
4
Courses, Curricula, and Interdisciplinary Programs
Important Points Made by Individual Speakers
- A residual effect of training students to work with data is that the training will empower them with a toolkit that they can use in multiple domains. (Joshua Bloom)
- Boot camps and other short courses appear to be successful in teaching data computing techniques to domain scientists and in addressing a need in the science community; however, outstanding questions remain about how to integrate these types of classes into a traditional educational curriculum. (Joshua Bloom)
- Educators should be careful to teach data science methods and principles and avoid teaching specific technologies without teaching the underlying concepts and theories. (Peter Fox)
- Massive online open courses (MOOCs) are one avenue for teaching data science techniques to a large population; thus far, data science MOOC participants tend to be computer science professionals, not students. (William Howe)
By the end of 2014, more than 30 major universities will have programs in data science.1 Existing and emerging programs offer many opportunities for lessons
______________
1 See the Master’s in Data Science website at http://www.mastersindatascience.org/ (accessed June 5, 2014) for more information.
learned and potential course and content models for universities to follow. The fourth workshop session focused on specific coursework, curricula, and interdisciplinary programs for teaching big data concepts. The session was chaired by James Frew (University of California, Santa Barbara). Presentations were made in this session by Joshua Bloom (University of California, Berkeley), Peter Fox (Rensselaer Polytechnic Institute), and William Howe (University of Washington).
COMPUTATIONAL TRAINING AND DATA LITERACY FOR DOMAIN SCIENTISTS
Joshua Bloom, University of California, Berkeley
Joshua Bloom noted that the purpose of graduate school is to prepare students for a career in the forefront of science. A residual effect of training students to work with data is that the training will empower the students with a toolkit that they can use even if they leave a particular domain. He pointed out that the modern data-driven science toolkit is vast and that students are being asked to develop skills in both the domain science and the toolkit.
Bloom then described upcoming data challenges in his own domain of astronomy. The Large Synoptic Survey Telescope is expected to begin operations in 2020, and it will observe 800 million astronomical sources every 3 days. A large computational framework is needed to support that amount of data, probably 20 TB per night. Other projects in radio astronomy have similar large-scale data production.
A goal in data science for time-domain astronomy in the presence of increasing data rates is to remove the human from the real-time data loop, explained Bloom—in other words, to develop a fully automated, state-of-the-art scientific stack to observe transient events. Often, the largest bottleneck is in dealing with raw data, but there are large-scale inference challenges further downstream.
Bloom pointed out that the University of California, Berkeley, has a long history of teaching parallel computing. The coursework is aimed at computer science, statistics, and mathematics students. Recently, “boot camps” that include two or three intensive training sessions have been initiated to teach students basic tools and common frameworks. The boot camp at Berkeley takes 3 full days. There are six to eight lectures per day, and hands-on programming sessions are interspersed. Bloom began teaching computing techniques to domain scientists, primarily physical-science students. His first boot camp consisted of several all-day hands-on classes with nightly homework. The student needed to know a programming language before taking the boot camp. In 2010, the first year, 85 students participated. By 2013, the boot camp had grown to more than 250 students. Bloom uses live streaming and archiving of course material, and all materials used are open-source. The course has been widely used and repeated; for instance, NASA Goddard Space Flight Center
used his materials to hold its own boot camp. Bloom noted, in response to a question, that instructors in his course walk around the room to assist students while they work. He posited that 90 percent of that interaction could be replaced with a well-organized chat among instructors and students; the course would probably take longer, and students would have to be self-directed.
Bloom explained that the boot camp is a prerequisite to Berkeley’s graduate-level follow-on seminar course in Python computing for science. The graduate seminar was the largest graduate course ever taught in Berkeley’s astronomy department; this indicated an unmet need for such a course at the graduate science level. Bloom said that the boot camps and seminars give rise to a set of education questions: Where do boot camps and seminars fit into a traditional domain-science curriculum? Are they too vocational or practical to be part of higher-education coursework? Who should teach them, and how should the instructors be credited? How can students become more (broadly) data literate before we teach them big data techniques? He emphasized that at the undergraduate level the community should be teaching “data literacy” before it teaches data proficiency. Some basic data-literacy ideas include the following:
- Statistical inference. Bloom noted that this is not necessarily big data; something as simple as fitting a straight line to data needs to be taught in depth.
- Versioning and reproducibility. Bloom noted that several federal agencies are likely to mandate a specific level of reproducibility in work that they fund.
Bloom suggested that there is a “novelty-squared” problem: what is novel in the domain science may not be novel in the data science methodology. He stressed the need to understand the forefront questions in various fields so that synergies can be found. For example, Berkeley has developed an ecosystem for domain and methodological scientists to talk and find ways to collaborate.
Bloom also noted that data science tends to be an inclusive environment that appeals to underrepresented groups. For instance, one-third of the students in the Python boot camps were women—a larger fraction than their representation in physical science graduate programs.
Bloom concluded by stating that domain science is increasingly dependent on methodologic competences. The role of higher education in training in data science is still to be determined. He stressed the need for data literacy before data proficiency and encouraged the creation of inclusive and collaborative environments to bridge domains and methodologies.
Bloom was asked what he seeks in a student. He responded that it depends on the project. He looked for evidence of prior research, even at the undergraduate
level, as well as experience in programming languages and concepts. However, he noted that a top-quality domain scientist would always be desirable regardless of computational skills.
A participant commented that as much as 80 percent of a researcher’s time is spent in preparing the data. That is a large amount of time that could be spent on more fundamental understanding. Bloom responded that such companies and products as OpenRefine,2 Data Wrangler,3 and Trifacta4 are working on data cleaning techniques. However, for any nontrivial question, it is difficult to systematize data preparation. He also suggested that a body of fundamental research should be accessible to practitioners. However, large-scale, human-generated data with interesting value do not typically flow to academe because of privacy and security concerns. He conjectured that the advent of the Internet of Things will allow greater data access, because those data will not be human data and therefore will have fewer privacy concerns.
Peter Fox, Rensselaer Polytechnic Institute
Peter Fox began by describing the Tetherless World Constellation5 at Rensselaer Polytechnic Institute (RPI). The research themes are divided loosely into three topics: future Web (including Web science, policy, and social issues), Xinfomatics (including data frameworks and data science), and semantic foundations (including knowledge provenance and ontology engineering environments). Fox indicated that his primary focus is Xinformatics. He deliberately did not define X, saying that it can mean any number of things.
Fox explained that to teach data science, one must “pull apart” the ecosystem in which data science lives. Data, information, and knowledge are all related in a data science ecosystem; there is no linear pathway from data to information to knowledge. He explained that he teaches or is involved in classes on data science, Xinformatics, geographic information systems for the sciences, semantic eScience, data analytics, and semantic technologies. The students in those classes have varied backgrounds. Last semester, his data science class had 63 students (most of them graduate students), and Xinformatics had about 35 students. Fox structures his
______________
2 See the OpenRefine website at http://openrefine.org/ (accessed June 9, 2014) for more information.
3 See Stanford Visualization Group, “Data Wrangler alpha,” http://vis.stanford.edu/wrangler/, accessed June 9, 2014, for more information.
4 See the Trifacta website at http://www.trifacta.com/ (accessed June 9, 2014) for more information.
5 See Rensselaer Polytechnic Institute (RPI), “Tetherless World Constellation,” http://tw.rpi.edu, accessed May 22, 2014, for more information.
classes so that the first half of the semester focuses on individual work and gaining knowledge and skills. The second half focuses on team projects (with teams assigned by him) to demonstrate skills and share perspectives.
Fox explained that he teaches modern informatics and marries it with a method: the method that he teaches is iterative and is based on rapid prototyping applied to science problems. The framework for the iterative model is shown in Figure 4.1. Fox stressed that technology does not enter the method until well over halfway through the spiral; technology will change, so it is important to impart skills before adopting and leveraging technology.
Fox explained that a report was produced for NSF (Borgman et al., 2008) and that a diagram was developed that describes five types of mediation of increasing complexity (shown in Figure 4.2). The five generations of mediation were designed to apply to learning, but they hold true for science and research as well. Fox explained that, in contrast with most generational plots, all generations are present and active at once in both the learning and teaching environment and the science and research environment.
Fox explained that data analytics is a new course at RPI, and his desired prerequisites are not taught at the university; as a result, his class has no prerequisites. After teaching a variety of computer application languages simultaneously, Fox now
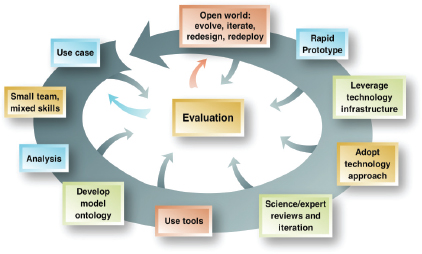
FIGURE 4.1 Framework for modern informatics. A technology approach does not enter into the development spiral until over halfway through the process. SOURCE: Fox and McGuinness (2008), http://tw.rpi.edu/media/latest/SemanticMethodologyPathwayPretty_v2.png.
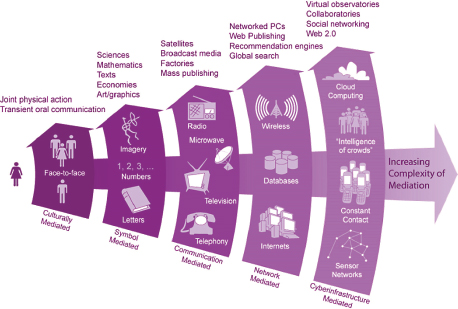
FIGURE 4.2 Generations of mediation, applied to the learning and teaching environment and the science and research environment. SOURCE: Illustration by Roy Pea and Jillian C. Wallis, from Borgman et al. (2008).
uses the R and RStudio6 environment exclusively. (Students preferred the simplicity of learning a single language.) The data analytics course builds from data to processing to reporting to analytics, both predictive and prescriptive. Fox explained that in the ideal scenario, value would be added as one progresses from one step to the next. Part of the challenge is to teach students to understand the value added and to teach them to identify when value is not being added. He emphasized the importance of understanding the value and application of data analysis, not just learning the individual steps. In response to a later question, Fox clarified that students work with self-selected, application-specific examples.
Fox then described information technology and Web-science coursework at RPI. RPI has an interdisciplinary program that consists of a B.S. with 20 concentrations, an M.S. with 10 concentrations, and a multidisciplinary Ph.D. offering.7 The program has four technical tracks—computer engineering, computer science,
______________
6 RStudio is an open source, professional user interface for R. See the RStudio website at http://www.rstudio.com/, accessed September 20, 2014.
7 See the RPI Information Technology and Web Science website at http://itws.rpi.edu (May 22, 2014) for more information.
information systems, and Web science—with numerous concentrations in each track. Fox said that the M.S. was recently revised to include data analytics in the core curriculum and that the M.S. concentrations were updated. He noted in particular the addition of the Information Dominance concentration, which is designed to educate a select group of naval officers each year in skills needed to execute military cyberspace operations.
Fox talked about the Data Science Research Center8 and the less formal Data Science Education Center at RPI. The centers are loosely organized; more than 45 faculty and staff are involved. RPI also maintains a data repository9 for scientific data that result from on-campus research.
He listed some lessons learned after 5 years with these programs:
- Be interdisciplinary from the start; grow both technical and data skills simultaneously. Fox noted that teaching skills (such as how to manipulate data by using specific programming languages) can be difficult; skills need to be continually reinforced, and he cautioned that teaching skills may be perceived as training rather than education.
- Teach methods and principles, not technology.
- Make data science a skill in the same vein as laboratory skills.
- Collaboration is critical, especially in informatics.
- Teach foundations and theory.
Fox stated that access to data is progressing from provider-to-user to machine-to-user and finally to machine-to-machine; the burden of data access and usability shifts from the user to the provider. In the current research-funding paradigm, data are collected, data are analyzed by hand for several years, and the results are then published. Although that paradigm has served the research community well, Fox noted that it fails to reflect the change in responsibilities that is inherent in the new information era, in which the burden of access shifts from the user to the provider.
Fox concluded by positing that the terms data science and metadata will be obsolete in 10 years as researchers come to work with data as routinely as they use any other research tool.
Bloom noted that there was no mention of “big data” in Fox’s presentation, only data. Fox stated that he does not distinguish big data from data. However, he acknowledged that, as a practical matter, size, heterogeneity, and structural representations will need to be parts of a student’s course of study.
______________
8 See the RPI Data Science Research Center website at http://dsrc.rpi.edu/ (May 22, 2014) for more information.
9 See RPI, “Rensselaer Data Services,” http://data.rpi.edu, accessed May 22, 2014, for more information.
EXPERIENCE WITH A FIRST MASSIVE ONLINE OPEN COURSE ON DATA SCIENCE
William Howe, University of Washington
William Howe stated that the University of Washington (UW) founded the eScience Institute in 2008 and that the institute is now engaged in a multi-institution partnership with the University of California, Berkeley, and New York University and is funded by the Gordon and Betty Moore Foundation and the Alfred P. Sloan Foundation to advance new data science techniques and technologies, foster collaboration, and create a cross-campus “data science environment.” According to Howe, the strategy is to establish a “virtuous cycle” between the data science methodology researchers and the domain-science researchers in which innovation in one field will drive innovation in the other. The eScience Institute works to create and reinforce connections between the two sides, and six working groups act as bridges. One of the working groups is involved with education and training.
Howe explained that the education and training working group focuses on different ways to educate students and practitioners in data science. Through the working group, the UW eScience Institute has developed a data science certificate for working professionals, an interdisciplinary Ph.D. track in big data, new introductory courses, a planned data science master’s degree, and a MOOC called “Introduction to Data Science.” Howe focused in more detail on his experiences in developing and teaching the MOOC. Teaching a MOOC involves a large amount of work, he said, and the course is continuously developing. The goal of the MOOC is to organize a set of important topics spanning databases, statistics, machine learning, and visualization into a single introductory course. He provided some statistics on the data science MOOC:
- More than 110,000 students registered for the course. Howe noted that that is not a particularly relevant statistic, inasmuch as many people who register for MOOCs do not necessarily plan to participate.
- About 9,000 students completed the course assignments. Howe indicated that that is a typical level of attrition for a MOOC.
- About 7,000 students passed the course and earned the certificate.
He explained that the course had a discussion forum that worked well. Many comments were posted to it, and it was self-sustaining; Howe tried to answer questions posed there but found that questions were often answered first by other engaged students.
The syllabus that defined his 9-week MOOC consisted of the following elements:
- Background and scope of “data science.”
- Data manipulation at scale.
- Analytics. Howe taught selected statistics concepts in 1 week and machine learning concepts in another week.
- Visualization.
- Graph and network analytics. Howe indicated this was a single, short module.
Howe explained that the selection of topics was motivated by a desire to develop the four dimensions of the course: tools versus abstractions (weighted toward abstractions), desktop versus cloud (weighted toward cloud), hackers versus analysts (balanced, although perhaps slightly in favor of hackers), and data structures and programming versus mathematics and statistics (weighted toward structures).
He conducted a demographic study of his MOOC participants and remarked that most of them were working professional software engineers, as has been reported for other MOOCs. He suggested that perhaps a MOOC could be used like a textbook, with instructors having their students watch some lectures and skip others, just as they do chapters of a book.
A teaching strategy that consists of both online and in-person components, he explained, has two possible approaches: offer the same course simultaneously online and in person or use the online component as a textbook and class time as an opportunity for practical application (juxtaposing the traditional roles of homework and classwork). There are examples of both teaching strategies, and it is unclear whether either will dominate. He also reiterated the importance of student-to-student learning that took place in his experience with a MOOC structure.
In the discussion period, a participant asked about the importance of understanding the foundations of programming and suggested that algorithms and data constructs should be taught to younger students, for example, in high school. (That last point generated some disagreement among participants. One suggested that even elementary school would be appropriate, but another was concerned that this might displace students from calculus and other critical engineering mathematics courses.) Howe replied that computer science enrollment is increasing at the undergraduate level by about 20 percent per year, and statistics departments are also seeing increased enrollment. Students understand that they need to understand the core concepts at the undergraduate level.
A workshop participant asked about other MOOC success stories in big data. Howe responded that he had only anecdotal evidence. Bloom concurred, noting that a graduate student who had participated in Berkeley’s data science boot camp conducted large-scale parallel computing work that resulted in a seminal paper in his field (Petigura et al., 2014).










{kind=link}