
5
Integration and Decision-Making for Predictive Toxicology
As described in Chapter 2, a robust integration and decision-making strategy is needed as part of the overall approach developed by the committee to predict acute, debilitating toxicity. Specifically, this chapter will describe general approaches and considerations for integrating data to make the categorization decisions outlined in the tiered prioritization strategy described in Chapter 2. Discussions of these topics are related to the task of evaluating chemicals for their potential to elicit acute toxicity. The committee has also noted a number of topics beyond its charge on which the Department of Defense (DOD) will need to make policy decisions in light of specific needs.
GENERAL APPROACH TO INTEGRATION AND DECISION-MAKING
Integration and decision-making to support prediction of the potential of chemicals to cause acute toxicity are needed at many levels. As described in Chapter 2, the goal at each tier of the prioritization strategy is to place chemicals in three categories: “high confidence of high toxicity,” “high confidence of low toxicity,” and “inadequate data.” Box 5-1 presents a simplified illustration of the process to base decisions on the results of a single model for a single end point. As illustrated in this simple case, categorization depends on defining clear benchmarks that set the boundaries for “high” and “low” toxicity and on taking uncertainty or confidence in each individual prediction into account. Key tasks for DOD will be determining the appropriate benchmarks for each end point that is relevant to the evaluation of acute toxicity and specifying the level of confidence appropriate to its needs.
In the more general case in which there are several predictions for multiple end points, the committee divided the integration and decision-making process into two parts, as illustrated in Figure 5-1:
• “Within–end point” integration and decision-making, which is based on integrating various data streams and predictions that inform a single acute-toxicity end point.
• “Cross–end point” integration and decision-making, which is based on integrating predictions from several acute-toxicity end points.
Within–End Point Integration and Decision-making
As discussed in Chapter 2, concern about potential acute toxicity spans a wide range of chemicals in terms of structures and physicochemical properties. Moreover, as shown in Chapters 3 and 4 and by others (Bauer-Mehren et al. 2012), no single prediction approach, whether a nontesting approach or an assay-based approach, is sufficient to capture the entire chemical domain. For some end points, such as a rat LD50, multiple models and tools that have
various degrees of accuracy are available (see, for example, review by Diaza et al. 2015), and it might be of interest to integrate their predictions into a single summary prediction. Furthermore, a chemical’s pharmacokinetics—absorption, distribution, metabolism, and excretion (ADME)—might contribute to its potency and toxicity. Therefore, even within an “end point” domain, there might be a need to integrate multiple databases, assays, models, and tools to develop an “integrated” prediction for that end point. The committee notes that using various integrative approaches might also help to identify biological responses that can explain chemical-induced adverse reactions (Bauer-Mehren et al. 2012).
BOX 5-1 Simplified Illustration of Integration and Decision-making
Models and End Points: At Tier 1, a single quantitative structure–activity relationship (QSAR) model is being used to predict rat LD50 values from chemical structure and physicochemical properties. No other models or end points are being considered. To illustrate a simplified approach, chemicals outside a specified applicability domain are placed in the “inadequate data” category for this example. For chemicals inside the applicability domain, the output of the model is an LD50 estimate with a confidence interval that reflects uncertainty.
Integration: Because only a single model and a single end point are being considered, there is no integration of different predictions.
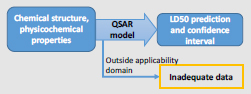
Category Benchmarks: A set of reference chemicals based on DOD interests that have known (possibly more than one) LD50 values are selected to represent the “high toxicity” and “low toxicity” categories from which category benchmarks are derived. For example, the “high toxicity” benchmark could be defined as the highest LD50 of the least toxic “high toxicity” reference chemical. For some end points, generic toxicity benchmarks are available, such as the European Union and Global Harmonized System categories for acute toxicity.
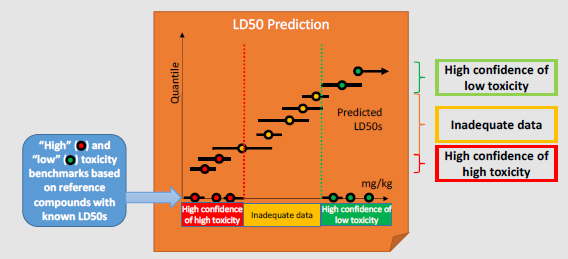
Decision-making: Decisions as to how to place chemicals into categories are based on the confidence bounds for each prediction:
- A chemical is categorized as “high confidence of high toxicity” if the upper confidence bound on the predicted LD50 is less than or equal to the “high toxicity” benchmark.
- A chemical is categorized as “high confidence of low toxicity” if the lower confidence bound on the predicted LD50 is greater than or equal to the “low toxicity” benchmark.
The remaining chemicals are categorized as having “inadequate data.”
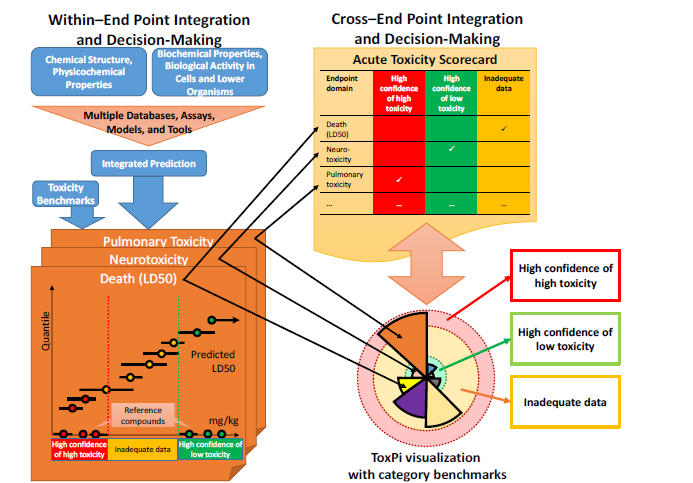
FIGURE 5-1 Illustration of a general approach to integration and decision-making for applying predictive approaches to acute, debilitating toxicity. “Within–end point” integration and decision-making has three basic steps: (1) developing an integrated prediction from potentially multiple databases, assays, models, and tools; (2) specifying toxicity benchmarks; and (3) placing chemicals into the appropriate category for the end point under consideration. “Cross–end point” integration and decision-making could consist of (1) a simple “scorecard” for a chemical in which each individual end point–specific decision is recorded or (2) more integrative approaches, such as ToxPi, that include the underlying toxicity end point predictions from which categories were assigned. The example presented here illustrates how information must be able to translate between within–end point and cross–end point integration.
A key task for DOD will be defining the most informative “end point domains” for its application, for example, whether to define an end point at a more general level, such as neurotoxicity, or at a more specific level, such as seizure or cholinesterase inhibition.
There are three steps in reaching a decision about a particular toxicity end point (the last two are the same as in the simple case described previously):
- Integrating potentially multiple databases, assays, models, and tools into an “integrated prediction,” with its confidence interval, as to a chemical’s toxicity potential for that end point.
- Specifying toxicity benchmarks that define the thresholds for what is considered “high” or “low” toxicity for that end point.
- Placing chemicals into categories on the basis of the specified toxicity benchmarks, taking into account the confidence interval of the integrated prediction.
Some of the available methods for each step are described in greater detail below.
Cross–End Point Integration and Decision-Making
As described in Chapter 2, the concern about potential acute toxicity spans a wide array of toxic end points and biological mechanisms. From a military perspective, any acute toxicity that is severe enough to cause debilitation or death is enough to warrant concern. Thus, a simple approach to cross–end point integration would be simply to summarize the categorization results for each end point in a single scorecard, as shown in the upper right of Figure 5-1. Each end point would be evaluated as described above as to whether for a given type of acute toxicity (such as neurotoxicity) the chemical exhibited “high toxicity,” “low toxicity,” or “inadequate data.” Then, in integrating into an overall evaluation, a chemical will be sorted into the “high toxicity” bin if at least one of the end points is “high toxicity,” the “low toxicity” bin if all the end points are “low toxicity,” and the “inadequate data” bin if neither of the first two conditions applies. That approach also has the advantage of retaining the end point–specific information, so that future data generation can be targeted better. The approach is also consistent with a low tolerance for false negatives in that each end point identified as predictive of an acute toxic (debilitating or lethal) response serves as sufficient evidence to place a chemical into a “high toxicity” bin.
Cross–end point integration can also be visualized in a recombination approach (such as ToxPi, discussed in more detail below) and perhaps even augmented with information on toxicity benchmarks as illustrated in Figure 5-1. The recombination approach, however, suggests an alternative integration that would not depend strictly on a simple decision rule related to the categories for each end point. For example, the ToxPi approach (see lower right of Figure 5-1) could also provide a summary measure that consists of a weighted sum of individual toxicity end points. Thus, even if each individual end point is rated as “inadequate,” it is conceivable that the presence of multiple end points close to their benchmark thresholds would allow the chemical to be categorized as “high” or “low” on the basis of the summary measure even if no individual end point were so rated. Setting up appropriate decision rules would be a key policy question for DOD if it chose to implement the committee’s suggested approach for predicting acute, debilitating toxicity.
The general approaches for integrating databases, assays, models, and tools are illustrated in Figure 5-2 with LD50 as an example end point. Broadly, they can be divided into approaches that combine individual predictions into an integrated prediction (upper panel, A) and approaches that first combine the underlying data from databases and assays before building an integrated model or tool (lower panel, B). Specific approaches are described in more detail below, particularly in relation to predicting acute toxicity; examples of applications to nontesting approaches (Chapter 3), biological assay-based approaches (Chapter 4), and combinations of the two are provided if possible.
Meta-Analytic Approaches
From a formal statistical perspective, the rich literature on meta-analysis offers guidance on how to aggregate information from multiple independent sources (Borenstein et al. 2009). It is expected that appropriate meta-analysis will help to improve the results from individual studies that might have been underpowered or have suffered from noise, bias, and absence of data. Meta-analysis can also help to reveal interesting patterns or relationships among studies and generate results that are statistically robust. The committee did not locate any examples of published meta-analyses of acute-toxicity predictions built from the types of data described in Chapters 3 and 4. However, for such an end point as LD50, for which multiple tools and models are available in the same chemical domain (for example, the five models reviewed by Diaza et al. 2015), a meta-
analytic approach might be considered to combine results. In addition to combining individual predictions, meta-analytic approaches could be applied to individual categorization decisions (for example, see Box 5-2).
Three key issues should be considered in conducting any meta-analyses, including those applied to acute-toxicity end points. First, individual results should be investigated to determine whether the data can be combined reliably (Crowther et al. 2010). For example, results that are to be combined should be associated with a common predicted acute-toxicity end point. Often, decisions on which statistical techniques to use for meta-analysis are not as important as decisions on which studies are to be combined because later analysis will not be able to correct for an inappropriate combination of studies. Second, an effective meta-analysis should ensure that “better” results receive more weight during information aggregation (Crowther et al. 2010). For example, it is reasonable for predictions that have less variance or that are based on a larger sample size to contribute more heavily to the overall summary statistic in a meta-analysis. Other factors, such as biases and methodological strengths and weaknesses of individual approaches, can also be included, either qualitatively or quantitatively. Third, several statistical methods can be used to combine results. They include methods that are based on results of significance testing, such as p values or z scores, and fixed and random effect models that use summary statistics, such as the mean and standard error derived from individual results (Hedges and Olkin 1985; Borenstein et al. 2009). For all three issues, sensitivity analysis can be performed to assess the effects of various choices on the results of a meta-analysis (Higgins and Green 2011).
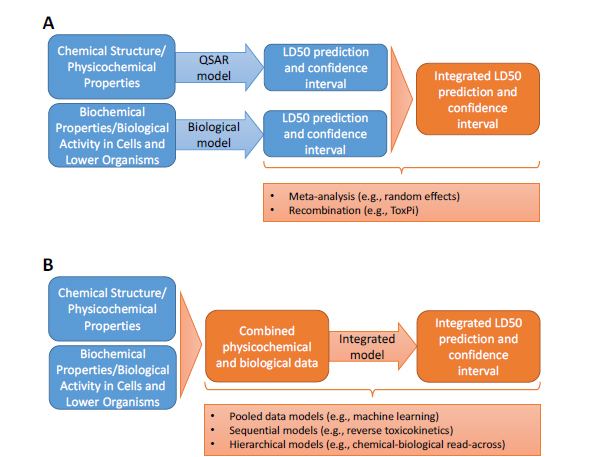
FIGURE 5-2 Approaches for integrating disparate datasets with LD50 as an example. A: approaches that keep datasets separate (such as physicochemical data and assay-based biological-activity data) and integrate predictions from models developed for each dataset independently. B: approaches that combine datasets before modeling and develop a new “integrated” model that makes a prediction from the combined dataset.
Recombination-Based Approaches
Several approaches for data integration have recently been developed to handle new problems presented by high-dimensional toxicity data, such as information from different biological assays. Because the results from different data streams are not strictly comparable, formal meta-analytic approaches are not immediately applicable. There are a variety of methods for weighting multiple streams of evidence differently, from largely qualitative, expert-judgment approaches (for example, Hill criteria) to quantitative statistical frameworks that formalize weighting schemes (Linkov et al. 2015). Given the need to categorize chemicals, intermediate approaches that are quantitative and incorporate expert judgment are likely to be most useful in predicting acute toxicity. The Toxicological Prioritization Index (ToxPi) developed by Reif et al. (2010) provides a useful illustration of how to combine multiple data streams (discussed at length in NRC 2014).
Meta-analytic approaches, such as the irreproducible discovery rate (IDR) (Li et al. 2011), can be used to measure the reproducibility of results from two independent studies and to filter noise in the results. In the example below, two studies (Study I and Study II) have made toxicity predictions, and the results are categorized into “low toxicity,” “inadequate data”, or “high toxicity,” on the basis of simulated category benchmarks with thresholds at values of [0–10], (10–60), and [60–100], respectively. However, many chemicals show inconsistent categorizations between the two studies. To integrate the two results, IDR considers the reproducibility between studies to assign a chemical-specific reproducibility measure. The far-right column presents the reproducibility measure as 1 – local IDR, where the chemicals that have the highest values are highlighted in red. Note that taking reproducibility among studies into account can change the categorization of “high toxicity.”
| Chemicals | Initial Toxicity Pediction Scores | 1 – local IDR | ||
| Study I | Study II | |||
| 1 | 99 | 100 | 0.99 | |
| 2 | 72 | 45 | 0.53 | |
Category Benchmarks by initial toxicity prediction scores:
|
3 | 70 | 58 | 0.91 |
| 4 | 66 | 0 | 0.00 | |
| 5 | 65 | 38 | 0.19 | |
| 6 | 62 | 49 | 0.59 | |
| 7 | 56 | 15 | 0.00 | |
| 8 | 51 | 60 | 0.62 | |
| 9 | 51 | 72 | 0.79 | |
| 10 | 47 | 59 | 0.45 | |
| The ones categorized as “high toxicity” by initial prediction scores are highlighted in Blue | 11 | 40 | 53 | 0.17 |
| 12 | 37 | 42 | 0.06 | |
| 13 | 36 | 31 | 0.03 | |
| 14 | 30 | 20 | 0.01 | |
| 15 | 30 | 20 | 0.01 | |
| The ones with top 6 (1‐local IDR) scores (or the 6 most reproducible results) are highlighted in Red | 16 | 29 | 35 | 0.02 |
| 17 | 24 | 28 | 0.01 | |
| 18 | 15 | 28 | 0.00 | |
| 19 | 14 | 43 | 0.00 | |
| 20 | 8 | 41 | 0.00 | |
The ToxPi combines data streams (physicochemical data, biological assays, or both) into a relative index to facilitate prioritization or categorization. At its most basic, a summary ranking is derived for each chemical on the basis of a weighted sum of rankings for different data sources. Although advanced statistical approaches could be used to group and weight individual pieces of evidence empirically, published applications have used substantial expert judgment and taken into account the specific sources of data being integrated and the context of integration. For example, binding assays for several cytochrome P450 (CYP) isoforms might be run to assess “xenobiotic metabolism,” but isoforms expressed in a target tissue of interest might warrant more weight. Thus, using the ToxPi approach and reference chemicals can provide an overall, integrated ranking that can be used for categorization decisions (see Figure 5-3). In addition, the ToxPi provides a visualization of the individual component ranks and so can be used to support a “multicriteria” decision-making scenario (Pavan and Worth 2008) in which categorization decisions involve integration of multiple, possibly conflicting criteria. For example, placing chemicals in the “high confidence of high toxicity” bin could necessitate synthesizing results when individual pieces of evidence serve as flags of high alert (such as solid evidence from a single assay that is deemed highly predictive of acute toxicity). The use of ToxPi for cross–end point integration is illustrated in the lower right of Figure 5-1, where axes are flagged if activity surpasses a benchmark threshold. ToxPi can also be applied to within–end point integration.
Pooled Data-Based Approaches
The basic idea behind pooled data-based approaches is the use of the same types of nontesting approaches (such as read-across and QSAR) to make chemical-based or biologically based predictions. Thus, the biological assay results are simply treated as additional “biological descriptors” that can be used with physicochemical descriptors in building quantitative models. Several examples of this approach applied to acute toxicity are described in Chapter 3 (Lee et al. 2010; Sedykh et al. 2011); they retrospectively apply statistical methods, such as k-nearest neighbor, random forest, or multiple linear regression to a combined dataset of chemical-structure data and literature-derived cytotoxicity data. The same approach could be used more prospectively, in which new biological activity data generated in Tier 2 are combined with chemical-structure information used previously in Tier 1 to develop an integrated prediction based on pooling of both datasets.
Hierarchical Modeling Approaches
Hierarchical approaches can build-in information on chemical structure or global performance to inform modeling decisions (Wilson et al. 2014). For example, as noted in Chapter 3, several groups have used biological data to stratify chemicals into clusters; more localized modeling, such as the use of QSARs, was then applied to each (Zhu et al. 2009; Zhang 2011; Lounkine et al. 2012). Zhu et al. (2009) applied such an approach to acute toxicity. Specifically, they grouped chemicals into those with and without good correlation between in vitro cytotoxicity IC50s and in vivo rodent LD50s. They then built one QSAR model to assign chemicals to each group and two additional QSAR models to predict LD50s for each group. They also compared their approach with the commercial TOPKAT software, using a set of chemicals that was outside the training set of both approaches. They found that their two-step hierarchy of QSAR models had a greater correlation coefficient and smaller mean absolute error. That type of stratification of QSAR models with biological information might be a fruitful integration approach that can be tried with other acute-toxicity end points.
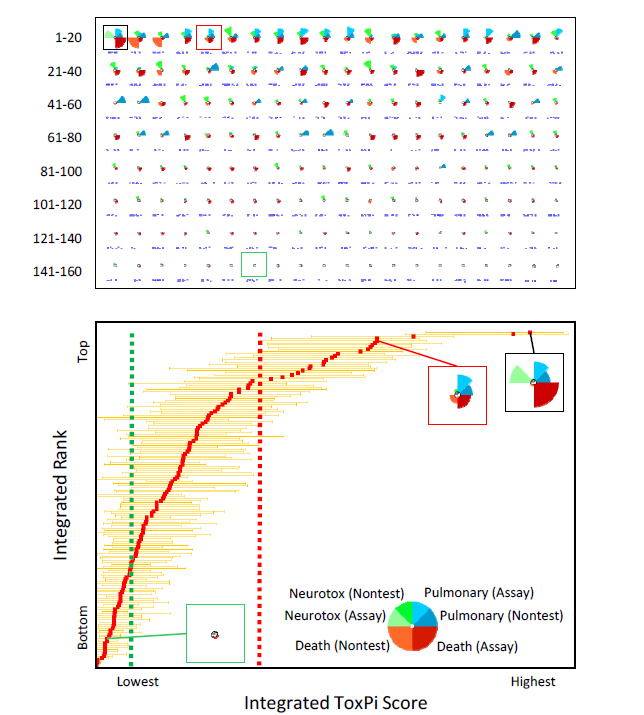
FIGURE 5-3 ToxPi model for integration of acute-toxicity potential. In this simulated example, data from nontesting approaches (Chapter 3) and assays (Chapter 4) have been integrated into a cross–end point ToxPi model for pulmonary toxicity, neurotoxicity, and death. The key (lower panel, inset) shows that evidence for the two “Death” slices have been given extra weight in determining the overall integrated ranking for acute toxicity. For each chemical profile, the distance of a slice from the origin indicates the relative potency. The “longer” slices indicate chemicals that are more potent than chemicals that have “shorter” slices or those deemed inactive (indicated by absence of a given slice). The upper panel shows all profiles in rank order. The lower panel translates the profiles into a plot of the integrated ranks vs scores, with 95% confidence intervals extending from the red square representing each chemical. The black-framed profile is the chemical that has the highest overall acute-toxicity potential (that is, rank = 1). The red-framed profile is the reference chemical for “high confidence of high toxicity,” and the green-framed profile is the reference chemical for “high confidence of low toxicity.” Note that the confidence intervals extending from each reference chemical define the category thresholds (vertical dashed red and green lines).
Sequential Modeling Approaches
Another approach to model-based integration is to connect models sequentially, that is, by using outputs from one model as part of the inputs into another model. Such an approach can be developed when there is a hypothesized chain of events that leads to acute toxicity. Specifically, as described in Chapter 3, nontesting approaches could be developed for initial or intermediate events along a mechanistic pathway. The predictions could then be inputs into models that predict acute toxicity on the basis of biological assay data on the intermediate events. As a result, predictions of acute toxicity that incorporate biological data could be made for chemicals for which biological assays have not yet been conducted.
For example, Chapter 3 discussed how chemical toxicity often results from nonspecific alterations in cell function; thus, in vitro cytotoxicity is likely to be a strong indicator of in vivo toxicity. Conceivably, a sequential model could be developed that combines a model that uses physicochemical data to predict cytotoxicity (reviewed in Chapter 3) with a model that uses cytotoxicity data to predict LD50s (reviewed in Chapter 4). In the future, one might envision using physicochemical information to predict bioactivity in more specific biological assays and then using existing models that use bioactivity measurements to predict in vivo acute toxicity.
Another area in which sequential modeling is common is in vitro–in vivo extrapolation (IVIVE). In particular, the results of in vitro assays constitute inputs into a reverse-dosimetry or reverse-toxicokinetic approach to derive the external dose that will result in the internal serum concentration equivalent to the bioactive concentration in the in vitro assay (Rotroff et al. 2010; Wetmore et al. 2012). Integration of ADME specifically is discussed further below.
Sequential modeling is not restricted to single assay results. The US Environmental Protection Agency (EPA) ToxCast program has generated in vitro high-throughput screening data on several assay technologies that assess multiple pathways, genes, and responses over hundreds of end points (Judson et al. 2010; Kavlock et al. 2012). The built-in redundancy in end points allows assays to be aggregated into a pathway context, so that multiple assay results are combined into a summary measure of pathway activity before a reverse toxicokinetic model is applied (Judson et al. 2011). Other researchers have attempted to integrate assays anchored to pathways to arrive at a summary outcome, specifically for skin sensitization (see, for example, Jaworska et al. 2013; Patlewicz et al. 2014; van der Veen et al. 2014).
Integrating Toxicokinetics to Determine Acute-Toxicity Potential
The recent investment in in vitro and high-throughput screening (HTS) strategies to inform chemical toxicity testing has led to increased debate about relating the resulting data (potency values derived on the basis of the nominal testing concentration ranges used in the wells of assay plates) to values that would be informative in predicting in vivo human health hazard. Some assay designs do not consider in vivo toxicokinetic processes, which ultimately dictate the extent of chemical toxicity or potency in animals or humans. No matter how active or potent a chemical might be in some in vitro assays, if it is not absorbed into the human body on exposure it will not be bioavailable to elicit any effect. Similarly, a chemical that is cleared rapidly might not be present in the body long enough to elicit an effect. Chapters 3 and 4 describe how modeling of biological (toxicokinetic) processes can reduce the gaps observed between results of in vitro assay and toxic response in humans or animals. Consideration of the potential effect of in vivo toxicokinetic processes improves interpretation of the results of in vitro testing and the overall predictive-toxicology approach.
Development of toxicokinetic and dosimetric tools to inform extrapolations—among species, dose ranges, and experimental systems (for example, in vitro to in vivo)—has been widespread over the last 30 years. Forward dosimetry with physiologically based pharmacokinetic modeling originally introduced in the assessment of volatile organic chemicals (Andersen et al. 1987) provides a strategy that relies on pharmacokinetic knowledge to relate a known external
exposure to an internal blood or target-tissue dose. Alternatively, reverse dosimetry is often used to relate a known internal dose (either from blood biomonitoring data or from an in vitro assay bioactivity concentration) to an external chemical dose (Tan et al. 2007; Lyons et al. 2008; Wetmore et al. 2012). The focus of much of the reverse-dosimetry work has been on exposure scenarios (chronic, low-level, repeat exposures) of concern to EPA or other regulatory bodies that have similar public-health protection mandates (Basketter et al. 2012; Wetmore 2015). Whereas it is useful to understand the dosimetric strategies described, it should be noted that not all tools are directly applicable for DOD’s purpose in which the exposure will be acute (probably at one time) and that acutely toxic chemicals might not require consideration of ADME to predict elicitation of debilitating effects. The following discussion provides a brief summary of the different components of ADME, tools available to predict the components, and probable effect of ADME on future attempts by DOD to predict acute toxicity.
Absorption or Bioavailability. Absorption via relevant routes of exposure (oral, dermal, and inhalation) and resulting bioavailability are important parameters for which there are predictive testing and nontesting tools (see Chapters 3 and 4). A conservative assumption of 100% absorption would be the most protective and should be assumed for chemicals for which available methods do not apply or do not provide sufficient predictivity. Computer models that describe the biochemical behavior of uptake by skin or gastrointestinal cells (McKone 1990; Jamei et al. 2009a; Rauma et al. 2013) can be applied in a sequential approach. However, the uptake models have been developed mostly for single-chemical exposure and rarely for acute conditions. If 100% absorption was initially assumed for a chemical and predictive tools indicate an adjustment away from that conservative default, the chemical might need to be downgraded or reassessed because lower absorption would indicate a lower potency or lower likelihood of acute toxicity. Chemicals that have other toxicity alerts that place them in the “high confidence of high toxicity” bin and identify them as readily absorbed should be noted because confirmation of high bioavailability will influence their ranking in that bin.
Distribution. Rapid accumulation throughout the body or in target tissues (such as skin, brain, and lungs) could lead to a substantial shift in acute-toxicity potential of a chemical. Some organophosphates, for example, are highly lipophilic and are readily distributed into fat and other tissues. Presence in the fat and slow release from the site will delay or prolong acetylcholinesterase inhibition (Karalliedde et al. 2003) and could lead to greater toxicity than that of chemicals that have lower distribution but a similar effect in an in vitro assay. Similarly, a chemical that is demonstrably neurotoxic in an in vitro assay and is identified as crossing the blood–brain barrier rapidly will likely be a more potent neurotoxicant than one that has similar in vitro toxicity and does not cross the blood–brain barrier. Blood transporters or lipoproteins can also shift the ability of a chemical to reach a toxicity target. Chemicals that bind to transporter proteins might reach target sites more easily than chemicals that are distributed solely by diffusion. Tools for predicting or assessing tissue partitioning and partition coefficients are available and can aid in predicting ADME behavior (Poulin and Haddad 2012, 2013). Distribution and metabolism (see below) are probably the two most important components to explore in modulating acute-toxicity potential. Distribution will indicate the amount of a chemical that is available to reach an in vivo targeted site. Modeling tools and simple in vitro experiments can estimate tissue or cell partitioning and thus provide a more accurate estimate of assay concentration that will generate a response.
Metabolism. Metabolism can lead to formation of a substantially more toxic metabolite, formation of an equally toxic metabolite, or detoxification of the parent chemical. Examples of chemicals that can be bioactivated into more toxic metabolites are the neurotoxic organophosphate insecticides, such as fenthion, parathion, diazinon, malathion, and chlorpyrifos, which are metabolized to potent oxon metabolites (Eisler 2007). Thus, metabolism is one ADME property that could substantially shift the potency of a chemical. Nontesting approaches for predicting metabolism are in various stages of development (see Chapter 3) and might be used to elucidate metabolites that could contribute to a parent chemical’s acute-toxicity potential. The best way to
incorporate the potential effect of toxic metabolite formation will depend largely on the chemical mechanism in relation to others that have similar acute-toxicity potencies and will need to be considered in relation to other toxicity information.
Excretion. The liver and kidney are the major organs responsible for excretion of chemicals from the body (via bile and urine). Physicochemical properties can be used to predict chemical excretion rates (Ghibellini et al. 2006; Shitara et al. 2006; Sharifi and Ghafourian 2014). Hydrophilic chemicals are more rapidly excreted from the body than lipophilic chemicals. The other ADME properties are more likely than excretion to have an important effect on chemical acute-toxicity potential. Reductions in excretion are likely to be secondary to renal toxicity, an end point that is likely to be specifically assessed with other testing and nontesting approaches.
In Vitro to In Vivo Extrapolation Modeling to Inform Tissue Dosimetry and Dosimetric Potential
Modeling approaches developed to inform dosimetry assessments use IVIVE. Measurements from in vitro assays and predictions from nontesting approaches can provide various model inputs (such as rate of absorption, metabolic activity, and tissue partitioning), which can be combined in a bottom-up approach to estimate an in vivo dose (Jamei et al. 2009b). The extrapolation of in vitro data typically assumes that metabolism of a parent chemical implies loss of potential for toxicity, which is not necessarily the case, but it is valuable in providing an understanding of the dosimetrics or bioaccumulative potential of a chemical.
Recently, a simplified IVIVE approach amenable to incorporation with HTS data was presented; it predicted external doses that are required to achieve steady-state blood concentrations similar to ones that elicit activity in in vitro HTS assays (Rotroff et al. 2010; Wetmore et al. 2012). The approach incorporated plasma-protein binding and hepatic metabolic and renal non-metabolic clearance (key determinants of chemical steady-state toxicokinetics) to estimate chemical steady-state behavior. The toxicokinetic measurements showed not only significant cross-species correlation but strong correlation between in vivo and in vitro values for several chemicals (Wetmore et al. 2013, Wetmore 2015). Steady-state concentrations are known to be more relevant for chronic and repeated exposure. Recent assessments by EPA demonstrated that in some cases steady-state concentration (Css) estimates were consistent with peak concentrations (Cmax); this relationship was not observed for a subset of chemicals that are rapidly or slowly cleared (Wambaugh et al. in press). A steady-state toxicokinetic assumption, however, can be valid for acute-toxicity assessment.
Many of the tools developed to predict ADME or pharmacokinetic properties were developed by using pharmaceutical chemicals, which represent a smaller chemical space than the chemical domain of concern to DOD. Tools to predict absorption, tissue partitioning, protein binding, and hepatic clearance might perform well only in a narrowly defined logKow space. Chemicals of concern to DOD will span multiple domains, and attempts to categorize their pharmacokinetic behavior might be severely limited.
Ultimately, one should recognize that the most reactive acutely toxic chemicals that are of top concern to DOD are likely to be rapidly lethal well before some metabolic or excretory processes are initiated. However, for a large percentage of the chemical space of concern to DOD, application of some of the physicochemical and assay tools to predict chemical toxicokinetics can probably be incorporated into the decision-making process reasonably efficiently. Overall, integration of the tools in a tiered testing framework will aid in refining estimates of the toxicity of chemicals and enable an appropriate and streamlined decision-making process.
As discussed in Chapter 2, the committee’s suggested prioritization strategy consists of a tiered approach to placing chemicals into three categories: “high confidence of high toxicity,”
“high confidence of low toxicity,” and “inadequate data.” As described earlier in this chapter, the process includes two key steps: setting benchmarks that define the thresholds for what would be considered high and low toxicity and assigning chemicals to categories, taking into account the confidence in the prediction.
Setting Benchmarks
The thresholds for high and low toxicity for a given toxicity end point can be defined in multiple ways, including the following:
- Using reference chemicals of high and low toxicity when the toxicity end point of interest has been measured or predicted. This approach was illustrated in the simplified example in Box 5-1 and in Figure 5-1 with LD50 as the toxicity end point.
- Using reference chemicals of high and low toxicity via clustering approaches. For example, the “nearest neighbors” to the high toxicity reference chemicals would also be considered to have high toxicity.
- Using pre-existing exposure-based thresholds if they exist for the toxicity end point of interest. For example, the European Union (EU) and the Globally Harmonized System of Classification and Labeling of Chemicals (GHS) each have pre-existing categories for acute oral toxicity in terms of milligrams per kilogram.
All the approaches require that the toxicity end point be a numerical value, such as an LD50 in milligrams per kilogram, and they do not work for qualitative or binary outputs, such as “active” and “inactive.”
Categorization Decisions under Uncertainty
With respect to assigning chemicals to categories and taking into account confidence, by definition, the assignments to the high and low toxicity categories need to have high confidence. It is therefore of paramount importance for the categorization process to characterize uncertainty in the prediction of the toxicity end point.
Uncertainty is an unavoidable aspect of knowledge discovery from large-scale heterogeneous data, such as those discussed in Chapters 3 and 4. It has two main sources: the data themselves and the modeling of those data. With respect to data, even physicochemical properties cannot be measured with perfect precision. Moreover, such data are usually obtained from databases, which can contain errors that are due to data entry or other processes related to creating and populating the databases (Fourches et al. 2010). For biological assays, uncertainties will vary considerably with the type of assay. Although automation of some assays has greatly improved their reproducibility, there is still variation among batches from a given assay and possibly even among chemicals in a given batch. Uncertainty arising from the modeling or analysis approach (different aspects of data handling and data analysis) varies with the model and among parameter values in a given model.
There is a rich literature on characterizing uncertainty in experimental and computational sciences that need not be recapitulated here. Suffice it to say that the existing approaches span a wide range that is based on both “frequentist” and “Bayesian” statistical principles and use analytical methods (for example, classical confidence intervals) and sampling or simulation-based methods (such as bootstrap and Monte Carlo). In some cases, specific guidance is available on characterizing uncertainty for a particular application, such as QSAR modeling, gene-expression analyses, and pharmacokinetic modeling (IPCS 2008).
For example, Chapter 3 discussed the availability of Organisation for Economic Co-operation and Development (OECD) and Registration, Evaluation, Authorization and Restriction of Chemi-
cals (REACH) guidance on evaluating the confidence in (Q)SAR models. Although internal and external cross-validation make up the current standard approach to characterizing uncertainty in QSAR predictions, alternative approaches are being pursued. For example, Gramacy and Pantaleo (2010) used a Markov Chain Monte Carlo sampling for the Bayesian Lasso model to assess prediction uncertainties in QSAR analyses. More discussion of other aspects of uncertainty in QSAR predictions can be found in Sahlin (2013). Parametric methods can also be used sometimes, but these might be less appealing for complex data from multiple sources because distributional assumptions are likely to be violated.
An additional useful tool for assessing confidence is sensitivity analysis, which can tell how the uncertainty in the toxicity prediction of a model or system can be apportioned to different sources of uncertainty in its inputs or, equivalently, how much each input is contributing to the uncertainty. For example, sensitivity analyses might be performed for several purposes:
- To test the robustness of results by random data perturbation.
- To decompose the prediction error by relating input and output variables in a model, which can help to understand the sources of variation in the model. Such analyses can identify inputs that are key contributors to uncertainty and thereby focus research or data generation on aspects that could improve or refine the model.
- To perform model selection through internal cross-validation or external validation. Internal cross-validation can also be used to quantify the degree of fitting or overfitting of a model. External validation (meta-analysis and related data streams) is preferred as an independent assessment of a model’s predictive ability.
Finally, it should be noted that these approaches to assessment of uncertainty and sensitivity might be applied not only to toxicity end point predictions but to the categorization decisions themselves. Application to the categorization decision is illustrated in Box 5-2, where uncertainty is analyzed by using the irreproducible discovery rate.
- Finding: The committee’s recommended prioritization strategy will require integration at various stages, and there are many approaches to integration, including formal statistical methods (such as meta-analysis), less formal “recombination” methods (such as ToxPi), methods that pool datasets, methods that use datasets hierarchically, and methods that link models sequentially.
- Finding: There are several possible approaches to placing chemicals in categories of “high toxicity,” “low toxicity,” and “inadequate data,” including quantitative thresholds based on reference chemicals (such as sarin), generic thresholds based on external criteria (such as those of the EU and the GHS), and clustering based on reference chemicals. The stability of and confidence in the results of any categorization will be enhanced if the uncertainties are properly quantified.
- Finding: Multiple levels of complexity require integration, and the committee has distinguished between integration of predictions among end points (cross–end point integration) and integration of different model predictions or data streams that inform a single end point (within–end point integration).
- Finding: Given the many types of end points that are relevant to acute, debilitating toxicity and the need to place chemicals into categories of “high toxicity,” “low toxicity,” and “inadequate data,” the simplest approach to cross–end point integration would be to summarize the categorization results for each end point in a scorecard.
- Finding: Some of the key policy decisions that DOD will need to make to use the committee’s recommended prioritization strategy are (1) the kinds of responses that would be considered appropriate end points (for example, neurotoxicity, seizures, or cholinesterase inhibition), (2) determination of high and low toxicity thresholds for each end point of interest, (3) the degree of confidence required to conclude high confidence, and (4) decision rules related to a determination of a summary conclusion of high or low toxicity on the basis of multiple end points.
- Finding: Toxicokinetic and ADME behavior can influence the prediction of a chemical’s acute toxicity potential and resulting categorization, and this emphasizes the need to include such considerations into the tiered prioritization strategy.
Andersen, M.E., H.J. Clewell III, M.L. Gargas, F.A. Smith, and R.H. Reitz. 1987. Physiologically based pharmacokinetics and the risk assessment process for methylene chloride. Toxicol. Appl. Pharmacol. 87(2):185-205.
Basketter, D.A., H. Clewell, I. Kimber, A. Rossi, B. Blaauboer, R. Burrier, M. Daneshian, C. Eskes, A. Goldberg, N. Hasiwa, S. Hoffmann, J. Jaworska, T.B. Knudsen, R. Landsiedel, M. Leist, P. Locke, G. Maxwell, J. McKim, E.A. McVey, G. Ouédraogo, G. Patlewicz, O. Pelkonen, E. Roggen, C. Rovida, I. Ruhdel, M. Schwarz, A. Schepky, G. Schoeters, N. Skinner, K. Trentz, M. Turner, P. Vanparys, J. Yager, J. Zurlo, and T. Hartung. 2012. A roadmap for the development of alternative (non-animal) methods for systemic toxicity testing - t4 report. ALTEX 29(1):3-91.
Bauer-Mehren, A., E.M. van Mullingen, P. Avillach, M.D.C. Carrascosa, R. Garcia-Serna, J. Piñero, B. Singh, P. Lopes, J.L. Oliveira, G. Diallo, E.A. Helgee, S. Boyer, J. Mestres, F. Sanz, J.A. Kors, and L.I. Furlong. 2012. Automatic filtering and substantiation of drug safety signals. PLoS Comput. Biol. 8(4):e1002457.
Borenstein, M., L.V. Hedges, J.P.T. Higgins, and H.R. Rothstein. 2009. Introduction to Meta-Analysis. Chichester, U.K: Wiley.
Crowther, M., W. Lim, and M.A. Crowther. 2010. Systematic review and meta-analysis methodology. Blood 116(17):3140-3146.
Diaza, R.G., S. Manganelli, A. Esposito, A. Roncaglioni, A. Manganaro, and E. Benfenati. 2015. Comparison of in silico tools for evaluating rat oral acute toxicity. SAR QSAR Environ Res. 26(1):1-27.
Eisler, R. 2007. Eisler's Encyclopedia of Environmentally Hazardous Priority Chemicals. Amsterdam: Elsevier.
Fourches, D., E. Muratov, and A. Tropsha. 2010. Trust, but verify: On the importance of chemical structure curation in cheminformatics and QSAR modeling research. J. Chem. Inf. Model. 50(7):1189-1204.
Ghibellini, G., E.M. Leslie, and K.L. Brouwer. 2006. Methods to evaluate biliary excretion of drugs in humans: An updated review. Mol. Pharm. 3(3):198-211.
Gramacy, R.B., E. Pantaleo. 2010. Shrinkage regression for multivariate inference with missing data, and an application to portfolio balancing. Bayesian Anal. 5(2):237-262.
Hedges, L.V., and I. Olkin. 1985. Statistical Methods for Meta-Analysis. New York: Academic Press.
Higgins, J.P.T., and S. Green, eds. 2011. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. The Cochrane Collaboration [online]. Available: http://handbook.cochrane.org/ [accessed March 24, 2015].
IPCS (International Programme on Chemical Safety). 2008. Uncertainty and Data Quality in Exposure Assessment. World Health Organization [online]. Available: http://www.who.int/ipcs/publications/methods/harmonization/exposure_assessment.pdf?ua=1 [accessed March 24, 2015].
Jamei, M., D. Turner, J. Yang, S. Neuhoff, S. Polak, A. Rostami-Hodjegan, and G. Tucker. 2009a. Population-based mechanistic prediction of oral drug absorption. AAPS J. 11(2):225-237.
Jamei, M., S. Marciniak, K. Feng, A. Barnett, G. Tucker, and A. Rostami-Hodjegan. 2009b. The Simcyp® population-based ADME simulator. Exp. Opin. Drug Metab. Toxicol. 5(2):211-223.
Jaworska, J., Y. Dancik, P. Kern, F. Gerberick, and A. Natsch. 2013. Bayesian integrated testing strategy to assess skin sensitization potency: From theory to practice. J. Appl. Toxicol. 33(11):1353-1364.
Judson, R.S., K.A. Houck, R.J. Kavlock, T.B. Knudsen, M.T. Martin, H.M. Mortensen, D.M. Reif, D.M. Rotroff, I. Shah, A.M. Richard, and D.J. Dix. 2010. In vitro screening of environmental chemicals for targeted testing prioritization: The ToxCast project. Environ. Health Perspect. 118(4):485-492.
Judson, R.S., R.J. Kavlock, R.W. Setzer, E.A. Cohen Hubal, M.T. Martin, T.B. Knudsen, K.A. Houck, R.S. Thomas, B.A. Wetmore, and D.J. Dix. 2011. Estimating toxicity-related biological pathway altering doses for high-throughput chemical risk assessment. Chem. Res. Toxicol. 24(4):451-462.
Karalliedde, L.D., P. Edwards, and T.C. Marrs. 2003. Variables influencing the toxic response to organophosphates in humans. Food Chem. Toxicol. 41(1):1-13.
Kavlock, R., K. Chandler, K. Houck, S. Hunter, R. Judson, N. Kleinstreuer, T. Knudsen, M. Martin, S. Padilla, D. Reif, A. Richard, D. Rotroff, N. Sipes, and D. Dix. 2012. Update on EPA's ToxCast program: Providing high throughput decision support tools for chemical risk management. Chem. Res. Toxicol. 25(7):1287-1302.
Lee, S., K. Park, H.S. Ahn, and D. Kim. 2010. Importance of structural information in predicting human acute toxicity from in vitro cytotoxicity data. Toxicol. Appl. Pharmacol. 246(1-2):38-48.
Li, Q., J.B. Brown, H. Huang, and P.J. Bickel. 2011. Measuring reproducibility of high-throughput experiments. Ann. Appl. Stat. 5(3):1752-1779.
Linkov, I., O. Massey, J. Keisler, I. Rusyn, and T. Hartung. 2015. From “weight of evidence” to quantitative data integration using multicriteria decision analysis and Bayesian methods. ALTEX 321(1):3-8.
Lounkine, E., M.J. Keiser, S. Whitebread, D. Mikhailov, J. Hamon, J.L. Jenkins, P. Lavan, E. Weber, A.K. Doak, S. Côté, B.K. Shoichet, and L. Urban. 2012. Large-scale prediction and testing of drug activity on side-effect targets. Nature 486(7403):361-367.
Lyons, M., R.S. Yang, A.N. Mayeno, and B. Reisfeld. 2008. Computational toxicology of chloroform: Reverse dosimetry using Bayesian inference, Markov Chain Monte Carlo simulation, and human biomonitoring data. Environ. Health Perspect. 116(8):1040-1046.
McKone, T.E. 1990. Dermal uptake of organic chemicals from a soil matrix. Risk Anal. 10(3):407-419.
NRC (National Research Council). 2014. A Framework to Guide Selection of Chemical Alternatives. Washington, DC: National Academies Press.
Patlewicz, G., C. Kuseva, A. Kesova, I. Popova, T. Zhechev, T. Pavlov, D.W. Roberts, and O. Mekenyan. 2014. Towards AOP application--implementation of an integrated approach to testing and assessment (IATA) into a pipeline tool for skin sensitization. Regul. Toxicol. Pharmacol. 69(3):529-545.
Pavan, M., and A. Worth. 2008. A Set of Case Studies to Illustrate the Applicability of DART (Decision Analysis by Ranking Techniques) in the Ranking of Chemicals. EUR 23481. Luxembourg: European Communities [online]. Available: https://eurl-ecvam.jrc.ec.europa.eu/laboratories-research/predictive_toxicology/doc/EUR_23481_EN.pdf.
Poulin, P., and S. Haddad. 2012. Advancing prediction of tissue distribution and volume of distribution of highly lipophilic compounds from a simplified tissue-composition-based model as a mechanistic animal alternative method. J. Pharm. Sci. 101(6):2250-2261.
Poulin, P., and S. Haddad. 2013. Hepatocyte composition-based model as a mechanistic tool for predicting the cell suspension: Aqueous phase partition coefficient of drugs in in vitro metabolic studies. J. Pharm. Sci. 102(8):2806-2818.
Rauma, M., A. Boman, and G. Johanson. 2013. Predicting the absorption of chemical vapours. Adv. Drug Deliv. Rev. 65(2):306-314.
Reif, D.M., M.T. Martin, S.W. Tan, K.A. Houck, R.S. Judson, A.M. Richard, T.B. Knudsen, D.J. Dix, and R.J. Kavlock. 2010. Endocrine profiling and prioritization of environmental chemicals using ToxCast data. Environ. Health Perspect. 118(12):1714-1720.
Rotroff, D.M., B.A. Wetmore, D.J. Dix, S.S. Ferguson, H.J. Clewell, K.A. Houck, E.L. Lecluyse, M.E. Andersen, R.S. Judson, C.M. Smith, M.A. Sochaski, R.J. Kavlock, F. Boellmann, M.T. Martin, D.M. Reif, J.F. Wambaugh, and R.S. Thomas. 2010. Incorporating human dosimetry and exposure into high-throughput in vitro toxicity screening. Toxicol. Sci. 117(2):348-358.
Sahlin, U. 2013. Uncertainty in QSAR predictions. ATLA 41(1):111-125.
Sedykh, A., H. Zhu, H. Tang, L. Zhang, A. Richard, I. Rusyn, and A. Tropsha. 2011. Use of in vitro HTS-derived concentration-response data as biological descriptors improves the accuracy of QSAR models of in vivo toxicity. Environ. Health Perspect. 119 (3):364-370.
Sharifi, M., and T. Ghafourian. 2014. Estimation of biliary excretion of foreign compounds using properties of molecular structure. AAPS J. 16(1):65-78.
Shitara, Y., T. Horie, and Y. Sugiyama. 2006. Transporters as a determinant of drug clearance and tissue distribution. Eur. J. Pharm. Sci. 27(5):425-446.
Tan, Y.M., K.H. Liao, and H.J. Clewell III. 2007. Reverse dosimetry: Interpreting trihalomethanes biomonitoring data using physiologically based pharmacokinetic modeling. J. Expo. Sci. Environ. Epidemiol. 17(7):591-603.
van der Veen, J.W., E. Rorije, R. Emter, A. Natsch, H. van Loveren, and J. Ezendam. 2014. Evaluating the performance of integrated approaches for hazard identification of skin sensitizing chemicals. Regul. Toxicol. Pharmacol. 69(3):371-379.
Wambaugh, J.F., B.A. Wetmore, R. Pearce, C. Strope, R. Goldsmith, J.P. Sluka, A. Sedykh, A. Tropsha, S. Bosgra, I. Shah, R. Judson, R.S. Thomas, and R.W. Setzer. In press. Toxicokinetic triage for environmental chemicals. Toxicol. Sci.
Wetmore, B.A. 2015. Quantitative in vitro-to-in vivo extrapolation in a high-throughput environment. Toxicology 332:94-101.
Wetmore, B.A., J.F. Wambaugh, S.S. Ferguson, M.A. Sochaski, D.M. Rotroff, K. Freeman, H.J. Clewell III, D.J. Dix, M.E. Andersen, K.A. Houck, B. Allen, R.S. Judson, R. Singh, R.J. Kavlock, A.M. Richard, and R.S. Thomas. 2012. Integration of dosimetry, exposure, and high-throughput screening data in chemical toxicity assessment. Toxicol. Sci. 125(1):157-174.
Wetmore, B.A., J.F. Wambaugh, S.S. Ferguson, L. Li, H.J. Clewell, III, R.S. Judson, K. Freeman, W. Bao, M.A. Sochaski, T.M. Chu, M.B. Black, E. Healy, B. Allen, M.E. Andersen, R.D. Wolfinger, and R.S. Thomas. 2013. The relative impact of incorporating pharmacokinetics in predicting in vivo hazard and mode-of-action from high-throughput in vitro toxicity assays. Toxicol. Sci. 132(2):327-346.
Wilson, A., D.M. Reif, and B.J. Reich. 2014. Hierarchical dose-response modeling for high-throughput toxicity screening of environmental chemicals. Biometrics 70(1):237-246.
Zhang, S. 2011. Computer-aided drug discovery and development. Methods Mol. Biol. 716:23-38.
Zhu, H. L. Ye, A. Richard, A. Golbraikh, F.A. Wright, I. Rusyn, and A. Tropsha. 2009. A novel two-step hierarchical quantitative structure-activity relationship modeling work flow for predicting acute toxicity of chemicals in rodents. Environ. Health Perspect. 117:(8):1257-1264.
















