
3
Advances in Data, Modeling, and Simulation
DATA, MODELING, AND SIMULATION
Key Questions
David Maier, Portland State University, Moderator
Moderator David Maier, Portland State University, explained that speakers would discuss recent advances in technology related to the use of big data, modeling, and simulation that might be useful for urban sustainability. He presented the following key questions as a guide for the discussion:
- What advances have been made in data, modeling, and simulation for air and water quality, network analysis and mobility, and traffic modeling?
- What is the state of the art in data, modeling, and simulation from each expert’s research area (both their work and the best work in the field)?
- How will advances in data, modeling, and simulation inform the work of cities and make an impact on urban sustainability problems?
Advances in Data, Modeling, and Simulation
Elena Craft, Environmental Defense Fund
Elena Craft, Environmental Defense Fund (EDF), described EDF as a U.S.-based nongovernmental organization of scientists, social scientists, and economists working on science-informed policy advocacy. One distinguishing factor of EDF is that it works directly with companies on their environmental problems.
Craft highlighted a number of ways in which EDF is involved with big data, including its initiative on methane. She described methane as more devastating to the climate than carbon dioxide because of its ability to absorb heat. It is essential to understand methane emissions in order to mitigate climate pollution. EDF began a 5-year, $20 million collaborative project with researchers from 40 institutions who studied the links in the oil and gas supply chain to identify leaks. Thirty-five peer-reviewed papers emerged from this project, each demonstrating that methane emissions were significantly higher than previously estimated, with a leak rate of approximately 4 percent. The results of this study were used as the foundation for the methane rules that went into effect during the Obama administration, Craft said. As part of this project, EDF and Google coordinated a data collection campaign to find methane leaks across the country. Sensors were placed on top of Google Street View cars to measure methane, and then maps of methane leaks across various U.S. cities were published. More leaks were found in older cities with older pipelines and transmission lines; newer cities with better infrastructure had fewer leaks. This work enabled EDF to help local utilities prioritize which leaks to address.
Craft explained that because that campaign was successful, EDF decided to outfit the Google Street View cars in Oakland, California, with an array of instruments that could measure particulate matter, ozone, nitrous oxide, nitrogen dioxide, black carbon, and ultrafine particles. EDF then partnered with Kaiser Research Group to discern health impacts at the neighborhood level. This method does not predict individual risk, but it shows the value of making this information available to residents, who can identify locations they visit on the maps and determine whether there is increased health risk from pollution. For example, this community now uses these maps for their proposals to secure funding through the California legislation AB 617, which enables some cap and trade proceeds to go toward reducing emissions in hot spot and environmental justice areas.
After this work in Oakland, EDF began integrating this systematic review and mobilization in Houston and London, with the goal of
providing more information to city planners, health departments, and advocacy groups to aid in the development of action plans to mitigate environmental pollution. Houston is now participating in a pilot program in which the measurement instruments are placed on vehicles in the city’s fleet instead of on Google Street View vehicles. The data being gathered could be used to identify potential pollution hot spots in the city. Houston’s public health department could then use these data to prioritize a mobile health unit to take additional measurements, information from which could be used during a future permit hearing for a refinery, for example. Craft emphasized the value of having this type of information at hand to make better decisions. Eventually, the process could be automated so that a person at a public health department could look at real-time data on a dashboard. EDF continues to try to find ways to better integrate with existing systems, disaster response teams, and public health policy representatives.
Public Health and Simulation for Supporting Urban Sustainability
Bryan Lewis, University of Virginia
Bryan Lewis, University of Virginia, explained that public health is essential both for urban living and for urban sustainability. Sanitation services, disease control, and strategies for cleaner food enable humans to survive and thrive in dense cities. He noted that open data and increased data sharing, in addition to increased computational power, allow for models to be more sophisticated and for real-world processes to be represented with fidelity. The use of machine learning, deep learning, and natural language processing tools for integrating data can also support decision making around public health issues and inform public health policy. Disease forecasting, course of action analyses, and modeling of complex disasters aim to capture and represent massively interdependent systems in simulation, which is safer and more cost-effective than running disaster experiments in the real world. Data analyses can help address many urban problems, although it is important to consider how to translate this information for governance purposes, he continued.
Lewis shared a few examples of how disease forecasting can be used to improve public health in cities. The Centers for Disease Control and Prevention sponsors an annual challenge to forecast the flu. Public health departments could use these data to determine appropriate hospital staffing levels to better prepare for flu outbreaks. Environmental niche models can generate warning signals about which locations residents should avoid in order to prevent illness. Forecasting for vector-borne diseases, such as Zika, is particularly challenging given the complex system of the
viruses and vectors, as well as the weather and human components. Forecasting for the Ebola virus is also difficult given that poor and sporadic data exist, yet rapid decision making to deploy support is crucial.
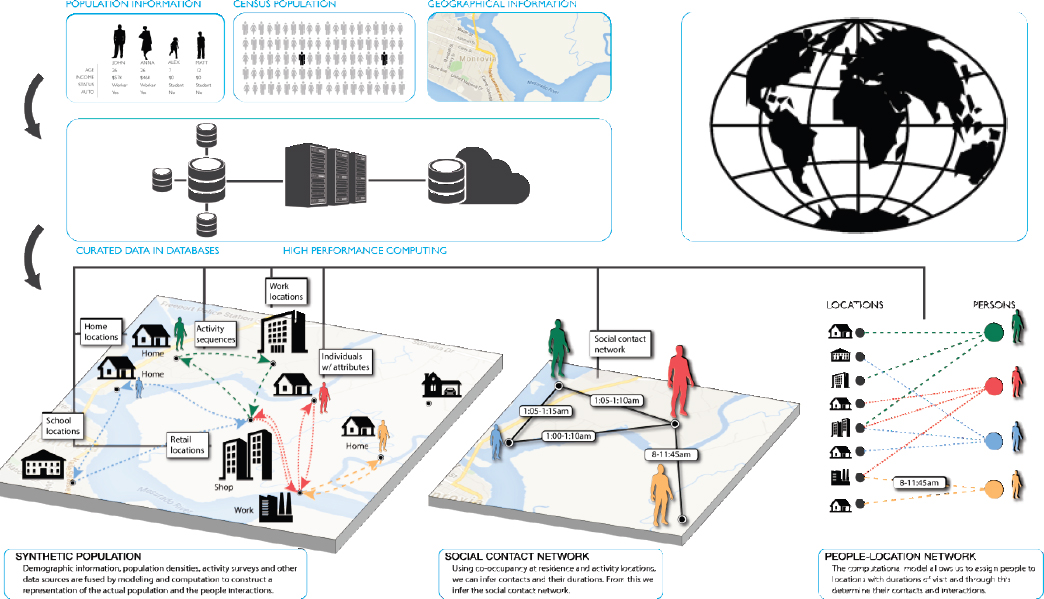
An important tool that is increasingly employed is a synthetic representation of an urban system (see Figure 3.1). Myriad data sources are synthesized to gain a robust representation of the population, which can be used to coordinate data analysis systems and assess options for mitigating impacts of disasters or devising policies for the real world.
Lewis described another project, which focuses on optimizing national resiliency, particularly during pandemics when medical supplies can be scarce. To be better prepared and have improved responses, it is possible to simulate pandemics, use real-time forecasting to estimate future deficits, explore the impact of policies, and determine how medical resources could be maintained, shared, or distributed during pandemics.
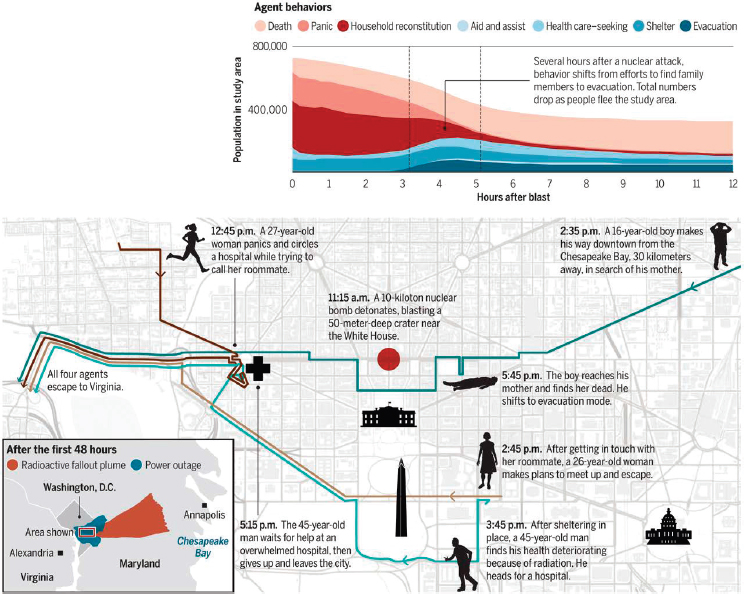
In another example, Lewis talked about National Planning Scenario Number One1 and discussed how modeling of complex disasters can help understand actions that could be taken to improve the resilience of a population (see Figure 3.2). Data about people and places are fused, multiple simulation modules interact, and experiments are designed to explore policies and response plans that would enable people to make better decisions during such events. From these experiments, it is possible to learn whether cities need better messaging and better education or infrastructure improvements. The representation shows that with such improvements, individuals could interpret conditions and make better decisions based on improved communications during a disaster. The next step is to consider how this could be integrated into the policy-making process.
In closing, Lewis emphasized that simulation technologies are essential for urban sustainability and described three new areas of study for public health:
- Model-guided machine learning (i.e., mechanistic models that guide statistical approaches) shows promise for extending the use of simulation.
- Virtual reality is now more affordable and approachable, enables collaborative work on problem solving, and improves the potential for analysis and exploration of complicated data sets.
- Engineering capabilities could help restructure governance and management to enable more efficient administration of communities.
___________________
1 For more information about National Planning Scenario Number One, see https://www.fema.gov/national-planning-frameworks, accessed March 12, 2019.
C2SMART: Data-Driven Transportation Modeling and Simulation
Kaan Ozbay, New York University
Kaan Ozbay, New York University, emphasized the importance of transportation systems in cities and provided an overview of uses of simulation for transportation systems. Ozbay’s C2SMART University Transportation Center2 works on modeling, simulation, and data-driven
___________________
2 For more information about the C2SMART University Transportation Center, see http://c2smart.engineering.nyu.edu, accessed March 12, 2019.
solutions for transportation. The two types of models he most often uses are activity travel behavioral models (e.g., how people make their decisions about travel, from both user and provider perspectives) and traffic flow/control models (e.g., how outcomes affect congestion, safety, and other externalities such as emissions and noise). He emphasized that modeling is rapidly evolving with the increased availability of open source data.
Ozbay explained that many types of traffic models exist, including macroscopic (i.e., fluid flow approximation of individual cars), microscopic (i.e., car-level traffic dynamics), mesoscopic (i.e., a hybrid between micro and macro models), and agent-based (i.e., individual driving and decision-making dynamics). Which model is chosen depends on the problem in need of a solution. Types of use cases for simulation and modeling include (1) proof of concept studies for evaluations where analytic models are very simplistic; (2) deployment decision support, which helps to understand the impacts of a scenario on a population and its existing infrastructure (often using the open source MATSim3 and SUMO4 models); and (3) real-time decision support for traffic operations and control.
Ozbay provided highlights of work at the C2SMART University Transportation Center, including a study on using autonomous buses to improve capacity in the Lincoln Tunnel that demonstrated that autonomous vehicle technologies could dramatically improve traffic flow. The C2SMART University Transportation Center is also working on macroscopic modeling and agent-based demand modeling to predict how to evacuate a large city and improve its resilience during a disaster (see Figure 3.3). He noted that data sets that were unavailable only 5 or 10 years ago—such as taxi trip data, subway data, and socioeconomic data—are now readily available. These data sets are used to build, validate, and calibrate evacuation models.
Another project involves using commercial models for large-scale simulations of disruptions. Simulation modeling was used for long-term construction planning for a highly congested, dense urban network (the New Jersey Turnpike) and to make decisions about which lanes to close, and when, based on levels of reasonable disruption. The C2SMART University Transportation Center is also engaged in work with modeling and simulation of connected vehicles in an effort to support the New York City Department of Transportation’s work in that area.
Ozbay described the value of open source tools such as MATSim, an agent-based modeling tool being used in research on redesigning citywide
___________________
3 For more information about MATSim, see https://matsim.org, accessed March 12, 2019.
4 For more information about SUMO, see https://sumo.dlr.de/userdoc/Tools/Main.html, accessed March 12, 2019.
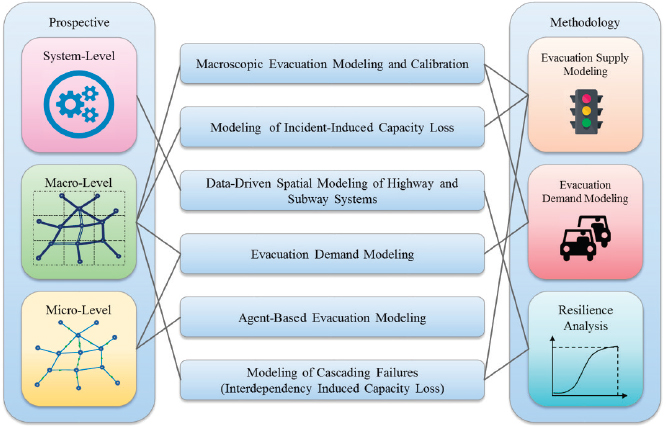
bus systems and in hurricane evacuation planning. Another open source tool, SUMO, can simulate pedestrians and traffic signals, which makes it possible to understand things at a microscopic level. With all of these innovations, Ozbay continued, an urban data observatory (i.e., warehouse) is needed to incorporate these data and use them in conjunction with various kinds of simulation and decision-making tools.
Ozbay summarized priority research areas in transportation modeling and simulation:
- Open source modeling tools, which are key to innovation in the transportation sector;
- Large and detailed data-driven models, which allow better calibration and validation;
- Multiscale models;
- Integrated models (e.g., traffic, climate, communication);
- Online calibration and learning using real-world data from probe vehicles and the Internet of Things; and
- Online and real-time use of simulation models for real-time decision making for traffic control, traffic safety, evacuation operations, and fleet optimization.
He concluded by mentioning the value of virtual/augmented reality for traffic simulations and noted that it is important to consider how simulations will be used as well as how to validate and calibrate models. He warned that simulations can become too computationally complex and can be misused or overused, so simulation should not be used for all types of transportation problems.
Discussion
Fred Abousleman, Oregon Cascades West Council of Governments, said that although massive modeling and simulation efforts have been funded for more than 20 years, he wondered whether the technologies were straightforward enough for local practitioners to use. It is difficult for smaller cities to make decisions about potential investments when the state of the art is changing so quickly. Lewis noted that tools are increasingly available and simulation costs have decreased, so it is easier to deploy technology, iterate solutions, and address problems more quickly. He suggested that there is a need for improved communication with local practitioners so that academic researchers better understand what their problems are and how they might be able to help. Ozbay acknowledged that it takes time for information to diffuse, but open source tools serve as evidence of the growing body of research.
Deborah Goodings, George Mason University, asked what specific changes have been made for people managing hurricane evacuations. Ozbay asserted that evacuations are likely still operating in the same way that they were 20 years ago because models are not being well used in decision making. Goodings wondered why taxpayers should continue to invest when there are no visible outcomes. Ozbay commented that even if progress is slow, there is still value in the work. He suggested that technologies be made open source to increase access instead of relying on commercial developers. Goodings emphasized that this community is responsible for taking action that could lead to real change.
INNOVATION IN GEOSPATIAL DATA SOURCES AND SPATIOTEMPORAL ANALYSIS
Hurricane Harvey: A Real-Time Role for Data Scientists
Katherine Bennett Ensor, Rice University, Moderator
Katherine Bennett Ensor, Rice University, explained that Hurricane Harvey demonstrated a real-time role for data scientists—the Urban Data Platform mentioned in Chapter 2 contains the only existing archive of
Hurricane Harvey data. She emphasized the strength of statistics and data science research and resources in this project, which built on the strength of existing long-term collaborations and was aided by university support (both financially and through recognition).
Ensor’s team also engaged in the redrawing of Houston’s floodplains. Her team was able to show the dramatic change in land cover over a 21-year period as a result of increased urbanization in Houston. This information will be fed into floodplain models, which are complex physics-based models. Her team then asked the following questions: Have extreme precipitation trends shifted over the past century? How are these changes in precipitation, land cover, and floodplain models related spatially? She explained that this is a challenging data science problem, and the solution has to match the level of the problem. She said that her team had to model the 3-day rain event of Hurricane Harvey using extreme value modeling. These models are difficult to fit, she continued, and require a lot of statistical thinking to generate relevant information. She highlighted the great science that enables spatiotemporal modeling of extremes in rare events. She added that there have been tremendous advances in the past 10 years in spatiotemporal modeling for both big and small data and with hierarchical models that allow relatively easy integration of complex data and process structures. Transparent machine learning models are being used more often, as are dictionary-based machine learning models. She said that it is critical to understand the questions that data address, the dependence structure of data, the uncertainty associated with a scenario or decision, and the reproducibility of results.
Big Data and Urban Science: Advancing Sustainability with High-Resolution Spatiotemporal Data and Data-Driven Modeling
Constantine Kontokosta, New York University
Constantine Kontokosta, New York University, explained that his work uses large-scale, high-resolution geospatial data to build data-driven models that address specific problems in urban operations, policy, and planning, particularly in sustainability and resilience. Urban scientists are excited to learn about the complex dynamics of a city using simulations with the “digital exhaust” of a city and citizen-generated data.
He shared some of his work from the Quantified Community at Lower Manhattan,5 which provides opportunities for situational intelligence and for using a variety of data sets (e.g., from credit card transactions, call data
___________________
5 For more information about the Quantified Community, see http://www.urbanintelligencelab.org/quantified-community, accessed March 12, 2019.
records, Wi-Fi probe requests, global positioning systems from sanitation trucks, and 911 incident data) to understand how humans and the physical environment of the city interrelate. These complex interactions are at the heart of urban planning.
Kontokosta’s laboratory is focused on understanding the pulse of New York City and modeling these dynamics, with a clear consideration for and understanding of the city’s socioeconomic and political realities. Computing with heterogeneous data sources is key to the laboratory’s work, as is understanding both data bias and algorithmic bias. It focuses on translational research, working hand in hand with city agencies, industries, and nonprofit organizations to inform decision making and policy. A persistent challenge is how to integrate and process the diverse massive data sets and how to target the appropriate problems to address.
Kontokosta categorized urban big data in three ways: (1) organic data flows (e.g., administrative records and social media), (2) sensors (e.g., data from mobile phones), and (3) novel technologies (e.g., light detection and ranging, and aerial imagery). A sample is used to understand an entire population, which requires an understanding of spatial and temporal dynamic data. Kontokosta said that cities are beginning to think about problems in terms of operations, policy, and planning. Because operations do not involve long legislative processes or citizen engagement, and are thus relatively straightforward optimization problems, most previous work has been focused in that space.
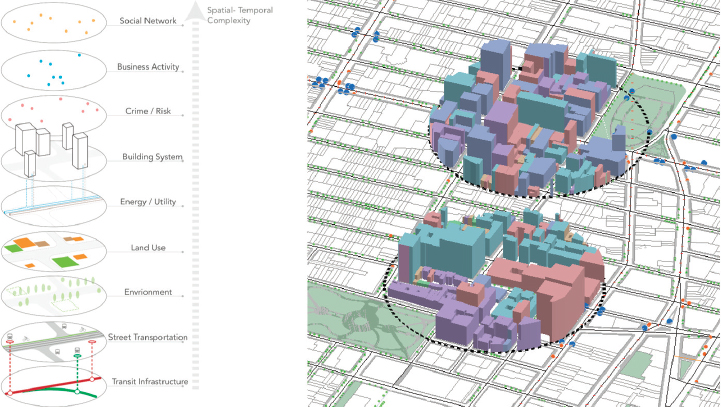
To work with city data, data integration along spatiotemporal dimensions as well as across sectors and domains is necessary. Kontokosta’s team developed a data-mining algorithm that retrieves data from 40 city agencies and other data sources for place-based studies (see Figure 3.4).
He described breaking through the different silos of sectors as another challenge. New York City’s DataBridge is a data repository for all of the city agencies to archive their data each night. However, it is difficult to retrieve the data and to integrate data across the city’s geographic and operational divisions.
Kontokosta described two projects that highlight the use of high-resolution, larger-scale data in the urban space. The first focuses on climate modeling and the leading role cities play in reducing energy use. Approximately two-thirds of carbon emissions in New York City come from buildings, but the transportation network has to be considered as well. New York City has a goal of reducing carbon emissions by 80 percent by 2050; after setting this goal, New York City began measuring, benchmarking, analyzing, and evaluating progress. Large buildings are required by law to report how much energy they use, and Kontokosta’s team has built an interactive online visualization tool that makes it easier to access, analyze, and compare these data. He mentioned that this platform could be used
in any city. His team, supported by a United Nations project, next built a high spatiotemporal resolution of carbon emissions across New York City and estimated the emissions from every building in the city and all traffic routes and vehicles across the city. This can be used to better understand hot spot locations and the patterns of energy dynamics across the city, which helps to target policies appropriately.
The next project he discussed focused on using geospatial data to understand mobility and behavior. Wi-Fi probe requests in New York reveal information about the way people move throughout the city. The goal of the project was to develop a real-time census and understand how many people are in any part of the city at any given time and segment them by behavior (e.g., into categories of resident, worker, or visitor). These models were validated against both census data and ground truth data (i.e., pedestrian counts on the street). His team is now working with the Fire Department of New York and other organizations, who want to better understand real-time populations. Kontokosta referenced Hurricane Harvey as an event from which geolocation data (i.e., from mobile phones) revealed information about a city’s evacuation, emergency response, and recovery. However, he emphasized that collecting this type of information highlights privacy concerns in using high-resolution data as well as the importance of data ethics and governance in the use of such data.
In closing, Kontokosta observed that there are limitations to the application of data-driven methods. Data access and management are nontrivial problems, and he discussed the challenges of developing standardized ontologies that work across domains and cities. There are also questions about privacy, the line between surveillance and observation, and bias in data. To illuminate this final point, he talked about a project to de-bias citizen-generated 311 complaint data in New York City to develop more fair and equitable service and resource allocation models. Some important questions remain in the path toward urban sustainability: What urban data are available and what urban data are needed? What models and methods work best for pattern and anomaly detection in different environments? What applications are possible for cities to use to meet their goals?
Satellite Imagery for Urban Sustainability
Rhiannan Price, DigitalGlobe
Rhiannan Price, DigitalGlobe, explained that DigitalGlobe, founded in 1992, is one of the leading satellite imagery providers in the industry. DigitalGlobe has a repository of nearly 20 years of very-high-resolution satellite imagery spanning the world. Its sensors are collecting 3 million square kilometers of imagery at sub-meter resolutions every day. In addition to resolution, spectral and other properties that cannot be seen with the human eye are important. Near infrared and shortwave infrared present exciting opportunities for cities in particular. Price showed a 30 cm image over a port from space to demonstrate just how much detail can be extracted from satellite imagery. These images can then be used to create digital elevation models.
Price explained that although DigitalGlobe has global coverage, it also images thousands of urban areas consistently, updating the areas annually. DigitalGlobe creates imagery-based maps that are between 30 cm and 50 cm resolution (see Figure 3.5). This means that cities will have regular high-resolution snapshots that could support a variety of use cases, including evidencing deforestation; analyzing watershed, traffic, and land use; responding to disaster; and monitoring large gatherings of people. Price believes that all 17 of the United Nations’ Sustainable Development Goals can be supported either directly or indirectly by remote sensing.
Price described the baseline and tipping and cueing process. This process involves using high-resolution base maps to inform where information will continue to be collected and where it is necessary to distill a signal from noise. DigitalGlobe has been working with various cities to create common geospatial information layers.

DigitalGlobe partnered with PSMA Australia to map the continent using satellite imagery, machine learning, and crowdsourcing. Every address in Australia was attributed with more than 40 different pieces of information, creating a large corpus of open geoinformation. This project demonstrated how diverse stakeholders could collaborate on urban sustainability. With all of this information, DigitalGlobe was able to create a data cube, co-registering the data so that they are interoperable and reveal more insights. Another example of tipping and cueing relates to disaster response. In 2017, DigitalGlobe used imagery to identify where a fire in California was burning most intensely, which was used to inform first responders. Tipping and cueing can also be used for damage assessment after a disaster. Before and after images can be useful for change detection as well as for monitoring and risk assessment, especially for infrastructure such as dams. Price emphasized that DigitalGlobe can provide actionable information that provides a common operating picture to coordinate efforts across the private and public sectors.
Price’s final point was about collaboration and acceleration. Partnerships are crucial to achieve goals, and crowdsourcing (e.g., citizens extracting information from satellite imagery) enables accelerated progress. Crowdsourcing tools can be tailored depending on the use case or the features desired from the imagery, help people think about their world spatially, provide actionable information, and begin to close the gap of
the digital divide. DigitalGlobe also leverages artificial intelligence to extract information accurately from large sets of imagery. She encouraged participants to embrace open imagery and open data and leverage them to achieve goals. Price said that there is an opportunity to accelerate this work by creating a “data collaborative” around urban sustainability and spurring machine learning, crowdsourcing, and other mechanisms to extract information.
Discussion
Andrews Simmons, Resilience.io/Ecological Sequestration Trust, asked Kontokosta about his work across domains. Kontokosta observed that although individual research teams are doing well with data integration, there is room for improvement collectively. Nonlinear causalities offer exciting opportunities to view interactions of different systems. He added that there are a number of interesting studies at the intersection of public health, data science, and urban planning that can be done with domain integration. Ensor cautioned about overinterpreting what the data show.
Ensor asked Price how DigitalGlobe deals with privacy. Price replied that in the high-resolution space, it is important to consider how the data are being disseminated and communicated. While she emphasized that DigitalGlobe works closely with its partners to discuss licensing and usage, it is ultimately the responsibility of the partner to ensure that people’s privacy is maintained. DigitalGlobe is heavily regulated by the U.S. government and the International Trafficking and Arms Regulations.
Elizabeth Zeitler, National Academies of Sciences, Engineering, and Medicine, noted that geospatial data come from cities, researchers, and members of the public. She wondered about Kontokosta’s and Price’s experiences with data accessibility and transparency as well as community members’ interest in the data and models. Kontokosta responded that much appropriate skepticism exists among city agencies and community organizations regarding work with large-scale geospatial data and machine learning algorithms. Having a conversation about transparency is important because it ties into all of the other questions about privacy, trust, and expectations for local government. He suggested finding the right use case, working closely with the partners to understand their needs, and delivering a solution that can be applied and implemented by the partners.
Seth Schultz, Urban Breakthroughs, asked if satellite imagery is being used to predict where urbanization is going to occur. Price said that DigitalGlobe has done informal settlement mapping in the Global South. Another project in Chile used call detail records and satellite imagery to
understand how travel safety is different for men and women and what that means for urban sustainability and policies. Price noted that a better repository is needed to share all of this work, increase collaboration, and move away from siloed research efforts. Kontokosta added that his team works in data-rich environments and looks for generalizability of an approach rather than generalizability of results.
PRIVATIZATION OF DATA AND DATA PRIVACY: TWO SIDES OF ONE COIN
Aniruddha Dasgupta, World Resources Institute, Moderator
Following Kontokosta’s discussion of localized data and Price’s discussion of massive geospatial data, Aniruddha Dasgupta, World Resources Institute, explained that the next step is to discuss how all of this work produces public goods or helps make decisions for the public good. The discussion that followed centered on how to manage the data governance process as data and data science evolve and as privacy concerns increase.
Comments on Privatization of Data and Data Privacy: Two Sides of One Coin
John L. Eltinge, U.S. Census Bureau
John L. Eltinge, U.S. Census Bureau, described the interface of urban sustainability with statistical methodology and technology. Turning the vision of big data into practical reality requires taking a nuanced assessment of statistical information products and services as a form of public good. It is important to reevaluate the traditional questions used to determine the value of public goods (based on a balanced assessment of quality, risk, and cost) with an added consideration for privacy and confidentiality.
Eltinge cited a standard definition of “public goods,” which is distinct from the broader concept “for the good of the public.” Public goods are nonexclusive (i.e., everyone can use them) and nonrivalrous (i.e., if someone else uses them, the value is not reduced). Examples of public goods include public roadways, free national parks, clean air, and even some information products and services provided by governmental statistical agencies. Because standard market mechanisms can be problematic for the production and provision of public goods, it is necessary to reevaluate resource allocation for statistical information products and services.
Eltinge mentioned that within the context summarized above, the literature on public goods also sheds light on issues related to privacy and privatization. He outlined five classes of questions pertaining to public goods and private rights, and he emphasized that there are no easy answers for any of these questions:
- Why are you producing this public good? What are the goals? Goals for statistical products can be characterized in terms of traditional statistical inference. These goals generally relate to one or more of the following: description, association, prediction, causality, or outright control. Some statements of “sustainable development goals,” and related indicators explored in this workshop, appear to reflect interest in statements of “outright control,” which can involve a very heavy lift in inferential rigor and data quality.
- How good is the information? How do customary measures of information quality align with risk, cost, and value? Some measures of quality are quantitative (e.g., accuracy) and others are qualitative (e.g., relevance, timeliness, granularity, comparability, coherence, accessibility).
- Who benefits from production of the good or service? Stakeholder standing and related use cases play important roles in expectations for quality. In addition, it is important to determine whether a given group of stakeholders has specific formal or implicit rights to a given set of data products, at a given level of quality.
- Who controls and how? For example, who frames—and then makes—the very difficult judgment calls about trade-offs among multiple dimensions of privacy, data quality, risk, and cost, at both broad policy levels and at more specific technical levels? Transparent multiway communication in these governance areas can be crucial to the reduction of information asymmetries and improvement of efficiency. Eltinge referenced Principles and Practices for a Federal Statistical Agency (NRC, 2013) as a good distillation of many of the underlying issues.
- Who pays for the good or service? How much is paid and what is the transfer mechanism? Costs are often measured through cash expenditures but also include burden on the data provider and several additional intangible or difficult-to-measure dimensions of resource requirements. Privacy rights for data sources and intellectual property rights for some data sources and intermediaries are examples of important intangibles.
In closing, Eltinge suggested that when thinking about privacy and privatization, it can be useful to frame some questions in the context of the
public goods literature. One should also consider the interface of public goods and private rights, which naturally involve complex trade-offs. He emphasized that clarifying what is known and unknown relating to those five classes of questions could help, as does communicating clearly and respectfully with stakeholders.
Privatization of Data and Data Privacy: Local Data Flows
Sallie Keller, University of Virginia
Sallie Keller, University of Virginia, discussed privatization of data and data privacy at local levels and provided the following definitions relating to her understanding of privacy:
- Privacy refers to the amount of personal information individuals allow others to access about them.
- Confidentiality is the process that data producers and researchers follow to keep individuals’ data private.
- Security applies to data storage and transport.
- Privatization of data is the collection, aggregation, and (re)processing of personal data to sell to consumers.
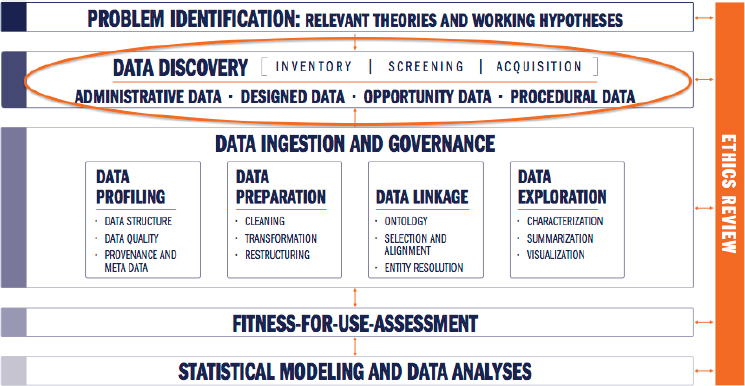
She suggested that the data pipeline begin with data discovery instead of data acquisition, because so much is gained from learning about and using new data sources when working to solve problems (see Figure 3.6).
To illuminate this point, Keller described a research problem about affordable housing. Data sources included designed data, administrative data, opportunity data, and procedural data, all of which provide different challenges with respect to privacy, confidentiality, security, and privatization. The discovery to find local housing data revealed more than 50 different potential data sources, including commercial, local, and state sources. This data discovery exercise illustrated that there is an abundance of housing data available and that the data discovery process is essential as a first step to solving a problem creatively or answering a research question. She emphasized that the data science steps to discover, profile, prepare, link, and explore data sources are not trivial. Statistical sciences provide the methods to integrate different units of analysis over time and space.
Keller noted that it is important to think about one’s purpose in using data when considering the role of informed consent. For example, policy-focused analyses are very different from case management. The
Commission on Evidence-Based Policymaking (2017, p. 24) explained the following:
Access to data held by the government should occur only in service to the public interest. Decisions about allowing data access must be calibrated according to a project’s potential public benefits, the sensitivity of a particular data set, and any risk that allowing access could pose to confidentiality. Access can and should be restricted to eligible individuals who demonstrate an understanding of their obligations for data stewardship.
She described these standards as similar to those set by institutional review boards (IRBs). The IRB principles govern the collection and use of data on human subjects or the use of archival data. Keller encouraged individuals who may be engaging with the ethical dimensions of data science research to take IRB training. She also shared a number of instances when it makes sense to waive informed consent, as detailed in the Federal Policy for the Protection of Human Subjects:
- The research involves no more than minimal risk to the subjects;
- The research could not practicably be carried out without the requested waiver or alteration;
- If the research involves using identifiable private information or identifiable biospecimens, the research could not practicably be carried out without using such information or biospecimens in an identifiable format;
- The waiver or alteration will not adversely affect the rights and welfare of the subjects; and
- Whenever appropriate, the subjects or legally authorized representatives will be provided with additional pertinent information after participation.6
For agencies, Keller continued, the Privacy Act of 19747 states that records can be used by researchers but only for statistical purposes. She reiterated that these rules apply to policy analyses, not to case management. Data sharing agreements with local governments have similar guidelines about the role of research for the public good. She shared a cautionary note about responsible analyses, using an example from Amazon’s expansion of Prime same-day delivery. Even though the algorithms did not use race as a factor, there were social biases in the data that led the algorithms to recommend that white neighborhoods receive same-day Prime delivery services and black neighborhoods do not.
Keller suggested that the Community Principles on Ethical Data Sharing (Data for Democracy, 2017) should be exercised continuously. She summarized these principles as follows:
- Fairness. Understand, mitigate, and communicate the presence of bias in both data practice and consumption.
- Benefit. Set people before data and be responsible for maximizing social benefit and minimizing harm.
- Openness. Practice humility and openness. Transparent practices, community engagement, and responsible communications are an integral part of data ethics.
- Reliability. Ensure that every effort is made to glean a complete understanding of what is contained within data, where it came from, and how it was created.
Keller concluded by commenting that the data revolution is changing the focus of the privacy discussion from the masking and suppression of data to maintain confidentiality to building trust, policy, and governance around data practices; this is in itself a revolution in both data and society (see Keller, Shipp, and Schroeder, 2016).
___________________
6Federal Register Vol. 82, No. 12 45 CFR 46.101(l), as amended June 19, 2018.
7 For more information about the Privacy Act of 1974, see https://www.justice.gov/opcl/ privacy-act-1974, accessed March 12, 2019.
Privacy Considerations for Integrated Data Efforts
Michael Hawes, U.S. Department of Education
Michael Hawes, U.S. Department of Education, discussed privacy considerations for integrated data efforts, why it is difficult to acquire data, and how people can acquire data more easily. Hawes said that he is both a privacy regulator and an advocate for data-driven decision making, so he works to find ways to protect student privacy while still enabling data analyses that have the potential to improve students’ educational experiences and outcomes. Noting that people sometimes incorrectly use the terms privacy, confidentiality, and security synonymously, he provided a series of definitions. Building on a Random House Dictionary definition, Hawes described “privacy” as protecting individuals from unreasonable intrusion or disturbance into their private lives or affairs. He added that components of privacy could include information privacy, bodily privacy (e.g., airport scanners and wearables), territorial privacy (e.g., entering one’s home without permission or collecting geospatial data), and communications privacy (e.g., mobile phones and eavesdropping). He said that “confidentiality” is a component of privacy, but it relates to protecting access to the information itself and keeping that information private. He described confidentiality in terms of appropriate data access and privacy as appropriate data use. “Security” relates to the systems on which data are hosted, and it protects the confidentiality, integrity, and availability of data.
Hawes explained that new data sources raise new privacy concerns relating to data access and sharing, data release, and transparency. He observed that it has become more difficult to obtain data, owing to recent proliferation of state and local privacy laws, improved agency awareness of existing legal requirements, greater scrutiny of agency data practices, and changes in agency risk tolerance. Strategies to navigate these challenges include knowing the relevant laws, practicing data minimization and use limitation, understanding and building a relationship with the data provider, and being transparent and explaining the value of the work. Data re-identification has become a major concern, causing many agencies to enhance their privacy rules for publishing data. To confront these challenges, Hawes suggested understanding the underlying methodological options and their differing impacts on data quality, discussing protection methodology requirements during the acquisition process and being ready to propose alternatives, and remembering to consider the cumulative impact of data releases on re-identifiability. He concluded by emphasizing that transparency is a key component of privacy; a lack of transparency can derail worthwhile data initiatives. To increase transparency, Hawes suggested proactively explaining data practices, soliciting
feedback from the community, and articulating the value of a project in tangible terms that relate to the data subjects. Hawes urged people who are interested in education data or data governance to visit the U.S. Department of Education Student Privacy website8 for resources.
Discussion
Dasgupta noted that each time a person “accepts” terms to use an app, that person has given up some of his or her privacy rights. However, the boundary between private use and public use of data is not always clear. He asked how to protect privacy while still working with data for greater public good. Hawes said that this is particularly complicated in education because schools collect a lot of information about students as part of providing an education. School administrators have to evaluate levels of risk and determine what uses of those data are appropriate. Because the parents and students do not decide if the use is appropriate, transparency is especially important. With transparent practices, parents and students have an opportunity to raise concerns and be part of the decision-making process. Keller noted that confidentiality practices have historically been built around bits of information. Instead, a paradigm shift from protecting data to protecting the use of the data is necessary. She emphasized that it is not possible to protect the privacy of individuals when all of their data are so readily available. She mentioned that those who work with medical data have made more progress in embracing this paradigm shift than those who work with social data. Eltinge said that a high degree of transparency is essential and that data providers should communicate clearly with decision makers. He suggested identifying critical use cases to start the conversation about privacy, risks, trade-offs, and value and added that formal legislation often responds to shifting social norms.
Ensor asked if there are (or should be) practical rules for republishing geospatial information. Keller thought that it would be useful to develop such rules to build more trust around the use of data. Dasgupta expressed skepticism about cities having systems in place and capabilities to manage and protect data, especially given the pace at which solutions and innovations are occurring. He wondered what could be done in the regulatory space to keep up with these infrastructure changes in cities. Hawes suggested a focus not only in the regulatory space but also in the technology space. Technologies such as secure multiparty computation offer a way to leverage disparate data that may have different regulatory
___________________
8 The U.S. Department of Education Student Privacy website is https://studentprivacy.ed.gov, accessed March 12, 2019.
privacy protections. Eltinge noted that new technologies can both benefit and harm society; however, harmful experiences can be mitigated by technological, regulatory, or societal buffers. In-depth exploration of relationships among inferential goals, methodology, and disclosure risk can offer insights on ways to reduce the likelihood and impact of substantial negative outcomes. Keller added, and Hawes agreed, that data misuse should always be punished or exposed in some way.
DATA USE EXPERIENCES ACROSS CITIES
Data Access and Innovation for Cities
Amanda Eichel, Global Covenant of Mayors for Climate and Energy
Amanda Eichel, Global Covenant of Mayors for Climate and Energy, described the Global Covenant of Mayors for Climate and Energy as an alliance of more than 9,000 cities (more than 7,000 of which are in Europe) that have agreed to take on climate change consistent with the Paris Climate Agreement targets. Eichel expects that more cities would join this initiative if they had additional resources to support implementation. The Global Covenant of Mayors helps ambitious cities that are not data rich to gain resources so that they can take action. The Global Covenant of Mayors creates a space in which all of its partners can work together to support these cities. It also focuses on vertical alignment, in which national governments work in partnership with local governments. The Global Covenant of Mayors is also essentially a data platform, making city data publicly available in a transparent and consistent way.
Cities have different tools available to them to take action (e.g., some can influence policy, some are policy implementers, and some are partners who set the stage for others to move things forward). The pathways to move from ambition to implementation are complex, making it difficult for many of the cities to scale their processes. Eichel explained that the Global Covenant of Mayors has thus started an initiative on research and innovation. Cities need support from partners in national and regional governments, academia, business, and civil society across three pillars: science and research, innovation and technology, and city-level data access. Three core initiatives are supported by the Global Covenant of Mayors and then deployed through regional covenants:
- Data4Cities. This initiative develops a new reporting standard as well as creates a database and website to open up access to data for cities to support climate action planning.
- Innovate4Cities. This initiative provides a research and innovation agenda to catalyze the scientific advances necessary to better equip cities with the intelligence and tools to take even more ambitious climate action. The initiative’s call to action includes advocating to national governments for commitments to specific, targeted funding; developing partnerships with the private sector; building a more consistent research agenda among city networks; and engaging with the research and academic communities.9
- Invest4Cities. This initiative aims to raise $800 million for technical assistance and credit enhancement financing as well as to pilot an effort to vertically integrate investment plans.
Eichel explained how to think about the flow of data in the city reporting space through a series of steps: (1) data gathering and analysis (to understand what is happening on the ground); (2) reporting (three platforms are available); (3) data management (a consolidated global database is being created to bring reporting from the three platforms together to make information available to the public and create more knowledge and insight); (4) auditing (ensuring that the reporting is consistent with what happens on the ground) and badging to recognize progress; and (5) data sharing and public access.
Eichel said that many cities do not have the data they need to meet these commitments, so the Global Covenant of Mayors launched a partnership with Google to share data with cities; the goal is to improve decision making around transportation and buildings. She noted that there are still privacy issues to be discussed in this partnership. The Global Covenant of Mayors also has a partnership with the World Resources Institute (WRI) to create a national data portal for cities.
Response to Data Access and Innovation for Cities
Jessica Seddon, World Resources Institute, Discussant
Jessica Seddon, WRI, observed that the Global Covenant of Mayors’ initiatives demonstrate effective ways to bring new data to bear on increasingly urgent and complex problems. Seddon explained that the WRI Ross Center for Sustainable Cities works mostly in the Global South with lower-information cities (i.e., cities without historic investment in statistical systems and national data) that are facing problems for which
___________________
9 For more information about the Innovate4Cities initiative, see https://www.globalcovenantofmayors.org/participate/innovate4cities, accessed March 12, 2019.
they need data. WRI also helps cities figure out how to use data that are outside of the public sector (e.g., remote sensing, citizen science, data generated by local universities, data from the private sector, activities data), and it works on issues related to air quality, flood modeling, land use change detection, and informal settlements.
Seddon emphasized the following points:
- You can lead a horse to water, but you can’t make it drink. City use of data is multifaceted. Individual adopters can implement specific changes, but systematic use of data within the broader bureaucratic processes (e.g., procurement, public investment planning, zoning, assessment of use of land, use of resources, and optimization of transport systems) is a substantial hurdle that often depends on the city structure. Many city systems are optimized around efficiency but not necessarily resiliency, and a change in institutional design (as opposed to a change in the data) is needed.
- The sovereign barrier exists. Once a city decides to use analysis that is based on data not from a concerted public investment in collection and analysis, a supply chain risk develops. Good precedents for being able to manage this risk and remain sustainable over time do not yet exist.
Discussion
Dasgupta asked how data are being used by the governments and mayors of data-poor cities who are partnered with the Global Covenant of Mayors. Eichel responded that of the nearly 2,000 cities outside of Europe, 30 percent have a climate action plan that they have begun to implement. The barrier for the remaining 70 percent is access to data, which will hopefully be alleviated by the new partnership with WRI. The Data4Cities and Innnovate4Cities initiatives could automate a process for cities so that a sufficient data inventory becomes something they can access and use to take action. Ultimately, the Global Covenant of Mayors hopes to automate a scenario planning or policy scenario planning process for cities.
Caetano de Campos Lopes, Citizens’ Climate Lobby, noted that information to benchmark return on investment is not available at the local level, and he wondered if there are any ongoing projects to address this issue. Eichel said that through its city network partners, the Global Covenant of Mayors is investing many resources in research around the benefits of taking action on climate change, including assessing the economic benefits, payback, jobs created, and health benefits of specific interventions. She agreed that information on return on investment is a
top priority. De Campos Lopes also asked Seddon about her opinion on the treatment of Scope 3 emissions in the Greenhouse Gas Protocol for Cities.10 Seddon said that WRI should have included Scope 3, and she confirmed that it is a top item on a future agenda for the report.
Price asked whether there is an opportunity for data-poor cities to leapfrog with technology advances or if there are systemic barriers in the way. Eichel commented that there is interest and ambition from various cities, and her organization would be interested in a partnership to figure out how to use those technologies. Seddon added that although the opportunity to leapfrog exists, it will not happen if concerns about the sanctity of the data supply chain, the incentives to manipulate or increase the cost of data, and the sustainability and consistency of metadata over time are not addressed. To enable leapfrogging, the gap between private-sector and public-sector data services must be bridged. Eichel wondered at what point data are sufficient to empower cities to take action at scale quickly while balancing precision.
Anu Ramaswami, University of Minnesota, suggested that stakeholders consider lessons, simplifications, and insights that can be drawn from work in certain cities and applied to others. Seddon agreed that science-based targets are important and that an increasing number of methods are available, although it is difficult to collect information in a consistent way. Keller asked whether there are linkages between city and state plans. Eichel confirmed that the Global Covenant of Mayors is still working on coordination between state and local actors. She added that this vertical integration is a challenge in both directions, especially at the global level when each country’s entities have different levels of control.
___________________
10 The Greenhouse Gas Protocol for Cities is a standard and set of tools to measure greenhouse gas emissions, build emissions reduction goals and strategies, and track progress comprehensively. Scope 3 emissions refers to the emissions from the upstream and downstream supply chain for a city, outside of Scope 1 (i.e., direct emissions within the city) and Scope 2 (i.e., emissions from the generation of energy that is imported into a city). The website for the Greenhouse Gas Protocol for Cities is https://ghgprotocol.org/greenhouse-gas-protocol-accounting-reporting-standard-cities, accessed April 4, 2019.


























