
8
Computer Hardware and Software for the Generation of Virtual Environments
The computer technology that allows us to develop three-dimensional virtual environments (VEs) consists of both hardware and software. The current popular, technical, and scientific interest in VEs is inspired, in large part, by the advent and availability of increasingly powerful and affordable visually oriented, interactive, graphical display systems and techniques. Graphical image generation and display capabilities that were not previously widely available are now found on the desktops of many professionals and are finding their way into the home. The greater affordability and availability of these systems, coupled with more capable, single-person-oriented viewing and control devices (e.g., head-mounted displays and hand-controllers) and an increased orientation toward real-time interaction, have made these systems both more capable of being individualized and more appealing to individuals.
Limiting VE technology to primarily visual interactions, however, simply defines the technology as a more personal and affordable variant of classical military and commercial graphical simulation technology. A much more interesting, and potentially useful, way to view VEs is as a significant subset of multimodal user interfaces. Multimodal user interfaces are simply human-machine interfaces that actively or purposefully use interaction and display techniques in multiple sensory modalities (e.g., visual, haptic, and auditory). In this sense, VEs can be viewed as multimodal user interfaces that are interactive and spatially oriented. The human-machine interface hardware that includes visual and auditory displays as well as tracking and haptic interface devices is covered in Chapters
3, 4, and 5. In this chapter, we focus on the computer technology for the generation of VEs.
One possible organization of the computer technology for VEs is to decompose it into functional blocks. In Figure 8-1, three distinct classes of blocks are shown: (1) rendering hardware and software for driving modality-specific display devices; (2) hardware and software for modality-specific aspects of models and the generation of corresponding display representations; (3) the core hardware and software in which modality-independent aspects of models as well as consistency and registration among multimodal models are taken into consideration. Beginning from left to right, human sensorimotor systems, such as eyes, ears, touch, and speech, are connected to the computer through human-machine interface devices. These devices generate output to, or receive input from, the human as a function of sensory modal drivers or renderers. The auditory display driver, for example, generates an appropriate waveform based on an acoustic simulation of the VE. To generate the sensory output, a computer must simulate the VE for that particular sensory mode. For example, a haptic display may require a physical simulation that includes
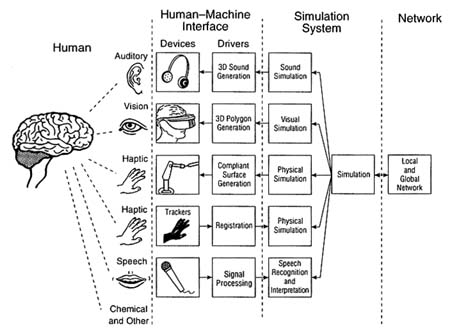
FIGURE 8-1 Organization of the computer technology for virtual reality.
compliance and texture. An acoustic display may require sound models based on impact, vibration, friction, fluid flow, etc. Each sensory modality requires a simulation tailored to its particular output. Next, a unified representation is necessary to coordinate individual sensory models and to synchronize output for each sensory driver. This representation must account for all human participants in the VE, as well as all autonomous internal entities. Finally, gathered and computed information must be summarized and broadcast over the network in order to maintain a consistent distributed simulated environment.
To date much of the design emphasis in VE systems has been dictated by the constraints imposed by generating the visual scene. The nonvisual modalities have been relegated to special-purpose peripheral devices. Similarly, this chapter is primarily concerned with the visual domain, and material on other modalities can be found in Chapters 3-7. However, many of the issues involved in the modeling and generation of acoustic and haptic images are similar to the visual domain; the implementation requirements for interacting, navigating, and communicating in a virtual world are common to all modalities. Such multimodal issues will no doubt tend to be merged into a more unitary computational system as the technology advances over time.
In this section, we focus on the computer technology for the generation of VEs. The computer hardware used to develop three-dimensional VEs includes high-performance workstations with special components for multisensory displays, parallel processors for the rapid computation of world models, and high-speed computer networks for transferring information among participants in the VE. The implementation of the virtual world is accomplished with software for interaction, navigation, modeling (geometric, physical, and behavioral), communication, and hypermedia integration. Control devices and head-mounted displays are covered elsewhere in this report.
VE requires high frame rates and fast response because of its inherently interactive nature. The concept of frame rate comes from motion picture technology. In a motion picture presentation, each frame is really a still photograph. If a new photograph replaces the older images in quick succession, the illusion of motion in engendered. The update rate is defined to be the rate at which display changes are made and shown on the screen. In keeping with the original motion picture technology, the ideal update rate is 20 frames (new pictures) per second or higher. The minimum acceptable rate for VE is lower, reflecting the trade-offs between cost and such tolerances.
With regard to computer hardware, there are several senses of frame rate: they are roughly classified as graphical, computational, and data access. Graphical frame rates are critical in order to sustain the illusion of presence
or immersion in a VE. Note that these frame rates may be independent: the graphical scene may change without a new computation and data access due to the motion of the user's point of view. Experience has shown that, whereas the graphical frame rate should be as high as possible, frame rates of lower than 10 frames per second severely degrade the illusion of presence. If the graphics being displayed relies on computation or data access, then computation and data access frame rates of 8 to 10 frames per second are necessary to sustain the visual illusion that the user is watching the time evolution of the VE.
Fast response times are required if the application allows interactive control. It is well known (Sheridan and Ferrell, 1974) that long response times (also called lag or pure delay) severely degrade user performance. These delays arise in the computer system from such factors as data access time, computation time, and rendering time, as well as from delays in processing data from the input devices. As in the case of frame rates, the sources of delay are classified into data access, computation, and graphical categories. Although delays are clearly related to frame rates, they are not the same: a system may have a high frame rate, but the image being displayed or the computational result being presented may be several frames old. Research has shown that delays of longer than a few milliseconds can measurably impact user performance, whereas delays of longer than a tenth of a second can have a severe impact. The frame rate and delay required to create a measurable impact will in general depend on the nature of the environment. Relatively static environments with slowly moving objects are usable with frame rates as low as 8 to 10 per s and delays of up to 0.1 s. Environments with objects exhibiting high frequencies of motion (such as a virtual handball game) will require very high frame rates (> 60 Hz) and very short delays. In all cases, however, if the frame rate falls below 8 frames per s, the sense of an animated three-dimensional environment begins to fail, and if delays become greater than 0.1 s, manipulation of the environment becomes very difficult. We summarize these results to the following constraints on the performance of a VE system:
Frame rates must be greater than 8 to 10 frames/s.
Total delay must be less than 0.1 s.
Both the graphics animation and the reaction of the environment to user actions require extensive data management, computation, graphics, and network resources. All operations that take place to support the environment must operate within the above time constraints. Although one can imagine a system that would have the graphics, computation, and communications capability to handle all environments, such a system is beyond current technology. For a long time to come, the technology necessary
will generally be dependent on the application domain for which the VE is being built. Real-world simulation applications will be highly bound by the graphics and network protocols and by consistency issues; information visualization and scientific visualization applications will be bound by the computational performance and will involve issues of massive data management (Bryson and Levit, 1992; Ellis et al., 1991). Some applications, such as architectural visualization, will require photorealistic rendering; others, such as information display, will not. Thus the particular hardware and software required for VE implementation will depend on the application domain targeted. There are some commonalities of hardware and software requirements, and it is those commonalities on which we focus in our examination of the state of the art of computer hardware and software for the construction of real-time, three-dimensional virtual environments.
HARDWARE FOR COMPUTER GRAPHICS
The ubiquity of computer graphics workstations capable of real-time, three-dimensional display at high frame rates is probably the key development behind the current push for VEs today. We have had flight simulators with significant graphics capability for years, but they have been expensive and not widely available. Even worse, they have not been readily programmable. Flight simulators are generally constructed with a specific purpose in mind, such as providing training for a particular military plane. Such simulators are microcoded and programmed in assembly language to reduce the total number of graphics and central processing unit cycles required. Systems programmed in this manner are difficult to change and maintain. Hardware upgrades for such systems are usually major undertakings with a small customer base. An even larger problem is that the software and hardware developed for such systems are generally proprietary, thus limiting the availability of the technology. The graphics workstation in the last 5 years has begun to supplant the special-purpose hardware of the flight simulator, and it has provided an entry pathway to the large numbers of people interested in developing three-dimensional VEs. The following section is a survey of computer graphics workstations and graphics hardware that are part of the VE development effort.
Notable Graphics Workstations and Graphics Hardware
Graphics performance is difficult to measure because of the widely varying complexity of visual scenes and the different hardware and software approaches to computing and displaying visual imagery. The most
straightforward measure is given in terms of polygons/second, but this only gives a crude indication of the scene complexity that can be displayed at useful interactive update rates. Polygons are the most common building blocks for creating a graphic image. It has been said that visual reality is 80 million polygons per picture (Catmull et al., 1984). If we wish photorealistic VEs at 10 frames/s, this translates into 800 million polygons/s. There is no current graphics hardware that provides this, so we must make approximations at the moment. This means living with less detailed virtual worlds, perhaps via judicious use of hierarchical data structures (see the software section below) or off-loading some of the graphics requirements by utilizing available CPU resources instead.
For the foreseeable future, multiple processor workstations will be playing a role in off-loading graphics processing. Moreover, the world modeling components, the communications components, and the other software components for creating virtual worlds also require significant CPU capacity. While we focus on graphics initially, it is important to note that it is the way world modeling effects picture change that is of ultimate importance.
Graphics Architectures for VE Rendering
This section describes the high-level computer architecture issues that determine the applicability of a graphics system to VE rendering. Two assumptions are made about the systems included in our discussion. First, they use a z-buffer (or depth buffer), for hidden surface elimination. A z-buffer stores the depth—or distance from the eye point—of the closest surface ''seen" at that pixel. When a new surface is scan converted, the depth at each pixel is computed. If the new depth at a given pixel is closer to the eye point than the depth currently stored in the z-buffer at that pixel, then the new depth and intensity information are written into both the z-buffer and the frame buffer. Otherwise, the new information is discarded and the next pixel is examined. In this way, nearer objects always overwrite more distant objects, and when every object has been scan converted, all surfaces have been correctly ordered in depth. The second assumption for these graphic systems is that they use an application-programmable, general-purpose processor to cull the database. The result is to provide the rendering hardware with only the graphics primitives that are within the viewing volume (a perspective pyramid or parallel piped for perspective and parallel projections respectively). Both of these assumptions are valid for commercial graphics workstations and for the systems that have been designed by researchers at the University of North Carolina at Chapel Hill.
The rendering operation is composed of three stages: per-primitive,
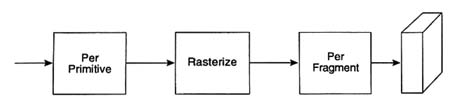
FIGURE 8-2 The graphics pipeline.
rasterization, and per-fragment (as shown in Figure 8-2). Per-primitive operations are those that are performed on the points, lines, and triangles that are presented to the rendering system. These include transformation of vertices from object coordinates to world, eye, view volume, and eventually to window coordinates, lighting calculations at each vertex, and clipping to the visible viewing volume. Rasterization is the process of converting the window-coordinate primitives to fragments corresponding to the pixels held in the frame buffer. The frame buffer is a dedicated block of memory that holds intensity and other information for every pixel on the display surface. The frame buffer is scanned repeatedly by the display hardware to generate visual imagery. Each of the fragments includes x and y window coordinates, a color, and a depth for use with the z-buffer for hidden surface elimination. Finally, per-fragment operations include comparing the fragment's depth value to the value stored in the z-buffer and, if the comparison is successful, replacing the color and depth values in the frame buffer with the fragment's values.
The performance demanded of such a system can be substantial: 1 million triangles per second or hundreds of millions of fragments per second. The calculations involved in performing this work easily require billions of operations per second. Since none of today's fastest general purpose processors can satisfy these demands, all modern high-performance graphics systems are run on parallel architectures. Figure 8-3 is a general representation of a parallel architecture, in which the rendering operation of Figure 8-2 is simply replicated. Whereas such an architecture is attractively simple to implement, it fails to solve the rendering problem, because primitives in object coordinates cannot be easily separated into groups corresponding to different subregions of the frame buffer. There is in general a many-to-many mapping between the primitives in object coordinates and the partitions of the frame buffer.
To allow for this many-to-many mapping, disjoint parallel rendering pipes must be combined at a minimum of one point along their paths, and this point must come after the per-primitive operations are completed. The point or crossbar can be located prior to the rasterization (the primitive crossbar), between rasterization and per-fragment (the fragment
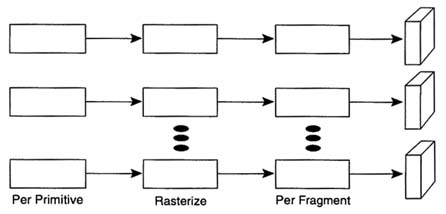
FIGURE 8-3 Parallel graphics pipelines.
crossbar), and following pixel merge (the pixel merge crossbar). A detailed discussion of these architectures is provided in the technical appendix to this chapter. There are four major graphics systems that represent different architectures based on crossbar location. Silicon Graphics RealityEngine is a flow-through architecture with a primitive crossbar; the Freedom series from Evans & Sutherland is a flow-through architecture with a fragment crossbar; Pixel Planes 5 uses a tiled primitive crossbar; and PixelFlow is a tiled, pixel merge machine.
Ordered rendering has been presented to help clarify a significant distinction in graphics architectures; however, it is not the only significant factor for VE rendering. Other primary issues for VE rendering are image quality, performance, and latency. Measured by these metrics, RealityEngine and PixelFlow are very effective VE machines architecturally. Freedom and Pixel Planes 5 are less suitable, though still useful.
Computation and Data Management Issues in Visual Scene Generation
Many important applications of VE require extensive computational and data management capabilities. The computations and data in the application primarily support the tasks taking place in the application. For example, in simulation, the computations may support the physical behavior of objects in the VE, while in a visualization application the computations may support the extraction of interesting features from a complex precomputed dataset. Such computations may require on the order of millions of floating point operations. Simulations currently demand
only modest data management capabilities but, as the complexity of simulations increases, the data supporting them may increase. Visualization applications, in contrast, often demand a priori unpredictable access to gigabytes of data (Bryson and Gerald-Yamasaki, 1992). Other types of applications can have similar demands. As computer power increases, more ambitious computational demands will be made. For example, an application may someday compute a fluid flow solution in real time to high accuracy. Such computations can require trillions of floating point operations.
An Example: The Virtual Wind Tunnel
In this section, we consider the implications of the VE performance constraints on the computation and data management requirements of a VE system. An example of an application that is both computationally intensive and works with large numbers of data is the virtual wind tunnel (Bryson and Gerald-Yamasaki, 1992). A modest modern problem in the virtual wind tunnel is the visualization of a precomputed dataset that gives five values (one for energy, one for density, and three for the velocity vector) at 3 million points at a time, for 106 times. This dataset is a total of 5.3 Gbytes in size, with each time step being about 50 Mbytes. If the virtual wind tunnel is to allow the user to interactively control the time-varying visualization of this dataset, each time step must be loaded, and the visualizations must be computed. Assuming that 10 time steps must be loaded per second, a data bandwidth of 500 Mbytes per second is required. The computations involved depend on the visualization technique. For example, the velocity vector field can be visualized by releasing simulated particles into the flow, which implies a computation requiring about 200 floating point operations per particle per time step. A typical visualization requires thousands of such particles and hundreds of thousands of floating point operations. The computation problem expands further as such visualizations are combined with other computationally intensive visualization techniques, such as the display of isosurfaces. It is important to stress that this example is only of modest size, with the size and complexity of datasets doubling every year or so.
It is quite difficult to simultaneously meet the VE performance constraints and the data management requirements in the above example. There are two aspects to the data management problem: (1) the time required to find the data in a mass storage device (seek time), which results in delays, and (2) the time required to read the data (bandwidth). The seek time can range from minutes in the case of data stored on tape through a few hundred thousandths of a second in the case of data stored on disk, to essentially nothing for data stored in primary memory. Bandwidths
range from a few megabytes per second in the case of tapes and disk to on the order of a hundred megabytes per second for RAID disks and physical memory. Disk bandwidth is not expected to improve significantly over the next few years.
Support is needed to meet the requirements of VE applications for real-time random access to as much as several gigabytes (Bryson and Gerald-Yamasaki, 1992). Whereas for some visualization techniques, only a small number of data will be addressed at a time, a very large number of such accesses may be required for data that are scattered over the file on disk. Thus the seek time of the disk head becomes an important issue. For other visualization techniques (such as isosurfaces or volume rendering), many tens of megabytes of data may be needed for a single computation. This implies disk bandwidths of 300 to 500 Mbytes/s in order to maintain a 10 Hz update rate, an order of magnitude beyond current commercial systems. For these types of applications, physical memory is the only viable storage medium for data used in the environment. Workstations are currently being released with as much as 16 Gbytes of memory, but the costs of such large amounts of memory are currently prohibitive. Furthermore, as computational science grows through the increase in supercomputer power, datasets will dramatically increase in size. Another source of large datasets will be the Earth Observing Satellite, which will produce datasets in the terabyte range. This large number of data mandates very fast massive storage devices as a necessary technology for the application of VEs to these problems.
Strategies for Meeting Requirements
One strategy of meeting the data management requirements is to observe that, typically, only a small fraction of the data is actually used in an application. In the above particle injection example, only 16 accesses are required (with each access loading a few tens of bytes) per particle per time step. These accesses are scattered across the dataset in unpredictable ways. The bandwidth requirements of this example are trivial if only the data actually used are loaded, but the seek time requirements are a problem: 20,000 particles would require 320,000 seeks per time step or 3.2 million seeks per second. This is two orders of magnitude beyond the seek time capabilities of current disk systems.
Another way to address the data size problem is to develop data compression algorithms. The data will be decompressed as they are used, trading off reduced data size for greater computational demands. Different application domains will make different demands of compression algorithms: image data allow "lossy" compression, in which the decompressed data will be of a slightly lower fidelity than the original; scientific
data cannot allow lossy compression (as this would introduce incorrect artifacts into the data) but will perhaps allow multiresolution compression algorithms, such as wavelet techniques. The development of appropriate data compression techniques for many application domains is an open area of research.
Another strategy is to put as much of the dataset as possible in physical memory. This minimizes the seek time but restricts the number of data that may be investigated. This restriction will be relieved as workstation memories increase (see Figure 8-4). Datasets, however, are expected to grow radically as the available computational power increases.
Computational requirements can be similarly difficult to meet. The above example of injecting 20,000 particles into a flow requires 4 million floating point operations, implying a computational performance of 40 million floating point operations per second (or 40 Mflops) just to compute the particle visualization. Such an application will often use several such visualizations simultaneously. As more computational power becomes available, we may wish to include partial differential equation solvers, increasing the computational requirements by several orders of magnitude.
There are many ways in which supercomputer systems have attained very high computational speeds, but these methods typically work only for special computations. For example, Cray supercomputers rely on a vectorized architecture, which is very fast for array-type operations but is
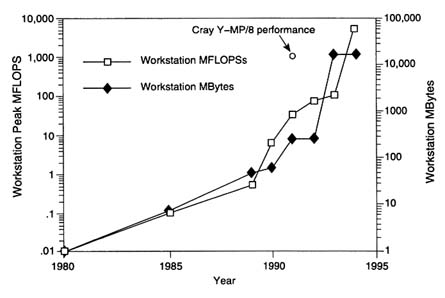
FIGURE 8-4 History of workstation computation and memory.
not so fast as for the particle example discussed above. Another example is the massively parallel system, which distributes memory and computation among many processors. Massively parallel systems are very fast for some applications, but are slow for computations that are not parallelizable or require large amounts of data movement. In a VE system, many kinds of computations may be required, implying that a unique computational architecture typically will be unsuitable. To maximize versatility, computations in VE systems should be based on a few parallel high-power scalar processors with large shared memory.
As Figure 8-4 shows, workstation computational power is increasing dramatically. It is expected that in 1994 workstations will be available that will match the computational power of the supercomputers of 1992.
The run-time software architecture of the VE is an area of serious concern. There are two run-time models that are currently common in computer graphics: the simulation loop model, in which all operations in the visualization environment (including interaction, computation, data management, and graphics) are performed in a repeated single loop; and the event-driven model, in which operations occur in response to various events (usually generated by the user). Neither model is attractive for large VEs.
The time required for a single loop in the simulation loop model may, due to the combination of data management, computation, and graphics, exceed the VE performance constraints. This is a particularly severe problem if these various operations are performed in sequence, drawing each frame only after the entire computation has been completed. This can lead to very low frame rates both with respect to display and interaction, which is unacceptable in a VE system. For multiprocessing systems, one answer is to put the computation and data management in one process while the graphics is in another, asynchronously running process. Then the graphics can be performed as fast as possible even though the computations may take much longer times. For multiprocessor systems, the computation can be parallelized as well, in which all computation takes place on as many processors as possible to reduce the overall time required for a computation. This parallel implementation of the computation is still a single loop. The time needed for execution will be determined by the slowest computation in that loop.
The event-driven model is unsuited for VE, as there are many events that may be generated at any one time (including repeated "compute the environment" events that amount to an effective simulation loop), and the time ordering and priority of these events are critical. For example, several user interaction events may occur simultaneously and the priority and meaning of these events will depend on their relationship to one another and their environment. Put more succinctly, the meaning of the
events will be context-sensitive and will require the system to interpret the state of the user. This operation will be difficult to do on the basis of an event queue.
An alternative run-time model that is gaining popularity is the concurrent model, in which different operations in the environment are running simultaneously with one another, preferably on several processors. The example of the simulation loop broken into the two asynchronously running graphics and computation processes discussed above is a simple example of concurrency. In full concurrency, one may assign a process to each element of the VE. These processes should be implemented as threads or lightweight processes, which are regularly preempted to prevent a single process from taking too much time. Each process would be a small simulation loop, which repeatedly computes and draws its object. The concurrent model has the advantage that slow processes will not block down faster processes. It has the disadvantage that processes requiring very different time scales (fast streamlines versus slow isosurfaces in a visualization application, for example) will not always be in sync. This is a serious problem for time-dependent environments, in which a concurrent implementation may lead to the simultaneous display of, for example, the streamline from one time and the isosurface from another. One can constrain the various processes to stay in sync, but the result would be an environment in which all processes are executed in a time determined by the slowest process (in effect, a parallelized simulation loop).
The choice of run-time architecture will be closely tied to and constrained by the operating system of the computer platform running the VE. In order to allow the parallelization of graphics and computation described above, the operating system should support many lightweight, shared-memory processes, thus minimizing the time required for context switching and interprocess communication. The operating system should be capable of ensuring that high-priority processes (such as the processes handling user tracking) can be serviced at very short and regular intervals. In addition, a synchronous process capability could be provided for various types of simulation computations. A further capability of operating systems that would significantly facilitate the development of VE applications is facilities for time-critical computing and rendering. While it is probably unreasonable to ask the operating system to schedule the time-critical tasks by itself, these facilities should provide the ability for the developer to determine scheduling through tunable parameters. Looking farther into the future, we expect that distributed VE applications will become common. Developing operating systems that make such distribution transparent and easy to implement then becomes high priority.
Another strategy to meet the computation and data management requirements is to distribute the computation and data management to several machines. There are several possible models for such a system. One is to keep all data and perform all computations on a remote supercomputer (Bryson and Gerald-Yamasaki, 1992). This approach is motivated when the local workstation does not have a large amount of computing power or large memory. Another approach is to distribute the data and computations among several computers. In the virtual wind tunnel example, there would be a density machine, which would contain the density data and handle all visualizations of the density field, a velocity machine, which would contain the velocity vector data and handle all visualizations of the velocity vector field, and so on. The resulting visualizations would be collected by the workstation that is handling the graphics and driving the VE interface. These distributed architectures would require fast low-latency networks of the type discussed elsewhere in this document.
There are many occasions on which the computations required to support the VE cannot be done to full accuracy within the VE speed performance constraints. The trade-off between accuracy and speed is a common theme in the design of VE systems. There are occasions in which faster, less accurate computational algorithms are desirable over slower, more accurate algorithms. It is not known at this time how to design these trade-offs into a system in a way that can anticipate all possibilities. Research into how these trade-offs are made is therefore needed. A current strategy is to give users full control over these trade-offs. A related issue is that of time-critical computing, in which a computation returns within a guaranteed time. Designing time-critical computational architectures is an active area of research and is critical to the successful design of VE applications.
Extrapolating current trends, we expect that VE applications will saturate available computing power and data management capabilities for the indefinite future. Dataset size will be the dominant problem for an important class of applications in VE. In the near term, an effective VE platform would include the following: multiple fast processors in an integrated unit; several graphics pipelines integrated with the processors; very large shared physical memory; very fast access to mass storage; operating systems that support shared-memory, multiprocessor architectures; and very high-speed, low-latency networks.
Graphics Capabilities in PC-Based VE Systems
Small VE systems have been successfully built around high-end personal computers (PCs) with special-purpose graphics boards. Notable
examples are the W Industries system from England, which uses an Amiga computer controlling auxiliary graphics processors. This system is capable of rendering several hundred polygons at about 15 Hz, and is used extensively in the Virtuality video arcade VE games. The Virtuality systems are networked and allow a few participants to play together in the same environment. Another common example is the use of an IBM-compatible personal computer with the Intel DVI graphics board, which is capable of rendering a few hundred textured polygons at 15-20 Hz.
PC-based VE systems are a natural consequence of the widespread availability of PCs. PC-based systems will provide the public with a taste of virtual reality that will eventually lead to demand for more capable computational and graphics platforms. It is anticipated that, by 1996, systems similar to the entry-level Indy machines from Silicon Graphics should replace the PC-based platforms as the total price of the PC system becomes comparable to that of the Indy. Already there are signs that computer graphics workstation companies are developing RISC CPUs with IBM PC compatibility nodes to simplify this transition.
SOFTWARE FOR THE GENERATION OF THREE-DIMENSIONAL VIRTUAL ENVIRONMENTS
There are many components to the software required for the real-time generation of VEs. These include interaction software, navigation software, polygon flow minimization to the graphics pipeline software, world modeling software (geometric, physical, and behavioral), and hypermedia integration software. Each of these components is large in its own right, and all of them must act in consort and in real time to create VEs. The goal of the interconnectedness of these components is a fully detailed, fully interactive, seamless VE. Seamless means that we can drive a vehicle across a terrain, stop in front of a building, get out of the vehicle, enter the building on foot, go up the stairs, enter a room and interact with items on a desktop, all without delay or hesitation in the system. To build seamless systems, substantial progress in software development is required. The following sections describe the software being constructed in support of virtual worlds.
Interaction Software
Interaction software provides the mechanism to construct a dialogue from various control devices (e.g., trackers, haptic interfaces) and to apply that dialogue to a system or application, so that the multimodal display changes appropriately. The first part of this software involves taking raw inputs from a control device and interpreting them. Several libraries
are available both as commercial products and as ''shareware" that read the most common interface devices, such as the DataGlove and various trackers. Examples of commercial libraries include World ToolKit by Sense8. Shareware libraries are available from the University of Alberta and other universities. These libraries range in sophistication from serial drivers for obtaining the raw output from the interface devices to routines that include predictive tracking and gesture recognition.
The second part of building interaction software involves turning the information about a system's state from a control device into a dialogue that is meaningful to the system or application, at the same time filtering out erroneous or unlikely portions of dialogue that might be generated by faulty data from the input device. The delivery of this dialogue to the virtual world system is then performed to execute some application-meaningful operation.
Interaction is a critical component of VE systems that involves both hardware and software. Interface hardware in VEs provides the positions or states of various parts of the body. This information is typically used to: (1) map user actions to changes in the environment (e.g., moving objects by hand, etc.), (2) pass commands to the environment (e.g., a hand gesture or button push), or (3) provide information input (e.g., speech recognition for spoken commands, text, or numerical input). The user's intent must be inferred from the output of the hardware as read by the computer system. This inference may be complicated by inaccuracies in the hardware providing the signal.
Existing Technologies
Although there are several paradigms for interaction in VEs, including direct manipulation, indirect manipulation, logical commands, and data input, the problem of realistic, real-time interaction is still comparatively unexplored. Generally, tasks in VEs are performed by a combination of these paradigms. Other paradigms will certainly need to be developed to realize the potential of a natural interface. Below we provide an overview of some existing technologies.
With direct manipulation, the position and orientation of a part of the user's body, usually the hand, is mapped continuously to some aspect of the environment. Typically, the position and orientation of an object in the VE is controlled via direct manipulation. Pointing in order to move is another example of direct manipulation in which orientation information is used to determine a direction in the VE. Analogs of manual tasks such as picking and placing require display of forces as well and therefore are well suited to direct manipulation, though more abstract aspects of the environment, such as background lighting, can also be controlled in this way.
When indirect manipulation is employed, the user performs direct manipulation on an object in the VE, which in turn controls some other aspect of the environment. This is an extension to VE of the concept of a widget, that is, a two-dimensional interface control used in graphics interface design. Thus one may directly manipulate a slider that controls the background color, while direct manipulation of another slider may control the volume of sound output. Several groups, including the University of North Carolina and the National Aeronautics and Space Administration (NASA), have developed this concept with generalizations of menus and sliders to VEs (Holloway et al., 1992; Jacoby, 1992; Conner et al., 1992). The term employed by these groups is three-dimensional widget. Creators of three-dimensional widgets go beyond the typical slider and checkboxes of traditional two-dimensional interfaces and attempt to provide task-specific widgets, such as the Computational Fluid Dynamics (CFD) widgets used in the virtual wind tunnel and surface modeling widgets (Bryson, 1992a). Indirect manipulation provides the opportunity to carry out many actions by using relatively few direct manipulation capabilities.
Logical commands detect the state of the user, which is then mapped to initiate some action by the environment. Logical commands are discrete events. The user's state that triggers the command may be detected via buttons, gestures as measured by haptic devices, voice commands, etc. The particular command triggered by a user state may depend on the state of the environment or on the location of parts of the user's body. For example, a point gesture may do different things depending on which virtual object happens to be coincident with the position of the user's hand. Logical commands can also be triggered via indirect manipulation using menus or speech recognizers.
Data or text input can be provided by conventional keyboard methods external to the VE. Within the environment, speech recognition may be used for both text and numerical input, and indirect manipulation of widgets provides limited numerical input.
There are high-level interfaces that should be explored. Research must be performed to explore how to use data measuring the positions of the user's body to interact with a VE in a way that truly provides the richness of real-world interaction. As an example, obvious methods of manipulating a virtual surface via a DataGlove have proven to be difficult to implement (Bryson, 1992b; Snibbe et al., 1992). This example demonstrates that research is needed to determine how user tracking data are to be applied as well as how the objects in the VE are to be defined to provide natural interaction.
In addition, research is needed on the problem of mapping continuous input (body movement) to discrete commands. There are significant
segmentation and disambiguation problems, which may require semantic decoding. Since such decoding is application-dependent, the VE user interface cannot easily be separated from the application in the way that it can be with current two-dimensional WIMP (windows, icons, mouse, pointer) interfaces.
Design Approaches and Issues to be Addressed
A crucial decision in designing the interaction is the choice of conceptual approach. Specifically, should researchers focus on ways in which the existing two-dimensional technology might be enriched, or should the starting point be the special attributes and challenges of three-dimensional immersive environments? Some researchers are recreating the two-dimensional graphic user interface (GUI) desktop metaphor in three dimensions by placing buttons and scroll bars in the environment along with the user. While we believe that there is great promise in examining the very successful two-dimensional desktop metaphor as a source for ideas, we also believe that there are risks because of the different sets of problems in the two environments. Relying solely on extensions of our experience with two dimensions would not provide adequate solution approaches to three-dimensional interaction needs, such as flying and navigation or to issues related to body-centered coordinates systems and lines of sight.
Two of the more important issues associated with interacting in a three-dimensional environment are line of sight and acting at a distance. With regard to line of sight, VE applications have to contend with the fact that some useful information might be obscured or distorted due to an unfortunate choice of user viewpoint or object placement. In some cases, the result can lead to misinformation, confusion, and misunderstanding. Common pitfalls include obscuration and unfortunate coincidences.
-
Obscuration At times, a user must interact with an object that is currently out of sight, hidden behind other objects. How does dealing with this special case change the general form of any user interface techniques we might devise?
-
Unfortunate Coincidences The archetypical example of this phenomenon is the famous optical illusion in which a person stands on a distant hill while a friend stands near the camera, aligning his hand so that it appears as if the distant friend is a small person standing in the palm of his hand. Such devices, while amusing in some contexts, could under other circumstances, such as air traffic control, prove quite dangerous. Perhaps we should consider alternative methods for warning the user when such coincidences are occurring or for ensuring that the user has enough depth information via parallax to perceive this.
When the user is immersed in a three-dimensional environment, he or she is interacting with objects at a distance. Some are directly within arm's reach, others are not. In each case, there is a question of how to specify the arguments to a particular command—that is, how does a user select and manipulate objects out of the reach envelope and at different distances from the user (that is, in the same room, the same city, across the country)? Will the procedure for distant objects be different from those used in selecting and manipulating nearby objects? Some solutions to the selection problem involve ray casting or voice input, but this leaves open the question of specifying actions and parameters by means of direct manipulation.
Some solutions emphasize a body-centric approach, which relies solely on the user's proprioceptive abilities to specify actions in space. Under this scheme, there is no action at a distance, only operations on objects in close proximity to the user. This approach requires one of three solutions: translate the user's viewpoint to within arm's reach of the object(s) in question, scale the user so that everything of interest is within arm's reach, or scale the entire environment so that everything is within arm's reach.
The first solution has several drawbacks. First, by moving the user over significant distances, problems in orientation could result. Next, moving objects quickly over great distances can be difficult (moving an object from Los Angeles to New York would require that the user fly this distance or that the user have a point-and-click, put-me-there interface with a global map). Finally, moving close to an object can destroy the spatial context in which that move operation is taking place. The second and third solutions are completely equivalent except when other participants or spectators are also in the environment.
Perhaps the most basic interaction technique in any application is object selection. Object selection can be implicit, as happens with many direct manipulation techniques on the desktop (e.g., dragging a file to the Mac trash can), or it can be explicit, as in clicking on a rectangle in any common GUI drawing package to activate selection handles for resizing. It is interesting to note that most two-dimensional user interface designers use the phrase "highlight the selected object," to mean "draw a marker, such as selection handles" on the selected object. With VE systems, we have the ability to literally highlight the selected object. Most examples thus far have used three-dimensional extensions of two-dimensional highlighting techniques, rather than simply doing what the term implies; applying special lighting to the selected object.
The following list offers some potentially useful selection techniques for use in three-dimensional computer-generated environments:
-
Pointing and ray casting. This allows selection of objects in clear view, but not those inside or behind other objects.
-
Dragging. This is analogous to "swipe select" in traditional GUIs. Selections can be made on the picture plane with a rectangle or in an arbitrary space with a volume by "lassoing." Lassoing, which allows the user to select a space of any shape, is an extremely powerful technique in the two-dimensional paradigm. Carrying this idea over to three dimensions requires a three-dimensional input device and perhaps a volume selector instead of a two-dimensional lasso.
-
Naming. Voice input for selection techniques is particularly important in three-dimensional environments. "Delete my chair" is a powerful command archetype that we should not ignore. The question of how to manage naming is extremely important and difficult. It forms a subset of the more general problem of naming objects by generalized attributes.
-
Naming attributes. Specifying a selection set by a common attribute or set of attributes ("all red chairs with arms") is a technique that should be exploited. Since some attributes are spatial in nature, it is easy to see how these might be specified with a gesture as well as with voice, offering a fluid and powerful multimodal selection technique: all red chairs, shorter than this [user gestures with two hands] in that room [user looks over shoulder into adjoining room].
For more complex attribute specification, one can imagine attribute editors and sophisticated three-dimensional widgets for specifying attribute values and ranges for the selection set. Selection by example is another possibility: "select all of these [grabbing a chair]." All of the selection techniques described above suffer from being too inclusive. It is important to provide the user with an opportunity to express "but not that one" as a qualification in any selection task. Of course, excluding objects is itself a selection task.
An important aspect of the selection process is the provision of feedback to the user confirming the action that has been taken. This is a more difficult problem in three dimensions, where we are faced with the graphic arts question of how to depict a selected object so that it appears unambiguously selected from an arbitrary viewing angle, under any lighting circumstances, regardless of the rendering of the object.
Another issue is that of extending the software to deal with two-handed input. Although manipulations with two hands are most natural for many tasks, adding a second pointing device into the programming loop significantly complicates the programmer's model of interaction and object behavior and so has been rarely seen in two-dimensional systems other than research prototypes. In three-dimensional immersive environments, however, two-handed input becomes even more important, as
individuals use both gestures and postures to indicate complex relationships between objects and operations in space.
If an interface is poorly designed, it can lull the user into thinking that options are available when in fact they are not. For example, current immersive three-dimensional systems often depict models of human hands in the scene when the user's hands are being tracked. Given the many kinds of actions that human hands are capable of, depicting human hands at all times might suggest to users that they are free to perform any action they wish—yet many of these actions may exceed the capabilities of the current system. One solution to this problem is to limit the operations that are possible with bare hands, specifying for more sophisticated operations the use of tools. A thoughtful design would depict tools that suggest their purpose, so that, like a carpenter with a toolbox, the user has an array of virtual tools with physical attributes that suggest certain uses. Cutting tools might look like saws or knives, while attachment tools might look like staplers. This paradigm melds together issues of modality with voice, context, and command.
Interaction techniques and dialogue design have been extremely important research foci in the development of effective two-dimensional interfaces. Until recently, the VE community has been occupied with getting any input to work, but it is now maturing to the point that finding common techniques across applications is appropriate. These common techniques are points of leverage: by encapsulating them in reusable software components, we can hope to build VE tools similar to the widget, icon, mouse, pointer (WIMP) application builders that are now widely in use for two-dimensional interfaces. It should also be noted that the progress made in three-dimensional systems should feedback into two-dimensional systems.
Visual Scene Navigation Software
Visual scene navigation software provides the means for moving the user through the three-dimensional virtual world. There are many component parts to this software, including control device gesture interpretation (gesture message from the input subsystem to movement processing), virtual camera viewpoint and view volume control, and hierarchical data structures for polygon flow minimization to the graphics pipeline. In navigation, all act together in real time to produce the next frame in a continuous series of frames of coherent motion through the virtual world. The sections below provide a survey of currently developed navigation software and a discussion of special hierarchical data structures for polygon flow.
Survey of Currently Developed Navigation Software
Navigation is the problem of controlling the point and direction of view in the VE (Robinett and Holoway, 1992). Using conventional computer graphics techniques, navigation can be reduced to the problem of determining a position and orientation transformation matrix (in homogeneous graphics coordinates) for the rendering of an object. This transformation matrix can be usefully decomposed into the transformation due to the user's head motion and the transformation due to motions over long distance (travel in a virtual vehicle). There may also be several virtual vehicles concatenated together.
The first layer of virtual world navigation is the most specific: the individual's viewpoint. One locally controls one's position and direction of view via a head tracking device, which provides the computer with the position and orientation of the user's head.
The next layer of navigation uses the metaphor of a virtual vehicle, which allows movement over distances in the VE greater than those distances allowed by the head-tracker alone. The position and orientation of the virtual vehicle can be controlled in a variety of ways. In simulation applications, the vehicle is controlled in the same way that an actual simulated vehicle would be controlled. Examples that have been implemented are treadmills and bicycles and joysticks for flight or vehicle simulators. For more abstract applications, there have been several experimental approaches to controlling the vehicle. The most common is the point and fly technique, wherein the vehicle is controlled via a direct manipulation interface. The user points a three-dimensional position and orientation tracker in the desired direction of flight and commands the environment to fly the user vehicle in that direction. Other methods of controlling the vehicle are based on the observation that in VE one need not get from here to there through the intervening space. Teleoperation is one obvious example, which often has the user specify a desired destination and then "teleports" the user there. Solutions have included portals that have fixed entry and exit locations, explicit specification of destination through numerical or label input, and the use of small three-dimensional maps of the environment to point at the desired destination. Another method of controlling the vehicle is dynamic scaling, wherein the entire environment is scaled down so that the user can reach the desired destination, and then scaled up again around the destination indicated by the user. All of these methods have disadvantages, including difficulty of control and orientation problems.
There is a hierarchy of objects in the VE that may behave differently during navigation. Some objects are fixed in the environment and are acted on by both the user and the vehicle. Other objects, usually virtual
tools that the user will always wish to have within reach, will be acted on by the head transformation only. Still other objects, such as data displays, are always desired within the user's field of view and are not acted on by either the user or the vehicle. These objects have been called variously world stable, vehicle stable, and head stable (Fisher et al., 1986). Although most of the fundamental mathematics of navigation software are known, experimentation remains to be done.
Survey of Hierarchical Data Structure Techniques for Polygon Flow Minimization
Hierarchical data structures for the minimization of polygon flow to the graphics pipeline are the back end of visual scene navigation. When we have generated a matrix representing the chosen view, we then need to send the scene description transformed by that matrix to the visual display. One key method to get the visual scene updated in real time at interactive update rates is to minimize the total number of polygons sent to the graphics pipeline.
Hierarchical data structures for polygon flow minimization are probably the least well understood aspect of graphics development. Many people buy workstations, such as the Silicon Graphics, that promise 2 million polygons/s and expect to be able to create realistic visual scenes in virtual worlds. This is a very common misconception. Visual reality has been said to consist of 80 million polygons per picture (Catmull et al., 1984). Extending this to the VE need for 10 frames/s minimum, 800 million polygons/s are needed.
Today, as noted above, workstations are advertised to have the capability to process approximately 2 to 3 million polygons/s (flat shaded, nontextured). If textured scenes are desired, the system will run slower at approximately 900,000 textured polygons/s. We expect to see 10 to 25 percent of this advertised performance, or 225,000 textured polygons/s. At 10 frames/s, this is 22,500 polygons per frame or 7,500 textured polygons at 30 frames/s (7,500 polygons is not a very detailed world).
The alternatives are to live with worlds of reduced complexity or to off-load some of the graphics work done in the pipeline onto the multiple CPUs of workstations. All polygon reduction must be accomplished in less time than it takes just to send the polygons through the pipeline. The difficulty of polygon flow minimization depends on the composition of the virtual world. This problem has historically been approached on an application-specific basis, and there is as yet no general solution. Current solutions usually involve partitioning the polygon-defined world into volumes that can readily be checked for visibility by the virtual world
viewer. There are many partitioning schemes—some of which work only if the world description does not change dynamically (Airey et al., 1990).
A second component of the polygon flow minimization effort is the pixel coverage of the object modeled. Once an object has been determined to be in view, the secondary question is how many pixels that object will cover. If the number of pixels covered by an object is small, then a reduced polygon count (low-resolution) version of that object can be rendered. This results in additional software complexity, again software that must run in real time. Because the level-of-detail models are precomputed, the issue is greater dataset size rather than level selection (which is nearly trivial).
The current speed of z-buffers alone means we must carefully limit the polygons sent through the graphics pipeline. Other techniques that use the CPUs to minimize polygon flow to the pipeline are known for specific applications, but those techniques do not solve the problem in general.
In a classic paper, Clark (1976) presents a general approach for solving the polygon flow minimization problem by stressing the construction of a hierarchical data structure for the virtual world (Figure 8-5). The approach is to envision a world database for which a bounding volume is known for each drawn object. The bounding volumes are organized hierarchically, in a tree that is used to rapidly discard large numbers of polygons. This is accomplished by testing the bounding volumes to determine whether they are contained or partially contained in the current orientation of the view volume. The process continues recursively until a node is reached for which nothing underneath it is in the view volume.
This part of the Clark paper provides a good start for anyone building a three-dimensional VE for which the total number of polygons is significantly larger than the hardware is capable of drawing.
The second part of Clark's paper deals with the actual display of the polygons in the leaf nodes of the tree. The idea is to send only minimal descriptions of objects through the graphics pipeline (minimal based on the expected final pixel coverage of the object). In this approach, there will be multiple-resolution versions of each three-dimensional object and software for rapidly determining which resolution to draw. The assumption of multiple-resolution versions of each three-dimensional object being available is a large one, with automatic methods for their generation remaining an open issue. Other discussions of this issue are found in DeHaemer and Zyda (1991), Schroeder et al. (1992), and Turk (1992).
Application-Specific Solutions
Polygon flow minimization to the graphics pipeline is best understood by looking at specific solutions. Some of the more interesting work has been done by Brooks at the University of North Carolina at Chapel Hill with respect to architectural walkthrough (Brooks, 1986; Airey et al., 1990). The goal in those systems was to provide an interactive walkthrough capability for a planned new computer science building at the university that would offer visualization of the internal spaces of that building for the consideration of changes before construction.
The walkthrough system had some basic tenets. The first was that the architectural model would be constructed by an architect and passed on to the walkthrough phase in a fixed form. A display compiler would then be run on that database and a set of hierarchical data structures would be output to a file. The idea behind the display compiler was that the building model was fixed and that it was acceptable to spend some 45 minutes in computing a set of hierarchical data structures. Once the data structures were computed, a display loop could then be entered, in which the viewpoint could be rapidly changed. The walkthrough system was rather successful, but it has the limitation that the world cannot be changed without rerunning the display compiler. Other walkthrough systems have similar limitations (Teller and Sequin, 1991; Funkhouser et al., 1992).
Real-time display of three-dimensional terrain is a well-researched area that originated in flight simulation. Terrain displays are an interesting special case of the polygon flow minimization problem in that they are relatively well worked out and documented in the open literature (Zyda et al., 1993a). The basic idea is to take the terrain grid and generate a quadtree structure containing the terrain at various display resolutions. The notion of the grid cell is used for reducing polygon flow by drawing
only those objects whose cell is also to be drawn (assuming the grid cell on which the object lies is known). This strategy works well for ground-based visual displays; a more comprehensive algorithm is required for air views of such displays.
World Modeling
Models that define the form, behavior, and appearance of objects are the core of any VE. A host of modeling problems are therefore central to the development of VE technology. An important technological challenge of multimodal VEs is to design and develop object representation, simulation, and rendering (RSR) techniques that support visual, haptic, and auditory interactions with the VE in real time. There are two major approaches to the RSR process. First, a unified central representation may be employed that captures all the geometric, surface, and physical properties needed for physical simulation and rendering purposes. In principle, methods such as finite element modeling could be used as the basis for representing these properties and for physical simulation and rendering purposes. At the other extreme, separate, spatially and temporally coupled representations could be maintained that represent only those properties of an object relevant for simulating and rendering interactions in a single modality (e.g., auditory events). The former approach is architecturally the most elegant and avoids issues of maintaining proper spatial and temporal correlation between the RSR processes for each modality. Practically, however, the latter approach may allow better matching between modality-specific representation, simulation, and rendering streams. The abilities and limitations of the human user and the VE system for each of the modalities impose unique spatial (e.g., scale and resolution) and temporal (e.g., device update rate and duration) constraints. For example, it is likely that the level of detail and consequently the nature of approximations in the RSR process will be different for each of the modalities. It is unclear, therefore, whether these modality-specific constraints can be met by systems based on a single essential or core representation and still operate in real time.
The overwhelming majority of VE-relevant RSR research and development to date has been on systems that are visually rendered (e.g., Witkin and Welch, 1990). The theoretical and practical issues associated with either of the two RSR approaches or variants in a multimodal context, however, have received minimal attention but are likely to become a major concern for VE system researchers and developers. For example, geometric modeling is relevant to the generation of acoustic environments (i.e., room modeling) as well as visual environments, and the development of physical models is critical to the ability to generate and
modulate auditory, visual, and haptic displays. Novel applications such as the use of auditory displays for the understanding of scientific data (e.g., Kramer, 1992; Blattner et al., 1989) require models that may not be physically based. In this section, we concentrate on the visual domain and examine the problems of constructing geometric models, the prospects for vision-based acquisition of real-world models, dynamic model matching for augmented reality, the simulation of basic physical behavior, and simulation of autonomous agents. Parallel issues are involved in the other modalities and are discussed in Chapters 3 and 4.
Geometric Modeling: Construction and Acquisition
The need to build detailed three-dimensional geometric models arises in computer-aided design (CAD), in mainstream computer graphics, and in various other fields. Geometric modeling is an active area of academic and industrial research in its own right, and a wide range of commercial modeling systems is available. Despite the wealth of available tools, modeling is generally regarded as an onerous task. Among the many factors contributing to this perception are sluggish performance, awkward user interfaces, inflexibility, and the low level at which models must typically be specified. It is symptomatic of these difficulties that most leading academic labs, and many commercial animation houses (such as Pixar and PDI), prefer to use in-house tools, or in some cases a patchwork of homegrown and commercial products.
From the standpoint of VE construction, geometric modeling is a vital enabling technology whose limitations may impede progress. As a practical matter, the VE research community will benefit from a shared open modeling environment, a modeling environment that includes physics. In order to understand this, we need to look at how three-dimensional geometric models are currently acquired. We do this by looking at how several VE efforts have reported their model acquisition process.
Geometric models for VEs are typically acquired through the use of a PC-based, Macintosh-based, or workstation-based CAD tool. If one reads the work done for the walkthrough project at the University of North Carolina (Airey et al., 1990), one finds that AutoCAD was used to generate the 12,000+ polygons that comprised the Orange United Methodist Church. In the presentation of that paper, one of the problems discussed was that of ''getting the required data out of a CAD program written for other purposes." Getting the three-dimensional geometry out of the files generated by AutoCAD was not difficult, but there was a problem in that not all of the data required were present in the form needed for the VE walkthrough. In particular, data related to the actual physics of the building were not present, and partitioning information useful to the real-time
walkthrough algorithms had to be added later "by hand" or "back fed in" by specially written programs.
The VPL Reality Built for Two (RB2) system (Blanchard et al., 1990) used a Macintosh II as its design station for solid modeling and an IRIS workstation as its rendering/display station. RB2 is a software development platform for designing and implementing real-time VEs. Development under RB2 is rapid and interactive, with behavior constraints and interactions that can be edited in real time. The geometric modeling function of RB2 was provided by a software module called RB2 Swivel and a data flow/real-time animation control package called Body Electric. RB2 has a considerable following in organizations that do not have sufficient resources to develop their own in-house VE expertise. RB2 is a turnkey system, whose geometric and physics file formats are proprietary.
In the NPSNET project (Zyda et al., 1992), the original set of three-dimensional icons used was acquired from the SIMNET databases. These models were little more than three-dimensional skins of the weapons systems known to SIMNET. As a result, project researchers have developed an open format for storing these three-dimensional models (Zyda et al., 1993a), added physics to the format (Zyda et al., 1992), and have rewritten the system to include object-oriented animation capabilities (Wilson et al., 1992). For example, at the Naval Postgraduate School, the NPSNET Research Group is currently using Software Systems' expensive and proprietary MultiGen CAD tool for the development of physics-free models for its SGI Performer-based NPSNET-4 system. Computer-aided design systems with retrofitted physics are beginning to be developed (e.g., Deneb Robotics and Parametric Technologies), but these systems are expensive and proprietary.
Many applications call for VEs that are replicas of real ones. Rather than building such models by hand, it is advantageous to use visual or other sensors to acquire them automatically. Automatic acquisition of complex environment models (such as factory environments) is currently not practical but is a timely research issue. Meanwhile, automatic or nearly automatic acquisition of geometric models is practical now in some cases, and partially automated interactive acquisition should be feasible in the near term (Ohya et al., 1993; Fuchs et al., 1994).
The most promising short-term approaches involve active sensing techniques. Scanning laser finders and light-stripe methods are both capable of producing range images that encode position and shape of surfaces that are visible from the point of measurement. These active techniques offer the strong advantage that three-dimensional measurements may be made directly, without the indirect inferences that passively acquired images require. Active techniques do, however, suffer from some
limitations: because sensor-to-surface distances must be relatively small, they are not applicable to large-scale environments. Surfaces that are nonreflective or obliquely viewed shiny surfaces may not return enough light to allow range measurements to be made. Noise is enough of a problem that data must generally be cleaned up by hand. A more basic problem is that a single range image contains information only about surfaces that were visible from a particular viewpoint. To build a complete map of an environment, many such views may be required, and the problem of combining them into a coherent whole is still unsolved.
Among passive techniques, stereoscopic and motion-based methods, relying on images taken from varying viewpoints, are currently most practical. However, unlike active sensing methods, these rely on point-to-point matching of images in order to recover distance by triangulation. Many stereo algorithms have been developed, but none is yet robust enough to compete with active methods. Methods that rely on information gleaned from static monocular views—edges, shading, texture, etc.—are less effective.
For many purposes, far more is required of an environment model than just a map of objects' surface geometry. If the user is to interact with the environment by picking things up and manipulating them, information about objects' structure, composition, attachment to other objects, and behavior is also needed. Unfortunately, current vision techniques do not even begin to address these deeper issues.
Dynamic Model Matching and Augmented Reality
The term augmented reality has come to refer to the use of transparent head-mounted displays that superimpose synthetic elements on a view of the real surroundings. Unlike conventional heads-up displays in which the added elements bear no direct relation to the background, the synthetic objects in augmented reality are supposed to appear as part of the real environment. That is, as nearly as possible, they should interact with the observer and with real objects, as if they too were real.
At one extreme, creating a full augmented-reality illusion requires a complete model of the real environment as well as the synthetic elements. For instance, to place a synthetic object on a real table and make it appear to stay on the table as the observer moves through the environment, we would need to know just where the table sits in space and how the observer is moving. For full realism, enough information about scene illumination and surface properties to cast synthetic shadows onto real objects would be needed. Furthermore, we would need enough information about three-dimensional scene structure to allow real objects to hide or be hidden by synthetic ones, as appropriate. Naturally, all of this would
happen in real time, in response to uncontrolled and unpredictable observer motions.
This sort of mix of the real and synthetic has already been achieved in motion picture special effects, most notably, Industrial Light and Magic's effects in films such as The Abyss and Terminator 2. Some of these effects were produced by rendering three-dimensional models and creating a composite of the resulting images with live-action frames, as would be required in augmented reality. However, the process was extremely slow and laborious, requiring manual intervention at every step. After scenes were shot, models of camera and object motions were extracted manually, using frame-by-frame manual measurement along with considerable trial and error. Even small geometric errors were prone to destroy the illusion, making the synthetic objects appear to float outside the live scene.
Automatic generation of augmented-reality effects is still a research problem in all but the least demanding cases. The two major issues are: (1) accurate measurement of observer motions and (2) acquisition and maintenance of scene models. The prospects for automatic solutions to the latter were discussed above. If the environment is to remain static, it would be feasible to build scene models off-line using interactive techniques. Although VE displays provide direct motion measurements of observer movement, these are unlikely to be accurate enough to support high-quality augmented reality, at least when real and synthetic objects are in close proximity, because even very small errors could induce perceptible relative motions, disrupting the illusion. Perhaps the most promising course would use direct motion measurements for gross positioning, using local image-based matching methods to lock real and synthetic elements together.
Physical Simulation for Visual Displays
In order to give solidity to VEs and situate the user firmly in them, virtual objects, including the user's image, need to behave like real ones. At a minimum, solid objects should not pass through each other, and things should move as expected when pushed, pulled, or grasped.
Analysis of objects' behavior at the scale of everyday observation lies in the domain of classic mechanics, which is a mature discipline. However, mechanics texts and courses are generally geared toward providing insight into objects' behavior, whereas to support VE the behavior itself is of paramount importance—insight strictly optional. Thus classic treatments may provide the required mathematical underpinnings but do not directly address the problem at hand.
Simulations of classic mechanics are extensively used as aids in engineering design and analysis. Although these traditional simulations do
yield numerical descriptions of behavior, they still do not come close to meeting the needs of VEs. In engineering practice, simulation is a long, drawn-out, and highly intellectualized activity. The engineer typically spends much time with pencil and paper developing mathematical models for the system under study. These are then transferred to the simulation software, often with much tweaking, and parameter selection. Only then can the simulation actually be run. As a design evolves, the initial equations must be modified and reentered and the simulation rerun.
In strong contrast, a mechanical simulation for VEs must run reliably, seamlessly, automatically, and in real time. Within the scope of the world being modeled, any situation that could possibly arise must be handled correctly, without missing a beat. In the last few years, researchers in computer graphics have begun to address the unique challenges posed by this kind of simulation, under the heading of physically based modeling. Below we summarize the main existing technology and outstanding issues in this area.
Solid Object Modeling Solid objects' inability to pass through each other is an aspect of the physical world that we depend on constantly in everyday life: when we place a cup on a table, we expect it to rest stably on the table, not float above or pass through it.
In reaching and grasping, we rely on solid hand-object contact as an aid (as do roboticists, who make extensive use of force control and compliant motion). Of course, we also rely on contact with the ground to stand and locomote.
The problem of preventing interpenetration has three main parts. First, collisions must be detected. Second, objects' velocities must be adjusted in response to collisions. Finally, if the collision response does not cause the objects to separate immediately, contact forces must be calculated and applied until separation finally occurs.
Collision detection is most frequently handled by checking for object overlaps each time position is updated. If overlap is found, a collision is signaled, the state of the system is backed up to the moment of collision, and a collision response is computed and applied. The bulk of the work lies in the geometric problem of determining whether any pair of objects overlap. This problem has received attention in robotics, in mechanical CAD, and in computer graphics. Brute force overlap detection for convex polyhedra is a straightforward matter of testing each vertex of every object against each face of every other object. More efficient schemes use bounding volumes or spatial subdivision to avoid as many tests as possible. Good general methods for objects with curved surfaces do not yet exist.
In fact, checking for object overlaps at each update is not sufficient to
guarantee noninterpenetration, because objects may have collided and passed through each other between the previous configuration and the new one. This is not merely an esoteric concern, because it means that rapidly moving objects, e.g., projectiles, may pass entirely through thin objects, such as walls, with no collisions ever being detected. Needless to say, large errors can result. Guaranteed methods have been described by Lin and Canny (1992) for the case of convex polyhedra with constant linear and angular velocity.
Collision response involves the application of an impulse and producing an instantaneous change in velocity that prevents interpenetration. The basics of collision response are well treated in classic mechanics and do not pose any great difficulties for implementation. Problems do arise in developing accurate collision models for particular materials, but many VE applications will not require this degree of realism.
To handle continuous multibody contact, it is necessary to calculate the constraint forces that are exchanged at the points of contact and to identify the instants at which contacts are broken. Determining which contacts are breaking is a particularly difficult problem, turning out, as shown by Baraff, to require combinatorial search (Baraff and Witkin, 1992; Baraff, 1989). Fortunately, Baraff also developed reasonably efficient methods that work well in practice.
Many virtual world systems exhibit rigid body motion with collision detection and response (Hahn, 1988; Moore and Wilhelms, 1988; Baraff, 1989; Baraff and Witkin, 1992; Zyda et al., 1993b). Baraff's system also handles multibody continuous contact and frictional forces for curved surfaces. These systems provide many of the essential elements required to support VEs.
Constraints and Articulated Objects In addition to simple objects such as rigid bodies, we should be able to handle objects with moving parts—doors that open and close, knobs and switches that turn, etc. In principle, the ability to simulate simple objects such as rigid bodies, together with the ability to prevent interpenetration, could suffice to model most such compound objects. For instance, a working desk drawer could be constructed by modeling the geometry of a tongue sliding in a groove, or a door by modeling in detail the rigid parts of the hinge. In practice, it is far more efficient to employ direct geometric constraints to summarize the effects of this kind of detailed interaction. For instance, a sliding tongue and groove would be idealized as a pair of coincident lines, one on each object, and a hinge would be represented as an ideal revolute joint.
The simulation and analysis of articulated bodies—jointed assemblies of rigid parts—have been treated extensively, particularly in robotics. In
addition to classic techniques such as Lagrangian dynamics, streamlined recursive formulations have been developed, making it possible to simulate forward dynamics of a kinematic chain in linear time, rather than the N∧3 time that Lagrangian dynamics requires. These methods only pay off for relatively long chains (N > 9, according to Featherstone) and in their original form do not readily handle closed loops in the graph of part connectivity. Building on the work of Lathrop, Schroeder demonstrated that it is nevertheless feasible to build a "virtual erector set" based on recursive formulations (Schroeder and Zeltzer, 1990).
Another approach to simulating constrained systems of objects builds on the classic method of Lagrangian multipliers, in which a linear system is solved at each time step to yield a set of constraint forces. This approach offers several advantages: first, it is general, allowing essentially arbitrary holonomic constraints to be applied to essentially arbitrary (not necessarily rigid) bodies. Second, it lends itself to on-the-fly construction and modification, an important consideration for VEs. Finally, the constraint matrices that form the linear system are typically sparse, reflecting the fact that everything is not usually connected directly to everything else. Using numerical methods that exploit this sparsity can yield performance that competes with recursive methods. Methods of this kind were used for animation by Platt and by Barzel and Barr (Platt and Barr, 1988; Barzel and Barr, 1988). Witkin et al. (1990) demonstrated a fully interactive snap-together construction system and showed how the constraint equations could be built on the fly and solved in a way that exploits sparsity.
Nonrigid Objects A vast body of work treats the use of finite element methods to simulate continuum dynamics. Most of this work is probably of limited relevance to the construction of conventional VEs, simply because such environments will not require fine-grained nonrigid modeling, with the possible exception of virtual surgery. However, interactive continuum analysis for science and engineering may become an important specialized application of VEs once the computational horsepower is available to support it.
Highly simplified models for flexible-body dynamics are presented by Witkin and Welch (1990), by Pentland and Williams (1989), and by Baraff and Witkin (1992). The general idea of these models is to use only a few global parameters to represent the shape of the whole object, formulating the dynamic equations in terms of these variables. These simplified models capture only the gross deformations of the object but in return provide very high performance. They are probably the most appropriate choice for VEs that require simple nonrigid behavior.
A special form of nonrigid modeling, constituting a potential VE application
in itself, is interactive sculpting of free-form surfaces. The general idea is to use simulated flexible materials as a sculpting medium. Flexible thin sheets are employed by Celniker and Gossard (1992) and by Welch and Witkin (1992). Szeliski and Tonnesen (1992) uses clouds of oriented particles to form smooth surfaces.
Motivated by the obvious need in both computer graphics and engineering for realism and physically based environments that support various levels of object detail and interaction (depending on the application), Metaxas (1992, 1993; Metaxas and Terzopoulos, 1992a, 1992b, 1993; Terzopoulos and Metaxas, 1991) developed a general framework for shape and nonrigid motion synthesis, which can also handle rigid bodies as a special case. The framework features a new class of dynamic deformable part models. These models have both global deformation parameters that represent the gross shape of an object in terms of a few parameters and local deformation parameters that represent an object's details through the use of sophisticated finite element techniques. Global deformations are defined by fully nonlinear parametric equations. Hence the models are more general than the linearly deformable ones included in Witkin and Welch (1990) and quadratically deformable ones included in Pentland and Williams (1989). By augmenting the underlying Lagrangian equations' motion with very fast dynamic constraint techniques based on Baumgarte (1972), he adds the capability to compose articulated models (Metaxas, 1992, 1993; Metaxas and Terzopoulos, 1992b) from deformable parts, whose special case for rigid objects is the technique used by Barzel and Barr (1988). Moreover, Metaxas (1992, 1993) also develops fast algorithms for the computation of impact forces that occur during collisions of complex flexible multibody objects with the simulated physical environment.
Issues to be Addressed Most of the essential pieces that are required to imbue VEs with physical behavior have already been demonstrated. Some—notably snap-together constraints and interactive surface modeling—have been demonstrated in fully interactive systems, and others—notably the handling of collision and contact—are only now beginning to appear in interactive systems (recent work by David Baraff at Carnegie Mellon University involves an interactive 2.5-dimensional simulation of noninterpenetrating objects). The most immediate challenge at hand is one of integrating the existing technology into a working system, along with other elements of VE construction software.
Many performance-related issues are still to be addressed, for example, doing efficient collision detection in a large-scale environment (systems with from 500 to 300,000 players or parts) and further accelerating constrained dynamics solutions. In addition, many of the standard
numerical techniques are not tuned to real-time systems. For example, the ratio of compute time to real time can vary by orders of magnitude in the simulation of noninterpenetrating bodies, slowing even further when complex contact situations arise. Maintaining a constant frame rate will require the development of new methods that degrade gracefully in such situations.
Autonomous Agents
The need for simulated autonomous agents arises in many VE application areas, such as training, education, and entertainment, in which such agents could play the role of adversaries, trainers, or partners or simply supernumeraries to add richness and believability. Although fully credible simulated humans are the stuff of science fiction, simple agents will often suffice. The construction of simulated autonomous agents draws on a number of technologies, including robotics, computer animation, artificial intelligence, and optimization.
Motion Control Placing an autonomous agent in a virtual physical environment is essentially like placing a robot in a real environment: the agent's body is a physical object that must be controlled to achieve coordinated motion. Fortunately, controlling a virtual agent is much easier than controlling a real one, since many simplifications and idealizations can be made. For example, the agent can be given access to full and perfect information about the state of the world, and many troubling mechanical effects need not arise.
Closed-loop controllers were used to animate virtual agents by McKenna and Zeltzer (1990) and by Miller (1988). More recently, Raibert and Hodgkins (1992) adapted their controller for a real legged robot to the creation of animation. Rather than hand-crafting controllers, Witkin and Kass (1988) solve numerically for optimal goal-directed motion, in an approach that has since been elaborated by Van de Panne et al. (1990) and by Cohen (1992).
Human Figure Simulation In many applications, a VE system must be able to display accurate models of human figures, possibly including a model of the user. Consider training systems, for example. Out-the-window views generated by high-end flight simulators hardly ever need to include images of human figures. But there are many situations in which personnel must cooperate and interact with other crew members. Carrier flight deck operations, small squad training or antiterrorist tactics, for example, require precise coordination of the actions of many individuals for safe and successful execution. VE systems to support training,
planning, and rehearsal of such activities must therefore provide computational models of human figures.
We call a computer model of a human figure that can move and function in a VE a virtual actor. If the movement of a virtual actor is slaved to the motions of a human using cameras, instrumented clothing, or some other means of body tracking, we call that a guided virtual actor, or simply, a guided actor. Autonomous actors operate under program control and are capable of independent and adaptive behavior, such that they are capable of interacting with human participants in the VE, as well as with simulated objects and events. In addition to responding to the typed or spoken utterances of human participants, a virtual actor should be capable of interpreting simple task protocols that describe, for example, maintenance and repair operations. Given a set of one or more motor goals—e.g., pick up the wrench and loosen the retaining bolts, or put the book on the desk in my office—a virtual actor should be capable of generating the appropriate motor acts, including necessary and implicit tasks and motor subgoals.
Beyond the added realism that the presence of virtual actors can provide in those situations in which the participants would normally expect to see other human figures, autonomous actors can perform two important functions in VE applications. First, autonomous actors can augment or replace human participants. This will allow individuals to work or train in group settings without requiring additional personnel. Second, autonomous actors can serve as surrogate instructors. VE systems for training, education, and operations rehearsal will incorporate various instructional features, including knowledge-based systems for intelligent computer-aided instruction (ICAI) (Ford, 1985). As ICAI systems mature, virtual actors can provide personae to interact with participants in a VE system.
The required degree of autonomy and realism of simulated human figures will vary, of course, from application to application. However, at the present time, rigorous techniques do not exist for determining these requirements. It should also be noted that autonomous agents need not be literal representations of human beings but may represent various abstractions. For example, the SIMNET system provides for semiautonomous forces that may represent groups of dismounted infantry or single or multiple vehicles that are capable of reacting to simulated events in accordance with some chosen military doctrine. In the remainder of this section, we confine our discussion to simulated human figures, i.e., virtual actors.
In the course of everyday activity, we touch and manipulate objects, make contact with various surfaces, and make contact with other humans either directly, e.g., shaking hands, or indirectly, e.g., two people lifting a
heavy object. There are other ways, of course, in which two or more humans may coordinate their motions that do not involve direct contact, for example, crew members on a carrier flight deck who communicate by voice and hand signals. In the computer graphics community, there is a long history of human figure modeling, but this work has considered, for the most part, kinematic modeling of uncoupled motion exclusively.
With today's graphics workstations, kinematic models of reasonably complex figures (say, 30 to 40 degrees of freedom) can be animated in real or near-real time; dynamic simulations cannot. We need to understand in which applications kinematic models are sufficient, and in which applications the realism of dynamic simulation is required.
Action Selection In order to implement autonomous actors that can function independently in a virtual world without the need for interactive control by a human operator, we require some mechanism for selecting and sequencing motor skills appropriate to the actor's behavioral goals and the states of objects—including other actors—in the VE. That is, it is not sufficient to construct a set of behaviors, such as walking, reaching, grasping, and so on. In order to move and function with other actors in a virtual world that is changing over time, an autonomous actor must link perception of objects and events with action. We call this process motor planning.
Brooks (1989) has developed and implemented a motor planning mechanism he calls the subsumption architecture. This work is in large part a reaction against conventional notions of planning in artificial intelligence. Brooks argues for a representationless paradigm in which the behavior of a robot is modulated entirely by interaction between perception of the physical environment and the robot's task-achieving behavior modules.
Esakov and Badler (1991) report on the architecture of a simulation-animation system that can handle temporal constraints for task sequencing, rule sets, and resource allocation. No on-line planning was implemented. Task descriptions were initially in the form of predefined animation task keywords. This keyword-based input constraint was subsequently relaxed to allow simple do-this/do-that commands, e.g., ''The man should flip (switch) tglJ-1 with his left hand and the woman should move (switch) twF-1 to position 1." Most recently, reactive planning based on sensory perception has been used in locomotion control (Beckett and Badler, 1993), as well as real-time collision avoidance. A high-level task expansion planner (Geib, 1993) creates task-actions that are interpreted by an object-specific reasoner to execute animation behaviors. Recent work by Badler et al. (1991) also involves the exploration of natural language as a means of communicating task descriptions. Badler's
new AnimNL project is deeply committed to high-level motion planning (Badler et al., 1993, 1991; Webber et al., 1993); various other motor planning issues have also been studied and published (Badler et al., 1993; Ching and Badler, 1992).
Magnenat-Thalmann and Thalmann (1990, 1991), and Rijpkema and Girard (1991) have reported some work with automated grasping, but their systems seem to be focused on key frame-like animation systems for making animated movies, rather than for real-time interaction with virtual actors. Maiocchi and Pernici (1990) describe the PINOCCHIO system, which is capable of animating realistic character movement derived from recorded human movements. Their system uses limited natural language for describing body configurations, e.g., dance motions. However, this has only limited use in describing interactions with objects in the environment.
Ridsdale (1990) describes the Director's Apprentice, which is intended to interpret film scripts by using a rule-base of facts and relations about cinematic directing. This work was primarily concerned with positioning characters in relation to each other and the synthetic camera, but it did not address the representation and control of autonomous agents. In later work, Ridsdale describes a method of teaching skills to an actor using connectionist learning models (Ridsdale, 1990).
Maes (1990) has developed and implemented an action selection algorithm for goal-oriented, situated robotic agents. Her work is an independent formalization of ideas discussed in earlier work by Zeltzer (1983), with an important extension that accounts for the continuous flow of activation energy among a network of motor skills. Routine, stereotypical behavior is a function of an agent's currently active drives, goals, and motor skills. As a virtual actor moves through and operates in an environment, motor skills are triggered by presented stimuli, and the agent's propensities for executing some behaviors and not others are continually adjusted. The collection of skills and the patterns of excitation and inhibition determine an agent's repertoire of behaviors and flexibility in adapting to changing circumstances.
Populating the World: NPSNET as an Example
One of the key aspects of a virtual world is the population of that world. We define population as the number of active entities within the world. An active entity is anything in the world that is capable of exhibiting a behavior. By this definition, a human-controlled player is an active entity, a tree that is blown up is midway between an active and static entity, and an inert object like a rock is a static entity. In the NPSNET system, all of the active entities have been divided into four general categories
based on the control mechanism: expert system, scripting system, network entity, and driven entity. Recently, the term computer generated forces (CGF) has been developed to group all entities that are under computer control into a single category. In NPSNET, the entities controlled by both the expert system and scripting system are part of this category. The controlling mechanisms of the expert systems and autonomous players are briefly discussed below.
The expert system is capable of executing a basic behavior when a stimulus is applied to an entity. Within NPSNET it controls those entities that populate the world when there are an insufficient number of human or networked entities to make a scenario interesting. These added entities are called noise entities. The noise entity expert system has four basic behaviors: zig-zag paths, environment limitation, edge of the world response, and fight or flight. These behaviors have been grouped by the stimuli that causes the behavior to be triggered. The zig-zag behavior uses an internal timer to initiate the behavior. Environment limitation and edge of the world response are both dependent on the location of the entity in the database as the source of stimuli. The fight or flight behavior is triggered by external stimuli.
The purpose of an autonomous force is to present an unattended, capable, and intelligent opponent to the human player at the simulator. In NPSNET, the autonomous force is broken down into two components: an observer module that models the observation capabilities of combat forces and a decision module that models decision making, planning, and command and control in a combat force. The autonomous force system employs battlefield information, tactical principles, and knowledge about enemy forces to make tactical decisions directed toward the satisfaction of its overall mission objectives. It then uses these decisions in a reactive planning approach to develop an executable plan for its movements and actions on the battlefield. Its decisions include distribution of multiple goals among multiple assets, route planning, and target engagement. The autonomous force represented in this system consists of a company of tanks. The system allows for cooperation between like elements as well as collaboration between individuals working on different aspects of a task.
The observer module, described by Bhargava and Branley (1993), acts as the eyes and ears of the autonomous force. In the absence of real sensors, the observation module uses probabilistic models and inference rules to generate the belief system of the autonomous force. It accounts for battlefield conditions, as well as the capabilities and knowledge of individual autonomous forces, to determine whether and with how much accuracy various events on the simulated battlefield can be observed. The system converts factual knowledge about the simulated environment into
a set of beliefs that might correspond to the beliefs that a real combat force might form under the given conditions. It does so by combining the agent's observations with evidence derived from its knowledge base and inference procedures.
Hypermedia Integration
If one considers three-dimensional VEs as the ideal interface to a spatially organized database, then hypermedia integration is a key technological component. Hypermedia consists of nonsequential media grouped into nodes that are linked to other nodes. If we embed such nodes into a structure in a virtual world, the node can be accessed, and audio or compressed video containing vital information on the layout, design, and purpose of the building can be displayed, along with historical information. Such nodes will also allow us to make a search of all other nodes and find related objects elsewhere in the virtual world.
We also envision hypernavigation, which involves the use of nodes as markers that can be traveled between, either over the virtual terrain at accelerated speeds or over the hypermedia links that connect the nodes. Think of rabbit holes or portals to information populating the virtual world. Hypermedia authoring is another growing area of interest. In authoring mode, the computer places nodes in the VE as a game is played. After the game, the player can travel along these nodes (which exist not only in space but also in time, appearing and disappearing as time passes) and watch a given player's performance in the game. Authoring is especially useful in training and analysis because of this ability to play back the engagement from a specific point of view. Some examples of the uses of hypermedia in virtual worlds are presented in the following paragraphs.
One application is the extension of hypermedia to NPSNET (Zyda et al., 1993a). Hyper-NPSNET combines virtual world technology with hypermedia technology by embedding hypermedia nodes in the terrain of the virtual world. Currently, hypertext is implemented as nonsequential text grouped into nodes that are linked to other text nodes. The NPSNET group also has embedded compressed video (QuickTime and Moviemaker) into its worlds. This video contains captured video of the world being represented geometrically. Thus it provides information not easily represented or communicated by geometry.
In another application, the University of Geneva has a project under way entitled "A Multimedia Testbed" (de Mey and Gibbs, 1993), in which an object-oriented test bed for multimedia is presented. This is a test bed for prototyping distributed multimedia applications. The test application of that software is a virtual museum. The museum is a three-dimensional
geometric structure, the Barcelona Pavilion, in which is embedded various multimedia objects, compressed video, audio, and still imagery.
HARDWARE AND SOFTWARE ISSUES TO BE ADDRESSED
In all likelihood, the main short-term research and development effort and commercial payoff in the VE field will involve the refinement of hardware and software related to the representation, simulation, and rendering of visually oriented synthetic environments. This is a natural and logical extension of proven technology and benefits seen in such areas as general simulation, computer-aided design and manufacturing, and scientific visualization.
Nevertheless, the development of multimodal synthetic environments is an extremely important and challenging endeavor. Independent of the fundamental psychophysical issues and device design and development issues, multimodal interactions place severe and often unique burdens on the computational elements of synthetic environments. These burdens may, in time, be handled by extensions of current techniques used to handle graphical information. They may, however, require completely new approaches in the design of hardware and software to support the representation, simulation, and rendering of worlds in which visual, auditory, and haptic events are modeled. In either case, the generation of multimodal synthetic environments requires that we carefully examine our current assumptions concerning VE architectural requirements and design constraints.
In general, multimodal VEs require that object representation and simulation techniques now represent and support the generation of information required to support auditory signal generation and haptic feedback (i.e., rendering). Both of these modalities require materials and geometric (i.e., volume) information that is not typically incorporated into today's surface-oriented geometric models. Consequently, volumetric approaches may become more attractive at all three levels of information handling (i.e., representation, simulation, and rendering). Not only may volumetric approaches facilitate the representation of the information needed for objects in multimodal VEs but they may also lend themselves to local interaction models of physics that are elegant and straightforward to implement (Toffoli, 1983). In addition, hardware to support this form of physical simulation is starting to become available on such machines as the CAM-8 and the FX-1 from Exa Corporation. These approaches have been successfully employed in the modeling of fluid flow (Frisch, 1987) and may point the way for future VE representation, simulation, and rendering approaches.
In addition, the concept of frame rate, both in terms of update rate
and acceptable lags previously discussed in this chapter, must be refined or altered. Display update rates, which may be perfectly adequate for visual-only synthetic environments, are wholly inadequate when we consider the auditory and haptic modalities. Auditory events not only require rendering at rates exceeding 40 kHz but also have a temporal extent that may be measured in seconds. Furthermore, in even moderately complex synthetic environments, several auditory events may need to be generated and spatialized at any given instant. Update rate requirements for haptic events are also problematic and may be viewed on two levels. The first level is that associated with rendering kinesthetic or gross position/force information. These events require an update rate approaching 20 Hz. At the second level, tactile information (e.g., texture) requires rendering rates measured in the hundreds of Hz.
From the perspective of temporal lag, the generation of VEs that have auditory and haptic displays also places unique burdens on computational elements. Visual, auditory, and haptic events must be displayed without unacceptable intermodal lags. Although currently an area of research for the three modalities, it is known that delays on the order of a few tens of milliseconds can cause undesirable perceptual effects (e.g., the decorrelation of visual and auditory stimuli such that they are perceived as belonging to separate events). It is likely that the temporal alignment of visual, auditory, and haptic stimuli will need to be on the order of 10 ms. This number can potentially place burdens on the computation system one order of magnitude greater than currently acceptable update rates of visual-only VE.
How these issues and the numerous others that are likely to be encountered with further exploration are to be handled by computational systems is still an open and important area for further research. Clearly, however, more attention must be given to these issues from a computer hardware and software perspective. Currently, auditory and haptic interactions are predominantly handled by devices outside the major computational (usually graphical) workstation. This approach makes the essential temporal correlation of trimodal stimuli even more problematic and costly. Current generations of computer workstations benefit tremendously from special-purpose hardware that supports the rendering of graphical information. Related hardware may also be needed to support the rendering of auditory and haptic events. In a like manner, special-purpose hardware to support the representation and simulation of objects within a multimodal VE may be beneficial. Multimodal VEs put an even higher premium on several issues and shortcomings associated with current computational systems, such as: (1) veridical, real-time, physically inspired, simulation technology; (2) high-bandwidth, low-latency, input-output capabilities; (3) multimodal representation and simulation information
exchange formats and methodologies; and (4) short- and long-haul information networking technologies. Finally, an area that presents both a challenge and the promise of multimodal VEs is the proper use of the three modalities in the control of VEs and other computational environments. Certain metaphors (e.g., pull-down menus), albeit flawed, have served us well in two-dimensional, graphically oriented human-machine interfaces. Metaphors for three-dimensional, multimodal systems will require further research.
RESEARCH NEEDS
The state of the art in computer technology for the generation of VEs is constantly shifting. We have tried to define the edge of the currently accessible and available technology and some of the difficult problems yet to be solved. We now turn to a discussion of the hardware and software needed to address these problems and to move the field forward.
Hardware
As noted in the opening section of this chapter, advances in graphics and computer hardware are key to the full realization of VEs. The hardware capabilities available today have given researchers, entrepreneurs, and consumers just a taste of virtual worlds and a promise of possible applications. Because of the potentially wide appeal and the large variety of applications with differing performance requirements, it is important to continue hardware development at several levels from the high-end multimodal workstations to the low-end personal workstation with modest visual-only three-dimensional capabilities. The following paragraphs detail some of the key technical needs generated by VEs.
There are several computer hardware requirements needed to support high-end VE systems in the future. Computer architectures that provide for applications with high computational demands are devices for which we already have a requirement. These machines must have very large physical memories (> 15 Gbytes), multiple high-performance scalar processors, high-bandwidth (> 500 Mbytes/s), low-latency (< 0.03 s) mass storage devices, and high-speed interface ports for various input and output peripherals. Disk bandwidth is not expected to improve significantly over the next few years. (Disk bandwidth and size thus arise as limiting factors in video on demand and hypermedia integration in virtual worlds.) Current projections suggest that workstations capable of supporting 15 Gbytes of physical memory might be available sometime in 1994 but that the cost will be prohibitive for all but the most well-funded research groups.
Extensive computational and data management capabilities will also be required. Physical modeling and visualization computations will be the driving force behind this computational requirement. Machines capable of 40 Mflops or greater are needed now for some problems. If we wish to add more data points or develop finer resolution models, we could easily use all of this level of available computing power. It is important to encourage the actual production of required machines.
There is not just one computer architectural requirement. Different VE systems require different computer architectures. Some systems require a few parallel, high-power scalar processors with large shared memories; others require large numbers of CPUs operating in parallel (CPUs perhaps without scalar processing capabilities). This flexible requirement for CPU configuration may not be possible if the majority of the hardware fabricators move into the PC clone business.
Extrapolating current trends, we expect that VE applications will saturate available computing power and data management capabilities for some time to come. Dataset size will be the dominant problem for an important class of applications in VE. In the near term, an effective VE platform would include multiple fast processors in an integrated unit; several graphics pipelines integrated with the processors; very large shared physical memory; very fast access to mass storage; operating systems that support shared memory within multiprocessed architectures; and very high-speed, low-latency networks.
To ensure continued development, it is necessary to encourage both private- and public-sector participation. A key concern is that the number of serious research and development efforts associated with VE design and implementation are decreasing. For example, the number of commercial companies in the business of producing special architectures for high-performance graphics rendering systems has decreased since 1988 to only a few today. Furthermore, the University of North Carolina is perhaps the only significant university-based computer graphics hardware research group in the United States that is still working. These developments have three important implications. First, with a small number of participants it is possible that fewer ideas will be generated. Second, the pace of development may be slowed and the cost to consumers may remain high due to lack of competition. Third, those few companies currently producing hardware for VE research and application may turn their interests to other technology areas that for the moment might appear more lucrative, such as video games or the television of the future. Such could be the consequence if corporate America continues its trend toward high-yield, short-term investment rather than the lower yields over the long term.
Software
Most current SE systems are built using commercial workstations running some variant of the UNIX operating system (which was not originally designed to meet real-time performance requirements). Other approaches are based on using collections of more specialized embedded computational elements (possibly with a general-purpose workstation acting as the "front end") running operating systems that have been designed to support real-time, distributed computation. The latter approach has been extensively used in fields having hard real-time requirements, such as process control and telerobotics, and is discussed in some detail in Chapter 9 of this report.
From the perspective of using commercial workstations and their powerful graphical capabilities, however, the committee feels that what is needed is either a new operating system (OS) architecture specifically designed for synthetic environment (SE) applications or upgrades and enhancements of existing operating systems. The operating system capabilities required for virtual environments include: support of very large numbers of lightweight processes communicating via shared memory, support of automatic and transparent distribution of tasks to multiple computing resources, support of time-critical computation and rendering, and very high resolution time slicing and guaranteed execution for high-priority processes (to within 0.001 s resolution). Although not specifically addressing all of these concerns, the efforts of the Institute for Electrical and Electronics Engineers (IEEE) Posix standards committee are starting to bring real-time capabilities to the open system workstation environment. In particular IEEE standard 1003.4 (on real-time extensions to UNIX), standard 1003.4a (on threads extensions to UNIX), and standard 1003.13 (on application environment profiles for real-time applications support) are important to SE developers requiring some level of real-time control. Substantial subsets of the capabilities specified in these standards are now available on some graphics workstations (e.g., SGI workstations running the IRIX 5 version of the operating system). Supporting these capabilities in the operating system will significantly facilitate the development of many SE applications, especially larger, more ambitious efforts.
Government funding for the development of such a VE operating system or upgrade should be accompanied by a plan to shift this new system to commercial sponsorship. In the past, the federal government has funded a considerable amount of operating system research, much of which has never made the transition from university research project to commercial viability. To make sure that VE systems are written using an appropriate operating system, a real, financially sound transition plan for
specially designed or upgraded operating systems must be formulated, funded, and executed.
A second critical need is for large, multiyear, basic science programs created for developing large-scale VEs. Current trends in computer science research funding are for small university research grants with a typical size of approximately $400,000 over three years. The great majority of VE researchers receive significantly fewer grant funds. In addition, the trend in research funding for most agencies is toward the funding of projects with firm deliverables and schedules. With these constraints we believe that the level of experimentation researchers are willing or able to engage in will decrease, and, as a result, we cannot hope to see major advances in the technology. An example of the problem is the tendency of some government agencies to divert funds from large software development projects to impressive technology demonstrations. Although such demonstrations are appropriate for the culmination of significant basic research projects, they have most recently been used for rushed presentations in which the software was pieced together over a few months rather than carefully planned and designed over three to four years. There is an important need for the funding of large software development projects in which the goal is the development of large, open-ended, networked VEs. It is critical to concentrate funding on the basics. An additional trend of concern in the research funding arena is that exemplified by the Technology Reinvestment Program (TRP). Much of the nation's research dollars are moving into the TRP, which requires that universities take on a corporate partner. Such moves lock up research results in proprietary agreements and diminish the likelihood of shared research results.
Interaction Software
The general problem of inferring user intentions so as to provide a natural interface for all tasks in a three-dimensional VE is an area requiring a great deal of further research. Because language, which provides much of the intentional information in the real world, is not currently available for use in virtual worlds, other options must be thoroughly explored and developed. Unfortunately, the size of current government research efforts for work on providing natural interfaces is small. One government agency recently indicated that their entire VE human computer interface budget was approximately $150,000; another program in VE interfaces was funded at $2.5 million, with the goal of supporting six universities over one year. The rationale for these limited efforts is the belief that much of the interface research will be funded and carried out
by industry. However, it seems likely that, once the novelty wears off, industry interest will wane. Thus it is unlikely that the private sector will take on long-term development efforts in the absence of standards.
Nevertheless, high-level interface issues should be explored. Specifically, research should be performed to examine how to use data measuring the positions of the user's body for interaction with the VE in a way that truly provides the richness of real-world interaction. Critical concerns are how to apply user tracking data and how to define objects in VE to ensure natural interaction.
One of the major research challenges that has both hardware and software implications is the continued use of the RS-232C interface for control devices. Current workstation technology typically provides one or two such ports. Control devices are usually attached to these ports, with commands sent via the UNIX write system call. There is a speed limitation on the use of these ports, a limitation often seen as latency in input response. It is not uncommon to hear 70 ms touted as the fastest response from the time of input device movement to the reporting of the change back to the application running on the workstation. That 70 ms is too long a delay for real-time interaction, for which a maximum of 10 ms is more appropriate. And there is the additional problem with UNIX system software layers that must be traversed for events to be reported back to the concerned VE application.
Current workstation manufacturers do not focus on the design of such high-speed ports. Even within one manufacturer there is no guarantee that such ports will behave consistently across differing models of workstations. Real standards and highly engineered ports are needed for control devices. In fact, a revolutionary redesign and restandardization of the input port is required if control devices are to take off. In addition, we need to rethink the layers of VE system architecture.
Visual Scene Navigation Software
Given the current workstation graphics polygon filling capabilities and the extrapolation of those speeds into the future, software solutions will be needed to reduce the total number of graphics primitives sent through the graphics pipeline for some time to come. The difficulty of polygon flow minimization depends on the composition of the virtual world. This problem has historically been approached on an application-specific basis, and there is as yet no general solution. Current solutions usually involve partitioning the polygon-defined world into volumes that can readily be checked for visibility by the virtual world viewer. There are many partitioning schemes—some of which work only if the world description does not change dynamically. We need to encourage research
into generalizing this software so that dynamically changing worlds can be constructed.
Furthermore, there is a need to encourage the funding of research to reach a common, open solution for polygon flow minimization. Current researchers who have tackled polygon flow minimization have closely guarded their developed code. In fact, most software source code developed under university research contract today in the United States is held as proprietary by the universities, even if that code was developed under government contract. This fact, coupled with the stated goal of federal agencies of recouping investments, is counterproductive and disturbing. The unavailability of such software increases the overall development time and cost of progress in technology, as researchers duplicate software development. These redevelopment efforts also slow the progress of new development.
There are additional technical issues in polygon flow minimization that are important. One of these issues, the generation of multiple resolution three-dimensional icons, is a closely related technological challenge. In much of the work of polygon flow minimization, it is assumed that multiple resolutions, lower polygon count, and three-dimensional icons are available. This assumption is a large one, with automatic methods for the generation of multiple-resolution three-dimensional icons an open issue. There is some work in this area, and it is recommended that a small research program be developed to encourage more (DeHaemer and Zyda, 1991; Schroeder et al., 1992; Turk, 1992). In fact, the development of such public software and a public domain set of three-dimensional clip models with geometry and associated behavior could go a long way toward encouraging the creation of three-dimensional VEs.
Modeling
Simulation Frameworks Research into the development of environments in which object behavior as well as object appearance can rapidly be specified is an area that needs further work. We call this area simulation frameworks. Such a framework makes no assumptions about the actual behavior (just as graphics systems currently make no assumptions about the appearance of graphical objects). A good term for what a simulation framework is trying to accomplish is meta-modeling. Such frameworks would facilitate the sharing of objects between environments and allow the establishment of object libraries. Issues to be researched include the representation of object behavior and how different behaviors are to be integrated into a single system.
Geometric Modeling Because geometric modeling is integral to the construction of VEs, its current limitations serve as limits to development. As
a practical matter, the VE research community needs a shared open modeling environment that includes physical and behavioral modeling. The current state of the art in VE technology is to use available CAD tools, tools more suited to two-dimensional displays. The main problem with CAD tools is not in getting the three-dimensional geometry out of the CAD files but rather the fact that data related to the actual physics of the three-dimensional objects modeled by the CAD systems are not usually present in such files. In addition, the partitioning information useful for real-time walkthrough of these data usually has to be added later by hand or back fed in by specially written programs. CAD files also have the problem that file formats are proprietary. An open VE CAD tool should be developed for use by the VE research community. This tool should incorporate many of the three-dimensional geometric capabilities in current CAD systems as well as physics and other VE-relevant parameters (i.e., three-dimensional spatial partitioning embedded into the output databases). It should also capture parameters relevant to haptic and auditory channels.
Vision-Based Model Acquisition Although CAD systems are useful for generating three-dimensional models for new objects, using them can be tedious. Currently, modelers sit for hours detailing each door, window, and pipe of a three-dimensional building. VEs could be much more widely used if this painful step could be automated, perhaps via laser range finders and the right ''surface generation to CAD primitive" software. Unfortunately, there is the very hard multiple view, laser range image correlation problem. Automatic model acquisition would be a good first step toward providing the three-dimensional objects for virtual worlds. However, the physics of the objects scanned would still need to be added. This technology has many uses beyond developing VEs. An additional application area of high interest is providing CAD plans for older buildings, structures designed and constructed before the advent of CAD systems.
Augmented Reality Real-time augmented reality is one of the tougher problems in VEs research. The two major issues are (1) accurate measurement of observer motions and (2) acquisition and maintenance of scene models. The prospects for automatic solutions to the scene model acquisition and maintenance were discussed above. The problems with measuring observer motion are more difficult and represent a major research area. Although VE displays provide direct motion measurements of observer movement, these are unlikely to be accurate enough to support high-quality augmented reality, in situations in which real and synthetic objects are in close proximity. Even very small errors could induce perceptible relative motions that could disrupt an illusion. Perhaps the most
promising course would be to use direct motion measurements for gross positioning and to use local image-based matching methods to lock real and synthetic elements together.
TECHNICAL APPENDIX
Graphics Architectures for VE Rendering
The rendering operation has three stages: preprimitive, rasterization, and prefragment. Because of the performance demand, all modern high-performance graphics systems are run on parallel architectures. To allow the many-to-many mapping, the parallel rendering pipes must be combined at one point along their paths. The three possible locations for the crossbar are illustrated in Figures 8-6 through 8-8. The primitive crossbar (Figure 8-6) broadcasts window-coordinate primitives from the engines that transformed and lighted them to the one or more rasterization engines that correspond to frame buffer regions that each primitive intersects. Depending on the window-coordinate size of a primitive, it might be processed by just one rasterization engine, or by all of the rasterization engines. Thus this crossbar is really a one-to-many bus.
The fragment crossbar (Figure 8-7) is a true, one-to-one crossbar connection. Each fragment that is generated by a rasterization engine is directed to the one fragment processor that manages the corresponding pixel in the frame buffer. Thus the fragment crossbar is itself more easily parallelized than the primitive crossbar, allowing for the necessarily greater bandwidth of rasterized fragments over window-coordinate primitives. The primary disadvantage of the fragment crossbar compared
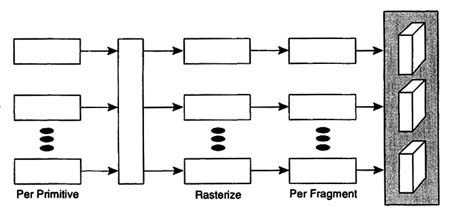
FIGURE 8-6 Primitive broadcast.
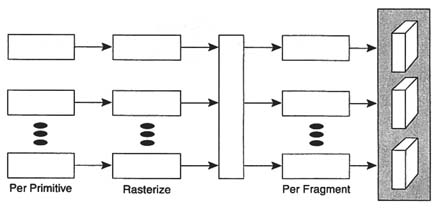
FIGURE 8-7 Fragment crossbar.
with the primitive crossbar is that fragment crossbar systems have difficulty rendering primitives in the order that they were presented to the graphics system, whereas primitive broadcast systems easily render primitives in the order presented.
Whereas the frame buffers in the primitive broadcast and fragment crossbar systems were disjoint, collectively forming a single, screen-size buffer, the frame buffers of a pixel crossbar system (Figure 8-8) are each complete, screen-size buffers. The contents of these buffers are merged only after all of the primitives have been rendered into one of the buffers. The primary advantage of such a system over primitive and fragment crossbars is that pixel merge, using the z-buffer algorithm to choose the final pixel value, is infinitely extensible with no performance loss. Again,

FIGURE 8-8 Pixel merge.
the term crossbar is misleading, since the pixel merge can be accomplished with one-to-one paths between adjacent buffer pairs.
The primary disadvantage of pixel merge systems is the requirement for large, duplicate frame buffers. A secondary disadvantage exists only with respect to primitive broadcast systems: the pixel crossbar, like the fragment crossbar, has difficulty rendering primitives in the order presented. (Each path renders the primitives presented to it in the order that they are presented, but the postrendering pixel merge cannot be done in order.)
The primary disadvantage of frame buffer size can be mitigated by reducing the size of each frame buffer to a subregion of the final, display buffer. If this is done, the complete scene must be rendered with multiple rasterization passes, with the subbuffers being merged into the final display buffer (which is full size) after each pass is completed. Application of such a multipass technique introduces the second differentiator of parallel graphics systems: whether the rendering is flow-through or tiled. Flow-through systems complete the processing of each primitive soon after that primitive is presented to the rendering system, in which "soon" is a function of the number of processing steps. Tiled systems accumulate all the primitives of a scene after the per-primitive processing is complete, then begin the rasterization and per-fragment processing. They must do this because frame buffer tiles are allocated temporally rather than spatially, and so are not available in the random sequence that the primitives arrive in. The primary disadvantage of tiled systems over flow-through systems is therefore one of increased latency, due to the serialization of the processing steps.
The third major differentiator is image quality: does the architecture support mapping images onto geometry (texture mapping), and is the sampling quality of both these images and the geometry itself of high quality (anti-aliasing)? This differentiator is less one of architecture than of implementation—primitive, fragment, and pixel crossbar systems, both flow-through and tiled, can be implemented with or without texture mapping and anti-aliasing.
The final differentiator is performance: the number of primitives and fragments that can be processed per second. Again this differentiator is less one of architecture than of implementation, although at the limit the pixel merge architecture will exceed the capabilities of primitive broadcast and fragment crossbar architectures.
Now we consider the architectures of four modern graphics systems, using the previously discussed differentiators. The Silicon Graphics RealityEngine is a flow-through architecture with a primitive crossbar. It therefore is able to efficiently render primitives in the order that they are presented and has low rendering latency. RealityEngine supports texture mapping and anti-aliasing of points, lines, and triangles and therefore is
considered to have high rendering image quality. RealityEngine processes up to 1 million texture mapped, anti-aliased triangles/s, and up to 250 million texture mapped, anti-aliased fragments/s. It is able to generate 1,280 × 1,024 scenes of high quality at up to 30 frames/s.
Freedom series graphics from Evans & Sutherland use a flow-through architecture with a fragment crossbar. Thus Freedom machines also have low rendering latency, but are less able than the RealityEngine to efficiently render primitives in the order that they are presented. Freedom machines support texture mapping and can anti-alias points and lines, but they are unable to efficiently anti-alias surface primitives such as triangles. Hence the rendering quality of Freedom machines for full-frame solid images is relatively low. Although exact numbers for Freedom fragment generation/processing rates are not published, the literature suggests that this rate for texture-mapped fragments is in the tens of millions per second, rather than in the hundreds of millions. If that is the case, then the performance of Freedom graphics is not sufficient to generate 1,280 × 1,024 images at even 10 frames/s, the absolute minimum for interactive performance.
Pixel Planes 5, the currently operational product of the University of North Carolina's research efforts, uses a tiled, primitive crossbar architecture. Because the architecture is tiled, the advantage of ordered rendering typical of primitive crossbar systems is lost. Also, the tiling contributes to a latency of up to 3 frames, which is substantially greater than the single-frame latencies of the Freedom and the RealityEngine systems. The rendering performance, especially the effective fragment generation/processing rate, is substantially greater than either the Freedom or RealityEngine systems, resulting in easily maintained 1,280 × 1,024 30 frame/s image generation. However, Pixel Planes 5 cannot anti-alias geometry at these high rates, so the image quality is lower than that of RealityEngine.
Finally PixelFlow, the proposed successor to Pixel Planes 5, is a tiled, pixel merge machine. Thus it is unable to efficiently render primitives in the order in which they are received, and the rendering latency of PixelFlow is perhaps twice that of Freedom and RealityEngine, though less than that of Pixel Planes 5. PixelFlow is designed to support both texture mapping and anti-aliasing at interactive, though reduced rates, resulting in a machine that can produce high-quality, 1,280 × 1,024 frames at 30 or even 60 frames/s.
Silicon Graphics from the IRIS-1400 to the RealityEngine 2
Silicon Graphics, Inc., a computer manufacturer, creates visualization systems with some of the more flexible and powerful digital media capabilities
in the computer industry, combining advanced three-dimensional graphics, digital multichannel audio, and video in a single package. Silicon Graphics systems serve as the core of many VE systems, performing simulation, visualization, and communication tasks. In such a role, it is critical that the systems support powerful computation, stereoscopic, multichannel video output, and fast input/output (I/O) for connectivity to sensors, control devices, and networks (for multiparticipant VEs). Textured polygon fill capability is also one of the company's strengths with respect to virtual worlds in that texturing enhances realism.
In support of this role, Silicon Graphics has engaged in the development of multiple processing, graphics workstations at the leading edge of technology since late 1983. A brief look at the graphics performance numbers of their high-end systems since that time is warranted (Table 8-1). Those systems comprise three generations, as described in the RealityEngine Graphics paper (Akeley, 1993). The 1000, 2000, and G are first generation, the GTX, VGX, and VGXT are second generation, and the RealityEngine and RealityEngine2 are third generation. Performance is listed for first-, second-, and third-generation operations for all these machines. Notice that the curve for first-generation performance falls off with second- and third-generation machines, because they are not optimized for first-generation rendering.
Onyx RealityEngine2
In January 1993, Silicon Graphics announced the Onyx line of graphics supercomputers, which incorporate a new multiprocessing architecture, PowerPath2, to combine up to 24 parallel processors based on the MIPS R4400 RISC CPU, which operates at 150 MHz. I/O bandwidth is rated at 1.2 Gbytes/s to and from memory, with support for the VME64 64-bit bus, operating at 50 Mbytes/s.
Onyx systems can utilize up to three separate graphics pipelines based on the new RealityEngine2 graphics subsystem. This new graphics system offers 50 percent higher polygon performance than the original RealityEngine introduced in July 1992. RealityEngine2 is rated at 2 million flat triangles/second and 900,000 textured, Gouraud shaded, anti-aliased, fogged, z-buffered triangles/s.
The optional MultiChannel board enables users to take the frame buffer and send different regions out to different display devices. Thus, a single 1.3 million pixel frame buffer could be used either as a 1,280 × 1,024 display or as four 640 × 512 displays. The MultiChannel option provides up to six separate outputs.
TABLE 8-1 Performance History for SGI Graphics
Evans & Sutherland Freedom 3000
Evans & Sutherland (E&S), and old line flight simulator company, has recently announced the Freedom Series of graphics accelerators targeted for the Sun Microsystems Sparc 10 line of workstations. The Freedom series offers a wide range of performance levels: from 500,000 polygons per second for the Freedom 1000 to 3 million polygons per second for the Freedom 3000. The Freedom series uses standard hardware and software interfaces to join seamlessly with the Sun Microsystems environment. The Freedom accelerators are programmable with Sun's standard interfaces and are software-compatible with workstations currently available from E&S and Sun.
The Freedom 3000 has 1,280 × 1,024, 1,536 × 1,280, and high-definition TV display formats. It also supports hardware texture mapping, including MIP-mapping, and resolutions up to 2,000 × 2,000. Additional features supported are: anti-aliased lines, dots, and polygons, alpha buffering, accumulation buffering, 128 bits per pixel, and dynamic pixel allocation.
The Freedom 3000 contains the following technology: five proprietary VLSI ASIC chips types using 0.8 µ CMOS, a parallel array of programmable high-speed microprocessors (DSPs), a very fast, proprietary graphics bus (G-bus) capable of speeds well beyond 3 million polygons/s, high-speed pixel routing interconnection, high-speed access to frame buffer for image processing (up to 100 million pixels/s), and a pixel fill rate of 95 million pixels/s.
Graphics Hardware from the University of North Carolina, Chapel Hill: PixelPlanes 4, 5, and PixelFlow
The University of North Carolina at Chapel Hill is one of the last schools still developing graphics hardware. Their efforts differ widely from what has been attempted in the commercial world, since their work is more basic research than machine production. Despite this research focus, the machines developed by Fuchs, Poulton, Eyles, and their colleagues have been close to the leading edge of graphics hardware at each of their prototypical stages (Fuchs et al., 1985, 1989). Pixel Planes 4 had a 27,000 polygons/s capability in 1988, with a follow-on machine Pixel Planes 5 shown first in 1991 with a 1 million polygons/s capability. The latest machine, PixelFlow, is still under development but shows great promise (Molnar et al., 1992). It is expected to be working in 1994.
PixelFlow and its graphics performance scalability are an important part of the future of high-performance three-dimensional VEs. PixelFlow, an architecture for high-speed image generation, overcomes the transformation
and frame-buffer access bottlenecks of conventional hardware rendering architectures (Molnar et al., 1992). It uses the technique of image composition, through which it distributes the rendering task over an array of identical renderers, each of which computes a full-screen image of a fraction of the primitives. A high-performance image-composition network combines these images in real time to produce an image of the entire scene.
Image composition architectures offer performance that scales linearly with the number of renderers. A single PixelFlow renderer rasterizes up to 1.4 million triangles/s, and an n-renderer system can rasterize at up to n times this basic rate. It is expected that a 128 renderer PixelFlow system will be capable of a polygon rate approaching 100 million triangles/s.
PixelFlow performs anti-aliasing by supersampling. It supports deferred shading with separate hardware shaders that operate on composite images containing intermediate pixel data. PixelFlow shaders compute complex shading algorithms and procedural and image-based textures in real time, with the shading rate independent of image complexity. A PixelFlow system can be coupled to a parallel supercomputer to serve as an intermediate-mode graphics server, or it can maintain a display list for retained-mode rendering.

























































