
5
Session 4: Learning from Multi-Source Data
SITUATIONAL AWARENESS FROM MULTIPLE UNSTRUCTURED SOURCES
Boyan Onyshkevych, Defense Advanced Research Projects Agency
Boyan Onyshkevych, Defense Advanced Research Projects Agency (DARPA), provided an overview of DARPA’s mission, which is to maintain technological superiority of the U.S. military and prevent technological surprise from harming our national security. Thus, DARPA funds research in industry, academia, and the government laboratories on projects that will strengthen national security.
He introduced three DARPA programs that enable future analytics for both intelligence community and Department of Defense (DOD) applications (see Figure 5.1). In Deep Exploration and Filtering of Text (DEFT), Low Resource Languages for Emergent Incidents (LORELEI), and Active Interpretation of Disparate Alternatives (AIDA), there are media-specific transforms that look at input data (i.e., unstructured) in certain modalities (e.g., video, image, language) and produce a set of structured objects as output. In this case, the output that the end users work with is in the form of knowledge objects,1 as opposed to language objects. Onyshkevych noted they are using these analytics to learn about the world as described in the corpus of available data by taking the knowledge objects and linking them to what is already known. This transition from document analytics to building a model about the world from the input data is where Onyshkevych suggested researchers dedicate their time moving forward. With such a model, researchers can conduct social network analysis, create entity relationship diagrams, and produce indications and warnings, without worrying about modality-specific problems.
Onyshkevych stated that the goal of the DEFT program, which is nearing conclusion, was to create automated capability to transform large volumes of unstructured text into structured data for use by human analysts and downstream analytics. DEFT’s approach involves (1) finding and representing key information (e.g., entities, relations, events, sentiments, beliefs); (2) aggregating information from multiple sources, detecting inter-document relationships, and representing the information in a structured knowledge base; and (3) exploring and filtering entities, relations, and events from formal and informal inputs. He explained that in DEFT, the source material could include unstructured multilingual input in the form of questions. Document-level annotations are made
___________________
1 “Knowledge object” refers to a “highly structured interrelated set of data, information, knowledge, and wisdom concerning some organizational, management, or leadership situation” (see Z.L. Berge and L.Y. Muilenburg, eds., 2013, Handbook of Mobile Learning, Routledge, New York).
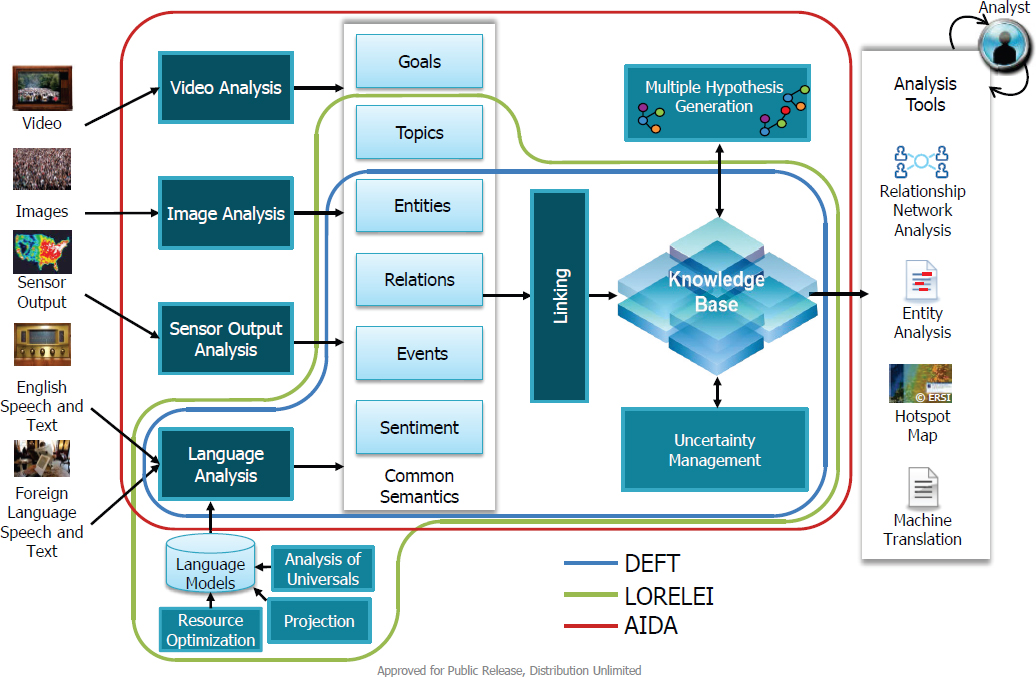
and integrated with the core knowledge base assertions. Input is then linked, and inferences are made around the knowledge base through visualization or downstream analytics before machine-readable (i.e., structured) output emerges. And no matter the language of the source, the output should be the same. Over the past 5 years, DEFT–National Institute of Standards and Technology (NIST) open evaluation tasks have evolved from single document analysis to a composite picture of the world, allowing for joint inference and a single pipeline of information. Onyshkevych encouraged participants to consider attending DEFT’s demonstration day in October, and he also noted that all DEFT code is open source.
The LORELEI Program, which is currently under way, uses the same model of converting unstructured input into structured, actionable output. However, this program specifically considers how to respond quickly to an emergent situation (e.g., humanitarian assistance and disaster relief missions) in a low resource language area. With more than 7,000 active languages in the world, and often no advance notice to secure interpreters or language technology resources, such work is crucial, Onyshkevych explained.
In the LORELEI scenarios, performers are given a language, must collect resources, and then are tested at checkpoints of 1 day, 1 week, and 1 month. There are three evaluation tasks: entity detection and linking, machine translation, and situation frames. The situation frames are designed to address the problem that during actual disaster relief, mission planners need to know what the need is, where it is located, how urgent it is, and whether
it has been met upon completion of the mission. Onyshkevych said that one of the challenges lies in building this capability without supervised training data. The team relies on some distant supervision and language universals (i.e., languages are not randomly created, and many are related to one another in some way)—for example, only 2 of over 7,000 languages order a sentence with the object first, verb second, and subject last. Accordingly, the team built resource sets for 24 languages that are representative of many language families. The process the team uses is not fully automated; two humans (a native speaker of a language other than English, but with some English skills, and a linguistics expert) provide information into the system when learning about a language. However, this human participation is limited to only a few hours of hands-on time.
A third DARPA program, AIDA,2 has not yet begun, but it plans to expand what DEFT did and what LORELEI is doing with unstructured and structured data. Onyshkevych commented that while LORELEI considers spoken and written language, AIDA will look at those plus image and video. From each situation, one can extract entities, events, and relations, link them to each other and to other knowledge sources, and then try to put together multiple hypotheses to explain as much of the situation as possible. Errors in processing, reporting, and misinterpretation are difficult to avoid, Onyshkevych explained. A key distinction with AIDA is that it can promote decision making based on multiple interpretations, whereas many decisions made currently rely on a single analysis that could perhaps have ignored important evidence. Allowing an end user to consider multiple possibilities and prepare for contingencies could be very useful, according to Onyshkevych.
Rama Chellappa, University of Maryland, College Park, asked Onyshkevych how confidence is measured for each modality. Onyshkevych would like to have combinable confidences across modalities but acknowledged that this is a question they have only just begun to explore. Chellappa then asked about the role of sensor fusion in AIDA. Onyshkevych responded that although AIDA will not look at structured sensors, it does build on the insight of previous sensor data exploitation. Josyula Rao, IBM, suggested that if solutions to particular conflicts depend on having a model across the different hypotheses, then multiple models of different realities could arise. Onyshkevych explained that DARPA is allowing rather than explicitly enforcing the ability to propagate multiple models. Rao added that there could be dissonance between the cognitive model that the human is working with and the model that has been programmed into the machine. Rao thus emphasized the need to converge the human–machine divide. Onyshkevych agreed that that is a non-trivial problem and noted that it may be explored in a future DARPA program. Jay Hughes, Space and Naval Warfare Systems Command, wondered how to revert back to the original source data in the hypothesis. Onyshkevych responded that no analytic product working with unstructured data will ever be 100 percent sure of anything. He continued that once one has hypotheses from earlier documents, and one is looking at the next document, these hypotheses carry some expectations, though different confidence levels may exist.
Chellappa asked if it is important to look at non-monotonic reasoning in these programs. Onyshkevych said that performers look at each piece of evidence only once before it ages out. Peter Pirolli, Institute for Human and Machine Cognition, asked whether the hypotheses are representative of what is in the document collection or if they are relevant to decisions that have utility or risk associated with them. Onyshkevych noted that those explanations are not mutually exclusive; AIDA will produce representations and hypotheses that explain the world from a particular data set. James Donlon, National Science Foundation, asked what the research community is discovering about the limits and capabilities of processing heterogeneous data sources. Onyshkevych responded that the notion of top-down expectations is something that many people rely on because trying to do purely bottom-up discovery of a model is not something people can yet do well enough. Donlon added that these DARPA programs are intriguing because they allow the performers to decide which techniques appear to be promising in new spaces.
___________________
2 For more information about the AIDA program, see Boyan Onyshkevych, “Active Interpretation of Disparate Alternatives (AIDA),” DARPA, https://www.darpa.mil/program/active-interpretation-of-disparate-alternatives, accessed August 27, 2017.



