
Computational Infrastructure—Challenges and Opportunities
It is in the nature of infrastructures to be ignored when they are functioning. When they crumble, it can cause major disruptions or collapse of the enterprises and communities that depend on them. Computational infrastructure underpins the entire climate modeling enterprise. This chapter reviews the risks posed to the current climate modeling infrastructure by changes in technology and proposes an expansion of the infrastructure that could dramatically alter the landscape of climate modeling. (Definitions of selected terms used throughout this chapter are provided in Box 10.1.)
Future generations of climate simulation models will place an ever-increasing demand on computational infrastructure. There are compelling scientific needs for higher levels of spatial resolution (e.g., cloud-resolving atmospheric component, eddy-resolving ocean component, landscape-resolving land-surface component), more extensive vertical domains (e.g., whole atmosphere), increased model complexity (e.g., treatments of parameterized processes as well as the addition of other simulation component models, such as marine and terrestrial ecosystem components), and larger simulation ensembles (e.g., 50-100 members). All these developments are seen as essential for more accurate, reliable, and useful climate projections and predictions. The current generation of supercomputer systems deployed partly or mostly to support climate modeling, such as the National Oceanic and Atmospheric Administration’s (NOAA’s) Gaea supercomputer and the National Center for Atmospheric Research’s (NCAR’s) Yellowstone system, provide an important capability that enables progress toward these goals, but they are only a first step in deploying rapidly evolving computational capabilities. Scientific advances and applications will motivate the national climate modeling enterprise to exploit these new computational capabilities; the complexity and diversity of climate model codes coupled with the expected nature of hardware advances will make this an increasingly challenging task over the next two decades.
As a rough guide, the ability to simulate 5-10 years per wall clock day of computing time continues to be regarded as necessary to make the climate modeling problem tractable.1 With the current generation of high-performance computing systems,
___________________
1 Climate model runs often simulate time spans of hundreds of years, meaning that a single run can take days or weeks to complete.
BOX 10.1 GLOSSARY OF SELECTED TERMS USED IN THIS CHAPTER
Computational infrastructure: the software basis for building, configuring, running, and analyzing climate models on a global network of computers and data archives. See Edwards (2010) for an in-depth discussion of “infrastructure” and software as infrastructure.
Refactoring: rewriting a piece of software to change its internal structure without in any way altering its external behavior. This is often undertaken to increase the efficiency or ease of use and maintenance of legacy software.
Core: an element of computational hardware that can process computational instructions. Some current computers bundle several such “cores” onto a single chip, leading to “multicore” (typically 8-16 cores per chip) and “many-core” systems (tens of cores per chip).
Node: an object on a network. In the context of high-performance computing (HPC) architecture it is a unit within a distributed-memory supercomputer that communicates with other nodes using network messaging protocols, i.e., “message passing.” It is the smallest entity within the cluster that can work as an independent computational resource, with its own operating system and device drivers. Within a node there may be more than one, indeed many, integrated but distinct computational units (“cores”) that can communicate using more advanced fine-grained communication protocols (“threading”).
Concurrency: simultaneous execution of a number of possibly interacting instruction streams on the same computer.
Flops: floating-point operations per second, a unit of computational hardware performance. Prefixed by the usual metric modifiers for orders of magnitude; a petaflop is 1015 flops and an exaflop is 1018 flops.
Exascale: computers operating in the exaflop range, coupled to storage in the exabyte range.
Threads: a stream of instructions executing on a processor, usually concurrently with other threads in a parallel context.
this allows global resolutions of 50 km. Each additional 10-fold increase in resolution leads to a more than 1,000-fold increase in operation count, before considering additional complexity. As recent history has demonstrated, the testing, debugging, and evaluation (e.g., participation in formal model evaluation processes, like the Coupled Model Intercomparison Project, Phase 5 [CMIP5]) required for any given model version continues to require ever-greater amounts of computing time as the model becomes more complex. Overall, the climate modeling enterprise relies on sustained improvements in supercomputing capabilities and must strategically position itself to fully exploit them.
Finding 10.1: As climate models advance (higher resolutions, increased complexity, etc.), they will require increased computing capacities.
PREVIOUS HARDWARE TRANSITIONS
As discussed in Chapters 3 and 4, higher spatial resolution is an important element of improving the fidelity and usefulness of climate models, but also dramatically increases their computational requirements. Thus, climate models have historically been among the principal drivers of HPC. The first coupled ocean-atmosphere model (Manabe and Bryan, 1969) was recognized as a landmark in scientific computing in a Nature survey (Ruttimann, 2006).
Coding models to take advantage of advanced and novel computational architectures has always been a significant activity within the climate and weather research and operations communities. During the 1980s and early 1990s, the climate simulation enterprise benefited greatly from computer architectures focused on high-performance memory systems, mainly in the form of vector computing, a technique of fine-grained array concurrency pioneered by Seymour Cray. Several models from many institutions were able to deliver sustained computing performance operating near the theoretical limits of these computing architectures. In the late 1990s, proprietary vector supercomputing architectures began to be supplanted by commodity off-the-shelf architectures. This was partly a result of market forces driving U.S. manufacturers of proprietary architectures out of this field. At least one company (NEC) soldiered on, with the SX series of machines successfully operating in subsequent generations until the present in this field in Japan, Australia, and Europe.
A disruptive transition in the late 1990s pushed climate modeling toward parallel and distributed computing implementations. Although this was viewed with trepidation at the time (NRC, 1998, 2001b; USGCRP, 2001), it is possible to see from the hindsight of 2011 that the community in fact weathered the transition with distinction. While actual sustained performance of climate codes relative to the theoretical peak hardware performance fell by an order of magnitude, time to solution continued to be reduced through exploitation of the aggregate performance of massively parallel machines. Adapting to parallel computing architectures did require pervasive refactoring of highly mature codes. This recoding process necessarily started prior to the establishment of a programming environment standard (e.g., shared memory parallel directives that evolved to SHMEM (Barriuso and Knies, 1994) and distributed-memory approaches (like Parallel Virtual Machine [Geist et al., 1994] that eventually evolved into the Message Passing Interface standard [Gropp et al., 1999]). Being out in front of the development of a programming model has been essential to navigating previous architectural transitions. But rather than insert these new methods throughout model codes, climate and weather modelers began to see these methods as part of infrastructure. Most institutions developing high-end models resorted to high-level
libraries where the standard and highly reusable computational methods were encapsulated. Scientists and algorithm developers were able to use abstractions that were scientifically intuitive, and the gory details of parallel programming were effectively hidden from those developing the scientific aspects of climate models. When the underlying hardware changed, the infrastructure changed with it, and the scientific codes remained largely intact.
Finding 10.2: The climate modeling community adapted well to the previous hardware transition by moving toward shared software infrastructure.
A similarly disruptive moment is now upon us. As described in the next section, all indications are that increases in computing performance through the next decade will arrive not in the form of faster chips, but more of them, with considerably more complex embodiments of concurrency. Deep and abstruse memory hierarchies, and processing element counts that push the limits of current parallel programming standards, both make for a challenging environment for application programmers. In this chapter, the committee argues that a renewed and aggressive commitment to shared software infrastructure across the climate and weather communities will be needed to successfully navigate this transition, which may prove to be even more disruptive than the vector-to-parallel transition. Indeed, conventional wisdom in the HPC community (see Zwieflhofer [2008] and Takahara and Parks [2008] for examples) is that the next generation conversion will be significantly more complex and unpredictable than previous changes, given the absence of a clear technology path, programming model, performance analysis tools, etc. The ratio of sustained performance to theoretical hardware peak may once again fall precipitously, as it once did during the vector to distributed-memory-parallel transition.
A second element of infrastructure that now pervades the field is the global data infrastructure for models. While this “vast machine” networking the globe is historically associated with the global observing networks, it now encompasses models as well (Edwards, 2010). The committee argues below that this infrastructure too is invisible and taken for granted, but that without proper provisioning for the future, it may be overwhelmed by projected growth and demand for access to data.
NEW ARCHITECTURES AND PROGRAMMING MODELS
This section summarizes trends in HPC hardware, the programming model for using such platforms, and the system software expected to be in place over the next two decades.
Hardware Assessment: Architectural Prospects for the Next 10-20 Years
Conventional high-end multicore microprocessor technology is approaching multiple limits, including power consumption, processor speed, per-core performance, reliability, and parallelism. Hardware assessments such as Kogge (2008) have shown that extrapolating current technologies such as those used in Oak Ridge National Laboratory’s (ORNL’s) Jaguar machine or NOAA’s Gaea leads to exascale machine configurations that can be ruled out on the basis of power consumption alone, which would reach the 100-megawatt range. Alternate technology paths in the next generation of machines include the Blue-Gene system-on-chip design. Using flops/watt as a key metric, this technology path scores better on the power efficiency front. However, the newest and largest machine of this class, the 20-petaflop Sequoia platform at Lawrence Livermore National Laboratory,2 will still require 6 megawatts of power to operate.
A second technology track aims at exploiting the fine-grained parallelism employed in contemporary graphics chips. Graphics processing units (GPUs) have been used to achieve very high concurrency for specialized graphics operations (such as rendering three-dimensional objects on a two-dimensional screen). More recently GPUs have become a viable alternative to conventional high-end microprocessors (CPUs), in part because of their high performance, programmability, and efficiency at exploiting parallelism for use in scientific and other nongraphics applications. This accelerator approach has been extended to allow for general-purpose computing on graphics processing units (GPGPUs) using a technique that combines programmable stages and highprecision arithmetic with the fine-grained parallelism for which GPUs were designed. This approach allows mapping of standard computational concepts onto the specialpurpose features of GPUs (Harris, 2005). The Intel Knights Corner chip, released at the 2011 Supercomputing Conference, is the latest extension of GPGPU technology called Many Integrated Core (MIC) architecture, utilizing many parallel lower-power cores. Such computer architectures as GPUs and MICs are expected to be an important step toward the realization of exascale-level performance in the next one to two decades.
Other novel technologies under consideration such as field-programmable gate arrays have not proved very suitable to complex multiphysics applications such as Earth system models: they are more intended for applications where a single set of operations is repeated on a data stream. Even more experimental approaches, based on biology, nanotechnology, and quantum computing, are not expected to be suitable for con-
___________________
2 http://nnsa.energy.gov/blog/sequoia-racks-arriving-llnl (accessed October 11, 2012).
ventional codes and will almost certainly require complete and radical rethinking of computational Earth system modeling if they are to be exploited.
Although there are architecturally different solutions to enhancing system performance, they share the characteristic that the increase in performance will come from exploiting additional concurrency at the node level. Extrapolating to an exaflop (1018 flops) with single thread clock speed of 1010 Hz leads to a required concurrency factor of 108-109. (Gaea, the largest machine today entirely devoted to climate modeling, is rated at ~1 petaflop to 1015 flops.)
There is no current comprehensive climate model (as opposed to process study model) operating anywhere remotely close to that level of concurrency. The best examples of parallel concurrency exhibit about 105 based on maximum processor counts reported for models in the CMIP5 archive (model descriptions are online3). The level of concurrency in comprehensive climate models lags the hardware concurrency of the leadership-class machines by at least a factor of 100. Based upon the community’s experience with the previous disruptive technology transition, where the ratio of sustained to theoretical peak performance dropped from ~50 percent to ~10 percent for typical climate codes, it would not be surprising if this ratio dropped again during the coming transition. This cannot be made up without a very substantial investment in research into basic numerical approximations and algorithms, which must then be adopted quickly by the simulation community.
Finding 10.3: Climate models cannot take full advantage of the current parallel hardware, and the gap between performance and maximum possible performance is likely to increase as the hardware advances.
Programming Models for the Next 10-20 Years
At this time the many emerging architectures do not adhere to a common programming model. While new ways to express parallelism may well hold the key to progress in this decade, from the point of view of the developer of scientific applications, a transition path is far from evident.
Assessments undertaken by the Defense Advanced Research Projects Agency (DARPA) and the Department of Energy (DOE) (e.g., DOE, 2008; Kogge, 2008) indicate profound uncertainty about how one might program a future system that may encompass many-core chips, coprocessors and accelerators, and unprecedented core counts requiring the management of tens of millions of concurrent threads on next-generation
___________________
3 http://q.cmip5.ceda.ac.uk/ (accessed October 11, 2012).
hardware. The President’s Council of Advisors on Science and Technology (PCAST) has called for the nation to “undertake a substantial and sustained program of fundamental research on hardware, architectures, algorithms and software with the potential for enabling game-changing advances in high-performance computing” (PCAST, 2010). This challenge will grow to a billion threads by the end of this decade. The standard du jour programming model for parallel systems is based on MPI (Lusk and Yelick, 2007), shared-memory directives (e.g., OpenMP [Chandra et al., 2001]), or a hybrid of both. These are likely to fail at the scales projected for next-generation systems. Several new approaches are being proposed: for instance, Partitioned Global Address Space languages (Yelick et al., 2007), which grew out of the DARPA High Productivity Computing Systems (HPCS) program to develop “high-productivity” programming approaches (Lusk and Yelick, 2007). In some instances they are entirely new languages such as X10 (Charles et al., 2005) and Chapel (Chamberlain et al., 2007), and in other instances extensions to existing languages, like Co-Array Fortran (Numrich and Reid, 1998) and Unified Parallel C (Carlson et al., 1999).
On longer time scales the exploitation of fine-grain parallism that minimizes data movement will be necessary. For certain hardware directions such as GPUs, a finegrained parallelism approach is immediately needed. A new programming standard suitable for GPUs and many-core chips is being proposed (OpenCL: see, e.g., Munshi, 2008). Experiments with hardware-specific programming models such as CUDA for Nvidia graphics chips indicate a potential for significant speedups at very fine grain (see, e.g., Michalakes and Vachharajani, 2008) but very extensive intervention is needed to translate these speedups to the entire application. There are efforts under way to introduce a directive-based approach that could potentially be unified with OpenMP. The most promising avenue at the moment appears to be OpenACC,4 but it is still early in its development.
The climate/weather modeling community has never retreated from experimenting with leading-edge systems and programming approaches to achieve required levels of performance. The current architectural landscape, however, is particularly challenging, because it is not clear what direction future hardware may follow. The International Exascale Software Project (Dongarra et al., 2011) promises a “roadmap” by 2013. The challenge is starkly presented as one that cannot be met without a concerted effort at exposing concurrency in algorithms and computational infrastructure.
Finding 10.4: Increases in computing performance through the next decade will arrive not in the form of faster chips, but more of them, with considerably more
___________________
4 http://www.openacc-standard.org/ (accessed October 11, 2012).
complex embodiments of concurrency; the transition to this new hardware and software will likely be highly disruptive.
System Software
System software, such as operating systems, file systems, shells, and so on, will also undergo radical change to cope with the changes in hardware. Input/output (I/O) in particular will be a profound challenge for climate modeling, which is generating data volumes on an exponential growth curve (Overpeck et al., 2011). Furthermore, and potentially more significantly, the highly concurrent machines of this decade have the potential for decreased reliability as the component count increases. Fault-resilient software to account for decreased reliability could reduce the effective computation rate, as many such methods involve redundant computations (Schroeder and Gibson, 2007).
With regards to fault resilience, architectures with extreme levels of concurrency and complexity may not guarantee that a program executes the same way every time. The possibility of irreproducible computation presents a challenge to testing, verification, and validation of model results. Chaotic systems with sensitive dependence on initial conditions will wander arbitrarily far outside any tolerance bound, given enough time. The key question in the climate context is to see whether trajectories subject to small changes at the hardware bit level stay within the same basin of attraction, or do these small errors actually push the system into a “different climate state.” Currently there is no other way to prove that an architectural or software infrastructure change has not pushed the system into a different climate other than computing the climatology of long (usually 100-yr, to take into account slow climate processes) control runs. This requirement is hugely expensive and a significant barrier to testing.
Can the climate modeling community adapt to a world where in silico experimentation is more like in vitro biological experimentation, where reruns of experiments are only statistically the same? Such adaptation would entail profound changes in methodology and be an important research challenge for this decade.
Substantial progress must be made in fault-resilient software. Fault tolerance generally implies redundancy layers, which can also imply a further decrease in achievable execution rate. Currently, the development efforts in high-end computing emphasize “peak flops,” and the climate modeling community would benefit from redressing this with increased efforts in fault-tolerant system software and workflows, echoing from previous National Research Council (NRC) reports that endorsed balancing support across the software life cycle. In conclusion, sharp decreases in reliability should be
anticipated as the hardware concurrency in machines grows. Investments that emphasize system software and workflow reliability and investments in achieving faster execution rates both need to be balanced.
Adoption of these approaches will involve extraordinary levels of effort by the climate modeling community, who will probably have a minimal influence on the hardware or the software roadmap. Various studies on exascale computing have noted that the computational profile of climate science is unique because of the tightly coupled multiphysics nature of the codes.
SOFTWARE INFRASTRUCTURE FOR MANAGING MODEL HIERARCHIES
The community is best served by adopting a domain-specific technical infrastructure under which its developments can proceed. At the scale of one lab, this has been widely adopted and extremely successful. For example, at most modeling centers, scientists do not directly apply MPI or learn the intricacies of tuning parallel file-system performance, but use a lab-wide common modeling infrastructure for dealing with parallelism, I/O, diagnostics, model coupling, and so on, and for modeling workflow (the process of configuring, running, and analysis of model results). Many things that are done routinely—adding a new model component, adapting to new hardware—could not be done without a growing reliance on shared infrastructure.
It was recognized over a decade ago that such software infrastructure could usefully be developed and shared across the climate modeling community. The most ambitious such project was the Earth System Modeling Framework (ESMF; Hill et al., 2004). It introduced the notion of superstructure, a scaffolding allowing model components to be coupled together following certain rules and conventions to permit easy interchange of components between models (Dickinson et al., 2002). See Box 10.2 for a further description of ESMF and how it has unfolded after a decade of development. ESMF and other examples of common infrastructures, including the Flexible Modeling System (FMS)5 developed by the Geophysical Fluid Dynamics Laboratory (GFDL), the Model Coupling Toolkit, extensively used in the CESM, and OASIS, a European model coupling project, are the subject of a comparative survey by Valcke et al. (2012).
This committee, which includes several members closely involved in the development of ESMF and other single-institution frameworks, observes that the idea of frameworks and component-based design is no longer novel or controversial. While switching
___________________
5 http://www.gfdl.noaa.gov/fms (accessed October 11, 2012).
BOX 10.2 THE EARTH SYSTEM MODELING FRAMEWORK (ESMF): CASE STUDY
Following reports on U.S. climate modeling in 2001, federal agencies made substantial investments in software infrastructure and information systems for both modeling and analysis. ESMF is a high-profile activity that was funded in 2001 by the National Aeronautics and Space Administration (NASA), and continues to be developed and maintained under funding by the Department of Defense, NASA, the National Science Foundation (NSF), and NOAA. The first cycle of ESMF was funded as a computational technology activity focused on model coupling in both the weather and climate community. In the second cycle of ESMF, the focus was extended from technology to the formation of a multiagency organization. As discussed in Chapter 2, this focus on process and governance included development of ways to manage sponsor and user expectations, requirements, and delivery.
Building upon earlier work at GFDL and Goddard Space Flight Center (GSFC), ESMF introduced the notion of a superstructure (Collins et al., 2008; Hill et al., 2004) providing a common vocabulary for describing model components (e.g., ocean, atmosphere, or data assimilation package), with their own gridding and time-stepping algorithms, and the fields they exchange. The common vocabulary permitted components to be coupled with relatively little knowledge of the internal working of other components, other than those exposed by the interface. This approach has proved very powerful and attractive for communities whose scientific activities depend upon component-level interoperability. In particular within the numerical weather prediction (NWP) community, many participants in the National Multi-Model Ensemble are building the National Unified Operational Prediction Capability,a which utilizes ESMF as part of its foundation.
ESMF is also used within some single-institution frameworks, such as the GEOS system from NASA GSFC, and the Coupled Ocean/Atmosphere Prediction System.
NCAR and GFDL have not adopted ESMF as their central framework. GFDL already had internally developed the FMS, from which ESMF borrowed ideas. NCAR was also actively testing another framework alternative, the Model Coupling Toolkit (MCT), while ESMF was under development, and for pragmatic reasons adopted MCT for high-level coupling while using some of the lower-level functionality of ESMF. However, their own frameworks remain architecturally compatible with adoption of ESMF; and in fact ESMF is often the lingua franca, or the common language, when their components are widely used in other communities (such as GFDL’s Modular Ocean Model).
___________________
a http://www.nws.noaa.gov/nuopc/ (accessed October 11, 2012).
between functionally equivalent frameworks has costs, few technical barriers to doing so exist should a compelling need arise.
With ESMF and other infrastructure activities, the climate modeling community is seeing the natural evolution of infrastructure adoption. Individuals, communities, and institutions are seeing advantage. The committee believes that the community is now at the point where the benefits of moving to a common software infrastructure out-
weigh the costs of moving to it. With the experience, successes, and lessons learned of the past decade, the climate modeling community is positioned to accelerate infrastructure adoption. Cross-laboratory intercomparisons are now routinely conducted and, more importantly, are the way forward. End users require climate model information to be robust and reliable. Common infrastructure improves the ability to enforce scientific methodology (e.g., controlled experimentation, reproducibility, and model verification) across institutions and is one of the primary building blocks of that robustness and reliability.
So far, no one software framework has become a universal standard, because modeling centers that initially invested in one framework have had insufficient incentive to switch to another. Nevertheless, we believe that two critical strategic needs—that the U. S. climate community needs to more effectively collaborate, and that it needs to nimbly adapt to a wave of disruptive new computing technology—position the community for a further unifying step. The vector to parallel disruption led to widespread adoption of framework technologies at the scale of individual institutions. The climate modeling community can now conceive of a framework that could be subscribed to by all major U.S. climate modeling groups, supports a hierarchy of models with component-wise interchangeability, and also supports development of a highperformance implementation that enables climate models of unprecedented resolution and complexity to be efficiently adapted to new architectural platforms. This idea is explored below.
Finding 10.5: Shared software infrastructures present an appealing option for how to face the large uncertainty about the evolution of hardware and programming models over the next two decades.
A NATIONAL SOFTWARE INFRASTRUCTURE FOR CLIMATE MODELING
Very complex models have emergent behavior whose understanding requires being able to reproduce phenomena in simpler models. Chapter 3 makes a strong case for hierarchies of models adapted for different climate problems. From the computational perspective, some model types can be classified by a rough pace of execution needed (i.e., model simulated time per computer clock time) to make efficient scientific progress:
• process study models and weather models (single component or few components; dominated by “fast” physics; 1 year/day),
• comprehensive physical climate models (ocean-atmosphere, land and sea ice,
includes “slow” climate processes important on decadal to centennial climate scales, 10 years/day), and
• Earth system models for carbon-cycle studies; paleoclimate models (most complex physics; dominated by slow processes and millennial-scale variability, 100 years/day).
A single national modeling framework could allow the climate modeling community to configure all of these models from a palette of available components of varying complexity and resolution, as well as supporting high-end modeling. This idea has been proposed in the past: the history of previous efforts is recounted in Chapter 2. The committee believes that current trends in our methodology, both its strengths and weaknesses, point in the direction of a concerted effort to make this a reality, for reasons that are outlined below.
A related methodological advance is the multimodel ensemble and the model intercomparison project, which has become ubiquitous as a method for advancing climate science, including short-term climate forecasting. The community as a whole, under the aegis of the World Meteorological Organization’s World Climate Research Programme—through two working groups, the Working Group on Climate Modeling and the Working Group on Numerical Experimentation—comes to consensus on a suite of experiments, which they agree would help advance scientific understanding (more information in Chapter 8). All the major modeling groups agree to a suite of numerical experiments defined for the current-generation Coupled Model Intercomparison Project (CMIP5) as a sound basis for advancing the science of secular climate change, assessing decadal predictability, etc., for participation in defining the experiments and protocols. The research community addressing climate variations on intraseasonal, seasonal, and interannual (ISI) time scales agrees on similar multimodel approaches for seasonal forecasting. A globally coordinated suite of experiments is then run, and results shared for a comparative study of model results.
The model intercomparison projects (MIPs) are sometimes described as “ensembles of opportunity” that do not necessarily sample uncertainty adequately. A second major concern is the scientific reproducibility of numerical simulations. Even though different models are ostensibly running the same experiment, there are often systematic differences between them that cannot be traced to any single cause. Masson and Knutti (2011) have shown that the intermodel spread is much larger than differences between individual ensemble members of a single model, even when that ensemble is extremely large, such as in the massive ensembles of QUMP (Collins et al., 2011) and CPDN (Stainforth et al., 2005). To take but one example of why this is so troublesome in the public sphere, consider different studies of Sahel drought made from the
CMIP3 experiments. Two studies, based on the GFDL (Held et al., 2005) and Community Climate System Models (CCSM; Hurrell et al., 2004), have roughly similar skill in reproducing late-20th-century Sahel drought, and propose roughly equivalent explanations of the same, based on Atlantic meridional temperature gradients. Yet the results in the future scenario runs are quite different, producing opposite sign projections of Sahel drought in the 21st century. Hoerling et al. (2006), in their comparative study of the CMIP3 models’ Sahel simulations, acknowledged these differences but could not easily point a finger at any feature of the model that could account for the differences: The differences are not easily attributable to any single difference in physics or process between the models, nor can the community easily tell which, if any, of the projections is the more credible. Tebaldi and Knutti (2007) also address this fact, that intermodel spread cannot be explained or even analyzed beyond a point.
This weakness in methodology requires the climate modeling community to address the issue of scientific reproducibility. That one should independently be able to replicate a scientific result is a cornerstone of the scientific method, yet climate modelers do not now have a reliable method for reproducing a result from one model using another. The computational science community has begun to take a serious look at this issue, with a considerable literature on the subject, including a special issue of Computing in Science and Engineering (CISE, 2009) devoted to the subject. Peng (2011) summarized the issue as follows:
Computational science has led to exciting new developments, but the nature of the work has exposed limitations in our ability to evaluate published findings. Reproducibility has the potential to serve as a minimum standard for judging scientific claims when full independent replication of a study is not possible.
Having all of the nation’s models buy into a common framework would allow this research to be systematized. Maintaining the ability to run experiments across a hierarchy of models under systematic component-by-component changes could hasten scientific progress significantly.
Research in the science of coupling is needed to make the vision a reality. Existing framework software does not specify how models are coupled. Software standards are one part of the story, but there will remain work to be done to define choices for coupling algorithms, fields to be exchanged, and so on.
An effective common modeling infrastructure would include
• common software standards and interfaces for technical infrastructure (e.g., I/O and parallelism);
• common coupling interfaces across a suite of model components of varying complexity;
• common methods of expressing workflow and provenance of model results;
• common test and validation methods;
• common diagnostics framework; and
• coupled data assimilation and model initialization framework.
ESMF and other frameworks meet many, but not all, of these requirements.Within the infrastructure described above, there is considerable scope for innovation:
• different dynamical cores and discretization methods for global and regional models;
• different vertical coordinates;
• new physics kernels where there is still uncertainty about the physical formulation itself (“structural”); and
• different methods contributed by different groups based on their interests and specializations (e.g., data assimilation).
Finding 10.6: Progress in understanding climate model results requires maintaining a hierarchy of models. There are barriers to understanding differences between model results using different models but the same experimental protocols. Software frameworks could offer an efficient way of systematically conducting experiments across the hierarchy that could enable a better characterization and quantification of uncertainty.
Data-Sharing Issues
The rapidly expanding archives of standardized model outputs from the leading international climate models have heavily contributed to the IPCC assessments. They have also made climate model simulations accessible to a wider community of users as well as researchers. This effort has been led by the DOE-sponsored Program on Climate Model Diagnostics and Intercomparison (PCMDI) at LLNL. While a centralized data archive was initially developed, the volume of model output has grown so much that this internationally-coordinated model data set is now distributed through the Earth System Grid,6 a linked set of data storage locations. Both the PMDI and Intercomparison and the Earth System Grid are fragile institutions, maintained by a mixture of volunteer effort and a succession of competitive grant proposals, but are a vital backbone for efficiently providing current climate model output to diverse user com-
___________________
6 http://www.earthsystemgrid.org/ (accessed October 11, 2012).
munities. The data infrastructure benefits from a “network effect” (where value grows exponentially as more nodes are added; see, e.g., Church and Gandal, 1992; Katz and Shapiro, 1985). It involves developing operational infrastructure for petabyte-scale (and soon exabyte-scale; see Overpeck et al., 2011) distributed archives. This infrastructure development has occurred through an international grassroots effort by groups such as the Global Organization of Earth System Science Portals and the Earth Systems Grid Federation.
More generally, needs for data storage, analysis, and distribution have grown significantly and will continue to grow rapidly as models move to finer resolution and more complexity and the needs of an increasing diversity of users become more sophisticated. Furthermore, the scientific research, observational devices, and computational resources are becoming increasingly nonlocal. NCAR has recently built the NCAR-Wyoming Supercomputer Center to house its supercomputer and data repository. NOAA has placed its Gaea supercomputer at ORNL serving research labs across the country. It is increasingly common for scientists at many institutions to modify and enhance models at remote institutions and to analyze results from other models. The need to use large volumes of remotely stored data places extreme strains on systems and requires systematic planning and investment as part of a national climate modeling strategy. This need is similar to that described in Chapter 5 related to the handling of observational data.
This combination of rapidly increasing climate simulation data objects with a more distributed set of supercomputers and data archives requires the climate modeling community to begin to make use of a separate backbone data-intensive cyberinfrastructure, based on dedicated optical lightpaths on fiber optics separate from the Internet, connecting these facilities with each other and with data-intensive end users. These “data freeways” have been developed nationally (ESnet, Internet2, National LambdaRail; see Figure 10.1) and internationally (Global Lambda Integrated Facility) over the past decade outside of the climate community, providing 10-100 gigabit per second (Gbps) clear channels for data movement. Dedicated 10-Gbps optical pathways enable moving a terabyte of data between two sites in 15 minutes, compared to 1-10 days to move a terabyte on the 10-100 Mbps shared Internet. An example of the use of such supernetworks in climate is the recent NOAA 10-Gbps optical network for moving large amounts of data between key computational facilities (including ORNL and GFDL) and end users. The new Advanced Networking Initiative7 is already developing a prototype scientific network that can operate at 100-Gbps speeds (Balman et al., 2012).
___________________
7 http://www.es.net/RandD/advanced-networking-initiative/ (accessed October 11, 2012).
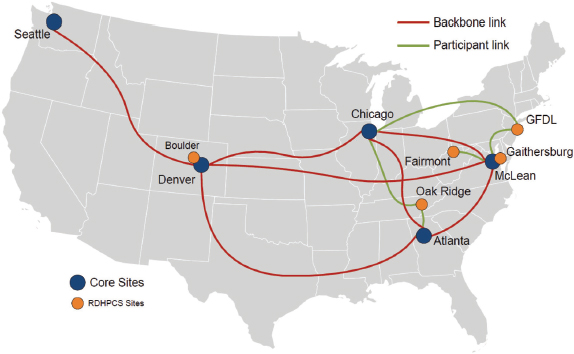
FIGURE 10.1 N-Wave, the NOAA Research Network. A high-performance network dedicated to environmental research and connecting NOAA and the academic and state research network communities. SOURCE: N-Wave website, http://noc.nwave.noaa.gov/.
Finding 10.7: The data-intensive cyberinfrastructure that will be needed to enable the distributed climate community to access the enormous data sets that will be generated from both simulation and observations will require a dedicated data-sharing infrastructure.
THE WAY FORWARD
Climate simulation is difficult because it involves many physical processes interacting over a large range of space and time scales. Past experience shows that increasing the range of scales resolved by the model grid ultimately leads to more accurate models and informs the development of lower-resolution models. Therefore, to advance climate modeling, U.S. climate science will need to make effective use of the best possible computing platform and models. To facilitate the grand challenges of climate modeling in support of U.S. national interests (Chapter 4), increased model resolu-
tion and complexity will be required, which in turn will result in the need to exploit enhanced computing power, (i.e., new hardware). Therefore, the committee recommends an expansion of the capabilities within the climate modeling community that includes three main elements: (1) a common software infrastructure shared across all U.S. climate modeling groups; (2) a strategic investment in continuing the ongoing deployment of advanced climate-dedicated supercomputing resources and in research about how to design climate models to exploit new computational capabilities, based on the common infrastructure; and (3) a global data-sharing infrastructure that is operationalized. The data-sharing infrastructure that exists is already vital to the climate modeling enterprise, but it is at risk because of tenuous recognition of its importance in the form of resourcing.
Evolving to a Common Software Infrastructure
The committee believes the time is ripe for a systematic cross-agency investment in a common U.S. software infrastructure designed in close collaboration with the major modeling centers (e.g., CESM, the Goddard Institute for Space Studies, the Global Modeling and Assimilation Office, GFDL, and the National Centers for Environmental Prediction). There is no reason it could not be globally shared, but the committee limits its discussions here to U.S. modeling centers in line with its statement of task (Appendix A). The infrastructure needs to support interoperability of climate system model components and common data-handling standards that facilitate comparisons between component models developed by different modeling groups, and across a hierarchy of component models of different levels of complexity, including regional models. Within this framework, there is still scope to address structural uncertainty (Chapter 6) by allowing competing representations of processes to be systematically compared. The common software infrastructure will follow coding conventions and standards enabling the construction of hierarchies of models of smaller scope to be run on a broad class of computing platforms (see Box 10.3 for further discussion).
While this investment could be justified purely on its potential for allowing more efficient use, comparison, testing, and improvement of U.S. climate models, it is more urgent in light of the upcoming transition to high-end computers that are based on much higher levels of concurrency (Figure 10.2). In particular, it would position the U.S. climate community to make the additional investment to redesign climate models to effectively use new high-end supercomputers, because of the possibility of configuring multiple scientifically credible versions of individual model components to run on such systems without enormous additional effort.
BOX 10.3 SOFTWARE INFRASTRUCTURE ANALOGY TO OPERATING SYSTEM ON A SMARTPHONE
The software infrastructure described in this chapter can be thought of as similar to the operating system on a smartphone. The software infrastructure is designed to run on a specific hardware platform (i.e., the phone), and climate modelers develop model components (i.e., apps) to run in the software development to simulate parts of the climate system like the atmosphere or ocean.
Right now, different modeling centers in the United States have different software infrastructures (operating systems) that run on different pieces of hardware; this would be like the iPhone compared to the Android, for example. This means that climate model components (apps) written for one software infrastructure will not work with another (i.e., iPhone apps will not work directly on an Android).
Ultimately, the vision is that the U.S. modeling community could evolve to use the same common software infrastructure (operating system), so that model components (apps) could be interchanged and tested versus one another directly. This would also mean that when the hardware (phone) advances, the software infrastructure (operating system) can be updated to continue to work with the new hardware without having to completely rewrite the climate model components (apps).
The committee recommends that the best pathway for achieving a common software infrastructure involves a community-based decision process. As discussed in Chapter 2 and Box 10.2 (ESMF), efforts to dictate transformations to specific infrastructures have met with less success than those that have come from the bottom up. This is described further in Chapter 13 in the discussion of the formation of an annual national climate modeling forum. The evolution to a common modeling infrastructure will require ongoing work, and a working group at such a forum could provide a venue for that work.
The evolution to a common software infrastructure will not be without risks and costs. A single infrastructure could inhibit the exploration of alternative approaches to software design and development. Frontier-scale computing is an evolving problem that could be challenging to adapt to a preexisting community framework. Communitybased decision processes require nurturing, have inefficiencies, and require compromise. Individual modeling centers may not easily be convinced to migrate from their current infrastructure. However, given a decade of experience, combined with a bottom-up, community design process, the committee believes that the climate modeling is ready to develop a capable and ambitious common software infrastructure whose overall benefits far outweigh the costs.
This evolution can only succeed with adequate sustained resources. It will benefit from the coordinated involvement of the funding agencies to help organize and sup-
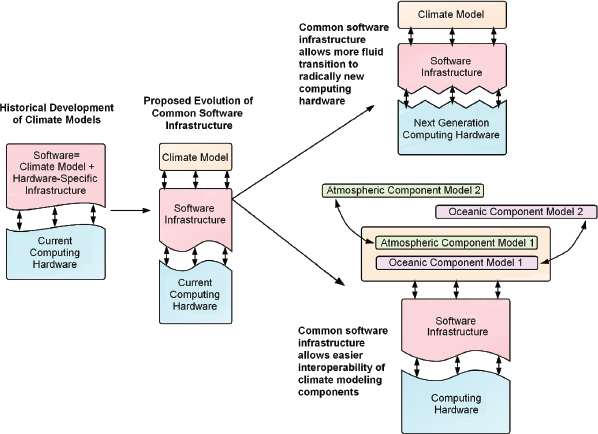
FIGURE 10.2 The development of a common software infrastructure will facilitate the migration of models to the next generation of computing platforms and allow interoperability of model components.
port the development of the new infrastructure and its implementation in the leading U.S. global and regional climate models, as well as its use in model comparisons and national climate model data archival. The U.S. Global Change Research Program (USGCRP) is expected to play an important role in this effort, having stated in its recent strategic plan that “Promoting the development and widespread use of such frameworks is a central task for USGCRP so as to maximize collaboration, co-development of models, and, ultimately, coordinate integrated research efforts” (USGCRP, 2012).
Addressing Climate Model Computing Hardware Requirements
As described earlier in this chapter, the future needs of U.S. climate modeling to provide climate data for decision makers and other users will outstrip its current computing capabilities. Chapter 13 discusses options for how to address these needs in
more detail in the context of how they might interact with existing climate modeling centers and regional modeling activities.
Operationalizing the Global Data-Sharing Infrastructure
Two observations can be made about the distributed nature of climate science today. First, the growth rate of climate model data archives is exponential. Without substantial research effort into new methods of storage, data decimation, data semantics, and visualization, all aimed at bringing analysis and computation to the data, rather than trying to download the data and perform analysis locally, it is likely that the data might become frustratingly inaccessible to users. Research efforts under NSF’s EarthCube and smaller projects funded by NOAA and DOE/SciDAC attempt to address this, but this is one realm that would benefit from the network effect and consolidation of effort across agencies, and in fact internationally. The challenges posed by a federated global archive demand an equally federated response.
Second, globally coordinated modeling experiments have become central to climate science. Climate science and policy-relevant science and decision making are increasingly dependent on the results of these experiments. The enterprise is critically dependent on a global data infrastructure for disseminating these results. It cannot continue to be developed and run by a dedicated but small cadre of technologists funded by separate, uncoordinated, unstable pools of grant-based resources. European organizations are attempting to do this through enabling an operational European Network for Earth Sciences. (See Chapter 9 for a further discussion of what constitutes “operational” infrastructure.)
The committee believes that climate science will continue to make advances based on globally coordinated modeling experiments based on a small but richly diverse set of models from different research institutions. The results of these experiments will continue to be a treasure trove for climate science, climate impacts science, and services for policy and decision support. The data requirements for modeling data described in this chapter and the observational data described in Chapter 5 both support the need for an enhanced information technology infrastructure for climate data. The committee believes that the existing data infrastructure efforts are too important to be allowed to rely on volunteer efforts and less than stable funding.
Recommendation 10.1: To promote collaboration and adapt to a rapidly evolving computational environment, the U.S. climate modeling community should work together to establish a common software infrastructure designed to facili-
tate componentwise interoperability and data exchange across the full hierarchy of global and regional models and model types in the United States.
Recommendation 10.2: In order to address the climate data needs of decision makers and other users, the United States should invest in more research aimed at improving the performance of climate models on the highly concurrent computer architectures expected in the next 10-20 years, and should sustain the availability of state-of-the-art computing systems for climate modeling.
Recommendation 10.3: The United States should support transformational research to bring analysis to data rather than the other way around in order to make the projected data volumes useful.
Recommendation 10.4: The data-sharing infrastructure for supporting international and national model intercomparisons and other simulations of broad interest—including archiving and distributing model outputs to the research and user communities—is essential for the U.S. climate modeling enterprise and should be supported as an operational backbone for climate research and serving the user community.






















