
Modeling Strategy: From Single
Attribute to Multiple Attributes
The vaccine prioritization techniques of the earlier Institute of Medicine (IOM) studies published in 1985–1986 and 2000 relied on two criteria: (1) reduction of health burden (IOM, 1985, 1986) and (2) incremental cost or savings (IOM, 2000) due to use of the vaccine in a defined population. More specifically, the 1985–1986 work used only a single attribute—infant deaths averted—for ranking vaccine candidates; it did not consider cost attributes. The 2000 report used an approach based on cost-effectiveness to prioritize vaccines.
Those studies saw the central “modeling task” as numerical estimation of the expected costs and benefits of the vaccines. The principles underlying this approach derive from the economic theory of social welfare as implemented in the classic utility frameworks (Garber and Phelps, 1997). The computational models were the key contributions of the 1985–1986 and 2000 reports. Their work involved many decisions concerning which costs and savings to include and how best to measure health gains.
New Vaccine Development (1985–1986) and
Vaccines for the 21st Century (2000)
The 1985–1986 report measured health benefits using infant mortality equivalents (IMEs), which involved subjective judgments relating to morbidity and mortality reductions compared to an equivalent number of infant deaths averted. Since the time that report was published, analytical techniques have advanced. Standardized measures of health-related qual-
ity of life (HRQOL) such as the Health Utilities Index Mark 2, or HUI2—a tool to measure morbidity reduction—have been developed using methods of multi-attribute utility theory (Feeny et al., 1996). HUI2 has been combined with actuarial measures of life expectancy changes in order to compute quality-adjusted life years (QALYs) as one of the main health valuation measures.
To derive its vaccine priorities, the 2000 report relied on incremental dollar costs per incremental QALY gained ($/QALY) for both preventive and therapeutic vaccines that are of importance to the United States. In the nearly three decades since the 1985–1986 report was published, the theoretical basis for its calculations has not changed. By contrast, in the years since the 2000 report, the methods of cost-effectiveness analysis have become somewhat more sophisticated when it comes to assessing the effectiveness of $/QALY values for health care technologies.
The self-reported health status data needed for population-based measures such as HUI2 are not available in much of the world. Instead, researchers at the World Health Organization in collaboration with researchers at other institutions developed a similar tool: disability-adjusted life years (DALYs). In calculating DALYs, disability weights are assigned to typical manifestations of a wide variety of diseases; such measures have been used for many countries around the world (Fox-Rushby and Hanson, 2001; Gold et al., 2002; Murray and Lopez, 2000).
Methods to incorporate uncertainties in decision models were undergoing rapid development at the time of the 2000 report. They have since progressed and become more generally applicable (Fenwick et al., 2001; Meckley et al., 2010). There have also been advances in population-based data collection supporting HUI2 and similar indexes of generic health-related quality of life that the 2000 report incorporated (Fryback et al., 2007, 2010; Luo et al., 2005, 2009).
In recent years, advances in complex systems modeling have helped characterize the nature and spread of infections in populations. These dynamical techniques can now be used for estimating the impact of a new vaccine for a specific population (e.g., Epstein et al., 2008). But the underlying decision framework and conceptual approaches to estimating costs and health benefits have essentially remained unchanged.
The previous reports developed a computational model based on two important (but distinctly different) attributes for prioritizing vaccines, although more sophisticated methods could have been used. The main criticism of the 2000 report was related to the basic framework itself: the system was too limited and considered only costs and aggregated health benefits (e.g., see Plotkin et al., 2000).
Modeling beyond cost-effectiveness
The committee revisited the assumptions and limitations of the 1985–1986 and 2000 approaches. Instead of taking the path of developing a de novo computational model, the committee chose to significantly expand the previous IOM works by using a multi-attribute utility framework and develop a novel software application. In this work, therefore, some aggregate measure of health benefits (such as infant deaths averted) or an efficiency criterion (such as cost-effectiveness) has simply become one among the many criteria—rather than the only criterion—that influence vaccine prioritization.
The committee took on the task of expanding the list of attributes characterizing vaccine candidates and developing a prototype software—SMART Vaccines Beta—to weigh not only economic and health attributes but also demographic, scientific, business, programmatic (field-level logistics), social, and policy aspects relating to new vaccine development. The short-listing of 29 attributes used in SMART Vaccines Beta was informed by stakeholder and concept evaluator feedback, committee discussions, and literature review (Burchett et al., 2011).
Values and objectives in priority setting
Priority setting means assigning values and objectives. If the main objective of a new preventive vaccine is to minimize the disease burden in the target population, then assuming that all else is equal, the highest priority typically would be given to the vaccine candidate expected to produce the largest health benefit compared to other candidates, and a set of vaccine candidates would be prioritized according to their expected health benefits, going from most expected benefits to least.
But all else is not equal. Priorities must also reflect such considerations as the fact that resources are constrained. Such a limited-resources constraint points to a different objective: to minimize the costs associated with bringing a vaccine to licensure and then administering it in the target population. If minimizing costs is the main objective, then the program with the lowest development and implementation costs would be favored, and priorities would simply be ordered according to the increasing costs of the different programs. These two objectives—maximizing health benefits and minimizing costs—are often in conflict. One vaccine candidate may potentially have a very large aggregate impact on health burden but also have greater expected costs than a vaccine addressing a different disease where the effect on health burden may be smaller.
When objectives are in conflict, decision makers often deal with trade-offs. In this case, each vaccine candidate is associated with expected health benefits and costs. Expressing a priority order among candidates requires us to weigh the extent to which each vaccine candidate achieves the two objectives jointly, perhaps preferring one objective over the other. In this case, cost-effectiveness analysis is appropriate and may be used to prioritize vaccine candidates when there are trade-offs between these two important attributes.
But several other objectives could also influence the ranking of vaccine candidates under consideration. These objectives depend on whose priorities are being expressed toward maximizing the overall value of the vaccines. For example, decision makers may want to represent a public desire to minimize the burden of disease in specific target populations such as women, infants, and children; the socioeconomically disadvantaged; or military personnel. There may be certain diseases that raise special concerns or fear in the public mind—for example, a rare but particularly grue-some condition, an unrelenting infection, or a terribly disfiguring disease. Extra priority may be given to a vaccine that prevents such a disease, escalating its priority despite high costs or a relatively small aggregate health burden imposed by the disease in the population compared to a vaccine preventing a condition that is more common but that has a relatively minor health burden.
Other objectives are also possible. One might wish, for instance, to maximize the benefit to future generations by investing in a vaccine that could eliminate a particular disease altogether or mitigate its epidemic potential. Similarly, one might wish to prioritize a vaccine that has the potential to significantly advance the scientific base, including new production, preservation, and delivery methods.
A prioritization exercise starts with a set of vaccine candidates, each of which is expected to meet, to a greater or lesser degree, a number of desired objectives. The basic purpose of prioritization is to place these candidates in order from “most preferred” to “least preferred” in accordance with values held by or represented in proxy by the decision maker. The methods used to accomplish this task in a rigorous fashion fall generally under the rubric “multi-criteria decision making.”
Multi-criteria decision-making methods
From the family of multi-criteria decision-making models, the committee chose to use a version of multi-attribute utility theory. As a starting point, the committee limited the models under consideration to those
that included multiple attributes. The committee heard from a number of stakeholders that the narrow range of attributes used to rank vaccine priorities in previous IOM studies significantly limited their value and applications. Thus, the committee reviewed three multiple-attribute modeling approaches (listed in the order of historical development): (1) mathematical programming (or optimization), (2) multi-attribute utility theory, and (3) analytical hierarchy process. The approaches were evaluated against four criteria: axiomatic foundation; priority scaling; sensitivity analysis; and transparency.
Multi-attribute utility theory and mathematical programming are based on axiomatic theory—the former being derived from principles of utility maximization (Krantz et al., 1971), and the latter being based on mathematical optimization. The analytical hierarchy process has an axiomatic base that the committee considered incomplete. To elaborate, the issue of independence from irrelevant alternatives (IIA) was of particular importance to the committee’s considerations. IIA means the following: Given a particular set of options (candidate vaccines) in which candidate A is preferred to candidate B, if an additional candidate C—unrelated to A and B—is added to the option set, then A continues to be preferred over B.
Consider, for example, a comparison of vaccines to prevent tuberculosis and malaria, ranked with one preferred to the other. Now suppose that the science and technology evolves to allow a new vaccine against dengue fever. IIA would mean that the ranking of vaccine candidates for tuberculosis and malaria remains unchanged when the dengue fever vaccine is added to the mix for consideration. The new dengue fever vaccine may be more or less preferred than either tuberculosis or malaria or both vaccines, but the rankings of tuberculosis and malaria vaccines with respect to each other must remain unchanged. Since the appearance of new candidate vaccines can be anticipated over time, the committee concluded that IIA was particularly important to consider.
The 1985–1986 and 2000 IOM reports relating to vaccine prioritization and the international stakeholder testimonies made it very clear that this committee’s work would need to offer greater value in terms of allowing different users to apply their individual preferences in a prioritization model. The committee defines the term “prioritize” consistently with the stan-
dard dictionary definition “to arrange in the order of relative importance.” Thus, prioritization at a minimum requires an ordinal ranking and nothing more—simply stating an order of preference. The three modeling methods considered by the committee all provide additional information beyond an ordinal scale—either interval or ratio scale numbers assigned to vaccine candidates to represent relative priority.
To use an analogy relating to temperature measurement, with interval scales the difference between two values has the same meaning at different points along the scale. For example, the difference between 20ºC and 40ºC has the same meaning as the difference between 30ºC and 50ºC. But 40ºC is not twice as hot as 20ºC. Ratio scales also provide information about relative values, thus requiring identification of true “zero” on the scale. Kelvin temperature allows for this: 300K is twice as hot as 150K, whereas statements about ratios of temperatures are incorrect in either ºC or ºF scales—but ratios of differences in temperatures are the same on K, ºC, and ºF scales. Since only ordinal ranking is required in prioritization, any modeling approach providing interval or ratio scaling is sufficient.
The committee also wanted to allow users to conduct sensitivity analysis on their results. This sensitivity analysis has several purposes, including (a) enhancing understanding of the inputs to which the results were most sensitive, (b) pointing toward areas where improved data have the greatest value, and hence potentially (c) spurring efforts and investments in data generation. All three modeling approaches had the capability for ably supporting sensitivity analyses.
Another important criteria for the committee was transparency. In the committee’s view, the multi-attribute utility approach was more transparent than other possible approaches. In mathematical programming, for example, one could subtly alter the constraint set (in ways very difficult for others to see) so as to eliminate some candidates from the solution set in favor of others, or else modify the way the objective function was specified. In analytic hierarchy process, the value weights emerge only after a long series of pair-wise comparisons have been recorded and modified through normalization processes involving complex matrix manipulations. By contrast, in multi-attribute utility theory the weights and data are available for everybody to see and use. In that regard, multi-attribute utility theory was
found to be the best fit for satisfying the transparency requirement. Indeed, the committee saw this as a strength of the SMART Vaccines, highlighting its potential in promoting cross-comparison of different users’ rationale and conclusions and leading to more informed discussions about priorities among different stakeholders. Each modeling alternative is summarized in the following sections.
Mathematical programming or optimization
Mathematical programming (linear programming, nonlinear programming, stochastic programming, and more complex optimization algorithms) has been widely and successfully employed in many areas to tackle complex challenges. In concept, mathematical programming is an appropriate method for vaccine prioritization. Its optimization characteristics are well understood (Rardin, 1997). In various formulations, it can provide output of at least ordinal nature (ranking) and, in many formulations, interval or ratio scale output, and software to carry out such calculations is widely available in numerous commercial and free-ware environments. It is also amenable to sensitivity analyses.
The primary uses of mathematical programming involve optimization of some value function (specified by the user) subject to a set of constraints which are often highly complex and frequently nonlinear. In classical linear and nonlinear programming, the values of relevant components of the model are known (e.g., cost, consumer preferences, and other factors). Stochastic programming emerged to provide optimization tools when uncertainty exists about certain components of the system under consideration. But, in general, the value of mathematical programming appears when there are many possible solutions (perhaps an infinite number) within the constraint set.
Prioritization of vaccines differs considerably from the usual uses of mathematical programming. Typically, only a small number of alternatives are considered in the set of potential vaccines (dozens, perhaps, but seldom hundreds, almost never thousands, and certainly not an infinite set of options). Separately, unless a customized stochastic programming method or some equivalent method is developed and used, the dearth of data in regards to new vaccines problem would likely render the optimization capabilities of mathematical programming questionable for the application.
Another issue also deterred the full consideration of mathematical programming for vaccine prioritization: Mathematical programming requires a pre-specification of the value function. This is a crucial issue,
since many users and stakeholders would not be able to competently specify a value function for such reasons as a lack of a quantitative background. Furthermore, there are no well-developed and tested methods for value elicitation associated with mathematical programming methods.
The analytic hierarchy process has many desirable attributes. It is widely used by people in business and other settings to assist in decision making, often under the tutelage of professional consultants. It provides a ratio-scale value function, which is more than sufficient for the committee’s ranking process. It has a well-developed process for eliciting values from users, based on a large set of pair-wise comparisons of different alternatives along the various attribute dimensions. The user must make a sizeable number (typically in the hundreds) of paired comparison assessments. For each pair of candidates (e.g., vaccines) A and B, and for each attribute, xj, the decision maker rates the comparison of xaj versus xbj using a scale of 9, 7, 5, 3, 1, 1/3, 1/5, 1/7, 1/9 to describe how much better A is than B on that attribute, where the numbers are meant to convey a ratio scale of relative performance. Although, in principle, any user can program the calculations necessary for deriving priorities1 from an analytic hierarchy process, most analysts use one of a number of proprietary software packages currently available. These packages lead users through the necessary steps and provide internal consistency checks for many of the comparative assessments.
Besides the complexity associated with value elicitation process, two other features make this analytic hierarchy process less friendly for vaccine prioritization. Perhaps most important, the analytic hierarchy process does not maintain IIA, a fact that is widely understood among both proponents and opponents of this method (Dyer, 1990; Saaty, 1987). Proponents of analytic hierarchy process cite this as a beneficial feature, noting that many real world decisions also do not have IIA. But the committee, for reasons stated previously, views IIA as a critical factor in vaccine prioritization.
___________________
1Among the users of analytic hierarchy process the word “priority” has a specific technical meaning (relating to a normalized eigenvector used in the model) that does not match the standard definition of priority mentioned earlier and used in this report. Thus, one should not confuse the specific analytic hierarchy process definition of priority with the one used by the committee.
Multi-attribute utility theory
A multi-attribute utility-based prioritization exercise consists of several steps. First, the set of vaccine candidates to be considered must be identified. Next, a set of objectives that underpin the valuation of candidates must be listed. For each objective there must be a specific measure—called an “attribute”—developed. The attributes may be natural scales (such as expected net present value of annualized dollar costs or savings), well-established indexes (such as net annualized increase in QALYs due to the vaccine), or customized categorical scales.
If we denote each candidate vaccine by xi, then the outcome attributes characterizing that vaccine may be viewed as a vector, ci = (xi 1, xi 2, … , xin), where n is the number of attributes being considered when setting priorities, and xij is the value of the scale for the jth attribute for the ith vaccine candidate. Multi-attribute utility models can combine attributes of each type, whether continuous or categorical.
Keeney and Raiffa (1976) as well as a number of others (Barron and Barrett, 1996; Edwards and Barron, 1994; Edwards and Newman, 1982; von Winterfeldt and Edwards, 1986) have described methods to specify n single-attribute functions, 0 ≤ uj (xj) ≤ 1, and a global utility function, U (ci) = f (u 1(xi 1), u 2(xi 2), … , un (xin)), such that 0 ≤ U (ci) ≤ 1. The function U is constructed so that ca is preferred to cb if and only if U (ca) > U (cb).
Often the function f is additive, U (ci) = w1u1(xi 1) + w2u2(xi2) + … + wn un (xin), where the wjs are constants that sum to 1. The ratios wj/wk reflect the change in value achieved by changing the jth attribute from its minimum to maximum level in the set of vaccine candidates versus making the corresponding change in the kth attribute. Although there are strong arguments for using an additive function as a first approximation (Edwards and Barron, 1994; Keeney and von Winterfeldt, 2007; von Winterfeldt and Edwards, 1986), in some cases a multiplicative function or multi-linear function might be more appropriate in order to account for interactions among the attributes based on user preferences (Keeney and Raiffa, 1976). Additive functions are often satisfactory for broad policy purposes. The committee employs an additive version of multi-attribute utility method in SMART Vaccines Beta.
Determining what weights (w 1, w 2, … , wn) to use is a separate problem from that of choosing the functional form (e.g., additive or multiplicative). Edwards and Barron (1994) proposed a method to approximate the wjs using the decision maker’s rank order of the relative importance of the attributes. In particular, they proposed using the rank order centroid method to derive weights for a set of attributes, a method that was later extensively evaluated by Barron and Barrett (1996).
The rank order centroid approximation
The decision maker’s major input is to produce a rank order of the relative importance of the attributes in order to differentiate the priority of the vaccine candidates. This induces a rank order on the weights in the additive model. Suppose that the rank order is w 1 ≥ w 2 ≥ … ≥ wn for n attributes. The rank order centroid approximation for the constants in an additive model would then be as follows:
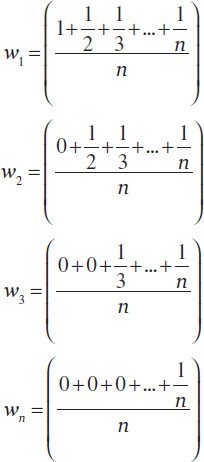
More compactly the weights can be expressed by
![]()
Barron and Barrett showed this rank order centroid approximation for weights to be superior to other often-proposed methods, such as the normalized sum of ranks. It is important to realize that rank order centroid weights are not essential to the multi-attribute utility models; rather they are an approximation used to reduce the workload of the potential user.
In SMART Vaccines Beta, the rank order centroid-based weighting approach was employed in order to speed up development of other parts of the model. In many policy settings using multi-attribute utility theory, these weights are developed with experts guiding the process of decision makers elucidating their preferred weights (Keeney and Raiffa, 1976; von Winterfeld and Edwards, 1986).
The multi-attribute decision techniques (or related proprietary software packages) have been used in practical applications in a number of
public policy settings, including to evaluate alternative plans to desegregate schools (Edwards, 1979), to plan wastewater treatment facilities (Keeney et al., 1996), to evaluate accounting regulations for control of nuclear materials (Keeney and Smith, 1982), and to evaluate homeland security decisions (Keeney and von Winterfeld, 2011). Additional applications have been reviewed by Keefer and colleagues (2004).
The multi-attribute utility approach places considerable data demands on users. The committee continually sought to balance the model’s capabilities and complexity with the data demands it would place on users. The challenge, however, spans every approach considered by the committee. It is intrinsic not to the multi-attribute utility approach itself, but rather to the underlying complexity of prioritization and how to model it. Had mathematical programming or analytic hierarchy process been adopted, a level of data demands similar to those in the multi-attribute utility theory would have been required. The only way to reduce data demands is to have limited capabilities in SMART Vaccines.
A parallel issue relates to how the necessary data must be structured. In the committee’s view, the data inputs necessary for the multi-attribute approach are at least as simple—and often simpler—for users to understand than would be the case in alternative models. For example, many formulations of mathematical programming have inequality constraints, a concept that could seem alien to many potential users of our software.
The modeling framework for SMART Vaccines Beta
Multi-attribute utility theory provides the analytical framework that underpins the committee’s work, and the specific model within this framework is an additive multi-attribute utility model. A schematic diagram of the model’s organization is presented in Figure 2-1.
Within the multi-attribute utility framework, a vaccine candidate is viewed as a means to achieve an end in a specified population. The various objectives that the development and delivery of a new vaccine may address include
• enhancing public health by reducing the burden due to a particular disease or condition;
• minimizing the societal costs of the disease, and its prevention and treatment;
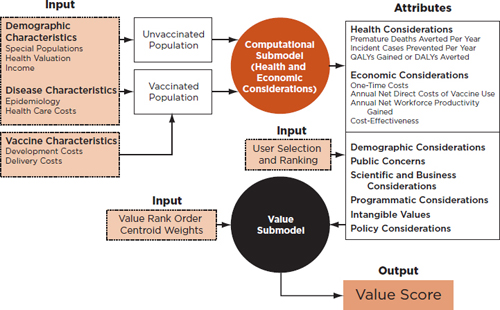
FIGURE 2-1
The modeling framework for SMART Vaccines Beta. The computational and value submodels cooperate to produce a value score based on user inputs and various attributes compared in populations with and without the vaccination against a particular condition.
• addressing public concerns relating to the target disease;
• improving the health of specific, priority populations such as infants and children and economically disadvantaged persons; and
• advancing national security by immunizing military personnel from specific diseases and addressing domestic and foreign policy concerns.
This list is illustrative and not meant to be all-inclusive. Many of these objectives were suggested to the committee during public sessions in which stakeholders from both U.S. and international organizations were invited to discuss their ideas concerning what objectives should be reflected in priorities for new vaccine development.
The 29 attributes in Table 2-1 include both quantitative and qualitative attributes which can be potentially important for many groups of stakeholders. This list is meant to offer a smorgasbord of choices from which stakeholders can select in accordance with their objectives. The committee tried to err on the side of “too much” rather than “too little” and to take the possible interests of various constituencies into account. The quantitative attributes are measures that are “computed” using the demographic,
economic, and new vaccine information provided by the user concerning a particular disease.
Figure 2-1 shows the inputs for the computational submodel that simulates the disease in a target population both in the absence and in the presence of a new vaccine. The output of this computation is the estimated impact of the vaccine on various measures of health burden in the population as well as on the costs associated with the disease, including disease care expenditure.
Table 2-1 contains three attributes describing simulated health impacts of the vaccine and four attributes related to the economic impacts of the condition. Six of these seven attributes are calculated using the computational submodel, which is described in the following section. The remaining 23 attributes for the candidate vaccines are directly scored by users based on their preferences and opinions. The result of the computations and user scores is a vector of attribute levels describing the relative achievement of each candidate vaccine on each of the 29 attributes.
Users are not required to include all 29 attributes when they run SMART Vaccines. In fact, the committee expects that users may not want to include all of the attributes as part of their prioritization process but will include only those that are most relevant to maximizing the value of new vaccines from their particular point of view. SMART Vaccines will be able to help determine the priorities among vaccine candidates for users only on the basis of the attributes they select and rank, which are expected to be different across the users. Stakeholders who use the same subset of attributes to determine priorities may very well weigh them differently per their values and constituencies.
Foundation for the computational submodel
Most of the attributes in Table 2-1 (e.g., whether or not the vaccine primarily targets health burden among infants and children) are qualitative assessments to be made by users in order to characterize aspects of the vaccine candidates that are beyond the capabilities of the computational submodel. But there are six attributes that quantify the impact of the vaccine on mortality and morbidity in the population and the costs of achieving these impacts.
The effects of vaccines in populations are complex functions of relatively well-known inputs. Thus in SMART Vaccines Beta these attributes are estimated using simulation modeling. The simulation model decomposes a complex quantitative issue into smaller parameters so as to allow specific data and targeted expert knowledge about population demography
TABLE 2-1
List of Possible Attributes in SMART Vaccines and Categorizations of the Measures for Domestic and International Comparisons
| Attribute | Definition | Categories: Level 1 = Highest Priority | |
| For International Comparisons | For Domestic Comparisons | ||
| 1. Health Considerationsa | |||
| Premature Deaths Averted per Year | The difference in the number of deaths in 1 year, assuming no routine vaccine use and assuming routine vaccine use against the disease in the population.b | Level 1: >1,000,000 Level 2: 500,000–999,999 Level 3: 100,000–499,999 Level 4: <100,000 |
Level 1: >20,000 Level 2: 5,000–19,999 Level 3: 1,000–4,999 Level 4: <1,000 |
| Incident Cases Prevented per Year | The difference in the number of incident cases of disease in one year, assuming no routine vaccine use and assuming routine vaccine use against the disease in the population.c | Level 1: >10 million Level 2: 1–10 million Level 3: 250,000–1 million Level 4: <250,000 |
Level 1: >75,000 Level 2: 50,000–74,999 Level 3: 10,000–49,999 Level 4: <10,000 |
| QALYs Gained or DALYs Averted | Net increase in QALYs gained or DALYs lost in the population vaccinated.d Computed as a difference between QALYs or DALYs experienced in stationary population followed until all have died, assuming vaccination versus assuming no vaccination. | Level 1: >25 million DALYs Level 2: 10–25 million DALYs Level 3: 500,000–10 million DALYs Level 4: <500,000 DALYs |
Level 1: >50,000 QALYs Level 2: 20,000–49,999 QALYs Level 3: 5,000–19,999 QALYs Level 4: <5,000 QALYs |
| 2. Economic Considerations | |||
| One-Time Costs | Sum of development plus licensure plus start-up costs. This attribute represents the magnitude of the financial barriers to bringing the vaccine to use in the population.e | Level 1: <$100 million Level 2: $100–$500 million Level 3: $500 million–$1 billion Level 4: >$1 billion |
Level 1: <$100 million Level 2: $100–$500 million Level 3: $500 million–$1 billion Level 4: >$1 billion |
| Annual Net Direct Costs (Savings) of Vaccine Use | The difference in the total health care costs without the vaccine and the health care costs with the vaccine and the vaccine administration costs for 1 year, assuming a steady-state population.f | Level 1: <$0 (cost saving) Level 2: $0-$100 million Level 3: $100-$300 million Level 4: >$300 million |
Level 1: <$0 (cost saving) Level 2: $0-$50 million Level 3: $50-$150 million Level 4: >$150 million |
| Annual Net Workforce Productivity Gained | Net workforce productivity gained is the difference in the annual productivity loss under the assumption of no vaccine use and annual productivity loss under the assumption of routine vaccine use.g | Level 1: >$10 billion Level 2: $5-$10 billion Level 3: $1-$5 billion Level 4: <$1 billion |
Level 1: >$10 billion Level 2: $5-$10 billion Level 3: $1-$5 billion Level 4: <$1 billion |
| Cost-Effectiveness | $/QALY gained or $/DALY avoided. | Level 1: <$0 (cost saving) Level 2: <$50,000 Level 3: $50,000-$150,000 Level 4: >$150,000 |
Level 1: <$0 (cost saving) Level 2: <$50,000 Level 3: $50, 000-$150,000 Level 4: >$150,000 |
| 3. Demographic Considerations | |||
| Benefits Infants and Children | Vaccine targets a disease occurring primarily among infants and children to prevent a serious disease with notable associated mortality and/or that often results in long-lasting serious morbidity. Examples: rotavirus, polio. | Level 1: Yes Level 2: No |
|
| Benefits Women | Vaccine targets a disease primarily affecting women. Example: HPV-caused cervical cancer. | Level 1: Yes Level 2: No |
|
| Attribute | Definition | Categories: Level 1 = Highest Priority | |
| For International Comparisons | For Domestic Comparisons | ||
| Benefits Socioeconom ically Disadvantaged | Vaccine targets a disease affecting economically disadvantaged population disproportionately. Example: malaria, tuberculosis, rotavirus. | Level 1: Yes Level 2: No |
|
| Benefits Military Personnel | Vaccine protects military personnel from a particular deadly disease. | Level 1: Yes Level 2: No |
|
| Benefits Other Priority Population | Vaccine targets a disease particularly prevalent in, say, immunocompromised individuals or other priority populations. | Level 1: Yes Level 2: No |
|
| 4. Public Concerns | |||
| Availability of Alternative Public Health Measures | Do relatively effective and inexpensive public health measures to reduce the impact of the target disease already exist? Example: bed nets for malaria. | Level 1: No Level 2: Yes |
|
| Potential Complications Due to Vaccines | Is there an expectation beyond what would be usual of potential risks of complications due to the vaccine? This might be inferred from similar vaccines produced using same platform. Example: high-risk live vaccines. | Level 1: No Level 2: Yes |
|
| Disease Raises Fear and Stigma in the Public | Vaccine targets a new or re-emergent disease that raises fear in the public mind and brings public and political calls for prevention. Examples: meningococcal disease, Ebola, SARS. | Level 1: Yes Level 2: No |
|
| Serious Pandemic Potential | Vaccine targets a disease with serious pandemic potential and socioeconomic disruption. Example: A human-to-human transmissible H5N1 influenza. | Level 1: Yes Level 2: No |
|
| 5. Scientific and Business Considerations | |||
| Likelihood of Financial Profitability for the Manufacturer | Is the vaccine likely to be a financially profitable endeavor for the producer?h | Level 1: Almost certainly will be profitable Level 2 Level 3 Level 4 Level 5: Almost certainly will not be profitable |
|
| Likelihood of Successful Licensure in 10 Years | Probability of successful licensure for the target populations in the next 10 years. | Level 1: Almost certainly will be licensed within 10 years Level 2 Level 3 Level 4 Level 5: Almost certainly will not be licensed within 10 years |
|
| Demonstrates New Production Platforms | Will this vaccine demonstrate a novel vaccine concept or platform technology to inform future vaccine science? | Level 1: Yes Level 2: No |
|
| Attribute | Definition | Categories: Level 1 = Highest Priority | |
| For International Comparisons | For Domestic Comparisons | ||
| Existing or Adaptable Manufacturing Techniques | Could this vaccine be developed using existing or adaptable manufacturing techniques? | Level 1: Yes Level 2: No |
|
| Potential Litigation Barriers Beyond Usual | From a manufacturer’s perspective, could this vaccine encounter potential litigation barriers beyond the usual? | Level 1: No Level 2: Yes |
|
| Interests from NGOs and Philanthropic Organizations | Could this vaccine generate interests from NGOs and other philanthropic and charitable organizations? | Level 1: Yes Level 2: No |
|
| 6. Programmatic Considerations | |||
| Potential to Improve Delivery Methods | Does the vaccine development have the potential to improve delivery methods or stimulate novel approaches to deliver vaccines? | Level 1: Yes Level 2: No |
|
| Fits into Existing Immunization Schedules | Could this vaccine fit into existing immunization schedules? | Level 1: Yes Level 2: No |
|
| Reduces Challenges Relating to Cold-Chain Requirements | Does the vaccine development have the potential to reduce challenges relating to cold-chain storage and related packaging and other requirements? | Level 1: Yes Level 2: No |
|
| 7. Intangible Values | |||
| Eradication or Elimination of the Disease | Vaccine presents potential for either global eradication of a serious disease entirely (e.g., smallpox, polio, measles) or elimination of the disease’s effects among humans. Example: anthrax, generic flu, malaria—diseases where the reservoir will not be eliminated and each new human generation will need to be vaccinated. | Level 1: Potential Eradication of the Disease Level 2: Potential Elimination from Humans Level 3: Neither of the above |
|
| Vaccine Raises Public Health Awareness | Could this vaccine help improve public health awareness and induce potential public behavioral change? (Example: HPV and safe sex.) | Level 1: Yes Level 2: No |
|
| 8. Policy Considerations | |||
| Special Interest for National Security, Preparedness, and Response | Is the development of this vaccine of special interest for reasons of national security? | Level 1: Yes Level 2: No |
|
| Advances Nation’s Foreign Policy Goals | Is the development of this vaccine of special interest for reasons of foreign policy, foreign assistance, or diplomatic goals? | Level 1: Yes Level 2: No |
|
Categories must be consistent and kept constant across vaccine candidates for a particular comparison. The “domestic” values for categorization refer to the United States. The “international” values refer to the remainder of the world in aggregate. If priorities are to be set solely within one country, they can be adjusted to levels meaningful for that country. Value scores are meaningful only among vaccine candidates compared on the same categorizations of variables. Categories for the United States are suggested for comparisons of vaccine candidates within and for the United States. Levels are assigned so that Level 1 is highest priority to be consistent with numbering in the 2000 report.
aEither QALYs or DALYs must be selected to apply to all alternatives being prioritized.
bBenchmarks for deaths averted per year:
• In 2009, 1.35 million deaths from tuberculosis in non-HIV infected persons (http://bit.ly/bZL4nh)
• In 2010, malaria caused 655,000 deaths worldwide (http://bit.ly/b5frdR)
• Rotavirus caused 352,000–592,000 deaths worldwide (http://1.usa.gov/GVqTKp)
• U.S. influenza deaths: 27,100–55,700 deaths (http://bit.ly/fPDqpf)
• U.S. septicemia deaths: 34,800 in 2007; U.S. bacterial sepsis of newborn deaths: 820 in 2007 (http://1.usa.gov/rbLHiL)
• U.S. hepatitis C deaths in 2007: rate of 4.58 per 100,000 or 1,400 in population of 300 million (http://1.usa.gov/GRlhnA)
These mortality levels may be overstated by large amount as we did not adjust for effectiveness. If on average we presume any program has 50 percent effectiveness then perhaps these boundaries should be cut by 50 percent to spread vaccine candidates more effectively across the categories.
cCase incidence:
• U.S. congenital CMV: 30,000/yr in newborns (http://bit.ly/hvVDz)
• U.S. influenza hospitalizations: 42,000 in 2009–2010 season (http://1.usa.gov/GKxQw7)
• U.S. influenza lab-tested specimens positive for influenza: 157,000 of 757,000 tested in 2009–2010 (a high-incidence season—pandemic level). Usual season level about 25 percent of this, or 39,000. Since lab specimens are collected in office visits, influenza-like illness generated at least 757,000 office visits (http://1.usa.gov/GKxQw7)
• U.S. influenza cases estimated at 24.7 million (2003 population) (Molinari et al., 2007)
• U.S. hepatitis C: estimated 2,600 new cases in 2009, with decreasing incidence over time (http://1.usa.gov/GJg90E)
• Worldwide incidence malaria: an estimated 225 million cases in 2009 (http://bit.ly/syqsq5)
dDALYs averted and QALYs saved:
• DALYs by cause globally:
ο 72.6 million DALYs due to diarrheal diseases lost in 2004 worldwide
ο 34.2 million DALYs due to tuberculosis worldwide in 2004
ο 33.9 million DALYs worldwide in 2004 due to malaria
ο 9.9 million pertussis, 14.8 million measles, 173,000 diphtheria, 5.3 million tetanus, 1.7 million schistosomiasis, 1.0 million hookworm disease cases
ο WHO data spreadsheet available at http://bit.ly/bmeNUc
• The diseases above seem to fall into four groups (>50 million, 20–50 million, 1–20 million, and <1 million); the DALY cutoffs have been set to reflect these groupings. Net DALYs averted may be considerably less since figures above assume 100 percent effectiveness with no DALYs due to side effects; boundaries between categories have been set assuming 50 percent net effectiveness.
• QALYs for United States by cause for benchmarks:
ο Universal influenza vaccination might save 34,000 QALYs (http://bit.ly/jgyd14)
• QALY boundaries have been set to reflect a very large amount of saved QALYs as in a pandemic, an average flu-year sized program, something smaller than flu, and a program which is quite small in overall QALY benefit.
eOne-time costs based on expert judgment of the committee. We do not assume these differ for vaccines produced for global use versus for use in the United States.
fNet direct costs boundaries should be set to divide the universe of viable vaccine candidates that do not actually produce savings into about tertiles. The boundaries here are set considering U.S. net costs and then doubling these for global vaccines. It is important to remember these net costs are the costs of vaccination net of the costs of health care for the disease in absence of the proposed vaccine (or net over an existing vaccine upon which it is desired to improve with the new vaccine). As of this writing, these boundaries have no empirical basis.
gProductivity gains are notoriously hard to estimate. For example, in a 2007 paper published in Vaccine, Molinari et al. estimate $16.3 billion lost annually due to illness and loss of life because of influenza in the United States, based on estimated 24.7 million cases (2003 demographics: 294 million population). The authors used an average $145 per day wage rate and discounted future years of wages lost to present value (Molinari et al., 2007). Boundaries for categories in the United States were set to emphasize large, medium, small, and very small wage loss using influenza as high-impact disease. Global categories have been set equal to the United States because U.S. productivity costs represent a substantial fraction of world productivity. Global losses to tuberculosis estimated at $12 billion in 2011 due to illness and to premature deaths (http://bit.ly/GJUHJ9). Given that this is roughly on same order of magnitude as influenza in the United States, we choose to set these categories the same until better data are at hand.
hNote that the computational model does not compute profits as producer costs are not included.
and disease epidemiology to be brought to bear on the issue at hand. The model then uses these components to compute quantities for which we do not have data and which are less accessible to expert opinion.
Five of the six attributes calculated by the computational submodel are annual quantities:
1. Annual number of premature deaths averted
2. Annual number of incident cases prevented
3. QALYs gained (or DALYs averted) per year
4. Annual net direct costs (savings) due to the vaccine
5. Annual net workforce productivity gained (in dollar-equivalents)
The sixth quantitative attribute is cost-effectiveness: the net present value of current and future costs of using the vaccine divided by the net present value of gains in QALYs due to the vaccine (or net reduction in DALYs). The cost-effectiveness ratio is an indicator of the efficiency of investing in the vaccine as a method to produce gains in QALYs (Gold et al., 1996). Although related to the annual measures above, the cost-effectiveness ratio considers both present and future benefits and costs of the vaccine to members of the population and is not derived directly from those quantities and is not redundant with information in those quantities.
The computational submodel in SMART Vaccines may be thought of principally as a population simulation run over time in 1-year cycles. The submodel is run twice, once assuming that the vaccine is not available and once assuming that the vaccine is in routine use in the population.
Parameters for this second run are set to reflect the assumption that the vaccine is at its steady state of use in the population. This assumption is used to avoid the transient effects caused by the start up and propagation of the vaccine through the age cohorts of the population until the point of full benefit for the population has been reached; by not including these transient effects, the computed annualized variables reflect the average benefit of the vaccine in steady state.
Consider the following example: Human papilloma virus (HPV) preventive vaccine is given to adolescent girls with the intent of conferring lifelong immunity in the target population. In the computational submodel the steady state assumption is used to set the parameters so that women in all age cohorts are assumed to have been offered HPV vaccination when they were adolescents. This assumption is used to evaluate the vaccine’s impact as if the present population has had it available for steady-state use over the long term. This would otherwise require using a dynamic population model over a long period of time to simulate vaccination in each suc-
cessive age cohort of adolescents until the members of the first cohort have aged through their lifetimes.
Annual Number of Premature Deaths
and Incident Cases Prevented
The computational submodel uses a life-table to simulate all-cause mortality in the current population. Data about case fatalities associated with the target disease are used to estimate all-cause mortality in the absence of the target disease. Data about age-specific health-related quality of life in the population serve as the baseline data for the no-vaccine simulation run.
Data about the target disease incidence and morbidity—including by age and by sex where such data are available—are entered for computation. Data from the literature and expert opinion are used to approximate the quality of life and health care costs for typical manifestations of the disease during its course. The assumed characteristics of the vaccine in use—such as coverage in the population, effectiveness, and duration of immunity—are inputs based on expert user judgments concerning the vaccine candidate being targeted for development.
With these data and assumptions, the difference between the number of deaths in the simulated population observed in the two runs—one run assuming no vaccine and one assuming vaccine use in steady state—is used to measure the attribute “Premature deaths averted per year.” Similarly, the difference between the incident cases of the target disease in the two runs is used to measure the attribute “Incident cases prevented annually.” These two attributes allow the user to see the estimated consequences of having the vaccine’s benefits available to the current population. These are, of course, hypothetical benefits, but they should be meaningful measures that allow users to understand what the benefits of the vaccine candidates would be if the vaccines were widely used today.
In SMART Vaccines Beta, the committee converted the continuous scales of deaths averted per year and incident cases prevented per year into categorical scales for two reasons. First, the computations in SMART Vaccines Beta are just approximations, and the committee does not wish to have users over-interpret the precision of the computational submodel’s output. A second, technical reason for categorization is that the range through which attributes vary can affect their effective weights in the multi-attribute utility model. Until the characteristics of the set of vaccine candidates to be appraised by the model are known, treating the quantitative attributes as categorical rather than continuous variables ameliorates the challenges in assigning weights.
The committee has attempted to set the categorical boundaries in a
meaningful fashion. As noted in the footnotes to Table 2-1, the boundaries are benchmarked against known causes of death and case incidences. The topmost level for each attribute is set such that it represents the largest number of deaths (or incident cases) caused by vaccine-preventable diseases and subsequent categories with decreasing number of deaths. If one were to use a baseball analogy, it could be suggested that Level 1 of the attributes would represent a “home run” and once the ball is over the wall it does not matter how far it goes beyond the wall. Levels 2, 3, and 4 represent smaller and smaller accomplishments. Users should consider the relative difference in achievement between Level 1 and Level 4 when ranking the importance of the attribute.
QALYs Gained or DALYs Averted per Year
The third annualized quantitative attribute, QALYs gained or DALYs averted, is also computed using the difference between the two 1-year runs of the simulation. The HRQOL values for manifestations of a typical course of the targeted disease are input as deviations (“tolls”) from usual age-specific HRQOL, along with the duration of the deviation.
For example, in the United States the disutility toll for influenza illness with an outpatient visit to a doctor is estimated to be 0.13 on the HUI2 scale and to have duration of 5 days (0.0137 years) (see Appendix B). Forty percent of influenza cases are assumed to have this level of disutility. One-half of 1 percent of cases are hospitalized, with an estimated disutility toll of 0.2 and an estimated duration of 0.0137 years. The remaining 59.5 percent of cases are people with a sufficiently mild case of the disease that they do not have an outpatient visit, and they are estimated to have disutility toll of 0.09 for the same duration. Based on U.S. national data, a man aged 45–49 averages HRQOL of 0.86 each year, as measured by the HUI2. All men of this age in the simulation who suffer influenza during the 1-year run of the model average a HRQOL change of 0.107 QALYs (that is, (0.4)(–0.13) + (0.005)(–0.2) + (0.595)(0.09)). So instead of an average of 0.86 QALYs accrued during the year, a man this age would accrue 0.75 QALYs (that is, 0.86–0.107) during the year in which he had influenza.
In the current version, SMART Vaccines Beta does not allow the same person to have influenza more than one time per year. In the simulation run with vaccine present, this same person will have a reduced chance of having influenza depending on vaccine coverage and effectiveness, so the QALYs loss will be less on average. Of course there are small chances of vaccine-related morbidity, and the disutility tolls for this are averaged into the calculations for people who are vaccinated.
Disease- and vaccine-related mortality are both presumed to occur at
mid-year, so instances of mortality in the simulation incur a loss of one-half of the potential age-specific QALYs to be accrued for that year. We anticipate the QALYs loss due to the disease to be more without the vaccine than with the vaccine in steady-state use, and the difference in average QALYs loss between the two runs of the simulation gives the QALYs gained in the population as a result of having the vaccine available.
DALYs express the sum of years of life lost (YLL) due to premature mortality plus years lived with disability (YLD). YLL is obtained by calculating the difference between life expectancy of the target population—currently around 90 years, based on the life expectancy of longest-lived Japanese women—and the life expectancy in the actual population. The difference between the target and actual life expectancy in any population is years of life lost (YLL). To calculate YLD, the number of years lived with disability is multiplied by a weight factor that reflects the severity of the disease, where a value of 0 means “perfect health” and 1 means “dead.” However, unlike QALY weights, DALY weights are determined by a panel of experts and not derived from patient populations (Murray and Lopez, 1996).
Also, depending on a person’s age, the DALYs indicate various weights on the outcome that are designed to reflect workplace productivity. Persons in peak productivity years (approximately 20–40 years) receive higher weights than young children and persons over 80. Representative DALY weights for various conditions include 0.105 for diarrhea, 0.229 for deafness, 0.271 for fractured leg, 0.552 for diabetes with blindness, and 0.666 for Alzheimer’s disease (WHO, 2004). For tuberculosis, DALYs are estimated to be 0.271.
Annual Net Direct Costs (Savings) and Net
Workforce Productivity Gained
Inputs such as average health care costs and frequencies of health care usage are used to compute health care costs of the disease in absence of the vaccine for the first run of the simulation. Because the number of cases will be reduced when the vaccine is in stable use, the computed total costs of health care for the disease will be less in the second run of the simulation.
But in the second run, with the vaccine in stable use, there will be costs of administering the vaccine and taking care of adverse events associated with the vaccine that must be taken into account. These costs are added to the health care costs of caring for the disease in the second run. The difference between the total costs in the two simulation runs is the annual net health care cost of preventing and treating the disease, the attribute entered into the MAU value model (if selected by the user). If the costs
in the vaccine run are less than the costs in the no-vaccine run, then the difference represents a net savings.
The annual net gain in workforce productivity is computed in a similar fashion. For persons older than 15 the time lost to the illness is valued at the national average age-specific wage rate. For children aged 15 or younger (those most likely to have an adult take time away from work to care for them), the time lost to the illness is valued at the national average age-specific wage rate for one person who is the average age of a parent for the particular age of the child. The net gain in workforce productivity is then the average reduction in dollar-valued time lost due to the disease between the two runs of the simulation.
Cost-Effectiveness
The cost-effectiveness attribute of the vaccine is computed differently. SMART Vaccines Beta uses U.S. guidelines for computing the cost-effectiveness of a health intervention in a population (Gold et al., 1996). In the simulation model this is done by age cohort in the current population, assuming benefits of having the vaccine available begin now for each cohort. The simulation is run for each age cohort until all members of that cohort reach age 100 or have died. This is done twice, once assuming that no vaccine is available, and once assuming the vaccine to be in stable use at the start of the simulation.
In the simulation the costs of vaccination are incurred according to a schedule of vaccination determined by assumed length of immunity. For example, if immunity is presumed to last 10 years, then one-tenth of the cohort is immunized in each year. For each cohort in each year of the simulation, the net health benefits measured as QALYs gained or DALYs averted are computed in the same manner as the annual measure described earlier. Similarly, the net health care costs are computed in each year of the simulation in a manner similar to the annual measures. But here the similarity to the annual measures ends.
From “now”—the start of the two simulations for each age cohort—and into the future until all persons in that cohort are aged 100 or deceased, the net health care costs are arranged as a time series into the future, with one entry per year. If “now” is time 0, and each year into the future is labeled 1, 2, 3, … , up to n, the final year of the simulation for that cohort, then we let the net cost in year i be NCi for i =1, … , n. The present value (PV) of NCi is the amount that, if set aside now at an annual interest rate r, would be worth NCi i years into the future.
![]()
Another way to say this is that the amount NC i to be received i years in the future has been discounted at a rate r to present value. The stream of net costs, NC 1, NC 2, … NCn, is discounted to present value with each cost being discounted the appropriate number of years, and the costs are then summed to get the net present value of lifetime health care costs (or savings) for each age cohort. This sum is the numerator of the cost-effectiveness ratio.
The denominator of the cost-effectiveness ratio is the sum of the corresponding stream of net QALY gains, one for each year into the future, where each of these annual gains is also discounted to present value at the same discount rate as were the costs in the numerator. In their guides to cost-effectiveness computations, Keeler and Cretin (1983) and Gold et al. (1996) discuss the rationale and importance for using the same discount rate in the numerator and denominator of the cost-effectiveness ratio. Using different discount rates—especially for preventive health care, where costs may be incurred years before benefits—can lead to incorrect and paradoxical results. The discount rate is an input to the model. In the United States the currently recommended discount rate is 3 percent for standardized cost-effectiveness models of health care.
If the numerator of the cost-effectiveness ratio is negative—that is, if the program is producing savings—then the new vaccine is a good investment indeed. However even if it is not cost-saving—and many health care interventions are not—it may still offer health benefits to the population. These benefits are measured in QALYs gained, and the cost-effectiveness ratio measures the anticipated cost per QALYs gained by individuals in the population, a measure of the efficiency with which the investment “buys” health.
In SMART Vaccines Beta this is a simple simulation, equivalent to running one simulation of the full population with all cohorts together until all members are age 100 or deceased. The figure of 100 was used as a cutoff because so few people live past that age and also because the number offered the committee a stopping point for the beta model simulation.
As noted earlier, the IOM report Vaccines for the 21st Century, issued in 2000, used only one of the 29 attributes—cost-effectiveness—to establish four priority groups. That report specified the highest priority, Level I (most favorable), as including those vaccine candidates projected to save money and to produce QALYs. In the remaining cases, where vaccination programs did not help save money, candidate vaccines were grouped according to efficiency of the investment: Level II (more favorable) included those where $/QALY < $10,000, Level III (favorable) included those candidates
for which $10,000 < $/QALY > $100,000, and Level IV (less favorable) was for candidates for which $/QALY > $100,000 for the vaccine.
Since that report there has been debate about which points to use as cost-effectiveness thresholds. Much of the cost-effectiveness literature in the United States since the early 1990s has used a threshold of $50,000/QALY to distinguish between medical interventions that are attractive and unattractive investments. Similarly, in the United Kingdom, the National Institute for Clinical Excellence has used an explicit threshold of £30,000/QALY. In the United States it has been argued recently that the threshold should be closer to $200,000/QALY. The World Health Organization has proposed using a threshold in developing countries of three times the per-capita gross domestic product (Braithwaite et al., 2008; Commission on Macroeconomics and Health, 2001). The committee used larger thresholds for efficiency than the previous report in order to reflect the more recent literature, but this is still a matter of great subjectivity and debate (Weinstein, 2008).
Foundation for the value submodel
The value submodel uses the subset of attributes selected by the user from the 29 attributes listed in Table 2-1. Let us assume that the user has selected K < 29 of the attributes. We renumber these K attributes to reflect the rank order of importance that has been given to the attributes by the user: A1, A2, … , AK, where A1 is the most important and AK the least important in the set of attributes. Some of these attributes may be among the quantitative attributes and some among the qualitative.
In SMART Vaccines Beta, each of these attributes has between 2 and 5 levels, depending on the attribute. Each level of each attribute is assigned a single-attribute utility score between 0 (the least preferred level) and 1 (the most preferred level). The specific single-attribute scores for the various levels of an attribute with a given numbers of levels are shown in Table 2-2.
Let i = 1, 2, … , M and Vi be vaccine candidate i, one among a set of M vaccines being ranked. If the level describing vaccine Vi on attribute Aj is denoted as Lij then each vaccine is fully described for the model as a vector of K levels:
![]()
There is a vector of single attribute scores, SVi, corresponding to the vector of levels, with the scores taken from the corresponding entries in Table 2-2:
![]()
As described earlier, the rank order centroid method is used in SMART Vaccines Beta to compute a weight for each attribute, wi, i= 1, 2, … , K (example weights are shown in Table 2-3). Finally, the value submodel computes a value score for Vi by using the weights to form a weighted sum of the single-attribute scores for the levels:
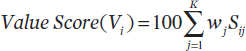
Sij scores are from the vector of scores above, which in turn represent the achievement of Vi on each attribute the user has selected. These are weighted by the importance given to each attribute by the user, and then summed. Because the single attribute scores for each attribute range from 0 to 1.0, and because the weights across the attributes sum to 1.0, the weighted sum of scores varies from 0 to 1.0. This weighted sum is multiplied by 100 to produce a range from 0 to 100.
If a vaccine were “perfect”—that is, the vaccine achieved the most preferred level (a single attribute score of 1.0) for each attribute selected—then it would receive a value score of 100. If it achieved the least preferred level on each attribute, it would have a single attribute value score of 0 on every attribute and thus a weighted sum of 0.
Of course, no vaccine candidate will be the most preferred or least preferred on every attribute. Depending on its level of achievement on the selected attributes and depending on the weights given to the attributes by the user, vaccines will have value scores between 0 and 100. The rank order of vaccines according to their value scores is the priority order of the vaccine candidates under the logic of the multi-attribute utility framework as implemented here.
TABLE 2-2
Single-Attribute Utility Scores for the Levels of Attributes with Varying Numbers of Levels
| Number of Levels | Scores for the Attribute Levels | ||||
| Level 1 (most preferred) | Level 2 | Level 3 | Level 4 | Level 5 (least preferred) | |
| 2 levels | 1.0 | 0.0 | N/A | N/A | N/A |
| 3 levels | 1.0 | 0.5 | 0.0 | N/A | N/A |
| 4 levels | 1.0 | 0.67 | 0.33 | 0.0 | N/A |
| 5 levels | 1.0 | 0.75 | 0.5 | 0.25 | 0.0 |
TABLE 2-3
Attribute Weighting Using Rank Order Centroid Method
| Rank | Number of Attributes Selected | |||||||||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
| 1* | 0.750 | 0.611 | 0.521 | 0.457 | 0.408 | 0.370 | 0.340 | 0.314 | 0.293 | 0.275 | 0.259 | 0.245 | 0.232 | 0.221 |
| 2 | 0.250 | 0.278 | 0.271 | 0.257 | 0.242 | 0.228 | 0.215 | 0.203 | 0.193 | 0.184 | 0.175 | 0.168 | 0.161 | 0.155 |
| 3 | 0.111 | 0.146 | 0.157 | 0.158 | 0.156 | 0.152 | 0.148 | 0.143 | 0.138 | 0.134 | 0.129 | 0.125 | 0.121 | |
| 4 | 0.063 | 0.090 | 0.103 | 0.109 | 0.111 | 0.111 | 0.110 | 0.108 | 0.106 | 0.104 | 0.101 | 0.099 | ||
| 5 | 0.040 | 0.061 | 0.073 | 0.079 | 0.083 | 0.085 | 0.085 | 0.085 | 0.084 | 0.083 | 0.082 | |||
| 6 | 0.028 | 0.044 | 0.054 | 0.061 | 0.065 | 0.067 | 0.068 | 0.069 | 0.069 | 0.069 | ||||
| 7 | 0.020 | 0.033 | 0.042 | 0.048 | 0.052 | 0.054 | 0.056 | 0.057 | 0.058 | |||||
| 8 | 0.016 | 0.026 | 0.034 | 0.039 | 0.043 | 0.045 | 0.047 | 0.048 | ||||||
| 9 | 0.012 | 0.021 | 0.027 | 0.032 | 0.036 | 0.038 | 0.040 | |||||||
| 10 | 0.010 | 0.017 | 0.023 | 0.027 | 0.030 | 0.033 | ||||||||
| 11 | 0.008 | 0.015 | 0.019 | 0.023 | 0.026 | |||||||||
| 12 | 0.007 | 0.012 | 0.017 | 0.020 | ||||||||||
| 13 | 0.006 | 0.011 | 0.014 | |||||||||||
| 14 | 0.005 | 0.009 | ||||||||||||
| 15 | 0.004 | |||||||||||||
| Total** | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
*Highest rank = 1.
**Totals may not add to 1.00 due to rounding.
In SMART Vaccines Beta, the weights are computed from a strict rank order of attributes supplied by the user. In future versions, the committee expects that this approximation will be replaced by a more elaborate elicitation of weights, perhaps using a hierarchical clustering of the selected attributes, and based at least in part on direct ratio estimates of the importance of the ranges of value described by each attribute. This elaboration will require considerable attention to the user interface design and was beyond the current demonstration of concept exercise.
Appendix B lists the computations described in this chapter.
User entries and prioritization categories
It is important that all of the vaccine candidates to be prioritized are assessed using the same criteria and measures. At the very outset the user must make two choices that must apply to all vaccine candidates in the set of candidates to be prioritized. The first choice is which metric will be used to measure health benefits—QALYs gained or DALYs averted. The second choice is the selection of attributes by which the value of the vaccines to be compared and prioritized will be measured in the SMART Vaccines Beta.
The reason that these choices, once made, are fixed across all vaccine candidates is that the priorities must be determined using the same criteria and measures for each alternative vaccine. The value scores computed for the alternative vaccines are only meaningful relative to one another. These scores have no intrinsic meaning per se, and they gain validity for comparisons only through the fact that exactly the same basis for evaluation is used for all the alternatives being considered.
The computational submodel requires knowledge of the target population for the vaccine. If vaccines are being prioritized for one country, then that country’s population is the one for which data are needed. If vaccines are being prioritized across a region with more than one country (say, a “super-nation” entity such as the Pan American Health Organization, which has dozens of member countries), the combined population of the region is the target. SMART Vaccines cannot at this time aggregate data across countries, although the current model can deal with multiple populations that have been aggregated a priori and then entered into SMART Vaccines as a new “region.”
The population is segmented by age groups—infants, children aged 1 to 4, and then 5-year age bins up to age 99—and also divided into males and
females. The average population is represented by the most recent available census data, with the number living in each age range and a standard life table.
Age-specific average health-related quality-of-life (HUI2) weights and average hourly wage rates (parental wage rates for persons aged less than 15) are also used in the software. In the United States, the life table data are available from the National Center for Health Statistics and the U.S. Census Bureau; the HUI2 data are available from population surveys (see, for example, Fryback et al., 2007; Luo et al., 2009); and the wage data are available from the Bureau of Labor Statistics.
International population data, which are available through the World Health Organization, have been used to pre-populate the data fields and are selectable by country. In the current version of the software, data for hypothetical vaccines for three conditions in South Africa and the United States have been entered. Vaccine selection criteria are discussed in Chapter 3. HUI2 data are not generally available outside of the United States and Canada unless special surveys have been completed, and DALY weights may be used instead. Wage data outside of developed countries where these statistics are usually maintained will have to be estimated subjectively.
SMART Vaccines Beta allows assumptions to be tailored for sub-groups of special interest or priority. For example, among persons with tuberculosis the subgroup with HIV infections is of special interest both because immunization may not be effective and because tuberculosis incidence is higher in this subgroup.
Infants and children or military personnel might also be the special targets of particular vaccination programs. The impact of the immunization program in a special population is controlled by different input constants than those used for the “usual” male and female populations. If a special population is specified, it must be subtracted from the general male and female populations so that the total population is the sum of the three parts; in SMART Vaccines Beta, this subtraction must be done outside the program before inputting data.
Disease epidemiology and clinical inputs
The computational submodel requires information on the incidence of the disease by sex and by age range as well as case fatality proportions. The time course of the disease is modeled by inputting time-limited states of illness without outpatient visits, of illness with outpatient visits, and of illness with hospitalization; the fraction of cases experiencing each of these; and the time that a typical person experiencing these states would spend in
the state. Permanent disability is modeled as a separate outcome, and the percent of cases experiencing permanent disability is entered.
The aggregate incremental costs of vaccination versus treatment of the disease are computed in the computational submodel shown in Figure 2-1. This submodel estimates the net incremental costs (or savings) of having a vaccine program versus not having one. The estimation is done by simulating the incidence of disease cases and then simulating the utilization of the units of care, such as visits to a physician’s office, a day of hospitalization, medications, and so forth.
To compute the costs of treatment for the target disease, common events in the care of patients, such as over-the-counter medications, a visit to a physician’s office, emergency department visits, and days of hospitalization, are needed as inputs. To compute the costs of vaccination, it is necessary to input the number of doses needed, the cost per dose for vaccine, and the cost per dose to administer the vaccine. Estimates for one-time costs are also entered: research costs for development of the vaccine, costs of the trials and data needed for licensure, and any one-time start-up costs for the initiation of a vaccination program.
The committee recognizes that the modeling of costs is at best a broad-brush approximation. But it is simply not possible—especially for hypothetical vaccines—to carry out a microscopic costing of all possible inputs, modeling the various intricacies of the vaccine delivery process. Accordingly, this model allows users to specify the main components of cost in a summary form common to all vaccines. It will require users to roll many aspects of costs into a few generic slots. For example, cost per dose will need to account for manufacturing, storage, transportation, and suitable profits for all private entities involved in these steps, all in one input number. Sophisticated cost-effectiveness models used to evaluate existing vaccines may break this one input into many subparts in the future, but for now SMART Vaccines Beta uses rough estimates for hypothetical new vaccines.
The health impacts of vaccination are modeled using estimated duration of immunity conferred, incidence of the disease, and vaccine-associated complications that may be experienced. The effectiveness of the vaccine is modeled by inputs quantifying anticipated uptake or coverage in the vari-
ous age groups targeted for vaccination. These estimates should take into account public perceptions of the disease; anticipated vaccine-induced complications, including potential deaths resulting due to the vaccine; and how well the vaccination schedule and doses required fit existing schedules in the health system. The herd immunity threshold is set at 100 percent in SMART Vaccines.
Disease burden summary measures
A number of measures of the health burden of disease are incorporated in the model. Some users may prefer to use premature deaths averted or cases prevented. Others may prefer measures such as DALYs averted or QALYs gained—measures that combine the effects of both mortality and morbidity into one number.
To compute QALYs, the model must know about the age-specific average health-related quality-of-life (HRQOL) as measured in the population. The impacts of the disease that could be prevented by vaccination are modeled by assessing a decrement, or “toll,” from the age-specific average for the various health states that an affected person might experience. The reduced HRQOL is then weighted by the length of time that the person is affected in order to get QALYs lost to the disease. SMART Vaccines Beta uses the Health Utilities Index Mark 2 (HUI2) to measure HRQOL, as did the 2000 IOM report.
The age- and sex-specific average population baseline HUI2 weights are input as population characteristics. For example, an average observed HUI2 weight of 0.81 is reported for women aged 60 to 64 years in the United States. The HRQOL tolls for the health states associated with the disease must be estimated. For example, using data from the U.S. National Health Measurement Study (Fryback, 2009), the estimated average decrement in HUI2 weight for adults who report “cough” versus those who do not report “cough,” age-adjusted, is –0.09. This is used as the daily decrement, or toll, from the population average for each day with influenza not requiring an outpatient health care visit. The decrement is –0.13 for those reporting fever, which is used as the daily toll in HUI2 weight for persons requiring an outpatient visit for influenza.
Cough and fever are not adjusted here for co-occurrence of other symptoms but rather are used as markers for health states that could be equivalent, on average, to the corresponding influenza health states. A day of hospitalization incurs a toll of –0.2 based on cost–utility analyses from the literature that involve acute illness hospitalization. The 2000 report from the IOM study used subjective role playing by committee members
using the HUI2 scales to record their level of functioning and symptoms for health states they were imagining. In the decade since that report more data sources have appeared, such as the National Health Measurement Study and published analyses, from which to estimate HUI2 tolls to model the time course of diseases.
Similarly, HUI2 weights must be estimated for permanent disabilities resulting from disease- and vaccine-related complications. Estimating the quantities needed for the computational submodel can be vexing, as the needed data are rarely available or reported in the literature. This is further discussed in Chapter 3. If the user elects to compute using DALYs, then similar average health and disability weights must be estimated for disease states.
If the user selects any other attributes listed in Table 2-1, then appropriate levels of the attributes for each vaccine candidate should be entered by the user. All of these attributes are categorical in nature, with some requiring a simple “yes” or “no” entry. The users will need to make subjective assessments where necessary to make the appropriate categorizations.
Attribute selection and ranking is accomplished by a drag-and-drop interface (which can be seen in the screenshots of the SMART Vaccines Beta found in Chapter 3). Attributes are selected one at a time and dropped into the ranking box. The selection and ranking of attributes is done once, and all the vaccine candidates are evaluated using the same criteria with fixed weights. This does not prohibit the user from entertaining “What if?” scenarios by changing the attribute selection or the rankings—or both—to see how the value score is affected. But any one set of priorities for vaccine candidates should be based on only one set of attributes and weights.
In SMART Vaccines Beta the user-selected attributes are not all equally important in establishing priorities. As discussed earlier in this chapter, the rank order of attributes is used to create a set of weights for the factors—the wjs in the equation that is used to compute priority value scores for the vaccines using the Edwards and Barron additive multi-attribute approach (Edwards and Barron, 1994).
This method for using the number and rank order of attributes to determine the weights gives most of the weight to the first few attributes in the rank order. The weights are assigned by an approximation algorithm—
rank order centroids—as discussed earlier in this chapter. Weights in the additive multi-attribute model are each bounded by 0 and 1, and they collectively sum to 1.
A vector of n weights, each a number between 0 and 1, may be viewed as a point in the n-dimension cube. Suppose a proper rank order of the set of weights is specified. Consider the subspace of the n-dimension cube formed by the set of all weight vectors that are consistent with the specified rank order and that sum to 1. The vertices (extreme points) of this subset form a simplex, and averaging the coordinates of the n vertices gives the centroid of the simplex. The rank order centroid algorithm takes this centroid as the set of weights to be used in the additive multi-attribute model for computing priority scores. It can be thought of as the average of all sets of weights consistent with the user-specified rank order; it is also the mean of a uniform probability distribution over the simplex bounded by the n vertices. Given no other information than the rank order of weights, the rank order centroid is the best statistical estimator for the vector of weights for the additive multi-attribute utility model.
Further development of SMART Vaccines can allow users to modify this set of weights by increasing or decreasing single attribute weights while maintaining the rank order. This would give selected attributes slightly more or less importance in the priority calculations. The rank order centroid can be easily extended to include ties in the rank order. But, as discussed by Barron and Barrett (1996), the key information is contained in the rank ordering, and refinements to the weights consistent with the rank order provide, at most, second-order changes.
There is one important factor that influences the weights: the number of attributes selected. Table 2-3 displays examples of rank order centroid weights for various numbers of attributes in the model. The first few attributes receive most of the total weight using this method, and adding more factors to the prioritization problem has a decreasing effect on the final priority ordering of vaccine candidates.
The committee considered limiting the number of weights to some arbitrary number (e.g., seven attributes). After considering this, the committee concluded that introducing a limit on the number of allowed weights would not affect the model much one way or the other, but proceeding without a limit would satisfy those users who really did wish to add a large number of attributes to the model. Users should be aware (see Table 2-3) that once 10 attributes are included, the weight on each subsequent weight is smaller than 0.01 (1 percent) and is extremely unlikely to affect rankings meaningfully. Indeed, even with just five attributes ranked, the weight on the fifth is only 0.04, and with seven attributes, the weight on the seventh is
only 0.02. In both cases, the final attribute has little effect on final rankings unless candidate vaccines diverge dramatically on the ranked dimension.
Moreover, the current model does not allow for ties in attributes because of the programming complexity in allowing ties in the rank order centroid process. Subsequent modifications to the software will allow users to establish their own rankings independent of this process, including the possibility of beginning with the rank order centroid weights and then altering pairs of them to allow for ties. For example, if users had five items ranked and wished to establish the top two as having equal weights, then the weights (say, 0.457 and 0.257) created by the rank order centroid method could be averaged as 0.357.
The meaning and interpretation of weights
This chapter would not be complete without a discussion of the meaning of the weights in the additive multi-attribute utility model. It is tempting to say, as indicated above, that these represent the importance of the different attributes in the prioritization problem. This is a common, but not technically accurate understanding.
The mathematical use of the weights is to change the natural attribute scales into a common unit of value. For each attribute in Table 2-1, there is a “most preferred” and “least preferred” level or category of the attribute, where “most preferred” means leading to the highest contribution to the priority value of the vaccine candidate. These most and least preferred categories define the range of value through which that attribute can change.
If the user defines a single-attribute value function, then each attribute will be equal to 1.0 for the most preferred category and to 0.0 for the least preferred one. Other categories between these are scaled linearly between these end values of the scale. A two-level attribute is simply scaled 1 or 0. A three-level attribute is scaled 1.0, 0.5, and 0.0. A four-level attribute will be scored as 1.0 if the attribute is in the highest category, 0.67 if in the second most preferred, 0.33 in the next lower category, and 0.0 in the lowest category. And, a five-level attribute is scaled 1.0, 0.75, 0.50, 0.25, and 0.0 from the most to the least preferred category.
Again, these linear scales are an approximation used to simplify the model for users. The next step in modeling is to allow users to specify the spacing between the categories on these single-attribute scales.
Consider two attributes in Table 2-1, say Cost-Effectiveness (CE) and Serious Pandemic Potential (SPP). The least-preferred level of CE is Level 4, and the least-preferred level of SPP is Level 2. Suppose there is a vaccine
candidate that has CE of Level 4 and SPP of Level 2. To determine which should have the higher weight—CE or SPP—the question arises: Which change improves the overall priority of the vaccine by the larger amount, changing CE to its Level 1 or changing SPP to its Level 1? If the answer is to change CE, then the weight assigned to CE should be larger than the weight assigned to SPP, and vice versa.
In the attribute selection and weighting phase of this model, the user is asked to pick those attributes from Table 2-1 that should serve as the basis of comparison for all vaccine candidates. The most- and least-preferred levels of each attribute are displayed to aid this choice. The user is instructed to pick the subset of attributes for which a change from lowest to highest level marks a significant change in priority of a vaccine. This sub-set is then to be rank ordered using exactly the same question as above—sorting the attributes pair-wise according to how much change in priority is implied by changing attributes from least to most preferred levels. The attribute at the top of the user’s rank order should have the largest implied change in overall priority when it changes from least to most preferred, and the attribute at the bottom of the user’s rank order will result in the least change in priority when it changes from the least-to the most-preferred level.
Selecting more than seven or eight attributes results in diminished or negligible weights for attributes ranked below 8 (see Table 2-3). This is not to say that the user is restricted from selecting all of the 29 attributes in Table 2-1. But it is true that a handful of attributes generally contain the most weight in establishing priorities. Adding additional attributes beyond seven or eight is unlikely to lead to a decisive change in the priority order of the vaccine candidates. However, Edwards, in an extended case study using multi-attribute utility theory to rank different desegregation plans for the Los Angeles school district (Edwards, 1979), observed that if a number of groups holding strong opinions are attempting to negotiate differences and agree on a ranking of decision alternatives, then one can end up including many attributes to make sure that each group sees all attributes of importance to its viewpoint in the final model. Edwards ended up using more than 100 attributes to tackle this challenge. But such efforts are very rare. Five to fifteen attributes in the final model is much more common (von Winterfeldt and Edwards, 1986).
The committee understands that the model (as presented) carries some risk of double counting some attributes. Double counting in multi-attribute
utility theory means putting weight on a pair (or a larger set) of attributes that are highly correlated. The higher the correlation between the attributes, the higher is the chance for double counting. The consequence of double counting is that users who include highly correlated attributes will (perhaps inadvertently) put more weight on the “concept” measured by these attributes than intended. The effect on final value scores will depend in part on how many attributes are included by the user and how high the correlated attributes are placed in the user’s ranking. If the user includes 10 to 15 attributes and places the highly correlated ones near the bottom of the list, the rankings will not change much, since they will receive little weight anyway. However, placing two highly correlated attributes at the top of a short list in the value function can lead to greater emphasis on that underlying concept than perhaps intended.
To avoid double counting, the committee selected for inclusion only those value attributes that are intended to capture something desirable about a vaccine that (because of limitations to the sub-sectioning of population variables) could not be captured directly in computed attributes. Thus the committee sought to exclude from consideration qualitative attributes that were otherwise used in the computation of quantitative attributes.
For example, the rate of uptake of a vaccine and a vaccine’s efficacy rate are used in the calculation of the number of persons effectively vaccinated (and hence in the calculation of reduced disease burden). Thus to include the rate of uptake or the efficacy rate as separate qualitative attributes would create the risk of double counting, and hence they are omitted.
The most obvious of these double-counting risks would involve the use of DALY or QALY measures of health gains (or losses). While they are not exact mirror images of one another, the DALY and QALY measures are sufficiently similar that the SMART Vaccines software blocks the simultaneous use of both as indicated attributes. If users select an efficiency measure, they can use $/DALY or $/QALY, but not both.
There still remains some potential for double counting. For example, deaths averted contains some of the same information as DALYs averted (or QALYs gained), but these measures do contain independent information about the disease burden. Deaths averted would implicitly count each life saved as the same, no matter what the age of the individual. Life years saved or the more sophisticated QALYs saved contain the additional dimension of duration of the saved life. The 1985–1986 IOM study used infant mortality equivalents prevented for a similar reason—to account for the longevity of the surviving persons.
Similarly, combinations of one or more computed quantitative variables can closely correlate with other computed variables. For example,
premature deaths averted per year can be closely approximated by the combination of incident cases prevented per year and fatality proportions. Thus including all three of these variables would lead to double counting. These are not identical in the case where a disease has lingering side effects that cause mortality in later years. An example would be an infection that created a chronic condition with some later-year mortality risk. Presently, the software does not take into account such nuances of double counting. However, the committee’s approach to dealing with these double-counting risks will necessarily involve more sophisticated programming in future versions of SMART Vaccines.
Discounting involves making events that occur in the future commensurate with those that occur in the present. Future events are brought to a “present value” by discounting them at a pre-selected annual rate. The default value in SMART Vaccines Beta is set at a discount rate of 3 percent, which is presently the standard rate in the U.S. cost-effectiveness literature for health and medicine (see Gold et al., 1996; Ramsey et al., 2005), but the user can alter this at any point. With discounting at 3 percent, an event that occurs 1 year into the future—cost or benefit—carries only 97 percent as much value as one occurring in the present year. An event occurring 2 years into the future as a present value is weighted at 0.972, or 0.9409. One occurring 3 years later would have a present value weight of 0.973, or 0.9127. The greater the discount rate—for example, 5 percent instead of 3 percent—the faster these present-value weights diminish over time.
Perhaps most important, SMART Vaccines Beta discounts both costs and benefits at the same rate. The logic for this comes from an extended discussion in the literature of cost-effectiveness analysis that generally concludes that discounting benefits and costs at the same rate is the only appropriate strategy (Keeler and Cretin, 1983). In its current version, SMART Vaccines Beta does not allow for different discount rates for costs and benefits.
The user must use the same discount rate for all candidate vaccines that are being compared. Using different discount rates could seriously distort the comparisons between vaccines. However, a feature that allows one to specify different discount rates for different vaccines has been included in SMART Vaccines Beta.
A separate issue remains regarding the handling of anticipated inflation rates within the economy in which the vaccine comparisons are being made. This is a challenge that is distinct from the question of discounting.
Many cost–benefit analyses presume some background rate of inflation in the economy—for example, 2 percent per year—so that $1 million in costs this year becomes $1.02 million in costs the following year. Adjusting for inflation before discounting is equivalent to simply computing all future economic costs and benefits in today’s dollars at today’s prices and not worrying about what inflation might be in the future. This is the approach taken by the current model. This is done to avoid questions concerning what inflation rate is appropriate—consumer price inflation, monetary inflation, or sectoral inflation confined to health care. For example the inflationary growth in wages, used to measure worker productivity losses and gains, is quite different from inflation in the costs of health care, which itself is a market basket of services and durable goods with different rates of inflation.
This model always operates within a fixed 100-year time horizon. This has been done to simplify the software programming and to reduce the potential for coding errors. SMART Vaccines Beta does not include the ability to set distributions on the input parameters to reflect uncertainties relating to the disease or vaccine data. Therefore, in its current version the multi-attribute output values do not have standard errors. A dynamic sensitivity analysis may be required to detect changes in the priority score with changes in key values. These possibilities, along with others, are discussed in Chapter 3.
The committee’s prototyping and testing efforts are described in Chapter 3, which also provides representative screenshots of SMART Vaccines Beta.








































