
2
Computation
Introduction: What is Computation?
Computation is one of the most important technologies that will control the makeup and performance of future naval forces. As information is key to military success, so computation is key to information—to its gathering, its extraction, and its use.
In the past two decades, digital computers have become ubiquitous—from our computerized cars and personal computers, to Wall Street, Hollywood, and the Internet. Our society (and the military) clearly has been drawn irreversibly into what has come to be known as the information revolution. It has changed how we work, how we communicate, and how we play. Its impact on naval forces over the 40 years of this study will be enormous, as is evident already from the recent appearance of such military terms as information warfare and the digital battlefield.
By computation we mean digital computation—the crunching of bits by some form of computer for some purpose mathematical, textual, or graphical. Of course analog computation certainly plays a role in a number of important sensor systems—for example, the lenses of optical systems and the dish antennas of radars function as analog computers performing naturally millions to billions of operations for which digital beamforming alternatives so far are only rarely attempted. But these applications are usually limited and specialized to the physics of the specific situation, whereas digital processing offers almost unlimited flexibility of application through its software programmability.
Computation has a wide range of digital hardware support—from special-purpose application-specific integrated circuits (ASICs), to digital signal processing
(DSP) chips, reduced instruction set computers (RISCs), complex instruction set computers (CISCs), central processing unit (CPU) chips, desktop computers, workstations, signal processors, mainframes, massively parallel processors (MPPs), and all kinds of multiprocessor supercomputers. The capability of this hardware has been growing exponentially for two to three decades and shows no signs of slowing down. This explosive growth has created the information revolution and will propel it into the future.
As the hardware has grown in capability, new tasks have been imagined and an ever-increasing myriad of algorithms has evolved for accomplishing those mathematical, textual, and graphical tasks. To provide the software for programming these algorithms, dozens of computer languages and software programming tools have been developed over the years, and new concepts (e.g., Java) continue to appear. This ability to accomplish new functions, previously not feasible, has led to many significant advances, including virtual reality, simulation-based design, Kalman filtering, better cars, and so on. Unfortunately, as the availability of computational power has increased, the size of software packages has also grown, with error densities and development costs growing even faster, until software has become one of the most critical issues of our time—perhaps the Achilles' heel of the whole information revolution. Many large computation-dependent systems today find their reliability and availability determined almost completely by software bugs, with few limitations supplied by the hardware.
In short, computation and its exponential growth offer enormous opportunities and many challenges for the future of society and the military. Whatever the challenges, there is no doubt that computation, in a multitude of forms, will be a dominant factor in all aspects of future naval forces.
Relevance: What Will Computation Do for the Navy and Marine Corps?
Computation and computers are already an integral part of all Department of the Navy activities. High-performance computers and workstations support finite element thermal and mechanical analysis and electrical and logic design and simulation of components and systems, as well as large-scale, linear and nonlinear analysis of critical physical phenomena, such as CFD, which is used extensively in aerodynamic design of modern aircraft, missiles, and gas turbines and is coming into greater use in ship and submarine design. Today's complex military systems can no longer be designed and manufactured without computer assistance. Desktop computers support the fusion of information and data from multiple sources; provide the capabilities for identifying, extracting, and displaying the meaningful information contained in the masses of data available; and supply the tools for planning and implementing naval force and logistics functions.
Long-range sensors, such as radar and sonar, are thoroughly dependent on embedded signal processors to transform the raw data into detailed information
|
Box 2.1 Naval Applications of Computation
|
about the targets and the environment being observed and to supply adaptive real-time modifications of the sensors' parameters to optimize their performance. In other scenarios, embedded computers in missiles support the tracking sensors and provide the automatic target recognition, aim point selection, and detailed weapons guidance commands required to accurately counter hostile threats. Applications of computation are indicated in Box 2.1.
Technology Status and Trends
Microelectronics
Mechanical assistance for computation has been evolving continuously, albeit slowly, for the past several thousand years—the abacus, the slide rule, Babbage's Difference Engine, and so on. During and just after World War II, the simultaneous needs of sophisticated nuclear weapons design and the challenges of cryptography (code breaking) led to the introduction of the first electronic computers—the Mark I built by IBM for Harvard University in 1944 and the Electronic Numerical Integrator and Computer (ENIAC) built at the University of Pennsylvania beginning in 1946. These early electronic computers employed rooms full of vacuum tubes for the implementation of the digital binary logic and as a result were large, slow, and power hungry. By the 1950s, the concept of the stored program had been introduced and the architectural concepts of the modern
computer were beginning to take shape. It needed only the inventions of the transistor in 1947 at AT&T's Bell Laboratories and the integrated circuit (IC) in the late 1950s to point the computer down the exponentially improving path it now follows into the information revolution. Without the integrated circuit, and the sophisticated semiconductor microelectronic technology that has developed around it, today's small, powerful, and relatively inexpensive computers—from DSP chips to supercomputers—would be unthinkable.
After a couple of decades of fundamental investigations of semiconductor materials and devices and the introduction of the IC in the 1960s, microelectronics based on silicon emerged as the front-running technology. Since the 1970s, silicon technology has been improving at an incredible rate. Most parameters that characterize microelectronics, such as increase in clock speed, decrease in size and cost, components per chip manufacturable with high yield, and the like, have been growing exponentially for the last two or three decades. These component-level technology growth patterns combine with computer architectural and algorithm and software advances to produce the explosive growth of computational power we are witnessing today.
The envelope of the technology growth curves is remarkably exponential, suggesting that extrapolation of these trends into the future should supply valid guidance as to the level of performance to be expected at various times. What these extrapolations do not indicate is which technology or specific devices will actually be developed to achieve the predicted envelope performance—these specifics are very difficult to forecast, but the levels of performance predicted are much more reliable. As long as no fundamental limits are in sight (e.g., the speed of light or the laws of thermodynamics), and this seems to be the case at least for the next 20 or more years, it is reasonable to assume that the observed exponential growth envelopes will continue into the future. As each implementation reaches its inherent limits, new concepts are introduced, improve rapidly as they stand on the shoulders of all that came before, achieve the increased level of performance, and saturate in their turn, and so on. As major changes in materials, architectures, processes, and fundamental physical operation occur, the slope of the growth curve may flatten for a time but is likely to resume along the exponential envelope. Obviously reaching out 40 years to 2035, as this study is attempting to do, involves a great deal of uncertainty but from the present point of view, the only other alternative seems to be pure conjecture, with even less basis and more uncertainty. The use and validity of envelope technology growth curves for technology forecasting are discussed again in Chapter 4 on sensors, again in the context of microelectronics.
Figure 2.1 illustrates the history and projected future growth of two of the key parameters that characterize modern microelectronics manufacturing—fabrication linewidth and transistors per chip. Obviously, decreasing the linewidths by which the individual devices are photolithographically defined permits more devices to be included on a given size chip, but the transistors-per-chip growth is
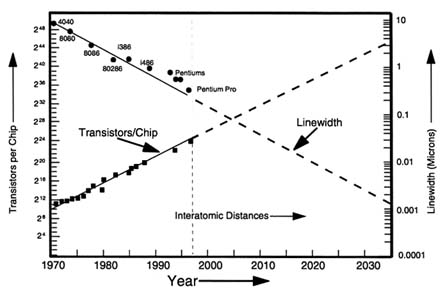
actually increasing faster than this because there is a concurrent but slower exponential increase in the size of defect-free chips. The two effects combine to produce the observed device-per-chip growth.
In 1965, Gordon Moore, founder of Intel, first publicized the exponential increase in transistors per chip, which at that time was doubling every 12 months. In practice, as Figure 2.1 indicates, the growth rate slowed somewhat, and Moore's Law, that is, the exponential growth of transistors per chip, has held consistently for almost three decades (i.e., from 1970 to the present) roughly doubling every 18 months. There is no obvious physical limit on devices per chip—e.g., table-sized chips are not practical, but are not excluded by any fundamental law of nature.
On the other hand, fabrication linewidth as shown in Figure 2.1 will encounter a fundamental limit near the end of our 40-year study window, namely interatomic dimensions. Dominated today by optical lithography, which has been refined well past the apparent limits of the technology as envisioned a decade ago, the current manufacturing state of the art is at the 0.25-µm level, with x-ray and electron beam technology ready to carry the linewidths smaller. Optical lithography is clearly heading toward additional practical obstacles in the next decade, as the wavelength of the light used moves further into the ultraviolet
(UV) where material absorption makes it harder and harder to find transparent optical materials for lenses. But these, too, may be overcome with new concepts, just as phase approaches have enabled the present practice to perform much better than the apparent wavelength limit.
Manipulation of nanosized clusters of atoms and even single atoms has been demonstrated. As the dimensions grow smaller, more quantum effects are encountered and the device technology will inevitably change from the structures of today's transistor concepts to advanced devices like single-electron transistors (SETs), which, although still macroscopic from an atomic point of view, operate on the basis of detecting the motion of single electrons. Room-temperature SETs have recently been reported, with transverse dimensions of 7 nm (0.007 (µm) to 10 nm, which is in the neighborhood of the fabrication linewidths predicted for the 2020 to 2025 time period, although the fabrication processes used do not yet lend themselves to reliable large-scale manufacturing.
As none of the other key microelectronic parameters is expected to reach fundamental limits before 2035 (there are certainly numerous practical limits to be overcome), it would appear that we can have some confidence in the expectation that digital microelectronics will continue to grow throughout the 40-year time period of interest. Actually, the speed of light introduces obstacles to the implementation of very high speed logic (e.g., 300-GHz clock speeds are anticipated by 2035), but this does not seem to offer the same kind of impenetrable barrier that atomic dimensions present for linewidth. There are options to deal with the high-speed logic problem, e.g., superconducting rapid single-flux quantum (RSFQ) logic, optical interconnects, parallelism, and so on.
Chapter 4 of this report, dealing with sensors, provides more detailed discussions of these issues and gives a more complete discussion of silicon and other semiconductor technologies relevant to present and future micro- and nanoelectronics.
Computer Performance
With the vacuum tubes replaced by transistors, computers have exploited the ever-smaller, faster, and cheaper development of microelectronic integrated circuits to provide a similar exponential growth in available computational power. Figure 2.2 illustrates this growth in a schematic way, i.e., without specific performance points indicated but with a smooth curve suggesting the general average level of performance that characterized the time at which each of the indicated computers was introduced. Two distinct families of processors are indicated: (1) the high-performance computing processors, i.e., supercomputers, that have been largely government-sponsored, are expensive, and at any given time represent the highest level of performance available, and (2) the functional and affordable computing processors, i.e., personal computers (PCs), that generally have been
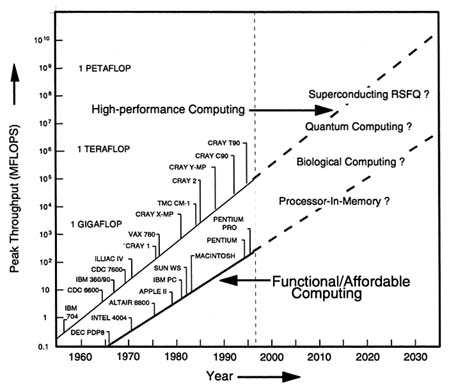
FIGURE 2.2 A history of computer throughput. SOURCE: Adapted from Brenner, Alfred E., 1996, "The Computing Revolution and the Physics Community," Physics Today, 49(10):24–30, Figure 1, October.
commercially developed, have lesser performance capability, and are relatively inexpensive.
The costs for high-performance computers have continued to rise with time as the supercomputers have grown more powerful—from the $4 million IBM 704 in 1956 to the Cray T-family of supercomputers that sell in the range of $10 million to $12 million each today. On the other hand, the costs for the functional/affordable computers have fallen dramatically as the processors have soared exponentially in performance—a DEC PDP-8 sold for several tens of thousand dollars in 1965, but a 200-MHz Pentium Pro PC can be purchased today almost anywhere for only a few thousand dollars, with a performance more than 1,000 times that of the PDP-8. It is difficult to believe that the cost trends exhibited by the affordable computers are not going to saturate soon, for costs on some quite powerful PCs have already dropped into the $300 to $500 range because of the fierce competition that drives this commercial market.
In the immediate future, there are plans to install a new generation of teraflop (1012 floating point operations per second) supercomputers at three national laboratories: a 1.8-teraflop Intel Pentium Pro-based multiprocessor at Sandia National Laboratories in late 1997, a 3.1-teraflop Cray/Silicon Graphics multiprocessor at Los Alamos National Laboratory in late 1998 or early 1999, and a 3-teraflop IBM multiprocessor at Lawrence Livermore National Laboratory sometime in 1998. Each of these falls somewhat above the extrapolated average performance curve for the time frame for which it is planned, but when the new supercomputers really come on-line is yet to be determined. In any case, high-performance computers will be limited in growth in the foreseeable future by technical issues, but economic constraints may also be a factor. People are already at work exploring the issues of achieving petaflop (1015 floating point operations per second) performance, which the extrapolation in Figure 2.2 suggests will become available near 2025. It seems possible that this level of high-performance computing will be achieved within the time frame of this study.
On the affordable PC side, Intel has announced plans for its P6 microprocessor line that will run at speeds of up to 400 MHz—twice the speed of the current high-end product, the 200-MHz Pentium Pro. Introduction of the P6 family over the next few years will conform closely to the extrapolated curve shown in Figure 2.2 for functional and affordable computing.
Lying between the two families of processors illustrated in Figure 2.2 are a number of powerful workstations that are not explicitly indicated. The Alpha chip, which powers the DEC workstation, clocks well above the PC state of the art at about 500 MHz and is a very capable microprocessor. There is no difficulty in envisioning this kind of chip migrating into PCs, and so the projected growth curves for functional/affordable computing will easily be met for the next decade or so. But, as is discussed further in Chapter 4 (Sensors), clock speeds will continue to increase—from decreasing linewidths (a 0.18-mm complementary metal oxide semiconductor [CMOS] circuit has been clocked at 1.14 GHz at Lincoln Laboratory, Massachusetts Institute of Technology) or perhaps from a change of technology, say from pure silicon to silicon germanide (SiGe), gallium arsenide (GaAs), indium phosphide (InP), silicon carbide (SiC), or some other system currently unimagined. Gigaflop (109 floating point operations per second) PCs by 2002 and teraflop capacity on the desktop by 2030 are realistic possibilities.
Multiprocessor Architectures
A computer's throughput performance depends not only on the speed of its hardware but also on its architecture—that is, the nature of and the relationships between its constituent parts. With clock speeds peaked at whatever the current technology can supply, additional performance can be extracted by exploiting parallelism—distributing the computations over multiple hardware components.
At the level of a single CPU, this is achieved by the parallel execution of instructions, through the incorporation of multiple adders, multipliers, and so on on a single processor chip. In this manner, rather than using on the order of 10 clock cycles to accomplish a single instruction, as was the case for the earlier microprocessors (e.g., the Intel 8086 or the Motorola 68000), today's microprocessors, through parallel execution, accomplish multiple instructions per clock cycle.
To achieve even more computational throughput, it is natural to combine the resources of multiple CPUs to produce distributed arrays of processors—that is, multiprocessors. Supercomputers have long employed this principle of parallel hardware units. The three supercomputers scheduled for installation at Sandia, Los Alamos, and Lawrence Livermore national laboratories in the next 2 years are all multiprocessor architectures, one of which envisions combining 4096 IBM/Motorola/Apple PowerPC processors and another of which links 9072 Intel Pentium Pro processors.
Cooperative behavior of multiple processors to provide efficient computation is not easy to accomplish. Depending on the tasks undertaken and the instantaneous state of the hardware, there can be many conflicts for access to the resources—the processors, the busses, the memory, the input/output (I/O) to the outside world, and so on. Many options have been explored and no single best multiprocessor architecture has yet been defined. And so architectures continue to evolve through engineering trades, improvements introduced to correct problems encountered in earlier generations, and the introduction of new component technologies and software concepts that alter the balance of the earlier tradeoffs. It seems likely that the architectures will continue to evolve throughout the window of this study, with completely new concepts appearing from time to time.
In terms of how instructions and data interact, multiprocessor architectures are broadly classified into two categories—single instruction multiple data (SIMD) and multiple instruction multiple data (MIMD). SIMD machines perform the same instructions on multiple sets of data simultaneously and thus are ideally suited for applications such as signal processing, image processing, or the investigation of physical phenomena involving multidimensional, multivariable differential or integral equations. With these special applications come special configurations of the hardware. The early Cray supercomputers, for example, contained pipelined vector processing units that repeated the same operations over and over as the data streamed through. They were extremely efficient once set up but took a significant amount of time to be reconfigured for different tasks. A decade ago, with large amounts of DOD support, one-dimensional vector processors were superseded by two-dimensional MPPs. These highly specialized processors consisted of two-dimensional arrays of relatively simple CPUs (sometimes a 1-bit processor), each with its own large memory stack, which all executed the same instruction synchronously with the others, but on different data. Ideal for image processing and the solution of some physics problems, MPPs
have been deployed already as signal processors in many problems. But the SIMD machines, although undeniably powerful for certain applications, have proven to be inflexible and somewhat difficult to program. They are not suited to general-purpose computation, and most, if not all, of the companies producing this class of processor are now out of business.
MIMD machines do not synchronize instructions but allow each processor to operate independently. Although somewhat less efficient on problems for which the MPP is matched, the MIMD class is completely flexible and, although still a challenge, easier to program than a SIMD. All future high-performance computers are likely to be MIMD multiprocessors.
On the battlefield, it will become more and more critical to ensure that the computational resources always work when required, make no errors, and when and if they do fail, do so in such a manner as to not endanger the people or the projects involved. In other words, the computers must be highly available, fault tolerant, and fail-safe. As the information revolution progresses, these features will cease being options and will simply be mandatory—whatever the apparent cost of implementation. It is already clear that we are so computerized and networked today that a single failed computer has the potential to bring an office, a factory, a city, a military force, and even a whole country to its knees—the costs of failure are going to overwhelm the cost of implementation. Hardware redundancy and careful design of the software and operating systems are the keys to achieving this robustness for both commercial off-the-shelf (COTS) and Navy Department computer systems.
Hardware Technology
Microprocessors
Complex Instruction Set Computing
Original microprocessor CPU designs were developed and incorporated into the hardware mechanisms for implementing all potentially useful elementary instructions as the assembly languages. Because the combinations of instructions that a programmer could employ were very large and unconstrained, designers added hardware mechanisms to deal with all potential on-board hardware conflicts. The result was a complex chip that generally needed multiple clock cycles to accomplish any given instruction. The processor, before implementing the next instruction, had to check to see if the last one was still using a resource (e.g., register, adder or multiplier, and the like) and then resolve any conflicts. These early architectures have come to be known as CISCs, in contrast to the more recent innovation of RISCs.
Reduced Instruction Set Computing
As programmers made the transition from assembly language to a strong reliance on high-level computer languages and compilers, it was realized that, in practice, very few instructions were used frequently. By limiting the instruction set supported directly by the hardware, the instruction decode logic could be reduced to 20 to 30 percent of the chip real estate versus 75 to 80 percent for CISC chips. A reduced instruction set with limited pipelining and instruction decode logic was first seen on the Cray-2 series of computers and achieved outstanding performance, exploiting the resulting small chip sizes and the fast clock speeds that the small chips permitted. Not yet known as RISC, the Crays were thought of as streamlined vector processors, optimized to carry out efficiently those arithmetic operations needed for the solution of high-powered mathematical and physics problems of nuclear weapons design, for which they were largely employed. Modern DSP chips follow this same path—they were efficient for repeated mathematical operations but not terribly flexible with respect to general programming.
In the 1980s, it was realized that most useful compiled software programs required only a small subset of the available CISC instructions. Also, once the code was written, the potential on-board hardware conflicts were defined and knowable in advance, before the code was run. Thus the final code could be passed through an optimizer software module that configured the sequence of instructions to avoid all on-board conflicts. The result was the RISC chips, which are simple and fast. Adding multiple arithmetic units on-chip and pipelining the instructions permitted the early RISC processors to perform an instruction per clock cycle. In the late 1980s, this provided an instant jump in microprocessor performance by a factor of almost 10, without any increase in clock speed. Examples of such RISC processors include the Sun Sparc, the HP PA-RISC 7000, the Motorola 88K, and the MIPS R3000.
With time, improvements were introduced to capitalize on the increased number of devices on a single chip and to run faster, as well as to overcome deficiencies in the earlier implementations or limitations of the associated components. To minimize main memory access (dynamic random access memory [DRAM] access times remained at 70 ns for a long time), large caches of up to 4 megabytes have been provided on-chip. Multiple arithmetic units with vector capability have been combined with multiple (up to four), long (up to six or eight stages) instruction pipelines and on-chip branch prediction logic added to deal with data-dependent branches, which are not predictable in advance. The resulting chips are known as superscalar RISC and include such examples as the DEC Alpha, the Sun Ultra Sparc, the HP PA-RISC 8000, the Motorola 600, and the MIPS R 10000. These processors operate at speeds of up to 200 MHz with the Alpha reaching 300 to 500 MHz. To achieve these features, the superscalar RISCs are beginning to resemble CISC, in that a larger fraction of the real estate
TABLE 2.1 Performance of Typical Microprocessors
|
Processor |
MHz |
SPECint95 |
SPECfp95 |
|
Power PC 604 |
225 |
8.7 |
7.5 |
|
HP PA-8000 |
180 |
10.8 |
18.3 |
|
MIPS R10000 |
200 |
9.2 |
17.6 |
|
DEC Alpha |
500 |
12.8 |
18.3 |
|
Sun Ultra Sparc 2 |
200 |
6.8 |
11.5 |
|
Pentium Pro |
200 |
9.0 |
6.2 |
|
SOURCE: Data from Raytheon Electronic Systems. |
|||
is necessarily devoted to instruction decode, cache management, and branch prediction (currently up to 75 percent of the chip area).
Table 2.1 summarizes the current state of the art for microprocessors, most of which are superscalar RISC architectures. The Intel Pentium chips resemble superscalar processors in terms of on-chip functionality except that they have relatively large, CISC-like instruction sets. The performance is measured separately for integer operations (SPECint95) and for floating point operations (SPECfp95).
Interconnects and Packaging
Interconnections between the processors and memories in a multiprocessor are key to performance. Data and information must flow quickly to where it is needed if computation is to proceed smoothly at the level desired. Many schemes for interconnecting processors have been considered, including two-, three-, and higher-dimensional arrays of busses and a variety of processor-to-processor configurations with two-, three-, and higher-dimensional connections to nearest neighbors, n-cube topologies, and others. Perhaps the most common today is the simple two-dimensional rectangular north-south-east-west array with each processor communicating only with its four adjacent neighbors. Obviously, minimizing the number of internal data transfers required is highly desirable as it brings up questions of communication routing, resource conflicts, and latency, which all can adversely affect overall computational performance. As the hardware speeds up, it becomes more and more important to avoid having any unplanned delays, for even a brief pause in a 100-GHz data stream can cause an enormous pileup of data and rapidly exceed temporary storage capability.
For large distances (i.e., centimeters to meters or kilometers) and high data rates, it is clear that fiber-optic telecommunication is the preferred approach for digital data transfer. Multigigahertz rates have been demonstrated, and higher are no doubt possible. Many modern radar systems with high data-rate requirements
already use COTS fiber-optic links to interconnect signal processors and control computers. This is clearly the right technology for these applications, although costs are still high for the highest-performance links. The cost of optical links will inevitably decrease under the impetus of the commercial telecommunication explosion.
But it is not only at the processor-to-processor level that optical communication technology will find a role in computation. Even in communicating digital signals board-to-board and chip-to-chip, optical technology offers solutions to future problems. A laboratory curiosity today, free-space optical interconnects between boards and chips will soon find their place in computer technology. Although the optical componentry is still lacking in some respects—in diode threshold power and reliability, in particular—as the clocks speeds increase, the optical interconnects will become more acceptable than electrical. Figure 2.3 illustrates the tradeoff between the use of a 3-µm-wide aluminum conventional electrical interconnect and a free-space optical interconnect using a 1-mW threshold laser operating at 9 percent efficiency. The curve is the break-even line length as a function of frequency for which the electrical and the optical interconnections require the same power to transfer the data. The results vary slightly for narrower Al lines and higher-power lasers, but the results are similar. Even at 50 MHz, for distances beyond 5 or 6 mm, optical interconnects provide a lower-power
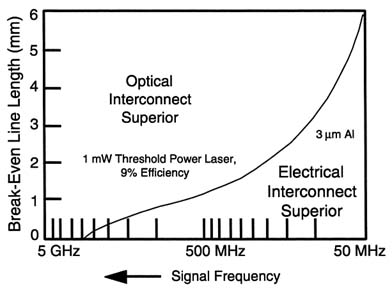
FIGURE 2.3 Break-even transmission line length—optical vs. electrical interconnect. SOURCE: Adapted from Cinato, P., and K.C. Young, Jr., 1993, "Optical Interconnections Within Multichip Modules," Optical Engineering, 32(4):852, April.
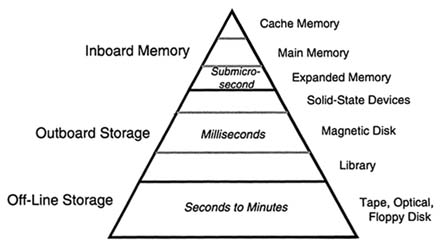
FIGURE 2.4 Computer data storage hierarchy. SOURCE: Adapted from Wood, C., and P. Hodges, 1993, "DASD Trends: Cost, Performance and Form Factor," Proceedings of the IEEE, 81(4):573–585, April.
solution. For rates of 500 MHz and above, the break-even distance drops below 1 mm, which means that very soon, optical interconnects will be viable for chip-to-chip interconnections inside mine countermeasure packages. In addition to these power advantages, optical interconnections have other virtues, such as that (1) they are free from capacitive loading and electromagnetic interference (EMI), which afflicts conventional electrical approaches, and (2) they are inherently parallel and permit a higher level of multipexing because of their high bandwidth, thereby offering excellent solutions for resolving chip I/O issues.
For the next 40 years, optical interconnections will play a major role in facilitating the implementation of very high speed (multigigahertz clocks) CPUs and multiprocessors for both high-performance and functional and affordable computing applications.
Memory
Memory, its storage and its access, is another key to the success of computation. Computers, from PCs to multiprocessor supercomputers, store data in a hierarchical form, with very-fast-access, small on-chip cache memories at the top, and very large, slow, off-line mass data storage at the bottom. Figure 2.4 illustrates this hierarchy. The performance and the price per bit stored generally rise as you move from the bottom to the top. At the top are semiconductor memories, with access times in the nanosecond range. At the bottom are removable
media, tapes and disks stored off-line, having access times measured in seconds to minutes. In the middle are the off-board hard disks and solid-state devices with access times measured in milliseconds.
As discussed above, many CPUs, particularly the superscalar RISCs, incorporate significant amounts of cache memory directly on the processor chip, while increasing amounts of discrete random access memory (RAM) characterize all modern computers. It is not unusual to find 32, 64, or even 128 megabytes of RAM in a PC these days. In keeping with the industry trends, we can expect this class of memory to continue to grow in size and to reduce access time, while the price is simultaneously decreasing. Fortunately, for these classes of working memory applications, volatility is quite acceptable, for it has proven extremely difficult to achieve nonvolatility while retaining access time performance in semiconductor memories. Although memory speed and capacity have been growing, they have not been growing as rapidly as processor speed and capacity. It is possible that memory limitations could impede the full utilization of the processing power that is expected to be available in the future.
The middle ground, i.e., outboard storage, has been, and continues to be, dominated by the magnetic hard disk. Access times are determined by the mechanical motions of the read/write arm and the rotation of the disk itself and are typically measured in several to tens of milliseconds. In the 1980s it was believed that magnetic recording had reached the technological limits for feasible data density (bits per unit area). However, the introduction of the optical disk in 1982, which at that time exceeded the density of the state-of-the-art magnetic devices by an order of magnitude, stimulated a new look at the subject, and continuous increases in recording densities have followed. By 1990, the optical disk advantage had vanished, and today, magnetic storage densities are increasing at a rate of 60 percent per year. The most advanced disks today have densities exceeding 150 megabits/square inch, and at least a gigabit per square inch is expected by 2000.
Solid-state competition for the hard disk, i.e., semiconductor memory packaged for lower price and lower performance than on-board RAM, does provide the fastest memory for outboard applications but is volatile. To date, nonvolatile solid-state memory, e.g., charge-coupled devices (CCDs), magnetic bubbles, and holographic storage, has not been able to match the price and performance of the hard disk, often falling short by orders of magnitude. At the bottom of the pyramid, optical disks and tapes have come into their own, competing successfully with magnetic tape for high-volume, low-cost removable storage. Optical disks and tapes have the advantage of much greater storage lifetimes.
Optical Data Storage
CD Technology.
The practicality of optical storage of digital data is obvious today. For music and movies, digital optical recordings such as compact disks
(CDs) and laser disks continue to increase in popularity, threatening to eliminate their analog magnetic tape competition, in spite of being more expensive. In the computer world, all new PCs come equipped with integral CD read-only memory (ROM) drives, and most new software is readily available only in CD form.
It is often suggested that the advantage of optical over magnetic digital data storage lies in an inherent ability of optics, highly focused laser beams, and the like to produce higher-bit densities than does magnetic recording. This, however, is not the case today. The very real advantages of optical over magnetic recording lie elsewhere.
When first introduced, in the early 1980s, the optical media area density of 155 kilobits/mm2greatly exceeded the 10 or 11 kb/mm2 of the magnetic recording technology of the time. The latter was thought to be approaching fundamental limits. But, as is frequently the case, the magnetic incumbent, with much to protect, responded vigorously and by the early 1990s, the advantage of optical over magnetic recording had vanished through inventions such as the magnetoresistive head. Today, practical area densities of magnetic hard disks can exceed those of comparable optical CDs by as much as an order of magnitude.
The optical CD drive is very similar in performance to the magnetic hard drive, in that it provides fast random access to any data recorded on the disk at rates and access times that approach those of the magnetic drives. The critical differences are in the optical recording media, which are simple, inexpensive, and durable, and the use of optical techniques that permit the read/write heads to stand well back from the recording surface with relaxed tolerances (disk surface motions are accurately tracked by sophisticated optoelectronic feedback loops, keeping the laser read/write beams continuously in focus on the surface where the data bits are recorded). The result is a removable optical disk with the performance of a magnetic hard disk, far exceeding the capabilities of removable magnetic floppy disks of similar size. Removable random-access data storage with long life without degradation is where optical storage excels.
On the other hand, although magnetic disks are infinitely rewritable, rewritable optical disks have proven more difficult to master. Writable and rewritable optical disk systems are available in limited quantities and are still in development and, as a result, are often expensive. Rewritable optical recording requires a different form of recording from the pits and bumps of read-only CDs, and two such candidates have been exploited so far—magneto-optic recording and phase-change recording. The magneto-optic systems can be directly rewritten without erasing, whereas the phase-change systems require a controlled anneal to restore the medium to writable form. Recently a CD recordable drive for less than S500 has become available. Progress in these areas has been rapid, and without doubt such versatile optical disk systems will soon be available at affordable prices.
Optical Tape. Beyond removable random-access high-capacity storage, optical storage technology offers a promising extension in the form of the optical tape
recorder for massive archival data storage where the high capacity and longevity of the optical medium offer significant advantages over magnetic storage. Using slightly modified read-write concepts, the optical tape stores its data in closely spaced parallel tracks along the length of the tape, which can be read out in parallel onto CCD detector arrays. With oversampling, i.e., more detectors than data tracks, electronic rather than physical tracking can be easily implemented. Because tape is so thin, enormous amounts of data can be stored in a very small volume. A standard 3480 magnetic tape cartridge today can hold 10 gigabytes of data. A comparable cartridge loaded with optical tape can handle almost 30 gigabytes. Reduction in tape thickness to 0.025 mm and the use of blue (415 nm) rather than red (633 nm) laser diodes will permit up to 200 gigabytes of data to be compressed into the same cartridge by the year 2000. The parallel readout enables continuous data readout rates of about 3 megabytes/s today and can be expected to reach 10 megabytes/s by 2000. As is characteristic of all tape storage concepts, random-access times are on the order of seconds (for tens of meters of tape running at tens of meters per second).
The Future. The area densities of two-dimensional optical storage devices will continue to improve through increases in the numerical apertures of the lenses, i.e., smaller spots, and the introduction of shorter-wavelength laser diodes (i.e., blue). Figure 2.5 illustrates the projected growth for both optical and magnetic disks and tapes over the next few years.
Three-dimensional Holographic Memories
Present disk and tape systems store data in two-dimensional formats on a surface. In a holographic memory, bits are stored in two-dimensional patterns, known as pages, using standard holographic interference techniques. An information and a reference beam are combined in a photorefractive material that modulates the index of refraction of the material in response to the interference pattern's distribution of electric fields. To pack more information into the same volume, additional pages are recorded on top of each other by varying the angle of incidence of the reference beam. Illuminating the storage medium by a reference beam reads out only the page that was recorded with that particular reference beam by projecting an image of the page on a two-dimensional photodetector array.
Although the number of superimposed holograms is limited by the dynamic range of the photorefractive material, in lithium niobate as many as 10,000 superimposed holograms have been demonstrated. Read-out rates are limited by the requirements for rapid, accurate generation of randomly accessed reference beams. The photorefractive materials identified so far tend to be expensive to grow in bulk form. Breakthroughs are being sought in the form of multilayer thin-film composite structures. While promising much, particularly for archival
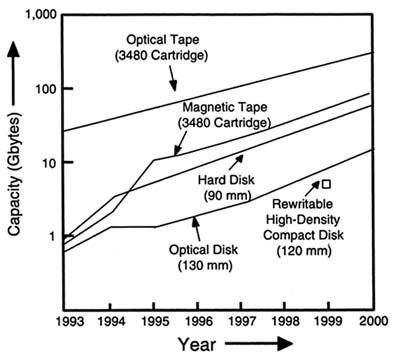
FIGURE 2.5 Comparison of optical and magnetic data storage. SOURCE: Adapted from Asthana, P., and B. Finkelstein. 1995. ''Super Dense Optical Storage," IEEE Spectrum, 32(8):25–3l, August.
applications, holographic optical storage's success seems to depend heavily on the occurrence of a significant advance in materials. It is too early to predict with any confidence what will happen to holographic memories.
Software
Computer Languages
As the hardware has grown in capability, new tasks have been imagined—and an ever-increasing array of algorithms have evolved to accomplish these tasks. To provide the software for programming computers to implement these algorithms, dozens of computer languages have been developed. Beginning with the low-level assembly language, which is different for each processor implementation and exercises direct control of the elementary steps of the computer hardware, a series of higher-order languages have evolved. Through a brilliant bootstrap technique called the software compiler, the programmer has been relieved
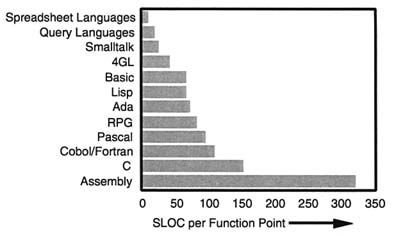
FIGURE 2.6 Power of programming languages in terms of source lines of code (SLOC) per function point. SOURCE: Adapted from Lewis, T. (ed.), 1996, "The Next 10,000 Years: Part II," COMPUTER, 29(5):81, Figure 5(b), May.
from the necessity of dealing with every minute detail, and greatly improved programming efficiency has resulted.
Figure 2.6 compares the programming power of different programming languages in terms of the average number of source lines of code (SLOC) in that particular language required to implement a function point (FP), i.e., a specific block of code. The function point, a useful metric introduced in the 1970s by Allan Albrecht of IBM, measures both the content of computer programs and the productivity of the programmer by counting the number of steps (input, output, memory access, and general processing) that define the block of code. As can easily be seen, there is a large advantage in compactness of code for all the high-order languages as compared with assembly language. Somewhat surprisingly, C (and C++, it must be assumed), which is the most popular programming language today, is the least compact high-order language as compared with assembly language. Actually the low-level characteristics of C are what makes it attractive to many programmers as it offers a deep level of control. Ada, on the other hand, the DOD's preferred but fading language, is more compact than C by a factor of two and has proven in practice to be an excellent language for the disciplined development of large military programs. Yet C remains enormously more popular, explained, perhaps, by the observation that Ada has garnered very little COTS support in the United States (more in Europe, ironically) and few, if any, universities offer courses in Ada whereas C and C++ enjoy all these advantages.
The evolution up the chart to more and more compact languages has been roughly, but not precisely, in temporal order. With the growth of more efficient high-order languages, programming productivity, as measured in average cost
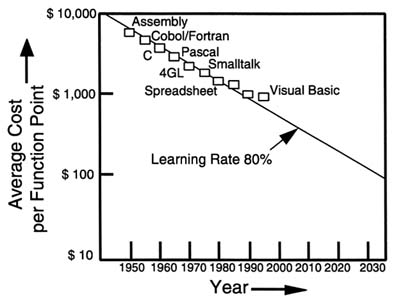
FIGURE 2.7 Average cost per function point. SOURCE: Adapted from Lewis, T. (ed.), 1996, "The Next 10,000 Years: Part II," COMPUTER, 29(5):81, Figure 5(b), May.
per function point, has been improving exponentially, as with the hardware parameters that drive the information revolution. Figure 2.7 shows costs per function point as a function of time. The exponential decrease indicated by the straight-line extrapolation represents a learning rate of about 80 percent over 5 years or roughly 5 percent per year, compounded.
Whether or not the slight deviation from the curve, evident over the past decade, is indicative of some kind of fundamental limit, is impossible to determine at this time. New concepts for even more productive languages may yet arise, and the final goal for 2035 of $100 per FP does not seem completely unreasonable.
Software Growth
As computational resources have grown, the size of the tasks undertaken have grown correspondingly. Unpleasantly, this exponential growth in the magnitude of software systems has serious consequences for cost and reliability. The error rate (i.e., errors per SLOC) does not remain constant but increases with the size of the programs. Figure 2.8 shows the growth in total code size, as measured by the size of the memory necessary to contain the code, for a number of National Aeronautics and Space Administration (NASA) space and military aircraft programs
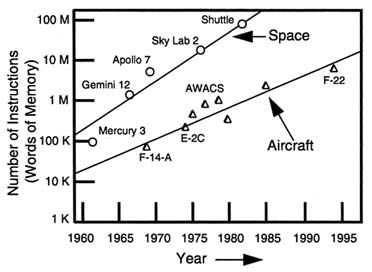
FIGURE 2.8 Growth in size of memory for application software. SOURCE: Adapted from Buckley, CAPT B.W., USN, 1996, "Software Production Efficiency Lags Computer Performance Growth," a viewgraph included in the presentation "Future Technologies for Naval Aviation," Naval Research Laboratory, Washington, D.C., July 22.
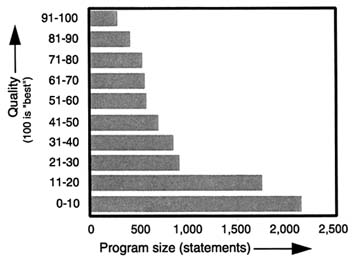
FIGURE 2.9 Software quality falls off as programs become larger. SOURCE: Adapted from Lewis, T. (ed.), 1996, "The Next 10,000 Years: Part II," COMPUTER, 29(5):85, Figure 8, May.
Extrapolating out to 2035, software code storage volumes considerably larger than 10 billion words of memory are suggested.
In strong contrast to most of the other growth patterns that characterize the information revolution, this trend should be reversed. Software quality definitely falls off as the programs get larger. Figure 2.9 illustrates this phenomenon. It suggests that a solution is to build large programs from small, reusable modules that can be independently and separately constructed and debugged. The growing size of software coupled with the strong negative correlation of software quality with size has focused attention on the software development process. Although software provides the source of the capability and much of the value in most large commercial and military systems, it also seems to be the source of most major overruns and schedule slips in the development stage, and it increasingly represents the major contributor to system failures in the field.
In recognition of the critical nature of software and in response to the above problems, the DOD initiated, about a decade ago, a software engineering initiative (SEI) to monitor and certify the software development processes in use by DOD contractors. Initial surveys revealed that most software developers had no structured and documented practices at all. Software development was thought to be more of an art than an engineering discipline. But as programs grew to millions of lines of code, the physical impossibility of generating a handful of artists became evident. With time and with SEI certification a formal requirement of the contract, contractors established structured software development practices and introduced the routine use of computer tools that have greatly reduced but not eliminated the risks in software development today; as the appetite of the information revolution inevitably grows and program sizes reach tens of hundreds of millions of lines of code, these problems will continue to plague us.
In the area of computer-aided design (CAD), software lags well behind hardware design, surprising in view of the early introduction of software tools for compiling, assembling, and so on. Given the desired input and output from a digital circuit (DC), logic synthesis programs routinely create credible logic implementations, which are correct by construction, by automatically performing the appropriate Boolean equations. Hardware designs need no longer be constructed by hand through analysis and intuition as software designs still are. Equivalent logic synthesis tools for software design should also be possible, although the underlying mathematics will not be a simple Boolean algebra. However, the software tools available today are frequently little more than bookkeeping tools that do help to maintain consistent forms and practice but do not help much in achieving a good design. A good software design is still largely up to the talents of the individual programmer. One possible solution to the software development cost, schedule, and quality problem is to develop software logic synthesis capabilities. This should be an ongoing topic of R&D for the future.
Object-oriented Programming
For most of the almost 50 years that people have been programming computers, the approach to constructing the software has been based on a viewpoint that emphasizes the function associated with the design. Emphasizing the flow of mathematical operations and the algorithms, this approach has been highly productive. For small systems it works well, giving excellent performance, and has produced proven methodologies for constructing hard real-time software systems, as many sensor, control, and weapons systems require. In addition, most operating systems developed to date, including the popular UNIX and WindowsNT operating systems, have been based on a functional decomposition model. During the last 5 years, UNIX attained major visibility in workstation applications, but recently interest has shifted rapidly in favor of WindowsNT because of its natural support for networking.
As the software program sizes continued to expand over the past decade, attention turned toward achieving software reusability, so that systems could be constructed from generic and reliable, small standard building-block modules. But reuse of modules constructed on functional decomposition principles turned out to be difficult because of a general fuzziness in the area of module-to-module interface definitions. A more promising approach was sought and found in the object-oriented programming (OOP) approach.
OOP takes quite a different point of view from that of functional decomposition, but one that is much better attuned to reusability. OOP emphasizes the objects that are acted on by the program, such as the data types, data structures, and interfaces, rather than the actions themselves. OOP looks at the nouns, whereas functional decomposition views the verbs in the ordinary language description of what the program is supposed to do. As such, these two approaches are duals of each other—the blobs in one representation of the program become the lines in the other. The OOP approach has its root in the proven methodology developed in the context of database management systems. Because of its explicit attention to interface definitions, OOP modules look like well-defined building-block modules and provide greater reuse possibilities because the data can be mixed and matched in many ways. On the other hand, OOP probably suffers performance penalties over functional designs because of data movement within structures and some difficulties in enforcing hard real-time constraints. But increasingly higher-performance processors and larger on-board caches will easily compensate for these deficiencies in the future.
Supported by several high-order languages (e.g., Smalltalk and C++), OOP promises to be a major factor in future software developments. A recent development, stimulated by the Internet, has been the creation by Sun Microsystems of Java. An interpretative, rather than compiled, object-based language, Java has the concept of objects, classes, and methods fully integrated within the language. Java has no operating-system calls. All such functions are accessed through a
universal I/O set of classes. Exception handling is accessed through a set of exception classes, graphics capability is accessed through a set of graphics classes, networking is supported through a set of network classes, and so on. The language allows the users to define their own classes and methods and provides unparalleled flexibility. Without the need for operating-system calls, Java programs become independent of the specifics of the platform and the operating system. The penalties associated with using an interpretative mode will fade in importance as processor speed and performance continue to improve. Other Internet providers are exploring similar concepts, and both Netscape and Active X offer products, with similar features to Java, that give them platform and operating-system independence. Java and other similar approaches offer new programming models that deserve further serious exploration.
Software Vulnerabilities
In many ways the software itself is its own biggest liability, for everything can be done by software, including crashing the system and producing unexpected or erroneous results. The software can do this through design faults or with outside help through the malicious introduction of viruses, bugs, and bombs. For more detail, see Chapter 3, Information and Communications.
Reliability
As the role of software grows, the impact of software defects on the overall system reliability becomes a critical issue. In contrast to hardware, software does not wear out with time and usage and become failure prone. In spite of good intentions, defects are built in through faulty logic, omission, coding errors, and the like. What is statistical are the number and kinds of defects that have been created that escape the developer's best attempts at testing and the associated user's mix of programming requests. To properly understand these factors, continuous and appropriate measurements must be made throughout the coding and testing and integration phases. We would like to know the rate of creation and the distribution of defects that are introduced, the efficiency of the testing procedures in uncovering them, the rate at which repair introduces new errors, and so on. Many statistical models are available that have been created to address these scenarios. These should be routinely applied to the software development process to improve and control practices and the quality of the final products.
Correctness
Evaluating software through traditional methods of exhaustive testing can never prove that the software is correct, that is, that it will do only what was intended and nothing else, independent of the inputs. On the other hand, formal
specifications, expressed generally in some executable high-order specification language, allow mathematical theorem-proving techniques and tools to be applied in practical ways that permit genuine proofs to be convincingly constructed. In other words, instead of building the software in the traditional manner and then testing it to discover what has emerged, we apply structured processes to its development to ensure that it is correct by construction. More generally within the industry, alternate methods of software development, such as IBM's so-called clean room technique, have been suggested that also rely on formal techniques and that are claimed to produce more defect-free code than does the traditional approach. For these several reasons, it is very appropriate to take a serious look at the role of formal methods in the efficient generation of reliable, safe, and robust software.
Information Warfare Attacks: Viruses and Bugs
The vulnerability of software-dominated systems to viruses and bugs, whether deliberately or inadvertently introduced, is an everyday experience for most computer users. The network server goes down and every computer connected to it freezes, or an electronic-mail message arrives and with it comes a virus that starts to do unpleasant things, or a proven piece of COTS software suddenly quits, dumping the file you just spent the morning on because of a bug. As the information revolution progresses, our whole society, the naval forces included, will become increasingly dependent on computational software and computers and thus increasingly vulnerable to deliberate interference with the software. Although virus-detection add-on software exists, it would be preferable if somehow the defense mechanisms were build into the software from the start as part of the overall design. How to design robust software, maximally resistant to external interference, is a theoretical question of great interest and should be the subject of research for the future.
Applications
The applications of computation are practically limitless, ranging from explicit mathematical calculations for the solution of equations describing physical phenomena and engineering analysis or the interpretation of sensor data, to the production and management of text files for documents and communication, and the generation and display of graphics, from simple line drawings to full-color, high-resolution, natural-looking synthetic scenes for virtual reality. The panel has chosen to classify these applications into three categories in terms of the computer hardware required to support them, as listed below:
- High-performance computing (i.e., supercomputers),
- Functional and affordable computing (i.e., desktop computers), and
- Embedded computing (i.e., integrated CPU and DSP chips).
With time, future workstations and PCs will eventually attain the computational capabilities that today can only be obtained from a supercomputer, and many of the high-performance applications will migrate to the functional and affordable class. Of course, there will always be problems large enough to challenge a supercomputer, because it is easy to expand the problems to match the capabilities available, by increasing the number of variables or the resolution or the number of interacting subsystems to be simultaneously simulated, and so on.
Because of the specialized application for embedded computers as real-time subsystems that are fully integrated into the sensors and the controls of radars, sonars, missiles, torpedoes, UAVs, UUVs, and other high-performance systems, these applications tend to remain distinct from those that find primary support from the other two categories of computers. Often, however, these same systems also contain a general-purpose computer, which is frequently a specially packaged, ruggedized version of a desktop computer. Also, there is widespread compatibility of the lower-level hardware components between all three classes. The multiprocessor supercomputers currently under development generally consist of distributed arrays of cooperating CPU chips that are identical to those that power the desktop computers, e.g., PowerPC or Pentium Pro chips. These same chips may find their way into embedded applications as well. The era of the special-purpose computer or signal processor for military applications has just about vanished, as the commercial developments have consistently outperformed these processors, frequently rendering them obsolete long before the systems are deployed. No doubt, the use of commercial chips in military systems will continue as newer, more powerful computational engines are developed as COTS products for the information-revolution markets.
High-performance Computing
Originally motivated by the demands of nuclear weapons design, supercomputers have found wide application in the physics, astronomy, and engineering communities for the investigation of difficult physical problems and the simulation of large, complex, engineering systems. Through finite difference and finite element approximations, the underlying mathematics is reduced to problems of linear algebra, frequently involving arrays defined on multidimensional grids and requiring computationally intensive matrix operations. Fortunately, these kinds of problems are compatible with parallel operations, and all supercomputers rely on this approach in a variety of ways: vector units, distributed multiprocessors, massively parallel architectures, and so on.
At least three application areas of high-performance computing are of direct interest to the Department of the Navy:
- Computational fluid dynamics—for the design of underwater and surface vehicles and aerial vehicles as well as for the modeling of atmospheric weather and ocean currents;
- Modeling of complex engineering structures—for the simulation-based design of ocean platforms, weapons, and other naval structures and systems; and
- Real-time virtual reality support—for viewing large, situational awareness databases, for training, and perhaps for control of complex systems.
Modeling of complex engineering structures and real-time virtual reality support are discussed in Volume 9: Modeling and Simulation and Volume 3: Information in Warfare, respectively, of this nine-volume study. Only the first topic, CFD, is discussed in detail here.
CFD represents the use of modern computational techniques to model fluid flows. Partial differential equations embodying approximate physical descriptions of the flow and related transport processes are reduced to differential equations on a discrete space-time grid, which, together with other equations describing fluid properties or processes, and further averaging approximations, are expressed in algorithms for computation. The grids can be fixed with respect to either the flow or boundaries and cover a wide range of scales. Gridding today remains a human-intensive task, although progress is being made in automatic gridding. CFD has developed along with progress in high-performance computing, for which it is one of the major challenges. Physical and engineering insights are essential inputs.
Vehicles of naval interest generally operate immersed in air and/or water, and dynamic and viscous resistance forces resulting from fluid flow absorb all of their effective propulsive energy. Dynamic fluid-flow reaction generates the lift for airplanes and certain kinds of ships and is the principal source of steady and time-varying forces and movements for vehicle or missile maneuver. Fluid flow transports energy in power plants such as gas turbines and nuclear power plants, as well as in many auxiliary systems. And fluid-flow processes dominate the meteorological and oceanographic environment in which naval forces must operate. Physical models of flow, including wind tunnels and ship towing tanks as well as full-scale tests, have long been employed in design and will continue to be used, but are inadequate or uneconomical for many important purposes.
CFD is used extensively in aerodynamic design of modern aircraft, missiles, and gas turbines and is coming into greater use in ship and submarine design. It is also fundamental to models employed to predict environmental effects. To make it computationally feasible for high-Reynolds-number cases of engineering importance, turbulence in the flows is approximated with models, and the limitations of these turbulence models are a principal constraint on practical applications. Another problem is the difficulty of building an appropriate mesh of grid points over which to solve the differential equations that approximate the differential equations of flow. Still another obstacle is the lack of high-quality experimental
data for CFD validation. As a result of these and other deficiencies, current CFD models for engineering use are not reliable in cases of extensive turbulent flows, separated flows, and flows with strong vortices. However, detailed numerical simulations of flow near boundaries have been successful in elucidating some mechanisms of turbulent drag reduction.
Except at low Reynolds numbers, detailed calculation of fully turbulent flows is likely to be beyond the capacity of even the most powerful computers projected for 2035. But improvements should move some approaches, such as large-eddy simulation, from a research technique to practical engineering application. An interplay between experiment and computation will continue to be needed because of their complementary strengths, with a trend toward greater reliance on computation.
There is reason to believe, based on physical grounds, that there is a great deal of room to improve the performance and economics of naval vehicles through better prediction and control of fluid-flow phenomena. For example, achievement of laminar, rather than turbulent, flow over the entire surface could, in principle, reduce parasitic drag by as much as an order of magnitude for some classes of vehicles. CFD analysis will permit speedup and reduced costs of design and manufacturing and will improve prediction of performance. The goal of solving the inverse problem, developing an optimized design based on specification of performance parameters, will be brought closer to practicality through computational fluid dynamics and advanced visualization techniques. Beyond this, interaction between CFD and other computational approaches to modeling structural response, control systems, stealth features, and propulsion will allow a closer approximation to a fully integrated modeling approach, with the goal of overall configuration optimization through simulation-based design.
Many improvements are needed to extend the applicability and ease of use of CFD. These include the following:
- Software for parallel computers, including methods for automatic adaptive grid generators, approaches to rapid setup and execution, and results visualization;
- Modeling of flows that deal with arbitrary geometries and that can resolve all important scales;
- Modeling of strong vortex interactions with control surfaces and propulsors for submarines and missiles, e.g., tail and missile tail control surfaces are inside their wakes; aircraft strong vortices are outside the tail;
- Modeling of high-lift transient and separated flows for vertical short take-off and landing (VSTOL) vehicles and UAVs;
- Modeling of separation postponement and drag mitigation by boundary modification, and;
- Coupled multimedia flow modeling for ships and air-sea interaction, and modeling of combustion turbulent amplification.
The fundamental need, however, is for rapid, affordable, but highly accurate and detailed computations of very complex flows. The crucial technological driver is more adequate turbulence modeling with appropriate physics approximations. This need is well recognized in the CFD technical community and is the subject of active research, but more work is needed. In particular, strong Navy Department guidance and support are essential to ensure that suitable turbulence models will be developed to meet the full range of needs that are of most direct concern to the naval services, such as strongly separated flows, flows with strong vortices (for submarines and missiles), and flows involved in powered-lift vertical landing. This will require a vigorous, focused, and integrated program of theoretical investigation, experimentation, and computation.
Normal development, fostered by industrial and academic concerns, will ensure that CFD will be an increasingly important tool for design and performance prediction of Navy systems. But CFD will realize its full potential to improve the efficiency and performance of naval vehicles only if the Navy and DOD sponsor and guide intensive, high-quality efforts to develop and test turbulence models applicable to the flow characteristics most important for naval applications. This should be a research priority for the Department of the Navy.
Functional and Affordable Computing
With a computer on every desk today, the applications of functional and affordable computing are familiar to us all. Just about any computational task can be undertaken on a workstation or PC, when fast, hard, real-time performance is not an issue. Mathematical calculations, word processing, spreadsheets, database management, graphics, CAD, finite element analysis, thermal or mechanical analysis, use of the Internet, and so on are all commonplace and well supported by the available hardware.
In addition to all of these, and of particular interest to the Navy and Marine Corps, are those applications related to achieving complete situational awareness, that is, data fusion and information mining. As sensors multiply on the battlefield, multiple streams of sensor data will inevitably converge at various collection points, where the information from all sources will be merged or fused into a single composite view of the battle space, which will be far more detailed and complete than can be obtained from any single sensor. The computers to support this activity will come from the functional and affordable class, that is, workstations or PCs. Algorithms and software to best accomplish data fusion are needed and are a Navy Department responsibility, as the commercial world is unlikely to address this uniquely military requirement.
With the proliferation of sophisticated sensors comes the danger of data overload; that is, the volume of the data and the rate at which they are generated are so large that the users cannot keep up and the useful information contained in the data is never recognized, extracted, and utilized. To avoid or to minimize this
problem, techniques of information recognition and extraction, i.e., data mining, should be developed. This is a task that the human performs with ease if given the time, but one that often leaves the all-too literal computers at a loss. Today the subject of university research, concepts for algorithms and software that will permit computers, without direct human intervention, to recognize what is important in any given data set need to be found.
Embedded Computing
Embedded computing is one of the most critical applications of computation, for it is directly coupled to the predicted evolution of sensors (see Chapter 4) and will be largely responsible for much of the anticipated performance improvements. For many of the long-range imaging sensors such as radars, sonars, and infrared optical systems, improved performance will come from increased processing of the sensor data with more complex, adaptive algorithms that cannot be implemented fast enough today to meet the hard real-time requirements of such military systems. With the exponential growth of computing capabilities, processing-based sensor performance improvements will follow. Automatic target recognition (ATR) capabilities will improve, digital beamforming of radar, sonar, and optical beams will become commonplace, and the all-digital radar will emerge with significant size and weight reductions and superior performance through extensive use of digital processing.
As computer capabilities continue to increase, while simultaneously decreasing in size and cost, the computational support for many sensors will merge with the sensing element; that is, both components will be implemented on the same semiconductor chip, giving rise to miniature smart sensors or sensors-on-a-chip. In this way, one can expect to see tiny, inexpensive MEMS-based inertial navigation systems in the future with accelerometers and solid-state gyros and the associated signal processing and computational logic integrated on a single chip. When coupled with advanced high-performance and inexpensive integrated imaging sensors (also with built-in computer capabilities for target acquisition, aim point selection, and guidance), these miniature inertial systems can lead to future generations of affordable, accurate weapons with the possibility of sizable reductions in acquisition and logistic costs.
Alternative and Breakthrough Computing Technologies
Molecular Computing
In many circumstances, biological systems act as massively parallel adaptive computers. Since the 1970s, computing models of biomolecular information-processing systems have been explored and numerous advances made in technologies that can contribute to the implementation of molecular computing systems.1
These include such topics as artificial membranes, recombinant DNA technology, protein engineering, and numerous biosensors for detecting biological substances and processes—e.g., protein, glucose, and fermentation.
Molecular computing differs fundamentally from digital computation in that information is processed as physical patterns rather than bit by bit, and the system learns dynamically as it adapts to its environment. Since the human brain is a form of molecular computer that is small in size, uses very little power, and performs extremely well—particularly on recognition tasks and ill-defined memory queries—it has often been conjectured that, ultimately, molecular rather than digital computation will be the more effective computing paradigm. However, just as our aircraft systems do not directly imitate the physical principles and configurations of birds, bats, and insects, so also it seems unlikely that we will abandon the unique high-speed, error-containing capabilities of digital computing. More likely, molecular computing will provide a way of augmenting digital-processing systems with biological-like capabilities, in terms of pre- and postprocessing pattern recognition, while the central processing tasks continue to be performed digitally. Although the future of molecular computing is cloudy at the moment, given the progress in the biological sciences anticipated for the oncoming decades, this potential breakthrough technology deserves careful attention in the coming years.
Quantum Computing
Of all the technologies discussed so far, quantum computing2 comes closest to what might be considered a true breakthrough technology. If successful, it would be a completely new approach to computing. Based on a novel and thoroughly quantum mechanical concept of elementary logic, quantum computing envisions a two-state logic structure, known as a qubit, which has the uniquely quantum mechanical virtue of being able to exist in a superposition of both states as long as no measurement is made. Using quantum dynamics to design computations that interfere constructively or destructively, remarkably powerful algorithms become possible. Analyses indicate that using Shor's prime factoring algorithm, quantum computers can solve, in polynomial time, problems that have no polynomial time solution on any classical machine. To date, rudimentary qubit logic has been demonstrated with a single or a few logic operations at a time and generally with a large amount of macroscopic hardware, i.e., not physically small, at this stage. Extending this to computationally useful complexities, however,
poses a serious problem in the form of loss of coherence. Decoherence of the quantum mechanical wave function, through unavoidable coupling to rest of the world, however weak, threatens to undo the whole scheme. At the moment interest is high in this unique technology, and whether it can, or will, lead to practical quantum computers is not yet known. At the very least, much insight into subtle quantum phenomena will be generated.
Future Impact on Naval Operations
The impact of computation on future naval operations is expected to be enormous. Computers and computation will be everywhere—an inevitable reflection of the information revolution. Combined with advanced distributed sensors, computation will be the primary enabler for achieving and exploiting complete situational awareness. For most sensors, the primary source of improved performance over the next 40 years will come from the application of more and more computational power to the processing and interpretation of the digitized sensor signals. In many cases, as computer hardware continues to become more powerful, smaller in size, and less costly, the sensing elements will become fully integrated with their supporting digital computer hardware to produce smart sensors or sensors-on-a-chip, such as a complete inertial guidance system with multiple MEMS-based accelerometers and gyros on a single silicon chip. Many important sensors, such as radars and sonars, which cannot be shrunk to a sensor-on-a-chip, will become almost completely digital, with analog-to-digital (A/D) converters at each transponder element and all internal signals transmitted and processed only in digital form, e.g., digital beamforming. With increasing amounts of computational power available, more systems will become adaptive, processing in real time the observed signals and altering their system parameters in response to the observations to optimize their overall performance.
Applied to missiles, future computational resources will permit the creation of very smart weapons capable of ATR, precision aim point selection, and extremely accurate terminal guidance performance. With high accuracy, i.e., very small circular error of probability (CEP), the number and size of the weapons needed to counter any given target can be reduced, thereby offering large future savings in acquisition costs and logistics. At the next level, functional and affordable desktop computers will facilitate the netting of resources, the fusion of data from multiple sources, the extraction of the meaningful information contained therein, and its display to provide the degree of situational awareness and real-time control needed to optimize the effectiveness of future naval forces operations. The other side of the coin, so to speak, will be a continuously increasing vulnerability to information warfare technology through both physical effects, such as electromagnetic pulse (EMP), or software attacks.
At the top level, high-performance computing will contribute in numerous
ways. The ability to perform vast numbers of elementary computations per second will permit timely, accurate investigation of large, complex physical systems, such as the fluid dynamics that is the subject of CFD or the modeling of the physics of warhead-target interactions. Detailed and accurate simulations of complex components and systems will permit simulation-based design and acquisition. And high-performance computers will provide support for highly realistic, real-time, virtual-reality interfaces for viewing situational awareness databases or simulation-based designs.
Developments Needed: Military Versus Commercial
Although today's commercial computer industry appears self-sustaining, its primary focus is functional and affordable computing. Because the markets for them are more limited and specialized, high-performance supercomputers and embedded signal processors are emphasized less than PCs by commercial developers. Several microchip manufacturers are developing concepts for multiprocessors, and workstations powered by very high performance chips have been developed to bridge the gap between high-performance computing and desktop computing, although the PC seems to be on a path to overtake the workstation within a few years. For embedded computing, several families of DSP chips have been created and could grow in the future at exponential rates, if pursued.
Generally, computer hardware components with ever-increasing capabilities will be supplied by the commercial sector, but the government and the Navy Department will still need to fund basic research, specially the research needed to advance the fundamental underlying technologies. Support for algorithms and software designed to implement applications specifically relevant to Navy and Marine Corps needs will be the responsibility of the Department of the Navy. Both high-performance computing and embedded computing will require special efforts. High-performance computing, because of its limited market potential, will require ongoing government support. The Department of the Navy will continue to rely on high-performance computers to carry out computationally intensive tasks such as CFD, atmospheric weather modeling, and simulation-based design and acquisition of new naval platforms.
In the application of computing to sensors and missiles, the Department of the Navy must take the lead in both writing the software and developing the militarized and special hardware configurations needed for sensor and weapons applications. There is no large commercial market to provide these.
Status of Foreign Efforts and Trends
Although Asia and, to a lesser extent, Europe compete successfully with the United States in microelectronics components and consumer electronics, the United States dominates the world in computer hardware technology and generally
leads substantially in all aspects of computer applications. There is little doubt that the United States will continue to run ahead of the rest of the world in computer hardware development and use for decades to come.
On the other hand, Europe has exhibited significant strength in software, particularly on the conceptual and theoretical side. Such critical issues as formal proofs of the correctness of software and the possibilities for software logic synthesis are the subject of intensive, competent research. Ironically, the language Ada, which is in fact a good language for the disciplined development of large software programs, has been completely ignored by those U.S. software developers and universities not under a DOD mandate. Ada has found profitable use in commercial development in Europe. Excellent air traffic control software, written in Spain in Ada, has found wide use in U.S.-produced air traffic control systems.
India also has become very strong in software and currently serves a good portion of U.S. commercial computer users through nightly debugging of code problems, exploiting the reversal of the day-night periods between the United States and India. Software factories in India are a real competitive possibility.
For the far future, it is less clear that the United States will always be ahead in technology for computation. Given Asia's demonstrated microelectronics development and production capabilities, there is no reason to believe that others cannot catch up, as long as they are willing to provide the substantial investments required. The explosive possibilities of the information revolution will make this option commercially attractive very soon. As for software, anyone can compete. It takes no large investments in capital equipment—just smart, educated people with modest computer resources. Computation technology is likely to be available everywhere in the far future, and success in exploiting it in warfare will go to the diligent, not automatically to the United States.
Time Scale for Development and Deployment
The time scale for the growth of computation over the next 40 years is illustrated in Figure 2.2. The simple exponential extrapolations for both high-performance computing and functional and affordable computing can be relied on to represent the order of magnitude of computational capabilities available in any given time frame. This will be true for the near term, i.e., the next 5 to 15 years, and perhaps throughout the whole of the next 40 years. For example, there certainly will be affordable gigaflop computers on the desktop well before 2005. Whether the petaflop level will be reached by 2025 is far less certain, but explicit efforts aimed at petaflop computing have already been initiated, and quite a lot can happen in 30 years.
On the pessimistic side, serious obstacles are anticipated in optical lithography as the wavelengths move further into the ultraviolet and conventional optical concepts begin to fail. This situation could slow the progress toward smaller
dimensions in microelectronics fabrication and consequently slow the increase in single-processor clock speeds. On the other hand, growth in computational throughput is accomplished not only through faster hardware, but also through the use of more parallel units in multiprocessor architectures. Any slowing of the growth rate of computational power owing to lithography limitations could be compensated for by parallel hardware.
Optimistically, several multiprocessor supercomputers, planned for operation in the next few years, are already targeting performance levels well above the extrapolated growth curves shown in Figure 2.2. Given the 40 years of consistent historical growth, it seems premature to conclude that this rate will change in the future, for either the better or the worse. For planning purposes today, it is best to assume that the extrapolations validly represent the level of performance that can be expected to be available in the time frame of interest. It should be remembered that these extrapolations do not indicate, and cannot predict, what detailed concepts or technology will permit these levels of performance at any given time. Nor can these extrapolated levels of performance be expected to be achieved continuously. Individual implementations grow rapidly at first to achieve and extend the technology envelope for a while before they reach saturation, as they encounter their limitations. The result is that the actual history of performance exhibits a step-like rather than a continuous growth curve. Since the individual steps are not predictable from past history, the smooth extrapolations must be treated as indicative of general performance capabilities rather than as predictive of actual performance.
Recommendation
Computer technology will be a major enabler of future naval operations. Computers will enable enhanced situational awareness, realistic modeling and simulation, faster warfighting decisions, more effective weapons, lower-cost platforms, and more efficient and effective use of people. The Department of the Navy should exploit the continual evolution of commercial computer technologies into robust computational systems.



































