
5
Causal Inference and the Assessment of Racial Discrimination
Because discriminatory behavior can rarely be directly observed, researchers face the challenge of determining when racial discrimination has actually occurred and whether it explains some portion of a racially disparate outcome. Those who attempt to identify the presence or absence of discrimination typically observe an individual’s race (e.g., black) and a particular outcome (e.g., earnings) and try to determine whether that outcome would have been different had the individual been of a different race (e.g., white). In other words, to measure discrimination researchers must answer the counterfactual question: What would have happened to a nonwhite individual if he or she had been white? Answering this question is fundamental to being able to conclude that there is a causal relationship between race and discrimination, which, in turn, is necessary to conclude that race-based discriminatory behaviors or processes contributed to an observed differential outcome.
To illustrate the problem, we turn to a classic Dr. Seuss book, The Sneetches (published in 1961), which describes a society of two races distinguished by markings on their bellies. In the story, one race of Sneetches is afforded certain privileges for having stars on their bellies, and the other race, lacking these markings, is denied those same privileges. There are, however, Star-On and Star-Off machines that can alter the belly and therefore the race of both Plain-Belly and Star-Belly Sneetches. Thanks to these machines, an individual Sneetch’s racial status and various outcomes could be observed more than once, both as a Plain-Belly and a Star-Belly Sneetch.
In The Sneetches, belly-based discrimination is evident in the society; the causal relationship between race and discrimination can be ascertained
because stars can be placed on or removed from any belly by a machine, and multiple outcomes can be observed for a single Sneetch. Therefore, one could readily answer the counterfactual question, saying with certainty what would have happened to a Plain-Belly Sneetch had he or she been a Star-Belly Sneetch (or vice versa).1 The phenomenon of a black individual passing as white (or vice versa) is an example of how race can be manipulated in this way in our society; thus, it is potentially interpretable causally. However, almost all the information on passing is anecdotal and there are few attempts to measure it systematically. Except under these circumstances, it is nearly impossible in the real world to observe the difference in outcomes across race for a single person; one must instead draw causal inferences.
DRAWING CAUSAL INFERENCES
In the context of measuring racial discrimination, researchers have developed alternative methods to answer the above counterfactual question and assess the incidence and effects of racial discrimination. A formal account of the counterfactual approach to causal inference provides a foundation for evaluating alternative solutions.
Counterfactuals and Potential Outcomes
Counterfactual analysis, combining elements of counterfactual and manipulability theories, is the dominant causal paradigm in recent literature in statistics. The past two decades have witnessed a growing literature formalizing the assumptions and the deductive process needed to draw cause-and-effect inferences from statistical data (Freedman, 2003; Holland, 1986, 2003; Pearl, 2000; Pratt and Schlaifer, 1984, 1988; Rubin, 1974, 1977, 1978; Spirtes et al., 1993; see Box 5-1 for a discussion of graphical approaches). The counterfactual approach to causal inference underlies work in sociology, appearing in both methodological discourse and substantive applications (see Gamoran and Mare, 1989; Lucas and Gamoran, 1991, 2002; Morgan, 2001; Sobel, 1995, 1996; Winship and Morgan,
1999; Winship and Sobel, 2004). Central to such cause-and-effect inferences is the notion of the manipulability of the potential causal variable, such as race. Because race cannot be directly manipulated or randomly allocated to study participants, researchers must be able to translate experimental results into a framework that allows them to address, in some form, causal statements regarding evidence of discrimination. Holland (2003) makes this point in detail and reiterates his earlier (1986) argument that one cannot have causation without manipulation. However, Holland also argues for the careful study of the interactions of race with manipulable variables. See Marini and Singer (1988) for a different perspective on causation.
As suggested above, causal questions are counterfactual questions. The causal effect of racial discrimination is the difference between two outcomes: the outcome if the individual were black and the outcome if the individual were white.2 Rubin (1974) describes the fundamental problem—the inability to simultaneously observe different outcomes for the same person—as a missing data problem: Each individual has potential outcomes under each set of circumstances, but only one of these outcomes is observed (or realized). The causal effect of interest is the difference between these potential outcomes—that is, the effect of racial discrimination. The entire enterprise of causal inference is centered on alternative approaches for overcoming our inability to observe both of these outcomes for a single individual.3
Imagine we want to estimate the effect of discrimination on earnings as experienced by a black person. At the individual level, the unit causal effect of racial discrimination (here, discrimination against a black individual) is
where Yb represents the black individual’s potential earnings, and Yw repre-
|
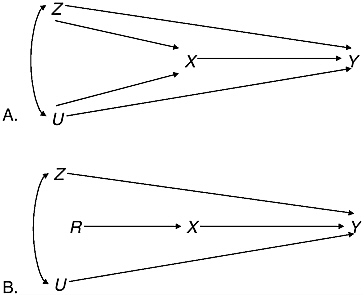
BOX 5-1 Over the past 15 years, directed acyclic graphs have been introduced into the statistical and philosophical literature to describe statistical models and the causal relationships they capture. In this type of graph, each node represents a separate variable, and it is important for the graph to include unobserved variables that influence observable variables. Directed edges between nodes represent causal relationships between variables. By definition, paths following the directed edges in an acyclic graph cannot lead from a node back to itself. In the formal statistical theory of directed acyclic graphs (Pearl, 2000), the absence of an edge in the graph corresponds to conditional independence of the variables corresponding to the nodes, given all of the other variables represented in the graph. This use of conditional independence allows the tie-in to the formal structure for causal inference we have just described. These diagrams offer a way to visualize causal relationships and the role of counterfactuals. In such graphs, manipulation in the sense we have described changes the graph by severing the links to other variables in the graph and, when done using formal randomization, adds a new random variable to the graph that breaks the link between the possible cause X and all of the other variables except for the outcome variable Y. Thus, we can conclude from the altered graph that X indeed causes Y, and we have a justification for the use of the experimental data to estimate the quantity in the text: α = E(Y | X = x1) – E(Y | X = x2). Figure 5-1 depicts two such graphs in accordance with the general framewo rk presented here. Graph A depicts the causal relationships in the observational setting; graph B depicts the causal relationships under randomized assignment. This is merely a graphical representation of the process described above, where X is the treatment or cause of interest, Z is a vector |
sents the potential earnings if the same individual were white.4 However, we observe only Y, one of the two potential outcomes (Yb or Yw), depending on whether the individual is, in fact, black or white. To draw a causal inference about the incidence and effect of racial discrimination, the researcher reframes the question at the population level and then exploits
knowledge of population averages of outcomes among aggregates of members of a racial group to estimate the average effect of racial discrimination.
Study Design and Statistical Methods
Research design is critical to the ability to draw causal inferences from data analysis. For purposes of causal inference, there is a hierarchy of approaches to data collection. As one moves from meticulously designed and executed laboratory experiments through the variety of studies based on observational data, increasingly strong assumptions are needed to support the claim that X “causes” Y. The more careful and rigorous the design and
control, the stronger are the inferences that can be drawn, provided that the design and control are used to address the causal question of interest.
Experimental Designs
The randomized controlled experiment is typically found at the top of the hierarchy of methodological approaches in terms of rigor and control. Such experiments involve direct manipulation of experimental treatments and random assignment of participants to treatments, which is believed to result in a balancing over unmeasured (and sometimes measured) variables whose effects must be controlled for if one is to infer causation. (We provide a more extensive discussion of experiments related to racial discrimination, as well as a variety of examples of such research, in Chapter 6.) Controlled experiments have internal validity associated with inferences about causation for the units of study in the experiment (i.e., the participant sample). But additional or extra-experimental information is required to achieve external validity, whereby researchers can generalize from the units in the experiment to some larger population.
One way to achieve external validity is to draw experimental participants from the population of interest. Another is to carry out a series of replications designed to allow for generalization from the set of experiments. Many researchers argue for the “universality” of the causal phenomenon measured in their experiment (i.e., the effect holds more generally, independently of both the other variables and context), but there is serious uncertainty about this claim in the absence of replications or other extra-experimental information. Many experimenters also argue for the role of experiments as demonstrations of the plausibility of particular causal processes, that is, as an existence proof that a particular phenomenon can, under at least some circumstances, occur in a particular manner. But this demonstration of plausibility does not address the issue of external validity. In any well-designed and well-executed experiment, randomization allows researchers to dismiss competing explanations as highly unlikely, but they are not entirely eliminated. For this reason, independent replication is important.
Holland (2003), in addressing related issues of causation and race, attempts to distinguish among three types of causal questions: (1) identifying causes, (2) assessing effects, and (3) describing mechanisms. Identifying causes is often a form of speculative postmortem. Randomized experiments are used to assess effects, but Holland argues that they can rarely be used to measure the effects of discrimination. On the other hand, Holland’s notion of describing mechanisms relates to what this report refers to as understanding the process whereby discrimination may be occurring. He argues that to conduct an experiment one does not need to fully describe mecha-
nisms. This report views the effort to measure the unobserved counterfactual usually associated with experiments as necessarily being linked to a detailed understanding of the process.
Observational Studies
Moving down the hierarchy with regard to rigor, especially for causal inferences, there are several intermediate steps between conducting controlled experiments and simply observing an event in an unstructured way. Nonexperimental methods differ from those used in experiments in that the analyst cannot assign particular (racial) attributes to particular subjects when in a nonexperimental setting. In observational studies, researchers have data on units at a point in time in a one-time sample survey, or longitudinally in a multiwave sample survey, or from another source (e.g., detailed case studies).
The available data may provide reports of perceived experiences of discrimination and discriminatory attitudes. Such data, obtained using random sampling and exhibiting low nonresponse and error rates, may allow for the external validity or generalizability that many experiments lack. However, because such survey-based studies measure subjective reports, they can be used to investigate only a limited number of phenomena related to but not measuring discrimination, such as trends in overtly discriminatory attitudes or in perceived discriminatory events (see discussion in Chapter 8).
Alternatively, the available data may provide information on differential outcomes (e.g., wage rates) for racial groups together with other variables that the researcher may use to infer the possible role of race-based discrimination. In such passive observation, the researcher lacks control over the assignment of treatments to subjects and attempts to compensate for this lack by “statistically controlling” for possible confounding variables (we elaborate on this issue in Chapter 7). In such circumstances, causal inferences can be controversial.
Statistical methods developed for drawing causal inferences are organized largely around trying to re-create, from observational data, the circumstances that would have occurred had controlled experimental data been collected. These statistical methods are discussed in some detail in Chapter 7, where we critically review the use of statistical models, particularly regression models, to draw valid causal inferences from observational data.
The Roles of Randomization and Manipulation
Researchers justify the substitution of population-level expectations for individual-level outcomes by designing experiments that incorporate ele-
ments of randomization and manipulability. Experiments allow us to distinguish more readily between prediction (or association) and causation (or intervention or manipulation). To predict a random variable Y from the variable X, we attempt to measure or estimate expected values or probabilities like
which is the probability that an outcome Y is equal to y, given that we have observed that some characteristic X is equal to x (e.g., lung cancer is more frequent among cigarette smokers). In contrast, to infer that smoking cigarettes causes an increase in the risk of lung cancer, we attempt to measure or estimate
which is the probability that an outcome Y is equal to y, given that we have an assigned value of x for the random variable X. That is, in experiments designed to demonstrate causation, researchers manipulate X, setting its value for each experimental unit. By using different values of the quantity X for different units in the study, researchers are able to compare outcomes conditional on each value of X; thus, they are able to estimate causal effects. In the first case, one estimates an association; in the second case, one estimates an effect.
To infer a causal relationship, researchers must eliminate alternative explanations. This is an omitted variable bias problem: Researchers must account for systematic effects of potentially omitted factors that both affect the outcome and are associated with the “cause” of interest. For example, in objecting to the hypothesized causal relationship between smoking cigarettes and lung cancer, noted statistician R.A. Fisher (1935) suggested that people’s genetic makeup might predispose them both to smoking and to developing lung cancer. This alternative explanation for the association between smoking and lung cancer was dismissed only after studies of identical twins revealed that a smoking twin was more likely to develop lung cancer than a nonsmoking twin (see further discussion below).
Randomization addresses the omitted variable problem by introducing a new random quantity, R, that identifies which treatment is assigned to the unit. Thus, for those units that are randomized according to the value R = x1, we set X = x1, and for those units that are randomized according to the value R = x2, we set X = x2. By introducing the new random quantity, we set the value of X and at the same time balance (on average) both observed and unobserved covariates across values of X. That is, random assignment makes treatment status independent of the other covariates, both observed and unobserved. Here, manipulation allows us to identify the
direction of the causal relationship and determine whether X causes Y or Y causes X. Together, randomization and manipulation legitimize the direct causal inferences from X to Y.
This result can be formalized within the counterfactual framework described above; here, we ask what would have happened to a unit for which we set X = x1 had we instead set X = x2 for that unit. Again, the problem is that in the randomized experiment the unit can take only one of these values. Once we have assigned X = x1, we cannot go back and investigate what would have happened had we set X = x2 under the identical circumstances. Therefore, we cannot identify a causal effect for a specific unit. Note that this parallels the problem of identifying, at the individual level, the effect of racial discrimination. What we can infer, however, is the value of
using averages across the distribution of Y. That is, we can infer the value of α, the average effect, from the difference in the expected values of Y when X is equal to x1 and when X is equal to x2. Randomization actually allows us to do this by using the X = x1 group to measure E(Y | X = x1) and the X = x2 group to measure E(Y | X = x2). That is, as alluded to above, we exploit knowledge of population averages of outcomes among multiple groups to estimate the causal effect. Because randomization has balanced the distribution of potential confounding variables across each group, this is an unbiased estimate of the average causal effect of X. Rubin (1976, 1978) provides a careful explication of this result, although different aspects of the result are implicit in the early descriptions of randomization in Neyman (1923) and Fisher (1935). As we have shown, counterfactuals go hand in hand with the notion of manipulation, but in practice they are rarely acknowledged as integral parts of the randomized controlled experiment.
Weighing Evidence from Multiple Studies
How is causality established in the absence of a perfectly designed and implemented experiment? It is possible to provide a stronger argument for causal inference by combining methods—from laboratory studies of proposed mechanisms, to field experiments demonstrating external validity, to natural experiments demonstrating policy relevance and efficacy.
Researchers can learn how the accumulation of evidence from multiple sources with a variety of research designs contributes to causal inference by examining a widely cited example of inferring causation in nonexperimental settings—the connection between smoking and lung cancer (see Box 5-2). The case of smoking and lung cancer illustrates how researchers can draw causal inferences in the absence of any single study that alone would have
|
BOX 5-2 In the 1920s, physicians observed a rapid increase in death rates due to lung cancer, but it took several decades before epidemiological studies began to “confirm” what some suspected—that the rise was due to smoking. Early retrospective case-control studies that attempted to match those with and without lung cancer convinced some researchers. Others posited alternative explanations, however, and various subsequent attempts at prospective cohort studies and the expanded study of “confounder” variables did little to convince the bulk of the research community and the public more broadly that the case against cigarette smoking was closed. For example, Fisher (1935), the noted statistician and creator of experimental design, advanced the “constitutional hypothesis” of a genetic predisposition to both smoking and having lung cancer. It ultimately took a series of twin studies to set this alternative aside, but the controversy still continued. Only after the intervention of public health experts and the ultimate downturn in lung cancer cases in the 1980s did the formal causal argument take its first form. Freedman (2000:16) argues that ultimately the strength of the case against cigarette smoking that emerged rested on “the size and coherence of the effects, the design underlying epidemiological studies, and on replications in many contexts. Great care was taken to exclude alternative explanations for the findings. Even so, the |
conclusively demonstrated a causal relationship. This causal link was not accepted until findings to that effect had consistently been produced in multiple settings and in varied study designs, both observational and experimental.
Note that consistent findings across observational studies of different populations are not sufficient in and of themselves to establish a non-spurious relationship; findings must also be consistent across research designs. Otherwise the same bias, replicated across similar studies, may be responsible for an observed “effect” of the potential cause of interest. Rosenbaum (2002:224) writes: “A nontrivial replication disrupts the circumstances of the original study, to check whether the treatment produced its ostensible effect, not some irrelevant circumstance.” Nontrivial replication permits researchers to exclude alternative explanations for the phenomenon of interest, and therefore to distinguish between mere associa-
|
argument requires a complex interplay among many lines of evidence.” The coherence of the results of the numerous epidemiological studies was particularly important. There was a dose–response relationship: Persons who smoke more heavily have a greater risk of disease than those who smoke less. The risk from smoking increases with the duration of exposure. Among those who quit smoking, excess risk decreases after exposure stops. Although one could in principle have designed an experiment in which smoking was manipulated and individuals were assigned to smoking and nonsmoking groups, this was never possible for a variety of reasons. That many of these epidemiological studies attempted to measure the causal effect in terms of odds ratios and adjusted odds ratios* was a major benefit. Despite the absence of randomized controlled experiments, the thoughtful use of controls in some studies, combined with the intervention results and the differences in the cohorts of men and women smokers, ultimately allowed for consensus on the causal conclusion (for further details, see Freedman, 2003; Gail, 1996). See also Hill (1987) for an earlier but less formal discussion of inferring causality. |
tions and actual causal relationships. It was the consistent pattern of evidence across studies with a variety of designs and conducted in a variety of contexts that permitted researchers to conclude that the association between smoking and lung cancer is causal.
In the U.S. context, we have a history of official legalized discrimination that is not in question. Thus, we do not have far to look for causal explanations of continuing disparities between outcomes for nonwhites and whites, and many believe that simple methods produce sufficient evidence to confirm discrimination’s continued existence. For example, consider a study of hiring behavior over time by an employer who, prior to the enactment of the provisions of the Civil Rights Act, had two categories of jobs—one for blacks and one for whites—with whites being paid higher wages than blacks. Following implementation of the act, the employer continued to have the same two types of jobs but now with a handful of blacks in
white jobs and no whites in black jobs. Attributing these racial differences to continued discrimination may make sense intuitively. However, in the absence of explicit racial discrimination, we need more comprehensive data and powerful statistical tools to determine whether differential outcomes by race are, in fact, attributable to racial discrimination.
SUMMARY AND CONCLUSION
Racial discrimination is difficult to measure. Researchers rarely observe discriminatory behavior directly. Instead, they attempt to infer from disparate outcomes whether racial discrimination has occurred. Establishing that racial discrimination did or did not occur requires causal inference. Identifying a racial disparity and determining that an association between race and an outcome remains after accounting for plausible confounding factors is a relatively straightforward task. The real difficulty lies in going beyond the identification of an association to the attribution of cause. Insights drawn from social science theory about types of discrimination and mechanisms through which discriminatory behavior and processes may operate can play an important role here, informing research design and models and assisting researchers in identifying and testing alternative explanations (see Chapter 4). Ultimately, researchers usually must rely on the evaluation of evidence from multiple studies—considering the strength of association, consistency, and plausibility of each study’s research design and findings—to draw causal conclusions.
All research methods have particular strengths and weaknesses with respect to measuring racial discrimination, particularly concerning the extent to which they support causal inferences. In particular, experimental designs facilitate causal inference but limit generalization, whereas observational designs facilitate generalization while limiting causal inference. In any research design, drawing a valid causal inference from a study requires careful specification of the assumptions and the logic underlying the inference.
In the next two chapters, we discuss in greater depth the existing literature that attempts to measure both correlations and causation between race and various outcomes. We provide a number of examples of studies that we believe to be particularly insightful or creative in the way they investigate the role of race in explaining outcomes across a variety of domains.
Conclusion: No single approach to measuring racial discrimination allows researchers to address all the important measurement issues or to answer all the questions of interest. Consistent patterns of results across studies and different approaches tend to provide the strongest argument. Public and private agencies—including the National Science













