
1
Introduction and Background1
Now is an exciting time for brain research due to enormous global investments that have enabled creation of the infrastructure required to generate great pools of neuroscience data and develop novel techniques. This has been facilitated in part by a shift in the way research data are shared over the past decade (see Figure 1-1). In the traditional model, data generated by one group of investigators may be shared with one or more other research groups, each of which builds its own tools to analyze and manipulate the data, resulting in a proliferation of datasets and research tool versions. This contrasts with the cloud model, where data and tools are co-located in a platform that enables multiple investigators to work with a single copy of the dataset using common tools.
The cloud model has led to a vast increase in the quantity and complexity of data and expanded access to these data, which has attracted many more researchers, enabled multi-national neuroscience collaborations, and facilitated the development of many new tools. Yet, the cloud model has also produced new challenges related to data storage, organization, and protection. Merely switching the technical infrastructure from local repositories to cloud repositories is not enough to optimize data use.
___________________
1 The planning committee’s role was limited to planning the workshop, and the Proceedings of a Workshop was prepared by the workshop rapporteurs as a factual summary of what occurred at the workshop. Statements, recommendations, and opinions expressed are those of individual presenters and participants; have not been endorsed or verified by the Health and Medicine Division (HMD) of the National Academies of Sciences, Engineering, and Medicine; and should not be construed as reflecting any group consensus.
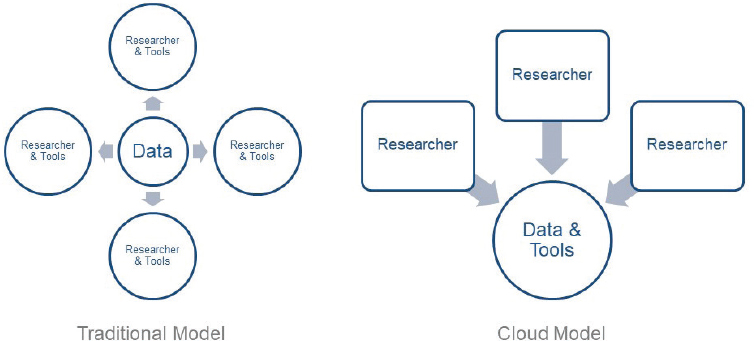
SOURCE: Presented by Nick Weber, September 24, 2019.
Thirty years ago, the National Institute of Mental Health (NIMH), the National Institute on Drug Abuse (NIDA), and the National Science Foundation (NSF) commissioned the Institute of Medicine (IOM) to consider the future of digital and networked neuroscience, recalled Michael Huerta, associate director of the National Library of Medicine (NLM). It is fitting that 30 years later, a group reconvened at the National Academies of Sciences, Engineering, and Medicine (the National Academies), which incorporates the former IOM, to explore the burgeoning use of cloud computing in neuroscience, said Huerta. On September 24, 2019, the National Academies’ Forum on Neuroscience and Nervous System Disorders hosted a workshop on neuroscience data in the cloud, co-chaired by Huerta and Deanna Barch, chair of the Department of Psychological and Brain Sciences at Washington University in St. Louis.2 Box 1-1 provides definitions for some of the core concepts related to cloud computing discussed throughout the workshop. The intention of the workshop, said Barch, was to focus on maximizing the benefits that can be realized from neuroscience data.
___________________
2 For further information about the workshop, including slides presented by speakers, see http://www.nas.edu/NeuroForum (accessed January 17, 2020).
WORKSHOP OBJECTIVES
The workshop brought together a broad range of stakeholders involved in cloud-based neuroscience initiatives and research to explore the use of cloud technology to advance neuroscience research and share approaches to address current barriers. These stakeholders represented academia, government, foundations, the pharmaceutical and information technology industries, and the legal system. They were tasked not only with identifying challenges, but also with suggesting solutions and best practices that can
help optimize the utility and increase the efficiency of cloud-based neuroscience initiatives, support ongoing efforts, and share information about the work of others, said Barch.
In addition to cloud-specific issues, the workshop covered a number of topics related to encouraging data sharing and open science, which are integrally relevant for, but not specific to, cloud-based platforms. Many discussions at the workshop covered issues, such as privacy protection, that are common across many types of data, not just neuroscience. The workshop provided a venue for members of the neuroscience community to come together to discuss approaches for tackling these common challenges, as well as challenges that are specific to neuroscience data and the cloud-based platforms that are dedicated to neuroscience or are frequently used by this community. Box 1-2 provides the workshop Statement of Task.
ORGANIZATION OF PROCEEDINGS
These proceedings reflect the organization of the meeting. Chapter 2 summarizes talks about the landscape of cloud-based technologies for neuroscience research. Two sets of breakout sessions are summarized in Parts 1 and 2, which organize issues by content area and types of data, respectively. In Part 1, Chapter 3 covers issues related to the protection of privacy; Chapter 4 addresses data management and interoperability issues;
Chapter 5 examines issues related to assignment of credit and data ownership; and Chapter 6 discusses platform governance. In Part 2, challenges related to different types of neuroscience data are examined: Chapter 7, clinical trial and research data; Chapter 8, genetic data; Chapter 9, neuroimaging data; and Chapter 10, real-world data. Chapter 11 concludes with a discussion of future directions, including identifying tangible next steps and promising areas for future action.
This page intentionally left blank.






