
9
Session 8: Use of Machine Learning for Privacy Ethics
TOWARD SOCIO-CULTURAL MACHINE LEARNING
Mark Riedl, Georgia Institute of Technology
Mark Riedl, Georgia Institute of Technology, explained that researchers want to develop artificial intelligence systems that can learn about societies and cultures and then act more ethically safe around humans. He made a distinction between artificial intelligence ethics and ethical artificial intelligence: Artificial intelligence ethics concerns the proper use of artificial intelligence technologies in society, while ethical artificial intelligence considers how to make systems safer to use. According to Riedl, machines will need to learn the culturally appropriate way to make decisions.
Riedl next discussed the issue of value alignment: intelligent, autonomous agents need to understand how the culture works so as to pursue only those goals that are beneficial to humans. There are, however, two perspectives of value alignment. The strong form of value alignment, which constrains robots from intentionally or unintentionally performing behaviors that would harm humans, seems nearly impossible to Riedl. The weak form of value alignment, which Riedl described as more reasonable, creates intelligent systems to share our values and perform behaviors that conform to them.
Riedl presented Asimov’s three laws of robotics1 as a way to address this issue of value alignment but explained that these laws would be insufficient because they offer no clear definition of “harm.” (i.e., Is harm physical, psychological, or both?) Because it is impossible to use hard-coded restraints for ethics, Riedl proposed an alternative way to address value alignment for artificial intelligence—reinforcement learning involves trial and error in a simulated or real environment and rewards an agent’s appropriate behavior accordingly. Using reinforcement learning requires that humans be very specific in their communications with robots; unfortunately, humans are generally not good at saying exactly what they mean. For example, if one tells a robot to pick up medication from the store, it will do just that (without paying for it). In addition to these types of sensor errors, he noted, there can also be motor errors, problems with long-term look-ahead, and corrupted rewards when deploying reinforcement learning on artificial intelligence. Reinforcement learning agents learn from feedback, demonstration, or stories, but they only learn about as much of the environment as they need to in order to achieve the rewards (see Figure 9.1).
___________________
1 For a description of Asimov’s laws, see The List of Lists, “Isaac Asimov’s ‘Three Laws of Robotics,’” https://www.auburn.edu/~vestmon/robotics.html, accessed September 4, 2017.
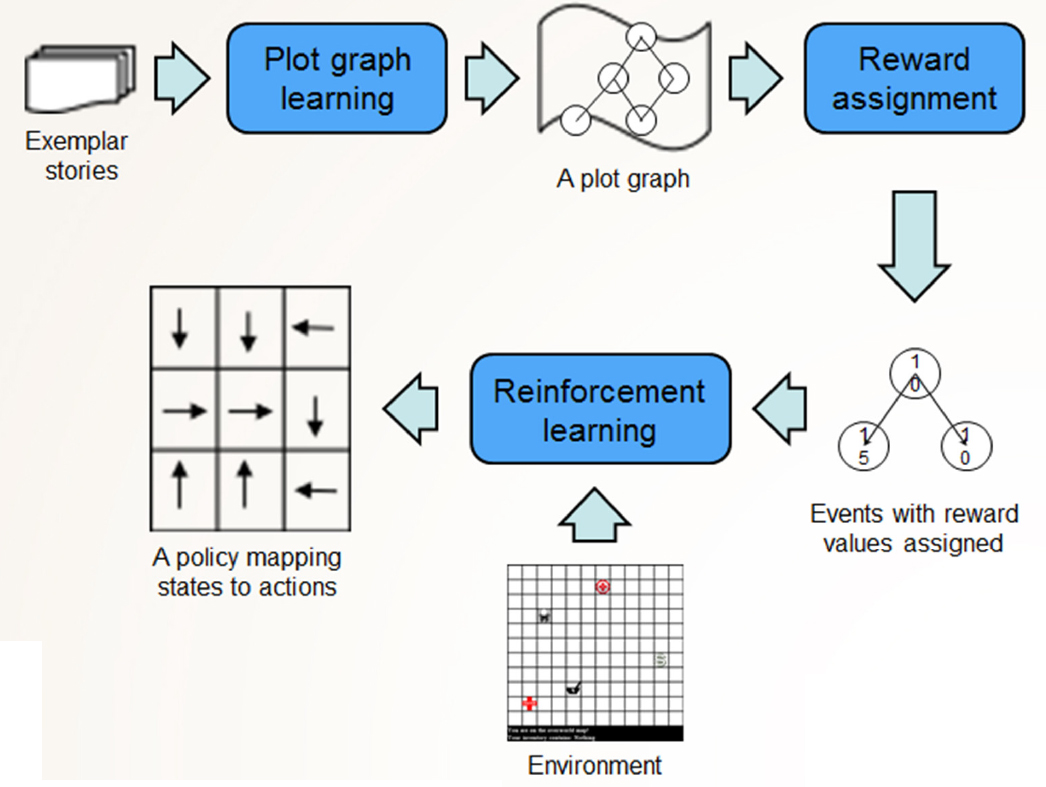
Riedl explained that the next challenge in creating ethical artificial intelligence is the question of how robots learn the rules of society: learning a little bit about everything is a daunting task, however. The rules of the world, often referred to as “commonsense knowledge,” can be either declarative or procedural. Procedural commonsense knowledge includes sociocultural conventions that reduce human–human conflict. Riedl pointed out that databases are being created to collect commonsense knowledge; however, declarative knowledge databases are missing information and, of course, contain no procedural information. One suggestion he mentioned is to put sensors everywhere in the world to collect video and then parse it to collect an infinite amount of information, but such an approach is neither realistic nor desirable.
Yet, Reidl noted, machines will still be expected to understand patterns of human behavior (“machine enculturation”) far beyond basic activity recognition. Rapid innovation continues in computational imagination by combining context with expectation to generate a prediction, mimicking humans’ ability to make inferences. Machine enculturation can look at issues in commonsense failure goals: if a robot does not complete a task in the exact way the human intended, is that considered a failure since the robot executed on the wrong goal? Machine enculturation can also be used to train humans to understand social conventions. In addition to reinforcement learning, he stated, videos and images can also be used to learn commonsense knowledge and machine enculturation. Human cultural values are implicitly encoded in stories told by members of a culture—for example, through allegories, fables, literature, television, and movies.
Riedl defined “curated corpora” as data that have been selected because they all relate to the same topic. Though it is difficult to create such a data set, it can be useful in teaching systems about common sociocultural conventions. When the data are curated, it is possible to learn some sort of model and see temporal relations between events (i.e., there are things that happen regularly, and they happen in a particular order). He noted that having a curated corpora can present a bottleneck, however, and deep learning is needed to learn human values/conventions from stories on the Internet. But since what happens next in a story is not always what actually happens next chronologically, a sparsity problem then results. Riedl emphasized that different agents will be needed for different cultures, so a question also arises about who will decide what the artificial intelligence sees, reads, and learns. And to improve predictions, Riedl noted that machine vision can be used alongside stories.
Researchers in the field are currently studying problems that will likely not emerge for another 5 or more years. Riedl noted that systems that are aware of sociocultural conventions or curated data sets do not currently exist, and researchers still do not know how to solve these problems using deep neural networks. Three to 5 years from now, Riedl expects agents to start using commonsense knowledge and world knowledge to address human needs; to engage in longer conversations; to rely on computational imagination; and to differentiate behavior based on cultural context. Ten years from now, he hopes to see an increasing presence of autonomous systems in social contexts (although the problem of humans understanding artificial intelligence and artificial intelligence understanding humans will be far from solved) as well as ways to address broader artificial intelligence safety concerns. And in 10–20 years, the use of military teammates could become more common.
Joseph Mundy, Vision Systems, Inc., asked if Google and Facebook are doing this type of research since systems such as Siri and Echo would need similar information for their tasks. Riedl acknowledged that these larger companies are starting to think about this in conjunction with academic researchers. Academic research is hopefully helping these organizations to develop a path forward. Rama Chellappa, University of Maryland, College Park, asked if the robot or the human should take responsibility for the illegal activity that resulted in Riedl’s example when the robot picked up the medication for the human without paying for it. Riedl explained that a question like this is precisely why the legal system needs to play a role in artificial intelligence.



