
2
What Is Computer Performance?
Fast, inexpensive computers are now essential to numerous human endeavors. But less well understood is the need not just for fast computers but also for ever-faster and higher-performing computers at the same or better costs. Exponential growth of the type and scale that have fueled the entire information technology industry is ending.1 In addition, a growing performance gap between processor performance and memory bandwidth, thermal-power challenges and increasingly expensive energy use, threats to the historical rate of increase in transistor density, and a broad new class of computing applications pose a wide-ranging new set of challenges to the computer industry. Meanwhile, societal expectations for increased technology performance continue apace and show no signs of slowing, and this underscores the need for ways to sustain exponentially increasing performance in multiple dimensions. The essential engine that has met this need for the last 40 years is now in considerable danger, and this has serious implications for our economy, our military, our research institutions, and our way of life.
Five decades of exponential growth in processor performance led to
____________________
1It can be difficult even for seasoned veterans to understand the effects of exponential growth of the sort seen in the computer industry. On one level, industry experts, and even consumers, display an implicit understanding in terms of their approach to application and system development and their expectations of and demands for computing technologies. On another level, that implicit understanding makes it easy to overlook how extraordinary the exponential improvements in performance of the sort seen in the information technology industry actually are.
the rise and dominance of the general-purpose personal computer. The success of the general-purpose microcomputer, which has been due primarily to economies of scale, has had a devastating effect on the development of alternative computer and programming models. The effect can be seen in high-end machines like supercomputers and in low-end consumer devices, such as media processors. Even though alternative architectures and approaches might have been technically superior for the task they were built for, they could not easily compete in the marketplace and were readily overtaken by the ever-improving general-purpose processors available at a relatively low cost. Hence, the personal computer has been dubbed “the killer micro.”
Over the years, we have seen a series of revolutions in computer architecture, starting with the main-frame, the minicomputer, and the work station and leading to the personal computer. Today, we are on the verge of a new generation of smart phones, which perform many of the applications that we run on personal computers and take advantage of network-accessible computing platforms (cloud computing) when needed. With each iteration, the machines have been lower in cost per performance and capability, and this has broadened the user base. The economies of scale have meant that as the per-unit cost of the machine has continued to decrease, the size of the computer industry has kept growing because more people and companies have bought more computers. Perhaps even more important, general-purpose single processors—which all these generations of architectures have taken advantage of—can be programmed by using the same simple, sequential programming abstraction at root. As a result, software investment on this model has accumulated over the years and has led to the de facto standardization of one instruction set, the Intel x86 architecture, and to the dominance of one desktop operating system, Microsoft Windows.
The committee believes that the slowing in the exponential growth in computing performance, while posing great risk, may also create a tremendous opportunity for innovation in diverse hardware and software infrastructures that excel as measured by other characteristics, such as low power consumption and delivery of throughput cycles. In addition, the use of the computer has becomes so pervasive that it is now economical to have many more varieties of computers. Thus, there are opportunities for major changes in system architectures, such as those exemplified by the emergence of powerful distributed, embedded devices, that together will create a truly ubiquitous and invisible computer fabric. Investment in whole-system research is needed to lay the foundation of the computing environment for the next generation. See Figure 2.1 for a graph showing flattening curves of performance, power, and frequency.
Traditionally, computer architects have focused on the goal of creating
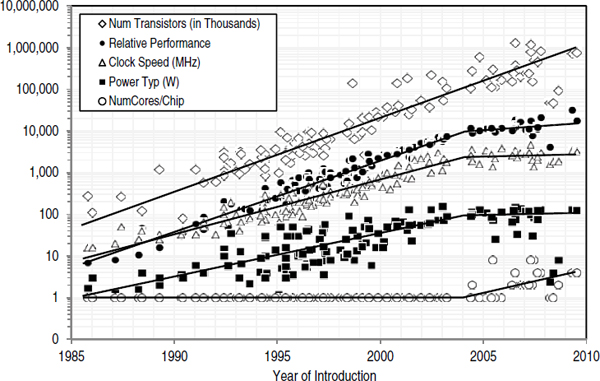
FIGURE 2.1 Transistors, frequency, power, performance, and cores over time (1985-2010). The vertical scale is logarithmic. Data curated by Mark Horowitz with input from Kunle Olukotun, Lance Hammond, Herb Sutter, Burton Smith, Chris Batten, and Krste Asanoviç.
computers that perform single tasks as fast as possible. That goal is still important. Because the uniprocessor model we have today is extremely powerful, many performance-demanding applications can be mapped to run on networks of processors by dividing the work up at a very coarse granularity. Therefore, we now have great building blocks that enable us to create a variety of high-performance systems that can be programmed with high-level abstractions. There is a serious need for research and education in the creation and use of high-level abstractions for parallel systems.
However, single-task performance is no longer the only metric of interest. The market for computers is so large that there is plenty of economic incentive to create more specialized and hence more cost-effective machines. Diversity is already evident. The current trend of moving computation into what is now called the cloud has created great demands for high-throughput systems. For those systems, making each transaction run as fast as possible is not the best thing to do. It is better, for example, to have a larger number of lower-speed processors to optimize the throughput rate and minimize power consumption. It is similarly important to conserve power for hand-held devices. Thus, power consumption is a
BOX 2.1
Embedded Computing Performance
The design of desktop systems often places considerable emphasis on general CPU performance in running desktop workloads. Particular attention is paid to the graphics system, which directly determines which consumer games will run and how well. Mobile platforms, such as laptops and notebooks, attempt to provide enough computing horsepower to run modern operating systems well—subject to the energy and thermal constraints inherent in mobile, battery-operated devices—but tend not to be used for serious gaming, so high-end graphics solutions would not be appropriate. Servers run a different kind of workload from either desktops or mobile platforms, are subject to substantially different economic constraints in their design, and need no graphics support at all. Desktops and mobile platforms tend to value legacy compatibility (for example, that existing operating systems and software applications will continue to run on new hardware), and this compatibility requirement affects the design of the systems, their economics, and their use patterns.
Although desktops, mobile, and server computer systems exhibit important differences from one another, it is natural to group them when comparing them with embedded systems. It is difficult to define embedded systems accurately because their space of applicability is huge—orders of magnitude larger than the general-purpose computing systems of desktops, laptops, and servers. Embedded computer systems can be found everywhere: a car’s radio, engine controller, transmission controller, airbag deployment, antilock brakes, and dozens of other places. They are in the refrigerator, the washer and dryer, the furnace controller, the MP3 player, the television set, the alarm clock, the treadmill and stationary bike, the Christmas lights, the DVD player, and the power tools in the garage. They might even be found in ski boots, tennis shoes, and greeting cards. They control the elevators and heating and cooling systems at the office, the video surveillance system in the parking lot, and the lighting, fire protection, and security systems.
Every computer system has economic constraints. But the various systems tend to fall into characteristic financial ranges. Desktop systems once (in 1983) cost $3,000 and now cost from a few hundred dollars to around $1,000. Mobile systems cost more at the high end, perhaps $2,500, down to a few hundred dollars at the low end. Servers vary from a few thousand dollars up to hundreds of thousands for a moderate Web server, a few million dollars for a small corporate
key performance metric for both high-end servers and consumer handheld devices. See Box 2.1 for a discussion of embedded computing performance as distinct from more traditional desktop systems. In general, power considerations are likely to lead to a large variety of specialized processors.
The rest of this chapter provides the committee’s views on matters related to computer performance today. These views are summarized in
server farm, and 1 or 2 orders of magnitude more than that for the huge server farms fielded by large companies, such as eBay, Yahoo!, and Google.
Embedded systems tend to be inexpensive. The engine controller under the hood of a car cost the car manufacturer about $3-5. The chips in a cell phone were also in that range. The chip in a tennis shoe or greeting card is about 1/10 that cost. The embedded system that runs such safety-critical systems as elevators will cost thousands of dollars, but that cost is related more to the system packaging, design, and testing than to the silicon that it uses.
One of the hallmarks of embedded systems versus general-purpose computers is that, unlike desktops and servers, embedded performance is not an open-ended boon. Within their cost and power budgets, desktops, laptops, and server systems value as much performance as possible—the more the better. Embedded systems are not generally like that. The embedded chip in a cell phone has a set of tasks to perform, such as monitoring the phone’s buttons, placing various messages and images on the display, controlling the phone’s energy budget and configuration, and setting up and receiving calls. To accomplish those tasks, the embedded computer system (comprising a central processor, its memory, and I/O facilities) must be capable of a some overall performance level. The difference from general-purpose computers is that once that level is reached in the system design, driving it higher is not beneficial; in fact, it is detrimental to the system. Embedded computer systems that are faster than necessary to meet requirements use more energy, dissipate more heat, have lower reliability, and cost more—all for no gain.
Does that mean that embedded processors are now fast enough and have no need to go faster? Are they exempt from the emphasis in this report on “sustaining growth in computing performance”? No. If embedded processor systems were to become faster and all else were held equal, embedded-system designers would find ways of using the additional capability, and delivering new functionalities would come to be expected on those devices. For example, many embedded systems, such as the GPS or audio system in a car, tend to interface directly with human beings. Voice and speech recognition capability greatly enhance that experience, but current systems are not very good at the noise suppression, beam-forming, and speech-processing that are required to make this a seamless, enjoyable experience, although progress is being made. Faster computer systems would help to solve that problem. Embedded systems have benefited tremendously from riding an improvement curve equivalent to that of the general-purpose systems and will continue to do so in the future.
the bullet points that follow this paragraph. Readers who accept the committee’s views may choose to skip the supporting arguments and move on to the next chapter.
- Increasing computer performance enhances human productivity.
- One measure of single-processor performance is the product of operating frequency, instruction count, and instructions per cycle.
- Performance comes directly from faster devices and indirectly from using more devices in parallel.
- Parallelism can be helpfully divided into instruction-level parallelism, data-level parallelism, and thread-level parallelism.
- Instruction-level parallelism has been extensively mined, but there is now broad interest in data-level parallelism (for example, due to graphics processing units) and thread-level parallelism (for example, due to chip multiprocessors).
- Computer-system performance requires attention beyond processors to memories (such as, dynamic random-access memory), storage (for example, disks), and networking.
- Some computer systems seek to improve responsiveness (for example, timely feedback to a user’s request), and others seek to improve throughput (for example, handling many requests quickly).
- Computers today are implemented with integrated circuits (chips) that incorporate numerous devices (transistors) whose population (measured as transistors per chaip) has been doubling every 1.5-2 years (Moore’s law).
- Assessing the performance delivered to a user is difficult and depends on the user’s specific applications.
- Large parts of the potential performance gain due to device innovations have been usefully applied to productivity gains (for example, via instruction-set compatibility and layers of software).
- Improvements in computer performance and cost have enabled creative product innovations that generated computer sales that, in turn, enabled a virtuous cycle of computer and product innovations.
WHY PERFORMANCE MATTERS
Humans design machinery to solve problems. Measuring how well machines perform their tasks is of vital importance for improving them, conceiving better machines, and deploying them for economic benefit. Such measurements often speak of a machine’s performance, and many aspects of a machine’s operations can be characterized as performance. For example, one aspect of an automobile’s performance is the time it takes to accelerate from 0 to 60 mph; another is its average fuel economy. Braking ability, traction in bad weather conditions, and the capacity to tow trailers are other measures of the car’s performance.
Computer systems are machines designed to perform information processing and computation. Their performance is typically measured by how much information processing they can accomplish per unit time,
but there are various perspectives on what type of information processing to consider when measuring performance and on the right time scale for such measurements. Those perspectives reflect the broad array of uses and the diversity of end users of modern computer systems. In general, the systems are deployed and valued on the basis of their ability to improve productivity. For some users, such as scientists and information technology specialists, the improvements can be measured in quantitative terms. For others, such as office workers and casual home users, the performance and resulting productivity gains are more qualitative. Thus, no single measure of performance or productivity adequately characterizes computer systems for all their possible uses.2
On a more technical level, modern computer systems deploy and coordinate a vast array of hardware and software technologies to produce the results that end users observe. Although the raw computational capabilities of the central processing unit (CPU) core tend to get the most attention, the reality is that performance comes from a complex balance among many cooperating subsystems. In fact, the underlying performance bottlenecks of some of today’s most commonly used large-scale applications, such as Web searching, are dominated by the characteristics of memory devices, disk drives, and network connections rather than by the CPU cores involved in the processing. Similarly, the interactive responsiveness perceived by end users of personal computers and hand-held devices is typically defined more by the characteristics of the operating system, the graphical user interface (GUI), and the storage components than by the CPU core. Moreover, today’s ubiquitous networking among computing devices seems to be setting the stage for a future in which the computing experience is defined at least as much by the coordinated interaction of multiple computers as it is by the performance of any node in the network.
Nevertheless, to understand and reason about performance at a high level, it is important to understand the fundamental lower-level contributors to performance. CPU performance is the driver that forces the many other system components and features that contribute to overall performance to keep up and avoid becoming bottlenecks
PERFORMANCE AS MEASURED BY RAW COMPUTATION
The classic formulation for raw computation in a single CPU core identifies operating frequency, instruction count, and instructions per cycle
____________________
2Consider the fact that the term “computer system” today encompasses everything from small handheld devices to Netbooks to corporate data centers to massive server farms that offer cloud computing to the masses.
(IPC) as the fundamental low-level components of performance.3 Each has been the focus of a considerable amount of research and discovery in the last 20 years. Although detailed technical descriptions of them are beyond the intended scope of this report, the brief descriptions below will provide context for the discussions that follow.
- Operating frequency defines the basic clock rate at which the CPU core runs. Modern high-end processors run at several billion cycles per second. Operating frequency is a function of the low-level transistor characteristics in the chip, the length and physical characteristics of the internal chip wiring, the voltage that is applied to the chip, and the degree of pipelining used in the microarchitecture of the machine. The last 15 years have seen dramatic increases in the operating frequency of CPU cores. As an unfortunate side effect of that growth, the maximum operating frequency has often been used as a proxy for performance by much of the popular press and industry marketing campaigns. That can be misleading because there are many other important low-level and system-level measures to consider in reasoning about performance.
- Instruction count is the number of native instructions—instructions written for that specific CPU—that must be executed by the CPU to achieve correct results with a given computer program. Users typically write programs in high-level programming languages—such as Java, C, C++, and C#—and then use a compiler to translate the high-level program to native machine instructions. Machine instructions are specific to the instruction set architecture (ISA) that a given computer architecture or architecture family implements. For a given high-level program, the machine instruction count varies when it executes on different computer systems because of differences in the underlying ISA, in the microarchitecture that implements the ISA, and in the tools used to compile the program. Although this section of the report focuses mostly on the low-level raw performance measures, the role of the compiler and other modern software system technologies are also necessary to understand performance fully.
- Instructions per cycle refers to the average number of instructions that a particular CPU core can execute and complete in each cycle. IPC is a strong function of the underlying microarchitecture, or machine organization, of the CPU core. Many modern CPU
____________________
3John L. Hennessy and David A. Patterson, 2006, Computer Architecture: A Quantitative Approach, fourth edition, San Francisco, Cal.: Morgan Kauffman.
cores use advanced techniques—such as multiple instruction dispatch, out-of-order execution, branch prediction, and speculative execution—to increase the average IPC.4 Those techniques all seek to execute multiple instructions in a single cycle by using additional resources to reduce the total number of cycles needed to execute the program. Some performance assessments focus on the peak capabilities of the machines; for example, the peak performance of the IBM Power 7 is six instructions per cycle, and that of the Intel Pentium, four. In reality, those and other sophisticated CPU cores actually sustain an average of slightly more than one instruction per cycle when executing many programs. The difference between theoretical peak performance and actual sustained performance is an important aspect of overall computer-system performance.
The program itself provides different forms of parallelism that different machine organizations can exploit to achieve performance. The first type, instruction-level parallelism, describes the amount of nondependent instructions5 available for parallel execution at any given point in the program. The program’s instruction-level parallelism in part determines the IPC component of raw performance mentioned above. (IPC can be viewed as describing the degree to which a particular machine organization can harvest the available instruction-level performance.) The second type of parallelism is data-level parallelism, which has to do with how data elements are distributed among computational units for similar types of processing. Data-level parallelism can be exploited through architectural and microarchitectural techniques that direct low-level instructions to operate on multiple pieces of data at the same time. This type of processing is often referred to as single-instruction-multiple-data. The third type is thread-level parallelism and has to do with the degree to which a program can be partitioned into multiple sequences of instructions with the intent of executing them concurrently and cooperatively on multiple processors. To exploit program parallelism, the compiler or run-time system must map it to appropriate parallel hardware.
Throughout the history of modern computer architecture, there have been many attempts to build machines that exploit the various forms of
____________________
4Providing the details of these microarchitecture techniques is beyond the scope of this publication. See Hennessey & Patterson for more information on these and related techniques.
5An instruction X does not depend on instruction Y if X can be performed without using results from Y. The instruction a = b + c depends on previous instructions that produce the results b and c and thus cannot be executed until those previous instructions have completed.
parallelism. In recent years, owing largely to the emergence of more generalized and programmable forms of graphics processing units, the interest in building machines that exploit data-level parallelism has grown enormously. The specialized machines do not offer compatibility with existing programs, but they do offer the promise of much more performance when presented with code that properly exposes the available data-level parallelism. Similarly, because of the emergence of chip multiprocessors, there is considerable renewed interest in understanding how to exploit thread-level parallelism on these machines more fully. However, the techniques also highlight the importance of the full suite of hardware components in modern computer systems, the communication that must occur among them, and the software technologies that help to automate application development in order to take advantage of parallelism opportunities provided by the hardware.
COMPUTATION AND COMMUNICATION’S EFFECTS ON PERFORMANCE
The raw computational capability of CPU cores is an important component of system-level performance, but it is by no means the only one. To complete any useful tasks, a CPU core must communicate with memory, a broad array of input/output devices, other CPU cores, and in many cases other computer systems. The overhead and latency of that communication in effect delays computational progress as the CPU waits for data to arrive and for system-level interlocks to clear. Such delays tend to reduce peak computational rates to effective computational rates substantially. To understand effective performance, it is important to understand the characteristics of the various forms of communication used in modern computer systems.
In general, CPU cores perform best when all their operands (the inputs to the instructions) are stored in the architected registers that are internal to the core. However, in most architectures, there tend to be few such registers because of their relatively high cost in silicon area. As a result, operands must often be fetched from memory before the actual computation specified by an instruction can be completed. For most computer systems today, the amount of time it takes to access data from memory is more than 100 times the single cycle time of the CPU core. And, worse yet, the gap between typical CPU cycle times and memory-access times continues to grow. That imbalance would lead to a devastating loss in performance of most programs if there were not hardware caches in these systems. Caches hold the most frequently accessed parts of main memory in special hardware structures that have much smaller latencies than the main memory system; for example, a typical level-1 cache has an access
time that is only 2-3 times slower than the single cycle time of the CPU core. They leverage a principle called locality of reference that characterizes common data-access patterns exhibited by most computer programs. To accommodate large working sets that do not fit in the first-level cache, many computer systems deploy a hierarchy of caches. The later levels of caches tend to be increasingly large (up to several megabytes), but as a result they also have longer access times and resulting latencies. The concept of locality is important for computer architecture, and Chapter 4 highlights the potential of exploiting locality in innovative ways.
Main memory in most modern computer systems is typically implemented with dynamic random-access memory (DRAM) chips, and it can be quite large (many gigabytes). However, it is nowhere near large enough to hold all the addressable memory space available to applications and the file systems used for long-term storage of data and programs. Therefore, nonvolatile magnetic-disk-based storage6 is commonly used to hold this much larger collection of data. The access time for disk-based storage is several orders of magnitude larger than that of DRAM, which can expose very long delays between a request for data and the return of the data. As a result, in many computer systems, the operating system takes advantage of the situation by arranging a “context switch” to allow another pending program to run in the window of time provided by the long delay in many computer systems. Although context-switching by the operating system improves the multiprogram throughput of the overall computer system, it hurts the performance of any single application because of the associated overhead of the contexts-switch mechanics. Similarly, as any given program accesses other system resources, such as networking and other types of storage devices, the associated request-response delays detract from the program’s ability to make use of the full peak-performance potential of the CPU core. Because each of those subsystems displays different performance characteristics, the establishment of an appropriate system-level balance among them is a fundamental challenge in modern computer-system design. As future technology advances improve the characteristics of the subsystems, new challenges and opportunities in balancing the overall system arise.
Today, an increasing number of computer systems deploy more than one CPU core, and this has the potential to improve system performance. In fact, there are several methods of taking advantage of the potential of parallelism offered by additional CPU cores, each with distinct advantages and associated challenges.
____________________
6Nonvolatile storage does not require power to retain its information. A compact disk (CD) is nonvolatile, for example, as is a computer hard drive, a USB flash key, or a book like this one.
- The first method takes advantage of the additional CPUs to improve the general responsiveness of the system. Instead of scheduling the execution of pending programs one at a time (as is done in single-processor systems), the operating system can schedule more than one program to run at the same time in different processors. This method tends to increase the use of the other subsystems (storage, networking, and so on), so it also demands a different system-level balance among the subsystems than do some of the other methods. From an end user’s standpoint, this system organization tends to improve both the interactive responsiveness of the system and the turnaround time for any particular execution task.
- The second method takes advantage of the additional CPU cores to improve the turnaround time of a particular program more dramatically by running different parts of the program in parallel. This method requires programmers to use parallel-programming constructs; historically, this task has proved fairly difficult even for the most advanced programmers. In addition, such constructs tend to require particular attention to how the different parts of the program synchronize and coordinate their execution. This synchronization is a form of communication among the cooperating processors and represents a new type of overhead that detracts from exploiting the peak potential of each individual processor core. See Box 2.2 for a brief description of Amdahl’s law.
- A third method takes advantage of the additional CPU cores to improve the throughput of a particular program. Instead of working to speed up the program’s operation on a single piece of data (or dataset), the system works to increase the rate at which a collection of data (or datasets) can be processed by the program. In general, because there tends to be more independence among the collected data in this case, the development of these types of programs is somewhat easier than development of the parallel programs mentioned earlier. In addition, the degree of communication and synchronization required between the concurrently executing parts of the program tends to be much less than in the parallel-program case.
Another key aspect of modern computer systems is their ability to communicate, or network, with one another. Programmers can write programs that make use of multiple CPU cores within a single computer system or that make use of multiple computer systems to increase performance or to solve larger, harder problems. In those cases, it takes much longer
BOX 2.2
Amdahl’s Law
Amdahl’s law sets the limit to which a parallel program can be sped up. Programs can be thought of as containing one or more parallel sections of code that can be sped up with suitably parallel hardware and a sequential section that cannot be sped up. Amdahl’s law is
Speedup = 1/[(1 – P) + P/N)],
where P is the proportion of the code that runs in parallel and N is the number of processors.
The way to think about Amdahl’s law is that the faster the parallel section of the code run, the more the remaining sequential code looms as the performance bottleneck. In the limit, if the parallel section is responsible for 80 percent of the run time, and that section is sped up infinitely (so that it runs in zero time), the other 20 percent now constitutes the entire run time. It would therefore have been sped up by a factor of 5, but after that no amount of additional parallel hardware will make it go any faster.
to communicate, synchronize, and coordinate the progress of the overall program. The programs tend to break the problem into coarser-grain tasks to run in parallel, and they tend to use more explicit message-passing constructs. As a result, the development and optimization of such programs are quite different from those of the others mentioned above.
In addition to the methods described above, computer scientists are actively researching new ways to exploit multiple CPU cores, multiple computer systems, and parallelism for future systems. Considering the increased complexity of such systems, researchers are also concerned about easing the associated programming complexity exposed to the application programmer, inasmuch as programming effort has a first-order effect on time to solution of any given problem. The magnitude of these challenges and their effects on computer-system performance motivate much of this report.
TECHNOLOGY ADVANCES AND THE HISTORY OF COMPUTER PERFORMANCE
In many ways, the history of computer performance can be best understood by tracking the development and issues of the technology that underlies the machines. If one does that, an interesting pattern starts to emerge. As incumbent technologies are stretched to their practical
limits, innovations are leveraged to overcome these limits. At the same time, they set the stage for a fresh round of incremental advances that eventually overtake any remaining advantages of the older technology. That technology-innovation cycle has been a driving force in the history of computer-system performance improvements.
A very early electronic computing system, called Colossus,7 was created in 1943.8 Its core was built with vacuum tubes, and although it had fairly limited utility, it ushered in the use of electronic vacuum tubes for a generation of computer systems that followed. As newer systems, such as the ENIAC, introduced larger-scale and more generalized computing, the collective power consumption of all the vacuum tubes eventually limited the ability to continue scaling the systems. In 1954, engineers at Bell Laboratories created a discrete-transistor-based computer system called the TRADIC.9 Although it was not quite as fast as the fastest vacuum-tube-based systems of the day, it was much smaller and consumed much less power. More important, it heralded the era of transistor-based computer systems.10 In 1958, Jack Kilby and Robert Noyce separately invented the integrated circuit, which for the first time allowed multiple transistors to be fabricated and connected on a single piece of silicon. That technology was quickly picked up by computer designers to design higher-performance and more power-efficient computer systems. This technology breakthrough inaugurated the modern computing era.
In 1965, Gordon Moore observed that the transistor density on integrated circuits was doubling with each new technology generation, and he projected that this would continue into the future.11 (See Appendix C
____________________
7B. Jack Copeland, ed., 2006, Colossus: The Secrets of Bletchley Park’s Codebreaking, New York, N.Y.: Oxford University Press.
8Although many types of mechanical and electromechanical computing systems were demonstrated before that, these devices were substantially limited in capabilities and deployments, so we will leave them out of this discussion.
9For a history of the TRADIC, see Louis C. Brown, 1999, Flyable TRADIC: The first airborne transistorized digital computer, IEEE Annals of the History of Computing 21(4): 55-61.
10It was not only vacuum tube power requirements that were limiting the computer industry back in the early 1060s. Packaging was a significant challenge, too—simply making all the connections needed to carry signals and power to all those tubes was seriously degrading reliability, because each connection had to be hand-soldered with some probability of failure greater than 0.0. All kinds of module packaging schemes were being tried, but none of them really solved this manufacturability problem. One of the transformative aspects of integrated circuit technology is that you get all the internal connections for free by a chemical photolithography process that not only makes them essentially free but also makes them several orders of magnitude more reliable. Were it not for that effect, all those transistors we have enjoyed ever since would be of very limited usefulness, too expensive, and too prone to failure.
11Gordon Moore, 1965, Cramming more components onto integrated circuits, Electronics 38(8), available online at http://download.intel.com/research/silicon/moorespaper.pdf.
for a reprint of his seminal paper.) That projection, now commonly called Moore’s law, was remarkably accurate and still holds true. However, over the years, there have been some important shifts in how integrated circuits are used in computer systems. Early on, various segments of the electronics industry made use of different types of transistor devices. For high-end computer systems, the bipolar junction transistor (BJT) was the technology of choice. As more BJT devices were integrated into the systems, the power consumption of each chip also rose, and computer-system designers were forced to use exotic power delivery and cooling solutions. In the 1980s, another type of transistor, the field-effect transistor (FET), was increasingly used for smaller electronic devices, such as calculators and small computers meant for hobbyists. By the late 1980s, the power-consumption characteristics of the BJT-based computer systems hit a breaking point; around the same time, the early use of FET-based integrated circuits had demonstrated both power and cost advantages over the BJT-based technologies. Although the underlying transistors were not as fast, their characteristics enabled far greater integration potential and much lower power consumption. Today, at the heart of virtually all computer systems is a set of FET-based integrated-circuit chips.
It now appears that in some higher-end computer systems, the FET-based integrated circuits have hit their practical limits of power consumption. Although today’s technologists understand how to continue increasing the level of integration (number of transistor devices) on future chips, they are not able to continue reducing the voltage or the power.12 There are several potential new technology concepts in the research laboratories—such as carbon nanotubes, quantum dots, and biology-inspired devices—but none of them is mature enough for practical deployment. Although there is reasonable optimism that current research will eventually bring one or more new technology breakthroughs into mainstream deployment, it appears today that the technology-innovation cycle has a substantial gap that must be overcome in some other way. The industry is therefore shifting from the long-standing heritage of constantly improving the performance characteristics of single-processor-based systems (sometimes referred to as single-thread performance) to increasing the number of processors in each system. As described in the following sections, that
____________________
12The committee’s emphasis on transistor performance is not intended to convey the impression that transistors are the sole determinant of computer system performance. The interconnect wiring between transistors on a chip is a first-order limiter of system clock rate and also contributes greatly to overall power dissipation. Memory and I/O systems must also scale up to avoid becoming bottlenecks to faster computer systems. The focus is on transistors here because it is possible to work around interconnect limitations (this has already been done for at least 15 years), and so far, memory and I/O have been scaling up enough to avoid being showstoppers.
puts substantial new demands and new pressures on the software side of multiprocessor-based systems.
Appendix A provides additional data on historical computer-performance trends. It illustrates that from 1985 to 2004 computer performance improved at a compound annual growth rate exceeding 50 percent, measured with the SPECint2000 and SPECfp2000 benchmarks, but after 2004 grew much more slowly.13 Moreover, it shows that the recent slow growth is due in large part to a flattening of clock-frequency improvements needed to flatten the untenable growth in chip power requirements. The appendix closes with Kurzweil’s observations on the 20th century that encourage us to seek new computer technologies.
ASSESSING PERFORMANCE WITH BENCHMARKS
As discussed earlier in this chapter, another big challenge in understanding computer-system performance is choosing the right hardware and software metrics and measurements. As this committee has already discussed, the peak-performance potential of a machine is not a particularly good metric in that the inevitable overheads associated with the use of other system-level resources and communication can diminish delivered performance substantially.
There have been innumerable efforts over the years to create benchmark suites to define a set of workloads over which to measure metrics, many of them quite successful within limited application domains. However, designing general benchmarks is difficult. Even considering hardware performance alone can be challenging because computer hardware consists of several different components (see Box 2.3). Computer systems are deployed and used in a broad variety of ways. As one might expect, different market segments have different use scenarios, and they stress the system in different ways. As a result, the appropriate benchmark to consider can vary considerably between market segments. For example,
- For casual home users, responsiveness of the GUI has high priority. The performance of the system when operating on various types of entertainment media—such as audio, video, or pictures files—is more important than it is in many other markets.
- In research settings, the computer system is an important tool for exploring and modeling ideas. As a result, the turnaround time
____________________
13SPEC benchmarks are a set of artificial workloads intended to measure a computer system’s speed. A machine that achieves a SPEC benchmark score that is, say, 30 percent faster than that of another machine should feel about 30 percent faster than the other machine on real workloads.
- In small-business settings, the computer system tends to be used for a very wide array of applications, so high general-purpose performance is valued.
- For computer systems used in banking and other financial markets, the reliability and accuracy of the computational results, even in the face of defects or harsh external environmental conditions, are paramount. Many deployments value gross transactional throughput more than the turnaround time of any given program, except for financial-transaction turnaround time.
- In some businesses, computer systems are deployed into mission-critical roles in the overall operation of the business, for example, e-commerce-based businesses, process automation, health care, and human safety systems. In those situations, the gross reliability and “up time” characteristics of the system can be far more important than the instantaneous performance of the system at any given time.
- At the very high end, supercomputer systems tend to work on large problems with very large amounts of data. The underlying performance of the memory system can be even more important than the raw computational capability of the CPU cores involved. That can be seen as an example of throughput as performance (see Box 2.5).
Complicating matters a bit more, most computer-system deployments define some set of important physical constraints on the system. For example, in the case of a notebook-computer system, important energy-consumption and physical-size constraints must be met. Similarly, even in the largest supercomputer deployments, there are constraints on physical size, weight, power, heat, and cost. Those constraints are several orders of magnitude larger than in the notebook example, but they still are fundamental in defining the resulting performance and utility of the system. As a result, for a given market opportunity, it often makes sense to gauge the value of a computer system according to a ratio of performance to constraints. Indeed, some of the metrics most frequently used today are such ratios as performance per watt, performance per dollar, and performance per area. More generally, most computer-system customers are placing increasing emphasis on efficiency of computation rather than on gross performance metrics.
BOX 2.3
Hardware Components
A car is not just an engine. It has a cooling system to keep the engine running efficiently and safely, an environmental system to do the same for the drivers and passengers, a suspension system to improve the ride, a transmission so that the engine’s torque can be applied to the drive wheels, a radio so that the driver can listen to classic-rock stations, and cupholders and other convenience features. One might still have a useful vehicle if the radio and cupholders were missing, but the other features must be present because they all work in harmony to achieve the function of propelling the vehicle controllably and safely.
Computer systems are similar. The CPU tends to get much more than its proper share of attention, but it would be useless without memory and I/O subsystems. CPUs function by fetching their instructions from memory. How did the instructions get into memory, and where did they come from? The instructions came from a file on a hard disk and traversed several buses (communication pathways) to get to memory. Many of the instructions, when executed by the CPU, cause additional memory traffic and I/O traffic. When we speak of the overall performance of a computer system, we are implicitly referring to the overall performance of all those systems operating together. For any given workload, it is common to find that one of the “links in the chain” is, in fact, the weakest link. For instance, one can write a program that only executes CPU operations on data that reside in the CPU’s own register file or its internal data cache. We would refer to such a program as “CPU-bound,” and it would run as fast as the CPU alone could perform it. Speeding up the memory or the I/O system would have no discernible effect on measured performance for that benchmark. Another benchmark could be written, however, that does little else but perform memory load and store operations in such a way that the CPU’s internal cache is ineffective. Such a benchmark would be bound by the speed
THE INTERPLAY OF SOFTWARE AND PERFORMANCE
Although the amazing raw performance gains of the microprocessor over the last 20 years has garnered most of the attention, the overall performance and utility of computer systems are strong functions of both hardware and software. In fact, as computer systems have deployed more hardware, they have depended more and more on software technologies to harness their computational capability. Software has exploited that capability directly and indirectly. Software has directly exploited increases in computing capability by adding new features to existing software, by solving larger problems more accurately, and by solving previously unsolvable problems. It has indirectly exploited the capability through the use of abstractions in high-level programming languages, libraries, and virtual-machine execution environments. By using high-level programming languages and exploiting layers of abstraction, programmers can
of memory (and possibly by the bus that carries the traffic between the CPU and memory.) A third benchmark could be constructed that hammers on the I/O subsystem with little dependence on the speed of either the CPU or the memory.
Handling most real workloads relies on all three computer subsystems, and their performance metrics therefore reflect the combined speed of all three. Speed up only the CPU by 10 percent, and the workload is liable to speed up, but not by 10 percent—it will probably speed up in a prorated way because only the sections of the code that are CPU-bound will speed up. Likewise, speed up the memory alone, and the workload performance improves, but typically much less than the memory speedup in isolation. Numerous other pieces of computer systems make up the hardware. The CPU architectures and microarchitectures encompass instruction sets, branch-prediction algorithms, and other techniques for higher performance. Storage (disks and memory) is a central component. Memory, flash drives, traditional hard drives, and all the technical details associated with their performance (such as bandwidth, latency, caches, volatility, and bus overhead) are critical for a system’s overall performance. In fact, information storage (hard-drive capacity) is understood to be increasing even faster than transistor counts on the traditional Moore’s law curve,1 but it is unknown how long this will continue. Switching and interconnect components, from switches to routers to T1 lines, are part of every level of a computer system. There are also hardware interface devices (keyboards, displays, and mice). All those pieces can contribute to what users perceive of as the “performance” of the system with which they are interacting.
___________
1This phenomenon has been dubbed Kryder’s law after Seagate executive Mark Kryder (Chip Walter, 2005, Kryder’s law, Scientific American 293: 32-33, available online at http://www.scientificamerican.com/article.cfm?id=kryders-law).
express their algorithms more succinctly and modularly and can compose and reuse software written by others. Those high-level programming constructs make it easier for programmers to develop correct complex programs faster. Abstraction tends to trade increased human programmer productivity for reduced software performance, but the past increases in single-processor performance essentially hid much of the performance cost. Thus, modern software systems now have and rely on multiple layers of system software to execute programs. The layers can include operating systems, runtime systems, virtual machines, and compilers. They offer both an opportunity for introducing and managing parallelism and a challenge in that each layer must now also understand and exploit parallelism. The committee discusses those issues in more detail in Chapter 4 and summarizes the performance implications below.
The key performance driver to date has been software portability. Once
BOX 2.4
Time To Solution
Consider a jackhammer on a city street. Assume that using a jackhammer is not a pastime enjoyable in its own right—the goal is to get a job done as soon as possible. There are a few possible avenues for improvement: try to make the jackhammer’s chisel strike the pavement more times per second; make each stroke of the jackhammer more effective, perhaps by putting more power behind each stroke; or think of ways to have the jackhammer drive multiple chisels per stroke. All three possibilities have analogues in computer design, and all three have been and continue to be used. The notion of “getting the job done as soon as possible” is known in the computer industry as time to solution and has been the traditional metric of choice for system performance since computers were invented.
Modern computer systems are designed according to a synchronous, pipelined schema. Synchronous means occurring at the same time. Synchronous digital systems are based on a system clock, a specialized timer signal that coordinates all activities in the system. Early computers had clock frequencies in the tens of kilohertz. Contemporary microprocessor designs routinely sport clocks with frequencies of over about 3-GHz range. To a first approximation, the higher the clock rate, the higher the system performance. System designers cannot pick arbitrarily high clock frequencies, however—there are limits to the speed at which the transistors and logic gates can reliably switch, limits to how quickly a signal can traverse a wire, and serious thermal power constraints that worsen in direct proportion to the clock frequency. Just as there are physical limits on how fast a jackhammer’s chisel can be driven downward and then retracted for the next blow, higher computer clock rates generally yield faster time-to-solution results, but there are several immutable physical constraints on the upper limit of those clocks, and the attainable performance speedups are not always proportional to the clock-rate improvement.
How much a computer system can accomplish per clock cycle varies widely from system to system and even from workload to workload in a given system. More complex computer-instruction sets, such as Intel’s x86, contain instructions that intrinsically accomplish more than a simpler instruction set, such as that embodied in the ARM processor in a cell phone; but how effective the complex instructions are is a function of how well a compiler can use them. Recent
a program has been created, debugged, and put into practical use, end users’ expectation is that the program not only will continue to operate correctly when they buy a new computer system but also will run faster on a new system that has been advertised as offering increased performance. More generally, once a large collection of programs have become available for a particular computing platform, the broader expectation is that they will all continue to work and speed up in later machine genera-
additions to historical instruction sets—such as Intel’s SSE 1, 2, 3, and 4—attempt to accomplish more work per clock cycle by operating on grouped data that are in a compressed format (the equivalent of a jackhammer that drives multiple chisels per stroke). Substantial system-performance improvements, such as factors of 2-4, are available to workloads that happen to fit the constraints of the instruction-set extensions.
There is a special case of time-to-solution workloads: those which can be successfully sped up with dedicated hardware accelerators. Graphics processing units (GPUs)—such as those from NVIDIA, from ATI, and embedded in some Intel chipsets—are examples. These processors were designed originally to handle the demanding computational and memory bandwidth requirements of 3D graphics but more recently have evolved to include more general programmability features. With their intrinsically massive floating-point horsepower, 10 or more times higher than is available in the general-purpose (GP) microprocessor, these chips have become the execution engine of choice for some important workloads. Although GPUs are just as constrained by the exponentially rising power dissipation of modern silicon as are the GPs, GPUs are 1-2 orders of magnitude more energy-efficient for suitable workloads and can therefore accomplish much more processing within a similar power budget.
Applying multiple jackhammers to the pavement has a direct analogue in the computer industry that has recently become the primary development avenue for the hardware vendors: “multicore.” The computer industry’s pattern has been for the hardware makers to leverage a new silicon process technology to make a software-compatible chip that is substantially faster than any previous chips. The new, higher-performing systems are then capable of executing software workloads that would previously have been infeasible; the attractiveness of the new software drives demand for the faster hardware, and the virtuous cycle continues. A few years ago, however, thermal-power dissipation grew to the limits of what air cooling can accomplish and began to constrain the attainable system performance directly. When the power constraints threatened to diminish the generation-to-generation performance enhancements, chipmakers Intel and AMD turned away from making ever more complex microarchitectures on a single chip and began placing multiple processors on a chip instead. The new chips are called multicore chips. Current chips have several processors on a single die, and future generations will have even more.
tions. Indeed, not only has the remarkable speedup offered by industry standard (×86-compatible) microprocessors over the last 20 years forged compatibility expectation in the industry, but its success has hindered the development of alternative, noncompatible computer systems that might otherwise have kindled new and more scalable programming paradigms. As the microprocessor industry shifts to multicore processors, the rate of improvement of each individual processor is substantially diminished.
BOX 2.5
Throughput
There is another useful performance metric besides time to solution, and the Internet has pushed it to center stage: system throughput. Consider a Web server, such as one of the machines at search giant Google. Those machines run continuously, and their work is never finished, in that new requests for service continue to arrive. For any given request for service, the user who made the request may care about time to solution, but the overall performance metric for the server is its throughput, which can be thought of informally as the number of jobs that the server can satisfy simultaneously. Throughput will determine the number and configuration of servers and hence the overall installation cost of the server “farm.”
Before multicore chips, the computer industry’s efforts were aimed primarily at decreasing the time to solution of a system. When a given workload required the sequential execution of several million operations, a faster clock or a more capable microarchitecture would satisfy the requirement. But compilers are not generally capable of targeting multiple processors in pursuit of a single time-to-solution target; they know how to target one processor. Multicore chips therefore tend to be used as throughput enhancers. Each available CPU core can pop the next runnable process off the ready list, thus increasing the throughput of the system by running multiple processes concurrently. But that type of concurrency does not automatically improve the time to solution of any given process.
Modern multithreading programming environments and their routine successful use in server applications hold out the promise that applying multiple threads to a single application may yet improve time to solution for multicore platforms. We do not yet know to what extent the industry’s server multithreading successes will translate to other market segments, such as mobile or desktop computers. It is reasonably clear that although time-to-solution performance is topping out, throughput can be increased indefinitely. The as yet unanswered question is whether the buying public will find throughput enhancements as irresistible as they have historically found time-to-solution improvements.
The net result is that the industry is ill prepared for the rather sudden shift from ever-increasing single-processor performance to the presence of increasing numbers of processors in computer systems. (See Box 2.6 for more on instruction-set architecture compatibility and possible future outcomes.)
The reason that industry is ill prepared is that an enormous amount of existing software does not use thread-level or data-level parallelism—software did not need it to obtain performance improvements, because users simply needed to buy new hardware to get performance improvements. However, only programs that have these types of parallelism will experience improved performance in the chip multiprocessor era. Fur-
thermore, even for applications with thread-level and data-level parallelism, it is hard to obtain improved performance with chip multiprocessor hardware because of communication costs and competition for shared resources, such as cache memory. Although expert programmers in such application domains as graphics, information retrieval, and databases have successfully exploited those types of parallelism and attained performance improvements with increasing numbers of processors, these applications are the exception rather than the rule.
Writing software that expresses the type of parallelism that hardware based on chip multiprocessors will be able to improve is the main obstacle because it requires new software-engineering processes and tools. The processes and tools include training programmers to solve their problems with “parallel computational thinking,” new programming languages that ease the expression of parallelism, and a new software stack that can exploit and map the parallelism to hardware that is evolving. Indeed, the outlook for overcoming this obstacle and the ability of academics and industry to do it are primary subjects of this report.
THE ECONOMICS OF COMPUTER PERFORMANCE
There should be little doubt that computers have become an indispensable tool in a broad array of businesses, industries, research endeavors, and educational institutions. They have enabled profound improvement in automation, data analysis, communication, entertainment, and personal productivity. In return, those advances have created a virtuous economic cycle in the development of new technologies and more advanced computing systems. To understand the sustainability of continuing improvements in computer performance, it is important first to understand the health of this cycle, which is a critical economic underpinning of the computer industry.
From a purely technological standpoint, the engineering community has proved to be remarkably innovative in finding ways to continue to reduce microelectronic feature sizes. First, of course, industry has integrated more and more transistors into the chips that make up the computer systems. Fortunate side effects are improvements in speed and power efficiency of the individual transistors. Computer architects have learned to make use of the increasing numbers and improved characteristics of the transistors to design continually higher-performance computer systems. The demand for the increasingly powerful computer systems has generated sufficient revenue to fuel the development of the next round of technology while providing profits for the companies leading the charge. Those relationships form the basis of the virtuous economic
BOX 2.6
Instruction-Set Architecture: Compatibility
This history of computing hardware has been dominated by a few franchises. IBM first noticed the trend of increasing performance in the 1960s and took advantage of it with the System/360 architecture. That instruction-set architecture became so successful that it motivated many other companies to make computer systems that would run the same software codes as the IBM System/360 machines; that is, they were building instruction-set-compatible computers. The value of that approach is clearest from the end user’s perspective—compatible systems worked as expected “right out of the box,” with no recompilation, no alterations to source code, and no tracking down of software bugs that may have been exposed by the process of migrating the code to a new architecture and toolset.
With the rise of personal computing in the 1980s, compatibility has come to mean the degree of compliance with the Intel architecture (also known as IA-32 or x86). Intel and other semiconductor companies, such as AMD, have managed to find ways to remain compatible with code for earlier generations of x86 processors. That compatibility comes at a price. For example, the floating-point registers in the x86 architecture are organized as a stack, not as a randomly accessible register set, as all integer registers are. In the 1980s, stacking the floating-point registers may have seemed like a good idea that would benefit compiler writers; but in 2008, that stack is a hindrance to performance, and x86-compatible chips therefore expend many transistors to give the architecturally required appearance of a stacked floating-point register set—only to spend more transistors “under the hood” to undo the stack so that modern performance techniques can be applied. IA-32’s instruction-set encoding and its segmented addressing scheme are other examples of old baggage that constitute a tax on every new x86 chip.
There was a time in the industry when much architecture research was expended on the notion that because every new compatible generation of chips must carry the aggregated baggage of its past and add ideas to the architecture to keep it current, surely the architecture would eventually fail of its own accord, a victim of its own success. But that has not happened. The baggage is there, but the magic of Moore’s law is that so many additional transistors are made available in each new generation, that there have always been enough to reimplement the baggage and to incorporate enough innovation to stay competitive. Over time, such non-x86-compatible but worthy competitors as DEC’s Alpha, SGI’s MIPS, Sun’s SPARC, and the Motorola/IBM PowerPC architectures either have found a niche in market segments, such as cell phones or other embedded products, or have disappeared.
and technology-advancement cycles that have been key underlying drivers in the computer-systems industry over the last 30 years.
There are many important applications of semiconductor technology beyond the desire to build faster and faster high-end computer systems. In particular, the electronics industry has leveraged the advances
The strength of the x86 architecture was most dramatically demonstrated when Intel, the original and major supplier of x86 processors, decided to introduce a new, non-x86 architecture during the transition from 32-bit to 64-bit addressing in the 1990s. Around the same time, however, AMD created a processor with 64-bit addressing compatible with the x86 architecture, and customers, again driven by the existence of the large software base, preferred the 64-bit x86 processor from AMD over the new IA-64 processor from Intel. In the end, Intel also developed a 64-bit x86-compatible processor that is now far outselling its IA-64 (Itanium) processor.
With the rise of the cell phone and other portable media and computing appliances, yet another dominant architectural approach has emerged: the ARM architecture. The rapidly growing software base for portable applications running on ARM processors has made the compatible series of processors licensed by ARM the dominant processors for embedded and portable applications. As seen in the dominance of the System/360 architecture for mainframe computers, x86 for personal computers and networked servers, and the ARM architecture for portable appliances, there will be an opportunity for a new architecture or architectures as the industry moves to multicore, parallel computing systems. Initial moves to chip-multiprocessor systems are being made with existing architectures based primarily on the x86. The computing industry has accumulated a lot of history on this subject, and it appears safe to say that the era in which compatibility is an absolute requirement will probably end not because an incompatible but compellingly faster competitor has appeared but only when one of the following conditions takes hold:
- Software translation (automatic conversion from code compiled for one architecture to be suitable for running on another) becomes ubiquitous and so successful that strict hardware compatibility is no longer necessary for the user to reap the historical benefits.
- Multicore performance has “topped out” to the point where most buyers no longer perceive enough benefit to justify buying a new machine to replace an existing, still-working one.
- The fundamental hardware-software business changes so substantially that the whole idea of compatibility is no longer relevant. Interpreted and dynamically compiled languages—such as Java, PHP, and JavaScript (“write once run anywhere”)—are harbingers of this new era. Although their performance overhead is sometimes enough for the performance advantages of compiled code to outweigh programmer productivity, JavaScript and PHP are fast becoming the languages of choice on the client side and server side, respectively, for Web applications.
to create a wide variety of new form-factor devices (notebook computers, smart phones, and GPS receivers, to name just a few). Although each of those devices tends to have more substantial constraints (size, power, and cost) than traditional computer systems, they often embody the computational and networking capabilities of previous generations of higher-end
computer systems. In light of the capabilities of the smaller form-factor devices, they will probably play an important role in unleashing the aggregate performance potential of larger-scale networked systems in the future. Those additional market opportunities have strong economic underpinnings of their own, and they have clearly reaped benefits from deploying technology advances driven into place by the computer-systems industry. In many ways, the incredible utility of computing not only has provided direct improvement in productivity in many industries but also has set the stage for amazing growth in a wide array of codependent products and industries.
In recent years, however, we have seen some potentially troublesome changes in the traditional return on investment embedded in this virtuous cycle. As we approach more of the fundamental physical limits of technology, we continue to see dramatic increases in the costs associated with technology development and in the capital required to build fabrication facilities to the point where only a few companies have the wherewithal even to consider building these facilities. At the same time, although we can pack more and more transistors into a given area of silicon, we are seeing diminishing improvements in transistor performance and power efficiency. As a result, computer architects can no longer rely on those sorts of improvements as means of building better computer systems and now must rely much more exclusively on making use of the increased transistor-integration capabilities.
Our progress in identifying and meeting the broader value propositions has been somewhat mixed. On the one hand, multiple processor cores and other system-level features are being integrated into monolithic pieces of silicon. On the other hand, to realize the benefits of the multiprocessor machines, the software that runs on them must be conceived and written in a different way from what most programmers are accustomed to. From an end-user perspective, the hardware and the software must combine seamlessly to offer increased value. It is increasingly clear that the computer-systems industry needs to address those software and programmability concerns or risk the ability to offer the next round of compelling customer value. Without performance incentives to buy the next generation of hardware, the economic virtuous cycle is likely to break down, and this would have widespread negative consequences for many industries.
In summary, the sustained viability of the computer-systems industry is heavily influenced by an underlying virtuous cycle that connects continuing customer perception of value, financial investments, and new products getting to market quickly. Although one of the primary indicators of value has traditionally been the ever-increasing performance of each individual compute node, the next round of technology improve-
ments on the horizon will not automatically enhance that value. As a result, many computer systems under development are betting on the ability to exploit multiple processors and alternative forms of parallelism in place of the traditional increases in the performance of individual computing nodes. To make good on that bet, there need to be substantial breakthroughs in the software-engineering processes that enable the new types of computer systems. Moreover, attention will probably be focused on high-level performance issues in large systems at the expense of time to market and the efficiency of the virtuous cycle.



























