
3
Session 2: Machine Learning from Image, Video, and Map Data
LEARNING FROM OVERHEAD IMAGERY
Joseph L. Mundy, Vision Systems, Inc.
Joseph Mundy, Vision Systems, Inc., explained that the extreme resolution of satellite imagery is beneficial for applications in intelligence and defense. Most importantly, satellite imagery can surveil denied territories without needing control of the airspace, which is necessary if using aerial video.
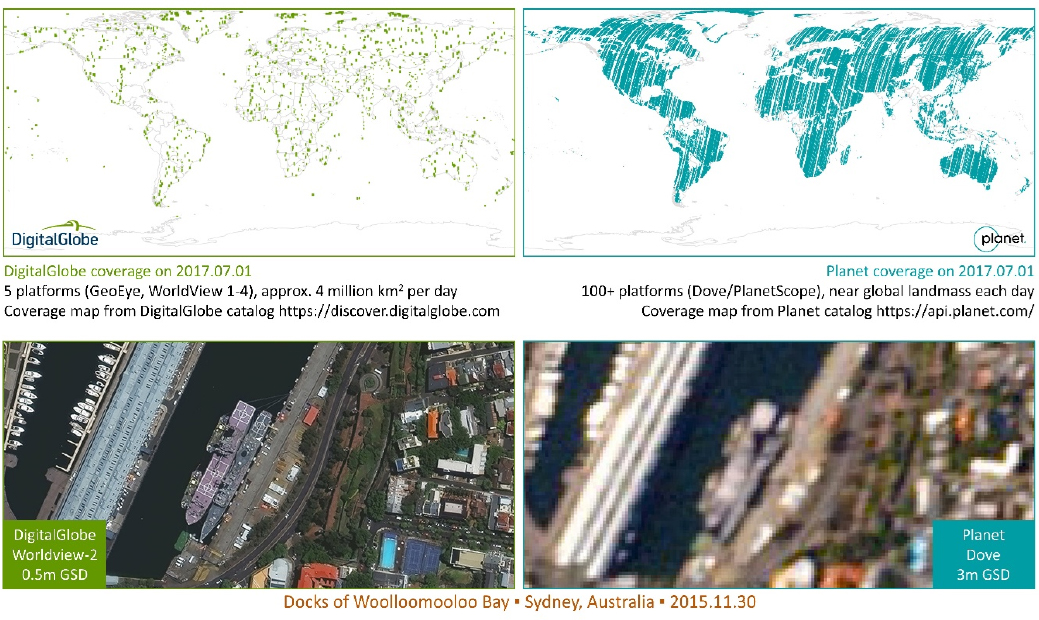
Mundy shared that while space-based imaging began with the Corona Project in 1960, commercial applications of space imaging did not begin until the 1990s. Today, DigitalGlobe1 is the largest provider of imagery to the Department of Defense (DOD). Commercial satellites range in size and cost, from the smallest costing approximately $100,000 and the largest costing approximately $50 million, according to Mundy. The Dove, which is similar in size to a shoebox, has a resolution of only about 3 m but can capture nearly every point on the surface of the Earth; larger satellites such as the WorldView4 have a resolution of approximately 30 cm but can provide views of only approximately 4 million km2 per day (see Figure 3.1).
Mundy described the three phases of satellite imagery analysis: (1) Viewing collected images, assembling important information, and reporting up the chain of command; (2) Monitoring military facilities over a period of days and reporting on activities; and (3) Using statistics to determine aspects such as urban growth, infrastructure, population change, or natural disaster over a period of weeks to years. While investments in this third phase have not yet been substantial, Mundy suggested that this is an area in which machine learning technologies can have the greatest impact.
To provide context for current work, Mundy gave a brief overview of the Research and Development for Image Understanding Systems (RADIUS) program (1993–1997), funded by the Defense Advanced Research Projects Agency (DARPA) and the Central Intelligence Agency, which detected events from imagery based on three-dimensional models created manually. In 2017, Vision Systems, Inc., collaborated with the Air Force Research Laboratory, using the same technology from the RADIUS program, to learn patterns of normalcy in regions of interest and to discover anomalous deviation from normalcy by studying event triggers. Mundy noted that although the technology from the 1990s still worked in 2017, today’s tools are much improved.
Mundy also revisited the three-dimensional reconstruction of the Corona era, when stereo pairs had to be
___________________
1 The website for DigitalGlobe is https://www.digitalglobe.com, accessed August 24, 2017.
carefully constructed, and explained that, today, machine learning and classification can be used for multi-view reconstruction. He shared an application of this technology from Mosul, Iraq, in which two digital elevation models (made from images collected before and after the Fall of Mosul in 2014) were compared to detect structural changes. With the ability to construct three-dimensional data, researchers can develop a deeper understanding of the underlying geometry and create additional structural models of the data. Mundy also briefly described work on modeling three-dimensional buildings to emphasize the value of combining machine learning with more well-understood theoretical principles.
Mundy returned to a discussion of satellite imagery to highlight the issue of training data. One way to secure large quantities of training data is to generate examples of objects and object categories synthetically. If synthetically generated data are combined with manually labeled samples, a neural network can be trained to do the classification and to recognize the objects picked up in the satellite imagery. However, he pointed out that this is no simple task when there is an abundance of objects of interest to analyze. And even with the integration of adaptive learning, he continued, synthetic imagery still has its limitations. Mundy also highlighted Carnegie Mellon University’s Terrapattern,2 an open source tool for query-by-example in satellite imagery. For wide-area search, researchers use already existing crowdsourced information to identify areas of interest.
The future of satellite imagery, according to Mundy, lies in deep semantics: (1) Mature ontologies and automated extraction provide vast sources of linked knowledge; (2) Geographic labels are just the first generation of labeled training data; (3) Context from semantic web increases detection/classification performance; (4) Rapid satellite revisit and event ontologies will enable classification of four-dimensional concepts and processes; and
___________________
2 The website for Terrapattern is http://www.terrapattern.com, accessed August 24, 2017.
(5) Automated discoveries expand linked knowledge to help “connect the dots.” Mundy proposed that geometry will remain important for many years into the future because it serves as the basis for all architecture, and he suggested that the integration of theory-driven and data-driven approaches (by using machine learning algorithms to hypothesize and geometric reasoning to prove) is the best way forward.
Travis Axtell, Office of the Under Secretary of Defense for Intelligence, asked Mundy if he has seen any work done with occlusion in outdoor exterior scenes. Mundy explained that although he has not yet seen any work in that area, occlusion should be considered if the satellite imagery is limited. Axtell then asked Mundy if he has seen any work with multiple sources of intelligence related to having partially occluded three-dimensional point cloud scenes. Mundy said that he had not, but he highlighted some of Vision Systems’s work in using three-dimensional scenes to fuse information from multiple sources. Rama Chellappa, University of Maryland, College Park, added that DARPA used multi-source integration for three-dimensional modeling in the late 1990s.
DEEP LEARNING FOR LEARNING FROM IMAGES AND VIDEOS: IS IT REAL?
Rama Chellappa, University of Maryland, College Park
Rama Chellappa, University of Maryland, College Park, agreed with Mundy that geometry and physics will always play important roles in the study of images and noted that ontology also remains useful because it provides a language for describing what is seen.
Chellappa explained that traditional computer vision approaches start with a problem, consider the best data (e.g., images, videos), identify the best features (e.g., interest points, stochastic models), and classify (e.g., using nearest neighbor rules, support vector machines). He emphasized that every problem has its own solution.
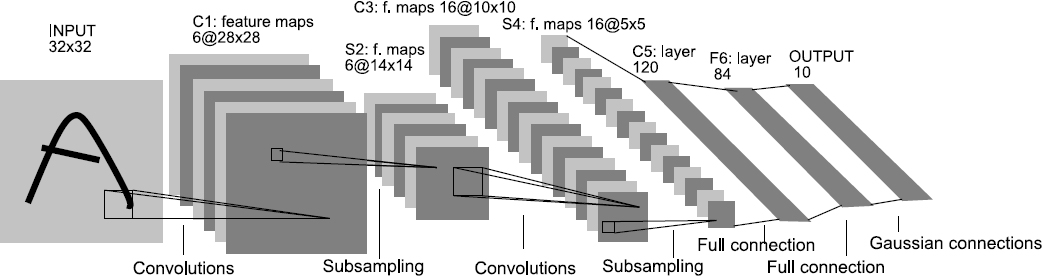
Chellappa explained that approaches for computer vision began to change with the increased use of neural networks in the late 1980s and early 1990s. Researchers discovered capabilities for face recognition, automatic target recognition, texture segmentation, optic flow computation, maxpooling, and image processing. Figure 3.2 shows the structure of LeNet, the first convolutional neural network. More recent developments in the field include graphical processing units, better understanding of non-linearities, and large annotated data sets. Chellappa noted that the deep convolutional neural networks (e.g., AlexNet) explored in 2012 are responsible for today’s significant reduction in error rates (e.g., the top-1 and top-5 error rates have improved by 8 percent).
Deep learning has become more prevalent in computer vision, according to Chellappa. The Intelligence Advanced Research Projects Activity (IARPA) Janus Program3 (2014–present) focuses on challenging problems related to verification, search, detection, and clustering. For example, the Janus team used different neural networks to try to optimize and extract deep features for face verification as well as three-dimensional models. He noted that some of Janus’s data sets are available to the public.
Chellapa highlighted the “community of networks” that is formed when combining multiple networks that each use different training data. These more diverse learning experiences result in better generalizations. To Chellappa’s surprise, deep learning has been working so well in Janus that the true accept rates have been higher than expected at 91 percent for 10-4 Federal Acquisition Regulation (FAR) for face verification.
Chellappa reiterated that computer vision uses reasoning to extend beyond pattern recognition. He emphasized that object detection, face detection, object recognition, and face recognition/verification have experienced improved performance and are essential for the computer vision community. Over the next 3–5 years, Chellappa hopes that advanced technologies will be able to address pose, illumination, and low-resolution challenges in unconstrained scenarios; handle full motion videos; enable sharing/transfer learning of features for different but somewhat related tasks; model/understand context and occlusion; handle a “reasonable” amount of noise in data; increase robustness to adversarial data; improve vision and language; and engage other multi-modal data.
Research prospects for the longer term include the following, according to Chellappa: theoretical investigation of why and when deep learning works; understanding of the minimum training set needed, given empirical distributions of the training set in the absence/presence of domain shift; advanced image formation, blur, geometry,
___________________
3 The website for the Janus program is https://www.iarpa.gov/index.php/research-programs/janus, accessed August 24, 2017.
shape, motion, texture, and occlusion models that can generalize using data; machine learning methods that generalize from small data and that deal with adversarial data; and domain knowledge and commonsense reasoning.
Chellappa added that students at the secondary and postsecondary levels are already doing machine learning and are eager to learn more. He expressed excitement about deep learning’s potential now and its improvement in the future, especially given user-friendly software and promising data-labeling results.
Devanand Shenoy, Department of Energy, asked Chellappa if one can solve a problem using metrics, such as accuracy, instead of trying to solve it independent of the desired outcome. Chellappa responded that such metrics can be used with the training data, bearing in mind the generalizations to test data.
LEARNING ABOUT HUMAN ACTIVITIES FROM IMAGES AND VIDEOS
Anthony Hoogs, Kitware, Inc.
Anthony Hoogs, Kitware, Inc., noted that there is a hidden contribution in deep learning: the open source culture that it has fostered. Deep learning flourished in the computer vision community in 2014 with the development of the open source software framework Caffe.4 Hoogs’s Kitware, Inc., has been an open source company for nearly 20 years. Primarily funded by the U.S. government, Kitware now has 25 open source toolkits.
Hoogs explained that video domains vary greatly; for example, they include wide-area motion imagery, narrow field-of-view unmanned aerial vehicle video, ground-level surveillance, and internet/web videos. Most historic computer vision work in video has been in action recognition, where a video clip has a single action that is identified and labeled. Now, the focus often turns to action detection, which is useful when one does not know when and where in the video something is happening. This temporal search problem in surveillance is difficult, he stated, because, most of the time, nothing of interest is happening in the footage.
He noted that data sets drive research in vision because one has to build a data set that addresses the problem in need of a solution. In order to publish, researchers must have the best scores on an established data set or a new, interesting data set they have created. One downside of this paradigm, Hoogs said, is that if a training data set is too different from real-world data, published results will not translate into comparable performance on operational data.
Deep learning is playing a prominent role in video research, according to Hoogs. The application of deep learning to video explores both time and sequential data. Emerging work in this area is in the use of recurrent
___________________
4 The website for Caffe is http://caffe.berkeleyvision.org, accessed August 31, 2017.
neural networks and long short-term memory networks.5 There is also work in fusing parallel convolutional neural networks together. However, he noted that as most of the work is in supervised learning, there is relatively little work so far in unsupervised learning or generative modeling for video. There has also been little work on fusing video and audio and on model transfer. He explained that, overall, deep learning has had less impact so far on video analytics than on image recognition.
Hoogs provided an overview of various methods used to address action recognition challenges (e.g., cluttered backgrounds, occlusion, spatiotemporal uncertainty, and high inter-class variability). There are a number of data sets that help to address these challenges, but caution needs to be used to ensure the data match the problem at hand. For action detection (e.g., surveillance video), temporal localization and spatiotemporal localization methods can be used.
The DOD community has funded substantial work in analytics for Wide-Area Motion Imagery (WAMI), primarily before the deep learning revolution, according to Hoogs. However, complex activity detection and graph matching problems are areas in which deep learning has not yet shown much progress. He next introduced the IARPA Deep Intermodal Video Analytics (DIVA)6 program for which Kitware creates the data set and develops an open source video analytics framework. DIVA works to improve activity detection in challenging conditions such as crowded scenes, low resolution, and low visibility. Hoogs mentioned the DARPA Video Image Retrieval and Analysis Tool (VIRAT) program7 that addressed some of these issues pre-deep learning during the course of its surveillance research.
Hoogs remarked that commercial investment is substantial in unmanned aerial vehicle video research for small drones, particularly in domains such as precision agriculture, infrastructure inspection, and sports. He suggested that the intelligence community and DOD invest in problems that are unique and leverage current research as opposed to investing in research that industry is already conducting. For example, DOD and the intelligence community could focus on and invest in alternative sensing modalities such as infrared and hyperspectral since they are of less interest to commercial investors. Hoogs also encouraged the intelligence and defense communities to support open source frameworks and data sharing within relevant agencies and to engage academic researchers in problem solving. He encouraged the development of training methods for noisy, small training sets with heterogeneous labels, as well as focusing on coincident sensor fusion and fine-grained problems. Within 3 to 5 years, Hoogs expects substantial advances in video using deep learning, progress on the surveillance problem, and the integration of text and video for querying. Within 5 to 10 years, Hoogs hopes to see structure learning of deep networks on a large scale.
Sanjeev Agarwal, DOD Night Vision and Electronic Sensors Directorate, asked if a vision framework of live spatiotemporal video processing is needed to attack big vision problems such as human visual perception. Hoogs responded that, on the software side, people are building a video framework, but more systems work is needed. Chellappa remarked that the human perception view has to be integrated into this work. Hoogs noted that neuroscientists are already using computer vision research to map detailed functional brain studies. Jason Duncan, MITRE, noted that while deep learning shows great successes if there is good training data, it is still important to know how to solve problems with limited data sets.
___________________
5 A long short-term memory network is a “specific recurrent neural network architecture that is well-suited to learn from experience to classify, process, and predict time series with time lags of unknown size” (See A. Azzouni and G. Pujolle, 2017, A long short-term memory recurrent neural network framework for network traffic matrix prediction, https://arxiv.org/abs/1705.05690).
6 The website for the DIVA program is https://www.iarpa.gov/index.php/research-programs/diva, accessed August 29, 2017.
7 For information about the VIRAT data set, see http://www.viratdata.org, accessed September 4, 2017.





