








































Below is the uncorrected machine-read text of this chapter, intended to provide our own search engines and external engines with highly rich, chapter-representative searchable text of each book. Because it is UNCORRECTED material, please consider the following text as a useful but insufficient proxy for the authoritative book pages.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 59 State Transportation Agencies 3.0 Utah DOT Findability Tests 3.1 Planning and Scoping Round 1 Utah DOT was interested in the NCHRP 20-97 project because they were in the process of implementing a new information indexing and discovery tool called âKnowvation,â provided by PTFS. This tool includes full text search, faceted search, and spatial (map-based) search capabilities. It also has the capability of âcrawlingâ specified disk locations and building an index of content. It extracts metadata from file information (e.g., file type and date) and parent directory names. For example, if documents are organized in folders based on the project, the project numbers are extracted as metadata. Multiple file types are extracted including data sets in various formats and text documents. Content is not ingested within UDOTâs implementation of Knowvation; the system creates an index to power search, and the content is accessed in its home location. Users of the system must have the necessary access privileges to view the files that they discover via the tool. In addition to the Knowvation tool, UDOT has implemented the ProjectWise (PW) engineering content management system, which is used across the Department for project design and development files. A variety of data sets and project-related documents are also discoverable and accessible via UPLAN, UDOTâs GIS portal. UDOT also provides access to data sets through its dashboard application. At the time of this pilot, UDOTâs PTFS project included indexed content from: ⢠A shared drive within UDOT Region 2 containing a variety of project-related files, ⢠ProjectWise folders maintained at the central office and within different regions, ⢠ArcGIS/UPlan â geospatial data available within UDOTâs data portal (UPlan), and ⢠Socrata data â datasets assembled for UDOTâs agency dashboards. The scope of the NCHRP 20-97 pilot was developed based on discussions with UDOT staff. Discussions were also held with representatives of Knowvation vendor to gain their perspective on key findability challenges and strategies being pursued as part of their project. These discussions identified the following search scenarios or âuse casesâ: ⢠Paving Project Scoping: Find old plans and background data for a site to inform development of a new project â specific information of interest includes: the award plan set, environmental commitments documentation, traffic analysis, pavement materials, bridge reports, billboard agreements, permits indicating who has right of access and who can put signs on the property. ⢠Corridor Study: Find information for a corridor to inform the study-specific information of interest includes: prior plans, project reports, agreements, concept reports, design exceptions, Planning and Environmental Linkage (PEL) reports, traffic impact studies, safety studies, data sets (traffic, environmental, socio-economic, land use, rail and transit facilities/routes).
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 60 State Transportation Agencies ⢠Environmental Analysis: Find resource reports to inform the analysis â for example, any previously conducted cultural resource or wetlands report as part of a federal or state environmental document. ⢠Public Records Requests: Respond to requests for information from the public â information may include accident reports, as-builts, environmental reports, traffic control plans, signal timing, old concept reports, and project-related emails. ⢠Research Agreements: Find an older agreement that may impact a current action. â Example 1: The Department had the opportunity to take down an old railroad bridge. DOT staff recalled that there might have been an agreement with the railroad that impacted the ability to do this. The railroad does not have the agreement. â Example 2: A project team is mapping out a drainage system as part of a stormwater pollution prevention plan development. They are focusing within a six-county area, inspecting the outfalls and checking water quality. They want to find any drainage agreements in place that may impact the identification of actions needed to meet water quality standards. Key findability challenges discussed were: ⢠ProjectWise is set up to best support searches for information about a specific project â as opposed to across projects. Knowvation can support this â but unless the user has specific access privileges to the source documents, they can only see a list of query results â they cannot access the original documents. ⢠Knowvation has indexed a large volume of documents â there are over 4 million records in the system, and this is anticipated to grow. While filter options are provided for the source, project number and name, route, year, document title, and file type (e.g., PDF, DOC, XLS), a query may retrieve several hundred documents. Added filters to narrow results by content type would be helpful. ⢠Most people want to search by route and milepost, so geo-locating information is essential. Because individual project files may not have spatial metadata, the spatial information about the project itself is being used to geo-tag its files. ⢠Both project numbers and route numbers exist in a variety of formats and need to be normalized to support searching. ⢠Many documents (mainly PDFs) are not text readable. The Knowvation tool can apply Optical Character Recognition (OCR) to the documents as part of the indexing process, but since the source document must be left in place as is (and not OCRâd), the tool is not able to highlight the appropriate search term within the returned (source) document. ⢠Knowvation supports concept searching and has a modifiable thesaurus, but this thesaurus needs to be customized for DOT-specific terminology. Following these discussions, we agreed to focus the scope of the NCHRP 20-97 test on auto- classification of content types â specifically agreements, and extraction of selected metadata elements from the agreements. Several additional types of tags were considered for future implementation:
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 61 State Transportation Agencies ⢠Location â the Knowvation product includes basic geocoding capabilities (e.g., to look up city and county names); we can consider supplementing these capabilities by adding the ability to pull out routes and street names. ⢠Content type (beyond agreements) â based on a tailored list of categories relevant to corridor planning â for example, âlocal comprehensive planâ, âtraffic studyâ, âpublic meeting minutesâ. ⢠Organizations â based on a tailored list of categories representing the originating or participating organization in creating the document â for example, Utah DOT, local agency, MPO, state economic development corporation, engineering/consulting firms, etc. ⢠Type of data or analysis â based on a tailored list of categories representing the type of data or analysis presented in the document â for example, traffic counts, bicycle/pedestrian counts, level of service, travel time/delay, crash/safety, air quality, etc. Round 2 A round 2 testing scope was developed to build on and extend the work on agreements in round 1 to other content types. Content types were selected based on meetings with representatives of project development and right of way functions. A task was also included to replicate the cluster analysis conducted for the WSDOT manuals. The round 2 scope was as follows: Auto-Classification and Entity Extraction ⢠Perform auto-classification and entity extraction for the following content types: project concept reports, design exceptions/waivers, quitclaim deeds, warranty deeds, and highway easement deeds. ⢠Create a file with the metadata tags assigned through auto-classification and entity extraction and provide this to the Knowvation vendor. These tags will enable demonstration of how metadata created through auto-classification can be used to improve search and discovery. Cluster Analysis ⢠Obtain a set of engineering manuals from UDOT that cover the same body of material that was included in the WSDOT first round of tests. Run the clustering analysis performed for WSDOT in the first round of tests. Compare the results from the two states to assess transferability of this type of analysis across states and the potential for developing common subject categories for search and discovery within engineering manuals across DOTs
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 62 State Transportation Agencies 3.2 Content Collection and Analysis Round 1 Content Collection UDOT staff downloaded content from the Region 2 file drive and ProjectWise. We requested that only text files (TXT, DOC, DOCX, PDF, RTF) be provided, but it was difficult to extract files from ProjectWise meeting these criteria â with the result that a large number of other file types were included in the corpus. The original corpus provided by UDOT contained roughly 272,000 files totaling 727 gigabytes. A smaller, more targeted corpus for analysis was created by: ⢠Filtering the files using the Windows: Kind=Document â this removed text-based files (such as .DGN) ⢠Filtering the files to those containing at least one of the following in the file name or contents: â âAGRâ â âUTâ â âBETTERMENTâ â âMAINTâ These terms were selected based on a review of UDOTâs ProjectWise file naming conventions for agreements and through a review of sample agreements of various types. They were designed to filter down the files received to a set that could potentially be agreements â but also to include a large number of files that were not agreements. This yielded a corpus of 5,683 files (4.59 Gigabytes). The auto-classification techniques would focus on identifying which of the files within this more limited corpus are agreements. Content Analysis and Processing An informal content analysis was conducted to understand the various content types within the corpus. Figure 11 shows the most frequently occurring content types (other than agreements). Figure 12 illustrates the different types of agreements within the corpus. Five types of agreements were selected for the analysis, and are shown in bold. Figure 13 illustrates variations for a single agreement type (utility agreements).
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 63 State Transportation Agencies Figure 11. Frequently occurring content types. Figure 12. Agreement types.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 64 State Transportation Agencies Figure 13. Utility agreement types. The next step was to assemble training sets of agreements for the machine learning exercise â as well as to inform the rule development process. This involved additional, more targeted searches and a manual process of inspecting the search results. Training sets were created for five different types of agreements, totaling 88 files: ⢠Utility Agreements ⢠Maintenance Agreements ⢠Cooperative Agreements ⢠Betterment Agreements ⢠Drainage Agreements Also, a training set containing files that were verified not to be agreements was assembled. Several challenges were faced in assembling these training sets. Based on searches, we found that the selected agreement types were sparsely represented in the corpus, which created concerns that there would not be a large enough number of files to include both in the training set and in the target corpus for analysis. We contacted UDOT and requested that they locate additional agreements for us â with a focus on maintenance agreements. Based on the use cases, maintenance agreements were of particular interest because they tend to extend beyond the timeframe of a construction project. In contrast, betterment and utility agreements tend to be related to cost sharing and division of responsibilities during the project itself. UDOT was able to supplement the corpus with additional maintenance agreements. In addition, some issues related to working with PDF files were discovered and addressed: ⢠Many PDF files were not text readable. We used the OCR conversion capabilities within Adobe Acrobat Standard to do the conversion. ⢠Some files had password protection which prevented OCR conversion from working. No solution was found to get around this issue â the original file creator must run OCR conversion on such files so that they can be searchable. ⢠Microsoft Windows file explorer (64-bit versions) will not automatically search within PDF files âout of the box.â One must use Adobe Acrobat for this, or download and install a
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 65 State Transportation Agencies registered IFilter for Microsoft Windows â and then reindex existing files (a time consuming process). Round 2 Content for Classification and Entity Extraction After work on round 1, UDOT completed an effort to apply OCR to files indexed in the Knowvation system. To take advantage of this larger corpus of machine readable files, we decided to work with an entirely new corpus of content for the round 2 tests. Utah DOT provided a set of TXT files that had been produced through OCR processing of their ProjectWise and ProjectWise Archive data sources. We requested the PDF files to facilitate our recall and precision testing process â since TXT files have been stripped of the formatting that enables one to easily identify a content type. UDOTâs contractor (PTFS) provided a set of OCR- processed PDF files corresponding to a subset of the content. PTFS was not able to provide a PDF file corresponding to each of the TXT files, since they only stored those PDFs that had required OCR processing; other PDFs that were originally machine readable were only available in their original locations. Because the TXT and the PDF files were produced through an automated data export routine, each of these datasets were provided in the form of multiple extract packages, with files assigned arbitrary names. Each package included a .csv file listing its contents and providing a key field allowing each file to be traced back to its parent file within ProjectWise. The .csv files from the PDFs also included available metadata elements from ProjectWise. We requested that this metadata be provided in order to assess the quality of existing metadata, and to validate our techniques for extraction of similar metadata elements (project numbers, locations). Using the .csv files for all of the extracts, we created a database with one record per TXT file, and columns for each of the .csv items from both the TXT file .CSVs and the corresponding PDF file .CSVs. This database allows the TXT files to be matched up with their corresponding PDF files â and associated metadata. Through creating this database, we discovered a large number of duplicate TXT files. These duplicates were marked in our database for exclusion from the final output files. A total of 782,807 TXT files were provided, of which 550,097 were unique. A total of 284,184 PDF files with metadata were provided. We also obtained a data extract from UDOTâs ePM system that includes a listing of projects with Project Identification Numbers (PINs), project numbers and locations (description, route, begin milepost, end milepost, county). The information in this file was to be used to supplement the entity extraction results â providing an option, for example, to look up location information for a document once the project number was known. Manuals Cluster Analysis We requested copies of manuals from UDOT that corresponded to the 18 WSDOT manuals included in WSDOTâs cluster analysis. UDOT only had 10 manuals â and collectively these manuals include 98 chapters (versus 350 for WSDOT). Several of UDOTâs manuals were in the
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 66 State Transportation Agencies process of revision, so some of the equivalent WSDOT manuals were not available or incomplete. We âchunkedâ the UDOT manuals into chapters, and ran a cluster analysis using the same technique (k-means analysis) used for WSDOT. We also re-ran the WSDOT cluster analysis with the same parameters to enable comparison across the two states. Figure 14 illustrates sample clusters identified through the analysis of UDOTâs manuals, along with the most representative terms for each cluster. Figure 14. Utah DOT manuals cluster analysis - sample clusters. Figure 15 shows which UDOT manuals included chapters falling into each of the 14 clusters. Figure 15. Utah DOT manuals cluster analysis: distribution of clusters by manual.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 67 State Transportation Agencies In general, we found that UDOTâs manuals had less overlaps in topics across manuals than WSDOTâs did. We also found that nine of the 14 clusters matched across the two states. Matching clusters are shown in blue in Figure 15. We then compared the top 25 words that defined these common clusters. As shown in Table 12, the Survey cluster had the most degree of commonality between the two states â with 17 of 25 words matching. The construction contracts cluster had the least degree of commonality, with only 6 of 25 words matching. Variation across the clusters with respect to common words reflects the presence of state-specific content within the manuals. Results from Table 12 indicate, for example, that the manual sections on the survey topic focused on technical content not specific to the DOT, whereas the manual sections including discussion of how to assemble construction contracts were more state-specific. Table 12. Comparison of cluster terms between WSDOT and UDOT Common Cluster # Top 25 Words In Common Survey 17 Stormwater 12 Geometrics 11 Environment 10 Consultant Services 9 Drainage 9 Utilities 8 ROW 7 Construction Contracts 6 3.3 Solution Development and Testing Round 1 The initial solution development for UDOT involved the following activities: ⢠Develop and apply rules and machine learning approaches for assignment of agreement types to files. Compare results obtained using these two approaches; ⢠Develop entity extraction scripts for Project Number (PIN), agreement party (who is the agreement with), Tax ID (for drainage agreements), and agreement date; and ⢠Create an output file with assigned tags and corresponding file references that can be used by PTFS to augment the existing metadata within Knowvation. Tool Selection We selected open source software programming language Python 3.6 with its various components to perform the analysis. We primarily used NLTK (Natural Language Toolkit) and
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 68 State Transportation Agencies SCIKIT-Learn modules within Python. NLTK is a Python module that provides a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning. SCIKIT-Learn is a machine learning library that features classification, regression and clustering algorithms including Naïve Bayes, Support Vector Machines, Random Forests, Gradient Boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy. For the entity extraction task, we use Pythonâs NLTK expression matching modules. To install most of the Python packages, we downloaded Anaconda 3, which is an open source distribution of Python and its various packages. Machine Learning Algorithms There are two main types of machine learning techniques used to classify text documents â supervised and unsupervised learning. When labeled/tagged data is available, supervised learning models are used; labeled data is used to train the model and then predictions are made on the unlabeled full corpus. The model is developed on a training set of documents and predictions are made on a test set to assess the performance of the model. If satisfactory, then the model is applied to the entire unlabeled corpus. ⢠Naïve Bayes Classifier is based on applying Bayesâ theorem with the ânaïveâ assumption of conditional independence between every pair of features given the value of the class variable. Despite this assumption, it works well for document classification and spam filtering. We used the Multinomial Naïve Bayes algorithm because our documents can belong to one of five different types of agreements. Multinomial Naïve Bayes implements the Naïve Bayes algorithm for multinomially distributed data and is one of the two classic Naïve Bayes variants used in text classification. See reference (4) for more information on Naïve Bayes. ⢠Support Vector Machines (SVM) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples that are each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier (although methods such as Platt scaling exist to use SVM in a probabilistic classification setting). An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall. SVMâs are inherently two-class classifiers but can be used for multi-class classification. Application of the machine learning approach involved the following steps: ⢠Convert word and PDF documents to text files. ⢠Pre-process the text files to perform tokenization, stemming, and remove punctuation and stop words. ⢠Extract features from the text files (the terms to be used for processing by the algorithms.) Two different approaches were tried for UDOT â application of Pythonâs
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 69 State Transportation Agencies CountVectorizer module which creates a simple âbag of wordsâ term frequency matrix, and a âterm frequency-inverse frequency distribution (tf-idf) matrixâ. Bag of words is basically a count (frequency) of all the words (terms) in a document. Tf-idf weights the frequency of a term in a document with a factor that discounts its importance when it appears in almost all documents. Therefore, the terms that appear too rarely or too frequently are ranked lower than terms that hold the balance. ⢠Specify the classes to be predicted by the model. A three-way classification was used: Maintenance Agreement, Other (Non-Maintenance) Agreement, and Non-Agreement. ⢠Assemble a training-test set to build the initial model that contains representative examples of the different classes to be predicted. Use 80% of the documents to build the model, and set aside 20% of this training-test set for testing the initial model. ⢠Build the initial model using the training set, and test it on the test set. Evaluate the results by comparing the predicted classifications versus the actual classifications in the test set. Adjust the model parameters to try and achieve a better result. Key parameters include thresholds specifying when to exclude certain terms from the analysis because they are either too common or too rare. For example, the UDOT models dropped terms that are in 70% of the documents or only in 1 % of the documents. ⢠Once the model prediction rate is good (over 80 percent correct predictions), test the model on a larger set of files from the full corpus. If the prediction rate drops significantly, augment the training set and re-fit the model. Iterate until satisfactory results are achieved. For the UDOT agreements classification, there were four iterations of model development. Initial model development found that the count vectorizer data set achieved better results than the tf-idf data set, so the count vectorizer data set was used for the final models. Rule-Based Classification The objective of rule-based classification is to find and classify documents by content type based on a set of logical rules. There are two basic approaches to rule-based classification. The first involves assigning documents to a particular category based on a set of logical (IF-THEN) statements. The second involves applying multiple rules, each of which assign scores to documents based on the presence of a term within a particular portion of the document. These scores summed across all rules, and the final score is used to assign the document to a category. The process for developing a classification rule set for the requires the following steps: ⢠Select document types to be classified. ⢠Manually create training sets with examples of the document types. Training sets should contain from ten to fifty representative documents (fewer if the document type is relatively uniform within the corpus; more if there are several variations in the corpus). ⢠Examine different documents in the training set to determine if there is a common document name included in the document â and if so, where it is typically located in the text.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 70 State Transportation Agencies ⢠Determine the character block (number of characters in a representative document) that the script will need to examine. Count characters from the beginning of the text. Define a character block that the script will examine to find a match. ⢠Analyze the various patterns that the document type name is represented in the documents. ⢠Write a set of rules that Python will use to screen the corpus for each document type. ⢠Test the script and rules against the training set. ⢠Examine each unclassified document to determine why it is not identified by the rule set. ⢠Edit the rule set to capture observed variations in the document type name not covered by the original rules. ⢠When satisfied that the rule set can positively identify the document type and differentiate all instances in the training set, switch to a random sample of the entire corpus to test. ⢠Test a random sample of documents from the corpus. ⢠Examine the results for positive matches, false positives, false negatives, and negatives. ⢠Edit the rule set to reduce incidence of false positives and false negatives. ⢠Run the final script to produce an output file that classifies each file in the corpus. Specific rules were written to identify each category of agreement: ⢠Utility Agreements ⢠Maintenance Agreements ⢠Cooperative Agreements ⢠Betterment Agreements ⢠Drainage Agreements Creating rules Examination of each of the training sets used for machine learning provided the evidence of the patterns in the text that could be used to create rules. For example, in the screenshot shown in Figure 16, the character string âMaintenance Agreementâ is in the header of the document. The rule that describes this pattern, in this case, would be: If the character string âMaintenance Agreementâ occurs within the first 1000 characters of a document, then assign a score of 10.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 71 State Transportation Agencies Figure 16. Maintenance Agreement Example 1. In a second, more complicated example shown in Figure 17, the words âMaintenance Agreementâ occur within the first 1000 characters, but there is a space between each character. Therefore, the rule was: If the character string âM A I N T E N A N C E A G R E E M E N Tâ occurs within the first 1000 characters of the document, then assign a score of 10. By examining a representative sample of maintenance agreements and noting the patterns of the way the characters are presented, a robust set of rules was created. Note that rules can be specified to be case sensitive or not; and to include or exclude leading and trailing spaces. Rules can also be specified to look only within a certain portion of a document â e.g. in the first 500 words. Rules were built and stored in an Excel .csv file that can be called from a Python script. In the rule set developed for the UDOT agreements, there are three columns in each rule set: the character string, the score assigned if there is a match and the number of characters in the document that are examined to find occurrences of the pattern.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 72 State Transportation Agencies Figure 17. Maintenance Agreement Example 2. Table 13 shows an example of the set of rules developed to identify maintenance agreements. Table 13. Maintenance Agreement Rules Character String Score Character Block Maintenance Agreement 10 1000 Agreement 5 500 maintenance 9 1000 M A I N T E N A N C E A G R E E M E N T 10 1000 made and entered into 8 1000 whereas 4 700 agenda -9 700 meeting -7 600 minutes -7 600 attendees -5 600 from: -5 700 to: -5 700
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 73 State Transportation Agencies Character String Score Character Block subject -3 700 sincerely -3 500 request for proposals -10 700 Easement -5 600 Checklist -5 600 Status Report -5 600 Inspector's Daily Report -5 600 Mitigation Bank -5 600 Standards and References -5 600 Change Order -5 600 Environmental Study -5 600 Manual of Instruction -5 600 Quitclaim Deed -5 600 Prospectus -5 600 Research Problem Statement -5 600 Note that there are positive and negative scores. The positive scores indicate that there is positive evidence that the document examined is a maintenance agreement. There are, however, instances in which the character string âmaintenance agreementâ is not found in an agreement. The character string may occur in an email or another type of document that is not an actual agreement. Thus, the rule set includes negative evidence which excludes document types that are not agreements. Hence, if the program finds the character string âagendaâ in the first 700 characters of a document, it is likely that it is not a maintenance agreement and more likely it is an agenda for a meeting. Negative evidence is significant to the process of identifying whether a document is a maintenance agreement or some other document type. When negative evidence was introduced, the ability of the program to correctly differentiate maintenance agreements was significantly improved. The ability to correctly identify maintenance agreements rose from 44% to over 80% when negative evidence rules were introduced. Tables 14-17 show the rules sets for Utility, Betterment, Cooperative and Drainage Agreements.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 74 State Transportation Agencies Table 14. Utility Agreement Rules Character String Score Character Block Utility Agreement 10 500 Utility Reimbursement Agreement 10 500 Utility Relocation Agreement 10 500 Agreement 5 500 utility work 10 1000 utility relocations 10 1000 betterment -10 1000 made and entered into 9 700 whereas 5 700 agenda -9 700 meeting -8 700 minutes -7 700 attendees -5 700 from: -5 700 to: -5 700 subject -3 700 sincerely -3 700 request for proposals -10 700 Table 15. Betterment Agreement Rules Character String Score Character Block Betterment Agreement 10 700 Agreement 5 500 betterment work 10 700 made and entered into 9 700 whereas 4 700 agenda -9 700 meeting -8 700
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 75 State Transportation Agencies Character String Score Character Block minutes -7 700 attendees -5 700 from: -5 700 to: -5 700 subject -3 700 sincerely -3 700 request for proposals -10 700 Table 16. Cooperative Agreement Rules Character String Score Character Block Cooperative Agreement 10 700 Cooperative 7 500 Agreement 5 500 Drainage -7 1000 Drainage Agreement -10 700 made and entered into 9 500 whereas 4 500 agenda -9 700 meeting -8 700 minutes -7 700 attendees -5 700 from: -7 700 to: -7 700 subject -3 700 sincerely -3 700 request for proposals -10 700
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 76 State Transportation Agencies Table 17. Drainage Agreement Rules Character String Score Character Block Cooperative Agreement 10 700 Cooperative 7 500 Agreement 5 500 Drainage -7 1000 Drainage Agreement -10 700 made and entered into 9 500 whereas 4 500 agenda -9 700 meeting -8 700 minutes -7 700 attendees -5 700 from: -7 700 to: -7 700 subject -3 700 sincerely -3 700 request for proposals -10 700 Rule-Based Classification: Description of the Python Code Logic Rule-based classification was accomplished by applying weights, both positive and negative, to phrases found in prescribed character blocks in a documentâs text. The rules are defined in an easy to generate and maintain CSV (comma-separated value) format that can be opened and edited in Microsoft Excel. Each type of agreement (Betterment, Utility, etc.) has a defined set of phrases or character strings, a positive or negative weight assigned and a description of the character block where the pattern occurs. The names of the CSV containing the rules are used to name the output folders that the documents are copied to upon classification. For example, the rule file for the category âBettermentâ is named âBetterment.csv,â and contains the following column header: Phrase, Weight, Character Block The header is followed by the list of rules, for example: Betterment Agreement,10,700
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 77 State Transportation Agencies In this rule, âBetterment Agreementâ is the phrase, 10 is the assigned weight, and 700 represents the character block (i.e., the first 700 characters of the document text). The code is written in Python and uses the Python Natural Language Toolkit (NLTK) and regular expressions. It is written as a command line script that accepts the following arguments: -r Rules folder â the full path for the folder where the CSV rule files are located. The name of each rule file is taken as the label for that category. -i Input folder â the full path for the root folder where the text versions of the input documents are located. The script iterates through all the subfolders under this folder to process all files. -o Output folder â the full path for the folder where the output files are generated. -t Weight Threshold â this value determines if the score for a document qualifies the document for a category or not. Values that meet and exceed the threshold are categorized into qualifying categories while the values lower than the threshold are rejected. First, a new folder is created under this folder with the timestamp from when the script starts as the name. Under this folder, each category (name of rule CSV file) gets a corresponding folder for grouping the documents. Also, a folder to copy documents that are not assigned to any category called âUnassignedâ is created here. Finally, this folder also holds the final output files in CSV format. The main output file that lists the documents assigned to each category, the classification score, and the data elements extracted from each document is named: UDOT_RBC_Results_<TIMESTAMP>.csv The file contains the header: "ID","Category","FileName","Score","Project #","PIN","Date","Party","Tax ID" The header is then followed by the output data, for example: "1_1","Betterment","doc-to-text-converted\07092009 - S jordan betterments.doc.txt","10","","","","","" A second file lists all the file names of the files that were not assigned to any category. This file is named: UDOT_RBC_Results_Unassigned_<TIMESTAMP>.csv â The script starts by analyzing the input parameters, generating a timestamp and the output folders, and setting up a series of internal structures to hold the output data in memory. It then iterates through the list of files sequentially from the input folder, running the list of files against one category rule file at a time. When the script processes a file, it first reads the text content of the file, and cleanses it of extraneous white spaces and other characters. For each rule in a CSV rule file, the script
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 78 State Transportation Agencies extracts the subset of the text according to the character block setting. If the character block is assigned the value of 0, then the entire text is used. The script then produces an n-gram list from the text with the same number of n-grams in the rule phrase. If the n-gram list contains the rule phrase or character set, then the rule is considered satisfied, and the score is added to the internal data structure. After all rules are exhausted, then the mean weight is calculated. If the mean weight exceeds the threshold, the document is assigned to that category. This information is registered in the internal data structure that holds documents and the categories they are assigned. If the document is not matched to any rules after application of all the rules is completed, then it is added to a different data structure that holds the âunassignedâ documents. Once the files are examined against all the rules, the list of assigned files is iterated from the internal structure and copied from the input folder to folders with names corresponding to the categories they are assigned. Similarly, the unassigned files list is also iterated and copied from the input folder to the âUnassignedâ output folder. Machine Learning vs. Rule-based Classification Results Comparison The accuracy of the classification results is measured using two calculations: Precision and Recall. The precision calculation measures the fraction of the retrieved documents that are agreements. The calculation yields a percentage which indicates the precision of classification. High precision means that the pattern matching algorithm returned substantially more correctly identified agreements than non-agreements. The recall calculation measures the fraction of relevant documents that are retrieved from the full set of relevant agreements. Thus, high recall means that the pattern matching algorithm returned a high percentage of relevant agreements The results for the machine learning approach and the rule-based classification approach are summarized in the Table 18. These results occurred after considerable iterative work on developing the training sets for machine learning and the rule set for rule-based classification. In each case, adding negative evidence that successfully identified non-agreements was critical to improving precision and recall.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 79 State Transportation Agencies Table 18. Machine Learning vs. Rule-based Classification Results Agreement Types Classification Approach Precision Recall Maintenance Agreements Machine Learning 93% 86% Rule-based 78% 95% Utility Agreements Rule-based 95% 7% Betterment Agreements Rule-based 82% 79% Drainage Agreements Rule-based 100% 75% Cooperative Agreements Rule-based 93% 71% For maintenance agreements, the machine learning approach yielded better precision than the rule-based approach. This means that the training set used in the machine learning example provided a more accurate set of example maintenance agreements allowing the algorithm to recognize patterns and identify correct matches. Ninety-three percent precision shows that 7% of the retrieved results were non-agreements. The training set and the machine learning algorithm was less successful at finding and categorizing all examples of the maintenance agreement. This is indicated by recall score of 86%. Thus, 14 percent of the total number of maintenance agreements were not correctly identified using the machine learning approach. The results of applying the rule-based classification method yielded positive results, but a somewhat different answer. The precision score of 78% indicates that of the results retrieved by the rule-based algorithm, 78% of the results were maintenance agreements whereas 22% were non-agreements or false positives. The recall percentage for the rule-based approach indicates that of the total number of maintenance agreements the rules could correctly match was 95%. Therefore 5% of the remaining maintenance agreements could not be identified by the rules set used in this analysis. The same logic applies to utility, betterment, drainage, and cooperative agreements. One outlier was the recall score for utility agreements. Seven percent recall was a result of a small sample size. Both techniques work best when the number of documents processed is in the tens of thousands. Industry standard precision and recall scores typically start at 60% and are improved iteratively. An algorithm that reaches 80% is considered a success. In all cases, the results can continue to be improved. Improving the results of the machine learning approach requires adding more positives examples of maintenance agreements plus more examples of non-agreements. Since the machine learning approach learns by example, increasing the number of example
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 80 State Transportation Agencies documents in the training set and increases the probability of covering all the patterns that drive a match. For the rule-based classification, improving the accuracy of results requires analyzing false positives. Recognizing the positive or negative evidence in a false positive allows the addition of new rules that can improve both precision and recall. Automated Data Extraction from Agreements After completing document classification, the next step in the UDOT project was to demonstrate how to extract data from the classified documents. The goal was to extract the following items: ⢠Project Number ⢠PIN ⢠Date of Agreement ⢠Party to the Agreement ⢠Tax ID (for drainage agreements only) By combining the agreement type with several of the descriptive metadata items extracted from the agreement document, a Boolean search can return old agreements with characterics sought by the user. The data extraction process that finds and extracts the data is a rule-based process that searches for a pattern of characters that occur in a document. The code logic for the data extraction process is documented in the following section. Automated Data Extraction: Description of the Python Code Logic To extract data from the documents classified in the previous step, each document is converted into plain text (a pure ASCII format), which is required to process documents using NLP tools. Once the documents are converted to plain text, the documents are examined sequentially, and the data elements are extracted. Date The date is extracted using a regular expression pattern. The first date encountered in the document text is picked as the value for this element. Project Identification Number (PIN) and Project Number: PIN and project numbers are extracted using a range of regular expression patterns that were identified by examining agreements in the input corpus. These patterns include spaces, colons (:), semicolons (;), periods (.) and other characters which must be accounted for during the matching process. Example project number patterns observed were: ⢠Project No.: ⢠Project No. ⢠Project No.; ⢠Project Number ⢠Project identified as:
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 81 State Transportation Agencies ⢠Project identified as Example PIN patterns observed were: ⢠PIN: ⢠PIN : ⢠PIN.: ⢠PIN. ⢠PIN ⢠PIN# ⢠PIN # ⢠PIN No. ⢠PIN Number Party Party name is the name of the entity the agreement has been entered with. It is extracted using the Stanford NER (Named Entity Extractor) library for the Python NLTK. Using this method, all the entities identified as âORGANIZATIONâ by Stanford NER tagger are collected into a list. Then the ORGANIZATION entity that follows any variations of UDOT and any words indicating the agreement is selected as the Party. Tax ID Tax ID is extracted using a range of regular expression patterns that were identified by examining a subset of the input corpus. These patterns account for spaces, colons (:), semicolons (;), periods (.) and other characters. Example Tax ID patterns observed were: ⢠Tax ID No. ⢠TaxiDNo. ⢠Tax i D No. ⢠TaxiDNo.: ⢠Tax i D No.: ⢠Tax ID No.: Once extracted, the data items are appended to the CSV file that contains the list of classified documents. Lastly, this file name is written to a CSV file. Similarly, the unassigned files list is also written out as a CSV file for output. Data Extraction Results Data extraction results varied by type of agreement and the type of data that was targeted to be extracted. The date was the most difficult data item to extract. Examination of the documents showed that the date was often entered by hand, and therefore was not recognized by the OCR program. Figures 18 and 19 show two examples of how the Project ID, PIN, Date, and Party appear in the documents and illustrates challenges of extracting the data from the documents. The first
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 82 State Transportation Agencies example illustrates that date is frequently not included in the agreement. Also, Project ID is listed here as âProject No.â, and PIN is listed simply as âPINâ without including a colon. Figure 18. Project ID, PIN, Date, and Party. The second example (in Figure 19) shows similar data. However, the pattern of characters for Project ID and PIN are different. In the City of Saint George example, the Project ID and PIN were in the header of the document and did not contain any punctuation marks between the characters and the number. The Project ID in the South Jordon City example is labeled Project No.: and PIN is labeled âPIN:â. Hence, data extraction from agreements requires identifying each pattern and rules that identify each pattern variation. Improving the results requires more runs of the Python script plus examination and identification of each variation in the presentation of characters. This process is repeated until data extraction reaches a satisfactory success rate.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 83 State Transportation Agencies Figure 19. Different patterns of Project ID, PIN, Date, and Party. Table 19 lists data extraction results after seven code improvement iterations. The figures shown in the table are the percent of agreements of each type for which a valid item was extracted. Note that not all agreements include the entity types tested so a 100% score is not feasible to achieve. The results would continue to improve with each successive run.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 84 State Transportation Agencies Table 19. Text Extraction Logic Data Item Extraction Logic Maintenance Betterment Cooperative Drainage Utilities Project ID Values are extracted by pattern matching with the known formats of these values using standard regular expressions 19% 18% 23% 5% 74% PIN Values are extracted by pattern matching with the known formats of these values using standard regular expressions 15% 40% 45% 11% 72% Party Party with whom UDOT signed the agreement 30% 30% 20% 74% 26% Date The first date to appear in the document that is not part of a sentence is extracted as the date of the document 4% 21% 5% 26% 5%
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 85 State Transportation Agencies Data Item Extraction Logic Maintenance Betterment Cooperative Drainage Utilities Tax ID Values from Drainage Agreements extracted by pattern matching with the known formats of these values using standard regular expressions NA NA NA 30% NA Round 2 The round 2 analysis used the same tools as round 1. The NLTK (Natural Language Toolkit) was used for classification, tokenization, stemming, tagging, and parsing. Round 2 only involved rules-based classification and entity extraction. Machine learning-based classification was not included. Training Sets UDOT staff created training sets for each of the five selected content types. They created the training sets by conducting searches within ProjectWise for representative terms. The number of documents in the training set for each content type varied widely. The training sets for the three right of way content types (quit claim deeds, warranty deeds and highway easement deeds) were quite small, due to either the fact that there were not many of these stored within ProjectWise, or because these documents were not machine readable and could not be easily identified through searches. The sizes of the training sets were: ⢠Project Concept Reports: 41 documents ⢠Design Exceptions/Waivers: 95 documents ⢠Quit claim deeds: 8 documents ⢠Warranty deeds: 10 documents ⢠Highway easement deeds: 6 documents Rule Development Classifying the document types in the UDOT corpus required creation of a set of rules that a computer script could use to evaluate each of the documents and documenting whether the document matched the rule or failed to match the criteria. This section describes the rules that were applied to find and tag documents. Examination of each of the training sets provided by UDOT established the evidence of the patterns in the text that could be used to create rules.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 86 State Transportation Agencies Concept Report Concept Reports were identified by examining each provided text file for positive matches to the Concept Report Rules. The sample Concept Report shown in Figure 20 shows that the phrase Concept Report occurs at the beginning of the document within the first 700 characters. Table 20 shows the rules developed for classification of Concept Reports. Figure 20. Concept Report example. Table 20. Concept Report Rules Phrase Weight Character Block Concept Reports 7 700 Concept Report 7 700 Concept Design Report 7 700 Conceptual Layout 3 700 Design Exception, Highway Easement Deeds, Quit Claim Deeds, and Warranty Deeds Rules for the remaining four content types were developed in a similar fashion to those for Concept Reports. Figures 21-24 show snippets of these content types; Tables 21-24 present the rules.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 87 State Transportation Agencies Figure 21. Design Exception example. Figure 22. Highway Easement Deed example.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 88 State Transportation Agencies Figure 23. Quit Claim Deed example. Figure 24. Warranty Deed example.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 89 State Transportation Agencies Table 21. Design Exception Rules Phrase Weight Character Block Design Exception 7 700 Design Exceptions 7 700 Design Waiver 5 700 Design Waivers 5 700 Table 22. Highway Easement Deed Rules Phrase Weight Character Block Highway Easement Deeds 10 700 Highway Easement Deed 10 700 Utility Easement 4 200 Highway Easement 1 700 Table 23. Quit Claim Deed Rules Phrase Weight Character Block Quit Claim Deed 8 700 QUIT CLAIM 8 700 QUIT CLAIM 8 700 QUIT CLAIMS 8 700 Claim Deed 5 700 Table 24. Warranty Deed Rules Phrase Weight Character Block Warranty Deeds 7 700 Warranty Deed 7 700 WARRANTY 2 100 Exclusions for Emails The rule shown in Table 25 was developed to tag documents that were likely to be emails. This rule was developed because a number of emails included references to the targeted content types.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 90 State Transportation Agencies Table 25. Exception Rule for Emails Phrase Weight Character Block From 0 100 To 0 250 Subject 0 400 utah.gov 0 150 Results After testing the rules and iteratively improving them based on the test results, the rules set were run against the UDOT document corpus of text files. After the analytical loop, each of the categories was assigned a score from 1 to 10. The category with the highest score was saved as a category match. If none of the rules applied, the document was assigned a score of 0 and therefore remained unclassified. Results of the classification were reviewed to establish a cutoff value for the score at which documents would be assigned a classification. Based on spot-checking documents with different scores, a cutoff value of 4 was established for Concept Reports and Design Exceptions; no cutoff value was required for the other document types. Concept Reports and Design Exceptions with a score greater than 4 were found much more likely to be correctly identified than those with a score less than 4. In these cases, only Concept Reports and Design Exceptions with large enough scores were accepted. No cutoffs were established for the other content types. Final classification results are presented in Table 26. A total of 5332 documents were classified as one of the five selected types, which is 0.97% of the entire corpus. Table 26. Round 2 Classification Results for the UDOT Corpus Number Percent of Total Precision Recall All Files 550097 100% n/a n/a Concept Reports 270 0.05% 89% 89% Design Exception/Waiver 748 0.14% 88% 96% Quit Claim Deed 1171 0.21% 98% 88% Warranty Deed 3109 0.57% 99% 62% Highway Easement Deed 24 0.00% 78% n/a All Positively Classified 5322 0.97% Computing Resources Required As noted above, each rule is applied sequentially to each document. Looping through each of the documents in the corpus took 374 computing hours. Eight virtual machines on Amazon web services were run simultaneously to compute the scores. The files were broken down into
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 91 State Transportation Agencies packages that contained approximately 50,000 documents each. Processing time and cost figures are shown in Figure 25. Figure 25. Document processing time and cost. Precision and Recall Assessment After classification, precision and recall were measured for each document type. These results are included in Table 26. Precision measures the reliability of the classification. A random subsample of each category was selected, and each document in these samples was viewed to determine if the document type is correct. Recall measures the completeness of the classification. A sample of each document type was assembled independently of our classification. These samples were assembled by searching the âfilenameâ field in the ProjectWise database for terms that are likely to be found in the filenames of those document types. For example, to assemble the Warranty Deeds sample, records were chosen such that their âfilenameâ field contained any of the strings âWarranty Deedâ, â_WD.â, â_WD2â, or â_WD3â. Each document in each recall sample was inspected by eye to ensure it was the correct document type. These samples were then checked against the list of classified documents. Warranty Deeds have a noticeably lower recall than other document types. These documents were more likely than the others to feature garbled text, indicating an OCR or text conversion issue. Highway Easement Deeds have a relatively low precision, but this is likely attributable to low sample size. There were also no discernable file naming patterns for Highway Easement Deeds, making it prohibitive to form an independent set for recall testing. Entity Extraction The classified documents were run through an entity extraction algorithm. The entities of interest for extraction were project numbers, PINs, Tax ID, parcel number, location (including route number and mile markers), project concept or description, project county, document Text Zip Folder Instance Type Cost Per Hour Processing Time( In Hour) Total Processing Cost(In $) pkg_6711f242-b820-4b55-b2e2-db459fa202eb.zip t3.medium 0.012 23 0.276 pkg_685e9b1b-edf1-4ff0-9f3a-390c73dbb105.zip t3.medium 0.012 21 0.252 pkg_68af5e73-df28-4f94-b316-e195fad27f8a.zip t3.medium 0.012 21 0.252 pkg_02cfc55c-8e3c-440a-8d1d-ade9109dfa7d.zip t3.medium 0.012 24 0.288 pkg_6e473452-11b6-4df0-b004-0baac967f663.zip t3.medium 0.012 21 0.252 pkg_7c9b0a68-929b-447c-952c-e05ba996606d.zip t3.medium 0.012 4 0.048 pkg_8588097b-0c78-48b9-bc0a-8533ad738b54.zip t3.medium 0.012 22 0.264 pkg_ad309096-03e1-442c-a0e5-1a15ee7c4dab.zip t3.medium 0.012 21 0.252 pkg_44513849-7b46-4dc3-8522-a529fa4801cd.zip m4.large 0.0324 15 0.486 pkg_7136560e-3e2b-4fd4-a315-e04a27869e27.zip m4.large 0.0324 23 0.7452 pkg_7222ed08-6422-4712-abce-5ea351bdbb5d.zip m4.large 0.0324 25 0.81 pkg_7fe908b1-d848-487b-8b1b-a4387b5a99ca.zip m4.large 0.0324 34 1.1016 pkg_858dce6c-7304-41dd-9790-c98927d567c7.zip m4.large 0.0324 23 0.7452 pkg_a8d311f6-6e7d-4094-99c7-f00f74c607bb.zip m4.large 0.0324 27 0.8748 pkg_b354c135-21f9-4053-8a58-7411d5caf25a.zip m4.large 0.0324 10 0.324 pkg_b8a2934c-89e2-49d8-a553-32b608d855b0.zip m4.large 0.0324 28 0.9072 pkg_f4fe16d9-2c84-4349-897d-f2e9ee53e26f.zip m4.large 0.0324 32 1.0368 Total 374 8.9148
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 92 State Transportation Agencies date, grantor, and grantee. Because every entity is not present in each type of document, each document type was run through its own script designed to extract only the entities relevant to that document type. Entities were extracted via two methods - âregular expressionsâ and âlookupâ. The regular expressions method involves searching the document for a key word (e.g. âPIN:â) and then extracting the characters following this key word. This is the approach used for the round 1 entity extraction. The lookup method uses an independent list of project numbers and PINs (obtained from UDOT) and finds any instances of these known project numbers and PINs in the document. The lookup method was added in round 2 to see if it could achieve better results than the regular expression method. The regular expressions method proved to be faster and more forgiving of variations in entity formatting since an exact match with the master source data is not required. However, it relies on the presence of standard phrasing and document structure, and works best when the document type is uniform, with few variations. The document types in the UDOT corpus had varying levels of heterogeneity. The scripts were written to extract information from a test set of each document type. These training sets did not necessarily include all possible document variations, which limited the performance of the entity extraction scripts. The most common error is that the script misses an entity because a particular document variation is not accounted for in the code. The next most common error is that the script extracts too much information (i.e. it extracts a Tax ID number, but also a large string after the Tax ID number). Adjustments to the scripts were added to limit the length of the extracted string, but given there is no reliable delimiter and the strings are of variable length, the results may still contain unwanted information. The lookup method is slower than the regular expressions method but obtains cleaner results (due to matching with a master list). Project numbers were extracted using the lookup method. These project numbers were then used to find PINs and location information in the master tables. All other entities were obtained using regular expression matching. When possible, we report the results found by searching the lookup table. If the lookup search had no match, and the regular expression did, we report the results of the regular expression match. Table 27 shows the percentage of documents of each type from which the script was able to extract each type of entity. Table 27. Round 2 Entity Extraction Results for the UDOT Corpus Document Type PIN Project Number Grantor Grantee Tax ID Parcel Location Concept/ Description Date County Concept Reports 54% 41% 49% 55% 52% Design Exception/Waiver 94% 95% 94% 84% 64% 90% Quit Claim Deed 49% 56% 47% 13% 26% 14% 49% 49% Warranty Deed 51% 52% 21% 35% 19% 24% 51% 51% Highway Easement Deed 29% 29% 29% 29%
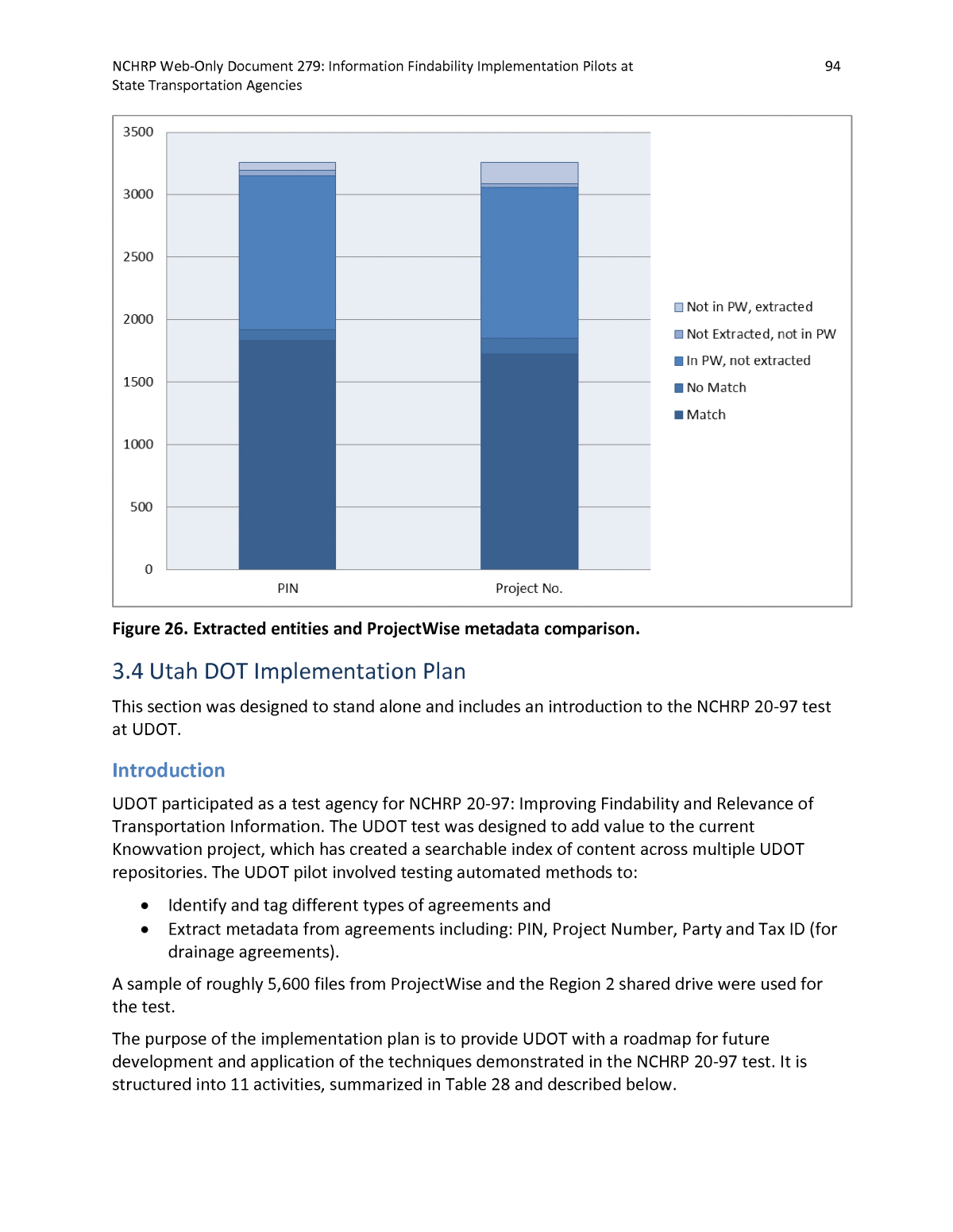
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 93 State Transportation Agencies Design Exceptions are highly standardized documents, and as such are suited to this type of entity extraction. They also tend to be clean, âborn digitalâ documents which are not subject to OCR errors. There was more variety in the other document types, explains their lower extraction rates. Quit Claim Deeds and Warranty Deeds in particular are highly variable documents with multiple templates and formats, making it difficult to code for each case. They also tend to be scanned documents, making them more prone to OCR errors, like garbled text or spacing issues. Comparison to ProjectWise Database The results of the entity extraction were compared to the metadata that was provided from the UDOT ProjectWise database. Of the 5,322 documents for which entities were extracted, 3,265 had a corresponding ProjectWise entry with some metadata. Figure 26 provides a comparison between ProjectWise metadata and the extracted entities for these 3,265 files. Metadata that was extracted had an excellent match with ProjectWise â 95% for PINs and 93% for project numbers. However, the ProjectWise metadata was much more complete â 97% of the ProjectWise records had a PIN; 94% had a Project Number whereas the entity extraction method produced PINs and project numbers for only 61-62% of these records. The extraction process was able to provide PINs and project numbers for some of the ProjectWise records that were missing metadata â it produced PINs for 2% of these records and project numbers for 5% of these records. These results indicate that the entity extraction methods could be used with some success to create PINs and project numbers for documents of the selected types that do not have pre-existing metadata (e.g. documents stored in shared drives and other repositories that do not have metadata). However, more work would be needed to improve the extraction rate (through refining the script).
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 94 State Transportation Agencies Figure 26. Extracted entities and ProjectWise metadata comparison. 3.4 Utah DOT Implementation Plan This section was designed to stand alone and includes an introduction to the NCHRP 20-97 test at UDOT. Introduction UDOT participated as a test agency for NCHRP 20-97: Improving Findability and Relevance of Transportation Information. The UDOT test was designed to add value to the current Knowvation project, which has created a searchable index of content across multiple UDOT repositories. The UDOT pilot involved testing automated methods to: ⢠Identify and tag different types of agreements and ⢠Extract metadata from agreements including: PIN, Project Number, Party and Tax ID (for drainage agreements). A sample of roughly 5,600 files from ProjectWise and the Region 2 shared drive were used for the test. The purpose of the implementation plan is to provide UDOT with a roadmap for future development and application of the techniques demonstrated in the NCHRP 20-97 test. It is structured into 11 activities, summarized in Table 28 and described below.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 95 State Transportation Agencies Table 28. UDOT Implementation Plan Overview Task Explanation 1. Establish a business case and strategy for information findability at UDOT Convene a group to assess the business value of potential future investments in enterprise or cross- repository search at UDOT. 2. Identify roles for continuing improvement of data and information findability at UDOT Identify who/what group will âownâ the vision and strategy for implementing standard metadata to enable integrated search across datasets and documents at UDOT. Identify who will âownâ identification and management of master data for key entities that are valuable for search (project numbers, locations, content types). Identify who will âownâ and continue to develop and apply rules for auto-classification and entity extraction. 3. Develop a metadata schema for UDOT content Establish a list of standard metadata elements that will be used to describe the documents in the corpus 4. Create a content type classification scheme Inventory and describe the different types of files within the repositories to be included within an enterprise search tool. Establish top level categories (e.g. Agreements) as well as sub-types (e.g. Utility Agreements). 5. Demonstrate value by ingesting metadata from the NCHRP 20-97 pilot into Knowvation Arrange a pilot with the vendor to test use of externally created content type tags and other metadata within the Knowvation tool. The initial pilot would involve importing a spreadsheet with document names, assigned content types and extracted metadata and enabling users to filter documents by content types. Use the pilot to demonstrate how the specific user information search needs would be met 6. Refine and test auto-classification results Revise the training sets created in NCHRP Project 20- 97 to reflect any adjustments to the included content types (agreements, concept reports, design exception/waiver, quitclaim deed, warranty deed, highway easement). Use these new training sets to update the auto-classification rules. Anticipate 3-4 cycles of testing and refinement.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 96 State Transportation Agencies Task Explanation 7. Refine and test entity extraction results Refine the rules to improve the accuracy of entity extraction. Anticipate 3-4 cycles of testing and refinement. 8. Evaluate commercial tools for auto-classification and entity extraction Commercial packages are available that can facilitate the process of rule development. Once UDOT has determined that auto-classification is of value, it may be appropriate to explore transition to one of these tools. 9. Design and test rule application within UDOTâs environment Design an approach to apply the auto-classification and entity extraction rules at UDOT. 10. Deploy solution Train users and assign responsibilities for ongoing maintenance and refinement. Implementation Activities 1. Establish a business case and strategy for improving information findability at UDOT. The Knowvation tool was able to demonstrate the capability to search across repositories. Other tools such as SharePoint, ProjectWise, UPlan, and Socrata have been deployed and provide search capabilities. In addition, documents are being moved from shared drives to Google Drive. There is a need to establish a coherent agency-wide strategy for information findability. This strategy should be grounded in a clear business case describing benefits to be realized through further investments in search and discovery capabilities. Establishing the business case will require an active effort to answer the following questions: (1) what audiences, content types and use cases do current UDOT content repositories and associated search capabilities serve? (2) what are the gaps â what types of needs are not being met and (3) what benefits might be realized through addressing these gaps â e.g. employee time savings, reduced re-work, better informed decisions. This effort will involve interviews with different types of users at headquarters and regions to understand how and where they search for information in the course of their daily work activities. These interviews can be used to create a series of âuser storiesâ that document how improved search capabilities would add value. Assuming a clear business case is established, the next step is to reach a common understanding of the role of existing and potential future tools for content management and search. This will involve a cross-functional group with representation of the different existing content management systems (web site, UPlan, ProjectWise, etc.) to clarify the role of each system and discuss the approach to meeting the gaps (e.g. cross-repository search). The business case and strategy should be documented and communicated widely within the organization.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 97 State Transportation Agencies 2. Identify roles for continuing improvement of data and information findability at UDOT At UDOT there are owners designated for individual content repositories, but there is no clear responsibility for an agency-wide, cross-silo approach to information findability. To make progress in this area, a champion should be designated for continuing improvements to data and information findability at UDOT. In addition, an agency information management group should be designated to ensure the engagement needed to coordinate future improvements. This group could serve as the steering team for the business case and strategy development effort described in step 1 above. Additional roles will be needed to achieve enhanced cross-repository search and integration capabilities at UDOT. A lead individual should be designated with responsibility for standardizing metadata (including linkage elements such as locations and project numbers) across repositories. This role could be part of the library function, enterprise architecture function or a data analytics function. This individual or a second role could also be assigned responsibility for continuing to develop capabilities for automating content classification and extracting metadata (i.e. those demonstrated in the NCHRP 20-97 UDOT pilot). They would likely need support from either consultant or UDOT technical resources with expertise in taxonomy development and text analytics. 3. Develop a metadata schema UDOT content A metadata schema is a list of metadata that will be used to describe the documents in the UDOT Corpus. Since the metadata in the UDOT corpus will be used to identify documents for further analysis some of the metadata items in the schema may include: ⢠File Type: html, .doc, .pdf, .xls, etc. ⢠Content Type: Agreement, Design Plan, Quitclaim Deed, Contract, Study ⢠Project ID ⢠PIN ⢠Party to Agreement ⢠Agreement Date ⢠Tax ID All of the metadata in the above example could be used in combination to search for or filter data to enable findability of specific documents. 4. Create a content type classification scheme The NCHRP 20-97 pilot identified several content types for analysis: agreements, project concept reports, design exceptions/waivers, warranty deeds, quitclaim deeds, and highway easement deeds. These content types were selected because there was an identified need to search for them after their associated project was completed. In addition, the search would be based on a location rather than a project number. A content type classification scheme should be created to provide the basis for searching by content type across repositories. This classification scheme would serve as the controlled vocabulary for a common content type metadata element at UDOT. The content type classification scheme should be hierarchical, starting with âbig bucketâ categories such as
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 98 State Transportation Agencies âdataâ, âstudiesâ, âlegal documentsâ and âplansâ. Sub-types under each category should be established based on reviewing existing document classification schemes or folder structures and analyzing samples of documents from the various repositories. Figure 11 shows an example of such an analysis conducted based on the sample of documents obtained for the NCHRP 20-97 round 1 test. The classification scheme need not exhaustively identify every specific type of content. It can begin by establishing a sound set of first and second level categories and then be completed over time, with an initial focus on priority content types needed for search. One initial focus area might be to build out the agreements content type taxonomy. In the pilot, we used five agreement types (betterment, cooperative, drainage, maintenance, utility), but as illustrated in Figure 12, there are over 50 additional agreement types. Building a hierarchical taxonomy of Agreement types would enhance discoverability and findability of agreements in the corpus. Since there are so many agreement types, a taxonomy would facilitate grouping like kinds of agreements together so that they could be filtered and retrieved more efficiently. Note that the agency content classification scheme need not disrupt or replace the existing content categories used within ProjectWise and other repositories. However, it should be possible to establish a mapping from agency categories to repository-specific categories. 5. Demonstrate value by ingesting metadata from the NCHRP 20-97 pilot into Knowvation Knowvation is the solution being piloted by the UDOT to index documents from various repositories, enabling spatial, full text and metadata-driven searches across these repositories. Currently the metadata-driven search options within Knowvation include file type, file source, project number, PIN, project name, year, route and document title. The content type classifications created within the pilot can be incorporated into Knowvation to demonstrate the value of this additional way of filtering content. 6. Refine and test auto-classification results Revise the training sets created in NCHRP Project 20-97 to reflect any adjustments to the included content types (agreements, concept reports, design exception/waiver, quitclaim deed, warranty deed, highway easement). Use these new training sets to update the auto- classification rules. Anticipate 3-4 cycles of testing and refinement. Increasing the number of documents in the training set (both for rules-based and machine learning classification) increases the probability that the pattern matching algorithm can correctly differentiate and match content types. The pilot achieved excellent precision and recall results, but these results can be improved with additional examples. Three or four further iterations of the machine learning approach or rule-based classification methodology would increase precision and recall of documents. Testing document classification after revising and improving the rules and Python scripts that process documents is acritical step in the process of validating that the algorithm is producing the expected results and that precision and recall are improving. Whether the machine learning approach or the rule-based classification approach is adopted for auto- classification, testing will provide the feedback necessary to improve the results.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 99 State Transportation Agencies 7. Refine and test entity extraction results The entity extraction rules need more work to increase the programâs ability to recognize and extract entities of interest (e.g. PIN, Project Number, Party, Tax ID, Parcel Number). Testing entity extraction is an iterative process in which results improve with each run. The process steps include running the script, examining the results, researching instances where the script failed to find the entity, and updating the program and rules to achieve a better result. For some types of entities (e.g. PIN, Project Number, and Route), lists from UDOT databases can be used as a master reference source to match with items in the text and improve results. 8. Evaluate commercial tools for auto-classification and entity extraction Scripting in Python is an excellent method for classifying content and for extracting entities. However, Python is a bespoke solution which requires that a developer rewrite or update the code to accommodate the lessons learned from a previous run of the program. Using Python and the NLTK tool set allows the use of the same NLP algorithms that are used in commercial products, but commercial products offer a graphical user interface to tweak results and decrease the setup time required for each iteration. Also, Commercial-Off-the- Shelf (COTS) Software may include workflow components that allow processing tasks to be sequenced without writing more code. There are several NLP packages that can be evaluated to further automate the process. After researching and testing COTS solutions, the team will need to decide to adopt a commercial solution or stay with the open source Python code created precisely to categorize agreements and to extract entities from agreements. 9. Design and test rule application within UDOTâs environment Design an approach to apply the auto-classification and entity extraction rules at UDOT. This would include: (1) designating a working area on an existing server for file storage and processing, (2) copying files from their current location to the working area, (3) applying OCR conversion to non-text readable PDFs, (4) converting files to .txt format, (5) applying the auto-classification scripts, (6) applying the entity extraction rules (7) reviewing results and adjusting as needed and (8) importing results into Knowvation. These procedures may also include extracting metadata from file names (PINs and agreement types are sometimes part of the file names). 10. Deploy solution Deploying the solution will involve training users on the process steps for auto- classification, entity extraction and importing tags into Knowvation (or other enterprise search tools). It will also involve assigning responsibilities for ongoing maintenance and refinement of the solution.
NCHRP Web-Only Document 279: Information Findability Implementation Pilots at 100 State Transportation Agencies Roles and Responsibilities The following list of roles can be used as a starting point for assigning implementation tasks to groups and individuals. ⢠Business Champion â UDOT manager responsible for leading initiatives to continue improving enterprise search capabilities, identifying resources for improvements, and ensuring value added for UDOT. This individual also has responsibility for communicating with various stakeholders and resolving management issues that arise. ⢠Metadata and Vocabulary Lead â UDOT staff responsible for coordinating development of the metadata schema and any controlled vocabularies for content type. ⢠Text Analytics Lead â UDOT staff (or consultant) responsible for refining and testing the auto-classification and entity extraction scripts. This role would also lead evaluation of COTS packages for text analytics. This individual should have basic level exposure to programming in Python or R, as well as experience and/or interest and aptitude for application of machine learning techniques.
