
4
Model Evaluation
INTRODUCTION
How does one judge whether a model or a set of models and their results are adequate for supporting regulatory decision making? The essence of the problem is whether the behavior of a model matches the behavior of the (real) system sufficiently for the regulatory context. This issue has long been a matter of great interest, marked by many papers over the past several decades, but especially and distinctively by Caswell (1976) who observed that models are objects designed to fulfill clearly expressed tasks, just as hammers, screwdrivers, and other tools have been designed to serve identified or stated purposes. Although “model validation” became a common term for judging model performance, it has been argued persuasively (e.g., Oreskes et al. 1994) that complex computational models can never be truly validated, only “invalidated.” The contemporary phrase for what one seeks to achieve in resolving model performance with observation is “evaluation” (Oreskes 1998). Although it might seem strange for such a label to be important, earlier terms used for describing the process of judging model performance have provoked rather vigorous debate, during which the word “validation” was first to be replaced by “history matching” (Konikow and Bredehoeft 1992) and later by the term “quality assurance” (Beck et al. 1997; Beck and Chen 2000). Some of these terms imply, innately or by their de facto use,
a one-time approval step. Evaluation emerged from this debate as the most appropriate descriptor and is characteristic of a life-cycle process.
Two decades ago, model “validation” (as it was referred to then) was defined as the assessment of a model’s predictive performance against a second set of (independent) field data given model parameter (coefficient) values identified or calibrated from a first set of data. In this restricted sense, “validation” is still a part of the common vocabulary of model builders.
The difficulty in finding a label for the process of judging whether a model is adequate and reliable for its task is described as follows. The terms “validation” and “assurance” prejudice expectations of the outcome of the procedure toward only the positive—the model is valid or its quality is assured—whereas evaluation is neutral in what might be expected of the outcome. Because awareness of environmental regulatory models has become so widespread in a more scientifically aware audience of stakeholders and the public, words used within the scientific enterprise can have meanings that are misleading in contexts outside the confines of the laboratory world. The public knows well that supposedly authoritative scientists can have diametrically opposed views on the benefits of proposed measures to protect the environment.
When there is great uncertainty surrounding the science base of an issue, groups of stakeholders within society can take this issue as a license to assert utter confidence in their respective versions of the science, each of which contradicts those of the other groups. Great uncertainty can lead paradoxically to a situation of “contradictory certainties” (Thompson et al. 1986), or at least to a plurality of legitimate perspectives on the given issue, with each such perspective buttressed by a model proclaimed to be valid. Those developing models have found this situation disquieting (Bredehoeft and Konikow 1993) because, even though science thrives on the competition of ideas, when two different models yield clearly contradictory results, as a matter of logic, they cannot both be true. It matters greatly how science and society communicate with each other (Nowotny et al. 2001); hence, in part, scientists shunned the word “validation” in judging model performance.
Today, evaluation comprises more than merely a test of whether history has been matched. Evaluation should not be something of an afterthought but, indeed, a process encompassing the entire life cycle of the task. Furthermore, for models used in environmental regulatory activities, the model builder is not the only archetypal interested party holding a stake in the process but is also one among several key players,
including the model user, the decision maker or regulator, the regulated parties, and the affected members of the general public or the representative of the nongovernmental organization. Evaluation, in short, is an altogether much broader, more comprehensive affair than validation and encompasses more elements than simply the matching of observations to results.
This is not merely a question of form, however. In this chapter, where the committee describes the process of model evaluation, it adopts the perspective, discussed in Chapter 1 of this report, that a model is a “tool” designed to fulfill a task—providing scientific and technical support in the regulatory decision-making process—not a “truth-generating machine” (Janssen and Rotmans 1995; Beck et al. 1997). Furthermore, in sympathy with the Zeitgeist of contemporary environmental policy making, where the style of decision making has moved from that of a command-and-control technocracy to something of a more participatory, more open democracy (Darier et al. 1999), we must address the changing perception of what it takes to trust a model. This not only involves the elements of model evaluation but also who will have a legitimate right to say whether they can trust the model and the decisions emanating from its application. Achieving trust in the model among those stakeholders in the regulatory process is an objective to be pursued throughout the life of a model, from concept to application.
The committee’s goal in this chapter is to articulate the process of model evaluation used to inform regulation and policy making. We cover three key issues: the essential objectives for model evaluation; the elements of model evaluation, and the management and documentation of the evaluation process. To discuss the elements of model evaluation in more detail, we characterize the life stages of a model and the application of the elements of model evaluation at these different stages. We organized the discussion around four stages in the life cycle of a regulatory model—problem identification, conceptual model development, model construction, and model application (see Figure 4-1). The life-cycle concept broadens the view of what modeling entails and may strengthen the confidence that users have in models. Although this perspective is somewhat novel, the committee observed some existing and informative examples in which model evaluations effectively tracked the life cycle of a model. These examples are discussed later in this chapter. We recognize that reducing a model’s life cycle to four stages is a simplified view, especially for models with long lives that go through
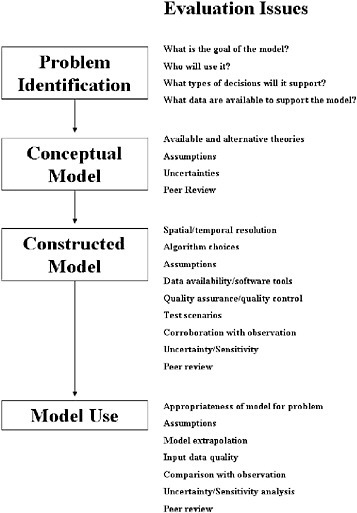
FIGURE 4-1 Stages of a model’s life cycle.
important changes from version to version. The MOBILE model for estimating atmospheric vehicle emissions, the UAM (urban airshed model) air quality model, and the QUAL2 water quality models are examples of models that have had multiple versions and major scientific modifications and extensions in over two decades of their existence (Scheffe and Morris 1993; Barnwell et al. 2004; EPA 1999c). The perspective of a four-stage life cycle is also simplified from the stages of model development discussed in Chapter 3. However, simplifying a model’s life cycle makes discussion of model evaluation more tractable.
Historically, the management of model quality has been inconsistent, due in part to the failure to recognize the impact of errors and omissions in the early stages of the life cycle of the model. At EPA (and other organizations), the model evaluation process traditionally has only begun at the model construction and model application stages. Yet formulating the wrong model questions or even confronting the right questions with the wrong conceptual model will result in serious quality problems in the use of a model. Limited empirical evidence in the groundwater modeling field suggests that 20-30% of model analyses confront new data that render the prevailing conceptual model invalid (Bredehoeft 2005). Such quality issues are difficult to discover and even more difficult to resolve (if discovered) when model evaluation applies only at the late stages of the model life cycle.
ESSENTIAL OBJECTIVES FOR MODEL EVALUATION
Fundamental Questions To Be Addressed
In the transformation from simple “validation” to the more extensive process of model evaluation, it is important to identify the questions that are confronted in model evaluation. When viewing model evaluation as an ongoing process, several key questions emerge. Beck (2002b) suggests the following formulation:
-
Is the model based on generally accepted science and computational methods?
-
Does it work, that is, does it fulfill its designated task or serve its intended purpose?
-
Does its behavior approximate that observed in the system being modeled?
Responses to such questions will emerge and develop at various stages of model development and application, from the task description through the construction of the conceptual and computational models and eventually to the applications. The committee believes that answering these questions requires careful assessment of information obtained at each stage of a model’s life cycle.
Striving for Parsimony and Transparency
In the development and use of models, parsimony refers to the preference for the least complicated explanation for an observation. Transparency refers to the need for stakeholders and members of the public to comprehend the essential workings of the model and its outputs. Parsimony derives from Occam’s (or Ockham’s) razor attributed to the 14th century logician William of Occam, stating that “entities should not be multiplied unnecessarily.” Parsimony does not justify simplicity for its own sake. It instead demands that a model capture all essential processes for the system under consideration—but no more. It requires that models meet the difficult goal of being accurate representations of the system of interest while being reproducible, transparent, and useful for the regulatory decision at hand.
The need to move beyond simple validation exercises to a more extensive model evaluation leads to the need for EPA to explicitly assess the trade-offs that affect parsimony, transparency, and other considerations in the process of developing and applying models. These trade-offs are important to modelers, regulators, and stakeholders. The committee has identified three fundamental goals to be considered in making trade-offs, which are further discussed in Box 4-1:
-
The need to get the correct answer – This goal refers to the need to make a model capable of generating accurate as well as consistent and reproducible projections of future behavior or consistent assessments of current relationships.
-
The need to get the correct answer for the correct reason – This goal refers to the reproduction of the spatial and temporal detail of what scientists consider to be the essence of the system’s workings. Simple process and empirical models can be “trained” to mimic a system of interest for an initial set of observations, but if the model fails to capture all the important system processes, the model could fail to behave correctly for an observation outside the limited range of “training” observations. Such failure tends to drive models to be more detailed.
-
Transparency – This goal refers to the comprehension of the essential workings of the model by peer reviewers as well as informed but scientifically lay stakeholders and members of the public. This need drives models to be less detailed. Transparency can also been enhanced
|
BOX 4-1 Attributes That Foster Accuracy, Precision, Parsimony, and Transparency in Models Gets the Correct Result
Gets the Correct Result for the Right Reason
Transparency
|
|
-
by ensuring that reviewers, stakeholders and the public comprehend the processes followed in developing, evaluating, and applying a model, even if they do not fully understand the basic science behind the models.
These three goals can result in competing objectives in model development and application. For example, if the primary task was to use a model as a repository of knowledge, its design might place priority on getting sufficient detail to ensure that the result is correct for the correct reasons. On the other hand, to meet the task of the model as a communication device, the optimal model would minimize detail to ensure transparency. It is also of interest to consider when a regulatory task would be best served by having a model err on the side of getting accurate results but not including sufficient detail to match scientific understanding. For example, when an exposure model can accurately define the relationship between a chemical release to surface water based on a detailed mass balance, should the regulator consider an empirical model that has the same level of accuracy? Here, parsimony might give preference to the simpler empirical model, whereas transparency is best served by the mass-balance model that allows the model user to see how the release is transformed into a concentration. Moreover, in the regulatory context, the more-detailed model addresses the need to reveal to decision makers and stakeholders how different environmental processes can affect the link from emissions to concentration. Nevertheless, if the simpler empirical model provides both accurate and consistent results, it should have a
role in the decision process even if that role is to provide complementary support and evaluation for the more-detailed model.
The committee finds that modelers may often err on the side of making models more detailed than necessary. The reasons for the increasing complexity are varied, but one regulatory modeler mentioned that it is not only modelers that strive to building a more complex model but also stakeholders who wish to ensure that their issue or concerns are represented in the model, even if addressing such concerns does not have an impact on model results (A. Gilliland, Model Evaluation and Applications Branch, Office of Research and Development, EPA, personal commun., May 19, 2006). Increasing the refinement of models introduces increasing model parameters with uncertain values while decreasing the model transparency to users and reviewers. Here, the problem is a model that accrues significant uncertainties when it contains more parameters than can be calibrated with observations available to the model evaluation process. In spite of the drive to make their models more detailed, modelers often prefer to omit capabilities that do not substantially improve model performance—that is, its precision and accuracy for addressing a specific regulatory question.
ELEMENTS OF MODEL EVALUATION
The evidence used to judge the adequacy of a model for decision-making purposes comes from a variety of sources. They include studies that compare model results with known test cases or observations, comments from the peer review process, and the list of a model’s major assumptions. Box 4-2 lists those and other elements of model evaluation. Many of the elements might be repeated, eliminated, or added to the evaluation as a model’s life cycle moves from problem identification to model application stages. For example, peer review at the model development stage might focus on the translation of theory into mathematical algorithms and numerical solutions, whereas peer review at the model application stage might focus on the adequacy of the input parameters, model execution, and stakeholder involvement. Recognizing that model evaluation may occur separately during the early stages of a model’s life, as well as again during subsequent applications, helps to address issues that might arise when a model is applied by different groups and for different conditions than those for which the model was developed. The committee notes that, whereas the elements of model evaluation and the
questions to be answered throughout the evaluation process may be generic in nature, what comprises a high-quality evaluation of a model will be both task- and case-specific. As described in Chapter 2, the use of models in environmental regulatory activities varies widely both in the effort and the consequences of the regulatory efforts it supports. Thus, the model evaluation process and the resources devoted to it must be tailored to its specific context. Depending on the setting, model evaluation will not necessarily address all the elements listed in Box 4-2. In its guidance document on the use of models at the agency, EPA (2003d) recognized that a model evaluation should adopt a graded approach to model evaluation, reflecting the need for it to be adequate and appropriate for the decision at hand. The EPA Science Advisory Board (SAB) in its review of EPA’s guidance document on the use of models recommended that the graded concept be expanded to include model development and application (EPA 2006d). The committee here recognizes that model evaluation must be tailored to the complexity and impacts at hand as well as the life stage of the model and the model’s evaluation history.
MODEL EVALUATION AT THE PROBLEM IDENTIFICATION STAGE
There are many reasons why regulatory activities can be supported by environmental modeling. At the problem identification stage, decision makers together with model developers and other analysts must consider the regulatory decision at hand, the type of input the decision needs, and whether and how modeling can contribute to the decision-making process. For example, if a regulatory problem involves the assessment of the health risk of a chemical, considerations may include whether to focus narrowly on cancer risk or to include a broader spectrum of health risks. Another consideration might be whether the regulatory problem focuses on occupational exposures, acute exposures, chronic exposures, or exposures that occur to a susceptible subpopulation. The final consideration is whether a model might aid in the regulatory activity.
If there is sufficient need for computational modeling, there are three questions that must be addressed at the problem identification stage: (1) What types of decisions will the model support? (2) Who will use it? and (3) What data are available to support development, application, and evaluation of a model? Addressing these questions is important
|
BOX 4-2 Individual Elements of Model Evaluation Scientific basis – The scientific theories that form the basis for models. Computational infrastructure – The mathematical algorithms and approaches used in the execution of the model computations. Assumptions and limitations – The detailing of important assumptions used in the development or application of a computational model as well as the resulting limitations in the model that will affect the model’s applicability. Peer review – The documented critical review of a model or its application conducted by qualified individuals who are independent of those who performed the work, but who are collectively at least equivalent in technical expertise (i.e., peers) to those who performed the original work. Peer review attempts to ensure that the model is technically adequate, competently performed, properly documented, and satisfies established quality requirements through the review of assumptions, calculations, extrapolations, alternate interpretations, methodology, acceptance criteria, and/or conclusions pertaining from a model or its application (modified from EPA 2006a). Quality assurance and quality control (QA/QC) – A system of management activities involving planning, implementation, documentation, assessment reporting, and improvement to ensure that a model and its component parts are of the type needed and expected for its task and that they meet all required performance standards. Data availability and quality – The availability and quality of monitoring and laboratory data that can be used for both developing model input parameters and assessing model results. Test cases – Basic model runs where an analytical solution is available or an empirical solution is known with a high degree of confidence to ensure that algorithms and computational processes are implemented correctly. Corroboration of model results with observations – Comparison of model results with data collected in the field or laboratory to assess the accuracy and improve the performance of the model. Benchmarking against other models – Comparison of model results with other similar models. Sensitivity and uncertainty analysis – Investigation of what parameters or processes are driving model results as well as the effects of lack of knowledge and other potential sources of error in the model. Model resolution capabilities – The level of disaggregation of processes and results in the model compared to the resolution needs from the problem statement or model application. The resolution includes the level of spatial, temporal, demographic or other types of disaggregation. Transparency – The need for individuals and groups outside modeling activities to comprehend either the processes followed in evaluation or the essential workings of the model and its outputs. |
both for setting the direction of the model and for setting goals for the quality and quantity of information needed to construct and apply the model.
At this stage, data considerations should be a secondary issue, though not one to completely ignore. Problem identification must not be anchored solely to the available data to avoid the situation where data dictate the problem identification of the form, “We have these data available, so we can answer this question….” However, there would have to be confidence that quantitative analysis could inform the problem and that some data would be available.
The problem identification stage answers the question of whether modeling might help to inform the particular issue at hand and sets the direction for development of conceptual and computation models. Although the committee is not endorsing a complex model evaluation at the nascent stage of problem identification, it is clear that setting off to develop or apply a model that will not address the problem at hand or that will take too long to provide answers can have serious impacts on the effectiveness of modeling. The key goal of the problem identification phase is to identify the regulatory task at hand and assess the role that modeling could play. At this stage, the description of the regulatory task and the way modeling might address this regulatory task should be open to comment and criticism. Thus, when formal model evaluation is performed in later stages of a model’s life cycle, it must take into account the problem identification and how it influenced the nature of the model.
EVALUATION AT THE CONCEPTUAL MODEL STAGE
Some of the most important model choices are made at the conceptual stage, yet most model evaluation activities tend to avoid a critical evaluation at this stage. Often a peer review panel will begin its efforts with the implicit acceptance of all the key assumptions made to establish the conceptual model and then devote all of its attention to the model building and model application stages. Alternatively, a late-stage peer review of a nearly complete model may find the underlying conceptual model to be flawed. Finally, data must be assessed at this point to ensure the availability of data for model development, input parameters, and evaluation. The result of this process is the selection of a computational modeling approach that addresses problem identification, data availability, and transparency requirements.
Evaluating the Conceptual Model
Quality of the Basic Science
It is important to evaluate the fundamental science that forms the basis of the conceptual model. One approach is to consider the idea of a pedigree of a domain of science, a word expressing something about the history—and the quality of the history—of the concepts and theories behind the model and, possibly more appropriately, each of its constituent parts (Funtowicz and Ravetz 1990). Over the years, the fundamental scientific understanding and other understandings that are used in constructing models have been consolidated and refined to produce a mature product with a pedigree. For example, a task, such as modeling of lake eutrophication, started as an embryonic field of study, passed through the adolescence of competing schools of thought (Vollenweider 1968) to the gathering of consensus around a single scientific outlook (disputed only by the sub-discipline’s “rebels”), and finally to the adulthood of the fully consolidated outlook, contested, if at all, only by those considered “cranks” by the overwhelming majority—a history partially recounted in Schertzer and Lam (2002). The status of a model’s pedigree typically changes over time, with the strong implication of ever-improving quality. Although some models may cease to improve over time, it is more common that they continue to be refined over time, especially for long-lived regulatory models. The concept of a pedigree can be applied to the model as a whole, to one of its major subblocks (such as atmospheric chemistry or human toxicology), or to each constituent model parameter.
Quality of Available Data
For environmental models, one of the issues often ignored at the conceptual stage is the availability of data. It is one of the major issues in the use of environmental models, and it has multiple aspects:
-
Data used as inputs to the model, including data used to develop the model.
-
Data used to estimate values of model parameters (internal variables).
-
Data used for model evaluation.
There is some overlap between the first and second types of data, depending on the model application, but in general these data needs can be viewed as separate. One major problem is that collecting new data at this early stage is rarely considered. Model development and evaluation and data collection should be iterative and proceed together, but in practice, these activities at agencies such as EPA often are done by separate groups that may not meet each other until late in the process. The critical issue is that, at this stage in a model’s life cycle, there should be a requirement for an assessment of the data needs and a corresponding data collection plan. Modelers should be building on-going collaborations with experimentalists and those responsible for collection of additional data to determine how such new data can guide model development and how the resulting models can guide the collection of additional data.
EVALUATION AT THE COMPUTATIONAL MODEL STAGE
In moving from the identification of the problem, the assessment of required resolving power and data needs, and the decision concerning the basic qualitative modeling approach to a constructed computational model, a number of practical considerations arise. As we observe in Chapter 3, these considerations include (1) choices of specific mathematical expressions to represent the interactions among the model’s state variables; (2) evaluation of a host of algorithmic and software issues relating to numerical solution of the model’s equations; (3) the assembly of data to develop inputs, to test, and to compare with model results; and (4) the ability of the model to arrange the resulting numerical outputs for comprehension by all the stakeholders concerned. A prime motivation at this stage of evaluation is, does the behavior of the model approximate well what is observed? For modelers, nothing is more convincing and reassuring than seeing the curve of the model’s simulated responses passing through the dots of observed past behavior. However, as discussed in Chapter 1, natural systems are never closed and model results are never unique. Thus, any match between observations and model results might be due to processes not represented in the model canceling each other out. In addition, simply reproducing results that match observations for a single scenario or several scenarios does not mean the model can represent the full statistical characteristics of observations.
The evaluation needs fundamentally to address the questions laid out at the beginning of this chapter: the degree to which the model is
based on generally accepted science and computational methods, whether the model fulfills its designed task, and how well its behavior approximates that observed in the system being modeled. A majority of model evaluation activities traditionally occur at the stages in which the computational model is developed and applied. These are the stages when quality assurance and quality control (QA/QC) efforts are documented, testing and analysis reports generated, model documentation produced, and peer review panels commissioned. However, these formal model evaluation activities must be cognizant of and built on earlier evaluation activities during the problem identification and model conceptualization stages.
Scientific Basis, Computational Infrastructure, and Assumptions
The scientific basis, the computational infrastructure, and the major assumptions used within a computational model are some of the first elements typically addressed during model evaluation. The initial evaluation of the scientific theories, possible computational approaches, and inherent assumptions should occur during the development of the conceptual model. Model builders must reassess these issues during the construction of a computational model by obtaining a wider array of peer reviewers’ and others’ comments. Indeed, these issues are typically the first elements assessed by outside evaluators when EPA models go before review panels, such as the SAB, or the public.
Code Verification of Numerical Solutions and Other Quality Assurance Procedures
Verification of model code and assurance that the numerical algorithms are operating correctly are the essence of QA/QC procedures. These activities evaluate to what extent the executable code and other numerical software in the constructed model generate reliable and consistent solutions to the mathematical equations of the model. The document prepared for a recent evaluation by SAB of the very-high-order 3MRA modeling system (the multimedia model described in Babendreier and Castleton [2005]) defines code verification as follows (EPA 2003e):
Verification refers to activities that are designed to confirm that the mathematical framework embodied in the module is correct and that the computer code for a module is operating according to its intended design so that the results obtained using the code compare favorably with those obtained using known analytical solutions or numerical solutions from simulators based on similar or identical mathematical frameworks.
Verification activities include taking steps to ensure that code is properly maintained, modified to correct errors, and tested across all aspects of the module’s functionality. Table 4-1 lists some of the software checks listed by EPA to ensure that model computations proceed as anticipated. Other QA/QC activities include (1) the use of the model in different operating systems with different compilers to make sure that the results remain the same and (2) testing under simplified scenarios (for example, with zero emissions, zero boundary conditions, and zero initial conditions) where an analytical solution is available or an empirical solution is known with a high degree of confidence.
Like so many things, concluding—provisionally—that the constructed model is working with a reliable code comes down to the outcomes of the most rudimentary tests, such as those “comparing module results with those generated independently from hand calculations or spreadsheet models” (EPA 2003e). These tests are the equivalent of the tests made time and again to ensure a sensor or instrument is working properly. They are tests that are maximally robust against ambiguous outcomes. As such, they only ensure against gross deficiencies but cannot confirm that a model is sufficiently sound for regulatory use. Constant vigilance is required. “Even legacy codes that had more than a decade of wide use experienced environmental conditions that caused unstable numerical solutions” (EPA 2003e).
Where models are linked, as in linking emissions models to fate and transport models as discussed in Chapter 2, additional checks and audits are required to ensure the streams of data passing back and forth have strictly identical meanings and units in the partnered codes engaging in these electronic transactions. Further, such linked models do not lend themselves to be compared with simple test cases that have known solutions. This makes QA/QC activities related to linked models much more difficult.
TABLE 4-1 QA/QC Checks for Model Code
|
Software code development inspections: Software requirements, software design, or code are examined by an independent person or groups other than the author(s) to detect faults, programming errors, violations of development standards, or other problems. All errors found are recorded at the time of inspection, with later verification that all errors found have been successfully corrected. |
|
Software code performance testing: Software used to compute model predictions is tested to assess its performance relative to specific response times, computer processing usage, run time, convergence to solutions, stability of the solution algorithms, the absence of terminal failures, and other quantitative aspects of computer operation. |
|
Tests for individual model module: Checks ensure that the computer code for each module is computing module outputs accurately and within any specific time constraints. (Modules are different segments or portions of the model linked together to obtain the final model prediction.) |
|
Model framework testing: The full model framework is tested as the ultimate level of integration testing to verify that all project-specific requirements have been implemented as intended. |
|
Integration tests: The computational and transfer interfaces between modules need to allow an accurate transfer of information from one module to the next, and ensure that uncertainties in one module are not lost or changed when that information is transferred to the next module. These tests detect unanticipated interactions between modules and track down cause(s) of those interactions. (Integration tests should be designed and applied in a hierarchical way by increasing, as testing proceeds, the number of modules tested and the subsystem complexity.) |
|
Regression tests: All testing performed on the original version of the module or linked modules is repeated to detect new “bugs” introduced by changes made in the code to correct a model. |
|
Stress testing (of complex models): Stress testing ensures that the maximum load (for example, real time data acquisition and control systems) does not exceed limits. The stress test should attempt to simulate the maximum input, output, and computational |
|
load expected during peak usage. The load can be defined quantitatively using criteria such as the frequency of inputs and outputs or the number of computations or disk accesses per unit of time. |
|
Acceptance testing: Certain contractually required testing may be needed before the new model or model application is accepted by the client. Specific procedures and the criteria for passing the acceptance test are listed before the testing is conducted. A stress test and a thorough evaluation of the user interface is a recommended part of the acceptance test. |
|
Beta testing of the pre-release hardware/software: Persons outside the project group use the software as they would in normal operation and record any anomalies encountered or answer questions provided in a testing protocol by the regulatory program. The users report these observations to the regulatory program or specified developers, who address the problems before release of the final version. |
|
Reasonableness checks: These checks involve items like order-of-magnitude, unit, and other checks to ensure that the numbers are in the range of what is expected. |
|
Source: EPA 2002e. |
Comparing Model Output to Data
Comparing model results with observations is a central component of any effort to evaluate models. However, such comparisons must be made in light of the model’s purpose—a tool for assessment or prediction in support of making a decision or formulating policy. The inherent problems of providing an adequate set of observations and making credible comparisons give rise to some important issues.
The Role of Statistics
Because (near) perfect agreement between model output and observations cannot be expected, statistical concepts and methods play an inevitable and essential role in model evaluation. Indeed, it is tempting to use formal statistical hypothesis testing as an evaluation tool, perhaps in part because such terms as “accepting” and “rejecting” hypotheses sound as though they might provide a way to validate models in the now-discredited meaning of the term. However, the committee has concerns that testing (for example, that the mean of the observations equals the mean of the model output) will fail to provide much insight into the appropriateness of using an environmental model in a specific application. As discussed in Box 1-1 in Chapter 1, the evaluation of the ozone models in the 1980s and early 1990s showed that estimates of ozone concentrations from air quality models were good when compared with observations for any choice of statistical methods, but only because the errors in the models tended to cancel out. Statistics has value for conceptualizing, visualizing, and quantifying variation and dependence rather than for serving as a source of “rigorous” or “objective” standards for model evaluation. The committee cautions, however, that standard, elementary statistical methods will often be inappropriate in environmental applications, for which problems of spatial and temporal dependence are frequently a critical issue.
Although epidemiologists and air quality modelers use statistical tests to compare models with data, it is difficult to find broad-based examples in regulatory models in which formal hypothesis testing (e.g., testing that the means of two distributions are equal based on the p-value of some test statistic) has played a substantial role in any model evaluation. What is needed is statistically-sophisticated analysts that can do non-standard statistical analyses appropriate for the individual circum-
stances. For example, air quality modelers commonly present a variety of model performance statistics along with graphic comparisons of model results with observations; these are sometimes compared with acceptability criteria set by EPA for various applications.
Comparing Models with Data—Model Calibration
Model calibration is the process of changing values of model input parameters within a physically defensible range in an attempt to match the model to field observations within some acceptable criteria. Models often have a number of parameters whose values cannot be established in the model development stage but must be “calibrated” during initial model testing. This need requires observations for conditions that must broadly characterize the conditions for which the model will be used. Lack of characterization of the conditions can result in a model that is calibrated to a set of conditions that are not representative of the range of conditions for which the model is intended. The calibration step can be linked with a “validation” step where a portion of the observations are used to calibrate the model, and then the calibrated model is run and results compared with the other portion of data to “validate” the model. The typical criteria used for judging the quality of agreement is mean square error, or the average squared difference between observed values and the values predicted by the model.
The issue of model calibration can be contentious. The calibration tradition is ingrained in the water resources field by groundwater, stream-flow, and water-quality modelers, whereas the practice is shunned by air-quality modelers. This practice is not merely a disagreement about terminology, but a more fundamental difference of opinion about the relationship of models and measurement data, which is explored in Box 4-3. However, it is clear that both fields, and modelers in general, accept a fundamental role for measurement data to improve modeling. In this unifying view, model calibration is not just a matter of fiddling about trying to find suitable best values of the coefficients (parameters) in the model. Instead, calibration has to do with evaluating and quantifying the posterior uncertainty attached to the model as a function of the measured data, prior model uncertainty, and the uncertainty in the measured data against which it has been reconciled (calibrated). This view is clearly Bayesian in spirit, using data and prior knowledge to arrive at updated posterior expectations about a phenomenon, if not strictly so in number-crunching,
computational terms. It is the recognition of the fundamental codependence of models and data from measurements that is common among all models.
|
BOX 4-3 To Calibrate or Not To Calibrate In an ideal world, calibration of models would not be necessary, at least not if we view calibration merely as the search for values of a model’s parameters that provide the best match of the model’s behavior with that observed of the real system. It would not be necessary because the model would contain only parameters that are known to a high degree of accuracy. To be more pragmatic, but nonetheless somewhat philosophical, there is a debate about whether to calibrate a model or not in the real world of environmental modeling. That debate centers around two features: (1) the principle of engaging models with field data in a learning context during the development of the model; and (2) the principle of using calibration for quantifying the levels of uncertainty attached to the model’s parameters, with a view to accounting for how that uncertainty propagates forwards with predictions. The former lies within the conventional understanding and interpretation of what constitutes model calibration. The latter requires a broader, but less familiar, interpretation of calibration. Taken together, calibration can be seen to be something more than a “fiddler’s paradise,” in which the analyst seeks merely to fit the data, no matter how absurd the resulting parameter estimates; and no matter the obvious risk of subsequently making confident—but probably highly erroneous—predictions of future behavior, especially under conditions different from those reflected in the data used for model calibration (Beck 1987). The nub of the debate turns on the extent to which the analyst trusts the prior knowledge about the individual components of the model, to which the parameters are attached, yet discounts the power of the calibration data set—reflecting the collective effects of all the model’s parameters on observed behavior of the prototype, as a whole—to overturn these presumptions. The debate also turns on the extent to which individual parameters can be “measured” independently in the field or laboratory under tightly controlled conditions. The more this is feasible, the less the need to calibrate the behavior of the model (as a whole). In this argument, however, it must be remembered that many parameters remain quantities that appear in presumed relationships, that is, mathematical relationships or models between the observed quantities, so that the problem of calibrating the model as a whole is transferred to calibrating the relationship between the observables to which each individual parameter is bound. This may seem less of a problem when needing to substitute a value for soil porosity into a hydrological model. But it is surely a problem when the need is to find a value for a maximal specific growth-rate constant for a bacterial population, which is certainly not a quantity that can itself be directly measured. Experience of model calibration and the stances taken on it differ from one discipline to another. In hydrology and water quality modeling it is unsurprising how the wider interpretation and greater use of calibration have become established practice. In spite of the relatively large volumes of hydrological field data customarily available, experience over several decades has shown that hydro |
|
logical and water quality models inevitably suffer from a lack of identifiability in that many combinations of parameter values will enable the model to match the data reasonably well (Jakeman and Hornberger 1993; Beven 1996). Trying to find a best set of parameter values for the model, even a best structure for the model, have come to be accepted as barely achievable goals at best. In a pragmatic, decision-support context, what matters—given uncertain models, uncertain data, and therefore uncertain model forecasts—is whether any particular course of action (among the various options) manages to stand out above the fog of uncertainty as clearly the preferred option. Under this view, the posterior parametric uncertainties reflect the signature, or fingerprint, of all the distortions and uncertainties remaining in the model as a result of reconciling it with the field data. In a more theoretical context, interpretation of the patterns of such distortions and uncertainties can serve the purpose of learning from having engaged the model systematically with the field data. In other disciplines, such as modeling of air quality, calibration is viewed as a practice that should be avoided at all costs. Inputs to these models include pollutant emissions (spatially, temporally, and chemically resolved), three-dimensional meteorological fields (such as wind speed and direction, temperature, relative humidity, sunlight intensity, clouds and rain, also temporally resolved). Air quality models also rely on a wide range of parameters used in the description of processes simulated by the models (such as turbulent dispersion coefficients for atmospheric mixing, parameters for the dry and wet removal of pollutants, kinetic coefficients for gas and aqueous-phase chemistry, mass transfer rate constants, and thermodynamic data for the partitioning of pollutants among the different phases present in the atmosphere). The need for the determination of all of these input values and parameters has resulted in a huge investment in scientific research funded by EPA, state air pollution authorities (especially California), National Science Foundation (NSF), and others to understand the corresponding processes and to develop model application-independent approaches to estimate them. Further, complex regional meteorological models (such as MM5 and RAMS), which are used for other applications, are used to simulate the meteorology of the atmosphere and provide the corresponding input fields to the air quality models. Meteorological models themselves take advantage of the available measurements of wind speed, temperature, relative humidity, etc. in the domain that they simulate, to improve their predictions. In a technique called data assimilation the available measurements are used to “nudge” the meteorological model predictions closer to the available measurements by adding forcing terms (proportional to the difference between the model predictions and the observations) to the corresponding differential equations solved by the model. This semi-empirical form of correction can maintain the meteorological model results close to reality and improve the quality of the input provided to the air quality model. This form of calibration is involved only in the preparation of the input to the air quality model and is independent of the air quality model, its prediction, and the available air quality modeling. The emission fields are prepared by corresponding emission models that incorporate the available information about the activity levels (for example, traffic, fuel consumption by industries, population density, etc.) and emission factors |
|
(emissions per unit of activity) for each source. Some of the best applications of air quality models have been accompanied by field measurements of emissions during the model application period (for example, transportation emissions in tunnels in the area, characterization of major local sources, even use of airplanes to characterize the plumes of major point sources, etc.). Boundary conditions are measured usually by ground monitoring stations or airplanes in selected points close to the model boundary (for example, in San Nicolas Island off the shore of Southern California). Laboratory (for example in smog chambers simulating the atmosphere) and field experiments have been used to understand the corresponding processes and to provide the necessary parameters. One could argue that the historical lack of reliance on model calibration for the air quality area has resulted in significant research to understand better the most important processes and in the development of approaches to provide the necessary input. This has required a huge investment by US funding sources (the State of California, EPA, NSF, etc.) but has also resulted in probably the most comprehensive modeling tools available for environmental regulation. One could also argue that the atmosphere is a much easier medium to model (after all air is the same everywhere) compared to soil, water, ecosystems, or the human body. However, the success of the “let’s try to avoid calibration” philosophy may be a good example in the long term for other environmental modeling areas. In sum, there is nothing wrong with the healthy debate over calibration. Either way—whether calibration is accepted practice or shunned—all agree that fitting a model to past data is not an end in itself, but a means: to the end of learning something significant about the behavior of the real system; and to the end of faithfully reflecting the ineluctable uncertainty in a model. |
One effect of the rejection of model calibration for regional air quality models is the idea that model results are more appropriate for relative comparisons than for absolute estimates. EPA guidance for the use of models for the attainment of ambient air quality standards (the attainment demonstration) for 8-hour ozone and the fine-particle particulate matter (PM) begins with the notion that model estimates will not predict perfectly the observed air quality at any given location at the present time and in the future (EPA 2005d). Thus, models for demonstrating whether emissions reduction strategies will result in attainment demonstrations are recommended for use in a relative sense in concert with observed air quality data. Such use essentially involves taking the ratio of future to present predicted air quality from the models to develop a ratio and then multiplying it by an “ambient” design value. The effect will be to anchor future concentrations to “real” ambient values. If air quality models were calibrated to observations, as is done with water quality models, there would be less need to use the model in a relative sense.
EPA also uses the concept that air quality models are imperfect predictors to argue for a weight-of-evidence approach to attainment demonstrations. Under a weight-of-evidence approach, the results of the air quality models are no longer the sole determining factor but rather one input that may include trends in ambient air quality and emissions observations and other information (EPA 2005d).
Comparing Models with Data—Data Quality
Not all data are of equal quality. In addition to the usual issues of systematic and random measurement errors, there is the issue that some “data” are the result of processing sensor information through instrumentation algorithms that are really models in their own right. Examples include the post-processing of raw information that is obtained from remote-sensing instruments (e.g., Henderson and Lewis 1998) or from techniques used to separate total carbon in an airborne PM sample into inorganic and organic carbon components (e.g., Chow et al. 2001). Thus, if the data and model output disagree, the extent of disagreement that is due to the model used to convert raw measurements into the quantity of interest must be considered. An additional and related difficulty with many data sets is that the standard assumption of statistically independent measurement errors can be untrue, including for remotely sensed data, greatly complicating model and measurement data comparisons.
Comparing Models with Data—Temporal and Spatial Issues
Even with data of impeccable quality, there are still many problems in comparing them with model output. One problem is that data and model output are generally averages over different temporal and spatial scales. For example, air pollution monitors produce an observation at a point, whereas output from regional-scaled air quality models discussed earlier in the report produces at best averages over the grid cells used in the numerical solution of the governing partial differential equations. However, if for no other reason than that the meteorological inputs into air pollution models will inevitably have errors at small spatial scales, there is no expectation that the models would reproduce actual average pollution levels over the grid cells, even if such an average could be
observed. The models may do somewhat better at reproducing averages over larger regions of space or over longer intervals of time than the nominal observation frequency, and a model that does well with such averages could reasonably be judged as functioning well. Similar problems underlie many health assessments, such as when pharmacokinetic models for one exposure scenario are compared with measurements from a different exposure scenario or when data from laboratory rats exposed for 90 days are used to estimate human risks from a continuous lifetime exposure. Even so, these dilemmas are the reason models are needed—it is impossible to measure all events of interest.
There are two potential approaches that can address some of these spatial and temporal problems. The collection of two or more measurements inside the same computational cell provides information on the spatial variability of the pollutant of interest within a grid cell. However, monitoring is not always available to obtain multiple samples within the same grid cell. For the temporal issue, the collection of high temporal resolution measurements, including continuous measurements, can allow the comparison to be performed at several different time-intervals. In this manner, a model could be “stressed” to produce, for example, diurnal profiles of the pollutant. Again, however, the availability of monitoring data is a limiting factor.
Comparing Models with Data—Simulating Events Versus Long-Term Averages
An important issue is whether models are expected to reproduce observations on an event-by-event basis. If the model is used for short-term assessment or forecasting, then such a capability would be necessary. For example, when assessing whether an urban storm-water control system would be overwhelmed, resulting in the discharge of combined storm-water sewage into receiving waters, only a single-event rainfall-runoff model might be required to treat each potential storm event individually. However, when the goal is to predict how the environment will change over the long term in response to an EPA policy, such a capability is neither necessary nor sufficient. General circulation models used for assessing climatic change may be an extreme example of models that cannot reproduce event-by-event observations but are able to reproduce many of the statistical characteristics of climate over long-tern scales.
Comparing Models with Data—Simulating Novel Conditions
The comparison of model and measured data under existing conditions, no matter how extensive, provides only indirect evidence of how well a model will do at predicting what will happen under novel or post-regulatory conditions. Yet, this comparison is a fundamental element of model evaluation and its relevancy is perhaps the biggest challenge EPA faces in assessing the usefulness of its models. When model results are to be extrapolated outside of conditions for which they have been evaluated, it is important that they have the strongest possible theoretical basis, explicitly representing the processes that will most affect outcomes in the new conditions to be modeled, and embodying the best possible parameter estimates. For some models, such as for air dispersion models, it may be possible to compare output with data in a wide enough variety of circumstances to gain confidence that they will work well in new settings. Satisfying all of these conditions, however, is not always possible, as the case of competing cancer potency dose-response models makes clear. Absent a solid understanding of underlying mechanisms, the best model for doing such an extrapolation is a matter of debate.
There is the potential to test some types of models in cases where the system behaves differently, such as when there is a significant change in pollutant loads. Air pollution studies have indicated that air quality models can be stressed by simulating special periods, such as the Christmas holidays, with its low traffic emissions and high wood burning; days with major power disruptions (for example, the blackouts in the Northeast); or days when most people go on vacation (as in Europe). Pope (1989) provides an example of the possible insights from developing a model under such novel conditions. This study used epidemiological modeling to look at the reduction in hospital admissions for pneumonia, bronchitis, and asthma that occurred in the Utah Valley when a major source of pollution, the local steel mill, was closed for 13 months. The observation of a statistically significant reduction in hospital visits correlated to reductions in ambient PM concentrations helped to initiate a reassessment of ambient air quality standards for this pollutant.
Comparing Models with Data—A Bayesian Approach
For models that are used frequently, a Bayesian approach might be considered to quantitatively support model evaluation (Pascual 2004;
Reckhow 2005). For example, prior uses of the model could provide comparison of pre-implementation predictions of the success of an environmental management strategy with post-implementation observations. Using Bayesian analysis, this “prior” could be combined with a prediction-observation comparison for the site and topic of interest to evaluate the model as well as improve the strategy.
Uncertainty Analysis
Formal uncertainty analysis provides model developers, decision makers, and others with an assessment of the degree of confidence associated with model results as well as the aspects of the model having the largest impacts on its results. As such, uncertainty analysis and related sensitivity analysis is a critical aspect of model evaluation during model development and model application stages. The use of formal qualitative and quantitative uncertainty analysis in environmental regulatory modeling is growing in response to improvements in methods and computational abilities. It also is increasing due to advice from other National Research Council reports (e.g., NRC 2000, 2002), mandates from the Office of Management and Budget (OMB 2003), and internal EPA guidance (e.g., EPA 1997b). As shown in Box 4-4, there are a number of policy-related questions that can be informed through formal uncertainty analysis.
However, a formal uncertainty analysis, in particular a formal quantitative uncertainty analysis, is difficult to carry out for a variety of reasons. As noted by Mogan and Henrion (1990), “The variety of types and sources of uncertainty, along with the lack of agreed terminology, can generate considerable confusion.” In the recent report Not a Sure Thing: Making Regulatory Choices Under Uncertainty, Krupnick et al. (2006) noted the lack of a universal typology or taxonomy of uncertainty, making any discussion of the topic of uncertainty analysis for regulatory models difficult. There is also a concern that uncertainty analysis can be difficult to incorporate into policy settings. Krupnick et al. (2006) concluded that one unintended impact of an increased emphasis on uncertainty analysis may be a decrease in decision makers’ confidence in the overall analysis. The SAB Regulatory Environmental Modeling Guidance Review Panel (EPA 2006d) elaborates on the concern about using uncertainty analysis in the policy process. Although the panel noted that evaluation of model uncertainty is important in both understanding a sys-
tem and in presenting results to decision makers, it raised the concern that the use of increasingly complex quantitative uncertainty assessment techniques without an equally sophisticated framework for decision making and communication may only increase management challenges. Further, it is very difficult to perform quantitative uncertainty analyses of complex models, such as regional air quality models (N. Possiel, EPA Office of Air Quality Planning and Standards, personal commun., May 19, 2006). As these complex models are linked to other models, such as those in the state implementation planning process discussed in Chapter 2, the difficulties in performing quantitative uncertainty analysis greatly increases.
Defining Sources of Uncertainty
Although a single uniformly accepted method of categorizing uncertainties does not exist, several general categorizations are clearly defined. As noted by Krupnick et al (2006), the literature distinguishes variability from lack of knowledge and uncertainties in parameters from model uncertainties. Variability represents the inherent heterogeneity that cannot be reduced through additional information, whereas other aspects of parameter uncertainties might be reduced through more monitoring, observations, or additional experiments. The distinction of model uncertainties from parameter uncertainties is also critical. Model uncertainties represent situations in which it is unclear what all the relevant variables are or what the functional relationships among them are. As noted by Morgan (2004), model uncertainty is much more difficult to address than parameter uncertainty. Although identifying and accounting for the consequences of model structural error and uncertainty has only recently become the subject of more sustained and systematic research (Beck 1987, 2005; Beven 2005; Refsgaard et al. 2006), most analyses that have considered the issue report that model uncertainty might have a much larger impact than uncertainties associated with individual model parameters (Linkov and Burmistrov 2003; Koop and Tole 2004; Bredehoeft 2005). Such structural errors amount to conceptual errors in the model, so that if identified at this stage of evaluating the constructed model, assessment should be cast back to reevaluation of the conceptual model.
Krupnick et al. (2006) also identified two other sources of uncertainty important for regulatory modeling: decision uncertainty and linguistic uncertainty. As first observed by Finkel (1990), there are uncer-
tainties that arise whenever there is ambiguity or controversy about how to apply models or model parameters to address questions that arise from social objectives that are not easy to quantify. Issues that fall into this category are the choice of discount rate and parameters that represent decisions about risk tolerance and distributional effects. Uncertainties associated with language, although implicitly qualitative, are important to consider due to the need to ultimately communicate results of a computational model to decision makers, stakeholders, and the interested public. As applied to computational models, sensitivity analysis is typically thought of as the quantification of changes in model results as a result of changes in individual model parameters. It is critical for determining what parameters or processes have the greatest impacts on model results. Figure 4-2 displays the differing interpretations associated with various descriptors that might be used to describe results from models.
Sensitivity and Uncertainty Analysis
Sensitivity and uncertainty analyses are procedures that are frequently carried out during development and application of models. As applied to computational models, sensitivity analysis is typically thought of as the quantification of changes in model results as a result of changes in individual model parameters. The concept of sensitivity analysis has value in the model development phase to establish model goals and examine the advantages and limitations of alternative algorithms. For example, the definition of sensitivity analysis developed by EPA’s Council on Regulatory Environmental Models (CREM) includes consideration of model formulation (EPA 2003d). The goal of a sensitivity analysis is to judge input parameters, model algorithms, or model assumptions in terms of their effects on model output. Sensitivity analyses can be local or global. A local sensitivity analysis is used to examine the effects of small changes in parameter values at some defined point in the range of these values. A global sensitivity analysis quantifies the effects of variation in parameters over their entire space of these values. When addressing global sensitivity, the effect of varying more than one parameter on the response must be considered. A common approach for assessing sensitivity and uncertainty is to run the model multiple times while slightly changing the inputs.
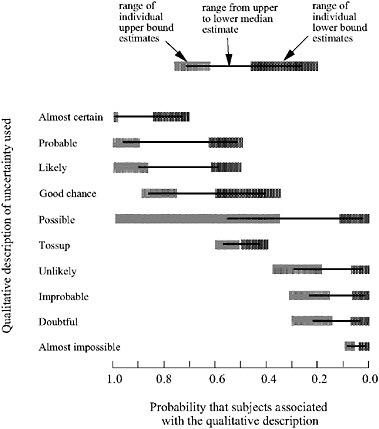
FIGURE 4-2 Range of probabilities that people assign to different words absent any specific context. Source: Adapted from Wallsten et al. 1986. Reprinted with permission; copyright 1986, Journal of Experimental Psychology: General.
Quantitative uncertainty analysis is the determination of the variation or imprecision in the output function based on the collective variation of the model inputs using a variety of methods, including Monte Carlo analysis (EPA 1997b). In a broader perspective, uncertainty analysis examines a wide range of quantitative and qualitative factors that might cause a model’s output values to vary. All models have inherent capabilities and limitations. The limitations arise because models are simplifications of the real system that they describe, and all assessments using the models are based on imperfect knowledge of input parameters. Confronting the uncertainties in the constructed model requires a model performance evaluation that (1) estimates the degree of uncertainty in the assessment based on the limitations of the model and its inputs, and (2) illustrates the relative value of increasing model complexity, of providing
a more explicit representation of uncertainties, or of assembling more data through field studies and experimental analysis.
Model Uncertainty Versus Parameter Uncertainty
Although a distinction between model uncertainty and parameter uncertainty is typically made, there is an argument over whether there is indeed any fundamental distinction. In the sense that both kinds of uncertainty can be handled through probabilistic or scenario analyses, the committee agrees, but notes that this applies only to the uncertainty about the output of models. For assessing uncertainty in model outputs, uncertainty about which model to use can be converted to uncertainty about a parameter value by constructing a new model that is a weighted average of the competing models (e.g., Hammitt 1990). But the issue of selecting a set of models that captures the full space of outcomes and the choice of weighting factors is problematic. Therefore, the committee considers that there is a worthwhile practical distinction between model and parameter uncertainty, if for no other reason than to emphasize that model uncertainty might dwarf parameter uncertainty but can easily be overlooked. This is particularly important in situations where models with alternative conceptual frameworks to the standard model are too expensive to run or do not even exist.
EVALUATION AT THE MODEL APPLICATION STAGE
A new set of practical considerations apply in moving from the development of a computational model to the application of the model to a regulatory problem, including the need for specifying boundary and initial conditions, developing input data for the specific setting, and generally getting the model running correctly. These issues do not detract from the fundamental questions and trade-offs involved in model evaluation. The evaluation will need to consider the degree to which the model is based on generally accepted science and computational methods; whether the model fulfills its designed task; and how well its behavior approximates that observed in the system being modeled. For models that are applied to a specific setting for which the model was developed, these questions should have been addressed at the model development stage, particularly if the developers are the same group applying the model.
However, frequently models are applied by users who are not the developers or even in the same institution as the developers. In many cases, model users might have a choice in the model to use and in alternative modeling approaches. In these cases, model evaluation must address the same fundamental considerations about the appropriateness of the model for the application and explicitly address the trade-offs between the need for the model to get the right answer for the right reason and the need for the modeling process to be transparent to stakeholders and the interested public. The discussion here focuses on the evaluation of model applications using uncertainty analysis. Later in this chapter, we discuss other elements of model evaluation relevant to this stage, including peer review and documentation of the model history. Chapter 5 discusses issues related to model selection.
Uncertainty Analysis at the Model Application Stage
At the model application stage, an uncertainty analysis examines a wide range of quantitative and qualitative factors that might cause a model’s output values to vary. Effective strategies for representing and communicating uncertainties are important at this stage. For many regulatory models, credibility is enhanced by acknowledging and characterizing important sources of uncertainty. For many, it is possible to quantify the effects of variability and uncertainty in input parameters on model predictions by using error propagation methods discussed below. They should not be confused with or used in place of a more comprehensive evaluation of uncertainties, including the consideration of model uncertainties and how decision makers might be informed by uncertainty analysis and use the results.
The Role of Probability in Communicating Uncertainty
Realistic assessment of uncertainty in model outputs is central to the proper use of models in decision making. Probability provides a useful framework for summarizing uncertainties and should be used as a matter of course to quantify the uncertainty in model outputs used to support regulatory decisions. A probabilistic uncertainty analysis may entail the basic task of propagating uncertainties in inputs to uncertainties in outputs (which would commonly, although perhaps ambiguously, be
called a Monte Carlo analysis). Bayesian analysis, in which one or more sources of information are explicitly used to update prior uncertainties through the use of Bayes’ theorem, is another approach for uncertainty analysis and is better, in principle, because it attempts to make use of all available information in a coherent fashion when computing the uncertainties of any model output. However, the committee considers the use of probability to quantify all uncertainties to be problematic. The committee disagrees with the notion that might be inferred from such statements as Gayer and Hahn’s (2005): “We think policy-makers should design regulations for controlling mercury emissions so that expected benefits exceed expected costs if that statement is interpreted to mean that large-scale analyses of complex environmental and human health effects should be reduced not only to a single probability distribution but also to a single number, the mean of the distribution.” Although it is hard to argue with the principle that regulations should do more good than harm, there are substantial problems in reducing the results of a large-scale study with many sources of uncertainty to a single number or even a single probability distribution. We contend that such an approach draws the line between the role of analysts and the role of policy makers in decision making at the wrong place. In particular, it may not be appropriate for analysts to attach probability distributions to critical quantities that are highly uncertain, especially if the uncertainty is itself difficult to assess. Further, the notion that reducing the results of a large-scale modeling analysis to a single number or distribution is at odds with one of the main themes that began this chapter, that models are tools for helping make decisions and are not meant as vehicles for producing decisions. In sounding a cautionary note about the difficulties of both carrying out and communicating the results of probabilistic uncertainty analyses, we are trying to avoid the outcome of having models (and a probabilistic uncertainty analysis is the output of a model) make decisions.
To see the difficulties that can result from this purely probabilistic approach to uncertainty analysis, consider the following EPA study that, in response to an OMB requirement, treated uncertainties probabilistically. In a study on emissions from nonroad diesel engines, one of the key parameters affecting the monetary value of possible regulations was the value assigned to a human life (EPA 2004b). A probability distribution for this parameter was obtained using the following approach. The 5th percentile of the value of a human life was set at $1 million, based on a study that had used this value as the 25th percentile. The 95th percen-
tile was set at $10 million, based on another study that had used this value as the 75th percentile. Then, using “best professional judgment” (see Table 9B-1 in EPA 2004b), a normal distribution was fit using the 5th and 95th percentile points, resulting in the mean value of a human life being $5.5 million. The numbers $1 and $10 million are rough approximations at least in part due to the decimal number system. Nevertheless, despite the arbitrary choice of highly rounded figures for the 5th and 95th percentiles, there is nothing preposterous about $5.5 million as an estimate of the value of a human life (although there is something disconcerting about the fact that this distribution assigns a probability of 0.0083 to the value of a human life being negative). However, the real problem here is not in the details of how this distribution was obtained, but that it was done with the goal of providing policy makers with a single distribution for the net benefit of a new regulation. Though the committee does not imply that such analysis arbitrarily assigns values, monetizing such things as a human life or visibility in the Grand Canyon clearly requires assessing what value some relevant population assigns to them. Thus, it is important to draw the distinction between uncertainties in such valuations and, say, uncertainty in how much lowering NOx emissions from automobiles will affect ozone levels at some location.
Another approach to uncertainty assessment is to calculate outcomes under a fixed number of plausible scenarios. If nothing in each scenario is treated as uncertain, then the outcomes will be fixed numbers. For example, one might consider scenarios with such names as highly optimistic, optimistic, neutral, pessimistic, or highly pessimistic. This approach makes no formal use of probability theory and can be simpler to present to stakeholders who are not fully versed in probability theory and practice. One advantage of the scenario approach is that many of those involved in modeling activities, including members of stakeholder groups and the public, may attach their own risk preference (such as risk seeking, risk adverse, or risk neutral) to such scenario descriptions. However, even using multiple scenarios ranging from highly optimistic to highly pessimistic will not necessarily ensure that such scenarios will bracket the true value.
In thinking about the use of probability in uncertainty analysis, it is not necessary or even desirable to consider only the extremes of representing all uncertainties by using probability or by not using probability at all. The assessment can have a hybrid approach using conditional distributions in which a small number of key parameters having large,
poorly characterized uncertainty are fixed at various plausible levels and then probabilities are used to describe all other sources of uncertainty.
To illustrate how conditional probability distributions can be used to describe the uncertainty in a cost-benefit analysis, consider the following highly idealized problem. Suppose the economic costs of a new regulation are known to be $5 billion with very little uncertainty. Furthermore, suppose that nearly all of the benefit of the regulation will be through lives saved. Thus, to assess the monetized benefits of the regulation, we need to know how many lives will be saved and what value to assign to each life. Suppose that, based on a thorough analysis of the available evidence, the uncertainty about the number of lives saved by the regulation has a median of 1,000 and follows the distribution shown in Figure 4-3a. Furthermore, as in EPA (2004b), assume that the value of a human life follows a distribution with $1 million as its 5th percentile and $10 million as its 95th percentile, but unlike the EPA study, we assume that this distribution follows what is known as a lognormal distribution (rather than a normal distribution), which has the merit of assigning no probability to a human life having a negative value.
This lognormal distribution is shown in Figure 4-3b. If we further make the natural assumption (see footnote) that the number of lives saved and the value of a human life can be treated as statistically independent quantities, then it follows that the distribution of the net benefits of the regulation is given by the distribution in Figure 4-4, which shows that the probability that the net benefit will be positive is slightly under one-fourth, and the expected net cost is approximately $630 million.1
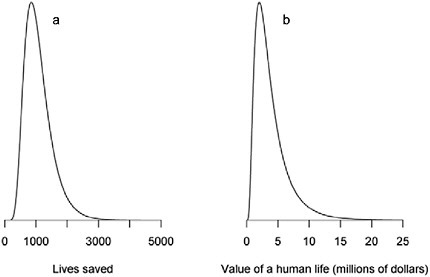
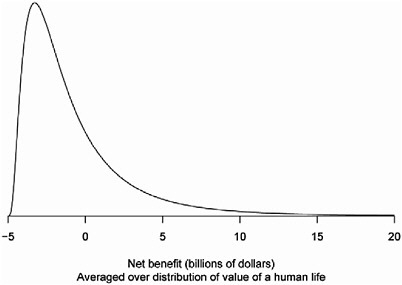
This conclusion is highly sensitive to the difficulty of quantifying the value of a human life. Instead of averaging over the distribution in Figure 4-3(b) for this value, cost-benefit analyses could give the distribution conditional on different values. For example, Figure 4-5 gives the conditional distribution of net benefits when the value of a human life is set at $1 million or $10 million (it also gives the unconditional distribution from Figure 4-4). It is now seen that if the value of a human life is set at $1 million, the probability that the regulation has a positive net benefit is essentially zero, whereas if the value of a human life is set at $10 million, the probability of a positive net benefit is large (about 0.96), the expected net benefit being over $5.8 billion.
We contend that Figure 4-5 is a clear and important improvement of Figure 4-4. Free software providing more sophisticated tools for visualizing conditional distributions is available, for example, in the lattice library for R (Murrell, 2006), or if interactive graphics are desirable, the program XGobi (Swayne et al. 2002) is available. Interactive graphics would allow the policy maker to choose values of one or more key parameters and then view the conditional distribution of the net benefit given these parameters. However, interactive computer programs are no substitute for human interaction, and the committee strongly encourages extensive interaction between scientists and policy makers when policy makers can ask various “what if” questions to help in their decision making.
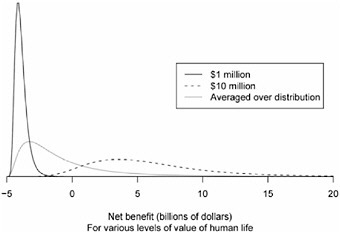
FIGURE 4-5 Conditional distributions of net benefit assuming different amounts for the value of a statistical life.
To use this hybrid approach to uncertainty analysis, the user will have to decide which uncertainties to average over (treat probabilistically) and which to condition on (consider some set of fixed values). Although there cannot and should not be hard and fast rules on this matter, the committee can offer some guidance. As already noted, quantities with large and poorly characterized uncertainties are prime candidates for conditioning. Value judgments, such as the worth of a human life or of high visibility at the Grand Canyon, may often fall into this category. Uncertainties about model choice are another example of an uncertainty that should not be addressed using an expected value. For example, in extrapolating animal studies of toxicity at relatively high doses to much lower doses in humans, conclusions may differ by large factors, depending on the assumptions made. Rather than attempt, via a Bayesian calculation, to average over a host of models that all fit the data about equally well but result in different conclusions about low-dose human toxicity, it may be better to give several possible conclusions under varying assumptions on how to extrapolate across species and doses.
In providing this guidance, it is not the committee’s intent to dismiss the considerable amount of work done on monetization of value judgments, nor the work on Bayesian model averaging (Hoeting et al. 1999). The committee is asserting, however, that policy makers should be informed of the impacts of changing assumptions about highly uncertain parameters on an analysis, and the impacts should not be buried in a technical analysis.
In addition to the plots of conditional distributions, other summaries of the uncertainty analysis should be given to decision makers. For example, distributions of quantities other than net benefit, such as those given in Figure 4-3, should be routinely included in the analysis.
Because most probabilistic uncertainty analyses, whether or not explicitly Bayesian, now would calculate distributions of outcomes of interest by using simulations, another approach to conveying the results of an uncertainty analysis would be to provide “typical” sample points from the simulation. For example, terms such as “optimistic” and “neutral” could be defined in terms of percentiles of the outcome distribution. To be specific, suppose “highly pessimistic” means the 5th percentile of the distribution of net benefits, “pessimistic” the 25th percentile, “neutral” the median, “optimistic” the 75th percentile, and “highly optimistic” the 95th percentile. The user could then present a table of key inputs (or intermediate outputs) for the sample points at those percentiles in the simulated distribution of net benefits. Alternatively, summaries of the distri-
butions of key inputs for various ranges of the net-benefit distribution could be used. In effect, the distributions would be conditional of the inputs given the net benefits rather than of the net benefits given certain inputs, as suggested above.
It might be argued that providing multiple summaries that include a combination of conditional distributions, typical sample points, and distributions of intermediate outputs will be too much information for policy makers. However, interviews conducted with former EPA decision makers on the use of uncertainty analysis in regulatory decision making do not support this pessimistic assessment of the quantitative literacy of environmental policy makers (Krupnick et al. 2006). If the uncertainty assessment is clearly presented, with succinct summaries of the major sources of uncertainty and their impacts on the conclusions (including a list of any potential nontrivial sources of uncertainty that were not taken into account), the committee considers that such an uncertainty analysis will help empower decision makers and improve the decision-making process, especially if decision makers are included interactively in the process of putting together the summaries of uncertainty.
Evaluation of Statistical Models
As discussed in various places throughout this report, statistical models often might involve the use of flexible regression models, for instance, using polynomials or splines to characterize the relationship between an exposure and a response of interest. Statistical models are widely used to analyze epidemiological data. Important considerations are adjusting for confounders, handling missing data, accounting for study design, and so forth; therefore, assessing the adequacy of statistical models may involve a complex set of considerations quite distinct from many of the other modeling settings discussed elsewhere in this chapter. Whereas assessing the adequacy of a process-based model, such as a mass-balance model for indoor air pollution, relies on general theory, epidemiological models tend to be specialized and tailored to the specific context at hand and cannot be assessed in the abstract. In contrast to many process-based models, technical aspects of epidemiological models may be simple—for example, relying on simple linear or logistic regression models. For such models, the model development and model application stages are the same.
The challenge, however, is in making sure that all the appropriate information has been incorporated in an adequate manner. For example, has the study design been appropriately reflected in the analysis? If the study population represents a probability-based sample, then it may be important to include sampling weights in the analysis before generalizing results to the full population. Data quality is another important consideration. For instance, if exposure assessment is subject to measurement error, it may be important to adjust for that to avoid bias associated with the error. A critical issue concerns whether the appropriate covariates have been identified so that potential confounding can be tested for and adjusted for. Missing data are an inevitable challenge in even the most well-run epidemiological study, so it is important to assess the impact of missing data, from the loss through the follow-up, to ensure that the analysis is not subject to bias. From a more technical perspective, it is important to ask whether the modeling assumptions are appropriate and whether the chosen model fits the observed data reasonably well. This question might involve assessment of the appropriateness of any linearity assumptions (testing for outliers, for example) and might be assessed by looking at residuals and applying goodness-of-fit tests. Were the appropriate steps taken to identify all the appropriate confounders? Was the method of covariate selection documented? Were covariates incorporated into the model in an appropriate way? If covariates are measured on a continuum, were nonlinearities tested for? Equally important is the question of how the primary exposure of interest was included in the dose-response model. Good model assessment and exploration include considerations of alternatives to the shape of the dose-response curve, exploration of possible lag effects, and so forth. Sensitivity analysis in general is a powerful and highly recommended strategy for ensuring that results are not driven by one or two key assumptions. Finally, it is important to be sure that the statistical software being used is numerically stable and reliable.
There is much literature on residuals analysis and goodness-of fit-analysis for statistical models, and there are a number of popular approaches. One technical concern to be aware of is that caution is needed when assessing model adequacy and goodness of fit using the same data as those used as the basis for fitting the model. There are a number of ways to address this concern. The Akaike information criterion (AIC) and the Bayesian information criterion (BIC) correspond to the estimated log-likelihood plus an additional penalty term that reflects the number of parameters in the model. Both AIC and BIC approaches are popular for
assessing goodness of fit and represent the differences between frequentist and Bayesian statistical methods. Formal Bayesian approaches are also possible, of course, in which case examination of posterior and predictive distributions play an important role in model assessment. Ideally, models would be checked against new, independent data. However, this is not always possible.
MANAGEMENT OF THE EVALUATION PROCESS
This section addresses practices for managing the evaluation process. The life cycle of a model can be complex for any single model and immensely difficult when the full range of EPA regulatory models are considered. Thus, the committee offers overarching principles for management of the evaluation process. At its core, the committee sees the need for a strategy for model evaluation (a model evaluation plan) and a description of the model’s historical development, use, and evaluation to follow a model throughout its life stages. This recommendation is not intended to be a bureaucratic exercise that relies on extensive documentation. Some model evaluation plans and histories for simple models may be limited. The goal to achieve is a substantive commitment from the agency to ensure that model evaluation continues throughout a model’s life. This goal raises the organizational question of accountability and responsibility for such efforts. The committee does not presume to make organizational recommendations, nor does it recommend the level of effort that should be expended on any particular type of evaluation. Because of the great diversity of models, no single approach is likely to be viable. However, EPA needs some mechanism that audits the process to make sure that (1) there is a life-cycle model evaluation plan, (2) there are resources to carry out the evaluation and pay the true costs, (3) the EPA modelers respond to peer reviews, and (3) they follow through in both completing the actions requested in the peer review and in continuing the peer review process. The crucial element is that the process should be a means to an end, namely, a model fit for its purpose and not an end in itself.
The Use of Model Evaluation to Establish Model Acceptability Criteria
The committee discussed the merits of providing a uniform set
of scientific and technical acceptability criteria applicable to all regulatory models. It became clear that the range of model types and model applications at a regulatory agency such as EPA will not work under an over-arching set of acceptability criteria except for the requirement that each model be based on methods, science, and assumptions that the agency accepts as appropriate. The committee found that no one had yet established such criteria, although work on this topic by the Netherlands National Institute for Public Health and the Environment (RIVM) has been done and is described at the end of this section. Even if such criteria were available, they might well not be applicable to the many and varied settings of EPA’s use of models. In addition, there is an intangible policy context to any choice about the acceptability of a model for a given regulatory setting. Resources, public and stakeholder buy-ins, and other factors can play a role. Regulations are never tied to model capabilities, so there is often an imperfect correlation between model capabilities and regulatory needs.
Acknowledging that this area is a matter for further substantial research, the committee considered what combination of scientific and technical factors and process steps should be considered in developing model acceptability and application criteria. The factors are the following:
-
Scientific pedigree
-
Model structure and components
-
Model capabilities and limitations
-
Inputs and outputs
-
Applicable space and time scales
-
Applicable substances
-
Key sensitivities and uncertainties
-
Model performance evaluation
-
Parsimony
-
Peer review
The committee notes that information on these factors should arise from the model evaluation process, it forming the basis for setting acceptability and applicability criteria for specific models and specific model applications. How the above factors are addressed in the model evaluation plan will vary among different model types. The committee envisions that the acceptability and applicability criteria be presented either within the model evaluation plan or in a separate document on the
basis of information provided about the factors. We consider below explicit examples of what several of these factors mean and how they relate to acceptability and applicability.
Scientific Pedigree. “Scientific pedigree” is a shorthand term for considering the fundamental science that forms the basis of the conceptual model. The scientific pedigree considers the origin and the quality of the concepts and theories behind the model and each of its constituent parts (Funtowicz and Ravetz 1990). Over the years, the fundamental scientific and other understandings that are used in constructing models have been consolidated and refined to produce—at maturity—a product with a pedigree. The merit in the scientific pedigree concept is that it is applicable, in principle, at various levels, from assessments of an integrated suite of models to its major subblocks (such as atmospheric chemistry and human toxicology) and down to the details of the parameters characterizing the mathematical expression of individual processes.
Model Structure and Components. Those who evaluate the acceptability of a model for a given purpose should see a diagram and brief description of the major components of the model. At one extreme, a model may have multiple models (such as source, transport, exposure, dose, risk, and uncertainty models) linked by managing software. Here, a diagram and a summary of structure and components are essential for judging acceptability and applicability. For example, if an atmospheric transport model is linked to a soil model and a surface-water model, it is important to know how the intermedia transfers from air to soil and air to water are managed, that is, in one or two directions. This information could determine acceptability for specific classes of pollutants. Another example is a one-box pond model that is applicable and acceptable for representing a small surface-water body but might not be applicable and acceptable for representing one of the Great Lakes, where there are potentially distinct subregions within the water body. A third example is regional mass-balance models designed to capture the chemical mass balance for aggregated sources over a large space and time scales but are not designed to capture detailed source-receptor relationships.
Model Capabilities and Limitations. The model evaluation plan should clearly distinguish the capabilities and limitations of a model. For example it will usually be important to identify whether a transport model can handle organic chemicals, inorganic chemicals, or microorganisms; whether an economic impact model is macro or micro in its level of resolution; or whether an exposure model works for the short term (minutes to hours) or the long term (days to years). Another exam-
ple is when an air dispersion model is used to assess how pollutant emissions translate to concentrations downwind from a source. This type of model is acceptable for modeling the transport of stack emissions but may not be acceptable for modeling such conditions as pesticide drift from field applications or for estimating exposure when the receptor population is indoors or moving in ways that are not captured in the model. Among the issues that should be covered in a statement of capabilities and limitations are the inputs required to run the model, the outputs provided by the model, the space and time scales for which the model applies, the types of substances that the model can address, and a discussion of key sensitivities and uncertainties.
Model Performance Evaluation. It is difficult to imagine that a model is acceptable for a regulatory application without some level of performance evaluation showing that the model matches field observations or at least that its results match the results of another well-established model. Acceptability will to some extent be proportional to the level of performance evaluation. Ideally but rarely, a model will be corroborated using one or more independent sets of field data similarly matched to the model’s operating domain. Model-to-model comparisons are useful adjuncts to corroboration and in some cases may be sufficient to establish acceptability in the absence of any relevant field data for model comparison.
Parsimony. In light of its recommendation on parsimony, the committee notes that acceptability and applicability decisions need information about parsimony. For those who must select an appropriate model, it is important to know if and how the model developers addressed the issue of parsimony. In particular, did they start with a high level of detail and reduce detail so long as it had no impact on the model or start with a simple model and add detail to meet performance criteria for “validation” and calibration? What type of sensitivity analysis was used to make this determination? There is also substantial literature in related fields that bears on the issue of how much precision or accuracy is needed to inform regulatory decisions. In law, this literature is referred to as the “optimal precision” literature (e.g., Diver 1983). In economics and risk assessment, the issue is referred to as the “value of information” or VOI approach (Finkel and Evans 1987). In terms of VOI, the choice to make models more detailed depends on the degree to which the more elaborate models are judged likely to improve policy outcomes and on the costs of developing and transitioning to more detailed models. In the committee’s
view, this choice should also include the impact of any loss of transparency.
Peer Review. In most cases, peer review is essential for acceptability, but the level of peer review depends on the nature of the model and its application. Peer review is also useful for providing details on model applicability. The peer review process can also be used to gather information on other factors discussed here to make a determination of model acceptability and applicability.
As a final point, the model evaluation plan created when the model was developed or the peer review process should provide some statement about when an accepted model is no longer acceptable or in need of updates. Some examples of events that make models no longer acceptable are (1) the model has been shown to produce erroneous results (false positives or false negatives) in important regulatory applications; (2) alternative approaches with higher reliability are available and can be developed without unreasonable costs, including transition costs; and (3) key inputs required by the model are found to be incorrect or out of date—for example, demographic data that are 30 years old and no longer updated.
An example of a systematic approach to scientific and technical acceptability criteria for scientific assessments, including those based on environmental modeling, is shown in the activities of the RIVM Environmental Assessment Agency (RIVM/MNP) in its “Guidance for Uncertainty Assessment and Communication” (van der Sluijs et al. 2003). RIVM/MNP’s guidance extends beyond the quantitative assessment of uncertainties in model results to focus on the entire process of environmental assessment. The guidance is composed of a series of interrelated tools, including a mini-checklist and a Quickscan questionnaire that asks analysts in a concise set of questions to reflect explicitly on how the assessment deals with issues related to problem framing, stakeholder participation, selection of indicators, appraisal of the knowledge base, mapping and assessment of relevant uncertainties, and reporting of the uncertainty information (Janssen et al. 2005). Other tools available include a detailed guidance document and a tool catalogue for uncertainty assessment (van der Sluijs et al. 2003, 2004). Underlying the checklist is the philosophy that there is no single metric for assessing model performance, there is no typically “correct” model, and models need to be assessed in relation to particular functions. This philosophy echoes this report’s discussion of models as tools. The checklist offers modelers a systematic self-evaluation that should provide some guidance on how the
modelers are developing the model. It should also help to determine where and why problems may occur (Risbey et al. 2005).
Developing a Model Evaluation Plan
As discussed earlier in this chapter, model evaluation is a multifaceted activity involving peer review, corroboration of results with data and other information, QA/QC checks, uncertainty and sensitivity analyses, and other activities. Viewed in this way, model evaluation is not a one-time event. Even when a model has been thoroughly evaluated and peer reviewed, new scientific findings may raise new questions about model quality, or new applications may not have been anticipated when the model was originally developed. Further, no two model evaluation plan will be alike. A plan should focus on the bigger picture—that model evaluation is intended to address the appropriateness of a given model for a given application and aid in a model’s improvement. This plan and the resources devoted to model evaluation should be commensurate with the scope, detail, and regulatory impacts of the model (for example, the scientific complexity, a new application of an existing model, and the likelihood of an application’s influence). This plan might evolve with time and experience, especially for long-lived models.
Such a plan could help address a critical shortcoming with regulatory model evaluation. A random sampling of the models listed in the CREM model database shows that most EPA models provide only limited information on model evaluation, and almost none of the models provide a model evaluation plan. Thus, there is typically no consideration of how long-term model evaluation will occur throughout a model life stages. Under the heading “Model Evaluation” in the CREM database, most models present individual statements, such as
-
“Currently undergoing beta-testing and model evaluation….”
-
“Code verification, sensitivity analysis, and qualitative and quantitative uncertainty analysis have been performed. The model has been internally and externally peer reviewed.”
-
“The program and user’s manual were internally peer reviewed.”
-
“The model and user’s manual were externally peer reviewed by outside peer reviewers and beta testers. The comments from these testers were reviewed by EPA’s Office of Research and Development….”
Some models have been subjected to more extensive model evaluation exercises, and at least one has followed through on a model evaluation plan. To gain some insight on how to develop and carry out a model evaluation plan, we consider two examples of models with implicit and explicit model evaluation plans—CMAQ and TRIM.FaTE. CMAQ, the community multiscale air quality modeling system, which is discussed in previous chapters, has been designed to approach air quality in an integrated fashion by including state-of-the-science capabilities for modeling multiple air quality issues, including tropospheric ozone, fine particles, toxics, acid deposition, and visibility degradation. TRIM.FaTE is a spatially explicit, compartmental mass-balance model that describes the movement and transformation of pollutants over time through a user-defined, bounded system that includes biotic and abiotic compartments (EPA 2003g). The extensive documentation on CMAQ includes discussions on the need for and approaches to model evaluation. For example, at one CMAQ workshop, Gilliland (2003) outlined the elements of the CMAQ model evaluation plan. However, the CMAQ web site and CMAQ documentation does not demonstrate an overall evaluation plan. Although it is clear that a number of model evaluations are performed with CMAQ, they typically seem to be directed toward a single aspect or application of the model. It is difficult to see how the plan’s activities were conceived, conducted, and fit into an overall scheme. In contrast to CMAQ (and most other EPA models), the TRIM.FaTE model project includes an explicit model evaluation plan in its initial documentation and in follow-up reports on its website (EPA 2006k). The plan identifies the goals and elements of the model evaluation, including conceptual model evaluation, mechanistic model evaluation, data quality evaluation, structural evaluation, and overall performance evaluation. For each of those elements, the model developers provide details on planned activities and the results of activities that have been carried out. The developers follow up with subsequent model evaluation reports that provide results from each of the elements. For the committee, the TRIM.FaTE model evaluation plan and its execution provides a useful example for how to prepare, conduct, and communicate a model evaluation plan for a model of this complexity and scope. It represents a base-case approach to the type of evaluation plan contemplated in this report. Box 4-5 discusses an additional example of life-cycle evaluation for models assessing the persistence and long-range transport of organic chemicals.
|
BOX 4-5 Life-Cycle Evaluation of Models for Assessing Persistence and Long-Range Transport Potential As discussed in the text, the EPA model TRIM.FaTE and the model CMAQ are examples of models that have been subjected to more extensive model evaluation exercises that were initiated early in the model development and continue through to the model dissemination stage. Another example that shows the value in evaluating a model from conceptual through use stages is the work of the Organization for Economic Cooperation and Development (OECD 2004) to develop a screening model for assessing the persistence and long-range transport potential of chemicals. The goal of this effort was a consensus model that was evaluated against a broad set of available models and data. The evaluation process began at a workshop in 2001 where the model performance and evaluation goals were set before model selection and development began (OECD 2002). To act upon the recommendations, an OECD expert group was established in 2002. This group published a guidance document on the use of multimedia models for estimating environmental persistence and long-range transport. From 2003 to 2004, the expert group performed an extensive comparison of nine available multimedia fate and transport models to compare and assess their performance (Fenner et al. 2005; Klasmeier et al. 2006). Following this effort, the expert group developed a parsimonious consensus model representing the minimum set of key model components identified in the model comparison. The expert group then convened three international workshops to disseminate this consensus model and provide an on-going model evaluation forum (Scheringer et al. 2006). In this example, significant effort was invested (more than half of the total effort in the OECD case) in the conceptual and model formulation stages. Moreover, much of this effort focused on performance evaluation. The committee recognizes that each model’s life cycle is different but notes that attention should be given to developing consensus-based approaches in the model concept and formulation stages. Conducting concurrent evaluations at these stages in this setting resulted in a high degree of buy-in from the various modeling groups. |
The committee recognizes the burden that could be placed on model developers to conceive and audit a model evaluation plan. However, the evaluation plan does not have to be a lengthy report. For simple models, it can be a page or two. The following are key elements of the model evaluation plan:
-
An evaluation plan for the life cycle of the model that is commensurate with the nature of the model (for example, scientific complexity, new model or application of an existing model, the likelihood of an application’s being influential).
-
Describe the model (in general) and explain its intended uses.
-
Use a thematic structure or diagram to summarize all the elements of the evaluation plan—in particular, the elements that will be used in different stages of model development and application (elements such as the conceptual model, data, model testing, and model application).
-
Discuss the events that could trigger a need for major model revisions or that make the model obsolete. This discussion should be specific to the model in question and could be fairly broad and qualitative, such as discussing new science that makes a current model outdated, new regulations, and substantial errors uncovered. The plan should provide criteria to differentiate the need to make a revision of substance rather than to expend resources unnecessarily on continual minor changes. The list of events triggering the need for a major model revision or that might render a model obsolete should itself be periodically updated.
-
Specifically identify responsibilities, accountabilities, and resources (for example, staff time, consultant time, and funding) needed to accomplish elements of the plan.
Model History
Models can be developed and applied over many years. During this time, a large number of people could be involved in various aspects of a model’s development, evaluation, and application. Many of these people may contribute to or have a specific interest in relatively few elements of this process. This life history of the model can be lost if experiences with a model are not documented and archived. Without an adequate record, a model may be applied incorrectly, or activities may be undertaken that are repetitive or ignorant of earlier efforts. For example, an expert peer reviewer of a model application needs to understand the full history of the model’s evaluation. Has another reviewer evaluated the mathematical algorithms in the original development phase? Has another expert determined that the databases used to develop the model are appropriate? What is the range of environmental parameters for which the model is
reasonably accurate and does the new application fall within those parameters? Thus, keeping such a model’s history is essential for effective model use. Maintaining a history of significant events regarding the model and a documentation of the model history would support transparency objectives and help modelers use and improve a model long after the original developers are gone and the verbal history is lost. Such a history could include the purpose of the model, major assumptions and modifications, and the history of its use and evaluation.
Peer Review
Peer review is the time-honored way to improve the quality of a scientific product. Experts in the field are the only ones with the capabilities of evaluating highly technical material. Even then, experts may require additional analyses or material to perform a rigorous review. Also, a peer review is only useful if the reviewers’ comments are considered and used appropriately to revise the model. The regulatory environment model setting also makes peer review fundamentally different from the review of other scientific products that do not have regulatory applications (Jasanoff 1990, 2004). These complexities are key reasons why a model evaluation plan and why a record of the model’s life history are needed.
The tradition of one-time peer review for models is essential but not sufficient. Having knowledgeable peers review the conceptual model could help to identify important issues related to transparency, such as how to explain the model and how to present the results, and whether the scope and impacts considered within the conceptual model are consistent with the regulatory problem at hand. It also could be helpful for models with large regulatory impacts or complex scientific issues to have a periodic peer review or peer advisory process in which the peers interact with the model developers and users throughout the model’s life. As noted in EPA’s most recent version of its peer review guidance, the agency is beginning to appreciate that obtaining peer review earlier in the development of scientific products might be desirable (EPA 2006a). The agency is also recognizing that multiple peer review events also might be useful, particularly when the work product involves complex tasks, has decision branching points, or is expected to produce controversial findings (EPA 2006a).
Although OMB encourages agencies to have peer reviewers run the models and examine the computer code (Schwab 2004), resources provided to reviewers are usually limited, and individual reviewers typically cannot do extensive testing or code verification. However, adequate peer review of a model may involve reviewers running the model results against known test cases, reviewing the model code, and running the model for an array of problems. It also may demand particular attention to the intended applications of a model, because a model that is well-suited for one purpose at one time may not be appropriate for another purpose at that time or the same purpose at a different time.
A peer review is so basic to model quality and its acceptance that it must be excellent in substance, as well as appearance. Therefore, careful attention must be given to the three foundations of selecting peer reviewers: scientific qualifications, conflicts of interest, and balance of bias. These issues are explained in some detail by EPA (2006a). All reviewers must be, without exception, scientific peers. They should be free of conflicts of interest (for example, the result of the review should not have a direct and predictable impact on the finances of the reviewer), and if that is not possible on rare occasions, they should be publicly justified and explicitly permitted by appropriate agency authorities. After the first two requirements for selecting peer reviewers are met, the peer review committee biases must be balanced. Biases cannot be eliminated because they are based on the experts’ perspectives, but a peer review committee should not be biased in any given direction. Finally, a high-quality peer review is the result of EPA’s commitment to the overall model evaluation process. More attention should be paid to providing sufficient time and material to the peer reviewers to enable them to fulfill a well-developed charge.
Adequate peer review of a model, especially a very complex model or a model that has a substantial impact on environmental regulations, may involve reviewers running the model results against known test cases, reviewing the model code, and running the model for an array of problems. It is unreasonable to expect such peer reviews to be done without compensation. To obtain such an in-depth peer review, the committee sees the need for support in the form of compensation and perhaps in running the model for conditions that the reviewers specify. The committee considers such peer review to be part of the cost of building and using models, especially models with a large impact on regulatory activities.
Stakeholder Review
Seeking involvement of stakeholders is sometimes seen as merely a legal requirement, which it often is, but a more flexible attitude may take greater advantage of this required process. Fundamentally, stakeholder review helps addresses the social, legal, financial, and political contexts of the designated task. Stakeholders may have information or perspectives that can help guide the process. All of those legitimately holding a stake in the outcome of the process of evaluation will not share the same formulation of the policy problem; nor, given widely differing attitudes toward risk, will they all come to the same conclusion or judgment, even under an identical formulation. The groups involved in the environmental regulatory process can be risk takers, risk averse, and risk managing, to name but three classes of perspective (Thompson 1989). They can be knowledgeable in a classic scientific sense, such as when an affected party has or hires experts, or in a realistic sense, such as when members of the public identify an exposure pathway that was not identified by the experts. These various groups can participate in the model evaluation process through various activities, including producing their own supporting or conflicting model results and challenging the legitimacy or accuracy of a model in public comments or judicial actions. However, to engage stakeholders fully in model evaluation, decision makers must understand the financial, legal, and political risks attached to the outcomes of the regulatory activities (for which the model has been designed); the cultural attitudes of the various stakeholders toward those risks; the ways that stakeholders might use to manipulate the task context; and the extent to which various stakeholders trust the process of model evaluation. Although the committee recognizes that encouraging stakeholder participation adds to the complexity of model evaluation, their involvement may result in a more transparent or more robust model.
Vigorously involving the general public is possible, as demonstrated in agency modeling activities that are site-specific. In designing cleanup plans for Superfund sites, for example, EPA not only must solicit the community’s input but also must often convene multiple interviews and educational meetings to provide the community with a sufficient opportunity to respond to agency risk assessments and cleanup proposals (for example, see National Contingency Plan, 40 CFR §
300.430[c])2 given the local impacts of these model-based regulatory decisions, the general public can invest considerable resources in overseeing the quality of EPA’s cleanup models and can even obtain grants to hire technical experts to review EPA’s technical assessments (40 CFR, Part 35, Subpart M [Technical Assistance Grants]). Even though the mandatory public participation requirements are relatively similar for diffuse, national issues, the level of involvement by the general public can increase dramatically as the agency’s decisions become localized and specific to a particular community.
The special needs of stakeholders should to be considered. Time for review can be a barrier. As mentioned above, stakeholders can have perspectives useful to those involved in the model evaluation process, but they must have time to develop such comments and transmit them to the peer reviewers to be effective. Special attention must be paid to involve stakeholders because most are not technically expert. Some groups may have the scientific staff or the budget to hire consultants to perform model review and often do so from their own perspectives. In contrast, other smaller organizations (for example, small businesses and small environmental advocacy groups) and the general public do not have the resources to comment on regulatory actions that may have a substantial impact on them. Such organizations and individuals must rely on the process to inform them and make recommendations that will protect their interests. However, these processes are typically not at all clear to these individuals and groups.
Thus, buy-in by some stakeholders and the general public may be based on trust of the model evaluation process rather than on the results of the process. Making progress in achieving meaningful peer review of science and models pertaining to regulation may depend more on having stakeholders agree in advance on appropriate methods and evaluation protocols than on subsequent (conventional) scientific peer review. Establishing and demonstrating the reliability and credibility of the peer review process itself is every bit as crucial as the conventional challenge of establishing the reliability and credibility of the information. Dealing effectively with stakeholders and the general public can have collateral benefits. Process transparency may enhance buy-in by stakeholders and the general public, especially if the regulation affects their behaviors, and later by the courts, if challenges are brought against a regulation.
Learning from Prior Experiences—Retrospective Analyses of Models
The final issue in managing the model evaluation process is management of the learning that is developed through the examination of prior modeling experiences. Retrospective analysis of models is important for developing improvements to individual models and regulatory policies as well as systematically enhancing the overall modeling field. There have been many examples of retrospective analysis of particular environmental modeling activities. Box 4-6 describes three such examples. However, even with the widespread use of models at EPA, there has been little attempt to generalize prior experiences with models and classes of models into systematic improvements for the future. One reason may be the reluctance by the agency to disclose errors, criticisms, and shortcomings in the adversarial and legally constrained setting that environmental regulatory modeling activities often occur. The discussion of groundwater model retrospective analysis of Bredehoeft (2003, 2005) demonstrates that generalizing prior experiences with models does not necessarily imply the commitment of a great deal of modeling resources but possibly does imply the use of the experiences of veteran modelers to provide insights.
The committee has considered the value of retrospective studies as a critical part of model evaluation from two primary perspectives. The first perspective is broad. It concerns the retrospective evaluation of classes of models—for example, models of groundwater flow, surface water, air pollution, and health risks assessment. The goal of such an approach would be to investigate whether there are systematic weaknesses that are characteristic of various types of models. For example, based on modeling experiences in his past work and work described by other hydrogeologists, Bredehoeft (2003, 2005) estimated that in 20-30% of groundwater modeling efforts, surprising occurrences indicated that the conceptual models underlying the computer models were invalid.
The second perspective is somewhat narrower. If a specific model is being used for several years for high impact issues, its performance for its intended use should be questioned. For such cases, data are probably available for retrospective analyses that were not available at the time of model construction. In addition to data that have been collected over time, other data that are critical to model evaluation may be identified
and collected specifically to address the question, “how well does the model work?”
With respect to the question of how well different classes of models work, it would be useful to know whether different classes of models have common weaknesses. As noted, Bredehoeft’s work suggests that groundwater models are subject to surprises that show their underlying conceptual models to be invalid. Bredehoeft reported that one suggestion arising from that observation is to carry alternative conceptual models
|
BOX 4-6 Retrospective Analysis of Model Predictions Retrospective analysis of environmental regulatory models often occurs when particular model predictions are later compared to measurements or results from other models. Examples include comparisons of estimates of regional light-duty-vehicle emissions and the effectiveness of emission-control policies with those predicted by the MOBILE model, an assessment of an air quality model’s ability to simulate the change in pollutant concentrations associated with a known change in emissions, and comparisons of groundwater conditions and containment transport with those predicted by groundwater models. Light-duty-vehicle emissions inventories are important for a wide range of air quality management activities, including serving as inputs to air quality models as well as direct indicators of the performance of emissions control policies. For regulatory activities outside of California, the MOBILE model is used for regulatory purposes. Methods that have been used for retrospective assessments of MOBILE’s vehicle emission estimates include remote sensing of vehicle exhaust emissions, direct emissions measurement at vehicle emissions inspection and maintenance (I/M) stations and other facilities; the use of fuel sales to model emissions; and measured concentrations of air pollutions, both in ambient air or in tunnels, to infer emissions (e.g., Stedman 1989; Fugita et al. 1992; Gertler et al. 1997; Singer and Harley 2000; Watson et al. 2001; NARSTO 2004). A recent NARSTO report on emissions inventories found significant improvements over the past decade in the correspondence of model predictions and observations of on-road emissions inventories, but with significant shortcomings remaining (NARSTO 2005). One particular issue related to MOBILE’s estimates of control program effectiveness that has gathered much interest is the comparison of modeled estimates of the benefits of I/M programs in reducing emissions to those estimated through remote sensing and other techniques (Lawson 1993; Stedman et al. 1997; Air Improvement Resources 1999; CARB 2000a; Wenzel 2001). An NRC study of I/M programs concluded that an earlier version of the MOBILE model overestimated emissions benefits (MOBILE5), though the most recent version of the model (MOBILE6) has reduced estimated I/M benefits (NRC 2001a; Holmes and Cicerone 2002). EPA’s Model Evaluation and Applications Research Branch is currently performing a retrospective analysis of the CMAQ model’s ability to simulate the change in a pollutant associated with a known change in emissions (A. Gilliland, EPA, personal commun., May 19, 2006, and March 5, 2007). This study, which |
|
EPA terms a “dynamic evaluation” study, focuses on a rule issues by EPA in 1998 that required 22 states and the District of Columbia to submit State Implementation Plans providing NOx emission reductions to mitigate ozone transport in the eastern United States. This rule, know as the NOx SIP Call, requires emission reductions from the utility sector and large industrial boilers in the eastern and midwestern United States by 2004. Since theses sources are equipped with continuous emission monitor systems, the NOx SIP call represents a special opportunity to directly measure the emission changes and incorporate them into model simulations with reasonable confidence. Air quality model simulations were developed for summers 2002 and 2004 using the CMAQ model, and the resulting ozone predictions were compared to observed ozone concentrations. Two series of CMAQ simulations have been developed to test two different chemical mechanisms in CMAQ to consider model uncertainty that is associated with the representation of chemistry in the model. Given that regulatory applications use the model’s prediction of the relative change in pollutant concentrations, dynamic evaluations such as these are particularly relevant to the way the model is used. Groundwater models are critical for regulatory applications, such as assessing containment transport from hazardous waste sites and assessing the long-term performance assessments of high level nuclear waste disposal sites. Bredehoeft (2003, 2005) summarizes a series of post-hoc studies where later observations were used to evaluate how well earlier groundwater modeling did in predicting future conditions. Besides errors in conceptual models of the system, which are discussed in the body of this report, Bredehoeft identified insufficient observations for specifying input parameters and boundary conditions as another critical reason why model predictions did not match observations. An additional issue cited was that, in some instances, the assumed environmental management actions that were modeled ended up to be very different from the actual actions taken. It is important to note that, while the number of studies discussed in Bredehoeft (2003, 2005) was extensive, the modeling resources involved was not. Instead, the insights were developed by having an experienced modeler look across a number of applications for overarching conclusions. This observation is important when considering the resource needs and scope of retrospective analysis. |
into an analysis. In his experience, Bredehoeft noted that alternatives are not carried into analysis. However, such an approach has been applied in the health risk assessment area. Distinctly different conceptual models for health risks from sulfur oxides in air were discussed in several papers by Morgan and colleagues (Morgan et al. 1978, 1984). These papers described alternative conceptualizations of the health risks that are incompatible with each other but that, at the time of the analyses, were supported by some data.
In his 2003 paper, Bredehoeft described the following difficulties with conceptual models:
-
Modelers tend to regard their conceptual models as immutable.
-
Time and again errors in prediction revolve around a poor choice of the conceptual model.
-
More often than not, data will fit more than one conceptual model equally well.
-
Good calibration of a model does not ensure a correct conceptual model.
-
Probabilistic sampling of the parameter sets does not compensate for uncertainties in the appropriate conceptual models or for wrong or incomplete models.
The point of this list is that models with conceptual problems cannot be improved by enhanced efforts at calibration or management of uncertainties. The best chance for identifying and correcting conceptual errors is through an ongoing evaluation of the model against data, especially data taken under novel conditions.
The question that should be explored is whether other classes of models share a common weakness. For example, as a class, what weaknesses would be identified by an evaluation of air dispersion, transport and atmospheric chemistry models, or structure-activity relationships? Identifying systemic weaknesses would focus the attention on the most productive priorities for improvement. With a long-term perspective, there will be cases in which it is possible to compare model results with data that were not available when the models were built.
A key benefit of retrospective evaluations of models of individual models and of model classes is the identification of priorities for improving models. Efforts to add processes and features of diminishing importance to current models may be of much lower benefit than revisions based on priorities derived from retrospective analyses. The committee did not identify a solid technical basis for deciding whether specific models should be revised other than to address the perception that a specific model was incomplete.
RECOMMENDATIONS
The committee offers several recommendations based on the discussion in this chapter. They deal with life-cycle model evaluation, peer review, uncertainty analysis, retrospective analysis, and managing the model evaluation process.
Life-Cycle Model Evaluation
Models begin their life cycle with the identification of a need and the development of a conceptual approach, and proceed through building of a computational model and subsequent applications. Models also can evolve through multiple versions that reflect new scientific findings, acquisition of data, and improved algorithms. Model evaluation is the process of deciding whether and when a model is suitable for its intended purpose. This process is not a strict verification procedure but is one that builds confidence in model applications and increases the understanding of model strengths and limitations. Model evaluation is a multifaceted activity involving peer review, corroboration of results with data and other information, quality assurance and quality control checks, uncertainty and sensitivity analyses, and other activities. Even when a model has been thoroughly evaluated, new scientific findings may raise unanticipated questions, or new applications may not be scientifically consistent with the model’s intended purpose.
Recommendations
Evaluation of a regulatory model should continue throughout the life of a model. In particular, model evaluation should not stop with the evaluation activities that often occur before the public release of a model but should continue throughout regulatory applications and revisions to the model. For all models used in the regulatory process, the agency should begin by developing a life-cycle model evaluation plan commensurate with the regulatory application of the model (for example, the scientific complexity, the precedent-setting potential of the modeling approach or application, the extent to which previous evaluations are still applicable, and the projected impacts of the associated regulatory decision). Some plans may be brief, whereas other plans would be extensive. At a minimum each plan should
-
Describe the model and its intended uses.
-
Describe the relationship of the model to data, including the data for both inputs and corroboration.
-
Describe how such data and other sources of information will be used to assess the ability of the model to meet its intended task.
-
Describe all the elements of the evaluation plan by using an outline or diagram showing how the elements relate to the model’s life cycle.
-
Describe the factors or events that might trigger the need for major model revisions or the circumstances that might prompt users to seek an alternative model. These could be fairly broad and qualitative.
-
Identify responsibilities, accountabilities, and resources needed to ensure implementation of the evaluation plan.
It is essential that the agency is committed to the concept that model evaluation continues throughout a model’s life. Model evaluation should not be an end unto itself but a means to an end, namely, a model fitted to its purpose. EPA should develop a mechanism that audits the evaluation process to ensure that an evaluation plan is developed, resources are committed to carry it out, and modelers respond to what is learned. Although the committee does not make organizational recommendations or recommendations on the level of effort that should be expended on any particular type of evaluation, it recognizes that the resource implications for implementing life-cycle model evaluation are potentially substantial. However, given the importance of modeling activities in the regulatory process, such investments are critical to enable environmental regulatory modeling to meet challenges now and in the future.
Peer Review
Peer review is an important tool for improving the quality of scientific products and is basic to all stages of model evaluation. One-time reviews, of the kind used for research articles published in the literature, are insufficient for many of the models used in the environmental regulatory process. More time, effort, and variety of expertise are required to conduct and respond to peer review at different stages of the life cycle, especially for complex models.
Recommendations
Peer review should be considered, but not necessarily performed, at each stage in a model’s life cycle. Some simple, uncontroversial models
might not require any peer review, whereas others might merit peer review at several stages. Appropriate peer review requires an effort commensurate with the complexity and significance of the model application. When a model peer review is undertaken, EPA should allow sufficient time, resources, and structure to assure an adequate review. Reviewers should receive not only copies of the model and its documentation but also documentation of its origin and history. Peer review for some regulatory models should involve comparing the model results with known test cases, reviewing the model code and documentation, and running the model for several types of problems for which the model might be used. Reviewing model documentation and results is not sufficient peer review for many regulatory models.
Because many stakeholders and others interested in the regulatory process do not have the capability or resources for a scientific peer review, they need to be able to have confidence in the evaluation process. This need requires a transparent peer review process and continued adherence to criteria provided in EPA’s guidance on peer review. Documentation of all peer reviews, as well as evidence of the agency’s consideration of comments in developing revisions, should be part of the model origin and history.
Quantifying and Communicating Uncertainty
There are two critical but distinct issues in uncertainty analysis for regulatory environmental modeling: what kinds of analyses should be done to quantify uncertainty, and how these uncertainties should be communicated to policy makers.
Quantifying Uncertainty
A wide range of possibilities is available for performing model uncertainty analysis. At one extreme, all model uncertainties could be represented probabilistically, and the probability distribution of any model outcome of interest could be calculated. However, in assessing environmental regulatory issues, these analyses generally would be quite complicated to carry out convincingly, especially when some of the uncertainties in critical parameters have broad ranges or when the parameter uncertainties are difficult to quantify. Thus, although probabilistic uncer-
tainty analysis is an important tool, requiring EPA to do complete probabilistic regulatory analyses on a routine basis would probably result in superficial treatments of many sources of uncertainty. The practical problems of performing a complete probabilistic analysis stem from models that have large numbers of parameters whose uncertainties must be estimated in a cursory fashion. Such problems are compounded when models are linked into a highly complex system, for example, when emissions and meteorological model results are used as inputs into an air quality model.
At the other extreme, scenario assessment and/or sensitivity analysis could be used. Neither one in its simplest form makes explicit use of probability. For example, a scenario assessment might consider model results for a relatively small number of plausible cases (for example, “pessimistic,” “neutral,” and “optimistic” scenarios). Such a deterministic approach is easy to implement and understand. However, scenario assessment does not typically include information corresponding to conditions not included in the assessment and whatever is known about each scenario’s likelihood.
It is not necessary to choose between purely probabilistic approaches and deterministic approaches. Hybrid analyses combining aspects of probabilistic and deterministic approaches might provide the best solution for quantifying uncertainties, given the finite resources available for any analysis. For example, a sensitivity analysis might be used to determine which model parameters are most likely to have the largest impacts on the conclusions, and then a probabilistic analysis could be used to quantify bounds on the conclusions due to uncertainties in those parameters. In another example, probabilistic methods might be chosen to quantify uncertainties in environmental characteristics and expected human health impacts, and several plausible scenarios might be used to describe the monetization of the health benefits. Questions about which of several plausible models to use can sometimes be the dominant source of uncertainty and, in principle, can be handled probabilistically. However, a scenario assessment approach is particularly appropriate for showing how different models yield differing results.
Communicating Uncertainties
Effective decision making will require providing policy makers
with more than a single probability distribution for a model result (and certainly more than just a single number, such as the expected net benefit, with no indication of uncertainty). Such summaries obscure the sensitivities of the outcome to individual sources of uncertainty, thus undermining the ability of policy makers to make informed decisions and constraining the efforts of stakeholders to understand the basis for the decisions.
Recommendations
Quantifying Uncertainty
In some cases, presenting results from a small number of model scenarios will provide an adequate uncertainty analysis (for example, cases in which the stakes are low, modeling resources are limited, or insufficient information is available). In many instances, however, probabilistic methods will be necessary to characterize properly at least some uncertainties and to communicate clearly the overall uncertainties. Although a full Bayesian analysis that incorporates all sources of information is desirable in principle, in practice, it will be necessary to make strategic choices about which sources of uncertainty justify such treatment and which sources are better handled through less formal means, such as consideration of how model outputs change as an input varies through a range of plausible values. In some applications, the main sources of uncertainty will be among models rather than within models, and it will often be critical to address these sources of uncertainty.
Communicating Uncertainty
Probabilistic uncertainty analysis should not be viewed as a means to turn uncertain model outputs into policy recommendations that can be made with certitude. Whether or not a complete probabilistic uncertainty analysis has been done, the committee recommends that various approaches be used to communicate the results of the analysis. These include hybrid approaches in which some unknown quantities are treated probabilistically and others are explored in scenario-assessment mode by decision makers through a range of plausible values. Effective uncertainty communication requires a high level of interaction with the
relevant decision makers to ensure that they have the necessary information about the nature and sources of uncertainty and their consequences. Thus, performing uncertainty analysis for environmental regulatory activities requires extensive discussion between analysts and decision makers.
Retrospective Analysis of Models
EPA has been involved in the development and application of computational models for environmental regulatory purposes for as long as the agency has been in existence. Its reliance on models has only increased over time. However, attempts to learn from prior experiences with models and to apply these lessons have been insufficient.
Recommendations
The committee recommends that EPA conduct and document the results of retrospective reviews of regulatory models not only on single models but also at the scale of model classes, such as models of ground-water flow and models of health risks. The goal of such retrospective evaluations should be the identification of priorities for improving regulatory models. One objective of this analysis would be to investigate systematic strengths and weaknesses that are characteristic of various types of models. A second important objective would be to study the processes (for example, approaches to model development and evaluation) that led to successful models and model applications.
In carrying out a retrospective analysis, it might be helpful to use models or categories of models that are old by current modeling standards, because the older models could present the best opportunities to assess actual model performance quantitatively by using subsequent advances in modeling and in new observations.
Models and Rule-makings
The sometimes contentious setting in which regulatory models are used may impede EPA’s ability to implement some of the recommendations in this report, including the life-cycle evaluation process. Even
high-quality models are filled with components that are incomplete and must be updated as new knowledge arises. Yet, those attributes may provide stakeholders with opportunities to mount formal challenges against models that produce outputs that they find undesirable. Requirements such as those in the Information Quality Act may increase the susceptibility of models to challenges because outside parties may file a correction request for information disseminated by agencies.
When a model that informs a regulatory decision has undergone the multilayered review and comment processes, the model tends to remain in place for some time. This inertia is not always ideal: the cumbersome regulatory procedures and the finality of the rules that survive them may be at odds with the dynamic nature of modeling and the goal of improving models in response to experience and scientific advances.
In such an adversarial environment, EPA might perceive that a rigorous life-cycle model evaluation is ill-advised from a legal standpoint. Engaging in this type of rigorous review may expose the model to a greater risk of challenges, at least insofar as the agency’s review is made public, because the agency is documenting features of its models that need to be improved. Moreover, revising a model can trigger lengthy administrative notice and comment processes. However, an improved model is less likely to generate erroneous results that could lead to additional challenges, and it better serves the public interest.
Recommendations
It is important that EPA institute best practice standards for the evaluation of regulatory models. Best evaluation practices may be much easier for EPA to implement if its resulting rigorous life-cycle evaluation process is perceived as satisfying regulatory requirements, such as those of the Information Quality Act. However, for an evaluation process to meet the spirit and intent of the Information Quality Act, EPA’s evaluation process must include a mechanism for any person to submit information or corrections to a model. Rather than requiring a response within 60 days, as the Information Quality Act does, the evaluation process would involve consideration of that information and response at the appropriate time in the model evaluation process.
To further encourage evaluation of models that support federal rule-makings, alternative means of soliciting public comment on model revisions need to be devised over the life cycle of the model. For example,
EPA could promulgate a separate rule-making that establishes an agency-wide process for the evaluation and adjustment of models used in its rules. Such a programmatic process would allow the agency to provide adequate opportunities for meaningful public comment at important stages of the evaluation and revision of an individual model, without triggering the need for a separate rule-making for each revision. Finally, more rigorous and formalized evaluation processes for models may result in greater deference to agency models by interested parties and by reviewing courts. Such a response could decrease the extent of model challenges through adversarial processes.
Model Origin and History
Models are developed and applied over many years by participants who enter and exit the process over time. The model origin and history can be lost when individual experiences with a model are not documented and archived. Without an adequate record, a model might be incorrectly applied, or developers might be unable to adapt the model for a new application. Poor historical documentation could also frustrate stakeholders who are interested in understanding a model. Finally, without adequate documentation, EPA might be limited in its ability to justify decisions that were critical to model design, development, or model selection.
Recommendations
As part of the evaluation plan, a documented history of important events regarding the models should be maintained, especially after public release. Each documentation should have its origin with such key elements as the identity of the model developer and institution, the decisions on critical model design and development, and the records of software version releases. The model documentation also should have elements in “plain English” to communicate with nontechnical evaluators. An understandable description of the model itself, justifications, limitations, and key peer reviews are especially important for building trust.
The committee recognizes that information relevant to model origins and histories is already being collected by CREM and stored in its model database, which is available on the CREM web site. CREM’s da-
tabase includes over 100 models, although updating of this site has declined in recent years. It provides information on obtaining and running the models and on the models’ conceptual bases, scientific details, and results of evaluation studies. One possible way to implement the recommendation for developing and maintaining the model history may be to expand CREM’s efforts in this direction. The EPA Science Advisory Board review of CREM contains additional recommendations with regard to specific improvements in CREM’s database.


































































