
4
Perspectives on the Internet Experience of September 11
The overall events of September 11 were so extraordinary and shocking that it is sometimes difficult to put them in perspective. There is a tendency to look for echoes of the Twin Towers’ fall in everything one sees. This chapter seeks to provide some of that perspective by examining other major communications events occurring on the Internet and seeing how they compared. Then it considers what could happen to the Internet if attacked directly (rather than suffering collateral damage) or if it were used as an integral part of the attack itself.
OTHER OUTAGES: OPERATOR ERRORS AND INFRASTRUCTURE FAULTS
The committee’s conclusion is that September 11, with respect to its impact on the Internet, was a relatively minor incident. Yet quantifying that observation has proved difficult. There are neither general norms of Internet performance nor infrastructure to monitor the network comprehensively. Rather, individuals and organizations rate the Internet’s performance differently, according to their own priorities.
Still, there are several basic measures that interested parties generally use to assess the Internet’s performance:
-
Traffic levels. How much does traffic vary from that of a typical day?
-
Border Gateway Protocol (BGP) reachability and update rates. How
-
many regions of the network are being advertised by BGP, and how often is the information about various parts of the network changing?
-
Measured reachability. Rather than relying on BGP, one can measure Internet connectivity directly by attempting to communicate with a number of systems scattered throughout the network and reporting on one’s actual ability to exchange data.
In the following paragraphs, these metrics are used to examine some recent Internet events that most people consider exceptional and to compare them with those of September 11.
Operator Error
Network operators often joke that a single misplaced comma in an appropriate configuration file could take down the Internet. While that was certainly true in the late 1980s,1 operators today have well-defined procedures and methods for checking configurations before putting them into their networks. Furthermore, most operators employ systems to protect their network from configuration errors in other networks. However, operational errors do still occur from time to time, and some of these have major effects.
To illustrate how local errors can have global impact, let us consider an example from the Domain Name System (DNS)—a distributed database that keeps the name-to-address mappings for the Internet. If a Web browser needs to find the Internet address of the name <www.nationalacademies.org>, for example, the browser queries the DNS.
The DNS is a hierarchical database that makes heavy use of caching. To explain the process by simplifying somewhat, the way that a name such as <www.nationalacademies.org> is looked up in the DNS is as follows: the browser asks a local DNS server if it knows the name <www.nationalacademies.org>. If the local server knows the name, it returns the IP address for <www.nationalacademies.org>; if not, the server consults 1 of 13 root servers. The root servers act as query managers; though they rarely answer a query themselves, they tell the local server what DNS server it should consult to get the definitive answer about <www.nationalacademies.org>.
What makes the DNS work and keeps the root servers from being overwhelmed with queries is the system’s use of caching. Once a local
server is told the address of <www.nationalacademies.org>, it is expected to cache that address for some period of time (a few hours or days), so that the next time the server is asked about <www.nationalacademies.org> it will not have to query the root servers again. The exact time that a name is cached is controlled by the owner of the name. For example, the National Academies determine how long the name <www.nationalacademies.org> can be cached at a server.
In February 2001, a router that connected the DNS servers for names ending in microsoft.com to the rest of the Internet was misconfigured, and the router stopped forwarding traffic. It turned out that, contrary to recommended practice, Microsoft had placed all the microsoft.com servers on the same local network; thus, when the router stopped working, no one could query about names ending in microsoft.com. Furthermore, Microsoft had decided to keep the cache times on its names very short— about 2 hours. As a result, within that time every name ending in microsoft.com effectively became unknown on the Internet.
Unfortunately, in terms of impact on the network, Microsoft names are very popular. As the DNS dropped Microsoft names from caches, any query about a Microsoft site had to be sent to the root servers, which would then point the queries at the microsoft.com servers. Because the servers were unreachable, the query would fail, no names would be cached, and the next query for a Microsoft site would again result in a query of the root servers. Loads jumped by 25 percent at some root servers until the misconfigured router was repaired.2 In contrast, the events of September 11 had no discernible effect on the number of queries to the root servers.
Infrastructure Faults
In many ways, the effects on the Internet from the September 11 attacks were similar to other, albeit accidental, “infrastructure faults” that the Internet has incurred. Figure 4.1 illustrates the effects on the global Internet of one such type of fault, a “fiber cut,” on November 23, 1999, when a major Internet link was severed. The figure plots Internet reachability using the same methodology as was used in Figure 2.2 in Chapter 2. The effects of the fiber cut are comparable to those of the September 11 damage—all in all, about a 6 to 7 percent loss in overall Internet connectivity, but short-lived. Figure 4.2 shows another outage
|
2 |
Nevil Brownlee, K.C. Claffy, and Evi Nemeth. 2001. DNS Measurements at a Root Server. Cooperative Association for Internet Data Analysis, San Diego. Available online at <http://www.caida.org/outreach/papers/2001/DNSMeasRoot/>. |
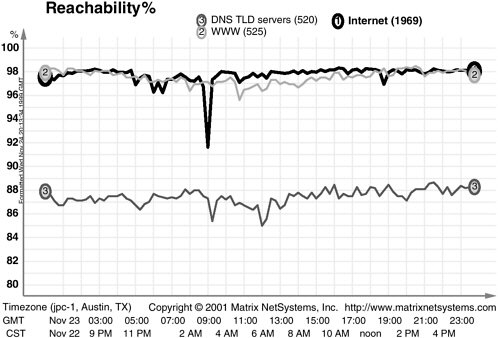
FIGURE 4.1 Impact of a 1999 fiber cut on the reachability of two representative sets of Internet hosts (1, 2) and the Domain Name System root servers (3). SOURCE: Matrix NetSystems, Inc.
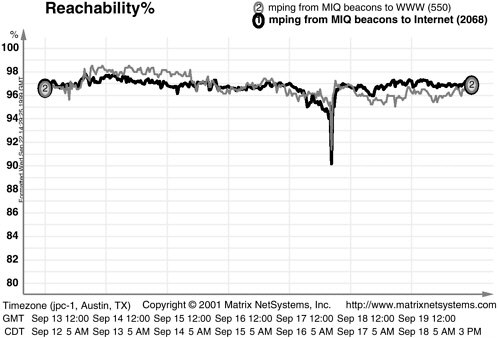
FIGURE 4.2 Impact of damage from Hurricane Floyd on the reachability of two representative sets of Internet hosts. SOURCE: Matrix NetSystems, Inc.
with similar effects but a different cause; here, the downward spikes on September 17, 1999, coincide near the peak of the physical damage inflicted by Hurricane Floyd. Again, the magnitude of the spikes are comparable with that of September 11, 2001.
ATTACKS ON, OR WITH, THE INTERNET
Baseline: Effects of Damage on September 11
On September 11, an important interconnection point (at 140 West Street in New York City) was severely damaged, some long-distance communications links (especially those under the World Trade Center complex) were severed, and there was a localized electrical power outage. Those experiences, together with discussions about them with several Internet service providers, give some indication of the Internet’s vulnerability to a direct and deliberate physical attack. As detailed in Chapter 2, the effects of the terrorist attacks were complex, but by simplifying somewhat, some broad patterns emerge:
-
Most of the attacks’ effects were local. The majority of the serious communications disruptions were suffered by networks and customers— such as the stock exchanges, Covad DSL customers, and the parts of NYSERNet in Lower Manhattan—physically close to 140 West Street. Effects of the attacks were substantially less notable in Upper Manhattan, and nationally they were hard to discern at all.
-
Nonlocal effects occurred in surprising places. Some Internet customers in western New England found that connectivity problems in New York affected their ability to dial in to their ISP. And one of the most seriously affected parts of the Internet turned out to be an ocean away—in South Africa.
-
Rich communications infrastructure and the flexibility of the Internet technology eased recovery. While a number of address ranges were briefly removed from the Internet by the attacks, most of them were back on the network in less than a day. The rich communications infrastructure of the United States made it feasible for most ISPs to reroute around the damage. In cases where rerouting was not an option (as at locations in Lower Manhattan), it was often possible to improvise new connectivity (e.g., a IEEE 802.11b wireless link extending out a window in New York City). Oversimplifying a little, it was only sites within a few blocks of the World Trade Center or sites with limited communications infrastructure (e.g., some of the non-U.S. areas affected by the collapse) that had difficulty recovering. And even in many of the difficult cases, recovery time was still measured in days (not weeks or months).
-
Long power outages caused serious harm to communications. One can argue that, from the perspective of the Internet, the most serious effect of the attacks on the World Trade Center was that power had to be shut off to Lower Manhattan. The power outage at Telehouse had an effect on Internet connectivity that was comparable to that of the Towers’ collapses earlier. Extended power outages tend to be a feature of physical disasters (whether they have human or natural causes), and they have great impact: the nation’s communications infrastructure ultimately relies on powered equipment to carry data.
If the Internet Were the Target, Would There Be Greater Impact?
If attackers were out to physically damage the Internet infrastructure directly, it is unlikely that 140 West Street would be near the top of their list. Even within Manhattan, several facilities contain substantially more Internet equipment and are more important to the Internet’s operation.
Many have speculated that a physical attack on one of the major Internet exchange locations, such as MAE-East (near Washington, D.C.) or the PAIX facility (near San Francisco), would cause serious disruptions. Internet exchange locations are facilities at which a number of ISPs install routers on a common network. This mode of interconnection is often more cost-effective than is arranging a separate physical connection to each network at which an ISP wishes to peer. Concern is simultaneously heightened as well: an attack on an exchange location would break multiple connections between ISPs.
But as best as the committee can determine, such an attack would not pose a serious risk to the Internet as a whole. Most ISPs are connected to it at more than one point, both to increase their redundancy in the face of unintended events—such as fiber cuts and power failures—and because they generally seek to exchange traffic with other ISPs as close as possible to the traffic’s origin, thereby avoiding additions to the load on their own networks. Indeed, the largest ISPs are connected to one another at dozens of points throughout the United States. The committee finds no reason to believe that there is a point (or even a small number of points) in the Internet that, if removed, would partition the country’s system into a disconnected group of networks.
Another concern is that an attacker could sever a critical fiber-optic link. However, as a matter of practice, large ISPs maintain networks with redundant paths to ensure connectivity in such circumstances. To be sure, the level of redundancy can turn out to be lower than the literal counting of links would suggest. In a number of places, fiber runs are concentrated in particular rights-of-way, as was illustrated by a 2001 inci-
dent in which a fire in a Baltimore, Maryland, train tunnel destroyed a number of links. But carriers work hard to discover such vulnerabilities, and large networks deploy geographically distinct links that allow a damaged link to be bypassed (though performance in terms of capacity or delay may suffer until that link is restored). The September 11 experience demonstrated such redundancy in major Internet links.
Indeed, it turns out that failures of one or more Internet components are not infrequent events. Fiber cuts occur often, and most major Internet exchange points have failed at one time or another. In the past, there have even been simultaneous failures of exchange points in at least three different locations. Some of these events have had noticeable effects on one or more ISPs, but the impact is not felt across the Internet. As is described in Box 4.1, the Internet’s basic design makes it resilient in the face of failures—incidents do not tend to ripple across the whole network.
There is, however, some reason to believe that it might be possible for a motivated attacker to cut the Internet links between the United States and other countries; these links appear to have less redundancy than is present within the backbones of major U.S. ISPs. It is highly likely that such an attack would also separate a number of countries outside the United States from each other. Moreover, such incidents could lead to indirect effects along the lines of the degradation of South Africa’s DNS capability following the World Trade Center attacks.
The principal issue with international connectivity is that most of the transoceanic fiber-optic communications cables land in North America at a few sites. As noted in Chapter 2, one reason why New York City is a superhub for the Internet is that a large number of the transatlantic cables make landfall close to the city. Similarly, Miami, Florida, is a hub for connectivity with Latin America. The vulnerability is further increased because, for economic reasons, most connections to these transoceanic cables are made at carrier hotels in New York City rather than at the landing points themselves; it is much cheaper to run one fiber-optic cable from the landing to an interconnection point than it is for each carrier wishing to connect to the fiber to run separate lines. Many of the individual landing points are themselves also vulnerable to attack.
It should also be noted that although it is difficult for a physical attack to damage the Internet as a whole, there are a number of ways to attack an individual ISP, many of which would cause problems for several hours or days. Economies of scale can be achieved by concentrating equipment in a small number of locations, and some ISPs, as well as content ISPs (which run large Web farms), seem particularly prone to doing so, even going so far as putting all their “eggs” (servers) in one “basket” (location), which obviously makes the ISP more vulnerable to physical attack. (Some ISPs
|
BOX 4.1 How the Internet’s Design Makes It Resilient The Internet differs fundamentally from most of the other communications networks in how it adapts to equipment failures and increases in traffic load, a legacy of the design goals of the early days of the ARPANET.1 Whereas the telephone network has very complicated switches but simple “edge devices” (i.e., telephones), the Internet places much of its intelligence in the end-hosts. The network provides a relatively simple service of best-effort packet delivery. Packets flow through the network independently and may be lost, corrupted, or delivered out of order. The fact that the Internet Protocol (IP) offers such a simple packet-delivery service makes it easier to continue providing the service during transient network failures. After a failure, the network routers communicate among themselves to compute a new path, if possible, to the packet’s destination. Some packets may be lost during this transition period, but the communication continues after the routers start using the new path. Building on top of the IP, the end-hosts implement transport-layer protocols that coordinate the end-to-end delivery of data between applications. The Transmission Control Protocol (TCP) underlies most communication on the Internet, such as the downloading of Web pages. TCP provides the main mechanism needed by most Internet applications—a logical connection that delivers a sequence of bytes from the sender to the receiver in an ordered, reliable fashion—and it is used for much of the traffic over the Internet. Hosts running TCP adapt their behavior to network congestion.2 In response to loss or delay, the TCP sender reduces the transmission rate to avoid overloading the network. During periods of heavy load, TCP senders traversing the same bottlenecked link transmit at a lower rate to share the limited resources. This adaptability has the advantage that application performance tends to “degrade gracefully” under heavy load, though such a degradation in performance may drop to a level that is unacceptable for some users. It may be acceptable for applications such as e-mail (which can be queued and delivered as bandwidth becomes available) and instant messaging (which requires little bandwidth), but it can be disruptive for Web downloads and can unacceptably degrade multimedia streaming. |
do operate multiple facilities, but even then, they tend to locate them within the same cluster of buildings. This strategy is not sufficiently robust, as power failures would likely cause problems across the entire complex.)
Finally, the committee learned during its workshop that a carefully designed distributed attack against a number of physical locations, especially if done in a repeating pattern, could be highly disruptive. An attack at a single point, however, is survivable.
POSSIBLE EFFECTS OF A DELIBERATE ELECTRONIC ATTACK WITH THE AID OF, OR AGAINST, THE INTERNET
As previously noted, the Internet itself was not a target on September 11, 2001, nor, apparently, was it used by terrorists for anything more than their own information-acquisition or communication needs. However, the Internet could plausibly play a more central role in future terrorist attacks. Acquiring the expertise necessary to use it in that way would be analogous to the efforts of the September 11 attackers in learning how to pilot jet aircraft. Once the expertise was acquired, the Internet could be
utilized by terrorists in a number of ways and in the pursuit of diverse goals.
The potential, range, and plausibility of terrorist attacks on or with the Internet are thoroughly explored in Making the Nation Safer: The Role of Science and Technology in Countering Terrorism, a recent National Research Council publication3 to which the committee defers for a complete discussion. This section only sketches some of the possibilities for terrorist use of the Internet, primarily to develop a contrast with the actual impact on the Internet from September 11.
If the aim is terror, then widespread Internet failures could cause confusion and possibly instill panic, particularly if such failures occurred in conjunction with separate physical attacks. Broader attacks of any form could have this effect, but the Internet would prove a particularly valuable element because of its use by some as a news channel and especially because its functioning and vulnerabilities remain a mystery to much of the populace—people might fear the worst if a significant disruption to the Internet were to occur.
A different Internet-related means for instilling panic would be to create misinformation. This could be done directly, by altering the contents of Internet news sites. Alternatively, information in the Domain Name System database could be changed to redirect names to incorrect addresses, or the routing system could be tampered with so that users would be connected to substitute servers.4 Each technique could expose users to Web pages, seemingly authentic, that contained either subtly or grossly incorrect information crafted by the attackers.
Attackers could also attempt to use the Internet either to directly inflict damage or to augment damage inflicted by other means. For example, they could undermine systems whose operations rely on using the Internet or are susceptible to manipulation through the Internet (see Making the Nation Safer for further discussion).
Another form of terrorist attack could involve the direct infliction of damage, by nonphysical means, on the Internet’s own systems. This might be done in several ways:
|
3 |
National Research Council. 2002. Making the Nation Safer: The Role of Science and Technology in Countering Terrorism. National Academies Press, Washington, D.C. Available online at <http://books.nap.edu/html/stct/index.html>. For an extended discussion, see the forthcoming Computer Science and Telecommunications Board report on information technology for countering terrorism. |
|
4 |
Some of the risks of DNS and routing attacks are described in Computer Science and Telecommunications Board, National Research Council. 1999. Trust in Cyberspace. National Academy Press, Washington, D.C. |
-
By the deletion of information (such an attempt might not be highly effective, however, as mechanisms exist to deal with the routine occurrence of corrupted information);
-
By disabling hardware (for some machines, it is possible to use software to render the hardware inoperable); or
-
By rendering services inaccessible (for example, if computers under attackers’ control continually flood a service with bogus traffic).
These threats might seem minor compared to physical damage that attackers could inflict, except that the scale of such software-based attacks is potentially immense. And it is well established that attackers can acquire access to hundreds or thousands of machines to be used as launching points for coordinated follow-on attacks.
Toolkits that exist for automatically scanning and exploiting a wide variety of security flaws in Internet servers could also be used as weapons. When coupled with software that then repeats the scanning and exploiting (using each newly compromised machine as an additional platform), they become a “worm” or a virus (the distinction being that viruses require some user action to activate them, while worms do not). Though not a new concept, worms recently gained notoriety with the advent, in the summer of 2001, of Code Red and Nimda—worms that infected several hundred thousand Internet hosts in a matter of hours.
Furthermore, recent theoretical work has pointed to more efficient spreading strategies that appear to enable a worm to compromise a vulnerable population of a million servers in a matter of minutes, perhaps even in tens of seconds.5 And a plausible potential exists for compromising perhaps 10 million Internet hosts in a surreptitious “contagion” fashion that, while taking longer than the quick propagation of worms such as Code Red, would make the worm much harder to detect; it would not exhibit the telltale scanning used by rapidly propagating worms.
The ability to acquire hundreds of thousands or even millions of hosts would enable terrorists to launch truly Internet-wide attacks. One form of attack would be distributed denial-of-service (DDOS) floods, in which an immense stream of traffic is sent to a particular Internet service or resource (such as a particular router or access link). Such attacks gained notoriety in February 2000 with a series of floods that targeted popular Internet sites such as Yahoo.
Given the state of the art in defending against such attacks, it would
be very difficult to deal with attacks from even a few thousand coordinated hosts. Thus a hundred or a thousand times as many hosts would utterly overwhelm any known defensive measures—with the result that attackers could launch many DDOS attacks simultaneously against a wide range of services. For example, they could plausibly target all of the root name servers (of which 13 are currently deployed and operated by various organizations) and all of the major Internet news outlets and the cyber-security analysis and response sites. Or, they could use the machines to overwhelm the components of the public telephone network. Or they could pursue both strategies at the same time.
The skills required to launch worm-based attacks are not extremely difficult to acquire, and the damage and confusion that they would cause could be quite significant. Thus, they appear to constitute a major form of Internet threat—one for which, at present, there is little in the way of defense. However, Making the Nation Safer does provide recommendations on some possible countermeasures for such cyberterrorism.












