
Appendix D
Critique of MIL-HDBK-217
Anto Peter, Diganta Das, and Michael Pecht1
This paper begins with a brief history of reliability prediction of electronics and MIL-HDBK-217. It then reviews some of the specific details of MIL-HDBK-217 and its progeny and summarizes the major pitfalls of MIL-HDBK-217 and similar approaches. The effect of these shortcomings on the predictions obtained from MIL-HDBK-217 and similar methodologies are then demonstrated through a review of case studies. Lastly, this paper briefly reviews RIAC 217 Plus and identifies the shortcomings of this methodology.
HISTORY
Attempts to test and quantify the reliability of electronic components began in the 1940s during World War II. During this period, electronic tubes were the most failure-prone components used in electronic systems (McLinn, 1990; Denson, 1998). These failures led to various studies and the creation of ad hoc groups to identify ways in which the reliability of electronic systems could be improved. One of these groups concluded that in order to improve performance, the reliability of the components needed to be verified by testing before full-scale production. The specification of reliability requirements, in turn, led to a need for a method to estimate reliability before the equipment was built and tested. This step was the inception of reliability prediction for electronics. By the 1960s, spurred on
_______________
1 The authors are at the Center for Advanced Life Cycle Engineering at the University of Maryland.
by Cold War events and the space race, reliability prediction and environmental testing became a full-blown professional discipline (Caruso, 1996).
The first dossier on reliability prediction was released by Radio Corporation of America (RCA); it was called TR-1100, Reliability Stress Analysis for Electronic Equipment. RCA was one of the major manufacturers of electronic tubes (Saleh and Marais, 2006). The report presented mathematical models for estimating component failure rates and served as the predecessor of what would become the standard and a mandatory requirement for reliability prediction in the decades to come, MIL-HDBK-217.
The methodology first used in MIL-HDBK-217 was a point estimate of the failure rate, which was estimated by fitting a line through field failure data. Soon after its introduction, all reliability predictions were based on this handbook, and all other sources of failure rates, such as those from independent experiments, gradually disappeared (Denson, 1998). The failure to use these other sources was partly due to the fact that MIL-HDBK-217 was often a contractually cited document, leaving contractors with little flexibility to use other sources.
Around the same time, a different approach to reliability estimation that focused on the physical processes by which components were failing was initiated. This approach would later be termed “physics of failure.” The first symposium on this topic was sponsored by the Rome Air Development Center (RADC) and the IIT Research Institute (IITRI) in 1962.
These two—regression analysis of failure data and reliability prediction through physics of failure—seemed to be diverging, with “the system engineers devoted to the tasks of specifying, allocating, predicting, and demonstrating reliability, while the physics-of-failure engineers and scientists were devoting their efforts to identifying and modeling the physical causes of failure” (Denson, 1998, p. 3213). The result of the push toward the physics-of-failure approach was an effort to develop new models for reliability prediction for MIL-HDBK-217. These new methods were dismissed as being too complex and unrealistic. So, even though the RADC took over responsibility for preparing MIL-HDBK-217B, the physics-of-failure models were not incorporated into the revision.
As shown in Table D-1, over the course of the 1980s, MIL-HDBK-217 was updated several times, often to include newer components and more complicated, denser microcircuits. The failure rates, which were originally estimated for electronic tubes, now had to be updated to account for the complexity of devices. As a result, the MIL-HDBK-217 prediction methodology evolved to assume that times to failures were exponentially distributed and used mathematical curve fitting to arrive at a generic constant failure rate for each component type.
Other reliability models using the gate and transistor counts of microcircuits as a measure of their complexity were developed in the late 1980s
TABLE D-1 MIL-HDBK-217 Revisions and Highlights
| MIL-HDBK Revision | Year and Organization in Charge | Highlights |
| 217A | Dec 1965, Navy |
Single point constant failure rate of 0.4 failures/million hours for all monolithic ICs |
| 217B | July 1973, Air Force Rome Labs |
RCA/Boeing models simplified by Air Force to follow exponential distribution |
| 217C | April 1979, Air Force Rome Labs |
Inadequate fix for memory due to instances such as when the 4K RAM model was extrapolated to 64K, predicted MTBF = 13 sec |
| 217D | Jan 1982, Air Force Rome Labs |
No technical change in format |
| 217E | Oct 1987, Air Force Rome Labs |
No technical change in format |
| 217F | Dec 1995, Air Force Rome Labs |
CALCE, University of Maryland—Change in direction of MIL-HDBK-217 and reliability prediction recommended |
(Denson and Brusius, 1989). These models were developed in support of a new MIL-HDBK-217 update. However, the gate and transistor counts eventually attained such large values that they could no longer be effectively used as a measure of complexity. This led to the development of updated reliability models that needed input parameters, such as defect density and yield of the die. But these process-related parameters were company specific and business sensitive, and hence harder to obtain. As a result, these models could not be incorporated into MIL-HDBK-217. For similar reasons, physics-of-failure-based models were also never incorporated into MIL-HDBK-217.
It was around the same time, in the 1980s, that other industries, notably, the automotive and telecommunication industries, began adapting MIL-HDBK-217 to form their own prediction methodologies and standards. The only major differences in these adaptations were that the methodologies were customized for specialized equipment under specific conditions. However, they were still based on the assumptions of the exponential distribution of failures and curve fitting to obtain a generic relationship. This approach was not surprising, because Bell Labs and Bell Communications Research (Bellcore) were the lead developers for the telecommunication reliability prediction method. Bell Labs was also one of the labs that the Navy had originally funded to investigate the reliability of electronic tubes in the 1950s; that investigation culminated in the drafting
of MIL-HDBK-217. Hence, with the automotive and telecommunication industries adopting methodologies similar to MIL-HDBK-217, the handbook’s practices proliferated in the commercial sector. While this was happening, there were also several researchers who had experimental data to show that the handbook-based methodologies were fundamentally flawed in their assumptions. However, these were often either explained away as being anomalies or labeled as invalid.
By the 1990s, the handbooks were struggling to keep up with new components and technological advancements. In 1994, there was another major development in the initiation of the U.S. Military Specification and Standards Reform (MSSR). The MSSR identified MIL-HDBK-217 as the only standard that “required priority action as it was identified as a barrier to commercial processes as well as major cost drivers in defense acquisitions” (Denson, 1998, p. 3214). Despite this, no final model was developed to supplement or replace MIL-HDBK-217 in the 1990s. Instead, a final revision was made to the handbook in the form of MIL-HDBK-217F in 1995.
At this stage, the handbook-based methodologies were already outdated in their selection of components and the nature of failures considered. In the 1990s, the electronic systems were vastly more complicated and sophisticated than they had been in the 1960s, when the handbook was developed. Failure rates were no longer determined by components, but rather by system-level factors such as manufacturing, design, and software interfaces. Based on the new understanding of the critical failure mechanisms in systems and the physics underlying failures, MIL-HDBK-217 was found to be completely incapable of being applied to systems to predict system reliability.
Moving forward into the 2000s and up through 2013, methodologies based on MIL-HDBK-217 were still being used in the industry to predict reliability and provide such metrics as mean time to failure and mean time between failures (MTTF and MTBF). These metrics are still used as estimates of reliability, even though both the methodologies and the database of failure rates used to evaluate the metrics are outdated.
The typical feature size when MIL-HDBK-217 was last updated was of the order of 500 nm, while commercially available electronic packages today have feature sizes of 22 nm (e.g., Intel Core i7 processor). Furthermore, many components, both active and passive, such as niobium capacitors and insulated gate bipolar transistors (IGBTs), which are now common, had not been invented at the time of the last MIL-HDBK-217 revision. Needless to say, the components and their use conditions, the failure modes and mechanisms, and the failure rates for today’s systems are vastly different from the components for which MIL-HDBK-217 was developed. Hence, the continued application of these handbook methodologies by the industry is misguided and misleading to customers and designers alike. The
solution is not to develop an updated handbook like the RIAC 217 Plus, but rather to concede that reliability cannot be predicted by deterministic models. The use of methodologies based on MIL-HDBK-217 has proven to be detrimental to the reliability engineering community as a whole.
MIL-HDBK-217 AND ITS PROGENY
In this section, we review the different standards and reliability prediction methodologies, comparing them to the latest draft of IEEE 1413.1, Guide for Developing and Assessing Reliability Predictions Based on IEEE Standard 1413 (Standards Committee of the IEEE Reliability, 2010). Most handbook-based prediction methodologies can be traced back to MIL-HDBK-217 and are treated as its progeny. As mentioned above, MIL-HDBK-217 was based on curve fitting a mathematical model to historical field failure data to determine the constant failure rate of parts. Its progeny also use similar prediction methods, which are based purely on fitting a curve through field or test failure data. These methodologies, much like MIL-HDBK-217, use some form of a constant failure rate model: they do not consider actual failure modes or mechanisms. Hence, these methodologies are only applicable in cases where systems or components exhibit relatively constant failure rates. Table D-2 lists some of the standards and prediction methodologies that are considered to be the progeny of MIL-HDBK-217.
TABLE D-2 MIL-HDBK-217-Related Reliability Prediction Methodologies and Applications
| Procedural Method | Applications | Status |
| MIL-HDBK-217 | Military | Active |
| Telcordia SR-332 | Telecom | Active |
| CNET | Ground Military | Canceled |
| RDF-93 and 2000 | Civil Equipment | Active |
| SAE Reliability Prediction | Automotive | Canceled |
| British Telecom HRD-5 | Telecom | Canceled |
| Siemens SN29500 | Siemens Products | Canceled |
| NTT Procedure | Commercial and Military | Canceled |
| PRISM | Aeronautic and Military | Active |
| RIAC 217Plus | Aeronautic and Military | Active |
| FIDES | Aeronautic and Military | Active |
In most cases, the failure rate relationship that is used by these handbook techniques (adapted from MIL-HDBK-217) takes the form of λp = f(λG,πi) where λp is the calculated constant part failure rate; λG is a constant part failure rate (also known as base failure rate), which is provided by the handbook; and πi is a set of adjustment factors for the assumed constant failure rates. All of these handbook methods either provide a constant failure rate or a method to calculate it. The handbook methods that calculate constant failure rates use one or more multiplicative adjustment factors (which may include factors for part quality, temperature, design, or environment) to modify a given constant base failure rate.
The constant failure rates in the handbooks are obtained by performing a linear regression analysis on the field data. The aim of the regression analysis is to quantify the expected theoretical relationship between the constant part failure rate and the independent variables. The first step in the analysis is to examine the correlation matrix for all variables, showing the correlation between the dependent variable (the constant failure rate) and each independent variable. The independent variables used in the regression analysis typically include such factors as the device type, package type, screening level, ambient temperature, and application stresses. The second step is to apply stepwise multiple linear regressions to the data, which express the constant failure rate as a function of the relevant independent variables and their respective coefficients. This is the step that involves the evaluation of the above π factors. The constant failure rate is then calculated using the regression formula and the input parameters.
The regression analysis does not ignore data entries that lack essential information, because the scarcity of data necessitates that all available data be used. To accommodate such data entries in the regression analysis, a separate “missing” category may be constructed for each potential factor when the required information is not available. A regression factor can be calculated for each “missing” category, considering it a unique operational condition. If the coefficient for the unknown category is significantly smaller than the next lower category or larger than the next higher category, then that factor in question cannot be quantified by the available data, and additional data are required before the factor can be fully evaluated (Standards Committee of the IEEE Reliability, 2010).
A constant failure rate model for non-operating conditions can be extrapolated by eliminating all operation-related stresses from the handbook prediction models, such as temperature rise or electrical stress ratio. Following the problems related to the use of missing data, using handbooks such as MIL-HDBK-217 to calculate constant non-operating failure rates is an extrapolation of the empirical relationship of the source field data beyond the range in which it was gathered. In other words, the
TABLE D-3 Constant Failure Rate Calculations of Handbook Methodologies
| Method | Failure Rate for Microelectronic Devices |
| MIL-HDBK-217 (parts count) | λ = λGΠQΠL |
| MIL-HDBK-217 (parts stress) | λ = ΠQ(C1ΠTΠV + C2ΠE)ΠL |
| SAE PREL | λp = λbΠQΠSΠTΠE |
| Telcordia SR-332 | λ = λGΠQΠSΠT |
| British Telecom HRD-5 | λ = λbΠTΠQΠE |
| PRISM | λp = λIA(ΠP + ΠD + ΠM + ΠS) + λSW + λW |
| CNET (simplified) | λ = ΠQ λA |
| CNET (stress model) | λp = (C1ΠtΠTΠV + C2ΠBΠEΠs)ΠLΠQ |
| Siemens SN29500 | λ = λbΠUΠT |
NOTES: ΠL is a learning factor, ΠT is the temperature factor, ΠE is the environment factor, ΠQ is the quality factor, C1 is the die complexity, and C2 is the package complexity. For additional details, see U.S. Department of Defense (1991).
MIL-HDBK-217-based constant failure rates are not applicable to failures related to storage and handling.
Table D-3 lists the typical constant failure rate calculations that are used by various handbook methodologies. Most of these methods have a form that is very similar to MIL-HDBK-217, despite the modifications that have been made for environmental and application-specific loading conditions. Some of these methodologies are described briefly in the following sections.
MIL-HDBK-217F
MIL-HDBK-217 provides two constant failure rate prediction methods: parts count and parts stress. The MIL-HDBK-217F parts stress method provides constant failure rate models based on curve-fitting the empirical data obtained from field operation and testing. The models have a constant base failure rate modified by environmental, temperature, electrical stress, quality, and other factors. Both methods are based on λp = f(λG,πi), but the parts stress method assumes there are no modifiers to the general constant failure rate. The MIL-HDBK-217 methodology only provides results for parts, not for equipment or systems.
TELCORDIA SR-332
Telcordia SR-332 is a reliability prediction methodology developed by Bell Communications Research (or Bellcore) primarily for telecommunications companies (Telcordia Technologies, 2001). The most recent revision of the methodology is Issue 3, dated January 2011. The stated purpose of Telcordia SR-332 is “to document the recommended methods for predicting device and unit hardware reliability (and also) for predicting serial system hardware reliability” (Telcordia Technologies, 2001, p. 1-1). The methodology is based on empirical statistical modeling of commercial telecommunication systems whose physical design, manufacture, installation, and reliability assurance practices meet the appropriate Telcordia (or equivalent) generic and system-specific requirements. In general, Telcordia SR-332 adapts the equations in MIL-HDBK-217 to represent the conditions that telecommunication equipment experience in the field. Results are provided as a constant failure rate, and the handbook provides the upper 90 percent confidence-level point estimate for the constant failure rate.
The main concepts in MIL-HDBK-217 and Telcordia SR-332 are similar, but Telcordia SR-332 also has the ability to incorporate burn-in, field, and laboratory test data for a Bayesian analytical approach that incorporates both prior information and observed data to generate an updated posterior distribution. For example, Telcordia SR-332 contains a table of the “first-year multiplier” (Telcordia Technologies, 2001, p. 2-2), which is the predicted ratio of the number of failures of a part in its first year of operation in the field to the number of failures of the part in another year of (steady state) operation. This table in the SR-332 contains the first-year multiplier for each value of the part device burn-in time in the factory. The part’s total burn-in time is the sum of the burn-in time at the part, unit, and system levels.
PRISM
PRISM is a reliability assessment method developed by the Reliability Analysis Center (RAC) (Reliability Assessment Center, 2001). The method is available only as software, and the most recent version of the software is Version 1.5, released in May 2003. PRISM combines the empirical data of users with a built-in database using Bayesian techniques. In this technique, new data are combined using a weighted average method, but there is no new regression analysis. PRISM includes some nonpart factors such as interface, software, and mechanical problems.
PRISM calculates assembly- and system-level constant failure rates in accordance with similarity analysis, which is an assessment method that compares the actual life-cycle characteristics of a system with predefined
process grading criteria, from which an estimated constant failure rate is obtained. The component models used in PRISM are called RACRates™ models and are based on historical field data acquired from a variety of sources over time and under various undefined levels of statistical control and verification.
Unlike the other handbook constant failure rate models, the RACRates™ models do not have a separate factor for part quality level. Quality level is implicitly accounted for by a method known as process grading. Process grades address factors such as design, manufacturing, part procurement, and system management, which are intended to capture the extent to which measures have been taken to minimize the occurrence of system failures.
The RACRates™ models consider separately the following five contributions to the total component constant failure rate: (1) operating conditions, (2) non-operating conditions, (3) temperature cycling, (4) solder joint reliability, and (5) electrical overstress (EOS). Solder joint failures are also combined with other failures in the model, without consideration of the board material or solder material. These five factors are not independent: for example, solder joint failures depend on the temperature cycling parameters. A constant failure rate is calculated for solder joint reliability, although solder joint failures are primarily wear-out failure mechanisms due to cyclic fatigue.
PRISM calculates non-operating constant failure rates with several assumptions. The daily or seasonal temperature cycling high and low values that are assumed to occur during storage or dormancy represent the largest contribution to the non-operating constant failure rate value. The contribution of solder joints to the non-operating constant failure rate value is represented by reducing the internal part temperature rise to zero for each part in the system. Lastly, the contribution of the probability of electrical overstress (EOS) or electrostatic discharge (ESD) is represented by the assumption that the EOS constant failure rate is independent of the duty cycle. This assumption accounts for parts in storage affected by this EOS or ESD due to handling and transportation.
FIDES GUIDE
The FIDES methodology was developed under the supervision of Délégation Générale pour l’Armement, specifically for the French Ministry of Defense. The methodology was formed by French industrialists from the fields of aeronautics and defense. It was compiled by the following organizations: AIRBUS France, Eurocopter, GIAT Industries, MBDA France, Thales Airborne Systems, Thales Avionics, Thales Research & Technology, and Thales Underwater Systems. The FIDES Guide aims “to enable a realistic assessment of the reliability of electronic equipment, including systems
operating in severe environments (defense systems, aeronautics, industrial electronics, and transport). The FIDES Guide also aims to provide a concrete tool to develop and control reliability” (FIDES Group, 2009).
The FIDES Guide contains two parts: a reliability prediction model and a reliability process control and audit guide. The FIDES Guide provides models for electrical, electronic, and electromechanical components. These prediction models take into account the electrical, mechanical, and thermal overstresses. These models also account for “failures linked to … development, production, field operation and maintenance” (FIDES Group, 2009). The reliability process control guide addresses the procedures and organizations throughout the life cycle, but does not go into the use of the components themselves. The audit guide is a generic procedure that audits a company using three questions as a basis to “measure its capability to build reliable systems, quantify the process factors used in the calculation models, and identify actions for improvement” (FIDES Group, 2009).
NON-OPERATING CONSTANT FAILURE RATE PREDICTIONS
MIL-HDBK-217 does not have specific methods or data related to the non-operational failure of electronic parts and systems, although several different methods to estimate them were proposed in the 1970s and 1980s. The first methods used multiplicative factors based on the operating constant failure rates obtained using other handbook methods. The reported values of such multiplicative factors are 0.03 or 0.1. The first value of 0.03 was obtained from an unpublished study of satellite clock failure data from 23 failures. The value of 0.1 is based on a RADC study from 1980. RAC followed up the efforts with the RADC-TR-85-91 method. This method was described as being equivalent to MIL-HDBK-217 for non-operating conditions, and it contained the same number of environmental factors and the same type of quality factors as the then-current MIL-HDBK-217. Some other non-operating constant failure rate tables from the 1970s and 1980s include the MIRADCOM Report LC-78-1, RADC-TR-73-248, and NONOP-1.
IEEE 1413 AND COMPARISON OF RELIABILITY PREDICTION METHODOLOGIES
The IEEE Standard 1413, IEEE Standard Methodology for Reliability Prediction and Assessment for Electronic Systems and Equipment (IEEE Standards Association, 2010), provides a framework for reliability prediction procedures for electronic equipment at all levels. It focuses on hardware reliability prediction methodologies, and specifically excludes
software reliability, availability and maintainability, human reliability, and proprietary reliability prediction data and methodologies. IEEE 1413.1, Guide for Selecting and Using Reliability Predictions Based on IEEE1413 (IEEE Standards Association, 2010) aids in the selection and use of reliability prediction methodologies that satisfy IEEE 1413. Table D-4 shows a comparison of some of the handbook-based reliability prediction methodologies based on the criteria in IEEE 1413 and 1413.1.
Though only five of the many failure prediction methodologies have been analyzed, they are representative of the other constant failure-rate-based techniques. There have been several publications that assess other similar aspects of prediction methodologies. Examples include O’Connor (1985a, 1985b, 1988, 1990), O’Connor and Harris (1986), Bhagat (1989), Leonard (1987, 1988), Wong (1990, 1993, 1989), Bowles (1992), Leonard and Pecht (1993), Nash (1993), Hallberg (1994), and Lall et al. (1997).
These methodologies do not identify the root causes, failure modes, and failure mechanisms. Therefore, these techniques offer limited insight into the real reliability issues and could potentially misguide efforts to design for reliability, as is demonstrated in Cushing et al. (1996), Hallberg (1987, 1991), Pease (1991), Watson (1992), Pecht and Nash (1994), and Knowles (1993). The following sections will review some of the major shortcomings of handbook-based methodologies, and also present case studies highlighting the inconsistencies and inaccuracies of these approaches.
SHORTCOMINGS OF MIL-HDBK-217 AND ITS PROGENY
MIL-HDBK-217 has several shortcomings, and it has been critiqued extensively since the early 1960s. Some of the initial arguments and results contradicting the handbook methodologies were refuted as being fraudulent or sourced from manipulated data (see McLinn, 1990). However, by the early 1990s, it was agreed that MIL-HDBK-217 was severely limited in its capabilities, as far as reliability prediction was concerned (Pecht and Nash, 1994). One of the main drawbacks of MIL-HDBK-217 was that the predictions were based purely on “simple heuristics,” as opposed to engineering design principles and physics of failure. The handbook could not even account for different loading conditions (Jais et al., 2013). Furthermore, because the handbook was focused mainly on component-level analyses, it could only address a fraction of overall system failure rates. In addition to these issues, if MIL-HDBK-217 was only used for arriving at a rough estimate of reliability of a component, then it would need to be constantly updated with the newer technologies, but this was never the case.
TABLE D-4 Comparison of Reliability Prediction Methodologies
| Questions for Comparison | MIL-HDBK-217F | Telcordia SR-332 | 217Plus | PRISM | FIDES |
| Does the methodology identify the sources used to develop the prediction methodology and describe the extent to which the source is known? | Yes | Yes | Yes | Yes | Yes |
| Are assumptions used to conduct the prediction according to the methodology identified, including those used for the unknown data? | Yes | Yes | Yes | Yes | Yes (must pay for modeling software). |
| Are sources of uncertainty in the prediction results identified? | No | Yes | Yes | No | Yes |
| Are limitations of the prediction results identified? | Yes | Yes | Yes | Yes | Yes |
| Are failure modes identified? | No | No | No | No | Yes, the failure mode profile varies with the life profile. |
| Are failure mechanisms identified? | No | No | No | No | Yes |
| Are confidence levels for the prediction results identified? | No | Yes | Yes | No | No |
| Does the methodology account for life-cycle environmental conditions, including those encountered during (a) product usage (including power and voltage conditions), (b) packaging, (c) handling, (d) storage, (e) transportation, and (f) maintenance conditions? | No. It does not consider the different aspects of environment. There is a temperature factor πT and an environment factor πE in the prediction equation. | Yes, for normal use life of the product from early life to steady-state operation over the normal product life. | No | No | Yes. It considers all of the life-cycle environmental conditions. |
| Does the methodology account for materials, geometry, and architectures that comprise the parts? | No | No | No | No | Yes, when relevant materials, geometry and such are considered in each part model. |
| Does the methodology account for part quality? | Quality levels are derived from specific part-dependent data and the number of the manufacturer screens the part goes through. | Four quality levels that are based on generalities regarding the origin and screening of parts. | Quality is accounted for in the part quality process grading factor. | Part quality level is implicitly addressed by process grading factors and the growth factor, pG. | Yes |
| Does the methodology allow incorporation of reliability data and experience? | No | Yes, through Bayesian method of weighted averaging. | Yes, through Bayesian method of weighed averaging | Yes, through Bayesian method of weighted averaging. | Yes. This can be done independently of the prediction methodology used. |
| Input data required for the analysis | Information on part count and operational conditions (e.g., temperature, voltage; specifics depend on the handbook used). | ||||
| Other requirements for performing the analysis | Effort required is relatively small for using the handbook method and is limited to obtaining the handbook. | ||||
| What is the coverage of electronic parts? | Extensive | Extensive | Extensive | Extensive | Extensive |
| What failure probability distributions are supported? | Exponential | Exponential | Exponential | Exponential | Phase Contributions |
|
SOURCE: Adapted from IEEE 1413.1. |
|||||
Incorrect Assumption of Constant Failure Rates
MIL-HDBK-217 assumes that the failure rates of all electronic components are constant, regardless of the nature of actual stresses that the component or system experiences. This assumption was first made based on statistical consideration of failure data independent of the cause or nature of failures. Since then, significant developments have been made in the understanding of the physics of failure, failure modes, and failure mechanisms.
It is now understood that failure rates, and, more specifically, the hazard rates (or instantaneous failure rates), vary with time. Studies have shown that the hazard rates for electronic components, such as transistors, that are subjected to high temperatures and high electric fields, under common failure mechanisms, show an increasing hazard rate with time (Li et al., 2008; Patil et al., 2009). At the same time, in components and systems with manufacturing defects, failures may manifest themselves early on, and as these parts fail, they get screened. Therefore, a decreasing failure rate may be observed initially in the life of a product. Hence, it is safe to say that in the life cycle of an electronic component or system, the failure rate is constantly varying.
McLinn (1990) and Bowles (2002) describe the history, math, and flawed reasoning behind constant failure rate assumptions. Epstein and Sobel (1954) provide a historical review of some of the first applications of the exponential distribution to model mortality in actuarial studies for the insurance industry in the early 1950s. Since exponential distributions are associated with constant failure rates, which help simplify calculations, they were adopted by the reliability engineering community. Through subsequent widespread usage, “the constant failure rate model, right or wrong, became the ‘reliability paradigm’” (McLinn, 1990, p. 237). McLinn notes how once this paradigm was adopted, its practitioners, based on their common beliefs, “became committed more to the propagation of the paradigm, than the accuracy of the paradigm itself” (p. 239).
By the end of the 1950s, and in the early 1960s, more test data were obtained from experiments. The data seemed to indicate that electronic systems at that time had decreasing failure rates (Milligan, 1961; Pettinato and McLaughlin, 1961). However, the natural tendency of the proponents of the constant failure rate model was to explain away these results as anomalies as opposed to providing a “fuller explanation” (McLinn, 1990, p. 240). Concepts such as inverse burn-in or endless burn-in (Bezat and Montague, 1979; McLinn, 1989) and mysterious unexplained causes were used to dismiss anomalies.
Proponents of the constant failure rate model believed that the hazard rates or instantaneous failure rates of electronic systems would follow a
bathtub curve—with an initial region (called infant mortality) of decreasing failure rate when failures due to manufacturing defects would be weeded out. This stage would then be followed by a region of a constant failure rate, and toward the end of the life cycle the failure rate would increase due to wear-out mechanisms. This theory would help reconcile both the decreasing failure rate and the constant failure rate model. When Peck (1971) published data from semiconductor testing, he observed a decreasing failure rate trend that lasted for many thousands of hours of operation. This was said to have been caused by “freaks.” It was later explained as being an extended infant mortality rate.
Bellcore and SAE created two standards using a prediction methodology based on constant failure rate, but they subsequently adjusted their techniques to account for this phenomenon (of decreasing failure rates lasting several thousand hours) by increasing the infant mortality region to 10,000 hours and 100,000 hours, respectively. However, the bathtub curve theory was further challenged by Wong (1981) with his work describing the demise of the bathtub curve. Claims were made by constant failure rate proponents suggesting that data challenging the bathtub curve and constant failure rate models were fraudulently manipulated (Ryerson, 1982). These allegations were merely asserted with no supporting analysis or explanation. In order to reconcile some of the results from contemporary publications, the roller coaster curve—which was essentially a modified bathtub curve—was introduced by Wong and Lindstrom (1989). McLinn (1990, p. 239) noted that the arguments and modifications made by the constant failure rate proponents “were not always based on science or logic … but may be unconsciously based on a desire to adhere to the old and familiar models.” Figure D-1 depicts the bathtub curve and the roller coaster curve.
There has been much debate about the suitability of the constant failure rate assumption for modeling component reliability. This methodology has been controversial in terms of assessing reliability during design: see, for
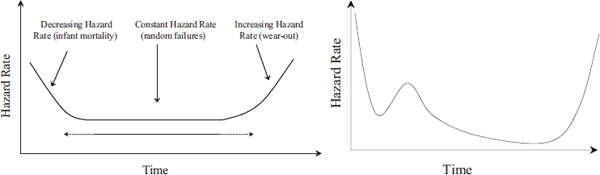
FIGURE D-1 The bathtub curve (left) and the roller coaster curve (right). See text for discussion.
example, Blanks (1980), Bar-Cohen (1988), Coleman (1992), and Cushing et al. (1993). The mathematical perspective has been discussed in detail in Bowles (2002). Thus, a complete understanding of how the constant failure rates are evaluated, along with the implicit assumptions, is vital to interpreting both reliability predictions and future design. It is important to remember that the constant failure rate models used in some of the handbooks are calculated by performing a linear regression analysis on the field failure data or generic test data. These data and the constant failure rates are not representative of the actual failure rates that a system might experience in the field (unless the environmental and loading conditions are static and the same for all devices). Because a device might see several different types of stresses and environmental conditions, it could be degrading in multiple ways. Hence, the lifetime of an electronic compound or device can be approximated to be a combination of several different failure mechanisms and modes, each having its own distribution, as shown in Figure D-2.
Furthermore, this degradation is nondeterministic, so the product will have differing failure rates throughout its life. It would be impossible to capture this behavior in a constant failure rate model. Therefore, all methodologies based on the assumption of a constant failure rate are fundamentally flawed and cannot be used to predict reliability in the field.
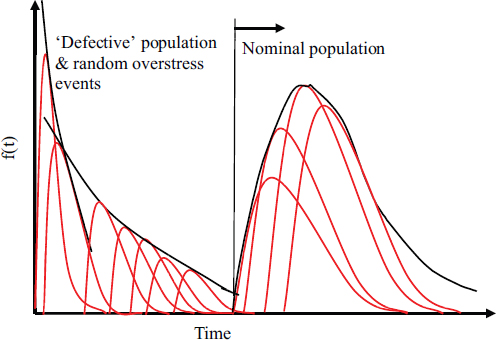
FIGURE D-2 The physics-of-failure perspective on the bathtub curve and failure rates. See text for discussion.
Lack of Consideration of Root Causes of Failures, Failure Modes, and Failure Mechanisms
After the assumption of constant failure rates, the lack of any consideration of root causes of failures and failure modes and mechanisms is another major drawback of MIL-HDBK-217 and other similar approaches. Without knowledge or understanding of the site, root cause, or mechanism of failures, the load and environment history, the materials, and the geometries, the calculated failure rate is meaningless in the context of reliability prediction. As noted above, not only does this undermine reliability assessment in general, it also obstructs product design and process improvement.
Cushing et al. (1993) note that there are two major consequences of using MIL-HDBK-217. First, this prediction methodology “does not give the designer or manufacturer any insight into, or control over, the actual causes of failure since the cause-and-effect relationships impacting reliability are not captured. Yet, the failure rate obtained is often used as a reverse engineering tool to meet reliability goals.” At the same time, “MIL-HDBK-217 does not address the design & usage parameters that greatly influence reliability, which results in an inability to tailor a MIL-HDBK-217 prediction using these key parameters” (Cushing et al., 1993, p. 542).
In countries such as Japan (see Kelly et al., 1995), Singapore, and Taiwan, where the focus is on product improvement, physics of failure is the only approach used for reliability assessment. In stark contrast, in the United States and Europe, focus on “quantification of reliability and device failure rate prediction has been more common” (Cushing et al., 1993, p. 542). This approach has turned reliability assessment into a numbers game, with greater importance being given to the MTBF value and the failure rate than to the cause of failure. The reason most often cited for this rejection of physics-of-failure-based approaches in favor of simplistic mathematical regression analysis was the complicated and sophisticated nature of physics-of-failure models. In hindsight, this rejection of physics-based models, without completely evaluating the merits of the approach and without having any foresight, was poor engineering practice.
Though MIL-HDBK-217 provides inadequate design guidance, it has often been used in the design of boards, circuit cards, and other assemblies. Research sponsored by the U.S. Army (Pecht et al., 1992) and the National Institute of Standards and Technology (NIST) (Kopanski et al., 1991) explored an example of design misguidance resulting from device failure rate prediction methodologies concerning the relationship between thermal stresses and microelectronic failure mechanisms. In this case, MIL-HDBK-217 would clearly not be able to distinguish between the two separate failure mechanisms. Results from another independent study by Boeing
(Leonard, 1991) corroborated these findings. The MIL-HDBK-217-based methodologies also cannot be used for comparison and evaluation of competing designs. They cannot provide accurate comparisons or even a specification of accuracy.
Physics of failure, in contrast “is an approach to design, reliability assessment, testing, screening and evaluating stress margins by employing knowledge of root-cause failure processes to prevent product failures through robust design and manufacturing practices” (Lall and Pecht, 1993, p. 1170). The physics-of-failure approach to reliability involves many steps, including: (1) identifying potential failure mechanisms, failure modes, and failure sites; (2) identifying appropriate failure models and their input parameters; (3) determining the variability of each design parameter when possible; (4) computing the effective reliability function; and (5) accepting the design, if the estimated time-dependent reliability function meets or exceeds the required value over the required time period.
Table D-5 compares several aspects of MIL-HDBK-217 with those of the physics-of-failure approach.
Several physics-of-failure-based models have been developed for different types of materials, at different levels of electronic packaging (chip, component, board), and under different loading conditions (vibration, chemical, electrical). Though it would be impossible to list or review all of them, many models have been discussed in the physics-of-failure tutorial series in IEEE Transactions on Reliability. Examples include Dasgupta and Pecht (1991), Dasgupta and Hu (1992a), Dasgupta and Hu (1992b), Dasgupta (1993), Dasgupta and Haslach (1993), Engel (1993), Li and Dasgupta (1993), Al-Sheikhly and Christou (1994), Li and Dasgupta (1994), Rudra and Jennings (1994), Young and Christou (1994), and Diaz et al. (1995).
The physics-of-failure models do have some limitations as well. The results obtained from these models will have a certain degree of uncertainty and errors associated with them, which can be partly mitigated by calibrating them with accelerated testing. The physics-of-failure methods may also be limited in their ability to combine the results of the same model for multiple stress conditions or their ability to aggregate the failure prediction results from individual failure modes to a complex system with multiple competing and common cause failure modes. However, there are recognized methods to address these issues, with continuing research promising improvements; for details, see Asher and Feingold (1984), Montgomery and Runger (1994), Shetty et al. (2002), Mishra et al. (2004), and Ramakrishnan and Pecht (2003).
Despite the shortcomings of the physics-of failure-approach, it is more rigorous and complete, and, hence, it is scientifically superior to the constant failure rate models. The constant failure rate reliability predictions have little relevance to the actual reliability of an electronic system in the
TABLE D-5 A Comparison Between the MIL-HDBK-217 and Physics-of-Failure Approaches
| Issue | MIL-HDBK-217 | Physics-of-Failure Approach |
| Model Development | Models cannot provide accurate design or manufacturing guidance since they were developed from assumed constant failure-rate data, not root-cause, time-to-failure data. A proponent stated: “Therefore, because of the fragmented nature of the data and the fact that it is often necessary to interpolate or extrapolate from available data when developing new models, no statistical confidence intervals should be associated with the overall model results” (Morris, 1990). | Models based on science/engineering first principles. Models can support deterministic or probabilistic applications. |
| Device Design Modeling | The MIL-HDBK-217 assumption of perfect designs is not substantiated due to lack of root-cause analysis of field failures. MIL-HDBK-217 models do not identify wearout issues. | Models for root-cause failure mechanisms allow explicit consideration of the impact that design, manufacturing, and operation have on reliability. |
| Device Defect Modeling | Models cannot be used to (1) consider explicitly the impact of manufacturing variation on reliability, or (2) determine what constitutes a defect or how to screen/inspect defects. | Failure mechanism models can be used to (1) relate manufacturing variation to reliability, and (2) determine what constitutes a defect and how to screen/inspect. |
| Device Screening | MIL-HDBK-217 promotes and encourages screening without recognition of potential failure mechanisms. | Provides a scientific basis for determining the effectiveness of particular screens or inspections. |
| Device Coverage | Does not cover new devices for approximately the first 5–8 years. Some devices, such as connectors, were not updated for more than 20 years. Developing and maintaining current design reliability models for devices is an impossible task. | Generally applicable—applies to both existing and new devices—since failure mechanisms are modeled, not devices. Thirty years of reliability physics research has produced and continues to produce peer-reviewed models for the key failure mechanisms applicable to electronic equipment. Automated computer tools exist for printed wiring boards and microelectronic devices. |
| Issue | MIL-HDBK-217 | Physics-of-Failure Approach |
| Use of Arrhenius Model | Indicates to designers that steady-state temperature is the primary stress that designers can reduce to improve reliability. MIL-HDBK-217 models will not accept explicit temperature change inputs. MIL-HDBK-217 lumps different acceleration models from various failure mechanisms together, which is unsound. | The Arrhenius model is used to model the relationships between steady-state temperature and mean time-to-failure for each failure mechanism, as applicable. In addition, stresses due to temperature change, temperature rate of change, and spatial temperature gradients are considered, as applicable. |
| Operating Temperature | Explicitly considers only steady-state temperature. The effect of steady-state temperature is inaccurate because it is not based on root-cause, time-to-failure data. | The appropriate temperature dependence of each failure mechanism is explicitly considered. Reliability is frequently more sensitive to temperature cycling, provided that adequate margins are given against temperature extremes (see Pecht et al., 1992). |
| Operational Temperature Cycling | Does not support explicit consideration of the impact of temperature cycling on reliability. No way of superposing the effects of temperature cycling and vibration. | Explicitly considers all stresses, including steady-state temperature, temperature change, temperature rate of change, and spatial temperature gradients, as applicable to each root-cause failure mechanism. |
| Input Data Required | Does not model critical failure contributors, such as materials architectures, and realistic operating stresses. Minimal data in, minimal data out. | Information on materials, architectures, and operating stresses—the things that contribute to failures. This information is accessible from the design and manufacturing processes of leading electronics companies. |
| Output Data | Output is typically a (constant) failure rate ‘λ’. A proponent stated: “MIL-HDBK-217 is not intended to predict field reliability and, in general, does not do a very good job in an absolute sense” (Morris, 1990). | Provides insight to designers on the impact of materials, architectures, loading, and associated variation. Predicts the time-to-failure (as a distribution) and failure sites for key failure mechanisms in a device or assembly. These failure times and sites can be ranked. This approach supports either deterministic or probabilistic treatment. |
| Issue | MIL-HDBK-217 | Physics-of-Failure Approach |
| DoD/Industry Acceptance | Mandated by government; 30-year record of discontent. Not part of the U.S. Air Force Avionics Integrity Program (AVIP). No longer supported by senior U.S. Army leaders. | Represents the best practices of industry. |
| Coordination | Models have never been submitted to appropriate engineering societies and technical journals for formal peer review. | Models for root-cause failure mechanisms undergo continuous peer review by leading experts. New software and documentation are coordinated with the various DoD branches and other entities. |
| Relative Cost of Analysis | Cost is high compared with value added. Can misguide efforts to design reliable electronic equipment. | Intent is to focus on root-cause failure mechanisms and sites, which is central to good design and manufacturing. Acquisition flexible, so costs are flexible. The approach can result in reduced life-cycle costs due to higher initial and final reliabilities, reduced probability of failing tests, reductions in hidden factory, and reduced support costs. |
|
SOURCE: Cushing et al. (1993). Reprinted with permission. |
||
field. The weaknesses of the physics-of-failure approach can mostly be attributed to the lack of knowledge of the exact usage environment and loading conditions that a device might experience and the stochastic nature of the degradation process. However, with the availability of various sensors for data collection and data transmission, this gap in knowledge is being overcome. The weaknesses of the physics-of-failure approach can also be overcome by augmenting it with prognostic and health management approaches, such as the one shown in Figure D-3 (see Pecht and Gu, 2009).
The process based on prognostics and health management does not predict reliability, but it does provide a reliability assessment based on in-situ monitoring of certain environmental or performance parameters. This process combines the strengths of the physics-of-failure approach with live monitoring of the environment and operational loading conditions.
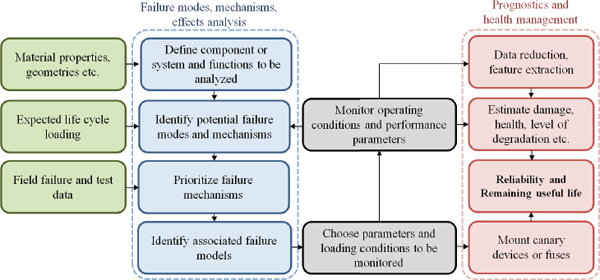
FIGURE D-3 Physics-of-failure-based prognostics and health management approach. For details, see Pecht and Gu (2009, p. 315).
SOURCE: Adapted from Gu and Pecht (2007). Reprinted with permission.
Inadequacy for System-Level Considerations
The MIL-HDBK-217 methodology is predominantly focused on component-level reliability prediction, not system-level reliability. This focus may not have been unreasonable in the 1960s and 1970s, when components had higher failure rates and electronic systems were less complex than they are today. However, as Denson (1988) notes, an increase in system complexity and component quality has resulted in a shift of system-failure causes away from components toward system-level factors, including the manufacturing, design, system requirements, and interface. Aspects such as human factors or operator errors, faulty maintenance or installation, equipment-to-equipment interaction, and software reliability also have a significant impact on the reliability of a system, and hence these factors should be accounted for in the reliability prediction (Halverson and Ozdes, 1992; Jensen, 1995).
Historically, none of these factors have been addressed by MIL-HDBK-217 (Denson, 1998). As a result, only a fraction of a total system failure rate is accounted for using handbook-based techniques: see the results from surveys conducted by Denson (1998) and Pecht and Nash (1994), shown in Table D-6. In order to estimate system-level reliability, MIL-HDBK-217 suggests that the individual reliabilities of components either be added or multiplied with other correction factors, all with the overarching assumption of constant failure rates.
Pecht and Ramappan (1992) reviewed component and device (electronic system) field failure return data collected between 1970 and 1990.
TABLE D-6 Causes of Failure in Electronic Systems, in Percentage of Total Failures)
| Category of Failure | Denson (1998) | Pecht and Nash (1994) |
| Parts | 22 | 16 |
| Design Related | 9 | 21 |
| Manufacturing Related | 15 | 18 |
| Externally Induced | 12 | - |
| Other (software, management, etc.) | 22 | 17 |
Their analysis revealed that even in 1971, part failures only accounted for about 50 percent of the total failures in certain avionics systems. A similar analysis conducted in 1990 on avionics systems that had been deployed for 2–8 years revealed that the fraction of total failures caused by part failures was almost negligible (Pecht and Nash, 1994). Similar results were found by organizations such as Boeing and Westinghouse (between 1970 and 1990) including Bloomer (1989), Westinghouse Electric Corp. (1989), Taylor (1990), and Aerospace Industries Association (1991), and, more recently, by the U.S. Army Materiel Systems Analysis Activity (AMSAA) (Jais et al., 2013).
Lack of Consideration of Appropriate Environmental and Loading Conditions
The common stresses and conditions that cause failures in electronics include temperature cycling, mechanical bending, and vibration. MIL-HDBK-217 does not account for these different environmental and loading conditions. In other words, the handbook-based prediction methodology does not distinguish between the various kinds of stresses that a device or component might be subjected to in its field operating conditions. It also does not distinguish between different kinds of failures in the computation of failure rates. The handbook-based approaches assume that the device will continue to fail at the same rate (constant failure rate) under each of those operating conditions. Consequentially, the failure rate provided by the handbook-based prediction methodology is not useful in serving as indicator of the actual reliability of a device.
While the first edition of the MIL-HDBK-217 only featured a single-point constant failure rate, the second edition, MIL-HDBK-217B, featured a failure rate calculation that later became the standard for reliability prediction methodologies in the United States. In 1969, around the time that revision B of the handbook was being drafted, Codier (1969) wrote
This traditional ritual is a flimsy house of cards which has almost no connection whatever with the 1969 realities of hardware development. The reason is, of course, that the failure rates are faulty. Frantic efforts are being made to bolster the theory by stress factors and environmental factors, but we cannot keep up. We are simply defining new constants whose values we cannot evaluate. The circulated draft of MIL-HDBK-217B proposes as many as five formal constants to use in determining the theoretical failure rate of a single part. In addition, is the following statement ‘The many factors which constitute the base for any prediction can be listed briefly…. All these factors play an important part in the accuracy of forecast.’ There follows a list of twenty-three factors.
Codier (1969) goes on to quote MIL-HDBK-217B: “In other words the forecast accuracy is based more on a prediction of program control effectiveness than it is on the inherent reliability of the design and its components.” This can be illustrated by considering one of the equations from the handbook—in this particular example, we use the equation for the failure rate of bipolar junction transistors (BJTs):
|
λp = λbπTπRπSπQπE failures/106hours, |
(1) |
where λb is the base failure rate, πT is the temperature factor, πR is the power rating factor, πS is the voltage stress factor, πQ is the quality factor, and πE is the environment factor. Hence, it is assumed that environmental conditions can be accounted for by using multiplicative factors that scale the base failure rate linearly. The rationale behind this calculation is unclear; however, these types of calculations are available for almost all component types—both passive and active. Hence, the reason for Codier’s skepticism is apparent—as there seems to be no scientific explanation as to why or how the factors are chosen, and why they have the values that they do. Furthermore, these factors do not specifically address the different failure modes and mechanisms that the device or component would be subject to under different loading or environment conditions.
The environment factor, πE, in (1) does not directly account for specific stress conditions such as vibration, humidity, or bend. It represents generic conditions, such as ground benign, ground fixed, and ground mobile. These conditions refer to how controlled the environments generally are under different categories of military platforms. If we consider solder-level failures (in packages such as Ball Grid Arrays and others), there is little reported about failures of solders under high temperature “ageing” or “soak,” even though these conditions could cause solders to be susceptible to failure under additional loads. However, solders are prone to failure in many ways, including in terms of thermal fatigue (temperature cycling) (see Ganesan
and Pecht, 2006; Abtew and Selvaduray, 2000; Clech, 2004; Huang and Lee, 2008), vibrational loading (Zhou et al., 2010), mechanical bending (Pang and Che, 2007), and drop testing (Varghese and Dasgupta, 2007).
In addition, different solders exhibit different reliabilities and lifetimes. The time to failure also depends on the loading rates (thermal shock or thermal cycling; mechanical bend; and vibration or drop). None of these parameters is accounted for in the MIL-HDBK-217-based methodologies, as it does not factor in environmental and loading conditions. Not only would it be futile to try to document all the different types of solders and loading conditions, but also because of how quickly technology is advancing in these areas, it would be impossible to prepare an exhaustive list of combinations of loading conditions and solder types together with other parameters such as package type, board finish, etc. Hence, this is another area in which no solution to “repair” the approaches of the existing handbook is available.
Absence of Newer Technologies and Components
Since its introduction, MIL-HDBK-217 has had difficulty keeping up with the rapid advances being made in the electronics industry. The handbook underwent six revisions over the course of more than 30 years, with the last revision being MIL-HDBK-217F in 1995. Moore (1965) predicted that the complexity of circuits would increase in such a way that the number of transistors on integrated circuits would double nearly every 2 years. This means that the number of transistors on the generations of integrated circuits between 1965 and 1995 had increased by a factor of nearly 215 (see Figure D-4).
The various handbook revisions were barely able to capture a small number of those generations of integrated circuits. Even with all its updates, the latest handbook revision, MIL-HDBK-217F, only features reliability prediction models for ceramic and plastic packages based on data from dual inline packages and pin grid arrays, which have rarely been used in new designs since 2003. Since the 1990s, the packaging and input/output (I/O) density of integrated circuits have advanced rapidly. Consequently, MIL-HDBK-217F, which does not differentiate between different package types or I/O densities, would not be applicable to any of the newer package types, including many of the new area array packages and surface mount packages. Hence, packages such as ball grid arrays (BGAs), quad-flat no-lead packages (QFN), package on package (PoP), and stacked die packages are not covered by MIL-HDBK-217F. Additionally, it would be a nearly impossible task to characterize the failure rates of all the different types of current generation packages, simply because of the sheer number of different packages.
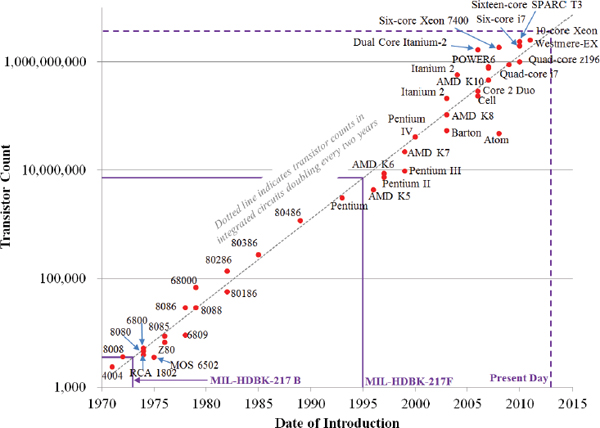
FIGURE D-4 Evolution of integrated circuits (Moore’s Law).
SOURCE: Transistor Count and Moore’s Law-2011 by Wgsimon (own work). Licensed under Creative Commons Attribution-Share Alike 3.0 via Wikimedia Commons. Available: http://commons.wikimedia.org/wiki/File:Transistor_Count_and_Moore%27s_Law_-_2011.svg#mediaviewer/File:Transistor_Count_and_Moore%27s_Law_-_2011.svg.
Moreover, even if it were possible to characterize the different package types and I/O densities, the life cycles (from design or conception to discontinuation) of modern electronic devices and components are much shorter than those of older components and systems. Some of the older package types, from the 1980s and 1990s, are still in use in legacy systems. Such components and systems had been made available for significantly longer than contemporary commercial electronic products, such as computers and cell phones, which typically have a life cycle of 2-5 years. These shorter life cycles pose a challenge to failure rate evaluations because of the short time frame available for the collection of failure data and the development of failure rate models. Hence, it would neither be pragmatic nor economical to invest in the development of such failure rate models.
The problem is not restricted only to active components: the discrete and passive component database of MIL-HDBK-217 is also outdated.
Discrete components, such as insulated gate bipolar transistors (IGBTs), surface mount tantalum capacitors, power sources such as Li-ion and NiMH batteries, supercapacitors, and niobium capacitors, all of which are used widely in the industry, are not, and probably will never be, covered by MIL-HDBK-217. Consequently, manufacturers and engineers are forced to identify the closest match in the handbook and then base their calculations on the guidelines prescribed for those older parts. This could potentially penalize a newer, more reliable component for the unreliability of its predecessors.
Historically, there have been precedents for such penalizations. For example, when the reliability, availability, and maintainability (RAM) model in MIL-HDBK-217B was extrapolated to include 64K RAM, the resulting mean time between failures calculated was a mere 13 seconds (Pecht and Nash, 1994). As a result of such incidents, a variety of notice changes to MIL-HDBK-217B appeared, and on April 9, 1979, MIL-HDBK-217C was published to “band aid” the problems. As a consequence of the rapidly advancing and ever-changing technology base, in the brief span of less than 3 years, MIL-HDBK-217C was updated to MIL-HDBK-217D in 1982, which in turn was updated to MIL-HDBK-217E in 1986. Hence, all the MIL-HDBK-217 revisions have had trouble keeping pace with the cutting edge of electronics packaging technology, and MIL-HDBK-217F is no exception. It would be easier to concede that the MIL-HDBK-217 methodology and approach are fundamentally and irreparably flawed than to update or replace it with something similar.
COMPARISONS OF HANDBOOK PREDICTIONS WITH FIELD DATA
Several case studies and experiments conducted have invalidated the predictions obtained from the handbook methodologies. These studies revealed that there were wild discrepancies between the predicted and actual MTBFs, often to several orders of magnitude. MTBFs and failures in time (FITs) are corollaries of the constant failure rate metric. For constant failure rates, the MTBF is simply the inverse of the constant failure rate, while an FIT rate is the number of failures in one billion (109) hours of device operation.
Some of the earliest studies that discovered the inconsistencies between test or field data and MIL-HDBK-217 predictions were published in the early 1960s (see Milligan, 1961; Pettinato and McLaughlin, 1961). The data from these tests indicated that the electronic systems of that time showed decreasing failure rates. However, as noted above, these findings were dismissed as anomalies. By the 1970s, there were more studies published—one of them identifying fluctuations in the field MTBF values when compared with the MIL-HDBK-217A-based predictions (Murata, 1975). In 1979,
another study provided well-documented results that provided an indisputable challenge to constant failure rate models (Bezat and Montague, 1979).
Around this time, MIL-HDBK-217 was revised several times in an effort to keep up with the constantly evolving technology and to temporarily fix some of the models. However, despite the updates, there were more studies revealing disparities between test data and predicted MTBF values. One such study, conducted on Electric Countermeasures (ECM) radar systems, was carried out by Lynch and Phaller (1984). They pointed out that not only were the assumptions made in the calculation for reliability prediction at the part level flawed, but they also had a significant role in contributing to the disparity between predicted and observed MTBF values at the system level. Since then, several similar studies have been published, with the Annual Reliability and Maintainability Symposium including one such paper roughly every year (e.g., MacDiarmid, 1985; Webster, 1986; Branch, 1989; Leonard and Pecht, 1991; Miller and Moore, 1991; Rooney, 1994).
In the 1990s, even the proponents of the handbook-based techniques conceded that “MIL-HDBK-217 is not intended to predict field reliability and, in general, does not do a very good job of it in an absolute sense” (Morris, 1990). Companies such as General Motors stated that “GM concurs and will comply with the findings and policy revisions of Feb. 15, 1996 by the Assistant Secretary of the U.S. Army for Research, Development and Acquisition…. Therefore: MIL-HDBK 217, or a similar component reliability assessment method such as SAE PREL, shall not be used” (GM North America Operation, 1996). U.S. Army regulation 70-1 stated in a similar vein that “MIL–HDBK–217 or any of its derivatives are not to appear in a solicitation as it has been shown to be unreliable, and its use can lead to erroneous and misleading reliability predictions” (U.S. Department of the Army, 2011, pp. 15-16).
The following section reviews the results from some of the numerous case studies on both military and nonmilitary systems that have discredited the handbook-based techniques. The differences between the predictions of several similar handbook methodologies are also reviewed.
STUDIES ON COMMERCIAL ELECTRONIC PARTS AND ASSEMBLIES
There have been studies conducted on several different types of commercial electronic parts and assemblies, such as computer parts and memory (see Hergatt, 1991; Bowles, 1992; Wood and Elerath, 1994), industrial and automotive (Casanelli et a.l, 2005), avionics (Leonard and Pecht, 1989; Leonard and Pecht, 1991; Charpanel et al., 1998), and telecommunication equipment (Nilsson and Hallberg, 1997). Each of these studies reveals that there is a wide gap dividing the predicted MTBF values from the actual field or test MTBFs.
Table D-7 shows results from some publications on the disparity between the MTBFs for different devices. It can be seen that the ratios of measured MTBFs to predicted MTBFs varies from 0.54 to 12.20 for these systems.
Studies on computer systems, such as those by Wood and Elerath (1994) and Charpenel et al. (1998), seem to indicate that measured MTBFs are considerably lower than the predicted MTBF values. The results from their studies can be seen in Figure D-5. Similar results can also be seen in
TABLE D-7 Ratio of Measured MTBFs to Handbook-Based Predicted MTBFs for Various Electronic Devices
| Product | Method | Measured MTBF (hours) | Predicted MTBF (hours) | Ratio | |||
| Audio Selector (Leonard and Pecht, 1991) | 6,706 | 12,400 | 0.54 | ||||
| Bleed Air Control (Leonard and Pecht, 1991) | 28,261 | 44,000 | 0.64 | ||||
| Storage (Hard) Disk (Wood and Elerath, 1994) | Bellcore* (*now Telcordia) | 2.00 | |||||
| Processor Board (Wood and Elerath, 1994) | Bellcore* | 2.50 | |||||
| Controller Board (Wood and Elerath, 1994) | Bellcore* | 2.50 | |||||
| Power Supply (Wood and Elerath, 1994) | Bellcore* | 3.50 | |||||
| PW2000 Engine Control (Leonard, 1991) | 42,000 | 10,889 | 3.90 | ||||
| JT9D Engine Control (Leonard, 1991) | 32,000 | 8,000 | 4.00 | ||||
| Memory Board (Wood and Elerath, 1994) | Bellcore* | 5.00 | |||||
| Spoiler Control (Leonard and Pecht, 1991) | 62,979 | 8,800 | 7.16 | ||||
| PC Server (Hergatt, 1991) | MIL-HDBK-217 | 15,600 | 2,070 | 7.50 | |||
| Office Workstation (Hergatt, 1991) | MIL-HDBK-217 | 92,000 | 7,800 | 11.80 | |||
| Avionics CPU Board | MIL-HDBK-217 | 243,902 | 20,450 | 11.90 | |||
| Yaw Damper | 55,993 | 4,600 | 12.20 |
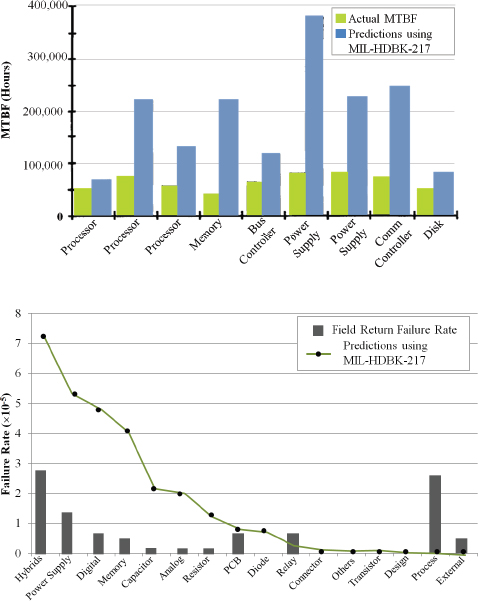
FIGURE D-5 Predicted MTBFs compared with field or measured MTBFs in Wood and Elerath (1994), top, and in Charpenel et al. (1998), bottom.
SOURCE: Top: Wood and Elerath (1994, p. 154). Reprinted with permission. Bottom: Charpenel et al. (1998). Reprinted with permission.
Hergatt (1991) regarding commercial computers, where the actual MTBFs of office workstations and PC servers were found to be three orders of magnitude greater than the predicted values. However, the results described in Table D-7 seem to indicate that handbook-based reliability prediction techniques can either arbitrarily underpredict or overpredict the true MTBF of a system in field conditions. Hence, handbook-based predictions are not always conservative. Even if the predictions were conservative, it would be impossible to determine the true margin between the predicted values and the actual values.
STUDIES ON MILITARY ELECTRONIC PARTS AND ASSEMBLIES
The errors in reliability prediction while using handbook-based methodologies are not restricted only to commercial electronics. A study conducted by the AMSAA (Jais et al., 2013) surveyed various agencies throughout the U.S. Department of Defense (DoD) by requesting reliability information on a variety of systems. The systems represented a variety of platforms, including communications devices, network command and control, ground systems, missile launchers, air command and control, aviation warning, and aviation training systems. The information requested included system-level predictions and demonstrated results (MTBFs from testing and fielding).
The results were filtered to only include estimates from predictions that were based purely on the methodologies prescribed in the MIL-HDBK-217 and its progeny. The ratio of predicted to demonstrated values ranged from 1.2:1 to 218:1: see Figure D-6. Jais et al. (2013, p. 4) stated that the “original contractor predictions for DoD systems [MTBFs] greatly exceed the demonstrated results.” Statistical analysis of the data using Spearman’s rank order correlation coefficient showed that MIL-HDBK-217-based predictions could not support comparisons between systems. The data and analysis demonstrated that the handbook predictions are not only inaccurate, but also could be harmful from an economic perspective if they were used as guidelines for sustainment, maintainability, and sparing calculations. The authors then considered why MIL-HDBK-217 is still being used for the DoD acquisition. They conclude that “… despite its shortcomings, system developers are familiar with MIL-HDBK-217 and its progeny. It allows them a ‘one size fits all’ tool that does not require additional analysis or engineering expertise. The lack of direction in contractual language leaves also government agencies open to its use” Jais et al. (2013, p. 5.)
Cushing et al. (1993) published data showing the discrepancies between the MIL-HDBK-217-based predictions of MTBFs for the Single Channel Ground Air Radio Set (SINCGARS) and the observed MTBFs during the 1987 nondevelopmental item candidate test. The data are shown in Table D-8. The errors in predictions were found to vary between –70 per-
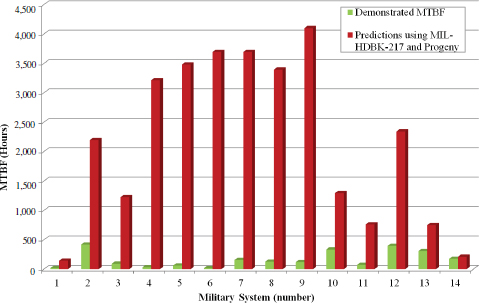
FIGURE D-6 Comparison of predicted and demonstrated MTBF values for U.S. defense systems.
SOURCE: Jais et al. (2013, p. 4). Reprinted with permission.
TABLE D-8 Results of the 1987 SINCGARS Nondevelopmental Item Candidate Test
| Vendor | Predicted MTBF (hours) | Observed MTBF (hours) | Error (%) | |||
| A | 811 | 98 | 728 | |||
| B | 1269 | 74 | 1615 | |||
| C | 1845 | 2174 | -15 | |||
| D | 2000 | 624 | 221 | |||
| E | 2000 | 51 | 3822 | |||
| F | 2304 | 6903 | -67 | |||
| G | 2450 | 472 | 419 | |||
| H | 2840 | 1160 | 145 | |||
| I | 3080 | 3612 | -15 | |||
|
SOURCE: Cushing et al. (1993, p. 543). Reprinted with permission. |
||||||
cent (underprediction) and 3,800 percent (overprediction). These data also highlight the issue with the ability of the handbook-based predictions to evaluate competing proposals. Hence, the column with the sorted predicted MTBF values does not provide an accurate ranking of the reliability of the vendors’ systems, as vendor F’s system was technically found to be more reliable than those of vendors G, H, and I and vendor E’s system performed more poorly than those of vendors A, B, C, and D. These results again demonstrate how the handbook predictions can be misleading and inaccurate.
VARIATIONS IN PREDICTIONS BY DIFFERENT METHODOLOGIES
There are also variations in the predictions of MTBFs of systems obtained by different 217-type methodologies. Oh et al. (2013) found that when predicting the reliability of cooling fans and their control systems using MIL-HDBK-217 and Telcordia SR-332, very different results were obtained. While the MTBF predictions based on MIL-HDBK-217 showed an error of 469–663 percent, the SR-332 prediction had an error of between 70 and 300 percent. Spencer (1986) compared the FIT rates of NMOS SRAM modules evaluated using MIL-HDBK-217, Bellcore (Telcordia), British Telecom HRD, and CNET based methodologies. He found that the failure rate increased with an increase in complexity for all the prediction methodologies.
Jones and Hayes (1999) performed a more comprehensive study comparing predictions from various handbook methodologies with actual field data on commercial electronic circuit boards. They found not only a difference between the predictions and MTBFs evaluated using the field data, but also significant differences between the various predictions themselves. Figure D-7 provides some details.
RIAC 217PLUS AND MIL-HDBK-217G
The Handbook of 217Plus Reliability Prediction Models, commonly referred to as 217Plus, was developed by the Reliability Information Analysis Center (RIAC), an independent private enterprise. 217Plus was written to document the models and equations used in PRISM, a software tool used for system reliability assessment, described above. 217Plus was also published as an alternative to MIL-HDBK-217F. 217Plus prediction model doubles the number of part-type failure rate models from PRISM, and it also contains six new constant failure rate models not available in PRISM. The Handbook of 217Plus was released on May 26, 2006.
217Plus contains reliability prediction models for both the component and system levels. The component models are determined first to estimate the failure rate of each component and then summed to estimate the sys-
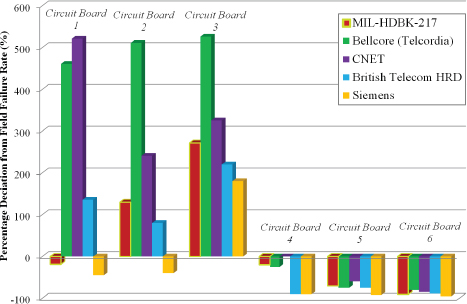
FIGURE D-7 Comparison of various handbook methodologies.
SOURCE: Adapted from Jones and Hayes (1999, p. 9). Reprinted with permission.
tem failure rate. This estimate of system reliability is further modified by the application of “system-level” factors (called process grade factors) that account for noncomponent impacts of overall system reliability. “The goal of a model is to estimate the ‘rate of occurrence of failure’ and accelerants of a component’s primary failure mechanisms within an acceptable degree of accuracy” (Reliability Information Analysis Center, 2006, p. 2). The models account for environmental factors and operational profile factors so that various tradeoff analyses can be performed. A 217Plus prediction can be performed using both a predecessor system and a new system. A predecessor is a product with similar technology and design and manufacturing processes. If the item under analysis is an evolution of a predecessor item, then the field experience of the predecessor item can be leveraged and modified to account for the differences between the new item and the predecessor item. The 217Plus methodology also accommodates the incorporation of test/field reliability experience into the analytical prediction of new systems.
Even if RIAC 217Plus overcomes some of the major shortcomings of MIL-HDBK-217, it is still built on the foundations of the handbook. As it stands now, it is unclear how 217Plus accounts for all possible equipment failure modes by focusing on component models and process grade fac-
tors. Although additive models help curb the “blow up” of MTTF values calculated at the high and low extremes, it still remains to be proven how this would provide more accurate estimates of failure rates and lifetimes. The implementation of such modifications as the additive models still does not account for common mode failures, which account for a significant portion of system-level failures. It is also unclear if 217Plus can account for the dependencies between the various components and their operations under different environmental conditions at the system level. Combining the failure rates estimated theoretically (by considering the system to be a superset of components) with results from Bayesian analysis and estimation of the failure rates using field and test data would account for some of these common mode failures. However, the validity and applicability of these failure rates depends on the assumptions made, specifically regarding the likelihood functions involved in the Bayesian analysis. The final calculations and estimates of lifetimes and failure rates also depend on how the results from the Bayesian analysis are merged with other analytical predictions. It is still not be possible to condense the results from the Bayesian analysis to give a point estimate of either the lifetimes or failure rates, because this point estimate would suffer from the same shortcomings that the constant failure rate estimates have, in that it would not be able to account for variations in field conditions.
Although the 217Plus methodology was developed by RIAC, the inclusion of “217” term in the title of the RIAC handbook seems to imply that it is officially endorsed by DoD as a successor to MIL-HDBK-217F. But 217Plus is far from being a successor to MIL-HDBK-217F. The 217Plus would have been capable of serving as an interim alternative to MIL-HDBK-217F as it is being phased out, if 217Plus were able to address system-level reliability and reliability growth. Its predictions would also need to take into consideration the physics of failure both at the component and system levels. However, because 217Plus is not capable of addressing system-level reliability or physics-of-failure issues adequately, it cannot really serve either as the successor or an interim alternative to MIL-HDBK-217F. The remedy to the damage caused by adopting MIL-HDBK-217 is not to substitute it with a “lesser evil,” but rather to do away with all such techniques.
The Naval Surface Warfare Center (NSWC) Crane Division announced its intent to form and chair a working group to revise MIL-HDBK-217F to Revision G by updating the list of components and technologies. But, as Jais et al., (2013, p. 5) have stated, “Simply updating MIL-HDBK-217 based upon current technology does not alleviate the underlying fundamental technical limitations addressed in the earlier sections. Predictions should provide design information on failure modes and mechanisms that can be used to mitigate the risk of failure by implementing design changes.” The NSWC Crane Division recognizes that MIL-HDBK-217 is known and
accepted worldwide and is used by commercial companies, the defense industry, and government organizations. Instead of educating users about the shortcomings of MIL-HDBK-217 techniques and assumptions, it prescribes standardization of the use of the 217 reliability prediction tool. The NSWC also stated that the end users of the 217 methodology prefer the relative simplicity of the prediction method. This approach demonstrates how the usage of the MIL-HDBK-217 methodologies has desensitized the reliability engineering community and the electronics industry as a whole. A new paradigm shift is needed, and the emphasis should not be on the relative simplicity of a reliability prediction methodology, but rather on the scientific merit and accuracy of the techniques.
SUMMARY AND CONCLUSIONS
MIL-HDBK-217 is a reliability prediction methodology for electronic components and devices that is known to be fundamentally flawed in many ways. The problems with the use of MIL-HDBK-217 can broadly be classified into two categories. The first category of problems arise from the fact that the MIL-HDBK-217 concept was developed, formalized, and institutionalized before the knowledge of electronics and degradation had become mature. Thus, the first version of the handbook featured a simplistic single point constant failure obtained by fitting a straight line through field failure data of vacuum tubes. Subsequent revisions of the handbook were influenced by the exponential distributions and the associated constant failure rates that were being used in actuarial studies. This constant failure rate then became the premise of MIL-HDBK-217. Because the methodology was built around this premise, the reliability prediction techniques excluded any consideration of the root causes of failures and the physics underlying the failure mechanisms and focused instead only on the linear regression analysis of the failure data. As a result, the handbook did not have guidelines or calculations to account for different types of environmental and operational loading conditions, and the predicted failure rates were assumed to be the same constant value in all conditions
The second category of problems arise from the fact that for a technique such as the MIL-HDBK-217 methodology, it becomes increasingly difficult to keep up to date with the fast pace of the development of electronics and changes in the supply-chain balance. With constant advances in packaging and interconnected technology and materials, both active and passive electronic components are evolving rapidly. Components such as insulated gate bipolar transistors and niobium capacitors, which are now used extensively in electronic systems, were not included in the last MIL-HDBK-217 revision. Furthermore, the life cycle of components in the 2010s is vastly shorter than the life cycle of components in the 1960s. With
the average life cycle of commercial electronic systems, such as smartphones and laptops, being about 2 years, it becomes very difficult to acquire field failure data and build failure models for every type of component used in electronic systems.
The progeny of MIL-HDBK-217 were all developed and promoted on the assumption that the only problem with the original methodology was that it was not up to date or that it did not meet the needs of a specific market sector. The progeny include such methodologies as SAE Reliability Prediction, Bellcore/Telcordia, PRISM, and RIAC 217Plus. While each of these methodologies might have application-specific test conditions or data for newer components that were excluded from MIL-HDBK-217, they all still use the constant failure rate assumption in some capacity. Hence, each of these “new” approaches continued to ignore the fundamental scientific principles that govern degradation and failure mechanics of electronic devices. These progeny, like their predecessor, failed to acknowledge that the degradation and failure of a component cannot be condensed into a single unique “constant failure rate” metric.
The inability of the MIL-HDBK-217 methodology and its progeny to predict failure rates has been demonstrated by numerous studies. In each of these studies the failure rate predictions end up either grossly overpredicting or underpredicting the actual failure rates. Therefore, we conclude that the MIL-HDBK-217 approach provides the user with values that are inaccurate and misleading. However, because adhering to MIL-HDBK-217 for failure rate calculations has often been a contractual requirement, and because this methodology was also adapted and used by the telecommunication and automobile industries, the practice of using the predictions based on these techniques trickled down the supply chain, thus pervading the electronics industry. This practice culminated in the proliferation of MIL-HDBK-217. As a consequence, the use of constant failure rate models is widespread even today, despite the fact that the handbook has not been updated in nearly 20 years. A NSWC CRANE survey in 2008 (Gullo, 2008) reported that 80 percent of its respondents still used MIL-HDBK-217.
The adoption and adaptation of constant failure rate models to evaluate the reliability of electronic systems was probably never a good idea. This practice has fundamentally affected how reliability prediction is perceived, both with regard to commercial and military electronics. The continued use of MIL-HDBK-217 or one of its adaptations can be destructive because it promotes poor engineering practices while also harming the growth of reliability of electronic products. Furthermore, MIL-HDBK-217 cannot be improved or fixed because the underlying assumptions governing the methodology are fallacious. It must be accepted that a reliability prediction methodology that is based on predicting the use conditions is not feasible. Moving forward, the solution is to do away with MIL-HDBK-217
by canceling and no longer recognizing it. DoD should strive for a policy whereby every major subsystem and critical component used in a defense system have physics-of-failure models for component reliability that have been validated by the manufacturer.
REFERENCES
Abtew, M., and Selvaduray, G. (2000). Lead-free solders in microelectronics. Materials Science and Engineering Reports, 27(5-6), 95-141.
Aerospace Industries Association. (1991). Ultra Reliable Electronic Systems—Failure Data Analysis by Committee of AIA Member Companies. Arlington, VA: Author.
Al-Sheikhly, M., and Christou, A. (1994). How radiation affects polymeric materials. IEEE Transactions on Reliability, 43, 551-556.
Asher, H., and Feingold, F.H. (1984). Repairable Systems Reliability: Modeling, Inference, Misconceptions and Their Causes, Lecture Notes in Statistics, Volume 7. New York: Marcel Dekker.
Bar-Cohen, A. (1988). Reliability physics vs. reliability prediction. IEEE Transactions on Reliability, 37, 452.
Bezat, A.G., and Montague, L.L. (1979). The effects of endless burn-in on reliability growth projections. Prepared for the Annual Reliability and Maintainability Symposium, January 23-25, Washington, DC. In Proceedings of the 1979 Reliability and Maintainability Symposium (pp. 392-397). New York: IEEE.
Bhagat, W.W. (1989). R&M through avionics/electronics integrity program. Prepared for the Annual Reliability and Maintainability Symposium, January 24-26, Atlanta GA. In Proceedings of the 1989 Reliability and Maintainability Symposium (pp. 216-220). New York: IEEE. Available: http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=49604 [December 2014].
Blanks, H.S. (1980). The temperature dependence of component failure rate. Microelectronics and Reliability, 20, 297-307.
Bloomer, C. (1989). Failure mechanisms in through hole packages. Electronic Materials Handbook, 1, 976.
Bowles, J.B. (1992). A survey of reliability-prediction procedures for microelectronic devices. IEEE Transactions on Reliability, 41(1), 2-12.
Bowles, J.B. (2002). Commentary—caution: Constant failure-rate models may be hazardous to your design. IEEE Transactions on Reliability, 51(3), 375-377.
Caruso, H. (1996). An overview of environmental reliability testing. Prepared for the Annual Reliability and Maintainability Symposium, January 22-25. In Proceedings of the 1996 Reliability and Maintainability Symposium (pp. 102-109). New York: IEEE. Available: http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=500649 [December 2014].
Cassanelli, G., Mura, G., Cesaretti, F., Vanzi, M., and Fantini, F. (2005). Reliability predictions in electronic industry applications. Microelectronics Reliability, 45, 1321-1326.
Charpenel, P., Cavernes, P., Casanovas, V., Borowski, J., and Chopin, J.M. (1998). Comparison between field reliability and new prediction methodology on avionics embedded electronics. Microelectronics Reliability, 38, 1171-1175.
Clech, J. (2004). Lead-free and mixed assembly solder joint reliability trends. Proceedings of the 2004 IPC/SMEMA Council APEX Conference, Anaheim, CA. Available: http://www.jpclech.com/Clech_APEX2004_Paper.pdf [October 2014].
Codier, E.O. (1969). Reliability prediction—Help or hoax? Proceedings of the 1969 Annual Symposium on Reliability. IEEE Catalog No 69C8-R, pp. 383-390. New York: IEEE.
Coleman, L.A. (1992). Army to abandon MIL-HDBK-217. Military and Aerospace Electronics, 3, 1-6.
Cushing, M.J., Mortin, D.E., Stadterman, T.J., and Malhotra, A. (1993). Comparison of electronics reliability assessment approaches. IEEE Transactions on Reliability, 42(4), 542-546.
Cushing, M.J., Krolewski, J.G., Stadterman, J.T., and Hum, B.T. (1996). U.S. Army reliability standardization improvement policy and its impact. IEEE Transactions on Components, 19(2), 277-278.
Dasgupta, A. (1993). Failure-mechanism models for cyclic fatigue. IEEE Transactions on Reliability, 42, 548-555.
Dasgupta, A., and Haslach, H.W.J. (1993). Mechanical design failure models for buckling. IEEE Transactions on Reliability, 42, 9-16.
Dasgupta, A., and Hu, J.M. (1992a). Failure-mechanism models for excessive elastic deformation. IEEE Transactions on Reliability, 41, 149-154.
Dasgupta, A., and Hu, J.M. (1992b). Failure-mechanism models for plastic deformations. IEEE Transactions on Reliability, 41, 168-174.
Dasgupta, A., and Pecht, M. (1991). Material failure-mechanisms and damage models. IEEE Transactions on Reliability, 40, 531-536.
Denson, W. (1998). The history of reliability prediction. IEEE Transactions on Reliability, 47(3), SP3211-SP3218.
Denson, W., and Brusius, P. (1989). VHSIC and VHSIC-like reliability prediction modeling. RADC-TR-89-177, Final Technical Report. Rome, NY: IIT Research Institute.
Diaz, C., Kang, S.M., and Duvvury, C. (1995). Tutorial: Electrical overstress and electrostatic discharge. IEEE Transactions on Reliability, 44, 2-5.
Engel, P. (1993). Failure models for mechanical wear modes and mechanisms. IEEE Transactions on Reliability, 42, 262-267.
Epstein, B., and Sobel, M. (1954). Some theorems relevant to life testing from an exponential distribution. The Annals of Mathematical Statistics, 25, 373-381.
FIDES Group. (2009). FIDES Guide 2009. Paris, France: Union Technique De L’Electricite.
Ganesan, S., and Pecht, M. (2006). Lead-Free Electronics. Hoboken, NJ: John Wiley & Sons.
GM North America Operation. (1996). Technical Specification Number: 10288874. Detroit, MI: General Motors Company.
Gu, J., and Pecht, M. (2007). New methods to predict reliability of electronics. Proceedings of the Seventh International Conference on Reliability and Maintainability (pp. 440-451. Beijing: China Astronautic Publishing House.
Gullo, L. (2008). The revitalization of MIL-HDBK-217. IEEE Transactions on Reliability, 58(2), 210-261. Available: http://rs.ieee.org/images/files/Publications/2008/2008-10.pdf [January 2015].
Hallberg, Ö. (1994). Hardware reliability assurance and field experience in a telecom environment. Quality and Reliability Engineering International, 10(3), 195-200.
Hallberg, Ö., and Löfberg, J. (1999). A Time Dependent Field Return Model for Telecommunication Hardware, in Advances in Electronic Packaging 1999: Proceedings of the Pacific Rim/ASME International Intersociety Electronic and Photonic Packaging Conference (InterPACK ’99), New York.
Halverson, M., and Ozdes, D. (1992). What happened to the system perspective in reliability. Quality and Reliability Engineering International, 8(5), 391-412.
Hergatt, N.K. (1991). Improved reliability predictions for commercial computers. Proceedings of the 1991 Annual Reliability and Maintainability Symposium. Available: http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=154461 [December 2014].
Huang, M., and Lee, C. (2008). Board level reliability of lead-free designs of BGAs, CSPs, QFPs and TSOPs. Soldering and Surface Mount Technology, 20(3), 18-25.
IEEE Standards Association. (2010). Guide for Developing and Assessing Reliability Predictions Based on IEEE Standard 1413. Piscataway, NJ: Author.
Jais, C., Werner, B., and Das, D. (2013). Reliability predictions: Continued reliance on a misleading approach. Prepared for the Annual Reliability and Maintainability Symposium, January 28-31, Orlando, FL. In Proceedings of the 2013 Reliability and Maintainability Symposium (pp. 1-6). New York: IEEE. Available: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6517751 [December 2014].
Jensen, F. (1995). Reliability: The next generation. Microelectronics Reliability, 35(9-10), 1363-1375.
Jones, J., and Hayes, J. (1999). A comparison of electronic reliability prediction models. IEEE Transactions on Reliability, 48(2), 127-134.
Kelly, M., Boulton, W., Kukowski, J., Meieran, E., Pecht, M., Peeples, J., and Tummala, R. (1995). Electronic Manufacturing and Packaging in Japan. Baltimore, MD: Japanese Technology Evaluation Center and International Technology Research Institute.
Knowles, I. (1993). Is it time for a new approach? IEEE Transactions on Reliability, 42, 3.
Kopanski, J.J., Blackburn, D.L., Harman, G.G., and Berning, D.W. (1991). Assessment of Reliability Concerns for Wide-Temperature Operation of Semiconductor Devices and Circuits. Gaithersburg, MD: National Institute of Standards and Technology. Available: http://www.nist.gov/manuscript-publication-search.cfm?pub_id=4347 [September 2014].
Lall, P., and Pecht, M. (1993). An integrated physics of failure approach to reliability assessment. Proceedings of the 1993 ASME International Electronics Packaging Conference, 4(1).
Lall, P., Pecht, M., and Hakim, E. (1997). Influence of Temperature on Microelectronics and System Reliability. Boca Raton, FL: CRC Press.
Leonard, C.T. (1987). Passive cooling for avionics can improve airplane efficiency and reliability. Proceedings of the IEEE 1989 National Aerospace and Electronics Conference. New York: IEEE.
Leonard, C.T. (1988). On US MIL-HDBK-217. IEEE Transactions on Reliability, 37(1988), 450-451.
Leonard, C.T. (1991). Mechanical engineering issues and electronic equipment reliability: Incurred costs without compensating benefits. Journal of Electronic Packaging, 113, 1-7.
Leonard, C.T., and Pecht, M. (1989). Failure prediction methodology calculations can mislead: Use them wisely, not blindly. Proceedings of the IEEE 1989 National Aerospace and Electronics Conference, pp. 1887-1892.
Leonard, C.T., and Pecht, M. (1991). Improved techniques for cost effective electronics. Proceedings of the 1991 Annual Reliability and Maintainability Symposium.
Li, J., and Dasgupta, A. (1993). Failure-mechanism models for creep and creep rupture. IEEE Transactions on Reliability, 42, 339-353.
Li, J., and Dasgupta, A. (1994). Failure-mechanism models for material aging due to inter-diffusion. IEEE Transactions on Reliability, 43, 2-10.
Li, X., Qin, J., and Bernstein, J.B. (2008). Compact modeling of MOSFET wearout mechanisms for circuit-reliability simulation. IEEE Transaction on Device Materials and Reliability, 8(1), 98-121.
Lynch, J.B., and Phaller, L.J. (1984). Predicted vs test MTBFs… Why the disparity? Proceedings of the 1984 Annual Reliability and Maintainability Symposium, pp. 117-122.
MacDiarmid, P.R. (1985). Relating factory and field reliability and maintainability measures. Proceedings of the 1985 Annual Reliability and Maintainability Symposium, p. 576.
McLinn, J.A. (1989). Is Failure Rate Constant for a Complex System? Proceedings of the 1989 Annual Quality Congress, pp. 723-728.
McLinn, J.A. (1990). Constant failure rate—A paradigm in transition. Quality and Reliability Engineering International, 6, 237-241.
Miller, P.E., and Moore, R.I. (1991). Field reliability vs. predicted reliability: An analysis of root causes for the difference. Proceedings of the 1991 Annual Reliability and Maintainability Symposium, pp. 405-410.
Milligan, G.V. (1961). Semiconductor failures Vs. removals. In J.E. Shwop, and H.J. Sullivan, Semiconductor Reliability. Elizabeth, NJ: Engineering.
Mishra, S., Ganesan, S., Pecht, M., and Xie, J. (2004). Life consumption monitoring for electronics prognostics. Proceedings of the 2004 IEEE Aerospace Conference, pp. 3455-3467.
Montgomery, D.C., and Runger, G.C. (1994). Applied Statistics and Probability for Engineers. New York: John Wiley & Sons.
Moore, G.E. (1965). Cramming more components onto integrated circuit. Electronics Magazine, 38(8), 4-7.
Morris, S. (1990). MIL-HDBK-217 use and application. Reliability Review, 10, 10-13.
Murata, T. (1975). Reliability case history of an airborne air data computer. IEEE Transactions on Reliability, R-24(2), 98-102.
Nash, F.R. (1993). Estimating Device Reliability: Assessment of Credibility. Boston, MA: Kluwer Academic.
Nilsson, M., and Hallberg, Ö. (1997). A new reliability prediction model for telecommunication hardware. Microelectronics Reliability, 37(10-11), 1429-1432.
O’Connor, P.D.T. (1985a). Reliability: Measurement or management. Reliability Engineering, 10(3), 129-140.
O’Connor, P.D.T. (1985b). Reliability prediction for microelectronic systems. Reliability Engineering, 10(3), 129-140.
O’Connor, P.D.T. (1988). Undue faith in US MIL-HDBK-217 for Reliability Prediction. IEEE Transactions on Reliability, 37, 468-469.
O’Connor, P.D.T. (1990). Reliability prediction: Help or hoax. Solid State Technology, 33, 59-61.
O’Connor, P.D.T. (1991). Statistics in quality and reliability—Lessons from the past, and future opportunities. Reliability Engineering and System Safety, 34(1), 23-33.
O’Connor, P.D.T., and Harris, L.N. (1986). Reliability prediction: A state-of-the-art review. IEE Proceedings A (Physical Science, Measurement and Instrumentation, Management and Education, Reviews), 133(4), 202-216.
Oh, H., Azarian, M.H., Das, D., and Pecht, M. (2013). A critique of the IPC-9591 standard: Performance parameters for air moving devices. IEEE Transactions on Device and Materials Reliability, 13(1), 146-155.
Pang, J., and Che, F.-X. (2007). Isothermal cyclic bend fatigue test method for lead-free solder joints. Journal of Electronic Packaging, 129(4), 496-503.
Patil, N., Celaya, J., Das, D., Goebel, K., and Pecht, M. (2009). Precursor parameter identification for insulated gate bipolar transistor (IGBT) prognostics. IEEE Transactions on Reliability, 58(2), 271-276.
Pease, R. (1991). What’s all this MIL-HDBK-217 stuff anyhow? Electronic Design, 1991, 82-84.
Pecht, M., and Gu, J. (2009). Physics-of-failure-based prognostics for electronic products Transactions of the Institute of Measurement and Control, 31(3-4), 309-322. Available: http://tim.sagepub.com/content/31/3-4/309.full.pdf+html [December 2014].
Pecht M.G., and Nash, F.R. (1994). Predicting the reliability of electronic equipment. Predicting the IEEE, 82(7), 992-1004.
Pecht, M.G., and Ramappan, V. (1992). Are components still the major problem: A review of electronic system and device field failure returns. IEEE Transactions on Components, Hybrids and Manufacturing Technology, 15(6), 1160-1164.
Pecht, M.G., Lall, P., and Hakim, E. (1992). Temperature dependence of integrated circuit failure mechanisms. Quality and Reliability Engineering International, 8(3), 167-176.
Peck, D.S. (1971). The analysis of data from accelerated stress tests. Proceedings of the 1971 Annual Reliability Physics Symposia, pp. 69-78.
Pettinato, A.D., and McLaughlin, R.L. (1961). Accelerated reliability testing. Proceedings of the 1961 National Symposium of Reliability and Quality, pp. 241-251.
Ramakrishnan, A., and Pecht, M. (2003). A life consumption monitoring methodology for electronic systems. IEEE Transactions on Components and Packaging Technology, 26(3), 625-634.
Reliability Assessment Center. (2001). PRISM—Version 1.3, System Reliability Assessmend Software. Rome, NY: Reliability Assessment Center.
Reliability Information Analysis Center. (2006). Handbook of 217Plus Reliability Models. Utica, New York: Reliability Information Analysis Center.
Rooney, J.P. (1994). Customer satisfaction. Proceedings of the 1994 Annual Reliability and Maintainability Symposium, pp. 376-381.
Rudra, B., and Jennings, D. (1994). Tutorial: Failure-mechanism models for conductive-filament formation. IEEE Transactions on Reliability, 43, 354-360.
Ryerson, C.M. (1982). The reliability bathtub curve is vigorously alive. Proceedings of the Annual Reliability and Maintainability Symposium, p. 187.
Saleh J.H., and Marais, K. (2006). Highlights from the early (and pre-) history of reliability engineering. Reliability Engineering and System Safety, 91, 249-256.
Shetty, V., Das, D., Pecht, M., Hiemstra, D., and Martin, S. (2002). Remaining life assessment of shuttle remote manipulator system end effector. Proceedings of 22nd Space Simulation Conference, Ellicott City, MD. Available: http://www.prognostics.umd.edu/calcepapers/02_V.Shetty_remaingLifeAssesShuttleRemotemanipulatorSystem_22ndSpaceSimulationConf.pdf [October 2014].
Spencer, J. (1986). The highs and lows of reliability prediction. Proceedings of the 1986 Annual Reliability and Maintainability Symposium, pp. 152-162.
Taylor, D. (1990). Temperature dependence of microelectronic devices failures. Quality and Reliability Engineering International, 6(4), 275.
Telcordia Technologies. (2001). Special Report SR-332: Reliability Prediction Procedure for Electronic Equipment, Issue 1. Piscataway, NJ: Telcordia Customer Service.
U.S. Department of Defense. (1991). MIL-HDBK-217. Military Handbook: Reliability Prediction of Electronic Equipment. Washington, DC: Author. Available: http://www.sre.org/pubs/Mil-Hdbk-217F.pdf [August 2014].
U.S. Department of the Army. (2011). Army Regulation 70-1: Army Acquisition Policy. Washington DC: U.S. Department of the Army.
Varghese, J., and Dasgupta, A. (2007). Test methodology for durability estimation of surface mount interconnects under drop testing conditions. Microelectronics Reliability, 47(1), 93-107.
Watson, G.F. (1992). MIL reliability: A new approach. IEEE Spectrum, 29, 46-49.
Webster, L.R. (1986). Field vs. predicted for commercial SatCom terminals. Proceedings of the 1986 Annual Reliability and Maintainability Symposium, pp. 89-91.
Westinghouse Electric Corporation. (1989). Summary Chart of 1984/1987 Failure Analysis Memos. Cranberry Township, PA: Westinghouse Electric Corporation.
Wong, K.D., and Lindstrom, D.L. (1989). Off the bathtub onto the roller coaster curve. Proceedings of the Annual Reliability and Maintainability Symposium, January 26-28, Los Angeles, CA.
Wong, K.L. (1981). Unified field (failure) theory: Demise of the bathtub curve. Proceedings of the 1981 Annual Reliability and Maintainability Symposium, pp. 402-403.
Wong, K.L. (1989). The bathtub curve and flat earth society. IEEE Transactions on Reliability, 38, 403-404.
Wong, K.L. (1990). What is wrong with the existing reliability prediction methods? Quality and Reliability Engineering International, 6(4), 251-257.
Wong, K.L. (1993). A change in direction for reliability engineering is long overdue. IEEE Transactions on Reliability, 42, 261.
Wood, A.P., and Elerath, J.G. (1994). A comparison of predicted MTBFs to field and test data. Proceedings of the 1994 Annual Reliability and Maintainability Symposium, pp. 153-156.
Young, D., and Christou, A. (1994). Failure mechanism models for electromigration. IEEE Transactions on Reliability, 43, 186-192.
Zhou, Y., Al-Bassyiouni, M., and Dasgupta, A. (2010). Vibration durability assessment of Sn3.0Ag0.5Cu and Sn37Pb solders under harmonic excitation. IEEE Transactions on Components and Packaging Technologies, 33(2), 319-328.
This page intentionally left blank.













































{kind=link}