
Page 15
Scientific Bases of Human-Machine Communication by Voice
SUMMARY
The scientific bases for human-machine communication by voice are in the fields of psychology, linguistics, acoustics, signal processing, computer science, and integrated circuit technology. The purpose of this paper is to highlight the basic scientific and technological issues in human-machine communication by voice and to point out areas of future research opportunity. The discussion is organized around the following major issues in implementing human-machine voice communication systems: (1) hardware/software implementation of the system, (2) speech synthesis for voice output, (3) speech recognition and understanding for voice input, and (4) usability factors related to how humans interact with machines.
INTRODUCTION
Humans communicate with other humans in many ways, including body gestures, printed text, pictures, drawings, and voice. But surely voice communication is the most widely used in our daily affairs. Flanagan (1972) succinctly summarized the reasons for this with a pithy quote from Sir Richard Paget (1930):
*Supported by the John and Mary Franklin Foundation.
Page 16
What drove man to the invention of speech was, as I imagine, not so much the need of expressing his thoughts (for that might have been done quite satisfactorily by bodily gesture) as the difficulty of ''talking with his hands full."
Indeed, speech is a singularly efficient way for humans to express ideas and desires. Therefore, it is not surprising that we have always wanted to communicate with and command our machines by voice. What may be surprising is that a paradigm for this has been around for centuries. When machines began to be powered by draft animals, humans discovered that the same animals that provided the power for the machine also could provide enough intelligence to understand and act appropriately on voice commands. For example, the simple vocabulary of gee, haw, back, giddap, and whoa served nicely to allow a single human to control the movement of a large farm machine. Of course, voice commands were not the only means of controlling these horse- or mule-powered machines. Another system of more direct commands was also available through the reins attached to the bit in the animal's mouth. However, in many cases, voice commands offered clear advantages over the alternative. For example, the human was left completely free to do other things, such as walking alongside a wagon while picking corn and throwing it into the wagon. This eliminated the need for an extra person to drive the machine, and the convenience of not having to return to the machine to issue commands greatly improved the efficiency of the operation. (Of course, the reins were always tied in a conveniently accessible place just in case the voice control system failed to function properly!)
Clearly, this reliance on the modest intelligence of the animal source of power was severely limiting, and even that limited voice control capability disappeared as animal power was replaced by fossil fuel power. However, the allure of voice interaction with machines remained and became stronger as technology became more advanced and complex. The obvious advantages include the following:
• Speech is the natural mode of communication for humans.
• Voice control is particularly appealing when the human's hands or eyes are otherwise occupied.
• Voice communication with machines is potentially very helpful to handicapped persons.
• The ubiquitous telephone can be an effective remote terminal for two-way voice communication with machines that can also speak, listen, and understand.
Page 17
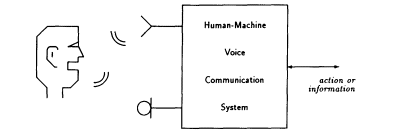
FIGURE 1 Human-machine communication by voice.
Figure 1 depicts the elements of a system for human-machine communication by voice. With a microphone to pick up the human voice and a speaker or headphones to deliver a synthetic voice from the system to the human ear, the human can communicate with the system, which in turn can command other machines or cause desired actions to occur. In order to do this, the voice communication system must take in the human voice input, determine what action is called for, and pass information to other systems or machines. In some cases "recognition" of the equivalent text or other symbolic representation of the speech is all that is necessary. In other cases, such as in natural language dialogue with a machine, it may be necessary to "understand" or extract the meaning of the utterance. Such a system can be used in many ways. In one class of applications, the human controls a machine by voice; for example, the system could do something simple like causing switches to be set or it might gather information to complete a telephone call or it might be used by a human to control a wheelchair or even a jet plane. Another class of applications involves access and control of information; for example, the system might respond to a request for information by searching a database or doing a calculation and then providing the answers to the human by synthetic voice, or it might even attempt to understand the voice input and speak a semantically equivalent utterance in another language.
What are the important aspects of the system depicted in Figure 1? In considering almost all the above examples and many others that we can imagine, there is a tendency to focus on the speech recognition aspects of the problem. While this may be the most challenging and glamorous part, the ability to recognize or understand speech is still only part of the picture. The system also must have the capability to produce synthetic voice output. Voice output can be used to provide feedback to assure the human that the machine has
Page 18
correctly understood the input speech, and it also may be essential for returning any information that may have been requested by the human through the voice transaction. Another important aspect of the problem concerns usability by the human. The system must be designed to be easy to use, and it must be flexible enough to cope with the wide variability that is common in human speech. Finally, the technology available for implementing such a system must be an overarching concern.
Like many new ideas in technology, voice communication with machine in its modern form may appear to be a luxury that is not essential to human progress and well-being. Some have questioned both the ultimate feasibility and the need for voice recognition by machine, arguing that anything short of the full capabilities of a native speaker would not be useful or interesting and that such capabilities are not feasible in a machine. The questions raised by Pierce (1969) concerning the goals, the value, and the potential for success of research in speech recognition stimulated much valuable discussion and thought in the late 1960s and may even have dampened the enthusiasm of engineers and scientists for a while, but ultimately the research community answered with optimistic vigor. Although it is certainly true that the ambitious goal of providing a machine with the speaking and understanding capability of a native speaker is still far away, the past 25 years have seen significant progress in both speech synthesis and recognition, so that effective systems for human-machine communication by voice are now being deployed in many important applications, and there is little doubt that applications will increase as the technology matures.
The progress so far has been due to the efforts of researchers across a broad spectrum of science and technology, and future progress will require an even closer linkage between such diverse fields as psychology, linguistics, acoustics, signal processing, computer science, and integrated circuit technology. The purpose of this paper is to highlight the basic scientific and technological issues in human-machine communication by voice and to set the context for the next two papers in this volume, which describe in detail some of the important areas of progress and some of the areas where more research is needed. The discussion is organized around the following major issues in implementing human-machine voice communication systems: (1) hardware/software implementation of the system, (2) speech synthesis for voice output, (3) speech recognition and understanding for voice input, and (4) usability factors related to how humans interact with machines.
Page 19
DIGITAL COMPUTATION AND MICROELECTRONICS
Scientists and engineers have systematically studied the speech signal and the speech communication process for well over a century. Engineers began to use this knowledge in the first part of the twentieth century to experiment with ways of conserving bandwidth on telephone channels. However, the invention and rapid development of the digital computer were key to the rapid advances in both speech research and technology. First, computers were used as tools for simulating analog systems, but it soon became clear that the digital computer would ultimately be the only way to realize complex speech signal processing systems. Computer-based laboratory facilities quickly became indispensable tools for speech research, and it is not an exaggeration to say that one of the strongest motivating forces in the modern field of digital signal processing was the need to develop digital filtering, spectrum analysis, and signal modeling techniques for simulating and implementing speech analysis and synthesis systems (Gold and Rader, 1969; Oppenheim and Schafer, 1975; Rabiner and Gold, 1975; Rabiner and Schafer, 1978).
In addition to its capability to do the numerical computations called for in analysis and synthesis of speech, the digital computer can provide the intelligence necessary for human-machine communication by voice. Indeed, any machine with voice input/output capability will incorporate or be interfaced to a highly sophisticated and powerful digital computer. Thus, the disciplines of computer science and engineering have already made a huge impact on the field of human-machine communication by voice, and they will continue to occupy a central position in the field.
Another area of technology that is critically intertwined with digital computation and speech signal processing is microelectronics technology. Without the mind-boggling advances that have occurred in this field, digital speech processing and human-machine communication by voice would still be languishing in the research laboratory as an academic curiosity. As an illustration, Figure 2 shows the number of transistors per chip for several members of a popular family of digital signal processing (DSP) microcomputers plotted as a function of the year the chip was introduced. The upper graph in this figure shows the familiar result that integrated circuit device densities tend to increase exponentially with time, thereby leading inexorably to more powerful systems at lower and lower cost. The lower graph shows the corresponding time required to do a single multiply-accumulate operation of the form (previous_sum + cx[n]), which is a ubiquitous operation in DSP. From this graph we see that currently avail-
Page 20
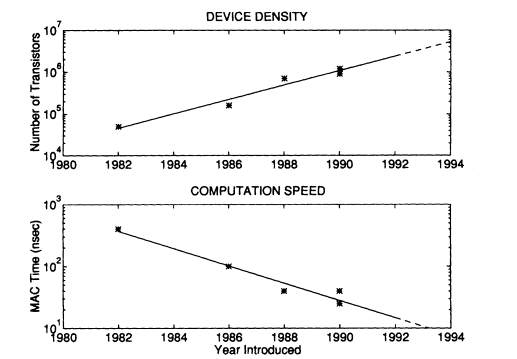
FIGURE 2 Device density and computation speed for a family of DSP
microcomputers (data courtesy of Texas Instruments, Inc).
able chips can do this combination of operations in 40 nanoseconds or less or the equivalent of 50 MFLOPS (million floating-point operations per second). Because of multiple busses and parallelism in the architecture, such chips can also do hundreds of millions of other operations per second and transfer hundreds of millions of bytes per second. This high performance is not limited to special-purpose microcomputers. Currently available workstations and personal computers also are becoming fast enough to do the real-time operations required for human-machine voice communication without any coprocessor support.
Thus, there is a tight synergism between speech processing, computer architecture, and microelectronics. It is clear that these areas will continue to complement and stimulate each other; indeed, in order to achieve a high level of success in human-machine voice communication, new results must continue to be achieved in areas of computer science and engineering, such as the following:
Page 21
Microelectronics. Continued progress in developing more powerful and sophisticated general-purpose and special-purpose computers is necessary to provide adequate inexpensive computer power for human-machine voice communication applications. At this time, many people in the microelectronics field are confidently predicting chips with a billion transistors by the end of the decade. This presents significant challenges and opportunities for speech researchers to learn how to use such massive information processing power effectively.
Algorithms. New algorithms can improve performance and increase speed just as effectively as increased computer power. Current research on topics such as wavelets, artificial neural networks, chaos, and fractals is already finding application in speech processing applications. Researchers in signal processing and computer science should continue to find motivation for their work in the problems of human-machine voice communication.
Multiprocessing. The problems of human-machine communication by voice will continue to challenge the fastest computers and the most efficient algorithms. As more sophisticated systems evolve, it is likely that a single processor with sufficient computational power may not exist or may be too expensive to achieve an economical solution. In such cases, multiple parallel processors will be needed. The problems of human-machine voice communication are bound to stimulate many new developments in parallel computing.
Tools. As systems become more complex, the need for computer-aided tools for system development continues to increase. What is needed is an integrated and coordinated set of tools that make it easy to test new ideas and develop new systems concepts, while also making it easy to move a research system through the prototype stage to final implementation. Such tools currently exist in rudimentary form, and it is already possible in some applications to do the development of a system directly on the same DSP microprocessor or workstation that will host the final implementation. However, much more can be done to facilitate the development and implementation of voice processing systems.
SPEECH ANALYSIS AND SYNTHESIS
In human-machine communication by voice, the basic information-carrying medium is speech. Therefore, fundamental knowledge of the speech signal—how it is produced, how information is encoded in it, and how it is perceived—is critically important.
Human speech is an acoustic wave that is generated by a well-defined physical system. Hence, it is possible using the laws of phys-
Page 22
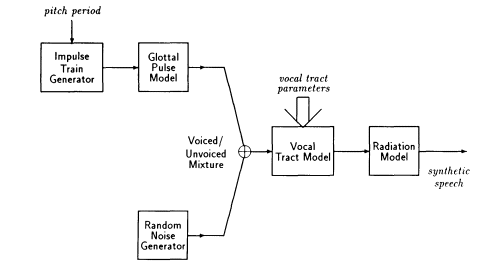
Figure 3: Source/system model for speech production.
ics to model and simulate the production of speech. The research in this area, which is extensive and spanning many years, is described in the classic monographs of Fant (1960) and Flanagan (1972), in more recent texts by Rabiner and Schafer (1978) and Deller et al. (1993), and in a wealth of scientific literature. Much of this research has been based on the classic source/system model depicted in Figure 3.
In this model the different sounds of speech are produced by changing the mode of excitation between quasi-periodic pulses for voiced sounds and random noise for fricatives, with perhaps a mixture of the two sources for voiced fricatives and transitional sounds. The vocal tract system response also changes with time to shape the spectrum of the signal to produce appropriate resonances or formants. With such a model as a basis, the problem of speech analysis is concerned with finding the parameters of the model given a speech signal. The problem of speech synthesis then can be defined as obtaining the output of the model, given the time-varying control parameters of the model.
A basic speech processing problem is the representation of the analog acoustic waveform of speech in digital form. Figure 4 depicts a general representation of a system for digital speech coding and processing.
Speech, like any other band-limited analog waveform can be sampled and quantized with an analog-to-digital (A-to-D) converter to pro-
Page 23

FIGURE 4 Digital speech coding.
duce a sequence of binary numbers. These binary numbers represent the speech signal in the sense that they can be converted back to an analog signal by a digital-to-analog (D-to-A) converter, and, if enough bits are used in the quantization and the sampling rate is high enough, the reconstructed signal can be arbitrarily close to the original speech waveform. The information rate (bit rate) of such a digital waveform representation is simply the number of samples per second times the number of bits per sample. Since the bit rate determines the channel capacity required for digital transmission or the memory capacity required for storage of the speech signal, the major concern in digital speech coding is to minimize the bit rate while maintaining an acceptable perceived fidelity to the original speech signal.
One way to provide voice output from a machine is simply to prerecord all possible voice responses and store them in digital form so that they can be played back when required by the system. The information rate of the digital representation will determine the amount of digital storage required for this approach. With a bandwidth of 4000 Hz (implying an 8000-Hz sampling rate) and eight bits per sample (with m-law or A-law compression), speech can be represented by direct sampling and quantization with a bit rate of 64,000 bits/second and with a quality comparable to a good long-distance telephone connection (often called "toll quality"). To further reduce the bit rate while maintaining acceptable quality and fidelity, it is necessary to incorporate knowledge of the speech signal into the quantization process. This is commonly done by an analysis/synthesis coding system in which the parameters of the model are estimated from the sampled speech signal and then quantized for digital storage or transmission. A sampled speech waveform is then synthesized by controlling the model with the quantized parameters, and the output of the model is converted to analog form by a D-to-A converter.
In this case the first block in Figure 4 contains the analysis and coding computations as well as the A-to-D, and the third block would contain the decoding and synthesis computations and the D-to-A converter. The output of the discrete-time model of Figure 3 satisfies a linear difference equation; that is, a given sample of the output de-
Page 24
pends linearly on a finite number of previous samples and the excitation. For this reason, linear predictive coding (LPC) techniques have enjoyed huge success in speech analysis and coding. Linear predictive analysis is used to estimate parameters of the vocal tract system model in Figure 3, and, either directly or indirectly, this model serves as the basis for a digital representation of the speech signal. Variations on the LPC theme include adaptive differential PCM (ADPCM), multipulse-excited LPC (MPLPC), code-excited LPC (CELP), self-excited LPC (SEV), mixed-excitation LPC (MELP), and pitch-excited LPC (Deller et al., 1993; Flanagan, 1972; Rabiner and Schafer, 1978). With the exception of ADPCM, which is a waveform coding technique, all the other methods are analysis/synthesis techniques. Coding schemes like CELP and MPLPC also incorporate frequency-weighted distortion measures in order to build in knowledge of speech perception along with the knowledge of speech production represented by the synthesis model. Another valuable approach uses frequency-domain representations and knowledge of auditory models to distribute quantization error so as to be less perceptible to the listener. Examples of this approach include sinusoidal models, transform coders, and subband coders (Deller et al., 1993; Flanagan, 1972; Rabiner and Schafer, 1978).
In efforts to reduce the bit rate, an additional trade-off comes into play—that is, the complexity of the analysis/synthesis modeling processes. In general, any attempt to lower the bit rate while maintaining high quality will increase the complexity (and computational load) of the analysis and synthesis operations. At present, toll quality analysis/ synthesis representations can be obtained at about 8000 bits/second or an average of about one bit per sample (see Flanagan, in this volume). Attempting to lower the bit rate further leads to degradation in the quality of the reconstructed signal; however, intelligible speech can be reproduced with bit rates as low as 2000 bits/second (see Flanagan, in this volume).
The waveform of human speech contains a significant amount of information that is often irrelevant to the message conveyed by the utterance. An estimate under simple assumptions shows that the fundamental information transmission rate for a human reading text is on the order of 100 bits/second. This implies that speech can in principle be stored or transmitted an order of magnitude more efficiently if we can find ways of representing the phonetic/linguistic content of the speech utterance in terms of the parameters of a speech synthesizer. Figure 5 shows this approach denoted as text-to-speech synthesis.
The text of a desired speech utterance is analyzed to determine its phonetic and prosodic variations as a function of time. These in
Page 25
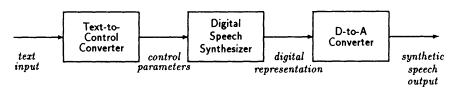
FIGURE 5 Text-to-speech synthesis.
turn are used to determine the control parameters for the speech model, which then computes the samples of a synthetic speech waveform. This involves literally a pronouncing dictionary (along with rules for exceptions, acronyms, and irregularities) for determining phonetic content as well as extensive linguistic rules for producing durations, intensity, voicing, and pitch. Thus, the complexity of the synthesis system is greatly increased while the bit rate of the basic representation is greatly reduced.
In using digital speech coding and synthesis for voice response from machines, the following four considerations lead to a wide range of trade-off configurations: (1) complexity of analysis/synthesis operations, (2) bit rate, (3) perceived quality, and (4) flexibility to modify or make new utterances. Clearly, straightforward playback of sampled and quantized speech is the simplest approach, requiring the highest bit rate for good quality and offering almost no flexibility other than that of simply splicing waveforms of words and phrases together to make new utterances. Therefore, this approach is usually only attractive where a fixed and manageable number of utterances is required. At the other extreme is text-to-speech synthesis, which, for a single investment in program, dictionary, and rule base storage, offers virtually unlimited flexibility to synthesize speech utterances. Here the text-to-speech algorithm may require significant computational resources. The usability and perceived quality of text-to-synthetic speech has progressed from barely intelligible and "machine-like" in the early days of synthesis research to highly intelligible and only slightly unnatural today. This has been achieved with a variety of approaches ranging from concatenation of diphone elements of natural speech represented in analysis/synthesis form to pure computation of synthesis parameters for physical models of speech production.
Speech analysis and synthesis have received much attention from researchers for over 60 years, with great strides occurring in the 25 years since digital computers became available for speech research. Synthesis research has drawn support from many fields, including acoustics, digital signal processing, linguistics, and psychology. Fu-
Page 26
ture research will continue to synthesize knowledge from these and other related fields in order to provide the capability to represent speech with high quality at lower and lower information rates, leading ultimately to the capability of producing synthetic speech from text that compares favorably with that of an articulate human speaker. Some specific areas where new results would be welcome are the following:
Language modeling. A continuing goal must be to understand how linguistic structure manifests itself in the acoustic waveform of speech. Learning how to represent phonetic elements, syllables, stress, emphasis, etc., in a form that can be effectively coupled to speech modeling, analysis, and synthesis techniques should continue to have high priority in speech research. Increased knowledge in this area is obviously essential for text-to-speech synthesis, where the goal is to ensure that linguistic structure is correctly introduced into the synthetic waveform, but more effective application of this knowledge in speech analysis techniques could lead to much improved analysis/synthesis coders as well.
Acoustic modeling. The linear source/system model of Figure 3 has served well as the basis for speech analysis and coding, but it cannot effectively capture many subtle nonlinear phenomena in speech. New research in modeling wave propagation in the vocal tract (see Flanagan, in this volume) and new models based on modulation theory, fractals, and chaos (Maragos, 1991; Maragos et al., 1993) may lead to improved analysis and synthesis techniques that can be applied to human-machine communication problems.
Auditory modeling. Models of hearing and auditory perception are now being applied with dramatic results in high-quality audio coding (see Flanagan, in this volume). New ways of combining both speech production and speech perception models into speech coding algorithms should continue to be a high priority in research.
Analysis by synthesis. The analysis-by-synthesis approach to speech analysis is depicted in Figure 6, which shows that the parametric representation of the speech signal is obtained by adjusting the parameters of the model until the synthetic output of the model matches the original input signal accurately enough according to some error criterion. This principle is the basis for MPLPC, CELP, and SEV coding systems. In these applications the speech synthesis model is a standard LPC source/system model, and the ''perceptual comparison" is a frequency-weighted mean-squared error. Although great success has already been achieved with this approach, it should be possible to apply the basic idea with more sophisticated comparison mechanisms based on auditory models and with other signal models.
Page 27
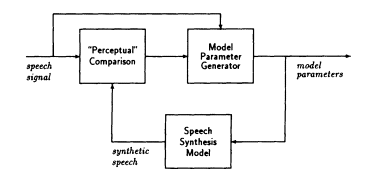
FIGURE 6 Speech analysis by synthesis.
Success will depend on the development of appropriate computationally tractable optimization approaches (see Flanagan, in this volume).
SPEECH RECOGNITION AND UNDERSTANDING
The capability of recognizing or extracting the text-level information from a speech signal (speech recognition) is a major part of the general problem of human-machine communication by voice. As in the case of speech synthesis, it is critical to build on fundamental knowledge of speech production and perception and to understand how linguistic structure of language is expressed and manifested in the speech signal. Clearly there is much that is common between speech analysis, coding, synthesis, and speech recognition.
Figure 7 depicts the fundamental structure of a typical speech
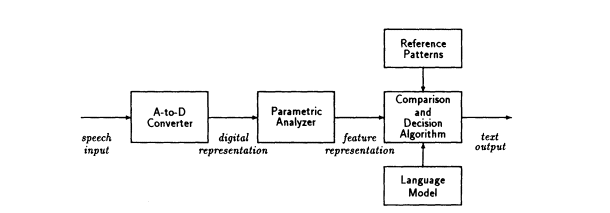
FIGURE 7 Speech recognition.
Page 28
recognition system. The "front-end" processing extracts a parametric representation or input pattern from the digitized input speech signal using the same types of techniques (e.g., linear predictive analysis or filter banks) that are used in speech analysis/synthesis systems. These acoustic features are designed to capture the linguistic features in a form that facilitates accurate linguistic decoding of the utterance. Cepstrum coefficients derived from either LPC parameters or spectral amplitudes derived from FFT or filter bank outputs are widely used as features (Rabiner and Juang, 1993). Such analysis techniques are often combined with vector quantization to provide a compact and effective feature representation. At the heart of a speech recognition system is the set of algorithms that compare the feature pattern representation of the input to members of a set of stored reference patterns that have been obtained by a training process. Equally important are algorithms for making a decision about the pattern to which the input is closest. Cepstrum distance measures are widely used for comparison of feature vectors, and dynamic time warping (DTW) and hidden Markov models (HMMs) have been shown to be very effective in dealing with the variability of speech (Rabiner and Juang, 1993). As shown in Figure 7, the most sophisticated systems also employ grammar and language models to aid in the decision process.
Speech recognition systems are often classified according to the scope of their capabilities. Speaker-dependent systems must be "trained" on the speech of an individual user, while speaker-independent systems attempt to cope with the variability of speech among speakers. Some systems recognize a large number of words or phrases, while simpler systems may recognize only a few words, such as the digits 0 through 9. Finally, it is simpler to recognize isolated words than to recognize fluent (connected) speech. Thus, a limited-vocabulary, isolated-word, speaker-dependent system would generally be the simplest to implement, while to approach the capabilities of a native speaker would require a large-vocabulary, connected-speech, speaker-independent system. The accuracy of current speech recognition systems depends on the complexity of the operating conditions. Recognition error rates below 1 percent have been obtained for highly constrained vocabulary and controlled speaking conditions; but for large-vocabulary, connected-speech systems, the word error rate may exceed 25 percent.
Clearly, different applications will require different capabilities. Closing switches, entering data, or controlling a wheelchair might very well be achieved with the simplest system. As an example where high-level capabilities are required, consider the system depicted in
Page 29

FIGURE 8 Speech recognition/synthesis.
Figure 8, which consists of a speech recognizer producing a text or symbolic representation, followed by storage, transmission, or further processing, and then text-to-speech synthesis for conversion back to an acoustic representation. In this case it is assumed that the output of the text-to-speech synthesis system is sent to a listener at a remote location, such that the machine is simply an intermediary between two humans. This system is the ultimate speech compression system since the bit rate at the text level is only about 100 bits/ second. Also shown in Figure 8 is the possibility that the text might be processed before being sent to the text-to-speech synthesizer. An example of this type of application is when processing is applied to the text to translate one natural language such as English into another such as Japanese. Then the voice output is produced by a Japanese text-to-speech synthesizer, thereby resulting in automatic interpretation in the second language.
If the goal is to create a machine that can speak and understand speech as well as a human being, then speech synthesis is probably further along than recognition. In the past, synthesis and recognition have been treated as separate areas of research, generally carried out by different people and by different groups within research organizations. Obviously, there is considerable overlap between the two areas, and both would benefit from closer coupling. The following are topics where both recognition and synthesis would clearly benefit from new results:
Language modeling. As in the case of speech synthesis, a continuing goal must be to understand how linguistic structure is encoded in the acoustic speech waveform, and, in the case of speech recognition, to learn how to incorporate such models into both the pattern analysis and pattern matching phases of the problem.
Robustness. A major limitation of present speech recognition systems is that their performance degrades significantly with changes in the speaking environment, transmission channel, or the condition of the speaker's voice. Solutions to these problems may involve the development of more robust feature representations having a basis in auditory models, new distance measures that are less sensitive to
Page 30
nonlinguistic variations, and new techniques for normalization of speakers and speaking conditions.
Computational requirements. Computation is often a dominant concern in speech recognition systems. Search procedures, hidden Markov model training and analysis, and new feature representations based on detailed auditory models all require much computation. All these aspects and more will benefit from increased processor speed and parallel computation.
Speaker identity and normalization. It is clear that speaker identity is represented in the acoustic waveform of speech, but much remains to be done to quantify the acoustic correlates of speaker identity. Greater knowledge in this area would be useful for normalization of speakers in speech recognition systems, for incorporation of speaker characteristics in text-to-speech synthesis, and for its own sake as a basis for speaker identification and verification systems.
Analysis-by-synthesis. The analysis-by-synthesis paradigm of Figure 6 may also be useful for speech recognition applications. Indeed, if the block labeled "Model Parameter Generator" were a speech recognizer producing text or some symbolic representation as output, the block labeled "Speech Synthesis Model" could be a text-to-speech synthesizer. In this case the symbolic representation would be obtained as a by-product of the matching of the synthetic speech signal to the input signal. Such a scheme, although appealing in concept, clearly presents significant challenges. Obviously, the matching metric could not simply compare waveforms but would have to operate on a higher level. Defining a suitable metric and developing an appropriate optimization algorithm would require much creative research, and the implementation of such a system would challenge present computational resources.
USABILITY ISSUES
Given the technical feasibility of speech synthesis and speech recognition, and given adequate low-cost computational resources, the question remains as to whether human-machine voice communication is useful and worthwhile. Intuition suggests that there are many situations where significant improvements in efficiency and performance could result from the use of voice communication/control even of a limited and constrained nature. However, we must be careful not to make assumptions about the utility of human-machine voice communication based on conjecture or our personal experience with human-human communication. What is needed is hard experimental data from which general conclusions can be drawn. In some very
Page 31
special cases, voice communication with a machine may allow something to be done that cannot be done any other way, but such situations are not the norm. Even for what seem to be obvious areas of application, it generally can be demonstrated that some other means of accomplishing the task either already exists or could be devised. Therefore, the choice usually will be determined by such factors as convenience, accuracy, and efficiency. If voice communication with machines is more convenient or accurate, it may be considered to be worth the extra cost even if alternatives exist. If it is more efficient, its use will be justified by the money it saves.
The scientific basis for making decisions about such questions is at best incomplete. The issues are difficult to quantify and are not easily encapsulated in a neat theory. In many cases even careful experiments designed to test the efficacy of human-machine communication by voice have used humans to simulate the behavior of the machine. Some of the earliest work showed that voice communication capability significantly reduced the time required to perform tasks involving simulated human-computer interaction (Chapanis, 1975), and subsequent research has added to our understanding. However, widely applicable procedures for the design of human-machine voice communication systems are not yet available. The paper by Cohen and Oviatt in this volume is a valuable contribution because it summarizes the important issues and current state of knowledge on human-machine interaction and points the way to research that is needed as a basis for designing systems.
The paradigm of the voice-controlled team and wagon has features that are very similar to those found in some computer-based systems in use today—that is, a limited vocabulary of acoustically distinct words, spoken in isolation, with an alternate communication/control mechanism conveniently accessible to the human in case it is necessary to override the voice control system. Given a computer system with such constrained capabilities, we could certainly go looking for applications for it. In the long term, however, a much more desirable approach would be to determine the needs of an application and then specify the voice communication interface that would meet the needs effectively. To do this we must be in a better position to understand the effect on the human's performance and acceptance of the system of such factors as:
• vocabulary size and content,
• fluent speech vs. isolated words,
• constraints on grammar and speaking style,
• the need for training of the recognition system,
• the quality and naturalness of synthetic voice response,
Page 32
• the way the system handles its errors in speech understanding, and
• the availability and convenience of alternate communication modalities.
These and many other factors come into play in determining whether humans can effectively use a system for voice communication with a machine and, just as important, whether they will prefer using voice communication over other modes of communication that might be provided.
Mixed-mode communication. Humans soon tire of repetition and welcome anything that saves steps. Graphical interfaces involving pointing devices and menus are often tedious for repetitive tasks, and for this reason most systems make available an alternate shortcut for entering commands. This is no less true for voice input; humans are also likely to tire of talking to their machines. Indeed, sometimes we would even like for the machine to anticipate our next command—for example, something like the well-trained team of mules that automatically stopped the corn-picking wagon as the farmer fell behind and moved it ahead as he caught up (William H. Schafer, personal communication, 1993). While mind reading may be out of the question, clever integration of voice communication with alternative sensing mechanisms, alternate input/output modalities, and maybe even machine learning will ultimately lead to human-machine interfaces of greatly improved usability.
Experimental capabilities. With powerful workstations and fast coprocessors readily available, it is now possible to do real-time experiments with real human-machine voice communication systems. These experiments will help answer questions about the conditions under which these systems are most effective, about how humans learn to use human-machine voice communication systems, and about how the interaction between human and machine should be structured; then the new "theory of modalities" called for by Cohen and Oviatt (in this volume) may begin to emerge.
CONCLUSION
Along the way to giving machines human-like capability to speak and understand speech there remains much to be learned about how structure and meaning in language are encoded in the speech signal and about how this knowledge can be incorporated into usable systems. Continuing improvement in the effectiveness and naturalness of human-machine voice communication systems will depend on cre-
Page 33
ative synthesis of concepts and results from many fields, including microelectronics, computer architecture, digital signal processing, acoustics, auditory science, linguistics, phonetics, cognitive science, statistical modeling, and psychology.
REFERENCES
Chapanis, A.,"Interactive Human Communication," Scientific American, vol. 232, pp. 36-49, March 1975.
Deller, J. R., Jr., Proakis, J. G., and J. H. L. Hansen, Discrete-Time Processing of Speech Signals, Macmillan Publishing Co., New York, 1993.
Fant, G., Acoustic Theory of Speech Production, Mouton & Co. N.V., The Hague, 1960.
Flanagan, J. L., Speech Analysis, Synthesis, and Perception, Springer-Verlag, New York, 1972.
Gold, B., and C. M. Rader, Digital Processing of Signals, McGraw-Hill, New York, 1969.
Maragos, P., "Fractal Aspects of Speech Signals: Dimension and Interpolation," Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 417-420, Toronto, May 1991.
Maragos, P.A., J. F. Kaiser, and T. F. Quatieri, "Energy Separation in Signal Modulations with Application to Speech Analysis," IEEE Transaction on Signal Processing, in press.
Oppenheim, A.V., and R. W. Schafer, Digital Signal Processing, Prentice-Hall, Englewood Cliffs, NJ, 1975.
Paget, R., Human Speech, Harcourt, New York, 1930.
Pierce, J.R., "Whither Speech Recognition?," Journal of the Acoustical Society of America, vol. 47, no. 6 (part 2), pp. 1049-1050, 1969.
Rabiner, L.R., and B-H. Juang, Fundamentals of Speech Recognition, Prentice-Hall, Englewood Cliffs, NJ, 1993.
Rabiner, L.R., and B. Gold, Theory and Application of Digital Signal Processing, PrenticeHall, Englewood Cliffs, NJ, 1975.
Rabiner, L.R., and R. W. Schafer, Digital Processing of Speech Signals, Prentice-Hall, Englewood Cliffs, NJ, 1978.



















