
InfoSleuth An Emerging Technology for Sharing Distributed Environmental Information
GREG PITTS and JERRY FOWLER
The rapid growth of the World Wide Web (or the Web) has profoundly affected the culture of information technology. The enormous increase in the number of users and the proliferation of Web sites have led information technologists to rethink the way that information is delivered via a computer. Previously, a computer mainframe provided data from a single structured database to a small group of users over dedicated lines. Today, anyone with a personal computer and access to the Web can read information distributed over computer networks, and, more importantly, they also can create and publish new information resources.
This rapid transformation of the culture along with increased expectations of Web users in all disciplines have led to two challenges. First, information discovery and retrieval is a problem that is addressed only superficially by the development and use of Web search engines (such as Alta Vista and Lycos) to handle the huge amounts of data accessible on the Web. Second, the structured databases that were carefully crafted with a small, knowledgeable user community in mind are now potentially accessible and useful to many additional users. These users, however, are unfamiliar with database query languages. The result is a need for information systems that can uniformly deliver both structured and unstructured data, access different structured databases using a single query language and logical structure, manipulate the data from these distributed sources, and communicate with users via software standards and behavior metaphors that they find comfortable.
Environmental information systems are no exception to this cultural revolution. Currently, it is very difficult to share environmental data because the information typically resides on geographically disparate and heterogeneous
systems. Because they were designed with little expectation of interoperability or widespread access, these systems are not easy to access by secondary users. This can frustrate attempts to fuse data from multiple sources in the interest of arriving at a comprehensive understanding of environmental conditions and actions.
The Environmental Data Exchange Network (EDEN) project was undertaken to address these issues. A collaborative effort of the U.S. Department of Defense (DOD), the U.S. Department of Energy (DOE), the U.S. Environmental Protection Agency (EPA), and the National Institute of Standards and Technology (NIST), the EDEN project seeks to provide a flexible dynamic system for accessing environmental data stored in diverse distributed databases. The underlying technology for EDEN is an emerging information technology called InfoSleuth™1 developed at the Microelectronics and Computer Technology Corporation (MCC). This chapter provides background on the InfoSleuth technology and its application in the EDEN project.
INFOSLEUTH
In the past, database research has been focused on the relatively static environments of centralized and distributed-enterprise databases. In these environments, information is managed centrally and data structures are fixed. Typically, the integration of concepts to specific sets of data is well known at the time that a database schema is defined, and data access can be optimized using precomputed approaches. Although these federated database systems support distribution of the resources across a network, they do not depart from the centralized model of a static database schema.
The Web presents a different paradigm. On the Web, there is a tremendous amount of textual information, spread over a vast geographic area. There is no centralized information management because anyone can publish information on the Web, in any form. Thus, there is minimal structure to the data. What structure there is may bear little relationship to the semantics. Therefore, there can be no static mapping of concepts to structured data sets, and querying is reduced to the use of search engines that locate relevant information based on full-text indices.
The InfoSleuth Project at MCC broadened the focus of database research to produce a model that seeks to combine the semantic benefits of structured database systems with the ease of publication and access of the Web (Bayardo et al., 1997). This change in fundamental requirements dictates a pragmatic approach to merging existing research in database technology with research from other computer disciplines. The result is an architecture that operates on heterogeneous information sources in an open, dynamic environment.
Information requests to InfoSleuth are specified independently of the structure, location, or even existence of the requested information. A key to the success of this approach is the development for each application of a unifying
ontology for the application domain. This enables the user to bridge the gap between different notions of data and different schema of databases. InfoSleuth accepts requests specified at a high semantic level in terms of the global ontology, and flexibly matches them to the information resources that are available and relevant at the time the request is processed.
InfoSleuth is an extension of previous MCC work, the Carnot project, which was successful in integrating heterogeneous information resources in a static environment (Huhns et al., 1992). In this previous work, MCC developed semantic modeling techniques that enabled the integration of static information resources and pioneered the use of intelligent agents to provide interoperation among autonomous systems. The InfoSleuth Project extended these capabilities into dynamically changing environments, where the identities of the resources to be used may be unknown at the time the system is designed. InfoSleuth observes the autonomy of its resources and does not depend on their presence. Information-gathering tasks, therefore, are defined genetically, and their results are sensitive to the availability of resources. Consequently, InfoSleuth provides flexible, extensible ways of locating information while executing a task and deals with incomplete information.
InfoSleuth Technologies
To achieve the necessary flexibility and openness, InfoSleuth integrates the following technological developments:
-
Agent technology. Specialized agents that represent the users, the information resources, and the system itself cooperate to address the users’ information processing requirements, allowing for easy dynamic reconfiguration of system capabilities. For instance, adding a new information source involves merely adding a new agent and advertising its capabilities. The use of agent technology permits a high degree of decentralization of capabilities, which is the key to system scalability and extensibility (Nodine and Unruh, 1997).
-
Domain models (ontologies). Ontologies give a concise, uniform, and declarative description of semantic information, independent of the underlying representation of the conceptual models of information bases. Domain models widen the accessibility of information by allowing multiple ontologies belonging to diverse user groups.
-
Information brokering. Broker agents match information needs, specified in terms of some ontology, with currently available resources. Retrieval and update requests then can be properly routed to the relevant resources (Nodine and Bohrer, 1997).
-
Internet computing. Java programs and applets are used extensively to provide users and administrators with system-independent user interfaces
-
and to enable ubiquitous agents that can be deployed at any source of information regardless of its location or platform.
Agents
The InfoSleuth system employs a number of intelligent software agents to perform its tasks, concealed from the user by a dedicated user agent. These agents operate independently in a distributed fashion and may be located anywhere over the network in the form of a Java program. Each agent provides a critical capability in the overall system, as described in the following:
-
User agent. Constitutes the user’s intelligent gateway into InfoSleuth. It uses knowledge of the systems’ common domain models (ontologies) to assist the user in formulating queries and in displaying their results.
-
Ontology agent. Provides an overall knowledge of ontologies and answers queries about ontologies. This permits users to explore the terminology of the domain and learn to phrase their queries to obtain useful results.
-
Broker agent. Receives and stores advertisements of capabilities from all InfoSleuth agents. Based on this information, it responds to queries from agents as to where to route their specific requests.
-
Resource agent. Provides a mapping from the global ontology to the database schema and language native to its resource and executes the requests specific to that resource, including subscription queries and notification requests. Resource agents exist not only for structured databases, but also for unstructured data sources that serve text or images.
-
Task execution agent. Coordinates the execution of high-level information-gathering subtasks necessary to fulfill queries and other information management tasks, such as the control of workflow processes.
-
Multiresource query agent. Uses information supplied by the broker agent to identify the resources likely to have the requested information, decomposes the query into pieces appropriate to individual resource agents, delivers these subqueries to the resource agents, and then retrieves and reassembles the results.
How InfoSleuth Works
Comparing the behavior of InfoSleuth to the administration of a library provides a good analogy for explaining how InfoSleuth works. At the physical level, the infrastructure of a library is its bricks, mortar, windows, wiring, plumbing, and shelves. Add a few books and you have an information system that is usable. However, a more usable system will have books classified and arranged by their classification.
To take advantage of the information in the library, a librarian needs to be provided with a set of subject headings, such as those provided by the Dewey decimal system, the Library of Congress system, or the National Library of Medicine medical subject headings, and a mapping from the subject headings to the library’s holdings. In addition, the books need to be organized according to these subjects, and the librarian needs to be given a resource locator list that identifies where books categorized by a particular subject can be found.
For library patrons to take advantage of the library, they need (in addition to the items mentioned above) a competent library staff person who can assist them in their searches, or at least direct them to the tools required to perform a search.
The InfoSleuth model of dynamic distributed information management has several strong parallels with a library system. A library’s physical infrastructure is its building; similarly, a distributed information system comprises the computers and the networks connecting them. The library’s books correspond to the databases and other information repositories that InfoSleuth serves. The library’s subject headings have an analogy in the domain ontology (stored in the ontology agent’s knowledge base) that InfoSleuth agents use to query their resources. Just as libraries benefit from the use of standard classification schemes such as that of the Library of Congress, InfoSleuth benefits from the use of global ontologies. This makes it possible to query diverse databases through a common query model. The broker agent’s knowledge base of agent advertisements can be thought of as combining knowledge of the library’s card catalog and holdings locator list with an administrator’s knowledge of the capabilities of the library staff.
Query Initiation
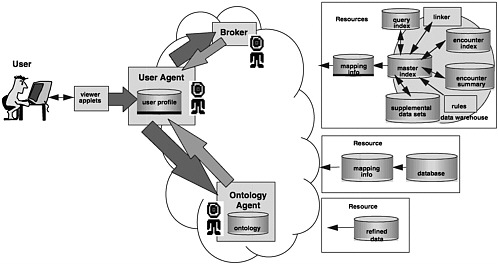
An InfoSleuth query can be described in terms of a visit to a library. For example, a professor at an academic institution instructs a graduate student to do research on phytoremediation of petroleum hydrocarbons (the specific domain of interest) at the library (i.e., where the Web browser or Viewer application points to the appropriate location to access the InfoSleuth system). The student (the user agent) walks in the front door and asks for help at the information desk. There, a librarian familiar with the collection and the staff (the broker agent) is available to direct the student to a research librarian familiar with the domain (see Figure 1).
Query Processing
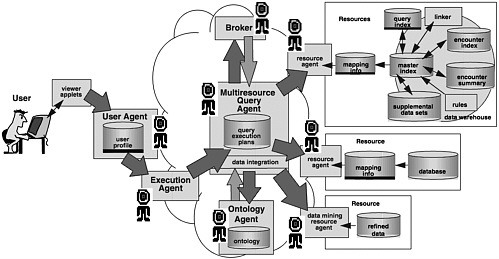
The student is told to go either to the engineering librarian, who is in another building, or to the earth sciences section of this library, which may have less information but is not so far away. The student finds a knowledgeable research librarian (execution agent) who helps to refine the query with the help of the subject headings (ontology), distilling the query (multiresource query agent) into specific queries about books and journals. The research librarian then assists the
student by issuing requests to library assistants (resource agents) to retrieve the books. For books that cannot be located, the librarian provides further assistance by issuing an interlibrary loan request (another resource agent) (see Figure 2).
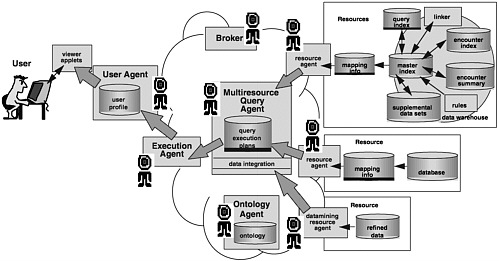
Query Response
When the books are retrieved, they are collected and given to the student (user agent), who then compiles and assesses the information. Eventually, the student provides an analysis in the form of a technical review that collates the results of the search and summarizes them into a single document (multiresource query agent) (see Figure 3). In reviewing the summary, however, the professor questions the validity of a conclusion drawn by one of the authors and requests that the student get the journal or book in question for a more detailed study. The student gets the journal or book in question, and the research query then is completed.
ENVIRONMENTAL DATA EXCHANGE NETWORK PILOT PROJECT
System Characteristics
The broad collaborative effort of the EDEN Project focuses on two areas. The first area is to describe the content of environmental information. What is it? What does it mean? What is its quality and utility? Why was it created and how? What specific data are desired from the data sources? The second area is to develop a means for sharing this information without incurring the financial and technical burdens of redesigning database systems or maintaining redundant databases. This is the immediate focus of EDEN’s pilot project.
To this end, EDEN Project participants have chosen the area of hazardous waste remediation for a pilot demonstration. Each government agency is contributing one or more databases (see Box 1). Portions of these databases will be made accessible through InfoSleuth.
Using intelligent InfoSleuth software agents and Java applets to access and retrieve information from disparate data sources, the EDEN pilot system supports a dynamic environment in which databases can be added or removed without affecting the basic behavior of the system. Thus, the project can be developed from a small initial group of databases and allows for additional databases to be added. The resulting technology demonstration is of immediate use in providing access to distributed environmental data resources via the Internet, as well as in guiding future expansion of the information system.
In addition, InfoSleuth provides a common vocabulary and a general query ability that simplifies the exchange and sharing of information among organizations. By establishing the common vocabulary, widely differing information resources can be “mapped” and easily accessed by a sophisticated system of
|
BOX 1
The pilot will also leverage work being done in two other important environmental information projects that are currently under way:
|
software agents that advertise, broker, and exchange the data requested by the user. In this way, the EDEN pilot system will provide uniform access to existing information resources without imposing requirements for restructuring or incurring the significant cost of conventional database integration.
Development Plan
The development plan for the EDEN pilot involves the following steps:
-
Create a conceptual model that will become the application’s domain ontology. To the extent possible, the ontology is being constructed using terms from the General European Multilingual Environmental Thesaurus
-
that are applicable to the domain of waste remediation. A graphic depiction of the ontological model that supports a set of queries chosen to show off the capabilities of the pilot is found in Figure 4. This figure shows the primary entities of the ontology linked by a collection of relationships that provide the best abstraction of the data to be found in the databases chosen for the pilot.
-
Develop mappings between each of the identified databases and the domain ontology and then configure a set of resource agents, each of which uses the appropriate mapping to translate between its database resource and the common vocabulary provided by the domain ontology.
-
Take advantage of the Environmental Data Registry (EDR) to assist in resolving value mapping between the different ways that database designers have used for storing data values that express the same concept (such as conversion between English and metric measures or reconciling different ways of identifying chemical contaminants).
-
Develop a flexible yet simple query tool that allows a user to pose queries over the domain ontology and retrieve answers whose appearance may be customized for an individual or group. The user interface is constructed using Java, which makes it portable across numerous operating systems
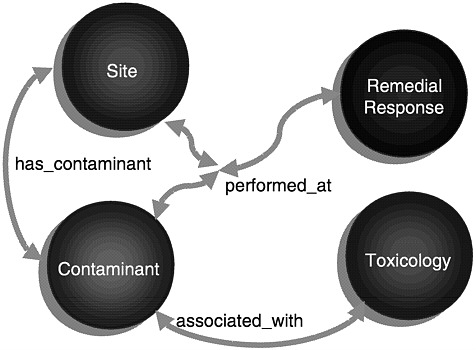
FIGURE 4 The ontological model that supports a set of queries for the selected databases.
-
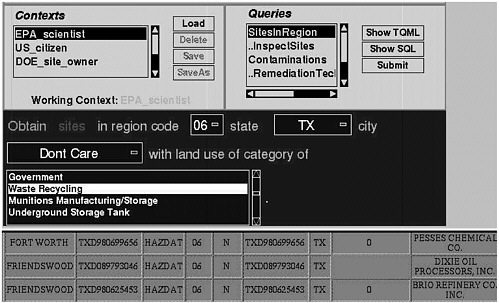
and graphic user interface environments. By using Java, it is possible for an end user to issue queries to the system with no more hardware or software than is necessary to support a Java-capable Web browser. Figure 5 depicts a user interface that has been configured to support a particular sequence of queries relating to the identification of remediation technologies associated with particular sites. The displayed results are a fragment of those retrieved from a demonstration system that accessed the Coordinated Emergency Response Cleanup and Liability Information System, the Hazards Data, and Innovative Treatment Technologies.
Two other complementary efforts are of importance. These are investigating the utility of integration of data analysis capabilities with intelligent agents and Web-based text and relating the work to proposed international data and metadata standards, such as American National Standards Institute X3L8 and International Organization for Standardization SC14.
SUMMARY
The potential for distributed hypertext as a means of managing and sharing environmental information is enormous. The Web provides clues as to what distributed information systems of the future can offer, but by no means can it be said that the Web itself is a solution to cooperative information management. Great strides remain to be taken in support of collaboration and intelligent information retrieval.
The EDEN Project is an ambitious effort to demonstrate the use of an agent-based system. As an application of the InfoSleuth intelligent agent technology developed at MCC, it represents a significant step forward in the potential to organize, access, and analyze environmental information. The collaboration between the participants is stimulating the development and adoption of appropriate data standards and methods for describing data elements that reaches well beyond the EDEN Project. If the pilot demonstration is deemed a success, it is anticipated that the InfoSleuth technology utilized in the demonstration will become commercially available.
ACKNOWLEDGMENTS
InfoSleuth2 was an MCC consortial research project sponsored by General Dynamics Information Systems (formerly Computing Devices International), NCR Corporation, Schlumberger, Raytheon Systems, Texas Instruments, TRW, and the DOD Clinical Business Area. This work was partially supported by NIST contract 50SBNB6C9076. The authors thank Mike Minock, Malcolm Taylor, and Vipul Kashyap at MCC for their contributions to this work.
NOTE
REFERENCES
Bayardo, R.J., W.Bohrer, R.Brice, A.Cichocki, J.Fowler, A.Helal, V.Kashyap, T.Ksiezyk, G.Martin, M.Nodine, M.Rashid, M.Rusinkiewicz, R.Shea, C.Unnikrishnan, A.Unruh, and D.Woelk. 1997. InfoSleuth: agent-based semantic integration of information in open and dynamic environments. Pp. 195–206 in Proceedings of SIGMOD 97, Phoenix, Arizona, May 1997. New York: ACM Press.
Huhns, M., N.Jacobs, T.Ksiezyk, W.M.Shen, M.Singh, and P.Cannata. 1992. Enterprise information modeling and model integration in Carnot. In Enterprise Integration Modeling: Proceedings of the First International Conference. Boston, Mass.: MIT Press.
Nodine, M., and W.Bohrer. 1997. Scalable Semantic Brokering of Agents in InfoSleuth. Paper presented at the 18th International Conference on Distributed Computing Systems, Amsterdam, The Netherlands, May 26–29, 1998. New York: ACM Press.
Nodine M., and W.Unruh. 1997. Facilitating Open Communication in Agent Systems: The InfoSleuth Infrastructure. In Proceedings of the Fourth International Workshop on Agent Theories, Architectures, and Languages, Providence, R.I., July 1997. New York: Springer-Verlag.














