
Agent-Based Modeling as a Decision-Making Tool
ZOLTÁN TOROCZKAI
Los Alamos National Laboratory
Los Alamos, New Mexico
STEPHEN EUBANK
Virginia Polytechnic Institute and State University
Blacksburg, Virginia
Researchers have made considerable advances in the quantitative characterization, understanding, and control of nonliving systems. We are rather familiar with physical and chemical systems, ranging from elementary particles, atoms, and molecules to proteins, polymers, fluids, and solids. These systems have interacting particles and well defined physical interactions, and their properties can be described by the known laws of physics and chemistry. Most important, given the same initial conditions, their behavior is reproducible (at least statistically).
However, other types of ubiquitous systems are all around us, namely systems that involve living entities (i.e., agents) about which we have hardly any quantitative understanding, either on an individual or collective level. In this paper, we refer to collectives of living entities as “agent-based systems” or “agent systems” to distinguish them from classical particle systems of inanimate objects. Although intense efforts have been made to study these systems, no generally accepted unifying framework has been found. Nevertheless, understanding, and ultimately controlling the behavior of agent systems, which have applications from biology to the social and political sciences to economics, is extremely important. Ultimately, a quantitative understanding can be a basis for designing agent systems, like robots or rovers that can perform tasks collectively that would be prohibitive for humans. Examples include deep-water rescue missions, minefield mapping, distributed sensor networks (for civil and military uses), and rovers for extraterrestrial exploration.
Even though there is no unifying understanding of agent systems, some control over their behavior can be achieved via agent-based modeling tools. The idea behind agent-based modeling is rather simple—build a computer model of the agent system under observation using a bottom-up approach by trying to mimic as much detail as possible. This can be rather expensive, however, because it requires (1) data collection, (2) model building, (3) exploitation of the model and the collection of statistics, and (4) validation, which normally means comparing the output of the model with additional observations of the real system.
The agent models described in this paper took about nine years to develop at Los Alamos National Laboratory. However, the framework for these models can be used to simulate many similar circumstances and to make predictions.
PROPERTIES OF AGENT SYSTEMS
Agent-based systems are hard to describe and understand within a unified approach because they differ from classical particle systems in at least two ways. First, an agent is a complex entity that cannot be represented by a simple function, such as a Hamiltonian function of a classical system (e.g., a spin system). Second, the interaction topology, namely the rules by which particles interact with each other, is generally represented by a complex, dynamic graph (network), unlike the regular lattices of crystalline solids or the continuous spaces of fluid dynamics. In many cases, the notion of “locality” itself is elusive in agent-based networks; in social networks, for example, the physical or spatial locality of agents may have little to do with social “distances” and interactions among them. To illustrate the complex structure of a “particle,” or agent, and its consequences we can use traffic, namely people (agents) driving on a highway, as an example. Keep in mind, however, that the statements in this description are generally applicable to other agent systems.
Agents have the following qualities:
-
A set of variables, x, describes the state of the agent (e.g., position on the road, speed, health of the driver, etc.). The corresponding state space is X.
-
A set of variables, z, describes the perceived state of the environment, Z, which includes other agents, if there are any (e.g., level of congestion, state/ quality of the road, weather conditions, etc.).
-
There is a set of allowable actions (output space), A (swerve, brake, accelerate, etc.).
-
A set of strategies, which are functions, s: (Z × X) → A, summon an action to a given circumstance, current state of the agent, and history up to time, t. These are “ways of reasoning” for the agent. One might think of strategies as behavioral input space. For example, depending on age, background, and other
-
factors, some drivers will brake and some will swerve to avoid an accident. Social studies and surveys can supply valuable statistical inputs, such as data showing that agents with n years of driving experience between ages a1 and a2 swerve f percent of the time and break g percent of the time.
-
There is a set of utility variables, u∈U (e.g., time to destination, number of accidents, number of speeding tickets, etc.).
-
A multivariate objective function, F:U → Rm, might include constraints (“rules”) (e.g., the agent has to stay on the road). The analogous version in physics is called action. The agent tries to optimize this objective function (e.g., by minimizing the time to destination, avoiding accidents, etc.).
Unlike particles in classical systems, agents usually have memory, which they can use to change/evolve strategies, a process called learning. Another important aspect of agents is that they can reason and plan, which entail searching the choice tree and assigning weights and payoffs in light of what other agents might choose. In realistic situations that involve hundreds of agents (such as markets or traffic), long-term planning and reasoning are impossible because of the combinatorial explosion of possibilities and also because not all of the information is available to any single agent. Therefore, agents try to identify and exploit patterns in the responses of the surrounding environment to past actions and use these patterns to discriminate among strategies, reinforcing some and diminishing others (reinforcement learning). This leads to bounded-rationality-like behavior and introduces de-correlations between strategies; for that reason, reinforcement learning actually makes statistical modeling plausible.
In the following sections, we briefly describe two large-scale agent-based models developed at Los Alamos National Laboratory, a traffic simulator (TRANSIMS) and an epidemics simulator (EPISIMS).
TRANSIMS
The transportation analysis and simulation system (TRANSIMS) is an agent-based model of traffic in a particular urban area (the first model was for Portland, Oregon). TRANSIMS conceptually decomposes the transportation planning task using three different timescales. A large time scale associated with land use and demographic distribution (Figure 1) was used to create activity categories for travelers (e.g., work, shopping, entertainment, school, etc.). Activity information typically consisted of (1) requests that travelers be at a certain location at a specified time and (2) information on travel modes available to the traveler. For the large timescale, a synthetic population was created and endowed with demographics matching the joint distributions in census data. Synthetic households were also created based on survey data from several thousand households that included observations of daily activity patterns for each individual in the household. These activity patterns were then associated with syn-
FIGURE 1 Large-scale view of the roadway network in Portland, Oregon.
thetic households with similar demographics. The locations of various activities were estimated, taking into account observed land-use patterns, travel times, and the dollar costs of transportation.
For the intermediate timescale (Figure 2), routes and trip chains were assigned to satisfy the activity requests. The estimated locations were fed into a routing algorithm to find minimum-cost paths through the transportation infrastructure consistent with constraints on mode choices (Barrett et al., 2001, 2002). For example, a constraint might be “walk to a transit stop, take transit to work using no more than two transfers and no more than one bus.”
Finally, a very short time-scale (Figure 3) was used, associated with the actual execution of trip plans in the road network. This is done by a cellular automata simulation through a very detailed representation of the urban transportation network. The simulation, which resolved distances down to 7.5 meters and times down to 1 second, in effect resolved the traffic congestion caused by everyone trying to execute plans simultaneously by providing updated estimates of time-dependent travel times for each edge in the network, including the effects of congestion. These estimates were fed to a router and location estimation algorithms that produced new plans.
The feedback process continued iteratively until the system converged in a “quasi-steady state” in which no agent could find a better path in the context of every other agent’s decisions. The resulting traffic patterns compared well to

observed traffic. Thus, the entire process estimated the demand on a transportation network using census data, land-usage data, and activity surveys.1
EPISIMS
Another application of the TRANSIMS model is in the field of epidemiology. Diseases, such as colds, flu, smallpox, and SARS, are transmitted through the air between two agents. These agents must either spend a long enough time in proximity to each other or be in a building with a closed air-ventilation system to transmit the disease. Thus, we can assume that the majority of infections take place in locations, like offices, shopping malls, entertainment centers, and mass transit units (metros, trams, etc.).
By tracking the people in our TRANSIMS virtual city, we generated a bipartite contact network, or graph, formed by two types of nodes—people nodes and location nodes. If a person, p, entered a location, l, an edge was drawn between that person and the corresponding location node on the graph. The edge had an associated time stamp representing the union of distinct time intervals the person, p, was at the location, l, during the day. If two people nodes, p1 and p2, had an incident edge in the same location node, l, the common intersection of the two time stamps told us the total time the two people spent in proximity to each other during the day, thus enabling us to determine the possibility of transmission of an airborne infection.
Using Portland as an example, there were about 1.6 million people nodes, 181,000 location nodes, and more than 6 million edges between them. This dynamic contact graph enabled us to simulate different disease-spread scenarios and test the sensitivities of epidemics to disease parameters, such as incubation period, person-to-person infection rates, influence of age structure, activity patterns, and so on. The epidemiological study tool thus generated, called EPISIMS, can be used as an aid to decision making and planning, for example, for an outbreak of smallpox.
Based on the Portland data, we arrived at the following findings for the spread of smallpox.2 First, a person who has been vaccinated can be removed from the contact graph, along with his or her incident links. Thus, an efficient vaccination strategy removes the smallest subset of nodes, so that the resulting graph has many small disconnected pieces, which eliminates the spread of disease throughout the population. Unfortunately, the smallpox vaccine is not entirely harmless. In some people, it causes a disease called vaccinia that is some-
|
1 |
More information, including availability of the software, can be obtained from http://transims.tsasa.lanl.gov. |
|
2 |
For more details on EPISIMS, see Eubank et al., 2004. |
times fatal. Therefore, to minimize the incidence of vaccinia, mass vaccination (proposed by Kaplan et al., 2002) must be a last resort.
After studying the projection of the bipartite graph onto people nodes, however, we found very high expansion properties, and the only way to avoid mass spread of the disease would be to vaccinate everyone who had 10 or more contacts during the day, which effectively meant mass vaccination. Ultimately, we found that vaccinating people who frequently took long-range trips across the city, corresponding to shortcuts in the network (Watts and Strogatz, 1998), made it possible for us to use a more localized graph with a larger diameter. In case of an outbreak, this would allow for a ring strategy for quarantining and further vaccinations to stop the spread of disease.
Finally, the crucial parameter in containing an epidemic is the delay in reaction time. If we assume that sensors can perform an online analysis of pathogens in the air, the question is where they should be placed to be most effective, that is, where they would capture the onset of the outbreak. Due to a particular so-called scale-free property (Albert and Barabási, 2002) of the locations projection of the bipartite network, one can pinpoint a small set of locations (the so-called dominating set, about 10 percent of all locations) that would cover about 90 percent of the population and would thus be optimal locations for detectors. The same locations could be used for distribution purposes (e.g., of prophylactics and supplies). Figure 4 shows the evolution of epidemics after a covert introduction in a particular location (at a university) when the disease is left to spread (left side) compared to using a targeted-contact tracing and quarantining strategy (right).
ACKNOWLEDGMENTS
This work was done in collaboration with the TRANSIMS and EPISIMS teams. EPISIMS was supported by the National Infrastructure Simulation and Analysis (NISAC) Program at the U.S. Department of Homeland Security. The TRANSIMS project was funded by the U.S. Department of Transportation. The work of Zoltán Toroczkai was supported by the U.S. Department of Energy.
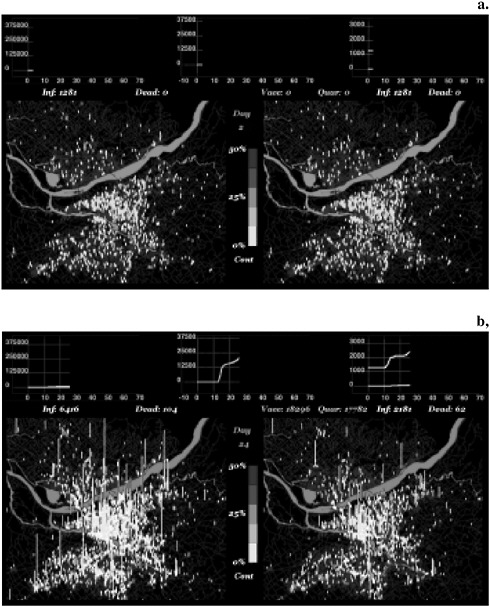
FIGURE 4 Comparison of baseline cases (on the left), with targeted (a.) vaccination and (b.) quarantining strategies (right). The bars represent the number infected at each location, and the light color represents the fraction of infected people who are infectious. The inserts show the cumulative number of people infected or dead as a function of time, and for the targeted response, the number vaccinated and quarantined. Note the different scales between the inserts. Source: LANL, 2005.
REFERENCES
Albert, R., and A.-L. Barabási. 2002. Statistical mechanics of complex networks. Review of Modern Physics 74(1): 47–97.
Barrett, C., R. Jacob, and M.V. Marathe. 2001. Formal language-constrained path problems. Journal on Computing 30(3): 809–837.
Barrett C., K. Bisset, R. Jacob, G. Konjevod, and M.V. Marathe. 2002. An Experimental Analysis of a Routing Algorithm for Realistic Transportation Networks. Technical Report No. LA-UR-02-2427. Proceedings of the European Symposium on Algorithms, Rome, Italy. Los Alamos, N.M.: Los Alamos National Laboratory.
Eubank, S., H. Guclu, V.S.A. Kumar, M.V. Marathe, A. Srinivasan, Z. Toroczkai, and N. Wang. 2004. Modelling disease outbreaks in realistic urban social networks. Nature 429(6988): 180–184.
Kaplan, E., D. Craft, and L. Wein. 2002. Emergency response to a smallpox attack: the case for mass vaccination. Proceedings of the National Academy of Sciences 99(16): 10935–10940.
LANL (Los Alamos National Laboratory). 2005. Controlling Smallpox: Strategies in a Virtual City Built from Empirical Data. Available online at: http://episims.lanl.gov.
Watts, D., and S. Strogatz. 1998. Collective dynamics of small-world networks. Nature 393(6684): 440–442.
ADDITIONAL READING
Barrett, C., S. Eubank, S.V. Anil Kumar, and M. Marathe. 2004. Understanding Large-Scale Social and Infrastructure Networks: A Simulation Based Approach. SIAM News, March 2004.
Barrett, C., S. Eubank, and J. Smith. 2005. If smallpox strikes Portland. Scientific American 292(3): 54–61.
Barrett, C., S. Eubank, and M. Marathe. Forthcoming. Modeling and Simulation of Large Biological, Information and Socio-Technical Systems: An Interaction-Based Approach. In Interactive Computation: The New Paradigm, edited by D. Goldin, S. Smolka, and P. Wegner. New York: Springer Verlag.
Halloran, M., I.M. Longini Jr., A. Nizam, and Y. Yang. 2002. Containing bioterrorist smallpox. Science 298(5597): 1428–1432.










