
3
Triangulation of Data Sources and Research Methods
Using multiple sources of data and research methods to understand phenomena yields many benefits, explained panel moderator Mark Liberman, University of Pennsylvania. Considering data and findings from multiple sources is valuable, he argued, because doing so serves as a safeguard against being misled by nonrepresentative samples and unreliable research methods. When the goal is to diagnose a problem or predict a future event, he added, using multiple sources of information and multiple methods also leads to more accurate results and conclusions. “As the methods of acquiring data, storing data, and processing data become easier and cheaper,” he said, “triangulation becomes a much more efficient thing to do as well as an intellectually better thing to do.” Presentations in this panel provided examples of and challenges encountered in triangulating sources and methods in social and behavioral science research.
USING MULTIPLE SOURCES OF DATA TO UNDERSTAND CONFLICT IN ORGANIZATIONS
Giuseppe (Joe) Labianca, University of Kentucky, discussed his research on conflict within organizations, work that entails analyzing networks of people to understand the antecedents and consequences of negative relationships and conflict through the use of survey responses and people’s daily communications. He noted that negative relationships in work settings are relatively rare compared with positive and neutral relationships, usually accounting for about 5 percent of the relationships within an organization. However, he added, their rarity can make them very powerful, explaining
that people tend to focus on negative relationships and that such relationships have disproportionate effects on performance and other important outcomes in organizations.
In his previous work, Labianca has collected social network data on communication within organizations through surveys after spending time developing trust with an organization’s members and meeting with them in small groups. In addition to questions about communication, he explained, these surveys have included questions on how people feel about other members of the organization and the strength of those feelings. He has found, for example, that people may be more willing to answer questions about hearing others’ negative gossip than about their own gossiping. Based on the survey responses, Labianca and his team have developed network diagrams and analyses.
Labianca noted that such techniques are useful for organizations of 200 people or fewer, and response rates tend to be very high (85–95%). In large organizations, he said, these same survey methods are not feasible. He went on to describe the methods he employed in studying two large companies that were merging, involving 1,500 corporate professionals. He and his colleagues analyzed many sources of data—e-mails, including both the content of messages and the associated metadata and attachments; survey responses about specific events (e.g., feelings about the recent merger) and about people within the organization and the organization itself; and information from the organization about employee performance, salary, promotions, and turnover.
Labianca reported that to understand conflict resulting from the merger, he and his team worked to develop methods for identifying negative ties from the communication data, rather than through survey responses. From existing qualitative research, the researchers were aware that negative interactions were occurring in the two organizations, including people seeking to undermine others, attempting to get them fired, or spreading disinformation. Prior to the merger, the organizations allowed the research team to talk to one division’s new product development group to gather data on members’ positive and negative feelings about others in the group.
“Using that set of negative ties that we already [knew] about [from the surveys],” said Labianca, “we [wanted] to use that to try to infer the negative ties in the broader group on top of the four-and-a-half years of qualitative observation and interview data that we already [had].” He added that computational social scientists worked with him to develop ways of using this 150-person dataset as a “training subset” to teach a computer model to infer negative ties in the organizations’ larger 1,500-person set. He characterized as a particular challenge that people rarely send negative e-mails directly to individuals with whom they have a conflict, but
instead are more likely to send such e-mails to a third person. In addition, he observed, people might not use the name of a person they dislike when complaining about that person to a friend, instead referring to the person obliquely (e.g., “the evil one”). Labianca cited as another challenge the need to identify such conflicts closer to real time. He explained that individuals at the top of an organization usually are not aware of the conflicts at the organization’s lower levels, in part because those involved attempt to keep this information from reaching top managers. In the case of the above two merging organizations, he added, individuals involved in leading factional conflicts were ultimately fired, but caused great harm to the organization in the interim.
Ultimately, Labianca and his colleagues would like to be able to use a combination of content, network, attitudinal, and behavioral data to understand negative ties in an organization. These approaches, he explained, can provide important insights into the distribution of power in networks, including who currently has power and who the emerging powerful actors are. Understanding power dependencies is also important, he added, arguing that looking only at alliances within networks often provides an incomplete picture of organizational dynamics.
To illustrate the effects of alliances and adversaries on power dependencies, Labianca described hypothetical power relationships among Egypt, Qatar, Saudi Arabia, and Turkey. When two allies (Egypt and Saudi Arabia) work together against Qatar, he explained, Turkey has more power in the network because Qatar needs its alliance with its sole ally (Turkey) even more given the adversaries it faces. As a result, he continued, Qatar would likely be willing to concede more to Turkey to maintain their alliance. He went on to observe that if Egypt gained another ally, the level of threat to Qatar would increase, further weakening Qatar’s power and thereby increasing Turkey’s power in the relationship even further. These same dynamics, he added, apply to individuals within organizations, as well as to how countries determine the size of military they need. “As you become more [relationally] powerful as a nation,” he elaborated, “you do not need to have as big of a military.1 That is a simple reaction. Or in the opposite direction, the less powerful you feel [in terms of your network relationship], the more likely you are to grow your military.”
Labianca continued by observing that these power dynamics among people in organizations can also yield important information that can explain how individuals with poor performance maintain their positions. He explained that poor-performing individuals can have allies who rely on
___________________
1 Smith, J.M., Halgin, D.S., Kidwell-Lopez, V., Labianca, G., Brass, D.J., and Borgatti, S.P. (2014). Power in politically charged networks. Social Networks, 36, 162–176. doi:10.1016/j. socnet.2013.04.007.
them more heavily because they have their own adversaries. He and his colleagues have been examining these relationships in varied settings, including among corporate professionals in health care and consulting service organizations. According to Labianca, identifying sources of conflict can help leaders track and mitigate these issues and determine whether their efforts to improve relationships are effective. His research is advancing the development of methods that can be used to understand networks and relationships, going beyond the use of surveys to employ multiple sources of data that can be collected in an unobtrusive manner.
USING DATA FROM SURVEYS, LABORATORY EXPERIMENTS, AND SOCIAL MEDIA TO UNDERSTAND MISINFORMATION
David Broniatowski, The George Washington University, described how using different data sources and research methods can contribute to a better understanding of causality. He explained that methods with high internal validity incorporate designs for identifying causality—Does the proposed treatment cause the proposed effect?—while ruling out other potential explanations for the effect. Alternatively, he continued, external validity is concerned with the extent to which findings are generalizable across settings (e.g., in the laboratory and in the real world). He noted that some methods provide information with high internal validity but low external validity and vice versa, but that triangulation by combining methods is a way to address the shortcomings of any single approach. He asserted that multiple studies using different methods and different data sources can be used to determine whether there are converging lines of evidence to support a theory. He illustrated this multiple-methods approach with his research on the effects of online misinformation on behavior. He emphasized that online misinformation has significant implications for national security because insurgents create different narratives to mobilize certain populations, as documented in military field and counterinsurgency manuals.
According to Broniatowski, online misinformation is also a public health concern, as demonstrated by the role of online narratives in communications about vaccines. Broniatowski and his colleagues examined the effects of narrative framing (the way the choice of words and images of a message affects how it is perceived) on people’s decisions. Quoting from a recent article, he said, “Narratives have inherent advantages over other communication formats. . . . They include all of the key elements of memorable messages—they are easy to understand, concrete, credible . . . and highly emotional. These qualities make this type of information compelling
(p. 3730).”2 Broniatowski used the example of stories conveyed online that describe children getting vaccinated and then developing autism. The gist of these stories, the take-home meaning, he said, is that vaccines cause autism, so that people assume a causal link between the two events when they are merely spuriously correlated.
According to Broniatowski, fuzzy trace theory illuminates how people search for meaning and causal explanations. He explained that this theory posits two types of memory—gist memory for basic meaning and verbatim memory for precise details. It posits further that decisions are based more on gist than on verbatim memory but that the two are encoded in parallel and that both can have an effect on the decisions made. Elaborating on the theory, Broniatowski noted that it also posits that Websites and online content that provide more coherent and meaningful “gists” are more likely to be influential, regardless of whether they are factually accurate, although he added that factual accuracy can have an effect.3
The hypotheses of fuzzy trace theory can be tested experimentally, Broniatowski observed. He noted that carefully designed laboratory experiments can have high internal validity because causal relationships between perception and decisions can be identified in controlled conditions. He then described a model for how fuzzy trace theory affects decision making that can be tested in a laboratory setting. First, he said, people are presented with a stimulus (an online narrative), which they then represent in different ways. Specifically, he continued, people encode those messages as precise verbatim facts (e.g., probabilities) and at multiple levels of gist (basic categorical takeaway messages). Each of these representations has a preferred decision outcome determined by a person’s values, which are stored in that individual’s long-term memory. The various representations are weighted according to that person’s personality traits, cognitive needs, competency with numbers, and motivation, among other individual factors. Ultimately, Broniatowski explained, the weightings assigned to the different representations encoded by the individual combine to result in a decision.
According to fuzzy trace theory, Broniatowski explained, the reason people make choices this way is because they interpret numbers in qualitative ways, such as “some” and “none.” Most people prefer this type of categorical gist interpretation (“fuzzy processing preference”), he added. He asked the audience to consider the following scenario. An individual must decide which program to adopt. If Program A is adopted, 200 people
___________________
2 Betsch, C., Brewer, N.T., Brocard, P., Davies, P., Gaissmaier, W., Haase, N., Leask, J., Renkewitz, F., Renner, B., Reyna, V.F., Rossmann, C., Sachse, K., Schachinger, A., Siegrist, M., and Stryk, M. (2012). Opportunities and challenges of Web 2.0 for vaccination decisions. Vaccine, 30(25), 3727–3733.
3 Reyna, V.F. (2012). Risk perception and communication in vaccination decisions: A fuzzy-trace theory approach. Vaccine, 30(25), 3790–3797.
will be saved; if Program B is adopted, there is a one-third probability that 600 people will be saved. In accordance with fuzzy trace theory, the stark categorical contrast between these two options has been eliminated, thereby also eliminating the framing effect. If messages are framed in terms of gain, Broniatowski said, people will choose the possibility of gaining, whereas if messages are framed in terms of loss, people will choose no loss.
Broniatowski and his colleagues tested these predictions using existing data from 30 years’ worth of framing and related research and were able to successfully predict choices in 93 percent of studies.4 In addition, he and his colleagues found other support for their model, providing evidence for the internal validity of their approach for detecting causal effects of framing on decision making.
In parallel, Broniatowski and colleagues tested the extent to which the results of these laboratory experiments were valid under real-world conditions by conducting a survey of patients and health care providers in the Johns Hopkins emergency department about the overuse of antibiotics. The researchers were aware that patients may weigh the choice of whether to take an antibiotic for their illness based on the chance that it might help even if they suspect they have a virus rather than a bacterial infection. “If they do take an antibiotic, given what they know, they may be getting better,” Broniatowski added. “They may be staying sick. You can think about this as a categorical framing problem,” he explained. His team labeled the gist predicted by fuzzy trace theory “Why not take a risk?”
Broniatowski explained that the survey questions asked respondents to rate the extent to which they agreed with different statements. He and his team then used fuzzy trace theory to test agreement with the “Why not take a risk?” gist and other key messages being tested.5 Their results supported fuzzy trace theory’s predictions, he reported. About three-fourths of patients endorsed the “Why not take a risk?” approach to decision making. Fewer than half of patients endorsed the alternative hypothesis, according to which patients who know the difference between bacteria and viruses will make choices consistent with that knowledge. In fact, Broniatowski observed, most people do not know the difference between the two, and even three-fourths of those that do still endorse the “Why not take a risk?” approach, suggesting that patients still believe it appropriate to take antibiotics even if they probably have symptoms of a virus. Moreover, he added, pilot data suggest that patients who endorse this thinking are also
___________________
4 Broniatowski, D.A., and Reyna, V.F. (2017). A Formal Model of Fuzzy-Trace Theory: Variations on Framing Effects and the Allais Paradox. Decision. doi:10.1037/dec0000083.
5 Broniatowski, D.A., Klein, E.Y., and Reyna, V.F. (2015). Germs are germs, and why not take a risk? Patients’ expectations for prescribing antibiotics in an inner-city emergency department. Medical Decision Making, 35(1), 60–67. doi:10.1177/0272989X14553472.
more likely to expect to receive antibiotics for future illnesses. Finally, he noted, clinicians who endorse “Why not take a risk?” are more likely to prescribe antibiotics.6
This study did have some limitations, however, Broniatowski acknowledged. First, he noted, the sample was not nationally representative; it was representative of an urban population of low socioeconomic status and included only a subset of patients who visited the Johns Hopkins emergency department—for example, any patients who were so ill or in pain that they were unable to provide a response were not included. In addition, he observed, those patients surveyed had many different conditions, not just upper respiratory tract infections. Moreover, he emphasized, retrospective observational studies such as this that lack experimental controls for other factors that can affect the behavior(s) of interest (e.g., in this case prescribing behaviors) can have limited validity. Finally, he noted, the study measured beliefs and attitudes, but not behavior.
Another line of Broniatowski’s research shows that survey and social media data can be used to cross-validate one another. To understand the spread of misinformation and disinformation online, for example, he and his colleagues examined both news reports and how people shared news about the outbreak of measles at Disneyland in 2014. This outbreak led to 11 cases of measles across several states and Mexico and sparked talk of enacting legislation to toughen vaccination requirements, he reported. He pointed out that individuals involved with public health and health communication would like to better understand whether providing facts or using narrative storytelling, or some combination of the two, is the most effective and ethical way to communicate messages designed to increase vaccination rates.
According to Broniatowski, fuzzy trace theory suggests that people encode both facts and gist in parallel. In the case of vaccination, he continued, the facts are the statistics about vaccination and the gist is the basic meaning—vaccination is the best way to protect your child. As he explained, “Stories are effective to the extent that they communicate a gist that cues motivationally relevant, moral, and social principles.” He and his colleagues coded about 4,500 articles to examine measles coverage on social media. Using the Facebook application programming interface (API), they measured how frequently those articles were shared, and using MTurk, they examined whether the articles included statistics about viruses or vaccines. In addition, they coded for whether the article had a gist or “bottom-line
___________________
6 Klein, E.Y., Martinez, E.M., May, L., Saheed, M., Reyna, V., and Broniatowski, D.A. (2017). Categorical risk perception drives variability in antibiotic prescribing in the emergency department: A mixed methods observational study. Journal of General Internal Medicine, 32(10), 1083–1089. doi:10.1007/s11606-017-4099-6.
meaning,” and controlled for other covariates based on prior literature. To ensure reliable coding, they used multiple coders and measured interrater reliability. Broniatowski observed that one advantage of using social media data is the lack of response bias that can occur when people know they are participating in a survey. In the case of this research, he asserted, the data represent people’s actual behaviors without any researcher intervention.
Broniatowski explained that the results of this research were consistent with the predictions of fuzzy trace theory. When an article conveyed a gist, he reported, it was 2.3 times more likely to be shared at least once relative to articles not containing a gist. Articles with statistics were also 1.3 times more likely to be shared than articles without statistics, but less so than those with a gist. No significant effects were observed for articles that conveyed a story but had no effective gist. Broniatowski added that among articles shared more than once, those that communicated positive opinions about both sides of the vaccination debate but then concluded with a recommended course of action and communicated a gist were shared, on average, 58 times more often than other articles.
Broniatowski emphasized that converging lines of evidence increase confidence in the conclusions of research, as one research approach can address the limitations of another. In the case of the research he described, he said, results across multiple settings, populations, and research methods support fuzzy trace theory’s predictions. He plans future work to examine the mechanisms that influence the decision to share an article and how this process influences an information cascade, in which people’s decisions are influenced by observing the behavior of others in combination with their own personal information.
CHALLENGES IN TRIANGULATING HEALTH CARE DATA
According to Philip Resnik, University of Maryland, natural language processing (NLP) combined with methodology from computational social science and triangulated with other sources of data can be applied to better understand the types of health issues that can affect national security. National security can be compromised if there are too few healthy young people to recruit, he noted, or if potential recruits see that veterans receive inadequate care for the aftereffects of war.7 Outside of the military, he continued, increased rates of suicide and opioid addiction force the nation to focus on these internal issues more than on foreign affairs and external threats.
___________________
7 Brooks, M. (2016). Want new recruits? Take care of the old ones. Modern War Institute at West Point, November 11. Available: https://mwi.usma.edu/want-new-recruits-take-care-old-ones [February 2018].
Using behavior to draw inferences about a population or individuals is a method with potentially broad application, Resnik observed. For example, he explained, many kinds of behavior can be thought of as a vote—a binary choice between options. Examples of ways in which people cast votes, he said, are “if you have a mechanism for real-time responses where people can say I agree or disagree with what I am hearing during a debate, or if you are looking at the Twitter stream where people are expressing positive or negative sentiment about something.”8 He noted that models of the voting behavior of legislators reflect this by taking into account drivers of their behavior, such as the popularity of a policy choice. He argued that although some models can show how behaviors map to liberal and conservative ideology, identifying themes associated with closely related terms from the language used in bills and speeches on the floor of Congress provides a richer source of data for explaining the influences of language on voting behavior. He and his colleagues showed that the words used to discuss topics frame issues in ways that help better predict how legislators will vote.9
Resnik presented a model of how different linguistic terms used during the discussion of the debt ceiling differentiated Tea Party Republicans from those who more represented the “establishment” wing of the Republican party (see Figure 3-1). This model includes two levels: agenda issues and framing of those issues. At one level (the top portion of the figure), the words cluster around macroeconomic issues, such as “balanced budget,” “national debt,” and “grandchildren.” However, Resnik noted, the framing of the Republican “establishment” (M1) tends to include terms that represent more practical considerations in that debate, such as “government shutdown” and “blame,” whereas the Tea Party framing (M3) emphasizes terms associated with party principles, such as “entitlements,” “debt,” and “taxes.”
The second level of framing in Figure 3-1 illustrates how similar analyses using NLP can be applied to understanding issues in health care and mental health, including depression and suicidality, by examining how people frame issues in their conversations. “For example,” Resnik said, “two people can be talking about [their] schedules. But [one] might be
___________________
8 Argyle, D., Resnik, P., and Eidelman, V. (2016). Using Ideal Point Models to Characterize Political Reactions in Non-Political Actors. Presented at Seventh Annual Conference on New Directions in Analyzing Text as Data, Northeastern University, October 14.
9 Nguyen, V.-A., Boyd-Graber, J., Resnik, P., and Miler, K. (2015). Tea Party in the house: A hierarchical ideal point topic model and its application to Republican legislators in the 112th Congress. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (pp. 1438–1448). Beijing, China: Association for Computational Linguistics. Available: https://aclanthology.info/pdf/P/P15/P15-1139.pdf [February 2018].
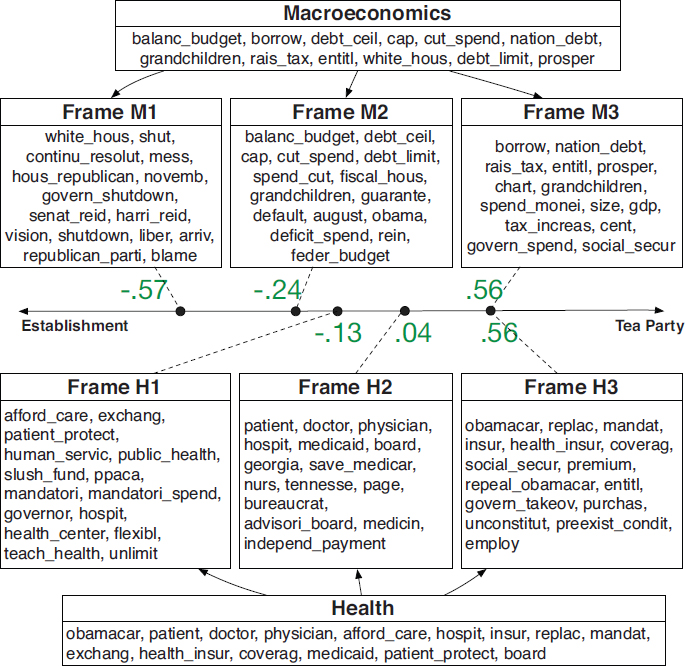
NOTE: The material above the line models the connection between ideological position and linguistic framing in floor debate on macroeconomics; the parallel information below the line models that connection in the context of health care. The horizontal line represents a spectrum of Republican ideology from more “establishment” oriented (left) to more “Tea Party” oriented (right).
SOURCE: Nguyen, V.-A., Boyd-Graber, J., Resnik, P., and Miler, K. (2015). Tea Party in the house: A hierarchical ideal point topic model and its application to Republican legislators in the 112th Congress. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (pp. 1438–1448, fig. 6). Beijing, China: Association for Computational Linguistics. Available: https://aclanthology.info/pdf/P/P15/P15-1139.pdf [February 2018]. Reprinted with permission from the Association for Computational Linguistics.
expressing it in terms of looking forward to the weekend, and [the other] might be expressing it in terms of how exhausted [he or she] is when getting up in the morning.” He added that studies testing this idea have found that such differences in the way people talk can predict mental health concerns.10
NLP has been growing as a discipline for roughly 40 years, Resnik observed, and since the early 1990s, it has been on the leading edge of machine learning and applied to understanding a variety of phenomena. Currently, he noted, NLP research can make use of a variety of large datasets. He illustrated this point with examples of publicly available datasets including 1.6 million tweets, 681,288 social media posts, more than 140 million words from online bloggers, and one terabyte-sized dataset containing every publicly available Reddit comment as of 2015.11 However, he argued, the state of the art for NLP in medical or clinical settings is about 10 years behind that for NLP in other application areas because available datasets in the health care domain are far fewer and much smaller. He gave examples of orders-of-magnitude differences in data availability, including one dataset from the Mayo Clinic containing 400 manually deidentified clinical notes and pathology reports from cancer patients and another dataset containing 65,000 posts from a mental health peer support forum. The limited number of records available, he asserted, fails to provide the “ground truth” sought by researchers of large datasets. He called attention to one recent improvement, the MIMIC (Multiparameter Intelligent Monitoring in Intensive Care) dataset with data from about 40,000 intensive care unit patients (albeit from just one medical center), which includes 2 million free-text clinical notes.12
According to Resnik, several problems contribute to the limitations of NLP in health research. First, he asserted, privacy laws with respect to health information discourage sharing of this information, which results in balkanizing research. Second, he said, linguistic data, compared with other health data, are difficult to fully deidentify. Even if as much as 99 percent of the data can be deidentified, he observed, the remaining 1 percent that
___________________
10 Resnik, P., Armstrong, W., Claudino, L., Nguyen, T., Nguyen, V.-A., and Boyd-Graber, J. (2015). Beyond LDA: Exploring supervised topic modeling for depression-related language in Twitter. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality (pp. 99–107). Denver, CO: Association for Computational Linguistics. Available: http://www.aclweb.org/anthology/W/W15/W151212.pdf [February 2018].
11 See https://www.reddit.com/r/datasets/comments/3bxlg7/i_have_every_publicly_available_ reddit_comment [February 2018].
12 Johnson, A.E.W., Pollard, T.J., Shen, L., Lehman, L.H., Feng, M., Ghassemi, M., Moody, B., Szolovits, P., Celi, L.A., and Mark, R.G. (2016). MIMIC-III, a freely accessible critical care database. Scientific Data, 3, 160035. doi:10.1038/sdata.2016.35.
cannot be is problematic given the millions of records involved. Finally, he said, electronic health records create pressure to avoid language because the new systems encourage the use of pull-down menus and checkboxes instead of recording of narrative clinical data. All of these barriers, he argued, discourage NLP researchers, who simply choose other topics to research. He asserted that addressing these barriers will require policy, not technical, solutions.
Resnik identified data donation as one approach to increasing the amount of health data available to researchers. He reported that one company, Qntfy, maintains a Website, OurDataHelps.org, that enables people to donate private social media data for mental health research (Qntfy anonymizes the data for research use and provides a consent structure). Taking approaches of this kind, he explained, would address the constraints imposed by the Health Insurance Portability and Accountability Act of 1996 (HIPAA) because it allows individuals to control their own health information. The founder of Qntfy, Glen Coppersmith, has used such data to study suicidality and other conditions, and Resnik is collaborating with Coppersmith (and Deanna Kelly at the University of Maryland School of Medicine) to take the same data donation approach in studying schizophrenia and depression.
Resnik concluded by suggesting that such repositories for data could be scaled up. He cited the University of Pennsylvania Linguistic Data Consortium, the National Institutes of Health’s (NIH’s) Precision Medicine Initiative,13 and other collaborations as examples of efforts to compile donated data for research, including NLP research. Although the NIH initiative is a very large project aimed at collecting donated data from 1 million people, he added, the early focus is not on collecting language data, because it is challenging to collect and deidentify such data. He ended by saying, “Language data as part of what you triangulate along with behavioral data and structure data, metadata, and so forth, is an enormously important resource, but we have a lot of catching up to do, and more needs to be done faster.”
DISCUSSION
Following the panel presentations, workshop participants discussed some of the ideas raised. The discussion, moderated by Mark Liberman, focused on several themes: (1) the need for methods that are adaptable, timely, and rigorous; (2) communicating with decision makers and building trust; (3) roles and limitations of automated and human data analysis; and (4) investments in data sources and data sharing.
___________________
13 See http://www.allofus.nih.gov [February 2018].
Need for Adaptability, Speed, and Rigor
One participant from the Intelligence Community (IC) noted that in that community, methods need to be adaptable to new situations and data sources, produce timely results, and be rigorous enough to provide confidence in the findings. Two panelists discussed the trade-offs of speed and rigor and ways to address them. Resnik said, “So much of what we do as data-driven scientists involves developing automatic methods, but I am firmly convinced that when you want to do things in the real world, you need to spend more time focusing on the human in the loop.” He added that the combination of automation and human analysis balances bottom-up approaches, in which conclusions are reached based on patterns that emerge from the data collected, and top-down approaches, in which humans help define categories used to interpret these patterns. When the two approaches are used together, he asserted, the limitations of either alone are balanced, lending confidence to the results.
Broniatowski noted that each method comes with pros and cons that must be weighed against the primary considerations of the researchers. For example, he observed, social media data can be collected very quickly, but rigorous methods for their analysis comparable to survey research methods have not yet been established. Alternatively, he suggested, when rapid results are required, such as during an outbreak of infectious disease, using a rigorously designed survey of people’s understanding and actions might not produce results in time, even if it yields robust findings. For these reasons, he argued, both researchers and consumers of research should be aware of the trade-offs entailed in selecting one approach over another. He added that being able to communicate these trade-offs and the nature of uncertainty to decision makers is of critical importance. This means, he elaborated, that analysts need to be clear on the central message, the gist, that they want to convey about the data while accurately portraying the degree of confidence in that message in an understandable way.
Broniatowski and Liberman also addressed the need for methods adaptable to new questions and contexts. Broniatowski explained that flexibility can be built into the structures that govern the flow of information in organizations, suggesting that resources and research are available to guide the examination and design of such structures. Liberman stated that the issue of generalizability—whether findings from one context hold true in another—is linked to the issue of communicating clearly to instill confidence in decision makers.
Communicating with Decision Makers and Building Trust
Several panelists and participants discussed how to communicate research findings to decision makers and the importance of trust in data sources, methods, findings, and communicators. A participant from the IC suggested that reducing barriers between academic work and decision makers through effective communication is one means of building trust, especially under conditions of uncertainty. He added that conveying the gist of the research, transparently and honestly, includes stating the limits of current knowledge and understanding and conveying uncertainty in ways people understand. Uncertainty and risk make people uncomfortable, he asserted, and being able to “tell a story with those concepts that imbues trust, I think that is the mechanism for going from the theoretical world to the applied world.”
Broniatowski explained that determining the gist to be conveyed sometimes requires particular expertise. A person who understands the methodology of researchers as well as the concerns of decision makers is the ideal expert for translating research, he argued. Often, he added, those skilled at data analysis are not skilled at communicating and vice versa, so he suggested considering utilizing people who can serve in translational roles.
Resnik agreed that having individuals serve in translational roles could help address the significant gap that often exists between analysts and the people their research is intended to serve in the national security contexts in which he works. In his view, more attention should be paid to developing better connections between technology or analytic models and the problems they are intended to help solve. He added that some mistakes erode trust in the system even if the system is accurate 99 percent of the time. He argued that avoiding those types of errors is essential for maintaining trust.
One participant noted that the source of data or of funding for research can contribute to a lack of trust in the conclusions of the research. For example, she has encountered situations in which research conducted or published outside the United States was considered potentially biased or suspect. In her experience, there has also been a tendency not to trust research unless it was funded by the Defense Advanced Research Projects Agency (DARPA), the Intelligence Advanced Research Projects Activity (IARPA), or other similar sources. She noted that this has had the effect of limiting the research considered potentially useful and suggested that triangulation could be one strategy for increasing confidence in the findings from these underutilized sources. Liberman noted that in his experience, DARPA- and IARPA-funded research has long been international, and researchers have utilized promising results from other countries.
Resnik suggested that authority based on a certain funding source no longer need be a basis for trust, particularly when datasets and codes for
analyzing them are increasingly available so that results can be verified and replicated. More peer review processes and conferences are valuing this type of transparency, he explained. He added that adhering to rigorous scientific methods and replicating results in multiple settings, including within and outside of the United States, can increase trust in the results.
The Roles and Limitations of Automated and Human Data Analysis
Participants also discussed the importance of both automated and human data analysis in social and behavioral science research. Labianca explained that although he is able to employ computers to examine e-mail content and survey data and to develop models for predicting behavior, these automated methods cannot produce an answer for why the models work. Liberman added that “the trend in our field broadly construed over the last few years is toward theories that work better and better and are explainable less and less. I think that is a challenge for the next decade.” Resnik noted that this trend is spawning an industry aimed at explaining these models and important aspects of data.
Other participants agreed that the human role in making meaning out of data is vital. For example, one participant suggested, an algorithm may assign a particular meaning to a pattern of data, but a person is still important for determining whether the algorithm assigned the correct meaning. Labianca explained that in NLP, punctuation and emojis can be important indicators of meaning, but that meanings associated with these symbols can differ in complex ways (e.g., an exclamation point can indicate that someone is yelling or that someone is pleased). He emphasized that understanding the true nature of interactions is essential for developing a theoretical explanation for phenomena. Resnik continued the discussion by identifying two components of meaning: the first is a representation that can be manipulated to accomplish the second—reasoning about the meaning, drawing inferences and conclusions, and making decisions.
Broniatowski explained that understanding the gist of a message necessarily means understanding the contextualized meaning. In his view, there is increasing recognition that to make sense of the data, the analyst must also understand the algorithms used to gather the data. He argued that analysts who understand both the algorithms and national security needs can better discern important meaning in the context of particular problems. “I think the royal road to doing that in a sense is to make sure that in addition to improving our analysis techniques, we are also making sure that we are improving our expertise in the interpretation of those techniques,” he said. Resnik agreed, emphasizing that in his view, humans will continue to fill these gaps in interpretation for “quite some time.” At the same time, he asserted, the data analysis field needs to advance toward systems that create
more meaningful representations useful for drawing inferences and answering fundamental research questions.
Investments in Data Sources and Data Sharing
Several participants emphasized the need for investments in data over the next decade. Labianca argued that mechanisms are needed to facilitate the secure sharing of deidentified data among universities or other research institutions. Liberman agreed, noting that these issues are especially sensitive and challenging when it comes to health data, and asserting that solutions will require both legal and procedural attention. He added that determining the most appropriate ways to share medical, organizational, and social media data for legitimate research purposes will require a great deal more discussion.
Broniatowski expanded on this idea, noting that data sharing can be considered one layer of a hierarchy. This layer is important, he said, because different people can examine the data and reach different conclusions. However, he also suggested that sharing interpretations of data and their relationship to decisions is another layer of the hierarchy that should be considered. He cited as an important investment establishing infrastructure across intelligence agencies to enable communication and lateral connections allowable by law at multiple levels—the data level, the level of interpretation of the data, and the decision-making level based on the interpretation.
Labianca suggested that incentives for sharing data should also be considered because some organizations, such as health insurance and social media companies, possess important data. He also emphasized the importance of bridging the gap between data and knowledge. With the current advances and interest in machine- and data-driven learning, he argued, more attention should be paid to using knowledge, such as meaningful categories and the relationships among them, to improve models and the understanding of phenomena.
















