
4
Methodological Issues in the Assessment of Technology Use for Older Adults
Christopher Hertzog and Leah Light
Principles of social research are abstractions that are made concrete and manifest through the decisions made by researchers. The research tools we use must be flexibly adapted to the complex problem of understanding how our population is embedded in and responds to a rapidly changing historical context. No context is more complex, it seems, than the flux and rapid progression that is technology use in modern Western societies. The start of the twenty-first century has been characterized by mind-numbing changes in the way in which we engage the world, from the advent of the microcomputer through development of mobile communications technology. Yet the evolution of technology is merely one aspect of the problem. Historical trends in technology encompass individuals who are more or less knowledgeable, more or less skilled, and more or less avoidant of learning how to engage technological innovation. Individual differences in existing knowledge and skill provide a background that strongly influences adaptation to new technologies (Czaja, Sharit, Charness, Fisk, and Rogers, 2003). Moreover, the normative and non-normative changes that accompany aging create a situation in which individuals with changing physical, social, and cognitive resources (the “gains and losses” associated with adult development) (Baltes, 1993) must adapt to new technologies while simultaneously adjusting to and compensating for various negative effects of aging so as to achieve “successful aging” (Rowe and Kahn, 1987).
Understanding the impact of technology on older adults thus requires empirical approaches that can gauge changes on numerous dimensions,
including physiological, behavioral, cognitive, and social psychological outcomes. Given the law of unintended consequences, not all effects of the introduction of new technologies are likely to be planned or even anticipated when the technology is designed. Furthermore, research on human factors and aging strongly indicates that technology designers often do not consider the information processing limitations of humans, let alone their existing behavioral repertoire of skills, their attitudes, and their preferences regarding how to achieve goals (Czaja, 2001). Thus, there is a critical need for effective and reliable methods for judging the efficacy of technological interventions for improving the functioning of older persons, for assisting them in performing tasks necessary for everyday living, for enhancing their capacity to engage in desired behaviors, and for generally improving their quality of life.
Fortunately, the means for accomplishing these tasks are, by and large, available. Social scientists have engaged the generic problem of effective methods for program evaluation in a variety of domains, including education and clinical psychology (e.g., Zigler and Styfco, 2001). The pioneering efforts of scientists such as Donald T. Campbell (Bickman, 2000; Campbell and Stanley, 1966; Cook and Campbell, 1979) in the latter half of the twentieth century have produced well-established principles for conducting experimental and quasi-experimental evaluations of social trends and interventions that are intended to modify them (e.g., Berk and Rossi, 1999; Boruch, 1997; Shadish, Cook, and Leviton, 1995). The seminal study by Campbell and Stanley (1966) also had a strong influence on thinking about how to approach problems of research on aging (Nesselroade and Labouvie, 1985; Schaie, 1977). The dominant approach has been to emphasize quantitative methods for evaluating program impact, but there has also been renewed attention to and appreciation of the benefits of qualitative approaches for certain questions and problems (e.g., Patton, 2001).
A hallmark of modern approaches to program evaluation is an appreciation of the critical role that measurement quality plays in generating valid research conclusions (e.g., Campbell and Russo, 2001). Arguably, selection or development of sensitive and valid measurement techniques is the most important aspect of successful evaluation research. Finally, our sampling methods (for example, ones that achieve representativeness to a target population) have evolved considerably over the past 50 years and are widely employed in sociology, demography, and other disciplines (for an introduction, see Babbie, 2003). These issues are of course highly relevant to research on aging (Alwin and Campbell, 2001; Lawton and Herzog, 1989).
Generally speaking, research design can be viewed as a process of making compromises regarding what and when one measures so as to
answer a research question (Cronbach, 1986; Hertzog and Dixon, 1996; Nesselroade, 1988). Design is the art of compromise because not all variables can be measured easily, and not all confounding variables can be directly controlled to rule out competing interpretations of the data. The practical realities of research necessitate exchanging the optimal for the feasible. Our belief is that theory-guided research is to be preferred when possible (Mead, Batsakes, Fisk, and Mykityshyn, 1999), but theory-guided evaluation may not always be possible or even desirable (e.g., Creswell, 1994). Nonetheless, explicit statements of the research questions, and explorations of what one is and is not attempting to accomplish, are critical first steps if we are to make valid decisions about design issues. Our goal in this chapter is not to provide a compendium of “dos” and don′ts” or a series of checklists for translational research, but rather to provide a vade mecum, or tour guide, for those embarking on such endeavors. We do not treat important practical issues associated with designing and implementing research in field settings (but see Ball, Wadley, and Roenker, 2003); instead we focus on an illustration of principles of research design that are generically relevant to applied research. We hope that consideration of issues involved in the assessment of the impact of technologies on the lives of older adults will help researchers to make thoughtful design decisions that maximize the usefulness of the evaluations they undertake.
We begin our discussion with an overview of some issues that apply quite universally to the design of studies to evaluate the impact of technological interventions on adaptive functioning in older adults. We then review in more detail some fundamental measurement issues as well as basic features of experimental and quasi-experimental intervention designs, ending with a short discussion of the social significance of research outcomes.
BASIC ISSUES IN EVALUATING TECHNOLOGICAL INTERVENTIONS
What Are the Research Questions?
It is important for social scientists to appreciate that the nature of the research question is often different in evaluation research than in research focused on identifying basic mechanisms. Experimental psychologists (like ourselves) are oriented toward isolating causal mechanisms through achieving experimental control over independent variables. The research questions they ask are about structure, mechanism, and process. Evaluation research often dictates a different kind of research question concerning the functional impact of existing or new conditions on the broader population (or specific subpopulations). Consider, for example, the dis-
parity between research questions focusing on understanding age changes in perception and the potential impact of such changes on cognitive performance. An experimental psychologist might ask whether age-related impairments in perception have a detrimental impact on comprehending presented information. Designing research on this topic might focus on manipulating stimulus parameters (e.g., background noise, illumination, glare) to determine the conditions in which perceptual deficits do or do not impact comprehension (e.g., Schneider and Pichora-Fuller, 2000; Wingfield and Stine-Morrow, 2000). The research question might dictate describing the relationship between manipulated perceptual deficit and comprehension outcomes. A practical outcome for comprehension researchers might be guidelines for stimulus characteristics in experiments that eliminate or at least minimize the influence of perceptual limitations on comprehension task performance. A researcher interested in the functional impact of perceptual limitations in typical environments would, in contrast, not want to remove the influences of perceptual limitations, except as the target of an intervention design. Instead, that researcher would first design a study that focused on observing or simulating conditions that constrain perception in common everyday environments and ask questions such as, “What proportion of the population is adversely affected by these kinds of conditions? What is the nature of the functional impact? What can be done to mitigate this functional impact?”
Gerontologists have long recognized that phenomena identified in the laboratory do not necessarily translate directly into improved lives for older adults (Birren, 1974; Czaja and Sharit, 2003; Schonfeld, 1974), although well-designed simulations of everyday tasks in the laboratory may well predict actual performance (e.g., Angell, Young, Hankey, and Dingus, 2002). Translating laboratory research into statements about functional impact on everyday life requires an understanding of the similarity and differences between the laboratory setting and the ecological setting, accounting for the vagaries of human behavior. People develop practical knowledge about how to achieve goals in everyday life that is difficult to “control” in the laboratory. In everyday life, for example, adults can change the requirements of a task by adjusting their strategic approach to the task. Remembering to take medications on schedule requires effective memory processes, unless the adult who is memory impaired obtains assistance from a care provider, family, or friends. Remembering to take medications may be as much a function of social support as it is an ecological test of intact memory functioning (see Park and Kidder, 1996).
Ultimately, understanding the functional impact of technology requires both an understanding of underlying mechanisms and an understanding of normal environmental contexts (e.g., ranges of variation in perceptual conditions, characteristics of persons in the populations) that affect this impact.
Such an assessment is likely to involve simultaneous consideration of many design features and outcome variables. For example, the ultimate standards for usability of a hearing aid for older adults are (a) whether it improves auditory discrimination in all or most of the contexts in which adults who are hearing impaired find themselves (rather than just in the tightly controlled conditions of an audiometric examination), (b) whether it improves not only hearing but also more-complex behaviors that rely on hearing (e.g., social interaction), (c) whether it has been designed to take into account problems in small motor control that might make fine adjustments of its settings difficult for the user, and (d) whether it is unobtrusive enough to permit use without stigmatization (Kemper and Lacal, this volume; Pichora-Fuller and Carson, 2001).
What Are the Populations (or Subpopulations) of Interest?
Any intervention or evaluation study must consider carefully the issue of the target groups of interest for the intervention. Research design needs to carefully consider rival explanations for observed outcomes—often referred to as internal validity threats (Berk and Rossi, 1999; Campbell and Stanley, 1966; Schaie, 1988)—so as to ensure a valid assessment of intervention effects, controlling for potentially confounded variables that could mimic the pattern of expected treatment benefits. Arguably, however, just as much attention needs to be given to matters of external validity—that is, designing studies with an eye to generalizing results of a specific study to different target populations, settings, and time periods (Cook and Campbell, 1979; Hultsch and Hickey, 1978). This is especially the case in technological interventions, which are often designed for compensatory or prosthetic support. Full understanding of the range of attributes in the target group to receive an intervention is critical to ensure that individuals have sufficient cognitive ability or comprehension skills to understand directions or training regimens. Furthermore, careful preliminary research on need and potential benefit may be critical for tailoring the intervention itself.
Older populations are a special case in point. They are characterized by heterogeneity, relative to younger populations (e.g., Nelson and Dannefer, 1992; Hultsch, Hertzog, Dixon, and Small, 1998). Some older adults function at extraordinarily high levels. Others are afflicted with physical and psychological burdens, including chronic diseases such as arthritis, frailty, or depression. Many lack the economic resources to be able to take full advantage of technological innovations that carry some financial costs for implementation and maintenance.
Some products or assistive technologies are designed explicitly for use by people who have disabilities or specific medical conditions. For
example, assistive listening devices are intended for people who have hearing difficulties, and blood glucose monitors are intended for people who have diabetes. However, everyone in our society, including those with functional limitations, needs to access a wide spectrum of technologies during the course of the day, at home, at work, and while carrying out the usual round of daily activities in the community. Most technological devices are designed for those in the 20-50-year age range (Kroemer, 1997). In considering the aging population, however, it is necessary to take into account the fact that aging, and a number of pathological conditions encountered with greater frequency during aging, lead to manifestations of a range of problems. Conditions that affect technology use may be associated with chronological age in a linear or in a quadratic fashion and will vary in severity and incidence, making it difficult to determine “the average person” who is the potential technology user. Vanderheiden (1997) suggests that many designers aim for usability by the upper 95 percent of the population. However, that 95 percent figure applies to each dimension that may lead to limitations in usability—e.g., poor vision, poor hearing, arthritis, learning disabilities. Although many such limitations are independent of each other, a given individual, especially an older individual, may have several. Taking a simple case in which the probabilities of each disability are independent and constant in magnitude, say 10 percent, if a product requires that a person lie in the upper 90 percent of each distribution, the percentage of individuals who can actually use the product will be much less than 90 percent.
Also, because relationships between individual abilities and performance may be nonlinear, there may be threshold effects in which a minimum level of memory, or reasoning, or physical mobility may be required. For example, those who score below a minimum level of performance may be unable to benefit from audiological rehabilitation programs in which complex new skills must be acquired (Pichora-Fuller and Carson, 2001). Some products or devices may be relatively costly and not subsidized by medical insurance—e.g., computers. It is critical, then, that any intervention study consider carefully the targeted recipients, their likelihood to benefit from the intervention, and any unanticipated costs or burdens that may be imposed by the intervention.
Attention to the issue of subpopulation selection also has critical importance for thinking about the nature of the intervention design. Often, interventions are cast in the traditional experimental framework and rely on analysis of variance approaches to identify average treatment benefit. Under these circumstances, individual differences are treated only as error variance. However, research in several domains, including human abilities, cognitive aging, and educational psychology, points to the fact that treatments or interventions may be differentially effective for indi-
viduals varying along some dimension (in analysis of variance terms, these are person by treatment interactions) (Baltes, Reese, and Nesselroade, 1988; Cook and Campbell, 1979; Cronbach and Snow, 1977).
Individuals differ in terms of the background skills, knowledge, beliefs, and behaviors that are relevant to shaping intervention effectiveness. For example, health beliefs play a great role in determining whether older adults will comply with physician instructions (Leventhal, Rabin, Leventhal, and Burns, 2001), and style of personal organization may be an important determinant of whether individuals successfully adhere to medication regimens (Brown and Park, 2003; Park and Kidder, 1996). In cognitive task environments, the particular strategies people select for approaching a task can have a profound impact on novice and skilled performance of older adults (Hertzog, 1985; 1996; Rogers, 2000; Touron and Hertzog, in press).
In the domain of technological intervention, individuals vary widely in past experience regarding computers, VCRs, ATMs, and other devices, and their attitudes toward technology, self-efficacy beliefs in technology use, and general ability may have important influences on their willingness to use and effectiveness in using complex technical devices (Czaja, 2001). For example, some window interfaces may work better for novices than for expert mouse users whereas other interfaces may work better for experts than for novices (Tombaugh, Lickorish, and Wright, 1987).
Evaluators of the usability of heads-up devices for detecting objects on the road ahead may focus on individuals who are familiar with a specific make of automobile or may test individuals new to both the type of auto used in the assessment and to the display device. Choice between these user groups will impact the conclusions that can be drawn.
Therefore, a critical issue for researchers is to determine whether an evaluation design needs to be able to detect interactions of person differences with the target outcome variables. If so, more-complicated statistical analyses are needed for designs that have identified the relevant variables, measured the relevant covariates, and have sampled enough individuals to be able to have the power to detect possible interactions between characteristics of persons and the benefit they derive from intervention. A prior question for the researcher is whether such heterogeneity should be explicitly evaluated, with a larger sample, or whether people will be deliberately selected for homogeneity on particular variables, arguing that a particular target group or groups is the right starting point for evaluating a technical intervention (see Schaie, 1973).
What Are the Outcome (Dependent) Variables of Interest?
Choice of dependent variables will necessarily depend on the research question at hand. In early stages of design and redesign of tech-
nology, the focus is likely to be on issues of usability and safety, rather than on costs and benefits of technology. Once implemented, the dependent variables of interest may shift more toward issues of costs and benefits. Costs and benefits can be assessed at a number of levels, but the nature of these must first be defined. They may be construed narrowly or broadly; as affecting the individual using the technology; as affecting others with whom the user interacts at home, in the workplace, and in the community; or as affecting society more broadly. They may be defined very specifically with regard to the task at hand. For example, the benefit of a telephone reminder system may be assessed quite simply by comparing rates of keeping appointments with healthcare providers or in terms of cost-benefit analyses that take into account the costs of missed appointments and the cost of implementing the reminder system.
The impact of a new technology in the workplace can be evaluated in terms of increased efficiency assessed by speed or accuracy of output (or some measure of efficiency that takes both into account), in terms of quality of interpersonal relationships among users of the technology, in terms of increased sense of well-being or efficacy on the part of the user, or in terms of increases or decreases in stress associated with performing particular tasks after introduction of the technology. The use of ATMs may produce benefits for both users and banks in terms of time saved for transactions, but there may be potential costs in terms of frustration in learning to use the ATM and in loss of personal contact with bank employees. Telemedicine may bring diagnostic and health maintenance services to those without transportation or who live far from specialized medical facilities, but there may be costs if the accuracy of the instrumentation is not high or if there are differences in the nature of information provided by patients to healthcare providers via telecommunication devices and in face-to-face interactions. Learning data entry or other computer skills may bring the opportunity of employment both in the work place and from the home (telecommuting) to older adults, providing enhancements in income during retirement. Maintaining the presence of older adults in the work force can have benefits at the individual level in terms of increased income and sense of self-worth, as well as effects at a societal level that may vary depending on the state of the economy and the need for workers in particular job categories. Use of the computer or telecommunication devices as adjuncts to psychotherapy for caregivers of patients with dementia can reduce the perceived burden of caregiving, provide information about support groups and other services, and allow for extended communication with family members. Below we dis-
cuss in more detail issues associated with the choice of specific measures for assessing outcomes.
Is Event or Time Sampling Needed?
Another critical design issue is whether individuals must be followed over time to evaluate treatment efficacy. Sometimes long-term retention of a newly acquired skill is a crucial issue, and a follow-up to training after an extended lag is needed to fully evaluate training effectiveness. For example, a critical test of a memory intervention may not be whether individuals′ memory performance is better immediately after training, but whether trained skills and memory performance improvements are maintained over days, months, or years (Neely and Bäckman, 1993). Furthermore, the nature of technology use can be conceptualized as the development of skilled behavioral repertoires over time. Hence, one may need to evaluate changes in behavior over the course of training in order to understand how skills develop over time, as well as the relevance of other variables as mediators or moderators of training effectiveness at various stages after the introduction of some technology (Kanfer and Ackerman, 1989).
The literature suggests that older adults can often acquire new skills, but that they do so more slowly at best, and are sometimes differentially susceptible to influences that can impede skill acquisition (Charness and Bosman, 1992; Kausler, 1994; Touron and Hertzog, in press). Nevertheless, assessment of skills or attitudes at a single point in time may not provide results that generalize to real-world settings, where skills are often acquired over long periods of time in intermittent, dispersed learning contexts. Assessment of change over time becomes critical for understanding how much or what kind of training produces optimal use of new technology.
Event sampling may be important for other questions. Event sampling here refers to collecting data when (or if) a specific event or state change occurs. For example, individuals may be maintained in a research panel but may be transferred to a different protocol contingent on specific events (e.g., progression of pathology to a functional level requiring new forms of technological support). Alternatively, data may be sampled according to the onset of specific events encountered by participants (e.g., elevation of blood pressure or blood glucose, a social encounter).
Time sampling may also be an important method for establishing preintervention equivalence when a randomized experiment is not feasible. Introduction of time or event sampling in the design can improve the ability of the design to address critical research questions, but it is almost always accompanied by an increase in the complexity of the design and the resulting data analyses.
MEASUREMENT ISSUES IN ASSESSMENT AND EVALUATION
Here we consider some general issues associated with common methods of measurement in the social sciences used in field and laboratory settings that are relevant to assessing the impact of technology for older adults.
Reliability and Validity
Any method used to decide whether outcomes are meaningful must involve measures that are reliable or consistent. Reliability is often operationalized as stable or consistent individual differences in item responses, either in terms of test-retest correlations, correlations of alternate forms, or measures of internal consistency in responses to sets of relatively homogeneous items (Guion, 2002). More generally, it is the ratio of consistent to total variance. Reliability, by standard accounts, is necessary but not sufficient for establishing construct validity—a variable can repeatedly and consistently measure something(s) other than the construct of interest. However, developmental methodologists have repeatedly shown that stable individual differences are not necessarily the critical measure of consistency; labile measures of psychological states (e.g., mood or affect) often show good reliability within an occasion, but little between-person correlation across different times (Hertzog and Nesselroade, 1987, in press; Nesselroade, 1991). To establish reliability and validity of a given variable, it is critical to consider whether the construct is static or dynamic and the conditions that would give rise to static or dynamic sources of measurement error.
Generically, the most important issue facing any research is ensuring the construct validity of target measures, that is, whether a measure actually taps the construct of interest as conceptualized in a research question (Cronbach and Meehl, 1955; Guion, 2002). This issue can be framed as one of considering the (potentially) multiple sources of variance that affect responses on questionnaires, surveys, or psychological tasks. Variables with higher ratios of construct-relevant variance to total variance, or in regression terms, higher validity coefficients, are of course preferred to variables with low validity coefficients. However, given that we cannot directly observe many important psychological constructs, the problem of comparing validity coefficients is not at all transparent.
What is needed is research that establishes what Cronbach and Meehl (1955) termed a nomological net, that is, a pattern of relationships among variables that is consistent with theoretical arguments about how a construct should relate to other constructs. Measures should show good convergent validity with other measures of the same construct, provided that
the same facets of the construct are being measured. At the same time, they should diverge from measures of related but distinct constructs (discriminant validity—Campbell and Fiske, 1959; see Campbell and Russo, 2001). They should also show differential patterns of predictive validity to related or cognate constructs.
In practice, addressing issues of construct validity often involves the use of complex multivariate statistics, such as confirmatory factor analysis and structural equation models (Hertzog, 1996; McArdle and Prescott, 1994; Schaie and Hertzog, 1985). These approaches can be used to estimate construct-related or method-related sources of variance (Widaman, 1985) and can be used to test hypotheses about construct relations in ways that adjust for measurement properties of the variables (e.g., Hertzog and Bleckley, 2001).
One important lesson that can be learned from validation research is that testing models of nomological nets cannot be separated from asking substantive questions about the possible implications of different theories from data. One does not create valid measures in a first step and then do substantive research on validated measures in a second step. Instead, the process of addressing substantive questions inevitably involves also collecting information on the validity of measurement assumptions and decisions and the behavior of variables.
The extent to which these considerations play a role in evaluating societal impact varies from domain to domain and research question to research question. Measures must always be reliable and valid, but validity may be easier to assess in some situations than in others. Face validity (what a scale seems to measure) of measures may be relatively transparent in many problems. Face validity is also often useful for promoting participant satisfaction and compliance (Babbie, 2003). If one wants to know whether use of infrared devices for detecting objects in the dark reduces nighttime accidents in older adults, archival records of accidents would be appropriate sources of evidence; and the operationalization of the measure and its relationship to the construct of interest is straightforward. If one wants to know whether changing the features on a mouse improves the ability to click on a small window on the screen, this too has a straightforward dependent measure with a straightforward interpretation. On the other hand, face validity can reduce construct validity if people react to the apparent goal of the measure by altering their responses (as in the case of emitting socially desirable responses).
Evaluating construct validity can be complex. Consider the case of caregiving and the Resources for Enhancing Alzheimer′s Caregivers′ Health (REACH) study. Gitlin et al. (2003) discuss two outcome measures. One was the Center for Epidemiological Studies—Depression
Scale (CES-D) (Radloff, 1977). The other was the Revised Memory and Behavior Problem Checklist (RMBPC) (Teri et al., 1992). Respondents were asked at baseline and 6 months later if their care recipients manifested each of a list of problem behaviors and, if so, how bothered or upset the caregivers were by each. Both the CES-D and the RMBPC are reliable measures that are widely used in studies of caregiving. In the Miami sample (and at other sites in this large multisite project), treatment had no effect on degree of change in RMBPC but there was an overall (although fairly small) effect of treatment over control on CES-D for some subsamples. Both the RMBPC and the CES-D might be considered to be measures of the impact of caregiving, but their precise relationship to each other depends on theories of the effects of stressors on perceptions of caregiver burden and the relationship between perception of burden and outcomes such as depression. Interpretation of what it means for one of these variables to show a treatment effect whereas the other does not also requires a theory of their relationship to each other and to other constructs.
A construct that illustrates the import of defining terms is the notion of quality of life. This term has been used to refer to a number of related but not necessarily identical concepts, including life satisfaction assessed either globally or in a particular domain, sense of well-being, social and emotional functioning, health, and social-material conditions (e.g., employment, income, housing), all highly relevant for assessing the impact of assistive technologies on everyday life (Gladis, Gosch, Dishuk, and Crits-Christoph, 1999; Namba and Kuwano, 1999). Instruments used to measure quality of life typically involve self-report, and there is a debate in the field as to whether there is a need for more putatively objective measures such as reports by clinicians or significant others. Gladis et al. note that the best way to operationalize the construct of quality of life may be different at different points in the life span for patients with dementia.
Quality of life is obviously a multifarious concept, and, as noted by Czaja and Schulz (2003), different facets of quality of life may be more appropriate outcome measures depending on the issue under study. Caregiver burden, ability to perform activities of daily living and instrumental activities of daily living, depressive symptoms, and enjoyment of leisure activities may all represent quality of life.
Measurement Equivalence
Research with older adults, as well as research on special subpopulations needing or benefiting from technology, often involves comparisons between subpopulations on variables of interest (e.g., background knowl-
edge about computers, attitudes toward technology). In addition, subgroups are often compared on correlations between two or more measures. Quantitative comparison of means, correlations, regression coefficients, and other test statistics between groups assumes that the variables being analyzed have equivalent measurement properties. That is, one cannot merely assume that the variable is reliable and valid in all the groups; one needs to also assume that the variable is equivalently scaled in different subpopulations (Baltes et al., 1988; Labouvie, 1980). Otherwise, quantitative comparisons of the variables are, strictly speaking, problematic. Use of comparative statistical techniques such as confirmatory factor analysis or item-response theory to evaluate scaling in different groups may be required.
Research has suggested, for example, that older and younger adults respond similarly to some but not all affect rating items (Hertzog, Van Alstine, Usala, Hultsch, and Dixon, 1990; Liang, 1985; Maitland, Dixon, Hultsch, and Hertzog, 2001); likewise, ethnic subgroups can differ in responses to such items (e.g., Miller, Markides, and Black, 1997). To take another example, it is often found that young and older adults give very similar subjective health ratings, but the number of medical conditions reported increases with age; this strongly suggests that young and older adults have different bases for assigning scale values on indices of subjective health. Some data also suggest that older adults differ from younger adults in responses to certain types of telephone-administered surveys (Herzog and Kulka, 1989). Special attention needs to be placed on ensuring that sensory and perceptual difficulties do not dilute the validity of older adults′ responses on questionnaires, interviews, and cognitive tasks (e.g., Schneider and Pichora-Fuller, 2000).
Measurement of Change
If the goal of the research is to assess change over time, a methodological issue that must be addressed is whether measures can be repeatedly administered without altering the validity of the instruments (see also the notion of response shift as in Schwartz and Sprangers, 1999). Some cognitive tests, for example, may be inappropriate for repeated multiple administrations because of reactive effects of testing or practice effects, memory for item solutions, etc. If an aim of the study is to measure intraindividual variability by repeated measurement (Nesselroade, 1991), then development of multiple equivalent or parallel forms is needed (e.g., Hertzog, Dixon, and Hultsch, 1992).
Some measures are also subject to contrast- and adaptation-level effects that occur over time. In a famous study, Brickman, Coates, and Janoff-Bulmer (1978) found that lottery winners did not differ in rated happiness from controls and that paraplegics were not as miserable as
intuition might predict, presumably because of adaptation to changed lifestyle or reassessment of earlier states. Concerns about adaptation or response shift effects are endemic to research in which self-reports are obtained, especially in the area of health evaluation, and have been observed (for example) in assessment of the effectiveness of hearing aids (Joore, Potjewijd, Timmerman, and Anteunis, 2002). Finding similar subjective health ratings in young and older groups may well be an example of such adaptation-level phenomena.
Another issue is whether the measures have been designed to be sensitive to change. Given that measures are often validated by seeking stable individual differences in responses, there can be some concern that a carefully validated measure might inadvertently emphasize (or diffentially weight) stable versus labile components of variance (Roberts and Del Vecchio, 2000).
The goal of evaluating individual differences in intervention effects requires an analysis of stability and change within a population of persons experiencing an intervention effect. Mean change (the average intervention effect, relative to an appropriate baseline comparison) can be contrasted with stability of individual differences within the intervention group, which reflects variation in the impact of the intervention on outcome measures (Campbell and Reichardt, 1991). Statistical estimation of the relative effect of variables predicting differential benefit may profit considerably from more-complicated models or methods for estimating change over time (e.g., Collins and Sayer, 2001; McArdle and Bell, 2000; see Hertzog and Nesselroade, in press, for a conceptually oriented review of these techniques).
Personalized Assessment
Another measurement issue is whether one should use the same variable to measure a hypothetical construct for every individual. For example, assume one wishes to evaluate individuals′ current technical competence with using a computer. It may be better to observe the ways in which different people actually use the computer and to evaluate competence in the context of success with frequently used software, as opposed to evaluating performance on a standard, uniform software program. In this sense, the construct of effective computer use is personalized to assess what individuals actually do and how effectively they do it. There are potential problems of equivalence of scaling across alternative methods, and almost certainly qualitative coding would be needed in some cases rather than development of quantitative conversions across different task types. Nevertheless, consideration of the potential benefits of tailored, personalized assessment could be crucial for measurement regarding some kinds of technology.
Self-Reports
Many measures assess personal characteristics of individuals by asking them to respond with what we can consider self-reports in individual or group interviews (including focus groups), questionnaires, or surveys (for more detailed discussion of these approaches, see Beith, 2002; Nielsen, 1997; and Salvendy and Carayon, 1997). Use of self-report measures requires attention to a number of methodological issues that we discuss in some detail because of their centrality to valid measurement.
“Objective” Versus Subjective Assessment
It is unfortunately easy to design interview and survey questions using implicit but erroneous assumptions of universal and rapid accessibility of target information. For example, one cannot assume that self-reports are inevitably a mirror into objective status. A large body of research shows that subjective health status, as measured by symptom checklists, ratings of functional health, or other methods (e.g., Liang, 1986), often correlates poorly with assessments of physical health by physicians (Pinquart, 2001). This does not imply that the self-reports are necessarily invalid; in fact, subjective health assessments may have better predictive validity for later development of morbidity and mortality than certain kinds of physician assessments.
A large body of literature also shows that self-reported memory complaints are not necessarily a proxy for objective memory problems, as measured by performance on standardized memory tests (e.g., Rabbit, Maylor, and McInnes, 1995). Memory complaints are often more correlated with feelings of depression than they are with actual memory problems. Hertzog, Park, Morrell, and Martin (2000) demonstrated that self-reports of problems with medication adherence had good predictive validity for later medication adherence problems, but that a standardized questionnaire for measuring memory complaints did not predict these problems.
The explanation of the difference appears to involve the fact that the subjective measures of adherence problems were done in the context of reporting medication regimens, and individuals were asked about problems taking the medications as they showed the interviewer the bottle of medication and the instructions on the bottle. As in the cognitive interview (see Jobe and Mingay, 1991), this approach may have created a rich retrieval context for episodes of memory failures. Furthermore, asking about specific behaviors rather than general classes of problems (e.g., “How often do you forget information you read in a newspaper?”) may increase the validity of self-reports.
The separation of objective and subjective status variables is not surprising, given that individuals′ beliefs about themselves and others are complex, multiply determined, and grounded in social contexts of personal experience and of self-reports. Nevertheless, scientists should not assume that self-report measures are inevitably useful substitutes for measures of background status variables or actual outcomes. A similar concern arises for evaluating the implications of attitudes toward technology for possible use of technology. Social psychologists have known for some time that there is a fundamental distinction between intentions and behavior. Asking individuals about their attitudes toward an assistive device, about their willingness to try to use such a device, or whether they would be likely to use an assistive device in the future are not equivalent to measuring the frequency of actual use. The self-reports of attitudes or intentions may have very little predictive value for actual behavior.
Context Effects
Crafting questionnaires is a highly skilled activity and there may be complicating factors when the sample includes older participants. To continue with the healthcare example introduced above, there is abundant evidence that responses to retrospective questions about personal behavior (e.g., medical healthcare visits over the past year) change as a function of the way in which the questions are asked, suggesting that individuals can respond on the basis of different sources of information (Jobe and Mingay, 1991). For example, the accuracy of retrospective estimates of the frequency of doctor visits increases when individuals are provided with a series of questions that establish a retrieval context for specific episodes of illness and treatment. Otherwise, individuals can base responses on some schema-based aspects of self-beliefs (e.g., “I′m a healthy individual, I didn′t go to the doctor last year”).
The content of prior questions can influence answers given to later ones in other ways. If asked about satisfaction with life in general, respondents who have just been queried about satisfaction with marriage are likely to include information about marriage in assessing overall satisfaction and may respond more positively if their response to the marriage question has been positive (Schwarz, Strack, and Mai, 1991). Primacy and recency effects may also occur. That is, particular items may be endorsed at higher rates depending on their position in a list, perhaps because list position is associated with cognitive resources necessary to evaluate the items. Such effects may be exacerbated by oral rather than visual presentation (e.g., Schwarz, Hippler, and Noelle-Neumann, 1992). Because older adults may have reduced resources that affect their ability to keep in mind either prior questions or lists of response alternatives, question or-
der effects are expected to be smaller than for young adults, whereas response order effects are expected to be larger in older adults. Knauper (1999) reviews evidence that this is indeed the case.
Even seemingly innocuous questions have the potential to affect responses to other questions. Take for example the role of filter questions in surveys (Martin and Harlow, 1992). Filter questions can be used to determine knowledge without directly asking for a self-report. So one might be asked, “Do you happen to remember anything special that your U. S. representative has done for your district or for the people in your district while he has been in Congress? (IF YES): What was that?” Such questions are difficult to answer, and failure to answer them correctly can lead to attributions about level of knowledge in some domain and to negative feelings about failure to answer correctly (e.g., embarrassment, disappointment, lack of self-efficacy). Failure to answer filter questions may also lead to distraction and reduction of effort in answering subsequent questions, leading to different patterns of correlations between responses to questions in related and unrelated domains. Whether such effects would be exacerbated in older groups is an interesting question in the context of technology use.
The Social Context of Self-Report
Interviews have been thought of as social exchanges with fairly circumscribed roles for the participants. The interviewer seeks information and the respondent provides it. The assumption is that the interviewer poses a question, the respondent divines the intent of the question and provides a full and unconditional response. Current theorizing has led to a much more complex view of the interview process in which the beliefs, attitudes, and expectations of both interviewer and respondent are critical determinants of how questions are interpreted and answered (e.g., Kwong See and Ryan, 1999; Merton, Fiske, and Kendall, 1990; Saris, 1991). A number of these issues are important for interviewing older adults. Interviewers may hold stereotyped views about cognition in old age, including views about reduced memory and language comprehension and they may, consequently, adopt an interview style believed to be more helpful to older adults (cf. Kwong See and Ryan, 1999; Belli, Weiss, and Lepkowski, 1999). Interviewers are expected to read questions exactly as written, to probe inadequate answers in a nondirective way, to record answers without distortion, and to be nonjudgmental about the content of answers (cf. Fowler and Mangione, 1990), but there is a fair amount of latitude inasmuch as respondents may not be responsive in choosing among alternatives that are provided, or may give responses that are internally inconsistent, or may ask for repetition or clarification (e.g., Schechter, Beatty, and Willis, 1999).
Deviations from exact wording by interviewers may affect accuracy of responses for retrospective questions, but it is possible that interviewer tailoring occurs more often for older adults and that the form of such tailoring is differentially effective (or costly) for older adults than for young adults. Belli et al. (1999) report that older adults “are more likely to engage in verbal comments such as interruptions, expressions of uncertainty, and uncodable responses” and that “interviewers are more likely to engage in verbal behaviors that are discrepant from the ideals of standardized interviewing with older respondents, perhaps as attempts to tailor their communication to meet the perceived challenges that they face (p. 323).” Interviewers tend to produce more significant changes in question reading, more probing, and more feedback for responses with older participants. Belli et al. suggest that these may constitute a form of “elderspeak”1 in the interview situation. To the extent that the interviewer, in deviating from the standard script for an interview, manages to convey negative impressions about aging, the self-efficacy of older adults about encounters with technology could affect their responses.
In carrying out laboratory experiments on cognitive aging, it is our experience that young and older adults construe the interaction between experimenter and participant in different ways. Young adults tend to be quite task oriented and may be participating to fulfill a course requirement or to earn small sums of money. Older adults are often interested in the scientific aspects of the work and view the experimental session as an opportunity for a social interaction. The extent to which such differences may impact the interview process is unknown.
In focus groups, small numbers of people are brought together to discuss a particular topic or topics under the guidance of a trained moderator (Morgan, 1998). Focus groups are useful for exploration and discovery when relatively little is known in advance about an issue or a group (e.g., Rogers, Meyer, Walker, and Fisk, 1998). In focus groups, unlike surveys, there is considerable flexibility in how questions are asked and how participants shape their responses and direct the flow of the conversation. The format permits participants to interact and to develop ideas in a dynamic way as they respond to each other′s ideas. It is the role of the moderator to make sure that the group stays on target and to ask follow-up questions to generate more information on relevant topics.
Focus groups are often used as the first stage in needs assessments or in the development of surveys or interventions. They generate opinions, rather than behavior, and, like other forms of verbal report, are not necessarily predictive of how people will in fact behave. Focus groups are
|
1 |
See Chapter 5, this volume, for a definition and discussion of elderspeak. |
potentially subject to the kinds of interviewer bias effects discussed above. They are also subject to problems of group dynamics associated with perceptions of rank or personality differences (Beith, 2002). For example, one could imagine that mixed groups of novice and expert users of web browsers might be dominated by experts, with novice users less willing to speak at all, much less to describe difficulties with particular aspects of software or hardware. There are alternative approaches. Instead of communicating verbally, participants can type in responses to questions and view their own responses and those of other group members anonymously presented on a screen. Or people can provide responses on paper that are compiled and returned to participants within groups or posted on bulletin boards where participants or researchers can sort them into categories based on similar responses.
Think-Aloud Strategies
There are several strategies for obtaining verbal reports from users of technological devices (Nielsen, 1997). Plausible applications are easy to envision. For example, people can be asked to verbalize their thoughts as they use the web to search for information needed to answer questions (e.g., Mead et al., 1999). Thinking aloud may provide a window on the user′s view of the application or device and may permit identification of the nature of specific areas of difficulty in conceptualizing procedures. Nonetheless, thinking-aloud strategies may not always be appropriate or easy to use (Nielsen, 1997). For example, the act of thinking aloud may change people′s strategies for better or worse. Thinking aloud also slows people down, so performance measures may not be comparable to those obtained under “normal” conditions. Thinking aloud may also be viewed as a form of divided attention—one reports on the task as it is being performed and the performance and the report must be coordinated, something that might prove difficult for older adults. Certain types of task may also not lend themselves well to this approach. Imagine thinking aloud while trying to evaluate information from heads-up devices that show obstacles ahead on the highway and simultaneously steering a vehicle. Verbalization may also prove more difficult for experts who have automatized certain procedural aspects of a task than for novices who are aware of each step they take.
Observational Evaluation Strategies
Given that people may not be good observers of their own behavior and may not be able to describe in detail how they behave in interacting with technological devices, observational techniques in which people are
monitored and perhaps recorded while actually engaged in using technology can be informative not only about the level of performance that is achieved but also about aspects of the technology that are problematic or stressful. For example, Fernie (1997) describes a procedure for assessing the usability of a four-wheeled walker. A video system tracked the movement of light-reflective markers on a participant standing on a large platform that could move unpredictably in one dimension or another. Electrodes applied to the skin measured electrical activity of the muscles, and there were load cells on the walker to measure the force applied to brake handles and force plates to measure components of floor contact.
Videotapes of users may also reveal musculoskeletal discomfort—e.g., rubbing one′s neck or fidgeting (Salvendy and Carayon, 1997). Czaja and Sharit (1993) monitored physiological indicators of stress while young and older adults engaged in three simulated real-world computer tasks (data entry, file modification, inventory management) and found that older adults showed increased arousal on a number of measures of respiratory function and also took longer to return to baseline on these measures than younger adults.
Keeping track of the sequence of actions performed while engaging in a task may reveal how efficient a user is, rather than just whether some task was completed successfully. For example, Czaja, Sharit, Ownby, Roth, and Nair (2001) assessed navigational efficiency for problems solved successfully in a complex information search and retrieval task. An on-line technique that may hold promise for elucidating problems in use of the Internet is eye movement tracking. Noting where people look as they search for information may be informative about optimal placement of information on a screen.
EXPERIMENTAL AND QUASI-EXPERIMENTAL DESIGN PRINCIPLES
Is a Randomized Experiment Possible?
One of the major considerations for evaluation research design is whether a randomized experiment is even possible (Boruch, 1997). A randomized experiment consists of a design with manipulated independent variables that have persons assigned at random to levels of the independent variable. For example, a researcher interested in evaluating a new technique for training data management might assign people at random to participate in either the new training protocol or a no-training or the current training control condition. All other things being equal, randomized experiments afford the greatest control of unwanted research confounds and are in general to be preferred to other approximate techniques
for evaluating effectiveness (Cook and Campbell, 1979). However, randomized experiments are frequently difficult to conduct. Random assignment of persons within an organization to preferred and nonpreferred treatment conditions could lead to imitation of treatments (where individuals in the control group give themselves the intervention without experimenter awareness), resentful demoralization (where persons learn they are in the control group and are not receiving the treatment, with derivative consequences for enthusiasm and morale), and other problems. Interventions that are not under the researchers′ control (e.g., introduction of a technology in the wider society) are not well suited for true experiments, unless screening on variables such as prior exposure to the technology is considered adequate, given the research questions. Furthermore, randomized experiments may not be warranted in some circumstances. For example, if the randomization would require withholding of effective treatment (such as a hearing aid) from a control group of individuals for which it had been recommended, this would be inappropriate on ethical grounds (e.g., Tesch-Römer, 1997).
Random assignment is irrelevant if the goal of the evaluation is to determine which aspects of a design seem to work and which cause usability problems for specific technologies within a particular organizational setting (e.g., Ellis and Kurniawan, 2000). In such circumstances, of course, the same kinds of issues about generalizability would arise as in other types of case studies—similarity of individuals, settings, and, here, technologies across groups to which extension is desired (see Yin, 2002, for a discussion of case study methodologies). In some cases, the goal is not only to develop particular technologies (e.g., the Nursebot, a robotic device capable, among other things, of tracking the whereabouts of people, guiding them through their environments, and reminding them of events or actions to be carried out), but also to develop them in ways that permit tailoring to the needs of individual users (e.g., Pineau, Montemerlo, Pollack, Roy, and Thurn, 2003). Here too, assessment is likely to be carried out at the individual level and considerations of random assignment are not at issue.
Randomized Experiments
The true (or randomized) experiment is generally considered an ideal in evaluation research, but one that may not be feasible due to practical constraints (Cook and Campbell, 1979). Figure 4-1 shows a typical intervention design, the pretest and posttest with randomized treatment and control groups. The design can be generalized to include multiple treatment conditions, or a factorial arrangement of treatment variables, following generic experimental design principles. It can also be extended to
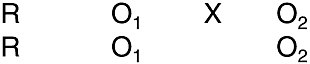
FIGURE 4-1 Standard representation of a randomized pretest-posttest design (see Campbell and Stanley, 1966). Individuals are randomly assigned (denoted by R) to one of two groups—the experimental group and the control group. After pretest (O1), the experimental group (first row) receives the intervention (denoted as X); the control group does not. Both groups are then given the posttest (O2). The design predicts equivalent pretest scores on all dependent variables (due to random assignment) but better performance at posttest (after the intervention) for the experimental group.
provide additional posttests to examine maintenance of intervention benefits over time. The central idea is that random assignment of persons to treatment conditions has the long-run expectation of equating groups on any and all individual differences characteristics. Therefore, any group differences in pretest scores should behave as if those differences reflect variation in random samples drawn from the larger population. The critical hypothesis is that the treatment group will improve more than the control group. Assuming an interval-scaled quantitative dependent variable, one would predict a reliable treatment X time (pretest-posttest) interaction.
The randomized design controls for a wide variety of potential confounded variables (Cook and Campbell, 1979) that are rival explanations for results that seem to indicate a treatment effect, including selection effects (differences in people chosen to be in the treatment and control groups). There are several advantages of the pretest-posttest feature of the design (over and above a posttest-only design). Repeated assessment typically produces a test of experimental effects that has greater statistical power (Cohen, 1988). The design′s hypothesized interaction effect (i.e., people in the treatment group should improve more than people in the control group) has fewer plausible rival hypotheses, generically, than a simple treatment versus control group comparison.
In general, designing a study to generate a specific pattern of results if the intervention is effective is the best way to guard against rival explanations of the results. For example, extending the design to include multiple posttests generates a more subtle hypothesis about treatment benefit and its maintenance over time (Figure 4-2). Perhaps most importantly, individual differences in degree of treatment benefit (indexed by the difference between pretest and posttest scores) can be measured and correlated with other variables in a pretest-posttest design. Thus, it becomes possible to test whether people′s characteristics, such as age, gender, back-
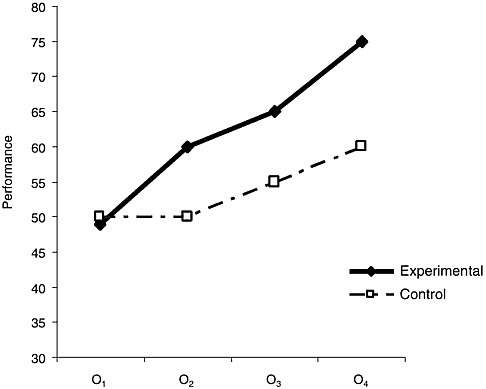
FIGURE 4-2 Hypothetical results from a multiple posttest design (in this case, O1 is the pretest, O2-O4 are the posttests). Note that, although the control group shows increases in performance from O2 through O4 (perhaps for unknown reasons), the experimental group shows the same increases, so the benefit of the intervention between O1 and O2 (manifested by the experimental group′s increase at O2, relative to the control group) is maintained over time.
ground knowledge, and attitudes, are systematically correlated with the magnitude of the intervention effect. This pattern can also be indirectly evaluated by comparing regression equations between control and treatment groups, examining whether predictors of treatment group performance differ from predictors of control group performance. Nevertheless, testing the hypothesis is more straightforward if estimates of experimental benefits are available for all individuals.
Often it is the case that evaluation requires sampling larger units and then assigning treatment conditions to persons within those units. For example, if one were interested in the benefits of technology in assisted living settings, one might find it necessary to provide technological innovations to all persons in a particular setting. This approach may achieve more cooperation from residents and staff and it avoids potential con-
founds such as resentful demoralization in the control group denied the benefits of the new technology. A randomized experiment can still be achieved in such contexts if a sampling frame of the larger units is pre-defined, and then units are randomly assigned to treatment or control conditions. This establishes a hierarchical data structure, and optimal estimates of treatment effects can be obtained through application of mixed model procedures that allow for multilevel analysis (e.g., Bryk and Raudenbush, 1987; Willett, Singer, and Martin, 1998).
Quasi-Experimental (Nonequivalent Group) Designs
Sometimes random assignment, even of larger sampling units, is simply not feasible. Under these conditions researchers can attempt to approximate the experimental method by administering interventions to intact groups. For example (continuing the assisted living example), if one has a limited number of assisted living units willing to participate, random assignment is not likely to produce approximate equivalence. Under these conditions researchers might try to approximate the randomized block design approach by first assessing resident and staff characteristics (e.g., location, socioeconomic status, nature of activity programs, size, resident/staff ratios) that might have an impact on the delivery and benefit of the technological intervention. Then they would purposively assign pairs of maximally similar units to receive the treatment or control condition in a manner that would preserve comparability between the units. In this case, of course, selection confounds are a primary concern, given the researchers′ deliberate selection of units to receive treatments. Statistical analysis of differences in pretest scores and other individual attributes becomes an important part of assessing whether the treatment and control groups are maximally similar on relevant variables prior to introduction of the treatment.
In such quasi-experimental contexts, experiments that can effectively employ within-subjects administration of treatment conditions are even more beneficial than when truly randomized experiments are feasible. One still benefits from the statistical power of repeated measures analyses (assuming the dependent variables are positively correlated across the different cells), and each person effectively serves as his or her own control. When a limited number of sampling units are contemplated, the problem becomes more interwoven with generalizability of estimated treatment effects to other contexts.
Principles of quasi-experimental design can also be applied to comparisons of self-selected populations (e.g., those who do and do not opt to use certain kinds of technologies). Here, the problem becomes one of achieving statistical control on nuisance variables, as well as statistical
evaluation of differences in persons experiencing the different conditions. In limited cases, matching of persons in quasi-experimental groups might be considered, but matching can be problematic when there are multiple characteristics that should be considered and when the persons to be matched differ in the aggregate (perhaps for unknown reasons) in the values of matching variables.
Generically a more valid approach that achieves statistical control is to collect large samples and use regression analysis to evaluate the consequences of technology use and the interactions of person characteristics with those consequences. Given this goal, and the need to control for static individual differences variables that are correlated with the outcomes measures of interest, repeated assessment of persons as they use the technology or become introduced to the technology becomes a valuable design feature. Longitudinal designs, in effect, become a more powerful means of evaluating changes in outcomes as a function of exposure to technology.
Time Series and Interrupted Time Series
In cases in which there is no opportunity for experimental or quasi-experimental manipulation of variables, observational designs can often be strengthened by conducting multivariate time-series observations on the critical variables of interest (Cook and Campbell, 1979; McCleary, 2000). This approach can sometimes produce better evidence for the link-age of technical changes with changes in outcome variables. Statistical models are available for time-series designs that allow for estimates of change in variables adjusting for regular temporal influences (autocorrelation) in the time series.
Intensive intraindividual assessment designs can also be helpful in evaluating coherence of variability in a person or set of persons. For example, if older adults′ subjective well-being is thought to be influenced by degree of e-mail contact with family and peers, intensive repeated assessment of well-being and communication patterns can establish whether there is covariation within persons of these variables (e.g., Molenaar, 1994; Nesselroade, 1991).
An important generalization of time-series principles for quasi-experimental designs is the interrupted time-series design (see Figure 4-3). Here, the idea is that one establishes time-related trends on relevant variables prior to introduction of the new technology and then observes whether this interruption produces qualitative change in the shape of the temporal function, or quantitative change in level, slope of change, or variability over time.
This type of design is recommended when it is not generically feasible to assign persons to different treatments and when a discrete inter-
FIGURE 4-3 Standard representation of an interrupted time-series design in a single group (see Campbell and Stanley, 1966). In this case, individuals are measured at five points in time prior to the intervention and then five points in time after the intervention. The hypothesis is that the intervention will result in a different curve than would have been observed in the absence of the intervention. In practice, a larger number of observation points would often be necessary to determine that the curves before and after the intervention are discontinuous (McCleary, 2000). The design can be strengthened by adding randomized or quasi-experimental groups that do not receive the intervention.
vention event (possibly not under control of the experimenter) is scheduled sufficiently far in advance to enable the researcher to collect adequate baseline data on the time series before it is interrupted. An audiologic rehabilitation program described by Pichora-Fuller and Carson (2001) exemplifies this approach. In the first phase of the project, the measures of interest were administered on two occasions separated by 6 months, permitting assessment of change over time without intervention. The program was then implemented and the same measures were administered twice more, also at 6-month intervals, permitting assessment of change after the intervention. Comparison of change scores before and after the intervention helps to rule out the alternative explanation that the observed gains after the intervention were due simply to the presence of the researchers at the residential facility at which the program was introduced.
A critical problem for time-series designs is accounting for autocorrelation and distinguishing seasonal or temporal cycles from effects of societal interventions (McCleary, 2000). Descriptive time-series analysis often produces apparently interpretable patterns of flux that can be attributed to multiple, time-varying causes. For this reason, there may be so many rival explanations for the trends that definitive statements about causes of change are not possible. In contrast, the judicious introduction and removal of treatments in the context of time-series observations should produce lawful displacements from temporal flux that covary with the treatment′s manipulations, provided that the intervention is effective (see Cook and Campbell, 1979; McCleary, 2000).
CONSIDERING THE IMPLICATIONS OF RESEARCH RESULTS
Within the community of physical and mental healthcare providers, issues of clinical significance are increasingly under evaluation (see e.g.,
Czaja and Schulz, 2003; Schulz et al., 2002). Czaja and Schulz (2003, p. 231) define clinical significance as “the practical importance of the effect of an intervention (treatment) or the extent to which the intervention makes a real difference to the individual or society. For the individual, clinical significance is obviously important. A treatment should effect a change on some outcome that is important to the life of an individual.” In formulating policy within social agencies, both private and public, the goal is to have evidence-based interventions. We believe that the framework in which Czaja and Schulz (2003) cast issues of clinical significance can be usefully extended to issues of evaluating the impact of technology. Following their exposition, we discuss (a) defining what is meant by a significant outcome and selection of measures to index these outcomes and (b) social significance.
Defining Significant Outcomes
Issues of “significance” are sometimes defined in terms of statistical significance, but because statistical significance is a function of sample size as well as the heterogeneity of the group or groups being assessed, the reliability of the measures involved, and other factors, some statisticians prefer to think instead in terms of effect sizes such as r2 or d. Deciding on the magnitude of an effect that is considered large or important, however, is a subject of some debate. For example, Cohen (1988) proposes that, for the t-test, ds of 0.20, 0.50, and 0.80 be considered small, medium, and large effect sizes. Rosenthal (1995) has noted that very small effect sizes may translate into important differences in terms of number of persons who benefit from medical treatments. Kazdin (1999) has also suggested that clinically significant outcomes can occur when change is large, small, or indeed absent!
What counts as a meaningful change in outcome measures will vary from domain to domain. Consider the case of CES-D as an outcome measure in the REACH study discussed above (Gitlin et al., 2003). In the Miami sample, one group of caregivers received an intervention called the Family-Based Structural Multisystem In-Home Intervention (FSMII) and another received the FSMII and a Computer Telephony Integration System (CTIS). The CTIS included use of a screen phone with text display screens and enhanced functions that allow both voice and text to be sent. The expectation was that this would facilitate communication in therapy sessions, increase access to support from family members and others, and provide access to medication and nutrition information and linkages to formal resources as well as some caregiver respite activities. A minimal support control group was also included. The group with CTIS showed a greater improvement in CES-D scores from baseline over a 6-month pe-
riod than did the control group (Gitlin et al., 2003). The control group showed a small change from 18.34 to 17.73, whereas the CTIS group showed a decline from 16.08 to 13.88. There are different ways of evaluating the importance of this effect. A CES-D score of 16 is treated as the cutoff for persons to be at risk for major depression. So one way to look at this is that the CTIS group moved out of the at-risk category. Another way to evaluate the outcome would be to ask whether the CTIS group mean at 6 months looks more like some normative group than it did at baseline. This of course presumes that there is an appropriate comparison group. Other approaches are also possible (e.g., Jacobson, Roberts, Berns, and McGlinchey, 1999). Note, however, that in absolute terms the change of the CTIS group was 2.20 points whereas that of the control group was 0.61 points. The change here, although significant, may not make what Kazdin (1999, p. 332) refers to as “a real (e.g., genuine, palpable, practical, noticeable) difference in everyday life to the clients or to others with whom the clients interact.” Here we could ask whether the CTIS led to perceived reductions in stress that were important to the caregiver′s sense of quality of life or increased the ability to provide care so that the care recipient remained at home or lived longer. Similar issues presumably arise when one considers the effects of assistive devices. One can ask whether the use of particular walkers leads to a significant decrease in number of falls at home, fewer visits to healthcare providers, greater independence, reductions in difficulty performing activities of daily living and instrumental activities of daily living—and of course all of the interpretive issues described above would apply. In the case of hearing aids, one can ask what it means to be able to report back correctly one more word or sentence in noise. And so on. In some cases, it is likely to be very difficult to quantify the outcomes. For example, older adults use the Internet to get information about health and to plan travel. What is the appropriate measure here for determining the effect that these uses have?
Social Significance of Outcomes
Here the issue is the extent to which an intervention generates outcomes that are important to or have an impact on society. Social significance can be defined fairly simply in some cases. For example, in the case of caregiving, Czaja and Schulz (2003) point to measures of residential care, placement, patient longevity, patient functional status, service utilization, impact on employment, and cost-effectiveness. Some of these, of course, are also highly relevant for evaluating the result of providing assistive devices to those who need them. Other measures will vary from application to application. There might be costs associated with use of
computers in interventions with caregivers—users might come to expect a higher level of accessibility to expert medical personnel, leading to additional issues of how to compensate healthcare providers for their time. Searching the Internet for medical information could lead to better informed physician-patient interactions but also to costs in terms of problems in understanding technical material available on the web and increases in self-medication or susceptibility to the consequences of faulty information sources (and scams). Providing state-of-the-art assistive devices such as artificial limbs might improve mobility and perceived quality of life, but such devices may be costly. Each of these examples suggests the need for definition of terms and selection of measures that are sensitive to the particular kinds of costs and benefits that are anticipated when a technology is implemented or discovered afterwards. How this might be accomplished is, regretfully, beyond the scope of this chapter.
CONCLUSIONS
We have attempted to identify the critical issues for researchers who are designing research to evaluate the impact of technological change on older adults. Our purpose in raising a number of difficult issues is not to imply that valid research in this area is impossible. To the contrary, we believe that inoculating researchers with information about challenges to good research in this domain is the best method of fostering quality research outcomes and sound scientific and policy inferences based on them. Indeed, the other chapters in this volume are a testament to the fact that high-quality scientific research about aging is abundant and is having a major impact on how we understand the aging process, older adults, and the impact of technology on them. Older populations present special problems for the researcher, as do the goals of evaluating older adults′ current practices and formulating effective interventions that enhance older adults′ functioning. We hope this chapter will raise awareness about the issues that must be tackled to ensure that our society responds to the challenges of enhancing the quality of life of older adults through technological innovation. If we have raised readers′ consciousness about the importance of actually evaluating impact and benefit of technology, rather than presuming it, then we have accomplished one of our major goals.
REFERENCES
Alwin, D.F., and Campbell, R.T. (2001). Quantitative approaches: Longitudinal methods in the study of human development and aging. In R.H. Binstock and L.K. George (Eds.), Handbook of aging and the social sciences (pp. 22-43). San Diego, CA: Academic Press.
Angell, L.S., Young, R.A., Hankey, J.M., and Dingus, T.A. (2002). An evaluation of alternative methods for assessing driver workload in the early development of in-vehicle information systems. (Report No. SAE 2002-01-1981). Warrendale, PA: Society of Automotive Engineers.
Babbie, E.J. (2003). The practice of social research (10th ed.). Belmont, CA: Wadsworth.
Ball, K., Wadley, V., and Roenker, D. (2003). Obstacles to implementing research outcomes in community settings. Gerontologist, 43(1), 29-36.
Baltes, P.B. (1993). The aging mind: Potential and limits. Gerontologist, 33, 580-594.
Baltes, P.B., Reese, H.W., and Nesselroade, J.R. (1988). Life-span developmental psychology: Introduction to research methods. Mahwah, NJ: Lawrence Erlbaum.
Beith, B.H. (2002). Needs and requirements in health care for the older adults: Challenges and opportunities for the new millennium. In W.A. Rogers and A.D. Fisk (Eds.), Human factors interventions for the health care of older adults (pp. 13-30). Mahwah, NJ: Lawrence Erlbaum.
Belli, R.F., Weiss, P.S., and Lepkowski, J.M. (1999). Dynamics of survey interviewing and the quality of survey reports: Age comparisons. In N. Schwarz, D.C. Park, B. Knauper, and S. Sudman (Eds.), Cognition, aging, and self-reports (pp. 303-325). Philadelphia, PA: Psychology Press.
Berk, R.A., and Rossi, P.H. (1999). Thinking about program evaluation (2nd ed.). Thousand Oaks, CA: Sage.
Bickman, L. (2000). Research design: Donald Campbell′s legacy. Thousand Oaks, CA: Sage.
Birren, J.E. (1974). Translations in gerontology from lab to life: Psychophysiology and the speed of response. American Psychologist, 29, 808-815.
Boruch, R.F. (1997). Randomized experiments for planning and evaluation. Thousand Oaks, CA: Sage.
Brickman, P., Coates, D., and Janoff-Bulmer, R. (1978). Lottery winners and accident victims: Is happiness relative? Journal of Personality and Social Psychology, 36, 917-927.
Brown, S.A., and Park, D.C. (2003). Theoretical models of cognitive aging and implications for translational research in medicine. Gerontologist, 43(1), 57-67.
Bryk, A.S., and Raudenbush, S.W. (1987). Application of hierarchical linear models to assessing change. Psychological Bulletin, 101, 147-158.
Campbell, D.T., and Fiske, D.W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56, 81-105.
Campbell, D.T., and Reichardt, C.S. (1991). Problems in assuming the comparability of pretest and posttest in autoregressive and growth models. In R.E. Snow and D.E. Wiley (Eds.), Improving inquiry in social science (pp. 201-219). Mahwah, NJ: Lawrence Erlbaum.
Campbell, D.T., and Russo, M.J. (2001). Social measurement. Thousand Oaks, CA: Sage.
Campbell, D.T., and Stanley, J.C. (1966). Experimental and quasi-experimental designs for research in teaching. Chicago: Rand McNally.
Charness, N., and Bosman, E. (1992). Human factors and age. In F.I.M. Craik and T.A. Salthouse (Eds.), Handbook of Aging and Cognition (pp. 495-552). Mahwah, NJ: Lawrence Erlbaum.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Mahwah, NJ: Lawrence Erlbaum.
Collins, L.M., and Sayer, A.G. (2001). New methods for the analysis of change. Washington, DC: American Psychological Association.
Cook, T.D., and Campbell, D.T. (1979). Quasi-experimentation: Design and analysis issues for field settings. Chicago: Rand McNally.
Creswell, J.W. (1994). Research design: Qualitative and quantitative approaches. Thousand Oaks, CA: Sage.
Cronbach, L.J. (1986). Social inquiry by and for Earthlings. In D.W. Fiske and R.A. Shweder (Eds.), Metatheory in social science: Pluralisms and subjectivities (pp. 83-107). Chicago: University of Chicago Press.
Cronbach, L.J., and Meehl, P.E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52, 281-302.
Cronbach, L.J., and Snow, R.E. (1977). Aptitudes and instructional methods: A handbook for research on aptitude-treatment interactions. New York: Irvington.
Czaja, S.J. (2001). Technology change and the older worker. In J. Birren and K.W. Schaie (Eds.), Handbook of psychology and aging (5th ed., pp. 547-568). San Diego, CA: Academic Press.
Czaja, S.J., and Schulz, R. (2003). Does the treatment make a real difference: The measurement of clinical significance. Alzheimer′s Care Quarterly, 4, 229-240.
Czaja, S.J., and Sharit, J. (1993). Stress reactions to computer-interactive tasks as a function of task structure and individual differences. International Journal of Human-Computer Interaction, 5, 1-22.
Czaja, S.J., and Sharit, J. (2003). Practically relevant research: Capturing real world tasks, environments, and outcomes. Gerontologist, 43, 9-18.
Czaja, S.J., Sharit, J., Charness, N., Fisk, A.D., and Rogers, W.A. (2003). Factors predicting the use of technology: Findings from the center for research and education on aging and technology enhancement (CREATE). Unpublished manuscript.
Czaja, S.J., Sharit, J., Ownby, R., Roth, D.L., and Nair, S. (2001). Examining age differences in performance of a complex information search and retrieval task. Psychology and Aging, 16(4), 564-579.
Ellis, R.D., and Kurniawan, S.H. (2000). Increasing the usability of online information for older users: A case study in participatory design. International Journal of Human-Computer Interaction, 12(2), 263-276.
Fernie, G. (1997). Assistive devices. In A.D. Fisk and W.A. Rogers (Eds.), Handbook of human factors and the older adult (pp. 289-310). San Diego, CA: Academic Press.
Fowler, F.J., Jr., and Mangione, T.W. (1990). Standardized survey interviewing: Minimizing interviewer-related error. Thousand Oaks, CA: Sage.
Gitlin, L.N., Belle, S.H., Burgio, L.D., Czaja, S.J., Mahoney, D., Gallagher-Thompson, D., Burns, R., Hauck, W.W., Zhang, S., Schulz, R., and Ory, M.G. (2003). Effect of multicomponent interventions on caregiver burden and depression: The REACH multisite initiative at 6-month follow-up. Psychology and Aging, 18(3), 361-374.
Gladis M.M., Gosch E.A., Dishuk N.M., and Crits-Christoph P. (1999). Quality of life: Expanding the scope of clinical significance. Journal of Consulting and Clinical Psychology, 67( 3), 320-331.
Guion, R.M. (2002). Validity and reliability. In S.G. Rogelberg (Ed.), Handbook of research methods in industrial and organizational psychology (pp. 57-76). Malden, MA: Blackwell.
Hertzog, C. (1985). An individual differences perspective: Implications for cognitive research in gerontology. Research on Aging, 7, 7-45.
Hertzog, C. (1996). Research design in studies of aging and cognition. In J.E. Birren and K.W. Schaie (Eds.), Handbook of the psychology of aging (4th ed., pp. 24-37). New York: Academic Press.
Hertzog, C., and Bleckley, M.K. (2001). Age differences in the structure of intelligence: Influences of information processing speed. Intelligence, 29, 191-217.
Hertzog, C., and Dixon, R.A. (1996). Methodological issues in research on cognition and aging. In F. Blanchard-Fields and T. Hess (Eds.), Perspectives on cognitive changes in adult development and aging (pp. 66-121). New York: McGraw-Hill.
Hertzog, C., and Nesselroade, J.R. (1987). Beyond autoregressive models: Some implications of the trait-state distinction for the structural modeling of developmental change. Child Development, 58, 93-109.
Hertzog, C., and Nesselroade, J.R. (in press). Assessing psychological change in adulthood: An overview of methodological issues. Psychology and Aging.
Hertzog, C., Dixon, R.A., and Hultsch, D.F. (1992). Intraindividual change in text recall of the elderly. Brain and Language, 42(3), 248-269.
Hertzog, C., Park, D.C., Morrell, R.W., and Martin, M. (2000). Ask and ye shall receive: Behavioral specificity in the accuracy of subjective memory complaints. Applied Cognitive Psychology, 14, 257-275.
Hertzog, C., Van Alstine, J., Usala, P.D., Hultsch, D.F., and Dixon, R.A. (1990). Measurement properties of the Center for Epidemiological Studies Depression Scale (CES-D) in older populations. Psychological Assessment, 2, 64-72.
Herzog, A.R., and Kulka, R.A. (1989). Telephone and mail surveys with older populations: A methodological overview. In M.P. Lawton and A.R. Herzog (Eds.), Special research methods for gerontology (pp. 63-89). New York: Baywood.
Hultsch, D.F., and Hickey, T. (1978). External validity in the study of human development: Theoretical and methodological issues. Human Development, 21(2), 76-91.
Hultsch, D.F., Hertzog, C., Dixon, R.A., and Small, B.J. (1998). Memory change in the aged. New York: Cambridge University Press.
Jacobson, N.S., Roberts, L.J., Berns, S.B., and McGlinchey, J.B. (1999). Methods for defining and determining the clinical significance of treatment effects: Description, application, and alternatives. Journal of Consulting and Clinical Psychology, 67(3), 300-307.
Jobe, J.B., and Mingay, D.J. (1991). Cognition and survey measurement: History and overview. Applied Cognitive Psychology, 5, 175-192.
Joore, M.A., Potjewijd, J., Timmerman, A.A., and Anteunis, L.J. (2002). Response shift in the measurement of quality of life in hearing impaired adults after hearing aid fitting. Quality of Life Research, 11(4), 299-307.
Kanfer, R., and Ackerman, P.L. (1989). Motivation and cognitive abilities: An integrative aptitude-treatment interaction approach to skill acquistion. Journal of Applied Psychology, 74, 657-690.
Kausler, D.H. (1994). Learning and memory in normal aging. New York: Academic Press.
Kazdin, A.E. (1999). The meanings and measurement of clinical significance. Journal of Consulting and Clinical Psychology, 67, 332-339.
Knauper, B. (1999). Age differences in queston and response order effects. In N. Schwarz, D.C. Park, B. Knauper, and S. Sudman (Eds.), Cognition, aging, and self-reports (pp. 341-363). Philadelphia, PA: Psychology Press.
Kroemer, K.H.E. (1997). Anthropometry and biomechanics. In A.D. Fisk and W.A. Rogers (Eds.), Handbook of human factors and the older adult (pp. 87-124). San Diego, CA: Academic Press.
Kwong See, S.T., and Ryan, E.B. (1999). Intergenerational communication: The survey interview as a social exchange. In N. Schwarz, D.C. Park, B. Knauper, and S. Sudman (Eds.), Cognition, aging, and self-reports (pp. 245-262). Philadelphia, PA: Psychology Press.
Labouvie, E.W. (1980). Identity versus equivalence of psychological measures and constructs. In L.W. Poon (Ed.), Aging in the 1980′s: Selected contemporary issues in the psychology of aging (pp. 493-502). Washington, DC: American Psychological Association.
Lawton, M.P., and Herzog, A.R. (1989). Special research methods for gerontology. New York: Baywood Press.
Leventhal, H., Rabin, C., Leventhal, E.A., and Burns, E. (2001). Health risk behaviors and aging. In J.E. Birren and K.W. Schaie (Eds.), Handbook of the psychology of aging (5 ed., pp. 186-214). San Diego, CA: Academic Press.
Liang, J. (1985). A structural integration of the Affect Balance Scale and the Life Satisfaction Index A. Journal of Gerontology, 40(5), 552-561.
Liang, J. (1986). Self-reported physical health among aged adults. Journal of Gerontology, 41, 248-260.
Maitland, S.B., Dixon, R.A., Hultsch, D.F., and Hertzog, C. (2001). Well-being as a moving target: Measurement equivalence of the Bradburn Affect Balance Scale. Journals of Gerontology Series B: Psychological Sciences and Social Sciences, 56(2), 69-77.
Martin, L.L., and Harlow, T.F. (1992). Basking and brooding: The motivating effects of filter questions in surveys. In N. Schwarz and S. Sudman (Eds.), Context effects in social and psychological research (pp. 81-95). New York: Springer-Verlag.
McArdle, J.J., and Bell, R.Q. (2000). An introduction to latent growth models for developmental data analysis. In T.D. Little, K.U. Schnabel, and J. Baumert (Eds.), Modeling longitudinal and multilevel data: Practical issues, applied approaches, and specific examples (pp. 69-107). Mahwah, NJ: Lawrence Erlbaum.
McArdle, R.D., and Prescott, C.A. (1994). Age-based construct validation using structural equation modeling. Experimental Aging Research, 18, 87-116.
McCleary, R.D. (2000). Evolution of the time-series experiment. In L. Bickman (Ed.), Research design: Donald Campbell′s legacy (Vol. 2, pp. 215-234). Thousand Oaks, CA: Sage.
Mead, S.E., Batsakes, P., Fisk, A.D., and Mykityshyn, A. (1999). Applications of cognitive theory to training and design solutions for age-related computer use. International Journal of Behavioral Development, 23(3), 533-573.
Merton, R.K., Fiske, M., and Kendall, P.A. (1990). The focused interview: A manual of problems and procedures (2nd ed.). New York: Free Press.
Miller, T.Q., Markides, K.S., and Black, S.A. (1997). The factor structure of the CES-D in two surveys of elderly Mexican-Americans. Journal of Gerontology: Social Sciences, 52, S259-S269.
Molenaar, P.C.M. (1994). Dynamic latent variable models in developmental psychology. In A. von Eye and C.C. Clogg (Eds.), Latent variables analysis: Applications for developmental research (pp. 155-180). Thousand Oaks, CA: Sage.
Morgan, D.L. (1998). The focus group guidebook: Focus group kit 1. Thousand Oaks, CA: Sage.
Namba, S., and Kuwano, S. (1999). Human engineering for quality of life. In P.A. Hancock (Ed.), Human performance and ergonomics (pp. 69-86). San Diego, CA: Academic Press.
Neely, A.S., and Bäckman, L. (1993). Long-term maintenance of gains from memory training in older adults: Two 3-year follow-up studies. Journal of Gerontology: Psychological Sciences, 48(5), P233-P237.
Nelson, E.A., and Dannefer, D. (1992). Aged heterogeneity: Fact or fiction? The fate of diversity in gerontological research. Gerontologist, 32(1), 17-23.
Nesselroade, J.R. (1988). Sampling and generalizability: Adult development and aging issues examined within the general methodological framework of selection. In K.W. Schaie, R.T. Campbell, W. Meredith, and S.C. Rawlings (Eds.), Methodological issues in aging research (pp. 13-42). New York: Springer-Verlag.
Nesselroade, J.R. (1991). The warp and woof of the developmental fabric. In R.M. Downs, L.S. Liben, and D.S. Palermo (Eds.), Visions of development, the environment, and aesthetics: The legacy of Joachim F. Wohlwill (pp. 213-240). Mahwah, NJ: Lawrence Erlbaum.
Nesselroade, J.R., and Labouvie, E.W. (1985). Experimental design in research on aging. In J.E. Birren and K.W. Schaie (Eds.), Handbook of the psychology of aging (2nd ed., pp. 35-60). New York: Van Nostrand Reinhold.
Nielsen, J. (1997). Usability testing. In G. Salvendy (Ed.), Handbook of human factors and ergonomics (2nd ed., pp. 1543-1568). New York: John Wiley and Sons.
Park, D.C., and Kidder, D.P. (1996). Prospective memory and medication adherence. In M. Brandimonte and G.O. Einstein (Eds.), Prospective memory: Theory and applications (pp. 369-390). Mahwah, NJ: Lawrence Erlbaum.
Patton, M.Q. (2001). Qualitative research and evaluation methods. Thousand Oaks, CA: Sage.
Pichora-Fuller, M.K., and Carson, A.J. (2001). Hearing health and the listening experiences of older communicators. In M.L. Hummert and J.F. Nussbaum (Eds.), Aging, communication, and health: Linking research and practice for successful aging (pp. 43-74). Mahwah, NJ: Lawrence Erlbaum.
Pineau, J., Montemerlo, M., Pollack, M., Roy, N., and Thurn, S. (2003). Towards robotic assistants in nursing homes: Challenges and results. Robotics and Autonomous Systems, 42, 271-281.
Pinquart, M. (2001). Correlates of subjective health in older adults: A meta-analysis. Psychology and Aging, 16, 414-426.
Rabbit, P., Maylor, E., and McInnes, L. (1995). What goods can self-assessment questionnaires deliver for cognitive gerontology? Applied Cognitive Psychology, 9, S127-S152.
Radloff, L.S. (1977). The CES-D Scale: A self-report depression scale for research in the general population. Applied Psychological Measurement, 1, 385-401.
Roberts, B.W., and Del Vecchio, W.F. (2000). The rank-order consistency of personality traits from childhood to old age: A quantitative review of longitudinal studies. Psychological Bulletin, 126, 3-25.
Rogers, W.A. (2000). Attention and aging. In D. Park and N. Schwarz (Eds.), Cognitive aging: A primer . Philadelphia, PA: Psychology Press.
Rogers, W.A., Meyer, B., Walker, N., and Fisk, A.D. (1998). Functional limitations to daily living tasks in the aged: A focus group analysis. Human Factors, 40(1), 111-125.
Rosenthal, R. (1995). Methodology. In A. Tesser (Ed.), Advanced social psychology (pp. 17-49). New York: McGraw-Hill.
Rowe, J.W., and Kahn, R.L. (1987). Human aging: Usual and successful. Science, 237, 143-149.
Salvendy, G., and Carayon, P. (1997). Data collection and evaluation of outcome measures. In G. Salvendy (Ed.), Handbook of human factors and ergonomics (2nd ed., pp. 1451-1470). New York: John Wiley and Sons.
Saris, W.E. (1991). Computer-assisted interviewing. Thousand Oaks, CA: Sage.
Schaie, K.W. (1973). Methodological problems in descriptive developmental research on adulthood and aging. In J.R. Nesselroade and H.W. Reese (Eds.), Life-span developmental psychology: Methodological issues (pp. 253-280). New York: Academic Press.
Schaie, K.W. (1977). Quasi-experimental designs in the psychology of aging. In J.E. Birren and K.W. Schaie (Eds.), Handbook of the psychology of aging (pp. 39-58). New York: Van Nostrand Reinhold.
Schaie, K.W. (1988). Internal validity threats in studies of adult cognitive development. In M.L. Howe and C.J. Brainerd (Eds.), Cognitive development in adulthood: Progress in cognitive developmental research (pp. 241-272). New York: Springer-Verlag.
Schaie, K.W., and Hertzog, C. (1985). Measurement in the psychology of adulthood and aging. In J.E. Birren and K.W. Schaie (Eds.), Handbook of the psychology of aging (2nd ed., pp. 61-92). New York: Van Nostrand Reinhold.
Schechter, S., Beatty, P., and Willis, G.B. (1999). Asking survey respondents about health status: Judgement and response issues. In N. Schwarz, D.C. Park, B. Knauper, and S. Sudman (Eds.), Cognition, aging, and self-reports (pp. 265-283). Philadelphia, PA: Psychology Press.
Schneider, B.A., and Pichora-Fuller, M.K. (2000). Implications of perceptual deterioration for cognitive aging research. In F.I.M. Craik and T.A. Salthouse (Eds.), The handbook of aging and cognition (2nd ed., pp. 155-219). Mahwah, NJ: Lawrence Erlbaum.
Schonfeld, D. (1974). Translations in gerontology from lab to life: Utilizing information. American Psychologist, 29, 796-801.
Schulz, R., O′Brien, A., Czaja, S., Ory, M., Norris, R., Martire, L.M., Belle, S.H., Burgio, L., Gitlin, L., Coon, D., Burns, R., Gallagher-Thompson, D., and Stevens, A. (2002). Dementia caregiver intervention research: In search of clinical significance. The Gerontologist, 42(5), 589-602.
Schwartz, C.E., and Sprangers, M.A.G. (1999). Methodological approaches for assessing response shift in longitudinal health-related quality-of-life research. Social Science and Medicine, 48, 1531-1548.
Schwarz, N., Hippler, H.-J., and Noelle-Neumann, E. (1992). A cognitive model of response-order effects in survey measurement. In N. Schwarz and S. Sudman (Eds.), Context effects in social and psychological research (pp. 187-201). New York: Springer-Verlag.
Schwarz, N., Strack, F., and Mai, H.-P. (1991). Assimilation and contrast effects in part-whole question sequences: A conversational logic analysis. Public Opinion Quarterly, 55, 3-23.
Shadish, W.R., Cook, T.D., and Leviton, L.C. (1995). Foundations of program evaluation: Theories of practice (2nd ed.). Thousand Oaks, CA: Sage.
Teri, L., Truax, P., Logsdon, R., Uomoto, J., Zarit, S., and Vitaliano, P.P. (1992). Assessment of behavioral problems in dementia: The revised memory and behavior problems checklist. Psychology and Aging, 7(4), 622-631.
Tesch-Römer, C. (1997). Psychological effects of hearing aid use in older adults. Journals of Gerontology Series B: Psychological Sciences and Social Sciences, 52B, P127-P138.
Tombaugh, J., Lickorish, A., and Wright, P. (1987). Multi-window displays for readers of lengthy texts. International Journal of Man-Machine Studies, 26(5), 597-615.
Touron, D.R., and Hertzog, C. (in press). Strategy shift affordance and strategy choice in young and older adults . Memory and Cognition.
Vanderheiden, G.C. (1997). Design for people with functional limitations resulting from disability, aging, or circumstance. In G. Salvendy (Ed.), Handbook of human factors and ergonomics (2nd ed., pp. 2010-2052). New York: John Wiley and Sons.
Widaman, K.F. (1985). Hierarchically nested covariance structure models for multitrait-multimethod data. Applied Psychological Measurement, 9, 1-26.
Willett, J.B., Singer, J.D., and Martin, N.C. (1998). The design and analysis of longitudinal studies of development and psychopathology in context: Statistical models and methodological recommendations. Development and Psychopathology, 10, 395-426.
Wingfield, A., and Stine-Morrow, E.A.L. (2000). Language and speech. In F.I.M. Craik and T.A. Salthouse (Eds.), The handbook of aging and cognition (2nd ed., pp. 359-416). Mahwah, NJ: Lawrence Erlbaum.
Yin, R.K. (2002). Case study research: Design and methods. Thousand Oaks, CA: Sage.
Zigler, E., and Styfco, S.J. (2001). Extended childhood intervention prepares children for school and beyond. Journal of the American Medical Association, 285, 2378-2380.




































