processes reproducible.
Metadata projects—that is, the effort to build metadata systems—are often framed by four considerations:
- The intended use of the system under development;
- The staff, contractors, capabilities, preferred methods, and software tools;
- The standards; and
- Other constraints.
As noted in the review of costs below (see Risks and Benefits), these projects involve staff from many areas—management, subject-matter experts, statisticians, information scientists, computer scientists, and IT specialists. These can be complex projects. Constraints include costs, time, functionality, scope, staff, resources, capabilities, and training. All are major factors in designing, building, and maintaining any system, and remain true for metadata systems. The novelty of a metadata system at a small agency, combined with uncertainty about its benefits, makes it difficult for the agency to be willing to use it.
Whether a metadata system is designed and built from scratch or the software for the system is borrowed or bought from another agency or a company, much development work is required. Collecting and storing metadata have additional requirements beyond just ingesting data into a database. Metadata are descriptive, so the need to make sure they describe the right objects, the descriptions are correct, and the descriptions are coherent with each other adds significant complexity. As with most system development and because of their novelty, metadata systems are best built iteratively, which includes the content in addition to the infrastructure (the software). Success is probable so long as the scope at each step is well
defined and narrow; there is support from upper management; there is technical and subject-matter support; funding is adequate for the proposed goals at each stage; the user community is knowledgeable and supportive and can provide feedback; and there is significant planning. Nevertheless, the novelty of metadata systems presents a considerable risk, which is attenuated by the iterative approach.
What slows down deployment is collecting, organizing, linking, and checking the quality of the metadata in a dedicated system. Metadata management is most successful when metadata are collected as they are created. An example is the definition of some concept, say a new category in an existing classification. Where is that definition stored? Usually, the answer is that it is stored in some Word or Excel file, but that solution affords little in the way of good metadata management. If, on the other hand, the definition were added to some existing system that manages categories in statistical classifications, none of the work to collect the definition post hoc is needed. Building and integrating the right tools for interacting with systems is a fundamental piece of an effective system. And even though the number of vendors and open-source tools for the statistical metadata community is limited, good ones nevertheless exist and are designed to be integrated.
To get off the ground, the development of metadata systems requires some kind of business requirement to motivate the process, and this, in turn, provides the justification for stakeholders to commit time and resources. Most of the time, the collaborative process is slower than the management of organizational development schedules can accommodate. This is a risk that needs to be acknowledged up front. Losing stakeholders in the middle of a development often causes that work to get bogged down further. If a stakeholder insists on a time schedule, either everyone must agree that the end product will probably be less than originally planned, or a new development round must be agreed to. Given the twin goals of transparency and interoperability in and among the 13 principal U.S. federal statistical agencies, collaborative projects are very likely the right way to proceed.
In addition to all of the above, achieving success requires that management and technical staff be supportive. The support of top management, especially, is necessary for two simple reasons: (1) control of the budget, and (2) the ability to direct their staff to perform certain tasks.
All-encompassing metadata systems are sometimes called “cathedrals”; they usually fail because they are too complex, take too long to build, and are too ambitious. Committed supporters of metadata management often make this mistake. Despite the skeptical view of those who refer to this work as cathedral building, in fact the metaphor also applies to what is needed to make it succeed: an incremental approach that allows sufficient time. Expectations need to be reined in by making the scope manageable
at each step. One cannot simply start building such a cathedral instantly; first, all the aspects of the standards and tools that will eventually need to be incorporated must be considered. New kinds of systems need to be built slowly, so while one cannot start assembling this cathedral initially or all at once, the broad vision needs to be kept in mind. The iterative approach means the ultimate design of the cathedral and what is achievable must be fluid. Yet all aspects of incorporating tools and conforming to standards need to be considered early on.
New kinds of systems, those that provide a new kind of functionality, need to be built slowly. This is especially true for metadata management, for all the reasons laid out above. Future iterations need to incorporate lessons learned from past steps. Few iterations will be mistake free, and often the best experience is one that involves some failure. The potential for metadata management is often not completely understood at first. This will most likely change as experience is gained through system development. The scope of a system may need modification as resources are re-examined midstream. Careful system development requires all these considerations, but they bear repeating as they are ignored easily. When new functionality is being considered, they are even more important.
RISKS AND BENEFITS
Given the costs and time that must be devoted to training and developing tools to adopt and make use of any of the six metadata standards described in detail later in this chapter, there is understandable hesitancy about building the capabilities of statistical metadata management. Some agencies view the making of informed use of metadata standards as “a bridge too far.” However, the costs are not excessive, and the benefits will extend long into the future. Metadata standards are a key tool in minimizing burden and enabling transparency and future sharing of information and data products.
No system development will be approved by upper management unless the system is expected to provide a return on investment. Here we discuss some of the main areas where metadata systems may produce a return on investment, in which the risks are outweighed by the benefits.
Building and using metadata systems include the following transformative benefits:
- Maintaining organizational knowledge. An agency’s knowledge is stored in documents and databases throughout the organization. These documents and data are metadata, because they describe something the agency planned, decided, built, used, or disseminated. Documents are usually written in prose and meant for
- humans to read. Metadata is a shorthand version of documents. By compressing the information contained in a document into attributes and their values, the metadata that result provide a shorthand for the prose. When stored in a repository, the metadata are made available for use by systems, human or otherwise. In this way, we see metadata systems supporting knowledge management and retention.
- Improving user experiences. A basic purpose of metadata systems is to help users find, understand, compare, and appropriately use data and other resources. Through the information contained in metadata, users are provided with a reference library that facilitates these activities. Metadata systems can also improve the public perception of an agency because they render data easier to use. User-provided metadata can also be added to systems, simplifying the experience of other users facing similar problems.
- Improving producer experiences. The production of statistics requires documentation for designs and processing steps. Increasingly, these are produced in a machine-readable form. In this form, metadata can be used as input parameters to processing systems, to trace or audit the development of output data, and to find ways to streamline and troubleshoot the production process.
- Ability to be reused. An advantage of machine-readable metadata is that they can be stored one time and reused. The Federal Data Strategy uses the phrase “Define once; use many times.” Metadata are reused when they help describe many resources. For instance, a variable used in every dataset produced by a monthly survey only needs to be described one time. Similar variables used in several surveys share common attributes, and those attributes need to and can be reused. There are many more of these kinds of examples.
- System development. By using established standards, automatically interoperable datasets may be produced. The metadata systems provide the necessary metadata and structure on how the data are to be organized for users on release. Another application is the automatic production of a survey instrument from a structured set of questions, response choices, question flow, and interviewer interface, all of which are metadata from the instrument point of view.
- Improvement to data governance. Having a recognizable and maintainable set of metadata concepts that can be administered by accountable entities can be used to align different statistical projects and to provide a commonly agreed-upon conceptual framework that can improve transparency.
These benefits accrue both to the agency that adopts metadata systems and to the users of the data they produce. Further, they enable transparency in the agency’s activities. Across agencies, metadata systems provide a common language for transparent communication.
Consider, now, the risks of metadata systems. Projects to create them involve staff from many areas—management, subject-matter experts, statisticians, information scientists, computer scientists, and IT specialists. Costs also involve staff capabilities and training. The novelty of such a system is one more thing that triggers resistance among staff to adopt it. Management and outside agency support could be important needed additions.
Next, planning for metadata management often necessitates a deep rethinking of how to organize information. Past inconsistencies, ambiguities, mistakes, and failures may be exposed, and these can be sensitive. Concerns also arise if too many people are found to be lacking in the skill or training needed for the tasks involved in creating a metadata system, which can seriously reduce management’s willingness to move forward. Often goals are reined in, and projects may not always recover their original intent.
Metadata are best recorded when descriptions of resources are first devised (at “think time”). Often, however, metadata management is an afterthought in the planning and design stages of the statistical or survey life cycle, and this leads to the perception that collecting metadata ex post facto is expensive and time consuming. This problem repeats often, and metadata systems are built rarely. Metadata management functions are not in the original plans for many systems and statistical programs, so retrofitting metadata into a system built later does not happen easily. The problem may be addressed by always planning for metadata management activities in any system design. This is a key habit to form.
In short, the costs of adopting metadata standards and management procedures are varied and can be significant. They are lower, however, if adoption occurs prospectively, or if the work of retrofitting established systems is done iteratively. Most important, the benefits discussed next outweigh these costs, whenever and however they are incurred.
There is the reverse question as to whether there is a cost to not building metadata systems. This is rarely considered. The following is a list of advantages metadata management provides,8 which easily translate into increased costs if these same advantages are not available:
- Better organization and search. Metadata make it possible to find data, know where they come from, who owns them, what they mean, and how to use them responsibly.
___________________
8 This list is taken from “The Value of Metadata,” by Kurt Cagle, published on February 26, 2019, at https://www.forbes.com/sites/cognitiveworld/2019/the-value-of-metadata/?sh=2ba581e56d30.
- Reduced software costs. Knowing what data mean and how they are structured makes it possible to write reusable, quality software more quickly and reliably.
- Richer data analytics. Datasets often have missing or erroneous values, and these can automatically be identified by checking values against metadata.
- Easier governance. Data governance focuses on the following correspondence to who, what, when, where, why, and how: authoritativeness (who is responsible for ensuring the integrity of that data), dominance (what constitutes a primary record), temporality (when were the data first known), provenance (where information comes from), purpose (why were the data captured in the first place), and definition (how exactly the information is defined, often including citational context).
- Understanding the external data environment. Metadata are needed to integrate internally obtained data with those from outside sources.
- Making your organization machine readable. When metadata are machine readable and actionable, this allows systems to speak a common language. In turn, this raises the value of the data the organization produces, because they can be integrated with other data more readily.
Each of these advantages becomes a cost when it is unattainable. Since each advantage depends on metadata being available, it is the existence of a metadata system that supports and affords the advantages. Not managing metadata is therefore a cost contributor.
For the National Center for Science and Engineering Statistics and U.S. statistical agencies to put into operation standards writ large, governance is required. The panel believes such a governance entity currently exists, namely the Interagency Council on Statistical Policy (ICSP).
Recommendation 5.1: The Interagency Council on Statistical Policy should develop and implement a multi-agency pilot project to explore and evaluate employing existing metadata standards and tools to accomplish data sharing, data access, and data reuse. The National Center for Science and Engineering Statistics should be an active agency participant in the project.
For this purpose, ICSP should form and monitor an interagency committee to design and implement a multi-agency project that benefits from the use of metadata standards and tools to increase transparency and to support interagency sharing of data and methods. The goal of the pilot project
would be to explore the issues associated with improving the transparency and efficiency of data transfers across federal statistical agencies through the more widespread use of metadata standards and tools. The pilot would document these issues for dissemination to the ICSP agencies and obtain a broader understanding and potential of the use of metadata standards. Such a pilot project should serve as a foundation for additional follow-up projects. These projects should lead to statistical agencies developing policies on the use of metadata standards and tools in documenting methods and retaining for their input data and official estimates for future use.
USING EXISTING SYSTEMS
Instead of designing new systems from scratch, the use of metadata standards greatly increases the likelihood that existing systems can be shared, recycled, and repurposed. Indeed, the advantage of adapting existing systems is a primary reason to adopt standards, as this reduces the costs of a new development, reduces the implementation time, increases quality (the system software is already tested), and improves collaboration across the statistics community.
Using metadata standards for systems integration would allow one to move to a new paradigm, in which the following actions would be effective:
- Analyze existing metadata systems for integration rather than building new systems by default;
- Extend existing systems if they do not cover all of the required statistical life-cycle activities or functionality;
- Design new systems only when required, and design for potential reuse so that they may be adopted by others in the future, thereby creating a value-added feedback loop.
The principles in the Common Statistical Production Architecture9 standard describe a framework for reusable systems architecture.
Here are some examples where metadata standards have enabled system sharing and reuse:
- The freely available SDMX tools,10 developed and maintained by Eurostat to disseminate SDMX data, are implemented by many agencies worldwide, thus lowering the barriers of SDMX implementation within and across countries.
___________________
9https://statswiki.unece.org/pages/viewpage.action?pageId=112132835.
10https://ec.europa.eu/eurostat/web/sdmx-infospace/sdmx-it-tools.
- The International Household Survey Network (IHSN),11 managed by the World Bank, is a program whereby guidance and tools are freely provided to developing countries using DDI-Codebook to help document their surveys and censuses.
- A statistical systems catalog12 lists open-source systems mapped to the Generic Statistical Business Process Model (GSBPM), enabling an architect to find a system to integrate or extend for the required statistical activity and purpose.
- The Web page data.gov,13 managed and hosted by the U.S. General Services Administration, provides tools and metadata schema for building and maintaining a dataset catalog, under the Resources tab on the project home page.
- The Web page schema.org14 is run by a collaborative program whose mission is to create, maintain, and promote schemas for structuring and describing data, especially on the Web, but which can be applied widely. Any dataset whose metadata are in schema. org is identified as a dataset in Google data search.
- The open-source .Stat platform15 is an SDMX-based and CSPA-inspired system for statistics data and metadata storage and dissemination, available from the Statistical Information System Collaboration Community (SIS-CC). It is used by several international agencies and organizations, enabling them to avoid having to develop such a platform themselves and instead benefitting from the collaborative developments from the SIS-CC community.
- Seasonal adjustment software JDemetra+16 from the European commission is implemented by many EU and non-EU agencies, helping standardize seasonal adjustment processes and lower costs.
The following are four examples of how metadata standards have been used to benefit transparency in the provision of official statistics: at the Bureau of Labor Statistics (BLS), the World Bank, the U.S. Census Bureau, and the survey contractor Westat.
At the Bureau of Labor Statistics
The Consumer Expenditure Survey (CE) program at BLS is used to measure spending by households in the United States. The data are also
___________________
12https://github.com/SNStatComp/awesome-official-statistics-software.
14https://schema.org/docs/documents.html.
15https://siscc.org/stat-suite/.
16https://ec.europa.eu/eurostat/cros/content/software-jdemetra_en.
used as input for calculating the Consumer Price Indexes. This short section is about the efforts at BLS to make CE more transparent.
CE is conducted through two ongoing surveys: the (weekly) Diary and (quarterly) Interview. Sampled households for the Diary survey are given a form to record small expenses for each of 2 consecutive weeks, and those in the Interview survey answer questions about large or recurring expenses for each of the previous 3 months for four consecutive quarters. The Interview survey is conducted every month on a rotating sample. The data are combined on a monthly basis to produce quarterly, semi-annual, and annual estimates and datasets. This includes the annual public-use microdata (PUMD) files. BLS posts these files on the CE Website along with a large (~120 pages) documentation file.
Achieving transparency for the PUMD requires more information than the annual documentation files can convey systematically. Over time, CE incorporates changes in the even years. The surveys collect some of the same data in different ways, so the provenance of the final data (the path from collection to dissemination) is complex. Nevertheless, all these considerations are necessary for understanding and using the PUMD, especially when using the data over time.
The CE office examined its transparency needs for the PUMD, for both the public and office analysts. A team was formed to recommend the development of systems built iteratively to demonstrate increased functionality toward the CE transparency goals. The team examined the DDI-Lifecycle standard (now version 3.3) from the DDI, and determined that it could satisfy their informational needs. Commercial software (Colectica) that would ensure conformance with the DDI-Lifecycle was purchased, and it was determined to be flexible enough to meet CE development needs. The current system is the fourth in the series.
Currently, this system is being moved to a production server to support internal CE analysts. The system contains mappings of all the variables to their respective questions and mappings of questions to the variables, satisfying the basic need to describe the data over time and across surveys. Another system is planned to make substantially the same information available to the public. Further development is planned as well, especially to describe all the processing steps (edits, coding, allocation, and imputation) used to transform the data after collection. Here is where the main differences between the internal and public systems lie: a public system must hide processing details, because some algorithms could be reversed to create disclosures.
Future planned work includes expanding the description of processing, especially for internal use, and improving the user interface to facilitate use among the public.
The idea for this project emerged as analysts’ needs were assessed and a middle manager saw an opportunity. Since each step of development has
been relatively small, risks have been minimized. Upper management has been willing to fund the iterative approach, one step at a time. While this slows progress, because there is then the need to create new statements of work, it provides time for upper management to demonstrate progress and new functionality. Such an iterative approach is often conducive to ensuring progress, because the goals are small each step of the way. An added advantage is the ability to change any long-range vision as lessons are learned along the way. Each phase of development was carefully constrained so development stayed within the stated goals. The current development is in the fourth phase, and the success at each phase has increased management support for the project.
At the World Bank
The World Bank maintains a Microdata Library, a catalog of more than 10,000 survey datasets originating from member countries and from regional and international organizations. To maximize the discoverability and usability of the data, the World Bank documents these datasets using the DDI Codebook and the Dublin Core metadata standards. A specialized software application for metadata editing facilitates this process, allowing fast documentation of the surveys, their data files, the variables they contain, and all related resources (questionnaires, manuals, reports, and others). An open-source cataloging application is used to catalog and disseminate the data and metadata. The DDI Codebook and Dublin Core metadata are stored as XML and JSON files. These formats ensure machine readability and offer all the flexibility needed to feed meta-databases and to generate human-readable output, including PDF documents, HTML Web pages, and others. The DDI Codebook and Dublin Core metadata provide rich, structured metadata that cover all dimensions of a data collection operation: objectives, concepts, methods, scope and coverage, universe, sampling methods, processing methods (editing and imputation methods), quality and relationships to other datasets, and a detailed data dictionary.
The result is transparency concerning what, how, why, when, and who. Metadata produced by data curators can be “augmented” using various machine learning techniques such as topic models, word embeddings, and image labeling. This information allows users to assess multiple dimensions of data quality for their specific purpose, including relevance, reliability, usability, and comparability. For example, the cataloging of variable-level information allows users of the World Bank Microdata Library to locate variables of interest in multiple datasets, then assess their consistency and comparability across sources and/or over time.
The World Bank is now expanding the scope of its cataloging system to other types of data, for which other metadata standards are used (such as
the ISO19139 standard for geospatial data, and a custom-designed schema to document reproducible analytical scripts). The combination of rich and structured metadata with advanced indexing and machine learning tools is expected to result soon in significant progress in data discoverability and transparency, including semantic searchability and recommender systems. And the metadata schemas are expected to evolve as new data collection modes and new data sources become more prevalent.
At the U.S. Census Bureau
A group of analysts at the Census Bureau are using metadata standards for data discovery. This is because their group makes use of administrative data that are often acquired and then rarely used because their existence is difficult to know about. Having a searchable metadata catalog was the solution, but their existing data management system did not have much in the way of file or variable metadata, so they needed to harvest such metadata directly from the data files that had been discovered (half a million data files from hundreds of data families). To collect these metadata, they created a data discovery interface to identify useful data files, whose metadata were then harvested. This enabled others to find and use these data files for their programs.
The Census Bureau believes it should make greater use of DDI Lifecycle and that the agencies within the U.S. federal statistical system should have greater participation in the development of DDI standards, other standards, and metadata tools than they currently do. This is because of the concepts DDI Lifecycle uses to represent variables, the file/table linkage concepts that support record linkage, and the above-noted use for multiyear studies. Also, use of DDI facilitates the transfer of metadata outside of an agency.
At Westat
Westat has had a contract for several data collection cycles with the Agency for Healthcare Research and Quality (AHRQ) to collect data for the Medical Expenditure Panel Survey (MEPS). Westat provides about 4,000 variables (many derived) to AHRQ, with about 200 deliverables annually stemming from the data collected. A major technical upgrade to the household component of MEPS (there are also provider and insurer components) was viewed as necessary due to the lack of flexibility of the data collection system, which had been in place for more than a decade. This lack of flexibility constrained access and the sharing of data and metadata. Part of the solution was a custom build-out of a new metadata system, using commercial off-the-shelf software. After reviewing several alternatives, Westat decided to use DDI for this purpose. Its advantages
were threefold: (1) it was already familiar to a large number of users from multiple disciplines; (2) multiple data products already used this metadata standard; and (3) it was based on a common programming language, XML.
Algenta Technologies, a research and development firm specializing in data management, assisted Westat in carrying out this implementation, using its Colectica software. Among the reasons for deciding to use Colectica were that it used an SQL17 database to store metadata in XML-based DDI 3.2, there was a high level of support from the company for this custom work, and it can be integrated with Blaise.18
At the same time, MEPS designed and implemented portions of a complex repository for the data and the metadata. The repository supports tracking questions and variables over time. Access is available either through a Web portal or through MEPS project-specific repository tools. As a result of these changes, MEPS has improved in the following ways: it is now DDI compliant, which makes it easier to access by users and makes its contents easier to understand; it supports a graphic user interface; it supports Blaise integration; it supports custom outputs; and it is designed to maintain data lineage.19
STANDARDS AND INTEROPERABILITY
This section discusses standards and whether they are based on reusable schemas. Standards are effective when they define schemas that are reusable across a range of applications. The range of applications, which is known as the scope of a standard, determines whether the underlying schema in a standard might apply.
Adopting standards is a means by which the separate U.S. federal statistical agencies can achieve some uniformity and interoperability among their data and metadata systems in terms of both data stores and services. When left to their own devices, the agencies build systems in their own ways. An example of the effect of this is the variation among the APIs that many of the agencies have built and promote. These APIs are designed for people wanting to access data programmatically from individual agencies, but their variation exacerbates differences—such as the differences in how the agencies format dates—and the APIs provide little metadata. This leads to incompatibilities that, given their multiplicity, are costly to overcome, since every pair of APIs has to be harmonized (13 principal statistical agencies
___________________
17 SQL is Structured Query Language, described at https://www.infoworld.com/article/3219795/what-is-sql-the-first-language-of-data-analysis.html.
18https://blaise.com/blaise/about-blaise.
19 For those interested in a non-U.S. example, please see the following on the Aristotle Metadata Registry: https://www.acspri.org.au/iassist2019/workshopAristotle.
leads to 78 pair-wise translations). This also leads to the inertia the U.S. federal statistical system finds itself fighting in the effort to overcome the differences the individual approach has fostered.
Participation in Standards Development
Standards are specifications designed to solve the problems described above and, in general, to satisfy the business requirements of stakeholders (those organizations with a material interest in the outcome of the standards development process) built through a consensus20 process where
- Each stakeholder is afforded the same rights as any of the others—the process is fair;
- Any interested party may examine the results of the development process at any time—the process is observable;
- All stakeholders are eligible to join in the development of the standard—the process is open; and
- The stakeholders represent the broader community of potential users of the standard—the process is balanced.
In this report, we will refer to a standards development process that satisfies the fair, observable, open, and balanced criteria and the standards that result from those as equitable. The openness criterion in an equitable standards development process means that any stakeholder can join the development effort at any time. Since standards are not static, they undergo periodic review to check for continued relevance. They can be updated to fix problems, expanded to address new requirements, held static, reduced because some features are no longer relevant, or dropped altogether. Therefore, stakeholders are encouraged to join groups developing and maintaining standards at any point in the development life cycle. Joining a development effort does not require participation from the beginning.
Usually, a standard is better when it meets more stakeholders’ needs, and this happens if more participate in its development. More participation means the chances all requirements are heard go up and are put on the table for consideration. This is what makes a standard useful for stakeholders. And the more useful a standard is, the better the chance it will be adopted.
On the other hand, each stakeholder has requirements that are unique, even though they might share most of their other requirements with the others. It is these unique requirements that sometimes lead to a decision not
___________________
20 Consensus, as used here, means general agreement with no sustained dissent. Consensus is possible even when some stakeholders just agree to go along, rather than raise dissent. This is the difference that distinguishes consensus from unanimity.
to adopt a standard if the standard does not meet the needs. Those unique requirements, moreover, can only be added if the stakeholder joins in the development process. If some important requirement is not included, the stakeholder will not adopt the standard, and this could lead to a business disadvantage when other similar organizations do adopt it.
The U.S. federal statistical agencies have many requirements in common, and these requirements are mostly shared with other statistical offices around the world as well. Therefore, the incentive for any agency to join a standards development effort might be lowered if that agency is aware that another agency is already involved. Failing to get involved because of this would not be the best practice, since the unique requirements are much less likely to be included, reducing the chances that the standard will evolve to meet their needs, as shown in the paragraph above, but in the current environment with tight budgets, it is still a strong possibility.
The U.S. federal statistical agencies are not business competitors, so for agencies with smaller staffs, it might be possible to let other, larger agencies develop the standards, which the smaller agencies could then adopt. In that case, it would be necessary to work with staff from a larger agency who are involved. In this way, any special requirements could still be heard about among the standards developers, though the arrangement is not optimal.
Employing Equitable Standards
For the U.S. federal statistical community, developing or using equitable standards should be the goal. Equitable standards are more likely to be adopted by agencies that were not directly involved in their development, because equitable standards stand a better chance of meeting the needs of those agencies. To identify sources of equitable standards, one must first know which standards development organization adhere to the principles for equitable standards given above.
Adopting standards across the agencies would make translating among the data and metadata from each agency simpler. It would mean the agency systems are already “speaking” the same language. For the user of U.S. federal statistical data, finding, understanding, and using (in particular, integrating) data from two or more agencies would be simplified. For example, if agencies report dates in the same format, those data would not have to be examined and translated. A computer could compare the dates with no extra work. If agencies all used the term frequency, for example, to name the idea of the interval between the times when an ongoing survey is conducted or an indicator is published, then a computer could be programmed to look for that attribute when it was set up to do comparisons.
Interoperability is the condition under which data and metadata are translatable across agencies. In general, interoperability means that a
receiver (user) of data (or metadata) can use those data without needing human intervention with the sender. There are several ways to subdivide the idea of interoperability, but for simplicity, we can describe the world as divided into syntactic and semantic interoperability. We illustrate this simply by using the examples above. If each agency uses the same format to transfer and publish dates, that is an example of syntactic interoperability. If each agency uses the same name for “frequency” (as described above), that is semantic interoperability. There are deeper considerations around this idea as well.
The adoption of standards is a means to achieve interoperability. However, what does it mean to adopt a standard? Often, in trying to be more precise, people refer to compliance as a way to express this. However, there is a precisely defined term of art, conformance, used by the ISO community. We will use this in what follows (and in Appendix B as well).
Standards are built using precise language called provisions. The term provision is defined in ISO/IEC Guide 2 and is illustrated in Appendix B, but we condense those discussions here for brevity. Provision and closely related terms can be described as follows:
- Provision: statement, instruction, recommendation, or requirement;
- Statement: expression that conveys information;
- Instruction: expression that conveys an action to be performed;
- Recommendation: expression that conveys advice or guidance;
- Requirement: expression that conveys criteria to be fulfilled.
Provisions are distinguished by the form of wording used to express them; instructions are expressed in the imperative mood, recommendations by the use of the auxiliary “should,” and requirements by the use of the auxiliary “shall.” Definitions, for instance, are statements, and they are often not written in sentences, so the form of statements varies. Conformance can thus be defined as satisfaction of all requirements. Satisfying a requirement might include needing to address some recommendations, statements, and instructions, too. In any case, this means that if a system satisfies all the requirements in a standard, it conforms to that standard. Again, the interested reader can consult Appendix B for more details and a worked example.
Our interest is interoperability, most of all, and this is why conformance to standards is useful. Standards can be developed for all kinds of purposes. Consider the colors used in traffic lights: red means stop, green means go, and amber means the light is about to turn red. These standard colors are used throughout the world in the same way. This is semantic interoperability. Revisiting the examples used earlier concerning date formats and the names used for frequency attributes, conformance to a standard
helps establish interoperability. So, one could establish a standard for how dates are formatted.
In fact, date format standards already exist: ISO 8601 (Data elements and interchange formats: Information interchange) and ANSI/INCITS.30 (Representation of Calendar Date and Ordinal Date for Information Interchange). The ISO standard is less useful since it specifies a number of formats. The ANSI standard provides for a single format, one of the many in ISO 8601. Concerning frequency attributes, statistical metadata standards, such as the United Nations Economic Commission for Europe (UNECE) Generic Statistical Information Model and the DDI-Lifecycle standard, do specify the attributes necessary to record metadata about frequency.
When a system has statements claiming conformance to some standards around its use, the receiver of data from that system already knows what to expect. The receiving agency can build its own system and know in advance it will be able to automatically read and understand the sender’s data. That is interoperability based on conformance.
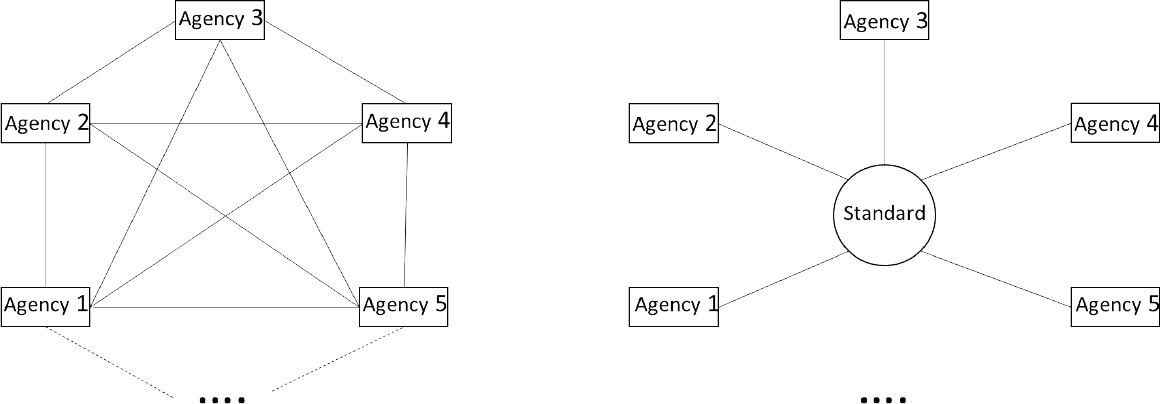
Conformance to standards simplifies the translation problem for exchanging and understanding data and metadata between agencies. As discussed briefly above, there are 13 principal U.S. federal statistical agencies. If each agency does its own development, ignoring any agreements or standards the agencies could share, a translation between every pair of agencies must be built to make data and metadata interchangeable. There are “13 choose 2” or 78 such pairings (or combinations), so producing standards this way would be prohibitively costly and time consuming. Worse, if one agency upgrades its systems, under that approach the translations would all have to be redone. In fact, agencies do upgrade systems fairly often.
See Figure 5-3 for an illustration of the differences in the number of translations needed for the status quo with pair-wise agency agreements in place versus the standards-based approach.
In our setting, building metadata systems through the adoption of consensus metadata standards has several advantages:
- Developers do not have to spend time modeling the necessary metadata, as this thought process will have already been undertaken.
- Conformance allows for interoperability, as the above makes clear, and this eliminates the need to translate between pairs of systems.
- Conformance occurs at the systems interface (either an API or a human user interface), so each organization can optimize its systems for local needs.
- Transparency of data and systems and reproducibility of results depend on metadata being available. The metadata needed are based on some schema defining the necessary attributes, and this
- can be achieved by adopting standards that specify those schemas and attributes.
EXAMPLES OF STATISTICAL METADATA STANDARDS
In this section, a brief description is given of six well-known metadata standards for statistics, including the main benefits each one has to offer. These six are the Generic Statistical Business Process Model. Generic Statistical Information Model. Common Statistical Production Architecture. Common Statistical Data Architecture. Data Documentation Initiative. and Statistical Data and Metadata eXchange.
Generic Statistical Business Process Model
The GSBPM is a matrix containing names and definitions for the business activities a statistical agency might employ to produce its data. It was produced under the auspices of the statistical program of UNECE. Even though the title of this standard includes the words “process model,” the standard does not describe processes. Instead, it names the activities that processes are built to realize.
This standard is intended to be interpreted and used flexibly. It specifies the possible steps in a statistical business life cycle. The framework is presented in a particular order, but this is not rigid, and the items may be followed in any order. In fact, some steps may even be repeated in iterative applications, such as with some machine learning applications or imputation methods. Viewed as a checklist, GSBPM may be used to ensure that all necessary steps have been considered for conducting some statistical activity.
GSBPM is very flexible and can be used in a myriad of ways. The most direct kind of usage is to take the set of phases and activities literally, and use the standard as a guide on how to conduct surveys and other statistical studies. This might not be useful, as the language used in GSBPM may not correspond to the terms used in each agency. While the Census Bureau and the BLS have both adopted GSBPM, neither is using the standard as is. Instead, each agency has adapted it to the particulars of the work of the agencies and the terms in use there.
GSBPM can also be used for classifying systems, software purchases, and development projects, which all represent important use cases. Every statistical agency develops software and builds systems for processing the data produced through surveys and other statistical programs. The systems and the projects to build them can be classified according to the phases and sub-activities in GSBPM. In fact, this is the main application of GSBPM for the BLS and Census profiles (adaptations).
Generic Statistical Information Model
The GSIM is an internationally endorsed reference framework for information describing statistical programs, processing, and data. It was developed under the auspices of the UNECE as a companion standard to GSBPM. This generic conceptual framework is designed to support modernizing, streamlining, and aligning the work of statistical offices, such as the principal U.S. federal statistical agencies, and is one of the building blocks for modernizing official statistics.
GSIM is a conceptual model of the kinds of objects—surveys, questionnaires, variables, datasets—needed to describe statistical programs, processing, and data. The model contains classes (kinds of objects) and relationships that identify, describe, and relate these objects. Each object corresponding to a class in GSIM is informational, that is, each one describes things statistical agencies need to manage. The data associated with these objects are metadata, and therefore GSIM is a statistical metadata standard.
There is a deep relationship between GSIM and GSBPM. The inputs and outputs of the processes implementing the activities of GSBPM are the classes in GSIM. This duality between GSIM and GSBPM is characteristic of the relationship between process and information models. In practical terms, it means that GSIM and GSBPM are designed to work together, and agencies that adopt both gain more than through the adoption of GSBPM or GSIM on its own.
Another effect of implementing GSIM in a statistical office is the possibility of discarding subject-matter silos, due to the organizationwide view that GSIM promotes. Similarities among objects from several statistical programs, rather than differences, may be highlighted through the use of GSIM. This is an advantage of corporate (agencywide) metadata management, which differs from metadata management implemented for each statistical program independently.
Common Statistical Production Architecture
The Common Statistical Production Architecture (CSPA) developed under UNECE is a reference architecture for the processing required to produce statistical data. Whereas GSBPM lays out the activities a statistical office might implement, CSPA calls for the processes implementing those activities to be built as services that any agency can use. This goal is very ambitious, but CSPA can be implemented within a statistical agency by building common services across business silos, such as statistical programs and agency divisions.
The main vision of CSPA is to enable the development of “plug and play” statistical services, which will increase the reuse of systems, thereby
reducing costs and increasing the speed of implementation. This is in contrast to the traditional development of stovepipe systems, each designed for a particular statistical program or within an agency silo, with the same kinds of services developed many times throughout a statistical agency (and the community at large) to solve the same or very similar problems. A simple example might be the need to build separate top-coding edit services for each statistical program that needs one. From a conceptual point of view, top-coding is a similar operation wherever it is used. Therefore, an important goal of CSPA is that the resulting services are interoperable with other CSPA services, and this means generically built services can work with others. The inputs and outputs of these services will be describable in GSIM, and it is possible for some of the outputs of one service to become the inputs of another.
CSPA consists of application and technology architectures and principles for the delivery of statistical services. One way to think of CSPA is as a service-oriented architecture that has been specially adapted for statistical activities and processes. It is not prescriptive of specific technologies or platforms.
CSPA can be combined with the GSBPM and GSIM frameworks. For example, if an agency has adopted GSBPM, and then has determined that a service is required for a GSBPM activity, then either
- the agency may develop a CSPA service, described in terms of the GSBPM activities it is used for, and other agencies may reuse it for those same activities; or
- the agency may identify and reuse a CSPA service already developed by another agency that matches the same GSBPM activity (a CSPA Global Artefact Catalogue exists for such services).
However, an agency may still benefit from the CSPA principles without fully implementing GSBPM or GSIM, especially to move toward a service-oriented architecture for statistical systems.
Common Statistical Data Architecture
The Common Statistical Data Architecture (CSDA), developed under the UNECE, is a reference architecture and set of guidelines for managing statistics data and metadata throughout the statistical life cycle. The latest version was published in 2018. As part of the family of UNECE standards, it has the same maintenance and governance administration as GSBPM and GSIM.
The purpose and use of CSDA is to act as a template for statistical agencies in the development of their own enterprise data architectures. In
turn, this will guide solution architects and builders in the development of systems that support the production of statistical products. Because data need metadata to be useful, CSDA covers both data and metadata, and it refers to them, taken together, as “information.” CSDA considers that the physical location of data does not matter (e.g., consider cloud storage), and in any case, the same principles apply. CSDA stresses that statistical information should be treated as an asset.
The benefits of using CSDA are a greater independence from technology, by being less dependent on proprietary software; greater sustainability, through use of a shared vocabulary; greater maintainability, through the shared architecture; and a cost-saving for global optimization strategies/solutions, thanks to sharing resources and technologies.
The CSDA standard consists of a set of key principles. These principles, their rationale, and their implications are described in Appendix A.
Data Documentation Initiative
The DDI, is a family of statistical metadata standards and other work products developed, maintained, and supported under a consortium called the DDI Alliance. This is managed through a secretariat at the Inter-university Consortium for Political and Social Research (ICPSR) at the University of Michigan. Below is a short description of the major standards, either published or in substantial draft form.
DDI2: Codebook
DDI2: Codebook, currently version 2.5, is used to describe a social, behavioral, or economic (SBE) research study, a one-time survey or experiment, or the data each might produce. There are many applications of Codebook in use. The data archive managed by ICPSR and the International Household Survey Network managed by the World Bank both use Codebook as their underlying metadata model. However, Codebook does not support reuse of metadata, so any interconnections have to be maintained outside Codebook itself. This feature makes it easy to implement but hard to discover inter-relationships. Codebook is sometimes used as the initial step in developing metadata management capabilities in the statistical domain. Codebook is managed in a directly implementable form in XML.21
___________________
21 XML is eXtensible Markup Language, described at https://www.w3.org/XML/. See https://ddialliance.org/Specification/DDI-Codebook/2.5/ for more details.
DDI3: Lifecycle
DDI3: Lifecycle, currently version 3.3, is used to describe the activities in the statistical life cycle for statistical programs, such as censuses and surveys. The statistical life cycle used in DDI3 is consistent with the phases of the GSBPM, and this is consistent with the work in U.S. federal statistical agencies. Reuse is a necessary part of the design of Lifecycle, because most high-profile surveys conducted by U.S. federal statistical agencies are ongoing. More statistical offices in the United States and around the world are adopting DDI3 for their metadata needs, including the Bureau of Labor Statistics, Statistics Canada, and the Australian Bureau of Statistics. Lifecycle is also managed in XML and is directly implementable.22 Because DDI3 supports GSBPM and is represented in XML, it is both consistent with GSIM and may be used as a physical (or implementable) manifestation of it. There is no need to build a bespoke implementation model for GSIM.
DDI4: Cross-Domain Integration
DDI4: Cross-Domain Integration (DDI-CDI), is the newest entry in the collection of DDI standards. A draft was released for public review and comments in April 2020. The final release of DDI-CDI is planned for the latter half of 2021. A new feature in DDI-CDI is the ability to describe data in four logical data formats. In addition to traditional survey data (microdata and multidimensional data), sources include administrative, remote sensor, Web scraping, and Internet streaming. Another feature is a generalized process model, which is used to describe how data are processed or produced, which includes the provenance of data. An innovation is the datum-centered approach. This allows any datum to be tracked through changes in representation, transformations during processing, and movement from one data structure to another. Metadata reuse is supported, and an infrastructure for integrating data from multiple sources is provided. The specification is built as a UML (Unified Modeling Language) model, and this facilitates easy maintenance. Multiple language representations can be generated, such as XML (which already exists), RDF (in production), and SQL (planned23). DDI-CDI has functionality that DDI3 lacks, and the two may be used together, but DDI-CDI was developed for independent purposes.
___________________
22 See http://www.ddialliance.org/Specification/DDI-Lifecycle/3.3/.
23https://ddi-alliance.atlassian.net/wiki/spaces/DDI4/pages/491703/Moving+Forward+Project+DDI4.
Statistical Data and Metadata eXchange
The Statistical Data and Metadata eXchange (SDMX) was developed by a group of international statistical offices and banks. Their need was to produce a standard exchange system for reporting data and metadata to them from data-producing organizations. This group comprises the Bank of International Settlements, the European Central Bank, Eurostat (the statistical office of the European Union), the International Monetary Fund (IMF), the Organisation for Economic Co-operation and Development, the United Nations Statistics Division, and the World Bank. Since the publication of the initial version in 2004, the number of implementations continues to grow, covering many domains in statistics. These include education, labor, national accounts, and sustainable development goals. The current revision work being done on the standard will improve its capability for the exchange of statistical information.
SDMX consists of three main elements:
- Technical standards (including the Information Model),
- Statistical guidelines (sometimes called Content Oriented Guidelines), and
- IT architecture and tools.
These three elements can be implemented in a stepwise approach.
SDMX can support various use cases and implementation scenarios. Whatever the scenario envisaged, the essence of SDMX is to provide a set of common tools, processes, terminologies, and methodologies facilitating the exchange of multidimensional statistical data and metadata between producers and consumers.
The typical use case for SDMX is reporting data and metadata from a data producer to an international organization under some mandate or agreement. For example, all countries report national indicators to the IMF via SDMX to the Dissemination Standards Bulletin Board at https://dsbb.imf.org/. The infrastructure defined and used by SDMX to achieve this reporting objective contains a network of registries that make specialized SDMX structures, called Data Structure Definitions (DSDs), publicly and centrally available. A DSD contains a description of the dimensions and measures used in multidimensional data. Additionally, there is a set of reporting formats as well as various IT tools to assist implementers. Full implementation of such infrastructure will support direct machine-to-machine interchange.
Another area SDMX supports is data discovery and visualization. In this case the objective pursued by a statistical organization is to make statistical data and metadata findable, understandable, and accessible by
external users. Data and metadata managed under SDMX are machine actionable, which means that data can be formally queried, not just indexed by keywords. The result is the ability to use many visualization tools with SDMX data. Another advantage to machine readability of SDMX data is for ETL (extract, transfer, and load) operations. These operations can be automated, providing many advantages.
Metadata and the U.S. Federal Statistical System
The decentralization of the U.S. federal statistical system increases the need for metadata, generally, and standards in particular. Metadata constitute the information needed to understand statistical data, designs, and processing. Since the U.S. federal statistical system comprises many agencies, the interoperability of those metadata is a necessary precursor to the goal of systemwide transparency and reproducibility. Data users should not have to translate metadata from one agency to the next, as this is an impediment to transparency. Finally, substantial changes in the kinds of work that statistical agencies perform may flow from the adoption of metadata standards and management, as staffing based on current work processes may be adjusted and streamlined.
There is now the opportunity to avoid this problem. The possibility of a common set of metadata standards that all or most statistical agencies share is discussed in Metadata Systems for the U.S. Statistical Agencies, in Plain Language.24
Threats impelling the adoption of our metadata standards and management recommendations are the flip side of that opportunity. Government-wide initiatives on transparency and reproducibility, including the Evidence-Based Policy Act, may be at risk if agencies do not coalesce on common frameworks for documenting and sharing data. The constraints of current data production and documentation and sharing procedures threaten to make it impossible for agencies to take on important, forward-looking work that is currently out of its reach.
CONCLUSION
Use of a standard framework or process model such as GSBPM allows users of official statistics to match data products with processes in a way that would allow them to better understand exactly how those products came to be. Use of information and data models such as GSIM and CSDA further enhance this link between data and business processes by
___________________
24 See https://nces.edu.gov/fcsm/pdf/Metadata.projects.plain.US.federal.statistics.pdf.
establishing standardized concepts and information objects that map between conceptual framework and implementation.
Adoption of standards such as DDI or SDMX is worthwhile, not only because transparency and reproducibility are inherently desirable as qualities that enhance the trustworthiness and reliability of statistical products and processes, but also because these standards were developed with the intention of helping national statistical agencies do more with less in a way that is interoperable and mutually intelligible. While it is difficult to accurately forecast issues that will arise in the long term, it is safe to say that the budgets and resources available to statistical organizations are not going to scale as quickly as the amount of data being produced will. Nor will they scale as quickly as the demand for quantitative evidence to inform policy addressing the myriad issues arising in our increasingly complex world. The case for implementing shared systems, models, and standards is further strengthened when considering that novel problems requiring statistical production may well be transnational or global in scope, and time spent attempting to translate between idiosyncratic terminology, processes, and practices of different nations’ statistical institutions will amount to wasted time, effort, and resources.
Recommendation 5.2: The Interagency Council on Statistical Policy should (1) prioritize and emphasize the importance and benefits of federal statistical agency staff engaging in international metadata standards and tool development, and (2) organize a discussion among statistical agencies that leads to an effective, coordinated, and accountable approach for staff in agencies that produce federal statistics to contribute to international metadata standards and tool development.
A number of federal government mandates have been issued during the past few years, including the Federal Data Strategy, U.S. Office of Management and Budget circulars, the Evidence Act, and others. One theme common to all of them is the need for transparency in statistical operation, methods, and analysis. It is not obvious that agency staff are aware of the content and requirements found in these directives.
Recommendation 5.3: The Interagency Council on Statistical Policy and the Chief Statistician of the United States should develop a continuing education program for agency staff on the nature and purpose of federal government requirements for statistical activities (such as the Foundations for Evidence-Based Policymaking Act and the Federal Data Strategy) that have been issued, the expected positive return to the agency for their implementation, and the need for transparency in agencies that produce federal statistics.
Individual agency staff should attend and participate in such continuing education programs with the goals of gaining professional familiarity with metadata standards and tools and improving the transparency of statistical methods, operations, and analysis in their data programs.




































