
5
Measuring Research Impacts and Quality
KEY POINTS IN THIS CHAPTER
- Metrics are used by various nations, by various types of organizations (e.g., public research universities, private industry), and for various purposes (e.g., to measure research impacts retrospectively, to assess current technology diffusion activities, to examine the return on investment in medical research). However, no metric can be used effectively in isolation.
- Industry tends to rely heavily on metrics and expert judgment to assess research performance. Because the goals of the private sector are different from those of the public sector, however, metrics used by industry may not be appropriate for assessing public-sector research activities.
- Universities often use metrics to make the case for annual budgets without infrastructure to analyze research outcomes over time. Alternative measures focus on presenting the income earned from and expenditures devoted to technology transfer activities, tracking invention disclosures, reporting on equity investments, and tracking reimbursement of legal fees.
- Many problems can be avoided if evaluation is built into the design of a research funding program from the outset.
Chapter 4 details the challenges of using existing metrics and existing data, even data from large-scale programs such as Science and Technology for America’s Reinvestment: Measuring the Effect of Research on Innovation, Competitiveness and Science (STAR METRICS), to measure research impacts and quality. Despite these challenges, a number of attempts have been made to make these measurements. In preparing this report, the committee drew on a number of relevant studies in the literature. Among the most useful was a recent study (Guthrie et al., 2013) by the RAND Corporation, Measuring Research: A Guide to Research Evaluation Frameworks and Tools, which is summarized in Appendix C and cited frequently in Chapter 4. We also relied on previous National Research Council (NRC) reports, including a report on innovation in information technology (IT) informally known as the “tire tracks” report (National Research Council, 2012a) and a summary of a recent workshop (National Research Council, 2011b) on measuring the impacts of federal investments in research. In this chapter, we review some of the relevant studies; we also examine the use of metrics by selected governmental, industry, and nonprofit organizations, pointing out the purposes for which these metrics are useful, as well as those for which they are not.
USE OF METRICS BY OTHER NATIONS
Many nations other than the United States, such as Australia, Canada, and the United Kingdom, and have struggled with the challenge of measuring research returns, and the committee drew substantially on the literature on those efforts. As noted in Chapter 3, the benefits of scientific research require extensive time to percolate and may not come to fruition for decades or even centuries. Canada’s National Research Council states:
No theory exists that can reliably predict which research activities are most likely to lead to scientific advances or to societal benefit (Council of Canadian Academies, 2012, p. 162).
This conclusion is particularly accurate because science is constantly changing in unpredictable directions. For example, progress in the IT field may depend on economics and other social science research on keyword auctions, cloud pricing, social media, and other areas. Economics and other social sciences are becoming even more critical fields of research with the increasing importance of understanding human and organizational behavior, which is needed to enable the adoption of new technologies. As a result, the social sciences are valuable contributors to interdisciplinary research and education.
Metrics have been developed that span multiple disciplines and countries. Nonetheless, the development of universal evaluation systems has
proven challenging, in particular because of variations in policies, research funding approaches, and missions (National Research Council, 2006). The United Kingdom’s Council for Industry and Higher Education describes three other factors that complicate the accurate assessment of publicly funded research impacts: (1) the influence of complementary investments (e.g., industry funding); (2) the time lag involved in converting knowledge to outcomes; and (3) the skewed nature of research outcomes, such that 50-80 percent of the value created from research will result from 10-20 percent of the most successful projects (Hughes and Martin, 2012). This last constraint might be addressed by analyzing the funding portfolios of each funding agency by research and development (R&D) phase/type and by assessing the behavior of individual researchers in addition to using outcome-based assessments (Hughes and Martin, 2012).
The Australian Group of Eight (Rymer, 2011) notes additional barriers to assessing research impacts: research can have both positive and negative effects (e.g., the creation of chlorofluorocarbons reduced stratospheric ozone); the adoption of research findings depends on sociocultural factors; transformative innovations often depend on previous research; it is extremely difficult to assess the individual and collective impacts of multiple researchers who are tackling the same problem; and finally, it is difficult to assess the transferability of research findings to other, unintended problems. Equally difficult to measure is the ability of research to create an evidence-based context for policy decisions, which is important but poses a formidable challenge (Rymer, 2011; National Research Council, 2012e).
Even when effective indicators and metrics are developed, their use to determine which research projects should be funded inevitably inspires positive and negative behavioral changes among researchers and research institutions (OECD, 2010), an issue noted also in Chapter 4. In Australia, Norway, and the United Kingdom, incorporating the number of publications into the grant review process led to a significant increase in publication output (Butler, 2003; Moed et al., 1985; OECD, 2010). This might be viewed as a positive effect except that in some cases, this increase in output was followed by a decline in publication quality as researchers traded quality for volume. (The quality of a research publication often is assessed by the quality of the journal in which it is published, which may depend on how widely cited the journal is. This can be problematic because the top research in some fields is presented at conferences, not published in journals, and not every study published in high-impact journals is exemplary of high-quality or high-impact research.) This negative effect was more pronounced in Australia than in Norway or the United Kingdom, as the latter nations rely on metrics that account for quality as well as quantity (Butler, 2003).
While metrics based on both quantity and quality have generally proven useful to other nations, two issues have arisen: the potentially subjective definition of a “high-quality” journal, and the difficulty of determining whether widely cited journals are in fact better than specialized or regional journals (Council of Canadian Academies, 2012). For instance, China provides strong incentives to publish in international and widely cited journals; researchers receive 15 to 300 times larger financial bonuses for research published in Nature or Science compared with that published in other journals (Shao and Shen, 2011). As described by Bruce Alberts in an editorial in Science (Alberts, 2013), however, the San Francisco Declaration on Research Assessment1 acknowledges the potential of journal impact factors to distort the evaluation of scientific research. Alberts asserts that the impact factor must not be used as “a surrogate measure of the quality of individual research articles, to assess an individual scientist’s contributions, or in hiring, promotion, or funding decisions.”
Serious consequences—both positive and negative—can occur when governments use metrics with the potential to change researchers’ behavior. Researchers and institutions can focus so intently on the metric that achieving a high metric value becomes the goal, rather than improving outcomes. In some cases, there is documented evidence of researchers and institutions resorting to questionable behavior to increase their scores on metrics (Research Evaluation and Policy Project, 2005). A recent survey published in Nature revealed that one in three researchers at Chinese universities have falsified data to generate more publications and publish in more widely cited journals. Some Chinese researchers report hiring ghostwriters to produce false publications (Qiu, 2010). Aside from ethical concerns, such practices have presented serious problems for other researchers in the field, who unknowingly have designed their own research studies on the basis of false reports in the literature. Another negative though less serious outcome occurred when the Australian Research Council incorporated rankings for 20,000 journals, developed through a peer review process, into its Excellence for Research in Australia (ERA) initiative (Australian Research Council, 2008). One year after being developed, the ranking was dropped from ERA because some university research managers were encouraging faculty to publish only in the highest-ranking journals, which had negative implications for smaller journals (Australian Government, 2011).
Additional concerns regarding the development and implementation of metrics have revolved around training and collaboration. The United Kingdom found that use of the Research Assessment Exercise (RAE), a peer-reviewed tool for assessing research strength at universi-
_____________
1The Declaration is available from http://am.ascb.org/dora/ [August 2014].
ties, significantly affected researchers’ morale as certain researchers were promoted as being “research active,” while some departments were dissolved because of poor reviews (Higher Education Funding Council of England, 1997; OECD, 2010). Researchers also have noted that the RAE discourages high-risk research because of its focus on outputs, and that it also discourages collaboration, particularly with nonacademic institutions (Evaluation Associates, Ltd., 1999; McNay, 1998; OECD, 2010). Another commonly used metric, previous external research funding, has been criticized by the Council of Canadian Academies as being subjective because of the nature of previous expert judgment and funding decisions (Council of Canadian Academies, 2012). Using funding as a criterion also poses the risk of allowing outside money to drive research topics (e.g., pharma funding for positive drug evaluation), as well as rewarding inefficient and costly researchers who ask for more money. Additional indicators, such as previous educational institutions attended by students and esteem-based indicators (e.g., awards, prestigious appointments) have been criticized as being subjective in countries such as Canada and Australia. Performance on these indicators may be influenced by external factors such as geographic location and personal choice rather than the institution’s quality, and the quality of a researcher’s work at the time of funding of a previous award may not characterize his or her current accomplishments (Council of Canadian Academies, 2012; Donovan and Butler, 2007).
IMPACT ASSESSMENTS IN THE UNITED KINGDOM
A review of UK research impact studies by the chair of the Economic and Social Research Council (ESRC) Evaluation Committee notes that so-called “knowledge mobilization”—defined as “getting the best evidence to the appropriate decision makers in both an accessible format and in a timely fashion so as to influence decision making”—can help overcome major impediments that would otherwise limit the economic and social impacts of high-quality research (Buchanan, 2013, p. 172). Beginning in the 1990s, a growing body of evidence in the United Kingdom (Griffith et al., 2001; Griliches, 1992; Guellec and van Pottelsberghe de la Potterie, 2004) suggested that the economic returns of research were limited by researchers’ weak attention to knowledge transfer. A 2006 report (Warry Report, 2006) strongly urges research councils to take the lead on the knowledge transfer agenda, to influence the knowledge transfer behavior of universities and research institutes, to better engage user organizations, and to consider metrics that would better demonstrate the economic and social impacts of scientific research. These metrics, it is argued, should assess research excellence as well as the relevance of research findings to user needs, the propensity for economic benefits, and the quality of
the relationship between research findings and their likely users (Warry Report, 2006, p. 19).
A report commissioned by Universities UK (2007) and a related paper (Adams, 2009) suggest that the research process might be aptly evaluated by being considered in terms of “inputs–activity–outputs–outcomes.” Moreover, indicators for one field of science may not be strong tools for assessing other fields. For example, bibliometric tools were found to be strong indicators of performance in some areas of the social sciences, such as psychology and economics, but not in more applied or policy-related areas. Publication counts were found to be similarly problematic, as they give an idea of a researcher’s output volume but do not reflect research quality or the potential for social or economic impact (Adams, 2009). In recognition of these findings, the Research Excellence Framework (REF) assessment2 in the United Kingdom will consider citation data in science, technology, engineering, and mathematics fields but not in the social sciences.
The ESRC issued a report (Economic and Social Research Council, 2009) identifying several drivers of research impact, including networks of researchers, the involvement of users throughout the research process, and the supportiveness of the current policy environment. A subsequent ESRC report suggests a more comprehensive picture of the interactions between researchers and policy makers might aid efforts to track the policy impacts of research (Economic and Social Research Council, 2012).
On the basis of this literature, the ongoing effort to develop an REF assessment promotes greater knowledge mobilization by compelling academic researchers to engage with the public and demonstrate more clearly the economic and social implications of their work. Current efforts are aimed at ensuring that the quality of research is not compromised by the emphasis on impact and open-access data. It remains to be seen whether and how this latest introduction of new incentives and measurement schemes in a highly centralized national research funding system will create perverse incentives for UK researchers, leading gifted scientists to devote more time to lobbying policy makers or industry managers, or whether it will enhance the impacts of the country’s publicly funded research. Nonetheless, these new evaluation measures likely have some potential to distort researchers’ behavior and reduce rather than increase positive research impacts.
_____________
2In 2007, the United Kingdom announced plans to establish the REF to gauge the quality of research in the nation’s institutions of higher education. According to the REF’s official website (http://www.ref.ac.uk/faq/ [August 2014]), the 2014 version of the REF will replace the nation’s former system, the RAE.
USE OF METRICS TO EVALUATE THE ECONOMIC RETURNS OF MEDICAL RESEARCH
Some major studies have sought to measure the economic returns on investments in medical research. In the United States, the Lasker Foundation supported a study leading to the 2000 report Exceptional Returns: The Economic Value of America’s Investment in Medical Research (Passell, 2000). In this report and a subsequent volume (Murphy and Topel, 2003), a number of economists describe the “exceptional” returns on the $45 billion (in 2000 dollars) annual investment in medical research from public and private sources and attempt to estimate the economic impact of diagnostic and treatment procedures for particular diseases.
The economic value of medical research was assessed by monetizing the value of improved health and increased life span (i.e., by adapting data from work-related studies performed in the 1970s-1990s), then isolating the direct and indirect impacts of medical research from gains unrelated to R&D (i.e., by accounting for the total economic value of improved survival due to technologies and therapies). The report offers the widely criticized calculation that increases in life expectancy during the 1970s and 1980s were worth a total of $57 trillion to Americans, a figure six times larger than the entire output of tangible good and services in 1999 (the year prior to the report’s publication). The gains associated with the prevention and treatment of cardiovascular disease alone totaled $31 trillion. The report suggests that medical research that reduces cancer deaths by just one-fifth is worth approximately $10 trillion to Americans—double the national debt in 2000. The report states that all of these gains were made possible by federal spending that amounted to a mere $0.19 per person per day. Critics of the report note that it simply attributes outcomes in their entirety to investments in medical research without considering, for example, how the returns on medical research in lung cancer might compare with the equally poorly measured returns on education in smoking cessation.
Researchers in Australia (Access Economics, 2003, 2008) sought to replicate this U.S. study. The first such study, which used the same value for a year of life as that used in the U.S. study, led to some anomalies. By using disability-adjusted life years (DALYs), a measure that accounts for extended years of life adjusted for the effects of disability, this study suggests that the value of mental health research was negative because of the decline in DALYs for mental health. A second Australian study used a different methodology, comparing past research investments with projected future health benefits and basing the value of life on a meta-analysis of studies.
In the United Kingdom, the Academy of Medical Sciences, the Medical Research Council, and the Wellcome Trust commissioned research
to assess the economic impact of UK medical research. According to the report:
The overall aim of the work was to compare the macroeconomic benefits accruing from UK medical research with the cost of that research—ultimately to give a quantitative assessment of the benefit of medical research to the UK. It was also expected that the research would critically appraise both the selected approach and previous attempts to estimate the economic returns from research. In this way, the goal was not to obtain a definitive answer about the returns on the investment in UK medical research, but to generate a piece of work that would help to move this young field forward and inform methodologies for future assessments (Health Economics Research Group et al., 2008, p. 3).
The study focused on cardiovascular disease and mental health. It used a “bottom-up” approach based on evidence on the “effects and costs of specific research-derived interventions, rather than [on] macro-level, temporal changes in mortality or morbidity” (p. 5).
These and other studies, including work by the Canadian Academy of Health Sciences (Canadian Academy of Health Sciences, 2009) and for the World Health Organization (Buxton et al., 2004), raise many issues concerning the valuation of research aimed at improving health:
- Measuring the economic returns on research investments—Approaches include using a benefit/cost ratio (ratio of the value of health benefits to the costs of research), a return on investment (ratio of the amount by which health benefits exceed research costs to research costs), or an internal rate of return (IRR, the rate of return for which net present value is zero or alternatively, the discount rate at which the net present value of research costs equals the net present value of health benefits over time). The UK study used IRR.
- Valuing health benefits—Examples include using a monetary value for a year of life or a quality-adjusted year of life, direct cost savings for health services, indirect cost savings when improved health leads to productivity increases, or increases in gross domestic product or other economic gains. These efforts, however, are widely criticized.
- Measuring the costs of research—Questions that arise include how costs of research are determined; how infrastructure is accounted for; whether measures of public and private research costs are comparable; and how the effect of research failures, which, as noted earlier, may advance knowledge, can be accounted for.
- Time lag—The appropriate time lag between research and health benefits must be determined.
- Global benefits—Issues include identifying the global health benefits from U.S. research and the health benefits that accrue to the United States from research in other countries, and determining how such international transfers of research knowledge should be accounted for.
- Attribution—It is difficult to disentangle how much of health improvement can be attributed to health care, as opposed to improved hygiene, diet, and other behaviors; to what extent behavior changes to improve health can be attributed to behavioral and social science research; and how the contributions of behavioral and social science research to improved health can be distinguished from those of medical research on therapeutics.
- Intangibles—The extent to which research in a health care system increases the system’s capacity to use research findings is difficult to understand (Belkhodja et al., 2007).
USE OF METRICS IN ECONOMIC IMPACT ASSESSMENTS OF FEDERAL PROGRAMS
Given that, as noted earlier, the results of basic research are largely public goods, the federal government funds a large portion of this research in the United States. There are also reasons why government funding may be needed for some technologies that have both public and private characteristics. These reasons include long gestation periods; the inability to capture the full economic value of an R&D investment; broad scopes of potential market applications; coordination difficulties among the various private-sector entities that must conduct the R&D and eventually integrate the resulting component into the final technology system; and the inability (often due to small firm size) to price an innovation at a level sufficient to rationalize the investment, assuming the generally large technical and market risks associated with R&D investments (Tassey, 2014).
As previously discussed, the typical industrial technology is a complex system combining multiple hardware and software technologies. Many of these component technologies are derived from multiple areas of science and developed by a range of public and private entities. The complex genealogy of many innovations of great economic value reflects the fact that private firms may lack sufficient incentives (e.g., assurance of a return on their investment) to support the development of technological knowledge of a quasi-public good nature, including standards and research infrastructure, or “infratechnologies” (see Chapter 2). Without adequate and timely investment in these technology elements, industry’s
investment in proprietary technologies or other innovations will be both inadequate and inefficient.
Federal R&D policy has implicitly embraced investment to overcome these market failures for agencies whose R&D targets social objectives such as defense (U.S. Department of Defense [DoD]), health (National Institutes of Health [NIH]), and energy (U.S. Department of Energy [DoE]). Thus, DoD funds technology platform research through the Defense Advanced Research Projects Agency, and DoE funds similar research through the Advanced Research Projects Agency-Energy. DoE also funds considerable research in measurement infratechnology and standards.
The National Institute of Standards and Technology (NIST), part of the U.S. Commerce Department, also focuses on infratechnology research. NIST undertook economic impact studies in the 1990s to demonstrate the value of its research. Over the past 20 years, it has conducted 40 such retrospective studies across a wide range of technologies that it supports. To undertake such studies, NIST had to choose a set of metrics from among three basic alternatives (see Figure 5-1):
- measures to guide public R&D policies such as allocation of resources, including those that influence investment decisions by firms and businesses (a process measure);
- measures to guide private industry investments in R&D, such as net present value, return on investment, and benefit-cost ratio (an output measure); or
- measures with which to evaluate the research and innovation systems, such as productivity growth, employment growth, and other economic and societal impacts (an outcome measure).
Because the focus of impact assessment was at the program level and evaluation budgets were limited, NIST chose the middle ground—the set used in corporate finance. Under the circumstances (no government-wide guidance and limited resources), this approach yielded the most useful quantitative impact data. NIST’s impact reports also provide considerable qualitative analysis, which is essential for interpreting the quantitative results and placing them in context.
USE OF METRICS TO EVALUATE DEPARTMENT OF ENERGY (DOE) FOSSIL FUEL R&D PROGRAMS
At the committee’s third meeting, Robert Fri of Resources for the Future discussed a retrospective study that looked at DoE-sponsored research from that agency’s inception through 2000 (National Research Council, 2001), as well as two prospective evaluations of DoE applied R&D (National Research
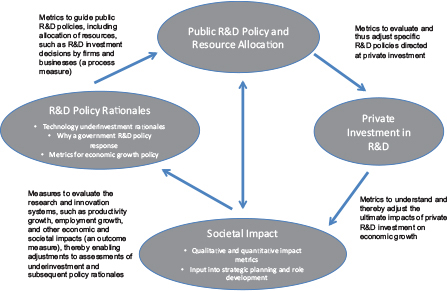
FIGURE 5-1 Influences of processes, outputs, and outcomes on research impact.
NOTE: Role rationalization and impact assessment are part of a recursive process. Both must be modeled correctly and their interactive nature recognized, as depicted in this figure. The conceptual argument for federal R&D funding (the existence of market failure) must be tested through economic analyses of industry investment patterns and the causes of any underinvestment trends determined. Such analysis leads to the design and implementation of policy responses, which are followed by periodic economic impact assessments. The results of these assessments then feed back into adjustments of existing policies and associated budgets, as indicated in the figure.
Council, 2005b, 2007b). The 2001 NRC study in particular used an evaluative framework that emphasized three types of benefits from DoE-sponsored R&D in energy efficiency and fossil fuels: (1) the economic benefits associated with technological advances attributed to the R&D; (2) the “option value” of the technological advances facilitated by the R&D that have not yet been introduced; and (3) the value of the scientific and technological knowledge, not all of which has yet been embodied in innovations, resulting from the R&D. Like most such retrospective studies, the 2001 study faced challenges in attributing these three types of benefits to specific DoE R&D programs, since substantial investments in many of the technologies were made by industry. An important source of the estimated economic benefits of DoE R&D pro-
BOX 5-1
Shale Oil Recovery
The potential importance of shale oil and gas has been known for more than a century, but only in the past decade have oil companies been able to access this vast resource. The booming industry that exists today was built on technologies that took decades to amass.
Today’s industry arose largely from federal investments in research and development (R&D), and two investments in particular: (1) a government-industry partnership known as the Gas Research Institute, and (2) a series of programs (e.g., the Eastern Gas Shales Program) developed by the present-day U.S. Department of Energy (DoE) to support research on high-risk energy sources. The three technologies at the core of the DoE investment were horizontal drilling, fracturing technology, and 3D seismic imaging.
The federal government invested approximately $187 million in the above programs, which generated an estimated $705 million in revenues to the gas industry (in 2001) and $8 billion in savings to consumers (National Research Council, 2001). This technology is not without controversy, however. Although natural gas is cleaner than coal, environmental problems still exist. Along with the increased benefits of shale oil extraction may come increased risks to society, including possibly disruption to the water table, which scientists today are exploring (Council of Canadian Academies, 2014; National Research Council, 2013e, 2013f).
grams was the programs’ contributions to accelerating the introduction of the innovations studied.
The attempt in the 2001 report to highlight the “options value” of technological advances points to another type of benefit that is difficult to capture in retrospective evaluations of R&D investments but is important nonetheless: in a world of great uncertainty about economic, climatic, and technological developments, there is value in having a broad array of technological options through which to respond to changes in the broader environment.3 The DoE programs examined in the 2001 study produced a number of innovations that were not introduced commercially simply because their characteristics and performance did not make them competitive with existing or other new technologies. But there is a definite value associated with the availability of these technological alternatives or options in the face of an uncertain future (see Box 5-1 for a discussion of shale oil extraction technologies, many of which benefited from DoE and other federal R&D but have been applied only in the past decade).
Deriving a quantitative estimate of the “option value” of such inno-
_____________
3Other academic studies of the options value of R&D investments include Bloom and van Reenen (2002) and McGrath and Nerkar (2004).
vations, however, is very difficult precisely because of the uncertainty about conditions under which they might be of use (this is an important difference between the value of financial and technological options). As with other retrospective evaluations, however, it was impossible to incorporate any quasi-experimental elements into the assessment scheme for these DoE programs. No effort was made to examine the question of what would have happened had these programs not existed (e.g., whether similar investments in R&D would have come from other sources). There was also no attempt to compare firms that exploited the results of DoE R&D with some type of “control” population, for obvious reasons. These limitations are hardly critical or fatal, but they illustrate the challenges of developing designs for R&D program evaluation that approximate the “gold standard” of randomized assignment of members of a population (of firms, individuals, institutions, etc.) to treatment and control groups.
The 2001 report also includes a detailed set of case studies of DoE R&D programs in the areas of energy efficiency and fossil fuels. Overall, the report states that in the area of energy efficiency, DoE R&D investments of roughly $7 billion during the 22-year life of this program yielded economic benefits amounting to approximately $30 billion in 1999 dollars. DoE fossil energy programs during 1978-1986 invested $6 billion in R&D (this period included some costly synthetic fuels projects) and yielded economic benefits of $3.4 billion (all amounts in 1999 dollars). DoE fossil energy programs during 1986-2000, by contrast, accounted for an investment of $4.5 billion and yielded economic benefits estimated at $7.4 billion (again in 1999 dollars). Many other significant conclusions in the 2001 report concern qualitative “lessons” for program design based on observations of successful and less successful programs.
An important source of estimated economic benefit for the DoE R&D programs examined in the 2001 NRC and related studies was the fact that the innovations that benefited from these federal R&D investments were in use, and their economic payoffs could be estimated relatively directly. Nevertheless, the efforts in these studies to at least highlight (if not quantify) the “options” and “knowledge” benefits of federal R&D investments are highly relevant to the present study.
The 2001 NRC and related studies further conclude that there is a need for broadly based incentives for the private sector to invest in basic research across a wide range of disciplines to increase the odds of success. The government plays an important role in sponsoring high-risk, mission-driven basic research; funding risky demonstration projects; partnering with industry-driven technology programs; and encouraging industry’s adoption of new technology.
USE OF METRICS BY PRIVATE INDUSTRY: IBM’S PERSPECTIVE
In his presentation to the committee, John E. Kelly, III, director of research for IBM, noted that metrics are essential tools for ensuring continued growth and competitiveness. To stay on the leading edge of technology, IBM designs metrics and processes around four primary missions: (1) seeing and creating the future, (2) supporting business units with innovative technologies for their product and service roadmaps, (3) exploring the science underlying IT, and (4) creating and nurturing a research environment of risk taking and innovation. In general, most research funding decisions made by IBM rely more heavily on judgment than on quantitative metrics, although the relative importance of qualitative versus quantitative data shifts during the transition from long-term research to near-term development.
Although industry’s goals for research differ from those of the government, strategic planning is a valuable way to identify gaps in existing platforms and infratechnologies, as discussed earlier in this chapter. IBM relies largely on a process called the Global Technology Outlook (GTO) to fulfill its mission of seeing and creating the future. Every year, it initiates a corporate-wide effort to look years into the future and shift its strategy based on the technology changes it foresees. As a result, IBM has been inspired to create new businesses, acquire companies, and divest itself of others. The GTO process has proven invaluable in efforts involving long lead times, such as architecture, where a correct or incorrect decision can have profound effects on a company. Metrics are used in the GTO process in an attempt to quantify how many future technology disruptions and business trends will be identified and how many will be missed. These predictive metrics emphasize qualitative information, relying heavily on the judgment of experienced managers and scientists.
To fulfill its mission of supporting business units with innovative technologies for their product and service roadmaps, IBM continually focuses on creating new technologies—innovative hardware or software features—to integrate into its product lines over 2- and 5-year horizons. The metrics used here include near-term and relatively easy-to-quantify outcomes such as product competitiveness and market share. IBM also measures the intellectual property being generated through counts of patents and other means.
According to Kelly, IBM believes a deep understanding of science is essential to making sustained progress; through this understanding, IBM fulfills its mission of exploring the science underlying IT. The company supports large research efforts in hardware, software, and service sciences (i.e., people and technologies organized in a certain way to produce a desired impact). Some of these efforts are enhanced by partnerships with universities, government, and industrial laboratories around the world.
Metrics used to assess progress toward fulfillment of this mission include those pertaining to key publications, recruiting and retention of top scientists, and impact on various scientific disciplines.
Finally, IBM supports its mission of creating and nurturing a research environment of risk taking and innovation by focusing on inputs. It makes a concerted effort to hire the best people and provide them with a large degree of freedom to pursue innovative ideas. According to Kelly, one cannot manage research the way one manages development or manufacturing. When it comes to research, micromanagement is counterproductive to growth, innovation, and competitiveness.
USE OF METRICS BY PRIVATE NONPROFITS: BATTELLE’S PERSPECTIVE
In his presentation to the committee, Jeff Wadsworth, president and chief executive officer of Battelle Memorial Institute, noted that metrics are critically important for guiding research investments and monitoring the success of R&D. Battelle uses metrics throughout the R&D process—from tracking the long-term success rate of its project selection process, to improving the productivity (and therefore capital efficiency) of its R&D activity, to tracking the financial contributions of its innovation system with lagging metrics such as percentage of sales from new products.
However, Wadsworth noted that while certain private-sector management approaches—such as DoD’s use of the business process improvement approach known as Lean Six Sigma or the national laboratories’ use of private management and operations contractors—may lend value to government research activities, many public-sector research activities require different measures from those used by the private sector since the latter are defined almost exclusively by economics (Cooper, 1986). Wadsworth suggested that economic analysis combined with analyses of future impacts can be used to measure the impact of public-sector research. For example, Battelle’s 2011 and 2013 studies suggested that the economic returns of the Human Genome Project have approached a trillion dollars (Batelle, 2013). That analysis, however, has not been universally accepted, in part because it examined only economic activity and not the impact on human health, and it attributed the economic returns to the government’s investment when other factors, including private investments in genomics, have contributed (Brice, 2013; Wadman, 2013a).
USE OF METRICS TO EVALUATE THE REGIONAL ECONOMIC IMPACTS OF RESEARCH UNIVERSITIES
Many public research and education institutions have conducted studies of their impact on local, regional, and state economies. Some institutions, such as Massachusetts Institute of Technology (MIT), have commissioned economic impact reports to illustrate these returns. Like many retrospective evaluations, however, such reports contain useful data but are rarely able to address the counterfactual issues that loom large: For example, what would have happened in the absence of a specific set of policies or channels for economic interaction between university researchers and the regional economy?
A 2009 study, Entrepreneurial Impact: The Role of MIT (Ewing Marion Kauffman Foundation, 2009), analyzes the economic impacts of companies started by MIT alumni. The analysis is based on a 2003 survey of all living MIT alumni and revenue and employment figures updated to 2006. The study concludes that if all of the companies (excluding Hewlett-Packard and Intel) were combined, they would employ 3.3 million people and generate annual revenues of $2 trillion, representing the 17th-largest economy in the world (Ewing Marion Kauffman Foundation, 2009). In addition, the study offers the following conclusions:
- An estimated 6,900 MIT alumni companies with worldwide sales of approximately $164 billion are located in Massachusetts alone and represent 26 percent of the sales of all Massachusetts companies.
- 4,100 MIT alumni-founded firms are based in California, and generate an estimated $134 billion in worldwide sales.
- States currently benefiting most from jobs created by MIT alumni companies are Massachusetts (estimated at just under 1 million jobs worldwide from Massachusetts-based companies); California (estimated at 526,000 jobs), New York (estimated at 231,000 jobs), Texas (estimated at 184,000), and Virginia (estimated at 136,000).
This study provides an accounting of the economic effects of firms founded by alumni of one research university, MIT. It does not isolate or highlight the mechanisms through which the economic benefits were realized, so one cannot conclude that some of the benefits would not have occurred otherwise. Moreover, research universities contribute to the production of knowledge for the development of new technologies and firms in many ways other than through alumni.
USE OF METRICS TO MONITOR TECHNOLOGY TRANSFER FROM UNIVERSITIES
Universities use various metrics to track the diffusion of technology resulting from the research they conduct (see Appendix B). Most of the metrics widely used for this purpose (e.g., inputs such as collaborations, intermediate outputs such as innovation creation and knowledge acceleration, and final impacts such as qualitative outcomes or economic development) have been criticized as ignoring some of the more important formal and informal channels of knowledge flow to and from universities (Walsh et al., 2003a, b). Examples of these channels include the flow of trained degree holders, faculty publications, sabbaticals in university laboratories for industry scientists, faculty and student participation in conferences, and faculty consulting. It should be noted as well that at least some metrics proposed or implemented for faculty evaluation at some universities, such as patenting, could have effects similar to the use of publication counts in China and other economies: if faculty perceive an incentive to obtain more patents, they are likely to file for more patents; however, the quality of these patents could well be low, and the legal fees paid by academic institutions to protect the rights to a larger flow of patent applications could increase.
Moreover, the appropriateness of commonplace metrics depends largely on whether the goal of the university’s technology transfer office is to increase the university’s revenue through licensing, to assist university entrepreneurs, to support small firms, to support regional development, to attract and retain entrepreneurial faculty, or any number of other goals. A disconnect often exists between the selection of metrics and the university’s broader strategic goals, which can make it difficult to use the metrics to analyze performance or draw comparisons among universities. Box 5-2 elaborates on the value of university technology transfer metrics.
EVALUATION OF RESEARCH FUNDING PROGRAMS
A fundamental question with which the committee grappled was how to assess which research funding programs are effective and how to choose among them to maximize returns to society (i.e., what areas of research should be funded and through what agencies). Addressing this question leads to evaluation of the effectiveness of the wide variety of programs adopted by research funding agencies in the United States to select individuals and groups for research support. The agencies employ two types of approaches—one for selecting recipients of research funding (i.e., prospective assessment) and another for evaluating the performance of those funded (i.e., retrospective evaluation).
Evaluating the effectiveness of a research funding program requires
BOX 5-2
Value of University Technology Transfer Metrics
To assess the value of technology transfer metrics and their utility for assessing the value of research, it is important to understand the nature of many technology transfer offices and the environment in which they operate.
Data from a survey conducted by the Association of University Technology Managers show that, even before subtracting expenses for patenting and staff costs, technology licensing and spin-out equity income averages less than 3 percent of the amount universities spend on research (Nelsen, 2007). Many more than half of university technology transfer programs bring in less money than the costs of operating the program, and only 16 percent are self-sustaining, bringing in enough income that sufficient funds are available to cover the operating costs of the program after distributions to inventors and for research have been made. Most universities that generate technology transfer revenue do so from a limited number of technology licenses, which typically are concentrated in biomedical disciplines (Abrams et al., 2009). Some technology transfer offices operate as service centers aimed at supporting the faculty who are interested in patenting their inventions and seeing them make a difference in the marketplace. As a result, patents are sometimes filed with no expectation of revenue.
Metrics are needed each year to justify budgets, but universities do not have the infrastructure in place to track outcomes over time, except perhaps anecdotally. Output measures are used as proxies in an attempt to assess longer-run outcomes. Measuring outcomes is expensive and requires commitment (staff and funds). Alternative measures focus on identifying the income earned and expenditures devoted to technology transfer activities, tracking invention disclosures, and
a different strategy and different forms of data gathering from those typically used by research funding agencies and program managers. As we have noted, neither the Executive Branch nor Congress has an institutional mechanism for attempting cross-field comparisons or undertaking an R&D budget portfolio analysis.
Moreover, few federal agencies dedicate resources within programs for retrospective evaluation. NIH has a separate evaluation staff that provides guidance to programs, but expects each program to implement its own evaluations. NIH programs tend to fund external research organizations to conduct both process and outcome evaluations early in the program and at about the 5-year point, respectively. Evaluations are rarely conducted beyond this point. The National Science Foundation (NSF) requires an evaluator for some of its grant programs, such as the 10-year Industry-University Cooperative Research Center Program and some of its educational grant programs. The outputs of these evaluation efforts are descriptive statistics and case studies, which are useful for describing
reporting on equity investments. These approaches may prove more useful and less expensive than measuring outcomes. As proxies for the success of technology transfer, they help set the stage for informed decision making by stakeholders, although they omit or overlook many of the most important channels through which universities “transfer” knowledge to and from industry.
It is interesting, however, to contrast the approach taken by the Massachusetts Institute of Technology (MIT) study discussed in the text (Ewing Marion Kauffman Foundation, 2009) with the use of “outcome measures” such as those discussed in the previous paragraph. The MIT study, an attempt to provide a long-term evaluation of MIT’s economic effects on the U.S. and regional economies (an evaluation that lacked a rigorous experimental design), largely overlooks the intermediate measures captured by most university technology transfer data. Indeed, the MIT study looks solely at a set of outcomes that are fairly removed from the sorts of technology transfer activities that preoccupy so many current critics and supporters of university-industry collaboration. The MIT study contains little information, for example, on the contributions of conventionally measured technology transfer to the establishment of the new firms that are central to the study’s measures of economic effects.
Even with its flawed design (which is nearly inevitable in a retrospective study), the MIT study highlights the value of a broad approach that avoids the myopic focus on patents, licensing fees, and invention disclosures that dominates many current discussions of the economic contributions of U.S. universities. Indeed, it is arguable (and ultimately unverifiable) that had MIT focused more narrowly on maximizing institutional licensing revenues during the period covered by the study, the institution’s catalytic effects on the formation of new firms by alumni and researchers might have been weaker.
the programs but rarely yield insights valuable for measuring impact. For other programs, NSF follows the same model as NIH and contracts with research organizations to conduct process and outcome evaluations.
Program managers at NIH generally are open to program evaluation. Accessing data is time-consuming and bureaucratic, but once access is obtained, NIH has more data in structured format, which facilitates data analysis. Obtaining access, however, may take several months. As previously noted, in addition to STAR METRICS, NIH research data systems include the Research Portfolio Online Reporting Tools, the Scientific Publication Information Retrieval and Evaluation System, and the Electronic Scientific Portfolio Assistant. NSF data often must first be “scraped” and computer programs (e.g., Python) used to create variables from unstructured text data.
Government-wide mandates such as the Government Performance and Results Act (GPRA) and the Program Assessment Rating Tool have been implemented with good intent, and their language focuses on mea-
suring outcomes and impacts. However, implementation focuses on measuring short-term outputs because they can be measured more easily than longer-term outcomes. Without staff resources dedicated to evaluation, it is difficult to do more. (See National Academy of Sciences [1999, 2011] for discussion of how GPRA has led to federal agency measurement of the performance of research.)
We distinguish between two types of comparison for program evaluation: (1) comparing different research areas, and (2) comparing proposals submitted by individuals or groups of researchers within a research area, either retrospectively or prospectively. The two approaches present very different analytic challenges.
In the committee’s judgment, comparisons involving the allocation of funding among widely varied research areas and those involving the assessment of different researchers or groups within a given research field or specialty are conceptually different tasks, and treating them as related or somehow similar is a source of confusion. Programs that allocate funds among different research areas, such as NSF’s Science and Technology Centers Program, are more difficult to evaluate than programs that allocate funds among researchers in a specific research area, such as economics research supported by NSF. One reason for this greater difficulty is the many alternative research funding programs with which the program under consideration should be compared. Even the attribution of outcomes may not be clear: If a new research program stimulates a research proposal that is funded by another program, to which program should the outcomes be attributed?
Further complication is introduced by efforts to measure the success of a program, even assuming that a clear set of agreed-upon outcome measures exists. Impact or outcome measures are ideal, but require data that may be impossible or very difficult to obtain at reasonable cost. Finally, it is not always clear that specific outcomes can be attributed to a research funding program when many other factors influence impact.
Guthrie and colleagues (2013) provide a synthesis of existing and previously proposed frameworks and indicators for evaluating research. They note that research evaluation aims to do one or more of the following:
- Advocate: to demonstrate the benefits of supporting research, enhance understanding of research and its processes among policymakers and the public, and make the case for policy and practice change
- Show accountability: to show that money and other resources have been used efficiently and effectively, and to hold researchers to account
- Analyse: to understand how and why research is effective and how it can be better supported, feeding into research strategy and decision making by providing a stronger evidence base
- Allocate: to determine where best to allocate funds in the future, making the best use possible of a limited funding pot (pp. ix-x).
In particular, Guthrie and colleagues (2013) reviewed 14 research evaluation frameworks, 6 of which they investigated in detail, and 10 research evaluation tools such as STAR METRICS. Most of these frameworks require data on inputs and outputs, as well as information about the scientific process.
While such evaluation approaches are valuable for many purposes, they do not address the fundamental question that faced the committee: What would have happened without the research funding program, or if the resources had been used on other programs or had been allocated in different ways within the program? Instead, these frameworks look at the allocations within programs and attempt to measure scientific productivity or even innovation, often using publications, patents, or related output measures. These are useful for performance measures (see the discussion in Chapter 6), but even if the outputs are assumed to be surrogates for eventual outcomes, they do not provide an evaluation without a counterfactual.
Research funding programs in which evaluation is built in from the outset are superior to those that attempt evaluation retrospectively, as the latter evaluations often are more prone to unmeasurable biases of various sorts. Few studies or approaches consider the role of formal statistical field studies or experiments with randomization used to control for biases and input differences.
The standard review mechanism for prospective evaluation of research grant and contract proposals is some form of peer review and assessment. Some have criticized peer review for discouraging the funding of high-risk research or radically new research approaches, but more recently, others have criticized it for the dilution of expertise in the NIH review process:
Historically, study sections that review applications were composed largely of highly respected leaders in the field, and there was widespread trust in the fairness of the system. Today it is less common for senior scientists to serve. Either they are not asked or, when asked, it is more difficult to persuade them to participate because of very low success rates, difficulties of choosing among highly meritorious proposals, and the perception that the quality of evaluation has declined (Alberts et al., 2014, p. 2).
Yet despite the need for improvements in the peer review process, and especially in light of the decreasing success rate for research proposals, there is limited experience with the widespread use by public agencies of
alternative mechanisms, and little existing evidence suggests that there is generally a better mechanism. The committee cautions that peer review is not designed to assess overall program effectiveness, but rather investigator qualifications and the innovativeness of individual projects within a given research program. Thus, peer review typically is most appropriate as a means of awarding funding rather than assessing performance. There have been cases, however, in which panels of experts have assessed the outputs of research programs using peer review and other approaches (Guthrie et al., 2013; National Academy of Sciences, 1999, 2011). Some interesting evaluation studies also have been conducted using the methodologies reviewed by Guthrie and colleagues (2013), but they appear to be limited both in focus and in implementation. Other evaluations, such as that by Jacob and Lefgren (2011) using a regression continuity design, appear to be internally focused (i.e., not comparative) and subject to many possible biases.
As an example, consider the NSF Science and Technology Centers Program, aimed at developing large-scale, long-term, potentially transformative research collaborations (National Science Foundation, 2014b). Efforts to evaluate this program have focused primarily on individual center reviews, both for the selection of centers for funding and for the assessment of ongoing effectiveness. Evaluation in this case does not attempt to compare the performance of different centers, nor does it assess the performance of centers funded versus those not funded by NSF (Chubin et al., 2010). Comparing funded centers with those not funded might somehow help, but such a comparison would be limited to an examination of this one program. To our knowledge, there have been no systematic reviews of unfunded center proposals and the research output of the investigators involved in these proposals. Nor has there been any counterfactual analysis of what would have happened had there been no Science and Technology Center funding or of what benefit for science might have been gained had the dollars been spent differently (i.e., on other programs).
Similar to the report by Azoulay and colleagues (2010) mentioned in Chapter 4, a study by Lal and colleagues (2012) evaluates the NIH Director’s Pioneer Award (NDPA). The authors set out to answer the following questions: To what extent does the research supported by the NDPA (or the “Pioneer”) Program produce unusually high impacts, and to what extent are the research approaches used by the NDPA grantees (or the “Pioneers”) highly innovative?
Inevitably the answers to such questions are comparative. Lal and colleagues (2012) conclude that the performance of the first three cohorts of Pioneer Award winners was comparable or superior to that of most other groups of funded investigators—excluding Howard Hughes Medical
Institute investigators, whose performance exceeded that of the Pioneers on some but not all impact indicators (e.g., on number of publications, number of citations per awardee, and journal rankings). Lal and colleagues set out to compare the effects of different funding programs using retrospective matching. Retrospective matching is inevitably inferior to prospective randomization as an evaluation design, and the analyses that use it cannot control adequately for the award mechanisms of the various programs and for the multiplicity of sources of funding that teams of investigators seek and receive. Nevertheless, this study was the best one could do after the fact, given the available information. Building evaluation into the program prospectively might have yielded quite different results.
We have discussed two types of comparison used in research program evaluation—comparing different research areas and comparing proposals submitted by individuals or groups of researchers within a research area, either retrospectively or prospectively. A third type is seen in international benchmarking, which uses review panels to assess the relative status of research fields among countries or regions (National Academy of Sciences, 1993, 1995, 2000). Although international benchmarking can be used to assess whether the United States is losing ground compared with other countries in certain research areas, it is not designed to assess the effectiveness of federal research programs in forestalling such declines. Instead, international benchmarking can only measure outcomes that may be loosely connected with the funding or management of research programs. Moreover, the selection of outcome measures in international benchmarking is even more difficult and controversial than in the other types of comparison.
All three types of comparison also face challenges of attribution of observed outputs, outcomes, or performance. The fundamental statistical tool of randomized experiments could play a role in these comparisons, but it may be feasible only for the first type—comparison of individuals or groups within a research area. Even so, very little evaluation has been conducted through randomized experimentation, and we believe there are both small and large opportunities for wider use of this method. We encourage continuing to experiment with modifications of this approach to evaluation for both prospective and retrospective assessments.
One opportunity for randomization would be to evaluate peer review. Awards could be randomized among proposals near the cut-off point for funding, and the results of both those funded and not funded could be followed up. Or randomization could be used among reviewers of proposals, because once the outliers of exceptionally good- or bad-quality proposals have been determined, variation among reviewers may exceed the variation among proposals.
Regardless of what approach to prospective evaluation of a research funding program is explored, it is preferable to build evaluation into the program from the very beginning. Doing so helps clarify goals and expectations and allows for the collection of important data that might otherwise be missed. If counterfactual models appropriate for the evaluation are defined in advance, data that allow for comparisons with those models can be identified for collection. Advance planning allows for interventions in the program that can be part of the evaluation.
The ideal design of an experiment for an evaluation may be achievable if it is built into new programs, but this approach requires the commitment of scarce funds and talent within federal research programs, including staff trained to carry out, or at least oversee, its implementation. Other requirements of a research program may compete for resources needed for evaluation. A program may be required to allocate all of its funds to awards for research, leaving none for evaluation. In some cases, programs may receive set-aside funds for evaluation, but only years after the program has begun.
Despite the difficulties, evaluation can be built into the design of a research program, as is illustrated by the Advanced Technology Program (ATP) in the Department of Commerce. That program conducted a number of evaluations, including comparisons with firms that had not applied for an ATP grant and with applicants that had applied but not been funded (Advanced Technology Program, 2005; Kerwin and Campbell, 2007). Evaluation was built into the design of the program, with data being collected throughout the life of a project and into its postfunding period.
Finally, evaluation can be conducted retrospectively. With this approach, an outcome is observed, and assuming that reasonable evaluators agree on its importance and measurement, the question for evaluation is whether this outcome was due to the research funded by the program. To answer this question, a different form of counterfactual analysis, sometimes referred to as “causes of effects,” is necessary. The potential outcomes of alternative treatments (e.g., program structures or portfolios), or at least a framework for speculating about them, need to be specified. This approach often requires many qualifications and assumptions (Dawid et al., 2013).
Regardless of what approach is used for evaluation, it is important to keep in mind the need for careful, controlled, systematic measurement of well-defined concepts:
Research that can reach causal conclusions has to involve well-defined concepts, careful measurement, and data gathered in controlled settings. Only through the accumulation of information gathered in a systematic
fashion can one hope to disentangle the aspects of cause and effect that are relevant (National Research Council, 2012e, p. 91).
Investment in scientific research propelled the U.S. economy to global leadership during the Industrial Revolution and again in the more recent Information Revolution. Today, the amount and composition of these assets are changing at an increasingly rapid pace, presenting leading economies, such as the United States, with challenges to maintaining competitive positions in a sufficient number of industries to achieve national economic growth goals, especially in employment and income. The levels, composition, and efficiency of federally funded research need to be adjusted to meet today’s circumstances. Better metrics can be developed to inform policy decisions about research. This can be the charge of a government unit with the capability to systematically evaluate the research enterprise, assess its impact, and develop policy options for federally funded research. As noted, however, no federal agency or department currently is tasked with performing policy analysis for research. And as observed in Chapter 2, while NSF’s National Center for Science and Engineering Statistics produces valuable data (e.g., Science and Engineering Indicators) that could be used in policy analysis, NSF’s role differs from that of federal policy analysis agencies or statistics agencies such as the Bureau of Economic Analysis or the Economic Research Service that conduct policy analysis. Therefore, the committee’s judgment is that no such institutionalized capability currently exists within the U.S. government.


























