
Privacy in a Networked World
REBECCA N. WRIGHT
Rutgers University
Piscataway, New Jersey
ABSTRACT
Networked electronic devices have permeated business, government, recreation, and almost all aspects of daily life. Coupled with the decreased cost of data storage and processing, this has led to a proliferation of data about people, organizations, and their activities. This cheap and easy access to information has enabled a wide variety of services, efficient business, and convenience enjoyed by many. However, it has also resulted in privacy concerns. As many recent incidents have shown, people can be fooled into providing sensitive data to identity thieves, stored data can be lost or stolen, and even anonymized data can frequently be reidentified. In this paper we discuss privacy challenges, existing technological solutions, and promising directions for the future.
Changes in technology are causing an erosion of privacy. Historically, people lived in smaller communities, and there was little movement of people from one community to another. People had very little privacy, but social mechanisms helped prevent abuse of information. As transportation and communications technologies developed, people began to live in larger cities and to have increased movement between communities. Many of the social mechanisms of smaller communities were lost, but privacy was gained through anonymity and scale.
Now, advances in computing and communications technology are reducing privacy by making it possible for people and organizations to store and process personal information, but social mechanisms to prevent the misuse of such information have not been replaced. While a major issue in computing and communications technology used to be how to make information public, we now have to work hard to keep it private.
The issue of confidentiality,1 or protecting information in transit or in storage from an unauthorized reader, is a well-understood problem in computer science. That is, how does a sender Alice send a message M to an intended receiver Bob in such a way that Bob learns M but an eavesdropper Eve does not, perhaps even if Eve is an active attacker who has some control over the communication network? Although some difficulties remain in practical key management and end-host protection, for the most part this problem is quite well solved by the use of encryption.
In contrast, a modern view of privacy is not simply about Eve not learning the message M or anything about its contents, but includes other issues such as Eve learning whether a message was sent between Alice and Bob at all, and questions about what Bob will and will not do with M after he learns it. This view of privacy in the electronic setting was first introduced in the early 1980s by David Chaum (1981, 1985, 1992). A growing interest in privacy in the computer science research community can be seen by the large number of annual conferences, workshops, and journals now devoted to the topic.2
It is easy to describe how to achieve privacy when it is considered in isolation: one can live in seclusion, avoid any use of computers and telephones, pay cash for all purchases, and travel on foot. Obviously, this is not realistic or even desirable for the vast majority of people. The difficulty of privacy arises because of the apparent conflict between utility and privacy, that is, the desire of various parties to benefit from the convenience and other advantages provided by use of information, while allowing people to retain some control over “their” information, or at the very least to be aware of what is happening to their information.
The problem is further complicated by the fact that privacy means different things to different people. What some people consider a privacy violation is considered completely innocuous by other people. Or what seems a privacy violation in one context may not seem to be one in another context. For this reason privacy is not a purely technological issue and cannot have purely technological solutions. Social, philosophical, legal, and public policy issues are also important. However,
technology can enable new policy decisions to be possible by instantiating solutions with particular properties.
Given the pervasive nature of networked computing, privacy issues arise in a large number of settings, including the following:
-
Electronic health records. In the United States there is a large effort to move toward electronic health records in order to improve medical outcomes as well as reduce the exorbitant cost of health care. Unless solutions can be developed that allow medical practitioners’ access to the right personal health information at the right time and in the right circumstances, while also ensuring that it cannot be accessed otherwise or used inappropriately even by those who have legitimate access, privacy will remain a barrier to adoption.
-
Government surveillance. In the interest of protecting national security and preventing crime, governments often wish to engage in surveillance activities and link together huge amounts of data in order to identify potential threats before they occur and learn more about incidents and their perpetrators if they occur. Most people want increased security, but many remain concerned about invasion of privacy.
-
Commerce and finance. Consumers have eagerly adopted online commerce and banking because of the great convenience of being able to carry out transactions from home or anywhere else. However, due to the use of personal information such as social security numbers and mother’s maiden name being used for authentication coupled with the ease with which this kind of personal data can be learned, this has resulted in a huge increase in identity theft. It also allows companies (particularly when data from multiple sources is aggregated by data aggregators) to gain great insight into customers and potential customers, often to the point where customers feel unsettled.
-
Pervasive wireless sensors. Sensors such as RFID tags (inexpensive tiny chips that broadcast a unique 96-bit serial number when queried and are used in mobile payment applications such as EZPass and ExxonMobil’s Speedpass, as well as increasingly being embedded in consumer products—or even in consumers themselves in some cases), mobile telephones and other personal devices that broadcast recognizable identification information, and GPS transmitters such as those used in popular car navigation systems. These devices can potentially be used to track individuals’ locations and interactions.
There are a large number of different kinds of solutions to various privacy problems, with different kinds of properties. Some aspects in which solutions differ are: transparent (users cannot even tell they are there, but they protect privacy in some way anyway) or visible (users can easily tell they are there and can, or even must, interact with the system while carrying out their tasks); individual user (in which an individual can unilaterally make a choice to obtain more privacy, say, by using a particular software package or configuring it in a certain way) or
infrastructure (in which some shared infrastructure, such as the Internet itself, is modified or redesigned in order to provide more privacy); focused only on notification (allowing or requiring entities to describe their data practices) or also on compliance (ensuring that stated practices are observed); and in other ways. However, unless a solution primarily favors utility and functionality over privacy when choices must be made, it will tend not to be widely adopted. I describe one kind of solution, privacy-preserving data mining, in further detail in the following section.
PRIVACY-PRESERVING DATA MINING
One area of investigation in privacy-related technologies is the use of distributed algorithms to process data held by one or more parties without requiring the parties to reveal their data to each other or any other parties. While this may seem contradictory at first, sophisticated use of cryptography can yield solutions with unintuitive properties. Specifically, the elegant and powerful paradigm of general secure multiparty computation (Goldreich et al., 1987; Yao, 1986) shows how cryptography can be used to allow multiple parties, each holding a private input, to engage in a computation on their collective inputs in such a way that they all learn the result of the computation but nothing else about each other’s data. This is achievable with computation and communication overhead that is reasonable when described as a function of the size of the private inputs and the complexity of the nonprivate computation.
One area in which one might seek to use these kinds of algorithms is in the area of data mining. However, because the inputs to data-mining algorithms are typically huge, the overheads of the general secure multiparty computation solutions are intolerable for most data-mining applications. Instead, research in this area seeks more efficient solutions for specific computations. Most cryptographic privacy-preserving data-mining solutions to date address typical data-mining algorithms, such as clustering (Vaidya and Clifton, 2003; Jagannathan and Wright, 2005), decision trees (Lindell and Pinkas, 2002), or Bayesian networks (Meng et al., 2004; Yang and Wright, 2006). Recent work addresses privacy preservation during the preprocessing step (Jagannathan and Wright, 2006) and the postprocessing step (Yang et al., 2007), thereby working toward maintaining privacy throughout the data-mining process.
Cryptographic techniques provide the tools to protect data privacy by allowing exactly the desired information to be shared while concealing everything else about the data. To illustrate how to use cryptographic techniques to design privacy-preserving solutions to enable mining across distributed parties, we describe a privacy-preserving solution for a particular data-mining task: learning Bayesian networks on a dataset divided among two parties who want to carry out data-mining algorithms on their joint data without sharing their data directly. Full details of this solution are described in Yang and Wright (2006).
Bayesian Networks
A Bayesian network is a graphical model that encodes probabilistic relationships among variables of interest (Cooper and Herskovits, 1992). This model can be used for data analysis and is widely used in data-mining applications.
Formally, a Bayesian network for a set V of m variables consists of two parts, called the network structure and the parameters. The network structure is a directed acyclic graph whose nodes are the set of variables. The parameters describe local probability distributions associated with each variable. There are two important issues in using Bayesian networks: (1) learning Bayesian networks and (2) Bayesian inference. Learning Bayesian networks includes learning the structure and the corresponding parameters. Bayesian networks can be constructed using expert knowledge or derived from a set of data, or by combining those two methods together. Here we address the problem of privacy-preserving learning of Bayesian networks from a database vertically partitioned between two parties. In vertically partitioned data one party holds some of the variables and the other party holds the remaining variables.
Privacy-Preserving Bayesian Network Learning Algorithm
A value x is said to be secret shared (or simply shared) between two parties if the parties have values (shares) such that neither party knows (anything about) x, but given both parties’ shares of x, it is easy to compute x. Our distributed privacy-preserving algorithm for Bayesian network learning uses composition of privacy-preserving components in which all intermediate outputs from one component that are inputs to the next component are computed as secret shares. In this way it can be shown that if each component is privacy preserving, then the resulting composition is also privacy preserving.
Our solution is a modified version of the well-known K2 algorithm of Cooper and Herskovits (1992). That algorithm uses a score function to determine which edges to add to the network. To modify the algorithm to be distributed and privacy preserving, we seek to divide the problem into several smaller subproblems that we know how to solve in a distributed, privacy-preserving way. Specifically, noting that only the relative score values are important, we use a new score function g that approximates the relative order of the original score function. This is obtained by taking the logarithm of the original score function and dropping some lower order terms.
As a result, we are able to perform the necessary computations in a privacy-preserving way. We make use of several existing cryptographic components, including secure two-party computation (such as the solution of Yao [1986], which we apply only on a small number of values, not on something the size of the original database), privacy-preserving scalar product share algorithm (such as the solutions described by Goethals et al., 2004), and a privacy-preserving
algorithm for computing xlnx (such as Lindell and Pinkas, 2002). In turn, these can be combined to create a privacy-preserving approximate score algorithm and a privacy-preserving score comparison algorithm, as described in Yang and Wright (2006).
The overall distributed algorithm for learning Bayesian networks is as follows. In keeping with cryptographic tradition, we call the two parties engaged in the algorithm Alice and Bob.
Input: An ordered set of m nodes, an upper bound u on the number of parents for a node, both known to Alice and Bob, and a database containing n records, vertically partitioned between Alice and Bob.
Output: Bayesian network structure (whose nodes are the m input nodes, and whose edges are as defined by the values of πi at the end of the algorithm).
Following the specified ordering of the m nodes, Alice and Bob execute the following steps at each node vi in turn. Initially each node has no parent; parents are added as the algorithm progresses. The current set of parents of vi is denoted by πi.
-
Alice and Bob execute the privacy-preserving approximate score algorithm to compute the secret shares of g(i, πi) and
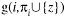 for any possible additional parent z of vi.
for any possible additional parent z of vi. -
Alice and Bob execute the privacy-preserving score comparison algorithm to compute which of those scores in Step 1 is maximum.
-
If g(i, πi) is maximum (i.e., no new parent increases the score) or if vi already has the maximum number of parents, then Alice and Bob go to the next node to run from Step 1 until Step 3. Otherwise, if
 is maximum (i.e., potential parent z increases the score the most), then z is added as the parent of vi by setting
is maximum (i.e., potential parent z increases the score the most), then z is added as the parent of vi by setting  and Alice and Bob go back to Step 1 on the same node vi.
and Alice and Bob go back to Step 1 on the same node vi.
Further details about this algorithm can be found in Yang and Wright (2006), where we also show a privacy-preserving algorithm to compute the Bayesian network parameters. Experimental results addressing both the efficiency and the accuracy of the structure-learning algorithm can be found in Kardes et al. (2005).
CHALLENGES FOR THE FUTURE
Many challenges, both technical and political, remain regarding privacy. These include social and political questions regarding who should have the right or responsibility to make various privacy-related decisions about data pertaining to an individual, as well as continued development and deployment of technolo-
gies to enable these rights and ensure that such privacy decisions, once made by the appropriate parties, are respected.
REFERENCES
Chaum, D. 1981. Untraceable electronic mail, return addresses, and digital pseudonyms. Communications of the ACM 24:84-88.
Chaum, D. 1985. Security without identification: Transaction systems to make big brother obsolete. Communications of the ACM 28:1030-1044.
Chaum, D. 1992. Achieving electronic privacy. Scientific American 267(2):96-101.
Cooper, G. F., and E. Herskovits. 1992. A Bayesian method for the induction of probabilistic networks from data. Machine Learning 9(4):309-347.
Goethals, B., S. Laur, H. Lipmaa, and T. Mielikäinen. 2004. On private scalar product computation for privacy-preserving data mining. Pp. 104-120 in Proceedings of the Seventh Annual International Conference in Information Security and Cryptology, volume 3506 of LNCS. Berlin, Germany: Springer-Verlag.
Goldreich, O., S. Micali, and A. Wigderson. 1987. How to play ANY mental game. Pp. 218-229 in Proceedings of the 19th Annual ACM Conference on Theory of Computing. New York: ACM Press.
Jagannathan, G., and R. N. Wright. 2005. Privacy-preserving distributed k-means clustering over arbitrarily partitioned data. Pp. 593-599 in Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press.
Jagannathan, G., and R. N. Wright. 2006. Privacy-preserving data imputation. Pp. 535-540 in Proceedings of the ICDM International Workshop on Privacy Aspects of Data Mining. New York: ACM Press.
Kardes, O., R. S. Ryger, R. N. Wright, and J. Feigenbaum. 2005. Implementing privacy-preserving Bayesian-net discovery for vertically partitioned data. Pp. 26-34 in Proceedings of the ICDM Workshop on Privacy and Security Aspects of Data Mining. New York: ACM Press.
Lindell, Y., and B. Pinkas. 2002. Privacy preserving data mining. Journal of Cryptology 15(3): 177-206.
Meng, D., K. Sivakumar, and H. Kargupta. 2004. Privacy-sensitive Bayesian network parameter learning. Pp. 487-490 in Proceedings of the Fourth IEEE International Conference on Data Mining. Piscataway, NJ: IEEE.
Vaidya, J., and C. Clifton. 2003. Privacy-preserving k-means clustering over vertically partitioned data. Pp. 206-215 in Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press.
Yang, Z., and R. Wright. 2006. Privacy-preserving computation of Bayesian networks on vertically partitioned data. IEEE Transactions on Data Knowledge Engineering 18:1253-1264.
Yang, Z., S. Zhong, and R. N. Wright. 2007. Towards privacy-preserving model selection. Pp. 11-17 in Proceedings of the First ACM SIGKDD International Workshop on Privacy, Security, and Trust in KDD. New York: ACM Press.
Yao, A. C.-C. 1986. How to generate and exchange secrets. Pp. 162-167 in Proceedings of the 27th IEEE Symposium on Foundations of Computer Science. Piscataway, NJ: IEEE.








