
8
A Computer Science Perspective on Computing for the Chemical Sciences
Susan L. Graham
University of California, Berkeley
As a computer scientist whose formal education in chemistry stopped at high school, my goal is not to describe aspects of computational chemistry. Instead, I will try to suggest to you, from a computing perspective, why high-performance computing is difficult. Then from a technical point of view I will summarize some of the issues that we have to contend with if we are really going to take advantage of all the exciting computational opportunities outlined by other participants in this meeting.
Let us first consider performance. If we want to get more out of computing, the way we get that is by using parallelism (Box 8.1). The reasons we use parallelism are (1) to reduce the overall elapsed time in doing a demanding computation; (2) to keep the calculation moving when delays arise in sequential computation; and (3) to overcome fundamental limitations, like the speed of light, that bound the speed of sequential computation. Parallelism has been used in computing for a very long time, and it exists at many, many levels of the computing hierarchy. So, there is a great deal of parallelism in the box that sits on your desk, in a single processor.
Higher-level parallelism than that found in a single processor can be achieved by using multiple
|
Box 8.1 Parallelism as Source of Computing Speed
|
processors in a variety of organizations, some of which share memory, some of which communicate over a network, some of which are tightly coupled, some of which are communicating over very long distances. That parallelism really does enhance our capability, but it doesn't come free.
Let us consider where some of the parallelism comes from (Box 8.2), to try to understand what it is that the programmers and the computer scientists do and also why the world, which is already complicated, is getting even more complicated from a computing point of view.
- Since the early days of computing there has been parallelism that goes on at the bit level. In other words the computer can access multiple bits of information at once and can operate on them in parallel. Fundamental hardware operations such as addition take advantage of that kind of parallelism.
- There is also parallelism at the single-instruction level. In virtually any modern processor it is possible to execute multiple instructions at the same time. In one instant, multiple instructions are both issued and executed.
- There is overlap between computational operations such as addition and data movement such as reading and writing values to memory. Thus, it is possible to write the data that must be saved and to read the data that will be used next at the same time that computation is going on.
- Finally, almost any software system one uses has parallelism in that multiple jobs can be executing at the same time. In particular, when one job stalls because it is waiting for data, some other job takes over and does its thing. That time-sharing technology is actually quite old at this point.
Part of the difficulty in exploiting the parallelism available even on a single processor is that the improvements in different aspects of a computer are not occurring uniformly (Figure 8.1). There are many versions of Moore's law, which predicts the rate of improvement in computing technology. It almost doesn't matter which one we use. The basic message in Moore's law is that the speed of processors doubles every 18 months, roughly speaking.
The speed of accessing memory improves as well, but it is improving at a much slower rate. So, over time, the gap between how quickly a processor can execute instructions and how quickly the same processor can read and write data is widening. That means that any time you have a computation that depends on accessing data, you can lose all the performance that you might have gained from the faster MIPS (million-instructions-per-second) execution rate because the processor is waiting to write what it has just computed and read what it needs next.
|
Box 8.2 Parallelism in Modern Processors
|
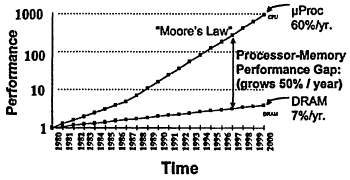
Figure 8.1
Processor-DRAM gap (latency).
Manufacturers aren't stupid. They are aware of that problem, so there are a number of technical devices that computer designers and manufacturers have used to try to mitigate that problem. The result is that storage has become more and more complicated.
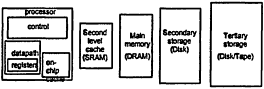
First consider the processor. Figure 8.2 shows the memory components and underneath indicates the approximate speeds of access and the sizes. There is very fast so-called main memory available to the processor. The processor also has a limited number of high-speed registers that provide even faster access to data values. Next are the disks attached to the processor directly. Disks and tape available through a network are at the far right of the diagram—they have substantially higher storage capacity, but much slower access.
On or between the processor and main memory are other storage devices called caches. Caches were introduced to bridge the gap between the speed of the processor and the speed of the memory. A cache can be thought of as a faster memory that holds a copy of the recently accessed data, or in the case of a program cache, a copy of a recently executed (or about-to-be executed) portion of the program. (In a
- Intended to mitigate processor/memory gaps
- As storage capacity increases, speed of access decreases
- Caches hold values that are spatially and temporally close
|
Speed (ns): |
1s |
10s |
100s |
10s ms |
10s sec |
|
Size (bytes): |
100s |
Ks. |
Ms |
Gs |
Ts |
Figure 8.2
Memory hierarchy.
computer, the program is stored in memory, and part of the slow-down in execution can come from accessing the next portion of the program.)
The point about the caches is that they hold chunks. So, when a cache is loaded, it is filled with a sequence of values that happen to be stored close together. What is held in this cache is that which has been used most recently, together with the values stored physically just before and just after. So, if the program jumps around wildly, accessing data that is over here and accessing data that is over there, the data that is over there overwrites what was in the cache. Now the processor has lost its very fast access to what was in the cache before. Consequently, the strategy from a programmer's point of view is to try to cluster all the information that is being used at approximately the same time so that while it is in use, it all lives in this very fast memory called the cache.
If a program is fetching chunks at a time, the only way to keep the needed information close by is to have actually stored it close together, because the hardware is going to grab it close together. That involves a certain amount of strategy in designing a program so that its data is close together and in the right place at the right time.
Now, suppose we consider high-end computing and some of the ideas that lead up to the kinds of systems Paul Messina has described, in which there are multiple processors (Box 8.3). Now this gap between the processor speed and the memory speed gets much more complicated. There are multiple processors executing at the same time, and logically at least they are sharing data. There are data written by a part of the computation executing on one processor and read by other parts of the computation executing on other processors. Maybe the processors are actually physically sharing memory as well; maybe they are not. So the latency—the delay in waiting to get the data—now increases. Furthermore, there is contention for the data because multiple processors may want the same information. Consequently, one needs mechanisms for synchronization to make sure that one processor does not try to read something before another processor has written it, to make sure that two or more processors don't try to write the same data at the same time, and so on. Now bandwidth, which is the volume of information that one can communicate at one time, also becomes more difficult to deal with because, in fact, it becomes less predictable.
The time it takes to get a certain amount of data from here to there is not necessarily precise, and it depends on what is going on with all these other processors. So, the different components that all
|
Box 8.3 Multiple Processors Complicate the Problem
|
together constitute the performance of one of these computing systems become very non-uniform, very interdependent on effects that are going on at all these different levels of memory hierarchy, and therefore very hard to understand and to predict.
In some sense the processors are now executing independently, but they are all cooperating to do the same computation. And so, there is an issue of how to use the different processors: What part of the calculation is done by each one of them, and how is that done so that the overall performance is as good as possible?
The real issue is end-to-end performance—how long it takes to execute the program and get the results. In a multiprocessor setting, end-to-end performance requires that all of the processors be kept busy all of the time doing useful work. Otherwise it doesn't matter what the theoretical speed is—you are not getting the benefit of it if some of the processors are sitting idle some of the time. In order to keep the processors busy all of the time doing useful work, the data they need must be in the right place in the right time. That means moving information around from one place to another in the memory hierarchy: from one memory to another, from memory to cache to registers and so on.
Some of that is under the control of the programmer, and some of it is not, but all of it affects the end-to-end performance of a calculation. For that reason, sometimes one sees that the peak performance of a system is something wonderful, but the actual performance that a given person is getting on his or her calculation is much worse, and it is very frustrating.
In order to cope with this memory/processor speed disparity and the scaling-up that Paul Messina talked about, different system designers have taken different architectural approaches. One of the other complications is that the strategies that cause computations to be done very efficiently on certain architectures are different from the strategies one would use on other architectures, even though the different architectural approaches all have their merits with benefits in terms of performance.
What software designers do to cope with this situation, in part, is to develop programming models—ways of thinking about what is going on with all the varieties of parallelism that attempt to match the architectural organizations. There are a number of these models. I am just going to show you two of them very briefly, just to look at their differences and to give you some sense of why what works well on one platform doesn't necessarily work well on another platform. Where I am going with this is to point out how very vulnerable legacy code is. In other words, code that has had an enormous development investment, that has really done good things for scientists, is aging very quickly. As we move through these architectural changes, it no longer performs very well, even though it might still manage to get some work done.
Without going into all the details, the first architectural paradigm in the multiprocessor world is that there is a collection of processors and they all share the same physical memory (Figure 8.3). There is some hardware in between the processors and the memory called the interconnect that allows them all to get to the same memory. The natural programming model that goes along with that architecture is to have the programs on each processor take the view that they are all looking at the same data. For example, if one has an array A, then all of the processors can access that same array. Therefore not only is it the case that one processor can write some information and the other One has it right there to read, but also the way that the different computations running on the different processors can communicate is by one writing data that the other one reads. The conceptual idea is that all the information is shared, and it is just the computational part that is being done in parallel.
In contrast, a lot of people believe that the only way you really scale up is to have a setup in which there is a collection of separate processors, and each one has its own memory (Figure 8.4). When the processors communicate, they communicate over a very high speed network. They each have their own local memories. Therefore the issue of when data is really shared and when a processor is reading or
- Processors all connected to a large shared memory
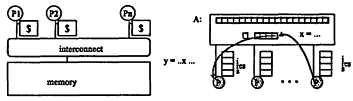
- Multiple processes (threads) use Shared Address Space
-
-
each has a set of private variables
-
collectively have a set of shared variables
-
communicates implicitly through shared variables
-
coordinate explicitly by synchronization operations on shared variables
Figure 8.3
Shared memory machine/programming model.
writing a copy of data—and therefore not necessarily the same copy that some other processor is looking at—now becomes more complicated. Deep down, communication is going on by sending messages back and forth over this high-speed network.
Now if there is an array A, it is actually physically scattered among the memory of the different processors. One might then choose to organize a computation so that each processor works on part of the data that is in its own memory because it can get to it much faster. Ultimately if they are doing a collaborative calculation, there is a point at which the different parts of the computation need to look at data that reside in memory on other processors, so latency kicks in again.
Latency is a problem because a program has to go out on the network to read the data on other processors, get it back, and write it in local memory, and only then can the program use those data. As part of the programming model, one of the big issues is how much the user needs to know about all the message passing. To what extent does that complexity need to be exposed to a computational scientist
- Each processor connected to own memory (and cache)
- Each "node" has a network interface (NI)
-
-
all communication and synchronization done through NI
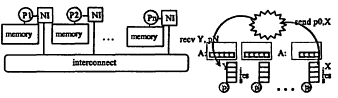
- program consists of a collection of named processes
- processes communicate by explicit data transfers (message passing)
- logically shared data is partitioned over local processes
Figure 8.4
Distributed memory machine/programming model.
whose real concern is not with moving data from here to there but whose real concern is solving a set of equations and getting some scientific answers?
So, what does a scientist do in order to create a parallel program in this environment (Box 8.4)? One of the hardest problems, and presumably one of the issues that came up repeatedly in other talks, is that in order to take advantage of parallelism one has to identify the work that can be done in parallel. Work can be done in parallel if one part of it isn't dependent on the results of another part.
The goal is to break up your calculations into components that can all be done at the same time, and then they can collaborate on communicating their results. That requires a high-level strategy about the problem, and it involves different problem-solving techniques, and it involves people who understand the domain in which they are solving the problems. It may not be something that can be decided in advance. It may be that where the parallelism is depends on the data, so that as the calculation proceeds it has to reorganize itself in order to maintain parallelism.
If that decomposition of the problem is done wrong, then you have the situation in which some processors sit idly waiting for other processors to complete. That situation sometimes is described as a load imbalance. If the computational load isn't equally distributed across the system, then the overall computational speed goes down. The computation is not getting the advantage of some of the processors.
So the user has to figure out where the parallelism is. Then he or she has to figure out how to partition the work across the processors, and how to partition the data so that the data sit close to the clients who want to use it (because of all the communication delays). Finally, at the lower level somewhere in the system, some piece of software or some programmer has to worry about actually describing the communication, describing the synchronization, and scheduling which work gets carried out on which processor.
The limitation in the speed of a parallel computation is determined by the parts that are not parallel, i.e., that are serial (Box 8.5). There is an inequality called Amdahl's law that says that the increase in speed you get by parallelism is limited by the portions of the computation that are sequential. That is where the delays are. That is where you have to wait. The best you can possibly do if you have P degrees of parallelism is to get a P-fold increase in speed; the advantage of more processors is going to be diminished by the sequential portions.
So, in figuring out how to find the parallelism in a computation you have to find it all to really gain
|
Box 8.4 Creating a Parallel Program
|
|
Box 8.5 Performance Goal Maximize speedup due to parallelism Amdahl's law Let s be the fraction of total work done sequentially Even if the parallel part speeds up perfectly, it may be limited by the sequential part. Problem size is critical! |
the benefit. Finding wonderful parallelism for a while and then having the world stop while the computation reconfigures itself can cause an enormous degradation in end-to-end performance.
Finally, let me mention one more complication. I said earlier that one must partition the work across the processors, to achieve parallelism, and also partition the data across processors, to reduce communication latency. Alas, these two strategies can conflict (Box 8.6). If there is more simultaneous computation, using local data, then there can be more data that needs to be pushed through the network to integrate the results of the parallel computations. Moving data around only indirectly advances the computation, and too much slow data movement can undo the benefits of high degrees of parallelism. And again, the trade-offs are different for different architectures.
The research challenges in Box 8.7 deal mostly with performance. Given a new problem that we want to solve, can we, the chemical scientists, find enough parallelism in the problem to be able to
|
Box 8.6 Locality and Load Balance Trade-off
|
|
Box 8.7 Research Challenges
|
exploit the platforms that are coming along? That depends on the problem, but it also depends on the strategy for solution.
To what extent can the computational science and computer science community hide from the applications programmer the lower-level details? Can we hide details about sending a message, receiving a message, synchronizing, and so on so that it doesn't clutter up the thinking about what is going on at the higher-level strategy? How can one describe these calculations so that they are readable by chemists, but so the description will still enable the generation of efficient code, meaning that there is a path that allows all that lower-level parallelism to be exploited as well? How can we do that so that it transcends changes in platform, so that once you have a strategy, it has some persistence over some of these changes in latency, in bandwidth, and in various aspects of performance?
Given that the strategy shift is a platform shift, how much can we continue to depend on libraries or on reuse of codes that have actually had a great deal of intellectual investment in them? Will they continue to give us the benefits that we want to believe they have, or does the performance simply degrade almost without people noticing until it is too late? Finally, given these complicated systems, such as the ASCI system that Paul Messina has described, how does one get a grasp on what is going on overall? How do we understand what the overall performance is and what contributes to it, and how does one get a mental model of what to do when things seem to be going wrong?
Now, as if that weren't complicated enough, the scientific community is becoming even more ambitious. Not only is there attention to high performance in the sense of computation, but now we also want to build computations, simulations in particular, that use massive amounts of data (Box 8.8).
|
Box 8.8 Now Generalize the Situation
|
Those data are gathered in a variety of ways. They live in a variety of places around the world and are represented in very diverse ways. We want to carry out simulations and modeling using components created by other groups, using other platforms and other data representations.
As we contemplate building these large, coupled, data-intensive simulations and models, the platforms that we might want to couple together to solve very hard problems are diverse. It is difficult enough to think about solving one application on one of these complicated parallel computing systems; now we want to reach out and get data from some other computational platform that has different characteristics.
Creating ambitious simulation and modeling systems requires collaboration. Collaboration is not just among people but also between people and devices, people and instruments, people and computational platforms. The problems that we want to solve are getting much bigger as well.
Consider the following situation, illustrated by two figures that come from Andrew Grimshaw at the University of Virginia. We are now in a situation in which, given the ascendancy of networks and the promise that they are going to get even better, we can think of doing an electronic experiment, having an electronic laboratory that can reach out electronically to other sites that have diverse, possibly unique capabilities (Figure 8.5). For example, there can be ways of doing real-lime data collection from observational data obtained from instruments that are attached to the network, and data repositories that exist at various remote sites. Figure 8.5 shows a map of the United States, but the resources might be anywhere in the world. In order to use them there needs to be some way of getting all these very diverse pieces to fit together. If you are a chemist carrying out an electronic experiment, you configure the experiment conceptually, assemble all the pieces, and describe at a very high level what it is you want to do, where you are getting the resources from, and how you are going to use them.
What a number of people are doing is building systems, such as the Legion system pictured in Figure 8.6, which provide so-called meta-computing capabilities. Computing at that level consists of staging the experiment: assembling the pieces, getting permission to use them, and getting them to interoperate, i.e., to work together. The vision is that the user sitting at a workstation puts this virtual environment together, identifies all the components, runs the electronic experiment, and looks at the results.
In addition to all the performance issues that are going to get even worse, there are issues about security. There are issues about fault tolerance—if you finally manage to get all the pieces coordinated and get your experiment going, you don't want it to die because one component failed, one processor went down. The way the network remains robust is by finding an alternative path if one path gets
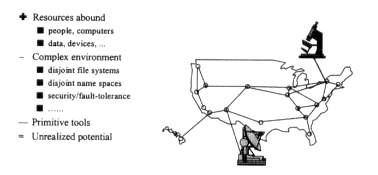
Figure 8.5
The opportunity.
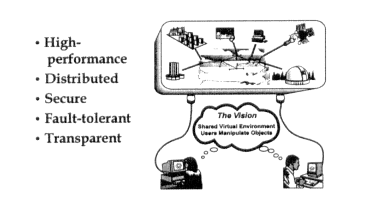
Figure 8.6
The Legion vision—one transparent system.
blocked. The goal is to do that in a transparent way, so that the user focuses attention on the experiment and not on the details that are below the surface of what is intellectually important in solving the problem.
There are also some non-technical issues of how we live in this emerging world (Box 8.9). There is a serious concern among the community about where the people are going to come from who are going to have the knowledge and skills to allow us to live in this computational world. The strategies one needs to solve scientific problems in the kinds of computing environments I have described require deep knowledge of the domain, in this case chemistry, and also deep knowledge of information technology in order to put things together and make it all work.
Ideally, one would have very expert computational chemists, people who are wonderful chemists and wonderful information technologists and understand how to put those two areas together. An alternative is to have multidisciplinary teams. To make multidisciplinary teams work, there are a lot of sociological issues that have to get solved about mutual respect for what the other side does, about talking the same language, about understanding how to identify what the real scientific and technical problems are. We are making progress there, but we still have a ways to go.
|
Box 8.9 More Issues
|
|
Box 8.10 PITAC Recommendations: Executive Summary Findings:
Recommendations:
SOURCE: Summarized from the President's Information Technology Advisory Committee's report to the President, Information Technology Research: Investing in Our Future, February 1999 advance copy, National Coordination Office for Computing, Information, and Communications, Arlington, Va. |
Where are the languages, the tools, and the libraries going to come from to do computation in this increasingly complicated world? There are needs that aren't peculiar to chemistry, and there are needs that aren't peculiar to science, and a lot of those will come from the marketplace. That is going to give us a lot of the networking technology we need.
There are other issues that are more peculiar to what we do in computational science. Scientific computing does not drive the market, and so we cannot expect that over time the vendors are going to step up and provide the specialized software solutions that are essential to at least part of what we are trying to do. That means that the scientific community is going to have to find a way to develop that software, and we are going to have to find a way to do it that provides high-quality robust software and doesn't consume all of everybody's time.
Finally, there is an issue that I know many people in the chemistry community have struggled with, namely, that even though in principle we can build these very high performance, very powerful systems such as the one Paul Messina described, how is the average bench scientist going to get access to them?
In closing, let me just say a little bit about the committee I am on, the President's Information Technology Advisory Committee (PITAC). When the High Performance Computing and Communication Act was passed in 1991 or so, part of the legislation said that there was to be an advisory committee for high-performance computing. It took until 1997 for the committee to be established and, by the time it was appointed, there were lots of issues on the table besides high-performance computing. The committee was given the additional task of looking at the next-generation Interact program that was then emerging in the government, and then broadened its agenda to look at information technology overall.
The committee is drawn primarily from the computer science and communications areas. It issued an interim report in July and will issue a final report early in 1999. The high-level findings and recommendations are shown in Box 8.10.
|
Box 8.11 Software Research Findings:
Recommendations:
Make fundamental software research an absolute priority. SOURCE: Summarized from the President's Information Technology Advisory Committee's report to the President, Information Technology Research: Investing in Our Future, February 1999 advance copy, National Coordination Office for Computing, Information, and Communications, Arlington, Va. |
The investment in research and development in information technology is not keeping up with the growth in the importance of the area. Furthermore, because of the tension caused by the shortage of money, the investment in R&D is increasingly short term. In other words, if we spend our money only to solve today's problems, which have measurable milestones and goals, we shortchange the longer-term investment in developing the new ideas that are going to fuel us in 10 or 15 years.
There are also recommendations concerning how to educate more people and how to give the average taxpayer access to computing and the like. I don't mean to dismiss these recommendations, but they are less relevant to this workshop than the research recommendations.
When this committee first met, everybody, no matter what field they came from, said, “The real problem is software." Our recommendation is that the research investment of the government be increased, especially in software, in scalable information infrastructure, in high-end computing, and in work force and socioeconomic issues. By scalable information infrastructure we mean not only networking, but also all of the information that lives on our networks—all the Web pages, databases, and mail systems; everything that involves using information in a networked environment. Thus there are significant software issues there as well.
In making software research a priority (Box 8.11), as with any grand challenge problem, you have to worry about more than how you are going to solve that problem with any strategy you can figure out. We also seek to develop some underlying solution technology that is reusable and that will allow you to solve next year's problems and the problems of the years after.
The committee work is an ongoing process. We are currently in the process of gathering feedback from all of the communities we talk to, so that the final report can be as strong as we can possibly make it so that we can actually see this exciting computational environment move ahead.
Acknowledgment: My thanks go to my colleagues Kathy Yelick, Jim Demmel, and David Culler for sharing the slides from their Berkeley graduate course in parallel computing, CS267.
Discussion
Barbara Garrison, Pennsylvania State University: I do computational chemistry, and I am inherently limited by Amdahl's law, yet I have problems where I could use parallel computing, but at times I feel like I am wasting cycles because of imperfect scalability. Has there been any effort to design hybrid serial parallel machines or operating systems where there could be sharing of the parallel resources so we are not in fact wasting the cycles?
Susan Graham: That is what the old operating systems notion of multiprocessing is really all about. The system can detect when you are waiting for something, and it can go and run somebody else's program meanwhile.
The complication when you now get these memory hierarchies is that if the system is going to run somebody else's problem while yours is waiting for its data, then the staging is going to fetch their data and flush your data out of the caches. That will affect your performance as well. Thus what you suggest can be done, but the extent to which it is really going to help is something that we don't totally understand. Having the system wait for you is going to be the most efficient thing for your job, but there is a question of throughput and how you share that resource with other people.
Evelyn Goldfield, Wayne State University: I have two questions. I am, also, a computational chemist who uses parallel programming and computing. One of the things that I have been wondering about is the different architectures. I use massively parallel distributed memory computers, but all these shared memory computers are coming along. I wonder to what extent the memory is actually shared, and to what extent we really do have to change our computing paradigms. How important is it for people to have different programs for different computing paradigms for different types of architecture? If we have to have completely different programs for different machines, it is going to be quite dismaying for people.
Susan Graham: This, again, is something that we understand imperfectly at this time. If you have distributed memory solutions, distributed memory strategies, it is not that hard to get them to do well on shared memory systems. It is going in the other direction that is harder, in my experience.
What one really wants, and this may not be something that is completely within one's control, is to have a certain amount of adaptivity. If your program makes it apparent where the parallelism is, where the opportunities are, and if a compiler can figure out where the communication has to be, where the sharing is and so on, then you want the system software to adapt the program communication, synchronization, etc. to the architecture. So, it is at the strategy level that it is really most important that you are not locking yourself in at the high level to particular details of the architectural model.
Evelyn Goldfield: I have one other question that I think is really key and that is, I think, in the minds of a lot of chemists. We are willing to waste computer time if it is a choice between wasting the computer's time and wasting our own time. The only thing we really, really care about, truthfully, is how long it takes us to get the job done as long as we get the cycles. I thought of this when you talked about load imbalance. You can have a lot of load imbalance and still get your job through on time. How much are chemists going to have to really worry about these computer science questions if you don't want us to waste the cycles? It seems to me it is the computer scientists that have to come up with that solution.
Susan Graham: It is not that we don't want you to waste the cycles. Somebody once said to me, "You know, people have telephones, and they don't worry about keeping the telephone busy all the time. It is an appliance, and it is there when they need it." That gets back to the kinds of problems you are trying to solve, and the economics. If you can afford to have a machine that sits on your desk that is powerful enough for what you want to do, then the primary issue is going to be ease of making it do what you want it to do. But there are chemists who have problems that even the ASCI System can barely handle. They cannot afford to have part of the system sitting idle, particularly when their access to it is once every so often for a limited amount of time.
Thom Dunning, Pacific Northwest National Laboratory: I had a couple of comments on your presentation. One is the emphasis on software that came out of the PITAC report. I have always felt that one of the major limitations in realizing the potential of the computing systems that we have had and are going to have in the future is software. So I was absolutely delighted to see this committee recognizing the importance of software, because it is so easy in a system like we operate in to look at the hardware, a physical object, and not recognize the fact that the hardware is absolutely useless without the software. Also, one comment relative to the question that Evelyn Goldfield asked is that we at Pacific Northwest National Laboratory, and people in other places, have developed computing infrastructures. Ours are called global arrays that actually run on distributed memory computer systems, shared memory computer systems, and a collection of workstations, all of which is entirely transparent actually to the applications programmer. This is the case because we have computer scientists who have implemented global arrays on all of these different types of architectures, and the only thing the applications programmer has to do is issue the calls to those particular subroutines. So, there are ways that one can actually write software that performs well on a number of different architectures.
Now, I am not at all clear that that is going to perform well on the types of architectures that Paul Messina described, but clearly many of these problems have been solved, and I have confidence in the creativity of both the chemistry and the computer science community and that we will see it solved for the types of very large systems that Paul described.
Robert Lichter, Camille & Henry Dreyfus Foundation: As a non-computational chemist and a non-computer scientist I want to thank you for an extraordinarily lucid description of how these things work. I think this is the first time I have run into the topic in a way that is comprehensible.
I was also struck by how much chemistry you do know, because the strategy that you described for solving problems—doing isolated computations and then pulling them together—is very much the way a synthetic organic chemist synthesizes a complex molecule. You do little pieces and then glue them together.
When looking at the kind of global picture of marrying hardware and software, we are limited by what exists. I would be very much interested in your wildest vision as a computer scientist of what could exist either in hardware or in software that we haven't even begun to think about now.
For example, one thing that even I am aware of is the concept of DNA computing, which nobody has talked about here. I don't know whether that's because it is not worth talking about, or whether it is not developed enough to talk about, but that is the kind of thing I'm referring to. I'm just curious to see if you could speculate wildly.
Susan Graham: I don't know whether I can do that. I can comment a little about DNA computing and things like that. That is one example of the part of the research agenda that we feel has been neglected of late. In other words, DNA computing is wildly speculative in the sense that the computational model
is totally different, and yet the attempt is to draw it from nature, from something that exists, and it potentially gives huge amounts of parallelism.
The issue from a computer science point of view is figuring out what the algorithms might be that would actually do well in that computational model, and of course, there are issues on how you build such a computer. I think it is really important to explore those directions.
There are people in my field who have wonderful imaginations about these things. I am not one of them and so I don't want to take up your immediate challenge except to say that I think you are right. People are most comfortable thinking sequentially. People are most comfortable thinking in the way I described, take some data, move it from here to there, and so on. We have to break out of that a little bit to at least experiment and see what might happen if we had a very different model.
Gintaris Reklaitis, Purdue University: You described an interesting model of a real-time environment in which you gather data from different sources and different instruments, run the data through a model, and then act upon the results. This is very much along the lines of the supply chain of interest in process operations. In your case, the information is obtained asynchronously, yet the computational models that you describe operate synchronously. Although you are parallelizing the computational tasks, under the synchronous model you are forced to wait for the slowest task to execute and you do not use all of the latest information in executing the tasks. Is there any work in progress on asynchronous parallel computing models?
Susan Graham: I was describing synchrony as a problem. There are times when you really have to worry about the temporal order in which things happen. It is possible, for example, in my shared memory situation that some of the processors are just filling that memory with interesting stuff while other processors are going on and doing their business and not worrying about that until they are ready. Asynchronous models in which one is notified—or the status is posted and whoever cares can look and find out the status—are actually in some ways much more comfortable. They can be easier to build, but they are harder sometimes for people to think about.
Now, it is possible we are not puffing as much attention on that as we might, and that is where the interaction with the application domain is so important. You describe to me what you want to do and then I start thinking about how can I help you do that.
















