
8
Theoretical Research: Intangible Cornerstone of Computer Science
The theory and vocabulary of computing did not appear ready-made. Some important concepts, such as operating systems and compilers, had to be invented de novo. Others, such as recursion and invariance, can be traced to earlier work in mathematics. They became part of the evolving computer science lexicon as they helped to stimulate or clarify the design and conceptualization of computing artifacts. Many of these theoretical concepts from different sources have now become so embedded in computing and communications that they pervade the thinking of all computer scientists. Most of these notions, only vaguely perceived in the computing community of 1960, have since become ingrained in the practice of computing professionals and even made their way into high-school curricula.
Although developments in computing theory are intangible, theory underlies many aspects of the construction, explanation, and understanding of computers, as this chapter demonstrates. For example, the concept of state machines (described below) contributed to the development of compilers and communications protocols, insights into computational complexity have been applied to improve the efficiency of industrial processes and information systems, formal verification methods have provided a tool for improving the reliability of programs, and advances in number theory resulted in the development of new encryption methods. By serving as practical tools for use in reasoning and description, such theoretical notions have informed progress in all corners of computing. Although most of these ideas have a basis in mathematics, they have
become so firmly fixed in the instincts of computer scientists and engineers that they are likely to be used as naturally as a cashier uses arithmetic, with little attention to the origins of the process. In this way, theory pervades the daily practice of computer science and lends legitimacy to the very identity of the field.
This chapter reviews the history and the funding sources of four areas of theoretical computer science: state machines, computational complexity, program correctness, and cryptography. A final section summarizes the lessons to be learned from history. Although by no means a comprehensive overview of theoretical computer science, the discussion focuses on topics that are representative of the evolution in the field and can be encapsulated fairly, without favoring any particular thesis. State machines, computational complexity, and verification can be traced to the work of logicians in the late 1800s and early 1900s. Cryptography dates back even further. The evolution of these subfields reflects the interplay of mathematics and computer science and the ways in which research questions changed as computer hardware placed practical constraints on theoretical constructs. Each of the four areas is now ubiquitous in the basic conceptual toolkit of computer scientists as well as in undergraduate curricula and textbooks. Each area also continues to evolve and pose additional challenging questions.
Because it tracks the rise of ideas into the general consciousness of the computer science community, this case study is concerned less with issues of ultimate priority than with crystallizing events. In combination, the history of the four topics addressed in this chapter illustrates the complex fabric of a dynamic field. Ideas flowed in all directions, geographically and organizationally. Breakthroughs were achieved in many places, including a variety of North American and European universities and a few industrial research laboratories. Soviet theoreticians also made a number of important advances, although they are not emphasized in this chapter. Federal funding has been important, mostly from the National Science Foundation (NSF), which began supporting work in theoretical computer science shortly after its founding in 1950. The low cost of theoretical research fit the NSF paradigm of single-investigator research. Originally, such work was funded through the division of mathematical sciences, but with the establishment of the Office of Computing Activities in 1970, the NSF initiated a theoretical computer science program that continues to this day. As Thomas Keenan, an NSF staffer, put it:
Computer science had achieved the title "computer science" without much science in it, [so we] decided that to be a science you had to have theory, and not just theory itself as a separate program, but everything had to have a theoretical basis. And so, whenever we had a proposal . . .
we encouraged, as much as we could, some kind of theoretical background for this proposal. (Aspray et al., 1996)
The NSF ended up funding the bulk of theoretical work in the field (by 1980 it had supported nearly 400 projects in computational theory), much of it with great success. Although funding for theoretical computer science has declined as a percentage of the NSF budget for computing research (it constituted 7 percent of the budget in 1996, down from 20 percent in 1973), it has grown slightly in real dollars.1 Mission-oriented agencies, such as the National Aeronautics and Space Administration or the Defense Advanced Research Projects Agency, tend not to fund theoretical work directly because of their emphasis on advancing computing technology, but some advances in theory were made as part of their larger research agendas.
Machine Models: State Machines
State machine are ubiquitous models for describing and implementing various aspects of computing. The body of theory and implementation techniques that has grown up around state machines fosters the rapid and accurate construction and analysis of applications, including compilers, text-search engines, operating systems, communication protocols, and graphical user interfaces.
The idea of a state machine is simple. A system (or subsystem) is characterized by a set of states (or conditions) that it may assume. The system receives a series of inputs that may cause the machine to produce an output or enter a different state, depending on its current state. For example, a simplified state diagram of a telephone activity might identify states such as idle, dial tone, dialing, ringing, and talking, as well as events that cause a shift from one state to another, such as lifting the handset, touching a digit, answering, or hanging up (see Figure 8.1). A finite state machine, such as a telephone, can be in only one of a limited number of states. More powerful state machine models admit a larger, theoretically infinite, number of states.
The notion of the state machine as a model of all computing was described in Alan Turing's celebrated paper on computability in 1936, before any general-purpose computers had been built. Turing, of Cambridge University, proposed a model that comprised an infinitely long tape and a device that could read from or write to that tape (Turing, 1936). He demonstrated that such a machine could serve as a general-purpose computer. In both academia and industry, related models were proposed and studied during the following two decades, resulting in a definitive 1959 paper by Michael Rabin and Dana Scott of IBM Corporation (Rabin
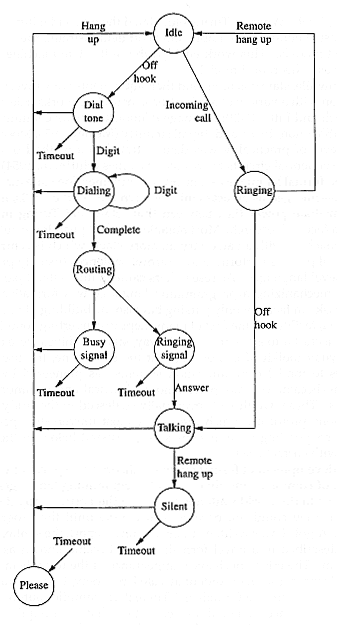
Figure 8.1
Simplified state diagram for supervising a telephone line. States are represented by circles, inputs by labels on arrows. Actions in placing a call lead down the left side of the diagram; actions in receiving a call lead down the right. The state labeled "Please" at the bottom of the diagram announces "Please hang up."
and Scott, 1959). Whereas Turing elucidated the undecidability2 inherent in the most general model, Rabin and Scott demonstrated the tractability of limited models. This work enabled the finite state machine to reach maturity as a theoretical model.
Meanwhile, state machines and their equivalents were investigated in connection with a variety of applications: neural networks (Kleene, 1936; McCulloch and Pitts, 1943); language (Chomsky, 1956); communications systems (Shannon, 1948), and digital circuitry (Mealey, 1955; Moore, 1956). A new level of practicality was demonstrated in a method of deriving efficient sequential circuits from state machines (Huffman, 1954).
When formal languages—a means of implementing state machines in software—emerged as an academic research area in the 1960s, machines of intermediate power (i.e., between finite-state and Turing machines) became a focus of research. Most notable was the ''pushdown automata,'' or state machine with an auxiliary memory stack, which is central to the mechanical parsing performed to interpret sentences (usually programs) in high-level languages. As researchers came to understand parsing, the work of mechanizing a programming language was formalized into a routine task. In fact, not only parsing but also the building of parsers was automated, facilitating the first of many steps in converting compiler writing from a craft into a science. In this way, state machines were added to the everyday toolkit of computing. At the same time, the use of state machines to model communication systems—as pioneered by Claude Shannon—became commonplace among electrical and communications engineers. These two threads eventually coalesced in the study of communications protocols, which are now almost universally specified in terms of cooperating state machines (as discussed below in the section dealing with correctness).
The development of formal language theory was spurred by the construction of compilers and invention of programming languages. Compilers came to the world's attention through the Fortran project (Backus, 1979), but they could not become a discipline until the programming language Algol 60 was written. In the defining report, the syntax of Algol 60 was described in a novel formalism that became known as Backus-Naur form. The crisp, mechanical appearance of the formalism inspired Edward Irons, a graduate student at Yale University, to try to build compilers directly from the formalism. Thereafter, compiler automation became commonplace, as noted above. A task that once required a large team could now be assigned as homework. Not only did parsers become easy to make; they also became more reliable. Doing the bulk of the construction automatically reduced the chance of bugs in the final product, which might be anything from a compiler for Fortran to an interpreter for Hypertext Markup Language (HTML).
State machines were developed by a mix of academic and industrial researchers. The idea began as a theoretical construct but is now fully naturalized throughout computer science as an organizing principle and specification tool, independent of any analytical considerations. Introductory texts describe certain programming patterns as state driven (Garland, 1986) or state based (Clancy and Linn, 1995). An archetypal state-based program is a menu-driven telephone-inquiry system. Based on their familiarity with the paradigm, software engineers instinctively know how to build such programs. The ubiquity of the paradigm has led to the development of special tools for describing and building state-based systems, just as for parsers. Work continues to devise machine models to describe different types of systems.
Computational Complexity
The theory of computability preceded the advent of general-purpose computers and can be traced to work by Turing, Kurt Godel, Alonzo Church, and others (Davis, 1965). Computability theory concentrated on a single question: Do effective procedures exist for deciding mathematical questions? The requirements of computing have raised more detailed questions about the intrinsic complexity of digital calculation, and these questions have raised new issues in mathematics.
Algorithms devised for manual computing often were characterized by operation counts. For example, various schemes were proposed for carrying out Gaussian elimination or finite Fourier transforms using such counts. This approach became more common with the advent of computers, particularly in connection with algorithms for sorting (Friend, 1956). However, the inherent degree of difficulty of computing problems did not become a discrete research topic until the 1960s. By 1970, the analysis of algorithms had become an established aspect of computer science, and Knuth (1968) had published the first volume of a treatise on the subject that remains an indispensable reference today. Over time, work on complexity theory has evolved just as practical considerations have evolved: from concerns regarding the time needed to complete a calculation, to concerns about the space required to perform it, to issues such as the number of random bits needed to encrypt a message so that the code cannot be broken.
In the early 1960s, Hao Wang3 noted distinctions of form that rendered some problems in mathematical logic decidable, whereas logical problems as a class are undecidable. There also emerged a robust classification of problems based on the machine capabilities required to attack them. The classification was dramatically refined by Juris Hartmanis and Richard Stearns at General Electric Company (GE), who showed that
within a single machine model, a hierarchy of complexity classes exists, stratified by space or time requirements. Hartmanis then left GE to found the computer science department at Cornell University. With NSF support, Hartmanis continued to study computational complexity, a field widely supported by NSF.
Hartmanis and Stearns developed a "speed-up" theorem, which said essentially that the complexity hierarchy is unaffected by the underlying speed of computing. What distinguishes levels of the hierarchy is the way that solution time varies with problem size—and not the scale at which time is measured. Thus, it is useful to talk of complexity in terms of order-of-growth. To that end, the "big-oh" notation, of the form O(n), was imported from algorithm analysis to computing (most notably by Knuth [1976]), where it has taken on a life of its own. The notation is used to describe the rate at which the time needed to generate a solution varies with the size of the problem. Problems in which there is a linear relationship between problem size and time to solution are O(n); those in which the time to solution varies as the square of the problem size are O(n2).4 Big-oh estimates soon pervaded algorithm courses and have since been included in curricula for computer science in high schools.
The quantitative approach to complexity pioneered by Hartmanis and Stearns spread rapidly in the academic community. Applying this sharpened viewpoint to decision problems in logic, Stephen Cook at the University of Toronto proposed the most celebrated theoretical notion in computing—NP completeness. His "P versus NP" conjecture is now counted among the important open problems of mathematics. It states that there is a sharp distinction between problems that can be computed deterministically or nondeterministically in a tractable amount of time.5 Cook's theory, and previous work by Hartmanis and Stearns, helps categorize problems as either deterministic or nondeterministic. The practical importance of Cook's work was vivified by Richard Karp, at the University of California at Berkeley (UC-Berkeley), who demonstrated that a collection of nondeterministically tractable problems, including the famous traveling-salesman problem,6 are interchangeable ("NP complete") in the sense that, if any one of them is deterministically tractable, then all of them are. A torrent of other NP-complete problems followed, unleashed by a seminal book by Michael Garey and David Johnson at Bell Laboratories (Garey and Johnson, 1979).
Cook's conjecture, if true, implies that there is no hope for precisely solving any of these problems on a real computer without incurring an exponential time penalty. As a result, software designers, knowing that particular applications (e.g., integrated-circuit layout) are intrinsically difficult, can opt for "good enough" solutions, rather than seeking "best possible" solutions. This leads to another question: How good a solution
can be obtained for a given amount of effort? A more refined theory about approximate solutions to difficult problems has been developed (Hochbaum, 1997), but, given that approximations are not widely used by computer scientists, this theory is not addressed in detail here. Fortunately, good approximation methods do exist for some NP-complete problems. For example, huge "traveling salesman routes" are routinely used to minimize the travel of an automated drill over a circuit board in which thousands of holes must be bored. These approximation methods are good enough to guarantee that certain easy solutions will come very close to (i.e., within 1 percent of) the best possible solution.
Verifying Program Correctness
Although the earliest computer algorithms were written largely to solve mathematical problems, only a tenuous and informal connection existed between computer programs and the mathematical ideas they were intended to implement. The gap between programs and mathematics widened with the rise of system programming, which concentrated on the mechanics of interacting with a computer's environment rather than on mathematics.
The possibility of treating the behavior of programs as the subject of a mathematical argument was advanced in a compelling way by Robert Floyd at UC-Berkeley and later amplified by Anthony Hoare at The Queen's University of Belfast. The academic movement toward program verification was paralleled by a movement toward structured programming, christened by Edsger Dijkstra at Technische Universiteit Eindhoven and vigorously promoted by Harlan Mills at IBM and many others. A basic tenet of the latter movement was that good program structure fosters the ability to reason about programs and thereby assure their correctness.7 Moreover, analogous structuring was to inform the design process itself, leading to higher productivity as well as better products. Structured programming became an obligatory slogan in programming texts and a mandated practice in many major software firms.
In the full verification approach, a program's specifications are described mathematically, and a formal proof that the program realizes the specifications is carried through. To assure the validity of the (exhaustingly long) proof, it would be carried out or checked mechanically. To date, this approach has been too onerous to contemplate for routine programming. Nevertheless, advocates of structured programming promoted some of its key ideas, namely precondition, postcondition, and invariant (see Box 8.1). These terms have found their way into every computer science curriculum, even at the high school level. Whether or
|
BOX 8.1 The Formal Verification Process In formal verification, computer programs become objects of mathematical study. A program is seen as affecting the state of the data with which it interacts. The purpose of the program is to transform a state with known properties (the precondition) into a state with initially unknown, but desired properties (the postcondition). A program is composed of elementary operations, such as adding or comparing quantities. The transforming effect of each elementary operation is known. Verification consists of proving, by logical deduction, that the sequence of program steps starting from the precondition must inexorably lead to the desired postcondition. When programs involve many repetitions of the same elementary steps, applied to many different data elements or many transformational stages starting from some initial data, verification involves showing once and for all that, no matter what the data are or how many steps it takes, a program eventually will achieve the postcondition. Such an argument takes the form of a mathematical induction, which asserts that the state after each repetition is a suitable starting state for the next repetition. The assertion that the state remains suitable from repetition to repetition is called an "invariant" assertion. An invariant assertion is not enough, by itself, to assure a solution. To rule out the possibility of a program running forever without giving an answer, one must also show that the postcondition will eventually be reached. This can be done by showing that each repetition makes a definite increment of progress toward the postcondition, and that only a finite number of such increments are possible. Although nationally straightforward, the formal verification of everyday programs poses a daunting challenge. Familiar programs repeat thousands of elementary steps millions of times. Moreover, it is a forbidding task to define precise preconditions and postconditions for a program (e.g., spreadsheet or word processor) with an informal manual running into the hundreds of pages. To carry mathematical arguments through on this scale requires automation in the form of verification tools. To date, such tools can handle only problems with short descriptions—a few dozen pages, at most. Nevertheless, it is possible for these few pages to describe complex or subtle behavior. In these cases, verification tools come in handy. |
not logic is overtly asserted in code written by everyday programmers, these ideas inform their work.
The structured programming perspective led to a more advanced discipline, promulgated by David Gries at Cornell University and Edsger Dijkstra at Eindhoven, which is beginning to enter curricula. In this approach, programs are derived from specifications by algebraic calculation. In the most advanced manifestation, formulated by Eric Hehner, programming is identified with mathematical logic. Although it remains to be seen whether this degree of mathematicization will eventually be-
come common practice, the history of engineering analysis suggests that this outcome is likely.
In one area, the design of distributed systems, mathematicization is spreading in the field perhaps faster than in the classroom. The initial impetus was West's validation of a proposed international standard protocol. The subject quickly matured, both in practice (Holzmann, 1991) and in theory (Vardi and Wolper, 1986). By now, engineers have harnessed a plethora of algebras (e.g., temporal logic, process algebra) in practical tools for analyzing protocols used in applications ranging from hardware buses to Internet communications.
It is particularly difficult to foresee the effects of abnormal events on the behavior of communications applications. Loss or garbling of messages between computers, or conflicts between concurrent events, such as two travel agents booking the same airline seat, can cause inconvenience or even catastrophe, as noted by Neumann (1995). These real-life difficulties have encouraged research in protocol analysis, which makes it possible to predict behavior under a full range of conditions and events, not just a few simple scenarios. A body of theory and practice has emerged in the past decade to make automatic analysis of protocols a practical reality.
Cryptography
Cryptography is now more important than ever. Although the military has a long history of supporting research on encryption techniques to maintain the security of data transmissions, it is only recently that cryptography has come into widespread use in business and personal applications. It is an increasingly important component of systems that secure online business transactions or maintain the privacy of personal communications.8 Cryptography is a field in which theoretical work has clear implications for practice, and vice versa. The field has also been controversial, in that federal agencies have sometimes opposed, and at other times supported, publicly accessible research. Here again, the NSF supported work for which no funding could be obtained from other agencies.
The scientific study of cryptography matured in conjunction with information theory, in which coding and decoding are central concerns, albeit typically in connection with compression and robust transmission of data as opposed to security or privacy concerns. Although Claude Shannon's seminal treatment of cryptography (Shannon, 1949) followed his founding paper on information theory, it was actually written earlier under conditions of wartime security. Undoubtedly, Shannon's involvement with cryptography on government projects helped shape his thinking about information theory.
Through the 1970s, research in cryptography was pursued mainly
under the aegis of government agencies. Although impressive accomplishments, such as Great Britain's Ultra code-breaking enterprise in World War II, were known by reputation, the methods were largely kept secret. The National Security Agency (NSA) was for many years the leader in cryptographic work, but few of the results were published or found their way into the civilian community. However, an independent movement of cryptographic discovery developed, driven by the availability and needs of computing. Ready access to computing power made cryptographic experimentation feasible, just as opportunities for remote intrusion made it necessary and the mystery surrounding the field made it intriguing.
In 1977, the Data Encryption Standard (DES) developed at IBM for use in the private sector received federal endorsement (National Bureau of Standards, 1977). The mechanism of DES was disclosed, although a pivotal aspect of its scientific justification remained classified. Speculation about the strength of the system spurred research just as effectively as if a formal request for proposals had been issued.
On the heels of DES came the novel proposal for public-key cryptography by Whitfield Diffie and Martin Hellman at Stanford University, and, independently, by R.C. Merkle. Hellman had been interested in cryptography since the early 1970s and eventually convinced the NSF to support it (Diffie and Hellman, 1976). The notion of public-key cryptography was soon made fully practical by Ronald Rivest, Adi Shamir, and Leonard Adleman at the Massachusetts Institute of Technology, who, with funding from the NSF and Office of Naval Research (ONR), devised a public-key method based on number theory (Rivest et al., 1978) (see Box 8.2). Their method won instant acclaim and catapulted number theory into the realm of applied mathematics. Each of the cited works has become bedrock for the practice and study of computer security. The NSF support was critical, as it allowed the ideas to be developed and published in the open, despite pressure from the NSA to keep them secret.
The potential entanglement with International Traffic in Arms Regulations is always apparent in the cryptography arena (Computer Science and Telecommunications Board, 1996). Official and semiofficial attempts to suppress publication have often drawn extra notice to the field (Diffie, 1996). This unsolicited attention has evoked a notable level of independence among investigators. Most, however, have achieved a satisfactory modus vivendi with the concerned agencies, as evidenced by the seminal papers cited in this chapter that report on important cryptographic research performed under unclassified grants.
|
BOX 8.2 Rivest-Shamir-Adleman Cryptography Before public-key cryptography was invented, cipher systems required two communicating parties to agree in advance on a secret key to be used in encrypting and decrypting messages between them. To assure privacy for every communication, a separate arrangement had to be made between each pair who might one day wish to communicate. Parties who did not know each other in advance of the need to communicate were out of luck. By contrast, public-key cryptography requires merely that an individual announce a single (public) encryption key that can be used by everyone who wishes to send that individual a message. To decode any of the messages, this individual uses a different but mathematically related key, which is private. The security of the system depends on its being prohibitively difficult for anyone to discover the private key if only the public key is known. The practicality of the system depends on there being a feasible way to produce pairs of public and private keys. The first proposals for public-key cryptography appealed to complexity theory for problems that are difficult to solve. The practical method proposed by Rivest, Shamir, and Adleman (RSA) depends on a problem believed to be of this type from number theory. The problem is factoring. The recipient chooses two huge prime numbers and announces only their product. The product is used in the encryption process, whereas decryption requires knowledge of the primes. To break the code, one must factor the product, a task that can be made arbitrarily hard by picking large enough numbers; hundred-digit primes are enough to seriously challenge a stable of supercomputers. The RSA method nicely illustrates how theory and practice evolved together. Complexity theory was motivated by computation and the desire to understand whether the difficulty of some problems was inherent or only a symptom of inadequate understanding. When it became clear that inherently difficult problems exist, the stage was set for public-key cryptography. This was not sufficient to advance the state of practice, however. Theory also came to the fore in suggesting problems with structures that could be adapted to cryptography. It took the combination of computers, complexity theory, and number theory to make public-key cryptography a reality, or even conceivable. Once the idea was proposed, remarkable advances in practical technique followed quickly. So did advances in number theory and logic, spurred by cryptographic needs. The general area of protection of communication now covers a range of topics, including code-breaking (even the "good guys" must try to break codes to confirm security); authentication (i.e., preventing imposters in communications); checks and balances (i.e., forestalling rogue actions, such as embezzlement or missile launches, by nominally trusted people); and protection of intellectual property (e.g., by making information theft-proof or providing evidence that knowledge exists without revealing the knowledge). |
Lessons from History
Research in theoretical computer science has been supported by both the federal government and industry. Almost without exception in the cases discussed, contributions from U.S. academia acknowledge the support of federal agencies, most notably the NSF and ONR. Nevertheless, many advances in theoretical computer science have emerged from major industrial research laboratories, such as IBM, AT&T (Bell Laboratories), and GE. This is partly because some of the areas examined developed before the NSF was established, but also because some large corporate laboratories have provided an environment that allows industry researchers to produce directly relevant results while also carrying on long-term, theoretical investigations in the background. Shannon, for example, apparently worked on information theory for a decade before he told the world about it.
Theoretical computer science has made important contributions to computing practice while, conversely, also being informed by that practice. Work on the theory of one-way functions, for example, led to the development of public-key cryptography, and the development of complexity theory, such as Cook's conjecture, sparked efforts to improve methods for approximating solutions to nondeterministically tractable problems. Similarly, the theoretical work in complexity and program correctness (or verification) has been redirected by the advancing needs of computing systems.
Academia has played a key role in propagating computing theory. By teaching and writing textbooks, academic researchers naturally influenced the subjects taught, especially during the formative years of computer science departments. However, some important synthesizing books have come from industrial research laboratories, where management has seen fit to support such writing to enhance prestige, attract candidates, and foster the competence on which research depends.
Foreign nations have contributed to theoretical computer science. Although the United States has been the center of systems-related research, a considerable share of the mathematical underpinnings for computer science can be attributed to British, Canadian, and European academics. (The wider practical implementation of this work in the United States may be explained by a historically greater availability of computers.) The major foreign contributions examined in this case were all supported by governments; none came from foreign industry.
Personal and personnel dynamics have also played important roles. Several of the papers cited in this chapter deal with work that originated during the authors' visiting or short-term appointments, when they were free of the ancillary burdens associated with permanent positions. Research-
ers in theoretical computer science have often migrated between industry and academia, and researchers in these sectors have often collaborated. Such mixing and travel helped infuse computing theory with an understanding of the practical problems faced by computer designers and helped establish a community of researchers with a common vocabulary.














