
2
Health Disparities Data Needs
This chapter summarizes presentations and discussion focused on data that could further the understanding of health disparities. Speakers participating in this session were asked to focus on the questions below. The brief overview of the input received from the presenters is followed by the committee’s conclusions.
- What are the limitations of the patient-centered outcomes research (PCOR) data infrastructure in terms of
- disparities in the data, including knowledge about patient outcomes, taking into consideration differences in patient preferences and values?
- challenges associated with using the data to understand disparities and health equity?
- lack of data on some populations?
- What are opportunities and priorities for enhancing data capacity in this area?
- What data capacity challenges is the U.S. Department of Health and Human Services (HHS) best positioned to address in the context of its public mission, authorities, programs, and data resources?
The first speaker, Karen Joynt Maddox, Washington University in St. Louis, argued that one of the main reasons why it is challenging to use health data for research in general, and for PCOR in particular, is that the health and personal data that are available are typically not collected for PCOR to begin with. Instead, the reasons for collecting the data tend to
be for recordkeeping for clinical care or for payment. As a result, the data available are not centered on the person and do not enable an understanding of the person’s context, including his or her medical journey, demographic information, health status, and comorbidities, as well as the social context in which the person lives.
Data that could be useful for studying disparities are collected in a variety of settings and are housed in separate databases. To take full advantage of the information, it is necessary to link these data, something that is often difficult to accomplish. Figure 2-1 is an illustration of these data silos. Joynt Maddox noted that one positive characteristic of the data collected on the social determinants of health is that some of the information available is particularly detailed. This includes, for example, data from hospitals’ electronic medical records modules, as well as data from social work and care coordination assessments.
Joynt Maddox highlighted Z-codes, which are a subset of the codes contained in the International Classification of Diseases (Tenth Revision, Clinical Modification, or ICD-10-CM). Z-codes are used to capture information such as the factors that influence a person’s health status and the reason for contact with health services. This includes information about employment, family characteristics, housing, psychosocial characteristics, socioeconomic characteristics, and nonadherence (e.g., intentional under-dosing of medication due to financial hardship). While these codes are widely available and detailed, they appear at a lower-than-expected rate in records, which suggests that they may be underused.
As an example of how data silos hinder the ability to answer policy questions, Joynt Maddox discussed efforts to answer the question of how
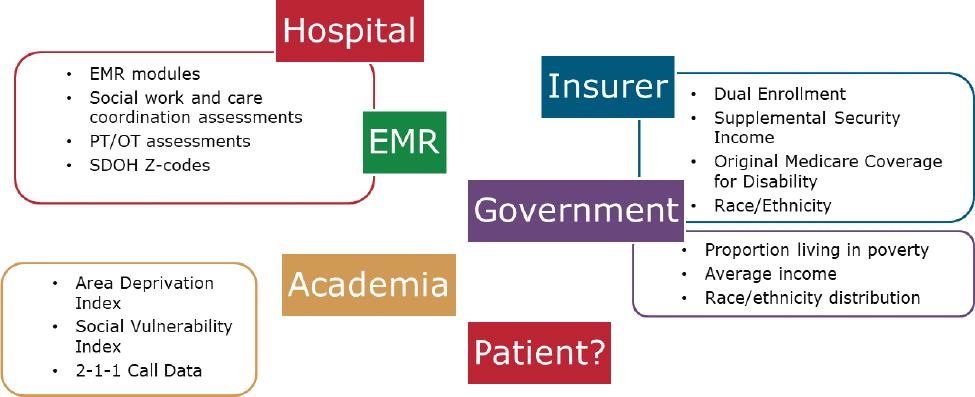
NOTES: EMR = electronic medical records; OT = occupational therapy; PT = physical therapy; SDOH = social determinants of health.
SOURCE: Workshop presentation by Karen Joynt Maddox, May 3, 2021.
potential Medicaid expansion in Missouri could impact equity in hospitalizations for complex cancer surgery. Box 2-1 summarizes the databases that could potentially be considered to examine this question, along with their limitations. None of these datasets has reliable information on social determinants of health.
Box 2-2 summarizes data sources that could be considered to examine another question with policy implications: the impact of the Hospital Value-Based Purchasing Program on equity in posthospitalization functional status.
The ideas shared by Joynt Maddox for improving the data available in this area were to (1) include hospital and state identifiers in national datasets, such as the National Inpatient Sample, and other related datasets from the Healthcare Cost and Utilization Project; (2) create mapping and linkages across data sources; (3) incentivize the collection of Z-codes relevant to social determinants of health and data on functional status through payment policy; and (4) make data available more quickly and more easily accessible for research and policy decisions.
Megan Morris, University of Colorado Anschutz Medical Campus, discussed data needs related to disability status. She noted that there is growing evidence that individuals with disabilities experience significant health
and health care disparities. She discussed recent work she conducted with support from the Patient Centered Outcome Research Institute (PCORI) to identify research priorities for advancing equitable health care for individuals with disabilities. As part of the study, she collected input from a range of stakeholders, including researchers, patient advocacy organizations, health systems, payers, policy makers, and agencies within the HHS. The key finding from this work was the need to improve data on people with disabilities.
Morris said that data on disabilities are rarely collected or documented in common data sources, such as electronic health records, patient experience surveys, or in big data sources, such as claims data. ICD-9-CM or ICD-10-CM codes are often insufficient for identifying who has a disability. For example, for a study of individuals who had total laryngectomies and were nonverbal, Morris reviewed medical charts and found that less than 30 percent of patients with this condition had an ICD-9-CM code for their communication disability in their medical record (likely because this code does not affect payment for the service).
Morris argued that the priority need in this area is for data that make it possible to (1) identify the quality of health and health care of individuals with disabilities; (2) develop, implement, and measure the effects of interventions; and (3) provide accommodations to individuals with disabilities.
In 2011, HHS released data collection standards that included standards for data on disability status. The HHS guidelines included six questions, and Morris suggested that these six could be integrated into electronic health
records, along with an additional question on communication disabilities. The question of communication disabilities has already been tested for potential inclusion in several national surveys. Box 2-3 reproduces these seven disability questions. Morris said her research indicates that these questions would be well received by patients.
To reduce disability disparities, Morris suggested (1) recognizing persons with disabilities as a population at high risk for experiencing health disparities; (2) supporting initiatives and infrastructure for documenting disability status at the point of care; (3) ensuring that disability demographics and accessibility quality measures are included in surveys; and (4) developing methods to identify persons with disabilities in claims data.
Mitchell Lunn, Stanford University, discussed health disparities among and the lack of data for sexual- and gender-minority populations. Lunn said that data collected by the Gallup organization indicate that sexual and gender minorities represent about 5.6 percent of the U.S. population. However, the lesbian, gay, bisexual, transgender, queer (LGBTQ+) population is a heterogeneous group, and the umbrella term encompasses people with differing health needs. Further, high-quality, detailed data on the breakdown of sexual and gender minorities by race and ethnicity are not available.
Lunn emphasized the differences among the concepts of sexual orientation, gender identity, and sex assigned at birth, and argued that data on sexual orientation and gender identity are inadequately collected in most clinical and research settings. As an example, the sexual orientation item
in the electronic health records used by Stanford Medicine collects information only on the identity construct, not on sexual attraction or sexual behavior. The options available to describe sexual orientation are more limited than the range of terms used by the community (for example, “pan-sexual” and “queer” are not available) and only one option can be selected, although a write-in option is available. In terms of gender identity, Stanford Medicine’s electronic health records also limit the answer to one option, with a narrower range of options than the terms used by the community.
To illustrate limitations in a research setting, Lunn discussed the All of Us program, a National Institutes of Health (NIH) research program that aims to enroll and collect data from more than one million participants. The sexual orientation and gender identity questions used by All of Us also measure the identity construct. The items were developed with input from subject matter experts and the community, and contain terms that are more commonly used by the community. It is also possible to select more than one answer for both sexual orientation and gender identity. Some of the options become available in the form of a submenu, and Lunn argued that it would be preferable to include more items on the initial list, since that would give respondents more options to consider that might be applicable to them. He added that some of the terms used in the NIH program are antiquated and are being revised.
Lunn also discussed the PRIDE study, a large-scale national health study of people who identify as LGBTQ+ or as another sexual or gender minority. He said that with multiple selections allowed in that study, around 35 percent of participants in the sample select more than one option for sexual orientation and around 18 percent select more than one option for gender identity. The terms used are revised every few years with community engagement.
Lunn argued that current clinical approaches, such as electronic health records systems and data models, do not allow patients to comprehensively report their sexual orientation and gender identity. Not using people’s stated identity (e.g., grouping or administratively classifying them instead) could result in the loss of valuable data that may have health implications. Research studies can serve as models for developing sexual orientation and gender identity data standards, because these studies tend to involve researchers who are focused on this field. Lunn also emphasized that sexual and gender minority terms tend to change at a rapid pace, and therefore frequent re-evaluation with community engagement is critical to selecting the optimal terms to use.
Kaleab Abebe, University of Pittsburgh, echoed comments made by other speakers related to some of the key challenges associated with the data infrastructure for PCOR. First, he said, regardless of what data are collected and in what context they are collected, it is important to ask
whether or not the data are representative of the population that could benefit from them. Second, data being housed in disparate locations and being owned by different entities leads to a substantial barrier to their use, and it is important to think of ways to curate and harmonize these data.
Abebe noted that the various data sources have varying degrees of completeness and representativeness. When these data sources are linked, the resulting datasets have their own patterns of data gaps and lack of representativeness, particularly in terms of the populations who could benefit from the availability of the data the most. He described this as “disparities on top of disparities.” If data are not available or are incomplete, it is difficult to act on the information in a way that could benefit people. Abebe also underscored the importance of efforts to standardize data but, again, without losing sight of the larger underlying question of whether the data have gaps in terms of the populations that are covered.
Thinking about opportunities, Abebe mentioned the example of the clinical trial infrastructure in the United Kingdom, which not only facilitates the carrying out of trials, but also aggregates the data that have been accumulated as part of trials. In the United States, it may be possible to build on what already exists to link more of the data. Abebe also highlighted opportunities to build on work already started that puts patient preferences in the center, including the development of an interoperable electronic care (eCare) plan. He also emphasized the need to develop metrics for the data infrastructure portfolio to enable researchers to better understand successes and failures and potentially utilize this information when considering future work.
Abebe noted that the social determinants of health can change over time, so measures need to be developed with the understanding that they need to be flexible. He also argued that there should be more of a spotlight on disparities, not only on measuring them but also on capturing metrics for ways of addressing disparities, whether in the form of interventions, therapeutics, or other potential solutions.
Thomas Sequist, Harvard University and Brigham and Women’s Hospital, discussed data needs with a particular focus on Native Americans. He said that during the COVID-19 pandemic it took a long time to recognize the impact of the pandemic on Native American communities, in part because of an inability to generate data at a level that would make it possible to understand the health issues specific to American Indians. One reason for this is that small sample sizes often result in data on American Indian populations being combined with data on other populations. Another challenge is that many studies on American Indians draw on data available from the Indian Health Service, but only about half of this population receives health care through that agency. The American Indian population that is left out of research that relies on that agency’s data is heavily skewed toward an urban population.
Sequist said that an important step toward addressing these challenges would be to develop more robust ways to identify American Indians in all existing datasets, which would make it possible to better characterize their experiences. Information about people’s tribal affiliations would further help in understanding their culture and the experiences they may have related to their health.
Sequist pointed out that social determinants of health come into play not only at an interpersonal level, but also at a geographic level, so better data are needed to understand these risk factors at that level. He discussed how geography can be relevant in addressing inequities, arguing that the use of geography needs to be carefully considered and standardized to better understand the interplay between it and race, ethnicity, and language.
Concerning language, Sequist highlighted the need for accurate and reliable data, noting that lack of standardization in the way language information is collected has been a challenge both for research and for improving health care. For example, he underscored the need to differentiate among someone’s preferred language, their primary language, the languages in which they are fluent, and the languages in which they have achieved health literacy. The COVID-19 pandemic, which affected non-English-speaking patients in a particularly severe way, has illustrated the need for language-appropriate care.
Sequist said that the array of information that exists on patient-reported outcomes does not always reflect the types of outcomes that patients themselves value or the experiences that they are having with the system, particularly concerning race-specific issues, ethnicity-specific issues, and language-specific issues. The relative value people place on various outcomes is likely to depend on their background, and substantial investments would be needed in patient-reported outcomes projects to begin to really understand those variations.
CONCLUSIONS
In this section we summarize the committee’s conclusions based on the presentations and discussion. The research of those experts who presented at the workshop focuses on health disparities in a variety of areas, affecting various populations. The underlying theme that emerged from the presentations was that there are data limitations for a variety of populations, and that these limitations hinder the ability to understand health disparities.
CONCLUSION 2-1: Health disparities can occur across a broad range of characteristics and populations. Data limitations affect the ability to identify and understand these disparities in many areas. Data for specific populations are sometimes unavailable or are not representa
tive. In other cases, the data might not be timely or might have other gaps that make it difficult to understand the impact of changes over long periods of time.
A fundamental reason for the data limitations that make it difficult to answer questions important for PCOR is that most of the data available for research are not primarily collected for research purposes. While research questions require a relational or integrative perspective, the data collected tend to be transactional, that is, collected for payment or treatment purposes, and therefore do not vary according to most personal characteristics. This has several implications for the data available. First, the data collected are typically limited to or organized within subpopulations (for example, those insured by Medicaid or Medicare). People who are uninsured, including those who have limited access or interactions with health care services, are likely to be underrepresented in many databases. Second, the information collected (and the absence of what is not collected) often makes the data poorly suited to answer a variety of research questions. Third, those who collect the data do not necessarily have an obvious incentive to collect information in a way that is useful for secondary purposes, such as research. The workshop identified a variety of data needs and potential opportunities for enhancing the data infrastructure, and these deserve further attention.
CONCLUSION 2-2: The data available for patient-centered outcomes research are often collected for reasons other than research, which limits their usefulness. Opportunities exist for increasing the utility of the data infrastructure by carefully considering the multiple uses to which the data might be applied.
The data that do exist are stored in a variety of databases across a fragmented health care system. The workshop identified data silos (e.g., within settings, at a point in time, or for a specific payer) as a major barrier to the efficient use of the information that is available.
CONCLUSION 2-3: Existing data on the social determinants of health are found in a variety of databases. Barriers to linking across these data silos represent a major challenge to understanding how social determinants of health affect health outcomes.
The workshop made it clear that the data available do not capture the complexities that are necessary to understand in order to determine how people’s characteristics and experiences influence outcomes. The speakers identified several potential ways of capturing more of these complexities, and they emphasized the need to build flexibility into the data collection
systems to allow them to adapt as both the terminologies and the available technologies for capturing and processing data evolve.
CONCLUSION 2-4: Existing data do not capture the richness of people’s characteristics and experiences. While such limitations are to be expected, opportunities exist for capturing data that are better able to characterize these complexities. A robust data infrastructure builds on the strengths of what is available today and has the flexibility to adapt, both as measures and terminologies become obsolete and as new technologies emerge.
The workshop underscored the magnitude of the data gaps in the area of health disparities. Improving the data available for understanding and addressing disparities would require an effort concentrated on this goal.
CONCLUSION 2-5: Prioritizing and improving the collection of data can lead to a better understanding of health disparities and to potential solutions for reducing disparities.










