
APPENDIX
F
Estimating Expected Errors from Past Errors
In this appendix, we develop a statistical model for predictive distributions of future country populations and the world population. A predictive distribution indicates the probability that future population levels will fall in a given range. The distribution is developed and estimated using information on errors in past U.N. forecasts, and the most recent U.N. forecast is used to give the point forecasts for the future growth rates.
The model has four features. First, it reflects the observed error in past forecasts. Second, it allows forecast uncertainty to increase with lead time or projection length. Third, it makes the scale of the error depend on past projection error for any given country. Fourth, it incorporates cross-correlation of errors between countries. The model is simplified in various ways but still captures such major features of past error.
Relying on empirical estimates of past errors has limitations. The data we consider, from 1970 onward (evaluated in Appendix B), cover a relatively short period that may be unusual for any given country. In addition, errors are highly correlated, so the observed values contain less information than if they had been independent. Still, the U.N. forecasts—we leave out forecasts from other agencies to simplify the exercise—cover all countries of the world, and the country projections can be viewed, to some extent, as replications of each other, so the weaknesses can be partially compensated.
First we work through the necessary equations, and then we present estimates of prediction intervals by region and for selected countries. The reader who is primarily interested in the results might focus on the latter
sections on prediction intervals and on the conclusions at the end of the appendix.
ESTIMATED ERROR OF GROWTH RATES
Average Growth Rates
We are interested in analyzing the forecast error for individual countries, groups of countries within geographic or economic regions, and the world as a whole. However, to simplify notation, we do not introduce country-specific indexing until the next section.
Let the integer t index the years of observation, and let V(t) be the population size of a country in the beginning of the year t. Defining the average growth rate during [t, t + 1) as
r(t) = log(V(t)/V(t − 1)),
we get that V(t) = exp(r(t))V(t − 1). It follows that for t > 0
V(t) = V(0)exp(r(0) + . . . + r(t − 1)).
We index the jump-off years of interest by k = 0, 5, 10, 20 that correspond to calendar years 1970 + k. Our data will be in the form of average growth rates during 5-year intervals. The endpoints of the intervals are indexed by m = 5, 10, 15, 20, 25, 30 corresponding to calendar years 1970 + m. The average growth rate during [m − 5, m) is
Effect of Data Errors
Due to imperfections in the operation of censuses and vital registration (or population registers), population sizes are not accurately known in many countries. We show how certain types of errors influence the data.
We can always write the estimated population size as
![]() (t) = exp(φ(t))V(t),
(t) = exp(φ(t))V(t),
where φ(t) represents (positive or negative) relative error. Therefore, the estimated average growth rate during [m − 5, m) is
where ∇5φ(m) = φ(m) − φ(m − 5) is the 5-year difference of the error series.
The error in population estimation may change over time both due to systematic factors (such as improved coverage of a census) and due to random factors (such as sampling variability, if survey techniques form part of the estimated population total; changes in population inclusion criteria; lost data; etc.). The simplest model containing both elements assumes that
φ(t) = α + βt + ν(t),
where E[ν(t)] = 0. We see that the constant term cancels in the difference and the estimated growth rate is of the form
Or the change in error rate introduces a bias β and a random error into the estimate. We show below that even β disappears from the estimated errors.
Actual Growth Rate
The true rate of growth is essentially equal to: (crude birth rate) − (crude death rate) + (net migration rate). A major advantage of the cohort-component method of forecasting is that the effect of age structure on crude rates can be accounted for. Therefore, let us assume that the true growth rate during the year t is of the form
r(t) = c(t) + Ψ(0, t) + ξ(t),
where c(t) is a function whose values can be forecasted using cohort-component methods; Ψ(0, t) represents gradual deviation from assumed fertility, mortality, and migration rates during [0, t); and ξ(t) represents unpredictable annual perturbations in fertility, mortality, or migration that can be caused by factors ranging from economic or social events to famine or war. Assume that the ξ(t)'s are independent and identically distributed (i.i.d.) with E[ξ(t)] = 0.
There is no single model for the gradual deviation from the assumed trends. A fairly general formulation assumes that the term Ψ(0,t) is defined at u = 0 by the formula Ψ(u,t) = ψ(u,t) = ψ(u) + . . . + ψ(t) where the ψ(t)'s are i.i.d. with E[ψ(t)] = 0. This is essentially a random walk.
It follows that the formula for the true average growth rate during [m − 5, m) is
where
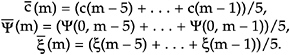
Estimated Error in the Average Growth Rate Forecast
For data analysis we need a formula for the estimated average growth rate, the forecast growth rate, and the estimated error of the forecast growth rate. Under the linearly—or more precisely, loglinearly—changing measurement error model the estimated average growth rate is
Consider now a forecast made for V(m) with jump-off time k. It can be written in the form
in terms of the estimated jump-off population and forecast growth rates. Since the actual forecasts are made using a cohort-component technique, care is needed in modeling the net effect on the growth rate forecast.
The true jump-off value of the growth rate is r(k − 1) = c(k − 1) + Ψ(0, k − 1) + ξ(k − 1). To start the forecast, one would like to know its “trend” value c(k − 1) + Ψ(0, k − 1). Let us suppose that one knows this value from estimates of past population within the estimation error β + ∇5ν(k)/5, a random factor π(k) that represents the smoothing error deriving from averaging over the ξ's, and errors of judgment. (The use of a 5-year period is somewhat arbitrary here.) Or the estimate is ![]() (k − 1) = c(k − 1) + Ψ(0, k − 1) + β + ∇5ν(k)/5 + π(k). We assume that the π(k)'s are i.i.d. with E[π(k)] = 0.
(k − 1) = c(k − 1) + Ψ(0, k − 1) + β + ∇5ν(k)/5 + π(k). We assume that the π(k)'s are i.i.d. with E[π(k)] = 0.
Assume then, that one can forecast c(t) − c(k − 1) for all t perfectly and that the forecasts of ξ(t) and of the random walk ψ(k, t) are optimal, or zero. It follows that the forecast for the growth rate for t ≥ k is of the form
Therefore, the forecast for the average growth rate during [m − 5, m) is
Consider now the estimated error of the forecast growth rate. By splitting the period [0, m) into [0, k) and [k, m) we can write, for m > k that are multiples of 5,
where
The sum involving Ψ(5n) is defined to be zero for m = k + 5. It follows that the estimated error is of the form
We note first that the bias term β vanishes from the estimated data although it was present in the forecast function. This implies that, for data analysis, systematic linear changes in the errors of demographic data do not matter. Note, however, that both α and β will continue to influence future forecast accuracy, because they both influence the accuracy of the estimate of jump-off population V(k) and β influences the forecast of the growth rate.
A STATISTICAL MODEL FOR ESTIMATION
Variances of Errors
In this section, we develop a model for the variance of the estimated error. We then discuss the estimation of autocovariances, and in the next section consider cross-correlation across countries.
To simplify notation, let us write Y(k,m) for the estimated error, where m > k are multiples of 5. Experimentation with the data showed that it was difficult to reliably distinguish between the proportion of variance that was due to measurement error and that due to other components. For this reason, we adopt a simplified model of the form
where the error component ∇5ν(k)/5 is absorbed into π(k) and the component ∇5ν(m)/5 is absorbed into ψ̅(m).
Define the following variances: Var(π(t)) = σπ2, Var(ψ(t)) = σψ2, Var(ξ(t)) = σξ2. We assume that the three sources of error are statistically independent of each other. This holds even after the approximation for m > k + 5 if the autocorrelations of the ν(t)'s are zero after lag = 5, as we would expect. If actual measurement errors are small relative to the other components, then it holds approximately for m = k + 5 as well. Under the independence assumption we get
From these moment equations we can solve ![]() using least squares regression on the squared values Y(k,m)2. A further calculation shows that
using least squares regression on the squared values Y(k,m)2. A further calculation shows that
so we can deduce the value of ![]() After that, a value for
After that, a value for ![]() can be deduced. If a negative variance estimate occurs, we replace the parameter by zero and proceed to estimate the remaining parameters.
can be deduced. If a negative variance estimate occurs, we replace the parameter by zero and proceed to estimate the remaining parameters.
Autocovariance Structure
We assume that the world has been divided into regions i = 1, . . . , I, with countries j = 1, . . . , ni. (The definition of the regions is taken up below.) All symbols are indexed accordingly, σπij2 = Var(πij(t)), σψij2 = Var(ψij(t)), and σξij2 = Var(ξij(t)). Experimenting with the country-specific estimates, we found that the estimates were unstable. Therefore, a more restricted model was adopted. It assumes that the variance parameters have a country-specific scale (or volatility) parameter cij such that σπij = cijσπi, σψij = cijσψi,andσξij = cijσξi, where the region-specific variance components are identified via the normalizing condition σπi2 + σψi2 + σξi2 = 1.
To estimate the region-specific components we used the normalized errors yij(k,m) = Yij(k,m)/{∑u,v Yij(u,v)2} 1/2, which are independent of the scales, as data. The moment equations derived earlier were then applied to each country within a region, and the estimates of the country-specific variance components were averaged. Whenever a country-specific estimate of a variance component was negative, it was replaced by zero in the calculation. The resulting estimates were then normalized so they sum to one for each region.
Since the relative magnitudes of the normalized components are the same for all countries j within region i, the autocorrelation structure of the errors is the same for all countries within each region. Moreover, up to a constant, the variance of the forecast error increases the same way for all countries within a region. However, the scales allow different countries to have different levels of variance within a region.
A simple direct estimate of the scale is
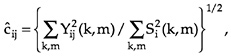
where
![]()
This estimate depends crucially on the estimated normalized variance components via Si. In particular, the scales are not directly comparable across regions, because different regions have different relative weights for the variance components. We will use bootstrap to quantify the uncertainty of estimation.
For some countries, the period from which the data come may have been unusually volatile or calm. An alternative estimator that tries to alleviate the problem is a composite estimator (see Ghosh and Rao, 1994) of the form
c̃ij = γiĉij + (1 − γi)ĉi,
where 0 ≤ γi ≤ 1, and
The so-called empirical Bayes estimators are of this form. Without strong assumptions, it is difficult to find an empirical basis for the determination
of the weights in the present context. However, the composite estimator with carefully chosen weights can be more credible than other available estimators. In any case, the composite estimator is useful in the study of the robustness of the results.
CORRELATIONS ACROSS COUNTRIES
Definition of Regions
Since the error in a forecast for the world population is a sum of the errors of the country populations, it is important that the correlations across countries are not underestimated. Otherwise the variance of the error of the world forecast may be underestimated. Empirical estimates of cross-country correlations depend essentially on the regions used.
We approximate the correlation structure by assuming that regions are independent, and countries within regions have a constant correlation. The regions used should correspond, as much as possible, to this model. Plausible criteria for defining regions are geographic proximity, level of economic development, and social and cultural traditions. The statistical definition of regions using these criteria is a vast task that has not been attempted. Instead we have used geographic proximity and, in borderline cases, the average past forecast error to define the regions. The world was divided into 10 regions: Western and Middle Africa; North, Eastern, and Southern Africa; the Middle East; South Asia and China; East Asia, excluding China; the Pacific Islands; Latin America and the Caribbean; Northern America and Australia; Western Europe; and Eastern Europe and the former Soviet Union ( Table F-1).
The most important cases in which past errors were used to distinguish areas involved Africa and the Middle East. For example, in the Middle East and Western and Middle Africa, average errors were almost evenly split between positive and negative numbers, but for North, Eastern, and Southern Africa, positive errors dominated. Similar considerations were involved in including Afghanistan, Turkey, and Iraq with Eastern Europe and the former Soviet Union rather than in the Middle East. The effect of selection may slightly exaggerate the average intraregional correlation, but the assumption that the regions are independent works in the opposite direction.
Approximating Spatial Correlations
The errors of forecasts may be spatially correlated within regions because demographic developments may be similar, or because errors of judgment on the part of the forecaster may be similar. This means that the
TABLE F-1 Regional classification used in estimating uncertainty
|
Western and Middle Africa |
North, Eastern, and Southern Africa |
Middle East |
East Asia, Excluding China |
South Asia and China |
Pacific Islands |
Latin America and the Caribbean |
Northern America and Australia |
Western Europe |
Eastern Europe and the Former Soviet Union |
|
Angola |
Algeria |
Bahrain |
Brunei |
Bangladesh |
Fiji |
Argentina |
Australia |
Austria |
Afghanistan |
|
Central Afr. Rep. |
Botswana |
Cyprus |
Burma |
Bhutan |
Fr. Polynesia |
Bahamas, The |
Canada |
Belgium |
Albania |
|
Cameroon |
Burundi |
Gaza Strip |
Cambodia |
China |
Guam |
Barbados |
New Zealand |
Denmark |
Armenia |
|
Congo |
Djibouti |
Israel |
Hong Kong |
India |
New Caledonia |
Belize |
U.S.A |
Finland |
Azerbaijan |
|
Gabon |
Egypt |
Jordan |
Indonesia |
Iran |
Papua New Guinea |
Bolivia |
France |
Belarus |
|
|
Equatorial Guinea |
Eritrea |
Kuwait |
Japan |
Nepal |
Samoa, Western |
Brazil |
Germany |
Bosnia-Herz. |
|
|
Chad |
Ethiopia |
Lebanon |
Korea, North |
Pakistan |
Solomon Is. |
Chile |
Greece |
Bulgaria |
|
|
Congo, Dem. Rep. |
Kenya |
Oman |
Korea, South |
Vanuatu |
Colombia |
Iceland |
Croatia |
||
|
Benin |
Lesotho |
Qatar |
Laos |
Costa Rica |
Ireland |
Czech Rep. |
|||
|
Burkina Faso |
Libya |
Saudi Arabia |
Malaysia |
Cuba |
Italy |
Estonia |
|||
|
Côte d'Ivoire |
Madagascar |
Syria |
Mongolia |
Dominican Rep. |
Luxembourg |
Georgia |
|||
|
Cape Verde |
Malawi |
United Arab Em. |
Philippines |
Ecuador |
Malta |
Hungary |
|||
|
Ghana |
Maldives |
Yemen |
Singapore |
El Salvador |
Netherlands |
Iraq |
|||
|
Guinea |
Mauritius |
Sri Lanka |
Guadeloupe |
Norway |
Kazakhstan |
||||
|
Gambia, The |
Morocco |
Thailand |
Guatemala |
Portugal |
Kyrgyz Rep. |
||||
|
Guinea-Bissau |
Mozambique |
Timor, East |
Guyana |
Spain |
Latvia |
||||
|
Liberia |
Namibia |
Vietnam |
Haiti |
Sweden |
Lithuania |
||||
|
Mali |
Reunion |
Honduras |
Switzerland |
Macedonia, FYR |
|||||
|
Mauritania |
Rwanda |
Jamaica |
United Kingdom |
Moldova |
|||||
|
Niger |
Somalia |
Martinique |
Poland |
||||||
|
Nigeria |
South Africa |
Mexico |
Romania |
||||||
|
Senegal |
Sudan |
Neth. Antilles |
Russia |
||||||
|
Sierra Leone |
Swaziland |
Nicaragua |
Slovakia |
||||||
|
Togo |
Tanzania |
Panama |
Slovenia |
||||||
|
Tunisia |
Paraguay |
Tajikistan |
|||||||
|
Uganda |
Peru |
Turkey |
|||||||
|
Western Sahara |
Puerto Rico |
Turkmenistan |
|||||||
|
Zambia |
Suriname |
Ukraine |
|||||||
|
Zimbabwe |
Trinidad-Tobago |
Uzbekistan |
|||||||
|
Uruguay |
Yugoslavia |
||||||||
|
Venezuela |
|||||||||
terms ψ(t) and π(k) used in the previous section can be positively correlated within regions that include similar countries. It is less plausible that the errors caused by unique shocks that are represented by ξ(t) would be spatially correlated. Nevertheless, a more transparent model is obtained when no distinction between the components is made.
To specify the correlation structure within region i, we assume that Corr(ψij(t), ψih(t)) = Corr(πij(t), πih(t)) = Corr(ξij(t), ξih(t)) = ρi for j ≠ h. This
is a simplification but allows us to capture the most important correlational effects.
To estimate the correlations we can use the maximum likelihood estimator of a simpler setting. Suppose that the vector Z = (Z1, . . . , Zn)T has elements Zi ~ N(0, σ2) such that Corr(Zi, Zj) = ρ for i ≠ j. In other words, the components are interchangeable. The maximum likelihood estimator (MLE) can be shown to be ![]() z = {(1TZ2 − ZTZ)/(n − 1)}/ZTZ, where 1 is a vector of n 1s. In words, the MLE is the average of the cross-products divided by the average of squares.
z = {(1TZ2 − ZTZ)/(n − 1)}/ZTZ, where 1 is a vector of n 1s. In words, the MLE is the average of the cross-products divided by the average of squares.
With i, k, and m fixed, the normalized variables yij(k,m) are interchangeable. Let us define a vector yi(k,m) = (yi1(k,m), . . . , yi,ni(k,m))T. We can then estimate ρi by ![]() yi(k,m). We combine the estimators over the values of k and m by averaging. Empirical estimates of the average correlations across all pairs of countries in each region are given in Table F-2. These correlations, which influence forecast uncertainty in an essential way, are generally low, their average across regions being 0.15.
yi(k,m). We combine the estimators over the values of k and m by averaging. Empirical estimates of the average correlations across all pairs of countries in each region are given in Table F-2. These correlations, which influence forecast uncertainty in an essential way, are generally low, their average across regions being 0.15.
The highest correlation of 0.50 was observed for Eastern Europe and the former Soviet Union. This correlation may somehow reflect the socioeconomic and statistical coordination within the region before the breakup of the Soviet Union and the Communist bloc. It is plausible that unpredictable political or social events similar to this breakup may affect entire regions in the future. Prudence dictates that we not think of such events as being less frequent in the future than in the past. To arrive at a plausible specification of the correlations we must keep in mind that r mea-
TABLE F-2 Estimates of within-region correlations of errors
|
Region |
Correlation |
|
Western and Middle Africa |
0.08 |
|
North, Eastern, and Southern Africa |
0.13 |
|
Middle East |
0.01 |
|
South Asia and China |
0.22 |
|
East Asia, excluding China |
0.05 |
|
Pacific Islands |
0.05 |
|
Latin America and Caribbean |
0.14 |
|
Northern America and Australia |
0.21 |
|
Western Europe |
0.07 |
|
Eastern Europe and former Soviet Union |
0.50 |
|
Mean |
0.15 |
sures correlations in the prediction errors, not in the processes themselves. To the extent that forecasters correctly anticipate the average trend within a region, no correlation would appear in the errors, even if the processes themselves had a strong common trend. To get a concrete example of how a correlation-inducing error might occur, we may think of fertility in Europe. It is generally believed that the current low levels will persist, but if they do not, it is likely that the forecasts for each country will have a similar (positively correlated) error. We present calculations that assume the intraregional correlation to be r = 0.15, 0.375, or 0.50, which covers the range from the observed mean to the observed maximum, with an intermediate value that might be considered more plausible than the other two.
PREDICTIVE DISTRIBUTIONS
Prediction Intervals for Individual Countries via Bootstrap
The probability model we have defined in earlier sections is a pure random-effects model with four variance parameters for each country j in region i: σπi2, σψi2, σξi2, and cij2. In addition, there are correlation parameters ρi for within-region correlation. Our empirical analyses gave us no information about the coefficients α and β related to the trend of data improvement. Most likely, systematic biases in population estimation exist in many countries. However, in the following we assume that α = β = 0. This leads to an underestimation of uncertainty. The random data errors νij(t), and any modeling errors (which we know exist because all identities implied by the model for the estimated error in the average growth rate forecast are not empirically satisfied), will be accounted for inasmuch as their effect is present in the estimated variance components.
Suppose we now make a new forecast at a future time k = K for the year K + t. After some algebra we find that, under our model, the ratio of the forecast to the true value is
If all the variance parameters were known a priori, the variance of the relative error would simply be
The first three columns of Table F-3 give the upper endpoints of 95-percent prediction intervals of the relative error for lead times t = 10, 30, 50, for selected large countries, based on the above variance and an assumption that the errors are normally distributed. We call these estimates naïve, because they do not incorporate estimation uncertainty.
In reality, both the scale parameters and the normalized variance components were estimated from data. Hierarchical Bayes methods can probably be applied in the present context (see Gilks et al., 1996). A less ambitious approach is to use bootstrap. We resample ni vectors (with replacement) from the set of country-specific estimates of the normalized variance components of region i. We calculate their average and reestimate the country-specific scales. Repeating this procedure, we get a randomization estimate of the conditional sampling distribution of the scales, given the observed sums ∑k,m Yij(k,m)2. Using the newly generated normalized variance components and scales, we can generate a sample path of the future relative error for each country. In this way, uncertainty concerning the relative shares of the three normalized variance components becomes a part of the estimated uncertainty of the forecast. The middle three columns of Table F-3 give the upper endpoints of the resulting bootstrap prediction intervals obtained for selected countries. We see that for t = 30 and t = 50 the bootstrap intervals are wider, as we would expect. If the bootstrap samples give high values for σπi2 and σψi2, as compared to σξi2, then the variances for large t go up. Correspondingly the variances for small t may go down. (Note that being conditional on the observed errors, the bootstrap does not account for the uncertainty of the scales.) Hence, for t = 10, the bootstrap intervals are narrower than the naïve intervals.
Intervals generated in this way can be interpreted in a purely frequentist manner. Or, in repeated realizations from such a probability mechanism, one would expect that the generated prediction intervals would cover the true value the chosen fraction of time. However, if we interpret the sampling distribution as a data-based posterior distribution, then the intervals calculated can also be interpreted as empirical Bayes prediction intervals.
A strength of the above procedure is that it makes minimal assumptions about the way different countries are considered as replications of each other. However, it is likely that for some countries the period of observation has been more volatile than the future will be. For others it may have been less volatile. A comparison to estimates of uncertainty derived from a more complex analysis can be made for the United States and Finland.
Lee and Tuljapurkar (1994) made a stochastic cohort-component forecast of the U.S. population using time-series analysis of data in the 20th
TABLE F-3 Upper endpoints of 95-percent prediction intervals for relative error at lead times of 10, 30, and 50 years, from naïve, bootstrap, and composite bootstrap procedures, and multipliers to obtain the average regional scale: Selected large countries
century. The ratio of the upper endpoint of their 95-percent prediction interval to the point forecast is 1.039 for lead time t = 10, 1.154 for t = 30, and 1.372 for t = 50. Taking exponentials of the bootstrap values of Table F-3, we see that the comparable ratios from the analysis are 1.018, 1.073, and 1.151 (= e.141) respectively. These are less than half of the values based on a longer data series. This suggests that the past 30 years have been less volatile in the United States than the average during the 20th century. A similar comparison can be made to the results for Finland in Alho (1998), in which historical Finnish time-series for mortality and fertility that start from 1751 and 1776, respectively, were used to make a stochastic cohort-component forecast. The ratios of the upper endpoint of the 95-percent interval to the point forecast are 1.030 for t = 10, 1.153 for t = 30, and 1.402 for t = 50. From estimates for Finland derived in the same way as those in Table F-3, we get 1.032 for t = 10, 1.142 for t = 30, and 1.309 for t = 50. The values are close for the first 30 years, but in the longer term there is a discrepancy. This is consistent with the assumption in Alho (1998) that, for the near future, uncertainty is comparable to that in the recent past, but, for 10-20 years ahead, uncertainty is at historical median levels.
There is no reason to assume that for all countries the intervals we have calculated are too narrow. For some they may be too wide. If countries were of approximately equal size, this would not make a difference, when world population is considered. However, if the scales for very large countries such as India or China are considerably off, then world totals could be affected.
The third panel of Table F-3 has been obtained in the same way as the bootstrap columns but with a composite estimate of the scale. The weight given to the country 's own data was γ = 0.85, and the weight given to the regional average was 1 − γ = 0.15. Since the width of the prediction interval is proportional to the scale of the country, it is possible to calculate how wide the interval should be, if the regional average were used as a scale, instead of the country's own empirical scale. The last column gives the multipliers that can be applied to the country-specific scales to get the average regional scale. Using the multipliers, the reader can easily calculate the widths of intervals corresponding to any composite estimator. For example, since the multiplier for India is 1.629 and the upper bootstrap endpoint for t = 30 in the second row of the table is 0.107, then the corresponding endpoint using the region's average scale would be 1.629 × 0.107 = 0.174. Therefore, the endpoint for a composite estimator corresponding to γ = 0.85 is 0.85 × 0.107 + 0.15 × 0.174 = 0.0910 + 0.0261 = 0.117.
We see that for all countries in Table F-3 except Mexico the multipliers are > 1. In other words, within a region the country scales are less than the average. Since the countries are big, we would expect them to be less volatile than smaller countries (see Appendix B). However, even the com-
posite bootstrap values for the United States (1.186 for t = 50, for example) are still much smaller than those derived by Lee and Tuljapurkar (1994). For the United States, at least, the data period has been unusual relative to the entire span of the 20th century. A calculation for Finland yields the ratio 1.336 for the composite estimator at t = 50, which still does not quite match the earlier estimate, so the period has been rather calm for Finland as well.
In forecasting we are interested in the future scales of the errors. The composite estimators tend to increase the scales of countries that are either large or have experienced a calm period of development recently, or both. Pulling scales toward the regional averages is a way of guarding against too-small scales for the larger countries. We present results with the following three values of weighting, γ = 1.0, 0.85, and 0.70. Based on the U.S. and Finnish experience, 0.85 appears more reasonable than 1.0, but this is not necessarily true for other countries. In particular, since we have assumed that changes in data errors do not influence the accuracy of future forecasts (by taking α = β = 0) and have not accounted for modeling error, parameter combinations yielding larger error variances may be more credible.
Prediction Intervals for World Population
We parametrize the models for future population size in terms of the scale parameter (γ = 1.0, 0.85, 0.70), and the intraregional correlation parameter (ρ = 0.15, 0.375, 0.50). For each combination of values, we simulate a predictive distribution of the world population. Thus, we produce a total of nine candidates for a predictive distribution. Views may differ on how likely these combinations are. We therefore provide summary data on each combination first and then give details for one model, the one corresponding to the values γ = 0.85 and ρ = 0.375.
For total world population, Table F-4 gives ratios of the upper end-point of the 95-percent prediction interval to the median forecast under each parameter combination. The results are given in terms of quantiles rather than moments because the predictive distribution is skew to the right. The main finding is that predictive distributions are fairly robust with respect to the parameters, in the ranges considered. The uncertainty increases with intraregional correlation ρ, as we would expect. Change as a function of γ is more complex. For lead times up to t = 30 years the uncertainty increases with γ, but for higher lead times, uncertainty decreases. This may be due to the fact that countries with large values for scale may increase their share of the regional total for large t more when γ = 1.0 than when γ < 1.0, and thus increase the average level of uncertainty of the area.
TABLE F-4 Ratio of the upper endpoint of the 95percent prediction interval to the median world forecast, for different parameter combinations and lead times
|
Within-region correlation (ρ) |
Country (vs. regional) weight (γ) |
Lead time (t) |
||
|
10 |
30 |
50 |
||
|
0.15 |
1.00 |
1.011 |
1.041 |
1.130 |
|
0.85 |
1.013 |
1.044 |
1.123 |
|
|
0.70 |
1.014 |
1.047 |
1.112 |
|
|
0.375 |
1.00 |
1.014 |
1.050 |
1.151 |
|
0.85 |
1.015 |
1.052 |
1.137 |
|
|
0.70 |
1.016 |
1.056 |
1.134 |
|
|
0.50 |
1.00 |
1.015 |
1.055 |
1.163 |
|
0.85 |
1.017 |
1.058 |
1.148 |
|
|
0.70 |
1.017 |
1.060 |
1.146 |
|
The high, medium, and low projections of the U.N. 1998 revision (United Nations, 1999) have 1995 as the starting population, whereas our calculations use the preliminary estimate for the year 2000 as the jump-off value. Comparisons can still be made by matching lead times. The ratio of the U.N. high projection to the U.N. medium projection is 1.013 for t = 10, 1.071 for t = 30, and 1.168 for t = 50. These agree surprisingly well with the values in Table F-4. Alho (1997) estimated that, for a lead time of t = 40 years, the ratio of the upper limit of a 95-percent prediction interval to the median would be 1.18. This calculation was based on 12 independent regions but with intraregional correlations of 1. The higher correlation partly explains the difference.
To see where the uncertainty comes from, we present first, in Table F-5, the U.N. forecast for the year 2050 for the 10 regions. We see that what happens in China and India—or more generally in developing regions rather than in the industrial regions in the last three rows —is decisive. The second column presents the ratio of the U.N. high projection to the U.N. medium projection for a 50-year lead time (this was calculated from the forecast for 2045, because the jump-off time of the U.N. forecast was 1995), and the third column gives the upper endpoint of a 95-percent prediction interval to the median. For developing regions, the U.N. high/ medium ratios are clearly lower than the ratios derived from the 95-percent prediction intervals, even though for the world as a whole the U.N. ratio is higher. This is due to the fact that the U.N. combines the high projections for all countries to get the high projection for the world,
TABLE F-5 U.N. forecast for 2050 and ratios of upper and lower bounds to 50-year medium or median forecast: World and 10 regions
|
Upper bound ratios |
Lower bound ratios |
||||
|
Region |
U.N. forecast, 2050 (millions) |
U.N. high to U.N. medium |
95% upper endpoint to median |
U.N. low to U.N. medium |
95% lower endpoint to median |
|
World |
8,909 |
1.17 |
1.14 |
0.85 |
0.92 |
|
Western and Middle Africa |
801 |
1.16 |
1.55 |
0.87 |
0.74 |
|
North, Eastern, and Southern Africa |
965 |
1.16 |
1.37 |
0.84 |
0.80 |
|
Middle East |
202 |
1.16 |
3.21 |
0.85 |
0.49 |
|
South Asia and China |
3,735 |
1.16 |
1.20 |
0.84 |
0.83 |
|
East Asia, excluding China |
1,010 |
1.18 |
1.24 |
0.84 |
0.82 |
|
Pacific Islands |
14 |
1.17 |
1.32 |
0.83 |
0.77 |
|
Latin America and Caribbean |
807 |
1.19 |
1.29 |
0.83 |
0.80 |
|
Northern America and Australia |
423 |
1.15 |
1.12 |
0.85 |
0.89 |
|
Western Europe |
344 |
1.12 |
1.10 |
0.90 |
0.91 |
|
Eastern Europe and former Soviet Union |
605 |
1.19 |
1.15 |
0.86 |
0.89 |
|
Note: Estimates for 95-percent intervals assume γ = 0.85 and ρ = 0.375 and are based on 10,000 simulations. U.N. bounds are for 2045, 50 years from the start of the projection. |
|||||
a method that is appropriate only if the projection errors are perfectly correlated across both countries and regions.
For industrial regions, the U.N. high/medium ratios are slightly higher than those based on the 95-percent prediction intervals. This is a possible further indication that the observation period may have been unusually calm for these countries.
The ratio based on the 95-percent prediction interval for the Middle East is surprising. During the observation period, the area experienced a war in Kuwait, and migration involving the oil emirates was unpredictable. A detailed look at the components of past errors would be needed to see whether the model, as we have specified it, needs to be modified for the Middle East.
A major finding emerging from Table F-3, Table F-4, and Table F-5 is, nevertheless, that the U.N. appears to underestimate the uncertainty of the forecasts for individual countries, especially in the developing world. However, the U.N. high-low projections for the world are very close to the 95-percent prediction intervals that one can reasonably infer from our empirical analysis based on past errors.
In Table F-6, we present quantiles of the predictive distribution of the world population in 2010, 2030, and 2050, under the assumption that the population in the year 2000 is known without error. The degree of skewness of the predictive distribution can be seen from the quantiles for 2050. The ratio of the upper endpoint of the 95-percent prediction interval to the median is 1.137, but the ratio of the lower endpoint to the median is 0.917. The U.N. medium forecast for 2050 is 8.902 billion (for the 182 countries included in the data). A comparison to Table F-6 shows that the median of the predictive distribution is 0.15 billion higher, even though we use the U.N. forecast as a point estimate. Mathematically, the difference is due to the fact that for skewly distributed, correlated random variables, the median of a sum or a product typically does not equal the sum or the product of the medians. The results of Table F-6 could be adjusted so the median exactly matches the U.N. point forecast. Both additive and multiplicative adjustments would lead to nearly the same results.
TABLE F-6 Quantiles of the predictive distribution for world population (in millions) in 2010, 2030, and 2050, when γ = 0.85 and ρ = 0.375
Adjustments for Jump-Off Error and Interregional Correlations
We have derived predictive distributions for future population from past errors of U.N. forecasts with jump-off years in 1970-1990. Many aspects of uncertainty are captured in these analyses, but not all. In particular, the analyses are conditional on how the future is assumed to compare with the data period. If the future were assumed to be more or less volatile, the results would have to be adjusted. The adjustments could vary by region. Their effects would depend entirely on the assumed magnitude of change in volatility. We can provide no adjustments for this uncertainty. However, we can provide rough estimates of the effects of three other factors that could affect the predictive distributions.
First, the estimates in the previous table assume that the population in the year 2000 is known without error. This is inaccurate because the U.N. actually projects from 1995, so that the lead time to 2010, for instance, is 15 years rather than 10 years. The first panel of Table F-7 provides estimates adjusted for this, obtained by linearly approximating the change in the upper/median ratios of Table F-4 (for the parameter combination γ = 0.85 and ρ = 0.375) to get approximate upper/median ratios for the years t = 15, 35, and 55. These approximate ratios, which more accurately represent the years 2010, 2030, and 2050, are 1.024, 1.073, and 1.159, respectively, that is, 1-2 percent higher than the equivalent ratios in Table F-4. The predictive distribution would therefore become slightly less concentrated around the median.
Second, the models we use assume no systematic change in measurement error, meaning no allowance for error in the jump-off population. Detailed empirical analyses would be needed to estimate these errors for each country. We can, however, adjust the earlier estimates for world population if we assume (as in Table B-14), that the error is 0.33 percent for world population (or the error is within 0.67 percent with probability 95 percent). The adjustment was made by adding, in the log scale, a normal random variable with standard deviation of 0.0033 to the deviation from the median. The second panel of Table F-7 gives the results. The median changes slightly due to sampling variation, but the upper/median ratios for the years 2010, 2030, and 2050 are virtually the same as in the first panel. Data errors of this magnitude are unimportant if the adjustment for the jump-off year has already been made. An important topic
TABLE F-7 Quantiles of the predictive distribution for world population (in millions) in 2010, 2030, and 2050, adjusted for possible errors and possible interregional correlation
for future research is more accurate determination of the level of error in current world population estimates.
Third, our models approximate the correlation structure across countries by defining 10 regions and assuming constant correlations across countries within regions but independent errors among regions. The data provide little information on interregional correlations because the data period is short and the observations are highly correlated over time. One might infer that various factors influence correlations in opposite directions. If unexpected migratory movements occur from one region to another, then errors will have a negatively correlated component. But if errors occur because overall trends in fertility or mortality are over- or underestimated, then the errors in different regions will tend to be similar and positively correlated. The assumption we used of zero interregional correlations could, therefore, be a reasonable approximation.
Nevertheless, simple back-of-the-envelope calculations show that this assumption has important consequences. Using a lognormal approximation to the regional populations, we find that assuming even a modest correlation of errors across regions of 0.1 would make the uncertainty estimates approximately 25-30 percent bigger. If the correlations were 0.2, then the uncertainty estimates would be approximately 50 percent bigger. The third panel of Table F-7 assumes interregional correlations of 0.1 and adjusts estimates accordingly. The upper/median ratios for the years 2010,
2030, and 2050 become 1.031, 1.093, and 1.202, respectively. The adjustments are much bigger than those obtained by varying the intraregional correlation parameter in Table F-4. The adjustments are large despite the fact that a correlation of 0.1 is so low that available growth-rate date are inadequate to distinguish it from a zero correlation. An important task for future research would be to take a closer look at interregional error correlations.
CONCLUSIONS
We have fitted a stochastic model to the past errors of U.N. forecasts with jump-off years in 1970-1990. The model consisted of three types of variance components. The first component (ψ) produces errors whose variance increases with the cube of the lead time. The second component (π) produces errors whose variance increases with the square of the lead time. The third component (ξ) produces errors whose variance increases proportionally to the lead time. Empirical data were used to estimate the relative magnitudes of these components for each region, and bootstrap was used to account for the uncertainty of estimation. Country-specific scales were estimated to allow for different levels of uncertainty within regions. We showed that the period of observation has been unusually calm for some countries (e.g., the United States), so composite estimation procedures were introduced to pull the estimates toward the regional means and get more robust estimates of future volatility. Cross-correlations of forecast error were approximated by a structure that assumes that the 10 regions used are independent, but within each region the annual error increments have a constant correlation. The correlations considered plausible were between the average and the maximum level estimated from the data.
Our empirical estimates of uncertainty reflect the conditions of the observation period. A reader who believes that forecasts are easier to make now than in the recent past may assume (with 95-percent confidence) that the relative error in a 50-year forecast for the world should not exceed 15 percent or so. A reader who believes that forecasts are more difficult now than in the recent past may assume that the relative error in a 50-year forecast could reach 20 percent.
For total world population, the uncertainty estimates are more reliable than those given for individual countries, because of the cancellation of error in the estimates of the scales. For individual countries, the error could be large. For the two largest countries, China and India, we can say (with 95-percent confidence) that the error should be 20-25 percent, while for countries like Mexico, Brazil, or Nigeria, the uncertainty is much higher. These intervals are clearly wider than those published by the U.N.
REFERENCES
Alho, J.M. 1997 Scenarios, uncertainty and conditional forecasts of the world population . Journal of the Royal Statistical Society, Series A, 160(1):71-85.
1998 A Stochastic Forecast of the Population of Finland. Reviews 1998/4. Helsinki: Statistics Finland.
Gilks, W.R., S. Richardson, and D.J. Spiegelhalter 1996 Markov Chain Monte Carlo in Practice. London: Chapman-Hall.
Ghosh, M., and J.N.K. Rao 1994 Small area estimation. Statistical Science 9:55-93.
Lee, R.D., and S. Tuljapurkar 1994 Stochastic population forecasts for the United States: Beyond high, medium and low. Journal of the American Statistical Association 89:1175-1189.
United Nations (U.N.) 1999 World Population Prospects: The 1998 Revision, Vol. 1, Comprehensive Tables. New York: United Nations.























