
1 Introduction
From the moment of birth to the signing of the death certificate, medical records are maintained on almost every individual in the United States (and many other countries). Increasing quantities of data are abstracted from written records, or entered directly at a workstation, and submitted by providers of healthcare to payer and regulatory organizations. Providers include physician offices, clinics, and hospitals, payers include managed care corporations and insurance companies, and regulatory organizations include state and federal government. Trends are towards making the flow of data easier, more comprehensive, and multi-faceted: through EDI (electronic data interchange), CHINs (Community Health Information Networks), and a seemingly ever more intrusive, detailed, and specific involvement by payors in the handling of care and compensation by and for providers.
These so-called clinical and financial administrative health care data are routinely massive. The Health Care Financing Administration's annual MEDPAR data base contains around 14 million discharge abstracts of every medicare-funded acute-care hospital stay. Individual state's administrative data of hospital discharges may include several million records annually. Data are collected in certain standard formats, including uniform billing (UB82, now UB92) for administrative data on hospital stays, and HEDIS (1.0, 2.0, 3.0) on patients in managed care. The more detailed data is often proprietary: for example HEDIS data is often proprietary to the specific payer organization, and includes data only on the organization's enrollees. More ambitious data collecting is underway in selected locations, through the systematic abstraction of supplementary clinical measures of patient health from medical records, through recording of additional patient characteristics, or through recording of more detailed financial information.
In principal the entire medical record is available. A written version might be available online in digital form as an image. Record linkage, for example between members of a family (mother and child), or through the use of unique patient identifiers across multiple episodes of treatment, or from administrative data to the registry of vital statistics (death certificates) and to cancer registries, provides important additional information. However, the availability of such information is, again, restricted.
A traditional uses of health data is in public health assessment and the evaluation of clinical efficacy of particular treatments and interventions.
These data are typically used differently: to analyze the system of health care delivery, seen as an aggregate of public and private, corporate and individual (physician) entities. These data are observational and comprehensive, i.e. a census; thus questions of accuracy and specificity—the appropriateness of the data to address particular clinical and financial concerns—predominate over statistical issues of sampling, estimation, and even censoring of data. Statistical tools may be relatively unsophisticated—with some exceptions (Silber, Rosenbaum and Ross (1995), and Harrell, Lee, and Mark (1995) and related papers)—but can be applied in massive fashion. Following a few further remarks to help set the scene, this paper is concerned with characterizing the interplay of statistical and computational challenges in analysis of massive data in healthcare.
In a real sense, the pressures of the competitive market place are pushing through healthcare reform in a manner which the political process has, in recent years, been poorly equipped to mandate. An oft-repeated criticism of the US health care delivery system has been that its high quality is associated with very high costs. A frequent rejoinder has been that some form of rationing of healthcare would be necessary in order to reduce costs. And indeed, the criticism now appears muted, and accounts of high costs appear to have given way, in the media, to accounts of the pitfalls of fairly apportioning care in a managed environment. Legislation, in New York and New Jersey and other states, has turned to mandating minimum levels of hospital care, notably for mothers delivering their babies.
The analysis of health care data, indeed, the massive analysis of massive health care data sets, has a central role in setting health care policy and in steering healthcare reform, through its influence on the actual delivery of healthcare, one hospital and one health maintenance organization at a time. In a nutshell, the twin objectives are for small consumption of resources, measured primarily in terms of cost, but also in terms of hospital length-of-stay, and for high quality. In practice the effective break-even point, between sacrificing quality and flexibility for resource savings, is obscured in corporate and institutional decision making and policy. Massive amounts of data analysis serves first of all to identify where savings might be made, or where quality might be inadequate. Most often, other hospitals or other physicians provide benchmarks in studying performance. Even relatively low cost and high quality hospitals can find room for improvement in the practice patterns of particular physicians or in treating particular types of patients.
No comparison is adequate without some effort at standardization of patient populations, or risk adjustment that accounts for individual patient characteristics. Adequate risk adjustment requires massive data sets, so as to provide an appropriately matched sample for any patient. Issues of model uncertainty, and the presence of multiple models, appear obviously and often. Orthogonal to patients are the number of possible measures, from overall measures of resource consumption and quality, to more detailed measures such as costs by individual cost center, the use of particular drugs and medications, and outcomes by type of complication. The next section gives a few details of COREPLUS and SAFs, two systems for outcomes analysis and resource modeling, including risk adjustment, developed in part by the author at Healthcare Design Systems.
The very large number of different questions in health care, and the specificity of those questions to individual providers, payers, regulators, and to patients, are compelling reasons to do massive analysis of the data. John Tukey has advised that, as CPU cycles are now cheaper than FTE's, the computers should be constantly running. The challenge is to devise a series of meaningful analyses that will use these resources (that are effectively free at the margin). In the following sections some graphical/tabular (Section 3), statistical (Sections 2 and 4), and computational (Section 5) aspects of implementation are addressed.
Massive analysis of massive health care data finds consumers at all levels, from federal government to state government, from payers to health systems, from hospitals to clinics, to physicians and to patients. The needs may differ in detail, but the overall strategy is dear: To provide multi-faceted insight into the delivery of health care. Consumption here includes both more passive and more active roles in preparing questions to be addressed through data analysis. Thus clinical professionals, their accountants and administrators, and patients, may assimilate already prepared reports and report cards, and they may seek immediate answers to questions generated on the spur of the moment, following a line of enquiry.
2 COREPLUS and SAFS: Case Studies In MDA
The following is a brief account of the evolution of two project in massive data sets undertaken by Healthcare Design Systems (HDS) and its collaborators. With its parent company, latterly Kaden Arnone and currently QuadraMed, HDS has provided consulting services and software services to the hospitals and managed care companies. COREPLUS, for Clinical Outcomes Resource Evaluation Plus, is a system for analyzing outcomes of hospital care. SAFs, for Severity Adjustment Factor computation, is a system for modeling resource consumption, including cost and length of stay. Both systems have been developed through a collaborative effort between clinical experts, healthcare information processing staff, statisticians, management, and marketing. Clinical expertise is obtained through the New Jersey Hospital Association, as well as in house and by way of hospitals and their physicians.
COREPLUS includes 101 clinical outcomes in six major outcome categories (Vaul and Goodall, 1995). These are obstetrics, including Cesarcan section and post-delivery complication rates, mortality, including overall and inpatient mortality, pediatric mortality, postoperative mortality (within 48 hours), stroke mortality, and mortality by major diagnostic category (MDC), subdivided into medical, surgery, oncology, and non-oncology patients, neonatal, including newborn mortality by birthweight category and newborn trauma, surgery, including post-operative infections and various complication rates, general, including laparoscopic percent of cholecystectomies, diabetes percent of medical cases, and cardiac, including C ABG surgery mortality, cardiac valve mortality, myocardial infarction, and male and female cardiac mortality.
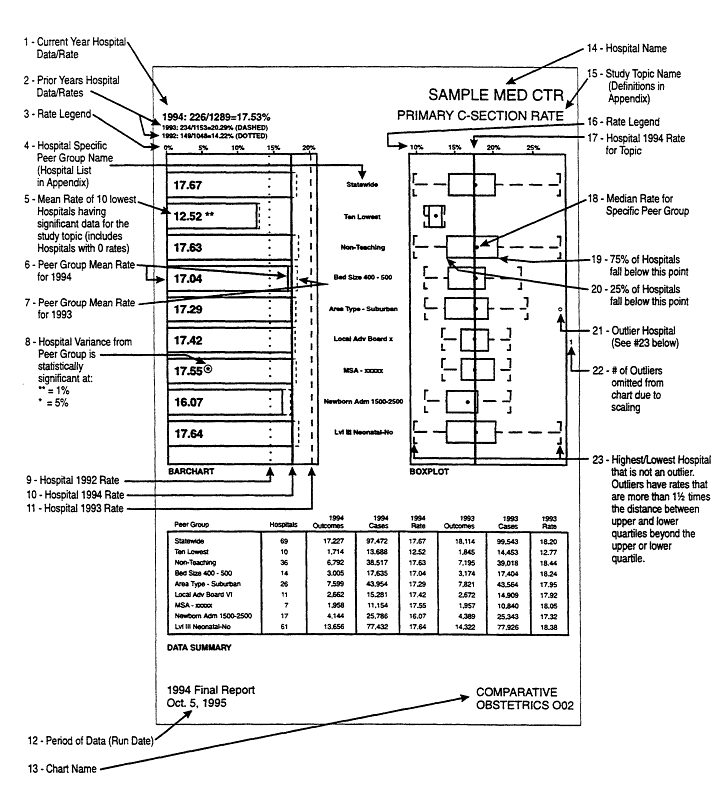
The sample sizes for the data included in each of these clinical outcomes ranges from several thousand to half a million for a single state (New Jersey, with around 1.3 million annual hospital discharges), and proportionately more for national data. The definition of the clinical outcomes is determined by clinical experts. Due to inevitable limitations in the data, some careful choices must be made in these definitions. Hospitals are compared in a comparative chart (Figure 1), using a variety of peer groups for comparisons.
Severity adjustment factors are computed in each of approximately 600
DRGs. We model length of stay, and costed data.
Prediction models in COREPLUS, and somewhat similarly for SAFs, are built using several categories of variables, including general variables , such as a function of age, sex, race group, payer group, and surgical use variables, general diagnosis and procedure variables, based on collections on one or more diagnosis and procedure codes in areas such as decubiti, sepsis, diabetes, renal failure, vents, and separately by principal and secondary diagnosis, specific diagnosis and procedure variables, specific to the outcome, and specific additional variables , for example birthweight. Hospitals are then compared in a predictive chart (Figure 2). The point here is not to provide a detailed explanation and justification of the system, but rather to illustrate the size of the problems that are encountered.
Variable selection is hindered by a ''large p'' problem: There are over 10,000 diagnosis and procedure codes to use singly, in aggregates (any one of the codes) or combinations (two or more codes simultaneously), as indicator variables in regression modeling. There is be a tight loop between statistical and clinical collaborators, within which data presentation is designed to convey information about potential variables and about the role of variables in fitting a statistical model to help elucidate clinical judgements.
Model building goes through several clinical and data-analytic steps, including: (1) provisional definition of an outcome in terms of elements of the data, (2) validation of the definition through running it against a data base, observing frequencies and dumps of individual patient detail, (3) marginal analysis of the association between potential predictor variables and the response, (4) determination of a set of candidate predictor variables based on clinical expertise supported by the data analysis, (5) predictive model building by a combination of hierarchical and variable selection methods, (6) review of results of model building for reasonableness of coefficients, (7) goodness of fit analysis overall and for subsets of patients, including those defined by the potential predictor variabels at step (3).
Beyond these steps, model validation is continual and on-going. A typical application of the systems is for quality assurance or utilization review staff at a hospital to undertake analyses of specific categories of patients, using COREPLUS and SAFs as guides towards problem areas. These might be patients whose outcome is contraindicated by the prediction. The patient medical record is consulted for further details, and that can expose factors that might be better accommodated in the definition of the clinical outcome,
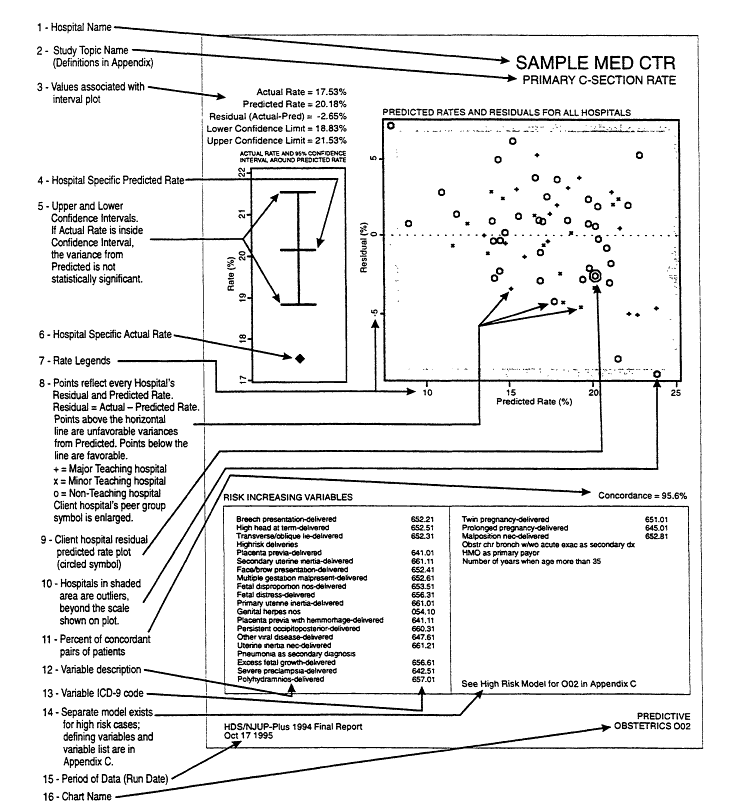
or in the predictive model.
To summarize, the COREPLUS and SAF applications are massive along several dimensions.
- The data are massive. The number of observations is in the millions or tens of millions, the number of fields in the hundreds.
- The number of variables that can be meaningfully derived from the fields in the data is in the tens of thousands, including aggregation and combinations of indicators.
- The clinical resource is massive, from the corpus of medical literature to live clinical expertise.
- The audience is massive, as every person is involved in a professional or in a patient capacity in healthcare.
- The varieties of questions that can be addressed are massive.
3 Presentation of Data Analysis
Massive analysis of massive health care data finds consumers at all levels, from federal government to state government, from payers to health systems, from hospitals to clinics, to physicians and to patients. The needs may differ in detail, but the overall strategy is clear: To provide multi-faceted insight into the delivery of health care. Consumption here includes both more passive and more active roles in preparing questions to be addressed through data analysis. Thus clinical professionals, their accountants and administrators, and patients, may assimilate already prepared reports and report cards, and they may seek immediate answers to questions generated on the spur of the moment, following a line of enquiry.
Massive analysis of massive data may be presented in two ways. One, as a carefully formatted, detailed report, that presents in tabular, graphical and textual form a balanced and informative account of one or more aspects of the data. Such a report is likely to be condensed into one or a few pages (Figure 1), but many such reports can be combined together to give insight into many aspects of the data. Some further specifics are given in Section 3. Conceptually, this is akin to designing a new subway map for London or New
York, with its goal of clear but dense information content. In the subway map, each component, a subway station or a stretch of track, has specific and individual meaning to many, if not all, users of the system; likewise each component of the graph must be labelled—the conventional scatter plot, comprising a scatter of points with perhaps a few outliers labelled, is not a high performer in this regard. Tools to develop such graphics are now available, eg using Splus (MathSoft, Inc.) and, increasingly, off-the-shelf PC spreadsheet and graphics programs.
The second presentation of massive analysis of massive data in health care is through user friendly, immensely flexible, software for data analysis. Such software is a front end for analysis of data bases abstracted from the massive parent data, and is tailored to the particular needs of the health care investigator. The data themselves are at a patient level, so that patient level detail can be used to help understand patterns among larger groups. However, it is reasonable to save summary statistics only for larger groups, which leads to a hierarchy of different data types within this software, and reports tailored to this structure.
There is no absolute dividing line between reports generated directly from the massive parent data, and reports generated from software at distributed locations. What is clear, however, is that the analysis of massive data is a specialized undertaking, and that exceptional computational resources, in terms of hardware, software, and personnel, as well as clinical and statistical expertise, must accumulate at those central locations. The corresponding computational resources that are available in distributed fashion to the consumers of these data are increasingly powerful, flexible, and user-friendly, but there must always be a significant gap between them and the centralized resources. Even without the difference in sheer computational horsepower, the expertise at a central location allows flexibility in report generation that is beyond the scope of user-friendly, and thus to an extent sanitized, software.
The internet provides additional dimensions that further facilitate massive analyses of data to suit many diverse objectives. A straightforward use of the internet is for data collection and transmittal, in an extensive and multi-layered network. At its highest level this network involves the transmission of massive data sets among state, federal, academic, industrial, and commercial repositories. The rapid evolution of paradigms on the internet, from ftp, to viewing world wide web (WWW) pages, to downloading software on an as-needed basis via WWW, will find echos in the handling of massive
data sets in health care. For example, a massive data set need not reside at a single location; instead, application daemons might visit a succession of sites, collecting and even summarizing information to compile together into a comprehensive analysis.
A first step in integrating the internet into the central-distributed model might include transmitting data on a daily basis from providers (physicians and hospitals) to a central information processing center and its return to the provider with added value, for example, including some standards and predictions for benchmarking. Second, in generating reports at hospitals, queries for additional information might be sent directly to the information processing (IP) center, perhaps complementing the summary statistics already in the provider data base with fully uptodate data, or summary data for a different category of patients. Third, in generating a comparative report for a provider with some additional fields beyond the standard set, the IP center might access comparable data using its priviledged access to other providers databases.
4 Statistical Challenges
In analyzing massive data in healthcare, several concerns are paramount
- Each patient is an individual. Patients are not exchangeable.
- No single set of variables can capture all pertinent information on a collection of individual.
- Even for only moderately large sets of variables, not even the most comprehensive efforts at modeling are enough.
If the cost of my hospitalization appears high, then that appearance is because of some internal benchmarking or expectations. I might ask the physicians who direct my treatment program for an explanation. I may also refine my benchmarks by looking at the costs of hospitalizations for other patients, perhaps initially for a broad group of patients, but increasingly for patients with similar environment and medical history to my own, a process that culminates in the use of one, but, better, many statistical models that provide patient-specific predictions (benchmarks). Of course, even then, the variables that really matter might not be in the patient records.
Each patient has very many alternative peer groups in a massive data set. In the setting of healthcare, massive data does not provide a 'law of large numbers' as protection for standard statistical analyses, but instead leads to a power law increase with sample size in the computational requirements.
These considerations throw the burden of analysis towards exploratory techniques. A starting place is simple 'odds ratio' statements of the form: Of 131,323 patients at risk for the outcome, 17,076 had the outcome, a rate of 13.00%. These data comprise patients with myocardial infarction during 1993 or 1994 in 10 states, and the outcome is death. Of the patients at risk, 24,986 patients had an initial acute myocardial infarction of the interior wall, with 4,065 deaths, a mortality rate of 16.27%. This particular AMI, ICD9 code 410.11, is just one of around 40 codes for AMI, which can be aggregated in diverse ways, or looked at in combination with other codes. There is thus a massive number of statistical statements, and insufficient resources for immensely detailed analyses of small data sets, such as the stack loss data. The need is for what might be called total analysis.
Beyond exploratory analysis, some statistical areas that appear particularly relevant are (i) advances in regression modeling, (ii) missing data methods, (iii) theory for observational data, and (iv) hierarchical models and Bayesian statistics (where reasonable computationally with large data sets).
Three further aspects are important. One is statistical computation and computational performance. A second is data, and the need for intense effort in understanding where the data come from and what are the alternatives. The third is organizational. In healthcare analysis, a divide and conquer strategy is natural given the pervasive subject matter knowledge: patients are naturally divided by major diagnostic category (MDC), for example, those with respiratory problems (MDC 4) and those with cardio-vascular problems (MDC 5). Some organizational/computational considerations of divide and conquer are considered in Section 5.
5 Organization of Computations
The problems of massive data analysis in healthcare involves as much organization as statistical analysis. A divide and conquer strategy becomes all-consuming: total data analysis in which all resources are devoted to the
maintenance, organization, and enhancement of the data.
Several statistical packages provide an "environment" for statistical analysis and graphics, notably SAS (SAS Institute, Cary, NC) and S (Becker, Chambers and Wilks, 1988). Although these systems provide a consistent interface to statistical functions, a programming language, graphics, an interface to operating system tools, and even a programmable graphical user interface, each has limitations. S has the more powerful and flexible environment, but SAS programming expertise is easier to find, SAS jobs are more likely to plug away until complete—inevitably massive data analyses are left to run "in batch" overnight and over the weekend, and it is better to pay a performance penalty than to risk non-completion. SAS programs are a little easier to read, less encumbered by parentheses. Neither environment fully supports imaging, graphics, and the World-Wide Web.
Thus there is a strong use for integration tools, that allow the best and brightest software to work together in a project-specific, possibly jury-rigged, system. Shell programming is important, but Perl stands out, and other approaches (tcl/tk) are promising. Another useful tool is DBMS Copy for transfering data between packages. Modern operating systems, for example IRIX version 5 or later, allow iconographic maintenance and operations. However, a graphical user interface is not so useful without scripting, as an adhoc analysis may be repeated many-fold.
Organizationally, the multi-dimensional arrays found in the the storage of data, where each element of the array is a single number, is echoed at a higher level in the organization of the components of massive data sets. In health care data, the dimensions of this meta-array might be year × state × outcome measure, where each element of the array is itself an array indexed by patient × measurement variable × hospital or episode. A summary of such data might be a table of C-section rate by state by year, including both mean and variation.
In principle these data might be organized into a six-dimensional array, either explicitly into an Oracle or Sybase database (say), or into a SAS or S dataset. Indeed, the present version of S, and even more so a future version, would support programming of a virtual array, in which the meta-array of arrays appears transparently as a six dimensional structure. Massive data sets in health care are constantly changing and evolving, and it is vital not to impose too rigid a framework. There might be a new hospital's data today, of a different sort, or a new type of data (images of patient records), or a
new measurement variable. It is most natural to maintain such data in the file system, not in a statistical package.
Thus the functions of operating system and statistical package meet one another. Simple standalone filters would be invoked from the UNIX shell, for example, to perform simple frequency analyses, merging, and tabulation directly from the command line. That is easily implemented using perl programs, possibly as wrappers for analyses using a statistical package.
Massive data are too large to be hidden in a .Data/ or sasdata/ directory. Instead, the meta-array is found in the file system. The hierarchical structure of the UNIX or DOS file system is limiting. I might wish that my data and their analyses are organized by outcome measure within state within year on one occasion, but, on another occasion, that they are organized by year within state separately for each outcome measure. Symbolic links can provide a clumsy implementation of alternative hierarchies in the file system, a better implementation would be an explicit UNIX shell for massive data sets.
A practical application of perl as an integration tool is to job scheduling. A specific example follows.
5.1 Example: Job Scheduling
An environment for analysis of massive data sets will more often contain multiple workstations (with different architectures), rather than be dominated by a single supercomputer. The analysis of massive data sets requires that these distributed computational resources be utilized in an effective and efficient—in terms of operator time—manner. This is a problem in the general area of job scheduling, but a specialized approach does not appear necessary.
As an example of implementation of the divide and conquer strategy, consider the script in Figure 3. The setup is of 101 outcome measures, each requiring a separate analysis of the data, to be performed on multiple machines. This simple perl script can be hugely effective.
The basic idea is to create an ascii 'state file' containing current state information to each outcome measure, or task, that can be read and written by different job schedulers. When a job scheduler is active on a task, the file is locked. Jobs, or subtasks, executed by the scheduler advance the state of the task; at all times the file contains the current state. When a job scheduler has completed all the subtasks it can with a particular task; the file

is unlocked. Conflicts are avoided by keeping state file operations small and fast, compared to the sizes of the subtasks themselves. With relatively long subtask times careful optimization of state file operations is unimportant.
There are several sophisticated features of (UNIX) operating systems that can be used, including shared memory, message passing (streams), file locking using flock, and shared data base technology. However, in a heterogeneous environment, including both UNIX workstations and personal computers say, scheduling must be extremely robust. It is the only dynamic component that must work across platforms. The tasks themselves may utilize ASCII files or various conversion utilities (UNIX-to-DOS, or data base copy of proprietary system's data bases across platforms using, eg, DBMS Copy). A perl script can run with little change on many different types of platform; communication using ASCII files containing state information separately for each task is highly robust.
The script shown in Figure 3 was written quickly, in part to exemplify the effectiveness of wide use of integration tools. Perl itself is eclectic, so no attempt was made for programming elegance. The script is run with several arguments, as in j s 4 A B C, where 4 is the power of the machine, and A, B, and C denote the tasks. State information is saved in files named A, B, C, automatically created if not present at task invocation, in the directory KeepTrack/. Each task comprises a sequence of states, tailored using a set of three associative arrays included in the perl script. Different types of task are accommodated using different initial states. A fourth associate array gives the size of the subtask from each state to the next.
Any number of j s jobs can be started at the same or different times, without explicit reference to other js jobs that are already running. Each job first places a lock on a free task by appending the string '.locked' to the state specified in the task's state file in KeepTrack/. The job proceeds through the states of the task, updating the task's state file, until either the task is complete, or the current subtask is too large for the size of the machine, or the system call returns an error status. The job then removes the lock and moves to the next task. Completed tasks are removed from the array of tasks; the script exits when that array is empty, or when the count of unsuccessful attempts exceeds a preset threshold (when this number exceeds a smaller threshold, a interval is set between attempts).
Environments such as SAS and S provide very powerful tools for statistical analysis. They may use parallel architecture, but they do not offer this kind
of simple support for distributed computing. The perl script given here, which could be implemented in SAS or in S, is an example of a software device that allows computational resources to be fully used with almost no additional effort. In the divide and conquer strategy employed in the analysis of health policy data, such tools are critical.
The script is easily modified and tuned to special situations. For example, in an environment where one machine is more powerful than the others, it may be useful to have job schedulers on that machine allocate effort to the most intensive subtasks when there is one to be done. Or, each task may have different overall size, which might be read from an ancillary file. Or, an upper limit might be placed on the number of active subtasks (because of storage bandwidth say), and a count may be maintained using a further file. Or, a breadth first scheduler may be required, instead of the depth first algorithm given. Or, in a primitive neural-net like approach, a script might learn which tasks and subtasks are accomplished most efficiently. Or, one task may depend on the completion of several other tasks, which can be implemented using an initial state and associated command that checks the states of the respective tasks in the files, possibly coupled with command line arguments that incorporate sublists of such tasks.
References
Harrell, F.E, Lee, K.L., and Mark, D.B. (1995). ''Multivariate prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Statistics in Medicine 14 to appear.
Iezzoni, L.I. (Ed.) (1994). Risk Adjustment for Measuring Health Care Outcomes . Ann Arbor, MI: Health Administration Press.
Silber, J.H., Rosenbaum, P.R., and Ross, R.N. (1995). ''Comparing the contributions of groups of predictors: Which outcomes vary with hospital rather than patient characteristics?" Journal of the American Statistical Association 907-18.
Vaul, J.H. and Goodall, C.R. (1995). The Guide to Benchmarking Hospital Value. St. Anthonys Publishing.

















