
7
Building Computing Systems of Practical Scale
Computer science values not only fundamental knowledge but also working systems that are widely useful. We deliver the benefits of computer science research through these large-scale, complex computing systems, and their design, development, and deployment constitute a fruitful area of research in itself. In doing so, we often raise new questions about fundamental issues.
Started as an attempt to share scarce computing resources, the Internet has become a ubiquitous global utility service, powering personal and commercial transactions and creating domestic and international policy challenges. Along the way it has provided a testbed for research that ranges from high-speed communication to social interactions to new business models. The remarkable success of the Internet, including its scalability and heterogeneity, results from inspired use of engineering-design principles. Peterson and Clark show how some basic principles of generality, layers of abstraction, codified interfaces, and virtual resources led to a system architecture that has survived many orders of magnitude of growth.
The creators of the Internet did not anticipate—couldn’t have anticipated—all of its consequences, including the emergence of the World Wide Web as the principal public-access mechanism for the Internet. The World Wide Web emerged through the synergy of universal naming, browsers, widespread convenient Internet access, the Hyper Text Transfer Protocol, a series of markup languages, and the (relative) platform independence of these mechanisms. The Web has presented new oppor-
tunities—including support for communication within distributed communities—and it has also led to a number of new problems, not the least of which are security and privacy. Bruckman assesses the emerging use of the Internet as a communication medium that links widely dispersed communities, and she analyzes the factors behind the development of these communities.
Sudan reviews the history of the cryptography and security mechanisms that underlie secure Web protocols and other forms of secure computer communication. Also evident is another example of how new opportunities arise when we find a way to eliminate a significant premise of a technology—in this case, the advance exchange of decryption information, or the codebook. Sudan also shows how the computational paradigm has changed even the basic notion of what constitutes proof in an authentication system.
Software engineering research is concerned with better ways to design, analyze, develop, evaluate, maintain, and evolve the complex systems that deliver the computing services described in Peterson and Clark, Bruckman, and Sudan. Shaw describes how software engineering researchers formulate and evaluate research of this kind and employ a variety of approaches to address the subdiscipline’s different types of problems.
THE INTERNET: AN EXPERIMENT THAT ESCAPED FROM THE LAB
Larry Peterson, Princeton University, and David Clark, Massachusetts Institute of Technology
The recent explosion of the Internet onto the world’s consciousness is one of the most visible successes of the computer science research community. The impact of the Internet in enabling commerce, allowing people to communicate with each other, and connecting us to vast stores of information and entertainment is undeniable. What is surprising to most people who now take the Internet for granted is that the underlying architecture that has allowed the Internet to grow to its current scale was defined over 25 years ago.
This remarkable story began in the late 1970s when a collection of computer science researchers, then numbering less than a hundred, first deployed an experimental packet-switch network on tens of computers connected by 56-kbps links. They built the network with the modest goal of being able to remotely enter jobs on each others’ computers, but more importantly, as an experiment to help them better understand the principles of network communication and fault-tolerant communication. Only in their wildest dreams did they imagine that their experiment would enter the mainstream of society, or that over the next 25 years both the bandwidth of its underlying links and the number of users it connects would each grow by six orders of magnitude (to 10-Gbps links and 100 million users, respectively). That a single architecture not only survived this growth, but also in fact enabled it, is a testament to the soundness of its design.
Layering and Abstraction
Several design principles, many of them sharpened by years of experience building early operating systems like Multics, helped shape the Internet architecture.
The most important of these was to employ multiple layers of abstraction (see earlier essays) to manage the complexity of the system. Networks cannot claim to have invented hierarchical abstraction, but they have become the most visible application of layering. At the lowest level, electrical-magnetic signals propagate over some medium, such as a copper wire or an optical fiber. At the next level, bits are encoded onto these signals. Groups of bits are then collected together, so abstractly we can think of machines sending self-contained messages to each other. At the
next layer, a sequence of machines forwards these messages along a route from the original source to the ultimate destination. At a still higher layer, the source and destination machines accept and deliver these messages on behalf of application processes that they host. We can think of this layer as providing an abstract channel over which two (or more) processes communicate. Finally, at the highest level, application programs extract meaning from the messages they receive from their peers.
Recognizing that layering is a helpful tool is one thing. Understanding the right layers to define is quite another. Here, the architects of the Internet were guided by another design principle, generalization. One dimension of generalization is to support as many applications as possible, including applications that have not yet been imagined. In terms recognized by all computer scientists, the goal was to build a network that could be programmed for many different purposes. It was not designed to just carry human voice or TV signals, as were other contemporary networks. Instead, one of the main characteristics of the Internet is that through a simple matter of programming, it can support virtually any type of communication service. The other dimension of generality is to accommodate as many underlying communication technologies as possible. This is akin to implementing a universal machine on any number of different computational elements. Looked at another way, the Internet is a purely logical network, implemented primarily in software, and running on top of a wide assortment of physical networks.
Next you need to codify the interfaces to the various layers. Here, early Internet researchers recognized the need to keep the common interfaces minimal, thereby placing the fewest constraints on the future users of the Internet, including both the designers of the underlying technologies upon which it would be built and the programmers that would write the next generation of applications. This allows for autonomy among the entities that connect to the Internet: they can run whatever operating system they want, on whatever hardware they want, as long as they support the agreed upon interface. In this case, the key interface is between code modules running on different machines rather than modules running on the same machine. Such interfaces are commonly called protocols: the set of rules that define what messages can be sent between a pair of machines, and under what circumstances.
In the early days of network design, it was not clear that we could actually write protocol specifications with sufficient clarity and precision that successful communication was practical. In the 1970s it was predicted that the only way to get different computers to communicate with each other was to have a single group of people build the code for all the machines, so that they could take into account all the details that would never be specified properly in practice. Today, the idea that protocols can
be well specified is accepted, but a great deal of work went into learning how to do this, including both practical experiments and theoretical work on automatic checking of specifications.
The general idea of abstraction takes many forms in the Internet. In addition to using layering as a technique for managing complexity, a form of abstraction known as hierarchical aggregation is used to manage the Internet’s scale. Today, the Internet consists of tens of millions of machines, but these machines cannot possibly all know about each other. How then, can a message be correctly delivered from one machine to another? The answer is that collections of machines are first aggregated according to the physical network segment they are attached to, and then a second time according to the logical segment (autonomous domain) to which they belong. This means that machines are assigned hierarchical addresses, such that finding a path from a source machine to a destination machine reduces to the problem of finding a path to the destination domain, which is then responsible for delivering the data to the right physical segment, and finally to the destination machine. Thus, just as layering involves a high-level protocol hiding the uninteresting details about a low-level protocol, aggregation involves high levels of the addressing and routing hierarchy masking the uninteresting details about lower levels in the hierarchy.
Resource Sharing
Networks are shared systems. Many users send traffic from many applications across the same communication links at the same time. The goal is the efficient exploitation of expensive resources. Long-distance communication links are expensive, and if many people can share them, the cost per user to communicate is greatly reduced.
The telephone system is a shared system, but the sharing occurs at the granularity of a call. When a user attempts to make a call, the network determines if there is capacity available. If so, that capacity is allocated to the caller for as long as the call lasts, which might be minutes or hours. If there is no capacity, the caller is signaled with a busy tone.
Allocating communications capacity for a period of minutes or hours was found to be very inefficient when computer applications communicated. Traffic among computers seems to be very bursty, with short transmissions separated by periods of silence. To carry this traffic efficiently, a much more fine-grained sharing was proposed. The traffic to be sent is broken into small chunks called packets, which contain both data to be sent and delivery information. Packets from many users come together and are transmitted, in turn, across the links in the network from source toward destination.
When the concept of packet was first proposed, there was considerable uncertainty as to whether this degree of multiplexing would work. If traffic from multiple users arrives to be sent at the same instant, a queue of packets must form until all can finally be sent. But if the arrival pattern of packets is unpredictable, is it possible that long, persistent queues will form? Will the resulting system actually be usable? The mathematics of queuing theory were developed to try to understand how such systems might work. Queuing theory, of course, is not restricted to network design. It applies to checkout lines in stores, hospital emergency rooms, and any other situation where arrival patterns and service times are predictable only in a statistical sense. But network design has motivated a great deal of research that has taught us much about statistical properties of shared systems. We now know the conditions to build systems like this with predictable stability, reasonable traffic loads, and support for a wide range of applications. The concept of the packet has turned out to be a very robust one that has passed the test of time.
More recently, as the Internet has grown larger, and the number of interacting traffic flows has grown, a new set of observations have emerged. The Internet seems to display traffic patterns that are self-similar, which means that the patterns of bursts that we see in the aggregated traffic have the same appearance when viewed at different time scales. This hints that the mathematics of chaos theory may be the tool of choice to increase our understanding of how these large, shared systems work.
Devising techniques to share resources is a recurring problem in computer science. In the era of expensive processors, time-sharing systems were developed to share them. Cheaper processors brought the personal computer, which attempts to side-step some of the harder sharing problems by giving each user his own machine. But sharing is a fundamental aspect of networking, because sharing and communication among people and the computers that serve them is a fundamental objective. So mastery of the models, tools, and methods to think about sharing is a fundamental objective of computer science.
Concluding Remarks
The Internet is arguably the largest man-made information system ever deployed, as measured by the number of users and the amount of data sent over it, as well as in terms of the heterogeneity it accommodates, the number of state transitions that are possible, and the number of autonomous domains it permits. What’s more, it is only going to grow in size and coverage as sensors, embedded devices, and consumer electronic equipment become connected. Although there have certainly been stresses on the architecture, in every case so far the keepers of the Internet have
been able to change the implementation while leaving the architecture and interfaces virtually unchanged. This is a testament to the soundness of the architecture, which at its core defines a “universal network machine.”
By locking down the right interfaces, but leaving the rest of the requirements underspecified, the Internet has evolved in ways never imagined. Certainly this is reflected in the set of applications that run on the Internet, ranging from video conferencing to e-commerce, but it is also now the case that the Internet has grown to be so complicated that the computer scientists that created it can no longer fully explain or predict its behavior. In effect, the Internet has become like a natural organism that can only be understood through experimentation, and even though it is a deterministic system, researchers are forced to create models of its behavior, just as scientists model the physical world. In the end, the Internet must be viewed as an information phenomenon: one that is capable of supporting an ever-changing set of applications, and whose behavior can be understood only through the use of increasingly sophisticated measurement tools and predictive models.
MANY-TO-MANY COMMUNICATION: A NEW MEDIUM
Amy Bruckman, Georgia Institute of Technology
In the early 1990s, computer-mediated communication (CMC) exploded in popularity, moving from a tool used by small groups of engineers and scientists to a mass phenomenon affecting nearly every aspect of life in industrialized nations. Even in the developing world, CMC has begun to play a significant role. Yet we are just at the beginning, not the end, of the transformations catalyzed by this technology. We can draw an analogy to an earlier era of intense social change launched by new technology: the introduction of the car. In the early days of the internal combustion engine, cars were called “horseless carriages”: we understood the new technology in terms of an old, familiar one. At that stage, we could not begin to imagine the ways that cars would transform the United States and the world, both for good and for ill. The Internet is in its “horseless carriage” stage. At this pivotal moment, we have a unique opportunity to shape the technology’s evolution, and the inevitable changes to society that will accompany it.
The key feature of this technology is its support for many-to-many communications. This paper will analyze the significance of many-to-many communications in key relevant application areas.
With many-to-many communications, individuals are becoming creators of content, not merely recipients. For example, we are no longer restricted to reading journalistic interpretations of current events, but can now also share our own views with friends and family. Opportunities for discourse on issues of import are at the foundation of a democratic society. We are experiencing a renaissance in public debate of serious matters by citizens.
Many-to-many communications are changing the nature of medicine. The new medical consumer arrives at the doctor’s office better informed. The Pew Center for Internet Life reports that “fifty-two million American adults, or 55% of those with Internet access, have used the Web to get health or medical information,” and of those, “70% said the Web information influenced their decision about how to treat an illness or condition” (Fox and Rainie, 2000). Patients can talk online with others with similar ailments, exchanging not just useful medical information but also emotional support. This emotional support is particularly valuable to care-givers of patients with serious illnesses, a group whose needs are often neglected.
Many-to-many communications are having a growing impact on business practices. In the field of retailing, consumers can now easily share
product recommendations, giving developers of quality products a competitive advantage. Competitive price information is available with unprecedented ease of access. The free many-to-many flow of information moves us closer to the ideal of an efficient market.
New kinds of commerce are emerging. We are no longer bound to have all purchases of second-hand goods go through middlemen like consignment shops, but can sell items directly to others. For example, in areas like antiques, collectibles, and used consumer electronics, for the first time in history a fair and efficient market has emerged. Items that would otherwise have been discarded can now find their way to just the person who needs them, leading to a less wasteful society.
The remainder of this paper discusses three application areas where the impact of Internet technology merits special attention: the expansion of scientific knowledge, entertainment, and education.
Accelerating the Expansion of Knowledge
The Internet’s most obvious capability is to distribute information. The World Wide Web was invented by Tim Berners-Lee and colleagues at CERN in order to accelerate scientific progress: researchers can exchange ideas must faster than was formerly possible. This has had particular impact in the developing world. Researchers in developing nations who could never afford subscriptions to research journals now have growing access to current scientific information and indirect participation in the international community of scientists.
Sociologists of science like Bruno Latour teach us that truth is socially constructed. This is true of the most basic “hard” scientific facts. A new idea begins attributed to a specific person: “Einstein says that E = MC2.” As it becomes more accepted, the attribution is dropped to a footnote: “E=MC2 (Einstein 1905).” Finally, the attribution is deemed entirely unnecessary, and one can simply say “E = MC2”—it has become an accepted scientific fact (Latour et al., 1986). The process of one researcher’s claim rising to the level of fact is fundamentally social. Initially, people are unsure—was the scientist’s work sound? Do others support this finding? As such questions are asked and answered, some claims are rejected and others become widely accepted. Truth emerges not from the work of one scientist, but from the community. It is not instantly revealed, but begins as tentative and solidifies over time. The Internet gets the most attention for its ability to support the exchange of factual information in the simple sense, as if it is merely a giant database that is unusually up to date. However, it is important to understand Latour’s subtler vision of how new knowledge is constructed, and the way that the Internet is uniquely well suited to accelerating that social process.
As we move forward, we need to find ways to enhance the ability of network technology to facilitate the free exchange of scientific ideas. Academic researchers in most fields are still rewarded for presenting ideas in peer-reviewed journal articles that may take years to appear in print. They are often reluctant to share ideas before they appear in officially credited form. Corporate researchers may be reluctant to share findings at all. Yet the entire endeavor of research can be enhanced through more immediate sharing of ideas via the Internet. The challenge, then, is to find ways to give individuals credit for ideas shared rapidly online, while at the same time maintaining the quality control of peer review. The field of online community research focuses on these issues, especially, what motivates individuals to contribute and how quality of discourse can be maintained (Preece, 2000). The design of our next-generation communication systems will help to accelerate the pace of discovery in all fields.
Online Entertainment
As we have seen, we can view the Internet as facilitating the exchange of scientific information; however, it is more far-reaching to see it as supporting the growth of a community of scientists (and information as a key product of that community). This fundamental insight applies not just to science, but to most domains. For example, the entertainment industry is no longer simply delivering content, but is using computer networks to bring groups of individuals together. New Internet-based forms of entertainment fall into a variety of genres, including bulletin-board systems (BBSs), chat, and games.
Internet-based communication provides opportunities for new kinds of socializing. In chat rooms and on BBSs, people gather together to discuss hobbies and to meet others. People with an unusual hobby find they are no longer alone but can meet like-minded others from around the world. Some of this social activity bridges into face-to-face activity. Hobbyists from geographically diverse areas may meet face to face at annual conventions and then maintain those ties online. In other cases, the social activity is local in nature. Computer-mediated communication is used to schedule face-to-face meetings and to continue discussion between such meetings. Sociologist Robert Putnam has documented a decrease in Americans’ participation in civic groups over the last half-century (Putnam, 1995). The ease of coordinating social and civic groups with the aid of new communications technologies has the potential to help begin to reverse this trend.
Popular types of Internet-based games include traditional games (like bridge and chess), fantasy sports, action games, and massively multiplayer games (MMPs). The most important characteristic these games
share is that they are social: people play with relatives, old friends, and new friends met online. For example, the author plays bridge online with her mother (who lives hundreds of miles away) and action games with friends from high school and graduate school living all around the country. Getting together to play online gives us occasions to keep in touch. This new entertainment form can help to maintain what sociologists call “strong ties” over distance and also create new “weak ties” (Wellman and Gulia, 1999). While one might be inclined to dismiss friendships made online as trivial, they are often quite meaningful to participants and sometimes have practical value as well. Howard Rheingold recounts how people who know one another from a California BBS called The WELL sent hundreds of books to a book-loving group member who lost all his possessions in a fire. WELL members also collaborated to arrange for the medical evacuation of a group member who became ill while in the Himalayas (Rheingold, 1993). These kinds of stories are not unusual. Every year, students in the “Design of Online Communities” graduate class at Georgia Tech are asked to write a short essay on their best and worst experiences involving Internet-based communications, and similar stories emerge each time.
It’s important to note that a number of aspects of online entertainment are discouraging. In particular, some online games are so compelling for many players that they may devote extremely large amounts of time to playing them. For example, as of fall 2001, the most popular MMP—Everquest, by Verant Interactive—had 400,000 registered members (Verant, 2001) who spent on average 22.5 hours per week playing (Yee, 2001). That mean figure includes a significant number who hardly participate at all, so the median is likely substantially higher. In other words, there are tens and possibly hundreds of thousands of people who devote all their non-work time to participation in the game. While we must be careful about passing judgement on how others spend their free time, the players themselves often find this problematic—so much so that the game is often referred to by the nickname “EverCrack.” Other games in this new genre have similar holding power.
MMPs are fun for players and profitable for game companies. In addition to charging people to buy the game initially, companies also charge a monthly fee. This lets companies make more money from a single development effort and gives them a more even revenue stream, making them less dependent on unpredictable seasonal sales and new releases. As a result, many companies are developing new MMP titles. While traditional multiplayer games allow a handful of people to interact in the same game space, MMPs support thousands. It’s likely we are just at the beginning of their growth in popularity. While they provide an entertainment offering that is both social and active, they also tend to lead to over-
involvement by some players. This is a key moment to ask: How can we shape this trend? How should we?
One constructive course of action is to create game-like environments that have educational content. For example, “AquaMOOSE 3D” is a three-dimensional virtual world designed to help high-school students learn mathematics (Edwards et al., 2001). See Figure 7.1. You are a fish, and you specify your motion in the graphical world mathematically. For example, swim in a sine in x and a cosine in y, and you move in a spiral and leave a spiral trail behind you. You can also create sets of rings in the water and challenge others to guess the equation that goes through them. Students create these mathematical puzzles to challenge their friends. AquaMOOSE looks much like the purely entertainment environments many students find so compelling, but time spent there is educationally valuable. We need to develop more such environments to encourage students to choose to spend their free time wisely.
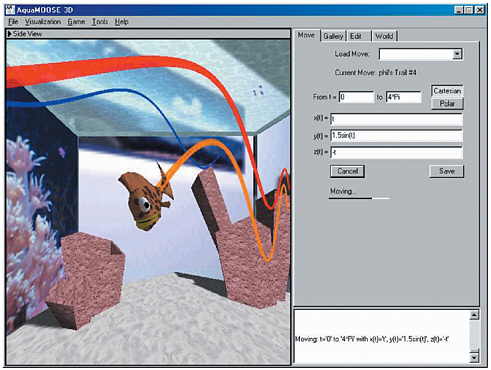
FIGURE 7.1 “AquaMOOSE 3D”: An Internet-based math-learning environment.
The Learning Potential of Internet Technology
Education is a key area where many-to-many communications have begun to have a strong positive impact. Many educational applications of Internet technology focus on information: in distance education information is delivered to the student. In online research projects, information is retrieved. In more innovative work, information is gathered by students and shared. While information-oriented applications of Internet technology are useful, the more exciting potential of this new learning medium is not about information but about community and collaboration. Online, groups of learners can motivate and support one another’s learning experiences.
Learning from Peers
Learning is fundamentally a social process, and the Internet has a unique potential to facilitate new kinds of learning relationships. For example, in the “One Sky, Many Voices” project by Nancy Songer at the University of Michigan (http://www.onesky.umich.edu/), kids can learn about atmospheric phenomena from scientists working in the field (Songer, 1996). More importantly, the students also learn from one another: kids in Montana studying hurricanes can talk online with Florida students in the midst of one. Learning from peers can be a compelling experience and is a scalable educational solution. If enough educational programs try to leverage the skills of adult experts, experts will ultimately spend all their time in public service. While the supply of experts is limited, the supply of peers is not.
Peers can be a powerful resource for children’s learning, if activities are structured to promote productive interactions. MOOSE Crossing is a text-based virtual world (or “MUD”) in which kids 8 to 13 years old learn creative writing and object-oriented programming from one another (http://www.cc.gatech.edu/elc/moose-crossing/). See Figure 7.2. The specially designed programming language (MOOSE) and environment (MacMOOSE and WinMOOSE) make it easy for young kids to learn to program. Members don’t just experience the virtual world—they construct it collaboratively. For example, Carrot1 (girl, age 9) created a swimming pool complex. Using lists stored on properties of the pool object, she keeps track of who is in the pool, sauna, or Jacuzzi, and who has changed into a bathing suit. You obviously can’t jump into the pool if you’re
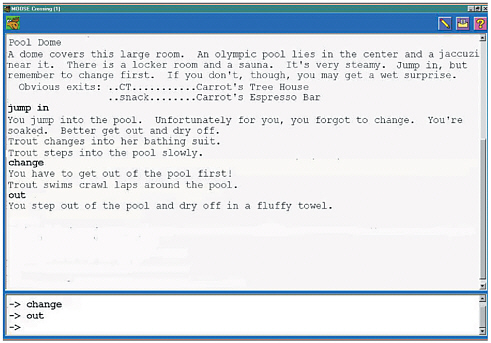
FIGURE 7.2 A text-based virtual world where kids practice creative writing and learn object-oriented programming.
already in the water . . . you need to get out first! This gives Carrot opportunities for comic writing as well as programming. The text-based nature of the environment is not a technical limitation, but rather a deliberate design choice: it gives kids a context for using language playfully and imaginatively. Carrot enjoys inviting other kids over to the pool. They in turn learn about programming and writing using her work as a model (Bruckman, 1998, 2000).
The online community provides a ready source of peer support for learning. Kids learn from one another, and from one another’s projects. That support is not just technical, but also emotional. In answering a question, one child may tell another, “I got confused by that too at first.” The online community provides a ready source of role models. If, for example, girls are inclined to worry that programming might not be a cool thing for a girl to do, they are surrounded by girls and women engaging in this activity successfully and enjoying it. Finally, the online community provides an appreciative audience for completed work. Kids get excited about being creative in order to share their work with their peers.
Elders as Mentors
Social support for learning online can come not just from peers, teachers, and experts, but also from ordinary members of the general population, who form a vast potential resource for our children’s education. Retired people in particular have a great deal they can teach kids and free time to contribute, but they need an easy and well-structured way to do so. In the Palaver Tree Online project (http://www.cc.gatech.edu/elc/palaver/, the dissertation research of Georgia Tech PhD student Jason Ellis), middle-school students learn about history from elders who lived through it. Teachers begin with literature that is part of their normal curriculum. Kids brainstorm historical questions based on what they’ve learned, interview elder mentors about their personal experiences with that time, and then write research reports about what they’ve learned. See Figures 7.3 and 7.4. In our studies to date, kids learning about World War II interviewed veterans, and kids learning about the civil rights years interviewed older African Americans. History learned from real people becomes more meaningful and relevant (Ellis and Bruckman, 2001).
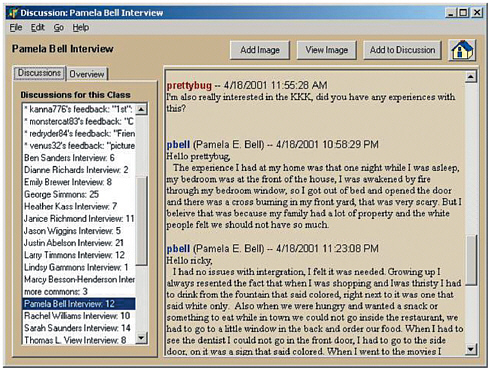
FIGURE 7.3 Eighth-grade students interviewing an elder mentor about her experiences growing up during the civil rights years. (All names have been changed.)

FIGURE 7.4 The project students created based on their interview.
Of course it would be better for kids to meet with elders face to face, but in practice this rarely if ever happens. In interviews with teachers who have tried such projects, we found that the logistics are too difficult to arrange for all involved. Elder volunteers, when asked if they will drive to an unfamiliar place and commit to multiple visits, often hesitate. However, when asked, “Would you be willing to log on for half an hour a day for a few weeks?,” they are enthusiastic. The Palaver Tree Online community makes this not only possible but also relatively easy for the elders, students, and teachers. Teachers are already overwhelmed with work, and any successful school-based learning technology needs to make their lives easier, not harder.
New Social and Technical Possibilities
Culture and technology co-evolve. The challenge as we move forward is to develop a vision of what is possible—to understand the more and less desirable outcomes, and try to steer in the right direction. Hardware and software infrastructure developed over the last 40 years are just now
becoming widely available and are finding a wide variety of new applications. The wide availability of Internet access has made many-to-many communications possible, and this capability has a profound impact on how we conduct business, manage our health, share knowledge, entertain ourselves and one another, and learn.
References
Bruckman, A., 1998, “Community Support for Constructionist Learning,” Computer Supported Cooperative Work 7:47-86.
Bruckman, A., 2000, “Situated Support for Learning: Storm’s Weekend with Rachael,” Journal of the Learning Sciences 9(3):329-372.
Edwards, E., J. Elliott, and A. Bruckman, 2001, “AquaMOOSE 3D: Math Learning in a 3D Multi-user Virtual World,” paper presented at the CHI 2001 Conference on Human Factors in Computing Systems, Seattle, Wash.
Ellis, J., and A.Bruckman, 2001, “Palaver Tree Online: Supporting Social Roles in a Community of Oral History,” paper presented at the CHI 2001 Conference on Human Factors in Computing Systems, Seattle, Wash.
Fox, S., and L. Rainie, 2000, The Online Health Care Revolution: How the Web Helps Americans Take Better Care of Themselves, Pew Internet and American Life Project, Washington, D.C.
Latour, B., S. Woolgar, and J. Salk, 1986, Laboratory Life,Princeton University Press, Princeton, N.J.
Preece, J., 2000, Online Communities: Designing Usability, Supporting Sociability, John Wiley & Sons, New York.
Putnam, R., 1995, “Bowling Alone: America’s Declining Social Capital,” Journal of Democracy 6(1).
Rheingold, H., 1993, The Virtual Community: Homesteading on the Electronic Frontier, Addison-Wesley, Reading, Mass.
Songer, N., 1996, “Exploring Learning Opportunities in Coordinated Network-Enhanced Classrooms: A Case of Kids as Global Scientists,” The Journal of the Learning Sciences 5(4):297-327.
Verant, 2001, “Sony Online Entertainment to Introduce New EverQuest Servers in European Markets: Verant Interactive.”
Wellman, B., and M. Gulia, 1999, “Virtual Communities Are Communities: Net Surfers Don’t Ride Alone,” in M.A. Smith and P. Kollock (eds.), Communities in Cyberspace, Routledge, New York.
Yee, N., 2001, “The Norrathian Scrolls: A Study of Everquest (2.5),” available at http://www.nickyee.com/eqt/report.html.
CRYPTOGRAPHY
Madhu Sudan, Massachusetts Institute of Technology
Consider the following prototypical scenario in the Internet era: Alice wishes to access her bank account with the Bank of Billionaires (Bob) through the Internet. She wishes to transmit to Bob her account number and password and yet does not want her Internet service provider to know her account number and password. The potential for commerce over the Internet relies critically on the ability to implement this simple scenario. Yet when one gets down to formalizing the goals of this scenario mathematically, one realizes this goal is almost impossible. After all the Internet service provider has access to every bit of information that enters or leaves Alice’s computer, and Bob has only a subset! Fortunately, there is a tiny crack in any such “proof” of impossibility (read “Computational Foundations of Cryptography” below for details)—a crack visible only when inspected with a computational lens—and from this crack emerges cryptography, the science of encrypting and decrypting messages.
Cryptography has been practiced for centuries now. Its need becomes evident in any situation involving long-distance communication where secrecy and (mis)trust are governing factors. Yet, till the advent of the 20th century much of cryptography has been misunderstood and practiced as “black magic” rather than as a science. The advent of computers, and the development of the computational perspective, has changed all this. Today, one can deal with the subject with all the rigor and precision associated with all other mathematical subjects. Achieving this progress has required the formalization of some notions—such as randomness, knowledge, and proof—that we rely on commonly in our lives but whose mathematical formalization seems very elusive. It turns out that all these notions are essentially computational, as is cryptography. Furthermore cryptography is feasible only if some very fundamental computational hypotheses (such as NP ≠ P; see Kleinberg and Papadimitriou in Chapter 2) hold out. This essay describes some of the salient events in the history of cryptography.
Cryptography in the Medieval Era
Traditionally, messages were encrypted with codebooks. Roughly, in this setup Alice and Bob initially share some secret information, called the codebook. This codebook might be something as simple as a letter-to-letter substitution rule, or something more complex—such as a word-to-word substitution rule, and so on. When Alice obtains some new information to
be transmitted secretly to Bob, she uses the codebook to translate the message and send it (through untrusted couriers) to the receiver. Now, assuming that the courier does deliver the encrypted message, the receiver uses his copy of the codebook to translate the messages back. The courier or any other eavesdropper, however, cannot in theory decipher the message, since he does not possess the codebook.
To compare the above system with some of the more recent themes in cryptography, let us compare some of the basic elements of the model and the associated assumptions. One of the primary features of the model above is the role of the codebook. It is what distinguishes the receiver from the eavesdropper (based on information the receiver possesses), and the initial cryptography protocols assumed (mistakenly, as it turned out) that the codebook was a necessary component for secret communication. Over time, the belief took on quantitative dimensions—the larger the size of the codebook, the more secure the encryption. For example, a letter-to-letter substitution rule applied to the English alphabet requires the testing of 26! possibilities. But most can be ruled out easily based on frequency analysis of English text. So letter-to-letter substitution rules, involving small codebooks, can be broken easily. Word-to-word substitution rules are harder to break, but it is still feasible to do so with decent computers.
The last of these observations, that better computers might lead to loss of secrecy, was worrisome. Maybe the advent of computers would lead to the ultimate demise of cryptography! In the face of such popular beliefs, it came as a startling surprise that cryptography could potentially thrive with advances in computing.
Computational Foundations of Cryptography
The foundations of cryptography were laid gradually. First came information-theoretic foundations, starting with Shannon in the 1950s, and a little later, in the 1970s, came the computational notions of Merkle (1978), Diffie and Hellman (1976), and Rivest, Shamir, and Adleman (1978).
Shannon’s theory (Shannon, 1949) formally asserted that secret communication is possible whenever the communicating parties, Alice and Bob, share some secret information. Furthermore, this secret information had to have some randomness associated with it, in order to prove the security of the transmission. Quantifying this notion (how random is the shared secret?) led to a quantification of how much information could be exchanged secretly. In particular, if Alice and Bob got together and picked a k-bit random string as the secret to share (where every bit is chosen uniformly and independent of other bits), then Alice could encrypt any k-bit message and send the encrypted message to Bob in the clear, such that the eavesdropper could get no information about the message while
Bob, with knowledge of the shared secret, could decrypt the message from the encrypted form. (For example, if the shared secret s is interpreted as a k-bit integer and the message m to be exchanged is also a k-bit integer, then the encrypted text can simply be e = (m + s) mod 2k. Bob, on receiving e, can recover m by computing e – s mod 2k).
The importance of this result is not so much in the protocol derived as in the notions defined. How do we determine secrecy? Why is the message m being kept secret in the above exchange? How do we prove it? The answers all turn out to be quite simple. Message m is secret because its encryption (which is a random variable dependent on the secret s) is distributed statistically identically to the encryption of some other message m′. Thus indistinguishability is the basis for secrecy.
What happens when Alice tries to transmit a message of more than k-bits to Bob (while they only share a k-bit secret)? Shannon’s theory explained that in this case the eavesdropper can get some information about the message m from the transmission (no matter what protocol Alice and Bob adopt). Shannon realized that this information may not provide any “usable” information about the message itself, but he was unable to exploit this lack of “usability” any further.
How is it possible that one has information about some string m, but is not able to use it? How does one determine “usability” so as to have a meaningful sense of this possibility? It turns out that these questions are essentially computational, and it took the seminal work of Diffie and Hellman (1976) to realize the computational underpinnings and to exploit them.
Diffie and Hellman noticed that several forms of computation transform meaningful information into incomprehensible forms. (As a side remark they note that small programs written in a high-level language immediately reveal their purpose, whereas once they are compiled into a low-level language it is hard to figure out what the program is doing!) They pointed out a specific algebraic computation that seems to have this very useful “information-hiding” feature. They noticed it is very easy to compute modular exponentiation. In particular, given an n-bit prime number p, an integer g between 2 and p – 1, and exponent x between 1 and p – 1, it is possible to compute y = gx (mod p) in approximately n2 steps of computation. Furthermore if g is chosen somewhat carefully, then this mapping from x to gx (mod p) is one to one and thus invertible. However, no computationally efficient procedure was known (then or now) to compute, given g, p, and y, an integer x such that y = gx. This task of inverting modular exponentiation is referred to as the Discrete Logarithm Problem.
Relying in part on the seeming hardness of the Discrete Log Problem, Diffie and Hellman suggested the following possibility for Alice and Bob to exchange secrets: to exchange an n-bit secret Alice picks a prime p and
an integer g as above and sends g and p (in the clear!) to Bob. She then picks a random integer x1 between 1 and p – 1, computes ![]() mod p, and sends this string to Bob. Bob responds by picking another random string x2 and sending to Alice the string
mod p, and sends this string to Bob. Bob responds by picking another random string x2 and sending to Alice the string ![]() mod p. At this point, Alice and Bob can both compute
mod p. At this point, Alice and Bob can both compute ![]() mod p. (Alice computes this as (g
mod p. (Alice computes this as (g![]() )
)![]() , while Bob computes this as (g
, while Bob computes this as (g![]() )
)![]() ).
).
What about the eavesdropper? Surprisingly, though all this conversation was totally in the clear, the eavesdropper seems to have no efficient way to compute ![]() . She knows
. She knows ![]() and
and ![]() but these do not suffice to give an efficient way to compute
but these do not suffice to give an efficient way to compute ![]() . (In all cases we don’t know that there is no efficient way to compute one of the unobvious cases—it is just that we don’t know of any efficient way to compute them and thus conjecture that these computations are hard.) Thus Alice and Bob have managed to share a “random secret” by communication in the clear that Alice can now use to send the real message m to Bob.
. (In all cases we don’t know that there is no efficient way to compute one of the unobvious cases—it is just that we don’t know of any efficient way to compute them and thus conjecture that these computations are hard.) Thus Alice and Bob have managed to share a “random secret” by communication in the clear that Alice can now use to send the real message m to Bob.
The protocol above provides a simple example of the distinction between information and its usability. Together, ![]() and
and ![]() specify
specify ![]() but not in any usable way, it seems. The essence of this distinction is a computational one. And it leads to a very computational framework for cryptography. The protocol can be used to exchange information secretly, where secrecy is now determined using a computational notion of indistinguishability, where computational indistinguishability suggests that no efficient algorithm can distinguish between a transcript of a conversation that exchanges a secret m and one that exchanges a secret m′. (Giving a precise formulation is slightly out of scope.)
but not in any usable way, it seems. The essence of this distinction is a computational one. And it leads to a very computational framework for cryptography. The protocol can be used to exchange information secretly, where secrecy is now determined using a computational notion of indistinguishability, where computational indistinguishability suggests that no efficient algorithm can distinguish between a transcript of a conversation that exchanges a secret m and one that exchanges a secret m′. (Giving a precise formulation is slightly out of scope.)
And what does one gain from this computational insight? For the first time, we have a protocol for exchanging secrets without any prior sharing of secret information (under some computational hardness assumptions).
Lessons Learned from Cryptography
The seminal work of Diffie and Hellman altered fundamental beliefs about secrecy. The natural guess is that any information that Bob may possess unknown to Alice would be useless in preserving the secrecy of a communication from Alice to Bob. A continuation of this line of reasoning leads to the belief that Alice can’t send secret information to Bob unless they shared some secrets initially. Yet the above protocol altered this belief totally. The intractability of reversing some forms of computations can lead to secret communication. Such intractability itself relies on some other fundamental questions about computation (and in particular implies P ≠ NP). In fact, it was the emerging belief in the conjecture “P ≠ NP” that led Diffie and Hellman to propose the possibility of such public-key
exchange protocols and posit the possibility of other public-key encryption systems.
In the numerous years since, cryptography has led to numerous computational realizations of conventional wisdom (and “computational” refutations of mathematical truths!). Numerous notions underlying day-to-day phenomena, for which formalization had earlier proved elusive, have now been formalized. Two striking examples of such notions are those of “pseudo-randomness” and “proofs.” We discuss these below.
Shannon’s theory had asserted that sharing a secret “random” string was necessary for a message to be secure. The Diffie-Hellman protocol managed to evade this requirement by showing how Alice and Bob could create a secret that they shared using public conversations only. This secret was the string ![]() . How random is this secret? The answer depends on your foundations. Information theory would declare this string to be totally “non-random” (or deterministic) given
. How random is this secret? The answer depends on your foundations. Information theory would declare this string to be totally “non-random” (or deterministic) given ![]() and
and ![]() . Computational theory, however, seems to suggest there is some element of randomness to this string. In particular, the triples (
. Computational theory, however, seems to suggest there is some element of randomness to this string. In particular, the triples ( ![]() ;
; ![]() ;
; ![]() ) and (
) and ( ![]() ;
; ![]() ;
; ![]() ) seem to contain the same amount of randomness, to any computationally bounded program that examines these triples, when x1; x2; x3 are chosen at random independent of each other. So the computational theory allows certain (distribution on) strings to look more random than they are. Such a phenomenon is referred to as pseudo-randomness and was first formalized by Blum and Micali (1984). Pseudo-randomness provides a formal basis for a common (and even widely exploited) belief that simple computational steps can produce a long sequence of “seemingly” uncorrelated or random data. It also provided a fundamental building block that has since been shown to be the crux of much of cryptography.
) seem to contain the same amount of randomness, to any computationally bounded program that examines these triples, when x1; x2; x3 are chosen at random independent of each other. So the computational theory allows certain (distribution on) strings to look more random than they are. Such a phenomenon is referred to as pseudo-randomness and was first formalized by Blum and Micali (1984). Pseudo-randomness provides a formal basis for a common (and even widely exploited) belief that simple computational steps can produce a long sequence of “seemingly” uncorrelated or random data. It also provided a fundamental building block that has since been shown to be the crux of much of cryptography.
A second example of a computational phenomenon is the age-old notion of a proof. What is a proof? Turn-of-the-20th-century logicians had grappled with this question successfully and emerged with a clean explanation. A proof is a sequence of simple assertions that concludes with the theorem by which each assertion can be easily verified. The term “easily” here requires a computational formalism, and in fact, this led to the definition of a Turing machine in the 1940s (see Kleinberg and Papadimitriou in Chapter 2). The advent of cryptography leads us back to the notion of a proof and some seemingly impossible tasks. To see the need for this notion, let us revisit the scenario introduced in the opening paragraph. The goal of the scenario can be reinterpreted as follows: Bob knows that Alice is the (only) person who knows a secret password m. So when some user comes along claiming to be Alice, Bob asks for her password, in effect saying “Prove you are Alice!” or equivalently “Prove you know m.” In traditional scenarios Alice would have simply typed out her password m
on her keyboard and sent it over the Internet. This would have corresponded to our standard intuition of a “proof.” Unfortunately this standard notion is a replayable one—any eavesdropper could listen in to the conversation and then also prove that he/she is Alice (or knows m). But the interaction above allows Alice to prove to Bob that she knows m (indeed she essentially sends it to him), without revealing m to the eavesdropper. So it seems Alice was able to prove her identity without revealing so much information that others can later prove they are Alice! How did we manage this? The most significant step here is that we changed our notion of a proof. Conventional proofs are passive written texts. The new notion is an “interactive randomized conversation.” The new notion, proposed by Goldwasser, Micali, and Rackoff (1989), retains the power of conviction that conventional proofs carry, but it allows for a greater level of secrecy. Proofs can no longer be replayed. As subsequent developments revealed, these proofs also tend to be much shorter and can be verified much more efficiently. So once again computational perspectives significantly altered conventional beliefs.
The Future of Cryptography
Cryptography offers a wonderful example of a phenomenon quite commonplace in the science of computing. The advent of the computer raises a new challenge. And the science rises to meet the new challenge by creating a rich mathematical structure to study, analyze, and solve the new problems. The solutions achieved (and their deployment in almost every existing Web browser!) as well as the scientific knowledge gained (“proofs,” “pseudo-randomness,” “knowledge”) testify to the success of cryptography so far. Going into the future one expects many further challenges as the scope of cryptography broadens and our desire to “go online” increases. One of the biggest challenges thus far has been in creating large, possibly distributed, systems that address the security of their contents. Cryptography may be likened to the task of designing secure locks and keys. No matter how inventive and successful one is with this aspect, it does not automatically lead to secure houses. Similarly, building secure computer systems involves many more challenges in terms of defining goals, making sure they are feasible, and then attaining them efficiently. Research in this direction is expected to be highly active.
To conclude on a somewhat cautious note: Cryptography, like many other scientific developments, faces the problem of being a double-edged sword. Just as it can be used to preserve the privacy of honest individuals, so can it equally well preserve the privacy of the communications of “bad guys.” Indeed, fear of this phenomenon has led to government oversight on the use and spread of cryptography and has raised a controversial
question: Is the negative impact sufficient to start imposing curbs on cryptographic research? Hopefully, the description above is convincing with respect to two aspects: cryptographic research is essentially just discovering a natural, though surprising, computational phenomenon. Curbing cryptographic research will only create a blind spot in our understanding of this remarkable phenomenon. And while the tools that the research invents end up being powerful with some potential for misuse, knowing the exact potential and limits of these tools is perhaps the best way to curb their misuse. Keeping this in mind, one hopes that cryptographic research can continue to thrive in the future uninhibited by external pressures.
REFERENCES
Blum, Manuel, and Silvio Micali, 1984, “How to Generate Cryptographically Strong Sequences of Pseudorandom Bits,” SIAM Journal on Computing 13:850-864.
Diffie, Whitfield, and Martin E. Hellman, 1976, “New Directions in Cryptography,” IEEE Transactions on Information Theory 22(6):644-654.
Goldwasser, Shafi, Silvio Micali, and Charles Rackoff, 1989, “The Knowledge Complexity of Interactive Proof Systems,” SIAM Journal on Computing 18(1):186-208.
Merkle, Ralph, 1978, “Secure Communications over Insecure Channels,” Communications of the ACM (April):294-299.
Rivest, Ronald L., Adi Shamir, and Leonard Adleman, 1978, “A Method for Obtaining Digital Signatures and Public-key Cryptosystems,” Communications of the ACM 21(2):120-126.
Shannon, Claude E., 1949, “Communication Theory of Secrecy Systems,” Bell Systems Technical Journal 28(6):656-715.
STRATEGIES FOR SOFTWARE ENGINEERING RESEARCH
Mary Shaw, Carnegie Mellon University
Software engineering is the branch of computer science that creates practical, cost-effective solutions to computation and information processing problems, preferentially applying scientific knowledge, developing2 software systems in the service of mankind. Like all engineering, software engineering entails making decisions under constraints of limited time, knowledge, and resources. The distinctive character of software—the form of the engineered artifact is intangible and discrete—raises special issues of the following kind about its engineering:
-
Software is design-intensive; manufacturing costs are a very small component of product costs.
-
Software is symbolic, abstract, and more constrained by intellectual complexity than by fundamental physical laws.
-
Software engineering is particularly concerned with software that evolves over a long useful lifetime, that serves critical functions, that is embedded in complex software-intensive systems, or that is otherwise used by people whose attention lies appropriately with the application rather than the software itself. These problems are often incompletely defined, lack clear criteria for success, and interact with other difficult problems—the sorts of problems that Rittel and Webber dubbed “wicked problems.”3
Software engineering rests on three principal intellectual foundations. The principal foundation is a body of core computer science concepts relating to data structures, algorithms, programming languages and their semantics, analysis, computability, computational models, and so on; this is the core content of the discipline. The second is a body of engineering knowledge related to architecture, the process of engineering, tradeoffs and costs, conventionalization and standards, quality and assurance, and others; this provides the approach to design and problem solving that
respects the pragmatic issues of the applications. The third is the human and social context of the engineering effort, which includes the process of creating and evolving artifacts, as well as issues related to policy, markets, usability, and socio-economic impacts; this context provides a basis for shaping the engineered artifacts to be fit for their intended use.
Software engineering is often—inappropriately—confused with mere programming or with software management. Both associations are inappropriate, as the responsibilities of an engineer are aimed at the purposeful creation and evolution of software that satisfies a wide range of technical, business, and regulatory requirements—not simply the ability to create code that satisfies these criteria or to manage a project in an orderly, predictable fashion.
Software Engineering
A physicist approaches problems (not just physical problems) by trying to identify masses and forces. A mathematician approaches problems (even the same problems) by trying to identify functional elements and relations. An electrical engineer approaches problems by trying to identify the linearly independent underlying components that can be composed to solve the problem. A programmer views problems operationally, looking for state, sequence, and processes. Here we try to capture the characteristic mind-set of a software engineer.
Computer Science Fundamentals
The core body of systematic knowledge that supports software engineering is the algorithmic, representational, symbol-processing knowledge of computer science, together with specific knowledge about software and hardware systems.
Symbolic representations are necessary and sufficient for solving information-based problems. Control and data are both represented symbolically. As a result, for example, an analysis program can produce a symbolic description of the path for a machine tool; another program can take this symbolic description as input and produce a symbolic result that is the binary machine code for a cutting tool; and that symbolic representation can be the direct control program for the cutting tool. Notations for symbolic description of control and data enable the definition of software, both the calculations to be performed and the algorithms and data structures. This task is the bread and butter of software implementation, and the existence of symbol strings as a uniform underlying representation of code, data, specification, analysis, and other descriptions simplifies both software design and tool support for software development activities.
Abstraction enables the control of complexity. Abstraction allows the introduction of task-specific concepts and vocabulary, as well as selective control of detail. This in turn allows separation of concerns and a crisp focus on design decisions. A designer of mechanical systems might work with (and expand) a set of abstractions having to do with shapes, weights, and strengths, whereas a designer of accounting systems might work with a set of abstractions having to do with customers, vendors, transactions, inventory, and currency balances. The ability to introduce problem-specific definitions that can, in most respects, be treated as part of the original design language allows software design to be carried out in problem-specific terms, separating the implementation of these abstractions as an independent problem. An additional benefit is that this leads to models and simulations that are selective about the respects in which they are faithful to reality. Some levels of design abstraction, characterized by common phenomena, notations, and concerns, occur repeatedly and independent of underlying technology. The most familiar of these is the programming language, such as Java. The recent emergence of UML has provided a set of diagrammatic4 design vocabularies that address specific aspects of design, such as the sequence of operations or the allowable transitions between system states. More specialized abstractions are now being used to define “software product families,” or design spaces that allow multiple similar software systems to be produced systematically and predictably.
Imposing structure on problems often makes them more tractable, and a number of common structures are available. Designing systems as related sets of independent components allows separation of independent concerns; hierarchy and other relations help explain the relations among the components. In practice, independence is impractical, but software designers can reduce the uncertainty by using well-understood patterns of software organization, called software architectures. An architecture such as a pipeand filter system, a client-server system, or an application-and-plugin organization provides guidance drawn from prior experience about the kinds of responsibilities to assign to each component and the rules that govern component interaction.
Precise models support analysis and prediction. These models may be formal or empirical. Formal and empirical models are subject to different standards of proof and provide different levels of assurance in their results. For example, a formal model of an interaction protocol can reveal
that implementations will have internal inconsistencies or the possibility of starvation or deadlock. The results support software design by providing predictions of properties of a system early in the system design, when repair is less expensive. Software systems are sufficiently complex that they exhibit emergent properties that do not derive in obvious ways from the properties of the components. Models that support analysis or simulation can reveal these properties early in design, as well.
Engineering Fundamentals
The systematic method and attention to pragmatic solutions that shapes software engineering practice is the practical, goal-directed method of engineering, together with specific knowledge about design and evaluation techniques.
Engineering quality resides in engineering judgment. Tools, techniques, methods, models, and processes are means that support this end. The history of software development is peppered with “methodologies” for designing software and tools for creating and managing code. To the extent that these methods and tools relieve the designer of tedious, errorprone details, they can be very useful. They can enhance sound judgment, and they may make activities more accurate and efficient, but they cannot replace sound judgment and a primary commitment to understanding and satisfying clients’ needs.
Engineering requires reconciling conflicting constraints and managing uncertainty. These constraints arise from requirements, from implementation considerations, and from the environment in which the software system will operate. They typically overconstrain the system, so the engineer must find reasonable compromises that reflect the client’s priorities. Moreover, the requirements, the available resources, and the operating environment are most often not completely known in advance, and they most often evolve as the software and system are designed. Engineers generate and compare alternative designs, predict the properties of the resulting systems, and choose the most promising alternatives for further refinement and exploration. Finding sufficiently good cost-effective solutions is usually preferable to optimization.
Engineering skills improve as a result of careful systematic reflection on experience. A normal part of any project should be critical evaluation of the work. Critical evaluation of prior and competing work is also important, especially as it informs current design decisions. One of the products of systematic reflection is codified experience, for example in the form of a vocabulary of solution structures and the situations in which they are useful. The designs known as software product lines or software product families define frameworks for collections of related software systems;
these are often created within a company to unify a set of existing products or to guide the development of a next-generation product.
Human, Social, and Economic Fundamentals
The commitment to satisfying clients’ needs and managing effective development organizations that guides software engineering business decisions is the organizational and cognitive knowledge about the human and social context, together with specific knowledge about human-computer interaction techniques.
Technology improves exponentially, but human capability does not. The Moore’s-law improvements in cost and power of computation (see Hill in Chapter 2) have enabled an unprecedented rate of improvement in technical capability. Unfortunately, the result has often been software products that confuse and frustrate their users rather than providing corresponding improvements in their efficiency or satisfaction. Software developers are increasingly aware of the need to dedicate part of the increase in computing capability to simplifying the use of the more-capable software by adapting systems to the needs of their users.
Cost, time, and business constraints matter, not just capability. Much of computer science focuses on the functionality and performance properties of software, including not only functional correctness but also, for example, speed, reliability, and security. Software engineering must also address other concerns of the client for the software, including the cost of development and ownership, time to delivery, compliance with standards and regulations, contributions to policy objectives, and compatibility with existing software and business processes. These factors affect the system design as well as the project organization.
Software development for practical software-intensive systems usually depends on teamwork by creative people. Both the scale and the diversity of knowledge involved in many modern software applications require the effort and expertise of numerous people. They must combine software design skills and knowledge of the problem domain with business objectives, client needs, and the factors that make creative people effective. As a result, the technical substance of software engineering needs an organizational setting that coordinates their efforts. Software development methods provide guidance about project structure, management procedures, and information structures for tracking the software and related documents.
Software Engineering Research
Software engineering researchers seek better ways to develop practical software, especially software that controls large-scale software-intensive
systems that must be highly dependable. They are often motivated by the prospect of affecting the practice of software development, by finding simpler ways to deal with the uncertainties of “wicked problems,” and by improving the body of codified or scientific knowledge that can be applied to software development.
Scientific and engineering research fields can be characterized by identifying what they value:
-
What kinds of questions are “interesting”?
-
What kinds of results help to answer these questions, and what research methods can produce these results?
-
What kinds of evidence can demonstrate the validity of a result, and how are good results distinguished from bad ones?
Software engineering research exhibits considerable diversity along these dimensions. Understanding the widely followed research strategies helps explain the character of this research area and the reasons software engineering researchers do the kinds of research that they do.
Physics, biology, and medicine have well-refined public explanations of their research processes. Even in simplified form, these provide guidance about what counts as “good research” both inside and outside the field. For example, the experimental model of physics and the double-blind studies of medicine are understood, at least in broad outline, not only by the research community but also by the public at large. In addition to providing guidance for the design of research in a discipline, these paradigms establish the scope of scientific disciplines through a social and political process of “boundary setting.”
Software engineering, however, is still in the process of articulating this sort of commonly understood guidance. One way to identify the common research strategies is to observe the types of research that are accepted in major conferences and journals. These observations here are based specifically on the papers submitted to and accepted by the International Conference on Software Engineering;5 they are generally representative of the field, though there is some dissonance between research approaches that are advocated publicly and those that are accepted in practice. Another current activity, the Impact Project,6 seeks to trace the
influence of software engineering research on practice; the emphasis there is on the dissemination of research rather than the research strategies themselves.
Questions Software Engineering Researchers Care About
Generally speaking, software engineering researchers seek better ways to develop and evaluate software. Development includes all the synthetic activities that involve creating and modifying the software, including the code, design documents, documentation, and so on. Evaluation includes all the analytic activities associated with predicting, determining, and estimating properties of the software systems, including both functionality and extra-functional properties such as performance or reliability.
Software engineering research answers questions about methods of development or analysis, about details of designing or evaluating a particular instance, about generalizations over whole classes of systems or techniques, or about exploratory issues concerning existence or feasibility.
The most common software engineering research seeks an improved method or means of developing software—that is, of designing, implementing, evolving, maintaining, or otherwise operating on the software system itself. Research about methods for reasoning about software systems, principally analysis of correctness (testing and verification), is also fairly common.
Results Software Engineering Researchers Respect
The tangible contributions of software engineering research may be procedures or techniques for development or analysis; they may be models that generalize from specific examples, or they may be specific tools, solutions, or results about particular systems.
By far the most common kind of software engineering research result is a new procedure or technique for development or analysis. Models of various degrees of precision and formality are also common, with better success rates for quantitative than for qualitative models. Tools and notations are well represented, usually as auxiliary results in combination with a procedure or technique.
Evidence Software Engineering Researchers Accept
Software engineers offer several kinds of evidence in support of their research results. It is essential to select a form of validation that is appropriate for the type of research result and the method used to obtain the result. As an obvious example, a formal model should be supported by
rigorous derivation and proof, not by one or two simple examples. Yet, a simple example derived from a practical system may play a major role in validating a new type of development method.
The most commonly successful kinds of validation are based on analysis and real-world experience. Well-chosen examples are also successful.
Additional Observations
As in other areas of computer science, maturation of software engineering as a research area has brought more focused, and increasingly explicit, expectations for the quality of research—care in framing questions, quality of evidence, reasoning behind conclusions.
Software engineering remains committed to developing ways to create useful solutions to practical problems. This commitment to dealing with the real world, warts and all, means that software engineering researchers will often have to contend with impure data and under-controlled observations. Most computer science researchers aspire to results that are both theoretically well grounded and practical. Unfortunately, practical problems often require either the simplification of the problem in order to achieve theoretically sound conclusions or else the sacrifice of certainty in the results in favor of results that address the practical aspects of the problem. Software engineering researchers tend to choose the latter course more often than the former.
The community of computer users seems to have a boundless appetite for information-processing capability. Fueled by our collective imagination, this appetite seems to grow even faster than Moore’s-law technology growth. This demand for larger scale and complexity, coupled with an increasing emphasis on dependability and ease of use—especially for users with little computer training—generates new problems, and even new classes of problems for software engineering.
































