
The first session of the workshop set the stage by discussing current approaches and potential future options for fisheries stock assessments. Some useful references for the opening session, as suggested by the workshop planning committee, include the following: Armstrong et al., 2006; Beijbom et al., 2012; Cadima, 2003; Cappo et al., 2006; Chen et al., 2006; Clarke et al., 2009; Kimura and Somerton, 2006; Mace et al., 2001; Mallet and Pelletier, 2014; NOAA Fisheries, 2012; Sale, 1997; Shortis et al., 2013; Spampinato et al., 2008, 2010; Sparre and Venema, 1992; Western Pacific Regional Fishery Management Council, 2004; and Williams et al., 2010.
Rama Chellappa (University of Maryland, College Park; chair, workshop planning committee) and Ned Cyr (NOAA Fisheries) opened the workshop and introduced the speakers of the first session: Benjamin Richards (NOAA Fisheries), Allan Hicks (NOAA Fisheries), Ruzena Bajcsy (University of California, Berkeley), and Steven Thompson (Simon Fraser University). In addition, the summaries of two later keynote speakers are included in this chapter: Demetri Terzopoulos (University of California, Los Angeles) and Concetto Spampinato (Università di Catania, Italy) spoke about computer graphics simulations of groups of fish and ongoing large-scale underwater video collection and identification of reef fish, respectively.
TYPES OF DATA USED IN FISHERY STOCK ASSESSMENTS
Allan Hicks, NOAA Fisheries
Allan Hicks began by defining fishery stock assessment models as “demographic analyses designed to determine the effects of fishing on fish populations
and to evaluate the potential consequences of alternative harvest policies” (Methot and Wetzel, 2013). In other words, assessment models are used to assimilate data and provide advice for fisheries management. The assessment models also characterize uncertainty and project into the future. Hicks stated that many types of data are used as input to the assessment models, including catch (amount and type), abundance (survey and fishery catch rates), and biological information (age, size, and maturity). The data are then input into a population model. The model may also use external information, such as climate and environmental observations. The model returns current and future projections of abundance and mortality. Hicks observed that a key step is fitting the model to data by minimizing the differences between observations and predictions.
Abundance data, said Hicks, may be the most informative type of data. Most fish abundance data are relative and provide information about changes from previous observations. While relative abundance provides information about trends in the fisheries populations, it does not provide information about total absolute biomass, the absolute mass of a given species in a particular area or fishery. Hicks explained that measurement of total absolute biomass requires that the following criteria be met:
- Complete spatial coverage of the stock’s range is needed.
- All potential sample sites within each stratum have a known probability of being selected. Hicks noted that habitat variability can hinder the selection of some sites.
- All fish at each selected site have a known probability of being detected. Ambiguous sample areas (e.g., stationary cameras) and unusual fish behavior (e.g., avoidance or attraction to measurement devices) can skew the probability of detection.
Hicks pointed out that biological data, such as length, weight, and age observations, are also important measures for the estimation of growth, recruitment, selectivity, and mortality rates. Maturity data (i.e., age of the fish) helps with understanding and measuring the spawning potential of the fish population. Ecological and environmental relationships can also be inferred. A participant noted that with computer vision, biomass may be able to be directly calculated by modeling the volume of fish, rather than relying on length-to-weight ratios.
Data are typically collected from two different sources, Hicks explained:
- Fishery-dependent data. These data are not scientific surveys; rather, they are derived from fishermen targeting a certain stock. Hicks noted that these ad hoc methods are not the optimal way to collect data, but that the data are easy to obtain. Fishery-dependent data may include measurements of
retained catch, discarded catch, fishing effort, catch-per-unit-effort (an indirect measure of abundance), and biological information. Fishermen are relying more on image and video data, and electronic monitoring is becoming popular.
- Fishery-independent data. These data are from scientifically designed surveys for collecting biological and abundance data. Hicks provided examples of a number of fishery-independent surveys, such as
- Capture surveys. Fish are caught and measured to provide abundance and biological data, such as a Bering Sea trawler that collects bottom species from hundreds of sites per year. Capture surveys are typically fatal to the fish.
- Acoustic surveys. Fish are found using an echosounder. Some capture is needed to benchmark the species’ composition and size. Acoustic surveys provide abundance data and some biological data.
- Visual and advanced surveys. In most cases, fish are observed without causing mortality. This can include scuba, camera drops, and the use of underwater vehicles.
Hicks stressed that other data can also be collected aside from abundance and biological data. Fish can be tagged to see if they return to an area; one can make visual observations of habitat; and one can make environmental observations, such as sea surface temperature.
Hicks explained that images and videos can assist in data collection and improve stock assessments due to the following:
- Fish mortality can be decreased with the increased use of video and images.
- Habitat information can be observed.
- Species that are typically not retained in a capture survey (such as very small fish) can be identified.
- Analysis speed is increased.
- Shapes and patterns can be recognized and classified.
Hicks concluded by noting that stock assessments consist of heterogeneous data from a variety of sources, and fishery-independent surveys, particularly bottom trawl surveys, are a key component to stock assessments. While relative indices are useful, absolute indices would be a big improvement.1 Finally, image and video
__________________
1 Relative indices provide measures of a fish population compared against the populations of other species of fish in the region, while absolute indices provide fixed measures of a fish population.
analysis will be increasingly useful tools to assist in the collection and analysis of fishery data.
OVERVIEW OF SAMPLING IN SPACE AND TIME
Steven Thompson, Simon Fraser University
A sample, Steven Thompson explained, is an observation in space and time that is made when one is interested in certain properties of a population but can only observe a portion of that population. He noted that populations usually have spatial and temporal structure that moves or changes in time, and those changes may not be predictable. Designs for sampling can progress dynamically through time and space. Detection and observation may not be ideal, said Thompson; for example, a collection net’s results depend on its mesh size. Thompson explained further that a population is not fixed. Rather, it can be considered a stochastic process that evolves in time, and the sampling process is also stochastic.
Thompson explained the spatial-temporal population model, which is used to assess the effectiveness of various sampling designs. The model includes the following:
- Clustering, mixing, and migration;
- Movements within and among groups; and
- Insertions and deletions of objects: birth and death processes and immigration and emigration processes.
The sampling design, Thompson said, is the procedure for selecting units to include in the sample. In the case of a fisheries stock assessment, the sampling unit may be a fish, but more often it is the path of trawl or of video, sonar, or other imagery. The acquisition process is the process by which units are selected into the sample, and the attrition process is the process by which units are removed from the sample. In a conventional design, the procedure through which samples are selected does not depend on the variable(s) of interest. In adaptive design, however, the procedure depends on observed values of the variable(s) of interest as well as other, auxiliary variables. Thompson explained that through inferences from sample data, one can make estimates of abundance.
Thompson said that there are two primary methods of approaching inference from sample data: through a design-based approach or a model-based approach. In a design-based approach, the values of the variable(s) of interest are considered fixed but unknown. In a model-based approach, the population variables are considered to be random variables. Thompson noted that model-based approaches can be computationally complex; the most practical implementation is a computational
Bayesian approach using Markov chain Monte Carlo and other methods. He explained that there can be a tension between communities that use a design-based approach and those that use a model-based approach; however, his own work has encompassed both methods. Thompson provided an example in catch-per-unit-effort data: ideally, if there are more fish, the catch-per-unit-effort will increase. However, catch alone may not be related to actual abundance. Commercial fisherman essentially create their own sampling designs that are (1) of unequal probability (e.g., fishermen tend to go to areas where they have had previous success or where they are familiar with the underwater terrain); (2) adaptive (e.g., fishermen may continue to focus in a small geographic region if they are having success or move further if they are not having success); and (3) non-ignorable, so that the design needs to be accounted for in estimation (e.g., fishermen use additional cues from their environment). Thompson suggested that information about the fishermen’s sampling design be included in modeling abundance.
Thompson concluded by stating that the science of sampling involves understanding how a sample is selected. Sampling designs rely on inference, experiments, and interventions, and the choice of sampling design can strongly affect the resulting data.
In a later discussion, several participants commented on the importance of a strong collaboration between data collectors and data analysts to make decisions about research experiments. Data analysts can provide information about how best to record data; this is particularly critical in situations in which detection probabilities are changing in time or where adaptive sampling is used.
NOAA FISHERIES STRATEGIC INITIATIVE ON AUTOMATED IMAGE ANALYSIS
Benjamin Richards, NOAA Fisheries
Benjamin Richards chairs the NOAA Fisheries Strategic Initiative on Automated Image Analysis. Another NOAA initiative has been established to examine the related topic of sampling in untrawlable habitats. From both initiatives, NOAA seeks to obtain better estimates of abundance to improve its estimates of fish populations and associated stock assessments.
In 2001, Richards said, NOAA developed its fisheries stock assessment improvement plan (Mace et al., 2001). That plan identified accurate and precise estimates of species-specific, size-structured abundance as a main impediment to stock assessment. In other words, the accuracy and precision of output estimates are directly linked to the quality of the input data. Richards stressed that optical technologies have many advantages: they are fishery-independent (i.e., they are not influenced by market drivers or other variables that can bias fishery-dependent estimates), non-
invasive (i.e., they can be used on overfished stocks or in protected areas without additional impact), efficient, and accurate. However, the use of optical technologies results in extremely large data sets, too large to be examined solely by human analysis. Millions of images collected in the span of a few days would take humans months or years to examine. He emphasized the need to reduce the burden on the human in image analysis, as well as the need to reduce the subjectivity associated with human data analysis. Richards later noted that human observers, in general, do not miss many fish, but they have a tendency to over-identify objects as fish (more false positives). Different human observers may also have divergent opinions on the identity of the same individual and may be more attuned to different species based on level of interests, expertise, or past experience. Human observers also can make subjective decisions. Presently, algorithms, while they tend to be more consistent among samples, also tend to miss fish (more false negatives) and misidentify fish.
Richards described a 2010 NOAA workshop on automated image analysis. The workshop specifically recommended increasing interdisciplinary collaboration between the marine research and computer vision communities, creating an international working group for the automated analysis of marine species, developing a database of commonly encountered fish that is accessible to the user community, and optimizing the allocation of resources and automation.
Richards explained that image data sets can be broken into categories: still versus video, mono versus stereo, static versus dynamic backgrounds, and natural versus artificial lighting. He then provided specific examples of the types of data that NOAA examines:
- Towed-diver benthic surveys. Richards said that towed-diver benthic surveys are a simple example of work conducted by the Pacific Islands Fisheries Science Center. In this case, a diver moves through the water at 0.5 knots, and a still camera captures a downward-facing image every 15 seconds in standard lighting conditions. Coral Point Count (or similar software) is used to distribute points, and humans then classify the benthic habitat at these points. The mission is conducted once or twice per year, with approximately 60,000 images collected, and some 6 million images have been archived. Five human analysts study these images.
- Habitat Mapping Camera System (HabCam). HabCam is a towed camera for benthic surveys, primarily targeting sea scallops, benthic invertebrates, and benthic fish by the Northeast Fisheries Science Center. A camera sled is towed at 5 to 7 knots at 1 to 3 m above the bottom. The sled contains stereo, digital, still cameras, using standard lighting to obtain 6 frames per second. Some 15 million images are in the archive. Approximately 10 ana-

FIGURE 2.1 Sample images captured by HabCam. Both images contain benthic fish. SOURCE: Courtesy of the HabCam Group.
lysts study these images, and NOAA is leveraging crowdsourcing2 to help with the analysis. Examples of images captured by HabCam are shown in Figure 2.1.
- SeaBED Autonomous Underwater Vehicle (AUV). An AUV is used for surveys of demersal fish3 by the Northwest Fisheries Science Center. The SeaBED AUV travels 3 m above the seafloor at 0.5 knots. It collects approximately 100,000 images per year, with a stored archive of 350,000 images. SeaBED AUV also has a video feed that produces around 100 hours of video per year.
- Cam-Trawl. Cam-Trawl, a combined stereo camera and trawl system, is used by the Alaska Fisheries Science Center to sample pollock stocks. The trawl is used as an aggregating device to bring fish before the camera. The camera is side-facing (relative to the trawl), and a homogenous static background is used to ease the fish segmentation and measurement activities. Cam-Trawl acquires 3 million to 4 million images per year, with an archive of 8.2 million images. A sample Cam-Trawl image is shown in Figure 2.2.
- QuadCam. QuadCam, a stereo camera platform used by the Southeast Fisheries Science Center to study reef fish, looks for fish against a complicated coral reef background. Fish come in and out of the image frames,
________________
2 For more information, see the Seafloor Explorer website at http://www.seafloorexplorer.org/, accessed June 6, 2014.
3 Demersal fish live and feed at or near the bottom of the ocean.

FIGURE 2.2 Sample image from Cam-Trawl. SOURCE: Cam-Trawl system, Alaska Fisheries Science Center, NOAA, courtesy of Kresimir Williams.
with varying levels of abundance and occlusion, and the ambient light conditions are constantly changing. A rosette of four stereo camera pairs takes images at 1.2 frames per second, resulting in 13.7 million image pairs per year and a large archive of 83 million images.
- Baited Remote Underwater Video Station (BRUVS). BRUVS is a stereo camera system used by the Pacific Islands Fisheries Science Center as well as the University of Western Australia and others. Like QuadCam, it also targets reef fish. It is a small, easy-to-use, and fairly inexpensive system that uses off-the-shelf commercial cameras.
- Bottom Camera Bait Station (BotCam). BotCam is similar to BRUVS and is used by the Pacific Islands Fisheries Science Center and University of Hawai’i to target deepwater bottom fish using ambient lighting at distances of up to 250 m. BotCam uses analog cameras that are targeted for light-gathering capability. Richards indicated that NOAA is transitioning
BotCam to a new digital camera system, which should improve automated analysis options. BotCam produces 100 hours of video per year.
Richards explained that NOAA maintains a website4 to collect images from different technology platforms and make them publicly available to research partners.
Richards briefly described the following main challenges with image analysis in fisheries stock assessment:
- Species identification,
- Unclassified targets,
- Occlusion,
- Cryptic or non-moving targets,
- Complicated, moving backgrounds,
- Fish that enter and reenter the frame,
- Catchability, and
- Scaling to absolute abundance.
Richards posited that a worthwhile goal is to develop a toolbox—a collection of open-source tools to automate image and video analysis—that could be made readily available to the public for research and general use. A participant later noted that any open-source toolbox would need to be maintained and tested, and it would need to be transitioned to a company or open-source association; such maintenance is unlikely to occur in academia.
In response to a later question, Richards explained that NOAA funds automated-image-analysis projects in three ways: (1) requests for proposals developed through working groups, (2) direct funding of projects through work on a strategic initiative, and (3) small business innovation research grants. Several participants suggested that NOAA advertise these programs more widely in the computer vision community to bring in new participants who may not be aware of these opportunities.
Ruzena Bajcsy, University of California, Berkeley
Ruzena Bajcsy explained that she would not discuss computer vision as a whole, but instead would focus on the specific computer vision challenges posed by fisheries stock assessment. She indicated that because the fisheries community seems
__________________
4 For more information, see the NOAA Fisheries Strategic Initiative on Automated Image Analysis website at http://marineresearchpartners.com/nmfs_aiasi/Home.html, accessed June 6, 2014.
well aware of the existing, standard computer vision technologies, this workshop could help provide additional information about new and novel ideas that can be applied to the specific problems in fisheries. She listed some fisheries-specific challenges, including the following:
- Light intensity (bright versus dark),
- Water clarity (clear versus murky),
- Background in images (homogeneous versus heterogeneous),
- Contrast (low versus high),
- Camera movement (stationary versus moving), and
- Assemblage type (shallow versus deepwater).
Bajcsy noted that many of these challenges result from poor signal-to-noise ratios. One option, studied by Ben Recht (University of California, Berkeley), is to frame denoising as an optimization problem. Bajcsy noted that signal-to-noise ratios can also be improved by including multiple cameras, as described below, a method that is more feasible now that cameras are less expensive.
Bajcsy then stated the goals of fisheries image analysis:
- Segment the fish into individual components and recognize the categories. Bajcsy noted that the difficulty of segmentation depends largely on the signal-to-noise ratio.
- Measure the body mass of each fish. To do this, one must first compute the volume.
- Compute the fish mortality.
- Compute the maximum sustainable yield.
Bajcsy explained that a fisheries stock is overfished when its cumulative biomass (measured in task 2) has fallen to a level below that which can produce the maximum sustainable yield. She also noted that there is a need to monitor the relationship of the fish mortality (task 3) and the level of total biomass (measured in task 2) at the maximum sustainable yield. Bajcsy stated that tasks 2, 3, and 4 have relationships that change as a function of time, and she noted that computer vision can be used to classify different species using the outline of the fish and standard machine learning technology for classification.
One method of improving the signal-to-noise ratio, Bajcsy noted, is through the use of a camera array (such as a 4 by 4 camera array) at a fixed length to a target. With a priori knowledge of the array construction, one can quickly compute dimensional information from sets of images. This is a novel way to implement computer vision, as most systems are limited to two or three cameras. While the
camera array has advantages in speed and quality, it is limited in size and must be moved along the ocean floor.
Bajcsy then pointed to a recent paper discussing feature extraction for segmentation and identification on fast feature pyramids for object detection (Dollar et al., 2014). To improve speed, this research suggests approximating multi-resolution image features by extrapolating from nearby scales rather than computing them directly. Bajcsy said that by selecting a desired resolution, one can leave out background information and focus on the feature(s) of interest. For example, Carson et al. (2002) used a joint color-texture-shape feature representation as “blobs” for segmentation and recognition. A similar paper in 2013 (Lee et al., 2013), Bajcsy said, takes advantage of the fact that some features do not change in time.
Bajcsy then listed a number of useful machine learning techniques that may be helpful in this community, including the following:
- Maximum likelihood estimation,
- Multivariate Gaussian distributions,
- Linear regression,
- Logistic regression, optimization support vector machines (SVMs),
- SVM non-parametric methods,
- Nearest-neighbor clustering,
- Decision trees,
- Neural networks,
- Unsupervised learning,
- Mode seeking, and
- Dimensionality reduction using principal component analysis.
Bajcsy noted that stereo camera systems and other techniques now provide the ability to generate multi-dimensional data (both three- and four-dimensional data). From these data, one can compute a measure of biomass. A superquadric representation5 gives a volumetric representation of an object to provide an assessment of biomass. The superquadric representation can be combined with other, more general, transformations in a systematic way to model other specific behaviors, such as twisting or bending.
Bajcsy concluded by stating that there is a clear need for the fisheries and computer vision communities to collaborate for mutual benefit. She suggested that the analyses of fishery data be framed as a food security issue, not just an ecological issue, to highlight its importance. She also suggested including the environment
__________________
5 Superquadrics are equations that define geometric shapes; they are similar to the equations that describe ellipsoids, but the squaring operation is replaced by an arbitrary power. This technique is commonly used in computer graphics.
in studies, not just fish: the data set becomes richer and potentially interesting to more communities. Other participants noted the importance of distributing data to a wider audience; casting a wider net will bring in more interested people.
SIMULATING FISH AND OTHER SWIMMERS
Demetri Terzopoulos, University of California, Los Angeles
Demetri Terzopoulos explained that his work (with his former Ph.D. student Xiaoyuan Tu) on simulating fish movement was first published nearly 20 years ago and focused on reverse engineering real-life swimming examples. The artificial life approach, according to Terzopoulos, yields lifelike, autonomous agents through the comprehensive modeling of animals. This includes not only conventional computer graphics models of the shape and appearance of animals, but also modeling the functionality of the animal (including biomechanics, perception, motor control, behavior, learning, and cognition).
Terzopoulos explained that each artificial fish’s components were developed in a bottom-up approach. The artificial fish agents are independent and make their own decisions in response to their environment. He later clarified that the artificial fish model has randomness included in it; fish randomly explore if no other stimulus (mating, feeding) is in place. The artificial fish model consists of the following elements, shown schematically in Figure 2.3:
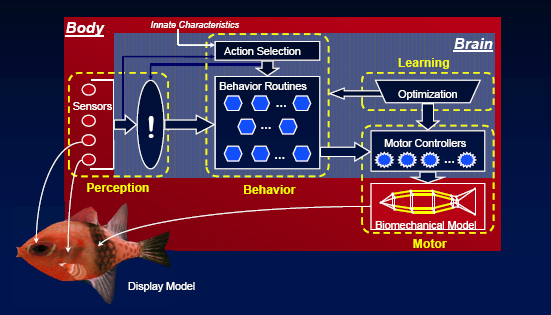
FIGURE 2.3 Schematic diagram of the components of the artificial fish model. SOURCE: Courtesy of Professor Demetri Terzopoulos, University of California, Los Angeles.
- Display model. This includes geometric and appearance representations. Terzopoulos indicated that the various fish display models were created using image-based modeling.
- Body model. This includes a biomechanical submodel, sensors (such as eyes and lateral lines), and a brain.
- Brain model. This includes a motor center to drive the biomechanical model, a perception center that interprets sensory information, a behavior center that ties percepts to the appropriate actions, and a learning center that enables the fish to learn from its experiences.
- Biomechanical submodel. Terzopoulos indicated that this was a simple physics-based model, yet it was capable of synthesizing visually realistic fish locomotion. The three-dimensional (3D) model consists of 23 lumped masses (particles) and 91 viscoelastic elements, 12 of which are contractile muscles. The model is mathematically characterized by a system of differential equations whose numerical time integration simulates the fish’s motion.
- Learning center. Terzopoulos indicated that fish locomotion tends to be energy efficient, so the locomotion learning problem can be solved using an optimization strategy, from which the natural rhythmic caudal fin beating pattern emerges.
- Perception center. This models the capabilities and limitations of the animal’s sensory apparati. Terzopoulos indicated that this consists of a sensorimotor perception system that includes both a stabilization module and a foveation module.
- Behavior center. Here, a set of behavior routines is organized in a loose hierarchy. Low-level behavior routines form a substrate supporting higher-level behaviors. The behavior models consist of three components: innate characteristics (such as gender, preferences, and capabilities), mental state (such as fear, hunger, and libido), and action selection. Action selection is prioritized by the level of perceived danger; for instance, first, a fish would avoid collisions, next, it would avoid predators, then, it would find food, and finally, it would find a mate.
Terzopoulos showed examples of synthesized fish motion that exhibited different behaviors, such as foraging, avoiding predators, and schooling. Schooling, Terzopoulos noted, is a distributed local model and does not require a leader; the behavior of each fish is guided by maintaining a certain distance to nearby animals and following the fish directly in front of it. A participant in the audience noted that schools can behave on a more macroscopic level: if a predator appears, the school coalesces into a ball. The fish in the middle are less likely to be caught, so
all the fish go to the middle. The simulation here does include simple predator-induced schooling behavior, and Terzopoulos responded that the behavior model is extensible and can incorporate more complex behaviors.
Terzopoulos explained that artificial fish were a popular topic in the late 1990s, and he referenced a best-selling book by Richard Dawkins (1996) that reviewed the artificial fish model and the journal Artificial Life, in which a technical paper on the model was published. He also noted the popularity of the virtual fish tank exhibit at the Boston Museum of Science, the Submarine Virtual Reality Theater, and popular screensavers showing animated fish.
Terzopoulos emphasized that the work on artificial fish was decades old and that a more complex model could be built today. His current models of human swimming include all the bones and almost all the relevant skeletal muscles in the body, along with a complex, 3D finite element model to simulate soft tissue behavior subject to the contractions of the embedded muscle actuators and induced water-pressure forces. The simulation of human motion consists of three interleaved simulators: rigid/articulated bone simulation, soft tissue simulation, and simulation of the surrounding water using computational fluid dynamics.
A participant asked if Terzopoulos studied inverse kinematics from a physiological point of view. He responded that he has forged relationships with biomechanics researchers who study human motion; for example, he was recently contacted by medical school researchers who were interested in neck motor control problems.
A participant noted that turbulence can be hard to model. Salmon may be able to swim upstream with greater than 100 percent efficiency by taking advantage of turbulence. Terzopoulos acknowledged that new literature exists on fast swimmers, such as tuna and salmon, who exploit turbulence and higher-order effects.
The discussion concluded with a workshop participant noting that the behavior of fishermen is complex and adaptive and may be much harder to model than fish.
THE FISH4KNOWLEDGE PROJECT: AUTOMATED UNDERWATER VIDEO ANALYSIS FOR FISH POPULATION MONITORING
Concetto Spampinato, Università di Catania (Italy)
Concetto Spampinato described the Fish4Knowledge (F4K) project, a large-scale underwater video collection and processing effort to enable dynamic browsing and presentation of massive amounts of marine data. F4K, which was a 3-year program funded at a level of 2 million euros, encompassed a variety of difficult environmental factors and differing user needs.
The F4K experimental design consisted of nine static cameras that filmed for 12
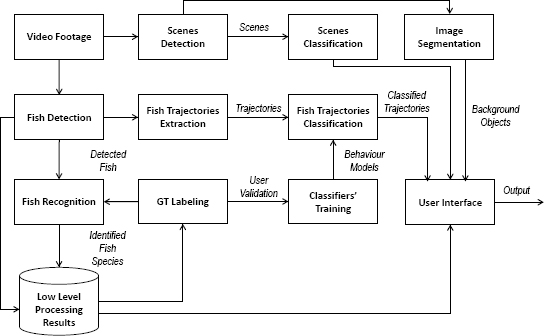
FIGURE 2.4 Schematic of the Fish4Knowledge video analysis system. SOURCE: Concetto Spampinato, Università di Catania (Italy).
hours per day for 3 years, resulting in several terabytes of data. Spampinato stated that within the F4K an automatic approach for fish detection and species classification was developed. As a result, from 3 years of videos, F4K identified a total of 1.55 billion fish, half of which were identified by species. Ninety-nine percent of the fish observed belonged to 1 of 23 species of fish.
F4K used high-performance computing facilities for processing. An interface allowed the user to filter the data by time of day, week of the year, year, location, or camera. F4K provided some information about relative abundance. Spampinato explained that all aspects of F4K remain publicly available, including the source code,6 user interface,7 and data.8
Spampinato described the video analysis system in detail and presented a schematic of the analysis system (shown in Figure 2.4). Annotated images were
__________________
6 For more information, see SourceForge, “Fish4Knowledge Project,” http://sourceforge.net/projects/fish4knowledgesourcecode/, accessed June 16, 2014.
7 The Fish4Knowledge user interface is at http://f4k.project.cwi.nl, accessed June 16, 2014.
8 For more information, seeFish4Knowledge, “Fish4Knowledge Video Sample Download Page,” http://groups.inf.ed.ac.uk/f4k/F4KDATASAMPLES/INTERFACE/DATASAMPLES/search.php, accessed June 16, 2014.
needed for testing the video analysis methods, and Spampinato indicated it was difficult to obtain volunteers for this large task. Instead, F4K developed an online game, among other interfaces for annotation collection, to encourage users to select and identify fish. With a large number of users, he reported that the quality of the annotations was high.
For fish detection in videos, F4K applied background modeling methods. F4K used neighborhood samples to model the background, instead of more traditional methods.
F4K initially used kernel density estimation9 for background and foreground modeling; Spampinato indicated that this method provided the best results among several tested techniques (Spampinato et al., 2014). He noted, however, that the kernel density estimation approach is slow, able to analyze about 1.5 frames per second. The ViBE10 approach worked more quickly but was susceptible to false positives from changes in the light intensity; because of its increased speed, however, it was selected in F4K’s system. To reduce the rate of false positives, a post-processing module was developed with rejection algorithms to assign an object a probability estimating the likelihood of that object being a fish. With this amendment, F4K was able to exploit the faster speed of the ViBE approach. To improve fish detection performance, both intraframe (boundary complexity, boundary color contrast, etc.) and interframe (motion on boundary, motion homogeneity, etc.) features were used in a naïve Bayes classifier11 (Spampinato and Palazzo, 2012).
After the fish were detected, they were classified by their species. A feature vector with 69 features (with metrics to describe color, boundaries, and texture) was used in a balance-guaranteed optimization tree12 (Huang et al., 2012). The classifier was applied to about 30,000 detections, and results were confined to the 23 most popular fish species. With rejection algorithms applied, the classification accuracy was about 65 percent.
Spampinato pointed out that the F4K system had over a billion detections; that amount of information can be exploited to improve detection and classification in the future.
F4K annotated two data sets: one data set consisted of 20 million images that were labeled as either having a fish or not having a fish; a second data set consisted of 2 million images annotated with labels of the 23 most common fish species.
__________________
9 Kernel density estimation is a smoothing function that non-parametrically estimates the probability density function of a random variable.
10 For more information, see ViBE Corporation, “Welcome to ViBE,” http://www.vibeinmotion.com/Home.aspx, accessed June 16, 2014.
11 A naïve Bayes classifier assumes that the presence of one feature is not related to the presence of any other feature.
12 A balance-guaranteed optimization tree is a decision tree that selects a subset of features at each node for object classification.
Spampinato explained that they then conducted semi-supervised learning: they first trained a classifier, and the most likely results were put into the training set for retraining.
Spampinato concluded by describing two new projects under development:
- AQUACAM. This is a program to introduce the F4K technology into the Caribbean to study biomass, marine protected areas, and preservation. Unlike F4K, this project will have a stereo-based approach for fish biomass, while it will conduct automatic species recognition on the most common Caribbean species, and provide a user interface for queries and results, as in F4K.
- UNDERSEE. This project will investigate how to automatically adapt to a change in domain using semantics-guided computer vision approaches.

















