
6
Evaluating Validity in the FSI Context
This chapter addresses a framework for an ongoing evaluation of the FSI test, which fundamentally relates to the validity of its scores. It follows the above chapters that discussed the elements that relate to the development of an assessment program: the understanding of language, the sociocultural and institutional contexts, and the target language use domain (Chapters 2 and 3); the tasks, the performances they elicit, and the resulting scoring of those performances (Chapter 4); and the interpretation of those scores that supports their use (Chapter 5).
An ongoing evaluation of the FSI test will need to consider such questions as the following:
- Do the results of the assessment mean what the test designers think they mean for the context in which the assessment is used, and does the assessment function in the way they intended?
- Are the interpretations of those scores useful, appropriate, and sufficient to make the high-stakes decisions that are made by FSI?
- Are the consequences of those decisions beneficial to everyone involved in the testing program and, overall, to the Foreign Service?
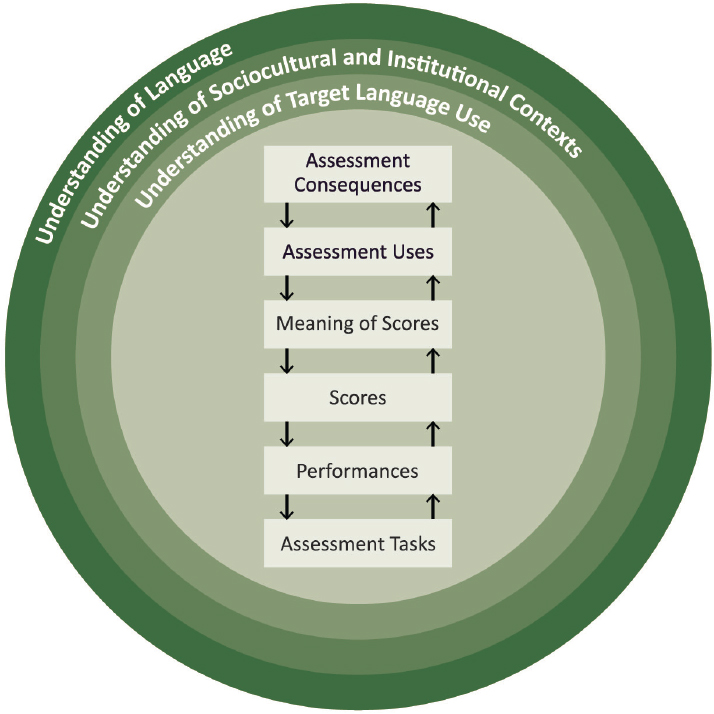
In Figure 6-1 (which reproduces Figure 1-1, in Chapter 1), these questions are captured by the arrows, which highlight the relationships among the contexts and elements of the assessment program.
It is important for any testing program to articulate the claims that a test is intended to support and to document the validity of these claims with empirical evidence. This evidence should also include information
about the technical qualities of the test scores, such as the extent to which they are reliable and generalize across assessment tasks, assessment occasions, and scorers. This evidence should also include results from studies of fairness, including analyses to check whether test performance is biased by any factors that are irrelevant to the test’s construct, such as the test-taker’s gender, age, race, or ethnicity. Evidence should also be collected about the consequences of the use of the test on the decisions the test is used to support, on the test takers, and on others in the Foreign Service.
The evidence about the test, its use, and its consequences should be considered in light of the current understanding of language, the sociocultural and institutional contexts of the testing program, and the target language use domain. This consideration of evidence related to the test and its functioning is not a one-time effort but needs to be an ongoing
program of research. Over time, there will be changes in the understanding of language, the contexts of the testing program, and the target language use domain, so there needs to be continuing effort to consider whether a test is working as intended.
This chapter first discusses examples of claims about performance on the FSI tests and strategies for evaluating their validity. It then provides an overview of relevant professional standards, which provide some generally applicable best practices related to the design and evaluation of assessment programs.
EVALUATING THE VALIDITY OF CLAIMS
This section offers four examples of claims made about test-takers’ performance on an assessment and the strategies for validating them; it draws extensively from Bachman and Palmer’s (2010) Language Assessment in Practice. It is not intended to be an exhaustive discussion of the process of evaluating the validity of test-based inferences but rather to provide a few concrete examples of the kinds of issues that need to be investigated during test validation.
Example Claim 1: Tasks and Performances
The first example claim relates to the tasks that are used in the assessment and the performances they elicit, as well as the target language use domain (the bottom two boxes and the inner ring in Figure 6-1):
- Claim: The characteristics of the assessment tasks and the performances they elicit correspond closely to the characteristics of the tasks and the performances they require in the target language use domain (Bachman and Palmer, 2010, p. 234).
This claim is fundamental because it focuses on the relationship between the test-taker’s performance in the assessment situation, which is a function of the characteristics of the assessment tasks used, and the test-taker’s performance in the real world in conditions with similar characteristics. In the context of FSI, this claim concerns the relationships between the proficiency needed to address the kinds of language-based tasks that are on the FSI test and the proficiency needed to address the kinds of tasks that Foreign Service officers need to carry out in the target language.
Performance on tasks in the assessment situation is never identical to performance in the real world. To demonstrate that this claim is reasonable and valid, it is necessary to gather data that allows FSI to estimate the extent of similarities and differences between task characteristics and the
performances they elicit to confirm that performance in the testing situation is likely to require similar levels of language proficiency as performance in the real world. It is also important to consider whether the key aspects of the target language use domain are represented in the assessment tasks.
One way to study the correspondence between the target language use domain and the task situations is to list the characteristics of the target language use domain tasks and the characteristics of the assessment tasks (Bachman and Palmer, 2010, p. 235). Conceptually, this correspondence exercise is simple, but it can be time-consuming to carry out. The test tasks can be readily examined by the test designer, but the understanding of the tasks and performances in the target language use domain could require a substantial data collection effort, using one of the analysis methods described in Chapter 3. For FSI, it is necessary to understand the full range of the tasks that Foreign Service officers need to carry out in the target language and their relative frequency and importance. For example, a language proficiency test that focuses on making formal presentations and reading news articles will not capture the full range of linguistic resources needed for a particular job task that primarily requires social conversation and the exchange of email messages.
Example Claim 2: Evaluating Task Performances to Produce Test Scores
The second example claim looks at the way the performances on the test are evaluated (the second and third lower boxes and the inner ring in Figure 6-1):
- Claim: The criteria and procedures for evaluating responses to the assessment tasks correspond closely to the way language users assess performance of language tasks in the target language use domain (Bachman and Palmer, 2010, p. 236).
This claim focuses on the way that performance on the assessment is evaluated in order to produce scores. Like the first claim, this claim involves comparing the test situation and the target language use domain, but here the focus is on the criteria used to assess performances. Ideally, performance on assessment tasks is evaluated with criteria that are relevant in the real world.
In evaluating this claim, it is important to investigate the similarity in the evaluation of performance between the target language use domain and the assessment. For example, consider the extent to which the use of standard grammar is valued in the target language use domain. If standard grammar is important in the real world, then it should be important on the
assessment—and vice versa. However, if accuracy is not as important in the target language use domain as, say, fluency, then the scoring criteria on the test should reflect that. This sort of evaluation will also rest on an analysis of the target language use domain using one of the methods described in Chapter 3, as well as on the understanding of language used and the understanding of the sociocultural and institutional contexts of the assessment.
For FSI, it will be important to consider what kind of task performance is adequate in the target language use domain for Foreign Service officers and what features of that performance are most important. In some situations, standard grammar, vocabulary, and accent may be critical; in other situations, an ability to communicate and understand meaning with less-than-perfect language may be sufficient. The scoring criteria should reflect the priorities in the target language use domain. Also, different tasks may require test takers to engage with different audiences for different purposes, and their performance might be scored differently for each task in accordance with how they would be evaluated in the target language use domain.
This claim is one for which issues of fairness may arise, with questions related to the criteria that are used in the scoring process.1 For example, even with an explicit scoring rubric that focuses on the communication of meaning, it could turn out that scorers primarily focus on errors in grammar and vocabulary or are strongly affected by particular accents. Studies of the scoring process using duplicate scoring by highly trained scorers might be a source of evidence about the way task performances are evaluated in the test situation.
Example Claim 3: Scores and Their Interpretation
The third example claim looks at the interpretations of the scores that are produced by the test (the middle two boxes in Figure 6-1):
- Claim: The test scores that summarize the test-taker’s performance are interpreted in a way that generalizes to performance in the target language use domain (Bachman and Palmer, 2010, pp. 237–238).
This claim focuses on the way that test users interpret the scores and the inferences about test-takers’ language proficiency that they believe are justified by the scores. The interpretation of a set of test scores again concerns a relationship with the target language use domain, but here the relationship is focused on inferences about the adequacy of a test-taker’s language proficiency that are made based on the test score.
___________________
1 For a comprehensive discussion of issues related to fairness, see Kunnan (2018).
For FSI, the current test is interpreted through the Interagency Language Roundtable (ILR) framework (see Chapter 5), and the interpretation suggests that test takers who receive a score of 3 or higher have adequate language proficiency to perform the tasks they will need to perform at their posts. Investigating this claim in the FSI context might involve collecting information from Foreign Service officers in the field about their ability to successfully carry out different typical tasks in the target language and comparing that information to their test scores. In other contexts, where a cut score between performance levels has been defined using a standard-setting process, investigating this claim might involve collecting evidence of the robustness of the judgments used in the standard-setting process.
Example Claim 4: Test Uses and Consequences
This claim concerns the way the test results are used and the consequences of those uses (the two uppermost boxes in Figure 6-1 and the ring related to sociocultural and institutional contexts):
- Claim: The consequences of using an assessment and of the decisions that are made on the basis of that assessment are beneficial to the test takers and to the Foreign Service generally (Bachman and Palmer, 2010, p. 178).
Tests are often used for high-stakes decisions that can have a major impact on a test-taker’s life and career. Identifying the consequences of these decisions is an important part of establishing the overall validity of a specific use of a test (e.g., Bachman, 2005; Messick, 1996). For a Foreign Service officer, passing or failing a language test can affect a test-taker’s salary and long-term retention in the Foreign Service, as well as a range of subjective attributes such as self-image. Beyond the test takers themselves, the use of the test to make decisions about the placement of Foreign Service officers also affects the ability of embassies and consulates around the world to carry out their work. Inaccurate decisions could result in placing unqualified personnel in overseas positions or in preventing the placement of qualified personnel in positions where they could be effective.
In addition, the FSI test affects instruction in FSI classrooms, as teachers react to the content and format of the test by adapting their teaching approaches and instructional materials to prepare their students to be successful. This instructional response is known in the field as washback. The FSI test outcomes may also be perceived by instructors and administrators as measures of the language program’s instructional effectiveness if the test takers had recently completed the FSI training program, a consequence of
the direct linkage between instruction and assessment. The goal should be to create a test that assesses the aspects of communicative competence that Foreign Service officers need, both to more accurately identify the language proficiency of the test takers and to encourage the language training program to develop the aspects of language proficiency that are needed.
This example claim involves a number of aspects of the use of test results, including process issues related to the communication of the test results in a clear, timely, useful, and confidential score report, as well as issues related to the consequences of the resulting decisions themselves (Bachman and Palmer, 2010, Ch. 9). For FSI, the last point would involve looking at outcomes related to the effectiveness of Foreign Service officers in carrying out language tasks and changes in the training program to develop language proficiency.
PROFESSIONAL STANDARDS FOR WORKPLACE TESTING
As suggested by the four example claims discussed above, evaluating the extent to which test scores can validly be interpreted and used as intended involves multiple investigations. For a high-stakes assessment program, investigating and establishing the validity of claims and documenting this process is a critical and ongoing feature of the overall program. Several professional organizations have articulated and published standards to guide the development and evaluation of assessment programs, focusing broadly on validity and the related issues of reliability, generalizability, and fairness.
In this section the committee offers an overview of the considerations raised by these professional standards. This overview does not detail the standards; rather, it highlights a set of best practices that are commonly discussed in the field and that work to ensure the validity of a test during its development, demonstrate its validity when it becomes operational, and guide the process of revision and renewal that is a necessary part of all ongoing testing programs. Some of these practices do not apply to all testing programs and all need to be shaped by a program’s specific context, but the entire list provides a quick overview of key practices that testing programs should consider.
The committee reviewed nine sets of standards documents, paying specific attention to the guidelines most relevant to language assessment and assessment related to professional purposes. Two of these sets of standards focus specifically on language assessment: the International Language Testing Association Guidelines for Practice2 and the European Association for
___________________
Language Testing and Assessment Guidelines for Good Practice.3 Three of the sets of standards address work-related assessment in the U.S. context: the Standards for Educational and Psychological Testing include a chapter devoted specifically to workplace testing and credentialing (American Educational Research Association et al., 2014); the Uniform Guidelines on Employee Selection Procedures,4 which are an important source of information about fairness issues in employment-related decisions; and the Principles for the Validation and Use of Personnel Selection Procedures (Society for Industrial and Organizational Psychology, 2018), which provide instructions for conducting validation studies for job-related tests. Two of the sets of standards are from the International Test Commission and focus on issues related to international assessment: one related to the competencies needed by test users (International Test Commission, 2001) and the other related to assessment in settings that are linguistically or culturally diverse (International Test Commission, 2018). Finally, two sets of standards address job-related assessment issues in the context of accreditation: the National Commission for Certifying Agencies Standards for the Accreditation of Certification Programs (Institute for Credentialing Excellence, 2016) and the American National Standards Institute standards for personnel certification programs.5
These different standards documents lay out guidelines for identifying competencies to be assessed; developing the assessment and specific assessment tasks; field-testing assessment tasks; administering assessment tasks and scoring responses; setting the passing standard; and evaluating the reliability of the scores, the validity of interpretations based on the assessment results, and the fairness of the interpretations and uses of these results. Although the standards articulated in each document are tailored to different contexts, they address a number of common points.
The committee identified 11 best practices that are relevant for all high-stakes testing programs.
- Practice 1: Work/Job Analyses. In the context of employment settings, test developers should conduct a work/job analysis regularly (typically every 3–5 years) to document the work and worker-related requirements to which test content has been linked. For FSI, this practice relates to the development of the understanding of the target language use domain for tests of language proficiency.
- Practice 2: Content-Related Validity Evidence. Test developers should maintain documentation of the procedures used to deter
___________________
3 See http://www.ealta.eu.org/guidelines.htm.
4 See http://www.uniformguidelines.com/uniform-guidelines.html.
5 See https://www.ansi.org/accreditation/credentialing/personnel-certification.
-
mine the content (knowledge, skills, abilities, and other characteristics) to be covered by the test and the formats for test tasks. Documentation should include procedures for developing and field-testing items and for determining those items acceptable for operational use. Documentation should include the qualifications of those involved in this process.
- Practice 3: Test Administration. Test developers should provide detailed instructions for administering the test under standard conditions and for providing testing accommodations to test takers who need them. Instructions should also include testing policies and guidance for maintaining the confidentiality and security of test content.
- Practice 4: Scoring Processes. Test developers should maintain documentation about the scoring rubric for the test and the procedures used for scoring performances. This documentation includes procedures related to rater selection, training, recalibration, retraining, and monitoring and evaluation, as well as disagreement resolution, analyses of inter-rater reliability and agreement, and rater effects.
- Practice 5: Cut-Score Setting. If performance or passing levels are defined with respect to the score scale, test developers should maintain documentation about the process by which the cut scores defining the performance or passing levels were set. This documentation should include details about the qualifications of panelists used to set cut scores, the instructions they were given, their levels of agreement, and the feedback provided to them in score reports.
- Practice 6: Psychometric and Other Technical Qualities. Test developers should specify a program of research to evaluate the technical qualities of the test and maintain documentation on the progress and results of these studies. This documentation should include procedures for estimating reliability and decision consistency, evaluating rater agreement for the scoring of constructed-response questions, evaluating differential item functioning, if possible, and comparing performance by race, ethnicity, age, and gender. This research should also include other relevant technical analyses, such as cognitive studies to understand how test takers process the test questions and domain analyses to understand the relative weight given to different aspects of the target language use.
- Practice 7: Fairness. Test developers should maintain documentation about efforts to ensure that scores obtained under the specified test administrations procedures have the same meaning for all population groups in the intended testing population and that test takers with comparable proficiency receive comparable scores.
- Practice 8: Score Reporting. Test developers should maintain documentation about score report design, contents, and implementation.
- Practice 9: Purposes and Uses of the Test. Test developers should have written documentation of the needs, objectives, uses, and stakeholders for which a high-stakes testing program exists.
- Practice 10: Explicit statement of the Validity Argument. The key elements of a validity argument/framework should be available in an up-to-date technical report that is public. Organizations with effective high-stakes testing programs develop a good documentation culture over time.
- Practice 11: Information for Test Takers. Test developers should maintain up-to-date test-taker familiarization guides to reduce differences across test takers in familiarity with the test format.
These best practices provide a concrete guide for the different aspects of a testing program that should be evaluated to help ensure and establish the overall validity of the program’s test results for its intended uses. In almost all cases, these considerations are relevant to FSI’s testing program.










